
Abstract
The development of artificial intelligence (AI) technology has enhanced the use of automated speech evaluation systems for language learners to practice speaking skills. This study investigated whether various automatic feedback offered by AI speech evaluation programs can help English as a foreign language (EFL) learners develop speaking skills. Forty EFL learners in China participated in this study. Data collection included qualitative and quantitative data. The results showed that the majority of participants believed they improved their speaking skills with the feedback offered by the AI speaking evaluation program. The findings also revealed that there were significant improvements in their mean scores of speaking skills in pre- and post-tests. Therefore, it is suggested that AI speaking evaluation systems could provide more varied textual feedback and practical suggestions to assist EFL learners in developing speaking skills.
Keywords
Introduction
Artificial intelligence (AI) is defined as a computer system and a virtual assistant tool that imitates human activities (Russell & Norvig, 2016). The development of AI technologies (e.g., speech evaluation programs with automatic speech recognition) have been applied to help EFL learners with their speaking practice (Kannan & Munday, 2018; Natale & Cooke, 2021). The AI speech evaluation program was found beneficial for second or foreign language learners’ development of speaking skills (Dai & Wu, 2023; Dizon, 2020; Wang & Young, 2015; Xiao & Park, 2021). It is also perceived to be interesting, user-friendly and beneficial for learners’ improvement in fluency, pronunciation, and intonation (Bahi & Necibi, 2020; Ding et al., 2019; Kan & Ito, 2020; Tai & Chen, 2023). Studies also found that AI speech evaluation programs can reduce learners’ speaking anxiety (Bashori et al., 2022a, 2022b; Chiu, 2013; Tai & Chen, 2023). Moreover, using social media among learners for collaborative learning while practice on AI speech evaluation programs can enhance learners’ language learning (Zou et al., 2023) because language learners can help each other to reinforce learning outcomes with collaborations in online or mobile learning environments (Zou et al., 2016, 2018). Therefore, AI speech evaluation programs are increasingly popular (Lehman et al., 2020). Some AI speech evaluation programs can provide automatic feedback including scores and text-based feedback, such as Duolingo (Rachels & Rockinson-Szapkiw, 2018), Babbel (Loewen et al., 2020), Rosetta Stone (Nielson, 2011), Liulishuo (Chang et al., 2022), and so on. These programs were claimed to be effective in improving EFL learners’ speaking skills (e.g., Chang et al., 2022; Loewen et al., 2019, 2020; Rosell-Aguilar, 2018). For instance, Loewen et al. (2019) analyzed the effectiveness of Duolingo by recruiting one group of participants (n = 9) to study Turkish as their second language for a semester. The results revealed that participants’ speaking skills were improved based on the scores of the Turkish 151 Test, which was derived from a summative university-level language exam that can comprehensively assess learners’ language proficiency including listening, reading, writing, and speaking. Additionally, Loewen et al. (2020) conducted a study to investigate the effectiveness of a Babbel to help learners speak a second language. The results showed that with 10 to 15 minutes’ study with Babbel per day, learners had increased their scores in pre- and post-test. However, there were also quantitative data showed that AI speech evaluation failed to improve EFL learners’ speaking skills (e.g., Lord, 2015, 2016).
The improvement in speaking skills may be attributed to automatic feedback provided by AI speech evaluation programs. Feedback plays an essential role in foreign language learning because of its positive implications on pedagogy (Li, 2013). For example, corrective feedback for speaking practices enables students to be aware of their spoken grammar mistakes and the differences between their utterances and standardized language patterns, making learners more motivated to modify their expressions (Penning de Vries et al., 2020). Many AI speech evaluation programs provide various speaking feedback in speaking tasks for learners. There are mainly two prevailing speaking tasks in AI speech evaluation programs: reading texts aloud (e.g., reading a sentence aloud) and spontaneous speaking (e.g., delivering a simple presentation) (Lehman et al., 2020). Speaking feedback may include scores, highlighted colors, sample answers, practice suggestions, and textual evaluation. Scores are numbers or stars evaluating learners’ speaking performances (e.g., Duolingo). The highlighted color indicates a visual stimulus indicating correctness (Heil et al., 2016). Some AI speech evaluation programs provide practice suggestions and sample answers when users finish speaking tasks (e.g., ELAi). Textual evaluation is short texts evaluating speaking performances (e.g., “Awesome!” in Rosetta Stone). Some research has examined the effectiveness of automatic feedback in AI speech evaluation programs. For example, Lehman et al. (2020) conducted a study with 94 EFL learners who used ELAi, which offers adaptive and targeted feedback, including the general evaluation and detailed textual feedback on different pages for users when they finish spontaneous speaking tasks based on various prompts, for 1 month to test the effectiveness of its automatic feedback and explored how learners interacted with the feedback. The results revealed that users’ speaking skills improved after using this App. Most participants checked the first page of feedback, which was general and straightforward, and few checked detailed feedback on their mobile devices on the following few pages. However, this study was conducted by Educational Testing Service (ETS) staff which may have a commercial purpose. The methodology section was also simple and not clarified, which may affect the validity of the findings.
