
Abstract
The widespread integration of generative AI into academic writing has created a new communicative context in which human authorship coexists with algorithmic fluency, yet their phraseological relationship remains insufficiently understood. To address this gap, this study examines the phraseological differences between human-authored and AI-generated academic writing within the emerging framework of Human–Artificial Intelligence Togetherness (HAIT). Using a comparative corpus-based approach, it analyzes three datasets: first-year English as a Second Language (ESL) student texts (F1C), fourth-year ESL student texts (F4C), and AI-generated texts (AIC) produced by five large language models. The analysis focuses on five key features—type–token ratio (TTR), collocations, colligations, lexical bundles, and formulaic sequences—to explore how phraseological competence develops in human learners and how it contrasts with the fluency produced by algorithmic simulation. Results indicate a clear developmental trajectory between F1C and F4C: lexical variety, structural complexity, and phraseological density increase incrementally, yet both human corpora remain thematically narrow, often restricting the prompt “social” to social media contexts. In contrast, the AI corpus exhibits immediate lexical breadth, thematic diversity, and syntactic precision, with frequent use of advanced academic bundles and stable colligational forms. However, AI texts lack the hallmarks of developmental authenticity, such as revision, contextual adaptation, and evidence of cognitive effort. This asymmetry highlights the ontological divide between experiential human authorship and statistically generated fluency. The findings highlight that using AI writing as a benchmark risks obscuring L2 development, urging pedagogy centered on reflection, phraseological visibility, scaffolded authorship, and epistemic integrity.
Plain Language Summary
This study investigates how English as a Second Language (ESL) students develop phraseology—the way words and grammatical patterns are combined—in academic writing, and how this process differs from the phraseological patterns produced by artificial intelligence (AI). We compared three collections of short academic texts written on the same topic: one by first-year ESL students, one by fourth-year ESL students, and one by AI systems including ChatGPT, Claude, Gemini, and Writesonic. The analysis focused on five features of phraseology: type–token ratio (lexical diversity), collocations (common word pairings), colligations (grammar-pattern combinations), lexical bundles (recurring 3–5 word sequences), and formulaic sequences (fixed expressions). Human learners showed a clear developmental path between the first and fourth years: vocabulary grew, sentence patterns became more stable, and phraseological density increased. However, both student groups tended to use a narrow set of topics, often limiting the word “social” to social media contexts. AI-generated texts were different. They showed wide-ranging vocabulary, thematic variety, and precise grammar, with advanced collocations, varied colligations, and polished lexical bundles appearing immediately. Yet, this fluency was not the result of gradual learning—AI outputs lacked the revision, adaptation, and cognitive effort that mark genuine phraseological development in humans. These findings have important teaching implications. Using AI-generated writing as a model may give an unrealistic picture of how phraseology is learned. Effective instruction should make learners’ phraseological growth visible, provide opportunities for scaffolded practice, and value the process of building phraseological competence over time, rather than only the final polished product.
Introduction
The emergence of Human–Artificial Intelligence Togetherness (HAIT) marks a paradigmatic shift in contemporary discourse production, whereby human authorship increasingly shares—and at times competes with—algorithmic fluency. Proposed in this study, HAIT denotes the communicative condition in which human- and AI-generated texts operate within the same discursive environment while remaining fundamentally distinct in origin and process. This condition is especially evident in academic writing, where the outputs of experiential learning and statistical generation can appear increasingly similar in form, despite their different developmental pathways. The widespread availability of generative AI systems—such as ChatGPT, Claude, Gemini, and Writesonic—has raised fundamental questions for applied linguistics concerning textual authorship, fluency development, and the modeling of academic writing in second language (L2) contexts (S. Li, 2025; Lin et al., 2025). Trained on massive corpora of natural language, these systems can produce syntactically accurate, lexically varied prose that conforms to academic discourse norms, complicating how fluency is recognized and assessed.
For English as a Second Language (ESL) learners, such outputs may serve as reference points, writing aids, or even serve as uncredited proxies for student-authored writing in academic contexts (Jacob et al., 2025; Mahapatra, 2024). However, AI-generated fluency—hereafter referred to as algorithmic fluency—must be critically distinguished from the
A central dimension of this developmental process is phraseological competence, encompassing the acquisition and appropriate deployment of collocations, colligations, lexical bundles, and formulaic sequences (Du et al., 2022; Hyland, 2008; Laufer & Waldman, 2011; Nesselhauf, 2005; Yoon, 2016). These features are not merely stylistic enhancements; they function as structural indicators of academic discourse familiarity and the cognitive entrenchment of language patterns (Biber & Gray, 2016; Hyland, 2008; Schmitt, 2010). Prior research in learner corpus linguistics has richly documented the progression of phraseological sophistication across proficiency levels and educational stages (Dang et al., 2022; Granger et al., 2015; Paquot, 2013).
However, the interface between this developmental trajectory and the phraseological patterns of AI-generated text remains underexplored. Whereas human learners internalize phraseology incrementally through instruction and use, AI models assemble text via probabilistic associations over vast datasets—indifferent to learner level, error sensitivity, or communicative struggle. Devoid of exposure-based acquisition, cognitive entrenchment, and pedagogical context, their fluency is statistical rather than developmental (Bender et al., 2021; Floridi & Chiriatti, 2020). This contrast has been widely noted in computational linguistics and the philosophy of AI, underscoring the absence of human-like acquisition.
Importantly, this divergence is more than ontological—it carries significant pedagogical implications. If ESL learners emulate AI-generated texts as developmental models without understanding the linguistic pathways through which such fluency is typically acquired, authentic phraseological growth may be bypassed or distorted (Agustín-Llach, 2023; Bui, 2021). This concern aligns with long-standing perspectives on L2 writing as a recursive, staged, and socially mediated process in which exposure, instruction, and revision are critical to phraseological maturity (Larsen-Freeman & Long, 2014). Nevertheless, most existing research on AI in L2 writing has prioritized utility—such as feedback generation, grammar correction, or evaluation—over critical engagement with AI outputs as discourse to be systematically compared against learner writing (Karataş et al., 2024; Ranalli, 2018). Consequently, there is a lack of empirical evidence on how AI-generated phraseology aligns with, or diverges from, the developmental progression observed in authentic learner texts.
This investigation addresses that gap through a corpus-based analysis of ESL academic writing at two distinct educational stages—first-year and fourth-year undergraduate students—alongside a parallel corpus of AI-generated texts produced in response to the same academic prompt, “social.” The AI corpus comprises outputs from five publicly accessible large language models: GPT-3.5, GPT-4, Claude 3, Gemini 1.5, and Writesonic. The purpose of this research is to compare the phraseological features of learner texts, across stages of development, with those of AI-generated texts, thereby identifying the structural, functional, and frequency-based contrasts that emerge.
Accordingly, this study is guided by the following research questions:
This inquiry offers the first corpus-based comparison of ESL phraseology across academic levels and AI-generated texts. While AI outputs may exhibit surface fluency, they lack the developmental phraseological progression that marks authentic L2 writing competence. By exposing this structural and functional asymmetry, the analysis provides critical insight into the risks of treating AI-generated texts as developmental benchmarks. Such reliance may obscure or bypass the cognitive, social, and rhetorical processes through which L2 learners build academic proficiency. In addressing this gap, the study not only advances applied linguistic understanding of phraseological development under the HAIT condition but also informs pedagogical reorientation toward safeguarding developmental authenticity in L2 academic writing.
Theoretical Foundations
Building on prior scholarship, this inquiry integrates three interrelated domains: second language phraseological development, algorithmic fluency in AI text generation, and critical applied linguistics perspectives on pedagogical authenticity.
In relation to L2 phraseological development, competence emerges through repeated exposure and contextual use. Hoey’s lexical priming theory explains how words become linked to typical collocates, colligations, and discourse positions (Hoey, 2005). Without such priming, L2 learners often face persistent difficulties in achieving phraseological fluency (Hoey, 1997, 2003, 2004a, 2004b). Empirical evidence further shows that collocations, lexical bundles, and formulaic sequences increase in complexity with proficiency, reflecting both linguistic maturity and disciplinary enculturation (Nesselhauf, 2005; Paquot, 2013).
By contrast, AI-generated language is assembled through probabilistic modeling. Large language models simulate coherence and lexical variety by calculating token likelihoods over vast corpora, without cognitive, social, or pedagogical development (Bender et al., 2021; Mitchell, 2021). Consequently, their fluency is statistical rather than experiential, lacking the developmental sensitivity of human writing (Floridi & Chiriatti, 2020; Marcus & Davis, 2020). This creates risks such as simulating authority without genuine learning (Weidinger, 2022). To address this asymmetry, this research advances the concept HAIT as a lens for examining the coexistence of algorithmic and human-authored discourse.
From a critical applied linguistics perspective, L2 academic writing is socially situated and recursively acquired. Using AI output as a model risks detaching learning from its epistemological, cultural, and identity-forming foundations (Canagarajah, 2002; Pennycook, 2021). Because phraseological growth is rooted in socialization, revision, and identity negotiation (Kramsch, 2009), emulating AI fluency without this process may yield polished performance but diminished authenticity (Agustín-Llach, 2023; Bui, 2021).
