
Abstract
When dealing with the structure, content, and quality of knowledge graphs (KGs), most analyses focus on entities, overlooking the significance of relationships and their evolution. In this article, we introduce
Introduction
Crowdsourcing techniques are essential to combine the collective intelligence of contributors with various areas of expertise and opinions (Sarasua et al., 2015). Some knowledge graphs (KGs) are built directly (e.g. Wikidata, Vrandečić & Krötzsch, 2014) or indirectly (e.g. DBnary, Sérasset, 2015; DBpedia, Auer et al., 2007; or YAGO4, Pellissier Tanon et al., 2020), using crowdsourcing resulting in KGs that reconcile high quality and large size (Liu et al., 2020; Oelen et al., 2022; Zhang, 2022). Social editing dynamics for semantic web received a lot of attention. Simperl and Luczak-Rösch (2014) describe how community-driven tools such as wikis have led to a consensus-building process. Furthermore, Piscopo and Simperl (2018) categorize editor tasks and roles to examine the links between task categories, user roles, and KG quality. To understand its social editing dynamics, Piao and Huang (2021) propose a method to predict whether a user will remain active on the platform. All these works are focused on social aspects, not on data (even if it has also been noticed that the editor community may be unbalanced, introducing biases into the produced data, leading to cultural or social biases Demartini, 2019). Obviously, schemas guide (or constrain) the editors for inserting new entities and new facts in each relationship (even if the schema itself is sometimes crowdsourced Vrandečić et al., 2023). Moreover, schema formalization and modeling have already been studied in depth in knowledge representation, with various works on Description Logics and Ontologies (Van Harmelen et al., 2008). However, this line of research does not explain how factual knowledge accumulates to describe entities.
To better grasp the content of KGs, many works aim at extracting statistical information (Ben Ellefi et al., 2018), summaries (Cebiric et al., 2018; Goasdoue et al., 2020), schemas (Kellou-Menouer et al., 2021), constraints (Rabbani et al., 2023), and so on. For instance, Figure 1(a) shows the distribution for

Place of birth relationship.
To address these two research questions, this article explores a novel technique that has not yet been applied to KGs, namely the modeling of complex network structures and dynamics (Barabási & Albert, 1999). This approach has gained momentum in fields as diverse as computer networks (Barabási & Albert, 1999) and biology (Barabasi & Oltvai, 2004). In particular, it has contributed a significant body of knowledge on the emergence of structures and their dynamics in web artifacts: HTML page networks and social networks (Barabási & Albert, 1999), or folksonomies resulting from distributed collaborative annotation systems (Halpin et al., 2007). Unfortunately, none of the stochastic models for complex networks can be applied to KGs, because they are a superposition of many bipartite graphs (for a definition of a bipartite graph see Section 3.1 and Figure 2). Indeed, each relationship is represented by a bipartite graph, whose every edge connects a vertex from subjects and objects. To the best of our knowledge, this particular structure has never been dealt with in the literature. In addition to this bipartite structure, the semantics behind each relationship have an impact on the concentration of links, which is a challenge to capture. We will see in Section 2 that such stochastic models are preferable to deep learning methods for generating graphs because the latter are black boxes (in addition to having other limits with respect to KG topology). Similarly, Section 2 presents heuristic methods for reproducing a target graph, but they require a lot of input parameters, including the degree distributions, whereas we would like our model to explain these distributions by construction.

