
Abstract
Study Design
Cross-Sectional.
Objectives
Adult spinal deformity (ASD) affects 68% of the elderly, with surgical intervention carrying complication rates of up to 50%. Effective patient education is essential for managing expectations, yet high patient volumes can limit preoperative counseling. Language learning models (LLMs), such as ChatGPT, may supplement patient education. This study evaluates ChatGPT-3.5’s accuracy and readability in answering common patient questions regarding ASD surgery.
Methods
Structured interviews with ASD surgery patients identified 40 common preoperative questions, of which 19 were selected. Each question was posed to ChatGPT-3.5 in separate chat sessions to ensure independent responses. Three spine surgeons assessed response accuracy using a validated 4-point scale (1 = excellent, 4 = unsatisfactory). Readability was analyzed using the Flesch-Kincaid Grade Level formula.
Results
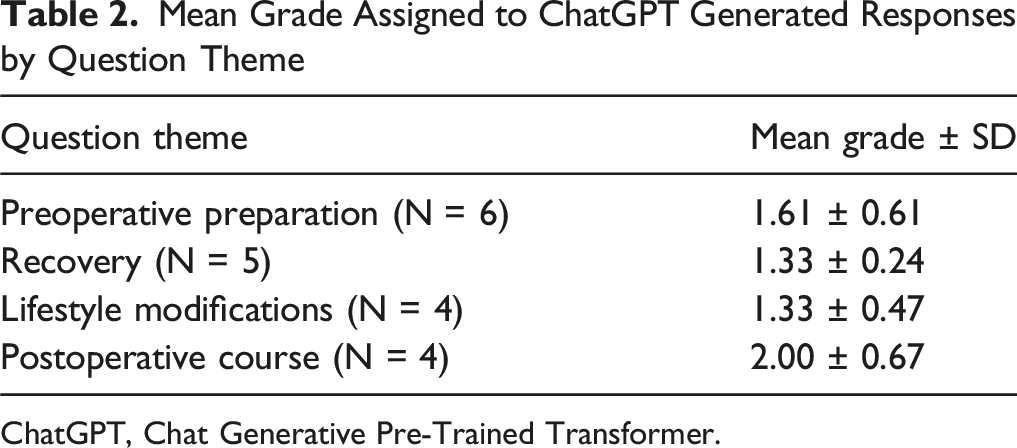
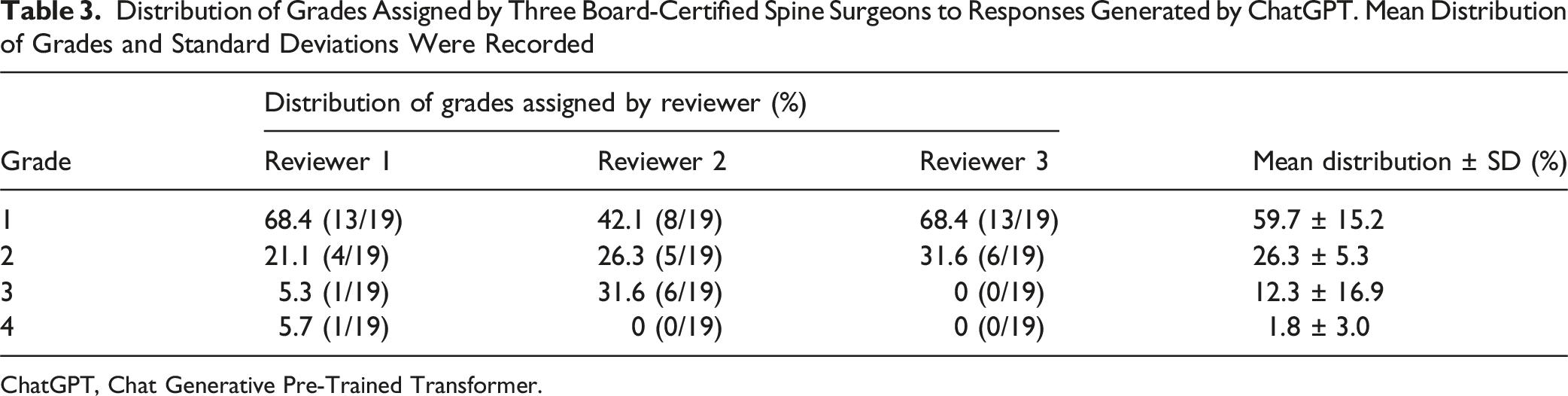
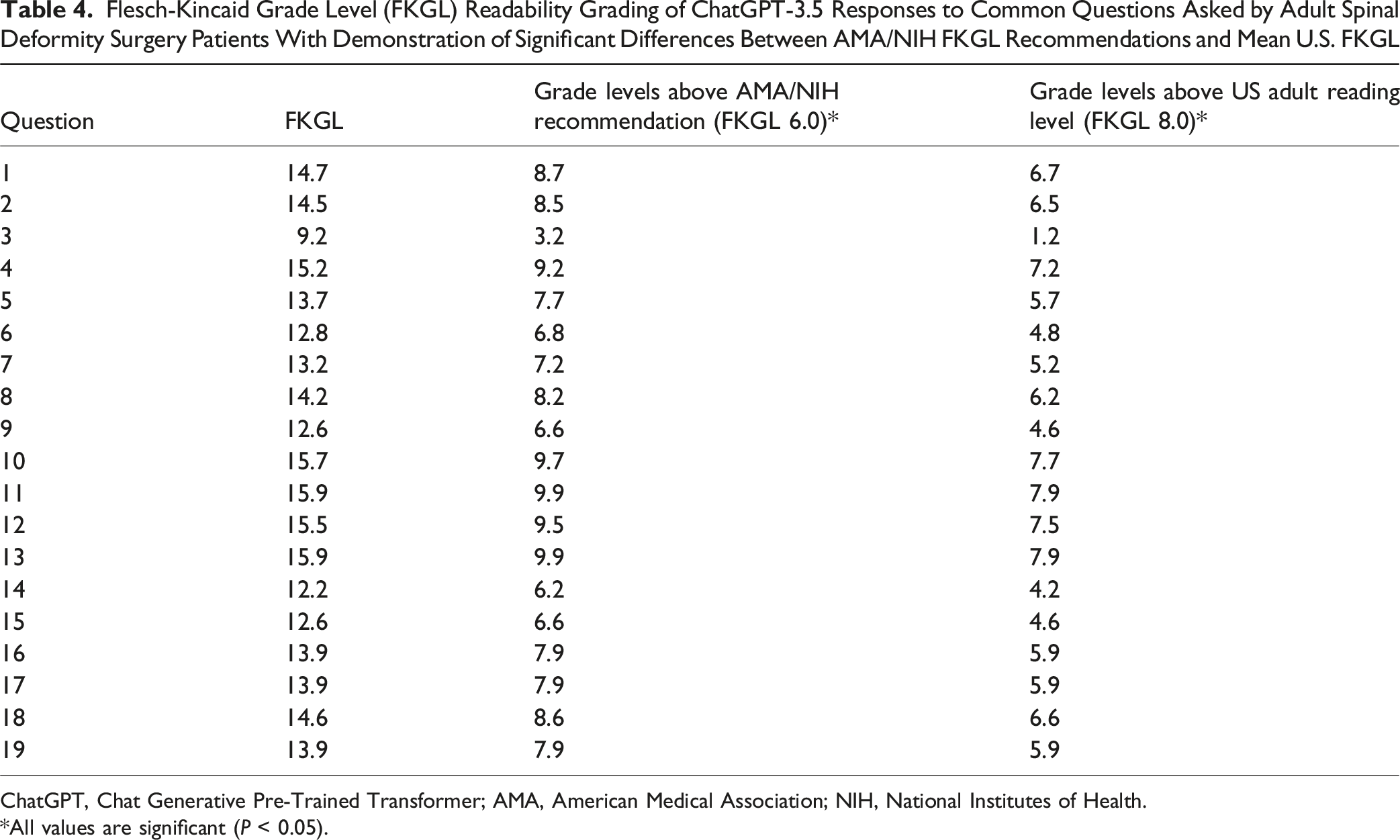
Patient inquiries fell into four themes: (1) Preoperative preparation, (2) Recovery (pain expectations, physical therapy), (3) Lifestyle modifications, and (4) Postoperative course. Accuracy scores varies: Preoperative responses averaged 1.67, Recovery and lifestyle responses 1.33, and postoperative responses 2.0. 59.7% of responses were excellent (no clarification needed), 26.3% were satisfactory (minimal clarification needed), 12.3% required moderate clarification, and 1.8% were unsatisfactory, with one response (“Will my pain return or worsen?”) rated inaccurate by all reviewers. Readability analysis showed all 19 responses exceeded the eight-grade reading level by an average of 5.91 grade levels.
