
Abstract
The study investigates the efficiency of ElevenLabs voice cloning software in dubbing Egyptian humor in Instagram reels into English. Furthermore, it aims at examining how the replication of tonal pitch nuances and original actors’ voices influence the translatability of humor into the target language. To examine the transfer of cultural and pragmatic aspects of humor, the study conducts multi-layer analysis for eight reels by adopting a multi-modal framework including Martínez-Sierra taxonomy of humorous elements and Juckel et al. typology of humor techniques. In terms of the preservation of the influence of prosodic cues on humor, an acoustic analysis was conducted for both of the source and target audios using Praat. Two questionnaires were designed to examine viewers’ perceptions toward using voice cloning as a dubbing tool to dub humor, oriented toward two participant groups: native English speakers and Arabic-English bilinguals. It revealed that voice cloning is more efficient in enhancing the tonal consistency in dubbing, particularly in conveying Egyptian performed humor into English compared to conventional dubbing and subtitling. However, further improvements are needed in terms of voice naturality and accuracy in transferring cultural aspects of humor. The analysis also sheds light on translation challenges regarding cultural and linguistic nuances in humor translation.
Introduction
Technological advancements in machine translation (MT), machine learning (ML) and artificial intelligence (AI) have triggered audiovisual industry to globalize their products to enter new markets. Various modes of Audio-visual Translation (AVT) including (subtitling, dubbing, voice over, and simultaneous interpretation, etc.) are used to present various audiovisual contents in other languages. However, these modes have various levels of limitation including accuracy, time constraints and financial cost, etc.
In AVT, humor translation has been a problematic issue specially if rendered using both of the main modes used namely, subtitling and dubbing due to its subjective percipience and cultural specificity (Dore, 2019). However, it is more problematic when it is dubbed because the audience only hear the voice of the dubbing actors instead of the original actors’ voices, reducing the emotional intensity of humor in actors’ tonalities (Baños & Chaume, 2009). Moreover, humor bound to a certain dialect is far tricky to be captured into other languages (Zabalbeascoa, 2005). For instance, Egyptian humor has its own cultural characteristics shaped out of the intervention of colloquial linguistic features, social culture, economy and political ideology, etc. Such Egyptian-bound features of humor pose a significant problem when they are to be dubbed or subtitled into another language, such as English. Egyptian dialect also gains further popularity especially in film and television production as Egypt pioneers in this aspect in the Arab region, especially its comedic productions which enjoy wide audiences in other parts of the Arab world. Therefore, it is difficult to dub this dialect into another language or dialect without a loss in the intended humor (Al-Abbas & Haider, 2021).
In its turn, the new emerging advanced AI and deep learning-based technologies such as deep fake and Voice Cloning have proved a great significance in audiovisual by mimicking human voice (Gambier, 2008). This technology uses pre-trained voice reference datasets to create a synthesized voice that closely matches the original human voice. Many movie production companies now can dub their cinematic products such as movies, TV shows, documentaries etc., into other languages using the cloned voices of the original actors to give their audience a more immersive experience in watching their favorite TV shows and movies. Therefore, voice cloning should be investigated as a new mode of AVT (Williams, 2024). This offers a brand-new creative method to reflect humor in dubbed audiovisual materials across various languages and cultures by replicating a voice’s subtle nuances including tone, timbre, and intonation, etc. instead of the unnatural conventional dubbing.
Therefore, this study aims at investigating the use of voice cloning in dubbing Instagram reels of Egyptian comedy shows into English. Moreover, the current study also examines the extent to which the sense of humor and cultural aspects in Instagram reels of Egyptian comedy shows is professionally dubbed into English using ElevenLabs voice cloning, focusing on the replication tonal nuances of actors’ voices. It also aims at assessing the extent to which the cultural aspect of humor is preserved and effectively conveyed by featuring the translation strategies the content creator has opted for. Most significantly, the study strives to investigate audience perceptions, precisely English natives and Arabic-English bilinguals, toward AI-assisted dubbing using voice cloning in by examining its performance terms of humor transfer compared to conventional dubbing and subtitling. Therefore, the current study aims at answering the following questions:
To what extent does ElevenLabs voice cloning software efficiently work in dubbing Egyptian comedy Instagram reels clips into English?
To what extent is the sense of humor in Egyptian comedy shows professionally dubbed into English using ElevenLabs voice cloning?
What are the audiences’ attitudes toward the efficiency of voice cloning in dubbing Egyptian reels into English?
Background
Díaz-Cintas (2009) put out dubbing as replacing the original soundtrack of the source language with a soundtrack of the target language to cast audiovisual in a way that fits the target audience culture and norms. However, dubbing is not limited to providing a translation with post-production synchronization. Another more recent and comprehensive definition of dubbing is stipulated by Chaume (2020, p. 104) as “a linguistic, cultural, technical and creative team effort that consists of translating, adapting and lip-syncing the script of an audiovisual text.”
Dubbing was first introduced as an AVT modality as result of the emergence of talking movies, commonly known as “talkies” (Chaume, 2020). This mode has gained popularity in some countries over others. This can be attributed to several factors including economy, technology, audiences’ cognitive recipience of languages, and political agenda. For instance, due to the high rate of illiteracy, most people couldn’t read (Chaume, 2020). Therefore, film production industries found switching to dubbing, though it is more costly than subtitling, a must to globalize their audiovisual products to a wider audience of various educational backgrounds (Chaume, 2020).
The relatively high cost of dubbing is attributed to its complex process. According to Chaume (2020), dubbing requires more than professional voice actors and actresses recording their voices in a studio. An audiovisual product goes through four steps before the dubbed version is released. First, the script of the audiovisual product is translated into the target language. The script is usually translated literally by a translator. Then, a dubbing translator adopts the raw translation to make it more natural to fit the target audience dialog, making sure that the dubbed recordings are properly synchronized in terms of the duration of the of soundtrack’s “takes” (Isochrony), lip movement (lip synchronization), and body language of the screens’ actors (Kinesic synchrony). The recent technologies of speech synthesis provide new potential that could be a game changer in AVT, in general, and dubbing in particular. Voice cloning is definitely one of the new speech synthesis tools that may revolutionize dubbing audiovisual content cross languages and cultures (Chaume, 2020).
Speech Synthesis and Voice Cloning
Speech synthesis is referred to as “a process of automatic generation of speech by machines/computers” (Balyan et al., 2013, p. 57). This voice technology aims to enable machines to act intelligently in producing natural, human-like, synthesized voices that integrate and revolutionize other disciplines and fields. The synthesized voice is generated by analyzing and simulating the acoustic properties of the human voice, breaking it into smaller vocal units such as phenoms (Klatt, 1987).
Voice cloning is one of the newcoming technologies in speech synthesis that appears as a result of fine-tuning AI Deep Learning neural networks of speech synthesis on samples of human voice. It is a highly personalized branch of speech synthesis that replicates human voice with its complex nuances and embeddings (Ma et al., 2024). Napolitano (2020) describes voice cloning as a “mask” of the invariable structure of text-to-speech synthesis. The advent of multilingual, multi-speaker and end-to-end neural networks have enabled speech synthesis models to generate cloned voices by identifying voice embeddings of a certain person voice through what is called speaker encoder (Jemine, 2019). Then, a speaker profile is made to create a clone that closely resembles the natural human voice of that speaker (Napolitano, 2020), without the burden of training models on mass labeled recorded data. The quality of synthesized voices, precisely personalized cloned ones, has drastically improved due to the use of new models that learn and train data on specific audio samples for a person rather than assembling and sorting vast amounts of data (Hu & Zhu, 2023).
Voice Cloning as Means of AVT
Voice cloning now has been integrated into various aspects of life including entertainment, education, communication, and media accessibility. Voice cloning proves great significance in AVT as an inclusive practical solution in terms of time and cost of production (Thomas, 2024). The wide proliferation of social media platforms alongside global availability of the internet, has also increased user-generated audiovisual various contents that usually orients a global audience around the world (Maksymchuk et al., 2023). Therefore, voice cloning applications facilitate the process of both creating content and providing it with a more innovative, immersive real-time AVT, especially user-generated content (Hatami et al., 2024).
In other words, voice cloning, in its turn, gives extra credit to the existing tendency toward dubbing by using the original voice of the speaker rather than using a voice talent from the target language. Using the cloned voice of the original speaker, viewers may feel that dubbed content is originally created in their first language. Unlike conventional dubbing, voice cloning also transfers the prosodic features of the original voice that covey certain pragmatic meanings, more precisely humorous meanings.
