
Abstract
This study proposes a preliminary descriptive framework of the Multilingual Conversion Error (MCE) to account for systematic errors made by L2 learners from non-native English-speaking countries when learning Chinese as a second language (L2) in an English-medium instruction (EMI) context. Unlike classical transfer models, the MCE framework emphasizes that language education often proceeds through an indirect route—from English (instructional language) to L1 (native language) to Chinese (target language). This indirect processing increases cognitive load and facilitates more cross-linguistic interference. Drawing on a collection of 68 compositions by beginning learners writing in Chinese at a university in Taiwan, the study identifies four typical error types: syntactic transfer, semantic transfer, literal idiom translation, and cultural-pragmatic misuse. These errors showcase the multilingual learners’ reliance on mental translation strategies and structural characteristics of their L1. The MCE Framework takes a different approach than the more traditional L1 to L2 transfer or interlanguage theories by highlighting instructional language as a non-neutral variable in learning, particularly when it is not a learner’s L1. The data show that EMI may inadvertently reinforce learners’ use of their first or native tongue as a mediator step, for conceptual mediation purposes, creating systematic error patterns in the learners’ output. The study contributes to viewing multilingual mediation as part of language processing and advocates for a re-evaluation of EMI in Teaching Chinese as a Second Language (TCSL). It also encourages the use of the target language in classroom instruction to maintain a lower cognitive load and facilitate language acquisition.
Plain Language Summary
This study looks at why students often make mistakes when learning Chinese in classes taught in English. For many learners, understanding goes from English to their own first language to Chinese, which makes learning harder and causes common errors. We built a new model (MCE Framework) to explain these mistakes and suggest that using more Chinese in teaching can help students learn faster and with fewer errors.
Keywords
Introduction
With the growing trend of language teaching in the context of globalization, English as a medium of instruction (EMI) has been more and more widely used in Chinese language classrooms, especially in international programs and linguistically diverse learning contexts (Duff & Li, 2004; Gong et al., 2020). According to Gong et al. (2020), English is commonly referred to as the medium of instruction, including in a variety of subjects in primary and secondary schools, even at home, but also in colleges and universities in China, and even in language courses with students learning Mandarin in colleges within China. However, in most research, English is considered a unidirectional language transfer, and the special information processing mode and error mechanism in situations where the instructional language is English and the learners’ mother tongue is not English remain underexplored.
This study explores a frequently neglected aspect of language learning: in beginning-level Chinese programs taught in English, learners typically start by understanding the input in English, transition to processing the content in their L1, and eventually output in Chinese. This “English to L1 to Chinese” conversion channel repetition access adds much to the cognitive burden and multiple layers of linguistic interference, which lay the foundation for systematic sources of errors to grow. These cross-linguistic effects are not L1 to L2 transfer in the classic sense, in that they extend beyond single-language mediation. Instead, the latter is an overarching phenomenon, which the paper refers to as “Multilingual Conversion Errors” (MECs) (Jarvis & Pavlenko, 2008; McManus, 2021).
For such errors, this paper outlines a conceptual framework of the Multilingual Conversion Error (MCE) grounded on linguistic and cognitive rationales. It simulates error output under conditions where the teaching language is English, non-native English students are involved, and the target is Chinese. This work extends beyond mere error repair at the surface level and gets at deeper processes of re-conceptualization at the word-order restructuring level, the semantic re-mapping level, and the pragmatic misalignment level (Odlin, 1989; Weinreich, 1979).
There are three primary questions addressed by the study:
What kind of systematic errors occurred in EMI Chinese classrooms among non-native English speakers?
Are these errors due to a multi-stage transformation of language, and not to the transfer of a single source language?
How do errors by language learners differ in both form and frequency as a function of the language of instruction (L1, L2)?
By drawing on language transfer, cross-linguistic influence, and cultural pragmatics based on empirical error analysis, this study intends to explore the formation of multilingual conversion errors and offer theoretical enlightenment and pedagogical implications to fill the void of Chinese language education research in the context of multilingual input.
Literature Review
Limitations of Traditional Language Transfer and Interlanguage Theories
The idea of language transfer has had a long historical standing in Second Language Acquisition (SLA) research, being used to describe the transfer of L1 phonological, syntactic, semantic, or pragmatic rules to the Target Language (TL) with both positive and negative effects (Odlin, 1989). Early research, for example, Weinreich (1979) has stressed the effect of language contact on the advent of errors. Corder (1981) and Selinker (1972) also added the concept of interlanguage and systematicity of learner errors, which have become the cornerstones of error analysis in SLA studies.
