
Abstract
Enterprises, especially virtual enterprises, are nowadays becoming more knowledge intensive and adopting efficient knowledge management systems to boost their competitiveness. The major challenge for knowledge management for virtual enterprises is to acquire, extract and integrate new knowledge with the existing source. Ontologies have been proved to be one of the best tools for representing knowledge with class, role and other characteristics. It is imperative to accommodate the new knowledge in the current ontologies with logical consistencies as it is tedious and costly to construct new ontologies every time after acquiring new knowledge. This article introduces a mechanism and a process to integrate new knowledge into the current system (ontology). Separate methods have been adopted for fuzzy- and concrete-domain ontologies. The process starts by finding the semantic and structural similarities between the concepts using WordNet and description logic. Description logic–based reasoning is used next to determine the position and relationships between the incoming and existing knowledge. The experimental results provided show the efficacy of the proposed method.
Keywords
Introduction
In the current era of globalization, industries are facing stiff competition through shorter product life cycles, volatile markets and swift technological advancement. Under these circumstances, enterprises are collaborating to form large supply chain networks or virtual enterprises (VE). Such networks or VEs allow enterprises to provide advanced and multifaceted products or services to customers while focusing on their core competencies and collaborating for other complementary aspects to remain competitive in the market. However, managing and operating a successful VE can be more complex than managing the individual member enterprises, and strong communication, cooperation and collaboration in line with interoperability are required between the member enterprises.
A successful VE needs to develop a mechanism for seamless transfer of data, information and knowledge among member enterprises. 1 Information and communication technology (ICT) can help to achieve collaboration in VEs at a technical level, 2 while ontologies have been proved to be important tools at the semantic level. Generally, each individual enterprise builds its own ontology, based on the domain of their operation, to represent the enterprise’s knowledge. It is imperative that enterprise ontology should hold two features: (1) interoperability (current aspect): to be able to collaborate with other enterprises and (2) maintenance (continuous or ongoing aspect): to accommodate new knowledge. Interoperability means that information and knowledge transferred using ontologies need to be understood accurately, that is, with correct intention and extension. 3 However, as ontologies may be developed independently to suit personal requirements, it is impossible to avoid heterogeneity in the terminology used for concepts and their relationships and mappings between ontologies are required to interrelate different concepts and to achieve interoperability. Many mapping techniques have been adopted and proposed, in the literature, to achieve uniformity and to tackle interoperability of the enterprise ontologies (current aspect).4,5
Nowadays, knowledge has become one of the most precious resources for any enterprise. However, this knowledge is more valuable if it can be made inferable and deducible. The future success of enterprises is coupled with their knowledge assets, so enterprises need to accumulate knowledge (or create knowledge) from information, for example, by updating their knowledge in the form of an ontology. According to Mo and Zhou, 6 knowledge is power, and its proper management is necessary to preserve valuable content, learn new things, solve problems, consolidate core competency and discover and implement new technologies. Enterprises should be able to maintain their ontologies to accommodate new knowledge, to stay competitive and successfully collaborate in VEs not only in the current time but also in the future. For this reason, maintenance of ontologies is termed as a continuous or ongoing aspect of VEs.
Ontologies definitely play important roles in knowledge management (KM), 7 but the knowledge discovery possess is equally important to identify and accommodate new knowledge within existing ontologies. The discovered knowledge will not be useful unless it is mapped semantically and structurally with the existing ontologies. To merge knowledge correctly, both the syntax and semantics must be considered, in order to
Deduce similar or new concepts;
Deduce the possibility of merging concepts, that is, by restructuring an ontology;
Achieve logically consistent mappings.
This article tackles all three of these problems and develops a mechanism for ontology mapping in the same domain, that is, by enhancing the enterprises’ knowledge by accommodating new knowledge into an existing ontology. Moreover, this article tackles the above problem by using the description logic (DL) paradigm as enterprises are increasingly using OWL (Web ontology language) to store, use and transfer data and knowledge through the Web, and OWL is based on DL which is a fragment of first-order logic (FOL). The proposed approach can be widely applicable in E-Commerce, 8 product design, 9 product development 10 and medical domain, 11 where new information is being gathered with time. Ontology-based knowledge merging approach, proposed here, will help in making their knowledge bases (KBs) coherent. Furthermore, nowadays, enterprises are moving from traditional product lifecycle management (PLM) to knowledge-based PLM, in which ontologies play a crucial role. 12 This approach can help enterprises in updating their KBs for improved and efficient knowledge-based PLM.
The next section reviews in detail the current progress in the area. Section “Theory of ontology” gives the preliminaries about ontology construction methods (DL, fuzzy logic, fuzzy-DL) and WordNet is used to identify the meaning and relationships of the words used for concept creation. Section “Ontology similarity” describes a method for finding similarity between concepts. The process of merging and reconfiguration is dealt with in section “Ontology merging and reconfiguration.” The proposed techniques have been implemented, and they are demonstrated through an example which is presented in section “Implementation method,” and section “Conclusion” concludes the article.
Literature survey
Exhaustive surveys have been carried out on KM13,14 and its tools. 15 KM in enterprises is mostly tackled at the subjective level, and this can be divided in three different stages: (1) knowledge creation, (2) ontology development for new knowledge and (3) merging new knowledge in to the existing sources.
Knowledge plays a significant role in the organizational performance. 16 Due to the widespread application of different information systems, a large amount of different knowledge is accumulated during collaboration between enterprises. One of the most important factors in KM is knowledge discovery. Proliferation of data has created a completely new and different area of KM 17 requiring the extraction of knowledge from abundant data and the organization and merging of this knowledge with existing knowledge. Existing knowledge supports organizations in creating new knowledge and updating the overall KB. 18 Knowledge discovery includes discovering implicit knowledge from the data, often using data mining techniques to extract knowledge from data sources. Exhaustive literature surveys illustrate that KM frameworks, knowledge-based systems (KBS), ICT, artificial intelligence and expert systems, database technology and so on have all been adopted by enterprises to exploit knowledge in order to solve their current problems and enhance their expertise. A detailed review has been done by Liao. 15 Pollalis and Dimitriou 4 first proposed the different initiatives needed for knowledge creation and then developed the requirements at each stage of the KM life cycle.
Ontology-based frameworks have been proven to be the ideal tools for knowledge representation as they provide uniform frameworks to identify similarities and differences between different entities in the specific domain. 9 Many researchers have proposed different methodologies for ontology creation from new knowledge. Huang and Diao 19 proposed a methodology for creating a concept map–based ontology construction method for knowledge integration. This accumulates knowledge in the business processes, and rules and constraints are implemented using semantic Web rule language (SWRL). However, to implement this in the VE scenario, enterprises need to reconstruct their ontology every time they move to a new collaboration. Ling et al. 20 proposed an ontology-based method to build an integrated KB from heterogeneous sources operating in a single domain. Rajsiri et al. 21 developed a knowledge-based ontology model for the collaborative business process model. A distributed enterprise system framework for KM is developed by Ho et al. 22 Pirró et al. 23 developed a framework for creating, managing and sharing knowledge within an organization with a distributed functional system. Mo and Zhou 6 developed tools and methods for managing the intangible knowledge of VE. Ling et al. 20 proposed an ontology-based method for knowledge integration in a collaborative environment. They used heterogeneous ontologies to build domain ontology, that is, by merging them and through inconsistency elimination. Chen et al. 24 used WordNet and fuzzy formal concept analysis for merging domain ontologies. Raunich and Rahm 25 proposed the automatic target-driven ontology merging (ATOM) for integration of multiple ontologies. The process was based on the equivalent relation between source and target taxonomy and merging them preserving the target taxonomy. PROMPT 26 uses the class-name similarities and relies on the user for specific merge operations, whereas OntoMerge 27 uses the bridge ontology concept for ontology merging.
It has been widely reported that classical ontologies are not appropriate to deal with imprecise and vague knowledge inherent to several real-world domains. 28 It is necessary to merge knowledge in an enterprise, not only for concrete domains but also for fuzzy domains. Recently, approaches have been reported for extending and reasoning with ontologies in fuzzy domains.28–30
It is clear from the literature survey that the third stage of KM in enterprises, that is, merging new knowledge with existing knowledge, has been given little or no attention. This article introduces a method to map discovered knowledge with existing knowledge using an ontology and, if needed, reconfiguring the ontology.
Theory of ontology
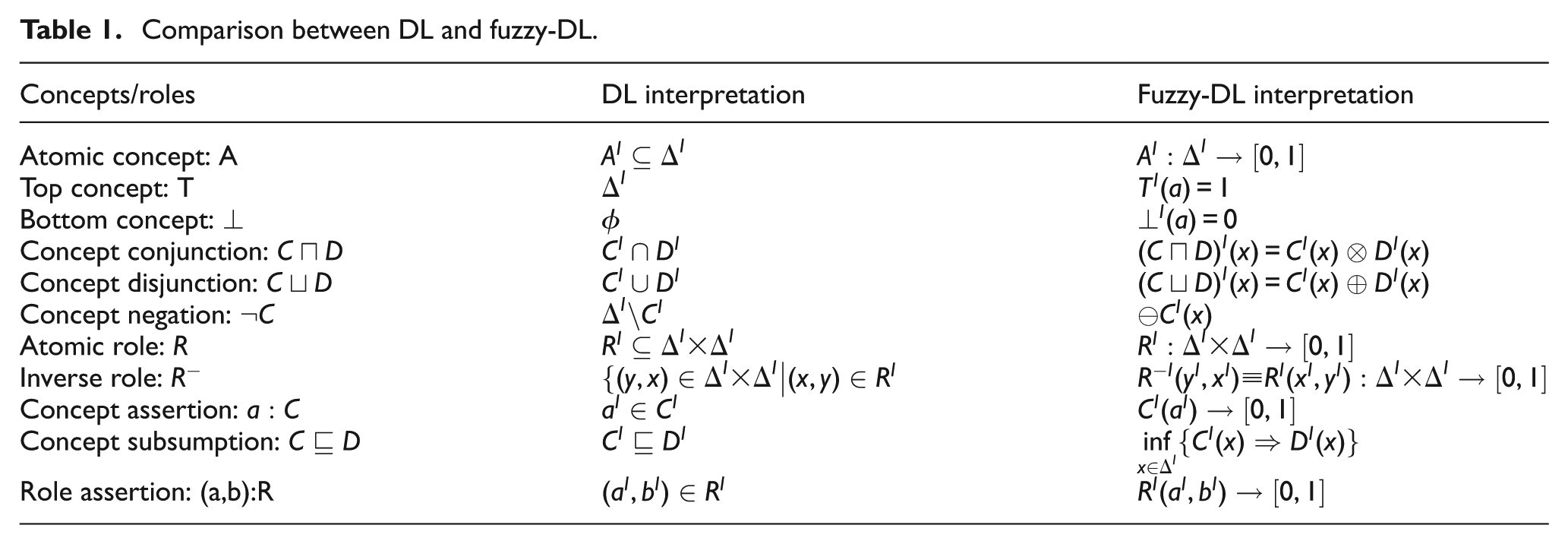
This section describes the DL, fuzzy logic, fuzzy-DL and WordNet used in this article. DL is a decidable fragment of FOL which acts as a backbone for ontology development. Fuzzy logic and consequently fuzzy-DL deal with the vague knowledge. WordNet is helpful in finding semantic similarities between words. A detailed description of each of these approaches is given in the following section.
DL
DL provides a logical construction for KBs and is composed of concepts, roles and individuals as basic building blocks. DL has been proved to be most promising for processing, sharing and interpreting knowledge especially using the Web. Ontologies play a key role in constructing KBs in a hierarchical manner of concepts and roles in a particular domain.
The formation of a KB in DL starts by defining the atomic concepts and atomic roles. Atomic concepts and roles generally represent the domain-specific, self-explainable entities that are not defined using other concepts and roles (for more details, see Baader et al.
