
Abstract
The current study examined the interaction effect of the number of models in videos and viewing type on the acquisition of a Tabata skill, a four-minute high-intensity interval training. We randomly recruited 316 Chinese undergraduate students (162 females and 154 males). They viewed either one model presentation or six models presentation under one viewing type (viewing alone vs. viewing in pairs). We found that for learners who viewed alone, those learning from the video with six models perceived higher levels of social presence, parasocial interaction, social partnership with models, motivation, learning satisfaction, and attention than those learning from the video with one model. The findings have some implications for the design of video presentations to teach motor skills: teachers are encouraged to design effective video presentations via presenting models and create co-viewing learning contexts to enhance learning experience and outcomes.
Introduction
Background
Image you learn Tabata from a video-model presentation, in which you should complete a four-minute high-intensity interval training protocol consisting of eight 20-s work intervals with 10-s rest periods. Would you prefer to view a presentation with a model or six models? Again, would you like to view it alone or with your peers? Research on video learning suggests that your learning will be influenced by the model and viewing pattern (Andel et al., 2020; Liu et al., 2024). As technology continues to advance, there are a considerable number of video-model presentations on various video media platforms (e.g., TikTok and YouTube) to teach motor skills (Leight et al., 2009; Yang, 2021; Yücekaya et al., 2021). Consequently, educators have attempted to apply video-model presentations in sports sciences (López-Carril et al., 2024). It is commonly believed that learners can learn motor skills equivalently from video-model presentations to the direct observation of a model in front of them (Lhuisset & Margnes, 2015; Yang, 2021).
Literature Review
Due to the popularity of video-model presentations, many studies have addressed optimizing the effectiveness of such presentations (H’mida et al., 2020). There is a consensus that social presence is crucial to enhancing video-based learning for declare and procedure knowledge (e.g., cooking and developmental psychology; Andel et al., 2020; Homer et al., 2008). Social presence is related to the subjective perception of feeling psychologically connected with others while engaging in social interactions through various media (Lyons et al., 2012). Social presence theory and numerous empirical studies have shown that learners’ high social presence leads to positive learning outcomes, such as increased motivation and attention engagement, better interpersonal relationships with models in videos, and high learning satisfaction in online learning contexts (Beege et al., 2023; Gunawardena & Zittle, 1997). For example, a study by Andel et al. (2020) found that when learners perceived higher social presence within video-based learning, they experienced higher satisfaction and better perceived learning when learning cooking. Other studies have demonstrated that higher social presence within a video-based environment contributes to greater perceived interactivity (Pimentel, 2021), parasocial interaction (Shin et al., 2019), and motivation (Z. Zhang et al., 2023). Taken together, the above studies have suggested that social presence is critical in enhancing learning with video presentations, and has great influences on learners’ social, motivational, and cognitive outcomes.
Researchers make great efforts to increase social presence within video-based learning (Alemdag, 2022; Beege et al., 2023; Henderson & Schroeder, 2021). They claim that presenting models is an effective way to maximize and enhance learners’ social presence and thus improve their learning. For instance, a recent meta-analysis reviewing 35 studies confirmed the model presence effect on learners’ social presence in various disciplines (Beege et al., 2023). However, on the one hand, previous studies have mainly focused on declare and procedure knowledge rather than motor skills, which consist of advanced, complex movements required to participate in sports, or other contexts involving specific physical activities (Logan et al., 2018; Lago-Rodríguez et al., 2014). On the other hand, previous studies only highlight the critical role of a model in videos and overlook whether more social presence cues (i.e., more than one model) trigger a high level of social presence and the role of offline co-viewers (Beege et al., 2023; Henderson & Schroeder, 2021).
