
Abstract
The adoption of Semantic Web and Linked Data technologies in web application development has been impacted by less-than-optimal development experience. Front-end web application development is inherently challenging, as developers must master a multitude of technologies and frameworks even to build simple applications. Adding Linked Data technologies to the mix further complicates this challenge by increasing the number of technologies that need to be learned. The Semantic Web community has historically struggled to provide front-end developers with quality tools and libraries for working with Linked Data; consequently, developers often prefer traditional solutions based on relational or document databases that offer far superior developer experience. To address this issue, we developed LDkit, an innovative Object Graph Mapping framework for TypeScript. The framework works as the data access layer, providing model-based abstraction for querying and retrieving RDF data. LDkit transforms the data between RDF representation and TypeScript primitives according to user-defined data schemas, simplifying the use of the data and ensuring end-to-end data type safety. This paper introduces LDkit, describes its design and implementation fundamentals with focus on its developer interface and integration with other related technologies. Building on community feedback and experience from using LDkit, we introduce major enhancements that simplify data querying and update for common and uncommon web application scenarios, further improving developer experience. Finally, we demonstrate impact of LDkit by examining usage of the framework in real-world projects. LDkit aims to enhance the web ecosystem by making Linked Data more accessible and integrated into mainstream web technologies.
Introduction
The Semantic Web and Linked Data have emerged as powerful technologies to enrich the World Wide Web with structured and interconnected data (Berners-Lee et al., 2001). These technologies enable a more meaningful representation of web content, facilitating advanced data integration and interoperability. However, despite their advantages, their adoption has been relatively slow. A primary obstacle is the difficulty of querying distributed Linked Data within web applications (Bizer et al., 2009), a challenge often framed as the expressivity/complexity trade-off.
Expressivity in Linked Data refers to the ability to represent rich semantics and relationships between resources, often using ontologies and domain-specific vocabularies (Heath & Bizer, 2011). A more expressive data model allows for precise and semantically rich descriptions, improving data integration and reasoning capabilities. However, this increased expressivity comes at a cost. Greater expressivity typically results in increased complexity in data retrieval and processing. More sophisticated data models require advanced query languages, such as SPARQL (Harris & Seaborne, 2013), and computationally intensive processing methods. As a result, working with Linked Data often demands significant development effort and extensive computational resources, creating barriers to its practical implementation in web applications.
To address these challenges, several tools have been developed to simplify Linked Data querying while maintaining its expressivity. Notable examples include Comunica, a modular query engine designed for querying heterogeneous Linked Data sources (Taelman et al., 2018), and LDflex, a domain-specific language that provides a more intuitive way to query RDF data (Verborgh & Taelman, 2020). These solutions help bridge the gap between expressivity and usability by abstracting the complexities of Linked Data querying. Nevertheless, the ecosystem of Linked Data tools for web development remains limited, with existing solutions lacking the maturity and comprehensive feature set found in more established web technologies.
Over the past decade, web development has undergone a profound transformation, driven by the increasing demand to migrate traditionally desktop-native applications to the web. As more complex software systems transitioned to web-based environments, the need for more powerful and scalable front-end technologies became evident. This shift led to the emergence and widespread adoption of advanced frameworks such as React, 1 Vue 2 and Angular, 3 which enabled the development of highly interactive and responsive web applications.
Alongside these advancements, the rise of TypeScript, 4 a statically typed superset of JavaScript, further strengthened the web development ecosystem. By introducing static typing, TypeScript improved code quality, enhanced developer productivity, and provided robust tooling support, making it more feasible to build and maintain large-scale applications. These innovations have collectively equipped developers with the necessary tools to create sophisticated, feature-rich web applications that rival their desktop counterparts in functionality and performance.
However, the recent advancements in web development have significantly expanded the skill set required of web developers, who now must navigate a growing ecosystem of technologies. The increasing complexity of web applications demands a deeper understanding of software architecture principles and many advanced concepts such as state management, asynchronous programming, security best practices, and performance optimization. In this context, the adoption of Linked Data in web applications presents yet another challenge for developers due to its inherent complexity. Unlike conventional data management approaches, Linked Data requires developers to work with RDF, SPARQL, and other knowledge graph technologies, which introduce unfamiliar paradigms and demand a deeper understanding of semantic data structures. Therefore, to ease this transition, it is essential to provide robust developer tools that abstract much of the complexity while preserving the expressiveness and power of Linked Data.
To address the needs of modern web developers, we created LDkit, a novel Linked Data abstraction designed to provide a data type-safe way for interacting with Linked Data from within web applications. LDkit enables developers to directly utilize Linked Data in their web applications by providing mapping from Linked Data to simple, well-defined data objects; it shields the developer from the challenges of querying, fetching and processing RDF data.
This paper extends our previous work on LDkit (Klíma et al., 2023) and makes three key contributions to the development of Linked Data applications and adoption of Semantic Web technologies:
First, it elaborates on the architecture and design of LDkit, providing an in-depth discussion of data schema construction, as well as data querying and updating. The paper includes numerous code examples that demonstrate typical Linked Data use cases, illustrating LDkit’s internal mechanisms such as SPARQL query generation and the transformation between the RDF data model and TypeScript objects. Second, it presents enhancements to LDkit introduced since the original publication, addressing former limitations and incorporating feedback from the community. These enhancements focus on improving the developer experience, including usability refinements and solutions to common challenges in working with Linked Data. Third, it provides an empirical analysis of LDkit’s usage, offering insights into adoption trends, real-world application scenarios, and performance considerations. This analysis not only validates the effectiveness of LDkit but also identifies areas for future research and optimization.
The remainder of this paper is organized as follows. Section 2 reviews related work. Section 3 provides an overview of the design, implementation, usage examples, and integration of LDkit in web applications, followed by Section 4 that provides a thorough overview of improvements in LDkit V2. Section 5 then discusses the developer experience aspects of LDkit, including comparison with related tools and current limitations. Section 6 evaluates performance of LDkit and discusses potential performance bottlenecks. Section 7 examines the usage of LDkit, presenting usage metrics and an analysis of its adoption in existing tools. Finally, Sections 8 and 9 outline directions for future research and provide concluding remarks.
This section presents an overview of the existing approaches and technologies that are closely related to LDkit.
The first subsection focusses on common web application data abstraction solutions and introduces several key data access libraries that are considered state-of-the art in web development. By examining these well-established solutions, we can infer a set of general qualities that a library such as LDkit should possess in order to achieve wide adoption, ensure usability, and integrate seamlessly with the web application development ecosystem.
The second subsection reviews existing RDF-specific JavaScript/TypeScript libraries, focussing on their capabilities, limitations and relevance to web application development. By examining these solutions, we aim to identify the gaps that remain unaddressed, especially when compared to traditional data abstraction tools.
The third subsection introduces alternative RDF querying approaches that leverage mainstream web application technologies, such as RESTful interfaces and GraphQL.
The fourth subsection examines RDF data documentation strategies and data descriptors, such as data shape definitions, and explores their potential use in Linked Data applications.
The last subsection provides an overview of the different JavaScript runtime environments that are relevant to the execution of LDkit and similar libraries. This technical background is important for understanding the broader context in which LDkit operates. Since LDkit is written in TypeScript and intended to be used in diverse web development environments, it is crucial to discuss the available runtime options, particularly how they affect TypeScript execution, development workflow, and the overall developer experience. Finally, this subsection also clarifies the runtime assumptions made in the paper.
This structure demonstrates how LDkit fits within the broader landscape of web development tools, while also illustrating the unique contributions it makes by integrating Linked Data into mainstream web technologies.
Web Application Data Abstractions
There are various styles of abstractions over data sources to facilitate access to databases in web development. These abstractions often cater to different preferences and use cases.
Object-Relational Mapping (ORM) and Object-Document Mapping (ODM) abstractions map relational or document database entities to objects in the programming language, using a data schema. They provide a convenient way to interact with the database using familiar object-oriented paradigms, and generally include built-in type casting, validation and query building out of the box. Examples of ORM and ODM libraries for JavaScript/TypeScript include Prisma, 5 TypeORM 6 or Mongoose. 7 Corresponding tools for graph databases are typically referred to as Object-Graph Mapping (OGM) or Object-Triple Mapping (Ledvinka & Křemen, 2020) libraries, and include Neo4j OGM 8 for Java and GQLAlchemy 9 for Python.
Query Builders provide a fluent interface for constructing queries in the programming language, with support for various database types. They often focus on providing a more flexible and composable way to build queries compared to ORM/ODM abstractions, but lack convenient development features like automated type casting. A prominent query builder for SQL databases in web application domain is Knex.js. 10
Driver-based abstractions provide a thin layer over the database-specific drivers, offering a simplified and more convenient interface for interacting with the database. An example of a driver-based abstraction heavily utilized in web applications is the MongoDB Node.js Driver. 11
Finally, API-based Data Access abstractions facilitate access to databases indirectly through APIs, such as RESTful or GraphQL APIs. They provide client-side libraries that make it easy to fetch and manipulate data exposed by the APIs. Examples of API-based data access libraries include tRPC 12 and Apollo Client. 13
Each style of abstraction caters to different needs and preferences. Ultimately, the choice of abstraction style depends on the project’s specific requirements and architecture, as well as the database technology being used. There are, however, several shared qualities among these libraries that contribute to a good developer experience.
