
Abstract
Legal Judgment Prediction (LJP) study is experiencing a growing need for automating legal judgment process to predict court decisions. In this context, the present paper provides a systematic literature review of previous LJP study, implementing machine learning (ML) as decision-making and natural language processing (NLP) to extract information from legal judgment documents. Relevant articles were found in reputable indexing databases through the search strategy, with the outcomes filtered by applying inclusion and exclusion criteria. Furthermore, six research questions were constructed to observe the datasets, topics/trends, NLP and ML methods, evaluation methods, and challenges. The LJP topic included three topics which were charge, law article, and term-of-penalty prediction. There were 21 NLP methods applied, emphasizing the highest implementation of Term Frequency-Inverse Document Frequency (TF-IDF) while the most implemented ML method was Support Vector Machine (SVM). Accuracy was the most used metric as an evaluation method. Additionally, this work emphasizes the importance of LJP and the potential use of NLP and ML. This study urges further investigation into NLP and ML, as well as practical uses of LJP. Low classification performance, low quantity of data, imbalanced dataset, data accessibility, data labeling, extraction of semantic information from natural language, expert involvement, generalizability issue, and multilingual datasets represent a few of the major problems that LJP faces, and the study is significant because it clarifies some of the major issues that LJP faces. Among those problems, low amounts of dataset and low classification performance were regarded as the most challenging tasks to deal with.
Introduction
The Legal Judgment Prediction (LJP) study refers to a field of study that predicts the court’s decision based on the facts given of a legal case (Aletras et al., 2016; Chalkidis et al., 2019b; Feng et al., 2022) and other information from legal documents (Gan et al., 2021; Malik et al., 2021; Sulea et al., 2017). LJP is considered as a data-driven decision-making in court’s decision based on relevant information. To accurately predict court’s decision, it is essential to identify prior cases with comparable legal principles, factual situations, and key arguments. LJP still acts as a complementary task as a decision support system for legal professionals, such as lawyers, judges, and other relevant decision makers.
The study of LJP has grown significantly over time, as seen from the increase in publications published in the last ten years. LJP study has accumulated an increasing amount of data such as legal documents. Several national and international courts around the world support the accessibility and digitally upload their legal documents to increase openness (Marković & Gostojić, 2018). Among LJP studies that have been published, mostly used dataset in LJP studies are from European Court of Human Rights (ECHR), accompanied by China Judgment Online (CJO), Judicial Yuan, and the Indian Supreme Court. These datasets are open access and used as benchmark to explore new techniques for LJP study. However, legal document is subsequently an unstructured document written in natural language, it is inherently difficult to organize and manage due to its lack of predefined format and its complexity because of large amount of data. Unstructured data can contain valuable insights, but it is more challenging to analyse and extract meaningful information from it (Dina & Juniarta, 2022). The automated analysis and representation of human language requires the use of NLP as a computational technique in order to cope with these limitations (Cambria & White, 2014). NLP can analyse large amount of data by allowing them to identify patterns and trends that would be hard or impossible to find with conventional data processing methods. In contrast to the purpose of implementing NLP for information extraction to identify patterns, ML methods in this study are implemented in predicting the court rulings. In existing studies, a variety of legal systems from various countries have been studied with the purpose of predicting court rulings using ML methods (Aletras et al., 2016; Katz et al., 2017; Kowsrihawat et al., 2018; Şulea et al., 2017; Virtucio et al., 2018).
The growing interest in LJP study has generated a need to identify the current technology of the existing scientific knowledge on this topic. Thus, this represents an opportunity to analyse the current discussion on this topic and identify avenues for further research by performing systematic literature review. Therefore, before conducting systematic literature review, we identified existing literature review papers on LJP topics to look for gaps.
Zadgaonkar and Agrawal (2021) have explored recent advancements in information extraction from legal documents and provided a comparative analysis. This emphasized the division of the implemented methods into three categories, namely NLP, deep learning, knowledge-based population. However, they only included legal judgment documents from Indian courts as their datasets and only evaluated Indian legal systems. Hence, the LJP studies conducted outside India are unknown. Feng et al. (2022) have presented a general overview of the present knowledge of LJP study. They only focused on feature-based and neural-based approach. They overviewed the LJP systems available in existing studies as a general overview. Medvedeva et al. (2023) also presented literature review of automatic court decision prediction system. They divided the system into three categories, namely outcome identification, judgment, and forecasting. This review limited the articles implementing ML methods, with the specified publication year ranging from 2015 to 2021. The number of summarized articles was only 27 papers, which defined the differences between outcome identification, judgment, and forecasting.
Among those three literature reviews, Medvedeva et al. (2020) mainly focused on the ML-based classification method in LJP studies while Feng et al. (2022) only paid attention to the specific information extraction method which were feature-based and neural-based approach. There is only one literature review that explored state-of-the-art approach in information extraction and classification methods from LJP studies, but they only included dataset from Indian courts (Zadgaonkar and Agrawal, 2021). Due to the limitations and gaps in these three secondary studies, this study aims to mainly review existing NLP and ML methods used in LJP. The patterns developed in the LJP study through the application of NLP and ML methods are interesting to explore, given that it is a new experimental area.
To the best of our knowledge, there is no literature review emphasizing the implementation of NLP and ML methods reportedly observed in the field of LJP study despite the existing variety of relevant analyses. Thus, the present study will be a pioneer performing systematic literature review on this topic to offer a scholarly view of the scientific contribution related to the topic. A thorough analysis of relevant literature having a clear overview of all major methods was also not found in any related reports. Thus, this represents an opportunity to analyze the current discussion on the LJP topic and identify avenues for further research. Therefore, this study aims to evaluate and contribute to the following, (a) determine NLP and ML methods used in LJP, and (b) summarize available datasets, study trends/topics, implemented NLP & ML methods, evaluation methods, and challenges encountered by legal scholars in the specified area. This analysis is conducted through systematic literature review method, this analysis identifies the current studies of the existing scientific knowledge on this LJP topic. This literature review analyzed the state of art on LJP studies. It focused on exploring the datasets, topics and trends, NLP methods, machine learning methods, evaluation methods, and challenges.
Methodology
This study follows three SLR stages based on (Kitchenham & Charters, 2007; Pollock & Berge, 2018), namely review planning, conducting, and reporting. By following the Preferred Reporting Items for Systematic Reviews and Meta Analytics (PRISMA) declarations and registering and publishing the protocol prior to the review, the PRISMA approach was used to reduce the possibility of bias and increase transparency in this study. In detail, the report was also written using the 2021 PRISMA Checklist as a guide (Liberati et al., 2009).
Review Method
The SLR method was commonly used to identify, evaluate, and interpret experimental outcomes, regarding the relevant questions formulated (Hariyanti et al., 2023). This method emphasized the existence of three stages, namely planning, constructing, and reporting, as comprehensively presented in Figure 1.

Systematic literature review.
Research Question (RQ)
Research questions were frequently formulated to facilitate the concentration of review process on the actual scope and discussion of a study. In this analysis, the research questions shown in Table 1, where RQ1, RQ3, RQ4, and RQ5 were mainly prioritized. RQ2 was also the complementary item formulated to understand the state-of-the-art LJP-based topic/trend. Meanwhile, RQ6 synthesized and summarized the challenges in LJP study area.
Research Question (RQ).

