
Abstract
Study Design
A comparative analysis of AI-generated vs human-authored personal statements for spine surgery fellowship applications.
Objective
To assess whether evaluators could differentiate between ChatGPT- and human-authored personal statements and determine if AI-generated statements could outperform human-authored ones in quality metrics.
Summary of Background Data
Personal statements are key in fellowship admissions, but the rise of AI tools like ChatGPT raises concerns about their use. While previous studies have examined AI-generated residency statements, their role in spine fellowship applications remains unexplored.
Methods
Nine personal statements (4 ChatGPT-generated, 5 human-authored) were evaluated by 8 blinded reviewers (6 attending spine surgeons and 2 fellows). ChatGPT-4o was prompted to create statements focused on 4 unique experiences. Evaluators rated each for readability, originality, quality, and authenticity (0-100 scale), determined AI authorship, and indicated interview recommendations.
Results
ChatGPT-authored statements scored higher in readability (65.69 vs 56.40, P = 0.016) and quality (63.00 vs 51.80, P = 0.004) but showed no differences in originality (P = 0.339) or authenticity (P = 0.256). Reviewers could not reliably distinguish AI from human authorship (P = 1.000). Interview recommendations favored ChatGPT-generated statements (84.4% vs 62.5%, OR: 3.24 [1.08-11.17], P = 0.045).
Conclusion
ChatGPT can produce high quality, indistinguishable spine fellowship personal statements that increase interview likelihood. These findings highlight the need for nuanced guidelines regarding AI use in application processes, particularly considering its potential role in expanding access to high-quality writing assistance and editing.
Introduction
Applying for spine surgery fellowship is a highly competitive process for orthopaedic and neurosurgical residents. 1 Personal statements play an important role in fellowship admissions, allowing applicants to showcase their unique personal experiences and characteristics which help assess their fit for the program. 2 Many applicants seek external guidance on their personal statements, from mentors in the field to commercial writing services.2,3 With the increasing availability of artificial intelligence (AI) tools, such as large language models (LLMs) like ChatGPT, these technologies have become popular among applicants due to their versatility and ease of use. 4 LLMs are designed for advanced language processing tasks, and can assist with various functions including brainstorming, grammatical editing, and even generating entire essays. 4 Advantages of using these AI tools include reducing time burden on busy applicants, providing support for those less proficient in English, and reducing the financial burden of professional writing services. 5
However, the use of AI and LLMs in academic writing has sparked significant debate.6,7 Residency admissions directors have expressed concerns that AI usage may obscure an applicant’s voice and limit the evaluation of written communication skills – attributes that are highly valued in prospective residents. 7 Additionally, ethical concerns have been raised regarding the integrity of using AI, with many considering AI-generated content as a form of plagiarism. 7 The lack of reliable AI detection tools makes it challenging for reviewers to distinguish between AI-generated and human-written essays, complicating efforts to enforce AI usage guidelines. 8
Previous research has shown that personal statements for residency applications generated by LLMs were often indistinguishable from those written by applicants and have received similar scores on quality metrics.9-11 However, these studies used limited prompting, testing only the very basic capabilities of LLMs. Additionally, no research has specifically examined the use of LLMs in generating personal statements for spine fellowship applications, which generally require more specialized content than residency applications.
In this study, we assessed whether evaluators could reliably differentiate between ChatGPT- and human-authored statements for spine surgery fellowship applications. Additionally, we used an extensive prompt designed to improve the narrative quality of ChatGPT-generated essays to explore whether ChatGPT-generated essays could potentially outperform human-authored ones.
Materials and Methods
Personal Statement Generation
A total of 9 (4 ChatGPT, 5 applicant) personal statements were compiled. For the AI-generated essays, ChatGPT (version 4o, OpenAI, San Francisco, California) was given the prompt, “Please compose a personal statement for my application to spine fellowship programs. I am currently in my fourth year of orthopedic surgery residency in the United States. The statement should adopt an academic tone without being pretentious, maintaining clarity over sophistication, and avoiding predictable transitions and extraneous wording. Emphasize cohesiveness and a smooth narrative flow. The essay should be narrative-driven, showcasing a unique and original story revolving around [fill in the blank]. Avoid simply listing achievements from my resume. The statement should not exceed 600 words.” To ensure the 4 responses were unique, the software was prompted to focus on 1 of 4 unique experiences: global health, family member injury, residency experience, and technology advancement. To evaluate the independent capabilities of ChatGPT, no additional information outside of the above prompt was given to the chat bot (ie, an applicant’s CV). Each essay was generated in a separate chat session to minimize AI self-referencing and to promote heterogeneity between personal statements.