Representing a relationship by a bipartite graph.
Studying the structure of KGs using existing stochastic models from network science is challenging because KGs incorporate semantics, thus they contain relationships across a wide variety of domains which are structured with respect to a logic. To meet this challenge, our contributions are as follows:
We present the first complex network model, named By analyzing this model, we prove that the degree distribution tends towards an exponential law for subjects and a power law for objects. This important theoretical result answers RQ1 by demonstrating the emergence of a stable structure in KGs. We show experimentally on four real-world KGs that our model succeeds in reproducing most relationships and outperforms baselines. A longitudinal study shows that our model is able to simulate the growth of Wikidata over the years.
The rest of this article is structured as follows: In Section 2, we analyze work related to graph models. Section 3 introduces definitions used later. In Section 4, we present the asymmetric bipartite graph model for KGs (algorithm and theoretical analysis). Section 5 presents a synthesis of experimental results obtained with the model. Section 6 discusses several practical applications of our model, and Section 7 concludes this work with perspectives.
This section reviews the main categories of existing approaches for generating graphs, and more specifically, KGs, highlighting both the similarities and differences with our approach, and clarifying what distinguishes our research from existing studies. Given the rise of deep learning in recent years, and the fact that the model we propose re-generates an artificial structure for KG relationships that mirrors real-world patterns, we reference in Section 2.1 various studies that use deep learning to model graph structures. In doing so, we emphasize the differences in objectives between those works and ours, addressing their limitations relative to our goals. Additionally, we examine in Section 2.2, heuristic methods for regenerating synthetic KGs, discussing their general limitations, particularly in the context of our specific objectives. More importantly, as the use of graph models for understanding knowledge-related data has already been widely studied (as shown for instance in survey, Drobyshevskiy & Turdakov, 2019), but not for KGs, we introduce those modeling techniques. For example, in the seminal paper (Barabási & Albert, 1999), Barabási and Albert devised a fundamental model (named Barabási-Albert model) to better understand networks such as the Web, or citation networks, by proving that the distribution of degrees follows a power law. Similarly, Ferrer i Cancho et al. (2005) model the organization of syntax as a scale-free network. This model explains the structural similarities in syntax between different languages. Also, Halpin et al. (2007) studied collaborative tagging using a model with a tripartite graph (users/tags/documents). Although the final distribution was not formally defined, their experiments also concluded that a stable structure emerges among tags, despite the diversity of contributors. All these studies clearly show the importance of graph models in understanding the structure of large-scale KGs. They are useful for predicting the evolution of knowledge structure and evaluating its stability. Thus, Section 2.3 provides a detailed examination of this type of models. As we will see in the following subsections, none of these existing approaches are suitable for our objectives or adequately address the research questions we have posed. We provide in Table 1 a synthesis that highlights this fact.
Comparison of Our Model With Related Methods.

