
Abstract
Study Design
Comparative Analysis.
Objectives
The American College of Surgeons developed the 2022 Best Practice Guidelines to provide evidence-based recommendations for managing spinal injuries. This study aims to assess the concordance of ChatGPT-4o and Gemini Advanced with the 2022 ACS Best Practice Guidelines, offering the first expert evaluation of these models in managing spinal cord injuries.
Methods
The 2022 ACS Trauma Quality Program Best Practices Guidelines for Spine Injury were used to create 52 questions based on key clinical recommendations. These were grouped into informational (8), diagnostic (14), and treatment (30) categories and posed to ChatGPT-4o and Google Gemini Advanced. Responses were graded for concordance with ACS guidelines and validated by a board-certified spine surgeon.
Results
ChatGPT was concordant with ACS guidelines on 38 of 52 questions (73.07%) and Gemini on 36 (69.23%). Most non-concordant answers were due to insufficient information. The models disagreed on 8 questions, with ChatGPT concordant in 5 and Gemini in 3. Both achieved 75% concordance on clinical information; Gemini outperformed on diagnostics (78.57% vs 71.43%), while ChatGPT had higher concordance on treatment questions (73.33% vs 63.33%).
Conclusions
ChatGPT-4o and Gemini Advanced demonstrate potential as valuable assets in spinal injury management by providing responses aligned with current best practices. The marginal differences in concordance rates suggest that neither model exhibits a superior ability to deliver recommendations concordant with validated clinical guidelines. Despite LLMs increasing sophistication and utility, existing limitations currently prevent them from being clinically safe and practical in trauma-based settings.
Keywords
Introduction
Among all fractures that commonly result from traumatic injury, spinal column fractures pose uniquely significant challenges that can portend long-term physical, social, and financial consequences for patients and their loved ones. These injuries require complex management, particularly when complicated by the risk of irreversible neural damage and the presence of other life-threatening injuries. 1 The decision-making process for spinal injury care remains intensely debated and often revolves around discussions of operative vs non-operative management, appropriate timing for surgery, mode and duration of steroid administration, and the most optimal hemodynamic targets prior to intervention.2,3 Despite advances in spinal injury classification and severity assessment, the approach to spinal cord injury management remains controversial. Such uncertainty has driven the creation and implementation of national guidelines that function to keep spine surgeons abreast of the newest literature and practice recommendations.
To assist with such intricate and multifactorial considerations when managing spinal cord injuries, the American College of Surgeons (ACS) developed the Best Practice Guidelines: Spine Injury in 2022. The ACS guidelines offer the most recently published evidence-based practical recommendations for the evaluation and management of adult patients with a spine injury, which encompasses both spinal column fracture and spinal cord injury. 3 The guidelines put forth a series of summative recommendations based on an expert working group evaluation of the available medical literature.
As these guidelines continue to be widely used as a central source of information on spine injury and its management, artificial intelligence (AI) chatbots continue to grow in parallel and are increasing in use among physicians and patients as both a supportive adjunct to clinical decision-making and a general information-gathering tool. OpenAI’s most recent ChatGPT model, ChatGPT-4o, and Google’s Gemini Advanced are large language models (LLMs) capable of integrating, understanding, and generating massive volumes of human language text. Both models have been trained on a vast array of publicly available and licensed data up until at least 2023, with Gemini offering internet access for queries, as well.
The utility of such chatbots in the medical context continues to be assessed, especially given the evidence that earlier ChatGPT models are capable of passing the USMLE exams. 4 Research in the fields of ophthalmology and urology, among others, has demonstrated ChatGPT’s commendable capacity to offer clinically accurate advice to patients seeking medical care.5,6 With regards to orthopedic spine surgery, ChatGPT’s clinical accuracy has been shown to be widely variable when queried on subjects such as antibiotic and thromboembolic prophylaxis, low back pain, degenerative spondylolisthesis, and cervical radiculopathy.7-11 Although these studies provide valuable preliminary insights into the potential role of chatbots in managing various spine-related conditions, none specifically address spinal cord injuries or compare ChatGPT with other leading LLM services, such as Google’s Gemini.
