
Abstract
Although AI-generated texts are increasingly attractive to the EFL/ESL researchers and teachers, few studies have examined those texts from logical and rhetorical perspectives. This study explored whether AI model can argue more sufficiently and tactfully than human writers. The data source consisted of 60 argumentative essays from EFL learners’ written corpus and a parallel ChatGPT-written corpus. Content analysis and quantitative analysis were employed to do the comparisons. The results displayed that the ChatGPT could argue more sufficiently than the EFL students by providing more grounds and warrants to justify the claims, and that it could only use monotonous type of warrant to gain argument sufficiency despite its same preference of argument width as the human writers, that is, using parallel arguments to support the claims. Moreover, the machine showed less tactfulness by expressing claims with more certainty and by using fewer concessions before refuting. Implications in writing instruction are emphasized such as the culturally and emotionally embedded nature of human communication.
Introduction
Toulmin model of argumentation (Toulmin, 1958, 1999) is increasingly used to examine the argumentation written in English as a Foreign/Second Language (EFL/ESL). The model consists of six elements: claim, ground, warrant, backing, rebuttal, and qualifier. The four elements—claim, ground, warrant and backing—expound and justify one’s view. The rebuttal entails opposition and refutation. The qualifier expresses the degree of force or certainty on the claim. Some related studies mainly concern the relationship between the Toulmin elements and argumentative writing quality (D. Liu et al., 2024; F. Liu & Stapleton, 2020; R. Yang, 2022). Others focus on the efficient ways of doing comparisons among different kinds of student essays (Crammond, 1998; D. Liu & Wan, 2020; Qin & Karabacak, 2010).
However, in all the related studies, argument sufficiency is unavoidably the major concern whether they focus on the assessment of argumentation quality or the teaching pedagogy. Johnson and Blair (1994) classify argument sufficiency into local and global. Local sufficiency refers to only working at justifying a claim and global sufficiency includes both justification of a claim and refutation of opposite views. In this sense, Toulmin model reveals global sufficiency. Using Toulmin model as theoretical basis, this paper focuses on global sufficiency. Moreover, tactfulness in argumentation originally included in Toulmin’s argumentation theory was mainly embodied in the use of qualifier to express one’s claim in an appropriate way (e.g., to moderate the tone, to be more objective and unbiased). Tactful language in argumentation dispels aggressiveness in refutation, adds prudence to the expressing of claims, and hence improves persuasiveness. Although tactfulness in argumentation is gaining attention by some teachers and textbooks for writing, unfortunately only a few studies explore the tactfulness from Toulminian perspectives (Berger, 2014; D. Liu et al., 2024; Majidi et al., 2021; R. Yang, 2022). In this study tactful language is not only revealed by the use of qualifier but also concession.
The integration of artificial intelligence (AI) in EFL writing instruction, particularly in the context of argumentative writing, has garnered significant attention. AI tools, such as ChatGPT, offer innovative approaches to improve writing proficiency among learners (Al Fraidan, 2025), to improve students’ writing through personalized feedback mechanisms (Guo et al., 2024; Li et al., 2023; Nazari et al., 2021; S. Yang et al., 2024), and to foster greater student motivation and engagement (He, 2024; Song & Song, 2023; Wei, 2023). However, its stunning ability to produce coherent and informative texts has caused concerns. Some researchers complain of the difficulty to differentiate a text generated by AI from the one written by a human, and worry about the possible increase in plagiarism and the laziness of the students (Chatterjee & Dethlefs, 2023; S. Yang et al., 2024). Although OpenAI has launched a classifier to distinguish between AI-written and human-written texts, this tool still has a few limitations. For example, it can be rather unreliable on short texts (below 1,000 characters).
In order to make better use of AI in language teaching, it is necessary to perform more comparisons and analyses of AI-generated and human-written texts and it might be more helpful to make investigation at rhetorical and logical level such as argument sufficiency and tactfulness in argumentation. This paper aims to conduct such exploration and make contributions to the identification of AI-generated shorter texts. The whole study was based on Toulmin model. By synthesizing several Toulminian analytical frameworks (D. Liu et al., 2024; D. Liu & Xiong, 2024) to measure argument sufficiency and tactfulness, this study compared the essays produced by ChatGPT and human writers, it will emphasize the irreplaceable nature of human work, especially the culturally and emotionally embedded nature of human communication and reasoning in writing instruction.
Argument Sufficiency and Tactfulness in Argumentation
Argument Sufficiency
Argument sufficiency as an important factor to assess argumentation, was initiated by Johnson and Blair (1994). Argumentation consists of an inference core and a dialectical tier. To be specific, arguers not only have to justify but also defend their arguments, that is, to consider and respond to those potential opposite views and critical questions raised by the rational opponents. Justifying the arguments entails inference, and defending the arguments involves both inference and dialectical tier. Thus, argument sufficiency is further divided into local and global sufficiency, according to Johnson and Blair (1994). Local sufficiency which refers to how arguers justify their arguments (i.e., to explicate and support the claims) cannot better reveal the essence of argumentation than global sufficiency. In order to achieve global sufficiency, the arguers must respond to the competing claims and grounds which their opponents hold, point out the mistakes of the claims and grounds, or even prove their inferiority or weakness.