Comparison of Our Model With Related Methods.
KRELM: Knowledge RELationship Model.
With the growing interest in deep learning, numerous approaches have been proposed for generating graphs (Guo & Zhao, 2022) either by generating the whole graph at once (global approach) or by generating the links one by one (sequential approach). At first sight, it might seem interesting to apply such approaches on KGs, which have worked successfully in several fields (e.g. molecular graphs, De Cao & Kipf, 2018). First, global approaches aim at reproducing graphs in one shot by benefiting from various architectures like autoencoder (Gómez-Bombarelli et al., 2018; Simonovsky & Komodakis, 2018) or generative adversarial networks (De Cao & Kipf, 2018). But, these methods do not reproduce the successive addition of facts that is the main mechanism of crowdsourced KGs. More interestingly, sequential approaches (Bojchevski et al., 2018; Li et al., 2018; You et al., 2018) generate a graph by adding at each iteration nodes and links. Unfortunately, deep learning methods are well suited only to small simplex networks (where all links are of the same type) such as molecule networks (De Cao & Kipf, 2018; Gómez-Bombarelli et al., 2018). In contrast, KGs are multiplex networks with millions of nodes and links of various types. Furthermore, all these approaches require a set of graphs as a training set, which is very restrictive for reproducing a given KG (necessarily unique). Finally, the learned model is a black box that does not enable us to understand and analyze the evolution of a graph. Conversely, using simple statistics, we will see that
Heuristic Methods
Several heuristic methods have been proposed for generating synthetic KGs that can be used as benchmarks for evaluating existing query engines. Their strength lies in their ability to take into account the specific features of KGs, by considering several types of relationships (in the manner of multiplex networks) and integrating a schema part (or T-box). Thereby, schema parameterization has become increasingly complex, from simple statistics (Guo et al., 2005) to rules extracted from the KG to be reproduced (Melo & Paulheim, 2017). However, the generation of the assertion part (or A-Box) has received much less attention. For instance, Theoharis et al. (2012) even ignore the generation of these assertions, because their aim was to reproduce the schema only. Other heuristic methods (Bagan et al., 2016; Feng et al., 2020; Guo et al., 2005) focus on ensuring that the assertions generated are consistent with the schema. However, one of the earliest methods only uses unrealistic uniform draws (Guo et al., 2005). More recent approaches allow to control the degree distributions to be reproduced by adding constraints as input parameters (e.g. uniform or truncated exponential distributions, Guo et al., 2005; Melo & Paulheim, 2017). These methods focusing on benchmark building do not aim to generate a crowdsourcing-like process. In particular, they have the disadvantage of being static and they do not allow a graph to be gradually completed to simulate the continuous arrival of new knowledge. This explains why these methods take distributions as input parameters, instead of reproducing these features by construction. As a result, they do not really model the work of editors for understanding the structuring of KG relationships. For this reason, our work is complementary to these approaches. By tackling only the reproduction of one relationship at a time, our model could be injected into these methods so that we no longer need to specify the expected distributions.
Stochastic Models for Complex Networks
Introduced by Barabási and Albert (1999), preferential attachment is one of the main mechanisms explaining the emergence of networks. It consists in associating each new link with an existing node, favoring those with larger connectivity. More precisely, the probability of adding a new link connecting an existing node
To conclude, Table 1 summarizes the characteristics of each method, highlighting their strengths (in bold). Importantly, none of the methods allows us to understand the underlying mechanisms of the KGs we are targeting with research questions RQ1 and RQ2. Deep learning and heuristic methods do not seek to model but to reproduce data, and stochastic models are not suited to the representation of a KG.
Preliminaries
Basic Definitions and Notations
KG (Hogan et al., 2021)
A KG of a set of edges
Given a relationship r,
Bipartite graph (Bondy & Murty, 2008)
It is possible to represent a relationship r by a bipartite graph
Methodology
In the rest of the article, we will follow the standard Modeling-Analysis-Verification methodology (Newman, 2018) to answer the two research questions identified in the introduction. In each step, original contributions are provided.
Modeling
For research question RQ2, we propose a stochastic model, named
Analysis
We analyze in Section 4.3 the stochastic model
Verification
We evaluate in Section 5 our stochastic model
KRELM
: Knowledge Relationship Model
Key Ingredients of the Model
Our goal is to propose a model to generate a random bipartite graph simulating the crowdsourcing of a relationship by its editors. One might think that subjects and objects would behave identically because of their definition within a relationship which plays a dual role. As some ontologies (e.g. Bekiari et al., 2021) systematically define an inverse relationship for any relationship, subjects and objects should exhibit similar behaviors. However, this does not seem to be the case in practice, particularly in crowdsourced KGs, as measured by experiments in Section 5. Instead, relationships are oriented from a more recent subject entity to an older object entity; from the more specific to the more general, and from the more concrete to the more abstract. Naturally, when a person is added to a KG, he or she is linked to existing entities such as place of birth or gender. Similarly, all the actors in a film already exist when we add it. We will see that this intuition about the importance of adding new entities and their order of arrival leads to an asymmetrical model. More precisely, the addition of a new fact by an editor can either lead to the addition of new entities or just complete the information of existing ones. For example, Figure 3 shows the editing process that led to the complete bipartite graph of Figure 2 by adding each fact one by one. It is easy to see that Steps 1 and 3 add both new subjects and new objects, but Step 4 with the addition of

