
Abstract
With the increasing utilization of Machine Translation, it is worth exploring in what areas it actually reduces translators’ effort. This study focuses on the English-Chinese language pair and compares the effort of human translation (HT) and that of post-editing (PE) in relation to text types, covering advertising, news, legal, and literary texts, via an eye-tracking and key-logging experiment and a follow-up questionnaire survey. It refers to Krings’ framework and explores effort in terms of temporal, cognitive, and technical dimensions. Data were obtained from 33 Chinese student translators, and data analyses lead to the following conclusions. First, PE involves less effort than HT, and PE increases productivity and improves translation quality. Second, the tendency that PE involves less effort is seen in the advertising, news, and literary text types, but the measures of effort show variation for the legal text. Third, the objective measures, including Seconds per Target Word, Edits per Target Word, Pause Count per Target Word, Pause Duration per Target Word, Source Fixation Duration per Source Word, and Source Fixation Count per Source Word, are reliable and well correlated with subjective measures.
Introduction
Machine Translation (MT) has enjoyed a considerable growth in utilization. It is being increasingly used by translators to improve productivity (Moorkens et al., 2018, p. 240), reduce cost and provide better support to international customers (Castilho, 2016, p. 7). The popularity of MT is attributable to its cost-effectiveness and efficiency (Krings, 2001, p. 33), and to the large volume of content to be translated nowadays (Castilho, 2016, p. 6; Vieira, 2016, p. 1). Besides, the MT technology has been advancing fast. The introduction of neural machine translation (NMT) addresses many shortcomings of traditional statistical MT and reduces errors by an average of 60% (Yamada, 2019, p. 88). It is commented that NMT output is more natural and fluent and breaks the quality ceiling of previous MT (Sánchez-Gijón et al., 2019, p. 32), but NMT products can have adequacy errors that are difficult to identify and correct (Vieira, 2019). The output of MT and even NMT requires post-editing (PE). PE is a translation-related task receiving increasing attention in the last two decades (Huang, 2018, p. 176), and it can significantly increase the usability of MT products (Hu et al., 2020, p. 522). Translators’ perception of PE, however, is different. While PE reduces cost in localization workflows and improves productivity, many translators dislike PE and prefer translation from scratch, as they feel constrained in PE (Guerberof-Arenas & Toral, 2020; Moorkens et al., 2018). The effort involved in PE and human translation (HT) is worth exploring in relation to the linguistic features of the source text (ST). For example, for texts requiring straightforward transfer, the effort of PE may be lower than that of HT, and for texts requiring creativity in translation, the effort of PE may be higher than that of HT. This study intends to compare the effort of PE of NMT output with that of HT in relation to text types via an eye-tracking and key-logging experiment and a follow-up questionnaire survey in the hope of identifying the types of texts for which PE would cause less effort and be more efficient.
Research Background
The Effort of HT and PE
PE refers to the act to “edit, modify, and/or correct” an MT translation (Allen, 2003, p. 297). It is a process of “correcting mistakes, revisiting entire, or, in the worst case, retranslating entire sections” of MT output (Somers, 2001, p. 138). A number of studies have been made to compare the effort of PE and HT, covering such language pairs as English and Spanish (Elming et al., 2014), and English and German (Čulo et al., 2014). It is found that PE saves time and takes fewer keystrokes (Elming et al., 2014), and PE involves fewer fixation counts on ST and HT causes longer average fixation duration on ST (Mesa-Lao, 2014). Therefore, it is proposed that PE is able to increase translators’ productivity and improve product quality (Hu et al., 2020, p. 522; Moorkens et al., 2018, p. 240; Senez, 1998; Vieira, 2016, p. 2). It is also emphasized that, as MT technology advances, further research is needed to inform the industry of how PE effort is affected, for example, by NMT (Guerberof-Arenas, 2020).
Meanwhile, research findings are not always in favor of PE. In some studies, no significant difference is found between HT and PE in terms of fixation count (Carl et al., 2011). Some research reports that there are more fixations on TT in PE than in HT (Mesa-Lao, 2014). It is suggested that translators’ effort is not necessarily reduced during PE (Guerberof-Arenas & Toral, 2020; Koponen, 2012, p. 181; Krings, 2001, p. 320), not even in the case of NMT (Sánchez-Gijón et al., 2019; Yamada, 2019). It is probably because PE entails a distribution of attention across ST, MT output, and the target text (Krings, 2001, pp. 166–167), while HT involves ST and the target text (TT) only. The effort involved in PE and HT is complicated and remains to be investigated.
Text type is a key factor that determines one’s effort. Although preliminary research reveals no close relationship between text type and PE effort, Krings (2001, p. 58) suggests that it is because the text types studied are relatively similar and investigations using more different or varied text types may produce different findings. The experiment materials used in the studies on translators’ effort in PE vary, covering authentic texts such as product documentation or Wikipedia excerpts to ensure ecological validity (Moorkens, 2018; Sánchez-Gijón et al., 2019; Yamada, 2019), or literary texts to explore the issue of creativity (Guerberof-Arenas & Toral, 2020), or a certain type of text like exposition (Huang, 2018) or news (Daems et al., 2017) to control text complexity. Researchers have also studied the effect of text types, such as business letter and legal contract (Dragsted, 2004), on translators’ effort in HT, revealing a close correlation between text type and cognitive effort. Still, the effort of HT and PE is rarely compared in relation to text types, and the issue remains to be further explored.
Measurement of Effort
Three Dimensions of Effort
In this research, as illustrated by Figure 1, translators’ effort is to be studied in terms of temporal, cognitive, and technical dimensions, as outlined in Krings’ framework, which is “relatively well established and widely used” (Moorkens et al., 2015, p. 270). Although the framework is developed for PE, the three dimensions also matter for HT. First, the most direct measurement of effort is the time spent on a task (Krings, 2001, pp. 178–179). Temporal effort is “the most important aspect” from an economic perspective (Krings, 2001, p. 54). It is formed by both the technical effort of keyboard and mouse operations and the cognitive effort of making decisions (Koponen, 2016, p. 21). While time has been a commonly used measure of effort (Koponen, 2012, p. 182), translation-related tasks like PE are complex and cannot be explained by temporal values only (Vieira, 2016, pp. 2–3). Second, cognitive effort refers to the “cognitive processes that must be activated” to finish a task (Krings, 2001, p. 179). It is a central variable influencing technical and temporal effort. Mounting evidence justifies exploring cognitive effort in lieu of temporal and technical effort (Vieira, 2014). Third, technical effort results from physical operations such as deletion, insertion, and rearrangement (Krings, 2001, p. 54). Although one’s cognitive effort is not necessarily proportional to technical effort, as some cognitive decisions do not involve edits (Vieira, 2017, p. 42), we hold that technical operations are the direct result of translators’ cognitive processes and should be taken into account.

Three dimensions of effort.