The exploration of sufficiency in argumentative writing from Toulminian perspectives has become an attractive approach in the recent decades. A variety of measures based on Toulmin model have been proposed to assess argument sufficiency in school writing. For example, Crammond (1998) and Qin and Karabacak (2010) used their modified Toulmin models as analytical framework to examine L1 and L2 students’ argumentative essays. Most of the subsequent studies apply their frameworks to analyze the essays written by the students of different backgrounds and at different proficiency levels (Abdollahzadeh et al., 2017; Cheng & Chen, 2009; F. Liu & Stapleton, 2014; Stapleton & Wu, 2015). Other studies make further modifications on those revised versions of Toulmin model to improve the accuracy of measurement, or to meet the needs of the students and teachers. D. Liu and Wan (2020) created a framework with seven elements: claim, subclaim, ground, warrant-backing, counterargument-claim, counterargument-ground, and rebuttal. They compared the English argumentative essays written by the first- and the fourth-year EFL students, focusing on both global and local sufficiency revealed by the frequencies of Toulmin elements and argument complexity. Majidi et al. (2021) further modified Toulmin model and introduce several structural elaborations. These adaptations include broadening the backing element to support warrants, ground, qualifiers, alternative solutions, counterarguments, and rebuttals. Unlike Toulmin’s original model, rebuttals are defined as responses to opposing views, and “alternative solutions” added as potential responses to the issue. R. Yang (2022) divided the element ground into reason and evidence to investigate sufficiency in argumentation, and used the revised Toulmin model as a scaffold in teaching argumentation.
Admittedly, the modifications of Toulmin model applied to teaching or analyzing different genres have certain facilitating effects. However, the deficiencies in those modified versions and discrepancies of views on certain Toulmin elements render the modifications stray away from the original Toulmin model. The deviation is caused by excluding or confusing such key elements as qualifier and warrant in Toulmin model. The warrant is an indispensable component making up the defining feature of an argument structure, together with the claim and data. The exclusion of warrant alters the Toulmin model because the reasoning from the data to claim is missing. The confusion of data with warrant undermines the basic triangle of Toulmin model as well. In general, those modifications endow the components with different meanings to adapt it to second language writing, and consequently simplify and even destroy the model.
Keeping the original idea of Toulmin model and adopting the concept of interaction in Pragma-dialectics (Van Eemeren & Henkemans, 2017), D. Liu and Xiong (2024) propose a modified version of the Toulmin model. The argument structure is termed justification-qualifier to remind the researchers and teachers of qualifier. Warrant is treated as critical in this model and can embody argument sufficiency together with ground. This model includes eight elements: Claim, Justification-ground (J-ground), Justification-warrant (J-warrant), Justification-rebuttal (J-rebuttal), Opposition-ground (O-ground), Opposition-warrant (O-warrant), Opposition-rebuttal (O-rebuttal), and Qualifier. The components in justification and opposition reflect the dialogical relationship between the writer and the reader, and the inclusion of warrant and qualifier preserves the integrity of the original Toulmin model. This Toulminian model is quite feasible for evaluating global sufficiency in argumentation.
Tactfulness
Tactfulness in argumentation refers to the moderate, polite, or acceptable way to express claims and refutation. Qualifier in Toulmin model of argumentation is treated as a tactful way of persuasion. Qualifier can “put them (claims) into debates in an uncommitted way, merely for purposes of discussion” (Toulmin et al., 1978, p. 90). Toulmin et al. (1978) put more weight on its function than its linguistic form. However, only a few studies focus on the tactfulness of expressing claims in argumentation. Berger (2014) categorizes qualifier into three types according to linguistic form: qualifier in word form, qualifier in participle form, and qualifier in sentence form. Based on Berger’s (2014) classification, R. Yang (2022) investigated the relationship between the holistic writing quality of the argumentative essays and the three types of qualifiers, and finally finds no relation between writing quality and the use of qualifier. Majidi et al. (2021) splits the qualifier into reservation in claim and constraints of claim. However, it is contended that the various divisions of qualifier in the previous studies go against Toulmin’s definition (D. Liu et al., 2024). Adhering to Toulmin’s definition, D. Liu et al. (2024) classify claims with/without qualifier into five ranks and apply this classification to argumentation teaching. This classification is conducive to writing instruction and assessment, as well as to this study.
Tactfulness in argumentation can also be revealed in other ways besides the use of qualifier. D. Liu et al. (2024) propose “concession” as an indicator of tactfulness in EFL argumentation. For one reason, aggressive refutation is highly probable to incur a quarrel and contrarily concession can moderate the rebutting language. The way to express disagreement or rejection determines the persuasive effect of the argument. For another, concession is usually included in the teaching materials or textbooks, even in the teaching syllabus of argumentation in college. D. Liu et al.’s (2024) experiment demonstrates that concession strategies can be taught and tactfulness can be improved. It is reasonable and feasible to use this skill as an indicator of tactfulness from rhetorical perspective. Based on this result, our study takes concession into consideration in the measurement of tactfulness.