Literature Review
Phraseological Development in L2 Writing
Within L2 writing scholarship, phraseology is widely recognized as a core dimension of academic proficiency, reflected in learners’ capacity to produce and control lexical bundles, collocations, and other formulaic sequences (Ädel & Erman, 2012; Chen & Baker, 2010; Yoon, 2016). Such competence encompasses not only linguistic proficiency but also disciplinary enculturation and metadiscursive awareness (Chen & Baker, 2010; Cortes, 2004; Durrant, 2017; Granger, 1998, 2018; Parkinson & Musgrave, 2014). Empirical studies consistently reveal a developmental trajectory in phraseological complexity across proficiency levels (Boers & Lindstromberg, 2012; Dang et al., 2022; Gilquin et al., 2007; Henriksen, 2013; Siyanova-Chanturia & Martinez, 2014). This pattern underscores that exposure, genre awareness, and cognitive entrenchment are essential for developing phraseological fluency.
AI-Generated Text and the Illusion of Fluency
Parallel to this, AI-generated academic writing has attracted both enthusiasm and concern. While recent work highlights the grammatical and lexical fluency of outputs from large language models (Kasneci et al., 2023; J. Li et al., 2024), scholars caution that such fluency is algorithmic rather than acquisitional, lacking any experiential, pedagogical, or epistemic grounding (Dentella et al., 2024; Mahowald et al., 2024). Most existing research treats AI primarily as a tool—emphasizing utility in feedback, summarization, or grammar correction—rather than interrogating its discourse patterns or implications for learner modeling (Dwivedi et al., 2023). Importantly, the phraseological architecture of AI outputs remains underexamined in comparison to L2 development (Agustín-Llach, 2023; Bui, 2021; Du et al., 2022; Fang et al., 2023).
Critical Perspectives on AI in Language Education
Generative AI, particularly ChatGPT, poses notable pedagogical risks in L2 writing. Barrot (2023) warns that its use can bypass essential process-based development, undermining learner autonomy. Kurt and Kurt (2024) show that AI-generated feedback may reduce critical reflection without human mediation. Lo et al. (2024) highlight risks of disengagement and overreliance, while Yao and Zhang (2024) identify threats to formative assessment and writing identity. S. Li (2025) introduces a “GenAI literacy” framework, cautioning that poor integration fosters superficial, product-focused writing. Zhang et al. (2025) find hybrid feedback improves quality but may hinder independent revision skills. Mohammed and Khalid (2025) report motivational and proficiency gains from AI feedback, yet warn of reduced self-regulation. Suh et al. (2025) show structured AI use via the CGCAW framework enhances critical thinking and coherence. Collectively, these studies stress the need for critical AI literacy (Celce-Murcia & Olshtain, 2000; Norton, 2001) to ensure AI supplements rather than replaces developmental processes.
The Research Gap
Despite growing interest in both AI and learner corpora, empirical investigations directly comparing the phraseological patterns of AI-generated and human-authored academic texts remain markedly underdeveloped. In particular, the structural, functional, and discourse-pragmatic contrasts between human and AI-generated phraseology remain largely uncharted. Recent comparative research has also begun to examine evaluative and phraseological variation across political, legal, and disciplinary domains, highlighting the need for updated, cross-contextual perspectives on human and algorithmic discourse (Hamed & Alqurashi, 2025a, 2025b, 2025c). This inquiry addresses that gap by systematically examining ESL writing from two educational stages alongside a multi-model AI corpus. This comparison generates new insights into the linguistic and pedagogical implications of positioning AI as a reference model in L2 academic writing.
Methodology
Research Design
This investigation employs a comparative corpus-based design to explore phraseological variation in learner-authored and AI-generated academic writing. The analysis draws on three purpose-built corpora, each developed in response to the same open-ended academic prompt, “social.” The learner corpora capture two educational stages—introductory-level and advanced-level undergraduate ESL students—while the AI corpus consists of outputs generated by five publicly accessible large language models: GPT-3.5, GPT-4, Claude 3, Gemini 1.5, and Writesonic. The inquiry systematically examines type–token ratio (TTR), collocations, colligations, lexical bundles, and formulaic sequences to assess variation in phraseological structure, frequency, and discourse function. Through this design, the study facilitates a direct comparison between the developmental authenticity characteristic of human L2 writing and the simulated fluency produced by algorithmic text generation.
To ensure valid cross-corpus comparison under the HAIT condition, the writing task was deliberately standardized across the three datasets. Restricting genre, topic, and approximate length minimized contextual and disciplinary variation that could artificially widen or obscure phraseological differences. These constraints reduce confounding factors such as topic familiarity, cognitive load, and rhetorical choice, thereby isolating developmental progression in learner writing and the distinct simulation patterns in AI-generated texts. This controlled design thus strengthens internal validity by ensuring that any observed phraseological contrasts arise from generative mechanisms rather than task-based variation.
The selection of the three datasets was driven by the developmental focus of this study. First-year and fourth-year undergraduate ESL writing enable a controlled comparison of phraseological progression within the same institutional and curricular setting, representing beginning and advanced stages of academic development. The inclusion of AI-generated texts, produced by multiple large language models, allows the study to distinguish experiential learner development from algorithmic fluency and avoids bias associated with single-system output. Collectively, this design ensures that developmental contrasts and human–AI differences are examined under matched task conditions. By operationalizing the HAIT condition within a controlled parallel corpus design, this study offers a methodological advance that enables direct, developmentally sensitive comparison of phraseological behavior across human and algorithmic writers responding to the same task.
Corpus Compilation
The investigation draws on three purpose-built corpora, each comprising 50 single-paragraph academic texts written in response to the identical prompt, “social.” The prompt “social” was selected for its accessibility to participants and its openness to a wide range of interpretations, enabling diverse yet thematically connected responses. All texts are controlled for genre, topic, and approximate length (mean ≈ 200 words), ensuring valid cross-corpus phraseological comparison.
The First-Year Corpus (F1C) contains 9,911 words produced by beginner-level L2 English learners in their first year of undergraduate English programs. Typically aged 18 to 19, these writers exhibit CEFR A1 to A2 proficiency, with texts characterized by limited syntactic variety, narrow lexical range, and frequent grammatical, orthographic, and mechanical errors. The Fourth-Year Corpus (F4C) comprises 10,579 words authored by advanced L2 learners in their final year of English language study. Aged 21 to 22, these students approximate CEFR B2 to C1 proficiency, demonstrating greater phraseological control, increased lexical density, and more complex syntactic constructions, though traces of L2 developmental features remain.
All learner participants were enrolled in a 4-year English-medium undergraduate program in the Faculty of Education at a national university. English is the primary language of instruction for their major courses, with curricular emphasis on academic writing and digital communication. The first-year students (F1C) were typically 18 to 19 years old and at the beginning of their university studies, while the fourth-year students (F4C) were typically 21 to 22 years old and approaching graduation with substantially greater exposure to academic English. This educational context provides a controlled progression in L2 academic writing development relevant to the comparative aims of the study.
Classification into proficiency levels was determined using the institutional CEFR-aligned placement test routinely administered at the beginning of each academic year for level progression within the English Department. This standardized assessment evaluates reading, grammar, and writing performance to ensure accurate proficiency identification. Accordingly, learners whose performance fell within the CEFR A1 to A2 bands were categorized as beginner-level (F1C), whereas students demonstrating B2 to C1 proficiency were classified as advanced (F4C). This transparent and empirically validated criterion confirms that the two learner corpora represent distinct and developmentally meaningful proficiency stages, rather than arbitrary or subjective labeling.
The AI Corpus (AIC) consists of 9,580 words generated by five large language models—GPT-3.5, GPT-4, Claude 3, Gemini 1.5, and Writesonic—under standardized input conditions. These outputs display high syntactic fluency and lexical sophistication but are devoid of the experiential, instructional, and socially mediated developmental processes that characterize human-authored L2 academic writing.
All datasets used in this study are primary sources created specifically for the research design. The learner-produced texts were collected in November 2024 from first-year and fourth-year undergraduate students in the English Department, Faculty of Education, National University, under supervised classroom writing conditions. The AI-generated texts were produced in December 2024 using five publicly accessible large language models (GPT-3.5, GPT-4, Claude 3, Gemini 1.5, and Writesonic) with standardized input prompts identical to those used for the learner datasets. No secondary or external datasets were utilized.
Annotation and Analytical Procedures
The analytical process comprised five systematic stages designed to capture, classify, and compare phraseological patterns across the three corpora in accordance with the study’s theoretical orientation.
Step 1: Type–Token Ratio (TTR) Extraction
Lexical diversity was quantified using the type–token ratio (TTR), calculated as (number of types ÷ number of tokens) × 100. This provided an initial indicator of phraseological volume and lexical variation, forming the basis for subsequent structural and functional comparisons.
Step 2: Identification of High-Frequency Word Combinations
All texts were processed in AntConc (Anthony, 2022) to extract recurrent phraseological units. Two principal categories were targeted:
- Collocations, defined as frequent two-word combinations, were identified using the T-score statistical measure, which isolates salient co-occurrences characteristic of both developmental and proficient academic writing.