Dynamic process of the bipartite graph representing the editing of the relationship.
Growth probability
With the addition of a new fact, editors regularly add new entities for both subjects and objects. We propose to model this proportion of new entities by one probability for subjects
Asymmetric attachment
When an editor does not create a new entity (i.e. with a probability Uniform attachment for subjects: In practice, attachment is often weak for subjects as growth probability is often close to one. Nevertheless, when there is an attachment, we choose one subject at random with a uniform probability. The intuition is that all subjects have the same chance of being described by a new fact. For the cast member relationship, for instance, movies have a similar number of actors, in other words, none concentrates all the actors. In Figure 3, the subjects’ attachment is exploited only in Step 4, where the fact Linear preferential attachment for objects: We choose one object at random with a probability proportional to the number of facts already describing the objects. The key idea is that an object that has already received a lot of facts will be more likely to receive others. For the birthplace relationship, it is clear that cities with many births are more likely to have a new birth. In the same way, popular actors who have already played in many films are more likely to be approached for a new film. In Figure 3, this means that in Step 3, the object
As mentioned in the state-of-the-art, our model

Figure 4 shows the out-degree distribution of subjects and the in-degree distribution of objects resulting from our asymmetric model
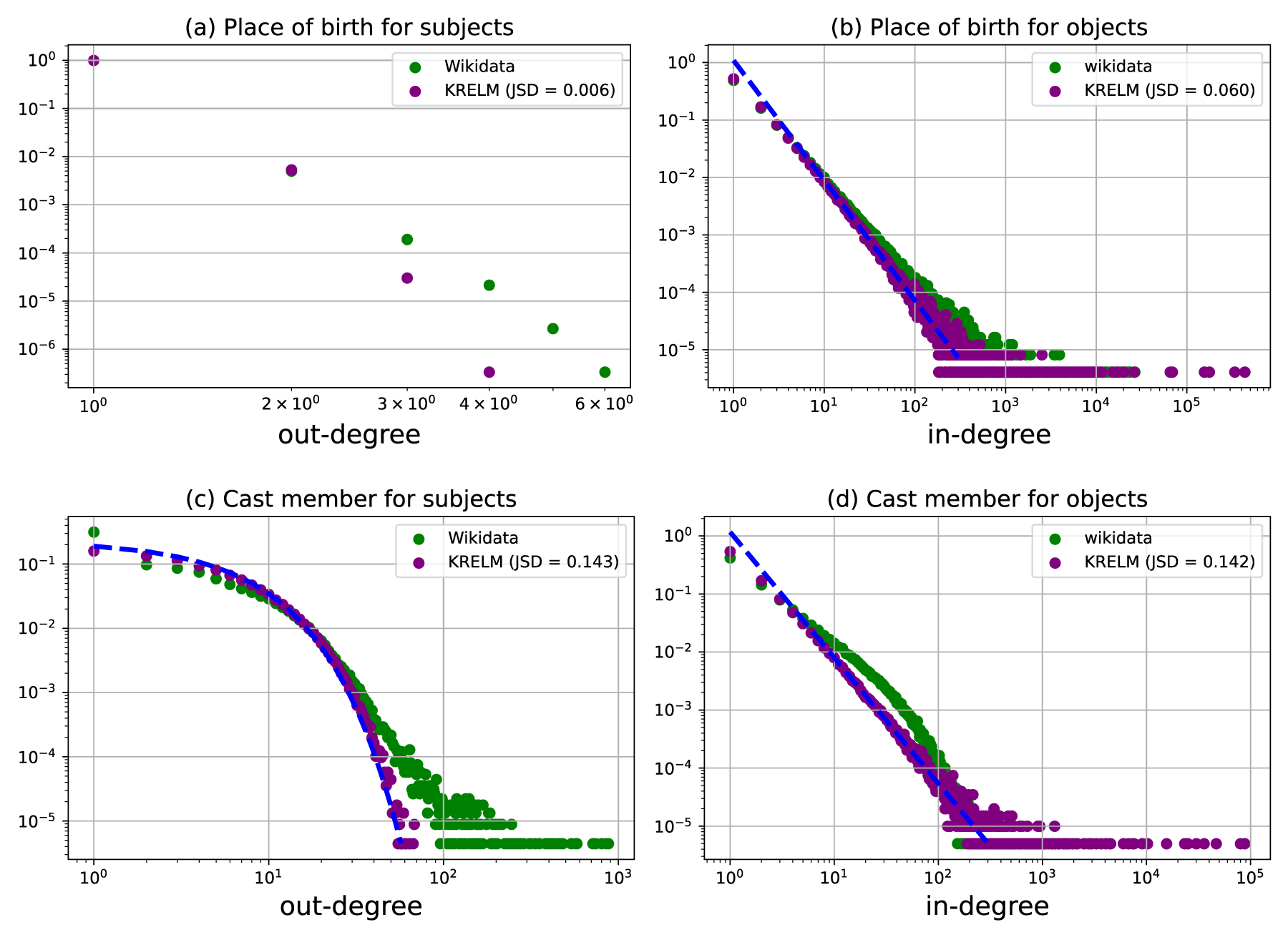
Place of birth and cast member relationships.
Algorithm 1 reproduces the main characteristics of the targeted relationship specified with the input parameters. Obviously, the number of edges
Under the bipartite graph model
Property 1 follows from the fact that after n calls of the function
Beyond finding the main characteristics, the theoretical study of 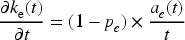
Under the asymmetric bipartite graph model 
To prove this result, we benefit from the mean-field theory already used in network analysis (Barabási et al., 1999). The out-degree 


