
Abstract
In the context of formative assessment in classrooms, the incorporation of automated evaluation (AE) systems and teachers’ interactions with them hold significant importance. This study aimed to investigate the cognitive processes of pre-service teachers as they engaged with an AE system. We developed an unsupervised learning-based AE system, the Scoring Assistant using Artificial Intelligence (SAAI). SAAI calculates scores without relying on predefined labels and generates scientific keywords from student responses to provide constructive feedback. We collected a substantial number of constructed responses from students, and four pre-service teachers evaluated these responses initially without any external assistance and then re-evaluated them using SAAI scores as a reference point. Employing a mixed-methods approach, this study demonstrated a strong level of consistency between human raters and SAAI scores. Pre-service teachers also reflectively recalibrated their assessments and adjusted their rubrics to identify students’ learning more accurately. This study highlights the practical application of AE in real classroom settings and demonstrates how AE can enhance efficiency and accuracy in K-12 science assessments, thus supporting teachers.
Introduction
The rapid advancement of technology has led to significant improvements in the performance of automated evaluation (AE) systems, expanding their role as valuable tools for supporting formative assessments conducted during ongoing teaching and learning activities (Burrows et al., 2015; Foltz & Rosenstein, 2015). By incorporating cutting-edge techniques from natural language processing, machine learning, and deep learning, AE now provides more accurate and reliable evaluations for constructed responses, even with limited data. This has resulted in considerable time and cost savings in training and monitoring human raters (Ramesh & Sanampudi, 2022). Many AE models have been designed to handle small volumes of constructed response data from individual classrooms while maintaining low error rates, effective result analysis, and high reliability. These advancements underscore the potential of AE to enhance formative assessment, provide immediate feedback, and contribute significantly to educational settings.
While ensuring valid implementation of AE systems in real classroom contexts remains a challenge, research has emphasized the importance of teacher involvement and decision-making when integrating AE results (Brew & Leacock, 2014; Noh et al., 2015). In particular, the incorporation of AE in classroom-based formative assessment necessitates context-based decision-making regarding different levels of teacher involvement (Han & Lu, 2021). Researchers have explored various models of harmoniously combining AE with human assessment practices to complement each other (Attali, 2009; Bridgeman et al., 2009; Shin et al., 2019; Williamson et al., 2012). However, much of this research has focused on the integration of human raters and AE within large-scale, high-stakes testing environments, determining the weighting of scores from both sources to compute final outcomes.
There is a need for more comprehensive research on how teachers respond to and adjust their scoring practices when integrating AE results into classroom-based formative assessment. Wilson et al. (2021) and Yuan et al. (2020) found that teachers adjusted the score results from AE with diverse objectives and approaches, such as addressing potential biases in AE scores and considering curriculum relevance. This adjustment is particularly crucial in contexts where the human rater effect is substantial or when notable discrepancies arise between AE results and teacher evaluations. Many studies have highlighted considerable variations in scoring severity, consistency, and decision-making processes among raters with differing levels of scoring experience (Attali, 2016). This means that teachers with limited assessment experience and grading expertise are more likely to exhibit a stronger rater effect and to display a wider range of dynamics and strategies in integrating the AE results into their own evaluations.
This study took a comprehensive methodological approach to carefully examine the extent to which teachers’ assessment processes are integrated with the implementation of AE systems to accurately reflect student achievement. We examined the cognitive processes of teachers when utilizing AE systems within the context of science education (Bridgeman, 2013; Walsh et al., 2021). In contrast to viewing AE systems solely as tools for reducing teacher workload or sharing assessment responsibilities, our approach integrated these systems with the human raters’ scoring processes to improve assessment validity by using them as valuable references (Wolfe & Wendler, 2020). By delving into the cognitive processes behind teachers’ use of AE, particularly those with limited assessment and grading expertise, we aimed to shed light on how these systems can be effectively harnessed to optimize teachers’ rubrics and the calibration processes.
In this study, we developed an unsupervised AE system called the Scoring Assistant Using Artificial Intelligence (SAAI) system, taking into consideration the practicality and cognitive processes of teachers using the system in real classroom contexts. Particularly in subjects like science, where assessment tends to involve evaluating evidence of students’ learning and content-based features, such as specific word and sentence expressions, the system identifies important linguistic expressions in students’ responses, clusters them based on extracted patterns, and conducts scoring accordingly (Basu et al., 2013). By adopting the mutual reinforcement principle of negative matrix factorization (Zha, 2002), the SAAI system we implemented in this study successfully achieved efficient summarization, scoring of student responses, and production of immediate feedback. This makes it highly adaptable to constructed responses and enables quick data processing in various assessment scenarios (Basu et al., 2013; Roy et al., 2016).