- Lexical bundles, defined as recurring sequences of three to five words, were extracted via the N-gram range function, applying a minimum corpus-wide frequency threshold of three occurrences. This threshold balanced statistical robustness with the productivity patterns of learner writing. Structural categories were not pre-restricted; however, all candidates underwent manual verification to ensure semantic integrity and pedagogical relevance.
Formulaic sequences were additionally identified through a qualitative review of recurring multi-word expressions exhibiting idiomaticity, pre-fabrication, or alignment with established ESL instructional materials. Unlike lexical bundles, their inclusion was based on semantic and functional unity rather than statistical criteria alone.
Step 3: Manual Identification of Colligations
Because AntConc does not provide grammatical pattern extraction, colligations were identified through systematic manual analysis of concordance lines. This involved examining recurring verb–noun, adjective–preposition, and prepositional phrase structures and distinguishing target-like patterns from learner-specific deviations (e.g., write in social vs. write on social media). Manual colligation analysis is widely adopted in learner corpus research to ensure grammatical accuracy and contextual validity where automated tools are limited (Nesselhauf, 2005).
Step 4: Cross-Corpus Phraseological Comparison
The resulting phraseological profiles were systematically compared to trace developmental patterns between F1C and F4C, and to contrast these with the AIC. This comparison focused on the degree of progression in collocational and bundling sophistication from lower- to higher-proficiency learners, and the ways in which AI-generated sequences, while syntactically accurate and lexically varied, diverged from human developmental patterns and lacked interlanguage features.
Step 5: Theoretical Interpretation of Findings
Findings were interpreted through Hoey’s lexical priming framework to account for the recurrence, contextual positioning, and structural patterning of phraseological items. Colligational priming theory informed the analysis of grammatical structuring and its developmental trajectory. AI outputs were examined through the construct of algorithmic fluency, highlighting their lack of acquisition-based grounding. Finally, a critical applied linguistics perspective was applied to consider the pedagogical implications of using AI-generated texts as developmental models detached from authentic social learning and learner identity formation.
To enhance analytical reliability, 20% of the annotated data underwent independent verification by a second coder. Inter-coder agreement reached 88% (Cohen’s κ = 0.81), with discrepancies resolved through discussion until consensus was achieved.
Quantitative and Qualitative Analysis
The quantitative component examined the frequency and distribution of key phraseological features—collocations, lexical bundles, formulaic sequences, and colligations—across the three corpora. All raw counts were normalized to occurrences per 1,000 words to enable valid cross-corpus comparison. Type–token ratio (TTR) was computed at the corpus level for F1C, F4C, and AIC (types divided by tokens, reported as a percentage) to index overall lexical diversity. Statistical significance of intergroup differences in feature counts was assessed using chi-square tests.
The qualitative analysis involved close examination of concordance lines to explore the contextual deployment of phraseological units. This included investigating their immediate lexical and grammatical environments, distribution across texts, recurrence patterns, and discourse functions. Findings were interpreted through Hoey’s lexical priming framework to account for recurrence, positioning, and association, and situated within a critical applied linguistics perspective to highlight contrasts in acquisition pathways and communicative orientations between learner-authored and AI-generated discourse.
Validity and Reliability
All corpus compilation procedures, AntConc settings, and identification thresholds were fully documented to ensure replicability. Inter-rater reliability was established through independent double-coding of 20% of the data (Cohen’s κ = 0.81), with discrepancies resolved through consensus. These measures ensure consistency and reproducibility of the analysis.
Figure 1 synthesizes the methodological process, illustrating how corpus construction, stepwise phraseological analysis, and validation procedures align within the theoretical orientation of the study.

Methodological flow diagram. Figure 1 presents the methodological flow diagram used in this study. It visualizes corpus construction and standardization, followed by five analytical stages addressing phraseological development, algorithmic fluency, and discoursal function. The diagram also includes quantitative and qualitative procedures and reliability checks. This visualization ensures transparency, supports replication, and clearly connects methodological steps with the study’s theoretical foundations.
Ethical Considerations
The study adhered to the ethical principles outlined in the Declaration of Helsinki. Written institutional approval was obtained from the relevant academic authority prior to data collection. All student participants provided verbal informed consent after being briefed on the study’s aims and procedures. Participant anonymity was strictly maintained, and no personal identifiers were recorded in any part of the corpus construction or analysis. AI-generated texts were collected using publicly accessible platforms under standard input conditions and did not involve human subjects.
Results
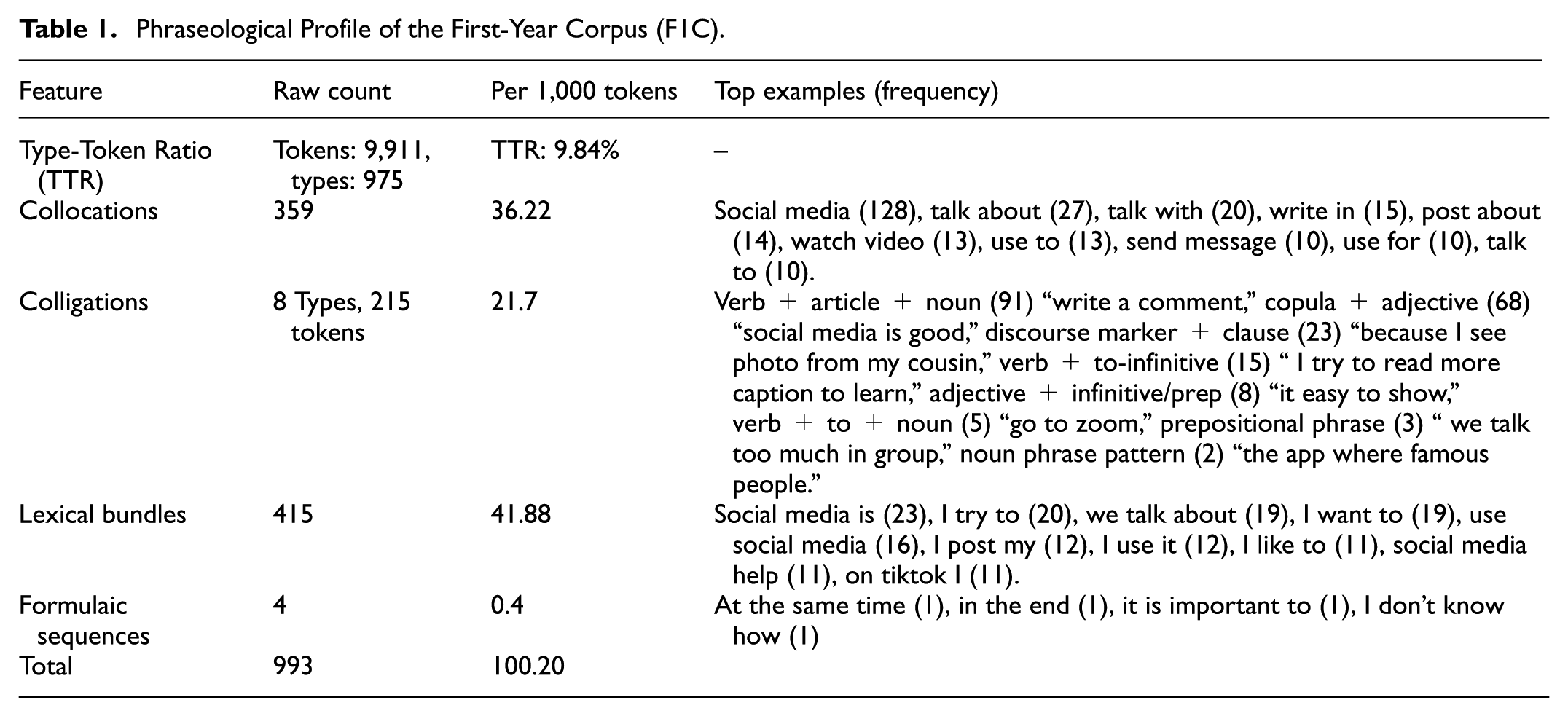
Tables 1 to 3 present the phraseological profiles of the three corpora examined in this study: F1CF4C, and AIC. Each table reports the total number of tokens and types, TTR, and the raw counts and normalized frequencies (per 1,000 tokens) for collocations, colligations, lexical bundles, and formulaic sequences.
Phraseological Profile of the First-Year Corpus (F1C).
Phraseological Profile of the Fourth-Year Corpus (F4C).

Phraseological Profile of the Artificial Intelligence Corpus (AIC).

Figure 2 synthesizes the data from Tables 1 to 3 by comparing normalized frequencies for the five key phraseological features—TTR, collocations, colligations, lexical bundles, and formulaic sequences—across F1C, F4C, and AIC. The grouped bar chart visually highlights the developmental progression from F1C to F4C and the distinct profile of AIC. Figure 3 compares the five most frequent collocations in F1C, F4C, and AIC, showing the dominance of “social media” in both learner corpora and the broader thematic spread in AIC. Figure 4 illustrates the proportional distribution of colligation types across the three corpora, highlighting the restricted range in F1C, the expanded variety in F4C, and the balanced, error-free use in AIC. Figure 5 contrasts the proportion of lexical bundles classified as social media–specific versus other, showing complete thematic confinement in F1C and F4C, and a broader thematic scope in AIC. Figure 6 presents the distribution of formulaic sequence types in the three corpora, showing the limited range in learner writing compared with the more varied and genre-aligned use in AIC.

