
Abstract
Relation prediction in knowledge graphs (KGs) aims to anticipate the connections between entities. While both transductive and inductive models are incorporated for context comprehension, we need to focus on two primary issues. First, these models only collate relations at each layer of the subgraph, overlooking the potential sequential relationship between different layers. Second, these methods overlook the homogeneity of subgraphs, thus impeding their ability to effectively learn the importance of relationships within the subgraphs. To address this challenge, we propose a hierarchical and homogenous subgraph learning model for KG relation prediction (HiHo). Specifically, we adopt a subgraph-to-sequence mechanism to learn the potential semantic associations between layers in the subgraph of a single entity, and thus model the hierarchy of the subgraph. Then, we implement a common preference inference mechanism that assigns higher weights to co-occurrence relations while learning the importance of each relation in the subgraphs of two entities, and thus models the homogeneity of the subgraph. In our study, we sequentially employ induction on each layer of subgraphs pertaining to the two entities for relation prediction. To assess the efficacy of our method, we perform experiments on five publicly available datasets. The results of our experiments demonstrate that our method surpasses the current state-of-the-art baselines in both transductive and inductive settings.
Introduction
Knowledge graphs (KGs) are structured collections of facts represented as triples (head entity, relation, and tail entity), playing a fundamental role in numerous natural language processing tasks, such as multihop query (Shang et al., 2024), question answering (Yang et al., 2023), recommendation systems (Wang et al., 2023a), and commonsense reasoning (Wu et al., 2023). Despite the success, most of the KGs often suffer from incompleteness, especially the missing relations between entities. Therefore, an increasing number of researchers are committed to predicting the missing relations between entities (Shi et al., 2023), and many different methods have been proposed. These methods can be roughly categorized into transductive methods and inductive methods.
Transductive methods refer to the traditional KG embedding methods, which can be divided into translation-based methods (e.g., TransE [Bordes et al., 2013] and TransR [Lin et al., 2015]), semantic matching methods (e.g., ComplEx [Trouillon et al., 2016] and DistMult [Yang et al., 2015]), path-based methods (e.g., CURL [Zhang et al., 2022a] and CPL [Fu et al., 2019]), and graph-based methods (e.g., TransEQ [Liu et al., 2023] and NoGE [Nguyen et al., 2022]). Despite their different forms, transductive methods mostly focus on learning a matching score for the relations of known inherent entities in KG. Many transductive methods have proven to be effective in predicting relations between entities, but they need expensive re-training to infer the relations between unknown new entities, which is impractical for real-world KGs that are constantly adding new entities.
Different from transductive methods, induction-based methods aim at learning the subgraph structure of entities to infer the relations between entities in KGs, where entities may be unseen in the training process. For instance, Grail (Teru et al., 2020) is a framework based on graph neural networks (GNNs) with strong inductive bias, which can learn relationship semantics unrelated to entities. Grail does not learn embeddings of specific entities, but predicts relationships from subgraph structures around candidate relationships. SNRI (Subgraph Neural Relational Inference) (Xu et al., 2022) incorporates complete relational information into the enclosing sparse subgraph in a global way for relation prediction. TACT (Topology-Aware Correlation Transfer) (Chen et al., 2021) predicts the missing link by learning the topology-aware semantic correlations between relations in an entity-independent manner. However, these methods only collect relations at each layer of the subgraph individually, without considering the back-and-forth associations of relations in different layers, so they lose the global nature of the relations. Furthermore, they approximate the commonalities between subgraphs by simply extracting their intersection, and they prune nodes that are isolated or located at a distance greater than a specified threshold (denoted as ”k”) from either of the target entities. But sometimes the intersection occupies only a small portion of the two subgraphs, which leads to many relations in the subgraphs being ignored.
To solve the above problem, we first reviewed the subgraphs of entities. Through our observation, we found that the subgraph of an entity consists of the neighboring entities and relations surrounding the entity. These neighboring entities and neighboring relations exist in the form of layers, and any level of the subgraph does not exist in isolation. For the
To implement the above process, we propose a subgraph-to-sequence (S2S) mechanism that converts the subgraphs of an entity into a sequence composed of layers, specifically we choose bidirectional gated recurrent unit (Bi-GRU) to encode the history and future information for the layers in the sequence to model the hierarchical nature of the subgraphs. Furthermore, we propose a common preference inference (CPI) mechanism that assigns higher weights to co-occurrence relations while learning the importance of each relation to both subgraphs. Also, to prevent over-preference for certain relations, a smoothing factor is added to CPI to balance the preferred and unpreferred relations. In this way, each neighbor relation is assigned a weight to indicate the importance of the relation in the two subgraphs. Finally, we alternately induct each layer of the subgraph of the head entity and the tail entity to predict the relation between them. In summary, our main contributions are as follows.
