
Abstract
In order to facilitate the instruction and acquisition of EFL writing, this paper compares the uses of the light verb get in English writing by Chinese and L1 undergraduates by drawing on insights from the theory of norms and exploitations (TNE). Corpus pattern analysis (CPA) is conducted to analyze the data taken from two comparable corpora of Chinese EFL learners’ and L1 undergraduates’ writing, unveiling both similarities and disparities between the two groups in terms of the patterning of get. Regarding similarities, most of the prototypical patterns identified in the two target corpora are identical, and both corpora show innovative exploitations of norms. In terms of differences, Chinese undergraduates misuses get in their writing in a varied but recognizable way. In addition, Chinese undergraduates are more likely than L1 undergraduates to overuse high-frequency patterns and semantic roles but underuse low-frequency ones, which may result in a lack of diversity in the range of patterns and complements. Chinese undergraduates’ uncertainty of registers is another notable feature in their writing. Based on the findings, the paper further discusses the implications for the teaching and learning of writing in EFL contexts.
Keywords
Introduction
Knowledge of language is increasingly considered equivalent to knowledge of patterns (i.e., the recurrent elements of languages that are entities, Alexander, 1977), as accentuated by pioneers of usage-based theories of language (e.g., Francis et al., 1996; Hanks & Pustejovsky, 2005; Sinclair, 1991). Corpus pattern analysis (CPA), which focuses on the lexical analysis of collocational patterns based on corpus evidence, is a promising technique for establishing lexical resources in order to elucidate word meaning in context (Hanks, 2008). This technique is based on the theory of norms and exploitations (TNE), a lexicocentric, corpus-driven, bottom-up theoretical approach proposed by Hanks (2013). Regardless of its comparatively recent origin, CPA has attracted plentiful attention and been substantially applied in natural language processing (NLP), computational lexicography, and language learning and teaching (Hanks, 2013; Hanks & Ma, 2021; Hanks & Moze, 2019; Maarouf & Baisa, 2013). The Pattern Dictionary of English Verbs (PDEV) is the main fruit of CPA, seeking to unfold a well-grounded corpus-driven account of English verbs (Bradbury & Maarouf, 2013). However, since the analytic procedure of CPA is labor-intensive and time-consuming, PDEV has only covered approximately 30% of the target verbs. For instance, light verbs (i.e., verbs that make relatively “light” contributions to the semantics of constructions, such as take in take a walk, get in get a peek, and give in give a kick) have not been fully compiled in this dictionary.
Light verbs play a central role in the English language due to their maximal analytic complexity and high frequency. Native speakers have internalized light verb patterns and are able to apply them in actual usage due to their lifelong exposure to such patterns. Learners of English as a foreign language (EFL), on the other hand, who lack such experience, have been observed to acquire these patterns in a different manner and with greater difficulty since they are only exposed to a new language later in life (Crosthwaite et al., 2020). In spite of the high frequency of light verb usage, EFL learners tend to consistently exhibit underuse, overuse, and misuse of these verbs due to their intricate semantics and syntax. Additionally, the light verb get appears to pose more challenges in EFL writing compared to other light verbs due to the fuzzy line between its light and heavy usages (Gilquin, 2019).
Consequently, this study aims to identify the similarities and disparities in the patterning of light verb get in both EFL and L1 writing using CPA. The findings from this research can offer guidance for the instruction and acquisition of English writing, while also shedding light on the pedagogical value of corpus-based patterns through the investigation of verb patterns utilizing CPA methodology.
Literature Review
English Light Verbs
The term “light verb” was proposed by Jespersen (1949, p. 117) and has since attracted particular attention across languages due to its popularity and complexity in language use. In his conception, light verbs (such as take, have, and get) carry little or no semantic weight in constructions (such as take a nap, make an effort, and have a presentation), and the meaning of light verbs is associated with its complementation. For instance, we will have a rest is similar to we will rest. With computational processing technologies continuing to grow, corpus-informed and corpus-based approaches are predominantly conducted for the study of light verbs from varied aspects, such as the comparison of light verb constructions (LVCs) and their verb counterparts (Brugman, 2001), argument structure (Piango et al., 2006), valency complementation (Kettnerová, 2021), and collocational patterns (Giparaite & Baliūte, 2019). The syntactic-semantic mismatch and unique distribution of light verbs pose a challenge in earlier NLP studies; corpus linguistics, however, brought light verbs to one of the foci in recent NPL studies in the context of language annotation, data retrieval, and disambiguation (J. Lin et al., 2014).
However, previous studies mainly focus on the typical light uses of English light verbs, remaining the holistic patterns of light verbs underexplored. Moreover, limited research is found on the mapping of the patterns and meanings of light verbs.
Comparative Studies on EFL and L1 English Writing
The past few decades have witnessed significant research comparing EFL and L1 writing at the undergraduate level, driven by advancements in computational processing technologies, and the utilization of corpus-informed and corpus-based approaches (Alfalagg, 2020; Chen, 2017; Shamalat & Ghani, 2020; Sun & Hu, 2023).