Considering this limitation, the goal of the present study was to evaluate the concordance of ChatGPT-4o and Gemini Advanced when compared to the 2022 ACS Best Practice Guidelines for spine injury. In doing so, we aimed to put forth the first expert assessment of ChatGPT-4o′s and Gemini’s capacities to provide accurate practice recommendations for managing spinal fractures and spinal cord injuries.
Methods
Institutional review board approval was not required for this study, as ChatGPT-4o and Google Gemini Advanced are publicly available resources, and no clinical data or patient information was used. The 2022 American College of Surgeons (ACS) Best Practices Guidelines: Spine Injury contains recommendations across 21 relevant sections, including imaging, spinal cord injury classification, spinal shock, and analgesia in spinal cord injury. 3 These 21 sections provide 52 key points to guide clinical decision-making in various spinal cord injury scenarios.
To simulate the interaction between a surgeon and the AI chatbots, the 52 ACS key points were rephrased into questions designed to elicit recommendations from the LLMs for each specific scenario. These questions were categorized into three groups: “Informational,” “Diagnostic,” and “Treatment.” Given that the wording of questions can influence LLM responses, the phrasing was carefully crafted to closely mirror the original language and tone of the ACS key points, ensuring reproducibility and minimizing subjective bias. A board-certified spine surgeon then reviewed the questions to ensure clinical relevance. In total, 52 questions (8 informational, 14 diagnostic, and 30 treatment-related) were generated and posed to ChatGPT-4o and Google Gemini Advanced on August 13, 2024. The questions were prompted to the LLMs only once, simulating a “zero-shot” learning scenario to assess their baseline capabilities without any prior learning or training bias. This approach also reflects typical clinical use, where clinicians or patients are unlikely to pose the same question to LLMs multiple times. Furthermore, to prevent stored memory from affecting subsequent responses, memory settings were disabled, and a new chat session was initiated for each question posed to the LLMs.
The ACS recommendations were compared to the responses provided by ChatGPT-4o and Google Gemini Advanced for each scenario. A complete list of the questions, corresponding ACS key points, and their subgroup categorization can be found in Table 3.