For the applicant essays, 5 de-identified essays were chosen from applicants who were granted interviews at our institution. Essays were chosen at random from 2017-2022, before ChatGPT was publicly available.
Evaluation Process
The personal statements were randomly ordered and reviewed by 8 blinded evaluators, composed of 6 spine surgery attending physicians with extensive experience in fellowship admissions and 2 current spine surgery fellows. Participants were instructed to grade each essay on a scale of 0-100 for readability, originality, quality, and authenticity. Additionally, participants were asked if they thought AI was used in the creation of the essay, and if they would grant this applicant an interview based on the personal statement.
Statistical Analysis
Quality metrics between applicant-authored and ChatGPT-authored personal statements were compared using independent samples t-tests. Univariate logistic regression was performed to evaluate the odds of receiving an interview recommendation and to assess whether reviewers could accurately identify ChatGPT-authored personal statements. Each reviewer’s evaluation of each personal statement was treated as a separate data point for statistical analysis. Inter-rater reliability for continuous variables was assessed using a Two-Way Mixed-Effects Model Intraclass Correlation Coefficient (ICC), while reliability for categorical variables was evaluated using Fleiss’ Kappa. All statistical analyses were conducted using SPSS (Version 29.0.2.0; Armonk, NY: IBM Corp.). P < 0.05 was considered statistically significant.
Results
Comparison of Quality Metrics Between Applicant-Authored and ChatGPT-Authored Personal Statements.
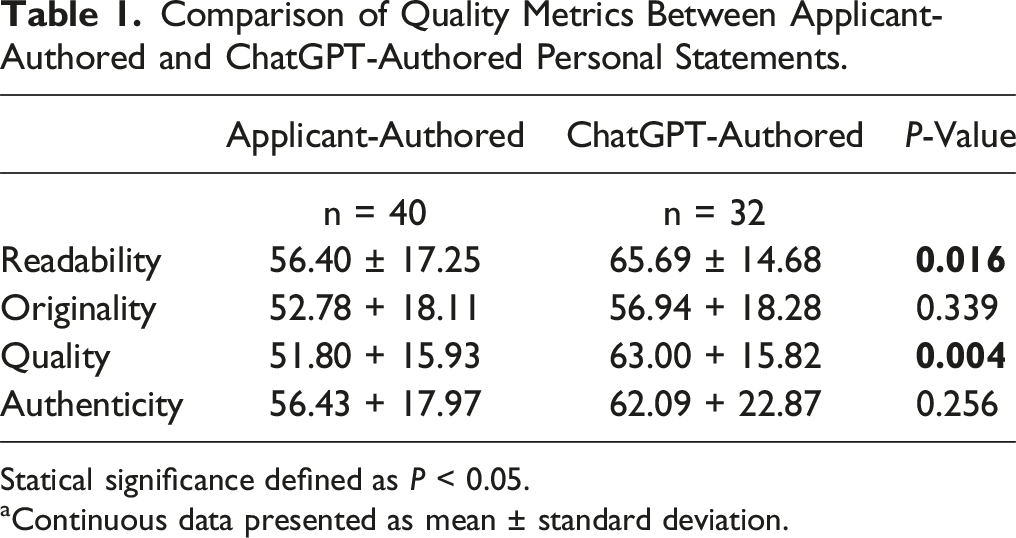
Statical significance defined as P < 0.05.
aContinuous data presented as mean ± standard deviation.
