
Abstract
E-learning systems are transforming the educational sector and making education more affordable and accessible. Recently, many e-learning systems have been equipped with advanced technologies that facilitate the roles of educators and increase the efficiency of teaching and learning. One such technology is Automatic Essay Grading (AEG) or Automatic Text Scoring (ATS) systems. To enable educators to remain more focused on teaching, there is a dire need to develop a more efficient use of their time. This is where automatic systems come into play, but they are still encountering an ongoing challenge due to many complex aspects, such as covering students’ creativity, novelty, context, subjectivity, coherence, cohesion, and homogeneity. The proposed study chose the Kaggle dataset of the Hewlett Foundation competition to cover this gap. It contains eight different essay sets based on student-written essays and their different range-based scores. Firstly, a score quantification method is applied to domain scores. Moreover, the proposed study covered four different aspects of student-written essays and extracted cohesion features via sentence connectivity, coherence via sentence relatedness, statistical lexical features via the Term Frequency (TF)-Inverse Document Frequency (IDF) method, and discourse macrostructural features via calculating the unique pattern of each essay. Three different experiments based upon the combination of these features are conducted, the most effective combination of features remains as statistical lexical features and discourse macrostructural features whereas the Linear Regression method is used for score prediction. The average Quadratic Weighted Kappa (QWK) score of 0.9339 was achieved and outperformed previous solutions in terms of time, computation, and performance.
Keywords
Introduction
E-Learning is increasing in demand as it offers flexibility for students in getting an education and involves less expense and cost for institutes (Mahlangu, 2018). With the transformation of the education system, it is essential to transform education and assessment styles too to facilitate the essay assessment task undertaken by educators. According to Brown et al. (2013), the essay assessment of students is common practice in educational institutes where these essays are most commonly designed to interpret the student’s ability to synthesize knowledge and to recall the concepts about any given topic (Pugoy, 2022).
Essay assessment plays a vital role in aggregating a student’s engagement with the concepts, instructed guidelines, and integration of ideas. Unlike short and multiple-choice question/answer sheets, essay writing is an open-ended task, and all students have different styles of writing. Hence, assessing essays written by students is regarded time-consuming by educators, requires their focus, is resource-intensive, and a domain knowledge-based task (Hendre et al., 2021). Perhaps with the development of AEG systems assessing student essays would flow better. Also, reducing the time educators spend on grading assessments through using automation enables more time for fruitful educational activities, such as allowing students to write notes with more insightful examples (Prasad et al., 2020). Consequently, to help educators achieve their targets in education and learning, the Automatic Essay Grading (AEG) or Automatic Text Scoring (ATS) systems need to be developed to be used to automatically grade students’ essays or textual documents (Lun et al., 2020). In addition, the use of the AEG systems could reduce the manual interpretation of essay grading and provide equally scaled grading to all students’ essays by reducing bias and the negative effect of lack of focus from educators. From a linguistic perspective, AEG systems analyze essays by extracting linguistic features such as grammar, vocabulary, coherence, and structure, which are used to determine the quality of the essay, mimicking the criteria used by human graders. From a technical perspective, the AEG systems typically employ rule-based approaches to process the extracted features and assign scores to the essays. Rule-based models are trained on datasets of essays with human-assigned grades, allowing the system to learn complex patterns and associations between linguistic features and grades. These models are then evaluated using metrics like QWK to assess their effectiveness in replicating human grading decisions. Although the AEG system reduces the time and effort needed to grade essays, it does not involve human interaction for grading. Consequently, it faces several challenges, such as the inability to capture emotional captions, novelty, and creativity in students’ writing (Zhang & Wallace, 2015). Comparably, Automatic Essay Scoring (AES) cannot identify other problems, such as cheating and test-taking anomalies. Also, educators are experiencing challenges when it comes to evaluating students’ essays and providing feedback, which requires giving assessments of high quality that positively affect the student’s performance (Ada, 2023; Elsayed & Cakir, 2023). Despite the challenges, AEG still attracts the attention of researchers to develop efficient AEG systems as it reduces human resource intensity (Li et al., 2021).