Some emerging studies have shown that offline or online co-viewers are crucial ways to enhance learners’ social presence and video-based learning (Fang et al., 2018; Liu et al., 2024; Lytle et al., 2018; Pi et al., 2022a). For instance, studies by Pi et al. (2022a, 2022b) found that co-viewing videos motivated learners’ to make more effort into learning, and a peer’s praising behaviors improved their learning performance when learning infectious diseases and English vocabulary words. Furthermore, a study by Lytle et al. (2018) evidenced the benefits of offline co-viewing videos for word learning. However, previous studies have not yet directly tested whether co-viewers offline enhance learners’ social presence and, thus, their learning motor skills from video-model presentations. Early social psychology studies have shown that co-viewers offline enhanced people’s imitation of actions (e.g., laughing) in video-model presentation, which referred to audience effect (Chapman & Wright, 1976; Drabman & Thomas, 1977; Leyens et al., 1982). Therefore, it is reasonable to postulate the audience effect when viewing a video-model presentation teaching motor skills in pairs.
The Present Study
The rationale for this study is that although much research has focused on social cues (i.e., model and audience presence) in learning with video presentations (Beege et al., 2023; Pi et al., 2022a), less research has investigated the mutual effect of model and audience presence on social, motivational, and cognitive outcomes in video presentations teaching motor skills. To bridge the gap, the current study examined the interaction effect of the number of models in videos (one vs. six) and viewing type (viewing alone vs. viewing in pairs) on learners’ social presence, parasocial interaction, social partnership, motivation, learning satisfaction, attention, and learning performance of a Tabata skill. We randomly assigned learners to one of four conditions: (a) one model + viewing alone; (b) six models + viewing alone; (c) one model + viewing in pairs; and (d) six models + viewing in pairs. Specifically, the present study aims to answer the following research questions (RQs).
RQ1: How does the number of models in videos and viewing type affect learners’ social presence while viewing video presentations to teach a Tabata skill?
H1: Learners who view the video with six models would experience increased social presence, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ2: How does the number of models in videos and viewing type affect learners’ parasocial interaction while viewing video presentations?
H2: Learners who view the video with six models would experience increased parasocial interaction, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ3: How does the number of models in videos and viewing type affect learners’ social partnership while viewing video presentations?
H3: Learners who view the video with six models would experience increased social partnership, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ4: How does the number of models in videos and viewing type affect learners’ motivation while viewing video presentations?
H4: Learners who view the video with six models would report increased motivation, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ5: How does the number of models in videos and viewing type affect learners’ learning satisfaction while viewing video presentations?
H5: Learners who view the video with six models would report enhanced learning satisfaction, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ6: How does the number of models in videos and viewing type affect learners’ attention while viewing video presentations?
H6: Learners who view the video with six models would report increased attention, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
RQ7: How does the number of models in videos and viewing type affect learners’ learning performance while viewing video presentations?
H7: Learners who view the video with six models would show increased immediate and delayed learning performance, compared to those who view the video with one model. This divergence is expected to be amplified when learners view the video in pairs instead of alone.
Method
Participants
We randomly recruited 316 bachelor’s degree students (162 females and 154 males) aged 16 to 25 years old (M = 19.85, SD = 0.87) from a university in China. They had various majors (e.g., computer science, finance, and public administration). They provided written informed consent after being provided information about the experimental procedures. Each participant obtained 50 RMB for participating. The local ethics committee approved the study protocol.
We adopted a between-subjects design. There were two between-subjects variables: (a) the number of models: one versus six and (b) viewing type: viewing alone vs. viewing in pairs.
Video-model Presentations
There were two video-model presentations to teach Tabata, a high-intensity interval training. Video-model presentations conducted eight actions (e.g., planks, squats, and high leg lifts) and lasted about 4 min. The two video-model presentations were as follows (Figure 1): (a) one model demonstration: the video was recorded by a physical education teacher; (b) Six models demonstration: the video was recorded by six physical education teachers. The two videos were recorded on the actual scene of the sports field. In each video, the instructor demonstrated each action for about 30 s, with the critical points of action presented as subtitles.

Screenshot of each video presentation.