Comparative Studies on AI-Generated and Human-Written Texts
Abundant studies on the comparison of AI-generated and human-written texts are mostly done from the angle of Natural Language Processing (S. Yang et al., 2024). In recent years the studies on AI-generated texts are increasingly diverse in many areas, with the studies on AI-generated research papers constituting the majority. Only a few studies focus on argumentative essays and produce controversial results. For example, Dilai and Dilai (2025) conducted a corpus-based study examining the essays produced by EFL students, native English speakers and ChatGPT. The results demonstrated that essays generated by ChatGPT exhibited greater analytical style, cognitive complexity, and lexical diversity. ChatGPT also tended to use certain low-frequency words while the human writers preferred light verbs and high-frequency words such as very, much, thus. The human-written essays are also characterized by subjectivity realized by I-words, tentative words and certitude words.
While AI-generated argumentative essays outperform human-written texts in language complexity, accuracy and lexical richness, human writers maintain a distinct advantage in conveying personal perspective, engaging readers, and organizing content in a more coherent and interactive manner (Herbold et al., 2023; Jiang & Hyland, 2025; Mizumoto et al., 2024). A recent study by Jiang and Hyland (2025) discussed the causes of differences of engagement markers in the essays generated by ChatGPT and those written by British student writers. The ChatGPT-generated essays exhibited the limitations in building interactional arguments. The differences were attributed to the statistical algorithms underlying ChatGPT and the language data used to train the model. ChatGPT’s reliance on probabilistic patterns, rather than an understanding of reader expectations, resulted in texts lacking interactive qualities that could help make human writing more persuasive and engaging. The findings might serve as a counterargument to any tendency to personify AI model. Unfortunately, the focus of the study on interactional elements offers inadequate evidence since the discourse markers cannot reveal the major characteristics at logic level but only a part of the interactional feature of argumentation.
At discourse level, S. Yang et al. (2024) examined the thematic choices and progression patterns in IELTS teacher-written and AI-generated argumentative texts within the framework of systemic functional grammar. The machine was found to use more concession to repeat information, but fewer modal adjuncts to interact with the readers. The frequent use of the constant thematic progression pattern in AI-generated texts “prevents the text from development and makes the text redundant and simplistic like a list of ideas” (P1). The results suggest that AI-generated texts are inferior to human-written texts in text organization and development.
Most of the studies on AI mentioned above focus on lexical level or syntactical level, with little attention paid to discourse level or logical reasoning. Although AI-generated discourse may surpass human output in linguistic accuracy and lexical diversity, it still lacks consensus on whether AI-generated discourse is deficient in deep thinking, comprehensibility, and interactivity. Moreover, although Hyland’s engagement model is a good yardstick for assessing interactivity of ChatGPT, argumentative features at logical and rhetorical levels can be better parameters and should be considered as measures to assess argumentation. Just as Jiang and Hyland (2025, p. 28) propose, “it may be necessary to modify the categories when seeking to characterize AI-generated content.” To meet those needs, this study explores from logical and rhetorical perspectives whether AI model can argue more sufficiently and tactfully than human writers.
Methods
Research Questions
Given the scarcity of the studies comparing human-written argumentation with AI-generated essays from a Toulminian perspective, this study aims to identify the argumentation features exhibited by ChatGPT 3.5. We raise the following research questions:
(1) Can ChatGPT argue more sufficiently than the EFL students? Does it use the same way to gain argument sufficiency as the EFL students?
(2) Does ChatGPT show more tactfulness than the EFL students?
Data Source
The dataset consists of 60 argumentative essays on the same topic: 30 essays authored by Chinese EFL students and 30 essays generated by ChatGPT. The essays written by EFL students were sourced from the Ten-thousand English Compositions of Chinese Learners (TECCL Corpus) (Xue, 2015), while the AI-generated essays were selected from the aiTen-thousand English Compositions of Chinese Learners (aiTECCL Corpus) (Xu & Sun, 2023).
The TECCL corpus contains approximately 10,000 essays written by the Chinese EFL learners. All essay contributors agreed to share their essays for academic purposes at the time of submission to the online system. Additional anonymization measures were implemented to minimize the risk of disclosing writers’ identities. The corpus features a wide range of topics and prompts, with an estimated 1,000 distinct essay topics. The writers represented in the corpus range from elementary school to postgraduate students, with the majority being undergraduates.
The aiTECCL corpus created by Xu and Sun (2023), serves as a parallel corpus of TECCL. The corpus features10,000 essays generated by the GPT-3.5 model prompted with the identical topics and directions in the TECCL corpus.