The probability that a subject 


Under the asymmetric bipartite graph model 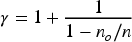
We can apply the same proof scheme. The in-degree 



These theorems are an important result since they qualify the structure of the relationships according to the bipartite graph model
The asymmetry between subject and object is a truly surprising result. Yet experimental results show that our model faithfully reproduces most relationships for both subjects and objects. This means that for a relationship, the distribution of facts for subjects follows an exponential law, while the distribution of facts for objects follows a power law (with an exponent
Regarding the example of the birthplace relationship, applying the exponent formula of Theorem 2 on the objects in relationship
The aim of this experimental study is to evaluate our model’s performance and compare it with two baselines. Firstly, after presenting the protocol followed in Section 5.1 we examine whether our model
As it generates the relations containing the most facts in just a few seconds on a personal computer, we do not present runtime results of KRELM. It is implemented in Java. Its source code, the description of relationships for each dataset, and results are publicly available: https://scm.univ-tours.fr/habdallah/KRELM/.
Protocol
Processing of KGs
We rely on four crowdsourced KGs: DBnary (Sérasset, 2015), DBpedia (Auer et al., 2007), Wikidata (Vrandečić & Krötzsch, 2014), and YAGO4 (Pellissier Tanon et al., 2020), that are available on the Web. We especially focus on Wikidata for the longitudinal study for which we have a snapshot for each year. We filtered each dump to remove literals and external entities because our model aims at understanding the internal topology of the entities belonging to a given KG. Literal values such as dates, strings, or images have therefore been removed. To focus on the graph, we only consider the entities whose uniform resource identifier (URI) is prefixed by http://dbpedia.org/, http://www.wikidata.org/, or http://yago-knowledge.org for DBpedia, Wikidata, and YAGO4, respectively. Table 2 indicates the main statistics of these four crowdsourced KGs after the preprocessing: number of relationships
Main Statistics of the Four Knowledge Graphs (KGs).