All of these libraries have static type support, which is especially beneficial for large or complex projects, where maintaining consistent types can significantly improve developer efficiency. Static types provide early error detection during compile time rather than runtime, which reduces bugs and unexpected behaviour in production since many common mistakes, such as assigning the wrong data type to variables or passing incorrect arguments to functions, are caught during development. In large projects, where many developers work on the same codebase, static types act as a form of self-documentation, improving code readability, maintenance, and developer collaboration.
Another aspect of the reviewed libraries, which is closely related to static types, is good tooling support: These libraries often provide integrations with popular development tools and environments. This support can include autocompletion, syntax highlighting, and inline error checking, further enhancing the developer experience and productivity.
Furthermore, most of these libraries offer a consistent API across different database systems, which simplifies the process of switching between databases or working with multiple databases in a single application. Finally, abstracting away low-level details allows developers to focus on their application’s logic rather than dealing with the intricacies of the underlying database technology.
JavaScript/TypeScript RDF Libraries
JavaScript is a versatile programming language that can be utilized in various execution environments, such as web browsers, servers, or desktop. As Linked Data and RDF have gained traction in web development, several JavaScript libraries have emerged to work with RDF data. These libraries offer varying levels of RDF abstraction and cater to different use cases.
Most of the existing libraries conform to the RDF/JS Data model specification (Bergwinkl et al., 2022), sharing the same RDF data representation in JavaScript for great compatibility benefits. Often, RDF libraries make use of the JavaScript Object Notation for Linked Data (JSON-LD) (Sporny et al., 2020), a lightweight syntax that enables JSON objects to be enhanced with RDF semantics. JSON-LD achieves this by introducing the concept of JSON-LD context, which is a mechanism used to map terms in JSON data to concepts and entities in external vocabularies via RDF property and type IRIs 14 . This mapping allows for JSON objects to be interpreted as RDF graphs.
One of the most comprehensive projects is Comunica (Taelman et al., 2018), a modular query engine for Linked Data, enabling developers to execute SPARQL queries over multiple heterogeneous data sources with extensive customizability.
LDflex (Verborgh & Taelman, 2020) is a domain-specific language that provides a developer-friendly API for querying and manipulating RDF data with an expressive, JavaScript-like syntax. It makes use of JSON-LD contexts to interpret JavaScript expressions as SPARQL queries. While it does not provide end-to-end type safety, LDflex is one of the most versatile Linked Data abstractions that are available. Since it does not utilize a fixed data schema, it is especially useful for use cases where the underlying Linked Data is not well defined or known.
There are also several object-oriented abstractions that provide access to RDF data through JavaScript objects. RDF Object 15 and SimpleRDF 16 enable per-property access to RDF data through JSON-LD context mapping. Linked Data Objects (LDOs) 17 leverage Shape Expressions (ShEx) (Prud’hommeaux et al., 2019) data shapes to generate RDF to JavaScript interface, and static typings for the JavaScript objects. Object-semantic mapping 18 utilizes proprietary model definition to map RDF data to model instances. Soukai-solid 19 provides OGM-like access to Solid Pods 20 based on a proprietary data model format.
Except for LDflex, the major drawback of all the aforementioned Linked Data abstractions is that they require pre-loading the source RDF data to memory. For large decentralized environments like Solid, this pre-loading is often impossible, and we instead require discovery of data during query execution (Taelman & Verborgh, 2023). While these libraries offer valuable tools for working with RDF, when it comes to web application development, none of them provides the same level of type safety, tooling support and overall developer experience as their counterparts that target relational or document databases.
Alternative RDF Querying Approaches
In addition to dedicated RDF libraries, several attempts have been made to simplify the integration of Linked Data into web applications by leveraging technologies familiar to web developers and abstracting away the complexity of SPARQL querying.
One such project is GRLC (Meroño-Peñuela & Hoekstra, 2016), a tool that transforms a set of SPARQL queries into Linked Data Web APIs. This enables application developers to interact with Linked Data via a REST API, without requiring knowledge of SPARQL. Furthermore, GRLC automatically generates an OpenAPI 21 specification, which developers can leverage as documentation and use to generate additional application artifacts, such as TypeScript definitions.
GRLC offers benefits to both application developers and RDF data providers. Developers may deploy GRLC as a security layer to prevent exposure of SPARQL queries and endpoints to end users. RDF data providers, on the other hand, may host a GRLC server alongside an existing SPARQL endpoint to facilitate easier access for developers unfamiliar with SPARQL, in order to simplify data browsing and querying. However, this extra architectural layer may be impractical or undesirable in certain scenarios, and may add significant performance overhead.
In recent years, the GraphQL 22 interface has gained popularity as an alternative to REST interfaces, due to its flexible data retrieval, strongly typed schema, and the ability to group multiple REST requests into one. A notable element of this interface is the GraphQL query language, which is popular among developers due to its ease of use and wide tooling support. However, GraphQL uses custom interface-specific schemas, which are difficult to federate over, and have no relation to the RDF data model.
That is why, in the recent years, we have seen several initiatives Taelman et al. (2018), Taelman et al. (2019) and Angele et al. (2022) attempting to bridge the worlds of GraphQL and RDF, by translating GraphQL queries into SPARQL, with the goal of lowering the entry-barrier for writing queries over RDF. While these initiatives addressed the problems to some extent, there are still several drawbacks to this approach. Most notably, similar to GRLC, it requires the deployment of a dedicated server.
RDF Data Descriptors
One of the key challenges in developing Linked Data applications is understanding what data is available within an RDF data source and how it can be explored effectively. While it is possible to investigate data directly using RDF data visualization tools or via SPARQL endpoint queries, this approach can be inefficient and opaque, particularly when dealing with unfamiliar or complex datasets. Consequently, various forms of documentation and data descriptors have been developed to facilitate comprehension, navigation, and use of RDF data.
ShEx (Prud’hommeaux et al., 2019) and the Shapes Constraint Language (SHACL) (Knublauch & Kontokostas, 2017) are two prominent schema languages designed to describe and validate RDF data structures. ShEx offers a compact and expressive syntax for defining graph patterns, enabling both validation and data documentation. SHACL, standardized by the W3C, employs an RDF-based syntax to define constraints and rules over RDF graphs, making it highly interoperable within the semantic web stack. These shape definitions may serve as means of accessing RDF data from web applications, as demonstrated by the aforementioned LDO library, which utilizes ShEx shapes to generate a type-safe RDF data access layer.
The JSON-LD context provides a form of RDF data description as well, albeit not as specific as ShEx or SHACL. For example, the LDflex library uses JSON-LD contexts to generate SPARQL queries and to map RDF data to JavaScript primitives.
Finally, the Vocabulary of Interlinked Datasets (VoID) (Alexander et al., 2011) provides a standardized way to describe metadata about RDF datasets, including structural metadata that describe the structure and schema of datasets. This is particularly useful for tasks such as querying and data integration. The SPARQL Editor 23 uses VoID description present in the triplestore to provide autocomplete features when composing SPARQL queries.
These data description technologies are typically employed in back-end systems or data pipelines, with the possible exception of JSON-LD, which benefits from a comprehensive web-based library 24 . Consequently, the available tooling for these technologies predominantly targets server-side technologies and programming languages. However, thanks to the general support of WebAssembly across modern web platforms, it has become feasible to leverage tooling originally developed for backend environments within web runtime contexts. Notable WebAssembly-enabled projects include Rudof (Labra-Gayo et al., 2024), a Rust library for handling RDF data models and shapes, and Oxigraph, 25 a graph database that implements the SPARQL standard.
Despite the portability advantages offered by WebAssembly, its integration into web applications must be approached with caution. The size of WebAssembly binaries and the startup latency they introduce can negatively impact the responsiveness of browser-based applications (for instance, the Oxigraph WASM binary is 3.5 MB). For these reasons, it may be more appropriate to deploy WebAssembly-based libraries in server-side JavaScript environments.
JavaScript Runtime Environments
JavaScript code can be executed in a variety of environments. The most widely used runtime is perhaps Node.js, 26 which pioneered usage of JavaScript outside of web browsers. Node.js benefits from a large ecosystem of libraries and tools, that is facilitated by the NPM 27 package registry, the largest software registry in the world. One of the drawbacks of Node.js is that it cannot execute TypeScript files directly – in order to achieve that, TypeScript must first be transpiled into JavaScript, either as a build step, or through just-in-time transformation using Node.js wrappers like ts-node. 28
Insufficient TypeScript support, antique CommonJS module system and absence of comprehensive development toolchain in Node.js gave rise to alternative JavaScript runtimes in recent years.
The most prominent of them is Deno. 29 The Deno runtime natively supports TypeScript, JSX and modern ECMAScript features with zero configuration. It is built on web standards, and includes essential tools to build, test and deploy applications. Even though Deno is backwards compatible with Node.js code and supports NPM package registry, Deno can import modules from any location on the web via URL, like GitHub, a personal webserver or a CDN like esm.sh. 30 Recently, the Deno team introduced JSR, 31 a modern open-source JavaScript package registry that is runtime agnostic and supports TypeScript natively.
Bun 32 is another JavaScript runtime. Similar to Deno, it is an all-in-one JavaScript and TypeScript toolkit for bundling and testing applications. Bun is designed as a drop-in replacement for Node.js, and includes an NPM-compatible package manager.
Web browsers represent the traditional platform for JavaScript execution, arguably the most important one when it comes to user-facing applications. Same as Node.js, web browsers do not support TypeScript and require script transpilation. Additionally, because some of the interfaces provided by Node.js or other runtimes do not have direct equivalents in browser environments, they need to be polyfilled to ensure full functionality. Polyfills allow developers to emulate missing features, providing a seamless and consistent experience across server and client-side executions.
The examples in the rest of the paper assume the usage of TypeScript and Node.js runtime, since it is predominantly used at the time of writing, but they are easily adaptable (with minimal changes) to other runtime environments as well.
LDkit
LDkit is a Linked Data OGM toolkit that provides a type-safe data abstraction layer for interacting with Linked Data from within web applications. It enables RDF data query and update over a variety of data sources. It is written in TypeScript and designed to be used on the client or server. In this section, we provide a high level perspective of LDkit design philosophy, architecture, capabilities and discuss some of its most important components.
Design Philosophy
The development of LDkit was driven by the following design principles, which evolved from the initial requirements (Klíma et al., 2023) to fully realized features:

In this section, we provide a high-level overview of how LDkit works, of its capabilities and discuss some of its most important components.
The primary objective of LDkit is to provide TypeScript native abstraction to RDF data. It achieves that using the Lens 33 component that provides a programming interface to query RDF using simple LDkit Query language. Using Schema, Lens translate the simple queries into SPARQL queries, which are then executed over a target RDF data source using Query engine. The Query engine returns retrieved RDF data back to Lens; the data is then decoded using Schema again to TypeScript native objects that are ready to be handled by the developer. The process is depicted in Figure 1.

Basic operation of LDkit.
Let us illustrate how to display simple Linked Data in a web application, using the following objective:
Query DBpedia for persons. A person should have a name property and a birth date property of type date. Find me a person by a specific IRI.

The example in Listing 2 demonstrates how to query, retrieve and display Linked Data in TypeScript using LDkit in only 20 lines of code.
On lines 4-11, the user creates a data Schema, which describes the shape of data to be retrieved, including mapping to RDF properties and optionally their data type. On line 13, they create a Lens object, which acts as an intermediary between Linked Data and TypeScript paradigms. Finally, on line 18, the user requests a data artifact using its resource IRI and receives a plain JavaScript object that can then be printed in a type-safe way.
Under the hood, LDkit performs the following: Generates a SPARQL query based on the data schema. Queries remote data sources and fetches RDF data. Converts RDF data to JavaScript plain objects and primitives. Infers TypeScript types for the provided data.
Listing 3 illustrates how exactly the data schema corresponds to the original RDF data and resulting TypeScript primitives, and presents an example of equivalent data models in both domains.

The schema is the key concept in LDkit; understanding of the term is essential for efficient use of the library.
On a conceptual level, a data schema is a definition of a data shape through which the RDF data are queried, and how the data are eventually transformed to JavaScript primitives. It is similar to a data model for standard ORM libraries. Through schema, the library users describe a class of entities and their properties to be retrieved from an RDF source.
Listing 4 includes a TypeScript definition of the schema object, including RDF types and properties specification. Any object that satisfies the Schema type is a valid LDkit schema.

RDF Type Definition
A schema may include a

Properties Definition
The schema lets developers define general shape of the data by specifying properties of entities, their data type (a primitive data type based on XSD (Peterson et al., 2012), a custom primitive data type, 34 or a nested schema), and arity.
A schema typically includes a map of multiple data properties, that is, a mapping from simplified names to RDF predicates specified by IRI.
In addition, each property definition may include one or more property modifiers, further specifying how the data should be queried and outputted. LDkit schema supports the following modifiers:
The RDF predicate IRI.
The RDF datatype of the property value. If omitted, defaults to
Nested subschema. It may contain the definition in place, or a reference to another JavaScript object containing LDkit schema specification, thanks to the composability properties of schema. Alternative to
If set, indicates that the property is optional. By default, properties are considered required, and LDkit will only query entities having such properties, or will require property values when creating or updating an entity.
If set, indicates to treat the property as having multiple values. By default, properties are considered single-value only. If there are multiple values, only one of them is accepted – the first one encountered in the dataset.
If set, LDkit will treat the property as language-enabled, that is, it will transform literal values annotated by
If set, indicates that the property is in an inverse relation, which is useful to represent incoming links. Normally, the properties are matched using
The modifiers may be combined together as required. For example, a property with the
The
In addition to the built-in types, LDkit may be extended by custom datatypes handlers. We discuss this in more detail in Section 4.
While property values of data entities are usually literals, in some cases it may be useful to query for named nodes (e.g. IRIs of linked entities) instead of literal property values. To address that, we introduced a special datatype
Finally, for developer convenience, the schema supports a shorthand property notation, where instead of a complex property definition using a key-value object, the developer provides only its predicate IRI. In such case, LDkit assumes that the property is required, of type
The LDkit schema support is designed with two important constraints. First, the schema cannot be recursive. Second, it must be possible to retrieve all the data necessary to populate the schema using a single SPARQL query, in order to apply data constraints directly in the query (e.g. ensure existence of all required properties).
Due to these constraints, although LDkit supports schema nesting and composition, a schema cannot reference itself, even transitively. This restriction is enforced syntactically in TypeScript, thereby preventing users from inadvertently creating invalid recursive schemas.
However, Linked Data often includes entities that reference others of the same type, and potentially the same schema. Such cases can be addressed through application level recursion. At the schema level, instead of referencing the complete schema recursively, users may retrieve only the IRIs of related entities, or use a subschema. Listing 6 illustrates a typical use case involving

Another common use case in Linked Data is the handling of complex data types, for example, those where the range of a property is the union or the intersection between two classes. There are two alternative strategies to address this scenario.
To illustrate these strategies, consider the
The first approach, demonstrated in Listing 7, is similar to the recursion example discussed earlier. It uses an intermediary schema to resolve RDF types of the linked entity. The application can then query additional data based on the resolved RDF types, ideally using dedicated schemas for Person and Organization.

The second strategy involves creating a synthetic schema that contains properties that belong to either Person or Organization entities, using the