Grouped bar chart of normalized phraseological features across F1C, F4C, and AIC. Comparison of normalized frequencies for five phraseological features—Type–Token Ratio (TTR, %), collocations, colligations, lexical bundles, and formulaic sequences—across the First-Year Corpus (F1C), Fourth-Year Corpus (F4C), and Artificial Intelligence Corpus (AIC). Frequencies are expressed as percentages for TTR and per 1,000 tokens for all other features. The chart illustrates the developmental progression from F1C to F4C and the marked contrast with AIC’s algorithmically generated fluency.

Top five collocations in F1C, F4C, and AIC. Horizontal bar charts showing the five most frequent collocations in the First-Year Corpus (F1C), Fourth-Year Corpus (F4C), and Artificial Intelligence Corpus (AIC). Frequencies are based on raw counts from each corpus. The comparison highlights thematic limitation in human-authored corpora—particularly the dominance of “social media” in both F1C and F4C—contrasted with the broader thematic range and abstract domain coverage in AIC collocations.

Colligation types across F1C, F4C, and AIC. Stacked bar chart showing the proportional distribution of colligation types in the First-Year Corpus (F1C), Fourth-Year Corpus (F4C), and Artificial Intelligence Corpus (AIC). Percentages are calculated within each corpus based on total colligation tokens. The figure illustrates developmental shifts from the limited, often imbalanced structural use in F1C toward greater syntactic variety and accuracy in F4C, alongside the balanced, fully accurate distribution characteristic of AIC’s algorithmic generation.
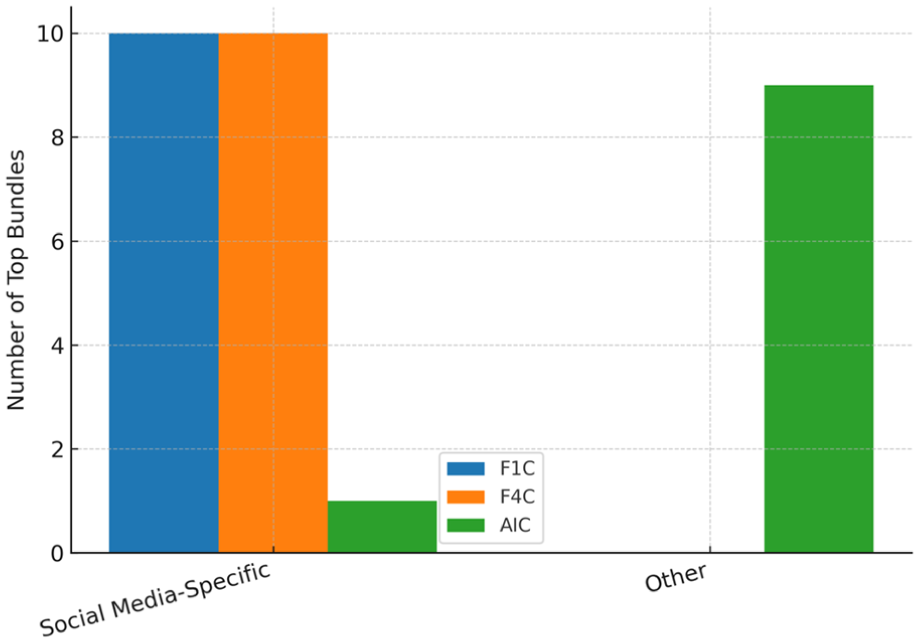
Social media-specific versus other lexical bundles across F1C, F4C, and AIC. Bar chart comparing the proportion of top lexical bundles classified as Social Media-Specific versus Other in the First-Year Corpus (F1C), Fourth-Year Corpus (F4C), and Artificial Intelligence Corpus (AIC). All high-frequency bundles in F1C and F4C are tied exclusively to social media contexts, reflecting thematic confinement of the prompt “social” to online platforms. In contrast, AIC demonstrates a more varied thematic scope, with only one social media-specific bundle among its top sequences, and the remainder encompassing general social and abstract/conceptual expressions.
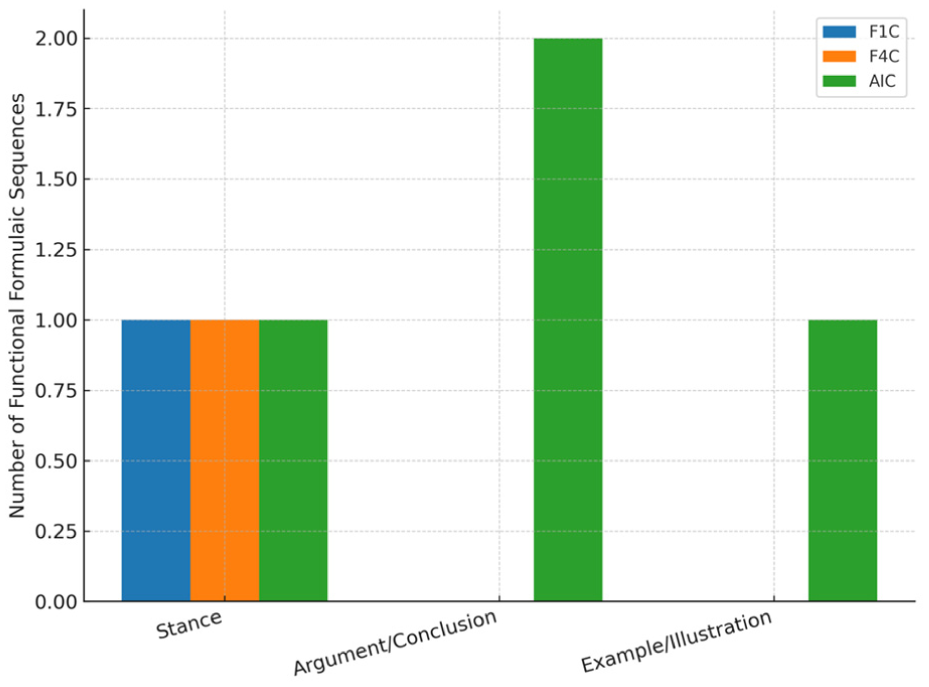
Distribution of formulaic sequences across F1C, F4C, and AIC. The chart illustrates the proportional presence of each identified formulaic sequence type within the three corpora, highlighting developmental differences between learner-authored texts (F1C and F4C) and the genre-oriented deployment in AI-generated texts (AIC).
Discussion
Figure 2 presents the normalized frequencies for TTR, collocations, colligations, lexical bundles, and formulaic sequences across F1C, F4C, and AIC. It shows a steady, acquisition-driven progression from F1C to F4C and a sharp contrast with AIC’s algorithmically generated output. Within the HAIT framework, the learner corpora reflect developmental authenticity through gradual lexical expansion, increased colligational density, and higher bundle counts. These patterns are consistent with selective repetition that allows familiar forms to accumulate and cross the frequency threshold of three corpus-wide occurrences used in this study. By contrast, AIC exhibits no developmental trajectory: from the first output it displays maximal lexical diversity, precise colligations, and broad thematic scope. Its deliberate avoidance of repetition results in fewer qualifying bundles despite their rhetorical sophistication. The figure thus captures two fundamentally different generative logics coexisting under HAIT—incremental, socially mediated acquisition in human writing versus immediate, variation-maximized fluency in AI output—providing the baseline for the detailed analyses that follow.
Discussion of RQ1: Phraseological Change Between First-Year and Fourth-Year ESL Writing
TTR and Phraseological Volume: Limited Density in F1C, Marked Expansion in F4C
TTR comparison F1C and F4C reveals a measurable developmental increase in lexical diversity. F1C contains 9,911 tokens and 975 types, yielding a TTR of 9.84%, while F4C includes 10,579 tokens and 1,132 types, resulting in a higher TTR of 10.70%. Although the percentage increase may seem modest, it reflects a substantial gain in lexical variety across texts produced by fourth-year students.
F1C writing is characterized by heavy repetition of a narrow set of high-frequency lexical items. Commonly recycled words include “video,”“photo,”“English,”“friend,”“app,” and “social media.” Recurrent structures such as “I watch video,”“I post photo,”“I use WhatsApp,” and “I learn English” dominate the corpus. For example, expressions such as “I watch prank video,”“I post my photo,”“I write comment,” and “I use TikTok before sleep” are repeated with minimal variation, indicating a constrained phraseological range.
In contrast, F4C writers exhibit more varied vocabulary and begin to produce longer, more elaborated constructions. While high-frequency words such as “social media,”“WhatsApp,” and “Instagram” persist, they co-occur with a more diverse range of content and modifiers. Examples from F4C include: “We discuss about project and exam,”“Social media platforms give opportunity to communicate with different people,”“I follow pages that show study tips and new words,” and “Social media communication make it easy to talk and learn.” The increased use of extended noun phrases, plural abstract nouns (e.g., “advantages,”“disadvantages”), and academic verbs such as “discuss,”“improve,” and “practice” reflects broader lexical access.
Moreover, fourth-year students display lexical productivity through compound expressions and varied prepositional structures, such as “I write caption in English,”“I join channel for grammar and vocabulary,” and “Social media platforms are now part of my study routine.” These longer, multi-word units signal emerging fluency and register sensitivity, contrasting sharply with the short, repetitive declaratives in F1C.