The evaluation of EFL writing performance in relation to L1 writing has been extensively explored, with a focus on complexity, accuracy, and fluency, including the investigations of cohesive devices (Alfalagg, 2020), personal pronouns (Maclntyre, 2019), hedging (Sun & Hu, 2023), among others. Previous studies consistently reveal the frequent occurrence of overuse, underuse, or misuse of these linguistic features in EFL writing, posing significant challenges for EFL learners (Chen, 2017). Guided by the findings of comparative research, pedagogical methodologies such as genre-based instruction (Zhai & Razali, 2023), task-based instruction (Derakhshan, 2018), and production-oriented instruction (Zhang, 2020) have demonstrated the potential to enhance learners’ motivation, self-efficacy, writing awareness, and language proficiency, consequently improving their writing performance. Despite its recent origin, data-driven learning (DDL) has emerged as a thriving field within EFL writing research (Flowerdew, 2015; Muftah, 2023; Sun & Hu, 2023). With the aid of corpus technology, DDL enables students to uncover language patterns using concordancing tools directly or by employing concordance-based analysis as part of their study.
Comparative studies have also investigated the use of light verbs in L1 and L2/EFL English varieties. According to Crosthwaite et al. (2020), comparing the similarities and disparities between learner corpora and L1 corpora can explicate the gap between native and non-native speakers’ language usage and enable the analysis of the linguistic challenges L2/EFL learners face. The majority of the comparative studies on light verbs focus on frequency analysis (Gilquin, 2019; Giparaite & Baliūte, 2019). For instance, when comparing Asian English varieties with British and American English, Giparaite and Baliūte (2019) found that there is a greater range of LVC types and modifiers in native English varieties than non-native ones. Furthermore, the study illustrates that native English varieties exhibit more diverse patterns of modification in their structure.
Despite the burgeoning body of comparative studies on EFL and L1 writing, still insufficient research has been conducted in the field of light verbs.
The Light Verb GET
In comparison with other light verbs, get is not only a high-frequency verb but also a widely-used one, the LVCs of which have been found in all the English varieties investigated by Kearns (2002) and are constructed more frequently in native and Asian varieties. Get in its heavy usages refers to receiving something, and when used in light usages, it becomes a metaphorical extension by making the subject the Beneficiary of the activity (Giparaite & Baliūte, 2019). This result is in accordance with Brugman (2001) who implies that the semantics of light verbs in light uses are related to their heavy uses to some degree. In addition, due to the fuzzy line between light and non-light usages, some LVCs are neither prototypical heavy usages of the verbs nor light usages in the strictest sense, but in between. The verbs within this category of light verb constructions (LVCs) are known as semi-light verbs, with get being a quintessential example (Bonial & Pollard, 2020). The semi-light nature of get renders its usage more challenging for non-native English speakers compared to other light verbs (Gilquin, 2019). Despite the semantic contribution of get in LVCs and the fuzzy borderline between its light and heavy patterns, previous studies show a scarcity of tackling its sense and pattern ambiguity.
Briefly put, therefore, the light verb and LVCs have become a hot research field for corpus linguistics. However, previous research has been subject to limitations. Firstly, there is still limited research on the association of English light verb patterns and meaning. Secondly, a holistic pattern analysis of the light verb which includes both its light and heavy usages calls for more investigation. Thirdly, comparatively little is known about how light verbs are patterned differently in Chinese and L1 writing. Fourth, the semi-light verb get displays the features of high frequency, wide use, polysemy, and semantic weight, making it an interesting research focus. As a promising technique for clarifying semantic and syntactic ambiguity, CPA can be a new ontology for analyzing this special type of verb via mapping meaning with use.
Based on the previous studies, the current study presents a CPA-based approach to explore how the meaning and use of the light verb get are mapped in different varieties of English, and aims to address three main research questions:
RQ1: What are the similarities in the patterning of get in Chinese and L1 undergraduates’ writing?
RQ2: What are the disparities in the patterning of get in Chinese and L1 undergraduates’ writing?
RQ3: What pedagogical implications the results can provide for facilitating the teaching and learning of EFL writing in Chinese universities?
Methodology
Corpora Description
The present study mainly used two corpora, that is, Chinese Undergraduate English Writing (CUEW), written by Chinese undergraduates, and a sub-corpus selected from British Academic Written English (BAWE), written by L1 undergraduates. The two corpora are comparable in that they are similar in size and both are argumentative essays written by undergraduates.
Since 2010, the National Association of English Writing (NAEW) in China has been holding automated English writing (AEE) competitions every 6 months which attract more than a million participants nationwide each time. All the participants in AEE competitions agree to share their assignments for academic use before submitting them to the system. CUEW is a collection of assignments randomly drawn from the automated English writing competitions for Chinese undergraduates from April 2019 to October 2020. The sub-corpus of CUEW contains 5,000 essays which have 1,874,512 words in total. CUEW is deemed to be a useful resource for Chinese EFL instructors, learners, and linguistic researchers in light of its ample and up-to-date data and the wide geographical spread of Chinese universities.
