
Abstract
Explainable artificial intelligence (XAI) attempts to give explanations for decisions made by AI systems. Despite the fact that for knowledge-based systems this is perceived as inherently easier than for black-box AI systems based on Machine Learning, research is still required for computing satisfactory explanations of reasoning results. In this article, we focus on explaining non-entailments as a result of semantic matching in
Introduction
Today, the vast amount of data that is available has driven research into machine learning (ML) and deep learning approaches, which provide AI systems with the possibility to autonomously learn and adapt to various scenarios. These models consist of black-box structures, that is, they provide outcomes without revealing any information about their underlying workings. To this end, with knowledge-based systems being inherently explainable, explanations techniques are more focused on black-box systems (Tiddi, 2020). However, the information that these approaches provide is often numerical, which lacks context and needs additional information to understand how a result was achieved or to interpret that result. Knowledge based systems and reasoning are well suited to provide help here, by encoding information and adding context to it, as well as providing the possibility to reason with that context. In addition, explanation techniques in Symbolic AI could help, when integrated with subsymbolic AI, to understand the underlying workings of subsymbolic approaches. Furthermore, the existing research in explainability for knowledge-based systems is not complete and has room for improvement. E.g., the already established methods of justifications (Kalyanpur et al., 2007) and proofs (Alrabbaa et al., 2020) provide excellent results when explaining logical inferences of knowledge bases. However, they fall short when explaining why observations are not a logical consequence of some knowledge base (Du et al., 2017; Haifani et al., 2022; Ouyang et al., 2023), when, in reality, they should be. Widely used approaches that are based on reasoning techniques in Symbolic AI, for example semantic matching, are enormously enhanced when explanations are introduced. Thus, research of explanation techniques for knowledge-based systems, even though perceived inherently easier than for black-box AI systems, is still a vibrant topic.
Ontologies offer a suitable way to capture and classify domain knowledge from human experts, making them practical in various substantial fields. SNOMED CT 1 is a standardized medical ontology that provides codes and definitions for medical terms (El-Sappagh et al., 2018), and the ChEBI ontology 2 represents chemical entities of biological interest (Degtyarenko et al., 2007), with both including over 300,000 axioms. In addition, ontologies have been developed for various industrial fields such as electronics (Liu et al., 2005), energy (Santos et al., 2018), process engineering (Wiesner et al., 2010), and construction (Sorli et al., 2006), to name a few. Besides modeling domain knowledge, ontologies offer numerous ways to support users’ decision making (Arena et al., 2017; Beimel & Albagli-Kim, 2024). This is achieved by means of logical reasoning, which provides the possibility to perform reasoning tasks such as consistency checking, instance retrieval, and inference. To further enhance the decision-making support, methods that provide explanations for reasoning results are included in knowledge-based systems (Alrabbaa et al., 2020; Kalyanpur et al., 2007; Horridge et al., 2008), thus creating explainability within the scope of Symbolic AI.
Ontologies are often used to represent domain knowledge in the form of axioms. Based on these axioms, reasoners are then utilized to infer new knowledge (axioms) that are a direct consequence of the modeled ones. The inferred axioms are called entailments. Naturally, methods to explain entailments are constructed, and are, in fact, quite thoroughly researched. For example, an established method to explain entailments are justifications, which provide a minimal subset of axioms from an ontology sufficient enough for an entailment to hold (Kalyanpur et al., 2007). Recently, proofs have also been used to explain entailments and present a step-by-step process of obtaining an entailment from a knowledge-base (Alrabbaa et al., 2020, 2021, 2022).
However, the question now asked is: how can we explain non-entailments? Non-entailments are axioms that do not logically follow from a knowledge base. Hence, if we would want to explain non-entailments, we would not be able to directly derive from the existing knowledge the reasons for why an axiom is not entailed. This indicates that we need to identify new knowledge, ‘‘missing’’ from the ontology, relevant to the concepts in the non-entailment, in order to explain it. Considering this, a classical approach to explain non-entailments is abduction, which is used to generate hypotheses that contain ”missing” knowledge, such that when added to the ontology the non-entailment becomes entailed. In recent years, an accent has been put on abductive reasoning in ontologies and creating methods to explain non-entailments (Calvanese et al., 2013; Haifani et al., 2022; Koopmann, 2021; Ouyang et al., 2023).
Naturally, in abduction, a set of possible abducibles is determined (Du et al., 2017; Koopmann, 2021). Such a set provides the possible concepts or axioms that could be abducted and it represents a form of a constraint on the hypothesis. Recently, homomorphisms have been used to generate abductive solutions for TBoxes (Haifani et al., 2022), which do not explicitly constraint the abduction to a set of predetermined abducibles. Still, they capture entailments through axioms that contain atomic concepts only. Though they extend the set of common minimality criteria (Calvanese et al., 2013), such as subset, size, and semantic minimality, and filter hypotheses that do not carry meaningful information, homomorphisms restrict hypotheses to concepts only and exclude role restrictions in abductive solutions, thus dismissing other potential abductive solutions. For example, considering TBox abduction, abductive solutions could be restricted to only include axioms of a certain type, such as concept inclusions of the form
One use case that can benefit from explaining non-entailments is semantic matching. Within Li and Horrocks (2003), semantic matchmaking (or semantic matching) and its most widely used degrees of matches are introduced, which are: exact, plugin, subsume and intersection. The idea of semantic matching consists of finding direct relations and retrieving promising counterparts between two proposed concepts (Colucci et al., 2007). Explaining the results of semantic matching helps make AI systems transparent and understandable. For example, in Gocev et al. (2020) semantic matching is used in an industrial scenario. At first, ontologies are used to represent machine knowledge and semantic matching is used to match machines’ capabilities with certain product requirements. Then, explanations for the outcomes of semantic matches are generated, which help users understand the reasons why a certain product cannot be produced. In the cases where the machine capabilities’ and product requirements are in a negative plugin, subsume or exact match, which are represented in the form of non-entailments, an explanation technique would allow for users to understand the reasons why a certain product could not be directly produced by a specific machine and what needs to be done to remedy that situation. In McGuinness et al. (2004) a satisfiability-based approach is presented to explain results of semantic matching and in Colucci et al. (2004) and Di Noia et al. (2003) we can see the utilization of semantic matching for an e-marketplace. To discover potential matches, they use abduction, which in a way explains why a negative result of a semantic match is obtained, by showing how the negative result can be converted into a positive one. The explanations allow users to ”fix” the negative matches, or, in other words present suggestions on how to fix them. Hence, explaining the cases in which outcomes of semantic matching present as non-entailments would aid knowledge-based systems in debugging and potentially extend existing knowledge and fix negative matches. This article addresses those cases of semantic matching.
Our main contribution in this article represents a method for explaining non-entailments as a result of semantic matching for the description logic
To solve abduction problems, some methods (Di Noia et al., 2003; Du et al., 2017; Elsenbroich et al., 2006; Klarman et al., 2011) impose constraints on the set of concepts and/or role restrictions that can be included in explanations. These constraints usually allow for abduction of concepts only, and omit role restrictions. In addition, they limit the types of complex expressions that can be included in explanations. The challenge here is to minimize those constraints and allow for all forms of complex expressions to be included in explanations. To this end, we present our approach using subtree isomorphisms and illustrate how abductive solutions, that contain both concepts and role restrictions, can be constructed. We present a semantic model for the representation of complex definitions consisting of concepts and roles, which is constrained only by the signature of knowledge bases, and formalize our approach. Finally, we present an implementation of our method and illustrate the results for a working example, as well as perform two types of experiments: (a) synthetic experiments in which we randomly generate various concept expressions that contain from smaller to larger number of concepts and roles with the goal of stressing the methods’ performance, and (b) experiments on realistic ontologies to test the practicality of our method. The experiments show that the method can correctly and practically compute solutions to abduction problems.
We improve existing results by generalizing our method to be equally able to abduct role restrictions as well as concepts, which renders it capable of finding solutions to abduction problems where other approaches fall short. In addition, our method performs abduction of all formats of complex concept expressions and does not have any additional constraints, other than the signature of the background knowledge. Compared to other methods, we also improve the time needed to compute abductive solutions.
The remaining of the article is structured as follows: Section 2 presents related work on abduction and methods for generating explanations of non-entailments in DLs, how explanation techniques are used for semantic matching, and limitations and challenges in the areas, Section 3 overviews the Description Logic
Related Work
The problem of explaining results of semantic matching has been treated in various different ways in the past. They can be outlined by two main categories: explaining entailments, and explaining non-entailments. An entailment is an axiom that logically follows from a knowledge-base, for example, an ontology or a knowledge graph. They are often referred to as logical inferences. One established method for explaining entailments are justifications (Kalyanpur et al., 2007; Horridge et al., 2008). A justification is a subset consisting of the minimal number of axioms from an ontology such that the entailment holds. Recently, proofs, in the form of directed hypergraphs, have been utilized to explain inferences for a defined logic
An abduction problem consists of a background knowledge and an observation that is not entailed. A solution, referred to as a hypothesis, is a set of axioms that when added to the background knowledge the observation becomes entailed. Since the hypothesis provides reasons for why the observation was not entailed in the first place, it is treated as an explanation for the non-entailment. Depending on the background knowledge and the observation, we can perform concept abduction (Bienvenu, 2008; Ouyang et al., 2023), where the hypothesis consists of atomic concepts restricted by the background knowledge, ABox abduction (Calvanese et al., 2013; Ceylan et al., 2020; Del-Pinto & Schmidt, 2019; Du et al., 2012, 2014; Halland & Britz, 2012; Klarman et al., 2011; Koopmann, 2021; Pukancová & Homola, 2017, 2020), where the background knowledge includes assertions and the observation is a query to the ABox (the hypothesis contains assertive knowledge), TBox abduction (Du et al., 2017; Haifani et al., 2022; Wei-Kleiner et al., 2014), specific for explaining observations in the form of general concept inclusion axioms, and knowledge base abduction (Elsenbroich et al., 2006; Koopmann, 2021), where the hypothesis consists of terminological and assertive axioms constructed from the background knowledge.
We can also see the utilization of abduction for semantic matching in Colucci et al. (2004); Di Noia et al. (2004, 2007), where a search is propagated for the assumptions needed for a supply to meet a demand. The focus is mainly on the abduction of concepts that are added or contracted from definitions of matching concepts, in order to achieve a certain degree of semantic similarity between them. The added concepts represent hypotheses that explain the negative outcome of the semantic match. However, this contraction or extension may change the original concept definitions and the explanations may not present as meaningful. To tackle this, specific constraints are introduced in the search for explanations. Our interest lies in preserving the definitions of matching concepts by finding direct relations between them, while putting minimal constraints on the process of abduction.
The problem of evaluating concept compatibility in semantic matching can be brought down to a search for a conjunction (or an extension of a conjunction) for given matching concept definitions. Ultimately, this search can be transformed into the subgraph isomorphism problem (Bartalos, 2011; Rouached & Godart, 2008). We present how the subgraph isomorphism problem can be utilized to explain non-entailments of semantic matching and a method that computes subtree isomorphisms to generate explanations for non-entailments of semantic matching.
Similarly to Colucci et al. (2004); Di Noia et al. (2004, 2007), abduction is used to generate explanations. However, our method focuses on obtaining direct relations between matching concepts, that is, general concept inclusions (GCIs), instead of concepts alone, to explain non-entailments of semantic matching. This approach preserves the structure of the definitions of matching concepts, thus filtering explanations that do not provide critical information for the outcome of semantic matching.
While graphs and homomorphisms have been used previously to solve abduction problems and to explain general concept inclusion non-entailments (Haifani et al., 2022), which our method also does, we do not search for relating concepts in TBoxes, but generate explanations of non-entailments that contain direct connections between complex concept definitions, which are obtained as a result of our semantic matching scenario.
In addition, we use subtree isomorphisms instead of homomorphisms between graphical representations of concept definitions to allow for abduction of not only concepts, but also role restrictions, which represents our major contribution in this article.
Previously, in our work (Gocev et al., 2022) we presented an approach for generating explanations for non-entailments in DLs using subtree isomorphisms. The approach is focused on explaining general concept inclusion non-entailments. Since the method in Gocev et al. (2022) finds direct relations between concepts in a non-entailment, it fits the use-case of semantic matching. In this article, we formalize our previous work and show how it can be used to generate explanations for results of semantic matching that are not entailed. We extend the definitions for subtrees and show in detail how subtree isomorphisms capture concept inclusions in semantic matching. In addition, we fully implement and test our method.
Preliminaries
In this section, we briefly summarize the description logic
Description Logic
We start by defining countably infinite disjoint sets,