We introduce an S2S mechanism to capture the hierarchical structure within the subgraph of an individual entity. This mechanism facilitates the understanding of the entity’s internal relationships and context. We propose a CPI mechanism to address the homogeneity within the subgraphs of the head and tail entities. CPI aims to model and leverage the shared characteristics present in both subgraphs, enhancing the predictive accuracy of relations between entities. We propose HiHo to predict the relations between entities by modeling the hierarchy and homogeneity of the subgraphs of entities. In this way, HiHo avoids learning to embed any specific entity, so it can predict the relations between emerging or unseen entities in the reasoning phase.
Related Work
Recently, researchers have focused on predicting relationships within KGs because it is essential for many tasks. As a result, more scholars are now studying this area. Existing KG relation prediction methods fall into two main categories: transductive and inductive methods.
Transductive Method
Transductive methods primarily concentrate on learning representations of entities and relations, employing a score function to determine the likelihood of a relation being associated with an entity (Li et al., 2023). These methods encompass various categories, and the most popular ones are translation-based methods, semantic matching methods, path-based methods, GNN-based methods, and graph-based methods.
Translation-based methods, such as TransE (Bordes et al., 2013), TransR (Lin et al., 2015), TransH (Wang et al., 2014), ExpressivE (Pavlovic & Sallinger, 2023), and ConvRot (Le et al., 2023) usually project entities and relations into the low-dimensional feature spaces, and assume that the distance between the embeddings of the tail entity and head entity is approximately equal to the relation embedding. Despite their simplicity and efficiency, they ignore the features in the multilayered neighborhoods of entities, which limits their ability to infer relations between entities.
Semantic matching methods, such as ComplEx (Trouillon et al., 2016), DistMult (Yang et al., 2015), QuatE (Zhang et al., 2019), and DRUM (Sadeghian et al., 2019) employ a scoring function grounded in similarity rules, building upon the framework of translation-based methods. Through this approach, they gauge the likelihood of connections between relations and entities by aligning the semantic associations of entities and relations within the embedded vector space. Nonetheless, their effectiveness heavily relies on the configuration of rules, and certain missing relations may remain uninferrable through any rule (Lin et al., 2021).
Path-based methods, such as P-INT (Xu et al., 2021), AstarNet (Zhu et al., 2022), HiAM (Ma et al., 2021), CURL (Zhang et al., 2022a), and CPL (Fu et al., 2019a), usually define a path as the sequence of relations and select relevant features from a path, then model the interactions between the paths to infer new relations between entities. However, in many KGs, the length and number of paths are not balanced, and some paths that are too much, too little, too long, or too short can affect the performance of relation reasoning.
Graph-based methods usually design a GNN to learn the subgraph structure of entities and obtain the representation of entities. On the basis of GAT (Velickovic et al., 2018), EIGAT (Zhao et al., 2022), and GGAE (Li et al., 2022) assign distinct attention weights to the neighbor entities or the neighbor relations of the central entity to obtain entity representation. And on the basis of GCN (Kipf & Welling, 2017), CompGCN (Vashishth et al., 2020), KE-GCN (Yu et al., 2021), and DA-GCN (Zhang et al., 2022b) models, the node or relationship features in the full graph are processed by convolution operations to obtain the entity representation. Although their implementation details are different, they all aggregate the neighboring features of nodes into the node representation (Wang et al., 2023b), which is the reference for relation prediction.
However, these methods can only model known entities and predict relations between known entities during training. Therefore, they require expensive re-training to model the constantly added unknown entities in KGs, and to infer the relations between unknown entities and the relations between unknown and known entities, which makes them difficult to apply to the ever-changing KGs.
Inductive Method
Inductive methods usually infer relations between entities from the subgraphs around entities, avoiding learning to embed any specific entity. They can be naturally generalized to unseen entities or emerging entities in KG, as they learn to reason over subgraph structures independent of any specific entity representation. Recently, inductive methods have been receiving more and more attention. They are classified into rule-based and subgraph-based methods.