After collecting responses from both LLMs, four independent reviewers evaluated each answer as either “concordant” or “non-concordant” with the ACS guidelines. In cases of disagreement between the reviewers, a joint discussion was held until a consensus was reached. A board-certified spine surgeon further validated all assessments. ChatGPT’s responses were graded as “concordant” if they accurately reflected all key aspects of the ACS recommendations. Responses that deviated from the guidelines were classified as “non-concordant” and further categorized as: 1. Insufficient: The response omitted one or more key elements of the guideline or lacked adequate specificity. 2. Contradictory: The response directly contradicted the ACS recommendations.
As an example, given the following diagnostic-related ACS key point:
“Plain radiographs of the cervical and thoracolumbar spine are not recommended in the initial screening of spinal trauma because of their low sensitivity” (Section: Imaging, page 14).
Figure 1 displays the respective question to ChatGPT and the response it elicited. ChatGPT’s concordant response to the ACS guideline-based clinical question.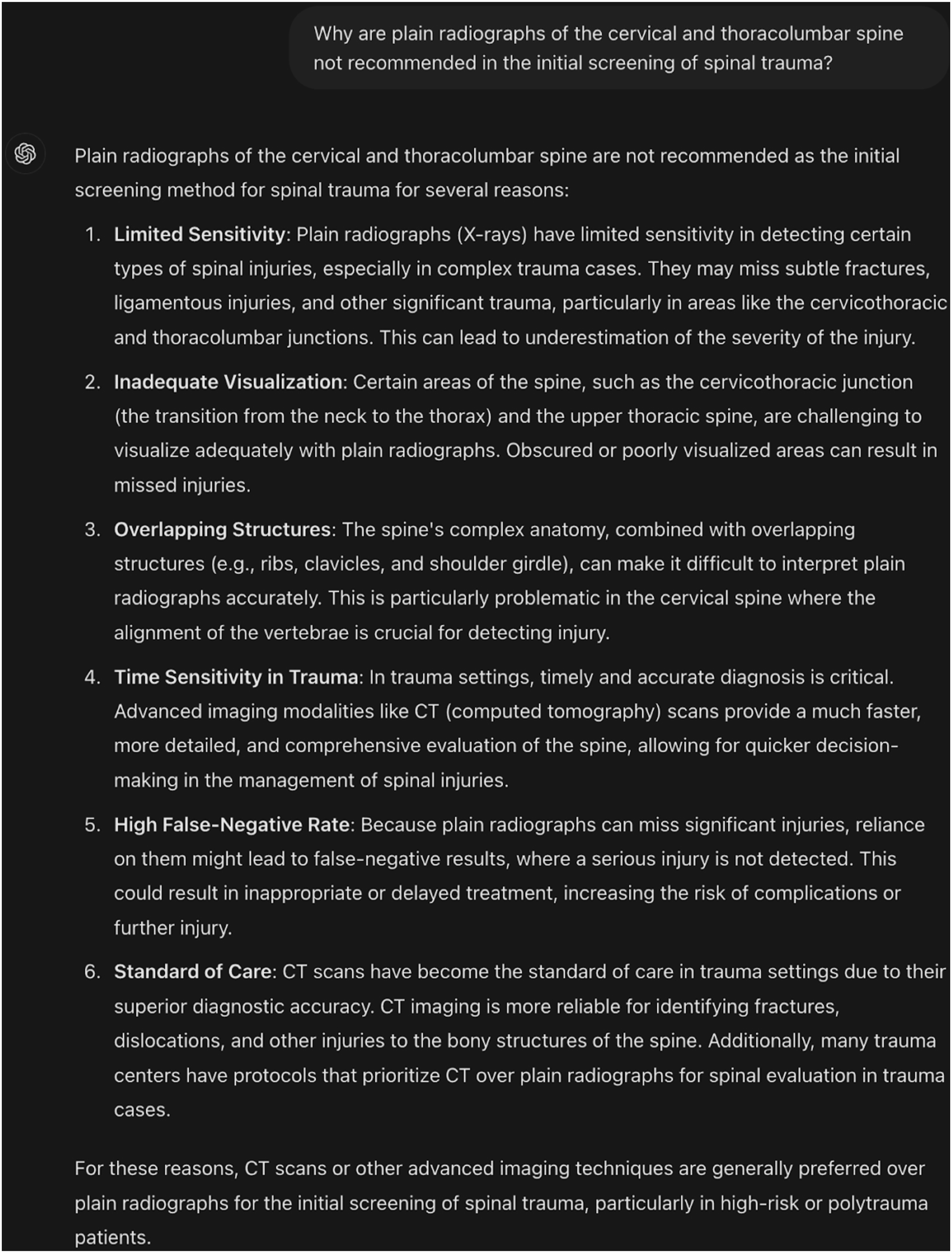
In this instance, ChatGPT’s response was graded concordant for accurately stating that plain radiographs are not recommended for initial spinal trauma screening due to low sensitivity.
As another example, given the following treatment-related ACS Key Point:
“Tracheostomy can be performed early after anterior cervical spinal stabilization without increasing the risk of infection or other wound complications.” (Section: Placement of Tracheostomy following Cervical Stabilization, page 58).
Figure 2 details the corresponding question to ChatGPT and the response it yielded. ChatGPT’s non-concordant, contradictory response to the ACS guideline-based clinical question.
This response was graded as non-concordant and contradictory. ChatGPT suggests caution in timing a tracheostomy after anterior cervical spinal stabilization, recommending a 3 to 7-day waiting period based on concerns about infection and wound complications. This contradicts the ACS key point, which states that early tracheostomy can be performed without increasing the risk of infection or other wound complications.
The concordance rates of ChatGPT and Gemini with the ACS guidelines were analyzed with Chi-Squared tests, with the significance level at alpha = 0.05.
Results
ChatGPT and Gemini Cumulative performance.