Previously developed AEG systems via handcrafted features (features engineered by domain experts or through manual analysis of the text data) mainly have time limitations, and their performance depends upon the quality used for feature extraction (Beseiso et al., 2021). Instead of using handcrafted or traditional feature extraction approaches, deep learning uses a dense vector approach. Deep learning extracts the complex and unique patterns present in a given instance. For textual data, it includes automatic feature extraction by covering global aspects of a text, such as Recurrent Neural Network (RNN), which showed better performance than traditional methods (Kwong et al., 2019). Although the RNN and Long-Short-Term-Memory (LSTM) models cover contextual aspects, they have a vanishing gradient (Deep networks struggle as signals fade in depth) problem due to larger inputs of essays or text (Beseiso et al., 2021). However, in deep learning-based AEG system development, another major challenge is the limited corpus to address this problem, different word embedding methods have been developed, such as Global Vectors for Word Representation (GloVe) proposed by Pennington et al. (2014) and Word to Vector (word2Vec) introduced by Le and Mikolov (2014). Although these embedding methods have important and insightful techniques to represent the words, they fail to give context.
To cover contextual features, attention-based (Focus on relevant parts, ignore distractions, understand better) models such as the Robustly optimized Bidirectional Encoder Representation Transformer approach (RoBERTa) have been proposed by Liu et al. (2019). These models have transformer-like structures which are trained on big datasets in an unsupervised manner. However, these models have issues regarding document length truncation when used in AEG system development. AEG system development comprises different stages; the first stage involves text preprocessing, which involves splitting data into sequences, removing stop words, converting characters in the texts to lowercase, etc. In the second stage, the feature extraction contains the vector representation of measurable quantities present in documents (Beseiso et al., 2021). It involved quantities that are hard to calculate manually, such as measuring the frequency of unique words, etc. Accordingly, the effectiveness of the AEG system depends on the features that are chosen while in development (Ramalingam et al., 2018).
The most common problems that are relevant to AEG system development using deep learning include the lack of a big data corpus to train the models and greater time consumption. However, feature extraction and choosing the most relevant features are the tasks that make the AEG system most effective. The effectiveness of the AEG system is usually measured using the QWK metric. The QWK measures the AEG system’s performance, factoring human-machine agreement and chance, providing robust evaluation. To solve the time consumption problem and to choose the most relevant features to improve the performance of the AEG system, the proposed study has used several methods, including a public dataset that is available on the Kaggle website; it contains 7th- to 10th-standard students’ written essays on eight different topics. Different human graders-based scores are given in this dataset on all essay sets, which are used as ground truth labels. However, the proposed AEG system has contributed in the following ways:
(1) To improve the performance of linear regression models, all essay sets’ scores are firstly mapped using a grades quantification method without affecting the originally assigned grades, thereby increasing the efficiency of the kappa metric.
(2) Multi-aspects covering features, such as cohesion, coherence, statistical lexical, and discourse macrostructural, have been extracted to collect important information from essays to increase the kappa metric score.
(3) Finally, the proposed study provided an efficient approach and an improved QWK score-based solution as compared to previous studies.
The remaining article is divided into four sections. Section 2 contains related work and discussion, Section 3 contains applied methods, and Section 4 contains results and a discussion. Finally, the conclusion is added to present the weaknesses and strengths of the applied framework.
Related Work
The AEG system has been extensively developed by researchers over recent decades. A few of them have been discussed here concerning their methods, datasets, the results they achieved, and the research gaps that they mainly solved. This section explores and reveals the applied methods for AEG system development, the publicly available datasets, and the results achieved by previous studies.
Tambe and Kulkarni (2022) used a score trait approach in which structural and grammatical features are considered for use; the Kaggle Automated Student Assessment Prize (ASAP) dataset is used, and the QWK metric is used to match the predicted scores using the applied approach. The BERT text embedding approach is used to cover the contextual representation of text while grammatical errors are solved and structural features are embedded via an LSTM model. The QWK score of 0.75 is recorded using structure-oriented features, and the 0.70 QWK score is achieved via grammatical features. It claims that these preprocessing steps are needed before applying embedding methods directly onto the text.
To cover the essay coherence problem, the RoBERTa method-based text embedding is extracted and trained over the Bi-LSTM model for essay grade prediction. The same Kaggle ASAP dataset is used where the QWK and F1-scores are used to predict the grades. Three additional state-of-the-art models were used to compare the performance of the proposed study methods. The multiple blocks of testing data were fed to RoBERTa models, which were subsequently provided to Bi-LSTM models to predict the essay grades. The achieved QWK score was 0.80.