The topic “online shopping” was chosen because it is familiar to university students, allowing them to express their views more easily. Topic familiarity is an important factor influencing idea generating, content organizing and language fluency. AI excels in collecting information, whether familiar or unfamiliar, whether fresh or outdated. In order to guarantee the fairness in data collection, we took the human students at the first consideration. The writing prompt is as follows:
In today’s world, online shopping has become an essential part of many people’s lives. Some believe it offers unparalleled benefits to our life, while others argue that it can be harmful. Write an argumentative essay on online shopping.
Both corpora contain 128 essays on the topic of online shopping. In selecting the 30 student essays, factors such as proficiency levels, testing conditions, and demographic characteristics (e.g., age and gender) were not taken into consideration, just because these variables were not directly relevant to the present study. The primary aim was to compare the argumentative features of human-written and ChatGPT-generated essays. However, to ensure that the two sets of essays were comparable in terms of overall writing quality, all the essays were evaluated using a five-scale scoring rubric, developed by Qin and Karabacak (2010). The selection of this rubric is based on two primary considerations: (1) it incorporates McCann’s (1989) clear descriptions of organizational structure and language use, alongside Nussbaum and Kardash’s (2005) comprehensive delineation of argument effectiveness; (2) it does not prioritize the Toulmin model, focusing instead on three general criteria for assessing effective argumentative writing. Specifically, this holistic rubric evaluates three key dimensions: overall effectiveness of the argument (including acknowledgment of potential counterarguments), overall organization, and general language use (see Appendix 1). Finally, 30 essays of each group were selected, with the score above 4. Table 1 shows the average scores of the two groups. An independent samples t-test reveals no significant difference between the two groups (t = 0.78, p = .44), indicating that the essays were produced at the same language proficiency level and could be used for comparative research.
Basic Information of the Two Groups of Essays.

The essay length of all the selected essays was 250 to 350, with a total number of words in the Chinese EFL learners’ essays 8,564 and that of ChatGPT group 9,799. The essays written by ChatGPT are slightly longer than those written by the human writers, since ChatGPT has “a tendency to generate essays that are longer than the desired length” (Herbold et al., 2023, p. 3). However, it is not a problem when length-normalized metrics are used in data analyses.
Data Collection and Analyses
This study adopts D. Liu and Xiong’s (2024) model in argumentation feature investigation. To answer the first research question, argument sufficiency was examined by comparing the use of the following elements: J-ground, J-warrant, J-rebuttal, O-ground, O-warrant, O-rebuttal. Ground and warrant can indicate argument sufficiency. The definitions are displayed in Table 2, with the examples selected from our data source.
Definitions of Elements to Measure Sufficiency (D. Liu & Xiong, 2024, p. 5, revised).

Warrant type is an important element to reveal the way to achieve argument sufficiency. This study not only examined its frequency but also types. Five warrant types were identified: a priori warrant, empirical warrant, institutional warrant, evaluative warrant, and descriptive warrant. The definitions are shown in Table 3.
Definitions of Warrants.

Another way to gain argument sufficiency is realized by argument width and depth. J-width refers to the number of parallel J-ground while J-depth means the number of J-ground at different vertical levels. For example, if there are 3 parallel J-grounds in an essay, its J-width is 3; if there are 2 J-grounds at two vertical levels, the J-depth is 2. It is the same case with O-width and O-depth. Argument width or depth reflects a writer’s preference of structure in proceeding argumentation. Moreover, argument width or depth does not indicate argumentation proficiency or writing proficiency, but the writer’s preference of the way to develop argumentation.
To address the second research question, we focused on qualifier and concession to measure tactfulness. D. Liu and Xiong (2024) expand the denotation of qualifier to cover both the expressions to hedge the claim and the concession to acknowledge the opponents. Considering the EFL writing in this study, we adopted D. Liu et al.’s (2024) concept of concession which could reveal finer features of L2 writing, and separated qualifier in D. Liu and Xiong (2024) into two parts: qualifier and concession. The definitions of argument elements were taken from the two studies, as is shown in Table 4.
Definitions of Elements to Measure Tactfulness.

In addition, to measure the quality of qualifier, “qualifier rank” proposed by D. Liu et al. (2024) was also utilized in this study, since qualifier ranks can reveal the degree of tactfulness in expressing claims. Five ranks from 1 to 5 were assigned to the qualifiers. The higher the score, the stronger and tougher the claim sounds, and the less tactful the writer shows.