BAWE is a collection of high-standard student assignments across disciplines and levels (over 6.5 million words; Nesi, 2008). BAWE is comprised of over 30 disciplines, categorized into the four disciplinary groups of arts and humanities, life sciences, social sciences, and physical sciences, from Level 1 to Level 3 undergraduates and masters, making up more than 2,700 assignments in total. To make BAWE more comparable, only the disciplines under the domain of arts and humanities from L1 to Level 3, which map with the argumentative writing in CUEW, are under investigation (651 texts and 1,479,912 words). Despite the disparate average length of the texts in CUEW and BAWE, both corpora could in a way be seen as representative of the target population’s English writing proficiency, and the sub-corpus of BAWE provides a high-quality standard for the essay writing of Chinese EFL undergraduates. In summary, the sub-corpus of BAWE is a rich lexical resource that supports the identification of writing characteristics of native English writing at the undergraduate level in the genre of argumentative writing; hence, it can be used as a comparable corpus to CUEW.
Furthermore, the British National Corpus (BNC), a 100-million-word native English collection built by the Oxford University Press, mainly from 1991 to 1994, on which PDEV is based, is used as a reference corpus to validate the patterns that are found in CUEW but not in BAWE. More specifically, if instances of such patterns exist in BNC and make sense in writing, they are accepted as systematic; if not, further analysis is required. Furthermore, BNC is adopted to validate the significant disparity across CUEW and BAWE: if a certain pattern is more present in CUEW than in BAWE, it is likely that the given pattern is commonly used in a colloquial situation rather than in formal writing. Therefore, a comparison of frequencies in both written and spoken texts in BNC can be conducted to confirm the degree of formality.
Data Collection
AntConc, a free concordancing software designed by Anthony Laurence, is used to extract the concordance lines of lemma get in CUEW and BAWE. A total of 2,631 instances of get were drawn (503 hits in BAWE and 2,128 in CUEW). Having removed duplicated and nonverbal usage manually, 2,507 qualified hits remained (449 hits in BAWE and 2,058 in CUEW).
Corpus Pattern Analysis (CPA)
CPA is primarily concerned with the lexical examination of collocational patterns by utilizing corpus evidence as textual sources. Each pattern set reveals both typical norms associated with a given word and atypical phraseologies that deviate from normal usage, which are categorized as exploitations (Hanks, 2013). This approach offers an alternative perspective on the structured characteristics of natural language, enabling computers to comprehend, process, and generate language data accurately (Hanks & Pustejovsky, 2005). As a result, there has been a growing interest in pattern-based lexical research employing CPA, including studies on metaphors and idioms (Hanks, 2004), similes (Hanks, 2008), nouns (e.g., “way,”Hanks & Moze, 2019), and verbs (e.g., “poison” verbs, Bradbury & Maarouf, 2013). Previous studies have shown that CPA facilitates the mapping of meanings onto word patterns and offers insights into how words are authentically used within specific contexts through the analysis of corpus evidence, thereby providing promising avenues for computational lexicography (Hanks, 2013).
Consequently, CPA has proven to be a reliable technique to analyze the collocational patterns of the light verb get in the present research and map the senses to different patterns, including both norms and exploitations. The process can be split into three subtasks, based on the task of building PDEV entries in Maarouf and Baisa (2013):
(i) CPA parsing: In this step, the concordance lines drawn from AntConc are syntactically and semantically parsed manually. Syntactic analysis comprises the specification and sorting of main collocations such as phrases, idioms, transitivity/intransitivity patterns, causative/inchoative alternations, and arguments (subject, object, complement, adverbial, and indirect object). The structures are then lumped or split by analysis of the semantic roles of each collocate based on the CPA Semantic Ontology on PDEV. For example, the line “the poor man is put to a double labor, first to get a little money for corn” is first specified as “the man get money,” then parsed with semantic roles, which is “[[Human]] get [[Asset | Physical_Object = Valuable]].”
(ii) CPA clustering: In this step, the patterns of the light verb get in each sentence are identified based on the parsing in the first step and categorized according to syntactic similarities. All sentences belonging to the same pattern are identified and tagged.
(iii) CPA lexicography: In this step, all the patterns are analyzed and grouped in terms of their senses, that is, implicatures. Each sorted pattern represents an implicature of get. For example, the pattern “[[Human | Institution]] get [[Asset | Physical_Object = Valuable],” represents the implicature of “[[Human | Institution]] obtains possession or use of [[Entity = Asset | Physical_Object = Valuable]], by purchasing or otherwise.”
To ensure clear and trustworthy annotation, four pre-trained annotators who are linguistics-major postgraduate and doctoral students, including the authors, are involved in the CPA process. Prior to the analysis, all annotators have achieved a high level of inter-annotator agreement (IAA). Each concordance line has been annotated by at least two annotators separately. We put forward any doubts at any moment which are then cleared via immediate discussion.