Williamson et al.’s (2012) suggestion of expanding the use of AE systems for novel-method approaches underscores the fact that the fundamental question of automated scoring for such applications is no longer “Can it be done?” but “How should it be done?” Enhancing a model’s accuracy from 88% to 90% holds significance; however, it is equally crucial to investigate how teachers incorporate AE into their grading to make informed decisions and effectively address student achievement. Even less accurate models that offer greater extensibility and interpretability can be valuable if they provide useful information and insights, ultimately facilitating valid assessment practices and assisting teachers in their decision-making processes (Bauer & Zapata-Rivera, 2020; Bridgeman, 2013). By examining how teachers respond to and incorporate AE results in their classroom assessments, particularly in cases of substantial discrepancies, researchers can gain valuable insights into the complex interplay between human judgment and automated scoring systems. This understanding can inform the development of more effective and contextually aware AE systems that better support and complement teachers’ professional expertise in evaluating student learning. In order to gather insights aimed at supporting teachers’ assessment processes and expertise, this study focused on pre-service teachers rather than professional in-service teachers. The following specific research questions will guide this study:
To what extent is the SAAI system consistent with pre-service teachers’ assessment results? a. What is the result of the correlation analysis between the pre-service teacher’s first round of scoring and the SAAI’s scoring? b. What is the result of the correlation analysis between the second round of scoring by pre-service teachers and the SAAI scoring undertaken while referencing the SAAI scoring results?
How do pre-service teachers use the results of the SAAI system in the second round of the scoring process?
Literature Review
AE Systems
AE systems in science education have made significant progress in effectively identifying specific content-based features in students’ responses, allowing educators to examine both how and what students currently understand (Burrows et al., 2015; Liu et al., 2016; Zhai & Nehm, 2023). Proficiency in constructed response tasks goes beyond simply recognizing what students know, since students are required to construct what they understand and convey their knowledge in their own words. In this regard, AE systems have been designed to have greater capability to assess semantic-domain features that showcase a deeper grasp of the subject matter than writing styles or syntactic elements can provide (Haudek et al., 2019; Mohler et al., 2011; H.-C. Wang et al., 2008). For example, when a student explains a scientific concept, demonstrates scientific reasoning, or solves a problem, these systems analyze the response using key expressions to determine whether it contains clear and rich domain knowledge. They also can measure the relevance and coherence of ideas using numeric data mapping.
Several studies (e.g., Foltz et al., 2020; Ramesh & Sanampudi, 2022) have emphasized that AE supports student learning through immediate feedback and teacher-student interaction, which formative assessment research (e.g., Black & William, 1998; Irons, 2008) has highlighted as key strategies for promoting and supporting learning. To be specific, by leveraging natural language tools, AE enables offering students immediate formative feedback based on their own responses that allows them to gain a more concrete understanding. This promotes self-directed learning, as students continuously monitor their learning process (Duit & Treagust, 2010). Teachers can also accurately identify learners’ comprehension levels, enabling meaningful interactions and providing targeted remedial activities (Lai & Chen, 2010). The integration of AE in the formative assessment approach enables teachers to tailor their instruction to cater to individual student needs, elevating the efficacy of day-to-day teaching.
AE systems use both supervised and unsupervised learning approaches to evaluate student responses (Burrows et al., 2015; Shermis & Burstein, 2013; Yan et al., 2020). However, in real-life educational contexts, particularly in K-12 environments, the use of unsupervised learning algorithms in AE holds appeal. Supervised learning relies on labeled training data, where human raters have previously scored responses, to develop a predictive model based on extracted features. In contrast, unsupervised learning algorithms operate on unlabeled data, aiming to identify hidden patterns and structures within the responses without the need for pre-existing scores (Basu et al., 2013; Colarusso, 2022). This is advantageous in classroom contexts where every task is unique, making it impractical to require ongoing teacher involvement to create labeled data, particularly in scenarios where labeled training data is limited or unavailable (Roy et al., 2016). For this reason, Rupp (2018) predicted that the methodological setup of supervised approaches may gradually disappear, and unsupervised approaches may become more common in K-12 education settings.
Relationship Between Teachers and AE Systems
It is essential to consider the teacher’s role as a main actor in the evaluation process when implementing AE systems. Several studies have reported the importance of teacher involvement and system flexibility for the effective implementation of AE systems. For example, Noh et al. (2015) revealed that higher teacher involvement significantly enhanced system performance compared to relying solely on automated grading. Brew and Leacock (2014) found that the process of extracting features from students’ answers and calculating scores also needs to be adapted to align with teaching and learning, such as by adjusting weights based on lesson goals, tasks, or relevant keywords, to elevate the validity and reliability of systems. In the context of formative assessment, Han and Lu (2021) found that the successful use of AE requires context-based decision-making regarding different levels of teacher involvement. They argue that, considering the goals of formative assessment, a combination of teacher and AE scoring could address the limitations of relying solely on either automated or manual assessment. This approach would enable teachers to provide timely and targeted feedback while engaging with students immediately after assessment, thus fine-tuning their feedback practices.
Some researchers explored various models of how AE can be harmoniously combined with human assessment practices to complement each other. Williamson et al. (2012) introduced implementation policies for automated scoring. One approach involves using AE as a quality control tool on human scoring by comparing scores from human evaluators and AE systems; discrepancies beyond a set threshold trigger a review by a second human evaluator, ensuring that the final score reflects a consensus or a human judgment, as seen in the GRE’s scoring method (Bridgeman et al., 2009). Another approach extends to averaging scores from an AE system and a human evaluator for a more balanced assessment. In cases where significant differences arise, a secondary human review is sought. This strategy of blending scores has been applied, for example, in the TOEFL (Attali, 2009). Recently, Shin et al. (2019) explored how AE could aid in the calibration and feedback process for human raters, suggesting the potential for AE to replace human judgment in certain monitoring aspects, particularly focusing on the consistency and severity of ratings.
