
Abstract
The measurement of investor sentiment in social media remains a challenging and unresolved issue. The lack of transparency in sentiment tracking tools and survey methodologies in financial research complicates the distinction between measurement noise and genuine online sentiment in historical studies. This review aims to provide structured recommendations for improving the reliability and standardization of investor sentiment measurement in social media. The findings contribute to enhancing the reliability, replicability, and comparability of studies on investor sentiment, offering valuable guidance for future research in this domain.
Introduction
Around 2001, sentiment analysis and opinion mining gained recognition as key research areas, laying the foundation for investor sentiment studies on social networks (Das & Chen, 2001; Dave et al., 2003; Dini & Mazzini, 2002; H. Liu et al., 2003; Morinaga et al., 2002; Nasukawa & Yi, 2003). Pang and Lee (2008) attributed this surge in research to three factors: the growing adoption of machine learning in natural language processing, the rapid development of the World Wide Web and social media, and the field’s extensive application potential.
In the era of big data and artificial intelligence, social media sentiment serves as a critical complement to traditional sentiment proxies, such as surveys, market indicators, and search engine results (Antweiler & Frank, 2004; Da et al., 2015; Q. Liu et al., 2022). Indeed, sentiment indicators built from large-scale online data accurately gage investor sentiment and can predict a variety of socioeconomic phenomena (Bollen, Mao, & Pepe, 2011; Bollen, Mao, & Zeng, 2011). Mining investor sentiment on social media has promising applications and offers a novel solution for understanding and measuring investor sentiment (T. Li et al., 2018).
Sentiment mining on social media is a branch of text mining (Kumar & Ravi, 2016; Onan, 2021). Each piece of social media content represents an individual opinion. Beyond analyzing the sentiment of a single text, it is essential to aggregate samples to reflect public sentiment as a whole (Bollen, Mao, & Pepe, 2011; Bollen, Mao, & Zeng, 2011). Researchers achieve this by summarizing the sentiment polarity or intensity extracted from a large number of texts over a specific time period, thereby capturing the overall sentiment of the public during that period (Gruca et al., 2005; Wu et al., 2014). As shown in Figure 1, sentiment mining from social media texts involves two fundamental steps: sentiment extraction and sentiment aggregation (Pang & Lee, 2008). Sentiment aggregation often relies on specific aggregation formulas (Antweiler & Frank, 2004). Consequently, historical studies have regarded text-based sentiment mining as the most critical component of investor sentiment analysis on social media (Kušen et al., 2017; Q. Li et al., 2018; Loughran & Mcdonald, 2016).

Methodology for developing an investor sentiment index with social media content.
Building on sentiment extraction from social media texts, researchers can construct investor sentiment measures based on specific sentiment aggregation formulas. Social media-based investor sentiment encapsulates the question, “What are investors thinking?” and holds fascinating application potential. However, due to the lack of standardized metrics or established best practices (Mayr & Weller, 2017), the reliability of sentiment measurement derived from social media remains subject to skepticism (Mao et al., 2011).
Investor sentiment from social media has been used to analyze various stock market dimensions, including stock prices (Q. Liu et al., 2022), returns (Bollen, Mao, & Zeng, 2011; Oliveira et al., 2013), volatility (Sprenger et al., 2014), and market indices (Cheng & Lin, 2013; Zheludev et al., 2014). However, findings have been inconsistent. While some studies suggest that social media sentiment lacks predictive power (Antweiler & Frank, 2004; Tumarkin & Whitelaw, 2001), others highlight its predictive capabilities or significant influence (Q. Liu et al., 2022; Mao et al., 2011). These discrepancies arise from two core issues:
(a)
(b)
Based on the above analysis, we believe that the inconsistency in existing research findings is primarily due to the lack of open and transparent descriptions of sentiment mining methodologies. To address this issue, this study systematically examines key research on sentiment mining from social media texts in financial literature published between 2004 and 2024. Our objectives are as follows:
•
•
•
We hope this study enhances the transparency and standardization of sentiment mining methodologies while establishing a theoretical and practical foundation for financial research based on social media sentiment.
The remainder of this paper is structured as follows: Section 2 outlines our review framework, detailing the core reference screening process and the paper’s organizational logic. Section 3 presents key methods for text sentiment mining, covering supervised learning, unsupervised learning, and validation, along with relevant recommendations. Section 4 discusses additional aspects of financial text mining, including research implications and limitations. Finally, the conclusion summarizes the key findings and contributions of the study.
Review Framework
Core Reference List
The core references for this study were identified through a systematic search on Google Scholar using the primary keywords “social media” and “investor sentiment.” The initial search yielded 500 articles, ranked by relevance and citation metrics. A preliminary screening was conducted to ensure that the selected studies were both impactful and directly aligned with the research focus, resulting in the retention of 300 articles.
Subsequently, we examined the titles and abstracts of these papers, eliminating 121 research studies that did not meet the inclusion criteria. We subjected a total of 179 articles to a comprehensive full-text examination, which led to the selection of 80 studies that met the specified inclusion criteria:
(a) The study constructs sentiment indices using text data from social media or investor forums.
(b) The study investigates the role of investor sentiment in financial markets.
(c) The study provides a detailed description of the dataset, sentiment mining methodology, and sentiment index construction process.
The final reference list added nine additional high-impact studies published in 2023 and 2024 to enhance the timeliness and relevance of the evaluation. Figure 2 visually summarizes the above-described screening process by outlining the systematic flow of article identification, selection, and inclusion. This diagram highlights each stage of the review process, from the initial search to the final compilation of 89 core references, ensuring transparency and replicability in the methodology. The final list of core references derived from this process is provided in Appendix A.

Flow diagram of studies included in review.
Figure 3 presents the annual distribution and citation statistics of our core reference list. The literature spans from 2004 to 2024, with an average citation count of 460 and a median citation count of 151. Therefore, this is a representative and influential set of important references.

Annual and prevalence distribution of core literature.
Review Process
Text sentiment mining methods can generally be categorized into two main approaches: supervised learning and unsupervised learning (Hastie et al., 2009). The defining characteristic of supervised learning is its reliance on labeled training data. After validating the model’s reliability, these rules are used to assist in extracting sentiment information from other texts (Cunningham et al., 2008; Q. Liu et al., 2022). In contrast, unsupervised learning does not depend on manually labeled data, reducing the complexity of data annotation (Oliveira et al., 2016). It is more convenient to use but is generally considered less accurate than supervised learning (Renault, 2017; Wu et al., 2014; Zheludev et al., 2014).
In the core literature we reviewed (see Appendix A), 32.9% of the studies adopted supervised learning methods, 45.1% employed unsupervised learning approaches, and 6.1% combined both methods (see Table 1). Additionally, approximately 15.9% of the studies could not be clearly classified, as they often relied on third-party sentiment extraction results or pre-labeled text (Guégan & Renault, 2021).
Categorization of Sentiment Mining Methods in Literature.