Querying Data
In Listing 2, we showed how LDkit can map a particular data entity specified by IRI from RDF to TypeScript model. When building web applications that browse data, a more advanced interface is required, so that the user can efficiently browse and utilize the data. For example, traditional ORM solutions provide a way to retrieve all entities, lookup entities based on particular criteria, or paginate results to support large datasets. LDkit strives to support the same use cases. A key differentiator of LDkit is the ability to retrieve previously unknown data entities without knowing their resource IRI upfront. In contrast, other existing RDF-based solutions typically require a starting IRI or having the entire dataset loaded into memory.
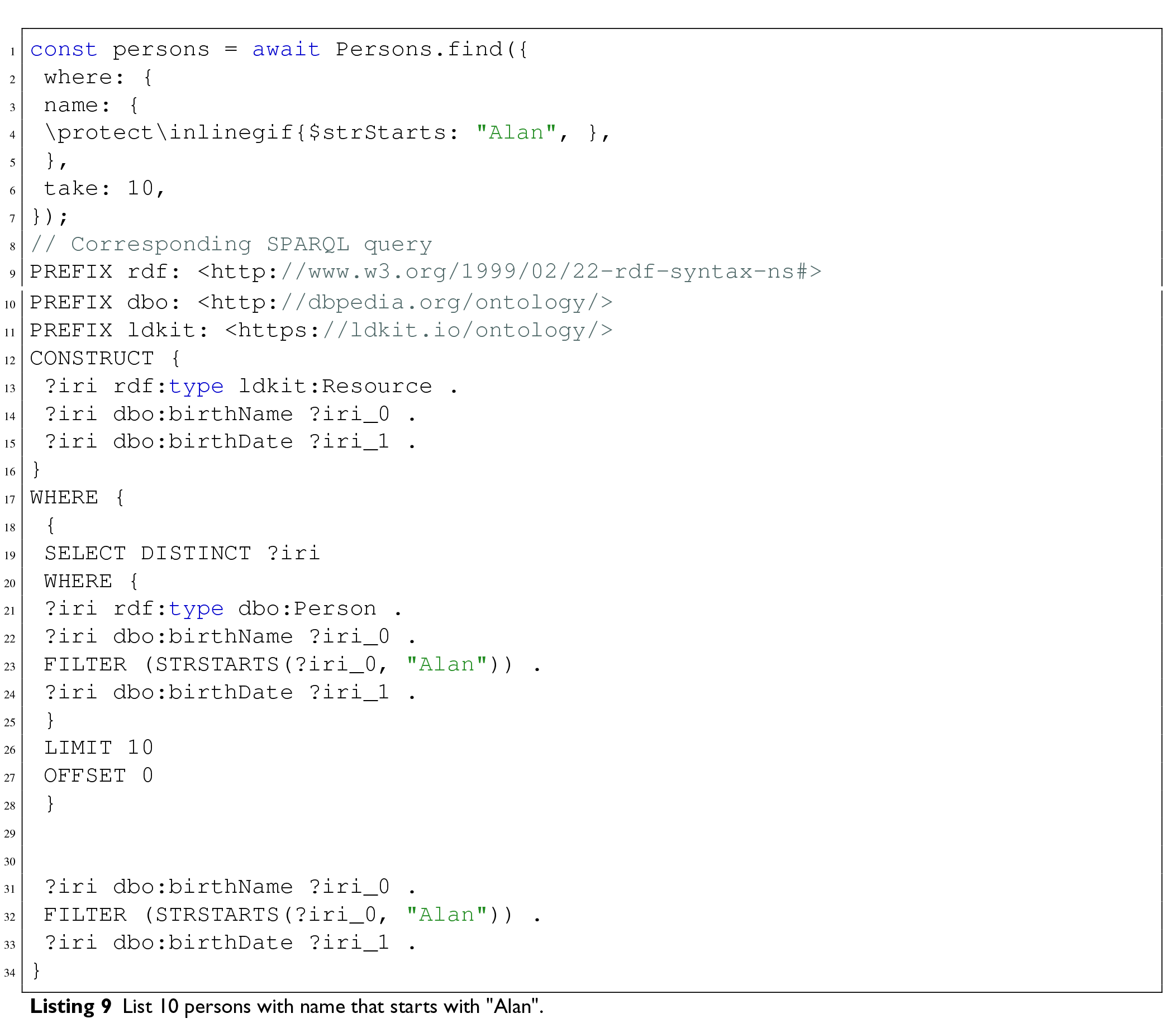
To support such advanced querying needs, LDkit introduces a custom query language that abstracts SPARQL and enables developers to perform filtering and pagination without writing SPARQL manually. This query language provides a familiar and declarative syntax akin to traditional ORMs. Listing 9 shows an example of how to fetch persons named ”Alan”, and limiting the total number of results to ten. It also shows the particular SPARQL query that is created and executed by LDkit under the hood.

The LDkit query may contain a where clause that lets the user restrict the values of specific properties. It uses
LDkit allows various search and filtering operations that are data-type specific, most of those operations are realized using built-in SPARQL functions. There is support for general comparisons 38 , string functions 39 , and array functions 40 . In addition, users can specify a custom filter expression that is inserted directly into the resulting SPARQL query. In addition, most of these filtering operations can be mixed together for a single entity property, so that users can for example query for a date range (Find all persons born after 1950 and before 1990).
For pagination, there are take and skip parameters, that correspond to the
In order to support this kind of query specification, the resulting SPARQL queries are quite complex. The queries can be broken down into three parts: First, a set of entities represented by their IRIs must be established. This is done using a Second, for each IRI found, a graph corresponding to the defined schema is matched, including optional properties. Filtering must be applied on this level as well in order to yield correct results. Third, the graph is finalized using
In summary, LDkit enhances data browsing by offering retrieval of data entities without known IRIs and does not require the entire dataset to be in memory. It features advanced search and filtering capabilities using SPARQL, allowing efficient exploration of large datasets. Users can filter data based on properties, use data-type specific operations, execute custom SPARQL expressions, and apply pagination, making it versatile for querying any kind of data.
Updating Data
LDkit provides means to insert, update and delete RDF data in a developer friendly way, centred around schema definition, similar as reading data. The read operations convert RDF data to TypeScript plain objects and primitives. The update operations work exactly in the opposite way – the input are plain objects holding information about entities, which are then converted to RDF and SPARQL Update queries. An example of creating a new entity is shown in Listing 10.
When updating the data, LDkit
In order to add new data, users need to specify a full entity (or entities) to insert, including all the required properties. For update operation, it is only needed to provide a subset of entity properties – only the ones that are supposed to change. Listing 9 shows an example of an update query.

The Singularization Problem
One of the peculiarities when working with Linked Data, or with graph data sources in general, is that more often than not, a particular property of an entity may have multiple values, and sometimes the list of values may be quite big. The majority of existing RDF abstractions deal with this issue in a Linked Data way – simply considering any property in data to have multiple values. That is however not good enough developer experience for a lot of scenarios, especially if one needs to rely on a particular data model, or has the data under their control. However, some of the available libraries provide means to define this behaviour.
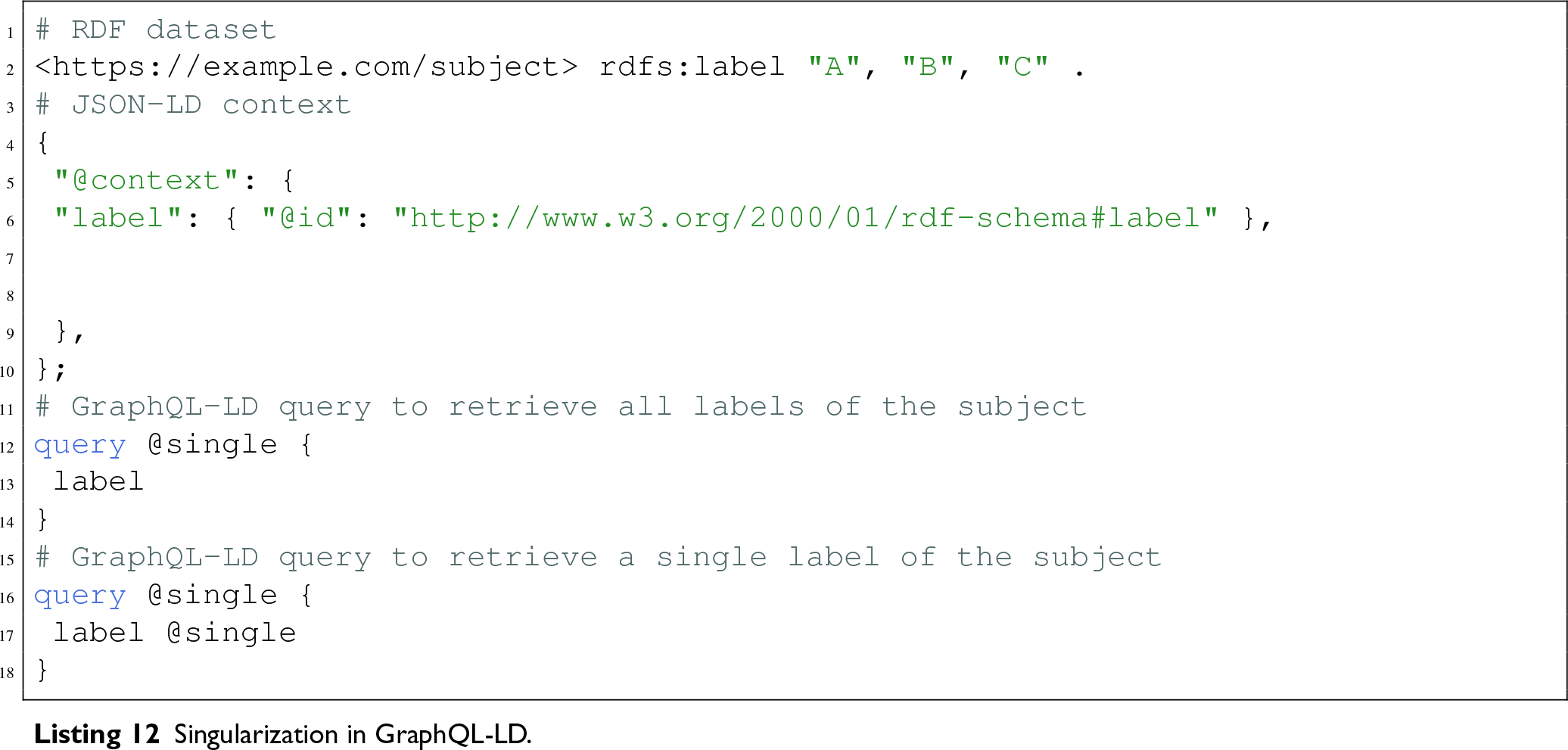
To better understand the issue, we provide examples of singularization in the GraphQL-LD and LDflex libraries.
The GraphQL-LD (Taelman et al., 2018) library treats all properties as arrays by default, but allows for

The LDflex (Verborgh & Taelman, 2020) library adopts a different approach by providing a fluid JavaScript interface for interacting with Linked Data, allowing users to traverse data similarly to local objects. When a user retrieves a property using
Singularization in LDkit
LDkit supports singularization definition directly within the model. In the data schema, users can specify which properties are restricted to single value (the default), and which may contain multiple values. This approach enhances the developer experience by ensuring data integrity and providing tailored methods for reading and writing properties based on whether they represent a singular value or an array.
Furthermore, as we mentioned earlier, some arrays may be quite large, raising the question of how to update such lists efficiently. The LDkit library addresses this challenge by offering developers a mechanism to set array-like properties to a specific list of values, add new values, or remove existing ones. This functionality enables efficient updates to large datasets without requiring the entire dataset to be transmitted. An example of such an update is shown in Listing 14.