However, much of the other research (e.g., Bennet, 2003; Wolfe & Wendler, 2020), including that mentioned above, has focused on the integration of human raters and AE within the context of large-scale, high-stakes testing environments, determining the weighting of scores from both sources to compute final outcomes. Studies of the deployment and analysis of AE in real classroom settings have also mainly focused on evaluating the system’s performance (e.g., Liu et al., 2016; H.-C. Wang et al., 2008) and the effectiveness of its feedback (e.g., Gao & Ma, 2019; Maier et al, 2016). This has led to an understanding of AE primarily through its sole validation rather than its integrated impact with teacher-led evaluations and adjustment in daily classroom environments.
Research pertaining to the teacher-AE combination in formative assessment has been a small but growing area of inquiry. Wilson et al. (2021) found that teachers put effort into aligning the decontextualized results from AE systems to their specific instructional systems, as they encountered challenges such as overly stringent scoring or differences in scaling systems. Teachers tried to ensure the systems effectively represent the intended learning objectives for curriculum-specific and contextualized implementation plans. In addition, Yuan et al. (2020) found that the deep learning-based AE model showed that it was necessary to be cautious about bias when dealing with extremely high or low scores. They suggest that teacher score adjustment is vital for enhancing AI algorithms, particularly in interpreting nuanced aspects like the student answers’ context and depth. However, these studies have demonstrated exemplary practices of teachers harnessing AE scoring. They have not comprehensively explored the patterns and features of teachers’ adjustment processes or how they compare and incorporate AE results with their own scoring to ensure assessment reliability and validity. In particular, when significant discrepancies emerge in the incorporation, teachers’ responses and adjustments of AE scoring results could give us insights into how AE can effectively assist teachers.
Cognitive Processes of Human Rating and the Role of AE
The use of AE not only depends on accurate overall performance but also involves a deeper understanding of human ratings, including cognitive processes and substantive grounding. Bauer and Zapata-Rivera (2020) suggested that there are two cases in which establishing the relationship between humans and AE is necessary: when the intended use depends not just on overall performance but on more detailed aspects of knowledge or skill, as in feedback for learning, and when a deeper understanding of human ratings, in terms of both cognitive processes and substantive grounding, helps researchers create more strongly grounded processes. The cognitive processes that have for years resided in raters’ heads hold insight into better AE processing. Finn et al. (2020) and Walsh et al. (2021) suggested a framework of sequential activities during training and scoring, with three key elements of cognitive activities: checking scoring rubrics, creating benchmark exemplars, and calibrating scores. While Walsh et al.’s study was conducted in the context of the GRE test, where rubrics and predefined training sessions were provided, our study focused on the assessment processes and cognitive activities that arise when teachers employ the AE system to support formative assessment. For this reason, to interpret our findings, we drew upon the factors proposed by Walsh et al. but reframed them to provide valuable insights into the evaluation processes undertaken by teachers and the cognitive activities associated with them within the K-12 educational setting.
Scoring rubrics serve as the established criteria for evaluating assignments and their content. To minimize the impact of the human rater effect (Bejar, 2017), external and internal mechanisms are employed to ensure the consistency and accuracy of their scoring, aligning it with the rubric across various scoring sessions. Raters are equipped with the rubrics at the beginning of their scoring sessions or when designing the evaluation tasks. This process aims to enhance raters’ understanding of the goal of evaluation and improve the accuracy and consistency of their scoring. Benchmark exemplars, sometimes referred to as anchors, introduce the characteristics of responses that correspond to specific score levels to create certification tests to demonstrate the characteristics of an essay at a particular score level (Parke et al., 2006). Benchmarks also serve as validity or monitoring samples, along with actual responses from test takers, for monitoring rater performance during operational scoring. They help establish a shared understanding among raters and promote inter-rater consistency, enhancing the overall reliability and validity of the scoring process. Calibration sessions play a critical role in ensuring that raters comprehend and internalize the scoring rubrics, enabling accurate scoring across all score points. Calibration serves the dual purpose of reinforcing the scoring criteria and acting as a gatekeeping mechanism. This process also ensures consistency in ratings across and between scoring sessions by providing a reference point for raters to align their evaluations with the established standards. Calibration further acts as a form of mutual validation, as it mirrors the cognitive process that automatic scoring algorithms aim to replicate, contributing to the mutual validity of the scoring process.