Indicators of Effort
In the MT industry, a major concern is to quantify PE effort to determine whether it is time and cost effective (Castilho, 2016, p. 39). Eye-tracking and key-logging techniques are often used in measuring effort of HT and PE (Huang & Carl, 2021). Key-logging tools can capture such data as translation time and edits, thus providing evidence for the temporal and technical effort. Cognitive effort can be measured via subjective ratings, pause data, and eye movement data (Moorkens, 2018, p. 55).
First, subjective ratings can reveal a global account of workload (Vieira, 2016, p. 30). Some research shows that human ratings are not reliable indicators of actual effort (Moorkens et al., 2015, p. 282), while some research finds that professional translators’ subjective ratings are strongly associated with objective measures (Vieira, 2017, p. 42). For this reason, subjective ratings need to be triangulated with other measures. In this study, we have used a post-task questionnaire to obtain participants’ subjective ratings of effort, which is complemented by key-logging and eye-tracking data.
Second, key-logging tools can record translators’ pause data. Typing is the materialization of mental processes (Vieira, 2017, p. 44). Accordingly, pauses imply interruptions due to various difficulties that translators may experience. Research shows a correlation between ST difficulty and pauses (Koponen, 2016, pp. 24–25). Therefore, examining translators’ pauses can shed light on their cognitive effort.
Third, the eye tracker can capture translators’ fixation data. Eye-tracking data are well established as indicators of cognitive effort (Castilho, 2016, p. 4). It is generally assumed that “there is no appreciable lag between what is being fixated and what is being processed” (Just & Carpenter, 1980, p. 331). Therefore, long fixations or multiple fixations on the same spot indicate increased cognitive effort (Miquel-Iriarte et al., 2012, pp. 263–264; Koponen, 2016, p. 25; Szarkowska et al., 2018, p. 189; Walker, 2018b, p. 227). Aside from fixation, there are other indicators of effort. For example, pupil dilation is used as a measure of cognitive effort, but is found to be inappropriate in some studies (Moorkens, 2018, pp. 58–59), as pupils are sensitive and there are individual differences (Caffrey, 2009, p. 70), and there is a capacity threshold for pupil dilation (Seeber, 2013, p. 26). In this study, we have mainly adopted the measure of fixation. Meanwhile, eye-tracking has its weaknesses, as it is based on foveal and parafoveal vision, and participants may be processing visual information that is not detected by the eye tracker (Teixeira & O’Brien, 2018, p. 25). We tried to triangulate it with key-logging data and subjective ratings to offset such weaknesses.
Research Objectives
This study intends to answer the following questions: whether PE causes more effort than HT in the case of English-Chinese translation; and for what text types PE can be more efficient than HT and involves less effort.
First of all, considering that there are contradictory findings or propositions regarding the effort of PE and HT, this research aims to further explore it focusing on the English-Chinese language pair. As mentioned earlier, on the one hand, MT is regarded to be able to improve translation quality and translators’ productivity (Elming et al., 2014; Hu et al., 2020, p. 522; Mesa-Lao, 2014; Moorkens et al., 2018, p. 240; Senez, 1998; Yamada, 2019); on the other hand, there are propositions that the effort involved in PE is generally higher than that of HT (Guerberof-Arenas & Toral, 2020; Koponen, 2012, p. 181; Krings, 2001, p. 320; Moorkens, 2018, p. 58; Sánchez-Gijón et al., 2019; Yamada, 2019). Besides, the studies have predominantly focused on the processing of alphabetic scripts, and research involving non-alphabetic scripts is quite rare (da Silva et al., 2015, 2017). Therefore, this research intends to compare the effort of HT and PE from English, an alphabetic language, to Chinese, a logographic language.
Second, considering that effort is associated with the difficulty of translation tasks and translation difficulty is attributable to textual features, this study aims to investigate the effort of PE and HT in relation to text types. Although text type has been identified as a key factor affecting translators’ effort and researchers choose experiment materials with care (Daems et al., 2017; Dragsted, 2004; Guerberof-Arenas & Toral, 2020; Huang, 2018; Moorkens, 2018; Sánchez-Gijón et al., 2019; Yamada, 2019), studies have mostly focused on the impact of text type on PE effort. To the best of our knowledge, research comparing the effort of HT and PE in the light of text types is rare. This study intends to explore this issue and targets four text types with distinct linguistic and stylistic features. More details about the experiment design will be provided in the following section.
The Experiment
Participants
In this study, we recruited 33 Chinese postgraduate students specializing in Translation Studies from the same college, including 26 females and 7 males, aged between 22 and 28 (M = 23.93, SD = 1.61), to participate in the experiment. They had completed the courses required for the graduate program and were in their second or third year of study. They had been interns in translation companies and received practical training in HT and PE. They were not yet professional translators, but they could be regarded as “semiprofessionals” because they were close to completing their studies (Krings, 2001, p. 72). One advantage of studying students from the same curriculum and college and at the same level of study is that the research findings are more generalizable than those based on professional translators who are more non-homogeneous in translation competence (Krings, 2001, p. 72). Among the participants, 28 were right-handed, and 5 were left-handed. All of them had normal or corrected-to-normal vision, with no history of neurological or psychological impairment and no current medication. We informed them of the purpose of our research, the detailed experiment procedure, and the anonymization of data in advance. We assured them that the data collected in the experiment would be used for academic research and would not be disclosed to any individual or institution and their privacy would be strictly protected. We also told them that they could withdraw from the experiment at any time. They signed the Consent Form and took part in the experiment voluntarily. After the experiment, we gave each of them a souvenir to thank them for their participation.
Tools
We used Google Translate (March 2021) as the only MT tool in this study, considering its performance and popularity. The system boasts 500 million monthly users and translates over 140 billion words a day (Hu et al., 2020, p. 525). It is based on NMT, and as mentioned earlier, the impact of NMT on PE effort remains to be further explored (Guerberof-Arenas, 2020). We also ran a test with a few MT tools and found Google Translate to be the most satisfactory, so we used it in this study. In exploring the effort of PE, a critical variable is translation quality (Krings, 2001, p. 55). Using Google Translate consistently guarantees that the translation quality is consistent and comparable.
We used Gazepoint GP3 HD Desktop Eye Tracker for the experiment, considering its efficiency and reliability in collecting data. The model provides binocular eye-tracking, with a sampling rate of 60 to 150 Hz and a visual angle accuracy of 0.5° to 1°. At the sampling rate of 150 Hz, it records eye movements every 6.7 ms, which could meet the needs of this study. To ensure the accuracy of eye-tracking, we prepared a chin-and-forehead rest which was placed 60 cm in front of a monitor with 1,920 × 1,080 resolution.
We used Translog-II to record key-logging data. Translog is specially designed for translation process research (Carl, 2012, p. 155). Translog-II records such user acclivity data as insertion, deletion, navigation, copy, cut-and-paste, mouse operations, translation time, and pauses. A major advantage is that it runs in the background and does not interfere with the translation process (Carl, 2012, p. 155).
