
Abstract
Threats to construct validity should be reduced to a minimum. If true, sources of bias, namely raters, items, tests as well as gender, age, race, language background, culture, and socio-economic status need to be spotted and removed. This study investigates raters’ experience, language background, and the choice of essay prompt as potential sources of biases. Eight raters, four native English speakers and four Persian L1 speakers of English as a Foreign Language (EFL), scored 40 essays on one general and one field-specific topic. The raters assessed these essays based on Test of English as a Foreign Language (TOEFL) holistic and International English Language Testing System (IELTS) analytic band scores. Multifaceted Rasch Measurement (MFRM) was run to find extant biases. In spite of not finding statistically significant biases, several interesting results emerged illustrating the influence of construct-irrelevant factors such as raters’ experience, L1, and educational background. Further research is warranted to investigate these factors as potential sources of rater bias.
Introduction
Finding sources of bias in language tests has perhaps been one of the most critical issues so far under scrutiny by researchers, testers, and teachers around the globe. As a detriment to construct validity (Eckes, 2005; Messick, 1989; Weir, 2005), bias can question the language skill measured either by large-scale testing organizations through standardized tests or teacher made small-scale language assessment tools (Angoff, 1989; K. H. Kim & Zabelina, 2015; O’Loughlin, 2001; Ross & Okabe, 2006). In either case, bias may give rise to score misinterpretations that need to be avoided at any cost so that test fairness can be assured (Kunnan, 2000, 2004; McNamara & Roever, 2006; Xi, 2010), and biased factors that favor one group of test takers over another can be eliminated (Lam, 1995; Saeidi, Yousefi, & Baghayei, 2013; Ying & Wei, 2016). This article attempts to examine raters’ experience, raters’ language background, and essay prompt as potential sources of bias in writing assessment. The goals sought by this research are to lessen or remove (if possible) the biases stemming from these issues using Multifaceted Rasch Measurement (MFRM) to find any interaction of raters’ main effects and essay prompt.
Review of Related Literature
Test takers’ occupational or educational status is largely contingent upon the scores they are granted for their ability in several skills by tests designed to measure those abilities. Now if these tests measure something other than certain abilities, not only does the validity of the tests become questionable but also they create bias toward test takers and make the tests an unfair assessment. Construct validity, test bias, and fairness are not born anew in our age. In 1990, Bachman states that “when systematic differences in test performance occur that appear to be associated with characteristics not logically related to the ability in question, we must fully investigate the possibility that the test is biased” (p. 272). McNamara and Roever (2006) also contend that bias does harm to construct validity, a unitary concept (Messick, 1989, 1995) and introduce construct-irrelevant variance into test scores and accordingly the interpretations made on its basis. McNamara and Roever (2006) state that bias can be seen from two angles: either bias stems from group differences that introduce systematic construct-irrelevant variance into test results distorting validity or it can be “a factor that makes a unidimensional test multidimensional: The test measures something in addition to what is intended to measure, and the result is a confound of two measurements” (p. 82).
In the past, several scholars figured out that for assessment to be fair, there is a need to find out the sources of bias which otherwise change the life trajectory of those sitting for high-stakes tests (Angoff, 1993; Bartlett & Brayboy, 2005; Bennett, Gottesman, Rock, & Cerullo, 1993; Blaisdel, 2005; Breland & Lee, 2007; Brown & Iwashita, 1996; Brownlow, Cicuto, Lomax, MacKinnon, & White, 1998; Busse & Seraydarian, 1981; Castro Atwater, 2008; Chen & Henning, 1985; Duran, 1989; Elder, 1997; Figlio, 2004; Gerritson, 2013; Greifeneder, Zelt, Seele, Bottenberg, & Alt, 2012; Jae & Cowling, 2009; Y.-H. Kim & Jang, 2009; Kunnan, 2000; McDavid & Harari, 1966; Nitko, 1983; Pae, 2004; Popham, 1981; Ross, 2000; Ryan & Bachman, 1992; Sasaki, 1991; Song, 2014; Ying & Wei, 2016; Zwick, Brown, & Sklar, 2004). What is common among all these researchers is that such factors as context, culture, language background, educational status, gender, socioeconomic status, age, name, and ethnicity may result in test, item, or rater bias.