Methods
Development of the SAAI System
The SAAI system developed in this study adopted the mutual reinforcement framework (MRF) principle proposed by Zha (2002) to summarize and cluster student responses, resulting in a central response that is subsequently scored through saliency score calculation (Ha et al., 2023). Additionally, the system can automatically generate individualized student feedback based on 10 key expressions extracted from the central response. Zha introduced a method that simultaneously extracts topic words, summarizes documents, and calculates feature scores through the application of sentence clustering and the mutual reinforcement principle. The MRF principle employs non-negative matrix factorization to generate multiple eigenvectors and corresponding singular values from the collected text, specifically sentences. This overcomes the limitations of latent semantic analysis and ensures accurate summarization. In contrast to latent semantic analysis, which can face challenges in interpreting meaning intuitively and may extract only a limited number of sentences as representatives, non-negative matrix factorization excels at summarizing and extracting sentences that exhibit the highest similarity using positive eigenvalues. This approach enables a more effective and comprehensive representation of the underlying meaning in the text. Saliency scores are derived from sentences and terms using the MRF, incorporating both word usage and document structure. Also, the SAAI system further models documents as weighted graphs and applies spectral graph clustering to generate topic groups. By utilizing these techniques, the SAAI system effectively summarizes and scores student responses, providing valuable feedback based on the central response. The SAAI system generates a conclusive score for each student’s response, which is influenced by the total word count within the dataset. For this reason, the scoring range varies across different classes and datasets and the observed scores span from 0 to 37.61 in this study. The SAAI system was designed as a web-based platform. When students’ responses are uploaded, the system extracts keywords and generates scores of students’ responses. Table 1 provides a detailed overview of how the SAAI system operates within the website layout and the information provided to users, including teachers.
A Detailed Overview of How the SAAI System Operates Within the Website.

Research Context and Data Collection
As the aim of this study included evaluating the effectiveness of the SAAI system, which scores students’ constructed responses in unsupervised learning, we collected students’ responses that had already been collected during assessments in real classroom settings. Students’ responses were collected from high schools and a university in the Philippines during the 2022 to 2023 academic year. As shown in Table 2, students’ responses in seven high school classes and one university course were collected in this study. Responses from 2,176 students were collected, resulting in a dataset of 32,144 responses. The responses were collected as a part of regular school assessments rather than specifically for the purpose of this study. All datasets collected were anonymized. Table 3 shows which subjects were assessed in each class and examples of questions and students’ responses. These assessments included six disciplines: physics, biology, chemistry, general science, applying science to everyday life, and philosophy of science. The sets of assessments used in this study were questions that teachers who taught the classes used in their actual classes.
Summary of Student Responses and Pre-Service Teacher Raters.

Examples of Assessment Tasks.
To examine the effectiveness of the SAAI system and its impact on teachers’ rescoring processes, we involved four pre-service teachers in their third or fourth year of college as human raters. Pre-service teachers were chosen because their assessment expertise was likely more limited than that of in-service teachers, making them an ideal group to investigate how the SAAI system can support scoring quality control and how teachers incorporate the system when discrepancies between scores are large.
The scoring process in this study was carried out through the following steps. First, the human raters and SAAI systems independently scored students’ responses. Pre-service teachers developed and used a five-tiered scoring rubric for assessments. The rubric’s criteria included distinct components and detailed expectations for each discipline, along with sample answers to guide grading (Appendix A). In the first scoring round, teachers used these rubrics independently. Upon receiving the SAAI scores, they adjusted and revised their rubrics for the second round of scoring. Details of these adjustments are presented in the results section. Second, the results of the SAAI system were provided to human raters as a reference. Third, human raters were asked to re-score the students’ previously scored responses. During both grading sessions, human raters assigned scores on a scale ranging from 0 to 4. A score of 0 indicated that the answer was completely incorrect and irrelevant to the given question, while a score of 4 represented a highly accurate and comprehensive response that demonstrated a deep understanding of the subject matter. This scoring scale provided a clear framework for assessing the quality and alignment of the students’ answers with the given questions.
Data Analysis
To address RQ1, which compares human rating and the SAAI system’s scoring, Pearson’s correlation analysis was used to evaluate the correlation between the scores assigned by human raters and the scores generated by the SAAI system. A baseline model that employed term frequency-inverse document frequency (tf-idf) weights served as a benchmark for comparing the performance of the SAAI system so that researchers could assess its effectiveness and improvements in automating the grading process. In addition, two variations of the SAAI system were tested: one with stopwords included in the analysis and another with stopwords removed. The results of these variations demonstrate the nuanced capabilities of the SAAI system in different operational settings.
To address RQ2, we examined the extent to which the SAAI system influenced the scoring processes of the pre-service teachers. First, a paired t-test was used to compare the results of the correlation coefficient between the pre-service teachers’ grading and the SAAI score in the first and second rounds. This statistical analysis identified significant differences between the two rounds, and we determined the potential influence of the SAAI system on changes in the pre-service teachers’ scoring. In addition, we investigated changes in the patterns of teachers’ scoring when using the SAAI system. The notable changes in each rater’s scoring were examined using ANOVA and Tukey’s test to identify statistical differences and features in the distribution of scores. The independent variable was the level of human scoring, which consisted of five categories: 0, 1, 2, 3, and 4. The dependent variable was the SAAI score assigned to each level of human scoring. These patterns of scoring changes were then categorized into the framework of sequential activities suggested by Walsh et al. (2021), and researchers interpreted the role of the SAAI system in influencing the scoring of the pre-service teachers.