Conclusion
ChatGPT-3.5 demonstrates potential as a supplemental patient education tool but provides varying accuracy and complex readability. While it may support patient understanding, the complexity of its responses may limit usefulness for individuals with lower health literacy.
Introduction
Adult spinal deformity (ASD) comprises a spectrum of disorders characterized by abnormal spine alignment. Deformity progression may cause pain and can lead to significant disability and decreased quality of life, necessitating surgical intervention. 1 However, the surgical management of ASD is associated with high complication rates and protracted recovery timelines. Thus, effective patient education is essential to help align patient expectations with realistic outcomes.2,3
Preoperative patient education has also been shown to reduce perioperative anxiety and pain across a variety of orthopaedic subspecialties.4-6 Unfortunately, nearly 50% of patients undergoing spine surgery are dissatisfied with the preoperative education they receive. 7 This may ultimately have a negative effect on their overall satisfaction with surgery. 8 The cause for dissatisfaction with preoperative education is likely multifactorial but includes (1) the limited time for patients to ask questions during clinic visits and (2) their difficulty in understanding available educational materials. Notably, the average American reads at a sixth-grade level (equivalent to that of an 11-12-year-old), yet most patient education materials are written at a ninth- to eleventh-grade level (suitable for individuals aged 14-17).9,10 This mismatch creates a substantial barrier to comprehension for many patients.
Patients now increasingly turn to online resources to fill in knowledge gaps regarding their diagnosis and planned surgery, with up to 64% using sources such as Facebook, WebMD, and YouTube. 11 In the past few years, online artificial intelligence (AI)-driven large language models (LLM) like ChatGPT (Open AI) have seen a rapid increase in popularity, representing a new resource for patients to obtain medical information. However, like other online resources, ChatGPT may generate inaccurate responses and should be thoroughly vetted by physicians prior to recommending its use. Initial research in orthopaedic surgery applications has shown promise: a series of studies in total joint arthroplasty found that ChatGPT can consistently and accurately address frequently asked questions related to these procedures.12,13
Despite these developments, there remains a gap in the literature regarding ChatGPT’s potential role in educating patients about ASD surgery. Given the prevalence of ASD and the lack of adequate patient education resources, it is important to explore how LLMs can serve as resources for patient education and investigate their accuracy within ASD correction surgery specifically. Therefore, the objective of this study is to assess whether ChatGPT can accurately answer frequently asked questions related to ASD surgery. A secondary aim is to evaluate whether ChatGPT’s responses are written at a readability level appropriate for the average American adult.
Methods
Question Curation
We identified patients who had undergone spine deformity correction surgery between 2020 and 2022 from our institutional database. This included patients with a diagnosis of ASD who had underwent at least a seven-level thoracolumbar spine fusion. Ten patients were randomly selected to be contacted and interviewed, of whom seven were willing to participate in the study. Eighteen open-ended questions, developed by fellowship-trained spine surgeons, were posed to these patients between July 2022 and March 2023 to assess preoperative expectations and postoperative outcomes. Analysis of unstructured interviews revealed four common themes: preoperative preparation, recovery, lifestyle modifications, and general postoperative course. In addition, we reviewed the “Frequently Asked Questions” pages from online health institutions, including OrthoInfo, Norton Healthcare, and Journal of Neurosurgery: Spine. Combining these sources, we generated 40 potential questions for ChatGPT. Questions that had repeated themes with similar phrasing were excluded to account for redundancy, which ultimately led to a final list of 19 questions (Supplemental Table 1). A board-certified spine surgeon (R.K.A) screened and approved the final selection. This study is classified as Institutional Review Board exempt as no patient-identifying data was collected or stored during the survey process.