The identification of each Toulmin element was primarily guided by its definition and semantic relations. Linguistic devices indicative of specific components served as supplement. For example, concessions were recognized through linguistic cues that acknowledge opposing perspectives, such as “Admittedly, there are a few concerns regarding online shopping…” The procedure of doing identification and annotation is as follows: claim > J-ground > J-warrant > J-rebuttal > O-ground > O-warrant > O-rebuttal > concession > qualifier. Once an element is identified, annotation with the name and number in brackets is written before it, such as
To ensure the validity of the identification of all the Toulmin elements, the two coders first discussed the definitions and some typical examples to get familiar with these elements, and then coded a sample respectively. The two coders discussed the discrepancies to clarify the interpretation of the coding rubric. Once a consensus was reached, the remaining essays were coded independently. The scoring of the elements to measure sufficiency and to identify the warrant types depended on the presence or absence. If an element was found appear twice in an essay, the frequency or the score was 2. The frequency of each Toulmin element was recorded in Microsoft Excel, with column headings representing the six elements and the far-left column indicating the essay group. The inter-coder reliability was measured by Cohen’s Kappa, and the result for each element is as follows: claim (0.96), J-ground (0.94), J-warrant (0.96), J-rebuttal (0.96), O-ground (0.94), O-warrant (0.95), O-rebuttal (1.00), qualifier (0.88), and concession (0.96). The process of identifying warrant types was conducted in a similar way to the Toulmin elements. The two coders independently reviewed all essays to identify the instances of warrants. Each identified warrant was annotated with its corresponding type and a numerical designation in brackets (e.g.,
After the data collection, Mann-Whitney U tests and Wilcoxon signed-rank tests were employed to do comparisons because our sample size was not large and the data were continuous. Another reason is that the two types of tests do not require the normal distribution of data (it is almost impossible for the studies focused on logical and rhetoric levels to produce the data of normal distribution. The Mann-Whitney U tests were conducted for inter-group comparisons in the use of Toulmin elements and warrant types, whereas the Wilcoxon signed-rank tests were applied to intra-group comparisons between argument width and depth. Although the Mann-Whitney U and Wilcoxon signed-rank tests operate on ranks, descriptive statistics such as the mean (M) and standard deviation (SD) of the raw frequency scores were also reported to provide a clearer summary of central tendency and dispersion within each group. Spearman correlation analyses were used to find out the relations between the Toulmin elements and argument width and depth, and hence to explore the contributing factors to argument width and depth. All analyses were performed via SPSS version 27.
Research Results
By comparing the argumentative essays written by the EFL learners with those generated by ChatGPT, the study investigates whether ChatGPT can argue more sufficiently and tactfully than the EFL learners, and whether they have the same way to gain argument sufficiency.
Argument Elements to Gain Sufficiency
As can be seen in Table 5, no elements other than J-warrants and O-ground display significant differences between the two groups of essays. Whereas the writing features of both groups exhibit similarities, ChatGPT demonstrates greater proficiency in constructing O-grounds and in linking J-grounds to claims. In contrast, EFL students tend to leave a significantly higher proportion of J-grounds unlinked.
Comparison of Sufficiency Elements Between the Two Groups.
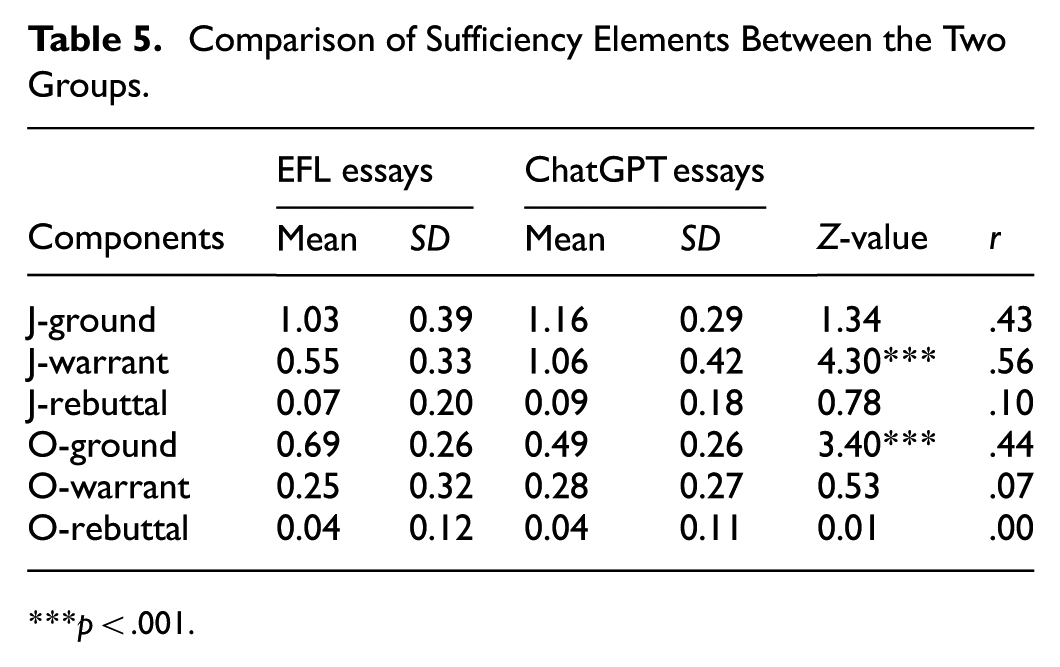
p < .001.
When it comes to warrant types, Table 6 reveals that among all the five types, both EFL learners and ChatGPT predominantly used empirical warrant. Aside from this preference, they both used only a limited number of warrants of other types, particularly a priori warrant. However, the differences in the use of evaluative and descriptive warrants between the two groups were statically significant, showing that EFL learners were better at employing evaluative warrant and descriptive warrant to connect grounds to claims.