Main Statistics of the Four Knowledge Graphs (KGs).
Baselines
As mentioned in related work, there is no method in the literature specifically designed for generating bipartite graphs from basic statistics (see Table 1). In particular, it is not possible to directly compare our method with existing stochastic models dedicated to traditional simplex graphs. Other methods require different parameters (more specific than simple statistics), making comparison impossible. On the one hand, deep learning methods cannot be applied because they require a training set and are limited to small graphs. For instance, to reproduce the birthplace relationship, we would need to retrieve equivalent relationships from many KGs. On the other hand, heuristic methods (Bagan et al., 2016; Feng et al., 2020; Melo & Paulheim, 2017; Theoharis et al., 2012) require the desired final distribution as an input parameter of their algorithms. For instance, for the birthplace relationship, this would be equivalent to estimating the exponent of the power law from real data, denoted as
Note that these two baselines are illustrated for place of birth and cast member relationships in Figure 5 (in red for

Place of birth and cast member relationships.
Evaluation measures
To assess the effectiveness of the different approaches, we employ the Jensen-Shannon divergence (D
JS
) measure (Menéndez et al., 1997) to compare the degree distributions generated by a model with those obtained from real KGs. 
When the number of entities in a relationship is low, the distribution of facts 

For each KG, we regenerate relationships in order to measure the precision and coverage of our model and compare it to the two baselines. Table 3(a) and (b) shows the results of our model,
Precision and Coverage for Four Crowdsourced KGs for
and the Two Baselines, for Subjects (a) and Objects (b).

Precision and Coverage for Four Crowdsourced KGs for
KGs: knowledge graphs; KRELM: Knowledge RELationship Model.
We first observe that our model
Precision Considering Properties That Have

KGs: knowledge graphs; KRELM: Knowledge RELationship Model.
More impressively, our model significantly outperforms the baseline for objects (except for the coverage in DBpedia), with coverage varying between 0.365 and 0.708 depending on the KG, and a very good precision ranging from 0.642 to 0.806. Also, for objects, our model outperformed the two baselines for relations with
Evolution of precision and coverage
For each year, we reproduced the Wikidata KG to assess the quality of our asymmetric bipartite graph model and compare it to the two baselines. Figure 6 plots the coverage and precision of our model (solid line) and the baselines (dashed line for

The evolution of precision and coverage metrics of Knowledge RELationship Model (
Predicting the evolution of Wikidata
Now, we want to check whether our model is capable of reproducing the dynamics of a KG by predicting the evolution of Wikidata. For each relationship