ChatGPT-3.5 Response Generation
On March 3, 2024, we entered the selected questions into the free online AI LLM chatbot, ChatGPT. Each question was asked in a “New Chat” to generate novel responses, as the AI learns from previous inputs within the same chat. We recorded initial answers and removed any statements deferring to the patient’s surgeon. Complete and adjusted responses produced by ChatGPT can be found in Supplemental Table 1.
ChatGPT Response Grading
Three board-certified orthopaedic spine surgeons evaluated ChatGPT generated responses to the 19 queries. The reviewers were instructed to assess the accuracy of ChatGPT responses adapted from a previously published study evaluating AI-generated responses in total hip arthroplasty
12
: 1. Excellent response not requiring clarification 2. Satisfactory response requiring minimal clarification 3. Satisfactory response requiring moderate clarification 4. Unsatisfactory response requiring substantial clarification
This scale was chosen as it can assess the clinical appropriateness and completeness of information, making it suitable for assessing the accuracy of ChatGPT’s responses.
Readability Grading
We evaluated the readability of complete ChatGPT responses using the Flesch-Kincaid Grade Level (FKGL) formula, a widely validated formula for measuring readability in terms of academic grade levels. Although other readability scales exist for analysis, the FKGL formula stands as the most extensively validated and accepted method.
14
FKGL was computed utilizing the Microsoft Word built-in calculator, adhering to the formula
15
:
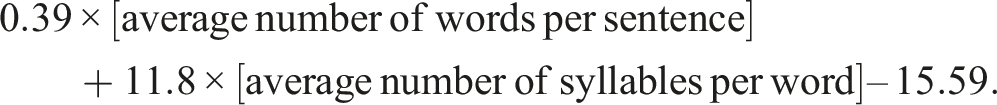
The resulting FKGL readability scores were then compared to the average US adult reading level (eighth grade) and the American Medical Association/National Institutes of Health recommended reading level (sixth grade).16,17
Statistical Analysis
The proportions of each grade to ChatGPT responses were calculated and reported as percentages. A two-way random effects intraclass correlation coefficient (ICC) was calculated to evaluate for interrater reliability of grading between three board-certified orthopaedic spine surgeons. Unpaired T-tests were performed to compare the FKGLs of ChatGPT responses with AMA/NIH recommended and mean US FKGLs. All analyses were conducted using Microsoft Excel (version 16.84). A P value of <0.05 was defined as significant.
Results
Seven patients who underwent ASD surgery between 2020 and 2022 were identified and agreed to participate in in-person interviews to assist with question generation.
Accuracy of Identified Themes
Our analysis identified four major themes from patient interviews: preoperative preparation, recovery, lifestyle modifications, and postoperative course. Three board-certified spine surgeons reviewed and graded 19 responses generated by ChatGPT (Supplemental Table 1).
Grading of Responses Generated by ChatGPT to Common Queries Posed by Adult Spinal Deformity Surgery Patients. The Grading Scale Is as Follows: (1) Excellent Response not Requiring Clarification; (2) Satisfactory Response Requiring Minimal Clarification; (3) Satisfactory Response Requiring Moderate Clarification; (4) Unsatisfactory Responses Requiring Substantial Clarification. Mean Grade per Question was Determined. Poor Agreement was Assessed Between Reviewers With an ICC of 0.255

ChatGPT, Chat Generative Pre-trained Transformer; ICC, Intraclass Correlation.
Mean Grade Assigned to ChatGPT Generated Responses by Question Theme
ChatGPT, Chat Generative Pre-Trained Transformer.
Questions
Distribution of Grades Assigned by Three Board-Certified Spine Surgeons to Responses Generated by ChatGPT. Mean Distribution of Grades and Standard Deviations Were Recorded
ChatGPT, Chat Generative Pre-Trained Transformer.
Readability
Flesch-Kincaid Grade Level (FKGL) Readability Grading of ChatGPT-3.5 Responses to Common Questions Asked by Adult Spinal Deformity Surgery Patients With Demonstration of Significant Differences Between AMA/NIH FKGL Recommendations and Mean U.S. FKGL
ChatGPT, Chat Generative Pre-Trained Transformer; AMA, American Medical Association; NIH, National Institutes of Health.
*All values are significant (P < 0.05).