Data Sources and Query Engine
In LDkit, a Query engine is a component that handles execution of SPARQL queries over data sources. The query engine must follow the RDF/JS Query specification (Taelman & Scazzosi, 2023) and implement the
LDkit ships with a simple default query engine that lets developers execute queries over a single SPARQL endpoint. It is lightweight and optimized for browser environment, and it can be used as a standalone component, independently of the rest of LDkit. The engine supports all SPARQL endpoints that conform to the SPARQL 1.1 specification (Harris & Seaborne, 2013).
LDkit is fully compatible with Comunica-based query engines. Comunica (Taelman et al., 2018) provides access to RDF data from multiple sources and various source types, including Solid pods, RDF files, Triple/Quad Pattern Fragments, and HDT files.
Converting Data Between RDF and TypeScript
LDkit implements a runtime RDF decoding mechanism that transforms RDF triples into structured TypeScript objects, according to a user-defined schema. This decoding is performed by the
The input of the decoding algorithm is an RDF graph, a schema, and an optional preferred language settings. The RDF graph is a set of triples (subject S, predicate P, object O) serialized in the following tree structure, grouping predicates by subject, and objects by predicate:

The decoding process operates in several stages, formally described in Algorithm 1.

To facilitate end-to-end type safety, in addition to the runtime type conversion provided by the
The resolution algorithm employed by
The
Since LDkit supports not only querying but also updating RDF data, conversion from TypeScript back to RDF is also required. This functionality is provided by the
However, the encoding algorithm is not entirely symmetrical, as updating RDF data involves more complexity than reading it. Data insertion is relatively straightforward: A data entity is transformed to a set of RDF triples, which are then added to the data store using the
Thanks to its modular architecture, components comprising the LDkit OGM framework can be further extended or used separately, accommodating advanced use cases of leveraging Linked Data in web applications. Besides Schema, Lens, Query engine, Decoder and Encoder already presented, LDkit also provides several additional components and utilities that facilitate developmetn with Linked Data.
The
LDkit also offers a general-purpose, type-safe SPARQL query builder that allows developers to construct arbitrary SPARQL queries programmatically using a fluent interface.
Finally, LDkit also includes Namespaces definitions for popular Linked Data vocabularies, such as Dublin Core, 44 FOAF 45 or Schema.org. 46
This level of flexibility means that LDkit could also support other query languages, such as GraphQL.
Implementation
The current version of LDkit is implemented in TypeScript, and requires TypeScript version 5.5 or higher to be used effectively in applications. For execution in a server environment, LDkit requires at least Node v20.19.3 or Deno v2.1. The source code is available under the
Following the standard practices, LDkit is published as an NPM package 49 and as a Deno module. 50 At the time of writing, the latest release is at version 2.5.1.
To make adoption easy for new developers, comprehensive documentation, API reference and code examples are available at https://ldkit.io or linked from the GitHub repository. This resource includes several examples of fully working demo applications covering both Node and Deno environments, and using vanilla JavaScript, React 51 or Preact 52 frameworks.
LDkit includes a comprehensive suite of over 200 unit tests and integration tests to verify the functionality and interactions of each component within the framework. By rigorously testing the library across various use cases and edge cases, LDkit ensures stability and dependability with each new release, facilitating seamless updates and enhancements while minimizing the risk of introducing regressions.
LDkit is actively developed and maintained by a group of researchers at Department of Software Engineering, Faculty of Mathematics and Physics, Charles University in Prague, Czechia.
LDkit V2 Improvements
The release of LDkit 2.0 addressed several limitations of its predecessor (Klíma et al., 2023), and since then LDkit has continued to evolve, introducing further refinements and capabilities to support a broader range of application development scenarios. In this section, we examine the major changes in the library.
LDkit Query Language
The most significant improvement in LDkit V2 is the introduction of the custom query language that enables filtering and pagination of data entities without requiring knowledge of the SPARQL language. This query language has been thoroughly described in Section 3.4. In V1, users had to provide either a full custom SPARQL query, or at minimum, a custom
Efficient Large Array Manipulation
Another major enhancement introduced in LDkit V2 concerns the manipulation of large arrays, or to be precise, multi-valued properties in RDF datasets. In earlier versions, modifying these array-like structures – such as adding or removing individual items – required either passing the whole updated array to LDkit, or specifying the RDF triples to insert and delete from the underlying datastore. This approach was not only error-prone but also placed a considerable cognitive and technical burden on developers, particularly those unfamiliar with RDF syntax and semantics.
LDkit V2 simplifies this process by introducing a high-level interface for array operations, that was described in Section 3.5. Developers can now perform incremental updates on array-like properties using concise and declarative commands, without the need to manage the RDF graph state manually. This abstraction aligns with the design principles of modern application frameworks, where collection manipulation is a routine task that should not involve low-level data operations. This improvement reduces the likelihood of inconsistencies or unintended side effects in the RDF graph.
Custom Data Types
In addition to built-in datatypes, LDkit supports custom two-way conversion based on datatype IRI between RDF literals and TypeScript native primitive or complex types. This is useful when working with complex data formats, such as geometrical points, dates, monetary values, or domain-specific representations that require special parsing and serialization.
In order to support custom types, including end-to-end type safety, developers must provide an explicit TypeScript type definition by augmenting the LDkit’s
To demonstrate the usage of custom datatypes, Listing 15 illustrates how to store a complex TypeScript object in RDF using JSON serialization.

Schema Generators
LDkit provides experimental schema generators that transform existing Linked Data definitions into TypeScript schemas compatible with LDkit. These tools are available via the LDkit CLI and support generating code directly from JSON-LD contexts or ShEx shapes.
Although the generators do not fully support the complete feature set of JSON-LD or ShEx – potentially omitting or simplifying complex validation rules, advanced constraints, and specialized constructs – the output schemas can nevertheless serve as a robust starting point for LDkit-based applications.
Using the CLI
The LDkit CLI is included in the NPM
The general command syntax:

The generators produce TypeScript code that can be used directly in LDkit projects. The CLI outputs the schemas to stdout which can be redirected to a file. For example, the following command transforms a JSON-LD context from a local file and writes the resulting LDkit schema to a schema.ts file:
The
Supported JSON-LD features:
property datatypes set via @type keyword containers of type @language, @set and @list @reverse properties nested @context entries
Since JSON-LD contexts do not support specifying property cardinality, all properties are treated as required by default in the LDkit schema, which may require manual adjustment. Nested context entries are transformed to explicit LDkit schemas, meaning that a single JSON-LD context may yield multiple LDkit schemas that can be used independently, if needed.
Example of a JSON-LD context transformation:

LDkit supports generating schemas from ShEx 2.1 using two commands –
Supported ShEx features:
explicit property types property types inferred from enumerations (value sets) property cardinalities, represented as optional and/or array LDkit properties expressions with choices, represented as optional properties inverse properties nested shapes (both explicit and anonymous) simplified AND/OR shapes logic reuse of named triple expressions
Explicit ShEx shapes result in corresponding LDkit schemas in the generated TypeScript code. Since ShEx language is more expressive than LDkit schemas, some of the ShEx rules need to be simplified – most notably, LDkit schema does not support alternative choices of any kind, that is, it cannot accurately represent constraints such as Schema S contains either property A, or property B. Such rules would be converted to the equivalent of Schema S contains an optional property A and an optional property B, meaning that the resulting LDkit schema is more permissive. Nevertheless, the converted schemas should work well enough with data that are valid according to the original ShEx schema.
Example of a ShExC schema transformation:

LDkit V2 includes built-in support for new RDF data serializations – N-Triples, N-Quads, and Trig. These formats complement the already supported Turtle and RDF/JSON serializations, increasing interoperability with a wider range of Linked Data sources and tools.
Additionally, V2 introduced support for inverse property relations in the schema using the @inverse property attribute, discussed in Section 3.3. In V1, the same result could only have been achieved by specifying custom SPARQL queries.
Developer Experience
Ensuring a positive developer experience is crucial for the adoption and success of any programming tool. This section explores the various ways in which LDkit improves the workflow for developers, making it easier for them to use Semantic Web and Linked Data technologies in their applications.
Comparison with Similar Tools
Table 1 presents a comparison of LDkit with other similar software based on key features. The comparison includes LDflex, which is the most widely used; LDO, which offers the most advanced TypeScript integration and type safety; and GraphQL-LD. Each of these libraries employs a different approach to querying Linked Data and offers a distinct developer experience. Together, they represent the state of the art in the development of web applications based on Linked Data.
Comparison of LDkit, LDflex, LDO, and GraphQL-LD.