Rule-based methods involve the explicit learning of logical rules for reasoning, which are independent of entities and thus considered inductive. Yang et al. (2017) introduced NeuralLP, the first end-to-end differentiable model inspired by TensorLog and neural networks, to learn variable rule lengths. This model merges first-order rule reasoning with sparse matrix multiplication and introduces a neural controller system featuring attention mechanisms and memory, enabling simultaneous learning of the parameters and structure of first-order logical rules. However, this model is constrained by the maximum length of rules and may inadvertently extract incorrect rules with high confidence. Sadeghian et al. (2019) improved NeuralLP with the introduction of Drum, where the learning confidence scores for each rule are related to the low-rank tensor approximation. They use BiRNN to share useful information across different relation learning tasks. However, they often overlook the structure surrounding the target triple, leading to limited expressive ability.
The method based on subgraphs can utilize structural information for inductive reasoning. GraIL (Teru et al., 2020) is the first method to learn entity-independent relational semantics to predict the relation between two entities by reasoning about the local subgraph structure around the two entities. TACT (Chen et al., 2021) transforms a KG to a relational correlation graph, and proposes a relational correlation network to learn topology-aware correlations between relations in entities’ neighborhoods in an entity-independent manner, to predict the missing relation. CFAG (Wang et al., 2022) utilizes a coarse-grained module to generalize the unseen entities with multiple relational semantics, then uses a fine-grained module to generate more accurate entity representations with certain query relations. MorsE (Chen et al., 2022) utilizes an entity initializer to generate each entity’s initial embedding through relation-domain embedding settings and relation-range embedding settings, then learns the neighbor structure of the entity to enhance entity embedding by a GNN modulator. Next, MorsE resorts to meta-learning to output an entity’s final embeddings. These methods model the rules between relations to generate relation preferences for entities. PathCon (Wang et al., 2021) proposes a multilayer relational message passing mechanism, which iteratively aggregates the relational context features of entities and the relational path features between entities to predict missing relations. SNRI (Xu et al., 2022) extracts complete neighboring relations for each entity and constructs neighboring relational paths by the mutual information maximization mechanism. By combining the above two approaches, SNRI can effectively integrate the comprehensive relational information into the subgraph of entities to improve the performance of relation prediction. StATIK (Markowitz et al., 2022) aggregates structure information from the neighborhoods of entities through a message passing neural network, then completes the missing relations by combining underlying textual descriptions of entities and relations through a pretrained language model. RMPI (Geng et al., 2023) utilizes novel techniques such as target relation-guided graph pruning strategies, target relation-aware neighborhood attention, handling empty subgraphs, and ontology-based relationship semantic injection to perform relation prediction through relation message passing. These methods are not simply graph-based iterative methods; they all choose to combine other methods to obtain a better relation prediction effect.
These methods infer the relation between two entities by generalizing the subgraphs around those two entities. However, these methods neglect the heterogeneity and hierarchy natures of subgraphs, which limits their performance in relation prediction.
Problem Definition
(KG)
(Inductive KG)
(KG Relation Prediction)
KG relation prediction aims to train models to predict missing relationships given a triplet
(Transductive Relation Prediction)
(Inductive Relation Prediction)
Illustration of the Transductive and Inductive Settings for Relation Prediction in Knowledge Graphs (KGs). The Transductive Relation Prediction Method Can Only Identify Known Entities, While Inductive Relation Prediction is Learned From the Training KG to Infer in Another KG Without Shared Entities. Green Entities Represent Known Entities During Training, Red Entities Represent Newly Emerged Entities, and the Red Dashed Lines Indicate the Relationships to be Predicted.
For a given entity pair (
To address this issue, we propose a new inductive relation prediction method. Specifically, we design S2S to infer the hierarchical information of a single subgraph. The GRU processes the state sequences within the S2S mechanism, allowing the model to capture the contextual relationships between the states and thus obtain the global characteristics of the subgraph. Then, we propose a CPI mechanism to learn the homogenous information between two subgraphs, and reduce the differences between subgraphs by strengthening their common parts, so as to obtain the local characteristics of subgraphs. The CPI assigns different weights to relations. This weighted information from the CPI is then used as part of the input features when the GRU in the S2S processes the state sequences. The GRU, influenced by the CPI’s weighted relations, further refines its capture of the hierarchical information within the subgraph layers. Moreover, this paper proposes an alternate induction method, which collects the relations in the subgraph of a head entity and the subgraph of a tail entity alternately to infer the relation between entities.