We had difficulty connecting the Gazepoint eye tracker with Translog-II, as the latter was not programmed for Gazepoint. We worked out a solution by using the “catch screen” function of Gazepoint to record participants’ eye movement data on the Translog-II window.
Experiment Materials
ST features influence MT quality and PE effort (Krings, 2001, p. 58; Vieira, 2017, p. 42). In this study, we mainly considered textual functions and linguistic features when selecting experiment materials, and we chose four text types with distinctive features, namely, advertising, legal, news, and poetic texts.
First, we targeted a relatively comprehensive coverage of major textual functions and selected the texts based on text typology (Reiss, 2000, pp. 24–43). The news and legal texts are mainly informative, the poetic text is expressive, and the advertising text is operative. We included the poetic text, because MT technology has been advancing and it is worth exploring the application of NMT to literature (Guerberof-Arenas & Toral, 2020). Subject to the textual functions, the translation of the four text types entails different degree of creativity. For example, advertising and literary translation can be more creative than the translation of legal and news texts.
Second, the four text types have distinctive stylistic features. The markers of a text are grammatical and lexical in nature (Shreve, 2018, p. 169), and the four text types demonstrate their own grammatical and lexical features. For the advertising text, the wording tends to be concise and catchy, and the syntactical structure is simple (Leech, 1966, pp. 186–193; UK Essays, 2018). Imperatives, interrogative, and elliptical sentences (Leech, 1966, pp. 110–119), and emotive adjectives (Delin, 2000, p. 132) often appear. For the legal and news texts, they have contrasting features. News is characterized by syntactic simplicity and semantic concreteness (Buono & Snajder, 2017). It does not require any expertise to read and understand news. In contrast, the legal text uses jargon (Howe & Wogalter, 1995, p. 430), and legal translation is difficult (El-Farahaty, 2016). For the poetic text, the language demonstrates freedom in lexical and syntactical deviations (Leech, 1969, p. 18). It is marked in terms of word order, syntax, and rhetorical figures among others (Nofal, 2011, pp. 61–62).
Third, we considered ecological validity when selecting the experiment materials. While using sentences would be easier to operate, translators usually translate passages in real life. In order to obtain results that are related to naturalistic environments (Vardaro et al., 2019, p. 10), we used short passages, as was appropriate for eye-tracking research (Saldanha & O’Brien, 2013, p. 140). We selected eight English passages for HT and PE, which were of similar length, varying from 44 to 51 words, and self-contained in meaning. The passages’ length was set with reference to professional translators’ average speed. A survey shows that 36% of respondents translate 1,500 to 3,000 words a day, 26% reach 3,000 to 5,000 words, and 21% translate fewer than 1,500 words (Tirosh, 2016). Considering that the participants were semi-professionals, we referred to the medium translation speed, 3,000 words a day. They would be requested to translate and post-edit 400 words, which might take 1 hour.
To assess the comprehensibility of the passages, we carried out a survey among 28 third-year undergraduates majoring in English. Although there are tools for measuring readability of texts, problems often arise when they are used to compare texts written in different languages (Pavlović & Jensen, 2009, p. 96). The texts would be used for the purpose of HT or PE, so we chose to conduct a survey and acquire undergraduates’ subjective ratings of the texts. We asked them to evaluate the linguistic complexity and translation difficulty on a five-point scale with 1 indicating “very simple” and 5 meaning “very difficult.” Then we calculated the mean score of each passage. The mean scores of the advertising, news, and poetic texts were below 3, which meant the texts were simple for English undergraduates. The mean scores of the legal texts reached 3.78 and 3.85, respectively, which could be attributed to the jargon and syntactic complexity. Since they were still under 4 (“difficult”), we believe they were suitable for the experiment, as the participants were postgraduates and were more experienced than undergraduates.
Procedure
The experiment covered four steps and took about 45 to 55 minutes to finish. Step 1 was a training session for the participants to get familiar with the lab context and the experiment procedure. We did not set any time limit, because no two translators worked at the same speed and using fixed time constraints could be defective in that some translators might experience time pressure while others would not (Hvelplund, 2011, p. 33). Still, the participants were expected to finish the tasks as quickly as they could. They were allowed to use an electronic dictionary. Having access to external sources could help to ease their tension and enhance the ecological validity of the experiment. The dictionary window was put on the right of the Translog window. We instructed participants not to move the two windows, as we would record their eye movement on fixed Areas of Interest such as ST and TT. We explained that the translation criteria were to transfer the meaning accurately and present it fluently in accordance with the original stylistic features.
In Step 2, we calibrated the eye tracker, and participants started to translate four passages from scratch. When they finished translation and turned off the Translog window, our research assistant would save the data for each passage separately.
In Step 3, the participants did PE. The procedure was the same as the second step, but they had a machine translated text in the window. We asked the participants to do HT and PE in separate steps because the two tasks had different features and mixing them up might have had a disruptive effect on the participants.
In Step 4, participants were invited to fill out an online questionnaire and rate their effort on a five-point scale. The questionnaire was anonymous to avoid any social desirability bias. We emphasized that our purpose was to learn about their effort and we would appreciate their truthful answers. The participants were cooperative and shared with us their ratings.
Processing of Data
Eye Movement Data
The eye movement data exported from the Gazepoint system include videos showing the participants’ eye track, hot spot maps demonstrating the distribution of their attention, and CSV files with detailed eye movement data. To start with, we watched the videos and hot spot maps to detect any abnormality. Two participants’ data were incomplete due to malfunctioning of the eye tracker. We deleted their data.
In this study, we have mainly examined fixation count and duration, which have been shown to correlate well with cognitive effort (Castilho, 2016, p. 43; Moorkens, 2018, p. 58; Vieira, 2017). Among the various measures related to fixation, Fixation Count per Word (FCW) has been proved to be reliable (Vieira, 2017). The Gazepoint software automatically summarizes fixation counts, but not all fixations are significant and concerned with cognitive processing. It is hard to define the valid fixation length for translation-related processes (O’Brien, 2011). Some researchers suggest the threshold range 200 to 250 ms (Alves et al., 2009, p. 272), and some researchers set the minimum threshold at 100 ms (Hvelplund, 2011, p. 110; Pavlović & Jensen, 2009, p. 97). Considering that translation involves reading, which is the basis for transferring between languages, and fixations in reading last from 100 ms to over 500 ms (Pavlović & Jensen, 2009, p. 97), we set the threshold at 100 ms and deleted the fixations lasting less than 100 ms. Besides, we calculated the Fixation Duration per Word (FDW) as a complement to FCW, because fixation duration could also reveal participants’ cognitive effort (Castilho, 2016, p. 43), and the measures of fixation calculated with reference to word count are more reliable (Vieira, 2017). We measured FCW and FDW for both ST and TT, which were calculated with the number of significant fixations and the total fixation duration divided by word count, namely, Source Fixation Duration per Source Word (SFDW), Target Fixation Duration per Target Word (TFDW), Source Fixation Count per Source Word (SFCW), and Target Fixation Count per Target Word (TFCW).