Results
Consistency Between Teachers’ Scoring and SAAI Scores
Table 4 shows the correlation between human raters and the three models: the tf-idf as a baseline, the SAAI system with stopword removal, and the SAAI system with stopwords included. The results show that the average correlation of the baseline model, which used tf-idf to calculate keywords’ weight, was approximately r = .17 (p < .033). The SAAI system achieved an agreement of approximately .40 (p < .049) with human raters on the dataset, which is similar to the reported result of .50 to .60 from other systems employing various unsupervised learning algorithms
Correlation Between Human Raters and the Three Models.

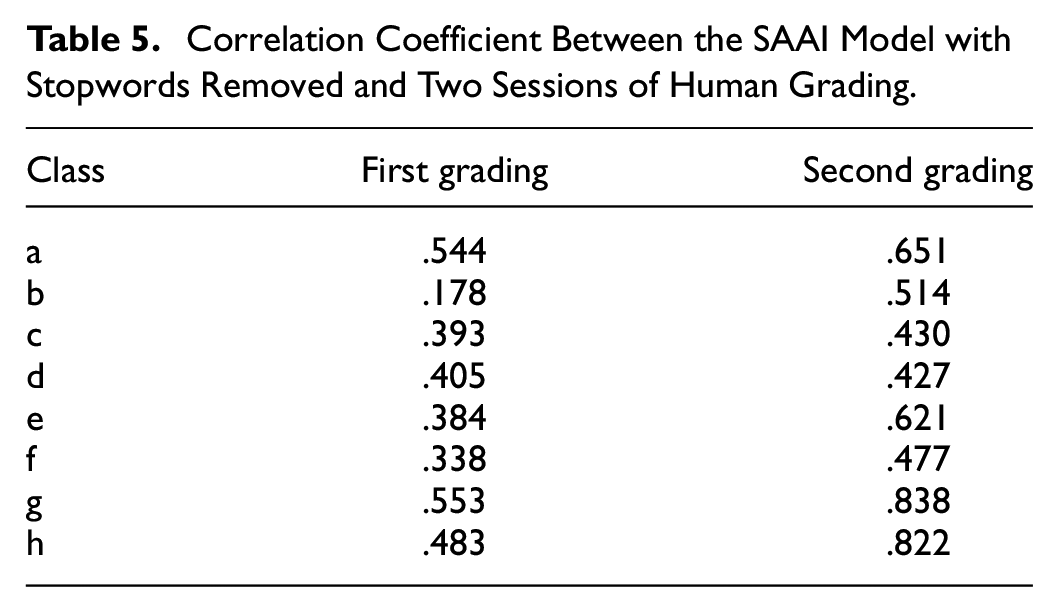
Table 5 shows the correlation coefficient between the SAAI model with stopwords removed and two sessions of human grading. There was a significant change in the correlation coefficient (r) from .40 (p < .049) in the first round of scoring to .68 (p < .009) in the second round of scoring. In the first round, 30% of the questions showed correlation coefficients above .5, whereas in the second round this percentage increased to 70%. Overall, the results demonstrated that the pre-service teachers’ scoring was comparable to the SAAI system’s scoring, and the correlation coefficients between the two improved after the second round of scoring. This finding demonstrated a higher average level of agreement between the scoring outcomes produced by the SAAI system and human scoring in the second round of grading sessions.
Correlation Coefficient Between the SAAI Model with Stopwords Removed and Two Sessions of Human Grading.
Changes Made in the Second Scoring When Using SAAI as a Reference
Examining the difference between the raters’ first- and second-round scoring and how they utilized the SAAI system in their second-round scoring, we found significant differences between the first and second round scores of raters except for Rater B. The results showed that the SAAI system functioned as a peer reviewer by supporting the raters’ grading processes, which does not necessarily mean that there were many grading errors. We used a t-test to examine whether there were statistically significant differences in the correlation coefficients between the two scoring rounds, aiming to demonstrate the impact of SAAI on the raters’ rating. Table 6 show the average and standard deviation of t-values and the average and standard deviation of p-values across 15 questions for each class. The findings indicated that there were significant differences (p < .000) in the correlation coefficients between the SAAI system and the two rounds of scoring, except for Rater B. Rater B did not exhibit significant changes (p > .05) in the correlation with the SAAI system between the first and second rounds. These findings suggest that the integration of automated scoring systems led to noticeable variations in the scoring patterns of three out of four teachers during their evaluation processes.
t-Test Between the First Scoring’s Correlation Coefficient and the Second Scoring’s Correlation Coefficient.

p < .05. **p < .01. ***p < .001.
To gain a deeper understanding of the aforementioned results in a more comprehensive and systematic manner, we used a combined analysis involving ANOVA and Tukey’s test and categorized scoring change patterns of teachers from qualitative perspectives. The patterns of scoring change were categorized based on the framework of Walsh et al. (2021), which delineates three categories: checking scoring rubrics, creating benchmark exemplars, and calibrating scores.