Subgraph Preparation
Unlike traditional methods that simultaneously collect entities and relations from the neighborhoods of entities into subgraphs, we only collect relations from each entity’s neighborhood into the subgraph. However, the relations in the neighborhood of some entities are too dense to be fully used. For example, we observe that there are thousands of relations in the third hop neighborhoods of some entities in the NELL995 dataset, while the first hop neighborhoods of some entities in some real-world KGs may encompass many thousands of relations, so it is impractical to store and model them all.
The solution to this problem is that, for entity
S2S Mechanism
The subgraph of the entity contains a vast number of relations. These relations exist in the form of layers, and any layer of the subgraph does not exist in isolation. Taking Figure 2 as an example, for the entity “Heartbleed Vulnerability,” each layer of its subgraph does not exist independently and has a semantic association with other layers. For instance, the first layer of “Heartbleed Vulnerability” contains the relation “exists in,” and we can infer that the type of the unknown tail entity 1 connected to “Heartbleed Vulnerability” may be “affects.” And the second layer contains the relation “runs on,” and we can infer that the type of the unknown tail entity 2 may be a larger range of location. By learning the semantic association between the first layer and the second layer in the subgraph, it can be inferred that the relation between “Heartbleed Vulnerability” and the unknown tail entity 2 may be “affects.” Thus, modeling the hierarchical nature of subgraphs, that is, learning the potential semantic associations between layers in individual subgraphs, can generate more accurate relation tendencies for entities.

The Framework Diagram of the Proposed Method, HiHo, Comprises Four Components: (1) Subgraph Preparation Selectively Samples up to K Neighbor Relations From Each Entity's Neighborhood into the Subgraph; (2) S2Smechanism Used to Capture the Semantic Associations Between Layers Within the Subgraph of a Single Entity and Achieve Hierarchy; (3) CPI Mechanism Which Assigns Higher Weights to Co-occurrence Relations and Learns the Importance of Each Relation in the Subgraphs of Two Entities; and (4) Alternating Induction Mechanism That Learns the Subgraphs of Two Entities to Predict Relations Between Them. S2S: Subgraph-to-sequence; CPI: Common Preference Inference.
Similar to Graph2Seq (Xu et al., 2019), we regard the subgraph
Next, we opted to use the Bi-GRU, which is a time series prediction method based on the gated recurrent unit (GRU). It combines the bidirectional model and the gating mechanism. The overall structure and the cell structure are consistent with those of GRU, thus enabling it to effectively capture the temporal relationships in time series data. The overall structure of Bi-GRU consists of two GRU networks in opposite directions. One network processes the time series data from the front to the back, and the other network processes it from the back to the front. This bidirectional structure can simultaneously capture both past and future information, thereby more comprehensively modeling the temporal relationships in the time series data. We use Bi-GRU to encode the features from the previous and later parts of the sequence for each state. This enables us to capture the contextual relationships between states, which are equivalent to the hierarchical information present between each layer of the subgraph. The output of the Bi-GRU can be described by equations (1) and (2):




By the above way, S2S transforms the subgraph
To better capture the homogeneity between the
Specifically, for




Finally, the CPI mechanism functions by assigning different weights
After learning the hierarchical features and homogeneous features of each layer of subgraphs of the head entity and tail entity, we alternately induct the





The final latent semantic feature


We train our method by minimizing the loss between the predicted relation type and the actual ground truth relation type, as shown in equation (15):

The algorithm of HiHo is shown in Algorithm ??. First, we collect the relations in the neighborhood of
Experiments
In this section, we assess the performance of our proposed method across five benchmark datasets. The subsequent subsections outline the statistics of these benchmark datasets and summarize the parameter settings. Then, the experimental metrics chosen for this paper are presented. Next, we validate the effectiveness of our method through performance comparison and analysis in both the transductive relation prediction task and the iterative relational prediction task. Subsequently, the effectiveness of different mechanisms on relation prediction is demonstrated. Finally, the influence of the parameters on the model is verified.
Datasets and Experimental Settings
The benchmark datasets selected in this paper are FB15K, FB15K-237, NELL995, WN18, and WN18RR, where FB15K and FB15K-237 are extracted from Freebase (Bollacker et al., 2008), NELL995 extracted from Nell (Mitchell et al., 2018), and WN18 and WN18RR are extracted from WordNet (Miller, 1995). And in addition, FB15K-237 and WN18RR are obtained by removing the inverse relations in FB15K and WN18, respectively. These datasets comprise numerous entities and relations, partitioned into training, validation, and test sets. Table 1 presents the statistics for these datasets.