For concise representation, we denote a conjunction of
The interpretation
A TBox
We denote axioms by
A TBox
A TBox
When an axiom
We introduce some fundamental concepts and notations from graph theory, that are used throughout this article.
A directed rooted tree is a directed acyclic graph, with the following characteristics: One node has been distinguished by the others and is designated as the root, that is, it has no in edges, All other nodes have exactly one in edge, and can have There is a path from the root to all other nodes, that is, it is connected, There do not exist any cycles, that is, it is acyclic.
We formally define directed rooted trees as a tuple
We denote nodes of trees by
Let
In a rooted tree there is a unique path between any two nodes. The length of a path is the number of vertices in a path, and is denoted by
Formally, we define the connected and acyclic characteristics of a tree
Nodes and edges of rooted trees can contain labels. A labeling is simply a map
A rooted tree
Semantic matching is a technique used to identify semantically related concepts (Bassiliades et al., 2017; Di Noia et al., 2003, 2003?; Li & Horrocks, 2003; Paolucci et al., 2002). Introduced in Li and Horrocks (2003), semantic matching determines whether two concepts are semantically similar (or compatible) w.r.t. some background knowledge, if their intersection is satisfiable. If the intersection of two concepts is not satisfiable w.r.t. some background knowledge, then they are not semantically similar, that is, the concepts are incompatible. We refer to the former as positive intersection matches and the latter as negative intersection matches.
Let