In summary, the TTR findings, substantiated by corpus-derived examples, demonstrate that while F1C writing is marked by lexical redundancy and limited elaboration, F4C writing reflects a shift toward increased lexical diversity, thematic expansion, and more complex phraseological structuring—a progression consistent with intermediate-to-advanced L2 development.
Collocational Usage: Repetitive Core Patterns in F1C versus Slight Task Expansion in F4C
The analysis of collocational usage reveals key developmental differences between beginner-level and advanced ESL writing (Tables 1 and 2). F1C includes 359 two-word collocations (36.22‰), while F4C, as shown in Table 2, includes 333 (31.48‰). Although F1C displays slightly higher raw frequency, this reflects dense repetition of a narrow core rather than broader lexical diversity. A chi-square test (χ2 = 4.32, p < .05) confirms that this difference is statistically significant, indicating that higher repetition in F1C contrasts with more varied functional deployment in F4C.
In F1C, collocational use is dominated by a small cluster of high-frequency, general-purpose expressions reflecting habitual routines and personal interaction. These include: “social media” (128 occurrences), “talk about” (27), “talk with” (20), “write in” (15), “post about” (12), “watch video” (11), “send message” (9), and “use WhatsApp” (9). They appear repeatedly in formulaic structures such as “I talk about homework,”“I write in English,”“I post about my cat,” and “I watch video before sleep.” The phraseological profile is marked by low semantic variation and syntactic rigidity, showing strong reliance on experiential, context-bound routines.
By contrast, while “social media” remains dominant in F4C (293 occurrences), additional collocations such as “I check” (13), “write caption” (5), “write comment” (4), “send message” (4), “post photo” (4), “join channel” (4), “join group” (4), and “follow page” (4) emerge with modest frequency. These support a wider range of communicative and academic functions across platforms. Representative examples include: “Every day I check WhatsApp for message from my class group,”“I write caption in English,”“I write comment and like post,”“We have group where we send message about homework and test,”“I post photo and write caption,” and “I join channel for grammar and vocabulary.” Such usage reflects learners’ increasing ability to integrate collocations into multi-functional discourse contexts aligned with digital study practices.
F4C collocations also appear in longer syntactic frames and coordinated structures, signaling early stages of structural flexibility and discourse elaboration. For instance: “I also use Telegram for grammar group. Every day I get message with sentence and explanation. I check my mistake and try to write again.” This embedding shows a shift from describing routine behavior to structuring interaction, signaling academic intent, and demonstrating awareness of communicative purpose.
This developmental movement from repetition-driven collocations in F1C to contextually adaptive, multi-platform phraseology in F4C represents a significant milestone in learner writing. It suggests a transition from lexical retrieval to lexical selection, where collocational use is shaped by task orientation and digital context rather than by memorized expressions. As illustrated in Figure 3, the top five collocations in both F1C and F4C are dominated by “social media,” underscoring the thematic confinement of learner writing despite the functional expansion observed in F4C. Pedagogically, this highlights the importance of extending learners’ functional control of collocations beyond dominant themes, encouraging the acquisition of a wider range of academically relevant, context-specific expressions that can support engagement across diverse topics and tasks.
Colligational Patterns: Increased Range and Stability Between F1C and F4C
The comparative analysis of colligational patterns in F1C and F4C, as outlined in Tables 1 and 2, reveals a clear developmental trajectory in both the syntagmatic range and grammatical stability of phraseological structures. Quantitatively, F1C contains 215 colligation tokens across eight structural types (21.70‰), whereas F4C records 273 tokens across the same number of types (25.80‰). This increased token density suggests that colligational structures are more frequently embedded in the discourse of advanced learners. A chi-square test confirms the statistical significance of this difference (χ2(1, N = 20,789) = 7.04, p < .01), indicating that the observed shift is unlikely to be due to chance and reflects a genuine developmental phase in linguistic competence.
The texts in F1C rely heavily on structurally simple yet frequently deviant constructions. Examples such as “My freind always joke in group chat. It make me laugh” and “I learn make sandwich from one video. My mom say it’s not real food” display subject–verb disagreement, article omission, and non-target-like verb complementation. Recurring forms such as “I read comment,”“my sister send me gif and sticker,” and “my cousin send message ‘come online’. He send me meme” reveal uninflected verbs, missing determiners, and clause chaining without coordination. These patterns suggest literal translation, rote memorization, or spoken-register interference, all typical of early interlanguage stages. Structurally, F1C is characterized by morphosyntactic inaccuracies and limited syntactic embedding, with recurring canonical patterns such as verb + article + noun and copula + adjective often appearing in unstable forms.
By contrast, growth in F4C does not arise from an expansion in the range of colligational types, but from more frequent and grammatically accurate deployment of established patterns. Examples include “My teacher discuss both social media communication in class especially how it can help learning” and “I believe social media application are part of student life today. We use it not only for fun but for learning too.” Verb–to-infinitive sequences such as “I’m going to talk about social media” and “I want to improve my writing” indicate greater syntactic control and thematic alignment. Prepositionally governed adjective phrases such as “important for my class group” and “useful for students” show improved precision in prepositional choice and adjective complementation. Canonical copula–adjective pairings like “is useful,”“is helpful,” and “is important” occur with increasing syntactic reliability, reflecting what Hoey (2005) describes as colligational priming, whereby grammatical preferences are acquired through repeated contextual exposure.
F4C also demonstrates emergent colligational maturity in other domains. Verb–to-infinitive constructions such as “I use social media application to connect with my friends” and “social media platforms help me to improve knowledge” occur with greater frequency and coherence. Prepositional phrases anchored in adjective or verb complementation—“WhatsApp is for communication with my classmate and teacher,”“I share ideas and I talk with people from different places,”“We talk about homework and exam”—indicate growing sensitivity to subcategorization frames. Nominal colligations like “write a caption,”“join a group,” and “send a message” reflect not only lexical competence but also syntactic packaging suited to task-oriented academic purposes.
As illustrated in Figure 4, the proportional distribution of colligation types shifts from the limited and structurally imbalanced patterns in F1C to the more varied and syntactically accurate configurations in F4C, even though both remain distinct from the balanced distribution seen in AIC. Taken together, these findings confirm that colligational range and grammatical embedding are valid indicators of L2 phraseological progress. Although traces of L2 interference remain in F4C—including article omission (“send message about homework”) and occasional verb-form errors (“it help me to improve”)—advanced learners demonstrate markedly higher syntactic fluency, phraseological density, and contextual appropriateness than their first-year counterparts. This developmental contrast reinforces a central finding of the study: phraseological competence in academic writing emerges incrementally, not only through vocabulary growth but through the stabilization of grammatical and discourse-bound patterns.Pedagogically, even at advanced stages such as F4C, it remains important to reinforce the grammatical stability of recurrent structures while diversifying colligational patterns beyond routine frames, enabling learners to transfer syntactic control across a wider range of academic contexts.
Lexical Bundles: Sparse Repetition in F1C, Inflated and Topic-Bound in F4C
A chi-square analysis of lexical bundle distribution between F1C and F4C reveals a statistically significant difference, marking a clear developmental shift (Tables 1 and 2). The F1C contains 415 lexical bundles distributed across 9,911 tokens, equating to 41.88 bundles per 1,000 tokens, while the F4C includes 684 bundles across 10,579 tokens, corresponding to 64.46 bundles per 1,000 tokens. The chi-square value for this comparison is χ2 = 49.45 (df = 1, p < .0001), indicating that the increase in phraseological density is not due to chance. This quantitative expansion reflects greater reliance on prefabricated multi-word units among fourth-year learners, signaling a rise in syntagmatic fluency. However, a close qualitative reading complicates this developmental trajectory, revealing that increased frequency does not necessarily entail greater lexical variety or rhetorical flexibility.
In the F1C, lexical bundles are primarily short, structurally repetitive, and semantically transparent such as “I try to” (20), “I want to” (19), “I post my” (12), and “on TikTok I” (11). They tend to appear in narrative and descriptive contexts, often situated in sentence-initial positions to introduce personal experiences or describe routine digital practices. Bundles such as “I try to post my picture,”“I want to write in English,”“we talk about WhatsApp,” and “I post my cat photo” exemplify the dominance of subject–verb–to-infinitive constructions and frequent phrasal verb combinations in the corpus, reflecting learners’ reliance on structurally simple yet functionally routine syntactic patterns. Although these expressions provide coherence and fluency at a basic level, they rarely extend beyond concrete recounting or personal stance. Moreover, many F1C bundles reveal morphosyntactic imprecision characteristic of lower-proficiency interlanguage. Instances like “on TikTok I watch video” and “social media help me to learn” display either article omission or subject–verb disagreement, indicating grammatical constraints typical of CEFR A1 to A2 learners. Even when structurally accurate, bundles such as “social media is very important” and “every day I use social media to talk” demonstrate overreliance on high-frequency frames with limited conceptual depth. Their discourse functions are largely additive or temporal—as seen in expressions like “at the same time” (9) and “in the same time” (7)—underscoring a restricted repertoire of textual organization and coherence devices.