According to Misener (2017), the Canadian startup company Lyrebird is a practical voice cloning software that replicates voices, first demonstrated by cloning former U.S. President Donald Trump’s voice in 2017. By training on speech recordings, Lyrebird’s software can recreate voices using just 1 min of audio. Users can create personalized “Lyrebird Avatars” for various purposes, such as chatbots, audiobooks, and video games. Lyrebird also supports ALS patients by helping them preserve their voices through “Project Revoice,” a non-profit initiative that uses deep learning to clone their voices, allowing them to communicate in their natural voice instead of a generic one (Project Revoice, 2019).
A recent study conducted by Williams (2024, p. 132) simply describes the process as “a voice is cloned by training a machine-learning algorithm, most often a deep neural network, using existing audio recordings to learn the unique characteristics of a voice.” Williams (2024) discusses the potential of voice cloning in film making, featuring the potential of voice cloning in replicating the voice of deceased individuals and bringing their voices back to life with their distinguished prosodic features. For instance, he reflects on using voice cloning in replication the voice of Anthony Bourdain, a deceased American author, chef, a travel documentarian who died in 2018, for filming a documentary on his career journey called Roadrunner in 2021. His AI-generated voice is integrated with the film as a voiceover that is synched with his mouth and facial expressions.
There are a few models the tackles voice cloning using fine-tuned neural network in text-audio data including Deep Voice 1 (S. Arik et al., 2017), Deep Voice 2 (Arik et al., 2017), Tacotron (Wang et al., 2017). For instance, the multi-speaker generative model proposed by S. Ö. Arik et al. (2018) is based on fine tuning the model with a set of audio-text pairs. Then, for voice cloning, speaker encoder is used to extract unseen speaker embedded characteristics such as accent and gender. Visual voice cloning is also an innovative voice cloning model which converts text to speech with a certain desired voice characteristic using audio reference. It derives various emotions of the audio from a video reference. This model is used to develop new synthetic speech apps and online software (Chen et al., 2022).
ElevenLabs
ElevenLabs is an AI audio research and deployment company which aims at making content universally accessible in any language and in any voice (ElevenLabs, 2024). Initiated in 2022 by Piotr Dąbkowski, an ex-Google machine learning engineer, and Mateusz Staniszewski, an ex-Palantir deployment strategist (ElevenLabs, 2024). Currently, the software supports 32 languages. ElevenLabs online software houses nine AI-driven voice tools including TTS, STS, Text to SFX (special effects), voice cloning, dubbing studio, voice-isolator, voiceover studio, voice library, and audio native. The software offers some of these tools for free; however, with limited potential in terms of number of characters in text to speech synthesis and the number of voices for cloning.
Humor in AVT
Zabalbeascoa (2020, p. 669) provides a comprehensive definition of humor as “a quality of a statement, action or situation that makes a person laugh or smile or feel similarly amused; consequently, a sense of humor is the ability to recognize, appreciate and sometimes produce such actions, situations, and statements.” Humor is very problematic in terms of linguistic and cultural transference. Just as the case in literary translation, humor’s interdisciplinary nature poses a problematic issue for translators. This is evident in the wide scope of theoretical approaches proposed for tackling humor in translation including Semantic-Script Theory of Humor (Raskin, 1985); The General Theory of Verbal Humor (Attardo & Raskin, 1991); Relevance Theory (Sperber & Wilson, 1986); Skopos theory (Vermeer, 1989); and verbally expressed humor (Chiaro, 2024), etc. Each theory classifies humor based on its own research perspective. Transferring humorous audiovisual contents adds to the already constrained and multi-semiotic nature of AVT (Dore, 2020). Precisely, transferring humor-based audiovisual content such as sitcoms, play, stand-up comedy, and comedy films takes higher regard in terms of preserving or reconstructing humorous patterns for the target audience (Zabalbeascoa, 2005).
In AVT of humor, translators should consider the cultural social background of the target audience, the linguistic and dialectal aspects and audience’s cognitive perspective, etc. Therefore, translators tend to adopt functional approaches such as “Text Analysis in Translation” (Nord, 1988/2006; 1997); Skopos (Vermeer, 1989/2012); Nida’s dynamic equivalence (Nida, 1964, p. 159) to transfer humor in comedy AV content.
Prosody of Egyptian Humor
Arabic preformed humor is often conveyed through prosody rather than lexico-grammatical content, particularly when dialects are involved. While Modern Standard Arabic is used in formal contexts, Colloquial Arabic encompasses regional dialects used in social communication, including films and social media (Nassif, 2021). Egyptian comedy, in particular, enjoys wide appeal due to the unique humor encoded in its dialect, with Egyptians being known as “ibn nukta” (son of the joke). Egyptian humor heavily relies on personal characteristics such as body language, facial expressions, and prosody, making it difficult to capture effectively in languages like English (Shehata, 1992, p. 76).
Previous Studies
There are few studies that tackle voice cloning dubbing in the world in general and in the Arab world in particular. Regarding the integration of the AI as tool in AVT in general and in cross-lingual dubbing in particular, Sanyal et al. (2024) conduct an experiment to evaluate the ability of their proposed AI model for speech synthesis to clone voice embeddings, expressions, emotional tone of the actors from Indian into English. The study further investigates the capacity of the proposed model in distinguishing the background noise and music of the movies and transferring it in good quality. The researchers propose a speech synthesis model with two stages of voice modeling. The first stage involves a speech extraction which consists of a Denoiser and spleeter. These components are of great significance since they distinguish and separates vocals from the background music. The data of the study is collected from over 50 Bollywood movies of various genres such as action, comedy, romance, and thriller. Involving various genres, the data aims at capturing wide range of emotions and storytelling styles.
Most importantly, they adopt a manual transcription and dubbing method because automated transcription and dubbing lacks accuracy, especially when dealing with diverse accents, tonal patterns and background noise. To evaluate the performance of the model, they employ both qualitative and quantitative methods. For qualitative analysis, Mel Cepstral Distortion metrics and the Relative Fréchet Distance metrics are used to evaluate the preservation of expressive aspects of the dubbed speech in terms of emotional content and naturalness. Quantitative analysis is employed to evaluate the performance of the dubbed speech in terms of clarity, intelligibility, and overall audio quality. The quantitative analysis reveals that the proposed model consistently excelled in preserving speaker expression and reducing background noise, outstanding existing state-of-the-art models. The results of STOI metric and Relative Frechette distance also reveals that the model is also efficient in preserving the embeddings, expressions and tonal patterns of the original Hindi audio when dubbed into English.
Federico et al. (2020) propose an enhanced text-to-speech (TTS) pipeline for multi-lingual dubbing. To test its performance, the researchers conduct an experiment to evaluate the automatic dubbed Ted talks videos from English into Italian. The pipeline integrates improved machine translation to control the length of translations, ensuring optimal alignment with the original audio’s timing and segmentation. It employs a neural TTS system consisting of a Context Generation module and a Universal Neural Vocoder. The Context Generation module is trained on speaker-specific Italian voices, while the Vocoder is pre-trained on a large dataset of voices. To synchronize the length of the Italian speech with the original English audio, the system resizes the output accordingly. Additionally, the U-Net architecture is used to separate speech from background audio, allowing the latter to be reverberated into the Italian dubs. An evaluation of voice naturalness was conducted on 24 selected clips. The participants, both Italian natives and Italian, focus on the resemblance of the dubbed speech to human speech in terms of acoustics and synchronization. The results highlight that while the pipeline performs a good synchronization at the phrasal level, prosodic alignment negatively impacts fluency and prosody. These disfluencies significantly affect Italian listeners, although non-Italian listeners perceive increased naturalness due to the enhanced audio rendering with background noise and reverberation.
Pérez et al. (2021) examine the use of text-to-speech synthesis systems at the University of Politècnica de València (UPV) to investigate the integration of such systems in educational institutions. The study focuses on training TTS models on UPV’s repository of educational videos, MediaUPV, to enable cross-lingual voice conversion for Spanish educational content. MediaUPV contains poliMedias (high-quality short recordings by UPV lecturers) and poliTubes. However, only poliMedias are used due to their consistent quality and simplicity. The baseline system aims to produce Catalan and English auto-dubbing for these Spanish videos. To evaluate the system, 98 UPV academic staff members participated in recording clean speech data during the 2016 to 2017 and 2017 to 2018 academic years. All participants were native Spanish/Catalan speakers, with an average age of 50, and evenly distributed by gender. Participants recorded at least 300 sentences in Spanish, Catalan, or English, with a minimum of 150 in each language, under controlled acoustic conditions. A set of 8,820 speech samples synthesized by Tacotron2-UPV was assessed by 47 lecturers, based on naturalness, speaker similarity, realism, and survey feedback. The qualitative analysis reveals that Catalan and English score high rate in terms of naturalness, speaker similarity, and realistic cloning. These results support the researchers’ conclusion that TTS technology is mature enough for massive machine dubbing of educational videos, even in cross-lingual cases.