A positive result of an intersection match (or a positive intersection match) occurs if two concepts
Positive and negative semantic matches of higher degrees are defined as follows:
Let






Let
There is a clear distinction between the types of semantic matches and results they provide, as well as the way the results present themselves w.r.t. some background knowledge. Intersection matches provide only information whether the concepts in the semantic match are compatible or not. For example, if two concepts are not compatible, the (negative) result of the intersection match between them presents as an entailment and to explain it we can invoke a justification, which will provide the reasons why the concepts are not compatible. However, if two concepts are, in fact, compatible, it presents as a non-entailment. To explain this (positive) result of their intersection match, we refer to exact, plugin, or subsume matches. To put it simply, the information that the positive intersection match gave can be further used to identify the degree to which the matching concepts could be, semantically similar. If we explain the extent of their similarity, we also inherently explain why they are compatible.
Let
Let

To explain non-entailments of semantic matching we opt to search for ”missing” connections between concept descriptions introduced in a negative match. The case of intersection matching is used purely to identify whether the background knowledge can, in fact, provide a consistent model of a semantic relation between matching concepts. For the negative outcomes of higher degree matches, we need to construct hypotheses that will contain the axioms such that when added to the background knowledge the outcome of the match becomes positive. To do this, we need to take into account the following: Hypotheses should contain axioms that preserve the structure of concept descriptions (definitions) introduced in matches, Hypotheses should take into account the structure of concept descriptions that cannot be preserved, Hypotheses should not unnecessarily omit parts of concept descriptions that preserve the structure.
The three points refer to the overall idea of performing abduction between matching concepts.
However, in some cases, this structure cannot be preserved. Take for example the concepts
Finally,
The idea of preserving the structure in
Let
The empty label represents the top concept (
We can recursively define a concept 

where
Likewise, if we have a concept definition

Representing concept definitions as description trees gives the potential to relate concepts w.r.t. a background knowledge. For example, homomorphisms between description trees capture subsumption between
Let
We write
We propagate the notation from Haifani et al. (2022), and distinguish description tree isomorphisms in two main ways: weak isomorphisms, that is, isomorphisms that satisfy the conditions in Definition 8, and Type Type Type
Let
Each type of a
Let
We are examining the case of
The proof is done by structural induction on the depth of
Assuming that
Considering that
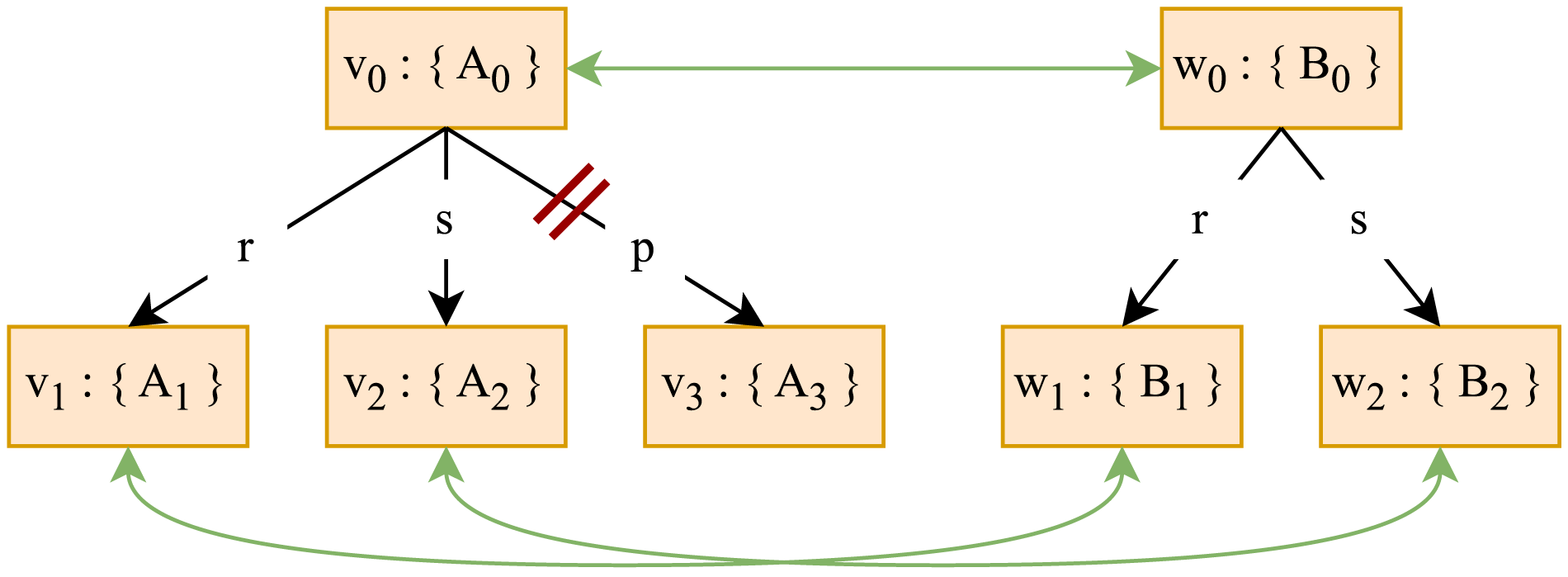
Let 
To illustrate how a
Let Example Description Trees