Measures
Physical Fitness
We used a physical fitness assessment to measure participants’ physical fitness levels prior to the experiment. The physical fitness assessment included eight components: body mass index, vital capacity, 50-m sprint, standing long jump, sit-and-reach flexibility test, distance run (1,000 m for males, 800 m for females), 1-minute sit-ups (females), and pull-ups (males). These components were chosen to provide a comprehensive evaluation of participants’ physical fitness, focusing on key areas such as movement speed (50-m sprint), flexibility (sit-and-reach), cardiovascular endurance (distance run), abdominal strength (sit-ups and pull-ups), and lower body strength (standing long jump). For example, movement speed was measured by the completion time of the 50-m sprint, flexibility was assessed in centimeters for the sit-and-reach test, cardiovascular endurance was measured by the completion time of the endurance run, core strength was evaluated through the number of sit-ups (females) or pull-ups (males) completed, and lower body strength was assessed by the distance achieved in the standing long jump. Each component was scored on a 4-point scale (1 = fail, 2 = pass, 3 = good, 4 = excellent), and the total score was used to represent the participant’s overall physical fitness level. The internal consistency of the scale in this study was 0.70.
Social Presence
We used the social presence scale (Lee & Nass, 2005) to measure participants’ feelings of actual conversation. The scale includes three items on a 7-point Likert scale (1 = Strongly disagree, 7 = Strongly agree). An example of the items is as follows: “I feel as if he were speaking directly to me.” The social presence scale was widely used to measure participants’ feelings of social presence when interacting with electronic equipment (Lee & Jang, 2013). The internal consistency of the scale in this study was 0.96.
Parasocial Interaction
We employed the experienced parasocial interaction scale (EPSI scale; Hartmann & Goldhoorn, 2011) and one item from the PSI process scale (Schramm & Hartmann, 2008). The scale includes seven items on a 7-point Likert scale (1 = Strongly disagree, 7 = Strongly agree). An example of the scale is as follows: “I felt like the tutor addressed me personally.” The internal consistency of the scale in this study was 0.97.
Social Partnership and Motivation
We adopted social partnership and motivation dimensions in the learning experience questionnaire (Stull et al., 2018). The dimension of social partnership included two items, and the dimension of motivation included six items. An example of the dimension of social partnership is as follows: “I found the instructor’s teaching style engaging.” An example of the dimension of motivation is as follows: “I enjoyed learning this way.” Participants rated all items on a 7-point Likert scale (1 = Strongly disagree, 7 = Strongly agree). The internal consistencies of the dimensions of social partnership and motivation in this study were satisfactory (Cronbach’s alpha = .94, .96, respectively).
Learning Satisfaction
We used the computer learning satisfaction scale (Wang, 2013) and deleted or modified some items according to our research context. The final scale included 17 items and four dimensions: the model’s teaching ability (six items), the content of the video (five items), model-student interaction (three items), and learning environment and equipment (three items). An example of the dimension of the model’s teaching ability is as follows: “The model can use teaching media flexibly, which is helpful to my learning.” An example of the dimension of the content of the video is as follows: “The amount and difficulty of tasks in the video are moderate.” An example of the dimension of model-student interaction is as follows: “Teaching by video presentations can make the learning atmosphere relaxed, lively, and orderly.” An example of the learning environment and equipment dimension is as follows: “I am satisfied with the normal operation of the video presentation.” Participants rated all items on a 7-point Likert scale (1 = Strongly disagree, 7 = Strongly agree). The internal consistency of the scale in this study was 0.98.
Attention
We adopted the flow scale developed by Jackson and Eklund (2004). The scale included six items and two dimensions: total concentration on the task at hand (three items) and altered sense of time (three items). It is widely used to assess flow in physical activity (Goddard et al., 2023). An example of the dimension of total concentration on the task at hand is as follows: “I had total concentration.” An example of the dimension of an altered sense of time is as follows: “It felt like time went by quickly.” Participants rated all items on a 7-point Likert scale (1 = Strongly disagree, 7 = Strongly agree). We used participants’ average rating of three items on the first dimension as their flow scores. The internal consistency of the scale in this study was 0.79.