User Activity Data
The user activity data captured by Translog in this study are all valid, including translation time, total edits, and pauses. We have mainly considered Seconds per Target Word (STW), Pause Count per Target Word (PCTW), Pause Duration per Target Word (PDTW), and as well as Edits per Target Word (ETW) in this study. We have chosen those indicators because the measures of pause calculated with reference to word count are more reliable (Vieira, 2017), and it is the same for key strokes (Huang & Carl, 2021). While the translation time and total edits could be exported from Translog directly, the processing of pause data was more complicated.
First, we did not distinguish between problematic and unproblematic pauses in this study. It is supposed that longer pauses indicate higher cognitive effort, and it is also suggested that there are problematic and unproblematic pauses (Vieira, 2017, p. 55). Unproblematic pauses refer to those which consist of reading MT output and leaving it unedited (Vieira, 2017, p. 55). However, even for the unedited content, the translator has to read and evaluate its appropriacy, and in this sense such pauses also indicate cognitive effort. Therefore, we did not distinguish between the two pause types.
Second, we set the threshold of significant pauses at 300 ms. Pause thresholds of 1,000 or 2,000 ms are frequently used as indicators of cognitive effort (see Lacruz & Shreve, 2014). However, we suspect that, at such thresholds, significant pauses may be neglected. As the time needed to type consecutive characters is usually up to 150 ms or more, a threshold below 200 ms is not appropriate (Lacruz et al., 2014, p. 75). Instead, 300 ms is a good choice, which “is not too short to be contaminated by normal typing activity, but is sufficiently short to capture much potentially informative pause activity” (Lacruz et al., 2014, p. 82). Therefore, we exported the pauses lasting for 300 ms or more from Translog.
Third, we used PCTW and PDTW as measures of cognitive effort. Studies referring to pause ratio (i.e., total pause duration divided by total editing time) to explore cognitive effort have different findings (see Daems et al., 2015; O’Brien, 2006). For example, O’Brien (2006) proposes that pauses alone are not a robust metric to estimate cognitive effort, and Daems et al. (2015) find a negative relation between pause ratio and cognitive effort. Instead, pause-to-word ratio has been shown to be more reliable (Vieira, 2017, p. 53). The pause-to-word ratio is obtained by dividing pause count by ST word count (Vieira, 2017, p. 48). Considering that pauses take place while translators work on the TT, so we used the TT word count in this study.
Subjective Measures
There were two types of subjective measures in this study. First, the participants’ self-ratings (SR) of their perceived effort were collected via an online questionnaire. Second, we graded the participants’ translations to evaluate their language and translation abilities which might have impacted their perception of effort. Three assessors specializing in Translation Studies graded the translations using the 100-mark system according to the following criteria: accuracy of meaning, fluency of expression, and reproduction of stylistic characteristics. The mean value for each translation was calculated as a participant’s average score (AS).
Research Findings
As eye-tracking data often violate the normal distribution requirement of inferential statistical tests, non-parametric tests are more appropriate (Liao et al., 2020, p. 80). In this study, we conducted non-parametric tests on the data, namely Wilcoxon signed-rank tests, and calculated r to estimate the effect size (Mellinger & Hanson, 2017, p. 108).
Temporal and Technical Effort
The results of Wilcoxon signed-rank tests on STW and ETW are as follows. (M = Mean, SD = Standard Deviation, ME = Median, CI = Confidence Interval, A = Advertisement, N = News, L = Law, P = Poem).
First, there is significant difference between HT and PE in terms of STW. As shown in Table 1, for the advertising text, STW of HT (M = 5.017, SD = 1.731, ME = 4.757, 95% CI [4.403, 5.631]) is higher than that of PE (M = 3.105, SD = 1.600, ME = 2.882, 95% CI [2.538, 3.672]), and such difference is statistically significant (z = 4.119, p < .001). The effect size is large (r = .717). For the news text, STW of HT (M = 4.259, SD = 1.878, ME = 3.778, 95% CI [3.594, 4.925]) is higher than that of PE (M = 2.410, SD = 1.171, ME = 2.406, 95% CI [1.995, 2.826]), and such difference is statistically significant (z = 4.512, p < .001). The effect size is large (r = .786). For the legal text, STW of HT (M = 5.054, SD = 1.467, ME = 4.976, 95% CI [4.534, 5.574]) is higher than that of PE (M = 2.777, SD = 1.326, ME = 2.308, 95% CI [2.306, 3.247]), and such difference is statistically significant (z = 4.976, p < .001). The effect size is large (r = .866). For the poetic text, STW of HT (M = 6.804, SD = 2.173, ME = 6.467, 95% CI [6.034, 7.575]) is higher than that of PE (M = 4.748, SD = 1.758, ME = 4.956, CI [4.124, 5.371]), and such difference is statistically significant (z = 4.172, p < .001). The effect size is large (r = .726). In one word, for all the four text types, the participants spent more time on HT than on PE, implying that they made more temporal effort in HT than in PE.
Wilcoxon Signed-Rank Tests on STW and ETW.

Second, there is significant difference between HT and PE in terms of ETW. As demonstrated in Table 1, for the advertising text, ETW of HT (M = 6.185, SD = 1.689, ME = 5.717, 95% CI [5.586, 6.784]) is higher than that of PE (M = 1.781, SD = 1.666, ME = 1.051, 95% CI [1.190, 2.372]), and such difference is statistically significant (z = 4.994, p < .001). The effect size is large (r = .869). For the news text, ETW of HT (M = 6.685, SD = 1.780, ME = 6.429, 95% CI [6.054, 7.316]) is higher than that of PE (M = 4.628, SD = 1.752, ME = 4.524, 95% CI [4.007, 5.249]), and such difference is statistically significant (z = 5.012, p < .001). The effect size is large (r = .872). For the legal text, ETW of HT (M = 5.942, SD = 1.237, ME = 5.516, 95% CI [5.504, 6.382]) is higher than that of PE (M = 1.066, SD = 0.654, ME = 1.014, 95% CI [0.835, 1.298]), and such difference is statistically significant (z = 5.012, p < .001). The effect size is large (r = .872). For the poetic text, the ETW of HT (M = 6.685, SD = 1.780, ME = 6.429, 95% CI [6.054, 7.316]) is higher than PE (M = 4.628, SD = 1.752, ME = 4.524, 95% CI [4.007, 5.249]), and such difference is statistically significant (z = 4.378, p < .001). It shows that participants made more edits when doing HT than PE, implying that their technical effort was higher in HT than in PE.