Zeng et al. (2023) claim that previous studies did not consider the training process to create an effective AEG system. They reported that curriculum learning during the training process of the AEG model could improve the model performance by up to 4.5%. It uses two datasets, Kaggle ASAS and AES (ASAP). It was customized to the Curriculum Learning (CL) process by including two factors of difficulty. These were predefined and automatic. In pre-defined, the difficulty is measured via length, distinct keywords, readability, and error estimation, whereas, in automatic difficulty measuring, a ratio is estimated using the probability of easiness or difficulty by validating the correct prediction during the training of the model. The achieved best results on both datasets reached to average QWK for ASAS of 0.657 and 0.740 for AES datasets.
Arabic essay grading systems are very few because of limited Arabic datasets (Awaida et al., 2019). An Arabic corpus dataset has been developed and Arabic WordNet (AWN) is used to find the synonym present in students’ essays to the equally scaled dataset. The tokenization and stop word removal are performed while the AWN method is used to embed the text. Also, the feature selection is performed using the F-score method of data classification, namely Support Virtual Machine (SVM), and results are evaluated using the cosine similarity index. The reported results indicate that two experiments were conducted mainly; with AWN and without using AWN, the most similar cosine index was achieved with the use of AWN.
Another study uses an Arabic dataset to develop an AEG system (ElNaka et al., 2021). It claims that more than 80 million students in Arab countries who took part in daily educational activities were an intrinsic part of their study. However, to the best of their knowledge, the authors claim that there is only one Arabic dataset on essay scoring available, namely “AR-ASAG,” while the authors published a new “Ara-Score-dataset.” Additionally, the applied methods were tested on three datasets; the AR-ASAG, the proposed AraScore-dataset, and the SAS (ASAS) datasets. It used sentence and word level embedding on all datasets, while supervised machine learning classifiers and regressors were used to predict the essay scores. The Mean Square Error (MSE) was calculated to evaluate the model performance of regression methods while accuracy was used to measure the classification model performances. The best MSE on the three datasets (SAS, AR-ASAG, Ara-Score) was achieved as 0.132, 0.265, and 0.073, respectively, via multi-layer-perceptron regressor (MLP-R), using sentence-level embedding. The best classification accuracy for the same datasets was achieved at 66.37%, 60.27%, and 94.70% via MLP-R. The summary of related work based on different datasets, applied methods, and achieved results is shown in Table 1 below.
Summary of Applied Methods, Datasets, and Their Results to Develop AEG System.

A novel method of semantic hashing is used via the K-means intelligent method (Tashu & Horváth, 2020). With a few instances as a model, other instances are scored. It provides a solution to create annotated data to remove the limited corpus availability for AES system development. It uses ASAS Kaggle competition data, whereas only 40% of training data was used to score other instances with 90.2% accuracy.
Another study claimed that when a different essay with high and low quality is added to the AEG system, then it causes a huge difference in estimated and real scores (Wang et al., 2023). To solve this problem, a three-way sequential decision was created with machine and human grading collaboration. A combination of Bi-LSTM and a three-way sequential decision method was evaluated with extensive experiments on the Kaggle ASAP dataset. Three baseline methods were compared with the proposed approach, and a 0.8967 QWK was achieved.
Different kinds of handcrafted, automatic features have been extracted and combined in different combinations to increase the QWK score of the ASAP dataset. Some of the studies focused on Arabic essay text grading. This research also investigates that after extracting features, these were subsequently fed to Deep and Machine Learning (ML) classifiers to predict the grading scores. Some of the studies used classification methods, whereas most of them used regression methods. The proposed study performed three experiments that utilized preprocessing methods to clean up essay data. Subsequently, coherence, cohesion, statistical lexical, and macrostructural features were extracted, whereas different combinations of them fed the LR model to reach the maximum QWK score.
Materials and Methods
The conducted study on AEG development used primary steps and multiple experiments to create an efficient AEG system. These primary steps are visually illustrated in Figure 1. The Kaggle ASAP dataset is used in this framework with eight different essay sets containing more than 12k essays written by students from the 7th to 10th grades. The essays are graded by multiple human raters with different grade ranges for each essay set. The essay texts are pre-processed at the first stage by removing grammatical errors, if any, and subsequently, spelling correction is performed on all texts. The Python language tool method has been used to perform grammatical error correction, whereas the text blob method is used to correct spellings if wrong spellings are found in the text.

A flowchart of the proposed AEG system contains a detailed description of all experiments that were conducted.