31
). Other general concepts and roles are defined using atomic concepts and general concepts, atomic roles and general roles and constructors (like union, intersection, quantifiers, etc.). For example, the concepts (
Fuzzy set and fuzzy logic
Fuzzy set theory and fuzzy logic
32
are widely adopted for capturing vague knowledge. Unlike the crisp set, where an element is either a member of a set or not, that is, the binary (0 and 1) relation, a fuzzy set (
Like DL, fuzzy logic also supports operations like complement, union, intersection, transitivity and so on with the help of strong mathematical principles. A fuzzy complement (
Fuzzy intersection, termed as t-norm, is defined by the function
Fuzzy union, termed as t-conorm, is a function defined by
One of the most important operations in fuzzy logic relating to classical logic is fuzzy implication. Fuzzy implication is defined by the function:
Although there are many functions related to fuzzy logic, Lukasiewicz, Godel, product and so on, Bobillo and Straccia 29 showed the benefit of using Lukasiewicz function, and this article uses these functions for fuzzy interpretation.
Fuzzy-DL
Fuzzy-DL is an extended version of DL, where concepts (unary relation) and roles (binary relations) are extended to fuzzy set and fuzzy binary relations. DL-axioms are also extended into fuzzy set using degree of truth. Similar to DL, fuzzy-DL consists of fuzzy-T-box and fuzzy-A-box. Fuzzy-T-box consists of the concepts (C, D) and role names (P, R) along with the general inclusion axioms, that is,
For individual a,
Comparison between DL and fuzzy-DL.
WordNet
WordNet (WordNet API), 33 created by Princeton University, is a dictionary of semantically similar English words, arranged structurally. Words are characterized based on the parts of speech, noun, verb, adjective and so on and linked together and categorized as synonyms, hyponyms and so on.
Ontology similarity
An ontology is the explicit specification of shared conceptualization.
34
In simple words, an ontology is a domain-specific knowledge representation specified in terms of concepts and their relations. An ontology can be represented as
In this article, an ontology O
1 is defined as the existing knowledge and O
2 as the new knowledge. Let
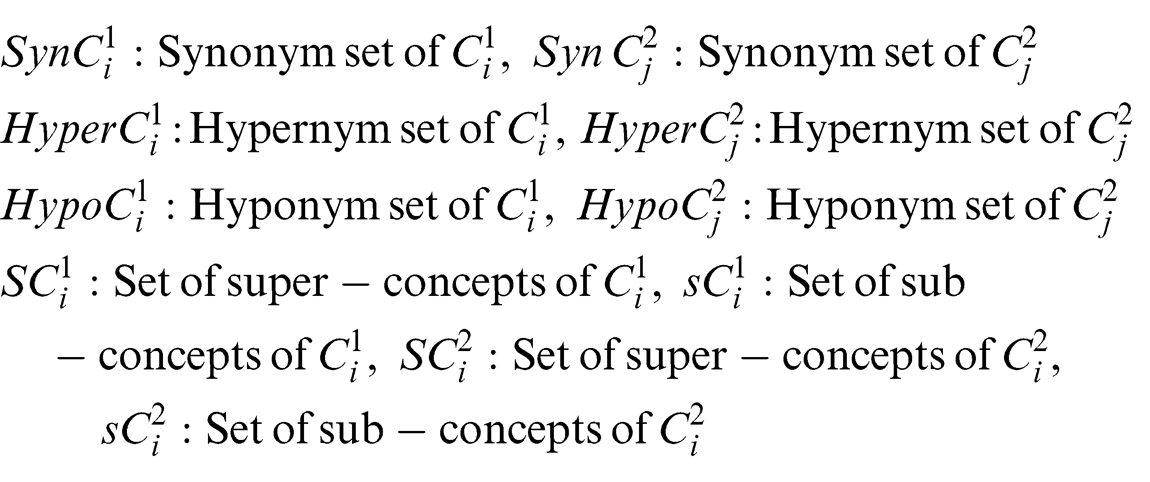
The methodology adopted in this article for knowledge merging, that is, ontology mapping and ontology reconfiguration, is based on two steps. In the first step, a similarity matrix or index is calculated. In the second step, merging and reconfiguration are carried out based on logical arguments to get a consistent final ontology.
For calculating the similarity matrix, two parameters have been taken into account: semantic similarity and structural similarity. Semantic similarity determines how closely two concept names are linguistically associated, whereas structural similarity determines the hierarchical relationship (equivalent, super and sub) between new concepts and concepts of existing ontology. The next section illustrates the process of calculating semantic similarity, structural similarity and hence the similarity matrix.
Semantic similarity
The semantic similarity between concepts is defined by the function
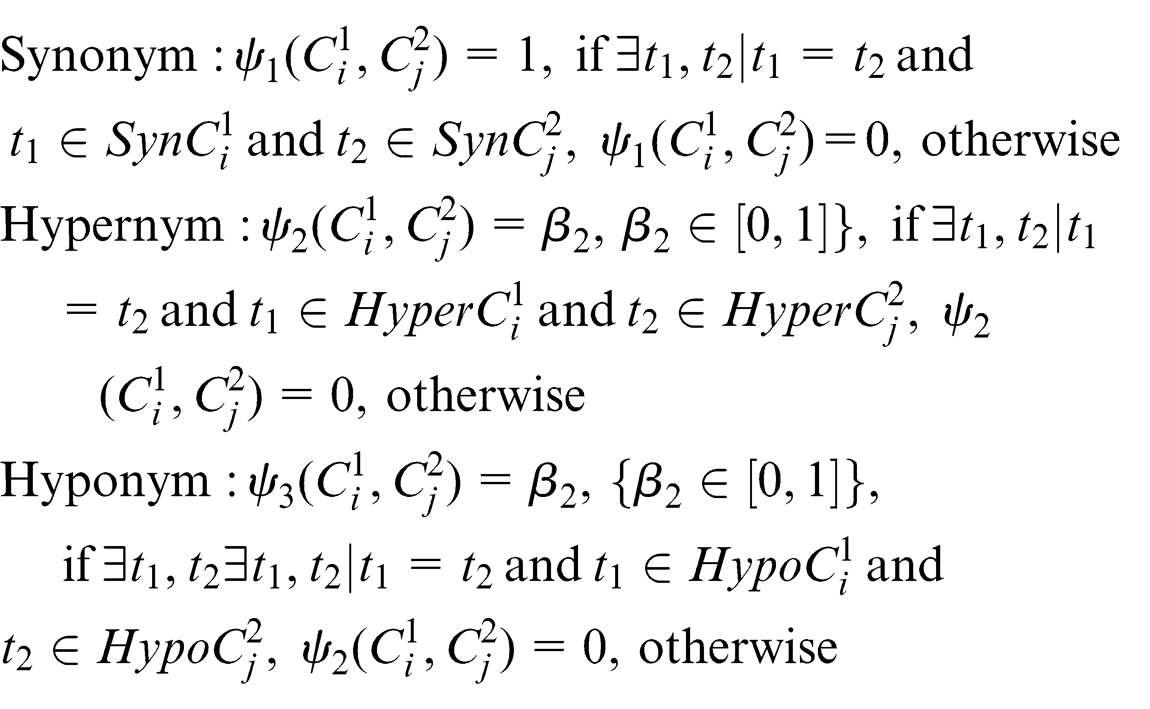
Here,
Structural similarity
The structural similarity between the concepts of two ontologies is the measurement of their association in terms of equivalence, super and sub relationships. The structural similarity is measured at three levels (equivalence, super and sub relation). As relationships between the concepts can be fuzzy, this article considers both the concrete domain (instance 1) and the fuzzy domain (instance 2) for structural similarity calculation. The procedure is explained next.
Equivalence relation similarity (ER)
Instance 1 (concrete domain)
In the concrete domain, an equivalence relation between two concepts is closely associated with the equivalence between their super and sub-concepts, respectively. Mathematically, the equivalence relation between concepts
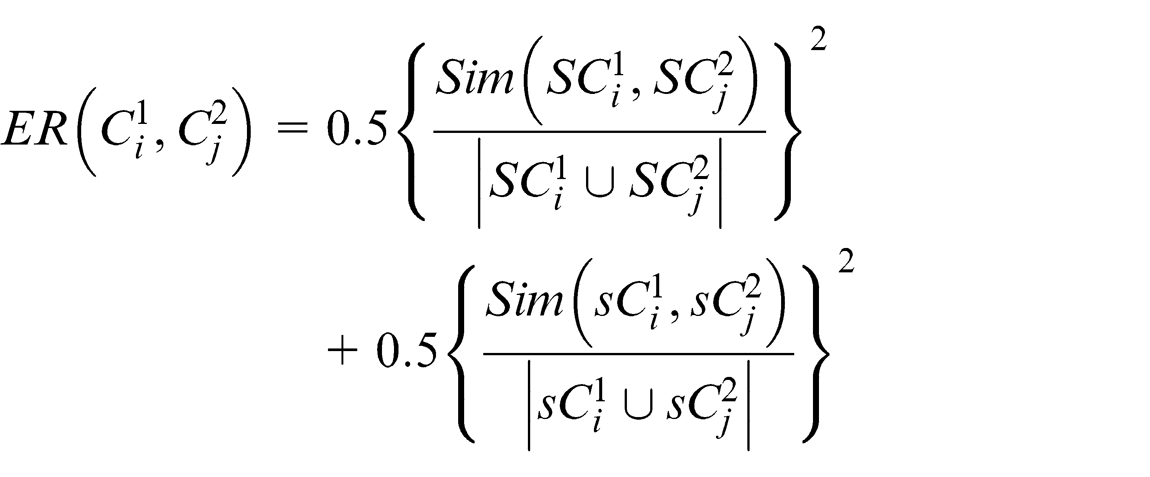
Here, function
Instance 2 (fuzzy domain)
In the fuzzy domain, the equivalence concept relation can be given as
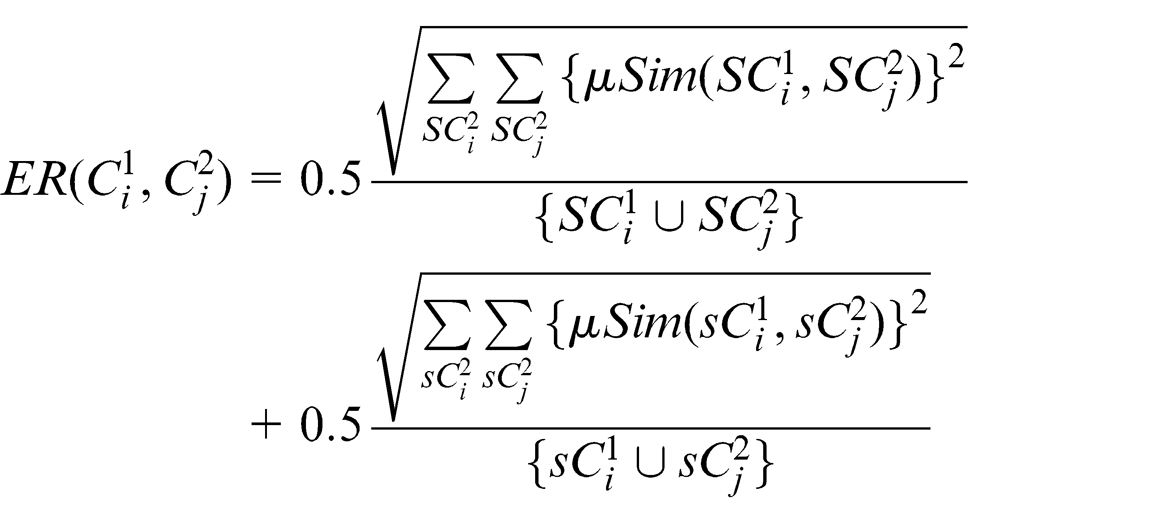
where
Super relation similarity (SR)
A concept is said to be in a super concept relationship with another concept when its sub-concepts match with the super concepts of the other. In this article, super relation similarity between the two concepts has been identified for both the cases as follows.