Having known that tests, items, and raters bias the interpretations of scores, researchers have tried to use different statistical analyses to spot these systematic (or unsystematic thereof) construct-irrelevant variances. To use a proper statistical analysis, the type of bias should be determined. van de Vijver and Poortinga (1997) categorized biases into three sorts: (a) Construct bias takes place when the construct being rated is not the same for different cultural groups of testees, (b) Method bias including sample bias, instrument bias, and administration bias, (c) Item bias which, based on Young, So, and Ockey (2013) “is a statistical method that examines if test takers from different groups have the same probability of answering an item correctly, given that their ability level on the target construct is the same” (p. 15). To detect item bias (Differential item functioning [DIF]), different techniques have been utilized in the course of time among which we can name item-score point biserials, chi-square, linear models, item difficulty, analysis of variance (ANOVA), Mantel-Haenszel Delta method, logistic regression, Standardization approach, Rasch, Rasch Likelihood Ratio, and Facets analysis (Angoff, 1989; Cardall & Coffman, 1964; Cleary & Hilton, 1968; Dorans & Holland, 1993; Elder, 1996; Green & Draper, 1972; Litaker, 1974; Liu, Schedl, Malloy, & Kong, 2009; Maw, 1976; O’Loughlin, 2001; Penfield, 2001; Ross & Okabe, 2006; Su & Wang, 2005; Swaminathan & Rogers, 1990; Takala & Kaftandjieva, 2000; Veale & Foreman, 1975; Zumbo, 1999; Zwick, Thayer, & Mazzeo, 1997). Ferne and Rupp (2007) state that apart from DIF, if we are including a number of items in DIF analyses, we are doing differential bundle functioning (DBF), if all items of a test are considered for DIF analysis, then differential test functioning (DTF) is conducted, and finally “if design facets such as raters are involved in such an analysis one speaks of differential facet functioning (DFF)” (p. 115). They also remind that the skills conducted focused more on reading, vocabulary, listening, and speaking, but they do not speak of writing skill. But we, now, can name many studies focusing on writing skill especially the role raters play in writing assessment.
“Rater bias refers to a systematic pattern of rater behavior that manifests itself in unusually severe (or lenient) ratings associated with a particular aspect of the assessment situation” (Eckes, 2012, p. 273). He further suggests that raters, when scoring, may exhibit more severity toward a specific group of examinees; also, different tasks could change raters’ scoring procedure: needless to say that raters are likely to be effected by scoring criteria. The term differential rater functioning (DRF) stems from raters showing different degrees of severity or leniency in scoring. Du, Wright, and Brown (1996) examined the effects of raters and topic type through MFRM. They found that some raters were biased which affected the estimates of examinees’ writing ability; moreover, examinees with different age and gender performed differently on topic types. Engelhard (2007) underscored the importance of DRF, which, in fact, is a way to control the ratings quality and lessens or removes raters’ unusual level of severity or leniency. A number of studies on raters’ bias have been conducted with varied foci considering the effect of rater language background and educational training on the assessment of medical students’ oral interview (Caban, 2003); also Johnson and Lim (2009), doing bias analysis of rater language background, found a minimal effect of rater language background on examinee scores. Y.-H. Kim (2009) inspected native and nonnative raters assessing students’ oral performance finding that raters performed differently when evaluation criteria differed. The effect of training on rater assessment and severity has been investigated by a number of scholars. For example, Elder, Barkhuizen, Knoch, and von Randow (2007) worked on the effect of rater online training on inter- and intra-rater reliability; they concluded that there were “limited overall gains in reliability” but “considerable individual variations in receptiveness to the training input” (p. 37). Likewise, Knoch, Read, and von Randow (2007) compared online and face-to-face training which resulted in overall improvement of raters’ assessment. Bias analysis of feedback to raters was carried out by O’Sullivan and Rignall (2007) working on writing module of International English Language Testing System (IELTS); they put forward the idea that “feedback delivered systematically over a period of time may result in more consistent and reliable examiner performance” (p. 446).