We can notice that
From this, it follows that
On the contrary,
and
Therefore, in this case
If relations between concepts are missing from some background knowledge
To allow for abduction of role restrictions we introduce subtree isomorphisms between
Let for each for any two nodes for all for all
If
A
We show that a From the definition of From the definition of By definition, for all By definition, for all From
Thus, a
If
The proof directly follows the definition of an induced subtree. We want to show for a description tree
Because
Let
where:


Definition 12 states that for a given weak isomorphism between two
Same as before, we distinguish three types of
Let Description Trees
On the other hand, we have that:
Same as before, we can use this weak isomorphism and the ”missing” relations to construct a hypothesis:



The final
Naturally, hypotheses that contain more complex expressions are harder to interpret in comparison to those containing simpler abductions. Moreover, for an abduction problem defined as in Definition 6, any arbitrary abduction up to the entire descriptions of the matching concepts can be used to explain the non-entailment. To this end, we introduce a minimality criteria which filters out hypotheses that contain unnecessary abductions of concepts and/or role restrictions.
To define minimal abductive solutions, we first impose a partial order on the isomorphisms.
Let

Definition 13 partially orders weak isomorphisms between
Given an abduction problem
We prioritize preserving the concept definitions, and, where necessary, find solutions obtained from minimal number of contractions to induce subtrees. To illustrate minimal solutions consider the following example.
Let

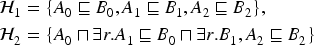
Isomorphisms between
One of the most fundamental computational problems on trees is the subtree isomorphism problem, which asks whether a given tree is contained in another given tree. The subtree isomorphism problem has a few variants, which are mainly dependent on whether the trees are rooted or unrooted, whether the degrees of nodes are bounded, and whether an order on their nodes must be preserved. We accustom the subtree isomorphism problem for the special case of description trees to solve abduction problems in
Let
To compute subtree isomorphisms between description trees and derive hypotheses to explain non-entailments of semantic matching we partition the children of vertices in their respective trees w.r.t. the labels of edges connecting parents to their children. We define an equivalence relation on the set of children for a vertex
Let
For
Thus,
An equivalence relation defines exclusive classes whose members bear the relation to each other and not to those in other classes. The set of all equivalence classes is defined as:

Let
Let
(1) We need to show that
(2) We need to show that if
(2.1) Let
(2.2) Suppose
Once the children are partitioned, vertices that belong in an equivalence class in one tree can be mapped to vertices that belong in an equivalence class in the other tree, such that the equivalence classes in the respective trees are obtained from same edge labels. Let

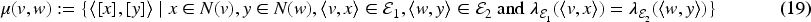
The relation
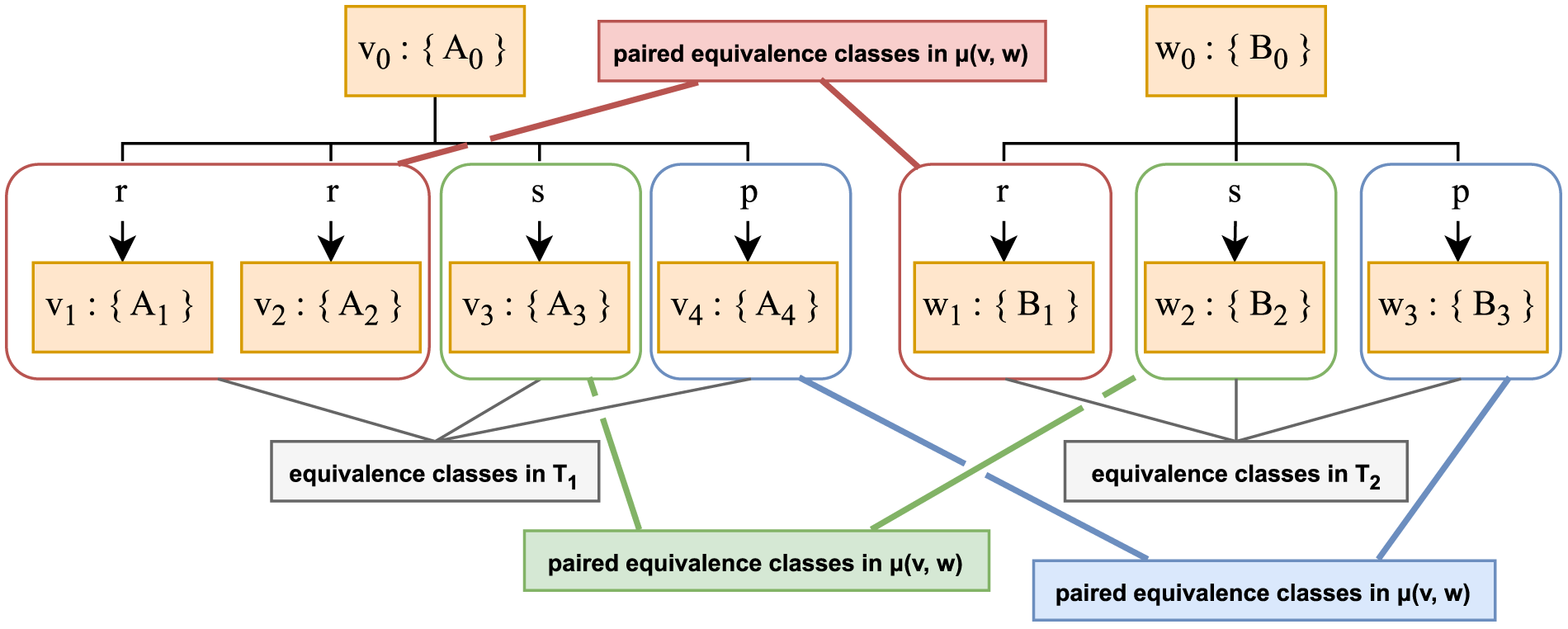
Example Description Trees
Finally, we map the partitioned nodes from the respective trees using the relation
To find all pairs of mapped nodes that preserve the structure, we compute injective maps between distinct subsets of the equivalence classes in
Let
Given two non-empty sets
We prove this by using Dirichlet’s principle (a.k.a. the pigeonhole principle).
Consider a mapping
Given two non-empty sets
The proof is ones again done by using Dirichlet’s principle.
Consider
Going back to our equivalence classes in
In any case, the injective mappings will be between subsets of
We can find injective mappings from