In the field of video game localization, voice cloning technologies also prove great significance. Nițu (2024) investigates the application of AI-driven automatic text translation and voice dubbing from English to Romanian in video games. The study employs ElevenLabs’ TTS model to clone the original voices of the actors of two games, that is, Pokémon FireRed and Fallout 4. The findings of the study reveal that the potential of AI-cloned voices in capturing vocal characteristics in offering “a unique perspective on the game’s story and characters which adds to the cultural value of localization beyond a simple translation” (Nițu, 2024, p. 7). The researcher concludes that incorporating AI voice cloning software such as ElevenLabs can add to the playability value of the game.
Methods and Procedures
Data Collection
To investigate the role of voice cloning software, precisely ElevenLabs, in recreating humor of various Egyptian comedy shows into English, the data, that is, Instagram reels, was obtained from two Instagram accounts: @vinga_23 and @motat.altaleem. The corpus of the study consisted of 65 reels which were quoted from different Egyptian plays and movies. However, the sample of the study consisted of eight representative reels that were purposefully selected to fit the study’s scope and to avoid repetitiveness as the majority of the reels share the same prosodic features and humorous effects. In other words, the criteria of inclusion for these reels were related to answering the questions and the objectives of the study. In addition, the inclusion criteria included only the reels that are more popular in the Arab world and those that have achieved high percentage of watching and preferences. Moreover, the study selected only the reels that have strong matching voices with the original ones to support the hypothesis of the study. While the exclusion criteria included the unpopular reels in the Arab world and those that have weak matches with the original ones.
These clips were downloaded using free website savefrom.com. For the acoustic analysis, audios were extracted from the aforementioned reels in WAV (Waveform Audio Format) form using Convertio free website. These Instagram reels were created from various Egyptian comedy shows including plays, such as School of Mischief “Madrast Al-Mushaghebeen,” 1973; No Longer Kids “El-Al-Eyal Kebret,” 1979; The Married Couples “Al-Motazawegoon,” 1976. The researchers used their own IG account to collect the data.
The study faced some limitations regarding different parts of the study. A key limitation was concerned with data collection. The data of the study were available on Instagram obtained from two accounts @motat.altaleem and @vinga_23. However, great portion of the data was lost as one of the accounts, @vinga_23 is no longer available on Instagram. Furthermore, the researchers found difficulties in contacting the content creators about detailed information concerning the use of ElevenLabs in cloning the content. Moreover, the accessibility of information about all ElevenLabs tools is limited for premium version subscribers. Most importantly, the cultural sensitivity that surrounds Egyptian humor added to difficulties of the analysis. Furthermore, the lack of literature on this area, especially concerning dubbing from Arabic into English presents a key limitation in the research. Most importantly, due to time constraints, the analysis of the study addressed few samples of the data.
Questionnaires
The participants of the study were 22 persons, 11 native speakers of English (eight females and three males) who are studying Arabic for non-native speakers in the Language Centre at Yarmouk University, and 11 English-Arabic bilinguals (six males and five females) who have MA in translation studies. The participants were orally informed about the objectives of the study and they were asked if they had the desire to participate in the questionnaire. All the participants showed their consent and happiness to participate in the answering the questionnaire. They confirmed that there is no harm or risk for participating in the questionnaire. Therefore, the questionnaire was made in a friendly and comfortable atmosphere to guarantee real results and effective participation. To analyze participants’ perceptions toward the use of voice cloning in dubbing Egyptian comedy in English, two questionnaires were designed. The first questionnaire was oriented toward 11 mixed-gendered English natives, eight females and three males. The questionnaire consisted of 18 questions labeled under seven categories. Six of these sections are obligatory including general perception of dubbed reels, voice cloning, and authenticity in the dubbed reels, comedic timing, and delivery, cultural understanding and adaptation, comparison between the dubbed and subtitled comedic content. Another section was added for the demographic information. The last section contained two questions related the participant’s familiarity with Egyptian humor and watching dubbed content. Similarly, another questionnaire was designed for 11 mixed-gendered English-Arabic bilinguals (six males and five females). The questionnaire consisted of 17 questions labeled under the same six obligatory sections provided in the first questionnaire but provided with original Arabic content as a reference. Furthermore, it consists of six sections to bring insights on their experience and preferences in terms of dubbed and subtitled content. Each section of the two questionnaires is hyperlinked with the dubbed reels, and the corresponding original Arabic content with English subtitle. The participants assessed the role of voice cloning in dubbing in terms of naturalness, authenticity of voices, the preservation of emotions and tone of the original, cultural understanding and adaptation, and the comedic timing and delivery. To check the validity and reliability of these two questionnaires, they were presented to and approved by a jury consisting of two professors of translation.
Procedures
The qualitative approach was more consistent with the study objectives. The analysis comprised three stages. The first stage was concerned with collecting the data from the two aforementioned IG accounts. Then, takes of original Arabic contents with the English subtitle were obtained via Netflix for participants comparative assessments. The opted sample for descriptive analysis was manually transcribed by the researchers for both the source Arabic comedic and English-dubbed reels. Then, the scripts were descriptively analyzed based on multimodal theoretical framework. The second stage included the acoustic analysis of humorous prosodic cues. As explained above, audios were extracted from eight reels in WAV form via free website called Conversion. Audio samples were analyzed through Praat, an open-source tool for speech synthesis analysis. The third stage involved the analysis of participants’ perceptions and induvial assessment in terms of naturality, speaker similarity, comedic delivery, trimming and cultural adaptation and the perseverance of humor tone of the original Arabic content.
To ensure that reliability and validity of the data collected analyzed, a jury of three professors of translation evaluated the questionnaire and their suggestions were taken into consideration. In addition, the reels were coded by ElevenLab’s tool, so the researchers took these reels as they are coded without making any amendment. The researchers trained well on using Praat Software in order to depict the prosodic features of the Source and Target voices. They also consulted a professor specialized in phonology to validate the matching of source and target voices.
Theoretical Framework
For the descriptive analysis, a multimodal framework was constructed to answer the study questions. For the categorization of the humorous elements in both the original Arabic content and the English dubbed reels, the study adopted Martínez-Sierra’s (2006) taxonomy of humorous elements. Furthermore, Juckel et al.’s (2016) humor typology is adopted for grouping humor into four macro categories in AVT. Each category contains sub techniques of humor. Martínez-Sierra (2006, pp. 290–291) classifies the following eight taxonomies of humorous elements:
Community-and-Institutions Elements refer to cultural or intertextual features that are rooted and tied to a specific culture.
Community-Sense-of-Humor Elements, the topics of which appear to be more popular in certain communities than in others, an idea that does not imply any cultural specificity, but rather a preference.
Linguistic Elements are based on linguistic features. They may be explicit or implicit, spoken or written.
Visual Elements comprise a differentiation between the humor produced by what we can see on the screen and those elements that in fact constitute a visually coded version of a linguistic element.
Graphic Elements: This type includes the humor derived from a written message inserted in a screen picture.
Paralinguistic Elements. This group includes the non-verbal qualities of a voice, such as the intonation, the rhythm, the tone, the timbre, the resonance, etc., which are associated with expressions of emotions such as screams, sighs, or laughter.
Non-Marked (Humorous) Elements represent miscellaneous instances that are not easily categorized as one of the other categories but are, nevertheless, humorous. They may have either an acoustic or a visual form, and can be either explicit or implicit.
Sound Elements. They are sounds that by themselves or in combination with others may be humorous. They are explicitly and acoustically found in the soundtrack and the special effects when these contribute to the humor.
Juckel et al. (2016) propose a comprehensive typology for humor in sitcoms. The taxonomy divides humor into four categories including language, logic, identity and action. Each category includes a group of humor techniques. However, to address the problem of the study, action techniques were not included in analysis (Figure 1).
Juckel et al.’s (2016) proposed typology for humor.
Findings and Discussion
Introduction
The current chapter presents the findings and discussion of the role of voice cloning in dubbing Egyptian humor into English in Instagram Reels. To evaluate the validity of the study’s hypothesis, the study conducts a mixed-method analysis. The first layer of analysis employes a multimodal framework. The framework comprises of Martínez-Sierra’s (2006) taxonomy of humorous elements, and Juckel et al. (2016) typology of humor techniques. Each instance of humor in the data sample is analyzed in terms of the categories of humorous elements, humor techniques, and the subtitling strategies adopted in conveying these instances into English. Featuring the role of prosodic cues in recreating humor in the target language, the study conducts an acoustic analysis for both the source and target audio using Praat. The second layer of analysis taps into viewers’ perception regarding the efficiency of voice cloning in conveying Egyptian humor into English-dubbed reels.
Analysis of VC Performance in Conveying Egyptian Humor in the English Dubbed Reels
Example (1) a dialogue between Lina and Masoud, The Married Couples, “Al-Motzawjoon.”