Log-Likelihood
To compare the two corpora in terms of differences in pattern frequency, log-likelihood (LL) was conducted to examine the similarities and differences in the use of the light verb get in native and non-native English writing. The higher the LL value, the more significant the difference between the two frequency scores is. An LL value of 6.6 or higher is significant at p < .01 (Rayson, 2003).
Results
This section explores the patterning of the light verb get in two steps. Firstly, it interprets the divergent patterns (patterns that deviate from those found in native English corpora) while distinguishing between systematic patterns (divergent patterns that make sense and are found in BNC) and erroneous patterns. Secondly, after the erroneous patterns in CUEW are excluded, the left patterns, that is, the refined patterns in the target corpora, are compared to analyze the similarities and disparities in Chinese and native English writing.
Interpreting the Divergent Patterns
As illustrated in Table 1, get is far more used in CUEW than in BAWE, with an LL value of +1,137.07 (p < .01). Via the CPA process, a total of 33 prototypical patterns (i.e., patterns that contain more than three concordance lines) are identified (28 patterns in both BAWE and CUEW respectively). Of the 28 prototypical patterns identified in CUEW, five are divergent patterns; that is, they are only found in CUEW but not in BAWE. It is worth investigating further to determine whether these divergent patterns are systematic or erroneous.
Total Hits and Patterns of get in CUEW and BAWE.

Note. RF = raw frequency; NF = normalized frequency per 1,000,000; PN = pattern number; “*” indicates p < 0.01; RF = raw frequency; NF = normalized frequency per 1,000,000; PN = pattern number; “+” indicates overuse in CUEW relative to BAWE; “−” indicates underuse in CUEW relative to BAWE.
Systematic Patterns of GET in CUEW
An investigation in BNC shows two systematic patterns, the details of which are presented in Table 2. Queries in BNC indicate that Patterns 20 and 28 are produced significantly more often in spoken texts than in written texts, suggesting that these two patterns are more likely to be used in informal contexts than formal ones. It can be inferred that Chinese undergraduates tend to show an uncertainty of registers in writing.
Systematic Patterns of get in CUEW.

Note. FC = frequency in CUEW.
p < .01.
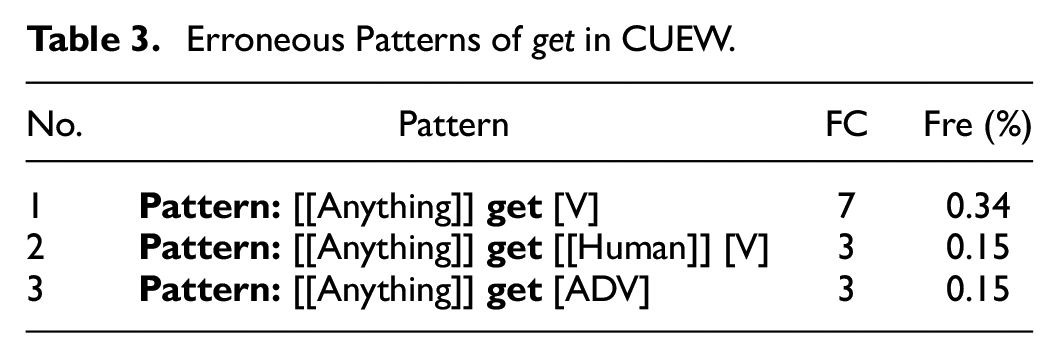
Erroneous Patterns of GET in CUEW
Table 3 gives the other three divergent patterns of get in CUEW that make no sense in written contexts, examples of which are presented in Tables 4 to 6.
Erroneous Patterns of get in CUEW.
Instances of Erroneous Pattern 1 of get in CUEW.

Instances of Erroneous Pattern 2 of get in CUEW.

Instances of Erroneous Pattern 3 of get in CUEW.

Regarding the first erroneous pattern [[Anything]] get [INF], it is worth noting that instances of this pattern can also be found in BNC, with 29 hits in written texts and 192 hits in spoken texts. This pattern shows an omission of the particle to in denoting [[Human | Institution]] manages or has the opportunity to do something, which has been adopted in speaking as it is fluid and flexible. However, this reduced pattern is considered grammatically incorrect and hence cannot be used in formal writing in a strict sense. The occurrences of this pattern in written texts in BNC imply that native speakers also make mistakes in formal writing. Whether Chinese learners make the same type of mistake requires a more detailed analysis of the instances.
Three sets of instances of Erroneous Pattern 1 are identified from the dataset by examining the meanings in the context (see Table 4). The first set includes ways of getting touch to the resources and we get embrace the challenges. Aligning with the result discussed in the previous paragraph, the implicature here can also be construed as [[Human | Institution]] manages or has the opportunity to do something, which is supposed to fall into the pattern [[Human | Institution]] get [to INF] but with an omission of to in infinitives. The second set contains instances 3 and 4, oddly saying people’s life get great improve and they won’t get respond, from which we may infer that the accurate structure conveyed in the contexts should be people’s life got great improvement and they won’t get a response. This suggests that Chinese learners tend to misuse different forms of the complements after get. The last set is the combination of get and an intransitive verb, the examples of which are education will get highlight and my video will get upload. What the learners are presumably trying to present is the auxiliary use of get, which is supposed to be followed by past participles, not the basic forms of verbs.