However, these approaches tend to use L1 as the central or exclusive source of transfer, or focus on the influence of a specific language system on the TL. While Jarvis and Pavlenko (2008) extended the concept with the notion of crosslinguistic influence, recognizing that multilinguals borrow from more than one source language, few studies explore cases where the language of instruction itself is not the learner’s L1. Specifically, in EMI settings where the language of learners is not English, the transfer becomes a multistage procedure—through English, L1, and Chinese—that produces mixed-source errors not easily explainable by existing theories (Hao et al., 2025; Jinghui, 2023; McManus, 2021).
The Need for a Multilingual Conversion Framework
To address these theoretical shortcomings, this article develops the Multilingual Conversion Error (MCE) Framework. It posits that, in such EMI-Chinese classrooms, learners often rely on an intermediary process of recasting English teaching input into their L1 conceptual structures before generating output in Chinese. Errors are commonly made at each of these stages. This translation involves not only formal structural transfer but also semantic logic formed by several languages and of pragmatic schemes embedded within diverse cultural systems (Baker, 2011; W. Li, 2018).
Observed errors tend to combine features of other languages: surface syntax may be similar to English, logical sequencing may resemble the learner’s L1, and pragmatic expression may differ significantly from Chinese norms. (Sun, 2021; Wierzbicka, 1997). These tendencies reveal the lack of those models proposed before that do not consider trilingual interactivity and indirect mediation within real-world learning environments.
In contrast to translanguaging theory (W. Li, 2018), which emphasizes fluidity, flexibility, and autonomy on the part of the learners in rendering their entire linguistic repertoire, MCE exhibits cognitive segmentation and sequencing while processing non-L1 instruction language. Instead of fluid in-betweenness, EMI settings subject learners to higher cognitive load, mediated overlaps, and sequenced interferences.
Like Mediated Discourse (MD) (Scollon & Scollon, 2004), it pays attention to semiotic and social features of discourse. But MCE does rather more specifically stand at the interface between psycholinguistics and pedagogy, interested in how gaps between instruction-input, cognition-process, and target-output generate systematic error. This direction has a natural role in underscoring the application relevance of this model to work in applied linguistics and SLA research.
Theoretical Development and Pedagogical Challenges of Chinese Teaching
In introductory Chinese courses, especially at the beginning level, English is used as a “working medium” to explain grammar rules and pragmatic contexts (Goh, 2017). However, English-based instruction makes learners process input again in the L1 before they can produce Chinese output, entailing higher cognitive load and higher error rates (Paas et al., 2003). Such indirect input–output mapping tends to cause semantic misalignment, word-order displacement, and pragmatic inappropriateness and supports the systematicity of multilingual errors.
Thus, a higher level of priority should be accorded to the use of the target language (Chinese) as a primary medium of instruction. Though this practice will create a primary challenge among new students, it can be complemented by using high-frequency vocabulary, drawings and photographs, body movements, and contextual exercises, enabling internalization of Chinese pragmatics and grammar and reducing dependency on indirect mediation (Wu, 2025; Wu et al., 2025).
In a broad perspective, classical transfer and interlanguage theories cannot entirely explain complexity in multilingual EMI contexts where neither the teaching medium nor the TL is congruent with learners’ L1. What emerges here is a gap that this article tentatively addresses through an MCE Framework that engages multi-stage mediation and cross-language interference for a better Chinese language analytical lens applicable across global EMI contexts (Jia et al., 2023; McKinley et al, 2023).
Theoretical Model: Multilingual Conversion Error (MCE) Framework
Rationale and Core Assumptions
Based on the theoretical problems found in previous studies, the present study presents a Multilingual Conversion Error (MCE) Framework to compensate for systematic error development if English is adopted as a medium of instruction and nonnative English-speaking learners study Chinese as an L2. The central assumption is that processing is a three-mediated process: learners must first process English instructional input, process it again in an L1 conceptual system to reconstruct it, and only then generate Chinese output. Such an indirect process sequence, a theoretically predicted process of cognitive load theory (Paas et al., 2003; Sweller, 1988), causes competition between the processing resources for comprehension and production, and thus the probability of cognitive overload and language errors is enhanced.
Three-Stage Conversion Model
The MCE Framework contains the following three phases:
Instructional Mediation (English Input): Learners are taught to read grammatical rules, semantic concepts, and pragmatic functions in English.
L1 Conceptual Relay: Learners restructure the input by mapping it onto their L1-based semantic and syntactic representations (Anderson, 1986) in order to achieve internal comprehensibility.
Target Language Output (Chinese): Learners may produce target language forms using L1-based data, leading to structural, semantic, and pragmatic incompatibilities.
As illustrated in Figure 1, the MCE Framework assumes a three-stage conversion pathway (see Figure 1):

Multilingual Conversion Error Framework.