Learning Performance
Based on pre-established Tabata scoring criteria, the motor skills test evaluates students’ exercise videos. Three professors in sports science assessed the participants’ motors, resulting in high inter-rater reliability (rs > 0.63). Each action is scored out of 12 points, with a total score of 96 points, calculated as the average score from three instructors. The learning performance was measured immediately after learning from video presentations and a week as their immediate and delayed performance, with consistent test content and Cronbach’s α were .79 and .76, respectively.
Procedure
The procedure is shown in Figure 2. Each participant was randomly assigned to one of four experimental conditions and briefly understood the procedure in about 5 min. First, participants were required to complete a physical fitness assessment in about 30 min. Then, participants watched corresponding video lectures and did exercises according to their assigned group for about 1 h. Next, they completed the flow scale, social presence scale, parasocial interaction scale, learning experience questionnaire, learning satisfaction scale, and immediate performance test of motor skills in about 30 min. Finally, 1 week later, participants completed a delayed performance test of motor skills in about 10 min.

Experiment procedure.
Data Analysis
To test the interaction effects of the number of models and viewing type, we conducted a series of 2 (the number of models: one vs. six) × 2 (viewing type: viewing alone vs. viewing in pairs) ANOVA for students’ social presence, parasocial interaction, learning satisfaction, attention, and learning performance. All data were analyzed using SPSS 27.0.
Results
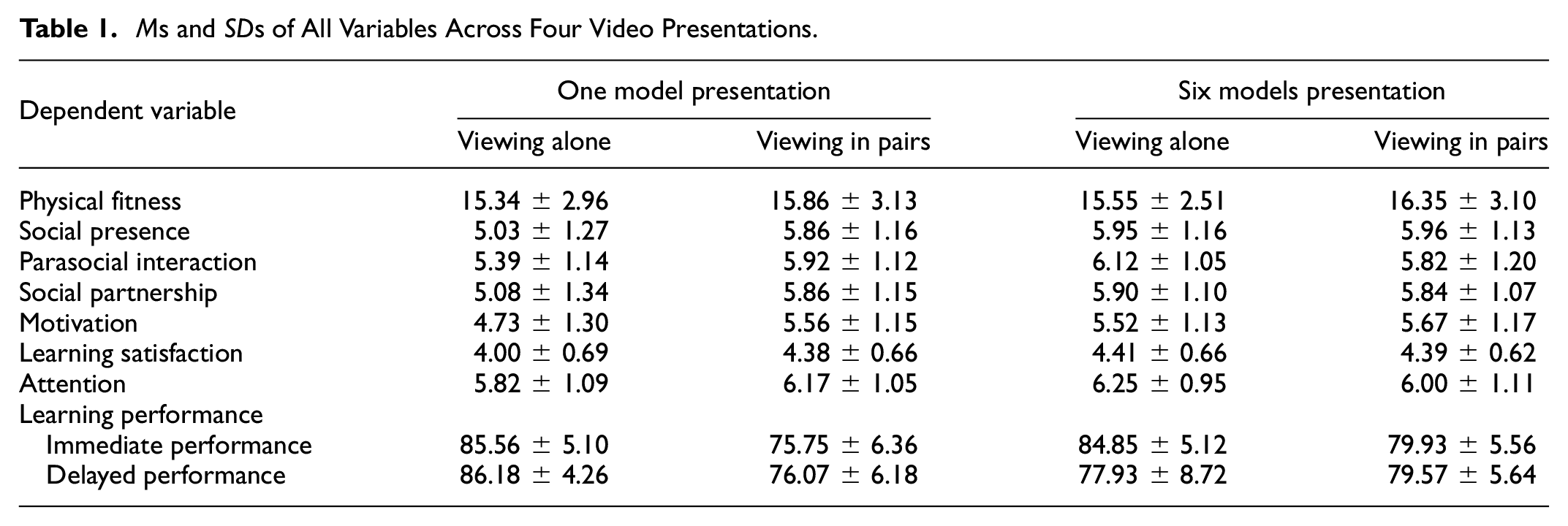
Table 1 shows the descriptive results of all variables. To test individual differences in participants’ physical fitness levels prior to the experiment, we analyzed the results of the physical fitness assessment. The results of the 2 (the number of models: one vs. six) × 2 (viewing type: viewing alone vs. viewing in pairs) ANOVA showed that none of the main effects of the number of models (F(1,307) = 0.99, p = .32,
Ms and SDs of All Variables Across Four Video Presentations.