However, it is still unclear whether AI speaking evaluation programs are effective for language learners to improve speaking skills (Heil et al., 2016; Loewen et al., 2019, 2020); therefore, more empirical evidence is needed (Burston, 2015; Zhang & Zou, 2022). In addition, speaking feedback should be optimally helpful for EFL learners (Shute, 2008). Still, rare studies investigated learners’ perceptions of AI speech evaluation programs. Therefore, the current study aims to investigate the effectiveness of current AI speech evaluation programs, especially focusing on learners’ perceptions of various feedback provided to assist learners in developing different speaking skills. The following research questions, therefore, guided the present study:
Methodology
Participants
Forty Chinese undergraduate EFL learners volunteered to participate in this study. We adopted convenience and snowball sampling to recruit these participants. Among the 40 participants, 12 of them were males and 28 of them were female. Most of them were from universities of China (97.5%), and the others studied outside China. 20% of participants were in the first year of undergraduate study, 60% were in the second year, and 15% were in year 3. Additionally, they were from a wide variety of majors, such as Business-related majors, Language-related majors, Communication, Computer Science, Architecture, and so on. Participants were required to practice their speaking skills for 1 month in the summer holiday of 2022 via various AI speech evaluation programs which are popular in China including Liulishuo, IELTS Liulishuo, EAP Talk, Shanbay, and so on. The distribution of preferred programs among participants was as follows: Liulishuo (30%), EAP Talk (40%), IELTS Liulishuo (45%), and Shanbay (32.5%). They did not use extra study materials during the study to practice speaking.
Research Instruments
This study adopted mixed research tools including questionnaires and semi-structured interviews to investigate user’s perceptions of improvement of different speaking skills. Moreover, pre- and post-tests were conducted to explore participants’ improvement of speaking skills.
The questionnaire consisted of 17 items in four sections. In the first section, 4 items were used to investigate users’ demographic information including the university, gender, year of study, and major. The next 7 items explored users’ perceived improvement of various speaking skills including oral fluency, grammatical range, and accuracy in speaking, pronunciation, oral rhythm, idea-organization skills, reading aloud skills, and spontaneous speaking skills. The reliability and validity of the items for measuring perceived improvement were tested. The value of Kaiser-Meyer-Olkin (KMO) of the items to measure perceived improvement was 0.837 (p < .01), and that of Cronbach’s alpha equaled to .930, which indicated high reliability and validity and these items were appropriate for factor analysis (Pallant, 2020). They were rated on a 5-point Likert scale (1 = strongly disagree, 2 = disagree, 3 = neutral, 4 = agree, 5 = strongly agree). After that, another section containing 5 items explored users’ patterns of use including preferred speaking tasks, preferred types of feedback, preferred level of detail of textual feedback, preferred programs, and frequency of use. The final section had 1 item to ask their willingness to participate in the follow-up semi-structured interviews.
Semi-structured interviews were used to explore further participants’ perceptions of improvement in details including different speaking skills, preferences of speaking tasks, speaking feedback, and the level of detail of textual feedback, and limitations of current speaking feedback. Twenty participants were randomly selected for individual interviews and were mainly asked about their experiences of using these AI programs, including their effectiveness, advantages, limitations, and evaluations of various speaking tasks and speaking feedback. The interviews were conducted in Chinese to ensure the qualitative data was reliable. They were recorded and later transcribed into English scripts.