The grammatically and spelling-corrected text is tokenized to perform multiple experiments. The score ranges were different in each essay set than when performing the score quantification process, and scores are equally mapped for all essay grades. It plays an important role in regressor performance improvement. Exclusively and inclusively, preprocessing operations were performed in three different experiments to increase the QWK rate. QWK is the chosen metric to evaluate the model performance that is selected based on its frequent use in previous studies. However, three experiments have been conducted with different combinations of features which are discussed in the coming sections.
Dataset Preprocessing and Grades Quantification
The dataset which is used in this study contains 12,976 instances corresponding to eight different essay sets. The essay text is written by 7th to 10th-grade students; therefore, the nature of informal writing environments, such as classroom assignments, can contribute to the presence of errors in student-produced texts to which graders assign grades based on content. To remove the grammatical errors and spelling mistakes, text preprocessing operations are performed. The Python language tool API is used to remove the grammatical errors and text blob API is used to correct the spellings. Both operations are mathematically shown in Equation 1.

In Equation 1, the output

The score quantification method considered the domain1 scorer column from the dataset to get scores, other scorer also exists in the dataset but most of them are not given for all essay sets only three columns contain full essay set grades.
Cohesion Features Extraction
To make a combined effect of sentences found in a single document or essay written by the student, the cohesion feature is calculated. To extract cohesion, the sentences of each essay are separated out, and subsequently, cohesion between consecutive sentences is calculated using features like word overlap or repeated words. The mathematical formation of the Cohesion feature is shown in Equation 3.
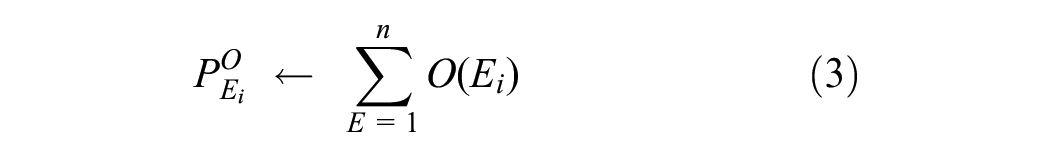
In Equation 3, the cohesion score of a single essay is calculated as
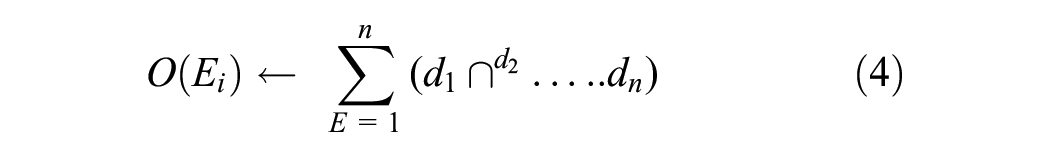
In Equation 4, the overlap for all essay sets (E) is calculated whereas the repeated words are also taken in count. The summation of all overlapping words and repeated words reflects a final cohesion score.
Coherence Features Extraction
To get overall consistency or to get a logical connection in an essay, the coherence feature is calculated, whereas the cosine similarity method is used in it. The sentence-wise feeding to function is given, whereas the cosine similarity is calculated as compared to the previous sentence. The overall score of similarity is mathematically shown in Equation 5.

The

In Equation 6, it is evaluated that each document (d) is given to a cosine similarity function which returns a score, the sentence-wise score is calculated which is later summed up to give an essay instance score.
Statistical Features Extraction
The statistical lexical features (

Equation 7 shows the general frequency function
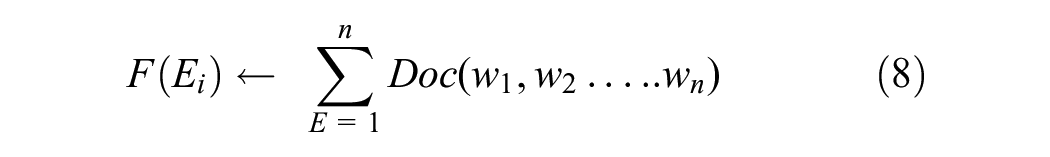
The inverse of Equation 8
Discourse Macrostructural Features Extraction
The grading score assigned to an essay also depends upon the descriptive nature of that essay. More description with more knowledge ultimately leads to higher grades. However, to understand the macro-level structure of the discourse, the macrostructural features are extracted. The mathematical representation is shown in Equation 9.