Humorous Elements
Community-and-Institution Elements
Based on example (1) above, the humorous load embedded in community-and-institution humorous elements appears in Egyptian cultural references including
Paralinguistic Elements
In addition to humor related to community-and-institution elements, humor is also marked by prosodic cues that, in its turn, contribute to the underlying socio-pragmatic meaning. These prosodic cues may be used to mark a specific style of humor related to the context of the comedic show or the humorous style of the characters in that show. For instance, Masoud’s humorous performance is distinguished by a relatively high mean pitch. Moreover, the high standard deviation of the mean pitch in both the source Egyptian audio, and the English cloned audio indicates the expressiveness and the emotionality of the voices. The following pitch analysis indicates the close match of pitch variables between the source and target audios (Figure 2).

The table indicates the close match of pitch variables between the source and the target audios in example (1).
To prove the validity of voice cloning in preserves the same tonality of the original audio in the English cloned audio. The following “screenshots” are taken from Praat showing the close match of the mean pitch of part of Masoud and Lina exchange (Figures 3 and 4).

Pitch analysis of the audio taken from the source Audio. The mean pitch measures 269.8 Hz.

Pitch analysis of the audio take from the target audio. The mean pitch measures 293.7 Hz.
Humor Techniques
Berger (2017) refers to the complexity that surrounds humor. Therefore, many techniques may be present at one time, and while some techniques may not be funny when used in isolation, they work when used in combination with others (Table 2).
Example (2) a dialogue between Masoud and Lina, The Married Couples, “Al-Mutazawjoun”.

Example (3) a dialogue between Masoud and Hanafi, The Married Couples, “Al-Mutazawjoun”.

Humorous Elements
Community- Sense-of -Humor Elements
Humor is provoked by reflecting on the dynamics of the relationship between Masoud and his close friend Hanafi. It taps into cultural norms where friends do each other favors without waiting for praise in return “يا جدع عيب ما تقولش كدا احنا اخوات “(Don’t say that, Man. We’re like brothers). However, in the case of Morsi and Hanafi, Masoud’s utterance انت قمت بدور العريس “معلش بس“... بطريقة (It’s okay, but you played the groom’s part brilliantly.), illustrates that the favor goes extremely as Hanafi pretends that he is the groom instead of Morsi, which is not exactly a common favor between friends. The humor technique used here is a pun as Masoud is playing with words to make fun. Humor is conveyed by means of direct transfer.
Non-marked Humorous Elements
Humor is also presented through unmarkable elements that relate to the context and the character’s personality. For instance, Masoud’s utterance “انا بهزر معك بأيدي انما دي مش ايد ده رجل طلع لها ايد” (I did it with my hand, but this is not a hand, it’s a foot that grew a hand) presents Masoud’s exaggerated and absurd statement about how Hanafi’s hand is strong intensifies the humor, allowing the scene to end on an absurd note. The humorous load is preserved through the use of literal or direct translation strategy to maintain the original text’s meaning.
Paralinguistic Elements
Humor is also prosodically marked by the slight rise of Masoud’s Relatively low pitch referring to Hanafi’s physical strength when he jokes around with him by batting Masoud on his shoulder win an exaggerated statement “انا بهزر معك بأيدي انما دي مش ايد ده رجلي طلع لها ايد.” (I did it with my hand, but this is not a hand, it’s a foot that grew a hand). The following screenshot from Praat analysis indicates that Masoud’s voice pitch slightly rises in his final statement in both the source Arabic audio and the cloned English dubbing (Figures 5 and 6).