The second divergent pattern of get is [[Anything]] get [[Human]] [V], some instances of which are shown as get people have the desire and getting them concentrate on their study (see Table 5 for details). Analyzing the meaning in the context indicates that what the learners are trying to convey here is [[Human 1 | Institution 1]] causes [[Human 2]] [to INF] by asking, persuading, or stimulating, the correct pattern of which should be [[Human 1 | Institution]] get [[Human 2]] [to INF]. Hence, this divergent pattern also shows an inappropriate omission of the article to in infinitives.
The third divergent pattern of get is [[Anything]] get [ADV], some instances of which are Internet get incisively and vividly and way gets easily (see Table 6 for details). Here, the learners are transferring their knowledge of the structure V + ADV to get + ADV but ignoring the fact that the word get can also be used as a linking verb instead of a content verb. Therefore, the accurate pattern would be [[Anything]] get [[ADJ], meaning [[Anything]] becomes [[ADJ]]. This erroneous pattern implies Chinese undergraduates’ misuse of the varied functions of get.
Comparing the Refined Patterns
When erroneous uses and instances of patterns that contain less than three occurrences are removed, totals of 418 and 1,990 refined hits of get are found in BAWE and CUEW respectively, with the latter seeing significantly more gets than the former (LL = +777.46, p < .01). As shown in Table 7, despite the slightly larger number in raw pattern numbers (28 for BAWE and 25 for CUEW), Chinese undergraduates appear to produce a significantly narrower range of normalized patterns in CUEW (LL = −34.29, NPNs = 66.99 and 12.56 respectively, p < .01). More details of the refined patterns are illustrated in the Appendix, which is ranked by the total number of instances presented in CUEW and BAWE.
Refined Hits and Patterns of get in CUEW and BAWE.

Note. NPN = normalized pattern number in 1,000 hits.
p < .01
Table 8 presents the frequencies and LL values of the 30 refined patterns of get identified in CUEW and BAWE, illustrating significant disparities in use across corpora. Chinese learners tend to overuse 17 patterns but underuse 13 patterns. Of the overused patterns, most are of high frequency, whereas the opposite is true for the underused ones, which implies that Chinese undergraduates are more inclined to overproduce high-frequency patterns of get but underproduce infrequent ones than their L1 counterparts. Furthermore, 11 patterns are significantly over-presented (Patterns 1–8, 10, 14, and 20, LL = +322.98, +230.50, +160.27, +176.51, +77.13, +16.89, +14.63, +39.00, +27.27, +7.79, and +8.15 respectively, p < .01), while two are significantly under-presented (Patterns 12 and 21, LL = −7.79 and −11.46 respectively, p < .01) in CUEW relative to BAWE. The patterns that are significantly different across corpora are presented in detail below.
Frequencies and LL Values of the Normal Patterns of get.

p < .01.
Analysis of Significantly Overused Patterns
A further investigation of the concordance lines of this pattern reveals that the two corpora share similar frequencies of semantic types in the subject slot but vary in the object slot. Seventy-five percent of the instances of this pattern are followed by the semantic type [[Eventuality]] in CUEW, while only 47.5% are found in BAWE, with an LL value of +8.32 (p < .01). The following are examples containing [[Eventuality]] after get in CUEW.
(1) “The Wandering Eart,” creates domestic hard science fiction,
(2) Almost all of us cannot be a hero who can
In contrast, the other two less frequent semantic roles [[Abstract_Entity]] and [[Psych = Feeling]] account for significantly fewer instances of Pattern 1 in CUEW than in BAWE, suggesting that Chinese undergraduates are more inclined to overuse frequent semantic roles and underuse infrequent ones.
Patterns 2 and 3 embody the heavy use of get (the meanings of get in such patterns are not bleached). While the light use of light verbs is abstract in nature, the heavy use of such verbs is more concrete in meaning, making it more comprehensible for language learners (Maouene et al., 2011). It can be inferred that Chinese undergraduates are more likely than native writers to employ the heavy use of get in their writing due to its concrete and comprehensible nature.
An in-depth investigation of the instances of Pattern 4 in CUEW reveals that a large percentage of the object slot is filled with high-frequency fixed expressions (get knowledge, get skill(s), and get information), as exemplified in (3). The same holds true for Pattern 5 (get attention), as instantiated in (4). The result indicates that Chinese learners are more likely to use fixed phrases of get than their L1 counterparts.
(3) We can
(4) To
Above are a further five significantly overused patterns of get. An observation in BNC unveils that all five patterns are significantly more frequent in spoken texts (NF = 314.51, 68.2, 104.61, 18.45, and 37.94 each) than in written texts (NF = 58.51, 15.13, 31.71, 8.10, and 14.96 respectively, p < .01). Therefore, it can be confirmed that such patterns are more commonly used in colloquial situations, whereas Chinese learners are inclined to overproduce them in formal writing.