Cognitive Effort
The results of the Wilcoxon signed-rank tests on fixation, pause, and SR data are as follows.
First, there is significant difference between HT and PE in terms of SFDW and SFCW. As shown in Table 2, for the advertising text, SFDW of HT (M = 2.290, SD = 0.865, ME = 2.072, 95% CI [1.973, 2.607]) is higher than that of PE (M = 1.378, SD = 0.662, ME = 1.263, 95% CI [1.135, 1.620]), and such difference is statistically significant (z = 4.527, p < .001). The effect size is large (r = .813). SFCW of HT (M = 9.052, SD = 3.357, ME = 8.178, 95% CI [7.820, 10.283]) is also higher than that of PE (M = 5.769, SD = 3.067, ME = 5.065, 95% CI [4.644, 6.894]), and such difference is statistically significant (z = 4.311, p < .001). The effect size is large (r = .751). There is no significant difference between HT and PE in terms of TFDW (z = −0.529, p = .608) and TFCW (z = −0.647, p = .529). For the news text, SFDW of HT (M = 2.595, SD = 1.382, ME = 2.210, 95% CI [2.088, 3.103]) is higher than that of PE (M = 1.105, SD = 0.511, ME = 0.989, 95% CI [0.918, 1.293]), and such difference is statistically significant (z = 4.840, p < .001). The effect size is large (r = .869). SFCW of HT (M = 10.497, SD = 5.084, ME = 9.224, 95% CI [8.632, 12.362]) is higher than that of PE (M = 4.562, SD = 2.407, ME = 4, 95% CI [3.679, 5.445]), and such difference is statistically significant (z = 4.840, p < .001). The effect size is large (r = .869). There is no significant difference between HT and PE in terms of TFDW (z = 0.647, p = .529) and TFCW (z = 0.745, p = .468). For the legal text, SFDW of HT (M = 2.871, SD = 0.907, ME = 2.838, 95% CI [2.539, 3.204]) is higher than that of PE (M = 1.434, SD = 0.755, ME = 1.290, 95% CI [1.157, 1.711]), and such difference is statistically significant (z = 4.840, p < .001). The effect size is large (r = .869). SFCW of HT (M = 11.710, SD = 3.352, ME = 12.156, 95% CI [10.481, 12.940]) is higher than PE (M = 5.694, SD = 2.927, ME = 4.891, 95% CI [4.621, 6.768]), and such difference is statistically significant (z = 4.860, p < .001). The effect size is large (r = .873). TFCW of HT (M = 4.681, SD = 1.659, ME = 4.613, 95% CI [4.072, 5.289]) is higher than that of PE (M = 4.014, SD = 2.117, ME = 3.281, 95% CI [3.238, 4.791]), and such difference is statistically significant (z = 1.881, p = .061). The effect size is medium (r = .338). There is no significant difference between HT and PE in terms of TFDW (z = 1.607, p = .111). For the poetic text, SFDW of HT (M = 3.599, SD = 1.327, ME = 3.375, 95% CI [3.112, 4.085]) is higher than that of PE (M = 1.569, SD = 0.917, ME = 1.423, 95% CI [1.232, 1.905]), and such difference is statistically significant (z = 4.840, p < .001). The effect size is large (r = .869). SFCW of HT (M = 13.802, SD = 5.035, ME = 13.591, 95% CI [11.955, 15.649]) is higher than PE (M = 5.969, SD = 3.655, ME = 5.660, 95% CI [4.628, 7.310]), and such difference is statistically significant (z = 4.840, p < .001). The effect size is large (r = .869). TFDW of HT (M = 1.939, SD = 0.855, ME = 1.791, 95% CI [1.625, 2.252]) is lower than that of PE (M = 2.331, SD = 1.015, ME = 2.364, 95% CI [1.959, 2.704]), and such difference is statistically significant (z = −1.724, p = .087). The effect size is medium (r = .310). There is no significant difference between HT and PE in terms of TFCW (z = −1.293, p = .202). To summarize, for all the four text types, there is significant difference between HT and PE in terms of SFDW and SFCW, and it shows that for student translators, HT demands more cognitive effort than PE. Meanwhile, there is variance for the fixation data related to the TT, and we will further explore the reliability of the measures of TT fixation later via correlation tests.
Wilcoxon Signed-Rank Tests on Fixation, Pause, and SR Data.

Second, there is significant difference between HT and PE in terms of PCTW and PDTW. As shown in Table 2, for the advertising text, PCTW of HT (M = 2.294, SD = 0.719, ME = 2.230, 95% CI [2.039, 2.549]) is higher than that of PE (M = 0.742, SD = 0.689, ME = 0.492, 95% CI [0.497, 0.986]), and such difference is statistically significant (z = 4.976, p < .001). The effect size is large (r = .866). PDTW of HT (M = 4.459, SD = 1.672, ME = 4.296, 95% CI [3.866, 5.051]) is higher than PE (M = 2.963, SD = 1.492, ME = 2.760, 95% CI [2.434, 3.492]), and such difference is statistically significant (z = 3.690, p < .001). The effect size is large (r = .642). For the news text, PCTW of HT (M = 1.889, SD = 0.536, ME = 1.786, 95% CI [1.699, 2.079]) is higher than that of PE (M = 0.498, SD = 0.498, ME = 0.316, 95% CI [0.321, 0.674]), and such difference is statistically significant (z = 4.958, p < .001). The effect size is large (r = .863). PDTW of HT (M = 3.771, SD = 1.871, ME = 3.347, 95% CI [3.108, 4.435]) is higher than that of PE (M = 2.315, SD = 1.106, ME = 2.298, 95% CI [1.923, 2.707]), and such difference is statistically significant (z = 4.065, p < .001). The effect size is large (r = .708). For the legal text, PCTW of HT (M = 1.990, SD = 0.665, ME = 1.953, 95% CI [1.754, 2.225]) is higher than PE (M = 0.471, SD = 0.311, ME = 0.386, 95% CI [0.360, 0.581]), and such difference is statistically significant (z = 5.012, p < .001). The effect size is large (r = .873). PDTW of HT (M = 4.474, SD = 1.432, ME = 4.412, 95% CI [3.966, 4.982]) is higher than that of PE (M = 2.711, SD = 1.336, ME = 2.204, 95% CI [2.238, 3.185]), and such difference is statistically significant (z = 4.833, p < .001). The effect size is large (r = .841). For the poetic text, PCTW of HT (M = 2.661, SD = 0.882, ME = 2.361, 95% CI [2.348, 2.974]) is higher than PE (M = 1.887, SD = 0.759, ME = 1.829, 95% CI [1.618, 2.157]), and such difference is statistically significant (z = 3.815, p < .001). The effect size is large (r = .664). PDTW of HT (M = 6.228, SD = 2.125, ME = 6.171, 95% CI [5.475, 6.981]) is higher than PE (M = 4.358, SD = 1.712, ME = 4.575, 95% CI [3.751, 4.966]), and such difference is statistically significant (z = 4.136, p < .001). The effect size is large (r = .720). It can be seen that participants made more and longer pauses when doing HT, implying that their cognitive effort was higher.