Comparison of warrant types between EFL Essays and ChatGPT Essays.

p < .05. **p < .01. ***p < .001.
Table 7 demonstrates that both EFL students and ChatGPT had statistical difference between J-width and J-depth as well as between O-width and O-depth. Both groups show a preference for J-width and O-width, relying more on J-grounds and O-grounds to support claims.
Comparisons Between Argument Width and Depth.

p < .001.
To investigate the relationship between Toulmin elements and argument width and depth in ChatGPT-generated and EFL students-produced essays, Spearman correlation analyses were conducted. As presented in Table 8, the EFL students’ J-ground exhibits the most significant positive correlation with J-width (rs = .88), and O-ground also positively correlates with O-width (rs = .83) and O-depth (rs = .78). In the ChatGPT essays, J-ground and J-rebuttal exhibit significant positive correlations with J-width (rs = 0.48, rs = 0.60). J-warrant is highly correlated with J-depth (rs = 0.52). Moreover, O-ground and O-warrant show highly positive correlations with O-width (rs = 0.91, rs = 0.65) and O-depth (rs = 0.78, rs = 0.52). Qualifier demonstrates highly positive correlations with O-width (rs = 0.52) but weak correlations with J-depth and O-depth.
Correlation Coefficients Between Toulmin Elements and Argument Width and Depth.

p < .05. **p < .01.
Tactfulness
Concession and qualifier are treated as two indicators of tactfulness in this study. Table 9 shows that more concessions were found in EFL essays than in ChatGPT-generated ones and the inter-group diferences were statistically significant (p < 0.05 and p < 0.01), but the frequency of qualifier was vice versa. Despite the controversial results of tactfulness, further comparison of the qualifier ranks in Table 10 provides more information to clarify the tactfulness. The mean rank of qualifier in EFL essays is significantly lower than that in the ChatGPT-generated ones (3.07 < 3.53). The two tables display a complete picture of the use of qualifier: ChatGPT preferred to use more qualifiers to restrict the claims but the qualifier quality is not high. It tended to use more expressions to highlight the writer’s discourse responsibility. The proportion of the first two ranks in the ChatGPT essays is lower than the EFL ones. In addition, most of the EFL students tended to use the first two ranks of qualifier since Table 10 displays that the standard deviation in the group is much lower.
Comparison of Tactfulness Elements Between the Two Groups.

p < .05. **p < .01.
Comparison of Qualifier Ranks Between the Two Groups.

p < .01.
Discussion
Argument Sufficiency and the Way to Gain Sufficiency
As is shown in the research results, ChatGPT can justify the claim more sufficiently than the EFL learners by providing significantly more O-grounds and J-warrants. In Herbold et al.’s (2023) study, ChatGPT performs better in writing argumentative essays than the EFL/ESL high school students especially in scientific language realized by nominalizations and sentence complexity. But it is unknown how ChatGPT outperforms human writers other than the lexical and syntactical features. Our study lends support to them by analyzing the argument elements. Higher frequencies of J-warrants and O-grounds indicate more argument sufficiency in justification and opposition, and hence more persuasiveness, as is suggested or proved in some related studies like Crammond (1998), D. Liu and Xiong (2024), and Liu and Wan (2020). In those studies, the expert or proficient writers used more J-warrants than the younger or less proficient students. In addition, the definition of J-ground in our study is loyal to Toulmin model, thus different from the previous studies which only count in examples and evidence. To put it another way, the concept “ground” in Toulmin’s theory is broader so that more J-grounds have been found in our study.
Both groups of essays show greater J-width than J-depth, and greater O-width than O-depth. As S. Yang et al. (2024, p. 1) comment, AI-generated essays are simplistic in organization only to present “a list of ideas.” Our findings partly concord to them in AI’s preference of argument type. Differing from their negative attitude, we treat this as a kind of preference at logical level. However, this preference is shared by the EFL students in our study. This divergence may be ascribed to the different proficiencies of the human writers and the different data sources. The human writers in the study of S. Yang et al. (2024) were three professional IELTS teachers experienced in teaching IELTS writing featured by argumentation; in contrast, the human writers in our study were EFL students far less proficient in English argumentation. Moreover, the 50 essays written by only three teachers might bear more obvious idiosyncratic features than the essays written by more different students. Thus, it might be hard to generalize the features of human-written essays, as the expert-written essays surpass not only those produced by AI and EFL students, but even some other teachers.