Crosslinguistic (CL) influence can occur at each stage, leading to commonly found error types such as syntactic transfer, semantic incongruence, literal translation of idioms, and cultural-pragmatic misuse (Bialystok, 2001; Corder, 1981).
Specific Characteristics and Interpretation Aspects
Unlike the traditional interlanguage theory, the MCE has three characteristics:
It highlights instructional language (English) as a non-neutral medium that brings in its noise wherever it isn’t the Learner’s L1.
It reveals that errors are due to intricate inter-system relations, not to one-directional translation from a single language source (Jarvis & Pavlenko, 2008).
It is a nonlinear, unbalanced sequence of understanding, understanding-based conceptual relay, and (output) construction, reflecting the cognitive load framework’s primary focus on the interplay between working memory constraints and task difficulty (Paas et al., 2003; Sweller, 1988).
Whereas the MCE Framework assumes a three-tiered chain from English to L1 to Chinese in language processing, the mental processes hypothesized for actual language processing are probably dynamic and interwoven. Green’s (1998) Inhibitory Control Model emphasizes that multilinguals must proactively control the activation and suppression of more than one language system. Likewise, in high cognitive load conditions, multilingual learners tend to resort to stable and predictable strategies for the management of semantic ambiguity and syntactic demands (Costa, 2005).
Data from the interviews in this study confirm this view. Many learners also claimed that they did not think in English and then translate directly into Chinese, but by way of an extra step, with their first language. For instance, one Vietnamese participant said, “When I am trying to make up a sentence in Chinese, I have to translate it in my mind to English, and then I modify it into Vietnamese, and I speak it out in the Chinese language.” Such reports outline how indirect conversion patterns generate strategic but error-prone utilization of L1 representations, supporting the psycholinguistic plausibility of the MCE Framework. (Sweller, 1988).
Suggested Visual Representation
We suggest that, to make the theory clearer for future publications, a visual model should be included in formal media. The figure is supposed to depict the trilevel process derailment sequence, cognitive flow, and error-prone regions, and thus render more tangible the actual dynamics of multilingual interference and crosslinguistic mediation.
Methodology
Context and Participants
Data for this research were drawn from a beginning-level Chinese language course in a university-affiliated language center in Taiwan. The subjects were non-native speakers of Chinese with different language backgrounds. 68 Chinese essays constituted the main corpus for error analysis. While the students were non-native English speakers, the course was delivered in English only, constituting a rather common English-as-a-medium-of-instruction (EMI) context. Thus, students process English instruction first, then reinterpret it in their L1, and only then produce Chinese output. Such an indirect English to L1 to Chinese conversion sequence matches MCE Framework assumptions (Goh, 2017; Gong et al., 2020).
The corpus-based analysis is especially successful in Chinese teaching research for helping discover the error patterns of beginner learners (Du, 2025). The present study takes the corpus linguistic method and develops an inductive framework for error taxonomy based on authentic learner data.
The participants were 18 to 24-year-old learners at the midpoint of an 18-week semester term of Chinese language instruction. They had moved beyond the extremely limited input and the basics of output, but they were still prone to errors such as incorrect word ordering, semantics, and pragmatics. All participants filled out a language background questionnaire, which indicated that their first language was Vietnamese and Indonesian. All students were learning Chinese in an English-mediated classroom where English was their L2.
Considering the linguistic distance and the disparity in the syntax of Chinese concerning the L1 of the learners, these learners were particularly susceptible to conceptual transfer and pragmatic interference, thereby making them an ideal group of candidates for exploring MCE (Cañizares-Álvarez & Gathercole, 2020; Kellerman, 1995).
Corpus & Coding
According to the MCE Framework, this study categorized learner errors into four error types:
Syntactic Transfer Errors: The movement or omission of word order patterns from L1 or English, perhaps, due to a lack of these syntactic elements in the latter (Ellis, 2009).
Semantic Transfer Errors: A semantic transfer was made between L1 or English logic and Chinese (Jarvis & Pavlenko, 2008).
Literal Idiom Translation: Direct translations of idiomatic fixed expressions, yielding inappropriate, illogical, or even culturally unacceptable expressions (Sun, 2021).
Cultural-Pragmatic Misuse: Chinese cultural-pragmatic norm violations (e.g., use of politeness formulas, terms of address, turn-taking) suggest L1 sociocultural framing interference (Hall, 2002; Wierzbicka, 1997).
To illustrate the example of the most common syntactic transfer error, the following was generated by one Vietnamese learner: “他去昨天學校” (intended: “他昨天去學校”). This shows the incorrect placement of the adverb “昨天,” which results from L1 transfer of Vietnamese placement for adverbs rather than word order at the level of SVO. This error reflects how L1 word order conventions can ruin the sentence structure in Chinese.