Moreover, an online speaking test was used to examine participants’ English speaking skills at the beginning and end of this study, therefore exploring whether participants had improved their scores by using these AI tools for speaking practice during the experiment. All testing was conducted remotely with each participant alone at home. Participants could select from a range of topics such as jobs, software, fun, travel, and so on to begin the test. Each topic includes three relevant questions, and participants are asked to answer each one, adhering to a time limit. The entire test takes approximately 10 minutes. Participants were required to choose the same topic in the pre- and post-tests. Each topic can evaluate their speaking skills holistically and give them a report comprised of the summary of scores including overall score and scores of pronunciation, fluency, vocabulary, and grammar, descriptive feedback, and per question transcript and feedback. The scores were based on IELTS. A Pearson correlation coefficient of 0.82 for test reliability can be observed by comparing their IELTS scores.
Procedure
The study consisted of three stages. In the first stage, participants were required to participate in pre-tests and post-tests before and after practicing English speaking through the selected AI programs. In the second stage, they were asked to complete the questionnaires. In the third stage, 20 of them were invited to participate in the follow-up volunteered semi-structured interviews. All participants agreed to take this experiment voluntarily. They were shown the participant information sheet and signed the consent forms before collecting data.
Data Analysis
The questionnaires, interviews and pre-and post-tests were analyzed based on the two research questions. IBM SPSS28 was used for quantitative analysis. Descriptive statistics were calculated for demographic information and participants’ general perceptions of using AI tools for speaking practice. To examine the impact of using AI speech evaluation programs on the speaking scores, several paired-sample t-tests were conducted. The differences of the pre- and post-test scores were normally distributed and there was no significant outliers in the difference scores. To further explore the influence of frequency of use on participants’ overall speaking scores before and after using AI speaking Apps, a mixed between-within-subjects analysis of variance (ANOVA) was adopted.
The interview data was recorded and transcribed into the computer. Interviewees were coded as P1, P2, P3, and so on. The qualitative data analysis process was based on King et al.’s (2019) system of thematic analysis. In the initial coding cycle, all participant’s answers were analyzed inductively based on the order of interview questions to identify descriptive codes that helped answer research questions. Descriptive codes were clustered and applied to interpretive codes in the second coding cycle. In the third coding cycle, four key themes were identified based on interpretive codes: perceived improvement in different speaking skills, preferences of speaking feedback, preferences of the level of detail of textual feedback, and perceived limitations of current speaking feedback. There were two coders involved in coding the interview data. They analyzed the data independently based on a mutually agreed-upon coding protocol. The level of agreement was over 90%, indicating a high inter-coder reliability.
Results
Improvement of Speaking Skills in Using AI Speech Evaluation Programs
According to the questionnaires, most participants agreed or strongly agreed that AI speaking programs help improve their speaking skills including oral fluency (75%; M = 3.95), grammatical range and accuracy in speaking (60%; M = 3.65), pronunciation (80%; M = 3.9), oral rhythm (65%; M = 3.75), idea-organization skills (82.5%; M = 3.9), reading aloud skills (87.5%; M = 4.18), and spontaneous speaking skills (80%; M = 3.98). The results revealed that AI speaking apps were perceived to help improve learners’ different speaking skills, especially reading aloud skills (M > 4).
The qualitative data from the interviews provided extra support for the finding above. According to the interviews, almost all the participants believed that their speaking skills improved after using AI speaking apps. In contrast, merely two participants (P3 and P19) claimed that there was no improvement after using those apps. Pronunciation and fluency were the most frequently mentioned speaking skills that could be improved by using AI speaking apps. For example, P4 commented: “It will definitely point out the mistakes in my oral English and correct my mistakes. The correction helped. Then in some respects, especially fluency pronunciation, there is a bigger and a very big improvement.” Similarly, P18 noted, “I think it is still very helpful to improve my speaking. In terms of your fluency, pronunciation, intonation, I think it is beneficial if it is a long-term training.”