Social Presence
Regarding the social presence, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 13.67, p = .00,

Differences in social presence among four groups.
Parasocial Interaction
Regarding the parasocial interaction, the results of the two-way ANOVA found both the main effect of the number of models (F(1, 312) = 5.67, p = .02,

Differences in parasocial interaction among four groups.
Social Partnership
Consistent with motivation, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 8.85, p = .003,

Differences in social partnership among four groups.
Motivation
Regarding the motivation, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 10.71, p = .001,

Differences in motivation among four groups.
Learning Satisfaction
Similar to the learning experience, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 7.95, p = .005,

Differences in learning satisfaction among four video groups.
Attention
Regarding attention, the results of the two-way ANOVA found the interaction effect (F(1,312) = 6.00, p = .02,

Differences in flow among four groups.
Learning Performance
Immediate Performance
Contrary to the questionnaire results above, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 6.79, p < .001,

Differences in immediate performance among four groups.
Delayed Performance
Contrary to the questionnaire results above, the results of the two-way ANOVA found the main effect of the number of models (F(1, 312) = 10.16, p = .002,
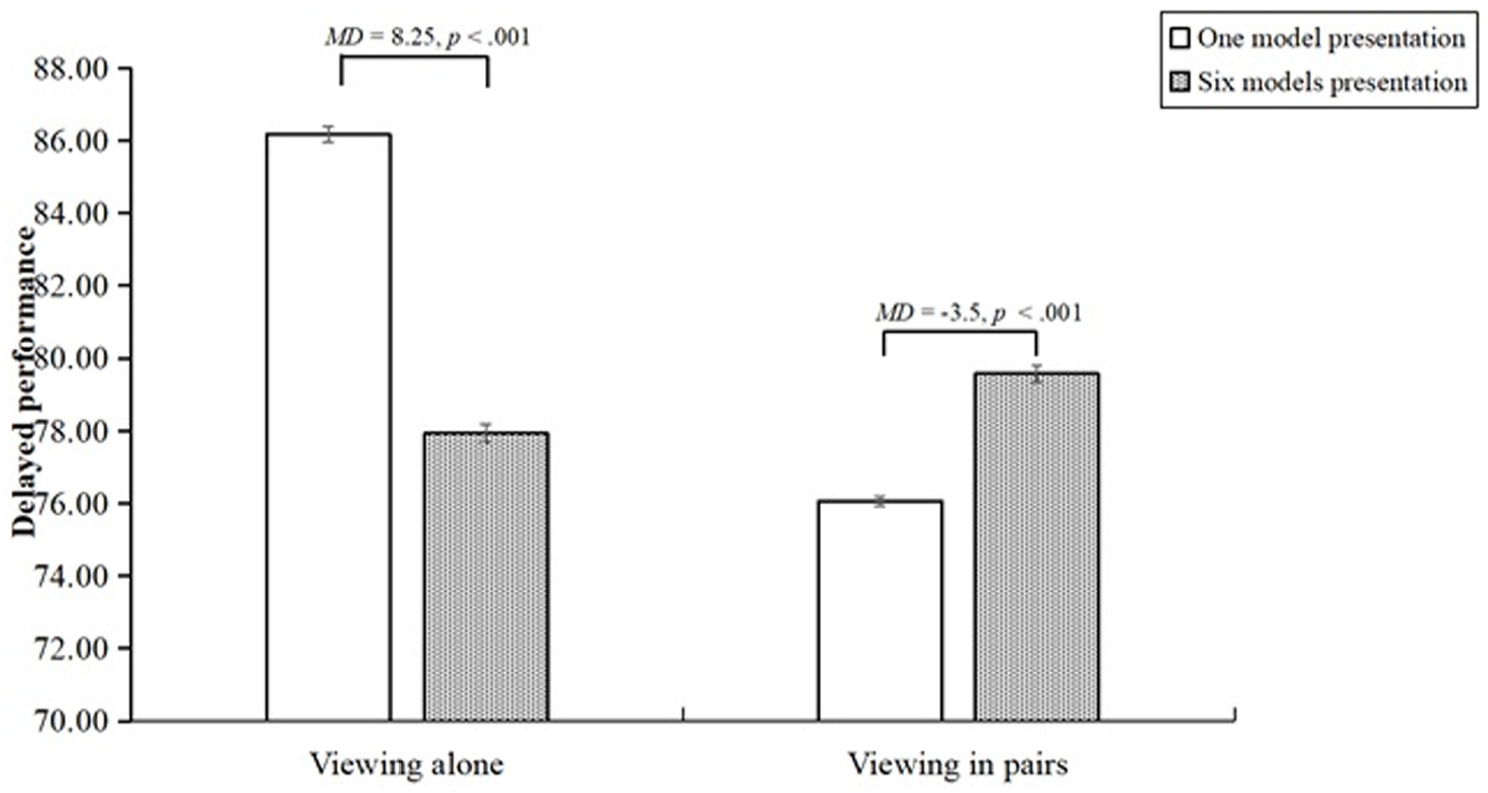
Differences in delayed performance among four groups.
Summary
Partially expected as our hypotheses, we found that for learners who viewed alone, those learning from the video with six models perceived higher levels of social presence, parasocial interaction, social partnership with models, motivation, learning satisfaction, and attention than those learning from the video with one model. However, for learners who viewed the video in pairs, those learning from the video with six models did not show a difference in those subjective experiences compared to those learning from the video with one model. More interestingly, the findings showed different trends in learning performance. For learners who viewed alone, those learning from the video with one model showed better delayed learning performance, compared to those learning from the video with six models. On the contrary, for learners who viewed in pairs, those learning from the video with one model showed worse immediate and delayed learning performance, compared to those learning from the video with one model.