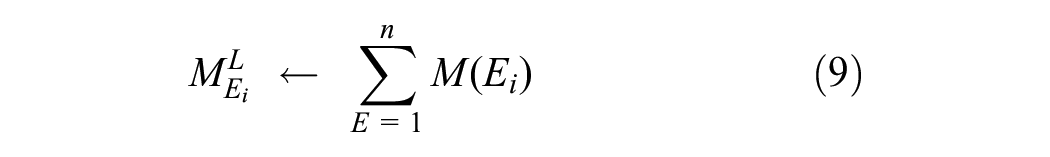
In Equation 9, the macrostructural estimation is represented as

The overall structure of an instance in each essay set is estimated and returns an integer value as a feature vector. In this way, the macro-level structure of discourse is calculated.
Features Fusion and Grades Estimator
To predict the quantified scores of each essay, the four types of features are extracted, and a linear regression model is trained. All features represent each essay pattern written by the student. However, the features were tried in different combinations, and upon those combinations, three experiments were conducted. The maximum achieved QWK value-based experiment is proposed in this study. In experiment 1, the cohesion, coherence, discourse macrostructural, and statistical lexical features are fused. The single feature-based effect is calculated first, and then feature fusion is tried to get multi-level feature extraction. In experiment two, only statistical lexical features are given to the linear regression method, which shows improved results compared to experiment 1. In experiment 3, the statistical lexical and macrostructural discourse features are fused, which increases the QWK score compared to experiment 2.
Results and Discussion
The preprocessed dataset is subdivided into training and testing subsets with an 80-20 ratio, whereas features were calculated for all, and the regressors were trained on the training set and tested on the test set. Three experiments-based results have been extracted, which are discussed in Section 3.6. The results of experiments 1 to 3 were improved gradually with different combinations of extracted features.
Dataset Description Before and After Quantification
The dataset description regarding each essay set with the number of essays present in each set is descriptively shown in Table 2. Most essay sets are in the range of 1,700 to 1,800 essays, whereas essay set 8 has fewer essay sets, even less than half. Therefore, this dataset has class imbalance with only one essay set. When looking at score ranges found in the dataset, it can be seen that diverse variations exist between all essay set scores. Hence, when there is one evaluator or grader, the scores should be equally scaled. The quantification method used in this study makes all essay grades range from 0 to 10.
Dataset Description with Number of Essays, Domain Scorer, and Quantified Score.

The domain1 scores were chosen from the dataset, the score ranges of which are given in Table 2. Essay sets 3 and 4 have the same ranges of 0 to 3, and similarly, essay sets 5 and 6 have equal ranges of 0 to 4. The minimum scores found in domain 1 score for essay sets 7 and 8 as 2 and 10, respectively. In parallel, essay sets 1 and 2 have 2 and 1 minimum scores, respectively. In the score quantification method, the minimum score for all essay sets is set to 0. Likewise, maximum scores are also mapped for all essay sets.
Experiment 1 Results
The topic-wise essays of each essay set should have coherence and cohesion involved in it to get higher grades, and if it is not present, the grades should be lower. The lower and higher grades based on these features are given to the linear regression model for training and testing. The preprocessing steps regarding grammatical error removal, spelling correction, and stop word removal are performed on essay texts. Subsequently, coherence, cohesion, discourse macrostructural, and statistical lexical features have been extracted from preprocessed data. With and without preprocessing operations, the same features have been extracted and given to the linear regression model for training and testing. The results are shown in Table 3 below.
Experiment 1 Based Linear Regression Model Results Using Fusion of Coherence, Cohesion, Statistical Lexical, and Discourse Macrostructural Features.

Two types of linear regression models were developed based on preprocessing operations, and their corresponding results achieved on testing data are described in Table 3. Firstly, preprocessing operations have been applied, such as removing grammatical errors, making spelling corrections, and stopword removal. Subsequently, the preprocessed data of all essay sets is fed to linear regression models for training, whereas 8 different regression models are trained using training data from each essay set. Testing data is fed to all regression models, and QWK is computed for all essay sets, whereas the achieved QWK of all testing sets is taken to compute the average QWK of the dataset. In the first results of essay sets by applying preprocessing operations, the results are lower than those without applying preprocessing operations. In the first results, when looking at essay sets, the lowest scores achieved by essay sets 3 and 4 are 0.4196 and 0.3828 QWK scores. This means that all kinds of features extracted from these essay sets are not effective, and important and relevant features need to be selected from each essay set.