Pattern 20 has been analyzed in Table 2, so no further discussion is carried out here.
Analysis of Significantly Underused Patterns
An observation of the instances of Pattern 12 found that Chinese undergraduates tend to use some fixed collocates, such as get it and get the point (66.67% of all 15 instances), as shown in examples (5) and (6), while their L1 counterparts tend to use more varied complements in the object slot, such as get the notion, get the patterns, and get the reason.
(5) Individuals can also
(6) …Chinese film easily so that they would
Moreover, both Chinese and L1 undergraduates produced get a/the picture in their writing several times, as exemplified in (7). The word picture, literally meaning a design or presentation made by various means (such as painting, drawing, or photography), is coerced by the context to denote a different meaning: the description of a mental image. The process of non-canonical coercion of a lexical item to have a different meaning due to the semantic type of the context is called semantic type coercion, which Hanks (2013) names among types of exploitation of language.
(7) As we have seen, tracing the imageries in the trilogy we can
Pattern 21 was only created by L1 writers, with no instances found in CUEW. Learners may be more familiar with [[Vehicle]] get [off] {the ground}, literally meaning [[Vehicle]] lifts off the ground and remains in flight than they are with Pattern 21. Pattern 21 here exploits the original one by shifting the semantic type in the subject slot to [[Human | Institution]], coercing the change of implicature to [[Human | Institution]] begins or causes something to begin to make progress. Here, Chinese learners may lack the cognition and employment of this exploited idiom.
Discussion
Similarities in Terms of Light Verb Patterns
The similarities in English writing by Chinese and L1 undergraduates in terms of light verb patterns mainly fall into two areas. Firstly, most of the prototypical patterns identified in the two corpora are used by both Chinese and L1 undergraduates. As shown in Table 8, most of the patterns, except a small proportion identified in either BAWE or CUEW, are shared by the two varieties of English. Secondly, both L1 and Chinese writers are capable of exploiting language innovatively in their writing, according to the results of refined patterns. The exploitation of norms plays a crucial role in linguistic innovation, making language use more vivid, dynamic, and interesting. It indicates that writers do not just exhibit their fundamental linguistic competence, but also occasionally exploit that competence to say new and interesting things or to say old things in a new and interesting way (Hanks, 2004; Hanks & Moze, 2019). Besides semantic-type coercion, typical means of exploitation of a norm found in both BAWE and CUEW include ellipsis, anomalous collocates, metaphors, and similes (Hanks, 2013).
Hanks (2013) highlights that words in isolation do not have meanings; rather, they have meaning potentials which can be activated by contextual triggers such as phraseologies and collocations. This research has also indicated that CPA/PDEV can be an effective method for describing light verb patterns through identifying norms, divergent patterns, and exploitations of norms in context. In view of the abstract nature of light verbs, CPA/PDEV can provide disambiguated patterns, as well as implicatures, frequencies, and authentic examples, making it a rich resource in furthering our understanding of how the meaning and use of English light verbs are associated, so as to clarify the semantic and syntactic ambiguity these polysemous light verbs entail.
Disparities in Terms of Light Verb Patterns
According to the results, there are four aspects to the disparities in terms of light verb patterns in BAWE and CUEW: erroneous patterns, overuse and underuse, language diversity, and register awareness. The contrasting patterns in learner corpora and native-speaker corpora can provide guidance in language acquisition for learners.
Erroneous Patterns
From the perspective of errors, Chinese learners tend to produce correct patterns most of the time and make mistakes in a varied but recognizable way. As revealed in the analysis of divergent patterns, only a few erroneous patterns of get in its heavy usages were found in CUEW, from which three types of errors can be identified: (1) the omission of to in infinitives; (2) the misuse of different forms of inflectional complements; and (3) the misuse of the varied functions of get. On the one hand, the influence of L1 is possibly the main reason for the errors made by Chinese undergraduates. As stated by Lu (2017), nearly all the recognizable erroneous usages of a second language created by Chinese learners could be traced back to their mother tongue. As an isolating language, Chinese does not present varied parts of speeches of a word via inflection; hence, it is difficult for some Chinese learners to distinguish the different forms of inflectional words. In addition, some Chinese learners are not able to differentiate English synonyms and polysemes from their corresponding Chinese translations. On the other hand, the target language influence is another possible explanation for the errors (Lu, 2017). For instance, some causative verbs such as have and make usually omit the infinitive marker to in their collocations with another verb, but it cannot be omitted in patterns such as [[Anything]] get [[Human]] [to INF in formal contexts. Some Chinese undergraduates in the study appear to have mistakenly omitted to in infinitives due to the influence of the English language per se. The erroneous patterns also reveal that not only are the light uses of light verbs problematic for EFL learners (Gilquin, 2019), but their heavy uses also pose a challenge for them.