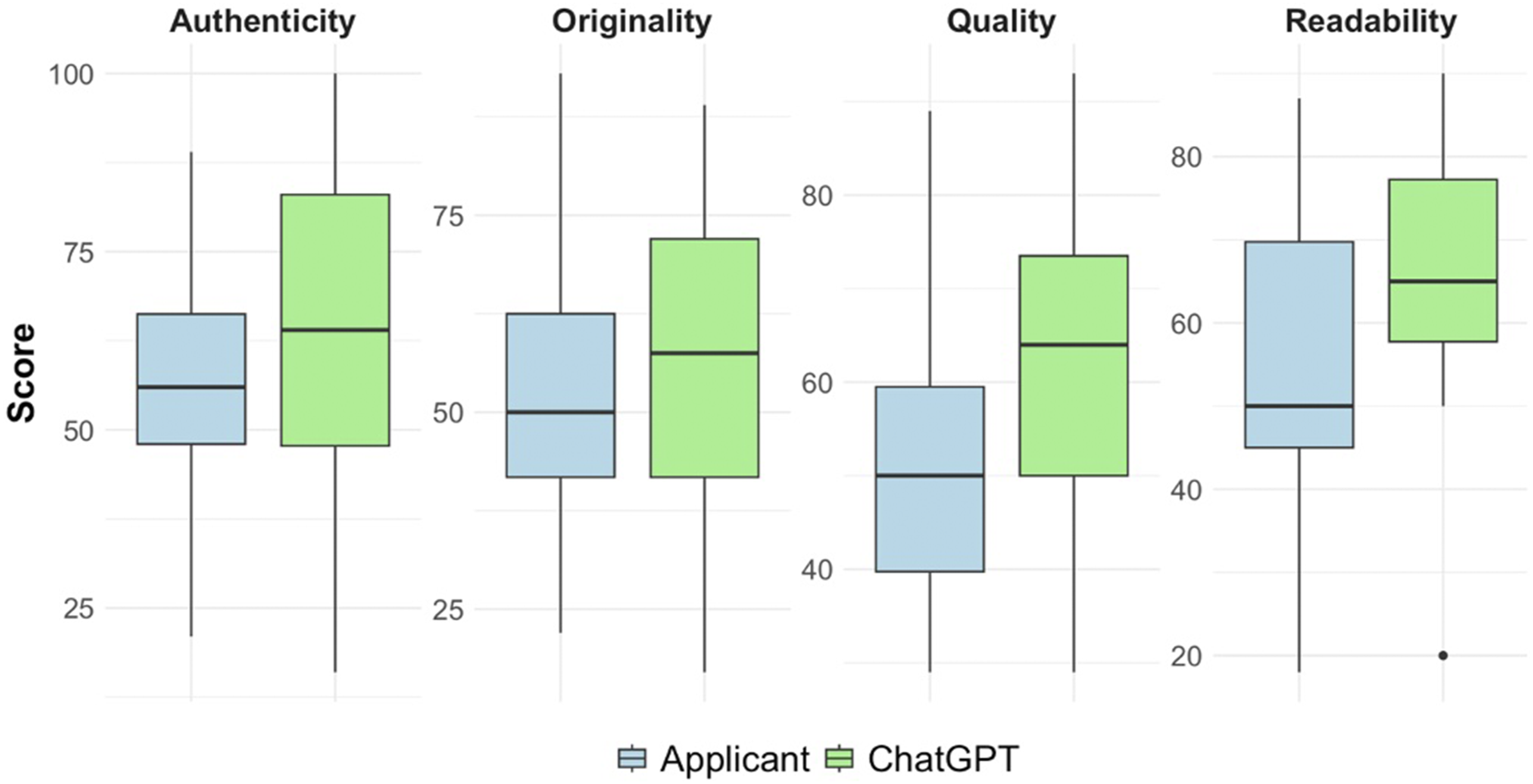
Comparison of quality metrics between applicant-authored and ChatGPT-Authored personal statements.
Reviewer Perception of Applicant-Authored and ChatGPT-Authored Personal Statements.

Abbreviations: AI = artificial intelligence, OR = odds ratio, 95% CI = 95% confidence interval. Categorical data presented as n (%). Statistical significance defined as P < 0.05.