Third, there is significant difference regarding participants’ SR. As shown in Table 2, for the advertising text, the SR of HT (M = 2.971, SD = 0.674, ME = 3, 95% CI [2.736, 3.206]) is higher than that of PE (M = 2.618, SD = 0.817, ME = 3, 95% CI [2.333, 2.903]), and such difference is statistically significant (z = 1.933, p = .065). The effect size is medium (r = .337). For the news text, the SR of HT (M = 2.818, SD = 0.727, ME = 3, 95% CI [2.560, 3.076]) is higher than that of PE (M = 2.515, SD = 0.755, ME = 3, 95% CI [2.247, 2.783]), and such difference is statistically significant (z = 1.801, p = .090). The effect size is medium (r = .314). For the legal text, the SR of HT (M = 2.818, SD = 0.635, ME = 3, 95% CI [2.593, 3.043]) is lower than that of PE (M = 3.061, SD = 0.864, ME = 3, 95% CI [2.754, 3.367]), but such difference is not significant (z = −1.398, p = .198). The effect size is moderate (r = .243). For the poetic text, the SR of HT (M = 3.727, SD = 0.911, ME = 4, 95% CI [3.404, 4.050]) is higher than that of PE (M = 3.364, SD = 0.859, ME = 4, 95% CI [3.0588, 3.668]), and such difference is statistically significant (z = 3.155, p = .002). The effect size is large (r = .549). It can be seen that participants’ SR generally show the same tendency with user activity and eye movement data, that is, they made more effort in HT than PE. Meanwhile, for the legal text, the participants’ perceived effort of HT is higher than that of PE, but the result is statistically insignificant and the effect size is moderate.
Correlation of Subjective and Objective Measures
Having analyzed the three dimensions of effort, we further explored the correlation of the subjective and objective measures. First of all, we compared participants’ AS of HT and PE.
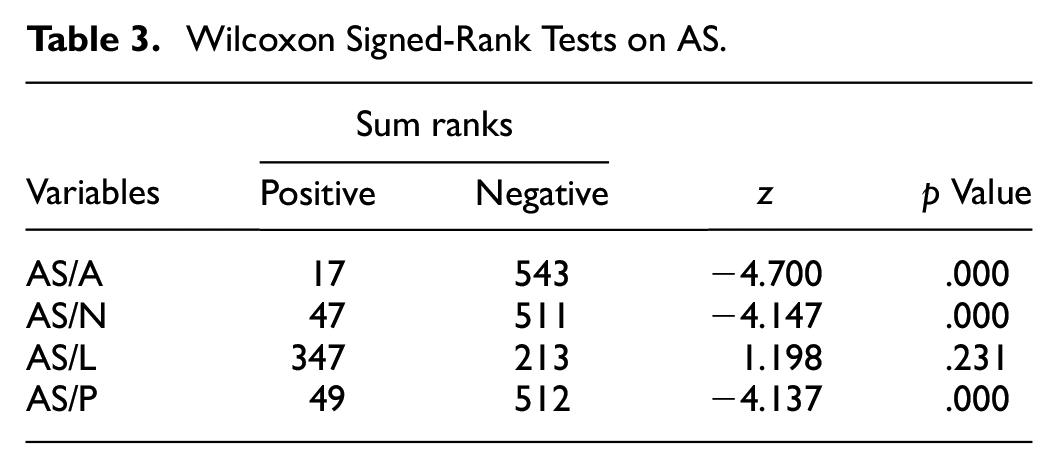
There is significant difference between the participants’ scores of HT and PE. As shown in Table 3, for the advertising text, the AS of HT (M = 84.384, SD = 4.410, ME = 84.667, 95% CI [82.820, 85.947]) is lower than that of PE (M = 89.051, SD = 1.272, ME = 90.333, 95% CI [89.599, 90.502]), and such difference is statistically significant (z = −4.147, p < .001). The effect size is large (r = .818). For the news text, the AS of HT (M = 84.283, SD = 3.964, ME = 85, 95% CI [82.877, 85.689]) is lower than that of PE (M = 88.202, SD = 2.673, ME = 88.333, 95% CI [87.254, 89.150]), and such difference is statistically significant (z = −4.700, p < .001). The effect size is large (r = .721). For the legal text, the AS of HT (M = 86.202, SD = 2.586, ME = 86.667, 95% CI [85.285, 87.119]) is higher than that of PE (M = 85.758, SD = 1.444, ME = 86, 95% CI [85.246, 86.270]), and such difference is statistically insignificant (z = 1.198, p = .231). The effect size is moderate (r = .208). For the poetic text, the AS of HT (M = 78.808, SD = 5.311, ME = 77.667, 95% CI [76.924, 80.691]) is lower than that of PE (M = 83.525, SD = 3.299, ME = 83.333, 95% CI [82.356, 84.695]), and such difference is statistically significant (z = −4.137, p < .001). The effect size is large (r = .720). It can be seen that the participants’ translation quality is generally better with PE than HT, but, for the legal text, the quality of HT is better. As the difference is not statistically significant and the effect size is moderate, it calls for further exploration.
Wilcoxon Signed-Rank Tests on AS.
Then we conducted Spearman’s Rank Correlation tests on the subjective measures and objective measures. As noted earlier, two participants’ eye movement data were incomplete. We deleted their user activity data and SR as well as AS to make sure that all participants’ data were strictly matched.