Statistics of Datasets.

Statistics of Datasets.
We employ Adam (Kingma & Ba, 2015) to train our method, the initial learning rate
Similar to the link prediction task, the relation prediction task aims to forecast the target relation between the head entity
This paper employs mean reciprocal rank (MRR) and HIT ratio with cut-off values of 

We conduct a comparative analysis of HiHo with other state-of-the-art transductive methods (TransE [Bordes et al., 2013], DRUM [Sadeghian et al., 2019], QuatE [Zhang et al., 2019], P-INT [Xu et al., 2021], KE-GCN [Yu et al., 2021], GGAE [Li et al., 2022], and ConvRot [Le et al., 2023]) in the transductive relation prediction experiment. Table 2 reports the results on five datasets. Specifically, the MRR increases of HiHo against the second-ranking method are 0.052, 0.006, 0.015, 0.015, and 0.039 on the five datasets, respectively; the HIT@1 increases of HiHo against the second-ranking method are 2.5%, 0.9%, 2.7%, 2.3%, and 3.4% on the five datasets, respectively; the HIT@3 increases of HiHo against the second-ranking method are 6.0%, 0.1%, 0.8%, 1.3%, and 0.3% on the five datasets, respectively.
The Performance of Different Models in the Transductive Relation Prediction Experiment.
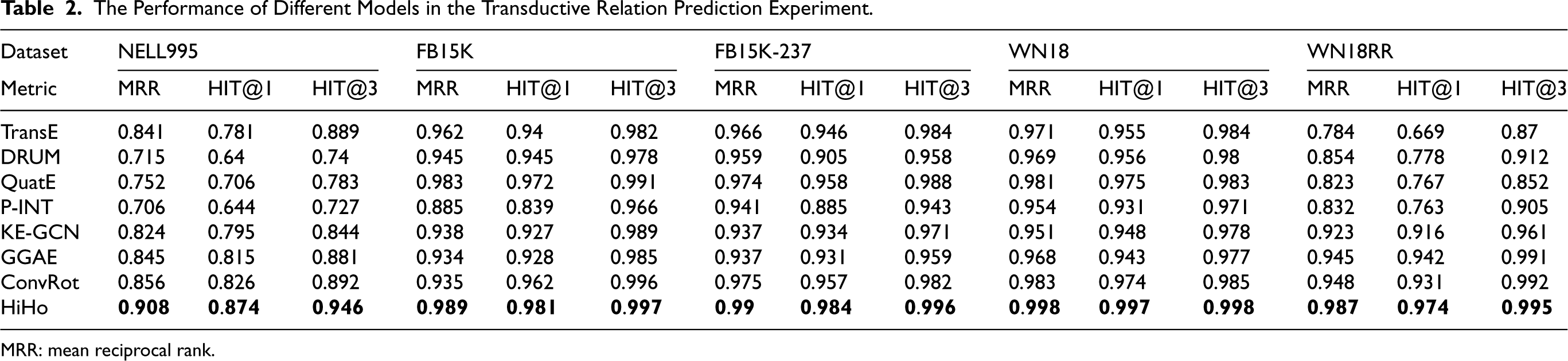
The Performance of Different Models in the Transductive Relation Prediction Experiment.
MRR: mean reciprocal rank.
According to the experimental results shown in Table 2, we compared HiHo with the baselines, and the analysis results are as follows:
Our method outperforms all baselines in all datasets, especially in the NELL995 dataset, where our method has significant advantages. The reason is that NELL995 is sparser than other benchmark datasets, which leads to the overfitting of the baselines and limits their learning ability of the baselines. The improvement of our method in NELL995 is quite significant because our method models the hierarchical and homogeneous nature of entities’ subgraphs, which makes our method easy to extract effective features of entities. In addition, our method has fewer parameters and can be applied to some KGs that are characterized by having relatively fewer connections or edges between entities compared to the total number of possible relationships, that is, sparse KGs. As a translation-based method, TransE (Bordes et al., 2013) and ConvRot (Le et al., 2023) models only the inherent characteristics of entities and relations; they ignore the multistep neighborhood features of entities, which limits their performance in relation prediction. As the semantic matching methods, DRUM (Sadeghian et al., 2019) and QuatE (Zhang et al., 2019) reason about what kind of relation exists between two entities by mining the underlying semantic association rules between entities and relations. However, they are very sensitive to rule settings, and some missing relations cannot be inferred from any rule (Lin et al., 2021). As a path-based method, P-INT (Xu et al., 2021) can extract rich features in the paths between entities to predict the relations between entities. However, not all entities have paths between them, which leads to unpredictable relationships between them. As the graph-based methods, KE-GCN (Yu et al., 2021) and GGAE (Li et al., 2022) learn the aggregated representation of entities by collecting information in their neighborhoods. However, the final representations of the head and tail entities are independent of each other, and they may have no common ground and lack the head–tail interactions, so the relation between them cannot be well reasoned.