Search Strategy
Relevant articles were searched from various electronic databases, such as link.springer.com, ieeexplore.ieee.org, dl.acm.org, scopus.com, and webofscience.com. In this context, specific keywords were selected to obtain significant publications suitable for the analyzed topic. This process led to the selection of the following keywords, “Natural Language Processing,” “Machine Learning,” and “Legal Judgment Prediction.” The keywords and the following search strings were also implemented through the Boolean operator,
(“Machine Learning” OR “machine learning”) AND (“Natural Language Processing” OR “natural language processing” OR “NLP”) AND (“Legal Judgment Prediction” OR “legal judgment prediction”)
The above strings were applied to search for study articles, restricting the publication period to the previous ten years, from January 2014 to 2023. In this case, the included publications were limited to full-text articles written in English. Table 2 shows the details emphasizing the search sources.
Search Sources.

Based on Table 2, five electronic databases were selected among others, to maximize the effectiveness of the search. For the inclusion of high-quality articles, several publications were also selected from WoS and Scopus databases because one source often contained articles that were not found in the others. Google Scholar (GS) was omitted because researchers do not recommend GS as a primary source regarding its limited indexing of grey literature (Gusenbauer & Haddaway, 2020; Imran et al., 2022) because articles published in grey literature databases are not all peer reviewed (Paez, 2017). In addition, Springer, IEEE Explore, and ACM Digital Library were included because of their popularity in the computer science domain.
Study Selection
According to several criteria, various articles were filtered when downloaded from the search stage. These criteria were determined from inclusion and exclusion strings, which were used to select and eliminate articles that do not meet and do not actualize the appropriate requirements, respectively. These inclusion and exclusion criteria are composed based on Meline (2006) that should follow several criteria, for instance, the inclusion should include studies that (a) have compared certain treatments; (b) be experimental studies; (c) have been published in a certain timeframe; (d) be certain publication types. At the same time, the exclusion criteria should exclude studies that (a) are a certain publication type (e.g., short papers, lecture notes, review papers, etc.); (b) were published before a certain; (c) was published in a language other than English.
Therefore, we designed several requirements that the articles must meet including the following, (I1) peer-reviewed articles, (I2) written in English, (I3) published between January 2014 and 2023, and (I4) connected to the search keywords used. The publications from (E1) short papers, lecture notes, tutorials, theses report, workshop, and review articles were subsequently not included. This was similar to the exclusion conditions of the articles (E2) published in predatory journals or conferences.
Using the PRISMA checklist, we ensured transparency in our systematic literature review so that other researchers could confirm the execution, quality, and rigor of this work (Kim et al., 2018). The systematic review criteria include several factors that encourage full reporting of the review’s methods and conclusions (Edmond et al., 2017; O’Dea et al., 2021). The number of studies that were screened, assessed for eligibility, and added to the review is displayed in Figure 2.

PRISMA flow diagram.
As more research becomes accessible, they also enable future synthesists to replicate the review without having to replicate the original synthesists’ effort in its entirety. This level of transparency is essential since certain systematic reviews face the risk of bias from deliberately adding and eliminating studies in a way that appears to favor one perspective of the study. Transparency and repeatability are enhanced when data and analytical code are made available when systematic reviews include a quantitative component (Goldacre et al., 2019; Haddaway et al., 2020; Hamilton et al., 2021; Page et al., 2022).
In acquiring more thorough outcomes and lowering the chance of ignoring relevant study, the backward and forward snowballing methods were implemented (Badampudi et al., 2015). This indicated that the backward snowballing was performed by searching more publications from each identified primary study while the forward snowballing was conducted through the determination of other articles citing primary studies. When evaluating papers during a systematic literature review, one should be aware of the possibility of selection bias (Booth et al., 2016; Linnenluecke et al., 2020). As can be seen in Table 3, a set of precise selection criteria served as the foundation for compiling and sifting the papers that would be utilized to address the research issue. To reduce this type of bias, the reviewer carefully adhered to the selection criteria. The whole research team collaborated to set the predetermined selection criteria. Three reviewers evaluated articles that were part of the search query in order to further reduce bias in the selection process.
Inclusion and Exclusion Criteria.

Quality Assessment
Schön et al. (2017) used quality assessment (QA) to examine the primary studies’ methodological quality. To guarantee the quality of the 38 primary studies, five checklists were used. QA1 evaluates each study’s goal. In 92.5% of the investigations, the response was positive. Ninety percent of the research received a satisfactory response to the QA2 assessment, which determines if the study offers a thorough explanation of the methodology. QA3 inquires about the result’s validation process. Of the research, only 95% used suitable validation techniques. 92.5% of the studies gave a favorable response to QA4, which evaluates if research, not opinion or viewpoint, is the basis for the study. The final QA5 looks at the quantity of citations that studies have received. As a result, other studies cited 57.5% of the studies more than five times. The relevant studies’ QA scores are displayed in Figure 3.

QA scores of relevant studies.
Data Extraction
The data extraction step was carried out in order to obtain pertinent data from the primary study, regarding the responses provided to the RQ. This step helped in organizing information toward synthesizing review and drawing a conclusion. According to Table 4, a specified extraction form was applied to extract relevant data from each included primary study. The primary studies addressing the RQ in the extraction step were also documented in a Microsoft Excel sheet, to gather responses to the research questions.
Data Extraction Stage.

Reporting Review
Review were reported by summarizing the primary studies outputs and responding to each RQ. Based on the data extraction analysis, several outcomes were determined and presented. More details on review interpretation were also emphasized regarding the results obtained.
Results and Discussions
This section was responsible for presenting reviews used to answer each RQ, with 38 primary studies included from 2014 to 2023.
Summary of Studies
According to review, a total of 38 primary studies were identified in the last ten years from 2014 to 2023. We included published article from the year of 2014 because back then in 2014 (Thammaboosadee et al., 2014) manually collected legal document from Criminal Law Code of Civil Law System of Thailand and they predicted charges for any violation in the dataset, and at the following year, the research about legal judgment prediction is growing along with the number of automation datasets related to legal case. Before those years, the quantitative research method was used to analyze case law (Medvedeva et al, 2020). These studies consisted of 21 (55.26%) and 17 (44.73%) articles from journals and conferences, respectively. Figure 4 also shows a line graph emphasizing the annual distribution of primary studies, where a higher number of LJP publications was observed in 2020, emphasizing 12 articles in a year. This upward trend started in 2017 with four publications and consistently increased each year, reaching its peak in 2020 and experiencing a decline from 2021 through 2023. This trend was influenced by the NLP studies, especially following the COVID-19 pandemic, which have been utilized to analyze public opinion on various studies. COVID-19 demonstrated significant variation in public opinion with regional variation in vaccination and mask policies (Al-Garadi et al., 2022). The NLP approach can replace survey-based approaches because it could offer deeper perspectives. Since then, studies about NLP have reached popularity in text-based approach study, NLP was able to do so because of the sheer amount of data able to be screened than any other approach. Chalkidis et al. (2019a) also played a significant role in the rapid growth in the number of legal judgment study in 2020 because a year before they enriched 11,000 ECHR cases into ECHR dataset (Chalkidis et al. 2019a). It is released with silver rationales obtained from references in court decisions, and gold rationales provided by ECHR-experienced lawyers. Thus, researchers have started to do experiments on the dataset and have influenced this trend. Furthermore, the 38 extracted articles originated from different publishers, proving that 13 (34.21%), 5 (13.15%), 4 (10.52%), 4 (10.52%), and 12 (31.57%) present literature publications were found in IEEE, Springer, Elsevier, ACM, and other journals, respectively, as shown in Figure 5 while the details emphasizing the journal/conference title presented in Figure 6. Based on Figure 7, the distribution of the first author countries was observed, indicating that the diversity of publications had an even allocation across continents. China produced the highest number of studies with eight publications.