Reliability Measures
Inter-rater reliability was measured using Cohen’s κ; the results are reported in Table 1 (see Table 1).
Interrater Agreement by Error Type (Cohen’s Kappa).

Note. Cohen’s κ values between .61–.80 indicate moderate to substantial agreement (Landis & Koch, 1977), suggesting satisfactory coding reliability for this study.
Analytical Strategy
This study is a mixed-methods paradigm study using qualitative and quantitative validation. All statistical analyses (e.g., ANOVA) were conducted using SPSS (version 26.0), ensuring reliability of results. Composition was marked sentence by sentence and classified according to the four types of error described above. Sources of group variance were ruled out by cross-referencing learners’ native languages to investigate L1-related variability within the L2 groups. A further 12 respondents were interviewed semi-formally to explore their language processing strategies and to develop a triangulation between their perceived strategies and triangulation between their observation and error analysis (S. Li, 2010; Richards, 1971).
This paper showed dialect heat maps that were distinctly shaped in the error distributions by the L1 backgrounds of the participants, in alignment with the MCE model’s prediction that cross-lingual influence is nonlinear and mediated. One Vietnamese respondent commented: “When I say a Chinese sentence, I’m translating it from Chinese into English and then scrambling for Vietnamese grammatical order in my head to say that sentence in Chinese.” Her written work featured regular preposition misplacement and misunderstanding about modal particles, a sign of interlanguage influenced by intermediate L1 mediation.
Results
Interrater Reliability (κ)
Table 1 shows Cohen’s κ numbers for every error of all kinds. All amounts are between .62 and .73, which, according to Landis and Koch’s (1977) rules, means fair to strong agreement. Thi͏s means that the coding method in this study has good trustworthiness and that the noted error types can be seen as steady for later tests.
Descriptive Statistics of Errors
The most and least frequent source errors are presented in Table 2 (see Table 2). As indicated below, the most common type of error was syntactic transfer (38.7%), followed by semantic transfer (25.0%), cultural-pragmatic misuse (22.3%), and literal translation of idioms (13.7%). Figure 2 also depicts the distribution of errors by type for the two groups of L1 learners (see Figure 2). While the Vietnamese learners produced more syntactic errors, the Indonesian learners produced more errors in pragmatics and idiomaticity. These differences are represented in reference to each other in Figure 3, which reveals that both the forms of errors and the rates at which they are repaired are influenced by the learner’s L1 background (see Figure 3). In Table 3, examples of learner errors possible learner errors and their categorization are summarized to show the relationship between particular examples and the four student error types from the MCE Framework (see Table 3). A complete matrix of error counts by composition and error type is provided in Appendix A. All these descriptive patterns are a similar form of multilingual mediation predicted by the MCE framework.
Distribution of Error Types across L1 Groups.

Note. Error for every 1,000 letters = all errors ÷ all characters × 1,000; this makes the error count equal across writings of different sizes.