We compare HiHo with other state-of-the-art inductive methods (GraIL [Teru et al., 2020], TACT [Chen et al., 2021], PathCon [Wang et al., 2021], StATIK [Markowitz et al., 2022], MorsE [Chen et al., 2022], and RMPI [Geng et al., 2023]) in the inductive relation prediction experiment. Similar to the inductive KG completion experiment conducted by using PathCon (Wang et al., 2021), we randomly sample approximately 20% of the entities present in the test set. Subsequently, we exclude these entities along with their connected relations from the training set. The rest of the training set is utilized to train the models. During evaluation, we reintroduce the removed relations back into consideration (Wang et al., 2021). As can be seen from the results in Figures 3 to 7. Specifically, compared with other baselines, the MRR of HiHo are improved by 0.008–0.184, 0.001–0.056, 0.019–0.066, 0.006–0.042, and 0.006–0.189 on the five datasets, respectively; the HIT@1 of HiHo are improved by 0.5%–21.0%, 0.5%–6.2%, 1.2%–4.9%, 0.2%–6.5%, and 1.6%–32.7% on the five datasets, respectively; the HIT@3 of HiHo are improved by 0.6%–25.4%, 0.2%–2.2%, 0.1%–3.1%, 0.1%–1.9%, and 0.2%–13.1% on the five datasets, respectively.
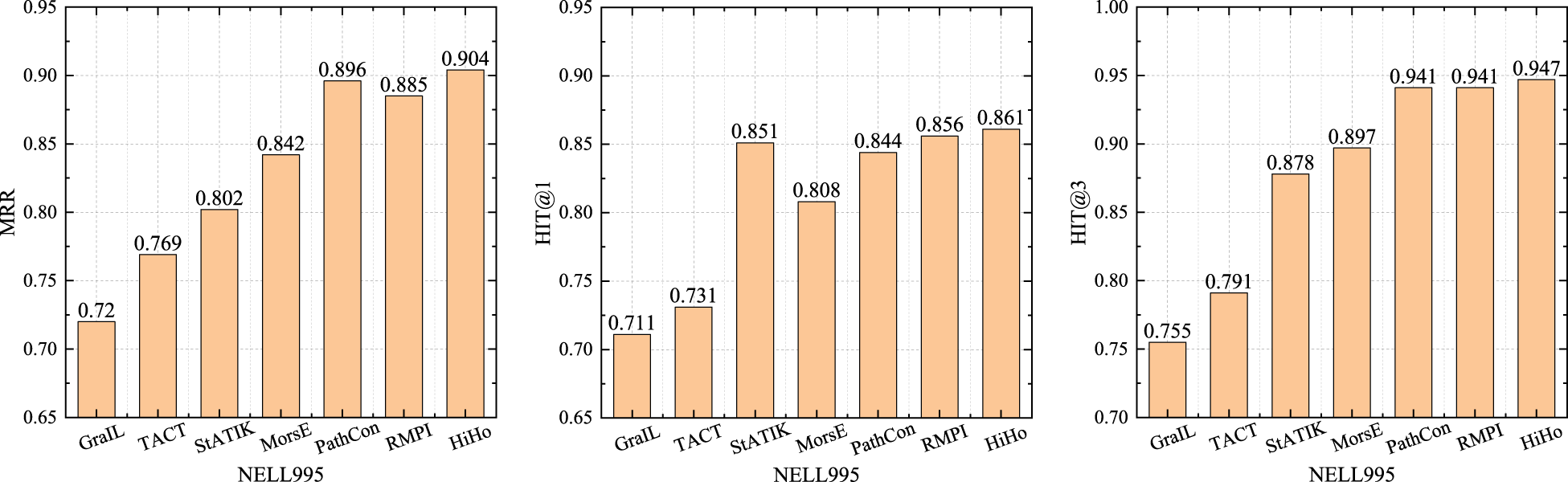
The Performance of Each Method on the NELL995 Dataset.