Distribution of selected studies.

Number of articles found by publisher.

Journal and Conference publications and distribution of selected studies.

Authorship distribution per country.
RQ1: What Datasets Are Used in LJP?
In the selected LJP study, most of the datasets, as many as 36 of 38 studies, were sourced from court websites. Accordingly, only two studies, by França et al. (2020) and Li et al. (2019), used private firm datasets, including driving and traffic accident instances, as well as a source supplied by a power supply company. Furthermore, all the legal judgment documents from any court were often publicly available, with exceptions for crimes committed by minors, national security cases, and other circumstances considered inappropriate for online publication. The datasets from multiple courts were also likely to be in different languages due to their origin within various countries. So, we also classified the dataset based on the language they have been written in.
The primary dataset used in this study was the European Court of Human Rights (ECHR), accompanied by China Judgment Online (CJO), Judicial Yuan, and the Indian Supreme Court. Based on the previous decade, ECHR, China Judgment Online, Judicial Yuan, and the Indian Supreme Court were implemented in five, four, two, and two studies, respectively. Table 5 also provides a breakdown of dataset distribution in the primary studies from the last ten years. Regarding language applied by the datasets, Figure 8 proved that the majority consisted of 55% English, 22% Chinese, 11% Portuguese, 3% German, 3% Thai, 3% Turkish, and 3% Persian. Detailed information about the datasets, including language, country of origin, and web address, were also found in Table 5.
Datasets.

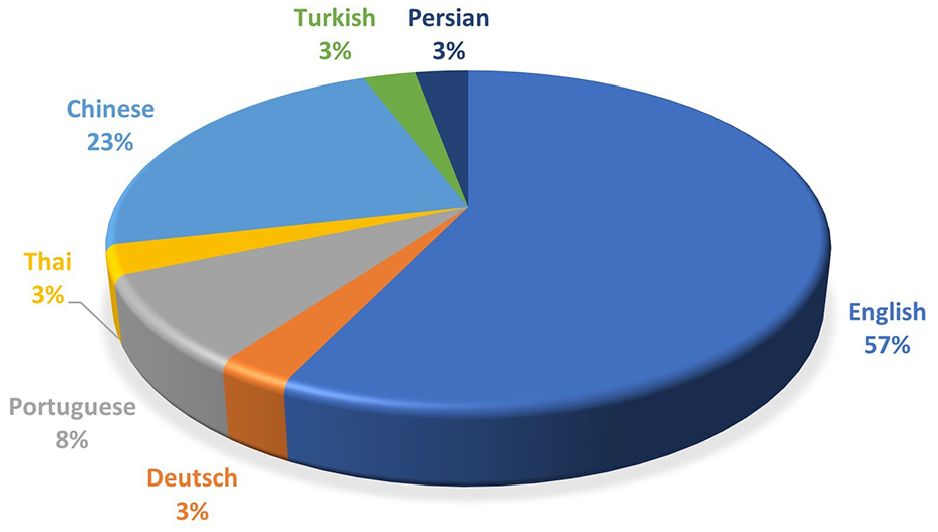
Language distribution of the datasets.
Moreover, the most used dataset was the ECHR, which emphasized an international court operating under the Council of Europe, upholding the European Convention on Human Rights. This court evaluated petitions alleging violations of one or more human rights, outlined in the convention or its optional protocols, by participating states considered as member parties (Quemy & Wrembel, 2020).
In 2016, Aletras et al. (2016) subsequently implemented the charge prediction emphasizing only three law articles of ECHR. A year after, a research group of Liu and Chen (2017) provided empirical investigation comparing charge prediction performance of ML algorithms. A research group from the Netherlands also implemented charge prediction and analyzed further about the language used in legal judgment documents (Medvedeva et al., 2018, Medvedeva et al., 2020). This study predicted legal judgment from 3,132 cases, which violated nine law articles. The same research group in 2020 studied further about language analysis and information extraction to perform quantitative analysis on legal judgment documents (Medvedeva et al., 2020).
The second most used dataset was CJO from the People Republic of China. This dataset was launched in July 2013 and served as a platform for Chinese courts to publish their legal judgment documents (Jiang & Zhang, 2023). It also provided a comprehensive information source for scholars, over 140 million archived cases, including criminal, civil, administrative, compensation, and miscellaneous types. Yang et al. (2020) conducted an empirical investigation using nine ML methods, to predict law article violations in motor vehicle traffic accident cases. Fang et al. (2020) predicted charges of the cases related to CJO-based labor and product liability disputes. Meanwhile, Zheng et al. (2021) adopted a different method, selecting cases from CJO using specific keywords within a defined period. This analysis identified over 500 cases of disputes between public authorities and private partners from July 2013 to June 2019. Besides CJO, there is also Judicial Yuan. Based on Liu et al. (2015), relevant law articles to the 1,518 cases were predicted from the Judicial Yuan in 2012. These cases were obtained from ten different types of crimes, namely offenses against public safety, larceny, fraud, causing bodily harm, forging instruments or seals, sexual autonomy, gambling, homicide, misappropriation, and personal liberty.
The third most frequently used dataset originated from the Indian Supreme Court. In India, the datasets were commonly from Indian Supreme Court, with District Courts being categorized under its jurisdiction. There were two studies that collected the data of the cases from Indian Supreme Court (Acharya et al., 2020; Bhilare et al., 2019). Acharya et al. (2020) and Bhilare et al. (2019) predicted charges and summarized the legal judgment documents to extract more information. Moreover, other study undertakings focused on District Courts, such as Kaur et al. (2019). This study collected a dataset about rape cases from Delhi District Court, between 2001 to 2012. The information about the rape cases within New Delhi was also emphasized, implementing data clustering to identify crime sensitive area and obtain relevant information about the crimes. Shaikh et al. (2020) utilized the dataset from the Delhi District Court, specifically criminal cases associated with murder. This study focused on 86 cases collected during 2017 and 2018, primarily predicting charges of each case. Another study by Sil and Roy (2020) utilized dataset from the West Bengal District Court, which was related to dowry cases, specifically those concentrating on dowry-related deaths and violence. Other datasets in literature studies were also from the United States, Brazil, Turkey, Thailand, Germany, the Philippines, and Canada, as presented in Table 5.
The data transparency about the dataset’s sources is shown by providing a web link to the data access to each dataset as seen in Table 5. The raw data can be accessed to enable readers and other researchers to conduct analyses, cross-reference conclusions, and potentially unearth additional insights. This open access fosters an environment of collaboration and independent verification.
RQ2: What Are the Study Topics/Trends of LJP?
During 2014 to 2023, LJP studies focused on various topics categorized into three primary areas, namely charge, law article, and term-of-penalty prediction. This LJP trend distribution is illustrated in Figure 9. Based on the results, the majority of primary studies (87%) focused on charge prediction which predicts charges from available legal judgment documents in courts. This was accompanied by the prevalence of law article prediction, which accounted for 8% of the primary studies. Law article prediction identifies which law articles were violated in a case. Meanwhile, the term-of-penalty prediction estimating prison terms represented the smallest portion of the study, comprising only 5%. LJP studies are also divided into two categories, the first category is single LJP task, and the second category is multiple LJP task. Mostly, primary studies have single LJP tasks, while only two studies have multiple LJP tasks. Some examples of multiple LJP tasks were Liu and Chen (2018) which addressed both law article violation and term-of-penalty prediction, and Farhadishad et al. (2023) addressed charge and term-of-penalty prediction.