In contrast, lexical bundles in the F4C are not only more numerous but also more contextually embedded within expository and semi-academic registers. They reflect a transition toward semi-academic evaluative discourse. Sequences such as “social media communication” (46), “social media platforms” (45), “social media advantages” (44), “social media disadvantages” (42), and “social media application” (38) are nominal and content-heavy, conveying abstract ideas and aligning with conventional academic discourse moves. Representative examples include “social media application also have social media communication that make learning easy and fun,”“social media platforms give opportunity to communicate,”“there are social media advantages like easy communication,”“social media disadvantages are real too,”“I use many social media applications every day like Facebook, WhatsApp, and Instagram,” and “I think social media is powerful tool.” These sequences reflect increased learner control over extended multi-word expressions and topic-relevant terminology, indicating a shift toward academic phrasing. However, this developmental gain is tempered by a pronounced lexical redundancy. The repeated use of “social media” as the fixed head noun across these bundles reveals a high degree of phraseological recycling, suggesting lexical inflation rather than diversification. Most bundles exhibit minimal syntactic variation and cluster around the same thematic and nominal structures.
The qualitative contrast between F1C and F4C bundle usage does not stem from thematic divergence—since both uniformly interpreted the prompt “social” through the lens of social media (Figure 5)—but rather from differences in structural complexity, syntactic organization, and rhetorical deployment. While F4C writers demonstrate improved fluency, lexical control, and discourse alignment, their phraseological repertoire remains constrained by structural recycling and thematic redundancy. In sum, the observed lexical bundle development is characterized by quantitative growth without equivalent diversification. Pedagogically, this highlights the need to support not only the accumulation of bundles but also their functional expansion across varied grammatical structures and rhetorical contexts to achieve deeper academic sophistication.
Formulaic Sequences: Marginal Presence in F1C, Controlled Uptake in F4C
A chi-square test comparing the frequency of formulaic sequences in F1C and F4C confirms a statistically significant developmental difference: χ2 = 9.23, p < .01 (Tables 1 and 2). While quantitatively limited in both corpora, their frequency rises from four occurrences in F1C (0.4 per 1,000 tokens) to 17 in F4C (1.6 per 1,000 tokens), indicating modest but meaningful growth in phraseological awareness.
In F1C, the few identified formulaic sequences—“at the same time,”“in the end,”“it is important to,” and “I don’t know how”—are isolated, serving basic evaluative or temporal functions without patterned rhetorical deployment or integration into broader discourse structuring. This scarcity reflects the minimal exposure first-year learners have to idiomatic or pedagogically pre-constructed expressions beyond immediate communicative need. By contrast, F4C writers begin to use formulaic language with clearer rhetorical purpose. Sequences such as “one of the,”“there are many,” and “in my opinion” not only occur more frequently but are functionally aligned with argumentative and expository discourse. These expressions, common in L2 writing textbooks and instructional settings, are often taught to support listing, exemplification, and personal stance. Their emerging integration into learner writing suggests improved familiarity with academic conventions.
Nevertheless, the total of 17 formulaic sequences in F4C remains modest compared to expected usage at higher proficiency levels (Figure 6). The repertoire is constrained by overreliance on a few familiar forms and a lack of diversification into more complex or genre-specific expressions (e.g., “as a result,”“from my perspective,”“it is widely believed that”). While the shift from F1C to F4C represents progress toward discourse fluency, it underscores the need for pedagogical focus on expanding both the range and rhetorical versatility of formulaic sequences. Instruction should prioritize recursive modeling and contextualized practice of multi-functional expressions that enhance coherence, stance, and argument development in academic writing.
Addressing RQ1: Comparative Phraseological Differences Between First-Year and Fourth-Year ESL Writing
A comparative analysis of phraseological features between F1C and F4C reveals clear developmental progression in L2 academic writing. F1C exhibits a lower TTR (9.84%) and heavily relies on repetitive vocabulary, while F4C demonstrates higher lexical diversity (10.70%) and more complex phraseological constructions. Although both corpora interpret the prompt “social” narrowly as “social media,” F1C collocations are routine and personal, whereas F4C collocations are more task-specific and academically aligned. Colligational use in F1C is limited and error-prone (21.70‰), in contrast to F4C’s more frequent, grammatically accurate, and contextually embedded structures (25.80‰). Lexical bundles also increase in F4C (64.46‰ vs. 41.88‰), indicating improved syntagmatic fluency, though this gain is offset by lexical redundancy and limited structural variation. Formulaic sequences, while few in both, show notable growth from F1C (0.4‰) to F4C (1.6‰), signaling emergent rhetorical awareness and highlighting the need for broader, genre-sensitive phraseological development.
These developmental patterns substantiate recent evidence that phraseological competence expands incrementally through exposure, usage, and task-embedded learning rather than through abrupt lexical diversification. The increased deployment of formulaic sequences in F4C aligns with Puimège’s (2024) and Hashizaki’s (2024) findings that such units emerge through meaning-focused participation and practice, while the reliance on routine frames in F1C echoes the early-stage phrase-frame limitations observed by Appel et al. (2024). Similarly, the syntagmatic growth and lexical bundle density detected in F4C are consistent with developmental profiles reported in corpus-based analyses of learner academic writing (Aybek, 2025). However, the thematic confinement and high redundancy observed in both corpora challenge assumptions that phraseological sophistication necessarily entails broader topical flexibility, indicating that progress in L2 phraseology may advance structurally without parallel expansion in conceptual range.
Discussion of RQ2: Phraseological Features in AI-Generated Academic Writing
TTR and Phraseological Volume: Maximized Diversity and Fluency in AIC
The AIC, comprising 9,850 tokens and 2,037 unique lexical types, yields a high TTR of 20.68%, indicating exceptional lexical density and minimal repetition (Table 3). This reflects wide-ranging lexical inventories and algorithmic optimization for diversity across outputs from GPT-3.5, GPT-4, Claude 3, Gemini 1.5, and Writesonic.
Phraseological variation appears in both vocabulary choice and academic expression. Multi-word noun phrases and high-level abstract constructs are frequent, for example, “Social imagination is the ability to envision alternative ways of living together,”“To be human is, in many ways, to be social,” and “In a time defined by digital hyperconnectivity, social isolation remains a paradoxical but pressing concern.” Recurring nominalized forms such as “imagination,”“identity,”“experience,”“communication,” and “perception” signal preference for a formal register. These often occur in multi-clausal structures oriented toward coherence and rhetorical fluency, as in: “In today’s fast-paced digital world, being social is no longer limited to in-person conversations,”“While it may take extra effort or money to act responsibly, the long-term benefits can be very rewarding,” and “However, social change can also be challenging, as it requires people to adapt to new ideas and abandon long-standing traditions.” Such constructions rely on logical connectors (“while,”“also”) and stance markers (“it is important,”“it is necessary,”“it is central”) to enhance cohesion and informational density.
Structural variation is deliberate, extending beyond content to stylistic rotation. Even when addressing similar topics, for example, social media, outputs avoid formulaic repetition, as in: “Social media, for all its promise, can flatten the complexity of being into performance,” and “As we navigate these platforms, perhaps the most radical act is to remain real.” Overall, the AIC’s high TTR is not a statistical artifact but evidence of internal richness in lexis, structure, and rhetorical patterning, shaped by multi-model input.
Collocational Usage: Controlled Precision and Semantic Targeting
The AIC contains 396 collocations (40.20‰, Table 3), reflecting algorithmic targeting and thematic coherence. Frequent items include “social media” (46), “social skills” (7), “social life” (6), “build relationships” (6), “connect with” (5), and “emotional well-being” (4), favoring abstract noun + noun or verb + noun structures that reinforce topical density (Figure 3). These appear in contextually stable, grammatically coherent environments, for example, “social media has become an essential part of modern communication,”“social skills build confidence and create opportunities for collaboration,” and “Social interaction also helps reduce stress and can even improve physical health.” Such sequences act as cohesive anchors sustaining expository structure while ensuring lexical variation.
Collocational selection aligns with thematic subdomains of the prompt “social,” including “social responsibility,”“social justice,”“social norms,” and “social identity,” used in semantically rich contexts: “social responsibility means acting in ways that benefit society,”“social justice movements aim to create a fairer society,” and “social norms are the unwritten rules that guide behavior/how we act.” These are strategically chosen to match the abstract dimensions of the prompt and simulate coherent academic argumentation.
AI-generated collocations avoid redundancy through syntactic expansion and conceptual variation. For instance, “Social media” appears in distinct frames: “social media platforms have revolutionized communication,”“Social media influencers have become a powerful force in shaping opinions,” and “social media plays a major role in how people interact.” While repetitive at the lexical core, this reflects algorithmic diversification rather than learner-style recycling.
Overall, AIC collocations exhibit semantic precision, thematic breadth, and grammatical consistency, simulating fluency through algorithmic optimization rather than developmental acquisition. The result is coherent and polished, but devoid of the experiential, pragmatic, and instructional grounding of authentic learner writing.
Colligational Patterns: Structural Range and Grammatical Reliability
AIC demonstrates an extensive repertoire of accurate colligational structures, totaling 373 instances with a normalized frequency of 36.63 per 1,000 words (Table 3). Predominant configurations include verb + article + noun (“can lead to a more balanced and fulfilling life”), copula + adjective (“is a constant part”), verb + to-infinitive (“lead to problems”), and adjective + preposition (“important for users”). These patterns consistently appear within fully formed, syntactically coherent clauses.