Instance 1 (concrete domain)
In the concrete domain, super relation similarity between two concepts is the similarity of their super and sub-concepts. Mathematically, this can be stated as
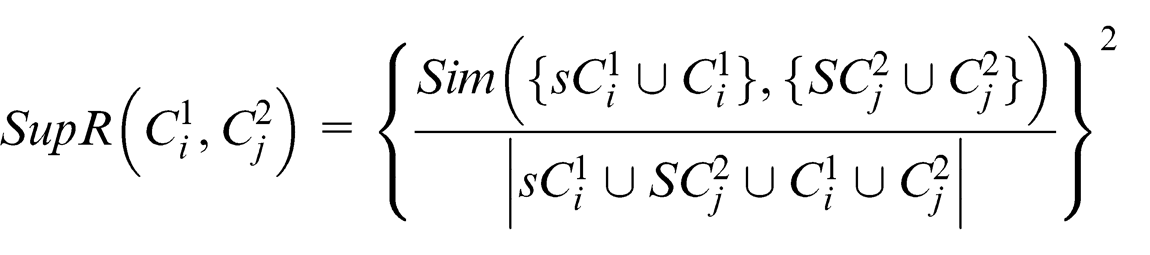
The super relation function (SupR) includes both concepts (
Instance 2 (fuzzy domain)
For the fuzzy case, super relation similarity is
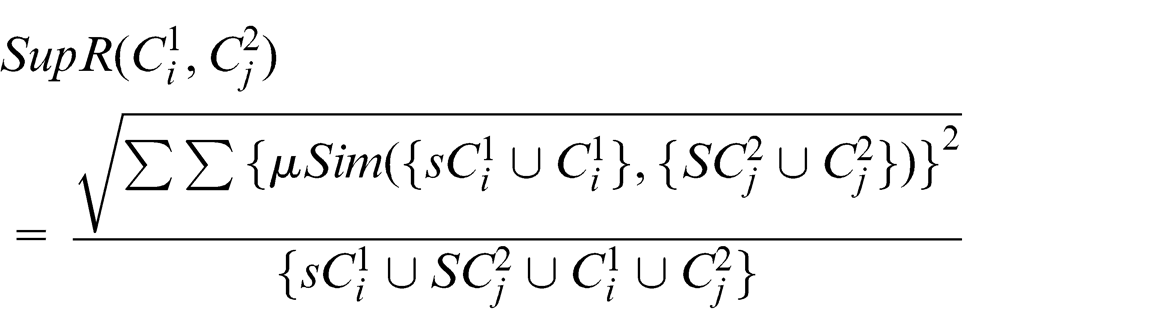
and is a measurement of the equivalent fuzzy value or truth value for the super relation between the two input concepts.
Sub relation similarity (sR)
In contrast with super relation similarity, a concept is in a sub relationship similarity with another concept if its super concepts match with the sub-concepts of the other. For both cases, this can be calculated as follows.
Instance 1 (concrete domain)
In line with the argument given in the super relation, a concrete-domain sub relation can be given as
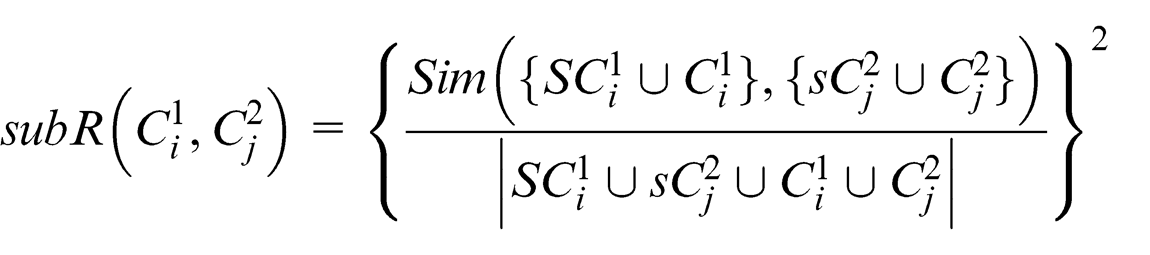
Instance 2 (fuzzy domain)
For fuzzy domain, it will be
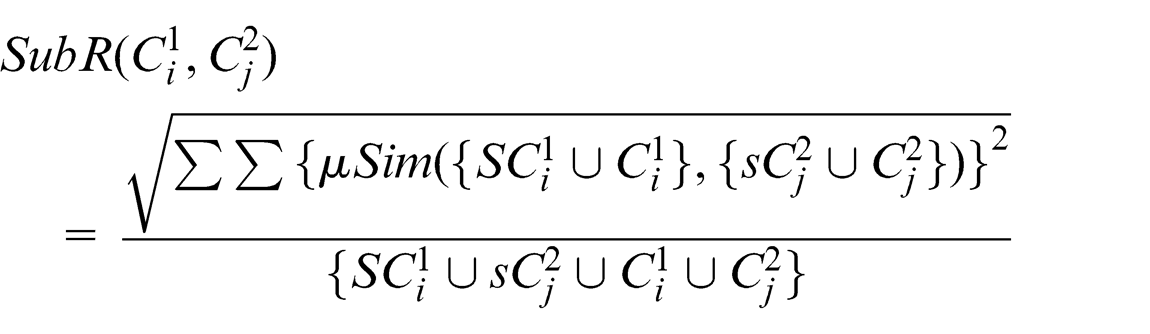
Now the overall mapping relation based on semantic and structural similarity can be given as
1. Equivalence relation
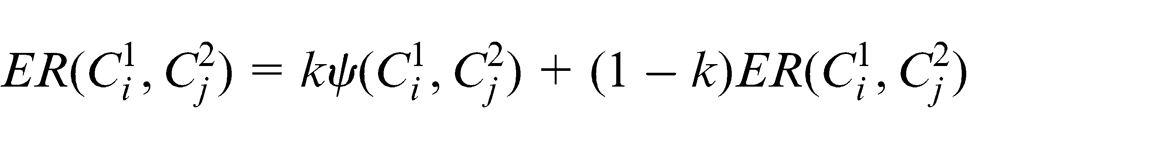
2. Super relation
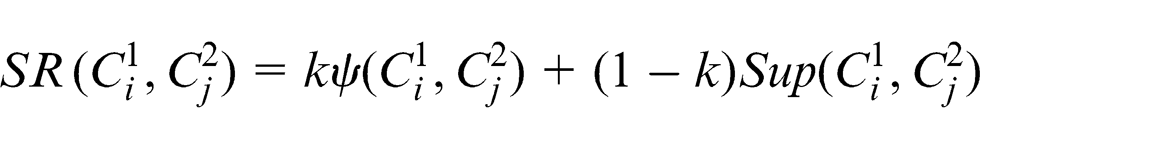
3. Sub relation
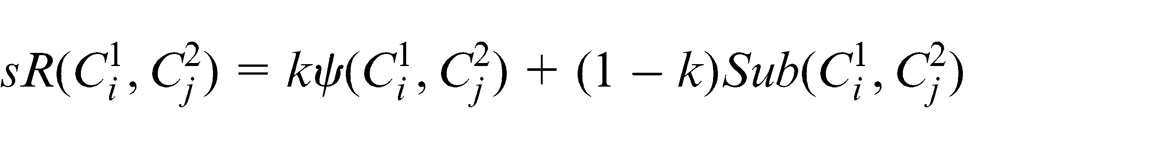
The constant
Ontology merging and reconfiguration
The relational matrix obtained in the previous section is used for ontology merging and, if necessary, for ontology reconfiguration. This approach first determines the greatest similarity in terms of equivalence, super and sub relations between the concepts of the ontologies. The next step involves establishing logical consistency, that is, the formation of a logically consistent merged and reconfigured ontology. This process is different for both the concrete and fuzzy domains. This section begins by explaining the process for the concrete domain and later deals with the fuzzy domain.
Concrete domain
In the consistency checking part, two concepts of two different ontologies are compared. This process first finds the maximum of
Equivalence relation
The easiest case is when the equivalence relation matrix is one (case 1) and the new concept
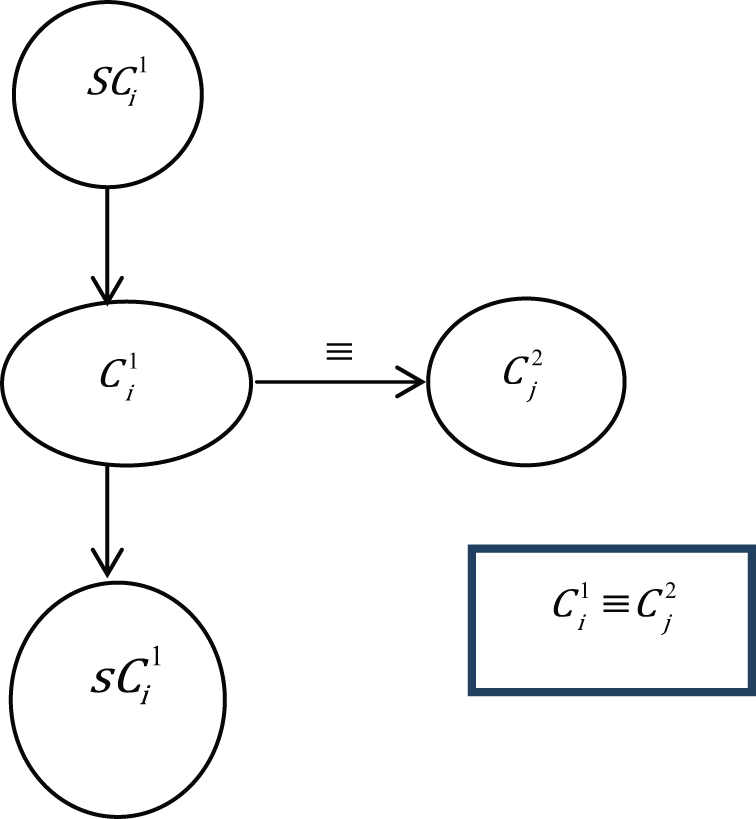
Case 1.
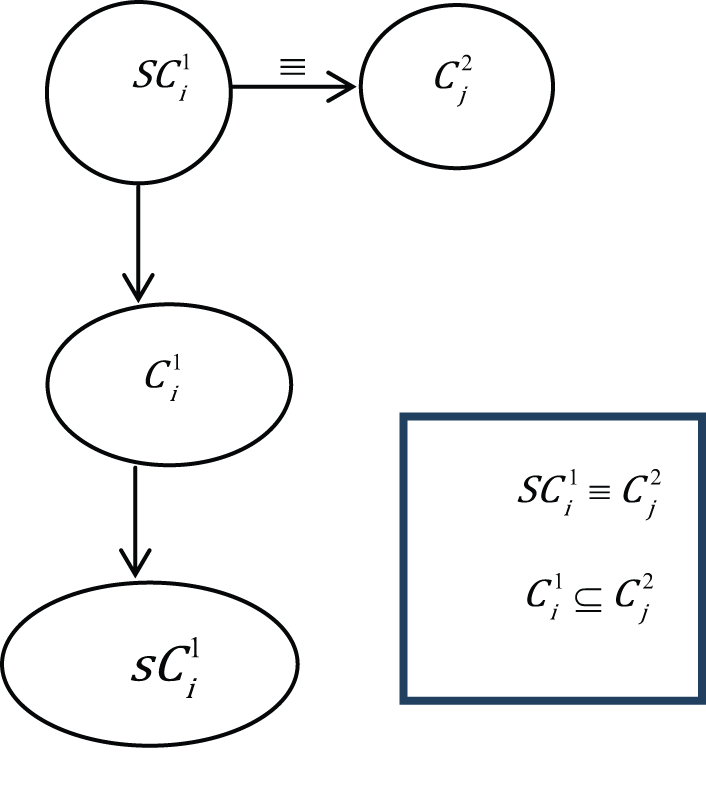
Case 2 (Figure 2) is where the equivalence relation matrix is less than one and a possible position for the new concept (
Case 2.
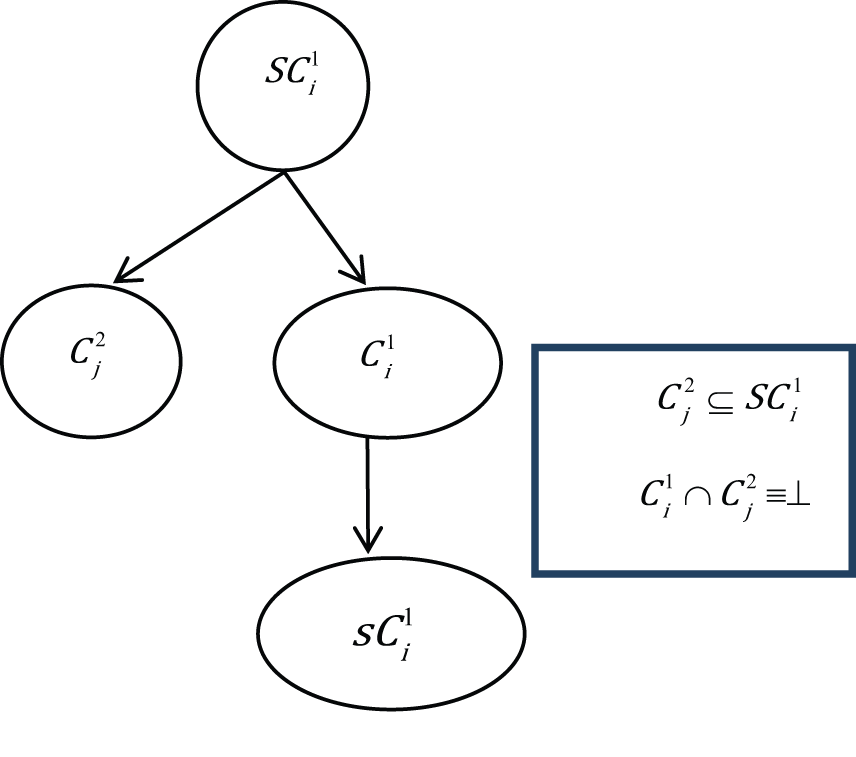
Sub relation
This is where the existing concept is in a sub-concept relation according to relational matrix, that is,
Case 3.