Note. Detailed data are shown in Appendix A.
In our review, we started with an examination of supervised and unsupervised learning methods, systematically evaluating the key techniques for sentiment mining in social media texts and providing practical recommendations based on their applications. Additionally, the outputs of sentiment mining tasks are typically categorized into two types: semantic orientation (polarity-based) and sentiment intensity (valence-based; Thelwall et al., 2012; Z. Zhang et al., 2012). The former focuses on classification tasks, dividing text sentiment into discrete categories such as positive, negative, or neutral. In contrast, the latter quantifies the strength or degree of sentiment, moving beyond binary or categorical classifications to provide a more nuanced analysis (Z. Zhang et al., 2012). Therefore, as part of our review, we also analyzed the differences between these two output paradigms.
After systematically reviewing methods for extracting financial market sentiment from social media, we focused on the validation of sentiment analysis results. This emphasis arises from the challenge researchers face in determining whether the extracted investor sentiment is sufficiently accurate and applicable to effectively support behavioral finance research without introducing systematic biases. Supervised learning, unsupervised learning, and the importance of validation collectively form the core of our review framework. As illustrated in Figure 4, the shaded areas intuitively depict the logical structure of the core review modules.
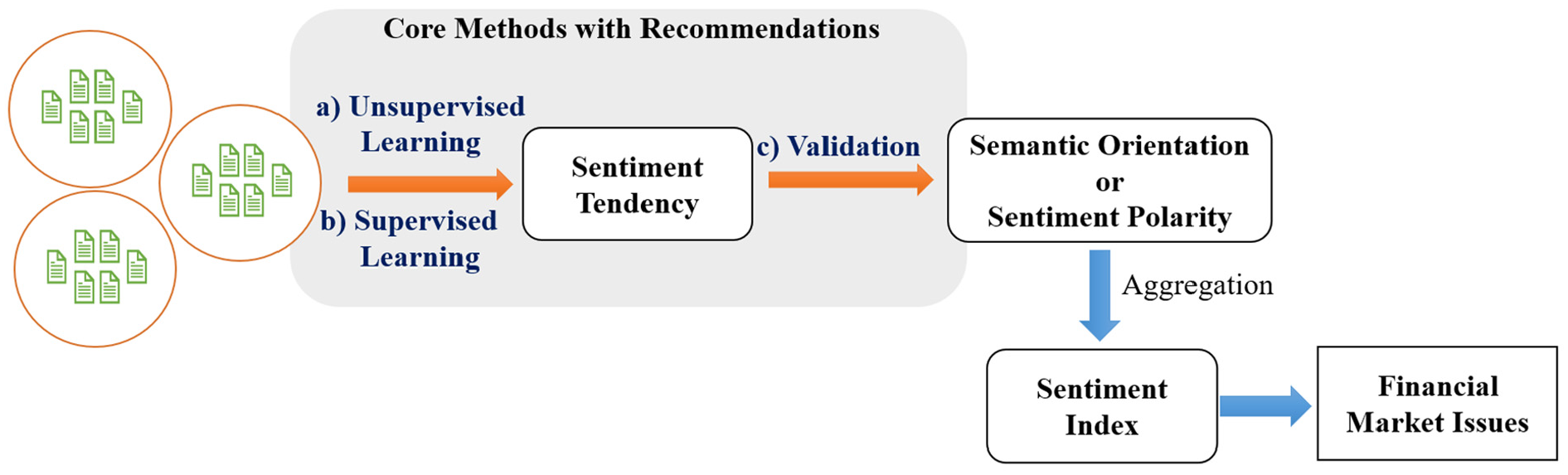
Review framework.
Core Methods and Recommendations
Unsupervised Learning
Sentiment in text is closely linked to semantics (Wierzbicka, 1995), making semantic models a central focus in sentiment analysis (Batbaatar et al., 2019; Wierzbicka, 1992). In our survey, over 90% of unsupervised sentiment classification tasks employed lexicon- and rule-based methods (see Appendix A). Pennebaker et al. (2001) described this approach as relying on linguistic inquiry and word count (LIWC), highlighting its core principles of lexicon use and semantic rules.
Lexicon- and semantic rule-based sentiment analysis methods typically determine the overall sentiment orientation of a document by analyzing the sentiment or semantic direction of individual words within the text (Karalevicius et al., 2018). The fundamental assumption of these methods is that the overall polarity of a text is an aggregation of the sentiment scores of individual words (Karalevicius et al., 2018).
These methods first represent the text as a collection of words, using approaches such as the bag-of-words model (Y. Zhang et al., 2010), word vector models (Bojanowski et al., 2017), or unordered/ordered word stacking representations (X. Zhang et al., 2011). Next, a sentiment lexicon is used to assign a sentiment direction or intensity to each word (Ackert et al., 2016). Finally, the overall sentiment representation of the text is generated by aggregating the sentiment directions or intensities of all the words (Z. Zhang et al., 2012).
Figure 5 illustrates a simplified workflow for lexicon- and semantic rule-based sentiment analysis. It is important to note that different studies may adjust specific steps in the sentiment parsing process according to practical requirements; however, the underlying principles consistently rely on lexicons and semantic rules (Hutto & Gilbert, 2014; Stone et al., 1966). Sentiment parsing represents social media texts as word bags, word vectors, or word collections. Usually, the form of expression aids in the implementation of semantic rules and can even be considered a component of these rules (Pennebaker et al., 2001). Therefore, we can view a text’s sentiment as a combinatorial strategy:


Simplified diagram of the process of dictionary-based sentiment analysis.
The lexicon and semantic rules used typically determine the performance of textual emotion parsing.
Lexicon
Sentiment lexicons are an important tool for sentiment mining (Xing et al., 2019). Scholars and linguists have provided many domain-specific sentiment lexicons. Table 2 displays some of the sentiment lexicon relevant to financial surveys. Panel A shows the relevant literature and links to sources of the lexicon, and Panel B is the relevant description of the lexicon. We must emphasize that this table is incomplete, and providing a complete one would be both impossible and futile.
Description of Some Lexicons.