Scoring Change Pattern 1: Revising Rating Scales in the Rubric
One scoring change pattern found in Rater D was revising rating scales in the rubric. During the first round of scoring, Rater D graded generously, while the SAAI system graded strictly. However, Rater D revised their rating scales strictly using the SAAI result as a reference. Table 7 shows the scoring change pattern of Rater D. Initially, Rater D gave scores of 3 to around 65% of students’ responses. Assigning a score of 3 to most students initially and then revising their scores to 1 indicates that the teacher initially assessed the students’ work as meeting a certain level of criteria (a score of 3), but upon further reflection, the teacher determined that the students’ work did not actually meet that level of criteria and deserved a lower score. Indeed, this process aligns with the findings from the SAAI analysis, which revealed that students who received a score of 3 had primarily employed basic keywords related to the questions, implying a limited depth of comprehension. A considerable number of students’ responses also lacked the inclusion of the top 10 keywords. Despite Rater D initially assessing the students’ responses as reasonably appropriate, the subsequent analysis from the SAAI system indicated that their answers did not adequately demonstrate a comprehensive grasp of the learning content.
Rater D’s Grading Frequency Distribution.

Rater D seemed to revise the rating scale of their rubric using the SAAI results as a reference point. This adjustment increased discrimination in grading, allowing for more precise differentiation of student performance levels and enhancing rating severity. For instance, in Question 5 “Why is cancer considered a malfunction of the cell cycle?” during the first round of scoring, Rater D gave a score of 2 to a student’s response of “Cells divide uncontrollably and spread into surrounding tissues” and gave a score of 3 to the response “It is a product of unchecked and excessive division.” However, in the second round of scoring, both responses were re-scored as 1. As the SAAI system highlighted keywords such as gene, DNA, and control, the SAAI system gave a relatively higher score to the responses in including the concept of breakdown. Rater D revised the rubric to ensure that it captured the desired responses and accurately represented the expectations for each score level. This adjustment was based on assessing the extent to which individual responses contained the keywords highlighted in the feedback word list accompanying the SAAI results (Table 8).
Example of Students’ Answers, SAAI Scores, and Rater D’s Scores on Question 5.

Scoring Change Pattern 2: Changing Benchmark Responses and Criteria in the Rubric
In the scoring patterns of Rater A, scoring changes were observed in the benchmarks and example responses within the rubric. It is noteworthy that Rater A did not make overall changes to the entire scoring, but rather adjusted the benchmarks for specific responses, resulting in changes to the scores of corresponding answers. As mentioned above, Rater D made comprehensive adjustments to the scoring scale of the rubric, applying a more severe grading approach across all students’ responses. The difference lay in the fact that Rater A only modified the scoring of specific responses based on the applicable benchmarks. These changes were directly influenced by Rater A’s revision of the criteria and benchmarks in their rubric, guided by the insights provided by the SAAI system.
Notable differences in the frequency of scores for Question 1 are an explicit example of this explanation. In this specific question, students were tasked with providing a binary response, selecting either “yes” or “no” and providing a concrete explanation to support their choice. In the first round of grading, teachers assigned 0 points for incorrect “yes” responses, while a brief “no” answer received 1 point. However, in the second round of grading, teachers acknowledged the significance of not only providing the correct response but also offering a more elaborate explanation using relevant keywords. As a result, higher scores were awarded to students who answered “no” and provided a more comprehensive and keyword-aligned explanation, as indicated by the SAAI system. This adjustment was aimed at capturing the depth of understanding and analytical skills demonstrated by the students in their responses by changing benchmark responses (Table 9).
Example of Students’ Answers, SAAI Scores, and Rater A’s Scores on Question 1.

Scoring Change Pattern 3: Micro-Calibration in Inconsistent Scoring
Rater C made micro-calibration in their second scoring, which contributed to a more consistent and accurate assessment of student responses. During their second grading session, they reviewed both students’ answers and their first grading with the SAAI score. They also checked the feedback of the SAAI to determine which and how many of keywords each student had missed. This allowed them to revise their scoring approach and ensure greater consistency and fairness in evaluating individual responses.
This issue was particularly evident in Question 8, which required students to provide examples from the lesson or real-life scenarios to demonstrate their understanding. As presented in Table 10, Rater C’s first-round scores revealed variations in the scores assigned to almost identical responses from Students 205, 208, and 56, with scores of 2, 3, and 1, respectively. The SAAI scores indicated that there were no significant differences in the missing keywords across a certain range of the students’ responses, prompting Teacher C to recalibrate their scoring approach and make necessary adjustments. Although Rater C’s initial evaluation of the responses exhibited more inconsistencies and discrepancies, they were able to elevate the reliability and validity of the overall scoring process through the second scoring session.
Example of Students’ Answers, SAAI Scores, and Rater C’s Scores on Question 8.

Discussion
Our aim in this investigation was to provide empirical evidence supporting teachers in their assessment roles involving AE systems, while also advancing the feasible integration of these systems within K-12 educational settings. We sought to examine the impact of AE systems and how teachers utilize them in their assessment practices, with the understanding of teachers’ cognitive processes of using AE, ultimately enhancing the overall quality of assessment. As part of our study, we analyzed the scoring of student data from the Philippines using both human raters and the SAAI system. It is important to note that the scoring process involved raters who had limited expertise in assessment. The scoring was conducted in two rounds, with the second round incorporating the SAAI system as a reference.