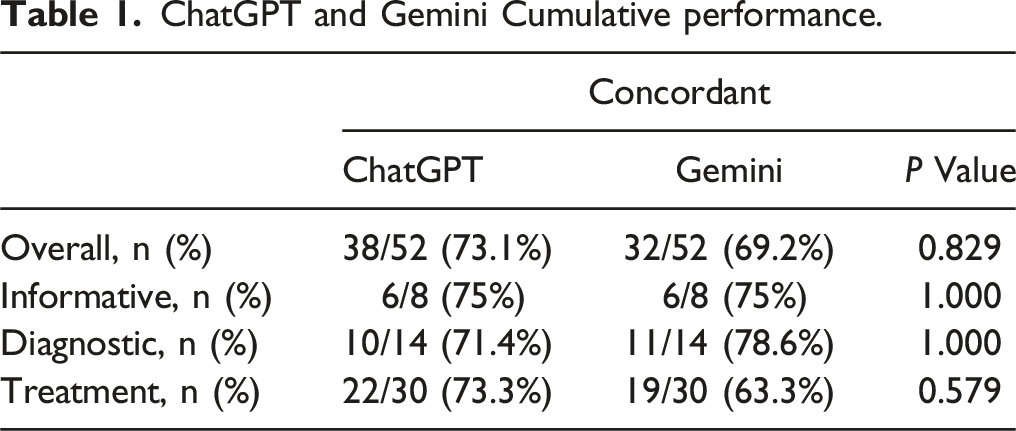
Overall, the two models conflicted on 8 out of 52 questions (15.38%), where one model was concordant with ACS guidelines while the other was not. In these instances of disagreement, ChatGPT provided the correct response in 5 out of 8 cases (62.5%), whereas Gemini was correct in 3 out of 8 cases (37.5%).
Subgroup Performance
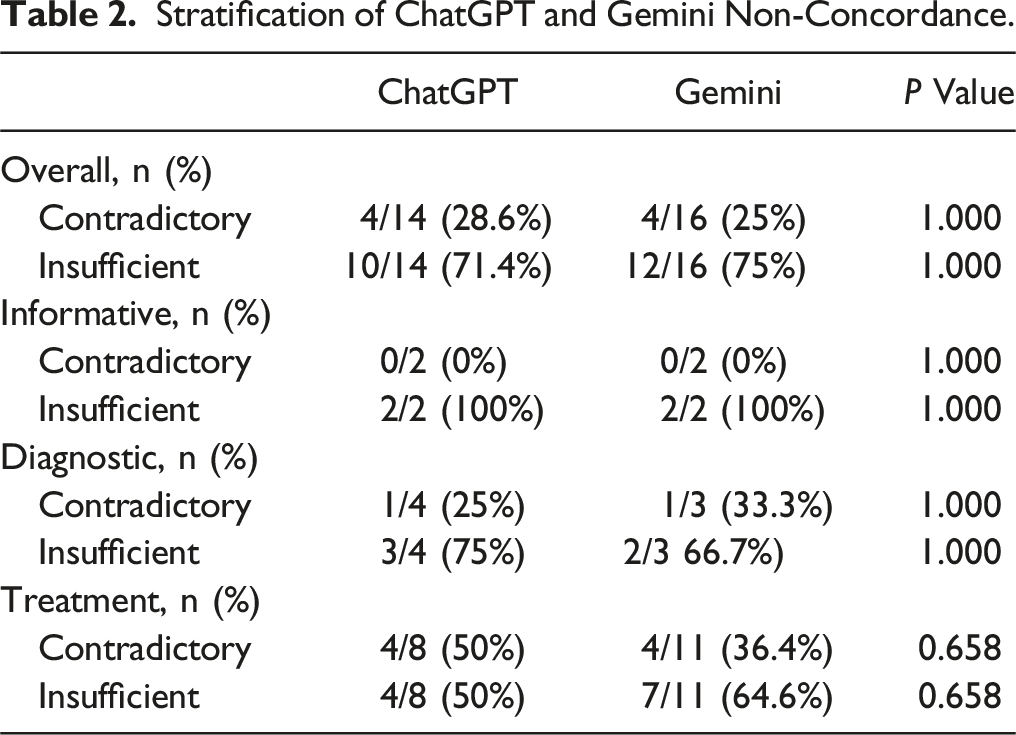
Stratification of ChatGPT and Gemini Non-Concordance.
American College of Surgeons guideline-based questions and our concordance grading rationale for ChatGPT and Gemini.