There is no doubt that scoring criteria plays a pivotal role in the course of assessing examinee performance. Therefore, a number of studies have attempted to find bias/interactions between raters and criteria (e.g., Knoch et al., 2007; McNamara, 1996; Schaefer, 2008; Wigglesworth, 1993). In one study, Wigglesworth (1993) discovered that some raters were consistently more severe on grammar as a scoring criterion whereas other raters rated more leniently on this rating criterion. As far as fluency and vocabulary were concerned, she found similar patterns of inter-rater severity.
The occurrence of rating criterion related to rater bias was specifically studied by Knoch et al. (2007). Comparing online and face-to-face training procedures, they found that after training just a few raters became less biased even though some developed new biases. McNamara (1996) investigating rater behavior in the Occupational English Test, found that raters had a bias toward grammatical accuracy while the underpinning of Occupational English Test was communicative. Schaefer (2008) investigates bias patterns of inexperienced Native English-speaker raters (North American, British, other) measuring students’ written English as a Foreign Language (EFL) essays. Raters used an analytic rubric comprising six criteria: content, organization, style and quality of expression, language use, mechanics, and fluency. The MFRM Rater × Criterion interaction analysis showed considerably significant bias terms. The pattern of rater-category interactions showed that raters who were severe toward content and organization were lenient toward language use and mechanics and vice versa. Some raters had unorthodox severity toward content and organization whereas others were highly lenient toward mechanics and language use. Other raters were highly lenient on organization and content, showing high severity about language use and mechanics. Therefore, raters could be incorporated within subgroups of lenient and severe when scoring for content and/or organization, on one side, and language use and/or mechanics, on the other side.
The subgroup distinct ratings in Schaefer’s research offer a relationship between scoring criteria and rater bias. There is a chance that Schaefer’s subgroup, who were severe on content and/or organization and were lenient on language use and mechanics, associated great significance to the first set of criteria and less importance to the second set of criteria. Therefore, it can be concluded that group-specific bias patterns stem from raters’ different understanding of the importance of rating criteria.
A number of studies have focused on using Many Facet Rasch measurement for bias analysis. Working on the Test of German as a Foreign Langauge (TestDaf), Eckes (2005) examined rater severity, bias/interaction of raters, examinees, rating criteria, and gender. He found significant bias between raters and examinees, raters and rating criteria, but no gender bias.
Schaefer (2008), using MFRM, observed many bias patterns between rater subgroups. As to rater-category bias interactions, “twenty-four out of the 40 raters had significant bias interactions with categories, and there were 57 significant bias terms in all. Twenty-seven of the significant bias interactions were negative (showing leniency), and 30 were positive (showing severity)” (p. 480).
To investigate the raters’ severity/leniency over assessment criteria, Eckes (2012) focused on the relation between rater cognition and rater behavior. In total, 18 ratings of raters were put to MFRM through which criterion-related bias measures were estimated. He reached the point that “criteria perceived as highly important were more closely associated with severe ratings, and criteria perceived as less important were more closely associated with lenient ratings” (p. 270). Writing assessment involves more than raters in the process. Factors as examinees and rating scales have also been scrutinized (Eckes, 2005, 2008, 2009, 2012, 2013a, 2013b; Goodwin, 2016; Saeidi et al., 2013; Weigle, 1998; Wolfe, 2004, among others). Schaefer (2008) thinks highly of MFRM because “it has shown great promise in the area of performance assessment and rating scale validation because it can analyze sources of variation in test scores beside item difficulty and person ability” (p. 466). Wiseman (2012) contends that “this model makes possible the analysis of data from assessments with multiple facets, such as in this case examinees, raters, rubrics, and essay prompts” (p. 62).