The quantity of ground (including J-ground and O-ground) in both groups contributes far more to argument width than to depth. As is shown in the result section of this study, J-ground in both groups correlates with J-width, and O-ground is highly correlated with O-width. However, the two groups differ in the elements affecting argument width. For the ChatGPT essays, J-rebuttal also correlates with J-width, and O-warrant and qualifier are closely related with O-width as well. The argument width is influenced by many elements, which suggests the orderliness and regularity in text organization. The ChatGPT might have been input considerable amount of the material of the English rhetoric and argumentation, through which it has acquired the convention and accordingly can produce English-style essays mechanically. In contrast, the argument width of the EFL students is affected mainly by the element of ground. The Chinese EFL students have learned to provide abundant examples, allusions, anecdotes, and evidence to support and illustrate their claims, whether in Chinese or English writing classes and textbooks. Sufficient grounds are deemed as an important criterion of good argumentation by the college students (D. Liu & Huang, 2021) and textbook writers (D. Liu & Xiong, 2024). It is reasonable in this context that the element of ground acts as the major contributing factor to argument width in the EFL essays.
With regard to the other way to gain argument sufficiency, EFL learners employed much more descriptive warrants than ChatGPT. The descriptive warrant widely used by the Chinese writers and treated as a particular feature in Chinese argumentation, reveals homiletic reasoning (D. Liu & Huang, 2021; D. Liu & Xiong, 2024). The writers subjectively, personally, and even emotionally explain their statements or evidence (J-ground), relying on imagination and association. Argumentation mixed with narration and description (jia xu jia yi) is considered as more persuasive, lively and interesting. For example,
Because of phrases like “eco-friendly” that are shown on the product packaging, many consumers want to satisfy a sense of environmental responsibility. They tend to ignore the product’s quality, even if its real quality is not as good as is displayed online. But when they later realize that the “eco-friendly” label is nothing but a lie, they feel cheated and betrayed and perhaps will never shop online.
The writer described the process of consumers’ psycho change vividly by depicting the details, using parallelism and emphatic expressions (e.g., nothing but, even if, will never). We cannot assert that the EFL students have transferred the Chinese writing strategies. However, they have stored both Chinese and English writing conventions in their mind, and they are at “rhetorical borderlands” (Mao, 2006, p. 79) of Chinese and English. It is highly possible for them to resort to Chinese rhetorical strategies.
The ChatGPT failed to follow the way of the EFL students to bridge the grounds to the claims. Much more empirical and evaluative warrants were presented in ChatGPT essays than in the EFL essays. Our research results also lend support to the findings of Jiang and Hyland (2025) from logical reasoning perspective. They have found that the student writers’ essays are injected with more interactive and personal touch, while the ChatGPT essays show limited use of personal asides and questions that are identified by Hyland as important for personal involvement. S. Yang et al. (2024) have the same finding that AI used fewer modal adjuncts to interact with the readers. The fact that AI can generate coherent text but fails to understand and adapt to the context in the way human writers do is attributed to the way of AI training: AI produces text based on statistical patterns drawn from the big training data (Byrd, 2023; Jiang & Hyland, 2025). To summarize, if writer-reader interaction, personal involvement and subjectivity are viewed as efficient strategies of pathos appeal, AI-produced essays are deficient at both logical and lexical levels.
Tactfulness in Argumentation
Both qualifier and concession have weakening effect. Qualifier enables a claim less subjective, and concession renders refutation less straightforward. More concessions are found in the EFL essays than in the ChatGPT-generated ones although the ChatGPT uses more qualifiers to restrict the claims. Moreover, concession has no correlation with argument width or depth, which indicates the independence of this element. Different from our finding, S. Yang et al. (2024, p. 1) contend that “the machine tends to use more concession signals to repeat information.” The incongruous results might be attributed to the divergence in the definition of concession. S. Yang et al. (2024) focused on lexical level and identify concession by the word while. We define concession in this study as acknowledging opposing grounds. Concession can be various expressions besides the clause beginning with the word while. Take for example, that sounds reasonable; there is something in it; I agree with them on this point. These expressions convey new information with positive attitude, instead of repeating the given information. When the writers show identification with the readers who hold different views, rather than refute them immediately, it is more likely to persuade the readers successfully to accept their claims.
Human writers in this study are more apt to consider the readers’ emotional needs and take tactful strategies. D. Liu and Xiong (2024) find that the Chinese writers who are more cognitively mature and socially experienced are more skillful at regulating straightforwardness by propriety, since straightforwardness in communication is much possibly viewed as rudeness and hence cause interpersonal conflict. The EFL students have acquired the social convention during the process of socialization and could apply it to writing argumentation. In contrast, ChatGPT might have not been trained adequately in social aspect so that it is not adept at employing the tactful concession strategy.
The other factor which may increase tactfulness is the use of qualifier to moderate the tone of the claim. The ChatGPT essays display more qualifiers to make the claims objective and rigorous. AI-generated language is found in previous studies to be more accurate in grammar (Markey et al., 2024; Mizumoto et al., 2024), rich in vocabulary (Herbold et al., 2023), and even objective and formal in style ( Dilai & Dilai, 2025; Jiang & Hyland, 2025; S. Yang et al., 2024). Objectivity is deemed negatively in those studies as impersonal and less readability. However, our finding differs from theirs in that we only consider Toulmin qualifier in the claim, not the tentative word or modal word in the whole essay. Objectivity revealed by qualifier in argumentation is regarded as a style encouraged in argumentative writing or discussion (Toulmin et al., 1978). The use of qualifier indicates that the writers have already examined or at least considered different views in their mind, rather than only concentrating on my-side view, and accordingly draw a conclusion with probability instead of certainty. A claim without qualifier sounds arbitrary and subjective, and might undermine the justification.