LJP tasks.
Charge prediction was the first topic of LJP, which predicted the outcome of court decision whether violated or non-violated charge. Mostly, there were only two labels for charge prediction, so the classification task was usually binary classification rather than multi-class classification. The second topic was law article prediction, which was infringed in a court case. The third topic was the term-of-penalty prediction, which calculated the potential jail time in a court case.
Figure 9 showed more information on the topics/trends in LJP study, where charge prediction was highly applied, accompanied by law article and term-of-penalty prediction. This proved that term-of-penalty prediction was considered the most challenging task due to the severity of the crimes and the judge’s decision because judges as legal expert have their own perspectives on appropriate sentencing so the judgments of different experts regarding the same case may be inconsistent (Farhadishad et al., 2023; Liu & Chen, 2018).
RQ3: What NLP Methods Are Used for LJP?
NLP in the primary studies could represent human language through textual data, extracting features and preprocessing text from legal judgment documents. These methods emphasized feature extraction tasks from legal judgment. The features were also used in ML methods for predicting legal judgment from court cases. This showed that the primary studies emphasized various NLP methods, with detailed information presented in Figure 10. Figure 10 also illustrates the distribution of the methods across primary studies.

NLP methods.
The most commonly implemented NLP method in primary studies was TF-IDF, which was applied by 13 studies for feature extraction. This method assigned important scores to words/terms. TF-IDF is suitable for large-sized datasets (Dina et al., 2021). Since TF-IDF prioritized word/term relevance, the identification of the most significant terms was then enabled. This enhanced feature extraction efficiency or identified document keywords. Furthermore, several studies combined TF-IDF with other methods, such as skip-gram (Raharjana et al., 2021), n-grams (Almuslim & Inkpen, 2022), and Jaccard similarity (Castro et al., 2022).
According to a comparison regarding data size and complexity handling, N-grams outperformed BoW. This was because N-grams were suitable for medium to large datasets, due to the size of the feature vector depending on the value of “N.” In this context, a larger “N” significantly led to a smaller feature vector. Meanwhile, BoW obtained the frequency of each word, leading to a larger feature vector. N-grams were also commonly implemented with other methods, such as spectral and LDA topic clustering. When the feature vector was generated using N-grams, then feature vector was clustered based on similarity using clustering algorithms. Topics were also derived from each cluster, which comprised data points exhibiting interrelated similarities concerning their relationship with surrounding information sources.
Moreover, primary studies exhibited spectral and LDA topic clustering, word2vec, doc2vec, law2vec (Blei et al., 2003; McConnell et al., 2021), and FastText as feature extraction methods. These methods were unique due to their ability to estimate the semantic proximity or similarity between words, compared to previous methods solely emphasizing word frequency without semiotic relationship assessment.
NLP has made significant advances, but there are still many issues and concerns to be addressed. These challenges not only show how complicated human language is, but they also emphasize how NLP systems must be developed carefully and responsibly. Some limitations in NLP are as follows: (a) handling ambiguity and context in language ambiguity: sentences and words frequently have more than one meaning, and context is crucial to determining the right interpretation. It is still difficult to create models that can correctly identify context and distinguish language remains a complex task; (b) contextual understanding: NLP models need to comprehend the larger context, which includes idiomatic phrases, cultural references, and domain-specific phrase. It takes advanced algorithms and a vast amount of diverse training data to reach this degree of comprehension; (c) processing multilingual content language diversity: The syntax, semantics, and organization of the languages spoken throughout the world vary greatly. It is quite difficult to develop NLP systems that can handle numerous languages efficiently, particularly ones with little data or those are less widely used; (d) cross-linguistic applications: Complex linguistic and cultural consideration must be taken into account when creating models that can accurately translate across a variety of languages or transfer learning from one language to another; (e) scalability and computational requirements resource intensity: Complex NLP models demand significant computational resources. This may restrict their accessibility and scalability; (f) real-time processing and responsiveness latency in applications: Real-time language processing is essential for applications such as real-time translation services. A difficult part of NLP is minimizing latency without sacrificing accuracy; (g) data quality and availability dependence on quality data: The quality and quantity of the training data have a significant impact on how well NLP models perform. Large, high-quality datasets might be difficult to obtain, particularly for specialized domain or languages with limited resources; (h) data annotation and curation: Developing a reliable NLP system is more difficult, time-consuming, and expensive because it requires a special annotation and curation process by the experts.
RQ4: What ML Methods are Used for LJP?
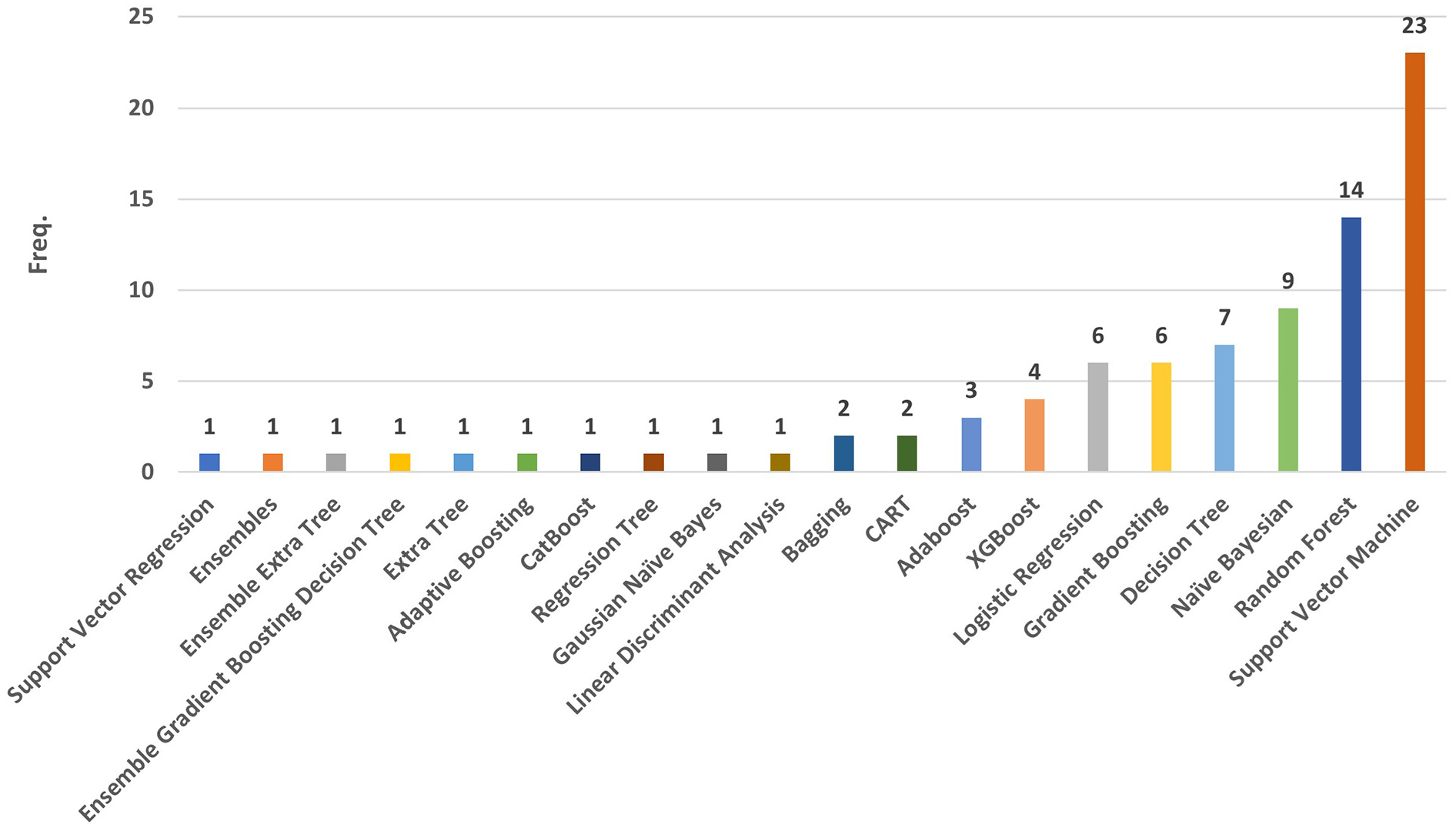
Several types of diverse method strategies were implemented in LJP study methodology. This was observed in Figure 11 to 14, where the distribution of ML methods from 2014 to 2024 was illustrated. According to primary studies, support vector machine (SVM) was the most applied method in LJP during the last 11 years. This method was applied by 23 studies, to predict legal judgment based on the legal judgment documents.