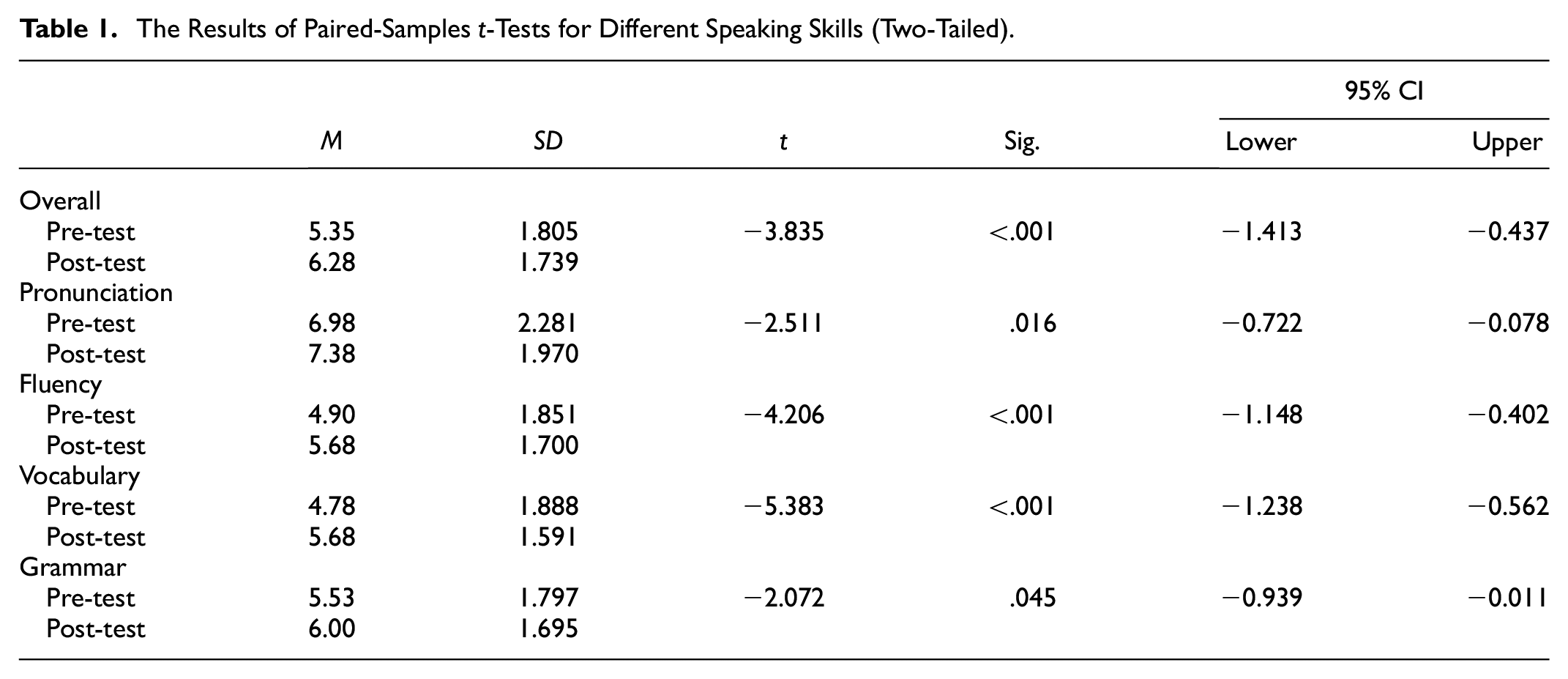
The results from paired-sample t-tests to compare mean scores of pre-tests and post-tests confirmed participants’ improvement in different speaking skills. As shown in Table 1, the mean overall speaking score increased by .93 from pre-test (M = 5.35, SD = 1.805) to post-test (M = 6.28, SD = 1.739). The increase was significant (p < .001) with a 95% confidence interval (CI) ranging from −1.413 to −0.437. The value of Cohen’s d was 1.526 > 0.8, which indicated a large effect size. Similarly, the mean pronunciation score increased .93 from the pre-test (M = 6.98, SD = 2.281) to post-test (M = 7.38, SD = 1.970). The increase was significant (p = .16 < .05) with a 95% confidence interval (CI) ranging from −1.413 to −0.437. The value of Cohen’s d was 1.008 > 0.8, indicating a large effect size. In terms of the fluency score, it increased significantly before (M = 4.90, SD = 1.851, p < .001) and after the use of AI speaking apps (M = 5.68, SD = 1.700, p < .001). The mean increase was .78, with a 95% CI ranging from −1.148 to −0.402. The Cohen’s d (1.165 > 0.8) indicated a large effect size. In terms of the vocabulary score, there was a significant difference between the pre-test (M = 4.78, SD = 1.888) and the post-test (M = 5.68, SD = 1.591, p < .001). The mean increase was .90, with a 95% CI ranging from −1.238 to −0.562. The value of Cohen’s d was 1.057 > 0.8, which indicated a large effect size. Finally, the grammar scores before (M = 5.53, SD = 1.797) and after using those AI programs (M = 6.00, SD = 1.695, p = .45 < .05) differed insignificantly. The mean increase in the grammar score was .47 with a 95% CI ranging from −0.939 to −0.011. Overall, all mean post-test scores of different speaking skills were higher than the initial scores and the mean vocabulary score improved the most. This result revealed that AI speaking apps effectively improved users’ different speaking skills, especially vocabulary.