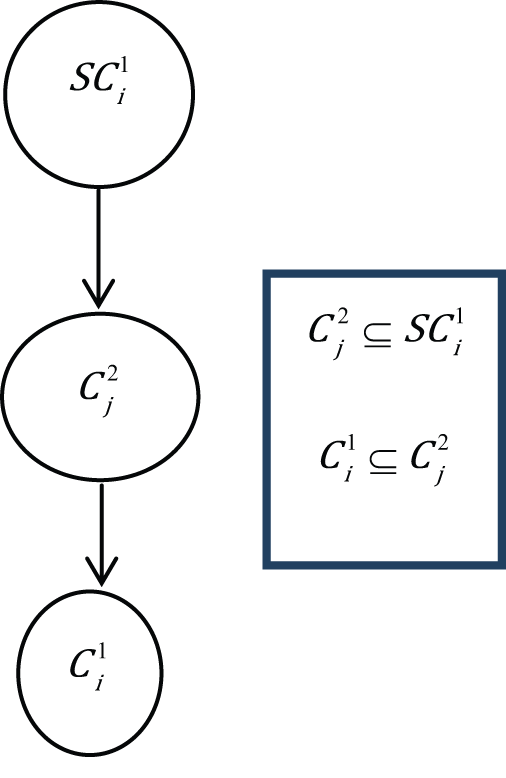
Case 4.
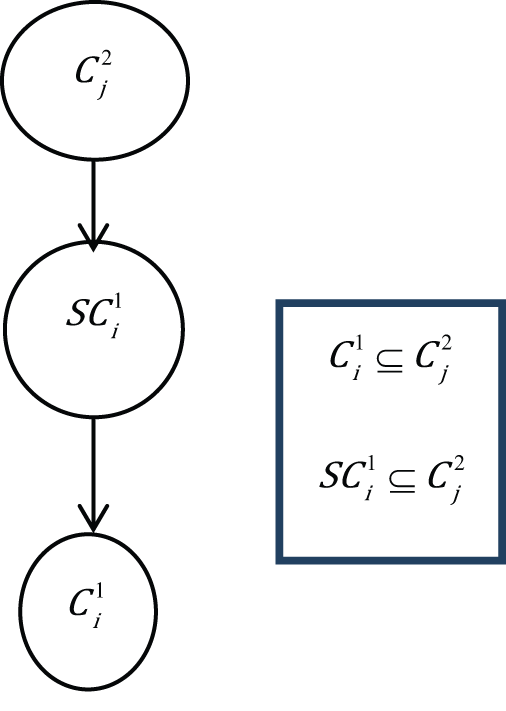
Case 5.
The first condition (case 3) arises when the new concept (
In this case, the position of
Super relation
This is where the existing concept is in a super concept relation according to the relational matrix, that is,
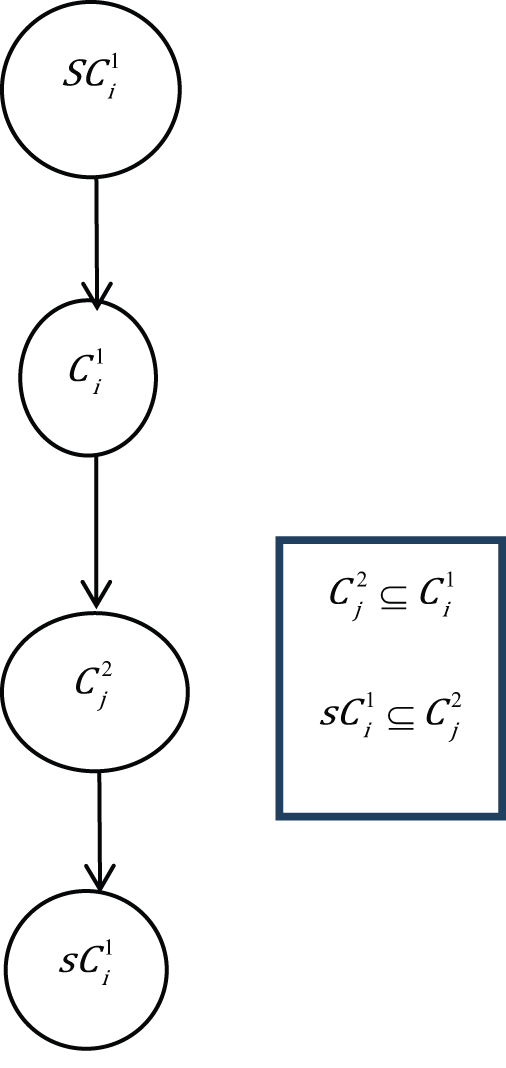
Case 6.
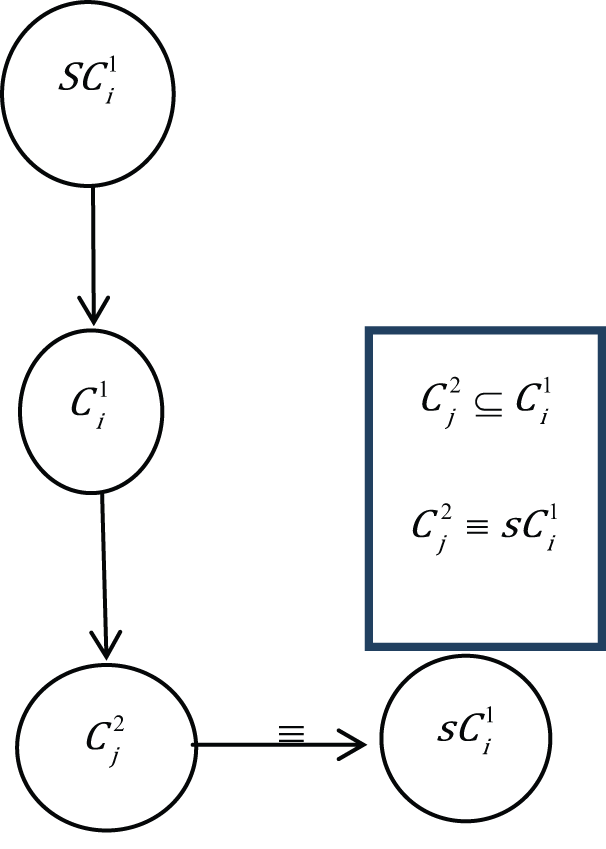
Case 7.
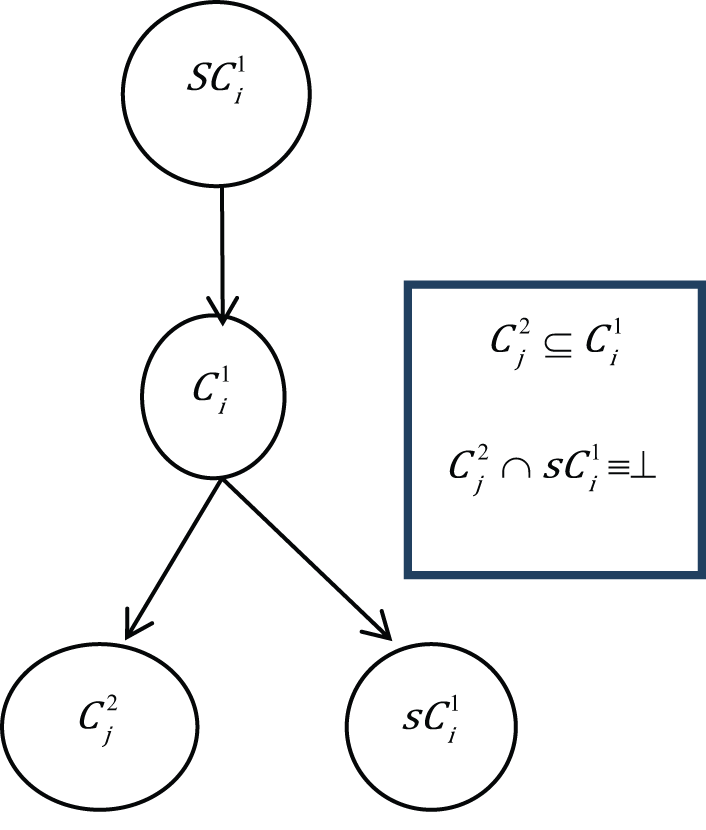
Case 8.
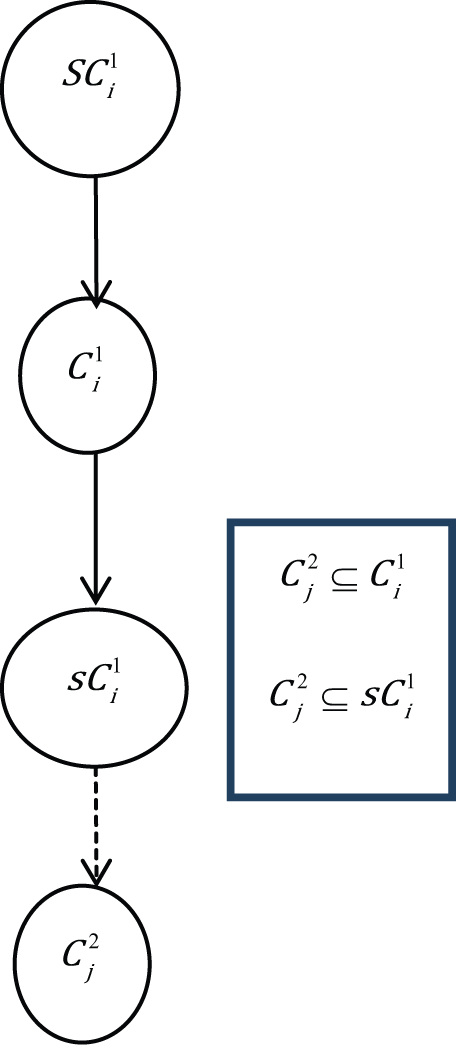
Case 9.