Since
Let
For
Let
By definition a function
Since
Since the subsets of
For each pair of equivalence classes obtained from the equivalence relation, we find the set of all injective maps, such that:


To illustrate how we find equivalence classes and how we generate the sets
Consider the description trees in Figure 4.
Example Description Trees 
We start from the roots of
Next, we partition
where
From here, we obtain
in which we can see that the partition w.r.t. the label
which are included in
We can see in
Notice that
To obtain isomorphic mappings, we construct a Solutions Tree.
A Solutions Tree is a node-labeled rooted tree

The solutions tree is a rooted tree, which contains mapped nodes between two

The set of all isomorphic mappings

For all
We prove this by structural induction on the induced
Let



From Proposition 6 it follows that each
To show that this holds for all nodes and not only the roots and one level below, we need to show that if


From Proposition 6 it follows that each
For two given 

In this section we present the implementation of our method for explaining non-entailments of semantic matching in
Implementation
The algorithm is implemented in Java using the OWL API (Horridge & Bechhofer, 2011). The classification and entailment checking is performed by the Pellet reasoner (Sirin et al., 2007).
The input to the algorithm is a non-entailment of a certain semantic match. More specifically, the algorithm receives some background knowledge ( Read input parameters for the abduction problem (background knowledge Get the description trees Compute the set Construct the set of hypotheses explaining the non-entailed semantic match w.r.t. Eq. (30) from the set
We will now present the implementation for Steps 2-4 of our method.
Step 2
In this step the respective description trees of the inputted concept descriptions are obtained. To do this, we first impose a standardization on inputted concept definitions.
Let
The approach to translate a concept description into a description tree starts with splitting the expression into two parts: the conjunction of atomic concepts, and conjunction of role restrictions. Further, a node is created and the set of concept conjuncts are added as a label of that node. Next, it is iterated over each role restriction and the children of the current node are constructed. Each edge is labeled w.r.t. the role names. Following this, the concepts restricted by the roles are added next in queue and the same is done for them. This follows the inductive definition of description trees presented in Section 5. Each concept description is written in OWL Manchester Syntax.
Step 3
This step contains the main algorithm for computing subtree isomorphisms between description trees. It is the main implementation of our methodology. Here are the steps of the algorithm for computing Read inputted description trees of concepts. Initialize the set of Initialize the solutions tree and its root by mapping the roots of the description trees. Add the root node of the solutions tree to the queue. Obtain the next node from the solutions tree in the queue. For each pair of mapped vertices in the current node find all children in the respective description trees and partition them w.r.t. the equivalence relation in Theorem 2. Construct the relation Construct Construct and save If there are no more pairs of vertices to evaluate go to the next step, otherwise go to For each If the queue is empty continue, otherwise go to Find all complete paths in the solutions tree and construct
To illustrate how we compute
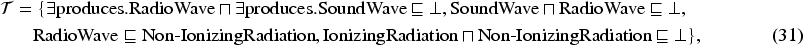
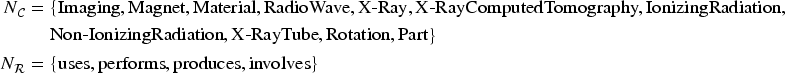

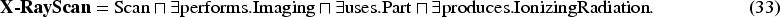
The description trees of the concepts

A Solutions Tree Containing the Subtree Isomorphism Between the Concepts CTScan and X-RayScan.
By definition, the roots of description trees need to be mapped in order to obtain an isomorphism. Thus, we construct the root of the solutions tree carrying the mapping
This partitioning is done according to the equivalence relation defined in Theorem 2. In the example, the equivalence classes contain the following vertices in
and in
Further, the relation from Eq. (19) is defined for
The relation
We are interested in all isomorphic mappings. Thus, to find all subtree isomorphism, we need to search for injective maps between pairs of equivalence classes (Eq. (20)). For the example, the set of injective mappings between equivalence classes is:
Finally, all unique combinations of injections are taken using Eq. (21):
A new node
In the next step the mapped vertices in the pairs
from which the mapping relations are formulated w.r.t. Eq. (19):
We can see that in this iteration there exist no nodes from either description tree that could be mapped in order to obtain an isomorphism. All nodes that could not be mapped in this iteration, because they are tails of edges that do not have corresponding labels and mapping them would not provide an isomorphism, are omitted from the final abductive solution. Thus, the method stops this iteration and goes onto the next. Since no new nodes are added in the queue to be evaluated, the method returns the solutions tree with all possible
From the solutions tree on Figure 5 we can see that the set of all complete paths is
where
The isomorphisms are built from top to bottom and the equivalence relation that partitions the nodes w.r.t. the edge labels, as well as the relation

Step 4
The final step of the main code takes as an input a set of weak Read the set of weak For each Construct the hypothesis for each
The algorithm for constructing the hypotheses from a set of weak
In our working example, we have one isomorphism,
In natural language this hypothesis states that ”X-Ray computed tomography is a type of imaging.”, ”X-Ray tube that rotates is a part.” and ”X-Ray is a type of ionizing radiation.”. In reality, an X-Ray computed tomography is a type of an X-Ray scan, because it is based on the same technique. In fact, an X-Ray computed tomography is a specific type of an X-Ray scan. The hypothesis clearly states what is missing from our background knowledge in order for the concepts
Since there is no standardized benchmark for
Simulations.
For the synthetic experiments, concept descriptions were randomly generated with different number of concepts and roles, with allowed repetition of role restrictions on various concepts. This way we also cover extreme cases in which concepts are restricted by the same role multiple times, possibly leading to a large number of abductive solutions. In each simulation two random numbers were taken from a uniform distribution in a provided interval. We constructed three scenarios each with an interval of:
We then obtained the description trees for the randomly generated concept descriptions and performed abduction using our method. We report on the above mentioned three scenarios. For each scenario we ran 250 simulations with the given parameters. The non-entailment of interest was designed as
Because our methodology focuses on finding abductive solutions that contain direct relations between concept descriptions and does not use information in the background knowledge to find connecting concepts, we opted to go for initially empty TBoxes in the synthetic experiments. In real scenarios, concepts can have multiple definitions in the background knowledge. For example, for some terminological knowledge
If we find that there are more than one definition of a matching concept, then we can perform our abduction process (activate our method) for all (or a chosen subset of) definitions w.r.t. the matching concepts. For example, if we have the non-entailment
Results
We measured the mean, median, and maximal values of the cardinalities of vertex sets (
Results From the Synthetic Experiments.