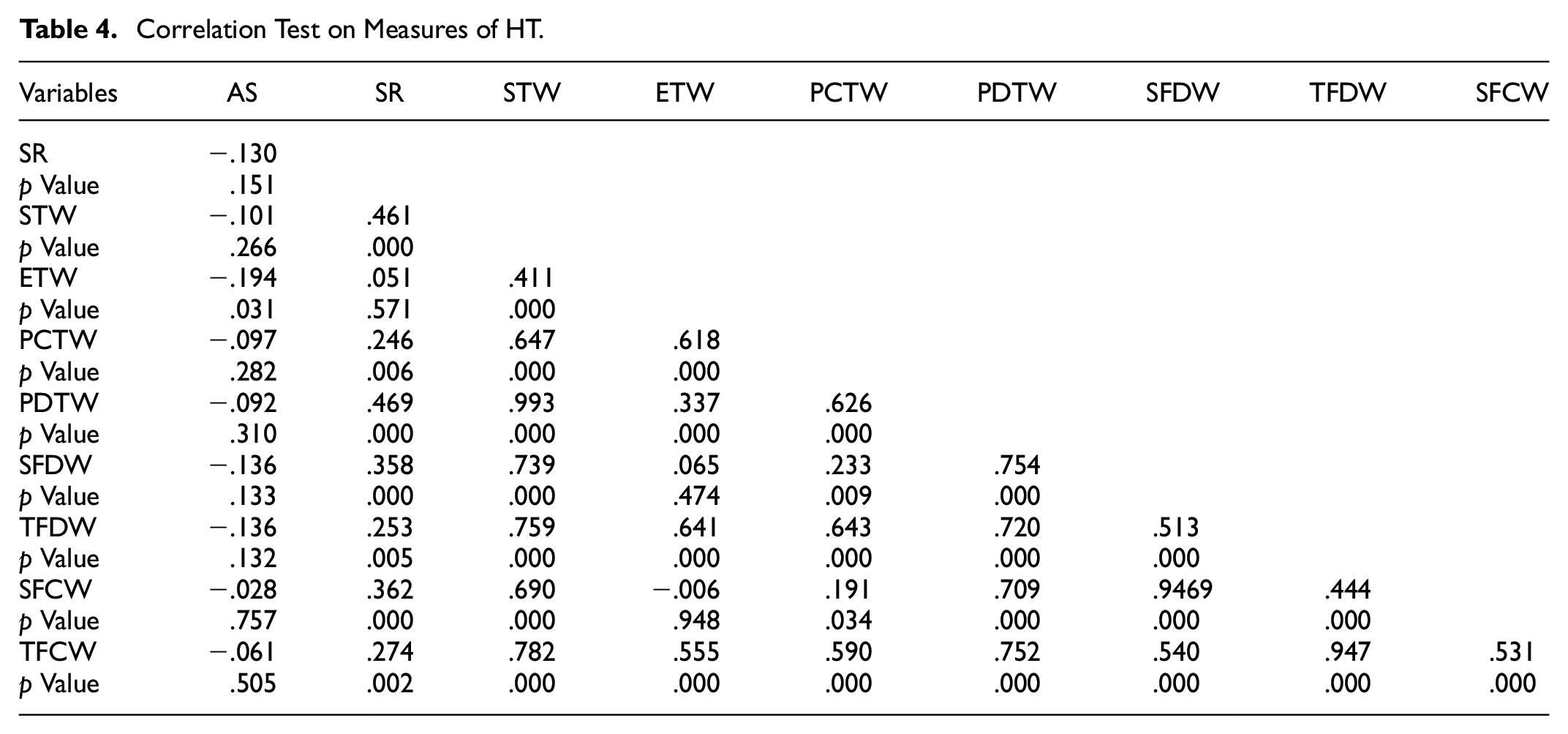
First, all the measures of effort, whether they are subjective or objective, are negatively correlated with participants’ translation scores. As shown in Table 4, for HT, the correlation coefficient between ETW and AS is −.194 (p = .031). As shown in Table 5, for PE, the correlation coefficient between SR and AS is −.279 (p = .002), that between STW and AS is −.276 (p = .002), that between ETW and AS is −.342 (p < .001), that between PCTW and AS is −.331 (p < .001), that between PDTW and AS is −.260 (p = .004), that between TFDW and AS is −.251 (p = .005), and that between TFCW and AS is −.203 (p = .024). Such negative and significant correlation shows that the participants experienced more effort when their translation score was lower, implying that effort is impacted by one’s language and translation abilities.
Correlation Test on Measures of HT.
Correlation Test on Measures of PE.

Second, the correlation between objective measures and subjective ones is significant. As shown in Table 4, for HT, the correlation coefficient between STW and SR is .461 (p < .001), that between PCTW and SR is .246 (p = .006), that between PDTW and SR is .469 (p < .001), that between SFDW and SR is .358 (p < .001), that between TFDW and SR is .253 (p = .005), that between SFCW and SR is .362 (p < .001), and that between TFCW and SR is .274 (p = .002). It is the same with the measures of PE. As shown in Table 5, the correlation coefficient between STW and SR is .233 (p = .009), that between ETW and SR is .208 (p = .020), that between PCTW and SR is .221 (p = .014), that between PDTW and SR is .226 (p = .012), that between TFDW and SR is .226 (p = .012), and that between TFCW and SR is .202 (p = .024). In one word, the objective and subjective measures are significantly and positively correlated, which implies that the measures are reliable indicators of effort.
Third, the correlation among objective measures is significant. As shown in Table 4, for HT, the pairwise correlation coefficients between the objective measures are all positive and significant except for that between SFDW and ETW and that between SFCW and ETW. For PE, as shown in Table 5, all the objective measures are mutually and positively correlated, and the correlation is statistically significant. Such strong internal correlation shows that the objective measures are consistent and reliable as indicators of effort.
Discussion
Lower Effort for PE
The data analyses indicate that PE of NMT output generally involves less effort than HT and thus provide further evidence that MT does improve translators’ productivity and translation quality (Castilho, 2016, p. 7; Moorkens et al., 2018, p. 240; Senez, 1998; Vieira, 2016, p. 2; Yamada, 2019). The temporal and technical effort of PE, reflected in such measures as STW and ETW, are significantly lower than those of HT for all the four text types, and the participants’ AS of PE are significantly higher than that those of HT for the advertising, news, and poetic texts.
This result brings us back to the issue mentioned in Introduction, that is, some translators do not like PE, and makes us wonder why translators would dislike PE which can actually raise their efficiency and translation quality. One possibility is that lower temporal and technical effort is not always equal to lower cognitive effort, and translators may still experience cognitive effort even when they work faster and produce better-quality translations. This, however, is not the case with our study, because the cognitive effort of PE, as reflected in such objective measures as PCTW, PDTW, SFDW, and SFCW, is significantly lower than that of HT for all the four text types, and the same tendency is found in SR for the advertising, news, and poetic texts. This finding is different from what has been suggested about PE involving more cognitive effort (Krings, 2001, p. 320; Koponen, 2012, p. 181; Moorkens, 2018, p. 58). The consistency of the results in temporal, technical, and cognitive dimensions drives us to reflect more deeply on the whole experiment design and the possible reasons as to why PE involves less effort for the participants.
First of all, the participants were student translators, and the lab context might have imposed some pressure on them. Student translators tend to prioritize accuracy over other parameters such as fluency in translation (Huang, 2018, p. 160). Professional translators, many of whom dislike PE, would appreciate more creativity and freedom instead (Guerberof-Arenas & Toral, 2020; Moorkens et al., 2018). The participants in the experiment had work experience in translation companies, but they were less experienced than professional translators. Although we asked them to relax, it was the first time for them to take part in an eye-tracking experiment and they were aware that their eye movements were being recorded. Under those circumstances, they might have been more concerned about finishing the tasks and producing passable translations than working creatively and freely, and having reference translations in PE was apparently easier and more convenient for them. Therefore, it is necessary to involve professional translators in future studies to compare the effort of HT and PE.