CPA enables the identification of disambiguated patterns in context with the auspices of semantic types, allowing the specification of divergent patterns used by a certain number of learners (Alqarni, 2019; Hanks, 2013). The identification of the erroneous patterns of the light verb get used by Chinese undergraduates can provide English teachers with implications and references for teaching light verbs in EFL contexts. Furthermore, the entries on PDEV can endow learners with access to a full range of accurate patterns, which can considerably improve the accuracy and utility of their use of English verbs, deduce usage restrictions, and permit native-like usage in production.
Overuse and Underuse
Chinese learners tend to use high-frequency patterns of get and frequent semantic roles that accompany this verb significantly more often than their L1 counterparts but use infrequent ones less often (Durrant & Schmitt, 2009; Gilquin, 2019). For instance, nearly all the overused patterns demonstrated in Table 8 are of high frequency, while the underused ones are far less frequent. A considerable proportion of the overused patterns consist of set phrases, such as get rid of, get used to, and get on well with. A possible reason for this phenomenon may lie in the fact that EFL learners have not mastered infrequent patterns and semantic roles, and therefore recurrently use those with which they are familiar, such as the heavy uses of get. As proved in the analysis of refined patterns, Chinese learners appear not to have mastered some infrequent phraseologies and idiomatic expressions, such as get off the ground.
Previous studies have also consistently found that the overuse, underuse, or misuse of English items tends to frequently occur in EFL writing and poses enormous challenges to EFL learners (Chen, 2017). Light verbs are often “lexical teddy bears” (Hasselgren, 1994) for non-native learners of English, being part of their vocabulary repository as preferred words because they are reckoned both safe and easy to use. The over-presentation of get revealed above, however, seems to contradict Gilquin (2019), who found that EFL learners tend to use LVCs with get less than native speakers. This phenomenon can be explained from two aspects: firstly, Gilquin only examined LVCs of get in spoken L2 English, while the current study investigated two written corpora, suggesting that language items are used differently across genres. Secondly, the former only investigated the light uses of get, whereas the current study investigated all prototypical patterns of get since the heavy uses are also proportional in frequency.
Language Diversity
One remarkable consequence of the over-repetition of frequent patterns and under-production of infrequent ones is a lack of diversity in the range of patterns. Although both Chinese and L1 undergraduates tend to produce a similar number of patterns, CUEW displays a much narrower range of normalized patterns. Additionally, L1 writers tend to use more diverse complements in a pattern while Chinese learners appear to use fixed expressions, such as get it, get the point, get knowledge, get skill(s), get information, and get attention. This result is consistent with previous studies which have argued that one characteristic of learner language is the usage of a limited width of senses and forms of polysemes (Alqarni, 2019; Altenberg & Granger, 2001; Wang et al., 2023).
Therefore, enhancing EFL learners’ language variety is of significance for writing proficiency. It is essential for English teachers in China to take a strong view that language variety is an indispensable feature of English writing proficiency. Firstly, EFL teachers can design classroom activities to motivate learners’ wide usage and creative exploitation of language patterns, such as brainstorming as many collocates of a word as possible before writing. Secondly, encouraging students to create topic-related corpora based on authentic written texts is also efficient in helping them to find and acquire diverse alternatives for a certain linguistic expression. Finally, with the auspices of corpus technology, data-driven learning (DDL) allows students to discover the regularities of language by using concordancing tools directly or adopting concordance-based output indirectly in their study, which can guarantee vast authentic exposure to contextualized linguistic data and a full range of word patterns in different varieties of English (Chang, 2020; Jablonkai & Csomay, 2022; Muftah, 2023; Sun & Hu, 2023). Data-driven PDEV can also be conducted by EFL learners to broaden their width of senses and forms of polysemes and bridge the gap that exists between EFL learners and native speakers in terms of pattern variety.
Register Awareness
Uncertainty of register is another notable feature in Chinese undergraduates’ English writing. The results suggest that Chinese learners appear to overuse some informal patterns that are rarely or not used by native speakers in formal contexts, such as get + V, get back to, and get over. This phenomenon aligns with the finding in M. H. Lin (2021) that Chinese scholars lack register awareness and appear to confuse informal and formal expressions in writing. As stated by M. H. Lin (2021), the degree of learners’ register awareness is also principally influenced by their L1s.
EFL teachers should attach importance to the cultivation of learners’ language awareness. Biber and Barbieri (2007) claim that spoken registers and written registers are strikingly disparate in terms of their lexico-grammatical features; hence, language teachers should apply different course management techniques for different types of classes. DDL is another promising approach that can be employed to raise learners’ register awareness and pattern awareness. This approach exposes learners to a wide range of texts of all genres and patterns, providing them with appropriate styles and linguistic features of varied production modes and exposing them to contextualized texts, which will bring about a rewarding result in raising learners’ register awareness and pattern awareness by reducing the influence of L1 and the target language (Larsson & Kaatari, 2020; M. H. Lin, 2021). Besides, students’ direct engagement in the concordancing and data-analyzing process promotes learner autonomy, language awareness, thinking skills, and cognitive abilities (Flowerdew, 2015). For instance, learners’ direct application of CPA can expose them to an enormous amount of authentic evidence and help them internalize complex English patterns autonomously, thus bolstering their language awareness and intuition.