Masoud’s slight rise in pitch signaling his sarcastic absurd statement measures 224.1 Hz.

Masoud’s slight rise in pitch signaling his sarcastic absurd statement measures 235.5 Hz.
Humor Techniques
Example (4) a dialogue between Masoud and Hanafi(2), The Married Couples, “Al-Mutazawjoun”.

Madrasat Al- Moshaghebeen (School of Mischief)
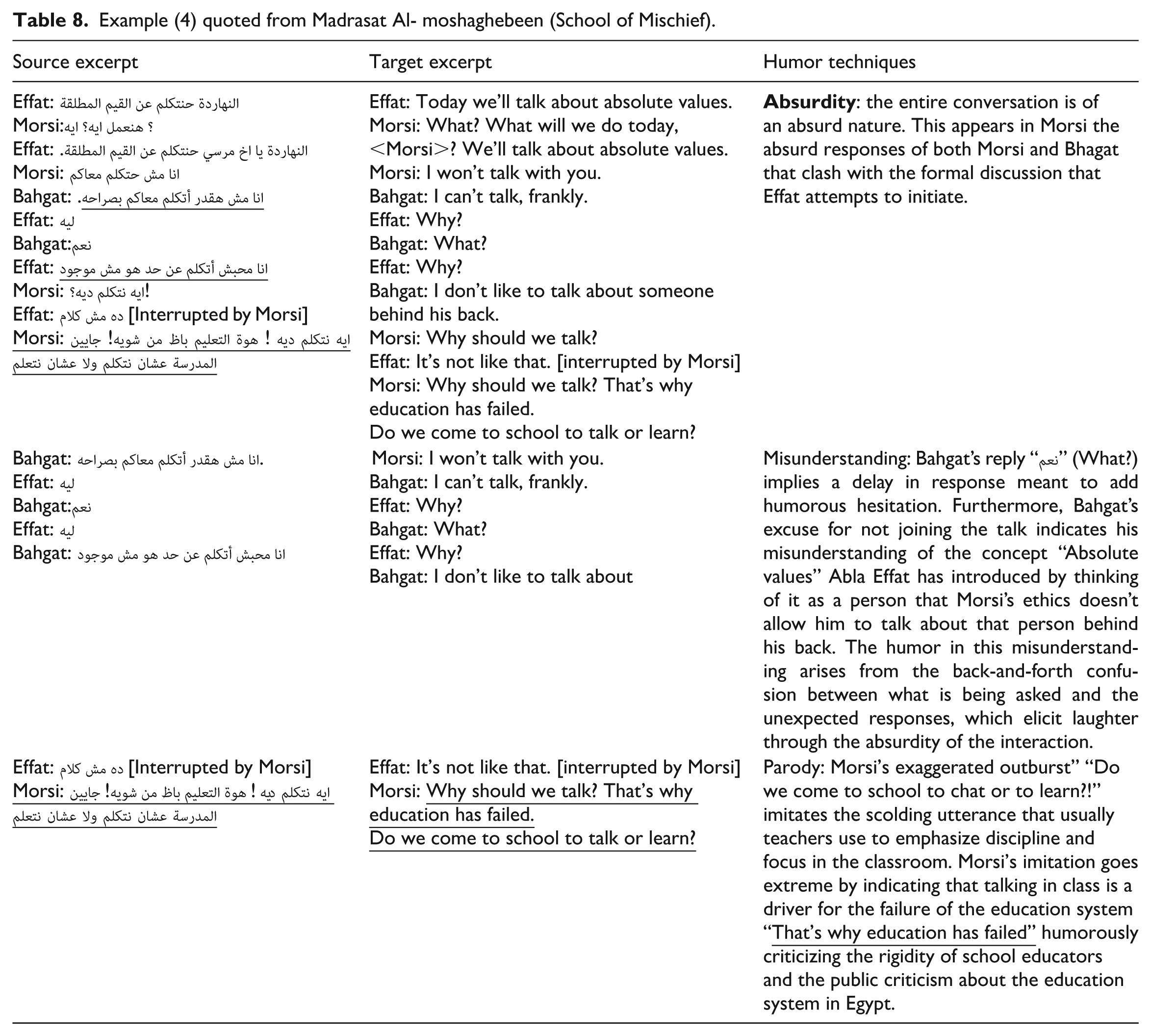
Example (3) quoted from madrasat al- moshaghebeen (School of Mischief).

Example (3) quoted from Madrasat Al- Moshaghebeen (School of Mischief).