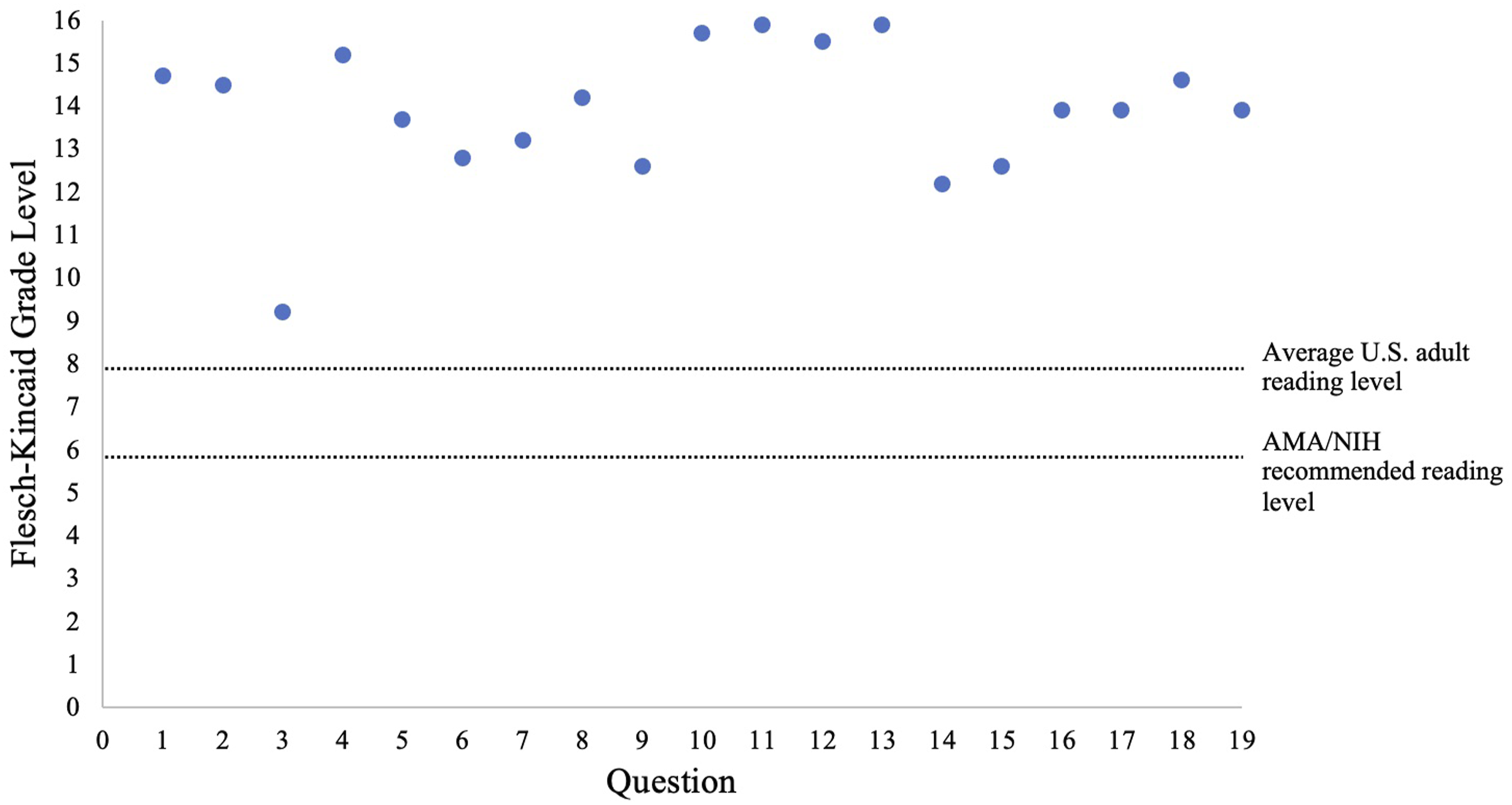
The Distribution of ChatGPT Generated Responses to Common Questions Regarding Adult Spinal Deformity Surgery by Flesch-Kincaid Grade Level Compared to the Average U.S. Adult Reading Level and AMA/NIH Recommended Reading Level. ChatGPT, Chat Generative Pre-Trained Transformer; AMA, American Medical Association; NIH, National Institutes of Health
Mean Flesch-Kincaid Grade Level (FKGL) of ChatGPT Generated Responses by Question theme

Discussion
AI-driven chatbots like ChatGPT represent a promising new technology with numerous potential applications in healthcare including patient education. The primary aim of this study was to evaluate the accuracy and accessibility of ChatGPT in responding to common patient questions regarding ASD correction surgery. The most important finding of our study was that ChatGPT can accurately answer questions related to ASD surgery: 86% of generated responses required minimal to no clarification based on the consensus opinions of three board-certified spine surgeons. However, the accuracy of the generated response varied based on the type of question asked, with ChatGPT performing better on questions related to preoperative preparation and worse on questions related to expected postoperative course. Moreover, the responses were at a reading level nearly six grades higher than the national average, which may limit the accessibility. The relevance of this study lies in its implications for patient education, the advancement of AI in healthcare, the need for accessibility in medical communication, and its potential to transform patient engagement and healthcare delivery systems.