Across the dataset, grammatical reliability is maintained regardless of construction type, with AI outputs avoiding common learner deviations such as tense shifts, article omission, or misaligned complementation. Illustrative examples include “try to fill the gap,”“aim to improve,” and “A social network is a group of connected people,” all of which are contextually appropriate and structurally stable. Such precision indicates a programed adherence to formal syntactic norms, rather than the gradual consolidation seen in learner development.
In sum, colligational usage in AIC is characterized by both structural variety (Figure 4) and syntactic precision. The output is grammatically coherent, free from interlanguage interference or learner-stage variability, reflecting algorithmic optimization for correctness rather than the iterative, error-mediated progression that marks authentic L2 acquisition.
Lexical Bundles: High-Density, Rhetorically Polished Academic Framing
Analysis of AIC lexical bundles shows rhetorically refined yet quantitatively limited use of 3 to 5 word sequences. The corpus contains 79 distinct bundles, yielding 8.02 per 1,000 words (Table 3). Although lower than in human learner corpora, this reduced frequency stems from AI’s deliberate lexical diversification and the distribution of outputs across multiple models, rather than from any structural limitation (Figure 5). These bundles nonetheless exhibit structural integrity and functional sophistication, reflecting controlled, context-sensitive constructions typical of academic register rather than routine learner phrasing. Frequent examples include “a sense of” (6), “social norms are” (4), “play an important” (4), “for example the” (4), “to be social” (4), and “connect with others” (3).
Bundles are embedded within extended, coherent sentences that advance argumentation and conceptual elaboration. For instance, “a sense of” appears in “and a sense of belonging are foundational for cognitive engagement,” framing abstract reasoning; “social norms are” introduces “Social norms are the invisible rules that guide behavior within a community or society,” providing a generalizable claim; and “play an important” appears in “Social events play an important role in bringing people together,” establishing causal and explanatory relations.
One of the most stylistically marked bundles, “the social is,” recurs across texts as a discourse-framing device. Examples include: “The social is a repository of both pride and pain,” using metaphor and dualism; “The social is not only what is—it is what could be,” employing parallelism and philosophical contrast; “At its heart, the social is not merely interaction—it is a condition of mutual presence,” offering a nuanced redefinition; and “It is in the everyday choices of individuals that the ethical potential of the social is realized,” highlighting moral agency. Although anchored by the same phrase, these instances vary from declarative framing to concessive contrast and embedded clause structures, demonstrating stylistic rotation within diverse rhetorical frames.
Overall, AIC bundles are consistently accurate, metadiscursively functional, and aligned with academic prose. While their frequency is modest, their discourse roles—framing, evaluation, exemplification, and elaboration—are clearly evident.
Formulaic Sequences: Genre-Conscious, Fluent Insertion
AIC demonstrates a rhetorically strategic, genre-conscious use of formulaic sequences (Table 3 and Figure 6), with 23 verified instances across 9,850 tokens (2.34 per 1,000 words). These expressions scaffold cohesion and reinforce the academic register typical of expository and argumentative writing. Most frequent are “for example” (11), “in conclusion” (10), “as a result” (1), and “it is important to” (1), each placed at syntactically and rhetorically appropriate points. “For example,” introduces specific support, as in “Social platforms facilitate civic engagement. For example, users can organize events or campaigns through digital tools.”“In conclusion” consistently marks summaries: “In conclusion, being socially responsible helps build stronger communities.” The lone “it is important to” is evaluative—“it is important to balance digital interaction with face-to-face communication to keep learning experiences meaningful and engaging”—while “as a result” appears in cause-effect structures, for example, “As a result, it becomes even more important to teach and practice social behavior.”
These insertions align with conventional academic practice, are free from grammatical or pragmatic errors, and are contextually integrated rather than mechanically placed. Their disciplined use in clause-initial and discourse-organizing positions reflects the models’ training on high-exposure academic corpora and their capacity to emulate human genre competence through statistically learned phraseology.
Addressing RQ2: Dominant Phraseological Features in AI-Generated Writing
The AIC presents a phraseological profile distinguished by elevated lexical variety (TTR 20.68%) and extensive thematic scope, achieved through distribution across multiple generative models. Collocations occur at 40.20‰, reflecting targeted semantic selection and broad topical coverage. Colligations reach 36.63‰, encompassing a wide spectrum of grammatical configurations executed with full morphosyntactic stability. Lexical bundles appear at 8.02‰, with limited recurrence due to deliberate variation, yet maintain structural cohesion and fulfill diverse discourse-organizing roles. Formulaic sequences register at 2.34‰, positioned to reinforce textual coherence and genre conformity. Together, these features show that AIC outputs achieve high-level phraseological orchestration through statistical patterning and rotational diversity, while remaining detached from the incremental, interaction-driven consolidation processes underlying genuine L2 developmental progress.
These findings reinforce emerging evidence that AI-generated texts construct fluency through statistical optimization rather than acquisitional growth. Emara (2025) similarly reports elevated lexical variation and syntactic precision in comparison to nonnative writing, yet emphasizes that such fluency lacks developmental grounding and does not reflect cognitively mediated phraseological consolidation. Moreover, the immediate rhetorical polish and thematic breadth observed in AIC resonate with broader concerns that generative AI simulates expert-like discourse through probabilistic rotation rather than socialized learning (Incelli, 2025). Thus, while the AIC demonstrates structurally sophisticated phraseology, its fluency remains algorithmic rather than experiential—underscoring the ontological divide between simulated performance and human developmental authenticity.
Comparing Phraseological Features in ESL and AI Writing: Structure, Frequency, and Discourse Function (Addressing RQ3)
Type–Token Ratio and the Divergence Between Human Development and Algorithmic Simulation
TTR comparison underscores a fundamental split in lexical behavior between human-authored and AI-generated texts (Tables 1–3). Learner writing shows incremental growth—F1C at 9.84% rising to 10.70% in F4C—while AIC reaches 20.68%, almost doubling the lexical diversity of advanced learners. These differences are highly significant: AIC versus F1C yields χ2(1, N = 10,886) = 539.16, p < .0001; AIC versus F4C yields χ2(1, N = 11,711) = 462.61, p < .0001. In learner corpora, increased diversity reflects gradual, usage-based acquisition shaped by repetition, thematic focus, and recursive deployment; in AIC, it results from algorithmic rotation, novelty maximization, and deliberate avoidance of repetition. This produces non-developmental lexical inflation—surface diversity without entrenchment, pragmatic anchoring, or communicative necessity. Whereas learners’ repetition serves pedagogical consolidation, AIC disperses lexis across abstract domains without recycling. TTR here is not simply a quantitative metric but a diagnostic indicator of the ontological divide between developmental authenticity and algorithmic simulation: the former grounded in cognitive and social learning sequences, the latter unconstrained by acquisition processes or communicative struggle.
Collocational Contrast Between ESL Learner and AI Texts: Developmental Progression Versus Algorithmic Stratification
Collocational patterns expose a decisive rupture between human developmental trajectories and AI-generated output (Tables 1–3). The F1C to F4C shift, though modest, is statistically significant (χ2 = 4.32, p < .05), reflecting reduced lexical recycling and gradual functional expansion. In contrast, AIC departs far more radically—AIC versus F1C: χ2(1, N = 10,267) = 10.94, p < .001; AIC versus F4C: χ2(1, N = 10,950) = 21.71, p < .0001—signaling a generative process divorced from acquisitional stages. Learner collocations emerge through constrained repetition, incremental recalibration, and growing genre awareness; AI collocations appear instantaneously optimized, semantically wide-ranging, and syntactically integrated across abstract domains. What learners achieve through iterative exposure and interlanguage negotiation, AI produces without cognitive constraint or contextual uptake. Collocation thus serves not merely as a lexical metric but as empirical proof of the ontological divide between experiential authorship and algorithmic design.
Colligational Contrast Between ESL Learner and AI Texts: Developmental Embedding Versus Algorithmic Precision
Colligational patterns mark a clear boundary between acquisitional progression and synthetic generation (Tables 1–3). Learner texts register a measured rise in density—from F1C (21.70‰) to F4C (25.80‰), χ2(1, N = 20,789) = 7.04, p < .01—whereas AIC attains a substantially higher rate (36.63‰), differing significantly from both F1C (χ2 = 39.05, p < .0001) and F4C (χ2 = 19.95, p < .0001). In human writing, such gains emerge through iterative exposure, gradual syntactic stabilization, and context-mediated refinement. In contrast, AIC produces structurally complete, morphosyntactically stable patterns immediately, bypassing the trial-and-error phases integral to interlanguage development. This precision reflects probabilistic modeling rather than cognitive acquisition, yielding a fluency that is formally accurate yet epistemically unanchored. Colligations thus serve as a diagnostic indicator of two irreconcilable generative logics: incremental, socially situated mastery in the learner corpus versus pre-optimized grammaticality in algorithmic output.