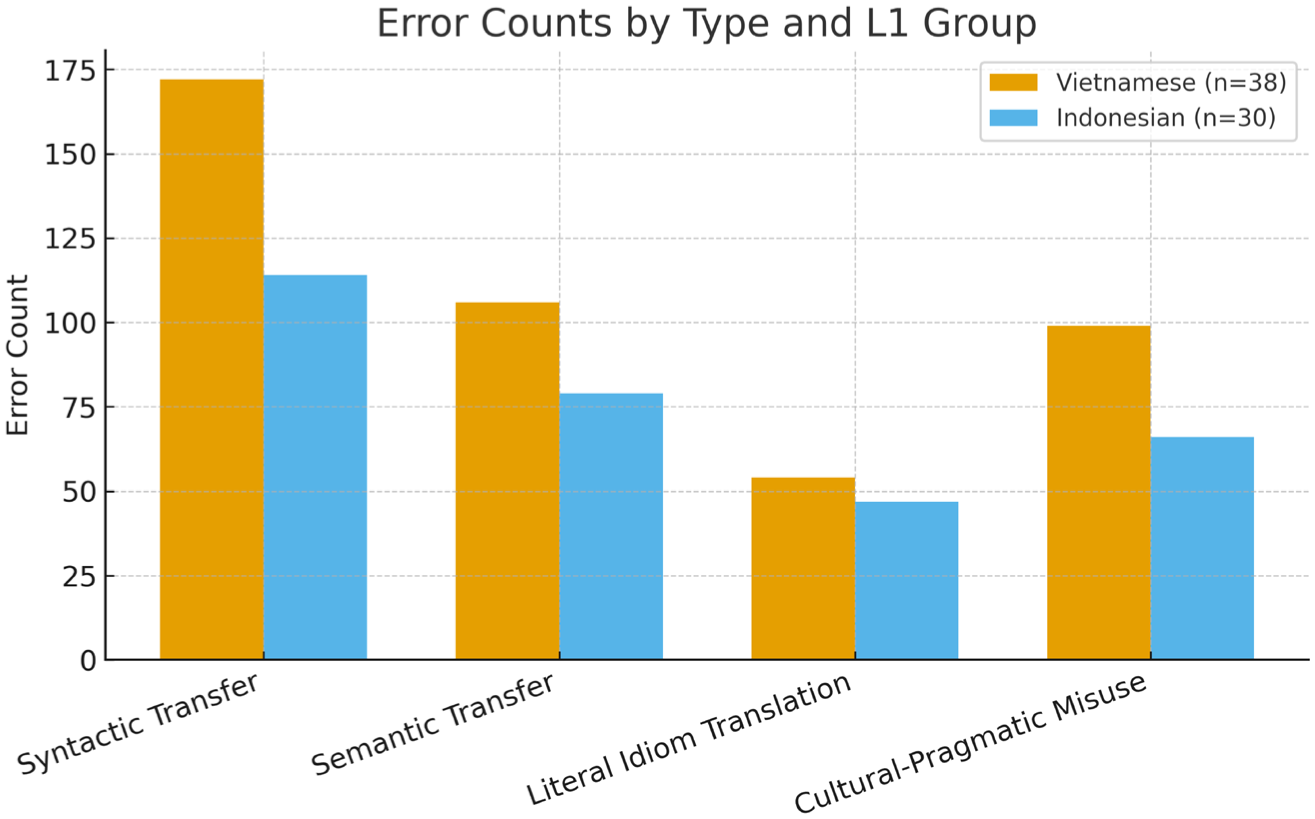
Distribution of Error Types across L1 Groups

Relative Error Distribution by Type and L1 Group
Representative Learner Errors and Classifications.

Indicates ungrammatical or pragmatically inappropriate learner sentences.
Representative Examples
Inferential Statistics
Statistical analysis confirmed these results. A one-way ANOVA investigated syntactic transfer error between L1 groups (see Table 4).
One-Way ANOVA for Syntactic Transfer Errors by L1 Group.

Note. SS = sum of squares; df = degrees of freedom; MS = mean square. p < .05.
Statistical significance was tested with a one-way ANOVA in which the learners formed the unit of analysis. The results revealed that there was a significant L1 group effect on syntactic transfer errors (F [1, 66] = 4.21, p < .05), suggesting that L1 structures affected conversion errors based on one’s own and others’ data.
Assumptions were assessed prior to conducting the one-way ANOVA. The distributions of the counts of syntactic errors did not differ significantly from normality (Shapiro–Wilk test; p > .05); and the assumption for homogeneity of variance was met (Levene’s, p > .05). In cases where the assumptions were borderline, the results were also checked using Welch's ANOVA, which yielded the same pattern and significance of results. To promote clear interpretation of results, the effect sizes (η2) were reported alongside the F-statistics.
Post hoc Tukey tests showed that the word order performance of participants with a fixed word order L1 (e.g., Vietnamese, which is SVO in the L1) was significantly better than that of participants with a more flexible word order L1 (e.g., Indonesian). This result also provides direct evidence for the claim made by the MCE model that L1 typology mediates error construction in multilinguals.
In other words, the MCE framework finds preliminary empirical support in this study, which contributes to the validation of error types and illustrates the influence of learners’ indirect multilingual conversion strategies, thus supporting its application to SLA studies by taking EMI as a case.
Process Visualization
As illustrated previously, the MCE Framework involves a three-stage conversion process (see Figure 1).
Discussion
Interpretation of Error Types
The analysis indicates that the four types of errors—syntactic transfer, semantic transfer, literal idiom translation, and cultural-pragmatic misuse—repeatedly appear in English-medium beginner Chinese classes. The numbers of counts show that errors in grammar (form and meaning) are the most frequent, but also cultural and idiomatic errors show that students blend their linguistic culture. The findings from them show that language-based learners think indirectly, which is why they make the same errors hundreds of times.
Instructional Language Choice and Cognitive Load
The current study presents evidence that there is a great deal of linguistic interference between beginner-level Chinese learners in EMI classrooms and their L1 and English. These are settings where multilingual conversion errors abound and lead to a large cognitive overhead in the production of output. As learners deal with both grammatical rules, semantic mappings, and cultural appropriateness at the same time, it makes them fall into semantic misalignments and pragmatic misjudgments (Paas et al, 2003; Sweller, 1988).