Based on the research questions, the findings of this study can be summarized as follows: First, we observed a significant level of consistency in the scoring outcomes between teacher ratings and the SAAI system. The SAAI model, developed using Zha’s (2002) MRF algorithm for unsupervised learning, demonstrated superior performance compared to the baseline tf-idf model. Out of the 120 items, approximately 60 items had correlation coefficients exceeding .6, which is a level similar to previous studies on power-grading data (Basu et al., 2013) and unsupervised models (Colarusso, 2022; Jadidinejad & Mahmoudi, 2014; Sultan et al., 2016), which reported correlation coefficients ranging from .5 to .6.
Second, the findings demonstrated the distinctive cognitive processes that emerge during the integration of AE and human scoring. In the second round of scoring, where SAAI scores were used as a reference, there was a noteworthy increase in the correlation between the teachers’ assessments and the SAAI scores, except for Rater B. The average correlations coefficient in the second round stood at .7, showcasing the significance of this change. This alteration was statistically meaningful as per the t-test, implying that the incorporation of SAAI scores in the second round had an impact. Rater D revised the scoring scale of their rubric and Rater A adjusted the criteria of their rubric, aiming to align with intended learning outcomes and accurately reflect the expectations for student learning. These changes exemplified how teachers integrated their assessment practices with the AE system, guided by the SAAI-generated scores and the degree to which individual responses contained the keywords highlighted in the feedback word list accompanying the SAAI results. In addition, Rater C recalibrated their scoring and made overall adjustments to ensure greater consistency and fairness in assessing students’ responses. They leveraged the SAAI score as quantitative data to identify and rectify errors and discrepancies between their assessments and the AE system. Although these three patterns of scoring adjustment were somewhat mixed among the three raters, each teacher exhibited a dominant pattern. For instance, in one of the tasks, Rater A recalibrated some students’ scores, but less frequently than Rater C, who did not change the scales overall.
These findings suggest that the quantitative data generated by SAAI helped teachers in obtaining a clearer understanding of the level of achievement within their classrooms. The effectiveness of SAAI in promptly capturing the characteristics of student responses and accurately reflecting them through scores and feedback serves as valuable evidence to support the teacher’s decision-making processes. Evidence-centered design, as introduced by Mislevy et al. (2006), supports this with a theoretical framework. This theory particularly expands on the intricate cognitive models and processes that teachers employ while utilizing AE, especially in constructed response tasks. This model can be used to explain that the response scoring process and the summary scoring process are particularly noteworthy, as they explain the strategies of teachers using AE. For instance, when it comes to evaluating constructed responses, relying solely on an observable binary of “right” or “wrong” is no longer sufficient. Using specific measurements to show how well students understand a topic and providing teachers with accurate data are vital parts of AE. On the other hand, the summary scoring stage involves a more complex process. In this process, human raters not only determine the extent to which their assumptions about a student’s learning need to be shifted based on the evidence but also assign weights to the variables that contribute to the final score. It becomes clear that while human raters demonstrate active engagement in high-order cognitive processes during the summary scoring process, the “identification” activity—focused on quantifying evidence objectively—takes on a more substantial role, thus underscoring the increased importance of utilizing AE systems.
This study demonstrates the implication of unsupervised learning algorithms in a K-12 context. Particularly, when considering the evaluation of constructed responses within the context of daily formative assessment, the importance of unsupervised learning becomes evident, offering a means to circumvent the pitfalls of the “teach to test” approach (Williamson et al., 2012). Raters C and D revised their rubrics to reflect whether students exhibited a precise understanding of the question requirements in their constructed responses. Through the report from the SAAI with targeted keywords and distinctive features, teachers were able to adeptly evaluate both the comprehension of students and the areas where misconceptions may arise, all in one comprehensive assessment, as highlighted in Knowing What Students Know (NRC, 2001). In addition, these unsupervised techniques, known for their adeptness in capturing essential features and identifying evidence, exhibit remarkable versatility, as they demand little to no modification when confronted with a range of tasks and formats. Indeed, the scope of questions examined within this study spans from the philosophy of science to biology, showcasing the system’s seamless and intuitive processing of students’ constructed responses.
The results also highlight the potential of AE systems as a valuable tool for teachers, assisting them to enhance their assessment expertise and make well-informed scoring decisions. Rather than attempting to adjust scores from individual teachers, especially if these adjustments might vary from day to day, a potentially fairer procedure is to make early identification of raters who are too lenient or too severe and support them to grade more appropriately.
Promoting teachers’ active reflection and ensuring consistent, accurate assessments. By providing teachers with opportunities to review their scoring practices in light of AE feedback and engaging them in meaningful discussions about assessment standards and best practices, educational institutions can foster a culture of continuous improvement and enhance the overall quality of assessments. This requires real-time tracking and monitoring of rater behavior. Such tracking also addresses a related problem: the tendency of human raters to avoid the extremes of the score scale by overscoring low-quality responses and underscoring high-quality answers (Myford & Wolfe, 2009). Shin et al. (2019) shed light on these dynamics, revealing that individual raters underwent notable accuracy improvements and/or adjustments in their categorization over time, all facilitated by the instant incorporation of AE.