Lexical Bundle Contrast Between ESL and AI Texts: Developmental Density Versus Algorithmic Non-repetition
The distribution of lexical bundles underscores a profound functional divide (Tables 1–3). Learner texts display substantial density—F1C at 41.88‰ and F4C at 64.46‰—in stark contrast to AIC’s 8.02‰ (AIC vs. F1C: χ2 = 257.27, p < .0001; AIC vs. F4C: χ2 = 370.84, p < .0001). In human writing, these clusters emerge from the reiteration of familiar phrasal frames, with F4C showing numerical expansion yet remaining heavily anchored in formulas such as “social media + noun.” Such thematic concentration reflects reliance on entrenched constructions rather than diversification of repertoire. The AI corpus, by contrast, disperses its bundles across a wide syntactic range, ensuring minimal recurrence and embedding each within a distinct rhetorical configuration. This yields a leaner but more varied set of sequences, unconstrained by the consolidation cycles that shape L2 phraseology. Here, lexical bundles operate as markers of two incompatible compositional logics: thematic concentration through patterned reuse versus dispersion through calculated lexical turnover.
Formulaic Sequences in ESL and AI Writing: Incremental Uptake Versus Algorithmic Fluency
Formulaic sequence use reinforces the divergence between developmental acquisition and generative simulation (Tables 1–3). Learner uptake rises from four instances in F1C to 17 in F4C (χ2 = 9.23, p < .01), signaling gradual incorporation of academic routines. AIC, with 23 occurrences (2.34‰), surpasses both corpora and diverges significantly from F1C (χ2 = 17.44, p < .0001) and F4C (χ2 = 4.10, p < .05). In learner texts, these expressions appear sporadically, with limited syntactic range; in AIC, they are strategically positioned—often clause-initial and anticipatory—reflecting genre-trained probabilistic modeling rather than instructional uptake. This distinction highlights the underlying difference between emergent usage grounded in developmental learning and the synthetic insertion of prefabricated sequences driven by algorithmic modeling.
Synthesis and Response to RQ3: Experiential Development Versus Algorithmic Simulation
Collectively, the cross-corpus contrasts underscore that human and AI texts embody fundamentally distinct phraseological systems. The incremental increases observed between F1C and F4C align with recent findings that L2 phraseological sophistication emerges through socially situated practice and recursive uptake (Hashizaki, 2024; Puimège, 2024 ). Improvements in syntagmatic density and phrase-frame complexity also converge with research linking phraseological expansion to gains in writing quality (Appel et al., 2024; Aybek, 2025). In stark contrast, the AIC exhibits synthetic fluency characterized by high lexical variety, structurally pre-optimized colligations, and rhetorically polished bundles from the outset—patterns consistent with studies demonstrating algorithmic text generation achieves surface expertise without developmental grounding (Emara, 2025; Incelli, 2025). Thus,
Addressing RQ4: Strategic Implications of HAIT and Phraseological Findings
The findings reveal a defining asymmetry within the HAIT condition: learner-authored and AI-generated texts coexist in the same pedagogical space yet arise from irreconcilable phraseological systems (Figure 2). Learner corpora display incremental, uneven growth—collocational refinement, limited but emergent formulaic use, and bundle deployment marked by thematic concentration—each shaped by instruction, feedback, and the constraints of interlanguage. The AI corpus, by contrast, presents instant lexical breadth, structurally consistent colligations, and rhetorically polished bundles from the outset, none of which derive from staged acquisition or pedagogical mediation (Figures 2 –6). This is not a mere technical disparity; it reframes the benchmark of “good” writing, risking the elevation of polished simulation over developmental authenticity.
If presented uncritically as exemplars, AI-generated texts can supplant process-oriented benchmarks with product-driven mimicry, obscuring the visibility of learner effort. To counter this risk, ESL pedagogy should adopt three evidence-based imperatives. First, instructors must implement controlled phraseological scaffolding that deliberately slows genre acquisition. This involves phased exposure to target bundles, structured micro-revision exercises, and cumulative collocation building—replicating the measured gains observed in F4C rather than the saturation patterns characteristic of AI output. Second, educators should explicitly position AI texts as genre simulations, not developmental models. This requires contrastive analysis tasks that reveal their omissions—lack of dialogic instability, absence of revision-mediated modulation, and minimal audience adaptation—features that remain integral to authentic learner progress. Third, assessment systems must be redesigned to capture phase-specific uptake in phraseological control, documenting the initial emergence, subsequent revision, and recontextualization of bundles across drafts. Such evaluative practices privilege developmental authorship over static accuracy, preventing the conflation of algorithmic fluency with acquisitional growth. HAIT is thus not a neutral context but a transformative condition, demanding that educators distinguish between fluency as an emergent property of sustained learning and fluency as a synthetic artifact, thereby preserving L2 writing as a site of cognitive, social, and rhetorical formation.
Study Limitations and Future Research
This study is limited by the thematic confinement of a single prompt (“social”), the cross-sectional rather than longitudinal design, and the exclusive focus on Arabic-speaking ESL students in similar institutional contexts, which together restrict thematic scope, developmental inference, and generalizability. The relatively small size of the three corpora places constraints on interpretability, particularly for low-frequency phraseological features, and may reduce the generalizability of the findings to broader ESL contexts.
Future studies will expand in scope by incorporating substantially larger corpora, diversifying prompts and genres, adopting longitudinal tracking, and including broader learner populations, thereby increasing the stability of frequency patterns, enhancing lexical and thematic variability, and enabling more generalizable distinctions between developmental authenticity and algorithmic fluency in L2 writing. In addition, examining multiple academic disciplines and real assessment conditions could provide further ecological validity for learner–AI comparisons. Incorporating mixed-methods evidence, such as learner interviews and process data, may also strengthen interpretation by revealing how phraseological decisions emerge during writing. Finally, the standardized 200-word expository task, while necessary for internal validity and controlled comparison across corpora, inevitably reduced natural variation in rhetorical development, a constraint that future studies can address by incorporating longer and more heterogeneous genres.
Conclusion
This study offered a contrastive phraseological analysis of ESL academic writing and AI-generated texts by examining first-year (F1C) and fourth-year (F4C) learner corpora alongside an AI corpus, focusing on five key features: type-token ratio (TTR), collocations, colligations, lexical bundles, and formulaic sequences. Results reveal a developmental trajectory among human learners: from the restricted, repetitive structures of F1C to the more diversified, genre-aligned phraseology of F4C. However, both F1C and F4C texts remained semantically narrow—largely confining “social” to social media contexts—demonstrating thematic limitation despite phraseological gains. In contrast, AI-generated texts displayed immediate lexical range, topic expansion beyond media domains, and structurally controlled phraseological integration, including high-frequency bundles and precise colligations. Yet this fluency, while rhetorically effective, lacked any signs of acquisition: there was no revision, approximation, or uptake. The findings thus expose the defining asymmetry of HAIT—not simply between human and machine, but between developmental scarcity and algorithmic saturation. Pedagogically, the risk lies in mistaking synthetic fluency for learner achievement. The study underscores the need to recalibrate writing instruction: emphasizing process, reflexive uptake, and phraseological authorship over surface polish. Developmental authenticity must be preserved not through imitation of AI outputs, but through visibility into the learner’s cognitive, social, and rhetorical effort.
Footnotes
Acknowledgements
The authors would like to acknowledge Deanship of Graduate Studies and Scientific Research, Taif University for funding this work. Their commitment to advancing academic inquiry has been instrumental in enabling this study.
Ethical Considerations
Ethical approval for this study was granted by the institutional authority of the Faculty of Education, Tanta University, Egypt, on 2 November 2024, following internal faculty-level review. As the institution does not operate a centralized research ethics committee, ethical oversight was provided through the faculty’s established governance procedures. All procedures involving human participants were conducted in accordance with the ethical standards of the institution and the 1964 Declaration of Helsinki and its later amendments. The approval covered all components of the study, including participant recruitment, informed consent, data collection, and analysis.
Consent to Participate
Verbal informed consent to participate in the study was obtained from all participants on 3 November 2024, after providing a standardized explanation of the study’s aims, procedures, voluntary participation, and confidentiality safeguards. Verbal consent to publish anonymized data for academic purposes was also obtained. Written consent was waived due to the non-invasive, low-risk, classroom-based nature of the study, where written documentation might have discouraged participation. This procedure was reviewed and approved by the institutional authority of the Faculty of Law, Tanta University, and conducted in alignment with institutional protocols and the Declaration of Helsinki. No vulnerable populations were involved, and no identifying personal data are included in the manuscript.
Author Contributions
The authors contributed equally to all major aspects of this study, ensuring a collaborative approach at every stage of the research process. The authors have approved the final version of the manuscript and are accountable for all aspects of the work, upholding the integrity of the research by ensuring that all questions related to accuracy or integrity are appropriately addressed. Their equal contribution reflects a shared commitment to the quality and ethical standards of this research.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Taif University.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and analyzed during the current study are not publicly available in order to protect participants’ privacy and confidentiality. However, the data may be made available upon reasonable request from the corresponding author, subject to institutional and ethical guidelines.
Permission to Reproduce Material from Other Sources
In accordance with the principles of fair use, the copyrighted material included in our paper is used solely for the purposes of criticism, review, or scholarly analysis. The excerpts quoted are limited in scope, are not substantial, and are necessary to support the critical arguments presented in the research. As such, explicit permission to reproduce these excerpts is not required under the fair use/fair dealing provisions.