In addition to this, by viewing the outcomes without applying preprocessing operations, it can be observed that the results of essay sets 3 and 4 are improved as compared to the first results with preprocessing operations and achieved scores of 0.4713 and 0.6324, respectively. Doubtlessly, each essay set’s results have improved in result two. The improvement in the results without applying preprocessing operations indicates that this study uses important information from essays when removing grammatical and spelling errors. It can also be assumed that scores are dependent on having grammatical and spelling errors in their essays. Due to these errors, the scores are assigned by scorers. However, feature selection is most important when checking the grading scores, as QWK scores are quite low with these features. Additionally, to check whether preprocessing operations matter or not, both types of results were attained in all experiments.
Experiment 2 Results
The current study has checked the multiple features-based results in Experiment 1 to check if results could be improved by removing results or not, additional experiments have been conducted. In Experiment 2, the single features of the statistical lexical method have been chosen, and regression models have been trained for all essay sets. Correspondingly to Experiment 1, with and without applying preprocessing operations, the results have been extracted in Table 4.
Experiment 2 Based on Linear Regression Model Results Using Statistical Lexical Features.

In Table 4, it can be seen that in the first results, by applying preprocessing operations, the results have improved compared to the results in Table 3. The results improve, showing that combining all kinds of features is not a good decision. However, selecting meaningful features could enhance the overall features. In the first results, all results are more than 90 except essay set 3 and 4, it seems that these features have lost important information by applying preprocessing operations which is cross-validation in the second results when the current study did not apply preprocessing operations. In the second result, without applying preprocessing operations, the results of essay sets 3 and 4 have been improved, and overall average results increased from 0.9109 to 0.9285. In this experiment, this study first distinguished the most important features among all extracted ones in Experiment 1.
Furthermore, it is observed that essay sets 3 and 4 have complex data on which feature extraction needs to be applied selectively. Henceforth, the extraction of results by applying different feature selections could improve the overall results. In this way, the results have been checked by including and excluding the essay set 3 and 4 features when performing the next experiments. To increase the QWK results, further feature combinations have been applied, and the most important or highly achieved results-based fused features are considered in Experiment 3.
Experiment 3 Results
In Experiment 3, one more feature (discourse macrostructure) has been fused with statistical lexical features. The selection of this feature is based on the performance of the model. In this way, the multi-type features have been extracted to cover the different aspects of essays written by students. However, the other combinations or fusion of features with statistical lexical or as an individual does not give improved scores of QWK. The discourse macrostructural features and statistical lexical feature-based linear regression results have been discussed in Table 5.
Experiment 3 Based on Linear Regression Model Results Using a Fusion of Statistical Lexical and Discourse Macrostructural Features.

In Table 5, likely both kinds of results by applying preprocessing operations and without applying preprocessing operations have been displayed. The first results, by applying preprocessing operations, achieved an average of 0.9150, which is a lower score than the results of experiment 2, which did not apply preprocessing operations. It means that important information has been lost during preprocessing operations in essay sets. It is important to note that for essay sets 3 and 4, the discourse macrostructural features are excluded, whereas applied on other essay sets because the average results were decreasing when macrostructural and statistical lexical features were fusing. Probably, in the second result, when preprocessing operations were not applied, the average results improved. It can be seen that in the second results, even essay set 3 and 4 results are improved which were 0.8883 and 0.8522 QWK in the first results but improved in the second results. For essay sets 3 and 4, the discourse macrostructural features were not improving their results. Thereby, without applying preprocessing operations and without fusing statistical lexical features for essay sets 3 and 4, the statistical feature is retained. In this way, the other essay sets on which two features were extracted and fused correspondingly improved the average QWK, and results reached up to 0.9339.
The variation between the predicted grades via regression models and the actual grades, which are mapped via the quantification method, could be visually illustrated via a scatter plot by drawing against predicted scores and actual grades in Figure 2.