Discussion
This study is the first to compare the performance of Open AI’s ChatGPT-4o and Google’s Gemini Advanced against an evidence-based clinical guideline for traumatic spinal injuries. ChatGPT-4o demonstrated a marginally higher but insignificant concordance rate compared to Gemini Advanced. Additionally, both models exhibited similar trends in their responses, with the majority of non-concordant responses from both LLMs being due to insufficient information rather than contradictory advice. When subgroup analyses were conducted based on guideline categories, each model displayed varied strengths and weaknesses in each category. Despite these differences, we found no statistically significant differences between ChatGPT-4o and Gemini Advanced in response concordance and tendencies. These findings are consistent with several previous comparison studies, which found that versions of ChatGPT and Gemini (previously Bard) could assist clinical decision-making but struggle to provide nuanced clinical guidance.8,11-14
Stratified Subgroup Findings
In our analysis of the subgroup questions, both ChatGPT-4o and Gemini Advanced displayed strengths in specific categories. This is again consistent with previous studies that indicate that LLMs can provide valuable information in the clinical setting.7,8,10,11,13
Informative
ChatGPT-4o and Gemini Advanced performed equally in the informative question subgroup, answering 6 out of 8 questions (75%) correctly. For questions that were answered concordantly with ACS Guidelines, both were able to correctly identify the content of the question and address all important aspects that were provided within the ACS Guideline’s key points. For example, when asked, “What is the typical outcome for the vast majority of penetrating spinal cord level injuries according to the ASIA impairment scale?” both ChatGPT-4o and Gemini Advanced correctly identified that the vast majority of such injuries result in complete injuries, classified as ASIA A, and result in total loss of sensory and motor function below the level of injury.
However, there were instances in which ChatGPT-4o and Gemini provided non-concordant answers that lacked sufficient detail. In questions such as “How can skin breakdown and decubitus ulcers be prevented following spinal cord injury?” both models offered comprehensive strategies for preventing skin breakdown and decubitus in patients with spinal cord injuries, but neither introduced the nuance of clinical judgment and validated assessment tools like the Spinal Cord Injury Pressure Ulcer Scale (SCIPUS) or Braden Scale nor did either emphasize avoiding known modifiable risk factors.15,16 This information is a critical component of the ACS Guidelines for preventing skin breakdown and decubitus ulcers, and its omission indicates the AI’s lack of regard for the more tactful aspects of spinal cord injury care necessary for proper injury management. This inconsistency and lack of sufficient detail is mirrored in other medical applications of LLMs. For instance, a study by Pirkle et al 17 found significant non-concordant answers regarding pediatric orthopedics, further highlighting the imperfect state of LLMs in their ability to provide consistent and accurate medical recommendations. 17 It is also noteworthy that both ChatGPT-4o and Gemini Advanced provided non-concordant answers to the same questions due to insufficient detail, suggesting a common gap in their training data or a more general deficiency in clinical understanding. Similar issues have been posited in other studies within orthopedic management, implying that AI models likely lack the depth required for accurate, complex clinical decision-making.7,11-13,17
Diagnostic
In the diagnostic subgroup, Gemini Advanced provided concordant responses for 11 out of 14 questions (78.57%). In contrast, ChatGPT-4o provided concordant responses in 10 out of 14 cases (71.43%), with both being non-concordant solely due to insufficient detail. In this subgroup, both models correctly recommended advanced imaging techniques, particularly CT scans, over plain radiographs for initial assessment of suspected spinal injury. As such, both LLMs accurately identified trauma-related contexts for spinal cord injuries and correctly identified best practices in line with ACS guidelines.