Humorous Elements
Linguistic Elements
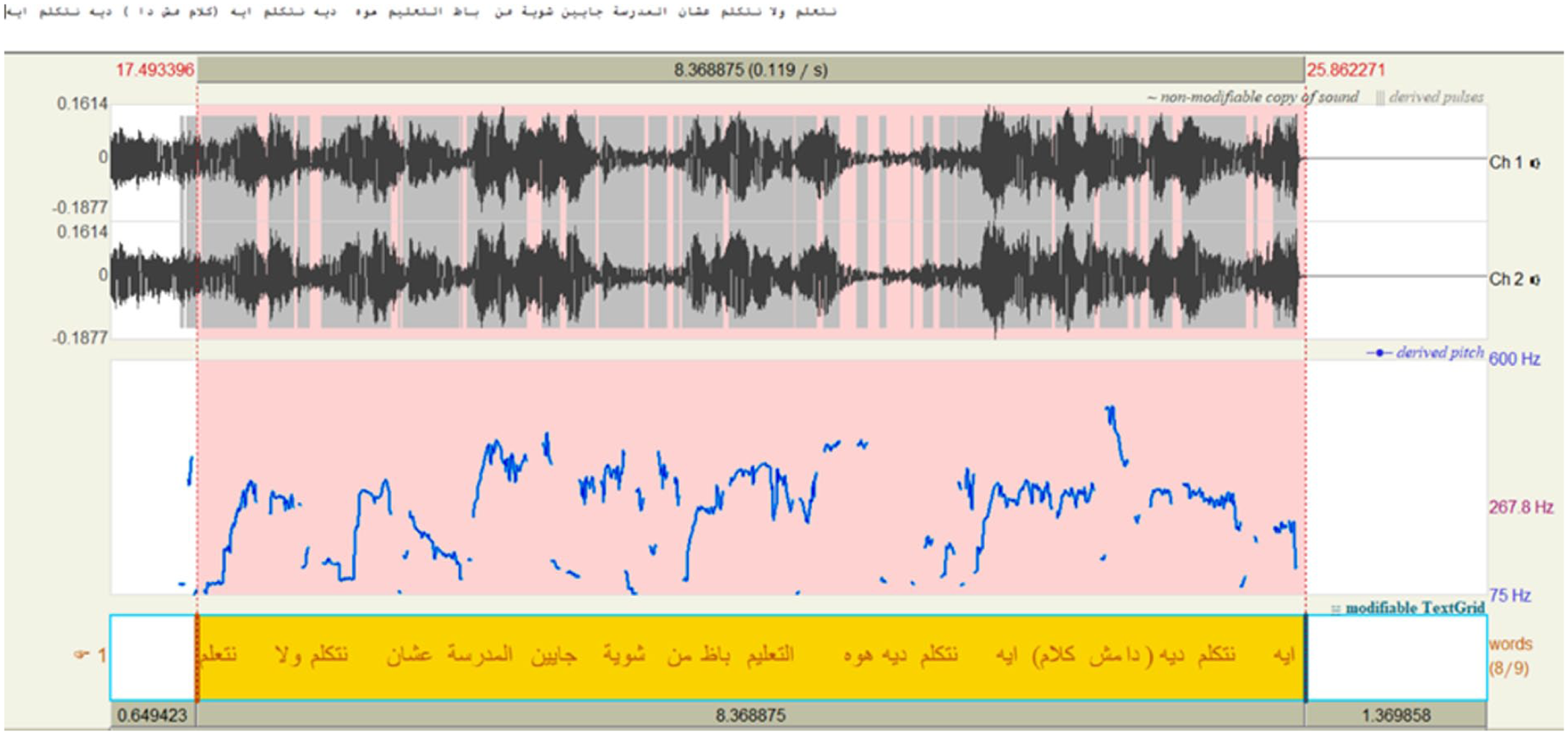
The humorous load is impeded in Bahgat’s erroneous use of a pronoun by imitating the 2nd person plural objective pronoun in معاكم to mock Ahmed’s statement and indicating that Bahgat is not taking Ahmed’s desire (not joining the plan in pranking the new-comer teacher Effat Abd AL-Kareem) seriously. Mocking someone’s speech or part of it indicates disapproval and understatement of their behavior or attitude which evokes humor throughout the development of the play’s events. Using the 2nd person plural objective pronoun in معاكم “ you” instead of the 1st person plural object pronounمعانا; in Bahgat’s question for Ahmed’s justification طيب انت مش” “هتشترك معاكم ليه؟. The humorous load that lies in the erroneous use of pronouns in the source language is lost in the target language. The 1st person plural objective pronoun “us” is used correctly rather than repeating the 2nd personal plural objective pronoun “you.”
Unmarked Elements of Humor
Humor appears in Morsi’s irrelevant question that shows his absurdity that clashes with the seriousness of Ahmed’s situation. The unmarked humor in Morsi’s question أيوه يعني.. لما بتاكل”“بتشعر بإييه is preserved and directly transferred into the English dubbing “The question is, how do you feel when you eat.”
Paralinguistic Elements of Humor
Preformed humor just as the case in comedic plays and stand-up comedy shows are mainly marked by speakers’ prosodic performance (Archakis et al., 2010). In conventional dubbing, voice talents are carefully chosen to dub comedy content based on how close their voices match the original voices. However, staged humor, such as stand-up comedy shows, and comedy plays are usually subtitled rather than dubbed because humor here is created by the way speakers say something rather than what they say. Figure 7 presents the close match of pitch analysis in both the original Arabic audio and the English cloned dubbing. The analysis reveals that voice cloning software in cross-lingual dubbing allows to closely clone the humorous tonality of the source audio, hence recreating humor marked prosodically in the target audio.

The table indicates the close match of pitch variables between the source and the target audios in Example 3.
More detailed examples of humor marked by pitch analysis appear in Morsi’s performance. The first humorous instance appears in Morsi’s utterance when he asked Ahmed about his different “situation” with irrelevant silly question. The question was uttered with a relatively calm pitch to indicate Morsi’s absurdity as illustrated in Figures 8 and 9. The marked humorous pitch appears in the following screenshots are taken from Praat pitch analysis

Pitch analysis of the audio take from the source audio. The mean pitch measures 193.8 Hz.
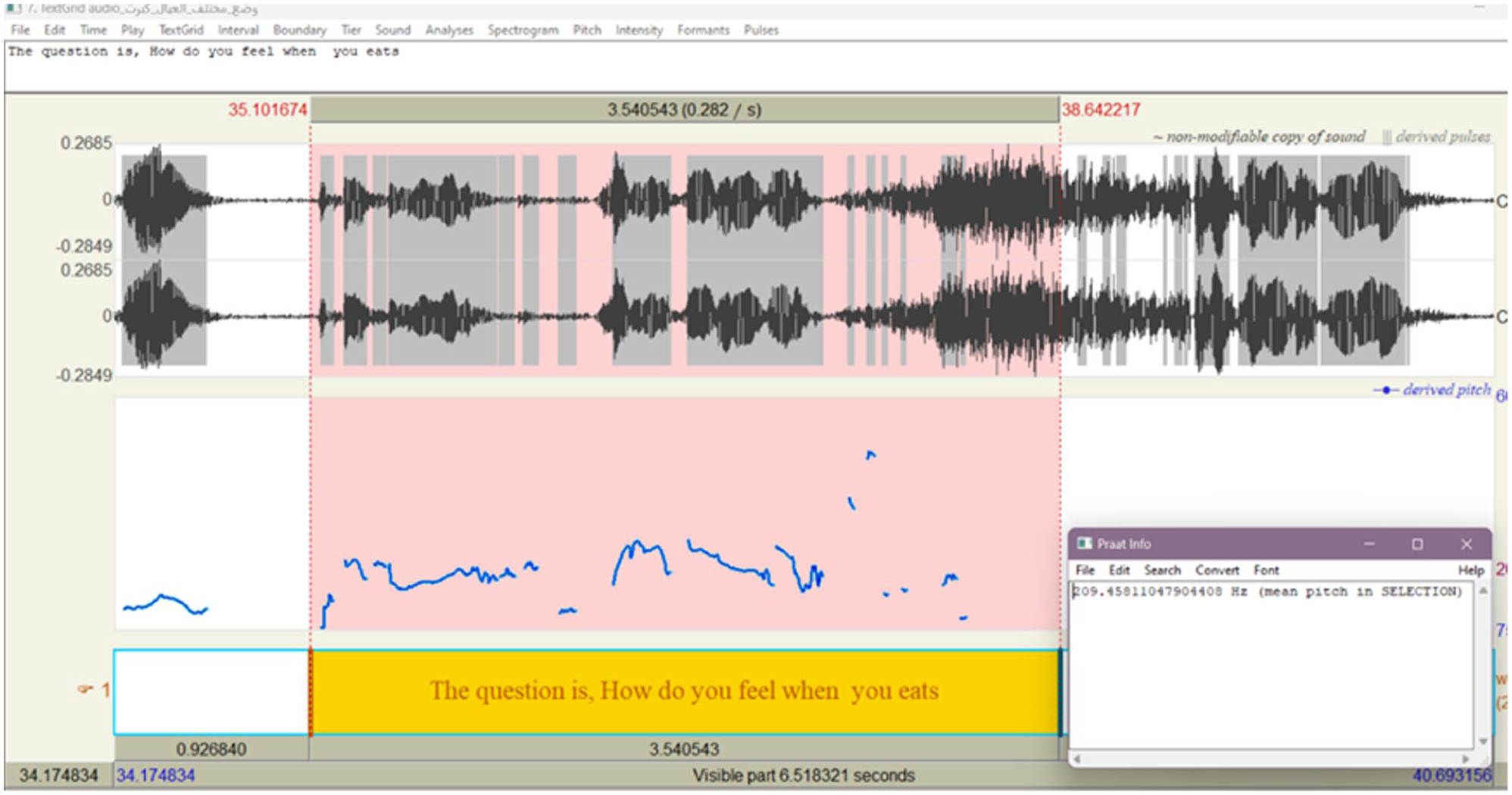
Pitch analysis of the audio taken from the target audio. The mean pitch measures 209.5 Hz.
Humor Techniques
Example (4): the source audiovisual content of the Reel.(4)
Example (4) quoted from Madrasat Al- Moshaghebeen (School of Mischief).