Results From the Synthetic Experiments.
Figure 6 represents the times needed to compute all solutions that an abduction problem has. On the x-axis, standardized values for the number of solutions (hypotheses - #

Simulation Results: (Standardized) Number of Hypotheses (#H) vs Time (t[s]) for Scenarios

Simulation Results: (Actual) Number of Hypotheses (#H) vs Time (t[s]) for Scenarios
We can see that there is some deviation in the results that show distinct cases where the method needs more time to compute subtree isomorphisms, which is due to the frequency of repetitive (identical) edge labels in description trees. It can be also noticed that for all three scenarios the median of the number of solutions is nearly a constant value, whereas the mean fluctuates. This points to the fact that no matter how many concepts are included in descriptions, and therefore in their respective trees, most abduction problems have only one or two solutions and very few abduction problems have a large number of solutions. Once again, this is due to the frequency of repetitive edge labels in the description trees. For example, if we have description trees with edges labeled with a unique role, then by the definition for description tree isomorphisms there exist many different combinations of concepts that could potentially be connected. On the other hand, if the description trees contain distinct roles as edge labels, then by the definition for description tree isomorphisms there would be fewer concepts that could potentially be connected.
For the concept definitions, this relies on how rich the background knowledge is, that is, how many distinct roles could be used when modeling concept descriptions, and how diversely the concept descriptions are modeled. If we have a rich background knowledge and diversely modeled concept descriptions, that is, distinct roles are used to represent restrictions of certain concepts, then no matter how many concepts are in the descriptions, there will be fewer concepts to potentially connect. On the other hand, if the background knowledge is not as rich and does not offer the possibility to use distinct roles to create more expressive concept descriptions, then there will be many repetitive roles (edge labels) in the description trees, and, thus, a lot more concepts that could potentially be connected.
Additionally, we obtained the average branching factors of the description trees and the sets of edge labels of description trees, which we define as 
Figure 8 presents the correlation between the Jaccard indices of the sets of edge labels of descriptions trees and the number of solutions for the abduction problems in those cases. Essentially, if there is a higher similarity of edge labels in description trees, then the nodes will be partitioned in fewer equivalence classes, but with larger cardinalities, that is, the equivalence classes may contain a large number of nodes that can be potentially mapped in various combinations. Since each unique combination of mapped nodes is part of a distinct subtree isomorphism, this will directly affect the number of abductive solutions. However, not all cases behave in this way.

Simulation Results: Jaccard Indices of Sets of Edge Labels of Trees vs (Actual) Number of Hypotheses (#H) for Scenarios
For example, scenarios
Generally, if there is a lower similarity of the sets of edge labels, or even no common edge labels, then there will be a lower number (or even none) partitions and vertices to map. Thus, the method omits those mappings between vertices that do not represent an isomorphism. These are the cases in which the method almost instantaneously computes subtree isomorphisms. On the other hand, higher similarity of edge labels in the trees may lead to a large number of hypotheses, as there may exist a lot more partitions and nodes to potentially map. However, this does not necessarily increase the number of solutions. In order to obtain isomorphic mappings we need to map nodes which are endpoints of edges that have same edge labels (condition 2 of Definition 8). Moreover, the mapped nodes should preserve the depth at which they are in their respective trees and the orientation of the edges, otherwise the structures of the rooted trees would not be preserved. Hence, even if there is a high number of common edge labels in trees, some depths may not contain common labels and the nodes there cannot be mapped. In these cases, the number of solutions would remain unchanged. To this end, there exist cases in which trees with higher Jaccard indices may have fewer solutions (Figure 8). In addition, for the cases in which multiple abduction problems have trees with same Jaccard indices, but different number of solutions, Figure 8 presents as shaded areas the 95% confidence intervals of the mean values of the number of solutions. We can see that cases in which there are higher similarities of the sets of edge labels show deviation in the number of solutions, which is a direct consequence of the approach of partitioning and mapping distinct nodes at equal levels in the trees.
To add to the explanation for the similarity of edge labels, the last correlation that was observed is shown in Figure 9, which shows the ratios of branching factors and the number of solutions for abduction problems for the three scenarios. For better presentability, the outliers above three standard deviations have been omitted. The ratio is calculated as the average branching factor of the first tree divided by the average branching factor of the second tree. A lower ratio of the branching factors between trees could potentially induce a higher difference of the sizes of equivalence classes. Thus, this will yield more combinations of isomorphic mappings, and, consequently, more solutions to abduction problems. This occurred mostly around a value for the ratio of the average branching factors of

Simulation Results: Ratios of Branching Factors of Trees vs (Actual) Number of Hypotheses (#H) for Scenarios
The average branching factor represents the average number of children at each node. If the average branching factor of a tree is high, then there are more nodes to partition into equivalence classes. However, this does not necessarily indicate larger equivalence classes and more solutions. If there is a high average branching factor of a tree and only a very few unique edge labels (roles) that partition those nodes, then there will be fewer equivalence classes that will contain a high number of nodes. Thus, if two trees have high branching factors and a ratio of their average branching factors
In addition to performing an experimental evaluation on randomly generated concept descriptions (synthetic experiments), to stress the computational capabilities of the method, we performed an experimental evaluation on realistic ontologies from the bio-medical domain (2017 snapshot of BioPortal Matentzoglu & Parsia, 2017) and the LUBM ontology (Guo et al., 2005). Each ontology in the corpus is restricted to its
Table 2 shows the results from the second type of experiments performed on real ontology datasets. We report on the number of abduction problems that were generated (#AP) of the form
Results From the Experiments on Real Ontology Datasets, Where Arbitrary Concepts are Picked to be Matched.