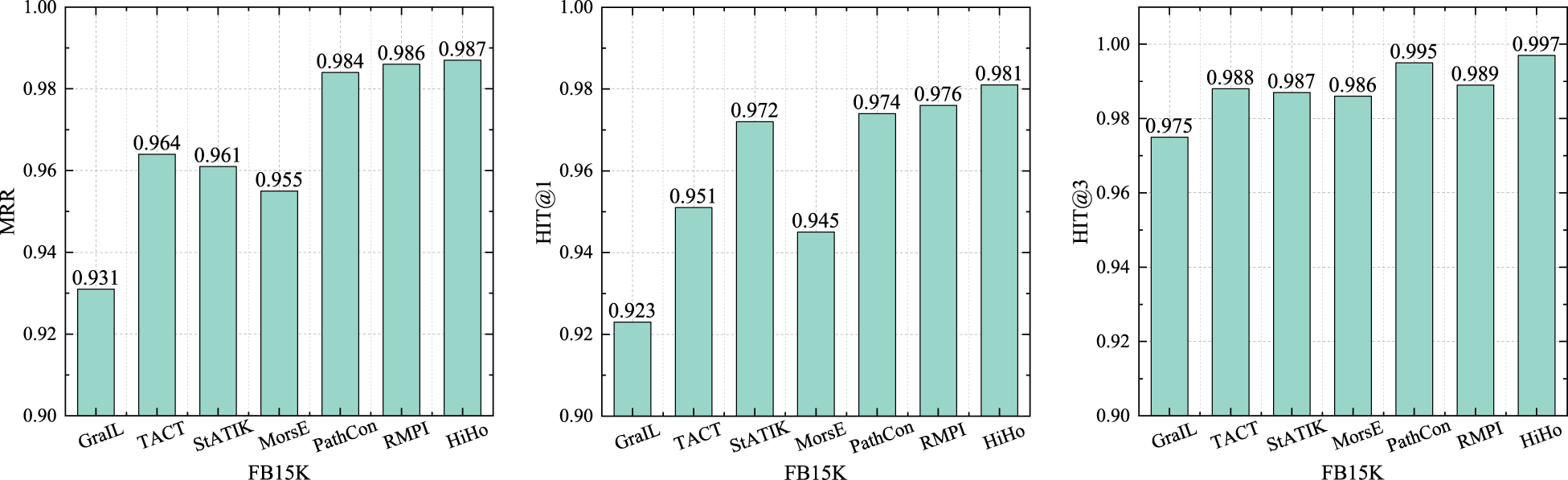
The Performance of Each Method on the FB15K Dataset.

The Performance of Each Method on the FB15K237 Dataset.

The Performance of Each Method on the WN18 Dataset.
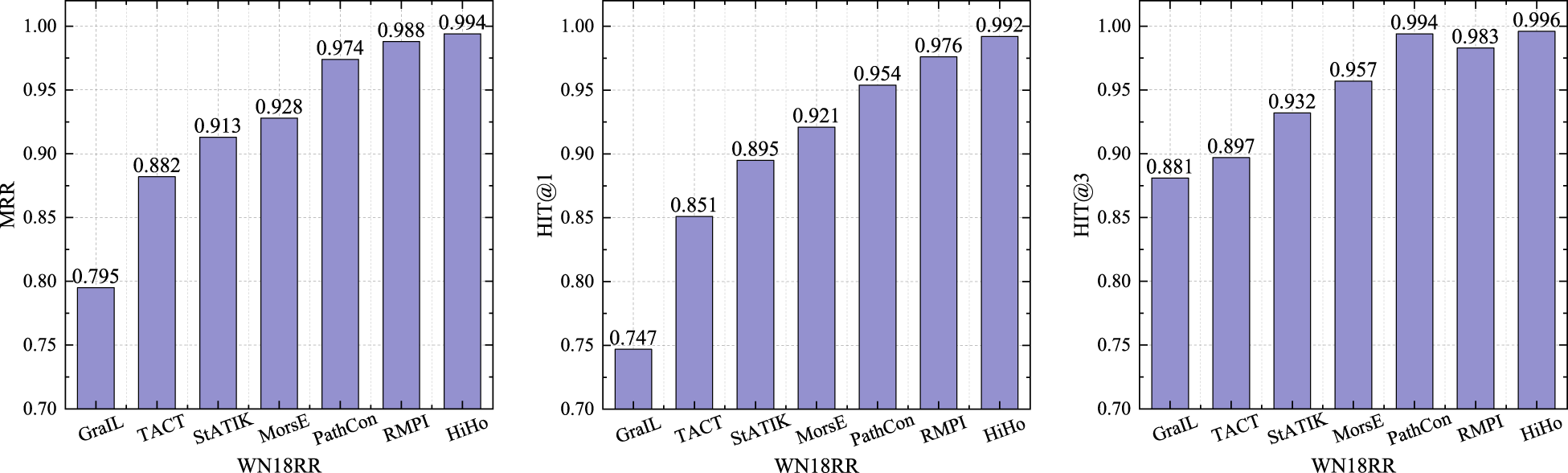
The Performance of Each Method on the WN18RR Dataset.