ML methods.
Supervised learning.

Unsupervised learning.

Ensemble learning.
Supervised Learning
A key component in the supervised ML method was the presence of labeled datasets, which taught algorithms in accurately predicting outcomes. The accuracy of this method was assessed by using labelled input and output data. Supervised learning also primarily handled two problems, namely regression and classification. In classification tasks, an algorithm was implemented to appropriately categorize test data. In the meanwhile, the relationship between independent and dependent variables was examined using regression. This enabled the usefulness of the method for predicting numerical values.
Based on Cortes and Vapnik (1995), SVM was an effective supervised learning method applied to both classification and regression applications. In order to transfer the data into a higher dimensional space where the classes were separated using planes or other functions, this method could do both linear and non-linear classification.
A supervised ML algorithm known as Random Forest (RF) was subsequently applied to classification and regression problems similar to SVM. This algorithm constructed a forest of DT, where each tree was trained using a subset of the randomly selected data. The aggregation of prediction was also developed by combining prediction of each individual tree (Geetha & Thilagam, 2021; Ray, 2019; Chen & Eagel, 2017). This algorithm was suggested as a solution to the overfitting issue while enhancing DT accuracy. DT was subsequently a common classification method in many different domains, which was understandable and applicable due to the treelike representation of their models and outputs.
The supervised learning algorithm, known as Naive Bayes (NB), was implemented for resolving classification problems, specifically in text categorization with large training sets. This method was unique due to being straightforward and highly efficient, facilitating the establishment of fast ML models with swift prediction capabilities. The algorithm known as Gaussian Naive Bayes was responsible for applying a probabilistic method and depended on Gaussian distribution. In this model, each feature or predictor independently contributed to predicting the output variable.
Linear Discriminant Analysis was subsequently responsible for dimensionality reduction in cases featuring more than two classes. Logistic Regression (LR) was a regression method providing a straightforward and efficient solution, specifically when handling linearly separable classes. Besides this, its primary application also depended on classification tasks. Classification and Regression Tree (CART) was responsible for exhibiting prediction of target variable values based on various factors. In this method, each branch of the DT represented a predictor variable, with the respective node providing prediction for the target variable at its end. Regression Tree also implemented adjusted split selection and stopping criteria, serving as a tool for explaining decisions, identifying potential events, and assessing prospective outcomes. This analysis could determine the best decision would be.
Unsupervised Learning
Unsupervised learning was able to assess and cluster unlabeled datasets using ML methods. Without requiring human assistance, these algorithms were able to uncover hidden patterns in the data.
Clustering, association, and dimensionality reduction were also the three basic tasks requiring the implementation of unsupervised learning models.
Hierarchical clustering was capable of treating each data point as an individual cluster. This method subsequently progressed through the following stages, (a) identifying the two clusters considered the closest neighbors and (b) merging the two most similar clusters (Fang et al., 2020).
K-Nearest Neighbors (KNN) was a non-parametric and unsupervised learning classifier using proximity to categorize or forecast the grouping of a specific data point. Meanwhile, K-means clustering was a vector quantization method emphasizing data partitioning into K clusters. In this case, the term “K” in K-Means prioritized the desired number of clusters, while representing the count of nearest neighbors determined by the selected distance metric in KNN.
Ensemble Learning
In order to improve classification performance and generalizability, ensemble learning was in charge of training several base learners and combining their predictions. This method exhibited potential in improving model robustness and accuracy (Elish et al., 2013; Ghaedi & Vafaei, 2017; Guo et al., 2021; Hansen & Salamon, 1990; Hosni et al., 2020). The underlying principle of ensemble learning also identified the imperfections and fallibility of individual ML models. In addition, ensemble learning prioritized three primary methods, namely boosting, bagging, and stacking (Kumar & Jain, 2020; Seni & Elder, 2010).
Bagging (Bootstrap Aggregating) simultaneously trained multiple homogeneous models by implementing bootstrap resampling, to select random subsets of data with replacement. These models’ outputs were combined using a linear aggregation rule determining variance within the ensemble method. In addition, bagging improved the ensemble model’s precision and robustness (Zounemat-Kermani et al., 2021).
Boosting, introduced by Schapire in 1990 (Schapire, 1990), was used to reduce variance and bias, absolutely yielding an ensemble model with enhanced accuracy. This method progressively transformed weak learners into stronger ones (Bhagat et al., 2021; Zhou, 2012; Zounemat-Kermani et al., 2021). Boosting progressively trained, typically homogeneous-based learners using bootstrap resampling from the primary dataset is comparable to bagging.
Stacking was a two-level procedure, where base learners were initially trained at the first level. In this case, a metamodel was used to combine the outputs at the second level (Breiman, 2001; Elmousalami, 2020; Freund & Schapire, 1996; Li et al., 2022; Re & Valentini, 2012; Schapire, 1990). Compared to other ensemble methods, stacking was compatible with heterogeneous base learners.
Based on the descriptions, the selection of a model significantly emphasized several competing considerations aside from performance. Metrics such model complexity, dataset size, computation time, and data type employed in the experimental condition were used to evaluate these considerations (Seni & Elder, 2010). This prioritized the need to assess various ensemble methods to help in selecting the optimal predictive model. Gradient Boosting was also the most frequently used ensemble learning model for predictive analysis in the primary studies, surpassing all other methods.
According to the comprehensive literature review, a significant number of primary studies used the supervised ML-method to analyze legal judgment documents. Figure 12 illustrated several supervised ML-methods, including SVM (23 studies), RF (14 studies), and NB (9 studies). Several reasons why supervised ML-method the highest number of research had than other methods were (a) the legal judgment played a significant role in decision-making, (b) the structure of legal judgment documents where target (labels) and predictor variables should be present in the input data for supervised ML methods to work. From this context, the predictor variables significantly affected the target determinants.
According to the number of research that used SVM as a classifier, it had a dominant position as classification approach in LJP. However, as applications evolve and data complexity increases, it is critical to comprehend SVM’s limitations, such as: (a) Problems with scalability as datasets get bigger and more complicated, SVM frequently has trouble maintaining its performance. The computational complexity of SVM training is usually quadratic, which makes them less appropriate for large-scale problems (Yu et al., 2023); (b) The “black box” nature of SVM, especially when using complex kernels, raises concerns about model interpretability and transparency. Therefore, it might be challenging to extract reasons for individual predictions from SVM models, which stakeholders and domain experts frequently want; (c) Dealing with imbalanced data that results from real-world datasets that often exhibit class imbalance can significantly degrade SVM classifier performance. The oversampling technique is necessary to overcome this imbalanced data.
Based on Figures 12 to 14, supervised learning tasks were used more frequently than unsupervised and other methods. Although unsupervised learning tasks were not widely implemented as supervised method, among 38 LJP studies, KNN, K-Means, and Hierarchical Clustering were still applied in fifteen, three, and one studies, respectively. Clustering analysis was useful in identifying specific legal judgment documents to be focused on (Acharya et al., 2020; Raghupathi et al., 2018). Besides supervised and unsupervised learning tasks, various ensemble methods were also used, including Gradient Boosting, XGBoost, AdaBoost, CatBoost, Bagging, and ExtraTree. In this case, boosting dominated the ensemble methods than bagging, which had only two studies. These ensemble methods integrate the predictions of several machine learning models to increase overall performance. It improves overall performance and lowers mistakes by combining the models. Because numerous models must be trained and stored, and their outputs combined, ensemble approaches have the disadvantage of being computationally costly and time-consuming. The system’s complexity and memory may rise as a result.
The potential limitations in the implementation of machine learning are as follows: (a) lack of common sense understanding because they are able to make predictions based only on statistical patterns without really comprehending them; (b) machine learning models are highly dependent on the data training, so the data training is considered very important. Machine learning models use the patterns they have discovered in past data to inform their predictions. They are unable to provide predictions or insights on occurrences or phenomena that are not covered by their training data; (c) model robustness: machine learning model could be sensitive. When applied in real-world settings where data is noisy or lacking, models’ sensitivity to even little changes in input data might become an issue so maintaining model robustness is a continuous task; (d) scalability: machine learning model cannot handle the increasing volume of data, therefore it might need to be redesigned in order to maintain performance.
RQ5: What Evaluation Metrics are Used in LJP?
In identifying frequently used performance metrics for evaluating LJP performance, the majority of evaluation metrics implemented in the primary studies emphasized the parameters obtained from the confusion matrix. These parameters included true positives, true negatives, false positives, and false negatives. From this context, the percentages of successfully and accurately identified samples were known as true positives and true negatives, respectively. Meanwhile, the quantities of incorrectly predicted and missed samples were false positives and false negatives, respectively. Accuracy, recall, precision, and f-measure were the commonly implemented metrics, as shown in Figure 15.