Although scholars and linguists offer many domain-specific lexicons of sentiment. However, in researching the use of an emotion lexicon, a number of barriers must be crossed to clarify whether this lexicon can be applied to the research; otherwise, this research may be considered unconvincing. In our literature survey, we found that these barriers include at least three dimensions:
The Field of Lexicon
Loughran and McDonald (2011) showed that almost three-quarters of the words identified as negative by the widely used Harvard lexicon are words that are not normally considered negative in a financial context. Hutto and Gilbert (2014) highlighted that although lexicons are commonly used for sentiment assessment in the context of social media, they are often applied with little regard for their practical applicability to the field. Renault (2017) argued that domain-specific lexicons are clearly superior to standard public lexicons.
Cultural Applicability
Nofer and Hinz (2015) noted that emotional expressions vary across cultures and languages, limiting the direct applicability of generic sentiment lexicons in cross-cultural studies. For instance, the Chinese term
B. Liu (2020) emphasized that the effectiveness of lexicon-based methods relies heavily on their adaptability to the target language and cultural context. This linguistic and cultural barrier is particularly pronounced in multilingual or cross-regional studies, often undermining the accuracy and credibility of sentiment analysis. To effectively address cultural matching challenges, we recommend that researchers implement a multicultural data calibration process, which includes the following strategies:
•
•
•
By employing these calibration methods, researchers can better address the impact of cultural differences on sentiment analysis. Cultural adaptation not only improves the accuracy of models but also enhances the generalizability and scientific validity of findings in cross-cultural sentiment research.
Timeliness
Y. Sun et al. (2018) emphasized that the rapid evolution of financial markets and the internet has led to the emergence of new financial terms. Expressions like
Moreover, the meanings of words or phrases can shift significantly over time. For example, Jatowt and Duh (2014) demonstrated that the emotional polarity of certain terms may change in response to evolving social or economic contexts. A term like “bear” might be a neutral descriptor during certain periods but could carry a stronger negative sentiment during times of market panic. This phenomenon, known as semantic drift, further complicates the applicability of sentiment lexicons across different time periods.
To address the challenge of timeliness, we propose the following recommendations: First, researchers must recognize the potential impact of outdated lexicons on study outcomes, especially in the rapidly evolving financial landscape. Second, maintaining dynamic corpora and regularly updating sentiment lexicons can improve research reliability and applicability. Finally, researchers should transparently disclose their lexicon update and validation strategies to enhance credibility and provide guidance for future studies.
Table 3 summarizes three key challenges in sentiment lexicon applicability: domain relevance, cultural alignment, and timeliness. Addressing these issues enhances research credibility and interpretability. However, as Xing et al. (2019) noted, constructing a universal sentiment lexicon that fully captures linguistic variations across domains is impractical. Researchers should therefore validate their chosen lexicons and ensure suitability for their specific context. This can be achieved by adopting validated domain-specific lexicons, creating custom ones, or adapting existing lexicons through supplementation and refinement.
Key Challenges in Lexicon Relevance for Financial Sentiment Analysis.

For instance, Y. B. Kim et al. (2016) employed the VADER lexicon for sentiment analysis and explicitly stated its parallel applicability to their research domain, which strengthened the persuasiveness of their findings. Additionally, to enhance the reliability of research conclusions, many scholars have opted to redesign sentiment lexicons tailored to their specific studies. The creation of sentiment lexicons has become a significant research topic, developed through two primary approaches: manual and automatic creation.
Manual lexicon creation typically involves linguists or domain experts classifying the sentiment values of each term, making it a high-cost and time-intensive process (Heerschop et al., 2011). Examples of this approach include the MPQA Subjectivity Lexicon (Wilson et al., 2005) and Harvard-IV-4 (X. Li et al., 2014). In contrast, automatic lexicon creation methods require less human labor and can quickly generate larger vocabulary sets, albeit often at the expense of some accuracy (Oliveira et al., 2016). For example, Cheng and Lin (2013) developed four lexicons containing bullish, bearish, degree, and negation terms to analyze sentiment more precisely. Similarly, Homburg et al. (2015) constructed positive and negative word lists based on annotated text.
In conclusion, we propose the following principle for sentiment extraction:
Measurement Rules
In lexicon- and semantic rule-based sentiment analysis, researchers start with a lexicon, which is a list of words that have known emotional meanings. They then use algorithms to figure out how the emotional meaning of a text will be based on how often these words appear (Neviarouskaya et al., 2007; Taboada et al., 2011). However, due to the lack of universal and effective parsing standards, the sentiment parsing rules adopted by different researchers often vary significantly (B. Liu & Zhang, 2012; Loughran & Mcdonald, 2016).
Y. Zhang et al. (2012) used SentiWordNet to encode the sentiment of each word in a sentence. An English word is assigned two scores in this lexicon: a positive score (p_score) and a negative score (n_score), with

Based on the above work, Y. Zhang et al. (2012) obtained the sentiment probability distribution of a text by calculating the proportion of positive, negative, and neutral words among all words in it. The sentiment with the highest probability is considered to be the sentiment polarity of the text.
Tetlock et al. (2008) used the Harvard-IV-4 psychosocial dictionary to quantify negative sentiment in texts. They first represented the text for the period t as a bag of words (Wallach, 2006). We then calculated the text’s negative tendency over time t:

Finally, they normalized the negative sentiment for time period t by subtracting the mean of the previous year’s negative words and dividing by the standard deviation of the previous year’s negative word scores:

Y. Sun et al. (2018) used the bullish word list (GL-Bull) and bearish word list (GL-Bear) from the GubaLex dictionary to divide the words in a text,

Leitch and Sherif (2017) used Loughran-McDonald’s Dictionary of Finance to calculate the number of positive and negative words for all tweets from each company. The sentiment index of the company was then constructed using the following formula:

where “Size of Positive Dictionary” and “Size of Negative Dictionary” represent the lengths of the positive and negative word lists in the dictionary.
We also found that some studies used extremely simple semantic rules, which made us question the results of sentiment mining. For example, See-To and Yang (2017) simply treated tweets containing the word “bullish” as bullish sentiment and tweets containing the word “bearish” as bearish sentiment. However, it is known that many tweets containing bullish sentiment do not necessarily contain the word “bullish,” while tweets containing the deny word and “bullish” can express bearish sentiment.
In lexicon-based sentiment analysis, the rules of analysis used in various studies are very different. W. Zhang and Skiena (2010) showed that, in the absence of any agreed gold standard for entity-level sentiment analysis, intuitive performance evaluation is not possible. However, clear disclosure of the parsing rules is still important because it enables other academics to replicate the relevant results, and clear and logical parsing rules can increase the article’s persuasiveness.
In summary, we offer our second recommendation:
Other Unsupervised Methods
In addition to lexicon-based semantic framework models, some scholars have used other semantic frameworks for sentiment parsing. For example, Latent Dirichlet Allocation (LDA) and Social Network Analysis (SNA).
The LDA topic model can accomplish the dimensionality reduction representation of text in semantic space, and it models the text with the likelihood of vocabulary, which alleviates the problem of data sparsity to some extent (Yu & Qiu, 2019; Y. Zhang et al., 2015). LDA is a three-level hierarchical Bayesian model in which each collection item is represented as a finite mixture over an underlying set of topics. Each subject is then modeled as an infinite mixture of underlying topic probabilities (Blei et al., 2003). LDA can divide large amounts of text into a small number of topics using semantic weights, allowing it to perform a function similar to unsupervised learning.
But traditional LDA models do not have the capability to assign sentiment. To address this limitation, Nguyen and Shirai (2015) introduced a novel topic model called Topic Sentiment Latent Dirichlet Allocation (TSLDA), which estimates different opinion word distributions for individual sentiment categories for each topic. TSLDA is a more complex version of the Latent Dirichlet Allocation model (Blei et al., 2003). The TSLDA model divides words in a document into three categories: topic words (c = 1), opinion words (c = 2), and other words (c = 0). Nguyen and Shirai (2015) stated that, depending on the topic, opinion words may express different emotional meanings. For example, the opinion words “low” in “low cost” and “low wage” have opposite polarity. In the TSLDA model, different topics, also represented by word distributions, will have different opinion word distributions.
Gloor and Zhao (2006) created a tool to develop a complex semantic social network analysis called Condor. Condor is able to obtain a web of information about a stock through multiple recursive searches of the web for a specific stock (Gloor et al., 2009). Based on this mesh information, Condor creates a list of terms with positive and negative sentiments for words and word pairs using a bag of words (T. Li et al., 2010). Semantic rules are then used to obtain the thematic sentiment status of a particular stock in the social network for a particular day.
It is straightforward to see that neither Latent Dirichlet Allocation (LDA) nor Social Network Analysis (SNA) moves away from semantic rules; they both ultimately require the construction of sentiment indices based on the sentiment of words. The effectiveness of LDA and SNA algorithms becomes more difficult to measure than that of lexicon- and semantic-rule-based approaches to social media sentiment extraction.
Supervised Learning
While the introduction of lexicons makes lexicon and semantic rule-based sentiment parsing methods more interpretative (Oliveira et al., 2016), it also makes the analysis results subject to lexicon and keyword selection noise (Giannini et al., 2018). There is a lot of evidence that algorithms that use supervised learning tend to be more accurate than those that use unsupervised learning:
• F. Li (2010) and Huang et al. (2014) showed that Naive Bayes methods outperformed dictionary and word count methods in predicting text sentiment.
• Wu et al. (2014) showed a classification accuracy of 81.82% for supervised learning methods, which was higher than the 75.58% classification accuracy for semantic methods.
• Zheludev et al. (2014) report that supervised SentiStrength tends to be more accurate than unsupervised SentiStrength.
• Thavareesan and Mahesan (2019) obtained the highest accuracy of 79% using supervised machine learning among multiple methods of emotion extraction based on lexicon and supervised learning.
• Audrino et al. (2020) showed that the predictive power of sentiment variables decreases when lexicon- and rule-based methods are used.
The availability of annotated training data is the defining feature of supervised learning (Hinz et al., 2011). The term refers to a supervisor who instructs the learning system on which labels to associate with the training data (Cunningham et al., 2008). In classification issues, these labels are often classified as class labels. Supervised learning techniques create models from this training data, which may then be used to categorize additional unlabeled data (Hastie et al., 2009). Figure 6 illustrates a brief flow of supervised learning, where obtaining usable, manually annotated text is the first step in the process.

Diagram of supervised learning.
Manual-Based Text Sentiment Annotation
Oliveira et al. (2016) stated that the task of text annotation is arduous. Saif et al. (2013) and Engelson and Dagan (1996) both emphasized that collecting high-quality, manually annotated text is quite expensive. The manual sentiment annotation of texts is an extremely subjective task. This brings into question the reliability of the annotation results (Ipeirotis et al., 2010). For example, Rechenthin et al. (2013) employed three staff members to annotate social media documents with sentiment “bullish” (positive outlook), “neutral,”“bearish” (negative outlook), or “off-topic.” A sample of the results found that approximately 70% of the posts were classified as off-topic. It is clear that accurate and reliable emotion annotation is not easy.
Hutto and Gilbert (2014) used four quality control measures to make sure that the labels on the sentiment data made sense:
• First, each rater was pre-screened for English reading comprehension.
• Each pre-screened rater had to complete an online sentiment scoring training and orientation course and score 90% or higher in matching the mean sentiment score of known (pre-validated) vocabulary items.
• For each batch of data (25), 5 of them were pre-annotated. If three or more of these five a priori criteria were incorrect at the time of annotation, all 25 were discarded.
• Incentives and rewards are given for high-quality work.
Due to the subjective nature of text annotation, this task is usually carried out by several people. The reliability of the annotation is then improved by cross-checking the results with each other:
• In the study by Hutto and Gilbert (2014), two human experts were engaged to scrutinize all 800 tweets separately and independently rate their emotional intensity on a scale from −4 to +4.
• To improve the accuracy of manual annotation, T. Li et al., 2018; Q. Li et al. (2018) required each tweet message to be manually classified by at least five different trusted contributors. The average agreement between the five contributors on the classification of individual messages was 73%.
• In Yang et al. (2016)’s study, each text was classified separately by three people, and if the classification results of the three persons did not agree, it was labeled as neutral or noisy.
• In Y. Li et al. (2020), each message was annotated by at least two analysts, and the annotation findings were then evaluated and compared. If a text had a different labeling result, they invited a third analyst to label it again, and the majority view was utilized as the final label for that message.
• In order to generate accurately labeled texts, Rechenthin et al. (2013) asked each worker to provide an explanation for the labeling results, and they discovered that this enhanced annotation accuracy. Three workers individually annotated each piece of social media text. Three workers agreed on the annotation results in 39.12% of the annotated data, and at least two persons agreed on the annotation results in 84.87% of them; texts that did not agree were eliminated.
The availability of manually annotated text data is a typical feature of sentiment classification based on supervised learning (Ipeirotis et al., 2010). If the quality of manually annotated text cannot be guaranteed, the results of text sentiment mining are bound to be unreliable. However, in our survey, we found that some studies simply disclose the manual annotation process (Giannini et al., 2018; Wu et al., 2014), which may reduce the credibility of the study.
In summary, we offer our third recommendation:
Models and Algorithms
Machine learning models acquire the ability to predict the label y using the feature vector x by learning a set of pre-annotated data and deconstructing the complex rules between x and y (B. Liu, 2011). For text mining tasks, x is a word vector constructed from text data, while y is the sentiment implied by the text (Hotho et al., 2005; Tan, 1999). In supervised learning-based social media sentiment parsing tasks, the construction of word vectors is a necessary prior step (Neviarouskaya et al., 2007; Tan, 1999).
Word Vector Construction
The process of constructing word vectors from raw text is the process of text pre-processing and text representation (Wu et al., 2014). Q. Liu et al. (2022) remove numbers, punctuation marks, extra spaces, and unintelligible special characters such as (, [, {, &, etc. from the text during text preprocessing. They then replace the web link in the text with the string “URL” and the username with the string “USERNAME.” Finally, the text was encoded using Word2vec. Q. Liu et al. (2022) also used Word2vec to transform text into word vectors. Word2vec is a two-layer neural network that transforms the input text data into a set of vectors as output (Church, 2017). This helps with the assumption of additional semantic features for text classification.
Word vectors can be constructed using N-grams from strings of n adjacent characters retrieved from a continuous chunk of text (Damashek, 1995; Robertson & Willett, 1998). As a result, the N-gram has become a common paradigm for modeling vector spaces (Sidorov et al., 2014). Wu et al. (2014) set the weights using N-gram feature selection, document frequency (DF) dimensionality reduction, and Boolean weighting methods. Specifically, let
J. Li et al. (2017) defined a document as a set of m features