The first condition (case 6) arises when
The last condition (case 9) describes the situation when
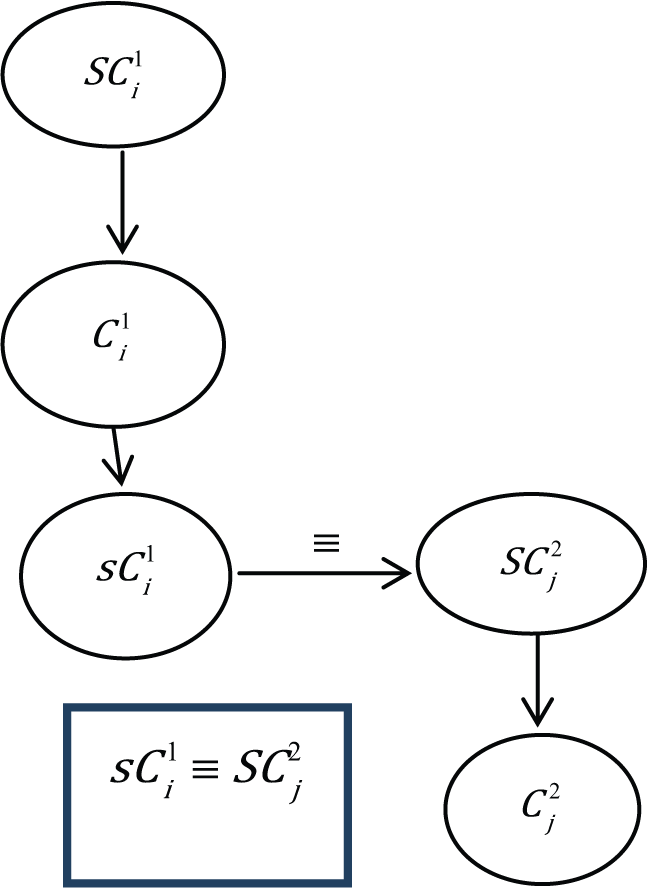
Although this approach has considered all possible conditions for equivalence, sub and super relations, it may also be possible that the new concept has no defined position or possibly has no relation with existing concepts (including cases 5 and 9). In this scenario, merging and reconfiguration is carried out using the super concept of the new concept. Let
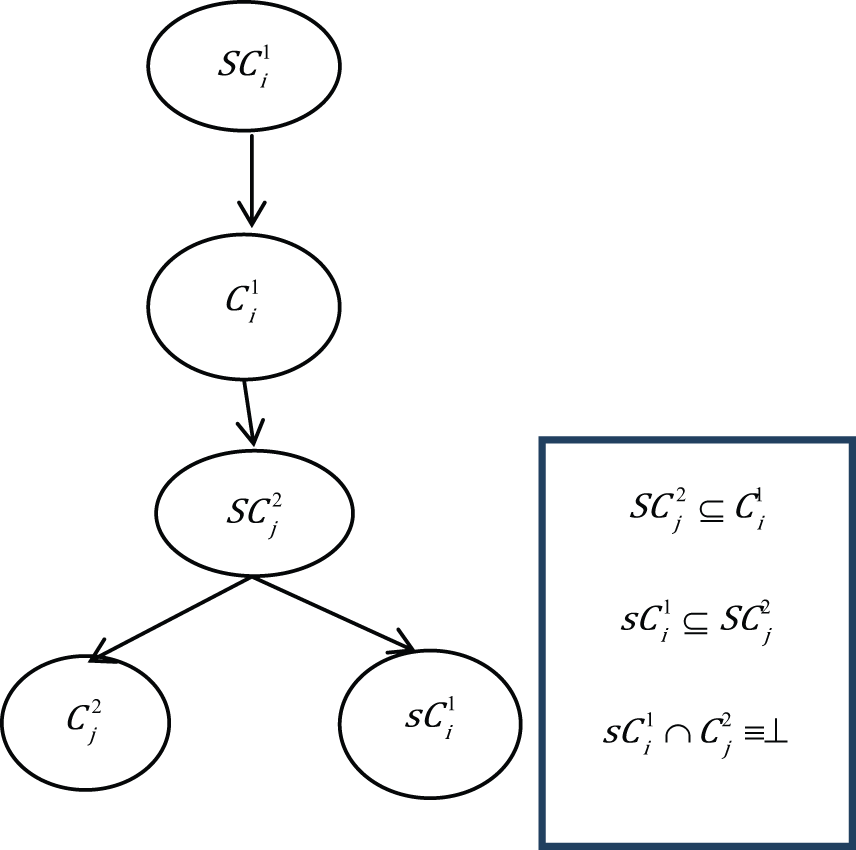
Super equivalence relation
In a super equivalence relation, the mapping of a new concept (
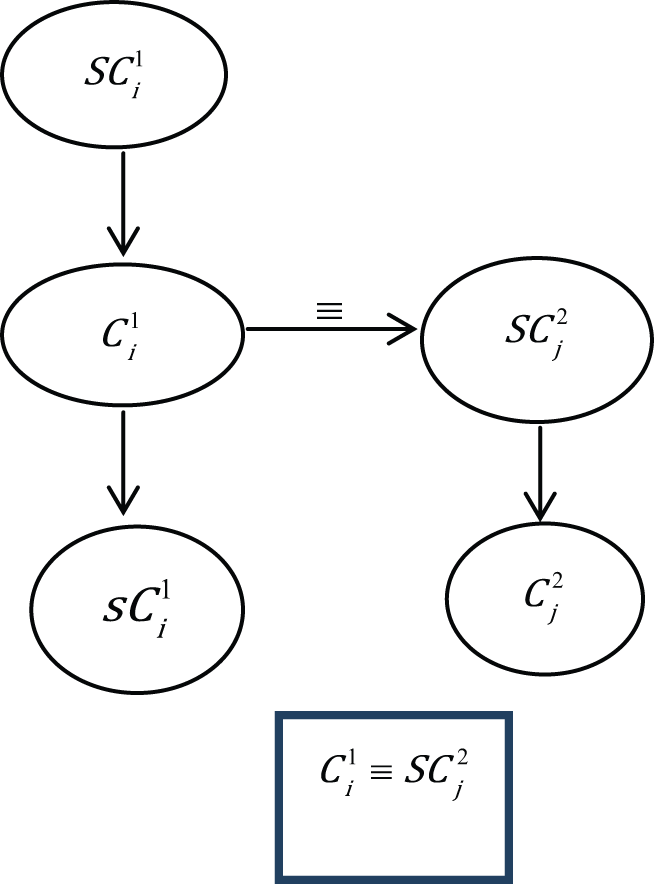
Case
Case
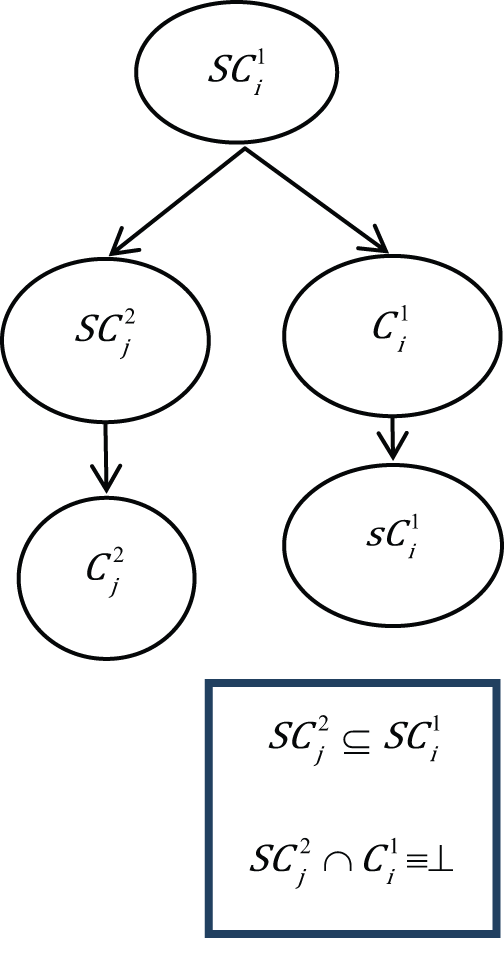
Super-sub relation
Super-sub relation mapping is carried out when the relational matrix entails that
Case
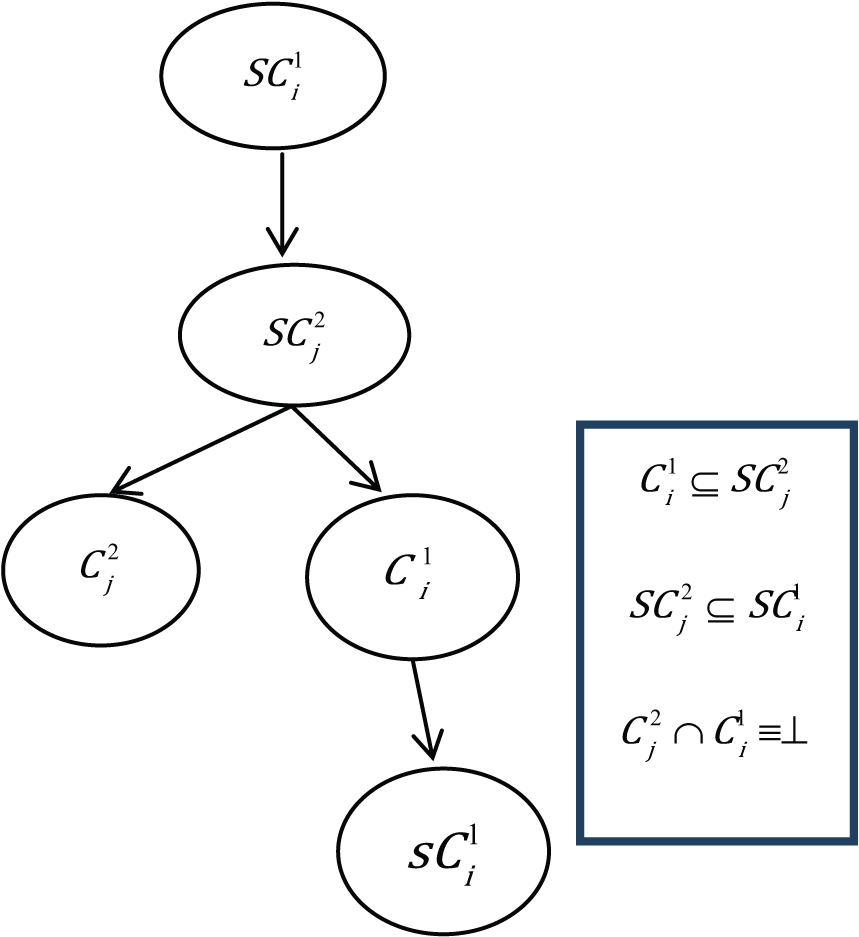
Case
Case
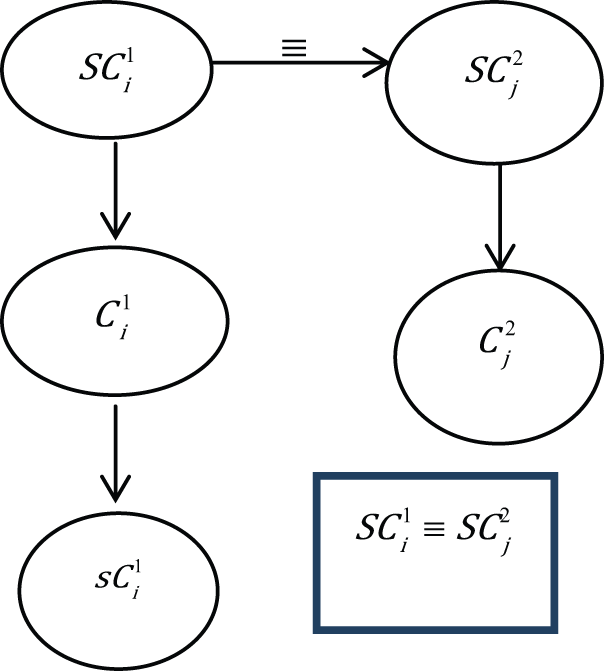
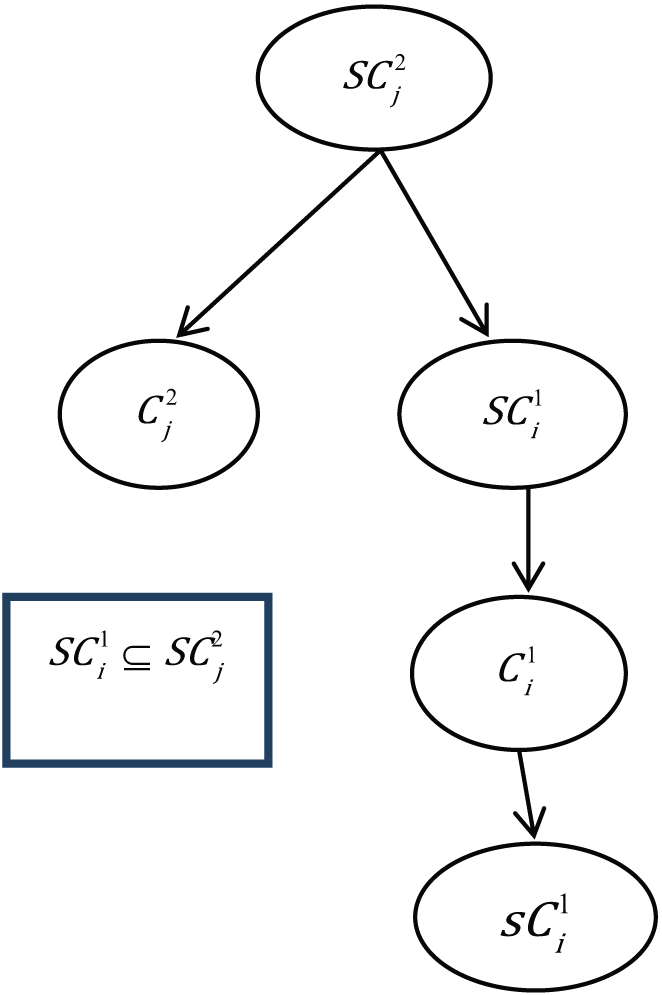
Super-super relation
Super-super relation mapping occurs when the relational matrix intimates that
Case
Case
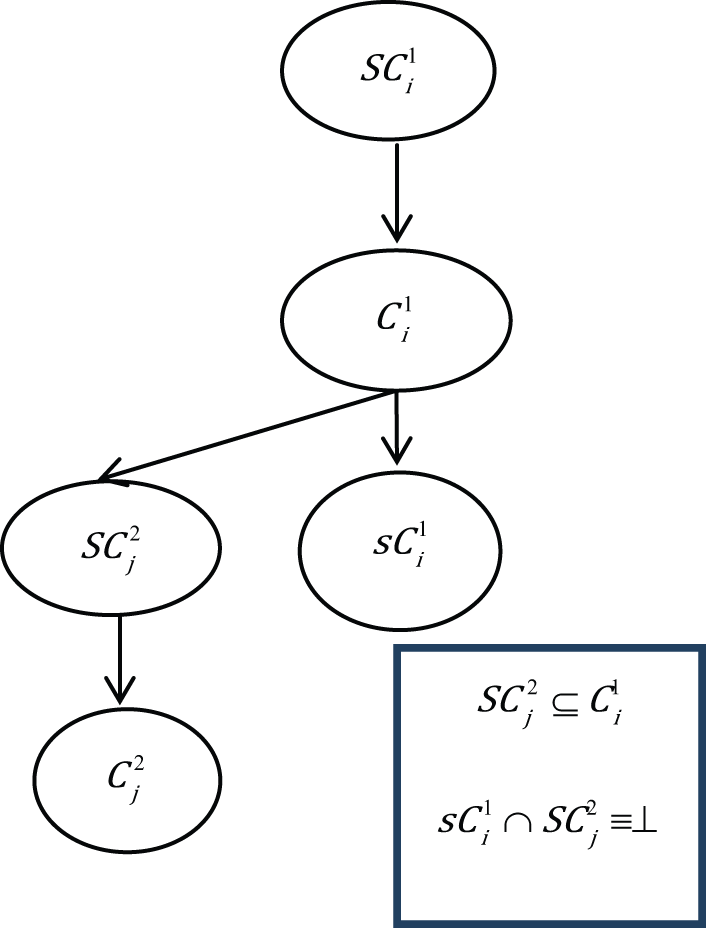
Case
Case
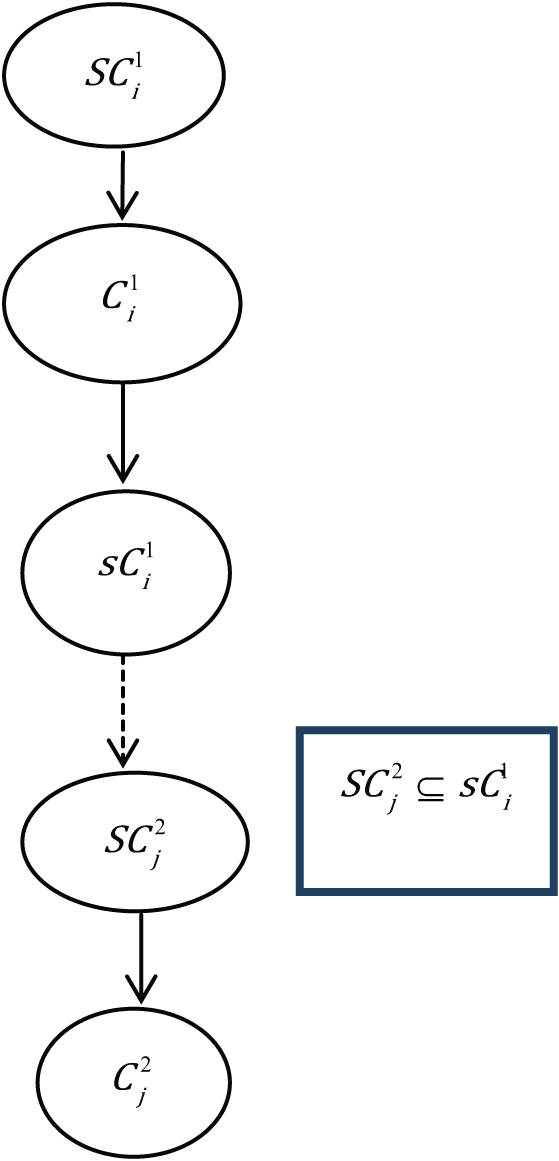
Similar to condition 9, in condition
If none of the conditions (cases 1–9 and cases
Fuzzy domain
In fuzzy-DL, two concrete concepts or even an assertion of individual in concrete concepts and roles are related with the fuzzy value or truth value as described in section “Theory of ontology.” Unlike the concrete domain, as explained earlier, a fuzzy-domain ontology not only requires mapping and reconfiguration of the ontology but also requires a fuzzy value or truth value to be calculated for the merged or reconfigured concept with the concepts of the existing ontology. The first step for fuzzy-domain ontology mapping and reconfiguration is similar to the concrete domain (i.e. finding the maximum). The second step is implemented in two stages: the first stage determines the position of the new ontology within the existing one (similar to case 1 to case