More of a concern in the present study is finding possible bias associated with raters’ experience, raters’ language background, and essay prompt. So far, a few studies have investigated these issues. Erdosy (2001, 2004) inspected rater’s ethnicity, culture, mother tongue, academic and assessment experience, teaching and learning experiences. However, raters’ assessment experience in itself has not been dealt with extensively because the term seems elusive for many scholars. Barkaoui (2010) states that “few studies have examined the relationship between teaching and rating experience and essay evaluation criteria” (p. 32). In his study, the term experienced raters met these criteria: Having master of arts or education degree, being either graduate or English as a Second Language (ESL) instructors, having been involved in teaching and rating ESL writing for a minimum of 5 years, having undergone special assessment training, and considering themselves as competent or expert raters. Considering the importance of further research in such factors as raters’ experience, language background, and the effect of essay prompt in writing assessment, we attempt to find answers to the following research questions:
Method
Participants
The total sample of raters formed a group of eight English native and L1 Persian individuals who scored essays on the basis of two standardized writing criteria: Test of English as a Foreign Language (TOEFL) iBT and IELTS with the former having a holistic and the latter an analytic rating scale. Two criteria for choosing these distinct groups were as follows: (2) the number of years they were involved in writing assessment and (b) their native language. Experienced raters were ESL instructors who had been certified and recertified by testing organizations; they had at least 5 years of teaching and assessing writing; also, they all had either masters or PhD in Teaching English to Foreign or Second Language Learners (TESL/TEFL).
Similarly, novice raters had either masters or PhD in TESL/TEFL; they, however, had no experience in assessing writing and did not consider themselves as experienced raters. Their age and gender were not controlled. Table 1 represents further details about the raters of the present study.
Raters’ Characteristics.

Note. TEFL = Teaching English to Foreign Language Learners; F = Foreign; SL = Second Language.
Instrument
Writing tests constituted the main instrument of the study. In total, 20 examinees were asked to write two essays one of which focused on descriptive writing and another on compare/contrast. The descriptive writing was major specific and the compare/contrast essay was a general topic. Also the raters were asked to complete a raters’ profile form (see Appendix A). Each essay was scored by eight raters. These raters rated essays analytically with regard to IELTS writing scoring guides and holistically considering TOEFL writing scoring guides. IELTS writing scoring guides are founded on the assessment of four main categories: (a) task response, (b) coherence and cohesion, (c) lexical resource, and (d) grammatical range and accuracy. The band score ranges between 0 and 9. TOEFL writing scales consider task fulfillment, organization and development, syntactic variety, and appropriate word choice as the main categories for assessing written essays (see Appendix B for further details).
Design
The present study deals with variables such as raters’ experience and mother tongue as well as the essay prompt as variables over which the researcher has neither control nor any intention to manipulate; therefore, the design of the study is descriptive in nature because it attempts to observe a specific behavior trying to find answers for its occurrence. Such exploration and description of variables will be a good ground to make hypotheses to be later investigated.
Procedure
There were 20 L1-Persian speakers of EFL who wrote two essays: one related to their major, another on a topic of general nature. These people earned Master of Arts in TEFL. These writings have been attempted to fulfill writing competency of these candidates before entering the PhD program. The essays were expository requiring learners to write 250 words. The specific topic asked the candidates to define “effective teaching” whereas the general topic revolved around the issue of compatibility or incompatibility of “technology and culture.” They had 40 min to complete the task. It should be noted that learners did not write two essays in one session but with a 1-week interval so that the researcher could mitigate the learners’ tiredness which might could otherwise modify the results.
The total number of samples came to 40 which were rated both holistically and analytically. Raters, prior to ratings, were oriented toward how to use both holistic and analytic rating scales. TOEFL rating scale differentiated examinees within its six bands; IELTS also could separate examinees’ different writing ability on a range of 0 to 9 (see Appendix B for these two rating scales). Each rater was provided with a stack of 40 essays which they scored holistically and analytically. The essays did not follow any special order so as to avoid any sources of invariant variance caused by essays and topic.