“Bag of words” is another commonly used method for building word vectors. The “bag of words” treats the list of words that make up a text as a sequence of features (Wallach, 2006). In conjunction with the word vector construction method, scholars often use the TF-IDF algorithm to weight lexical feature vectors (Roelleke & Wang, 2008):
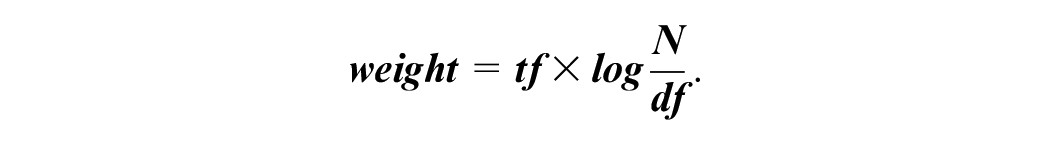
The IDF (inverse document frequency) is the log of the number of texts divided by the number of texts that contain the word, whereas the TF (term frequency) is the number of times a word appears inside the texts (Bafna et al., 2016; Trstenjak et al., 2014).
Although some studies have compared various methods of constructing word vectors in the hope of achieving higher classification performance, for example, Rechenthin et al. (2013) used the “bag of words” feature set, the meta-data feature set, and the combined “bag of words” and meta-data feature set for prediction performance comparison. However, we cannot estimate the difference in sentiment classification performance based on differences in word vector construction methods used by the scholars.
Machine Learning Algorithms
Having constructed the word vectors, the researcher was given a dataset that could be used for supervised learning model training:
Table 4 provides statistics on the main machine learning algorithms used in our survey of supervised learning-based investor sentiment resolution work. It is easy to see that finance researchers mainly use traditional machine learning algorithms such as Naive Bayes, Support Vector Machines, Maximum Entropy, K-Nearest Neighbor, etc. Our conclusions are supported by the recent findings of Zad et al. (2021) on text sentiment mining. In particular, the Naive Bayes algorithm based on probabilistic models is the most popular among finance academics, and more than half of the supervised learning-based studies on investor sentiment in social media use the Naive Bayes algorithm.
Statistics of Machine Learning Algorithms for Social Media Investor Sentiment Mining.

Note. See Appendix A for detailed data. The sum of the percentage columns is greater than 100% due to the fact that some studies used multiple algorithms.
The Naive Bayes algorithm treats each word in a given text message as a “feature,” and the given text message is used to construct a feature vector (S.-H. Kim & Kim, 2014). Each text message has a “label,” that is, sentiment polarity (“buy” or “sell”) or sentiment temperature (Huang et al., 2014). The Naive Bayes rule is used to figure out the probability of a label given “features,”
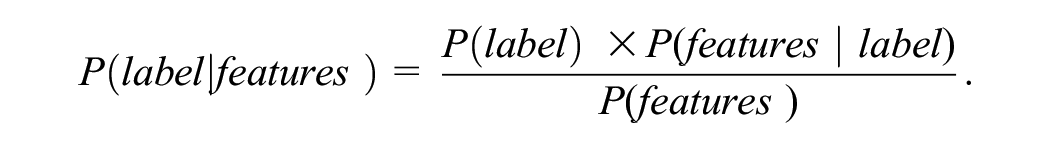
The Naive Bayes classification method assumes that feature occurrences, when given a “label,” are unrelated to one another. If there are n independent features (e.g., a series of words),