Conclusion
Drawing on insights from TNE, his paper compared the patterning of the light verb get in English writing by Chinese and L1 undergraduates via CPA. The results show that Chinese undergraduates share similarities with native undergraduates in associating light verb meaning with use but also have their own distinct writing features. On the one hand, most of the prototypical patterns identified in the two corpora are identical, and both Chinese and native writers show exploitations of norms. On the other hand, Chinese undergraduates prefer to overuse high-frequency patterns and semantic roles but underuse low-frequency ones to avoid making mistakes. This behavior may be attributed to their limited proficiency in infrequent patterns and idiomatic expressions, likely leading to a lack of diversity in the range of patterns and complements used. Another remarkable disparity is Chinese undergraduates’ uncertainty in registers due to a lack of register awareness. In addition, Chinese learners make mistakes in their writing in a varied but recognizable way, mainly ascribed to L1 influence and target language influence. To enhance the writing proficiency of Chinese EFL learners and achieve native-like usage in production, various classroom activities and teaching methods can be implemented, such as brainstorming, encouraging learners to create their own corpora, and direct/indirect DDL. Besides, CPA and PDEV can be adopted directly or indirectly in EFL teaching and learning to broaden learners’ width of senses and forms of polysemes and bolster their language awareness and intuition.
Limitations and Suggestions
The present study, however, only tackled a restricted range of issues in a wide and complicated research field, leaving the ground open for further studies. Firstly, due to practical constraints, this study did not provide a holistic picture of how different levels of learners use light verbs in their writing. Thus, further comparison of how different levels of learners use light verbs is needed, which could pave the way for a better understanding of developments in light verb patterning. Secondly, as the process of CPA is labor-intensive and time-consuming, only one light verb was analyzed in the study. How light verbs other than get are used in native and non-native English writing also merits further investigation.
Footnotes
Appendix
Refined Patterns of get Identified in CUEW and BAWE.

| No. | Pattern and implicature | FC (Fre, %) | FB (Fre, %) | LL | |
|---|---|---|---|---|---|
| 1 | 585 (28.43) | 80 (17.82) | +322.98 | ||
| 2 | 467 (22.69) | 75 (16.70) | +230.50 | ||
| 3 | 308 (14.97) | 46 (10.24) | +160.27 | ||
| 4 | 203 (9.86) | 9 (2.00) | +176.51 | ||
| 5 | 89 (4.32) | 4 (0.89) | +77.13 | ||
| 6 | 62 (3.01) | 21 (4.68) | +16.89 | ||
| 7 | 49 (2.38) | 13 (2.90) | +14.63 | ||
| 8 | 49 (2.38) | 3 (0.67) | +39.00 | ||
| 9 | 25 (1.21) | 30 (6.68) | −2.40 | ||
| 10 | 41 (1.99) | 4 (0.89) | +27.27 | ||
| 11 | 24 (1.17) | 14 (3.12) | +0.83 | ||
| 12 | 15 (0.73) | 30 (6.68) | −9.27 | ||
| 13 | 12 (0.58) | 21 (4.48) | −5.07 | ||
| 14 | 17 (0.83) | 3 (0.67) | +7.79 | ||
| 15 | 8 (0.39) | 14 (3.12) | −3.38 | ||
| 16 | 4 (0.19) | 6 (1.34) | −1.01 | ||
| 17 | 6 (0.29) | 3 (0.67) | +0.44 | ||
| 18 | 3 (0.15) | 6 (1.35) | −1.85 | ||
| 19 | 4 (0.19) | 4 (0.89) | −0.11 | ||
| 20 | 7 (0.34) | 0 (0) | +8.15 | ||
| 21 | 0 (0) | 7 (1.56) | −11.46 | ||
| 22 | 3 (0.15) | 3 (0.67) | +0.08 | ||
| 23 | 3 (0.15) | 2 (0.45) | +0.03 | ||
| 24 | 1 (0.05) | 4 (0.89) | −2.71 | ||
| 25 | 0 (0) | 4 (0.89) | −6.55 | ||
| 26 | 0 (0) | 4 (0.89) | −2.23 | ||
| 27 | 0 (0) | 4 (0.89) | −6.55 | ||
| 28 | 3 (0.15) | 0 (0) | +3.49 | ||
| 29 | 2 (0.10) | 1 (0.22) | +0.15 | ||
| 30 | 0 (0) | 3 (0.67) | −4.91 | ||
| Total | 1,990 (96.70) | 418 (93.30) | |||
Acknowledgements
We would like to thank all the reviewers who have given suggestions on this paper. Our special thanks go to Prof. Patrick Hanks and Pro. Su Hang for their insightful comments and profound questions which motivated us to enhance this study from diverse aspects.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a grant from the SISU Postgraduate Research Innovation Project in 2024 (No. SISU2024XK001).
Ethical Approval
This article does not contain any studies with human or animal subjects.
Data Availability Statement
The data supporting the findings of this study is available from the corresponding author upon request.