Humorous Elements
Linguistic Elements
The use of certain linguistic forms also adds to the overt humor elements. For instance, Moris’s fierce interrupting repetition of parts of Effat speech (what do you mean by let’s talk)“ ايه نتكلم دي! ايه نتكلم دية” indicates his frustration and disapproval to join the discussion in a childish way. Humor is also evoked by the semantic deviation of the use of the verb “نتكلم" (to talk (in the exchange from the intended meaning by Effat which is “to discuss.” While Effat uses the verb with intention to mean “to discuss” a topic such as “Absolute values,” Morsi and Baghat interpret it as a casual or inconsequential conversation. The contrast between what is intended (a serious discussion) and what is understood (a trivial conversation) produces comedic tension, making the exchange humorous.
Non-marked Humorous Elements
Non-marked humorous elements are encoded within the context of the exchange and its absurdity. For instance, Morsi’s statement“أنا محبش أتكلم عن حد هو مش موجود” (I don’t like to talk about someone behind his back) indicates that he has no clue about what the concept “Absolute Values” is. Moreover, Morsi exaggerated exclamation of the notion “talking” shift the focus from the serious settings of the discussion into an irrelevant absurd conversation.
Paralinguistic Humorous Elements
Tonality plays significant role in highlighting humor in the scene, precisely Morsi’s high pitch in expressing his frustration disapproval to Effat initiation of a topic. The following screenshots from Praat indicates how tone pitch marks and preserve humor in English by means of voice cloning (Figures 10 and 11).
Morsi’s relatively high pitch indicating his exaggerated frustration measures 267.8 Hz.

Morsi’s relatively high pitch indicating his exaggerated frustration measure 285.2 Hz.
Humor Techniques
Example (4) quoted from Madrasat Al- moshaghebeen (School of Mischief).
Example (5): quoted from Madrasat Al-Moshaghebeen.
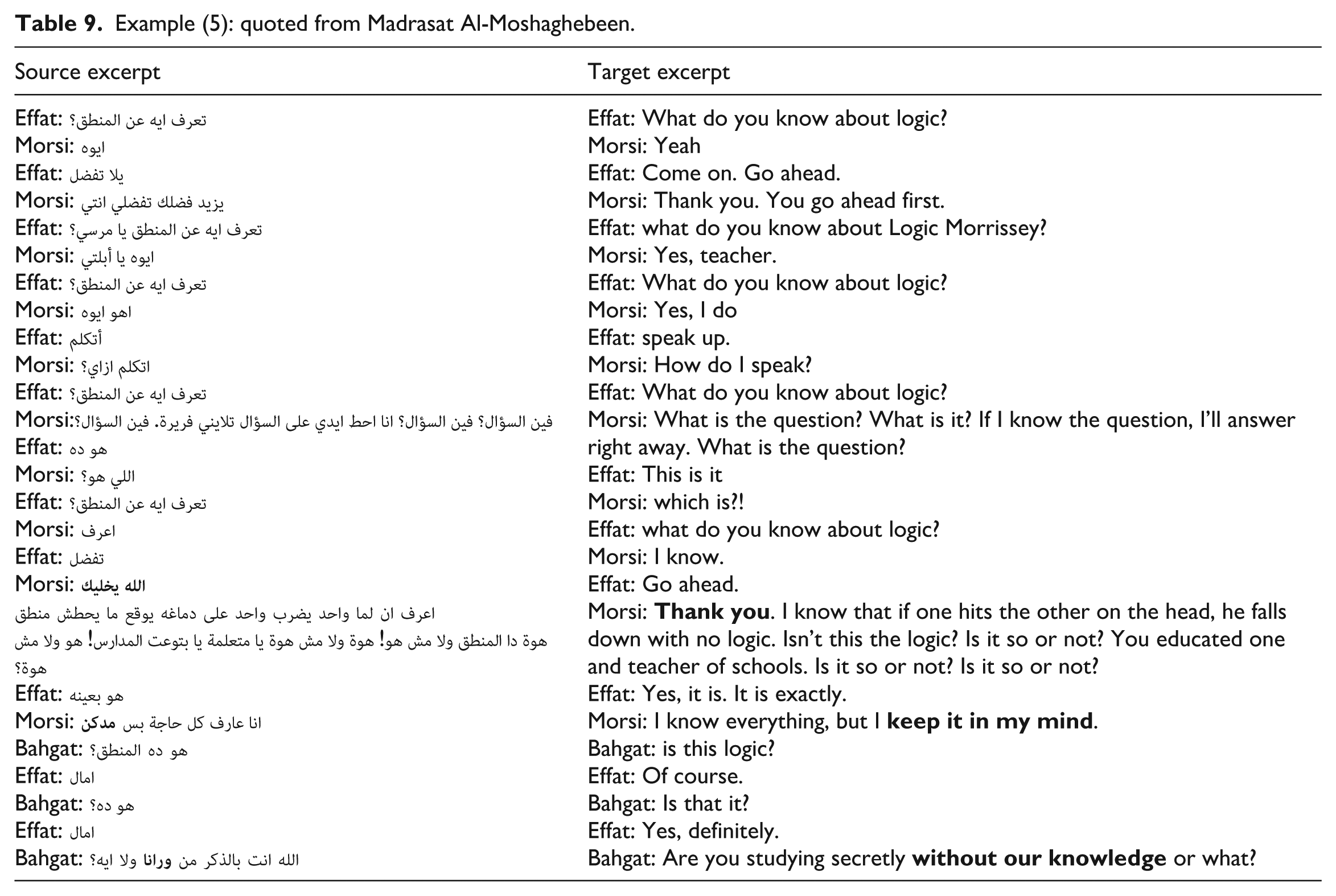
Example (5): quoted from Madrasat Al-Moshaghebeen.