Considering case 4 as shown in Figure 4, the following fuzzy values are available
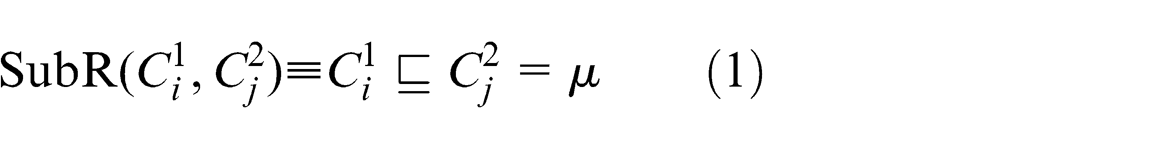
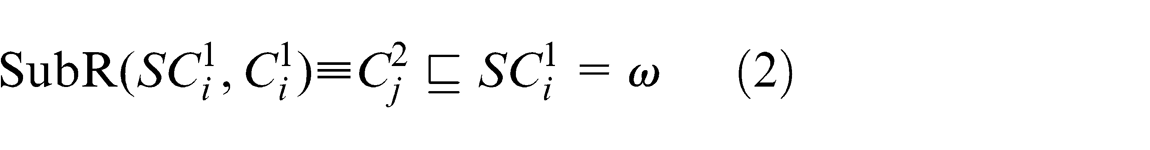
From equations (1) and (2), it is clear that
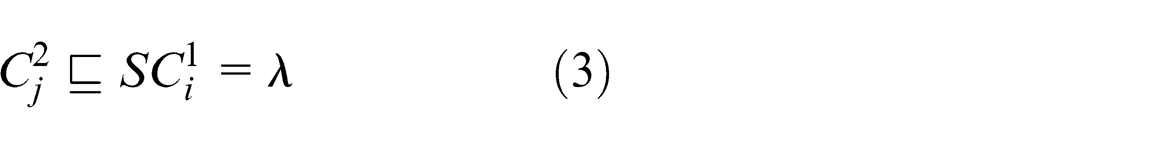
Now the sub-concept relation
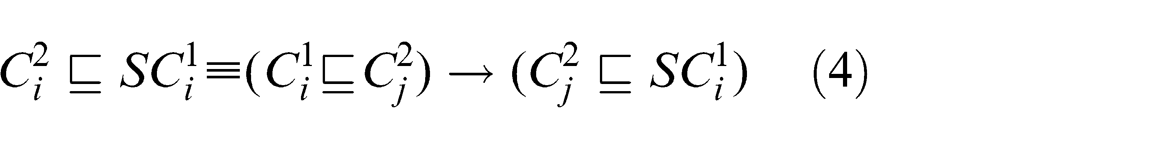
Using the Lukasiewicz implication function and equations (1)–(4)

The method shown above for truth value recalculation has considered only truth values equal to some constant, but a similar approach can be used in cases where the truth value is greater than or less than some constant value. The rest of the ontology mapping and reconfiguration in fuzzy cases can be obtained for all cases (case 1–case
Implementation method
The proposed methodology for ontology merging and reconfiguration for both concrete and fuzzy domains can be created in an OWL API such as Protege 35 and its plug-in fuzzy-DL. 36 Merging and reconfiguration is carried out in Java. The overall implementation method is summarized in Figure 19. Jena parser, a Java API, is used as the Ontology API to get the concept names without the namespace. WordNet API 33 (WordNet) is used to get the synonym, hyponym and hypernym of the concepts for carrying out the word similarity and finally calculating the Lexicon similarity matrix. A structural similarity matrix is calculated as previously described. Pellet reasoner 37 is used to find the relationship between concepts (i.e. equivalence, super, sub). As the two ontologies considered here are from the same domain, the assumption that they are built on the same base ontology is valid. This assumption has been used for building the T-box and A-box for reasoners.
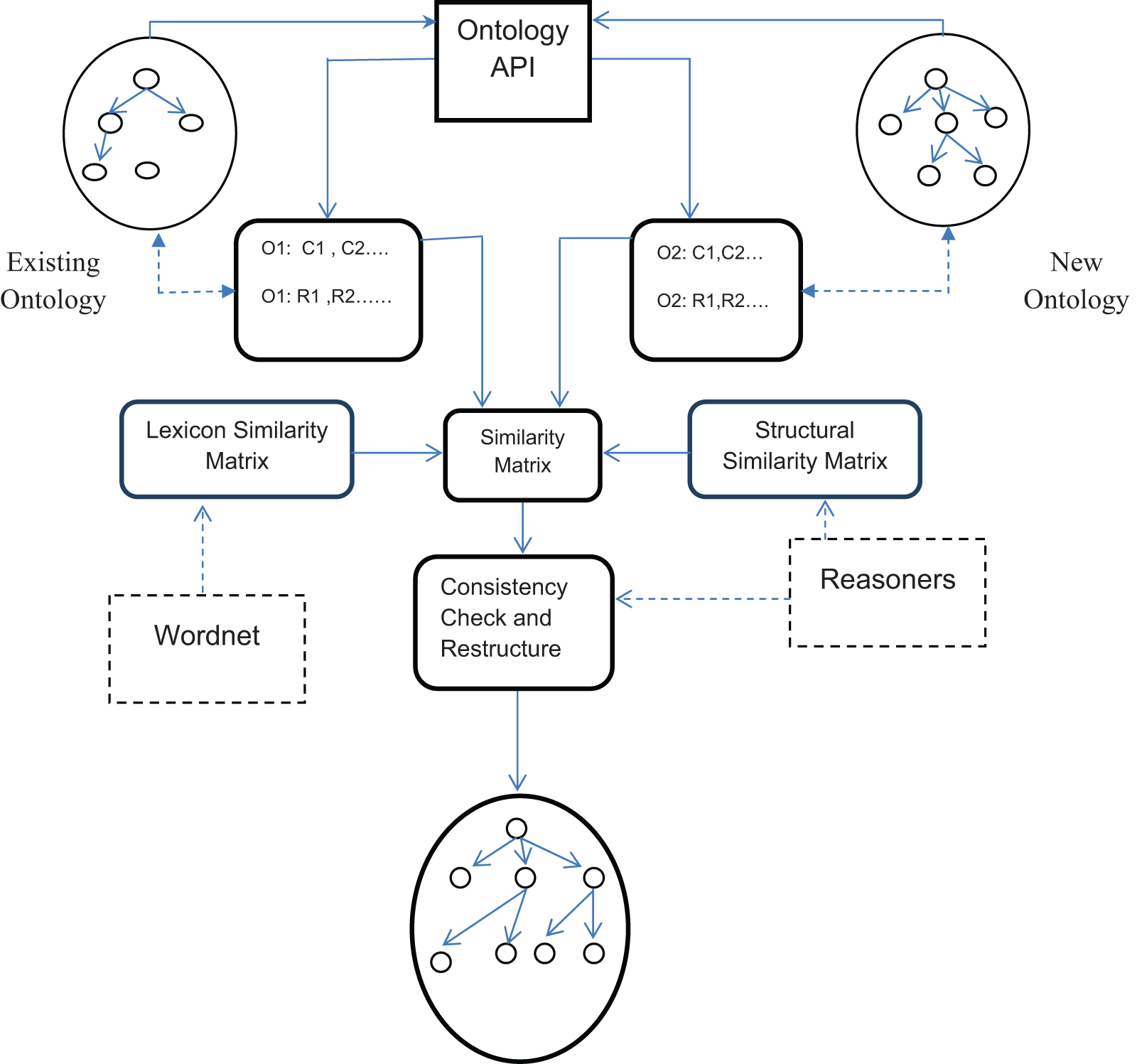
Merged/reconfigured ontology.