Among non-concordant responses, ChatGPT-4o and Gemini Advanced shared responses to two questions. When asked about the initial imaging modality of choice for the cervical and thoracolumbar spine, ChatGPT-4o and Gemini Advanced contradicted the ACS Guidelines by suggesting that X-rays are the ideal initial imaging modality. The ACS Guidelines prioritize CT scans due to their superior sensitivity and specificity, and this direct contradiction further reinforces the need for verification of LLM responses, which is counter to the goal of reducing physician burden in the clinical setting. This issue of reliance on older, less accurate protocols is consistent with findings in the study by Howard et al, which analyzed ChatGPT’s recommendations in infectious disease management and highlighted the model’s tendency to rely on outdated information when no current literature is available. 18 Similarly, Sosa et al’s study on orthopedic management highlighted the tendency for LLMs to reference outdated and inaccurate information. 12 Such discrepancies may also stem from both models’ reliance on older clinical protocols in their training data, which historically emphasized radiographs before the broader adoption of CT scanning.19,20
Additionally, there were three responses to which only one of the models responded non-concordantly. These responses included when ChatGPT-4o was asked, “When should universal screening for blunt cerebrovascular injury using a whole-body CT scan be considered?”. The model was unable to recommend universal screening for all major trauma patients using a whole-body CT scan and instead suggested that screening should be specific and determined based on high-risk factors, injury patterns, and clinical signs. This approach reflects older screening protocols prevalent in the literature before the recent shift toward universal screening.21-25 Due to how LLMs are trained, the data that ChatGPT-4o was trained on may have been outdated or led it to believe that the majority consensus was with the older approach. In contrast, Gemini Advanced was unable to completely answer the question, “When can surveillance duplex ultrasound for VTE be considered in asymptomatic patients in the case of spinal cord injury?” in that it only suggested surveillance duplex ultrasounds may be used broadly for asymptomatic patients as opposed to the ACS Guidelines that generally recommend reserving such imaging for high-risk patients who cannot receive chemoprophylaxis. This suggests that Gemini may overlook the nuanced clinical practicality of certain recommendations, as the high cost and low yield of routine surveillance in low-risk patients make such practices impractical. 26
Treatment
ChatGPT-4o displayed a relatively strong performance in the Treatment Subgroup with 22 out of 30 (73.33%) concordant responses, outperforming Gemini Advanced’s 19 out of 30 (63.33%). Examples of prompts that were successfully answered include a question on safe techniques for tracheostomy following spinal cord injury. Both ChatGPT-4o and Gemini Advanced responded with the two techniques recommended by ACS Guidelines, suggesting that both open and percutaneous tracheostomies are safe for spinal cord injury patients. This is further supported by Lorenzi et al, who examined ChatGPT-4 and Gemini Advanced’s ability to provide accurate recommendations for head and neck malignancies, finding similar concordance rates for surgical advice. 14
Of the non-concordant responses, ChatGPT-4o and Gemini Advanced shared 7 out of 30 questions that they answered non-concordantly and consistently shared reasons for why both were non-concordant. An instance where both models shared a non-cordant response was when prompted, “What should be initiated for all patients with acute spinal cord injury?”. In their responses, both were marked insufficient due to the absence of the recommendation for initiating a bowel management program, which is a critical aspect of care that is outlined in the ACS Guidelines. This mirrors findings from Sosa et al, who observed that LLMs often omitted essential treatment protocols in orthopedic care guidance. 12 Another involved the prompt, “Have any other potential therapeutic agents demonstrated efficacy for motor recovery and neuroprotection?” where both ChatGPT-4o and Gemini Advanced were marked contradictory for suggesting that there are therapeutic agents that may benefit in motor recovery and neuroprotection. This is in direct contradiction with ACS Guidelines, which asserts that no other agents have demonstrated efficacy in this regard. The issue of incorrect recommendations has been similarly highlighted in several studies. Lum et al examined the accuracy of generative AI in orthopedic resident-level decision-making, while Kumar et al focused on comparing the ability of LLMs to generate differential diagnoses for neurosurgical disorders. Both studies underscore the potential risks of relying on AI for critical medical decisions without a deeper understanding of its limitations.27-29 This pattern continues to indicate that all the use of LLMs in clinical practice is promising as a supportive tool for supplementary information and clinical guidance, current limitations require careful clinician verification, which can make their use redundant. Additionally, there is a risk that AI-generated information could reinforce pre-existing incorrect clinician assumptions without such oversight, emphasizing the need for these tools to serve strictly as adjuncts rather than primary sources of decision-making.