Recent literature has evaluated the accuracy of ChatGPT-generated responses to medical inquiries within the fields of orthopaedic and bariatric surgery. In a study conducted by Wright et al, the ability of ChatGPT to deliver accurate and comprehensive information regarding total hip and knee arthroplasty was assessed.12,13 Researchers posed the 20 most frequently Google-searched questions on this topic to ChatGPT, and the responses were subsequently graded by five orthopaedic surgery residents. The findings revealed that ChatGPT’s responses achieved an accuracy rate of 85.2% and a comprehensiveness rate of 75.8%. Similarly, Samaan et al. examined ChatGPT’s performance in addressing questions related to bariatric surgery. 18 Utilizing a Likert scale that integrated both accuracy and comprehensiveness, the study found that 86.8% of ChatGPT’s responses were rated as accurate and comprehensive by two board-certified, fellowship-trained bariatric surgeons.
Similar to the aforementioned studies, we also found ChatGPT can generate highly accurate responses for ASD surgery. While there was poor interrater reliability, this likely reflects the nuanced and complex nature of clinical scenarios under evaluation in addition to a small number of reviewers. The high accuracy rate of 86%, combined with the minimal need for clarification, highlights ChatGPT’s strong potential to provide more accurate and reliable medical information to patients than currently available online resources. For example, prior reviews of various websites, such as the Mayo Clinic and WebMD, addressing orthopedic disorders have found that only 29-44% of the search results contained suitable information.19,20 These results collectively suggest that ChatGPT can serve as a valuable tool in clinical settings, not only for delivering precise information but also for enhancing patient education and engagement. ChatGPT has the potential to support informed decision-making and foster more effective communication between patients and healthcare providers.
The use of ChatGPT may be more limited in addressing patient questions about their postoperative course, which had an average accuracy score of 2.0. Previous research found that ChatGPT’s responses to postoperative questions are harder to understand and less actionable compared to a Google search. 21 Mika et al. found ChatGPT responses to questions pertaining to the general postoperative course after total hip arthroplasty required moderate clarification. 12 We believe this decline in accuracy may be due to the subjective nature of these questions, which often require individualized answers. For example, the question: “Is there a chance my pain will return and get worse after undergoing spinal deformity surgery?” had both the most disagreement between graders, as well as the lowest grade, receiving an average score of 3.0. Answering this question relies on many variables (ie, type of procedure, type of deformity, preoperative pain severity, associated health issues, etc.) and would require the patient to enter in specific personal and procedural information. Additionally, the chatbot would need to exercise higher order thinking to adequately answer a question like this, an area where ChatGPT has shown limitations.22-24 Furthermore, some ChatGPT responses contained misconceptions. For example, recommendations regarding the use of specific furniture or braces appeared to be influenced more by market forces and anecdotal sources than by evidence-based guidelines. These suggestions may lead patients to make unnecessary financial investments without clear benefits to postoperative outcomes.