The semantic similarity matrix and structural similarity matrix are used to calculate the relational similarity matrix. The next steps, merging, reconfiguration and consistency checks, are illustrated in Figure 20.

Procedure for ontology merging and reconfiguration.
Example
Concrete domain
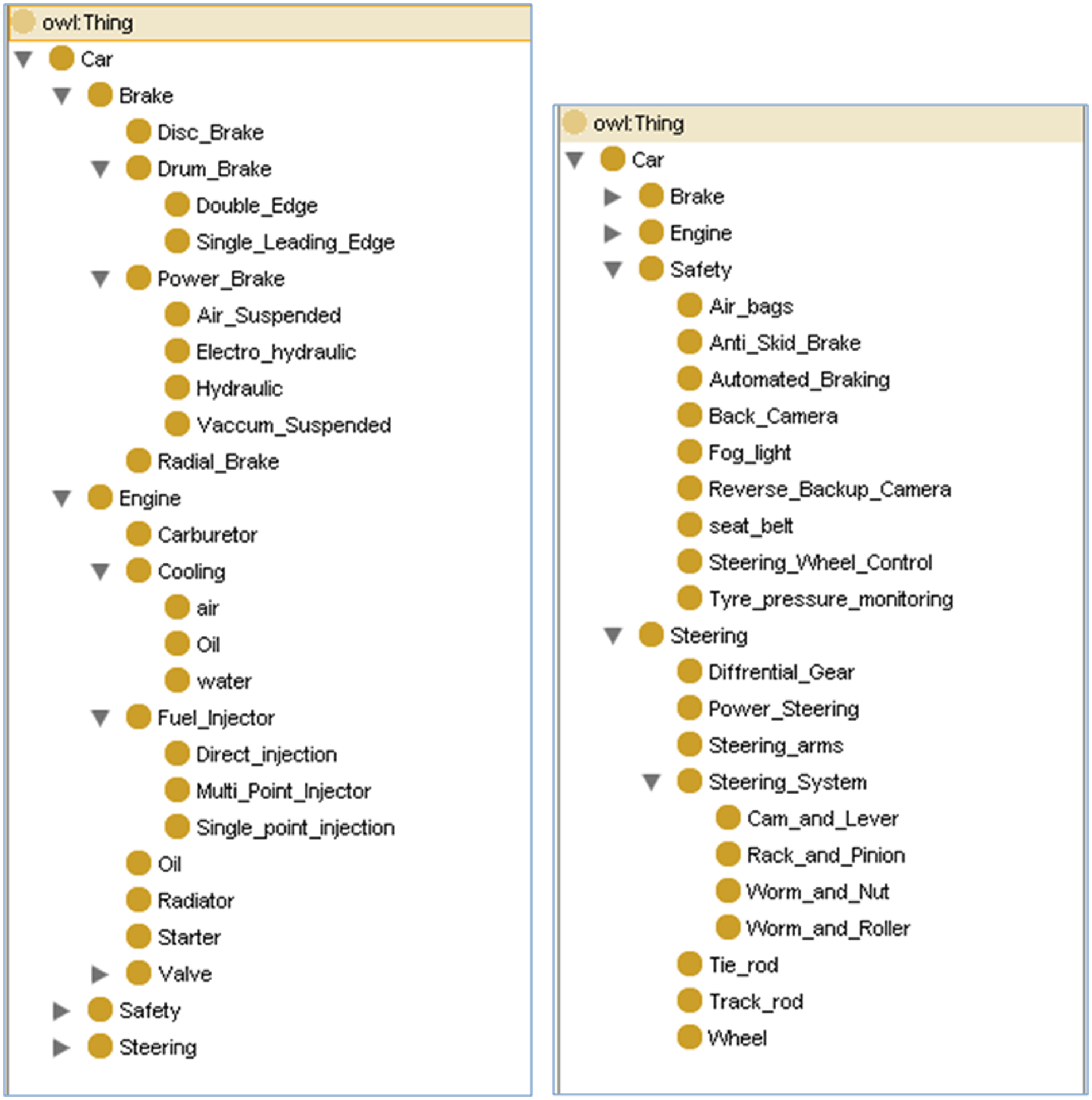
In order to illustrate the overall procedure, two ontologies in the concrete domain of car manufacturing have been developed from different car parts websites availables on the Internet. As shown in Figure 21, the Car ontology describes the current knowledge of the field, whereas the New Car ontology represents new knowledge in the field of car manufacturing. In order to merge the two ontologies, reconfigure an existing ontology (Car ontology) or incorporate the new knowledge (New Car ontology), the process as described in the previous section is carried out.

Input ontologies.
With the help of the Jena parser, concept names are identified. The next step involves calculating the similarity matrix. This step comprises of calculating the Lexicon similarity matrix and structural similarity. Consider the two concepts: Water from the Car ontology (C: Water) and Oil from the New Car ontology (NC: Oil). As there is no similarity between the two concepts in terms of synonyms, hypernyms and hyponyms, their lexicon similarity
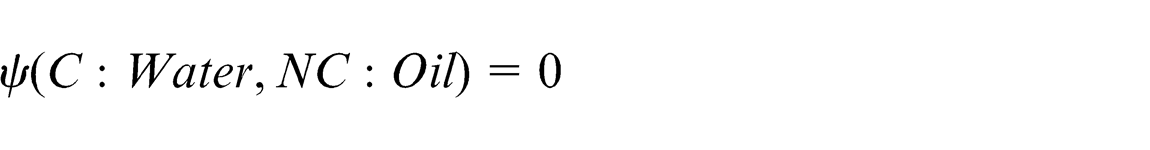
For calculating the structural similarity, super and sub-concepts need to be identified

As both child concepts are empty sets
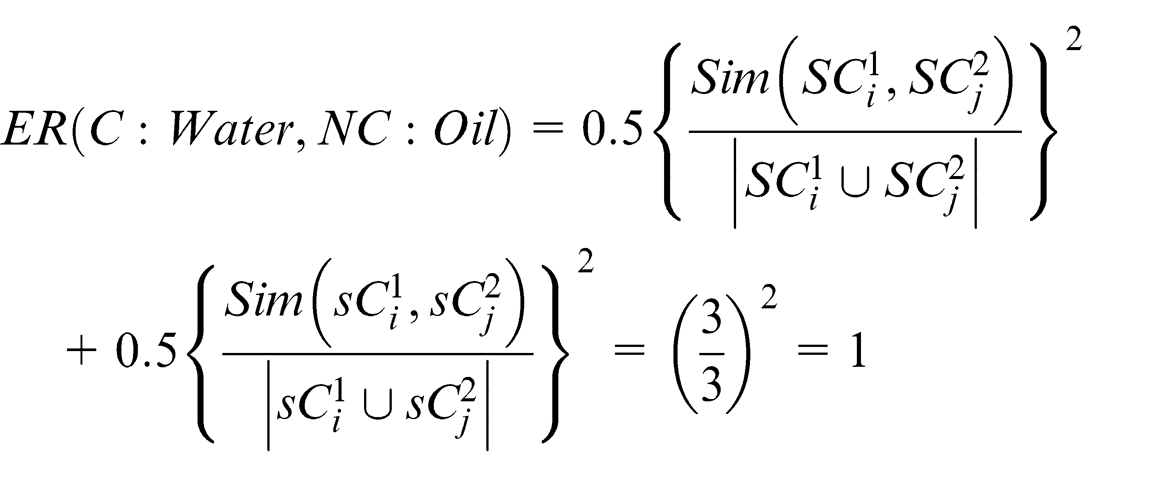
As both child concepts are empty sets it follows that
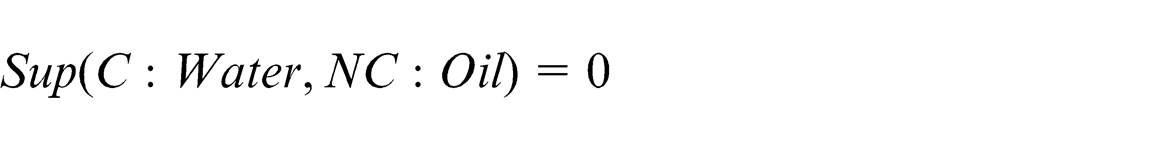
and
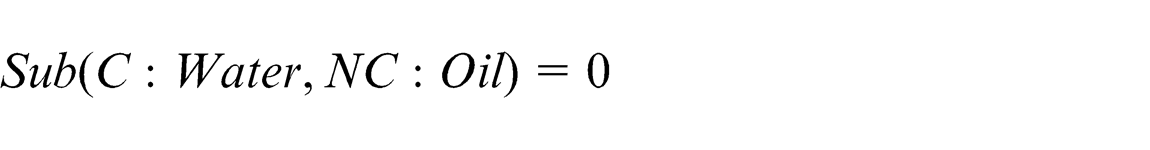
Now, considering equal weightage for semantic similarity and structural similarity
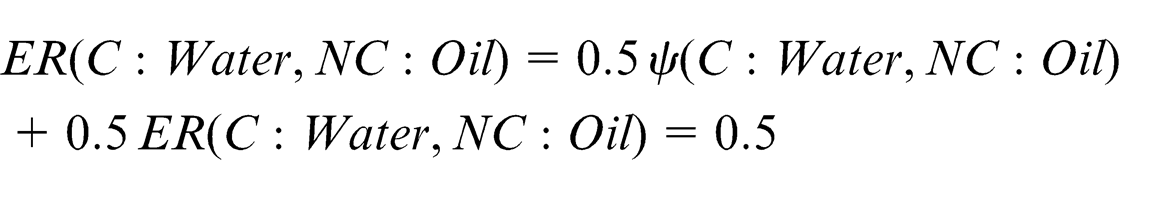
Similarly
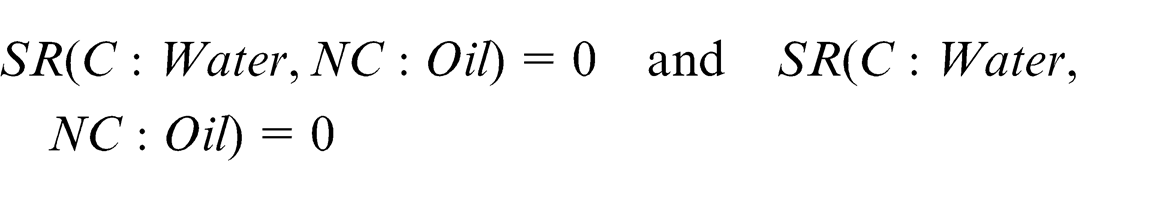
In a similar manner, the similarity matrix is calculated between “
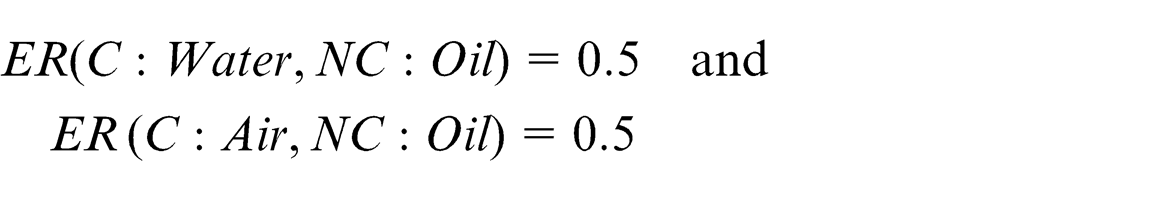
The next step involves the merging of the new concept into the existing concept. As both the similarity matrix indexes have the same value, that is, 0.5, the algorithm arbitrarily selects one of them and tries to merge it logically into the existing concept as explained in section “Ontology merging and reconfiguration.” Taking “C: Water,” the logical relations obtained are
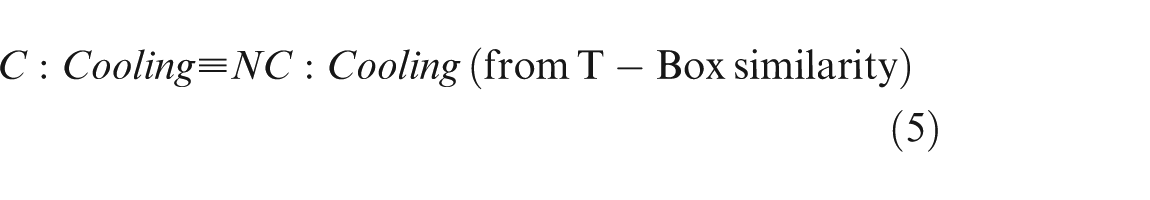
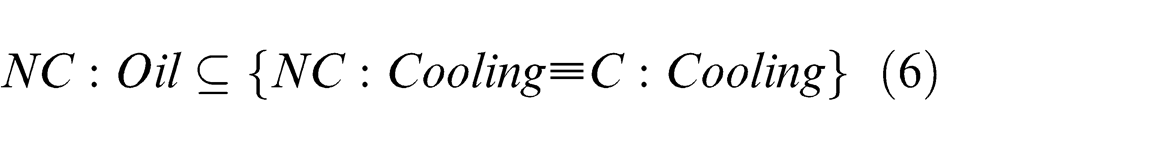

Clearly, conditions (5), (6) and (7) lead to the case (2), and “
Merged/reconfigured ontology.