In instances where only one model responded non-concordantly, it was found that ChatGPT-4o had isolated non-concordant responses to 1 out of 30 questions while Gemini Advanced had isolated non-concordant responses to 4 out of 30 questions. With ChatGPT-4o, the model contradicted ACS Guidelines when prompted, “When can tracheostomy be performed after anterior cervical spinal stabilization without increasing the risk of infection or other wound complications?”. Instead of stating that tracheostomy can be performed early without increasing the risk of infection or other wound complications, ChatGPT-4o contradictorily recommended up to a 7-day waiting period before tracheostomy. This is clinically significant as if a physician were to follow ChatGPT’s recommendations to delay tracheostomy after anterior cervical spinal stabilization, it could lead to multiple adverse outcomes. Delayed tracheostomy, defined as occurring more than 7 days post-ACSF, has been associated with increased morbidity, longer ICU stays, prolonged mechanical ventilation, and extended hospital stays.30-33 For cases where only Gemini Advanced responded non-concordantly, 3 out of the four questions were due to insufficiency, while 1 out of 4 were due to being contradictory. An example of an insufficient response is when Gemini Advanced was prompted, “Why is pain management a priority in the care of acutely injured spinal cord injury (SCI) patients?”. In the model’s response, Gemini Advanced did not explicitly provide information regarding preventing dysautonomia symptoms that may be triggered by uncontrolled pain, a critical component of ACS Guideline reasoning. This omission in Gemini’s recommendation could lead to adverse consequences if followed by a physician, as preventing dysautonomia symptoms, particularly autonomic dysreflexia, is crucial after spinal cord injury due to the severe cardiovascular and systemic complications associated with the condition.34,35 In one instance, Gemini Advanced provided a contradictory response, suggesting that steroids can be used in penetrating spinal cord injuries when asked, “What is the recommendation for the use of steroids in penetrating spinal injury?” However, the ACS Guidelines clearly state that steroids are not recommended for such cases. The isolated errors suggest that while ChatGPT-4o may have a slightly higher concordance rate overall, both models exhibit unique limitations depending on the clinical context. As pointed out by Zaidat et al, AI models require continuous updates and integration of high-quality evidence to enhance their reliability in clinical care before their use can be consistently recommended. 10
Future Directions
While this study provides valuable insight into the comparative performance of ChatGPT-4o and Gemini Advanced in providing clinical guidance in a spinal trauma setting, several key areas require further exploration and development to enhance the clinical utility of LLMs in healthcare.
Firstly, future efforts and research should ensure that LLMs prioritize training on the latest medical literature. As found in previous studies, AI models can become outdated if not updated with a focus on the most recent evidence, ultimately limiting their clinical accuracy and relevance.7-9,11-14,28,36 This could be performed in conjunction with the customization of LLMs like ChatGPT-4o and Gemini Advanced to specific guidelines relevant to medical subspecialties like orthopedics. From the results of this study and others, LLMs are incredibly useful due to their flexibility and broad base of understanding.7,10,12,27 However, this type of focus limits such LLMs to processing context and producing recommendations for complex and specialized situations. Thus, future research should explore how LLMs can be trained with specialized data sets, like clinical guidelines for treating spinal trauma or back pain, which could benefit the LLM’s ability to provide contextually appropriate recommendations. Such an approach could involve incorporating case-based training to refine models’ understanding of specific clinical situations and guidelines alongside uploading clinical guidelines that are influential to a certain subspecialty and prompting the LLM to focus on such reasoning. Avenues that could potentially be explored include the utilization of OpenAI’s “Create a GPT” function, where users can customize a GPT to function based on specific prompts, uploaded documents, and extra functionalities offered by OpenAI. 37
Given the many controversies in acute SCI management, the alignment of AI platforms with clinical guidelines may be shaped not only by their intrinsic capabilities but also by the inherently contentious nature of the subject matter.38-40 Our findings highlight an important consideration: non-concordance in AI-generated recommendations may stem from the lack of consensus within the medical community or insufficient evidence supporting a unified guideline. These challenges reflect the difficulty of translating nuanced or controversial clinical topics into standardized guidance. Alternatively, variability in platform responses could indicate differences in the quality and scope of their training data, the sophistication of their natural language processing algorithms, or their ability to interpret and incorporate clinical context effectively. Future studies could stratify the questions posed to AI platforms into two categories: (1) Topics with well-established consensus based on robust clinical guidelines. (2) Topics that remain contentious within the medical community.