Evaluation methods in LJP.
Based on Figure 14, the SLR study showed that the performance metrics, such as accuracy, precision, recall, and f-measure, frequently assessed the efficiency of LJP models. These metrics were consistently applied in the 38 primary studies, emphasizing their applicability and reliability in evaluating the analyzed models. Besides, the primary studies also incorporated AUC, MCC, Cohen Kappa Score, MSE, RMSE, NRMSE, AMI, and R 2 metrics. This proved that the established performance metrics emphasizing predictive capabilities in legal judgment played a central role in evaluating LJP models. In this case, the majority of primary studies prioritized the enhancement of LJP model performance through the implementation of NLP methods for feature extraction.
Although Figure 15 listed several evaluation methods, each metric had flaws. For example, accuracy as the most frequently used metric in primary studies measures how effectively a model predicts the correct class. It was computed as the ratio of correct predictions to the total number of predictions. However, accuracy might be misleading when assessing a binary classification model on an imbalanced dataset since it just considers the total number of accurate predictions without taking the imbalance of the dataset into account. A model that reliably predicts the majority class may show great accuracy in situations with imbalanced datasets, but it may have trouble correctly identifying the minority class. In the real world, imbalanced datasets are a prevalent problem. For this, a more effective method of evaluating a classifier’s performance than relying just on accuracy must exist.
Since metric selection can influence which model is considered better or worse, this leads to the assumption that the selection of metrics was done carefully. However, metrics are often selected without convincing arguments (Opitz, 2024). After reviewing the selected primary studies, there was no justification for how the studies selected certain metrics. This is evidenced by the similar LJP case study, the evaluation metrics used by each study are different. The majority only rely on accuracy as seen on Figure 15, but other studies also measure other metrics as a set of metrics such as precision, recall, f-measure, etc. This causes potential bias in the selection of evaluation methods. To overcome this issue, some practical approach to select evaluation metrics are as follows: (a) select metrics that suit the problem such as classification or regression model; (b) take into consideration dataset imbalances, giving preference to measures f-measure, precision, or recall in skewed situations; (c) select metrics that help with interpretability; (d) present multiple metrics so complementary metrics can provide insight into a classifier’s empirical dataset correctness and its robustness to changes in class distribution, for example, if one of the classes has less number than other classes, consider presenting class-wise recall scores to assess generalizability.
RQ6: What are the Challenges of Using NLP and ML Methods for LJP?
Multiple challenges were reported from primary studies, such as those emphasizing classification performance, dataset, semantic information, domain dependent, and language.
Classification Performance
The evaluation result of previous studies was not in line with the expectations of the scholars. This was because the performance in the studies averagely ranged from 65% to 79% accuracy. According to Virtucio et al. (2018), the lowest accuracy value was 55% due to a lack of legal judgment documents. This scarcity was a consequence of legal judgment documents not yet being available in digital form. Meanwhile, Quemy and Wrembel (2020) and Thammaboosadee et al. (2014) achieved higher accuracy values, with their outputs influenced by imbalanced and small datasets. For Thammaboosadee et al. (2014) a 92% accuracy was obtained with a dataset containing only 150 cases. Quemy and Wrembel (2020) also acquired 98% accuracy, with their dataset suffering from a severe class imbalance, leading to model underfitting. This challenge was severely felt because the imbalance commonly occurred due to limited data quantity (Amin et al., 2016). In this case, the different proportions of the imbalance data led to the model being more biased toward the majority class than minority group. An issue was also observed in understanding the performance of a model. This proved that a model effectively predicting the majority class was capable of achieving high performance in basic metrics, such as accuracy. However, the poor performance of the model when assessing classification on imbalanced data led to the acquisition of unacceptable accuracy (Kumar et al., 2021). Primary study studies also exhibited unanimous agreement among scholars, indicating that achieving high classification performance remained a major challenge.
We discovered that the imbalanced dataset and small-sized dataset were the source of inaccurate prediction in LJP. When a classifier can achieve high accuracy on highly skewed data by simply selecting the majority class, it is said to have imbalanced data. One way to avoid this imbalanced data is to under sample or remove observations from the majority class until a balance is reached. But doing so comes at the expense of reducing the amount of data, which may be harmful to classification. As an alternative, the minority class can be oversampled by interpolating or duplicating data (Chawla et al., 2002; Fernández et al., 2018; Graa & Rekik, 2019). However, this approach has a greater risk of noise and overfitting (Tan et al., 2007). In order to deal with the imbalanced data, potential solutions for imbalanced dataset to obtain optimal classification results are as follows: (a) generate synthetic minority class data points; (b) randomly under sampling the majority class or oversampling the minority class; (c) stratified batch sampling to ensure each batch is balanced at the intended sampling rate.
Overfitting, which happens when a model performs well on training data but badly on new, independent testing data, can negatively affect a model’s performance on a relatively small dataset. As a result, the model’s generalizability and transferability are low. The data is considered small when there are less than 1,000 data, the dataset covers the distribution poorly, or there are not enough data to identify significant features (Safonova et al., 2023). At the beginning when LJP was introduced the number of legal documents was small, for example Thammaboosadee et al. (2014) only have a dataset that consists of 150 legal documents. However, currently the number of legal documents has increased because legal documents have been digitized. For automated LJP, the small-sized dataset would be insufficient, even though it might be enough for humans to begin determining which features can best describe the target. Transfer learning is able to help solving the issue of small-size data without sacrificing model’s performance because transfer learning reuses a data-driven model trained for one task (source) for other related tasks (target). It can assist in resolving the problem of small-size data without compromising the performance of the model. In addition, transfer learning can reduce the data dependency on large-sample learning.
As the amount and diversity of data continues to increase, machine learning-based prediction research may be threatened by scalability problems. Therefore, scalable machine learning that is adapted to the challenges presented by heterogeneous data in a distributed setting must be developed. Discovering efficient ways to apply scalable machine learning in distributed data platforms is necessary to address problems like data variety, scalability, and distributed processing. This leads to better data processing and decision-making capabilities across a range of domains. It seeks to enhance machine learning’s potential in distributed data platforms and enable more effective and efficient data analysis for a range of sectors and applications, including the legal domain.