HiHo outperforms all other inductive methods. The reasons are: (1) GraIL, TACT, and RMPI focus on modeling the intersection of two subgraphs, but sometimes the intersection only accounts for a very small proportion of the two subgraphs, which leads to many relation types in the subgraphs being ignored. (2) StATIK and MorsE model the subgraph of the head entity and the subgraph of the tail entity separately without considering the commonality of the two subgraphs. (3) PathCon predicts relations by alternately generalizing the context of two entities and modeling the relational path between two entities, but the relational path used by PathCon suffers from the same problems as the path-based methods. In addition, the above method only learns the features of the
To demonstrate the individual effects of the proposed S2S and CPI components, we conduct an ablation experiment on the NELL995 dataset. Specifically, we exclude each component from the proposed method separately and evaluate its impact on the experimental results.
As shown in Table 3, compared to our whole model, the MRR, Hit@1, and Hit@3 of the model without S2S dropped by 0.23, 6.2%, and 1.5%, respectively; and the MRR, Hit@1, and Hit@3 of the model without CPI dropped by 0.46, 8.3%, and 3.9%, respectively. Therefore, we can obtain the following conclusions: (1) Without S2S, the performance of our model degrades severely, which proves that the lack of modeling the hierarchy of subgraph can seriously affect the effectiveness of relation prediction. (2) Without CPI, the performance of our model degrades slightly. The reason is that all the benchmark datasets used in this paper, even the NELL995 dataset, are relatively dense. We quantify density as the ratio of existing edges to the total possible edges [calculated as
Ablation Study on NELL995 Dataset.

Ablation Study on NELL995 Dataset.
MRR: mean reciprocal rank; S2S: subgraph-to-sequence.
The maximum number of layers in the neighborhood
Figure 8 shows the performance of the different values of

The Effect of the Maximum Number of Layers in the Neighborhood and the Maximum Number of Relations in Each Layer.
In this paper, we propose the HiHo model to predict the relation between entities in the inductive setting. Specifically, we propose an S2S mechanism to model the hierarchy of subgraphs by learning the semantic associations between layers in the subgraph of a single entity. And we propose a CPI mechanism to model the homogeneity of subgraphs by assigning higher weights to co-occurrence relations and learning the importance of each relation in the subgraphs of two entities. Finally, we alternatively generalize the subgraphs of two entities to infer the relations between them. And compared with the baselines, our method has better performance.
Although the proposed method has shown good performance in the relation prediction task, it may encounter challenges when dealing with rare relations or complex subgraph structures. For rare relations, due to the lack of sufficient data, it is difficult to learn reliable patterns, which may lead to inaccurate predictions. In the future, we plan to adopt data augmentation techniques to alleviate this problem. For complex subgraph structures, the high connectivity and intertwined relationships may exceed the capacity of the model, making it difficult to capture meaningful information. In the future, we plan to develop a more advanced GNN architecture with hierarchical or multiscale processing mechanisms to decompose the complexity and focus on relevant substructures, so as to achieve the effective extraction and utilization of information in complex subgraph structures. In addition, this paper has only explored the application of the proposed method in small- and medium-sized real-world KGs. In future work, we will further explore its application in ultra-large-scale KGs.
Footnotes
Funding
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: This research was partly funded by National Natural Science Foundation of China (62272163), Henan Provincial Department of Science and Technology (252102210054, 252102210101), Research and Practice Project of Research Teaching Reform in Undergraduate Colleges and Universities in Henan Province (202338870), Zhengzhou University of Light Industry Fund (2022BSJJ016, 23XJCYJ070), and Key Research Projects in Higher Education Institutions in Henan Province (25A520054).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.