Inter-rater reliability was poor for readability (ICC: 0.28 [0.75-0.81]), but moderate for originality (ICC: 0.72 [0.31-0.93]), overall quality (ICC: 0.68 [0.23-0.92]), and authenticity (ICC: 0.66 [0.17-0.91]). There was poor inter-rater reliability for identifying ChatGPT-generated personal statements (κ: 0.16 [0.04-0.29]) and for recommending a personal statement for an interview (κ: 0.15 [0.03-0.27]).
Discussion
This study comparing ChatGPT- and human-authored personal statements for spine surgery fellowship applications revealed that ChatGPT can produce essays that outperform authentic submissions in certain evaluation criteria. Evaluators failed to distinguish between ChatGPT and human authors and rated the ChatGPT-written statements higher for readability, quality, and likelihood of earning interview recommendations.
Previous studies have also reported that reviewers typically cannot reliably distinguish between ChatGPT-generated and human-authored statements, with both scoring similarly across quality metrics in contexts such as general surgery, orthopaedic surgery, plastic surgery, and anesthesia residency applications.9-13 However, our study is the first to analyze personal statements within the fellowship application process and to demonstrate that ChatGPT-generated essays can potentially exceed human-written content on key evaluation criteria. We attribute these results to our unique prompting strategy. Whereas earlier studies used either basic, single-sentence prompts or more detailed, content-focused instructions, our approach employed a comprehensive prompt that emphasized humanistic writing style and allowed ChatGPT greater flexibility to craft content within defined parameters. This strategic shift in prompt design likely contributed to the significantly higher readability and quality scores observed in our study.
It is perhaps unsurprising that ChatGPT can generate high-quality, humanistic personal statements, given that LLMs are trained on vast datasets of human-written content and established quality benchmarks. However, not all studies align with our results. For example, Nair et al.’s research on internal medicine residency personal statements found that reviewers could identify AI-generated content. 14 Their use of an exaggerated prompt, such as “you want an outstanding and unique personal statement that will captivate and wow the readers on the admission committee”, may have resulted in an overly dramatic writing style that signaled AI authorship. 14 However, this study underscores the pivotal role of prompt engineering in shaping AI-generated outputs, likely explaining the large differences between study results. Furthermore, while prior research predominantly employed ChatGPT-3.5 or −4, our study utilized the latest iteration, ChatGPT-4o, highlighting the rapid advancements in generative AI technology. These findings highlight the powerful capabilities of current generative AI technology and introduce key considerations for future application processes in medical education.
The use of generative AI in medical education applications has created significant debate within medical admissions committees, with concerns centered on authenticity, essay homogenization, and the loss of the applicant’s voice. 7 Research by Whitrock et al. reveals strong opposition among faculty and residents as 66.7% oppose AI use in personal statement writing, and 80% said AI usage would impact their opinion of an applicant. 12 This issue is further complicated by limitations in AI detection tools and reviewers’ ongoing difficulty in identifying AI-generated content, as seen in this study. 8
The discourse surrounding AI in applications warrants a nuanced approach that considers its diverse capabilities rather than treating it as a binary choice. Many agree that using AI-generated content as one’s own work is a form of plagiarism. While this study investigated this most extreme use of AI in personal statement writing, complete ghostwriting, generative AI can be used in ways that do not challenge the accuracy, authenticity, and integrity of applications.4,7 For example, The United Kingdom’s shared admissions service for higher education endorses AI’s use for essay organization, grammar checking, and improving readability. 15 Furthermore, AI-powered tools like text correctors and suggestion features have become seamlessly embedded in daily workflows that they are often overlooked as standard functionalities and not acknowledged as “products” of AI.
Applicants have long sought external assistance in writing personal statements, whether through multiple rounds of mentor feedback or expensive professional editing services costing hundreds to thousands of dollars.2,3 In this context, publicly available free AI platforms could expand access to high quality writing assistance, potentially benefiting applicants with limited access to mentorship or financial resources. 7 Koaum et al further argued that AI tools can help bridge the fluency gap for those with English as a second language, helping compose a compelling narrative while retaining the authenticity of the applicant’s experiences. 7 This study shows that, when prompted effectively, current AI models can generate engaging and effective narratives, offering a powerful editing tool for applicants to convey their experiences. Chen et al suggest that if the primary goal of a personal statement is to communicate unique information about applicants not covered elsewhere in the application, then generative AI can help achieve this. 4
In 2024, the AAMC updated its personal statement guidelines, shifting from the requirement that personal statements “must be your own work and not the work of another author or the product of artificial intelligence” to “the use of AI tools is acceptable for brainstorming, proofreading, or editing the personal statement, but the final submission should represent your own work.” 16 This change signals a growing acceptance of limited AI use in medical education.