Although English can be used as a convenient lingua franca in educational contexts, Foreign Language (FL) needs to be further translated into the learner’s L1 for them to be able to fully understand and internalize its contents. This roundabout manner of processing impedes cognitive operations such as syntactic restructuring, increasing the risk of both semantic errors and pragmatic deviations, and thus hindering Chinese as a target language (Goh, 2017; Lightbown & Spada, 2013).
Cultural-Pragmatic Insights
In student works, we encountered several cases of cultural-pragmatic misuse. For example, a few students translated Vietnamese greetings directly (e.g., “你吃飯了嗎?” “Have you eaten?”) when talking to professors. While this is grammatically acceptable in Chinese, these expressions can seem overly intimate and are socially inappropriate in formal and academic settings where Chinese norms are followed. Doing this would causally appear as if a learner was following Chinese norms because they would be greeting a person using greetings such as “老師您好” or some honorific like “教授.” In another case, students inappropriately referred to strangers in terms of kinship (e.g., “哥哥, 姐姐”), a reflection of L1 rather than L2 sociocultural transfer, and only in rare cases did one student refer to someone of equal status as “朋友”, not recognizing that it was against politeness norms. One of the most overused expressions related to someone of relative authority was the use of the neutral pronoun “他” (he) instead of the title “老師” (teacher). For example, one student used “他要我們在教室裡休息” (He wants us to rest in the classroom). Specifically, the local and colloquial use in Taiwan may allow this in spoken expression; however, in formal discourse, especially written, it would be expected that things be treated explicitly with hierarchy respect that is recognized with 老師.
These cases clearly indicate that findings of cultural-pragmatic errors are not just encounters of linguistic transfer but also mismatched expectations of register and respect. This means that learners should be provided with opportunities to attend to language forms (e.g., grammar and vocabulary) while also attending to pragmatic relations (e.g., addresses, honorifics, politeness). Teachers can mediate this awareness by modeling expressions of regard and further accommodating discourse related to expressions that are simply colloquial.
Pedagogical Implications
Compared to the too-heavy dependence on English explanations and translations, the teaching of Chinese, whether it is the program for beginners, should reflect, very consciously, the practice of using the target language (Chinese) as the primary language of instruction. While this method is somewhat daunting for beginners, supported treatment (including the use of high-frequency words, visuals, gestures, drills, and other interactive activities) results in language learning that is stronger in pragmatic intuition and structural intuition and less prone to relying upon interlingual translation (Lyster, 2007; VanPatten, 2015).
It also offers the ability for students to directly build internal language representation and to establish syntactic and semantic relationships in the target language. Therefore, learners tend to produce more linguistically accurate and contextually appropriate output (Gay, 2010; W. Li, 2018).
The results also demonstrate that teachers’ perception of multilingual conversion errors is very important in planning English for Specific Purposes (ESP) teaching activities. Teachers can help prevent error fossilization by varying the use of instructional language, question type, and when feedback is provided. It is important for teachers to have a rudimentary understanding of the linguistic backgrounds of their learners to be able to predict crosslinguistic interference patterns and scaffold the learning of differences between language systems (Ellis, 2009; Walsh, 2011).
Curriculum design should also include contrastive linguistic approaches and pragmatic scenario shifting to encourage students to step out of linguistic routines and become sensitive to appropriateness at a sociocultural level and contextual variation. With such a curriculum design, students solidify their intercultural communicative competence (Byram, 2008; Wierzbicka, 1997).
Another important line of inquiry is the distinction between formal canonical/standard use versus informal colloquial use. For example, a number of learners referenced teachers with the neutral pronoun “他” (he), claiming that local speakers do so as well. This is certainly a true observation in a colloquial context, but in formal academic writing and classroom assessment, there is the expectation to use the canonical form “老師” (teacher). Thus, there is a need for teachers to explicitly identify the context challenge for learners: colloquial forms may be appropriate when interacting with peers, but in exams and in written assignments, students should be required to use standardized forms to communicate in formal contexts. Not only does highlighting this difference limit an error from being fossilized, but it also develops learners' awareness of pragmatic differences of register (i.e., language use in context) and situational appropriateness in Chinese.
Summary
In conclusion, this is a preliminary, evidence-informed framework that reveals the cognitive and linguistic hazards attributed to the use of EMI in beginner Chinese classrooms. These failures materialize as systematic errors due to heightened cognitive load and intricate interlingual processing. Thus, curriculum development, instruction policy regarding linguistic use, corpus compilation, and teacher training all require precise alignment in this direction. Such changes will maximize instruction and support more accurate, contextually sufficient learner output.