Discussion
Empirical and Theoretical Contributions
The current study examined the mutual effects of the number of models in videos and viewing type on learners’ social, motivational, and cognitive outcomes. Regarding RQ1-5 on social and motivational effects, the present study first found learners’ increased social presence, parasocial interaction, social partnership with models, motivation, and learning satisfaction in viewing the video with multiple models alone. The results were in line with the social presence theory and the model presence effect, indicating that learners like the visual presence of a model, usually one model in videos (Beege et al., 2023; Gunawardena & Zittle, 1997; Wilson et al., 2018). They perceive enjoyment and interest and are motivated by the model presence to increase subjective engagement (Beege et al., 2023; Henderson & Schroeder, 2021). Our findings advanced previous studies by manipulating the number of models, suggesting that more models in videos teaching motor skills benefit learners’ social and motivational experience when they view videos alone.
However, the present study did not find that learners who viewed in pairs report different social and motivating experiences in viewing the video with different number of models (RQ1-5). One possible reason is that the co-viewer can also act as a social presence cue, and such a cue is enough to trigger learners’ social response, even in a video with one model. The explanation was evidenced by the main effects of viewing types on social presence, social partnership, and motivation. Furthermore, previous studies on peer presence have shown the audience effect (Chapman & Wright, 1976; Drabman & Thomas, 1977; Leyens et al., 1982) and suggested that viewing videos in pairs boosts learners’ social presence and enhances their motivation to learn (Liu et al., 2024; Lytle et al., 2018; Pi et al., 2022a).