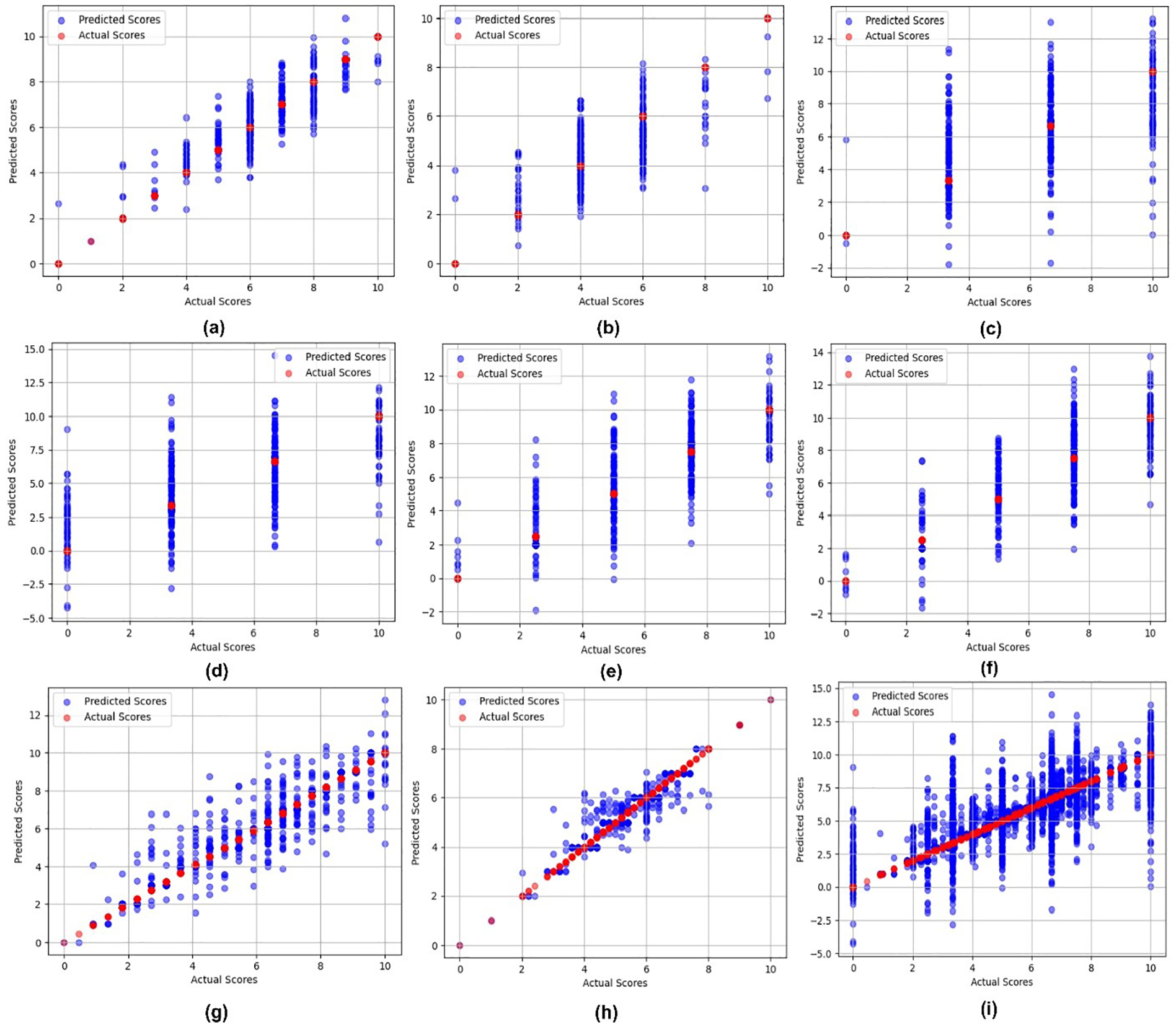
Scatter plots to see variation between predicted and actual scores for all essay sets as essay set: (a) 1, (b) 2, (c) 3, (d) 4, (e) 5, (f) 6, (g) 7, (h) 8, and (i) average scores of all essay sets.
In Figure 2, instead of only variation, the multiple aspects could be explored regarding scores of essays. When looking at (a) for essay set 1, the red color balls show the actual scores of the dataset, and the blue shows the predicted score by the linear regression model. The red color shows that actual scores are in the range of 0 to 10, which were mapped using the quantification method, whereas predicted scores slightly deviate up and down each score in subsection (a). When looking at (b) for essay set 2, the actual scores were in the range of 1 to 6, which are clearly shown in subfigure (b) that scores remain in between 6 parts only with 0, 2, 4, 6, 8, and 10 whereas all predicted scores slightly deviating above and low to these scores. In subsection (c) of Figure 2, the actual scores were in the 0 to 3 range which is mapped using the quantification method and then mapped to 0, 3, 7, and 10, whereas predictions remain also in the range of these integers but this essay set shown more variation as compared to essay set 2. Presumably essay set 4 having subsection (d) shows a similar deviation as of (c). It can be concluded from here that essay sets 3 and 4, having QWK lower as compared to other essay sets, are due to their predictions exhibiting significant variance.