Limitations and Future Directions
Theoretical Scope and Applicability
Even though this study develops the MCE Framework and a conversion model based on three stages in the language mediation process, this theory is bounded by a specific learning situation: the language of teaching is English, the learners are non-native speakers, and the target language is Chinese. Accordingly, it does not consider other instructional settings or student populations. Some potential examples could be that of the language of instruction matching with the learner’s L1 or that of the learners being already bilingual or trilingual, and then the conversion path taken could be very different from the model proposed in this study (Gass & Selinker, 2008; Jarvis & Pavlenko, 2008).
Moreover, the MCE Framework reduced the language translation process to a straightforward linear trilinear structure (English to L1 to Chinese). Language processing is far more dynamic, recursive, and interactive (DeKeyser, 2007; Tomasello, 2003). Yip (1995) also suggests that target language learning difficulties stem not only from L1 transfer effects but also from learners’ ability to internalize and formulate syntactic and word order rules in the L2. Thus, subsequent work should explore further how deep learning processes and cognitive modeling can illuminate the acquisition of semantics and grammar in a range of multilingual contexts.
While the current study examined learner output and interview data, it did not focus on online processing. Process-tracing evidence is needed to draw causal inference. Future studies could incorporate protocols such as think-aloud, eye-tracking, and reaction time experiments to track the learners’ intermediate representations and confirm whether the English to L1 to Chinese mediation sequence takes place in real time.
Corpus and Analytical Constraints
The corpus in this study was retrieved from a single class in one institution and was unevenly divided across L1 backgrounds. Heterogeneity between linguistic distance and syntactic structures across L1 groups renders statistical strength suspect. Although interview-based triangulation was employed, some errors remain unclearly originating due to both interlanguage interference and interlanguage indeterminacy. These limitations reinforce a need to further investigate learners’ internal linguistic processing, perhaps by collecting data on broader scales, longitudinally, or across multiple sites.
Future Research Directions
Our research asserts that for the MCE Framework, there are three main avenues so far in which the method can be further developed and can be utilized:
Expansion of Language Pairings: Further studies could be conducted to verify whether multilingual errors remain stable across various instructional and target language pairs (e.g., compare “English to Chinese” and “L1to Chinese” paths) between the different paths to investigate the model of cross-linguistic generalization coverage.
Dynamic cognitive analysis methods–such as think-aloud procedures, eye-tracking, and “air traffic control”–mode task observation–can provide process-tracing evidence. The air traffic control metaphor (Isaac & Ruitenberg, 2017; Kendall-Taylor et al., 2013) assists in explaining how multilingual learners' cognitive systems continuously manage various language resources, deciding whether to switch a system on or off at the moment. Such evidence would substantiate whether, in fact, errors are produced at the purported stages of the MCE model.
Instructional Intervention Experiments: Target-language–driven curricula, versus Bilingual Education (BE)-informed and EMI-informed curricula (Lightbown & Spada, 2013; Lyster, 2007) could be developed, and similar effects of instructional language on error frequency, pragmatic accuracy, and internalization of target-language norms could be analyzed to examine the pedagogical utility of the MCE framework.
Cross-Contextual Validation and Quantitative Testing
For increased external validity of the MCE model, it is suggested to conduct further studies in various geographic regions and educational institutions, especially those having different cultural and language policy contexts. Cross-contextual comparative studies will enable us to evaluate the cultural adaptability and generalizability of the model.
Additionally, Chi-square tests and ANOVA tests can also be implemented to measure the extent of the importance of error type variation across L1 groups, thus substantiating the empirical basis and the explanatory power of the hypothesized model.
Summary
This paper provides a tentative theoretical frame and an empirical model of multivalent-conversion errors in EMI-oriented Chinese teaching for non-native English learners. Although theoretically limited and based on restricted sampling, the investigation paves the way for a new research avenue in how indirect multilingual processing influences learner production. Future studies need to improve the architecture of the model, add more language pairs to it, and adapt it to dynamic processing to achieve a more general framework of multilingual error formation in L2.
Conclusion
This study positions itself within the often underserved but highly relevant environment of Teaching Chinese as a Second Language (TCSL) to non-native English-speaking learners in English-medium instruction (EMI) contexts. To explain such systematic and consistent errors made in such multilingual contexts, this research presented the Multilingual Conversion Error (MCE) Framework as a preliminary descriptive framework that assumed that learners would follow an indirect process pathway—from English input through L1 conceptual relay to Chinese output. Three-stage mediation accounts for the cognitive load, linguistic interference, and pragmatic misalignment observed in the learner data.