Legal document as main object in LJP studies is considered as historical data. Historical data describes the compilation of historical records, information, and data points that detail activities, events, and results during a given time frame. A limitation of historical data when used to make predictions in LJP studies is that the predicted results may not be accurate in predicting future legal judgments. The amount of historical data affects the accuracy of the predictions, the more data the better. LJP offers valuable insights into new legal concerns by assisting in the identification of trends and patterns in the legal cases. By examining case outcome and historical data, legal professionals might better grasp how particular variables impact legal judgments. Based on historical data, supervised learning approaches have demonstrated potential in predicting case outcomes by using labelled datasets to train algorithms. Although these models are capable of learning from previous cases and adjusting to new data, but the models’ ability is heavily dependent on the quality and quantity of training data (Coyle & Hwang, 2020).
Dataset
A lack of data and information accessibility were common problems of dataset commonly caused by the limited number of open access legal judgment documents. Since the documents were primarily in hard copy form, hence, lack number of legal judgment document in digital format (Wang & Tian, 2023). This showed that previous reports commonly implemented a relatively small training dataset due to under sampling, causing an insufficient representation of the feature space and underfitting (Jouloudari et al., 2023). Underfitting also occurred when learning models oversimplified the information in the dataset, leading to low variance and a significant bias in the models. Furthermore, severe imbalanced dataset was another consequence of under sampling. In this context, the court frequently favored violation cases over non-violation cases, indicating an imbalanced dataset in legal judgment documents. This led to the significant need for rebalancing, to prevent bias toward one class during classification. However, most primary studies in literature review did not address dataset rebalancing processes. Another limitation in terms of datasets is the diversity and the geographic bias. The dataset sources of primary studies come from a limited number of countries. In addition, datasets from different countries also tend to use different languages due to their origins. Thus, the problem of generalization caused by geographic bias is absent in LJP studies. To address this geographic bias, there is a need to improve the accessibility of open access court legal judgment documents.
Semantic Parsing and Information Extraction
A challenging NLP problem was the extraction of semantic information from natural language, with word embedding being a suitable solution. This indicated that the implementation of word embedding emphasized the development of vector representation with lower dimensional space. Word vectors were also used in semantic parsing, to obtain meaning from text and enable natural language interpretation. Moreover, TF-IDF, BoW, n-grams, TF, word2vec, and topic clustering demonstrated effectiveness as predictive feature sets and required further testing to fully comprehend their use.
Semantic ambiguity was another issue, which occurred when two texts appeared to be distinct but imply similar interpretation (Degani & Tokowicz, 2010). This led to the suggestion that computer systems should be able to acquire semantics on a legal basis. Furthermore, legal concerns were commonly embedded behind the information often unrelated to the relevant legal issues under consideration. This was the main cause of misclassification of legal judgment documents. Since the interpretation of the predicted results was challenging (Park & Chai, 2021), the features extraction from legal judgment documents using NLP methods was essential.
The involvement of experts was also required to determine the ideal combination of professionals, crowds, and algorithms, since it is likely to generate an effective prediction model for various relevant problems. In this context, legal experts were capable of manually assisting in sorting case decisions into laws/crimes. These legal experts were required due to their professional perspectives about legal judgment.
Domain Dependent
Domain dependent refers to a system that is unable to be universally applied in all context settings. In this situation, the outcomes of LJP studies implementing NLP method showed that their applicability was not universal across all issue settings due to contextual and domain dependence. This limitation became evident during the application to domains or issues different from the training data, such as legal systems emphasizing various information types from several relevant sources. However, the implemented strategies were applicable to a wide range of datasets. For example, Aletras et al. (2016) and Visentin et al. (2019) successfully predicted legal judgment from cases within the ECHR, specifically exhibiting their suitability for ECHR datasets. This was not in line with Liu and Chen (2018), where criminal codes were exclusively emphasized, limiting the direct application of the outcomes to other legal areas due to the different characteristics of various laws.
Language
Language used in legal judgment documents was observed to vary by country, with eight languages identified as datasets. This indicated that English was the predominant language in twenty studies, accompanied by Chinese in eight studies. Besides these major language, other studies also implemented datasets in Deutsch, Portuguese, Persian, Thai, and Turkish. A case study was subsequently examined by Pudaruth et al. (2018), where the dataset implemented comprised two languages. From this study by Pudaruth et al. (2018), legal system of Mauritius (hybrid legal system) was governed by the French Code Napoleon and British common law, indicating that judgment documents were composed in both French and English. Therefore, the present Mauritian legal system primarily comprised two-thirds of its origin to English law and one-third to French laws, respectively (Angelo, 2016).
The datasets implemented in language aside from English subsequently presented issues when overcoming word stemming in the preprocessing step. This was because word stemming emphasized the issue of word affixing, with the English affix being different from other language. When comparing systems with different languages, direct comparisons were not feasible due to their development of specific languages and potential variations in legal systems across countries.
Practical Implications
Practical implication regarding LJP means considering the potential effects of their usage on legal practice and law ecosystems, for instance, if courts were to base their rulings on the results of LJP, this may support the idea that computers are capable of legal reasoning, diminish the importance of human judgment, devalue legal thinking, and de-skill judges. If the LJP is used as decision making system rather than as decision support system, the impact might be more pronounced. In that regard, the failure of LJP to provide legally based response could have dire consequences. Significant consequences might result from even minor mistakes or biases in LJP. We must clarify that LJP is an algorithmic exploration and will not yet be implemented directly in court in light of these concerns. The main goal is to provide courts with recommendations rather than rendering final judgments devoid of human intervention. In real world applications, human judges should be the last resort for justice and equality.
Generalization in machine learning refers to the ability of a trained model to generate accurate predictions on unseen data. Because it enables the creation of models that can provide accurate predictions in real-world situations, generalization is fundamental. A model that does not generalize will probably perform poorly on real-world scenarios, even if it may show high accuracy on the training set. Due to this restriction, the model is unreliable and impracticable for use in real-world scenarios. However, the existing research is domain-specific or jurisdiction-specific, limiting the broader applicability of findings to diverse legal domains. To evaluate the generalizability of NLP and machine learning approaches across different legal domains and jurisdictions, a more comprehensive methodology is required.