In subsections (e) and (f), the score ranges were 0 to 4 originally, when these scores were mapped, it can be seen that their mapped scores were 0, 3, 5, 7, and 10 whereas prediction variations were similar as in section (c) and (d). In sections (g) and (h), the scores were originally in the range of 2 to 24 and 10 to 60, whereas after mapping, these scores are remapped, and we can see how generously the scores are mapped. In (g), even 0 to 2, 5 scores are laying, which means the overall deviation which was in 2 to 24 is subdivided and scores mapped to decimal scores on a single integer. In the (h) section of Figure 2, most of the scores are laying in between 2 and 8, referring that most of the graded scores are in between this range. However, the essay set has a much lower number of essays than other essay sets, and due to this, the lower number of training instances gives more deviation in prediction, which can be seen in section (h). In the (i) section of Figure 2, the overall scores in the range of 0 to 10 mean that all essay sets graded scores are in a particular range, which reduces a lot of overfittings and underfitting problems for the machine learning method where also reduces the variation range.
Comparison with State-of-the-Art Methods
The dataset used in this study is used in previous studies for AEG systems. However, the achieved results are more confident in terms of achieved score, extracted features, and most importantly, like other large language models, these proposed study-based features are not time-consuming. Consequently, the proposed study provides a timely, efficient, important feature selection-based solution for AES system development. The comparison with other start-of-the-art methods is performed in Table 6.
Comparison of Achieved Results of the Proposed Study With Previous Studies.

In Table 6, it can be observed that the proposed study uses different features as compared to previous studies, since most of them used deep learning-based solutions, which are time-consuming too. Moreover, the average results achieved on the same dataset for all essay sets are also less than the proposed study results. It is also important to note that comparative studies are mostly used deep learning solutions to get contextual information with famous methods such as Roberta, and Bi-LSTM, but their results still did not reach the promising stage. The proposed study does not use four different categories of features, statistical, structural, and contextual relativity. The coherence and cohesion-like features have been extracted. However, those features do not give higher results for all essay sets.
Conclusion
The increasing academic load on educational institutes is now forcing them to transform their educational structure and many of the institutes have taken the initiative of adopting e-Learning systems. E-learning systems are beneficial not only at the educational level but also in extending teaching to a wider audience. Nevertheless, they place a burden on educators by increasing the number of papers to assess (Maatuk et al., 2022). Thus, not only for e-learning system-based text grading or scoring problems but also for physical education, a plethora of issues that appear in AEG or ATG systems become an essential need. Due to the AEG system development, the load on educators regarding essay/coursework assessment will be effectively reduced. The AEG system development is in process and has been for many years. It is improving day by day but still, its improvement is a substantial challenge due to many hidden aspects that need to be covered. In this study, a timely and performance-efficient AEG system is proposed based on the famous Kaggle ASAP dataset. Four different kinds of features have been extracted from the text of the dataset, namely statistical lexical, coherence, cohesion, and discourse macrostructural. The dataset grading range for all essay sets varied, as such, a score quantification method is applied to equalize the scoring range of essays. The dataset contains eight different kinds of essay sets and eight different linear regression models that have been trained and tested. The eight essay sets based on separate QWK metrics are calculated, and an average QWK is calculated from them. Three different experiments have been conducted with different combinations of extracted features, and a performance-based two-feature selection was performed. Among all experiments, the statistical lexical and discourse macrostructural features were proven to be the most effective features and given an average QWK of 0.9339. The achieved results are time-wise, performance-wise, and computationally better than previous studies on the same dataset.
The proposed study covers four aspects of written essays or from text. Future studies could extract different kinds of information to increase AEG system performance and its robustness. Furthermore, we should enhance AEG systems development and integrate AI for plagiarism detection to streamline essay assessment. Maintaining a balanced approach with various assessment methods ensures comprehensive evaluation with respect to students and industry.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by King Saud University for funding this work through Researchers Supporting Project number (RSPD2024R799), King Saud University, Riyadh, Saudi Arabia.
Ethics Statement
Not applicable.