Comparison of LDkit, LDflex, LDO, and GraphQL-LD.
JSON-LD: JavaScript object notation for linked data; LDO: linked data objects; ShEx: shape expressions.
LDkit provides a simple way of Linked Data model specification through schema, which is a flexible mechanism for developers to define their own custom data models and RDF mappings that are best suited for their application’s requirements. The schema syntax is based on JSON-LD context, and as such it assumes its qualities: it is self-explanatory and easy to create, and can be reused, nested, and shared independently of LDkit.
The Lens interface for reading and writing Linked Data should feel familiar even to developers new to RDF, as it is inspired by interfaces of analogous model-based abstractions of relational databases. LDkit provides tooling support by incorporating end-to-end data type safety, giving developers instantaneous feedback in the form of autocomplete or error highlighting within their development environment. The development experience is further enhanced by the fact that the typings of data entities are inferred directly from the defined schema during development time, without the need to generate additional TypeScript artifacts or provide explicit type information, which is the case for all other similar tools.
Other Linked Data libraries, like LDflex or LDO, make use of the JavaScript Proxy object to allow virtual access to data and override some of their properties. While that approach may be effectively used for developer-friendly paradigms like fluent interfaces, it may be problematic when working with complex data. The reason for that is that proxied objects cannot be in principle cached, serialized, printed, or sent from server to client. LDkit on the other hand opts for representing the data always as JavaScript plain objects and primitives that inherently share all the aforementioned properties. This approach is implemented by the most advanced ORMs, such as Prisma.
Integration and Compatibility
LDkit adheres to selected W3C standards and recommendations, ensuring compatibility and integration capabilities within the Semantic Web and Linked Data ecosystem. The core of the toolkit is based on the RDF/JS data model (Bergwinkl et al., 2022) and query (Taelman & Scazzosi, 2023) specifications, which standardizes the representation of RDF in JavaScript. To interact with data sources, LDkit utilizes SPARQL Query Language (Harris & Seaborne, 2013) and SPARQL Update (Gearon et al., 2013); its built-in query engine interacts with SPARQL endpoints using SPARQL Protocol (Feigenbaum et al., 2013).
One of the key features of LDkit is its Promise-based API, which aligns with modern asynchronous programming practices in JavaScript. As a result, LDkit can be easily integrated with existing frontend and backend frameworks, such as React, Angular or Express. Whether developers are building complex single-page applications or more traditional multi-page websites, LDkit enables RDF data integration and manipulation across different parts of an application.
Further extending its versatility, LDkit is compatible with multiple JavaScript runtimes, including Node.js, Deno, and Bun. This compatibility ensures that LDkit can be used in a variety of execution environments – from server-side applications, serverless and edge workers, to client-side interfaces. This wide range of applicability allows developers to deploy LDkit in diverse scenarios, whether they are building backend services, interactive client-side applications, or applications requiring low-latency responses at the edge.
The Expressivity/Complexity Trade-Off
In this section, we examine how the use of LDkit affects expressivity and complexity inherent in Linked Data applications.
LDkit provides a schema-based abstraction over RDF data. Using this schema, LDkit reduces the complexity of RDF data querying by automatically generating SPARQL queries, fetching data from a data source, and transforming it into TypeScript native types. This preserves the expressivity of the data model through semantic mapping in the schema, while eliminating the need for direct SPARQL querying and RDF data mapping in developer code.
However, building the schema can be challenging, as it requires knowledge of data ontologies and possibly the data itself. To reduce schema creation complexity, LDkit provides converters that enable the reuse of existing ShEx shapes or JSON-LD contexts to generate an LDkit schema.
When using LDkit, the expressivity of data querying is deliberately reduced through its interface, based on the assumption that typical application use cases do not require the full degree of expressivity offered by SPARQL. Instead of SPARQL, developers use an ORM-like programming interface along with simplified query expressions to filter data.
For less typical use cases, LDkit offers an advanced interface that allows developers to specify custom SPARQL queries to execute against the data source or explicitly define triples to insert into or remove from the data source. Even in these cases, complexity is still reduced, as LDkit handles query execution and potentially data retrieval and transformation. Additionally, LDkit includes a type-safe SPARQL query builder with a fluent interface that helps to create syntactically correct queries.
In summary, LDkit simplifies RDF data access by reducing complexity while maintaining sufficient expressivity for typical and advanced Linked Data use cases.
Current Limitations
To date, the greatest limitation of LDkit remains the inherent complexity of the SPARQL queries it generates to read and update data in RDF data sources. Since the complexity of such queries is directly proportional to the complexity of the data schemas, the more properties developers add to the schema, the less performant the LDkit becomes.
Section 6 presents performance tests of LDkit using various schemas, ranging from simple to complex. These tests provide insight into the expected performance and help identify the threshold of schema complexity at which LDkit continues to operate efficiently. In cases where performance issues arise, we recommend refactoring the data schemas by removing unnecessary properties, splitting the schemas into multiple simpler ones, or reducing schema nesting. In many instances, executing several simpler SPARQL queries can be much faster than running a single complex one.
Performance
In our previous work (Klíma et al., 2023), we evaluated the performance of LDkit using three typical scenarios involving data queries of increasing complexity, executed via the DBpedia SPARQL endpoint 54 . The experiments showed that the overall performance of LDkit is primarily determined by the execution speed of the SPARQL query engine. The library itself maintained stable performance without substantial degradation, even as the complexity of the scenarios increased. In other words, the majority of the processing time is attributable to the execution of the SPARQL query.
While the evaluation demonstrated that LDkit’s performance is adequate for use in Linked Data-based applications and confirmed our assumption that increasing data schema complexity affects performance, it did not provide detailed insight into the extent of this impact – for example, the performance degradation associated with adding a single new property to the data schema.
To address this limitation, we designed a new performance test that would better indicate the impact of complexity of data schemas. A synthetic dataset was constructed comprising 10,000 entities, each containing 10 simple properties, 10 array properties and 10 object properties. Each array property holds three literal values, and each object property includes a sub-entity with three simple properties. To ensure consistency, UUIDv4 random string values were assigned to all properties. The resulting dataset contains a total of 910,000 explicit RDF statements.
The test scenario involves querying all entities in the dataset over 10 iterations, retrieving 1000 entities in each iteration. To accurately measure the performance overhead introduced by LDkit, each query was executed twice: First using LDkit, and then directly against the SPARQL endpoint using the same SPARQL query 55 . To reduce the influence of outliers, the minimum and maximum execution times were discarded, and the remaining values were averaged to yield the mean query time in milliseconds per 1000 entities.
The sole test parameter – and the only variable across the test runs – is the data schema used for retrieving the data. To evaluate the limits of LDkit, we employed five distinct data schema types:
The number of properties in each schema type ranged from one to ten. For the composite schema types AB and ABC, this range applies to each individual property type. Listing 16 presents an example of the ABC(1) schema type along with the corresponding entity.