Tactfulness is complicated in this study. Neither group is perfectly tactful, at least less tactful than the participants in D. Liu et al.’s (2024) study. It could be attributed to their experiment which was conducted to teach the tactful strategies, activate and reinforce the schema. In our study AI is even less tactful than the EFL students despite its higher frequency of qualifier. It is speculated that AI is more obedient to the instructions in the training so that ChatGPT essays are more complete in form (e.g., more uses of qualifier). In addition, human children usually take years to acquire a certain culture including its rhetoric, convention and pragmatic use. During this process they get socialized gradually. Once they have acquired the culture, it can be deeply rooted and even affect the foreign language writing, for example rhetoric transference, translingual writing, and hybrid rhetoric. However, AI needs a great amount of input and training before showing some culture-specific features. At present the input and training imposed on AI is within the western rhetorical framework. It is different from human learners who first begin with the mother language and then learn the foreign language. When the human learners write in the foreign language they can employ the rhetoric strategies acquired in their mother language and even adjust the strategies to the contexts. It might constitute the weakness of AI at present.
Conclusion
Focusing on logical reasoning and rhetorical strategy, this study compared the argumentative essays written by the EFL students and ChatGPT. The following conclusions can be drawn tentatively. Firstly, the ChatGPT outperformed the EFL students in argument sufficiency. It did not use totally the same way to achieve argument sufficiency as the human writers: the ChatGPT relied almost solely on empirical warrants. Secondly, the ChatGPT in general presented less tactfulness than the EFL students, despite its higher frequency of qualifier.
Some previous studies have found that although AI-generated texts are useful for producing structured and coherent content, they fall short in areas requiring human creativity, originality, ethical accountability, and nuanced voice. Our study provides more supporting evidence: AI can imitate human writers’ preference in argument style and excels in logical reasoning but weaker in adapting rhetorical strategy to the context and readers. Human writers have emotions and can hardly refrain from revealing emotions in communication. Especially in certain cultures, writers are encouraged to appeal to emotion to enhance persuasiveness. Modern English writing conventions lay more weight on ration and logical reasoning rather than emotional appeal, for example in the textbooks for writing compiled by Langan (2007), Kanar (2011), and Johnson-Sheehan and Paine (2013). When input enough materials, AI can perform mechanically according to the instructions, regardless of the rhetorical aspect.
This study has significant pedagogical implications, particularly for teachers of writing. As AI tools become more integrated into educational environments, instructors face the challenge of determining how to effectively incorporate AI into their teaching practices. This study offers practical insights into how AI can be used to complement traditional teaching methods, helping students develop and enhance their writing skills. To be specific, as AI excels in gaining argument sufficiency by generating more grounds and warrants, teachers may consider using AI to open a topic, broaden the students’ view and enrich their ideas in argumentation training and practice. However, students might be dissuaded and even restricted to rely on AI so heavily as to produce some stiff texts lacking persuasion since AI shows less tactfulness in argumentation. Another implication for teaching consists in the identification of plagiarism. It would be easier for teachers to differentiate AI-generated texts from human-written ones in terms of tactfulness in argumentation. In summary, teachers will be motivated to reflect on how to best integrate AI in their classrooms, ensuring that their students not only benefit from technological advancements but also continue to cultivate their communicative abilities.
The major limitation in this study is the small sample size. Only 60 essays were selected from the corpora although this sample size aligns with those used in previous corpus-based and discourse-analytic studies of argumentative writing. To guarantee the validity of group comparisons, all essays were strictly evaluated under a standardized scoring rubric, and the detailed quantitative analyses were conducted in this study in the hope for providing a robust basis for the findings reported. However, a larger sample will be more statistically powerful. It is recommended that more corpora should be built and utilized to do such comparisons between AI and human writers.
Footnotes
Appendix 1
Acknowledgements
Thanks go to Miss Yuzhu Wei who is a PhD student in Southeast University and helped in our data collection.
Ethical Considerations
This study obtained ethical approval from the Research Ethics Committee of the School of Foreign Languages in Southeast University. All methods performed in the study were carried out in accordance with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. This study used two parallel open corpora and involved no human or animal studies.
Author Contribution
Donghong Liu: Conceptualization, Methodology, Writing—Original Draft, Writing—Review & Editing, Supervision, Funding acquisition. Pengfei Wu: Methodology, Validation, Formal analysis, Investigation, Writing—Original Draft. All authors have read and agreed to the revised version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by the National Social Science Fund of China (Grant No. 21FYYB016).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data source used in this study can be accessed at http://114.251.154.212/cqp/teccl/ and ![]() . Raw data supporting this study’s findings are available from the corresponding author, upon reasonable request.
. Raw data supporting this study’s findings are available from the corresponding author, upon reasonable request.