Humorous Elements
Linguistic Humorous Elements
Morsi’s witty use of language, precisely using stalling utterances “فين السؤال؟ فين السؤال؟”,“ايوه” (Ok, what is the question?) and (How can I speak?)“أتكلم ازااي” presents the way he manipulates the conversation to stall the answer to Effat’s direct question instead of explicitly saying that he doesn’t know the answer. Morsi’s absurd answers to Effat’s serious question create humorous tension that keeps the audience tuned for Morsi’s next utterance.
Community-and-Institutions Elements
Humor is also coded in certain social and cultural references that present particular social and cultural dimensions of the Egyptian community. For instance, Morsi’s sarcastic addition after his absurd answer about logic “يا متعلمه يا بتوعت المدارس” (You educated one and teacher of schools) pokes the fun through mocking the notion that formal education necessarily leads to better understanding. Morsi shifts the power dynamic, making himself seem wiser or more intellectual, despite of being ignorant.
Community- Sense-of-Humor Elements
Morsi’s absurd answer to Effat’s serious question draws insights on Morsi limited intellectual capability. Morsi oversimplified a complex topic such as Logic into a violent action “لما واحد يضرب واحد على دماغه يوقع ما يحطش منطق,” ( I know that if one hits the other on the head, he falls down with no logic), yet he acts as if he has just provided a perfect reasonable answer. His attitude presents a common tendency in Arabic society in general and Egyptian society in particular to oversimplify complex topics, which are out of their knowledge, into references from daily life. Humor is relatable to the audience since they are familiar of Morsi’ s absurd attitude.
Unmarked-Humorous Element
The unmarked humorous element is highlighted by Bahgat’s final exclaiming utterance reflecting on Morsi’s absurd answer “ الله انت بالذاكر من ورانا ولا ايه” (Are you studying secretly without our knowledge or what?). Not realizing the absurdity of Morsi’s answer, Bahgat turns back to Morsi and accuses him of betraying them by studying secretly. Humor is layered in the clash between what would normally be expected of a student to do and Bahgat scolding reaction as if studying is not a thing they should do, and Morsi has deviated this norm by studying secretly without their knowledge.
Paralinguistic Humorous Elements
Tonality significantly marks humor in this scene, particularly Morsi’s exaggerated verbal performance. The drastic shift in Morsi’s tonality from his low pitch in stalling utterances to a higher pitch in his exaggerated absurd response. The following screenshots from Praat indicates how Morsi’s high voice pitch marks and preserves humor in English by means of vocie cloning (Figures 12 and 13).

Morsi’s relatively high pitch in his exaggerated response measures 337 Hz.

Morsi’s relatively high pitch in his exaggerated response measures 305.4 Hz.
Humor Techniques
Discussion of the Findings
The first layer of analysis drew insights on the humorous elements found in the data classified based on Martínez-Sierra’s (2006) Taxonomy of Humorous Elements, and humor techniques used in the content based on Juckel et al. (2016) typology of humor techniques. The analysis marked a variety of humorous elements in the reels, stemming from the diversity of the original content. Precisely, the analysis identifies culture-related elements, such as community-and-institution elements and community-sense-of-humor elements. By identifying these elements and understanding how they contribute to the overall humorous effect, the translator was able to make translation choices that preserve humorous effect in the English-dubbed reel, especially elements that hold some cultural and social specificity, such as community-and-institution elements and community-sense-of-humor elements. Most significantly, the role of paralinguistic elements, particularly prosodic cues, such as voice pitch in delivering humor was also marked in all reels, with minor instances of language-based humor. The analysis indicates that ElevenLabs’ voice cloning technology effectively replicates these prosodic cues, with differences in voice pitch between the original and cloned voices ranging from 10 to 30 Hz, which is deemed insignificant. These differences are attributed to voice cloning’s control over aspects like pitch, volume, and intensity, making differences related to voice pitch between characters more pronounced. Moreover, lower quality of the original recordings, often from older films and plays also contribute to these minor differences.
The majority of the verbal content was directly transferred into English, which maintained the humor in some cases but led to losses in others. To handle cultural references, colloquial structures, and idiomatic expressions, the translator employed a mix of translation strategies, including paraphrasing, resignation (intentionally omitting a part of the source text because it hard to translate in the target language), expansion, omission, and condensation (shortening or simplifying the text), making the humor more relatable and natural to an English-speaking audience.
Regarding humor techniques, the contents involved a mix of techniques related to language (e.g., irony, repartee, wit), logic (e.g., absurdity, conceptual surprise, outwitting, misunderstanding), and identity (e.g., parody, rigidity, self-deprecation). As it was evident in the analysis, most of the used humor techniques are related to logic, particularly absurdity, conceptual surprise, and misunderstanding. These techniques were preserved into the English dubbing by means of direct transfer strategy.
Viewers’ Perception Toward Voice Cloning as a Dubbing Tool
This layer of analysis draws insights from viewers’ perceptions regarding voice cloning efficiency in dubbing Egyptian Comedy into English. The analysis compares the perceptions of two groups of the study’s population including Arabic-English bilinguals and English natives. The sample of population consists of 11 participants from each group. Both of the questionnaires tackle viewers’ perceptions toward the preservation of various aspects of humor, such as cultural adaptation, comedic timing, humor tonality and most importantly the validity of voice cloning in conveying humor compared with subtitling and conventional dubbing.
As it appears in Figure 14, most of Arabic-English bilinguals enjoyed the dubbed reels; however, find them less humorous than the original Arabic content. Their views varied regarding the naturalness of the cloned voices. While the slight majority found that voice cloning preserved key vocal qualities, some reflected dissatisfaction regarding its ability in capturing comedic timing and cultural humor. More than the half of the participant found humor rendered well into English, yet they struggled to understand some cultural references. They generally agreed on the fact that voice cloning is as a more effective dubbing tool in preserving voice authenticity compared with conventional dubbing. Nevertheless, opinions on its revolutionary potential were divided. On the other hand, English natives enjoyed and comprehend the dubbed reels, with being mostly satisfied with naturalness and the consistency of the cloned voices. Moreover, they deemed voice cloning effective in preserving emotional tone and personality alignment. However, views were neutral regarding comedic timing while cultural adaptation was not adequately reflected in the dubbed reels. Though most of them prefer subtitles, they acknowledged that voice cloning made the humor more accessible compared with subtitling and conventional dubbing. Briefly, both groups recognized voice cloning’s potential as a dubbing tool, though slight improvements in voice quality and naturalness were suggested, along with better renditions of cultural elements.

Viewers’ perception toward voice cloning as a dubbing tool.
Conclusions
The study revealed that the English dubbing maintained the essence of humor by means of literal or direct translation strategy, particularly humor evoked by means of techniques related to logic and character identity. However, the English dubbing fell shorts to account for some of the cultural contextual aspects of a few instances of humor when transferred directly. It was evident in the data analysis that most of the cultural assets of humor were paraphrased and resigned to fit with target audience cultural background and social dynamics. Nevertheless, there were a slight majority of English natives who found some cultural assets of humor confusing. According to English natives, the dubbed contents were at some various levels of enjoyment. Bilinguals, on the other hand, mainly indicated that the dubbed contents are much less funny compared to the source Arabic ones. This variety of enjoyment is mainly affected by the extent to which the viewer is familiar with Arabic humor in general and Egyptian humor in particular.
Regarding the efficiency of voice cloning as a dubbing tool in dubbing Egyptian humor into English, the majority of both groups found voice cloning relatively efficient in capturing the emotions and tone of the original comedy. Therefore, voice cloning outperformed subtitling in terms of making humor more accessible and comprehensible to English speaking audience. Most significantly, the slight majority of both groups believe that voice cloning, to some extent, outperformed conventional dubbing in conveying Egyptian humor. These findings asserted that viewers assumption that voice cloning is likely to be considered as an effective tool for dubbing comedy content into English. The study recommends that experts in AVT industry should be more open to the integration of advanced AI technologies such as AI voice cloning to enhance the tonal and emotional fidelity in dubbed content, especially comedic content where the delivery of humor is highly dependent on preformed vocal nuances. Therefore, a hope for a full dubbing conducted in professional settings, produced by high quality voice cloning technology will be realized. Future research is recommended to account for the utility of voice cloning in dubbing other genres of audiovisual contents bedside comedy such as drama, documentaries, horror and cartoons etc.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on request.