As a result, the likelihood of a label conditional on “features” can now be stated as:
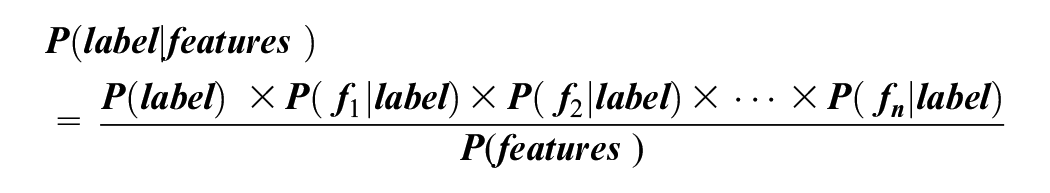
The general idea behind the maximum entropy (ME) classification is that when nothing is known about the distribution, it should be homogeneous, that is, have maximum entropy. Consider the example of trying to classify documents as positive, negative, or neutral, where we are only told that 50% of documents containing the word “buy” are considered positive. Intuition tells us that if a document has the word “buy” in it, then it has a 50% chance of being a positive post, a 25% chance of being negative, and a 25% chance of being neutral. If we do not have the word “buy” in our document, then we will assume that it has a 33% even distribution of probability of belonging to each category.
To extract more reliable sentiment from social media texts, many researchers use a combination of machine learning algorithms for sentiment mining (Giannini et al., 2018; Rechenthin et al., 2013). For example, Y. Zhang et al. (2012) used eight classifiers in their study to evaluate the performance of different text sentiment classification algorithms. These algorithms include the Probabilistic Indexing Model (Maron & Kuhns, 1960), Expectation Maximization (Dempster et al., 1977), Kullback–Leibler divergence (Kullback & Leibler, 1951), K-Nearest Neighbor (Salzberg, 1991), Maximum Entropy (Ratnaparkhi, 1997), Naive Bayes (Y. Li et al., 2020), Support Vector Machine, and Term Frequency Inverse Document Frequency. Some studies using multiple algorithms have used the parsing result of the best-performing algorithm as the final sentiment parsing result (Y. Zhang et al., 2012), while others have used the average voting result of multiple algorithms as the final sentiment parsing result (Rechenthin et al., 2013).
The construction of word vectors and machine learning algorithms goes hand in hand. Furthermore, Kraaijeveld and De Smedt (2020) showed that different data pre-processing methods have a large impact on the performance of social media sentiment mining. Although we cannot intuitively estimate from the sentiment mining processes described by the researchers (data preprocessing, text representation, and machine learning algorithms) whether the performance of sentiment mining meets the need for research precision, the necessary description of these processes is still very relevant. This allows us to check whether the authors’ work conforms to the basic logic of natural language processing (Nadkarni et al., 2011; Ratnaparkhi, 1997) and makes it possible to reproduce the results of the study.
Sample Size
Q. Liu and Son (2024) conducted a statistical analysis of investor sentiment studies based on social media text and found that the median data size used by researchers was 1,109,500 entries, with an average of 23,643,300 entries. This highlights that sentiment extraction from social media is typically a classic big data application scenario.
Training sample size plays a crucial role in supervised sentiment analysis. Renault (2020) observed that as the dataset size increased from 250,000 to 500,000 messages, the prediction accuracy stabilized; further increasing the size to 1,000,000 messages improved accuracy by only 0.31 percentage points. This indicates that while larger datasets may increase research workload and complexity, existing studies have not reported adverse effects of larger data sizes on prediction outcomes.
However, our investigation revealed cases where the training sample size was evidently insufficient. For example, Sprenger et al. (2014) conducted sentiment classification on 45 million social media messages but used only 2,500 training samples—just 0.01% of the total dataset. In such cases, if researchers fail to demonstrate the applicability of their models under small sample conditions, the classification performance becomes unconvincing.
In the absence of unified guidelines for sample size, we recommend researchers critically consider the following questions:
• Is the chosen training sample size adequate to support the complexity of the predictive task?
• Do the training samples sufficiently represent the relationships between features and sentiment labels within the overall dataset?
In summary, we offer our fourth recommendation:
Verification
We use supervised or unsupervised learning to parse investor sentiment from social media texts. Following the basic recommendations of R1, R2, R3, and R4 enhances the credibility of the study and makes it possible to replicate its results. However, we are not sure whether the extracted investor sentiment can be used in behavioral finance research without incurring additional systematic errors. As shown in Figure 7, we need to perform an acceptance exercise to demonstrate that we have assigned sufficiently accurate sentiment polarity, or sentiment temperature, to the texts in social media (Giannini et al., 2019; Q. Liu et al., 2022; Xiong et al., 2017).

The role of validation.
Verification of Supervised Learning
In supervised learning, we enable the annotation of unannotated text with sentiment by training a machine learning model on manually annotated social media texts. These annotated texts act as “mentors.” The algorithmic part encompasses the implementation process of sentiment analysis, including pre-processing, vector construction, and model selection. Therefore, we can describe supervised learning-based sentiment extraction from social media texts as a function of the text, the sentiment annotation, and the algorithm:

A scientifically rigorous text annotation and algorithm design procedure can elevate our expectations of supervised learning outcomes and bolster the study’s credibility; however, it does not establish its validity (Hastie et al., 2009; Nasteski, 2017). Sentiment extraction by supervised learning requires a calibration session to validate its efficacy (W. Li et al., 2019; Y. Zhang et al., 2019).
Similar to unsupervised learning, the benchmark for validating the sentiment analysis capability of supervised learning models also relies on manually labeled sentiment texts (ChandraKala & Sindhu, 2012; H. Zhang et al., 2014). However, compared to unsupervised learning, validation in supervised learning is generally more straightforward, as the same labeled data used for “supervision” can also serve as the basis for evaluation.
In our review of studies on investor sentiment derived from social media, 63.33% of sentiment analyses based on supervised learning disclosed performance metrics for sentiment extraction (detailed data available in Appendix A). This proportion is significantly higher than the 23.07% observed in studies using unsupervised learning. One possible reason for this disparity is that many studies adopt unsupervised learning sentiment analysis methods specifically to avoid the labor-intensive process of manually labeling investor sentiment data (Oliveira et al., 2016).
Antweiler and Frank (2004) investigated the correlation between the textual sentiment of communities and stock prices. They verified the classification performance of the plain Bayesian algorithm using 1,000 hand-labeled observations. They showed that their algorithm does not misclassify “bullish” messages as “bearish” or “bearish” messages as “bullish,” so their constructed sentiment index is credible.
Q. Liu et al. (2022) employed a deep learning model to mine social media text sentiment in their investigation of the synergy between investor sentiment and stock prices in social media. The combined accuracy of the network model they employed for classifying the sentiment of unlabeled investor messages was 89.14%, higher than Antweiler and Frank (2004)’s 88.1% and Xiong et al. (2017)’s 85.4%, with high confidence and no systematic error.
Go et al. (2009) achieved over 80% accuracy in classifying tweet sentiment with emojis using various algorithms, such as Naive Bayes, Maximum Entropy, and SVM. Rechenthin et al. (2013) and Y. Zhang et al. (2012) used a variety of machine learning algorithms for sentiment analysis. They compared and analyzed the performance of these machine learning algorithms for sentiment classification.
The supervised learning-based behavioral finance studies that have been marked with a “1” in the “Results Checked” column in Appendix A have all disclosed the sentiment analysis performance to support the study. Following R3 and R4’s recommendations boosts the study’s credibility but not its reliability. The validation of the sentiment analysis results is a fundamental way to demonstrate the reliability of investor sentiment.
Verification of Unsupervised Learning
Lexicon and semantic rule-based methods dominate sentiment parsing approaches based on unsupervised learning. Lexicon- and semantic-rule-based sentiment parsing methods regard text sentiment as a function of text, lexicon, and semantic rules:

However, we cannot intuitively assess the reliability of sentiment parsing based on the lexicon features and parsing rules described by the researchers (Pang & Lee, 2008). This is especially true when we question this study’s lexicon or parsing rules. For example, Loughran and McDonald (2011) have shown that almost three-quarters of the words identified as negative by the widely used Harvard-IV-4 dictionary are words that are not normally considered negative in a financial context. However, there is still a large body of research using the Harvard-IV-4 dictionary to parse the sentiment rules of financial texts (Tetlock et al., 2008). However, Karalevicius et al. (2018) only took into account the first occurrence of dictionary words when parsing texts, whereas additional research indicates that multiple occurrences of mood words are significant for mood temperature (Chen et al., 2014; Loughran & McDonald, 2011).
To address concerns about parsing results, it is necessary to calibrate the results of parsing (Geva & Zahavi, 2014). However, our survey revealed that only 17.6% of lexicon and semantic rule-based studies performed this calibration (see Appendix B for detailed data). In the absence of calibration criteria, manual-based sentiment classification becomes an accepted and reliable standard of comparison (Homburg et al., 2015).
Cheng and Lin (2013) verified the accuracy of post sentiment classification using 140 manually labeled “bullish” posts and 140 “bearish” posts. These manually labeled posts were independently judged by three people, and if all three people judged the post as “bullish” or “bearish,” the post was marked as “bullish” or “bearish.” If the three people do not agree on the marker, the post is discarded. It is easy to see that collecting high-quality, manually annotated text is quite expensive (Saif et al., 2013), and the process of manual tagging often needs to be disclosed in detail; otherwise the accuracy of manual classification may be questioned (Wilson et al., 2009).
In summary, there is no universally accepted golden rule for lexicon- and semantic rule-based sentiment parsing (W. Zhang & Skiena, 2010). Following the guidelines of R1 and R2 can enhance the study’s credibility, but it doesn’t demonstrate the reliability of the parsing results. However, validating the sentiment parsing results is an effective method to demonstrate the reliability of investor sentiment.
Validation of Third-Party Tools
As shown in Table 1 and Appendix A, a number of additional studies used other people’s algorithms or other tools for investor sentiment parsing, which we refer to collectively as “third-party tools.” For example:
• Piñeiro-Chousa et al. (2016) and Deng et al. (2018) used the CoreNLP toolkit of Stanford. The CoreNLP toolkit provides an extensible pipeline that provides core natural language analysis (Manning et al., 2014; Rao & Srivastava, 2012). It contains complete and high-quality analysis components and does not require the use of a large number of related data packages, allowing for the simple application of machine learning to natural language processing (Kaur & Agarwal, 2018). The software uses the Sentiment Treebank corpus, the first corpus with fully labeled parse trees (Socher et al., 2013).
• Fan et al. (2020) used the TextBlob toolkit, which is a simple API provided by the Python library, to perform certain natural language processing tasks (Gujjar & Kumar, 2021) and to provide polarity scoring for tweets (Shekhawat, 2019).
• The study by Nisar and Yeung (2018) used Umigon for sentiment parsing, a lexicon-based sentiment classifier that provides sentiment detection for tweets. Umigon also provides indications of other semantic features present in tweets, such as temporal indications or subjectivity markers.
Studies that have utilized third-party tools for sentiment parsing frequently cite the disclosed sentiment parsing performance as proof of the validity of their own research (Audrino et al., 2020; Nisar & Yeung, 2018; Zheludev et al., 2014). However, additional evidence suggests that this is not reliable. For example:
• With lexicon and semantic rule-based approaches, the choice of lexicon can have a significant impact on classification performance (Oliveira et al., 2016), and researchers need to consider whether the lexicon employed by a third-party tool and their own study are a sufficient match in terms of the research domain, regional culture, and timeliness.
• X. Sun et al. (2020) show that Tencent’s NPL service cannot be applied to the sentiment classification of finance texts due to a lack of finance-specific text training.
• PaddlePaddle is one of the most advanced natural language processing models in China, and PaddlePaddle’s website claims that its sentiment classification accuracy can exceed 88%, but it can only achieve about 60% accuracy when dealing with finance texts (Wang et al., 2022).
In summary, even when researchers use third-party tools for sentiment measurement, they still need evidence that the third-party tools are effective for their particular sentiment mining task. Drawing from the aforementioned discussion, we present our fifth recommendation:
Summary and Comparison
As shown in Table 1, our core literature review reveals no significant difference in the number of studies utilizing supervised and unsupervised learning methods for extracting financial sentiment from social media. This finding suggests that the academic community has yet to reach a consensus on whether one method outperforms the other in sentiment analysis tasks. Instead, researchers tend to base their choice of methodology on specific research objectives and data characteristics.
We have visualized this comparison in Figure 8, highlighting the applicability of both approaches. Regardless of the chosen method, data collection and preprocessing remain foundational prerequisites for financial sentiment analysis. Similarly, validating the results of sentiment extraction is essential for enhancing the robustness of research findings. These fundamental steps are consistent across both approaches.

Comparison chart of supervised versus unsupervised learning in sentiment analysis.
The primary differences between the two methods lie in their basis requirements and modeling approaches:
Basis
•
•
Models
•
•
Advantages and Disadvantages
Existing studies indicate that both methods have their strengths and limitations.
•
•
In summary, the effectiveness of a study depends more on the researchers’ transparency in disclosing their methodological choices, parsing rules, and validation processes than on the specific method employed. Transparent and standardized research designs are particularly crucial, as they facilitate reproducibility and enhance the reliability and academic contribution of the findings. However, with the rapid advancement of natural language processing technologies, employing cutting-edge techniques not only improves the precision and efficiency of sentiment analysis but also fosters greater trust in the reliability of the research (Onan, 2021). In the next section, we will delve deeper into this perspective.
Discussion
Lags in the Application of Technology
We also found that the latest natural language processing techniques have not been applied to the parsing of text sentiment in social media. We searched Google Scholar for the keyword “text sentiment analysis” and restricted the years of publication to 2018 to 2024. To obtain a representative cross-section of results, we screened the top 100 documents with the highest relevance to the keywords and obtained 61 pieces of core literature with a minimum citation count of 20. As shown in Panel A of Table 5, the average number of citations in these literatures is 174, which constitutes a high level of impact.
Literature Statistics for a Survey of Advances in Sentiment Mining Techniques.

Note. See Appendix B for detailed data.
The citation count data comes from Google Scholar as of November 30, 2024
The literature we surveyed includes 59% of the literature in the field of computing and IT and 41% in other fields such as finance, business, and economics. As shown in Panel B in Table 5, more than 3/4 of the research belonging to the computer and IT technology domain is based on neural networks, and deep learning remains at the forefront of text sentiment mining. In contrast, only 36.0% of the sentiment parsing techniques used in other research areas employ neural network techniques—a rate that is less than that of research in computing and IT. So, there is a distance between the techniques applied in sentiment mining in non-computer and IT areas and the latest technological advances.
Financial studies based on social media investor sentiment are no exception to the textual sentiment parsing techniques applied in these studies, which benefit from a technological spillover from the computer and IT fields (Pang & Lee, 2008). Our findings indicate a lagging trend in this technological spillover. As shown in Appendix B, the field of finance has not been interested in the spillover of computer technology, preferring to use readily available, simple, traditional methods for parsing investor sentiment in text.
In summary, we offer our sixth recommendation:
Recommendations
Based on a review of historical literature, we propose key norms and recommendations for financial researchers conducting sentiment analysis using social media text. Table 6 summarizes these recommendations, which include the applicability of lexicons (R1), transparency in parsing rules (R2), reliability of manual annotations (R3), scientific and standardized experimental setups (R4), validation of sentiment analysis results (R5), and the application of cutting-edge natural language processing techniques (R6).
The Basic Recommendations for Measuring Investor Sentiment in Social Media.