Figure 2 presents the test results, showing the average time required to query 1000 entities using the different data schema types. The tests were conducted on a PC with an Intel CPU @ 2.40 GHz, 8 GB RAM, running Windows 10. To minimize the impact of network latency, a local installation of GraphDB version 11.0 was used as the triplestore. The test scripts, the dataset generator, execution instructions, and raw results are publicly available on GitHub 56 .
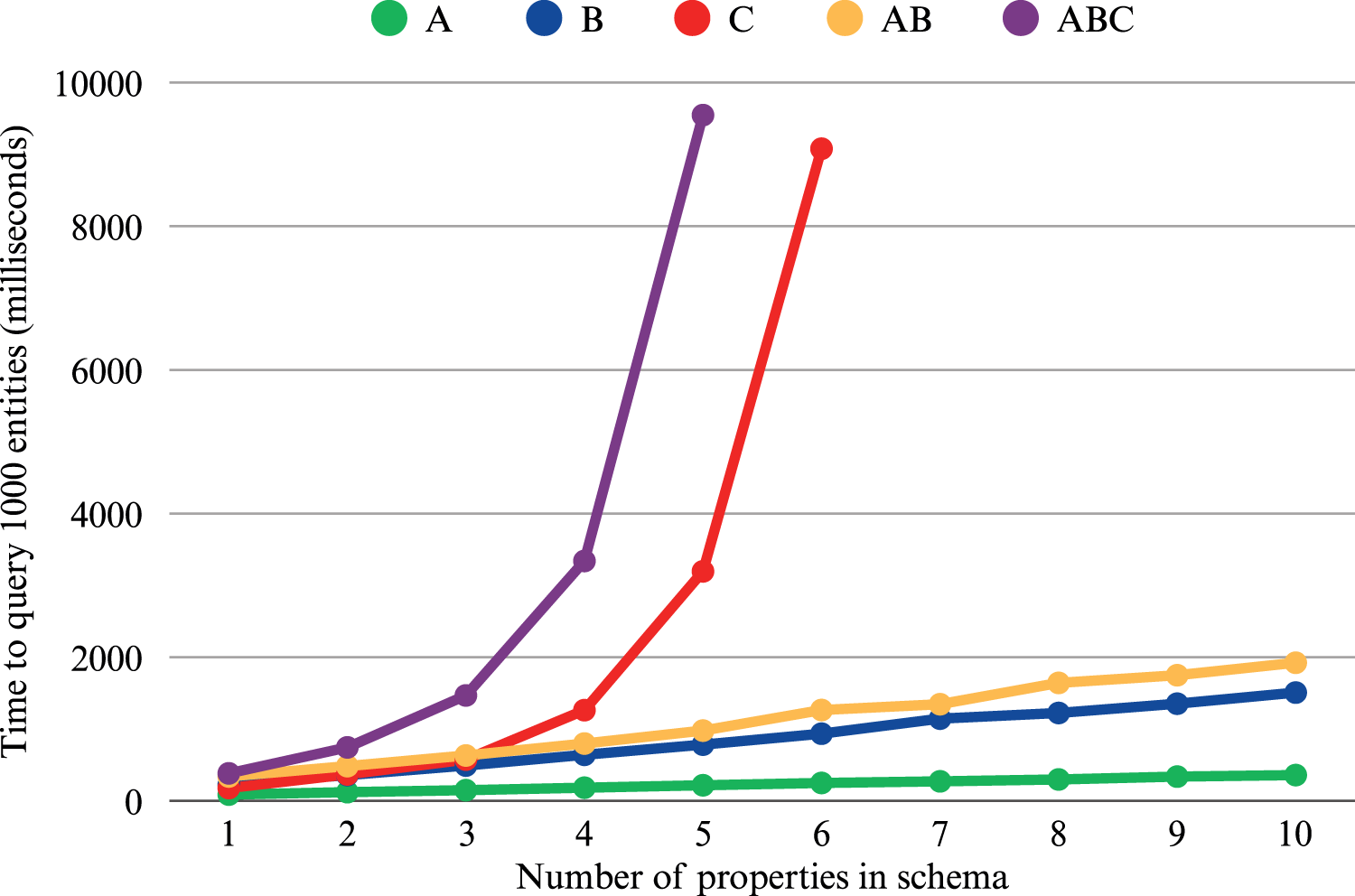
Performance test results of LDkit showing execution time for five different schema types based on the number of properties the schemas include. Schema A includes only simple properties with one value, schema B includes properties with sub-entities (each of those containing three simple properties), and schema C includes array properties containing three values. Schemas AB and ABC are the combinations, for example, Schema AB with five properties includes five simple properties and five properties with sub-entities.
The results demonstrate that LDkit performs efficiently when handling simple properties or properties with sub-entities. For instance, for a schema with ten simple properties, the average execution time to query 1000 entities was 374 ms. Similarly, for a schema of type AB, comprising 10 simple properties and 10 sub-entities, the average execution time was 1923 ms, which is considered satisfactory. However, the results clearly indicate that array properties have a significant negative impact on performance. When the number of array properties exceeds four, the execution time surpasses two seconds, rendering such schemas impractical for use in web applications.
The findings also help identify the potential limits of LDkit schema complexity and suggest strategies to enhance performance in web applications. If performance is suboptimal, one viable approach is to refactor the schema by extracting some or all array properties into separate schemas, which can then be queried independently using the same entity IRI.
Finally, comparing the execution time of LDkit with direct SPARQL endpoint queries, the average overhead introduced by LDkit was 7.47% per test case. Figure 3 illustrates the overhead in various test schemas. This overhead is more pronounced for simple schemas and lower for more complex ones, especially those containing multi-value properties. As the SPARQL query execution time increases, LDkit benefits from the streaming nature of result processing, enabling it to process much of the data in parallel as it is received from the SPARQL endpoint.