In contrast to classic theories of language transfer and interlanguage, which typically assume a unidirectional influence of L1 to L2, the MCE Framework emphasizes that these errors stem from multi-layered, recursive, and cross-mediated processes. Learners’ errors aren’t merely structural mismatches, but products of conceptual re-mediation, translation-based overreliance, and pragmatically inappropriate strategies conditioned upon EMI. This broader theoretical description gives a finer, holistic description of multilingual error production.
Empirically, a four-type error taxonomy—syntactic transfer, semantic transfer, literal idiom translation, and cultural-pragmatic misuse—was constructed in this research through an examination of 68 Chinese beginner-level learners’ writings. These categories, supported by both corpus evidence and interview data, yield evidence of systematic effects of L1 typology and English mediation in error formation. Statistical testing further confirmed the significance of L1 group effects, supporting the psycholinguistic plausibility of MCE.
Pedagogically, research suggests that there is a strong need to revisit the choice of linguistic instruction in TCSL. EMI might be expedient, but it could reinforce a translation-based approach and cognitive overload. It is thus contended that instruction should utilize the target language (Chinese) to a larger extent and employ scaffolding strategies such as pictures, gestures, and high-frequency words. Teachers’ training should emphasize consciousness about multilingual conversion errors and equip instructors with strategies to prevent, detect, and thwart crosslinguistic interference.
The MCE Framework is not a developed theory, but instead, serves as an early descriptive model that further elaborates already existing constructs (crosslinguistic influence, cognitive load, inhibitory control) and puts them into a relevant pedagogical context.
In summary, this study contributes empirically and theoretically by producing a new MCE lens transferable to studies on production error in EMI-supported Chinese education. Whilst narrow in scope and sample size, the work makes new possibilities accessible concerning cross-context validation between disparate populations, process-tracing on cognitive processes, and experimental investigation into education.
Beyond the empirical findings, this study contributes an epistemological research approach to SLA research. Whereas classical error analysis and transfer research frequently stay at a description or operational level, this study argues for a reframing of multilingual error production as a problem of knowledge mediation. By framing MCEs as produced out of a stratified sequence of representational transformations (English to L1 to Chinese), this study proposes a tentative taxonomy and conceptual model that accounts for the cognitive and epistemic conditions under which systematic errors occur.
What this MCE Framework does in this way is highlight how a medium of instruction often taken to be a neutral channel is a constitutive agent in structuring learner cognition and linguistic production. This epistemological move does not replace existing interlanguage theory or transfer research but completes them by offering a model of multilingual mediation that places a role for linguistic instruction in the structure of knowledge construction in SLA.
It is incumbent upon us to keep in mind that SLA’s development as a field has long been constructed upon not empirical data banked in the immediate present but upon theoretical constructions informed by knowledge-based reasoning. Pioneering works such as the Input Hypothesis, Interaction Hypothesis, and Sociocultural Framework were all formulated as theoretical proposals before empirical testing and refinement thereafter.
With this venerable tradition in mind, this study situates the MCE Framework within the same lineage: that of a theoretically motivated model whose strength lies in offering a new explanatory perspective on multilingual conversion error, and whose empirical investigation will naturally follow in subsequent research. If anything, this research does not seek to diverge from SLA theorizing’s foundational bases, but rather to make explicit what has often gone implicitly in SLA’s theoretical roots.
Footnotes
Appendix
Matrix of Error Counts by Composition (Document ID × Four Error Types).

| Composition ID | L1 Group | Syntactic | Semantic | Idiom | Pragmatic | Total errors |
|---|---|---|---|---|---|---|
| VN01 | Vietnamese | 5 | 2 | 1 | 0 | 8 |
| VN02 | Vietnamese | 3 | 1 | 0 | 2 | 6 |
| VN03 | Vietnamese | 4 | 3 | 0 | 1 | 8 |
| … | … | … | … | … | … | … |
| ID01 | Indonesian | 7 | 2 | 1 | 1 | 11 |
| ID02 | Indonesian | 6 | 4 | 0 | 2 | 12 |
| … | … | … | … | … | … | … |
Acknowledgements
The author would like to thank the reviewers and editor for their valuable comments and suggestions that helped improve this manuscript.
Ethical Considerations
The study did not require formal institutional ethics approval, as it involved adult learners in regular classroom activities and did not collect sensitive personal information. Anonymity and confidentiality were ensured throughout the research process.
Consent to Participate
The author clarifies that this study analyzed anonymized student compositions produced in the normal course of instruction. All participants were adult learners. They were verbally informed of the research purpose, and consent was obtained for their written work to be used for research purposes. No sensitive personal information was collected, and anonymity was strictly preserved. As the data came from regular classroom practice and involved no intervention, formal IRB approval was not required.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and analyzed during the current study are not publicly available due to the privacy and confidentiality of student work, but they are available from the corresponding author on reasonable request.