The Results of Paired-Samples t-Tests for Different Speaking Skills (Two-Tailed).
Regarding participants’ frequency of use, the questionnaire data showed that 32.5% of them used AI speaking apps daily, 37.5% several times a week, and 30% almost once a week. The results from a mixed between-within-subjects ANOVA further explored the influence of three different use frequencies (group 1 = every day, group 2 = several times a week, group 3 = almost once a week) on participants’ overall speaking scores before and after using AI speaking apps. Frequency of use and the use of AI speaking apps had no significant interaction effect, Wilks’ Lambda = .932 > .05, F (2, 37) = 1.343, p = .273, partial eta squared = .068 > .06, indicating a medium effect size. Overall, speaking scores of every frequency group increased after using AI speaking apps, and group 1 improved the most (see Figure 1). However, the main effect of frequency of use was not significant, F (2, 37) = 0.080, p = .923 > .05, partial eta squared = .004 < .01, indicating a very small effect size, although the main effect of the use of AI speaking Apps was significant, F (1, 37) = 15.410, p < .001, partial eta squared = .294, indicating a large size effect. This finding revealed that frequency of use did not affect the improvement of speaking skills via AI speaking apps, although it was found that the group with the highest frequency of use improved the most in the overall speaking scores.
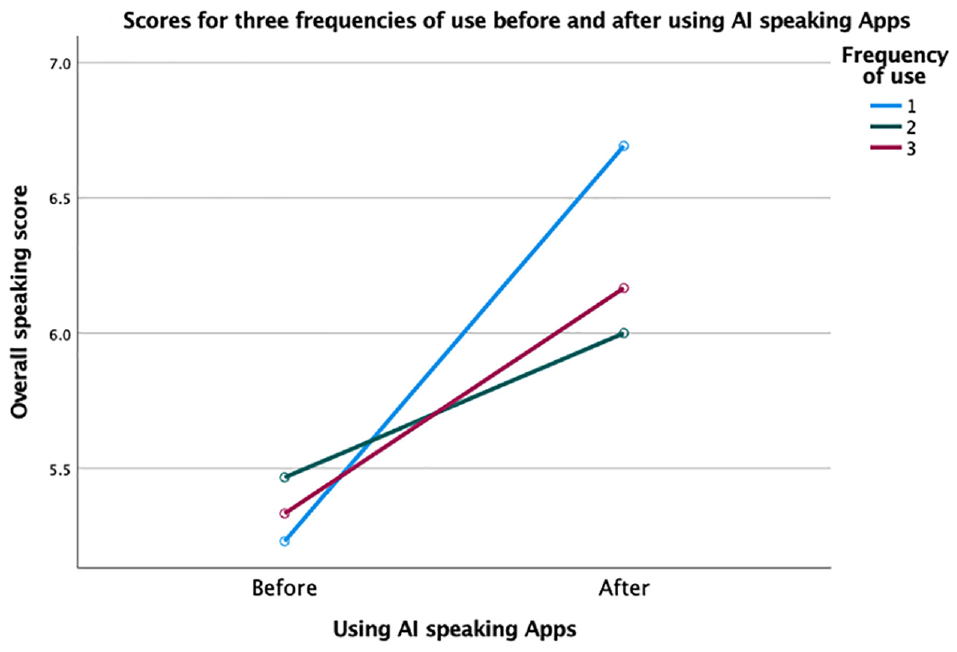
Scores for three frequencies of use before and after using Al speaking Apps.
The Usefulness of Various Feedback
According to the questionnaires, more subjects liked reading texts aloud tasks (42.5%) than spontaneous speaking tasks (15%), and the rest favored both tasks. The qualitative data from the semi-structured interviews provide reasons for choosing their preferred speaking tasks. The participants who preferred reading tasks claimed that their primary purpose for using AI program was to improve their pronunciation and fluency (P7, P9, and P13) while the participants who preferred spontaneous speaking tasks aimed to improve the content of their speech (P4 and P17). This revealed that the participants paid extra attention to their improvement of pronunciation and fluency in reading texts aloud tasks while caring about improving the contents of their speech in spontaneous speaking tasks. This suggested that AI speech evaluation programs might provide more feedback of pronunciation and fluency in reading-aloud tasks and more feedback on the content of speech in spontaneous speaking tasks to satisfy users’ needs.