Performance test results of LDkit showing execution time overhead as the percentage increase in execution time compared to direct SPARQL endpoint queries. Schemas A, B, C, AB, and ABC are the same as in Figure 2: Schema A includes only simple properties with one value, schema B includes properties with sub-entities (each of those containing three simple properties), and schema C includes array properties containing three values. Schemas AB and ABC are the combinations, for example, Schema AB with five properties includes five simple properties and five properties with sub-entities.
The performance of LDkit was also independently evaluated (González, 2025) together with six other RDF data abstraction libraries, including LDflex and LDO. Although the evaluation has not been published or peer reviewed at the time of writing, the dataset and results are publicly available on GitHub 57 .
The repository provides a detailed description of the performance scenarios, including the steps required to reproduce the tests.
The evaluation assessed library performance across two use cases: Fetching a set of entities from an RDF data source, and fetching a set of entities that satisfy a specific condition.
Statistical analysis 58 indicates that LDkit outperforms all other evaluated libraries and demonstrates significantly better performance than both LDflex and LDO.
In this section, we present overview of practical adoption and application of LDkit across various platforms and projects. Understanding the extent of LDkit’s utilization not only validates its effectiveness but also demonstrates its impact within the developer community. We explore this through Usage metrics, which quantifies its integration into development environments, and In-use analysis, which provides qualitative insights from real-world applications and developer experiences.
Usage Metrics
The adoption and popularity of LDkit can be partly quantified by several key metrics commonly used within the open-source community.
Since the source code of LDkit is hosted on GitHub, we can inspect some of the statistics that the platform provides. As of November 2025, the LDkit repository gained 69 stars from other GitHub users, and there are 13 other public repositories that depend on LDkit directly. There seems to be no transitive dependencies, which is an indicator that LDkit is being used in applications and not in libraries, exactly as intended.
We can gather additional insight from the NPM platform 59 where the Node.js version of LDkit is being hosted. The public NPM statistics indicate that the total number of downloads of the LDkit package between February 1st 2024 and February 1st 2025 was 11,819, averaging more than 227 downloads per week. Similar to GitHub, NPM does not indicate any dependent packages, confirming the assumption that LDkit is being used in user applications, not in libraries or similar tools.
As we mentioned earlier, LDkit is also available as a Deno module. 60 Unfortunately, the Deno platform does not provide download statistics or dependencies information, therefore we cannot easily gauge the adoption of LDkit for this particular JavaScript runtime.
It is important to note that while these metrics offer valuable insights, they come with certain limitations. For instance, LDkit’s usage on platforms like Deno is not tracked, and projects hosted in private GitHub repositories, or other source code platforms such as Bitbucket or GitLab are not included in these metrics. This lack of comprehensive tracking can lead to underestimations of the actual usage figures. Additionally, the metrics from GitHub and NPM might not fully capture the toolkit’s impact and adoption due to these platforms’ inherent tracking limitations and the fact that they do not encompass all usage scenarios or the variety of developer environments. Moreover, the number of downloads reported by NPM may be overestimated, as a portion of these downloads could be attributed to automated processes such as bots, rather than actual human users.
Thus, while the data from GitHub stars, project dependencies, and NPM downloads are informative, they should be considered indicative rather than exhaustive. These metrics, albeit with their imperfections, still provide a snapshot of LDkit’s presence and relevance in the field of Linked Data application development.
In-Use Analysis
This section presents qualitative analysis of selected projects that use LDkit: Dutch Digital Heritage Network, Assembly Line (AL) for conceptual models, Dataspecer, TypeSPARQ, Schema Forge, and LDE – Linked Data Engine. Two of these projects include contributions from the authors of this paper, as noted in the respective subsections below.
Netwerk Digitaal Erfgoed
Netwerk Digitaal Erfgoed (NDE), 61 or the Dutch Digital Heritage Network, is a collaborative initiative in the Netherlands focussed on improving access to and preservation of digital heritage collections from Dutch museums, archives, libraries, and other cultural heritage institutions.
The main goal of NDE is to make the rich digital heritage of the Netherlands accessible, sustainable, and interconnected for users, researchers, and the public. It aims to foster cooperation among heritage institutions and promote the use of open standards, linked data, and sustainable digital practices.
A core component of NDE is The Network of Terms 62 – a search engine for finding terms in terminology sources, such as thesauri, classification systems and reference lists. Given a textual search query, the engine searches one or more terminology sources in real-time and returns matching terms, including their labels and URIs, aggregating the results to the SKOS data model.
This project uses LDkit to query JSON-LD datasets, using Comunica as a query engine. The authors created a complex data schema that employs very advanced LDkit usage. It includes numerous data properties with various data types and leverages features such as nested schemas, arrays, optional properties, and multilingual support.
AL for Conceptual Models
LDkit is used in a project for the Czech government 63 that aims to build a set of web applications for distributed modelling and maintenance of government ontologies 64 . The ensemble is called AL (Klíma et al., 2023). It allows business glossary experts and conceptual modelling engineers from different public bodies to model their domains in the form of domain vocabularies consisting of a business glossary further extended to a formal UFO-based ontology (Guizzardi et al., 2022). The individual domain vocabularies are managed in a distributed fashion by the different parties through AL. AL also enables interlinking related domain vocabularies and also linking them to the common upper public government ontology defined centrally. Domain vocabularies are natively represented and published 65 in SKOS (business glossary) and OWL (ontology). The AL tools have to process this native representation of the domain vocabularies in their front-end parts. Dealing with native representation would be, however, unnecessarily complex for the front-end developers of these tools. Therefore, they use LDkit to simplify their codebase. This allows them to focus on the UX of their domain-modelling front-end features while keeping the complexity of SKOS and OWL behind the LDkit schemas and lenses. On the other hand, the native SKOS and OWL representations of the domain models make their publishing, sharing, and reuse much easier. LDkit removes the necessity to transform this native representation with additional transformation steps in the back-end components of the AL tools.
Disclaimer: Authors of the paper contributed to this project.
Dataspecer
Dataspecer (Stenchlák et al., 2022), a tool for management and modelling of data specifications based on a domain ontology. Using Dataspecer, the users can generate technical artifacts such as data schemas, for example, in JSON Schema or XML Schema, and human-readable documentation for a specific dataset based on the provided ontology while maintaining the semantic mapping from the generated artifacts to the ontology. This significantly eases the task of developing data specifications and keeping the corresponding technical artifacts consistent in the process.
Dataspecer provides support for the implementation of artifact generators for any target format, including LDkit. Using Dataspecer, users can automatically generate ready-to-use LDkit data schemas based on generic data specification. These schemas are generated as TypeScript files that are ready to use in an LDkit-based application, speeding the development time considerably.
Disclaimer: authors of the paper contributed to this project.
TypeSPARQ
TypeSPARQ 66 is a dynamic and user-friendly service that simplifies the process of exploring and extracting data from SPARQL endpoints. With TypeSPARQ, users can easily navigate and understand the schema of a SPARQL endpoint, thanks to its graphical interface that provides a visual representation of the endpoint’s schema.
Additionally, TypeSPARQ enables users to visually select data structures or subsets of ontologies and directly generate a starter LDkit application from those selections. This includes the specification of the endpoint, data schemas, and Lens components necessary for the development.
As a result, using TypeSPARQ enables application developers to bootstrap their Linked Data applications easily, even without previous knowledge of RDF and related technologies. TypeSPARQ produces a ready-to-use starter template that provides an end-to-end type-safe access to selected data in the target SPARQL endpoint. This accessibility significantly lowers the barrier to entry for new developers in the field of Semantic Web and Linked Data, allowing them to focus more on application logic and less on the complexities of RDF data handling. This approach not only simplifies the initial setup process but also accelerates the development cycle, making it more approachable and manageable for developers of all skill levels.
Schema Forge
Schema Forge 67 is a low-code, pattern-driven schema engineering tool designed to facilitate the interactive exploration and authoring of RDF-based ontologies. It supports the ingestion of ontologies serialized in formats such as Turtle and JSON-LD, enabling users to navigate classes, properties, and relationships through a dynamic graphical interface, including visualization of ontology structures.
To enable dynamic retrieval of ontology elements, Schema Forge integrates LDkit for querying Linked Data resources. Specifically, it utilizes LDkit’s querying capabilities to obtain class hierarchies and enumerate subclass relationships within the connected dataset, thereby ensuring type-safe and schema-aware interaction with RDF data.
While Schema Forge is currently in an early stage of development and lacks some features required for production-level deployment, it provides a functional foundation for ontology exploration and editing. The project appears to be under active development, with a publicly available roadmap indicating planned features and enhancements.
Linked Data Engine
The LDE 68 is a modular suite of Node.js libraries that are designed to support the development and execution of Linked Data applications and data processing pipelines.
The project encompasses a broad set of functionalities, including dataset modelling, downloading dataset distributions, and retrieving dataset descriptions from DCAT registries. It also facilitates the deployment of local SPARQL endpoints for testing purposes, as well as the import of data dumps into local SPARQL endpoints for querying.
LDE is currently under active development. A public roadmap outlines upcoming features, including a pipeline builder tool to query, transform and enrich Linked Data.
At present, LDE utilizes LDkit to query dataset descriptions from DCAT-AP 3.0 registries. The implementation includes a custom DCAT namespace, a dataset schema built upon this namespace, and leverages LDkit filtering and pagination capabilities.
Future Work
While LDkit is a production-ready toolkit suitable for developing most common Linked Data-based applications, several aspects could be improved in future iterations.
First, LDkit is currently RDF graph-agnostic when reading and writing data. To enhance flexibility, we plan to introduce support for named graph constraints in LDkit resources, allowing users to specify particular graphs for their data. A key challenge in this implementation is determining how to handle resources that span multiple graphs. This raises the question whether to enforce graph constraints at the resource level or at the property level.
Second, LDkit users would benefit from support for RDF containers and collections, enabling the retrieval of ordered or unordered lists of entities – a common requirement in application development. Since LDkit relies on SPARQL queries for data retrieval and updates, effective support for these RDF structures must first be implemented in SPARQL to ensure efficient integration into LDkit and similar tools. While SPARQL 1.1 introduced support for property paths, making it somewhat easier to work with ordered lists, it still leaves a lot to be desired.
Finally, to support the development of user-friendly applications, LDkit must be able to query data fast. As previously discussed, more complex data schemas result in more complex SPARQL queries, leading to longer execution times within query engines. Addressing this challenge is nontrivial, as SPARQL performance issues stem from graph-based data model, inefficient storage or indexing, and the computational cost of joins and path queries. Given these constraints, there are limits to the performance improvements that can be reasonably expected from SPARQL query engines in the future. Instead, performance optimizations could be implemented at the LDkit level by leveraging knowledge of the data schema. This could involve decomposing complex SPARQL queries into smaller queries, deferring their execution, or supporting the retrieval of partial results.
Conclusion
Web application developers face considerable challenges, primarily due to the vast array of technologies they need to master. The addition of Linked Data into the web development mix introduces yet another layer of complexity with its distinct set of technologies and standards. This exacerbates the learning curve and can detract from a positive development experience. Historically, the Semantic Web community has struggled to keep pace with the rapid evolution of application development standards, and there has been a notable scarcity of robust, production-ready frameworks or libraries that adequately support developers in integrating Semantic Web technologies smoothly. Consequently, despite the potential benefits of Semantic Web technologies, their adoption within the broader web development community remains limited.
LDkit 2.0 represents a major step forward in lowering the barrier to the adoption of Linked Data and Semantic Web technologies. LDkit is the result of a decade-long effort and experience of building front-end web applications that leverage Linked Data, and as such it is a successor to many different RDF abstractions that we have built along the way. It is specifically designed to simplify the complexities associated with querying RDF data, while still providing developers complete control over semantic data mapping through its schema-based approach. By abstracting the intricacies of SPARQL queries and RDF data handling, LDkit allows developers to focus on the logic of their applications rather than getting bogged down by the underlying data structure complexities. The framework offers a schema-driven approach that enables precise control over how data is mapped and manipulated within applications. This means developers can define custom data models that directly correspond to their application needs, ensuring that the integration of semantic data is both seamless and efficient.
In conclusion, we believe that LDkit is a valuable contribution to the Linked Data community, providing a comprehensive abstraction of Linked Data technologies. Throughout this paper, we have presented evidence to support this claim, demonstrating how LDkit addresses specific web development needs and its utility in real-world scenarios. We have illustrated its impact by presenting both quantitative and qualitative insights from existing projects that currently utilize LDkit, including those that further simplify the use of Semantic Web technologies for developers. Based on this evidence, we are confident that LDkit will foster further adoption of Linked Data in web applications.
Funding
The authors received the following financial support for the research, authorship and/or publication of this article: This research was supported by SVV project number 260 698.
Footnotes
Declaration of Conflicting Interests
Ruben Taelman is a postdoctoral fellow of the Research Foundation – Flanders (FWO) (1202124N). The remaining authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.