Explainability and interpretability are crucial issues in LJP as they may boost user trust by giving a user an explanation for every decision the LJP takes. Researchers studying LJP have looked at interpretability approaches, which provide a LJP the capacity to justify its decisions. Current studies proposed pre-explanation approaches and post-explanation approaches (Chalkidis et al., 2021; Malik et al., 2021; Zhong et al., 2020). Those are the two categories into which these interpretability strategies may be separated. In pre-explanation techniques, a system generates explanations beforehand and then uses these explanations to make predictions. Chalkidis et al. (2021) provided one of the pre-explanation techniques to predict law articles and the underlying rationales, which are drawn from the case in question. In particular, the asserted legal articles are projected based on the extraction of the paragraphs supporting the decision. The inability to clearly see the reasoning behind the LJP predictions is a major flaw in this extraction method of explanation generation. Meanwhile, in post-explanation approaches, explanations are created after prediction. Malik et al. (2021) suggested a post-explanation method based on a sentence-level schema, where the important sentences in a case that are pertinent to prediction are identified. According to a different study, the court considers that the human judge generates and utilizes an explanation for the ruling (Wu et al., 2020).
Ethical Implications
The ethical implication of the increasing adoption of LJP in the legal justice system have come to light. Significant consequences might result from even minor mistakes or biases in LJP. Given these worries, we must state that LJP is an algorithmic exploration and will not yet be applied directly in court. Rather of making final decisions without human involvement, our objective is to offer recommendations to judges. Human judges ought to be the last line of defence for justice and equity in real-world applications. In order to guarantee the model’s fairness, we want to investigate ways to detect and reduce biases in the future. When implementing LJP, ethical issues should be taken into account because the advice they offer may influence a human’s judgment or decision. LJP need to be designed to support, not to take the place of legal experts in their decision-making procedures and to offer legal advice to those who lack legal expertise (Tsarapatsanis & Aletras, 2021). In other words, the legal professionals should continue to make the final judgments. Different prediction errors may have different costs in LJP. For example, misdemeanour charges could only result in penalties, whereas felony charges would result in the death penalty. As a result, predicting felony charges incorrectly might have significantly more more serious consequences than misdemeanour charges.
All individuals must be treated fairly and equitably in order for there to be legal justice, regardless of their nationality, gender, region, and age (Binns, 2018; Leins et al., 2020; Veale & Binns, 2017). However, human judges may be influenced by their personal opinions as well as their own ideologies and beliefs. Because LJP are trained on datasets where the labels and choices were made by human judges, these biases may be passed down to the algorithms. According to empirical findings, current LJP may be biased toward region because of the underlying datasets, which do not disguise demographic information during data development (Chalkidis et al., 2019a). There may be more biases that have not yet been identified, even though a number of attempts have started to debias models, for example, by employing named entity recognizer to replace all identified region information with insensitive tags (Chalkidis et al., 2019b). For instance, biases can be encoded by word embeddings and the data that pre-trained models have learned from pre-training datasets. Generally speaking, it is important to make sure that LJP are objective, and it is crucial to learn how to develop and train them without prejudice.
Conclusion
In conclusion, a thorough literature review on various primary studies was conducted, emphasizing the dataset, topic/trend, NLP and ML methods, evaluation, and challenges encountered in the last ten years regarding LJP studies. This review examined 99 publications from five electronic databases, applying the inclusion-exclusion criteria that led to the retainment of 38 articles. Six research questions were also formulated to guide SLR in identifying relevant dataset, topic/trend, NLP and ML methods, evaluation, and challenges. Based on the first RQ, 23 datasets were observed in 38 studies for LJP. Most used datasets were European Courts of Human Rights (ECHR) and China Judgment Online (CJO) in six (26.08%) and four (17.39%) studies, respectively. The limitation in terms of dataset is the diversity and the geographic bias. The dataset sources of primary studies come from a limited number of countries. In addition, datasets from different countries also tend to use different languages due to their origins. Thus, the problem of generalization caused by geographic bias is absent in LJP studies. To address this geographic bias, there is a need to improve the accessibility of open access court legal documents in each country. The second RQ revealed the existence of three LJP topics/trends, including charge, law article, and term-of-penalty prediction. From this context, 87% of literature analyzed charge prediction in the last 10 years.
According to the third RQ, 12 NLP methods were implemented by LJP research group. These methods included TF-IDF, which was highly used during the selected period, prioritizing 42.10% of the 38 study items. TF-IDF demonstrated effectiveness as predictive feature sets, but it lacks context and word order. The TF-IDF does not consider the context in which a word appears and instead handles each word in a document separately. As a result, it cannot infer the meaning of a word from its surrounding words or overall semantic structure of the text. Meanwhile, explainability and interpretability are crucial issues in LJP so to capture semantic meaning of words, it is recommended for future research to apply pre-trained word embeddings in the legal domain to capture the context of words. This indicates that words in the embedding space are closer to one another when used in similar contexts. The model finds it simpler to classify documents according to their content. The fourth RQ also proved that the SVM classifier was predominantly used by relevant authors in 23.23% of the total articles. However, SVM classifier has limitations related to scalability as SVM classifier is less appropriate for large scale problems because of its quadratic computational complexity, and it has limitation in prediction model’s interpretability and transparency. In the fifth RQ, 87.87% of the 38 studies subsequently predominantly used accuracy as the primary evaluation method for assessing the models but there was no justification for how the studies selected certain metrics. It is advisable to give several metrics rather than just one, and complimentary metrics in particular can provide insight into a classifier’s correctness on empirical datasets and robustness to changes in the class distribution. Meanwhile, the last RQ emphasized the challenges encountered in implementing NLP and machine learning methods in LJP models across the primary studies. Based on the results, SLR offered a thorough and precise summary of current developments and trends in NLP and ML methods in LJP studies. This analysis served as an invaluable reference for various scholars and legal professionals.
Footnotes
Acknowledgements
We would like to express my deepest gratitude to the anonymous peer reviewers who have dedicated their time and expertise to provide valuable feedback and constructive criticism on this research paper.
Ethical Considerations for animal and human studies
There were no human and no animal subjects.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by UM International Collaboration Grant ST080-2022.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.