Results From the Experiments on Real Ontology Datasets, Where Arbitrary Concepts are Picked to be Matched.
Out of the 438 ontologies in the BioPortal dataset, 316 were successfully loaded and reasoned with. After restricting each ontology to its
When the trees do not contain any common labels on the first level, the trivial solution is the only one that can be obtained and the method stops the search, hence the almost instantaneous computation. Most cases in the experiments consisted only of the trivial solution. The reasons for this are: (i) the method computes only direct connections between matching concept definitions and does not search for intermediate concepts within the ontologies that can be connected, that is, when concepts in the ontology can also be used to connect the matching concepts then the outcome of the abductive solutions may change, and (ii) although there were ontologies in the dataset containing thousands of axioms, the knowledge is well represented and definitions contain very few concepts and roles.
For the cases in which the only solution was not the trivial one, the method showed to be practical and successfully and quickly generated abductive solutions. We single out these cases in Table 3.
There were 302 cases in which non-trivial solutions were successfully computed for the BioPortal data. Since the LUBM ontology contains very few axioms and concept definitions, no cases were generated in which non-trivial solutions existed. We can see that the cases in which the trivial solution was computed, did not impact the runtime, because the method can very quickly check whether there exist common labels of edges from the roots to the children in the respective trees.
The third type of experiments were conducted on the same ontologies, but with concept definitions that were already matched in them, that is, those were in a known semantic match. We present these results in Table 4.
These experiments were formulated on the classical use-case of semantic matching, to observe how well the method computes abductive solutions in cases where concepts should, in fact, be in positive semantic matches. We managed to generate 1780 abductive abduction problems for the BioPortal ontologies, and 91 abduction problems for the LUBM ontology. The Pellet reasoner was used to check whether the picked concepts were matched. It can be seen that as in the previous experiments, the method has nearly an identical performance and obtains similar results. Similar as with the second type of experiments, this cases also consists of a high percentage of trivial solutions and the reasons for that are same as the aforementioned ones, that is, the method does not search fo intermediate concepts to construct hypotheses that contain more connected concepts, and very few concepts are represented by complex definitions.
We compare our method, where possible, to similar existing ones, that is, the methods in Haifani et al. (2022) and Du et al. (2017), and present in Table 5 the comparison. We associated all methods whether they completed and successfully generated non-empty solutions, as well as the number of abductive solutions that were generated, their cardinalities, the number of concepts and roles included in abductive solutions and the runtime. To create a more eligible comparison, it was performed on comparing the methods when obtaining abductive solutions for non-entailments that contain arbitrary concepts, as this type of experiment was common for all methods. In addition, the comparison with (Haifani et al., 2022) was done on the BioPortal data and with (Du et al., 2017) on the LUBM ontology, because they were the common datasets.
Results From the Experiments on Real Ontology Datasets Where Only Non-Trivial Solutions Were Obtained.

Results From the Experiments on Real Ontology Datasets Where the Concepts Were Known to be Matched.

Comparison to Existing Abduction-Based Methods.