More interestingly, regarding RQ6 on attention effects, the present study observed that learners viewing alone perceived greater attention engagement with the video presenting multiple models than with the video presenting one model. The results were consistent with a series of experiments in the study by Wilson et al. (2018). They found that learners reported greater attention engagement with the video presenting a model than with the video not showing a model. Wilson et al. (2018) explained that learners were motivated to pay great attention to the model, and they might interpret their attention being captured by the model as being engaged with the learning content, feeling an increased sense of ease in attention. They may not realize that they are attending to a model not germane to the learning content being taught in the video or missing relevant learning content. The same phenomenon might occur in the present study. Learners indeed paid greater attention to multiple models in the video, leading to missing some information about motor skills. Some eye-tracking studies on videos have shown that learners pay great attention to the model and there was no decline in attention to the instructor over time (Pi & Hong, 2016; van Wermeskerken et al., 2018). Therefore, the social and motivating benefits of multiple models might be offset by cognitive loss. This might explain why learners showed better learning performance in videos with one model, compared to videos with six models (RQ7). Future work is needed to measure how learners pay attention to process models in video presentations.
On the contrary, the present study did not observe that learners who viewed in pairs perceived differences in attention engagement with the two videos (RQ6). However, they showed better learning performance in the video presenting multiple models than in the video presenting one model (RQ7). The results were consistent with a previous study on imitation, suggesting that learning context similarities increase automatic imitation (Genschow et al., 2021). One possible explanation is that when viewing videos in pairs, the learning context offline was like videos showing six models of Tabata training. In such a learning setting, learners might be more likely to be infected with and imitate models’ actions. Previous studies also have shown that learners engaged in neural mirroring processes when observing the model’s actions in videos and learners viewing videos in pairs exhibited more imitation of the models (Lytle et al., 2018; Pi et al., 2022b).
Limitations and Future Work
We recognize two limitations in our study and recommend caution when generalizing the findings. First, we did not record learners’ behavioral responses while viewing video presentations. We found that some learners imitated models’ actions, and some did not by informal observation. The number of models and viewing type might influence their imitation and, thus, their acquisition of motor skills. Future research should examine the effects of the number of models and viewing type on learners’ actions during viewing video presentations. Second, we did not measure learners’ attention to models via accurate technologies (i.e., eye tracker). Previous studies have shown that models in video presentations distract learners’ attention, leading to great attention to models rather than learning content (Pi & Hong, 2016; van Wermeskerken et al., 2018). Their attention allocation in videos presenting models also influences their learning performance (H. Zhang et al., 2020). Future work is needed to measure the effect of the number of models and viewing types on learners’ attention allocation in videos teaching motor skills.
Conclusions and Practical Implications
In conclusion, the findings evidenced the interaction of the number of models in videos and viewing type. The main finding was that more models in videos promote the social and motivational experience of learners who viewed alone and promote the motor skills of learners who viewed in pairs. The findings have some implications for the design of instructional videos to teach motor skills: teachers are encouraged to design effective instructional videos via presenting models and create co-viewing learning contexts to enhance learning experience and outcomes. Specifically, first, more than one model is presented in videos to promote learners’ subjective experience, but one model is presented to promote their motor skills when learners view videos alone. Second, more than one model is shown in videos to promote learners’ motor skills when learners view videos in pairs.
Footnotes
Author Contributions
Feng Xu: Conceptualization; Writing – original draft; Formal analysis; Funding acquisition; Project administration. Qiudong Xia: Writing – original draft; Formal analysis. Minxue Li, Jie Dai, and Zhongling Pi: Methodology; Zheng Zheng: Writing – original draft; Project administration; Writing – review & editing.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Key Project Supported by Zhejiang Province Association for Higher Education in 2023 [KT2023044], the 2022 Research Project of East Asian Institute of Zhejiang Gongshang University [22JDDYZS04WT], 2023 Zhejiang Gongshang University Curriculum Ideological and Political Teaching Research Project, and 2023 Zhejiang Gongshang University Curriculum Ideological and Political Teaching Research Project, 2024 Zhejiang Gongshang University Higher Education Research Project [9], and 2023 Zhejiang Gongshang University Postgraduate Course and Ideological and Political Teaching Demonstration Course [22].
Research Ethics Committee and Ethical Approval
The protocol was approved by the Ethical Committee of the Zhejiang Gongshang University.
Data Availability Statement
Our data and material are not yet available online in any institutional database. However, we will send the whole data package and material by request.