As AI technologies continue to advance, it is imperative for fellowship and residency matching organizations to develop clear and well-considered guidelines regarding the appropriate use of AI in application processes. Given the expanding capabilities of LLMs and their integration into everyday workflows, outright prohibition of these tools is both impractical and unenforceable, particularly in the absence of reliable detection methods. However, it is crucial to establish explicit definitions for the ethical use of LLMs within higher education, as current policy development lags behind the rapid pace of technological advancement. Future research should focus on assessing the prevalence of AI usage in personal statement writing, exploring program directors’ views on various AI applications after they have been fully informed about the technology’s capabilities and limitations, and determining where boundaries should be set for acceptable and ethical use.
Limitations
This study has several limitations. Our use of a single prompt for generating personal statements likely underestimates AI’s potential, as optimal performance typically involves iterative prompting with human intervention and editing. The evaluation metrics such as “overall quality” were intentionally broad but susceptible to individual reviewer interpretation. While we used the free version of ChatGPT due to its widespread accessibility, other LLMs such as Claude, Perplexity, and Gemini, may offer enhanced creative writing capabilities. In the essay review process, we included current spine surgery fellows who do not have extensive experience in fellowship admissions, leading to potential inaccuracies in grading. ChatGPT was not provided with real applicant information, such as a CV, and instead generated fictional candidates from scratch based around a theme. While this could be seen as unfair, since ChatGPT could fabricate any story, it aligns with the study’s goal of assessing whether it can produce an adequate personal statement without specific applicant input. Furthermore, because personal statements are often judged on subjective elements like personal motivations and experiences rather than on the quality metrics or achievements that can be seen on an applicant’s CV, this approach provided a reasonable basis for comparison between cohorts. 2 Finally, the study’s small sample size of 9 personal statements, limited number of reviewers, and exclusive focus on ChatGPT constrain the generalizability of the findings and prevent definitive conclusions about ChatGPT or other LLMs. This is particularly relevant given that some results were borderline significant (eg, referral for interview: P = 0.045). Nonetheless, this research lays the groundwork for future investigations into the capabilities and ethical usage of ChatGPT and other LLMs in this context.
Conclusion
This study demonstrates that ChatGPT can produce personal statements for spine surgery fellowship applications that are indistinguishable from human-written essays and may also surpass human-written essays in quality, readability, and likelihood of securing interviews, highlighting the capabilities of current AI technology. While concerns about authenticity and academic integrity persist, the medical education community must provide nuanced guidelines that acknowledge both the benefits and limitations of AI in application processes, particularly its role in expanding access to high-quality writing and application assistance, while balancing its use with human creativity and applicant voice (Supplemental Material).
Supplemental Material
Supplemental Material - Artificial Intelligence vs Human Authorship in Spine Surgery Fellowship Personal Statements: Can ChatGPT Outperform Applicants?
Supplemental Material for Artificial Intelligence vs Human Authorship in Spine Surgery Fellowship Personal Statements: Can ChatGPT Outperform Applicants? by William J. Karakash, BS, Henry Avetisian, MS, Jonathan M. Ragheb, BA, Jeffrey C. Wang, MD, Raymond J. Hah, MD, and Ram K. Alluri, MD in Global Spine Journal.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the William Karakash, Henry Avetisian, and Jonathan M. Ragheb have nothing to disclose. Jeffrey C. Wang has received intellectual property royalties from Zimmer Biomet, NovApproach, SeaSpine, and DePuy Synthes. Raymond J. Hah has received grant funding from SI bone, consulting fees from NuVasive, and support from the North American Spine Society to attend meetings. Ram K. Alluri has received grant funding from NIH, consulting fees from HIA Technologies, and payment from Eccentrial Robotics for lectures and presentations.
Institutional Review Board
This study was Institutional review board (IRB) exempt.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.