In comparison to the similar method in Haifani et al. (2022), for the BioPortal data, our method has a slightly better runtime performance. On average, it computes abductive solutions faster. However, the method in Haifani et al. (2022) focuses on obtaining abductive solutions for intermediate concepts within a background knowledge, whereas our method focuses on finding abductive solutions that consist of direct relations between matching concept definitions. As a consequence, the method in Haifani et al. (2022) obtains hypotheses slightly slower, but with smaller sizes, since it can find intermediate connecting concepts in the background knowledge and use them in abductive solutions. On the other hand, our method provides more concise abducted expressions in the hypotheses that contain fewer concepts and it also includes role restrictions in abductive solutions, which provides higher possibility of our method to successfully complete.
Compared to Du et al. (2017), we only managed to obtain the LUBM dataset. For this dataset, our method provided abductive solutions more quickly. Nonetheless, the runtime in Du et al. (2017) is heavily dependent on computing patterns to use and obtain abductions, but this provides the possibility to generate more solutions. A variety of patterns could in some cases present more explanations that would adhere to the users’ preferences. Because we were able to obtain only information regarding the runtime and total number of solutions that were obtained, the comparison with (Du et al., 2017) was done on these performance characteristics only.
The explanatory power of our method can be viewed from two perspectives: (i) finding minimal connections between concepts to explain non-entailments, and (ii) computing solutions that contain as concise as possible abductive solutions, that is, hypotheses that do not contain arbitrarily complex expressions.
Regarding (i), the explanatory power of our method adheres to the one in Haifani et al. (2022). Even though both methods differ when computing abductive solutions, they are based on the same idea of searching for concept relations using morphisms, which renders them powerful in finding minimal connections between concepts. The difference is for which concepts the methods search abductive solutions. By allowing existing concepts that are already connected in the background knowledge, as in Haifani et al. (2022), the outcome of the abduction can be changed. In this case, hypotheses can potentially contain less complex connecting concepts. Complementary to the approach in Haifani et al. (2022), our method can perform abduction of role restrictions, which finds hypotheses that otherwise would have been omitted. Hence, the explanatory power of our method is similar to the one in Haifani et al. (2022), because instead of allowing in abductive solutions existing concepts that are already connected in the background knowledge, our method accommodates this by allowing role restrictions in hypotheses. However, our method can be easily extended to use existing knowledge in abductive solutions. For example, a heuristic-based search can be performed to obtain a list of potentially connecting concepts within the background knowledge and our method can be used to extend that list and find the missing knowledge that would ultimately connect the matching concepts. Similarly, semantic similarity techniques can be used to acquire recommendations w.r.t. matching concepts, which will consist of semantically similar concepts within the background knowledge, that our method would take as inputs and connect. Essentially, our method could be used to relate disconnected components in the background knowledge. Therefore, to improve our method, as part of our future work, is integrating it with a technique to search for potentially connecting concepts within the background knowledge, compute abductive solutions between those concepts, and perform a more thorough comparison.
If we view the explanatory power as in (ii), our method manages to construct relations using only the essential concepts and roles, without the need to perform abduction of unnecessarily complex expressions. This is as a result of our method filtering hypotheses w.r.t. the minimality criteria in Definition 14. Compared to the other methods, our method obtains hypotheses containing fewer concepts. However, a more accurate examination of this case is needed. Therefore, as part of our future work we intend on conducting user surveys, in order to better evaluate and improve the interpretability and comprehensibility of the hypotheses that our method obtains.
Although our method is focused on explaining non-entailments of semantic matching, our main contribution is the extension of the state of the art method for abduction in ontologies, by generalizing abduction to axioms consisting of role restrictions too, and not only of atomic concepts.
The utilization of homomorphisms between description trees to solve abduction problems in
The problem of abduction of concepts as well as role restrictions is tackled in Du et al. (2017). This is done by constraining the abductive process by a set of predefined patterns that can be abducted. Apart from specializing our method for semantic matching, we do not constrain the form of expressions included in the abducted axioms; instead, our method is constrained only by the signature of the background knowledge. This will assure not to overlook certain patterns of nested expressions. Although we compute abductive solutions in a more timely manner and generate fewer and more concise solutions, the generation of patterns based on justifications that are used for formulating abductive solutions offer a large variety of formats of abductive solutions that can be used as explanations and for ontology debugging.
In Colucci et al. (2004), Di Noia et al. (2004), Di Noia et al. (2007) abduction methods for semantic matching in more expressive DLs are presented. In comparison, instead of reducing matching concept descriptions or introducing new concepts to reach a positive semantic match, our method searches for direct relations between concepts and role restrictions in matching concepts, thus preserving the original definitions of matching concepts.
Subtree isomorphisms have also been previously used with ontologies. In Kindermann et al. (2024), subtree isomorphisms have been used to determine term equivalence to rewrite finite formal languages. The approach can significantly reduce the size of ontologies by capturing repeated expressions. Similarly, we use node and edge labeled trees, but we capture semantic relations through subtree isomorphisms instead, rather than terms. In addition, they propose equivalence classes of macros, that capture ontology terms that are equivalent, whereas we partition nodes of description trees into equivalence classes that can capture semantic relations. Furthermore, our subtree isomorphism definition is a variant of their definition, in which they search for subtrees in one tree that are contained in another entire tree. Our methodology focuses on preserving the semantic structure of concept definitions and thus introduces a condition that the roots of the trees of the original concept definitions must be mapped.
In Hakeem et al. (2004) subtree isomorphisms are used to match video patterns represented by ontologies. The approach uses a naive search to obtain maximal subtree isomorphisms, whereas we employ (i) trees that are additionally edge-labeled, and (ii) a top-down approach using the edge labels to partition nodes and accumulate mappings that are isomorphic. Still, if we have description trees that contain only a unique edge label, then our method is generalized and can be said that solves the problem of computing subtree isomorphisms on unlabeled rooted trees. This can drastically increase the number of solutions in our case. A solution to this, which we currently work on, would be to introduce heuristics based on the complete paths in trees that would compute approximative solutions, but would decrease the method’s runtime.
On the more general note, the authors in Shamir and Tsur (1999) offer a method for finding the largest possible subtree of a tree that is isomorphic to some other tree. There are several differences between the method in Shamir and Tsur (1999) and our method. First, the problem in Shamir and Tsur (1999) is defined as a decision problem, that is, the algorithm answers the question whether there exists a subtree of one tree that is isomorphic to another given tree. It can also be transformed to a search problem to find a solution that satisfies this condition. However, our problem is defined as finding subtrees of both trees that are isomorphic, as opposed to finding if a subtree of one tree is isomorphic to an entire other tree. In addition, we look to compute all solutions, rather than decide whether there is a subtree isomorphism or find a solution that satisfies that condition. We compute all solutions in order to find all potential explanations for a non-entailment. However, a limitation of this is that the problem can exhibit a very high complexity. Next, we present a top-down approach that works with labeled directed rooted tree, whereas the method in Shamir and Tsur (1999) is bottom-up and focuses on unlabeled and not directed rooted trees. Finally, a bipartite graph is constructed from the children of nodes, for which the matching number (or a maximal matching) is computed, which will ultimately lead to deciding whether the answer to the problem is positive, or to find a solution that satisfies that condition. This is similar to our way of partitioning the nodes w.r.t. edge labels in description trees in equivalence classes and finding the bijective mappings between those classes. We opt to compute all bijections between equivalence classes, which could correspond to finding perfect matchings in bipartite graphs. This can potentially be implemented to
On the other hand, (Abboud et al., 2018) offers a different approach for identifying subtree isomorphisms for unlabeled binary and ternary trees. Given two trees, they reduce the problem of finding a subtree of one tree isomorphic to other tree to the Orthogonal Vectors (OV) problem. The inputs to the OV problem are two lists of
Limitations
One limitation of our method is scalability with large concept definitions. The method computes abductive solutions by partitioning the nodes in graphical representations of concepts, based on the roles that restrict (possibly nested) complex expressions. It then matches concepts that are restricted by same roles in both concept definitions. If all role restrictions are by the same role, that is, we have a high repetition of role/s restricting concepts, then the number of solutions can increase by a factor of
In Haifani et al. (2022), the abduction method via homomorphisms adheres to a connection-minimal criteria, which essentially connects two concept
Although our method is specialized to find subtree isomorphisms and semantic layers explicitly between input concept definitions and it does not consider within the background knowledge alternative definitions that a matching concept may have, an extension can easily be integrated with our method. Currently, it only uses the background knowledge to verify that a solution to an abduction problem does not produce unsatisfiable concepts. However, an extension can be easily made to this. An initial solution would be to find all possible definitions for matching concepts w.r.t. some background knowledge and to perform abduction between all pairs of those definitions. Another possibility, as seen in our experimental setup, is to combine all definitions of a concept in a match into one single one. In addition, the search for alternative definitions of concepts can be enhanced by the existing semantics of the background knowledge. This would also render our method useful in other scenarios, for example, more complex systems based on semantic matching and even ontology debugging and repair, and ontology completion. To this end, our ongoing work consists of two main things: (a) formulating a heuristics based on the complete paths in description trees to assist our method in finding maximal subtree isomorphisms and abductive solutions w.r.t. our minimality criteria, and (b) integrating our method with a search technique to find potentially related concepts within the background knowledge, for which we can find hypotheses and ultimately connect matching concepts.
Conclusion
We presented a method for explaining non-entailments of semantic matching in
There are several ways to improve our method. First, the complexity of our method rises with the size of concept descriptions, therefore the size of description trees. Moreover, a combinatorial explosion occurs when there is higher repetition of roles in concept descriptions. A more thorough complexity analysis needs to be carried out. To this end, part of our future work consists of identifying the frequency of common edge labels at each level in the trees and analyzing how the repetition of edge labels at equal levels in the trees influences the overall number of solutions. To improve the scalability of our method and the search for isomorphic mappings, we want to introduce heuristics based on the level of information concepts and roles carry in concept descriptions w.r.t. the background knowledge. This would return the hypotheses that carry the most information and exclude those that are similar or carry less information. In addition, we are researching the possibility of computing isomorphisms from paths in description trees, since paths from the root to a leaf node in rooted trees are unique, and preserved up to isomorphism, they could limit the search space even further. Finally, we want to look into the possibility of extending our method to more expressive description logics.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
3.
Appendix A Functions
Here are additional functions used in the main implementation of our method.