In addition to potential limitations regarding specific question types, we also found that ChatGPT responses may be challenging to comprehend. On average, ChatGPT responses surpassed the average U.S. reading level (eighth grade) by an average difference of 5.9 grade levels. Although ChatGPT boasts the advantage of being easy to access, its base response to prompts may not be as easy to understand as prior literature might indicate. 18 Previous studies have investigated ChatGPT’s ability to provide ‘easier’ responses in the setting of total hip arthroplasty and total knee arthroplasty. 13 Wright et al found that ChatGPT can significantly reduce reading levels of its responses, however, it coincided with a significant decrease in comprehensiveness, possibly due to the chatbot removing key info at the expense of creating a more accessible reading level. These findings reinforce the idea found within the literature that ChatGPT-3.5, in its current version, is most appropriate as an adjunct and not a replacement to discussions with a physician. 25 Unlike AI models, physicians can dynamically adjust the complexity and depth of their explanations to match each patient’s educational background and specific inquiries, a capability not yet replicated by current AI technologies. Nonetheless, ChatGPT may serve as a valuable supplemental tool; physicians could consider using AI-generated responses to frequently asked questions as the basis for patient education materials such as brochures.
This study has several limitations. First, the sample size was relatively small, with only seven patients. This limitation was partially mitigated by referencing frequently asked questions from health institutions to help develop the question set. Additionally, two of the reviewers (RJH, RKA) were not blinded to the study due to their involvement in the study design. We recognize this could have led to bias in the assessment of their responses. Another limitation to our study was the absence of a comparison group; for example, we did not directly compare web results for internet searched questions to ChatGPT’s responses. External validity is also limited by continuous updates from OpenAI, such as the launch of GPT-4. Identical questions posed to the chatbot in the future may yield significantly different results. Furthermore, the substantial variability in reviewer scores may have skewed the response rating, thereby limiting the strength and generalizability of the conclusions drawn from these aggregated scores. Lastly, surgeon-related factors (eg, skill and experience) and approach-specific variables (eg, open vs minimally invasive techniques) may have contributed to the variability in the accuracy grading of ChatGPT’s responses.
Future research should explore two key areas: first, whether prompting ChatGPT to adjust its language complexity to specific reading levels can maintain accuracy while providing more tailored, accessible information; and second, if incorporating patient health data and procedural details into ChatGPT can enhance the accuracy of its postoperative care guidance. These investigations will be crucial in optimizing ChatGPT’s integration into clinical settings and its potential to improve patient education and satisfaction.
Conclusion
ChatGPT demonstrates significant potential as a technological tool in healthcare, particularly in addressing common preoperative education questions. However, its responses to postoperative care queries were less reliable, and its high readability level may limit accessibility for patients with lower health literacy. Unlike physicians, ChatGPT cannot adapt responses to individual comprehension levels. Thus, while it may serve as a useful adjunct, it should not replace direct physician-patient communication. Future research should focus on developing LLMs that can adjust response complexity based on patient health literacy.
Supplemental Material
Supplemental Material - Evaluating the Accuracy and Readability of ChatGPT in Addressing Patient Queries on Adult Spinal Deformity Surgery
Supplemental Material for Evaluating the Accuracy and Readability of ChatGPT in Addressing Patient Queries on Adult Spinal Deformity Surgery by Fergui Hernandez, BS, Rafael Guizar III, BS, Henry Avetisian, MS, Marc A. Abdou, MS, William J. Karakash, BS, Andy Ton, MD, Matthew C. Gallo, MD, Jacob R. Ball, MD, Jeffrey C. Wang, MD, Ram K. Alluri, MD, Raymond J. Hah, MD, and Michael Safaee, MD in Global Spine Journal.
Footnotes
ORCID iDs
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interest
Fergui Hernandez, Rafael Guizar III, Henry Avetisian, Marc A Abdou, William J. Karakash, Andy Ton, Matthew C Gallo, Jacob Ball, and Michael M. Safaee have nothing to disclose. Jeffrey C. Wang has received intellectual property royalties from Zimmer Biomet, NovApproach, SeaSpine, and DePuy Synthes. Raymond J. Hah has received grant funding from SI bone, consulting fees from NuVasive, and support from the North American Spine Society to attend meetings. Ram K. Alluri has received grant funding from NIH, consulting fees from HIA Technologies, and payment from Eccential Robotics for lectures and presentations.
Data Availability Statement
Data is not publicly available but can be available upon request.
IRB Statement
This study is classified as Institutional Review Board exempt as no patient-identifying data was collected or stored during the survey process.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.