Additionally, it is valuable to continue exploring how to combine AI’s strengths with clinician oversight. Due to gaps in accuracy displayed by ChatGPT-4o and Gemini Advanced in this study, AI may be best suited as a tool to validate clinical judgment. This role is already being explored within areas like Electronic Medical Records (EMR), with companies like Epic Systems already implementing AI in various roles. 41
To successfully integrate AI into clinical practice, it is essential to prioritize reducing bias and enhancing transparency in LLMs. Since LLMs operate as “black boxes,” with their internal reasoning and response generation largely opaque, gaining a thorough understanding of their mechanisms is crucial before they can be fully trusted as primary clinical tools.42,43 Although we can guide LLMs to focus on specific areas, the uncertainty about how they generate their answers means that clinicians and patients may never fully trust their recommendations or be confident that inherent biases are adequately addressed without a clearer understanding of the frameworks within which these models operate.
Limitations
This study has several limitations that warrant consideration. Firstly, the responses generated by ChatGPT, which is based on an LLM trained on data up to April 2023, may lack awareness of significant discoveries or updates in the field made after this date. Similar to how clinical guidelines require periodic revisions to incorporate the latest evidence, LLMs also need regular updates to align with the most current medical literature. Additionally, since the CNS guidelines were published in 2022, the LLM’s access to more recent data may have influenced the concordance. Secondly, the scope of this study was limited, as it only evaluated a specific set of questions related to a single set of guidelines for spinal cord injury. Therefore, the findings may not be generalizable to other medical conditions or interventions beyond spinal cord injuries. Although no current guidelines are universally regarded as the gold standard for SCI treatment, the ACS guidelines were chosen for this analysis because of their comprehensive scope, encompassing epidemiology, diagnosis, conservative treatment, surgical intervention, and special considerations, all based on the best available evidence at the time. In contrast, the American Association of Neurological Surgeons and Congress of Neurological Surgeons Guidelines for the Management of Acute Cervical Spine and Spinal Cord Injuries, last updated in 2013, may not reflect the most current research. 44 Similarly, while the AO Spine Clinical Practice Guideline for the Management of Acute Spinal Cord Injury is comprehensive, providing recommendations on surgical timing, anticoagulant thromboprophylaxis, preoperative imaging, and rehabilitation, its guidelines are based on literature published up until 2017. 45 The AO Spine & Praxis Spinal Cord Institute Guidelines for the Management of Acute Spinal Cord Injury, published in 2024, have a relatively narrower focus on surgical decompression timing, spinal cord perfusion optimization, and intra-operative SCI management. 46 However, the 2024 AO Spine guidelines identify critical knowledge gaps and propose future research directions, emphasizing that all guidelines are dynamic, evolving with emerging evidence, and must be applied judiciously in clinical practice based on individual patient factors such as presentation, frailty, and comorbidities. 47 These recommendations are inherently shaped by current data limitations and the need for continuous refinement to enhance SCI management. Future research could explore the alignment of these evolving guidelines with LLMs to expand AI applications in SCI management, assess their potential for real-time adaptation to new evidence, and evaluate their capability for personalized risk assessment.
Additionally, while a board-certified spine surgeon verified the grading of the LLMs’ concordance with guideline categories, the process was inherently subjective and did not represent a precise quantitative measure of the model’s accuracy. This subjectivity may introduce bias into the evaluation. Despite these limitations, this study provides valuable insights into the ability of ChatGPT-4o and Gemini Advanced to generate evidence-based recommendations for spinal cord injury management, offering a useful starting point for further exploration of LLMs in clinical decision-making.
Conclusion
Our analysis indicates that both ChatGPT-4o and Gemini Advanced have the potential to be a valuable asset to healthcare providers by providing responses aligned with current best practices in spinal injury management. However, the marginal and insignificant differences in concordance rates suggest that neither ChatGPT-4o nor Gemini Advanced have a superior ability to successfully provide recommendations that are concordant with a validated clinical guideline. As such, our findings highlight the current state of AI and LLMs in healthcare: although AI models like ChatGPT-4o and Gemini Advanced are becoming increasingly sophisticated and useful, their current level of performance still exhibits limitations that currently bar them from being clinically safe and practical in a trauma-based setting.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Disclosure
Samuel K. Cho, MD, FAAOS. AAOS: Board or committee member. American Orthopaedic Association: Board or committee member. AOSpine North America: Board or committee member. Cerapedics: Fellowship support. Cervical Spine Research Society: Board or committee member. Globus Medical: IP royalties, fellowship support. North American Spine Society: Board or committee member. Scoliosis Research Society: Board or committee member. SI-Bone: Paid consultant.