Furthermore, the participants’ preferred speaking feedback in both tasks was investigated to explore which type of feedback should be provided. Figure 2 illustrates participants’ preferred speaking feedback in both tasks. Notably, scores and practice suggestions were their favorite two speaking feedback in both tasks, with more than 70% of people favoring them, while sample answers, highlighted colors, and textual evaluation were favored by fewer people (ranging from 47.5 to 57.5%). This indicated that participants preferred an intuitive evaluation of their performance and corresponding practice suggestions. The qualitative data provided extra support for the finding. As indicated by P1: “Score feedback will be very good, and you can intuitively see what kind of level you are.” It was also found that they liked colour feedback as well because it was also intuitive. P2 commented, “I think I prefer some intuitive feedback, such as score feedback and colour feedback.” Participant 3 added, “I like score feedback and colour feedback because I think score feedback and colour feedback will be more intuitive. I like something more intuitive.” This suggested that AI programs could pay attention to designing intuitive feedback such as scores and highlighted colors and providing practice suggestions for EFL learners.

Participants’ preferred speaking feedback in two tasks.
Additionally, the participants’ preferences of the level of detail of textual feedback were investigated to explore how to provide textual feedback for them. According to the questionnaires, 5% of them only needed a simple overall evaluation in reading text aloud tasks; 35% preferred further pointing out which aspect they performed well or poorly; 60% also wanted a further explanation of why they performed poorly, practice suggestions, and sample answers. Similarly, in spontaneous speaking tasks, a few subjects only needed simple overall (2.5%), but more subjects preferred further information about the aspect they performed well or poorly (27.5%). Most of them favored further explanations of why they performed poorly, practice suggestions, and sample answers (70%). This indicated that participants preferred detailed textual feedback after finishing speaking tasks. Furthermore, the interview data confirmed the quantitative finding. When discussing the further improvements of AI speaking apps, many participants hoped that the feedback given by the AI system could be more detailed and targeted at their weaknesses and their personalized needs, which enabled them to know how to improve themselves further (P2, P7, P10, P11, P12, P17, P20). For example, P11 said: “I think the more detailed the feedback is, the better it will be.” This suggested that when providing textual feedback, AI speaking apps may emphasize the level of detail.
Moreover, the qualitative data regarding the participants’ perceived limitations of current speaking feedback was analyzed to understand how to improve current speaking feedback. Score feedback of AI speaking apps might be limited because it was difficult for them to see their improvements in their speaking skills after using AI apps. Their speaking scores often deviated from their expectations, making them feel unpleasant. As indicated by P8: “I don’t feel very happy. I used IELTS Liulishuo. The scores of my IELTS mock exam are bad. I get very low scores every time, like 6 and sometimes 5.5. I will wonder, my EAP speaking score is not bad, but why the IELTS speaking score given by AI is so low when I take the test on my mobile phone. Is it because I am not ready or something else? There will be such doubts.” P9 added, “Today I get a grade, and there will be other grades tomorrow, and it will feel like a long time. I cannot see my improvement. It’s always been here, and sometimes it’s even worse, and of course, it’s unpleasant.” This indicated that the inaccuracy of score feedback and its inability to record users’ improvement produced unpleasant feelings. This suggested that AI speech evaluation systems should guarantee accuracy and emphasize users’ progress when providing score feedback.
Discussion
The finding from questionnaires and semi-structured interviews revealed that AI speech evaluation programs were perceived as effective for improving EFL learner’s speaking skills including oral fluency, grammatical range and accuracy in speaking, pronunciation, oral rhythm, idea-organization skills, reading aloud skills, and spontaneous speaking skills. Most participants agreed or strongly agreed that they improved speaking skills after practicing spoken English via these AI programs. Specifically, participants believed that their reading aloud skills, fluency, and pronunciation improved the most. The findings are in accordance with other research examining the perceived effectiveness of AI speaking apps in enhancing speaking skills (Chang et al., 2022; Rosell-Aguilar, 2018).
Furthermore, the finding from empirical evidence, namely pre-and post-tests, confirmed that AI speaking apps effectively improved speaking skills for learners including pronunciation, fluency, grammar, and vocabulary. Considering the large effect size in all pair-sampled t-tests, the finding can be theoretically and practically significant (Pallant, 2020). This finding is in line with previous research that found improved scores in various speaking tests in EFL learners after using AI speaking apps (Loewen et al., 2019, 2020).