Our research highlights the immense potential of utilizing AE as a peer reviewer, a highly adaptable approach that can be applied to various local contexts worldwide. By fostering consistency and minimizing rater effects on assessment, AE serves as a powerful tool for the global educational community (Han & Lu, 2021; Z. Wang & von Davier, 2014). While specific implementation examples may differ based on subjects, standards, or test policies across nations, the core operation of AE remains a harmonized approach that can be adopted to various local contexts worldwide. Consequently, the methodologies presented in this study provide valuable insights into the prospective application of AE for rater monitoring. This research paves the way for future investigations and applications within the field of educational assessment, offering promising solutions to challenges faced by educators and policymakers worldwide in ensuring fair, reliable, and consistent evaluation practices.
In addition, the case of Rater B, who showed no significant adjustment changes in second-round scoring despite the incorporation of AE, lead us to consider practical implications and the broader issue of variability in technology adoption among educators. Zhai and Nehm (2023) emphasized the growing prevalence of AI in education and the necessity of tailoring AE systems to meet the diverse needs and expectations of individual teachers. The finding from the Rater B scenario underscores the potential for AE to reveal distinct rater behaviors but also stresses the importance of tailoring AE implementation to meet the unique needs of each teacher. While the reasons behind Rater B’s resistance to adapting AE remain unspecified, the development and implementation of AE can focus on the support mechanisms for teachers who may be hesitant or unsure of how to integrate these systems into their teaching methodologies. The ultimate goal is making AE a useful, accessible, and beneficial tool for all teachers, thereby enhancing the overall quality of formative assessments.
This study has both limitations and recommendations for future research. First, the SAAI developed in this research generated task-level scores based on the word statistics embedded within the dataset, resulting in score variations influenced by responses. As such, it becomes imperative to explore methods of standardizing these scores. Moreover, to attain a more comprehensive understanding of the cognitive processes of teachers, there is potential for additional qualitative research, incorporating techniques such as interviews and observations. The case of Rater B, for example, who exhibited consistent grading during the second round, calls for a comprehensive analysis of the underlying mechanism that contributed to this consistency and an exploration of the specific ways in which AE is not integrated into certain contexts. Moving forward, the study could be further enhanced by delving into the intricacies between AE and teachers. This exploration would further uncover models that maximize the support for teachers using AE in their classrooms, thereby elevating the overall validity and reliability of the assessment process.
Footnotes
Appendix
Test Scoring Rubric for General Science tasks

| Points | Criteria |
|---|---|
| 4 | The response provides all aspects of a complete interpretation and/or a correct solution. The response thoroughly addresses the points relevant to the concept or task. It provides strong evidence that information, reasoning, and conclusions have a definite logical relationship. It is clearly focused and organized, showing relevance to the concept, task, or solution process. Sample Response: “List the steps of the scientific method. Briefly explain each one.” 1. Ask a question: Ask a question about something that you observe: How, what, when, who, which, why, or where? 2. Do background research: Use library and internet research to help you find the best way to do things. 3. Construct a hypothesis: Make an educated guess about how things work. 4. Test your hypothesis: Do an experiment. 5. Analyze your data and draw a conclusion: Collect your measurements and analyze them to see if your hypothesis is true or false. 6. Communicate your results: Publish a final report in a scientific journal or by presenting the results on a poster. |
| 3 | The response provides the essential elements of an interpretation and/or a solution. It addresses the points relevant to the concept or task. It provides ample evidence that information, reasoning, and conclusions have a logical relationship. It is focused and organized, showing relevance to the concept, task, or solution process. Sample Response: “List the steps of the scientific method. Briefly explain each one.” 1. Ask a question. 2. Do background research: Use library and internet research. 3. Construct a hypothesis: An educated guess about how things work. 4. Test your hypothesis: Do an experiment. 5. Analyze your data and draw a conclusion. 6. Communicate your results. |
| 2 | The response provides a partial interpretation and/or solution. It somewhat addresses the points relevant to the concept or task. It provides some evidence that information, reasoning, and conclusions have a relationship. It is relevant to the concept and/or task, but there are gaps in focus and organization. Sample Response: “List the steps of the scientific method. Briefly explain each one.” 1. Ask a question. 2. Do background research. 3. Construct a hypothesis. 4. Test your hypothesis. 5. Analyze your data and draw a conclusion. 6. Communicate your results. |
| 1 | The response provides an unclear, inaccurate interpretation and/or solution. It fails to address or omits significant aspects of the concept or task. It provides unrelated or unclear evidence that information, reasoning, and conclusions have a relationship. There is little evidence of focus or organization relevant to the concept, task, and/or solution process. Sample Response: “List the steps of the scientific method. Briefly explain each one.” Ask a question, hypothesis, do an experiment, analyze your data. |
| 0 | The response does not meet the criteria required to earn one point. The student may have written on a different topic or written “I don’t know.” |
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2021S1A5A2A03061991)
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.