Simulating Wikidata evolution over time.
The experimental study in the previous section has validated the ability of our model to reproduce real-world crowdsourced KGs at a given point in time. It also validates that the model reproduces the evolution in time, with the longitudinal study. We can therefore confidently answer Research Question 2: The accumulation of facts in KGs regularly adds entities (growth), distributing facts evenly across subjects (uniform attachment) and, conversely, concentrating facts on certain objects (linear preferential attachment). Furthermore, the theoretical study of our model in response to RQ2 has enabled us to provide a precise answer to Research Question 1: The structure of relations is globally stable for both subjects (see Theorem 1) and objects (see Theorem 2).
Now, we want to underline the importance of these fundamental results by discussing several practical use cases:
Benchmark improvement
Our approach can improve methods aiming at generating synthetic graph data similar to real KGs, making them simpler and more realistic. Despite the strengths of the existing methods, they have limitations. Some methods (Guo et al., 2005) focus on creating benchmarks but overlook crucial aspects—the continuous growth in KGs, and the asymmetrical attachment so they use only one type of attachment for graph entities, whether they are subjects or objects. These aspects are important and removing them will alter the results as demonstrated in the experiment section. Some methods (Bagan et al., 2016; Feng et al., 2020; Melo & Paulheim, 2017; Theoharis et al., 2012) inject the desired distribution in the parameters of the algorithm (e.g., a power law with an exponent calculated from real data) and then aim to reproduce this distribution. Therefore, we believe that integrating our model into these existing methods will significantly enhance their results and optimize their algorithms, so they no longer need to specify the expected distributions and try to reproduce them.
Model-based computation
At present, most approaches to KG analysis rely on data as an approximation to the actual distribution. This data is often costly to retrieve and manipulate. But above all the data itself remains a sample of an underlying distribution (i.e. the power or exponential laws we have identified) that it is often preferable to handle directly. For instance, the Gini coefficient (Ceriani & Verme, 2012) is a measure of statistical dispersion (useful in many applications including gap discovery Ramadizsa et al., 2023). When calculating the Gini coefficient for the distribution of facts related to a relationship like birthplace, determining the number of births for each city can be challenging due to current limitations in the Wikidata query service of time-out exceptions when a query needs high processing time. However, leveraging Theorem 2 and Newman’s (Newman, 2005) formula, we can directly estimate the Gini coefficient for a relationship by executing only simple SPARQL queries, which request just the number of objects and the number of facts. This light approach simplifies the calculation process, especially for methods that need to calculate the Gini coefficient for multiple relations. We demonstrated the usefulness of this observation by building a method that automatically generates ranking indicators from Wikidata (Abdallah et al., 2024).
Topological analysis
Moreover, the knowledge about how the bipartite graph of a relation is growing brings insights to many tasks performed on crowdsourced KGs. For instance, to the best of our knowledge, systems supporting Wikidata “patrollers” (who fight vandalism) are based on the topological characteristics of entities and do not consider the topological characteristics of relations. In network science, complex network models serve to evaluate the robustness of a network. In fields where they are applied, robustness is essentially about checking whether the removal of nodes or links breaks the network’s connectedness (Albert et al., 2000; Holme et al., 2002). For example, removing central servers may prevent some remote machines from communicating with each other. In the case of a KG, we think that connectedness itself is less meaningful. Corrupting a KG is more about deleting information or inserting fake information. Intuitively, information is less vulnerable if it is based on a large number of facts. For example, by deleting the fact
Conclusion
This article introduces the first complex network model for simulating the construction of relationships in crowdsourced KGs. It complements the results already established by works focused on social editing, knowledge engineering, and KG profiling. Compared to deep learning and heuristic methods for generating synthetic KGs, this new model includes continuous growth and asymmetrical attachment, which are more realistic for replicating KGs’ relationships. The model’s theoretical study leads to two major new results: facts are distributed on subjects according to an exponential law, and they are distributed on objects according to a power law with an exponent greater than 2. The extensive experimental study on four KGs, with a longitudinal study concerning Wikidata, demonstrates the effectiveness of KRELM in reproducing current and predicting future relationships’ structures. Experiments also demonstrate the model’s generality in generating property distributions very similar to a large proportion of existing relationships, with excellent precision and coverage. They also show that it behaves better compared to two baselines, one without growth, and one with reverse attachments (evaluating the two main ingredients of our model). The source code of the model, description of relationships, and experimental results are provided: https://scm.univ-tours.fr/habdallah/KRELM/. This work provides a fundamental understanding of KGs that paves the way for numerous research directions. For instance, although KRELM ignores the interrelationships phenomena, it works very well for individual relationships. Thus, it could be used to generate benchmarks (Bagan et al., 2016; Feng et al., 2020; Guo et al., 2005; Melo & Paulheim, 2017; Theoharis et al., 2012) with more realistic characteristics and less parameters by injecting our model. In data analysis (Newman, 2005) applied to KGs, having such a model makes it possible to analyze data evolution in greater detail, which is useful for anomaly detection and prediction. These are not the only directions that may be studied, another application field could also be in query engine optimization: our model could be useful for refining cost models often relying on heuristics (Abdelaziz et al., 2017; Ali et al., 2022). A primary direct application of this model is presented by Abdallah et al. (2024), where we use KRELM to optimize the complexity cost of computing the Gini coefficient.
Footnotes
Acknowledgements
The University Technical Institute of Blois partly supports this work. We thank Louise Parkin who recently joined our team for her rigorous proofreading and numerous suggestions for improvement.
Funding
The authors received the following financial support for the research, authorship and/or publication of this article: This work was supported by the University of Tours through PhD funding.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.