The results showed that participants had different preferences for speaking feedback in reading texts aloud and spontaneous speaking tasks. With respect to reading texts aloud tasks, they were more willing to receive speaking feedback regarding fluency and pronunciation. In terms of spontaneous speaking tasks, they preferred speaking feedback on the content of their speech. This could be explained by participants’ different expectations on two tasks. They might expect to improve their pronunciation and fluency via reading texts aloud tasks and the content of speech via spontaneous speaking tasks. Thus, they were more willing to receive speaking feedback accordingly. However, it might be challenging for AI speech evaluation programs to provide detailed feedback such as speech content in spontaneous speaking tasks (Lehman et al., 2020). Therefore, it is indicated that AI speech evaluation programs could provide feedback on pronunciation and fluency in reading texts aloud tasks, and simultaneously give feedback for speech content in spontaneous speaking tasks.
Moreover, another important finding based on questionnaire data was that participants’ scores and practice suggestions were the most favorite speaking feedback in both tasks. Qualitative data added that they also favored highlighted colors. The interview data showed the reason for this finding that participants liked speaking feedback of scores and highlighted colors because they were intuitive. This finding is partly consistent with Wang and Young’s (2015) research in which young EFL learners preferred explicit speaking feedback to show which word was pronounced inaccurately. This suggested that AI speech evaluation programs may provide more intuitive speaking feedback such as scores and colors and offer corresponding practice suggestions to assist EFL learners in improving their speaking skills efficiently.
Additionally, participants believed that the detailed and targeted textual feedback could point out their speaking weaknesses and satisfy their personalized needs. However, in previous research, EFL learners’ perceived preferences were inconsistent with their learning behavior. Lehman et al. (2020) investigated learners’ behavior of checking textual feedback in ELAi. Most of them checked the first page of feedback which was general and straightforward, and few checked detailed feedback on the following few pages. Likewise, Lehman et al. (2020) further pointed out that it was difficult for spontaneous speaking tasks to provide detailed feedback to satisfy learners’ needs. However, ELAi seemed to be the only AI speech evaluation program that was investigated, and more research is needed to confirm learners’ behavior in checking textual feedback. Therefore, AI speech evaluation programs may overcome technology barriers to provide more detailed textual feedback for EFL learners.
Finally, according to qualitative data, there were mainly two limitations of feedback in AI speech evaluation programs: lack of accuracy and difficulty in tracking improvement. This finding partly echoes previous studies in which participants also reported the problem of the inaccuracy of speech recognition (Young & Mihailidis, 2010). Regarding tracking the improvement of EFL learners, according to qualitative data, they felt unpleasant when they did not see their improvement. Therefore, AI speech evaluation programs could provide score feedback more accurately so that learners could see their progress. At the same time, they might also develop relevant functions to help learners track their improvement conveniently to increase their confidence.
Conclusion
This study investigated the effectiveness of AI speech evaluation programs with various feedback to improve the different speaking skills of EFL learners. The results revealed that AI speech evaluation programs were perceived and tested as effective in improving participants’ various speaking skills. Thus, the findings suggested that AI speaking speech evaluation programs could (1) provide more feedback regarding fluency and pronunciation in reading texts aloud tasks while the content of speech in spontaneous speaking tasks and (2) offer more intuitive speaking feedback and corresponding practice suggestions and (3) provide detailed textual speaking feedback (4) emphasize the accuracy of the scoring system and develop improvement tracking functions to assist EFL learners in developing speaking skills effectively.
Admittedly, there are some limitations in the current study. Firstly, the experiment only lasted for 1 month and did not have a control group, which may affect the validity of the findings. However, the investigation was conducted during a summer holiday when learners did not have much time to participate in the experiment and might not have extra learning materials to practice English speaking skills. In addition, the sample size was not large enough to generalize the findings well. Future studies could apply a larger sample and set up the experiment group and the control group at the same time. Despite it, this study may provide insights and recommendations for teachers from various contexts and countries when they intend to adopt an AI speech evaluation program for teaching purposes. It also offers suggestions for designers of AI speech evaluation programs from various countries to learn what AI programs could bring more benefits to language learners.
Footnotes
Data Availability Statement
Data sharing not applicable to this article as the university ethical issue.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by REF-21-02-004 in XJTLU.