These recommendations address the critical aspects of extracting financial sentiment from social media text. We emphasize that adherence to these norms can significantly enhance the reliability, reproducibility, and academic contribution of sentiment analysis research. Beyond providing practical guidance for investor sentiment studies based on social media text, these recommendations establish a more robust academic foundation for exploring sentiment in financial markets.
Research Implications
This study contributes to both academia and practice by providing methodological support and practical insights for analyzing investor sentiment on social media.
Academically, it outlines key principles of sentiment analysis, focusing on lexicon use, parsing rules, and effectiveness. By standardizing these elements, it enhances research reliability, reproducibility, and comparability, addressing inconsistencies caused by varying tools and data processing methods. Additionally, it identifies gaps in the literature, particularly in sentiment index validation and the influence of sentiment analysis on financial research.
Practically, this study offers a structured approach to constructing sentiment indices, enabling researchers to derive more reliable indicators for decision-making. It also provides a systematic framework for scholars reviewing related studies. By establishing clear guidelines, it delivers actionable insights for both academia and industry, improving sentiment analysis credibility and application.
More broadly, this research demonstrates the value of social media sentiment analysis in financial markets, shedding light on its relationship with market behavior. Beyond finance, its findings hold relevance for sentiment analysis in other socio-economic contexts and support future cross-lingual and cross-cultural research.
Limitations
This study provides a comprehensive review of key methods for extracting financial sentiment from social media and offers relevant recommendations. However, several limitations must be acknowledged.
Bias in Data Representativeness
While we have compiled a core set of representative literature, it may not fully capture research conducted across diverse linguistic and cultural contexts. Sentiment analysis studies in non-English environments may be underrepresented, potentially limiting the generalizability of our findings. Additionally, some studies may exhibit regional or platform-specific biases, challenging the universality of the conclusions.
Limitations in Method Applicability
This study does not thoroughly examine how different sentiment analysis methods perform under specific financial market conditions. Some techniques may be more effective in particular markets or economic scenarios, yet their contextual suitability is not comprehensively addressed. Additionally, emerging approaches, such as multimodal data analysis (integrating images and videos) and network relationship analysis, are beyond the scope of this review
Limitations in Method Applicability
This study does not thoroughly examine how different sentiment analysis methods perform under specific financial market conditions. Some techniques may be more effective in particular markets or economic scenarios, yet their contextual suitability is not comprehensively addressed. Additionally, emerging approaches, such as multimodal data analysis (integrating images and videos) and network relationship analysis, are beyond the scope of this review.
Impact of Large Language Models (LLMs)
Advances in natural language processing, particularly generative pre-trained models like GPT-4, are reshaping sentiment analysis. These models enhance semantic understanding and improve sentiment classification. However, this study does not assess LLM-based sentiment analysis methods. Their adoption may not only alter technical methodologies but also redefine the analytical frameworks of financial sentiment research.
Challenges of a Dynamic Data Ecosystem
The evolving nature of social media platforms and shifting user behaviors create highly dynamic data characteristics, complicating sentiment analysis. As platforms update policies and data structures change, the recommendations provided in this study may require adaptation to maintain their effectiveness.
In conclusion, this study systematically reviews key sentiment extraction methods and provides actionable recommendations for financial market research. However, the identified limitations highlight areas for further exploration.
Conclusion
Investor sentiment in social media has fascinating applications. Scholars have studied the relationship between social media sentiment and financial markets from different perspectives, but these studies have not reached a consensus (Nguyen et al., 2015). The diversity of sentiment tracking tools and the openness of sentiment mining elaboration in the financial literature make replication and comparison studies difficult to carry out. Through a literature survey, this study aims to summarize the parsing and elaboration norms that future researchers should follow in social media sentiment mining.
In this study, we reviewed a body of key financial literature on investor sentiment derived from social media, aiming to address the aforementioned challenges. We thoroughly examined essential components of sentiment text mining, such as sentiment lexicons, semantic rules, sentiment text annotation, and supervised learning. Based on these reviews, we proposed critical guidelines and recommendations for sentiment analysis in financial studies (see Table 6). We emphasize that adhering to these principles can help reduce noise in constructing investor sentiment metrics and improve the reliability and scientific rigor of related research.
To the best of our knowledge, there has been no systematic review and synthesis focusing specifically on sentiment parsing methods in the construction of investor sentiment. This study fills an important gap by offering significant reference value in this area. Theoretically, this research integrates the strengths and limitations of sentiment analysis methods, establishing a framework tailored to financial studies that can enhance consistency and reproducibility. By emphasizing the importance of transparency and standardization, this study provides a solid theoretical foundation for social media-based investor sentiment research and future financial market analyses.
Practically, this research offers vital guidelines for policymakers, supporting the development of more precise financial regulatory strategies to address market volatility and mitigate risks of manipulation. For investors and financial institutions, it provides practical guidance to optimize the construction of sentiment indicators, thereby improving decision-making efficiency. Moreover, the study offers valuable insights for other socio-economic fields and lays a solid foundation for future research in cross-linguistic and cross-cultural contexts.
Through a systematic review of literature spanning 2004 to 2024, this study thoroughly examined critical aspects of text mining for social media-based sentiment measurement. Despite the limitations of length and resources, we confidently present a comprehensive snapshot of sentiment text mining in the context of investor sentiment, providing valuable references for future research.
Due to the limitations of this study, future research should mainly focus on two main areas: first, finding out how new natural language processing technologies, like generative pre-trained models (e.g., GPT series), can be used in sentiment mining and how well they do in dynamic data and multimodal analysis; and second, exploring the potential of these technologies in more depth. Second, we should further investigate the adaptability of sentiment lexicons and parsing methods in cross-linguistic and cross-cultural contexts, with the aim of developing sentiment measurement tools that are more generalizable and accurate.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440251328535 – Supplemental material for Text Sentiment Mining used for Constructing Investor Sentiment in Social Media: Survey and Recommendations
Supplemental material, sj-docx-1-sgo-10.1177_21582440251328535 for Text Sentiment Mining used for Constructing Investor Sentiment in Social Media: Survey and Recommendations by Qing Liu and Hosung Son in SAGE Open
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.