In addition, this study focuses on the English-Chinese language pair. The linguistic differences between the two are more prominent than those between alphabetic languages (da Silva et al., 2017). Accordingly, translating from scratch from English to Chinese can exert considerable amount of effort. As shown by the analyses, the participants made more and longer fixations on ST and had more and longer pauses and when doing HT. It is the same with the findings of da Silva et al. (2015) involving the Portuguese-Chinese language pair, where participants with at least 1-year experience as professional translators were recruited. There is evidence that ST reading in translation involves parallel processing of both ST and TT (Balling et al., 2014). Longer fixations on ST as well as longer pauses in this study suggest that the participants might have been experiencing difficulty in comprehending the meaning of the English texts and coming up with appropriate Chinese translations due to the significant difference between the two languages. It also explains why the participants found PE easier, as having a reference translation could mitigate the difficulty caused by the linguistic differences.
Impact of Text Type on Effort
Text type does not show significant impact on participants’ effort in HT and PE as we expected. As explained earlier, the texts selected for this study have distinctive features in terms of diction and syntax, and their translation requires different degree of creativity. We supposed that in principle PE would cause more effort on the part of translators when it came to text types entailing flexible or creative translation. The statistic analyses, however, reveal that PE can save translators’ effort regardless of text types. This outcome of “no result” may signal the need for a revision of either the data collection methods or the interpretative tools (Walker, 2018a, p. 2). Two factors might have contributed to this result. As just discussed earlier, student translators tend to prioritize accuracy in terms of semantic meaning and the participants might have paid less attention to stylistic features than professional translators. In addition, we chose short passages for the experiment, considering the huge amount of data collected in the eye-tracking experiment and the participants’ translation speed. The stylistic features of the four text types might have been mitigated by the length of the passages. Therefore, in the future research, to compare student translators’ performance with that of professional translators and select longer passages that demonstrate textual features more fully will be essential.
Despite the insignificant impact of text type on PE and HT, the statistics regarding the legal text are worth further reflection. The participants’ SR indicate more cognitive effort in PE than HT for the legal text, and their AS of HT is higher than PE. The legal text is distinctive in terms of jargon and complex syntactic structure. Such complexity made legal translation hard for the participants, and MT did not seem to help. We further examined the legal passages used in the experiment and found that a number of participants made the same mistake when post-editing a term “representative” in the sentence “Litigants and their representatives could choose to file a case in any court nearby.” The MT translation provided a straightforward Chinese equivalent “
Correlation Between Objective and Subjective Measures
The objective measures of user activity data and eye movement data are significantly correlated with subjective measures in this study. It is in line with the finding of Sánchez-Gijón et al. (2019) that the professional translators’ perception of effort matches their performance in general, and the point made by Vieira (2017, p. 42) about professional translators, but not about students. The participants in our study were 33 students or semi-professionals, differing from the study of Vieira (2017) which involved ten professionals and nonprofessionals, but we filtered the fixation and pause data in the same way as Vieira (2017). Our study provides strong evidence that, even for student translators or semi-professionals, there is significant correlation between subjective and objective measures of effort.
This result differs from the proposal that human ratings are not completely reliable (Moorkens et al., 2015, p. 282). There are three major differences between the investigation of Moorkens et al. (2015) and our research. First, Moorkens et al. (2015) involved 6 professional translators and 33 undergraduate and Master level translation students, while our study involved 33 Master level translation students only. The participants in our study were from the same level of study and more homogeneous. Second, we used different measures. For the temporal effort, Moorkens et al. (2015) measured the time spent on a language segment, while we measured STW; for cognitive effort, Moorkens et al. (2015) measured fixations and mean fixation duration, while we measured SFCW, SFDW, TFCW, and TFDW, which were supplemented by PCTW and PDTW. The weak correlation between objective and subjective measures found by Moorkens et al. (2015) might have been attributable to the measures selected. Third, we set the minimum threshold at 100 ms for fixation (Hvelplund, 2011, p. 110; Pavlović & Jensen, 2009, p. 97), and 300 ms for pause (Lacruz et al., 2014, p. 82), which are regarded to be related to one’s cognition, as done in Vieira (2017). Moorkens et al. (2015) did not mention how they processed the fixation data. Filtering the data could have helped to enhance the correlation between objective and subjective measures. In short, the participants in our study were more homogeneous, the objective measures covered fixation and pause calculated in relation to word count, and the fixation and pause data were processed and filtered. Under such circumstances, we found significant correlation between the objective and subjective measures of effort.
Despite the strong correlation between objective and subjective measures, the measures of TFCW and TFDW may not be ideal for comparative research on the effort of HT and PE. They are correlated well with SR, but they do not show significant difference between HT and PE for all the four text types as analyzed earlier. It is attributable to the fact that translators generally assign more attention to TT than ST (Castilho, 2016, p. 46). For both HT and PE, translators need to work on TT which is their final product, and hence no significant difference between HT and PE in terms of TFCW and TFDW. In addition, the SR for the legal text shows no significant difference between HT and TT. It is likely that, since the legal discourse is complicated, whether there was a reference translation or not, the participants would need to figure out the syntactical structure and semantic meaning of the text they were working on and such cognitive processing impacted their SR. In this way, SR may not be ideal either for exploring the effort of HT and PE when it comes to legal translation. Still, as the sample size of this study is limited, we hope to further explore these measures in the future studies.
Conclusion
To conclude, this study compares the effort of HT and PE in the light of text typology via an eye-tracking and key-logging experiment and a post-task questionnaire survey. It measures the participants’ effort in terms of temporal, technical, and cognitive dimensions with reference to eye movement data, user activity data, and subjective ratings and has the following major findings. First, with the advanced NMT, PE involves less effort than HT and improves translation quality, as far as student translators working between English and Chinese are concerned. PE takes less time, fewer and shorter fixations and pauses, and fewer key strokes and mouse operations, which are indicators of less effort. Second, text type does not show significant impact on the participants’ effort in doing HT and PE. The tendency that PE entails less effort than HT is seen in the objective measures for all the text types. However, SR and AS show that it is the other way around for the legal text. As the difference is not statistically significant, further investigation is needed to confirm this point. Third, this study shows that objective measures of STW, ETW, PCTW, PDTW, SFDW, SFCW, TFDW, and TFCW are reliable, as the correlation between those measures and SR is positive and significant and the correlation among those objective measures is strong. However, TFCW and TFDW might not be ideal measures for comparing the effort of HT and PE. Meanwhile, this research has limitations. The participants were all student translators, and there were no professional translators involved, who might have demonstrated different characteristics when doing HT and PE. Besides, the length of passages used in the experiment was limited, which in a way weakened the distinctive lexical and syntactical features shown by the text types. Taking into account these limitations, in the future studies, we intend to recruit professional translators and choose passages that are longer and show their distinctive features more comprehensively in order to test the current findings, investigate the possible impact of text type on the effort of HT and PE, and further explore the reliability of the measures of effort.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.