Merging process outcome.
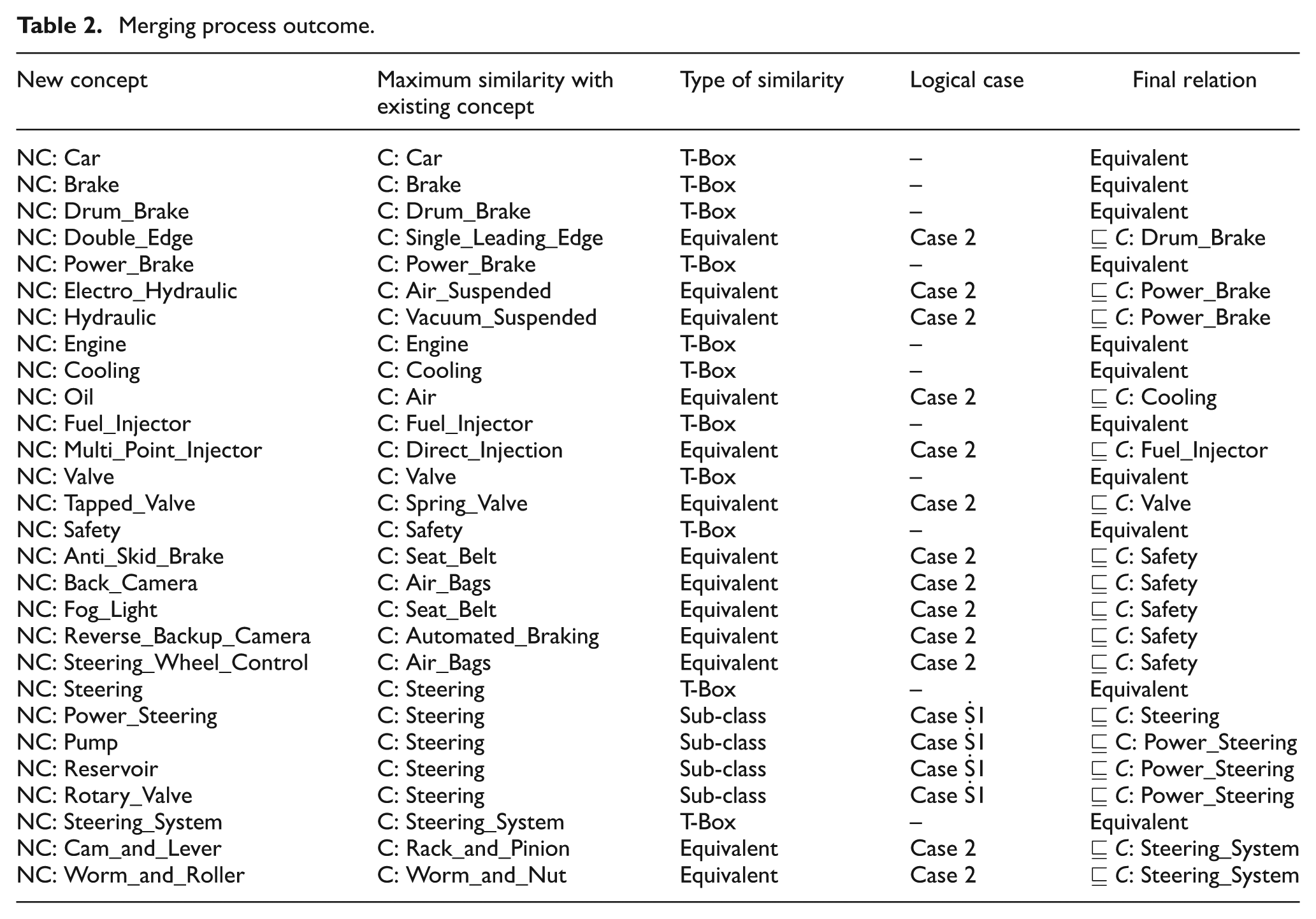
Although the example presented here describes the knowledge merging process within an enterprise, this process can be extended in the case of merging two different enterprises with different ontology-based databases built for the same domain.
Fuzzy domain
In the case of a fuzzy ontology, the process of finding the similarity index and determining the position of merging of a new concept with the existing ontology has been explained in sections “Ontology similarity” and “Ontology merging and reconfiguration.” In this process, fuzzy-domain ontologies differ from concrete-domain ontologies only in the step comparing the fuzzy values of the new concept with the existing ones.
Taking an example as shown in Figure 23, a concept “Engine failure” has different sub-concepts with different fuzzy values, for example, “Low fuel
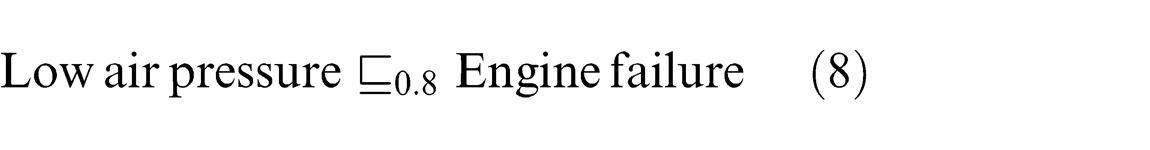
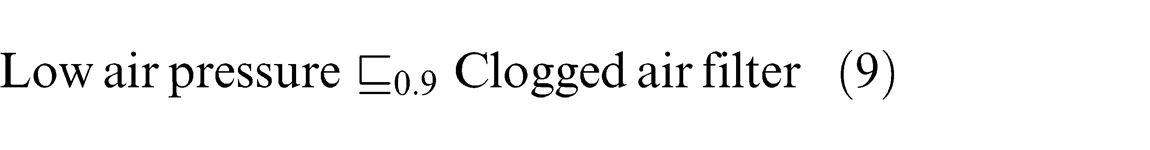
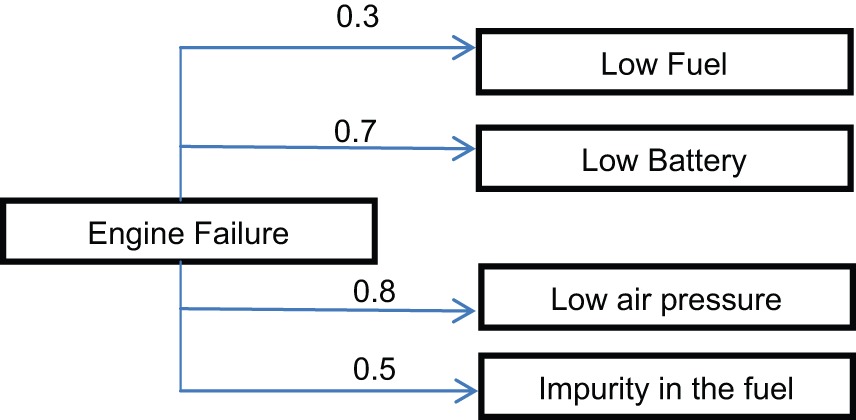
Fuzzy existing knowledge.

Fuzzy new knowledge.
The unified ontology needs to find the fuzzy value of “ Clogged air filter

Using the Lukasiewicz implication function: 0.8 = min (1, 1 − 0.9 + β) = min (1, 0.1 + β), clearly, β = 0.7 as shown in Figure 25. Using this process, all other fuzzy values for the fuzzy relation can be defined.
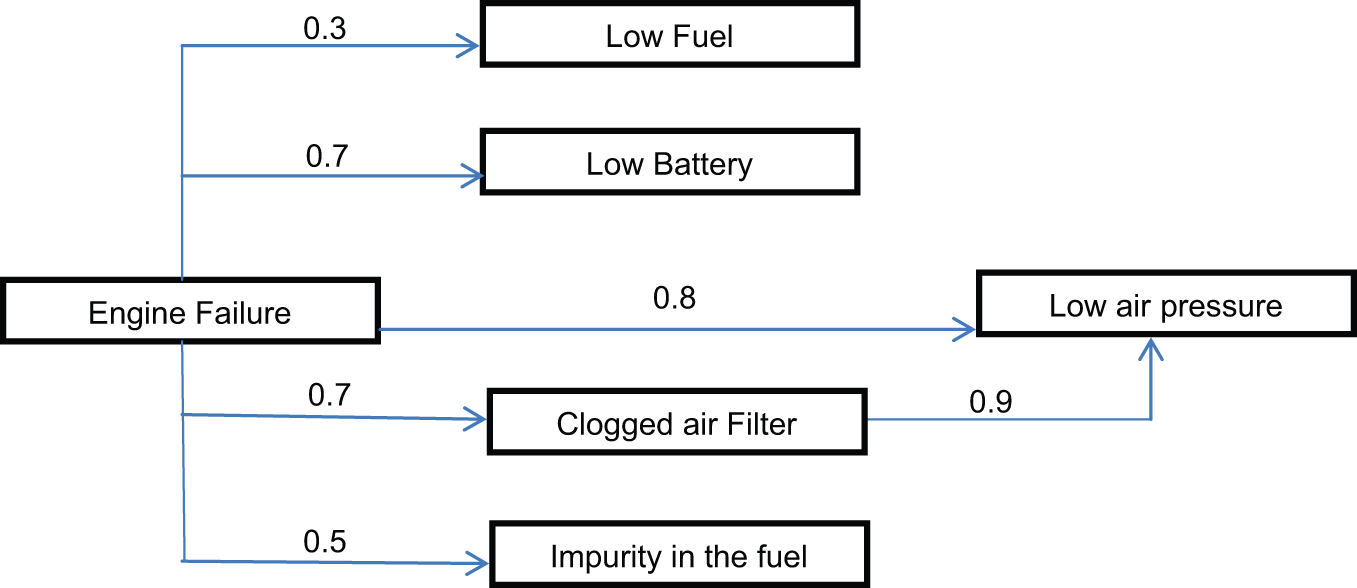
Fuzzy merged knowledge.
Conclusion
This article addresses the issues related to combining new and existing knowledge in the form of an ontology. The advantage of the proposed method is that enterprises need not reconstruct their existing ontology to accommodate newly acquired knowledge. This methodology merges the new knowledge into an existing ontology using ontology merging and reconfiguration. It also checks for any inconsistencies. The process of merging and reconfiguration first identifies the similarity between the concepts of two ontologies and then, with the help of reasoning, identifies the positions where the new concepts will fit into the existing ontology without any inconsistencies. This approach not only considers the concrete domain but also the fuzzy domain. The proposed approach can also be used in any ontology-based KB with different application domains such as product data management (PDM), PLM 12 and product development. 10 OWL representations of knowledge have been presented by many researchers,10,38,39 and in all such cases, new knowledge can be merged into the existing database in the form of an ontology, built in the same domain, using this approach.
Footnotes
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.