Analysis
All data were submitted to analysis using MFRM modeling software. Facets (Linacre, 2010) was chosen because it can expand the Rasch model to incorporate many facets especially judge severity in the analysis. The MFRM model (Linacre, 1989) is an extension of the Rasch model which is based on the idea that the probability of correct responses is the function of the ability of the person and the difficulty of the item; if we include more facets such as rater severity/leniency, prompt difficulty, then the Rasch analysis may be extended to many facets: one dealing with more than two facets (i.e., ability-difficulty). MFRM is an additive log linear model:

Bn is the ability of examinee n, Am is the challenge of prompt m, Di is the difficulty of item i, Cj is the severity of judge j, Fk is the barrier to being rated in category k relative to category k – 1, Pnmijk is the probability of examinee n being awarded a score of category k on prompt m on scale k by rater j, Pnmij(k – 1) is the probability of examinee n being awarded a score of category k – 1 on prompt m on scale k by rater j.
In this study, five facets were taken into account: raters, examinees, raters’ experience, raters’ language background, and prompt difficulty, the last three serving as dummy facets to help investigate rater × dummy facet interaction/bias analyses.
To run MFRM, first two models were written for the analysis. Eight NSs and NNSs raters with or without experience, 40 examinees, two writing tasks (one general and one major-specific prompt) were taken into account. Written essays were scored both analytically and holistically. Because IELTS scoring band ranges from 0 to 9 with decimals, a weighted model was used: Model = ?, ?, ?, ?, ?, R18, 0.5. On another side, TOEFL scores have a range of 0 to 30 with three bands: Limited = 0 to 16, Fair = 17 to 23, and Good = 24 to 30; on this basis, the model = ?, ?, ?, ?, ?, MY3. Figure 1 demonstrates the variable map calibrating raters, examinees, experience, language background, and prompt difficulty onto the Logit scale. The first column is the Logit scale and the second column belongs to raters with the severe ones at the top and the lenient ones at the bottom. The third column shows examinees the most able of whom stand at the top and the least able at the bottom. The asterisk (*) indicate one candidate. The fourth column demonstrates experience variation among raters again with this default that the most experienced one at the top and the novice ones at the bottom. The next column shows language background with natives at the top and non-natives at the bottom. The sixth column demonstrates prompt difficulty and in the right far column you can see rating scores based on IELTS rating scale. Because Facets data must be integers and scores range between 0 and 9, the scores have been multiplied by two and weighted. As can be seen, raters who were scoring analytically stand at the same level (1.09-1.52) with Raters H and D less severe than Raters A, B, C, E, F, and G. Figure 1 shows that the variability across examinees in their level of ability is substantial. The other facets of our concern indicate no difference in fact, native or non-native raters whether they be novice or experienced performed similarly when scoring two tasks analytically. Raters who were using holistic scoring scales of TOEFL, on the other hand, show significant variation in severity and/or leniency. The range of variation is –0.57 to 1.42 with Rater B as the most lenient and Rater H as the most severe (see Figure 2).

All facet vertical rulers for IELTS-based analytic rating scale.

All facet vertical rulers for TOEFL-based holistic rating scale.
Variations abound as far as the ability of examinees is concerned and other facets show the same pattern as that of analytic scoring based on IELTS rating scales. However, experience, language background, and prompt difficulty almost are situated at the same Logit scale (i.e., gathering around 0.0), perhaps not inducing bias into the measurement.
Fit indices for IELTS depict that raters show overfitting but no underfitting of the model, whereas two TOEFL raters (i.e., Raters B and C) illustrate underfitting (1.75 & 1.58, respectively). Tables 2 and 3 demonstrate that, in both IELTS and TOEFL, the standard errors (SEs) were low (0.3 & 0.5, respectively), picturing a high precision of measurement. Rater separation ratio for TOEFL is 1.57 which means that the difference between rater severity is almost one and a half times greater than the error which these levels measure. For IELTS, though, this is very negligible (0.33). The fixed (all-same) chi-square for TOEFL is not significant (p > .05), showing that raters are not different in severity; this is also true for IELTS signifying that raters performed similarly scoring on the basis of IELTS analytic rating scale.
Fit Statistics of Raters’ Analytic Scoring.
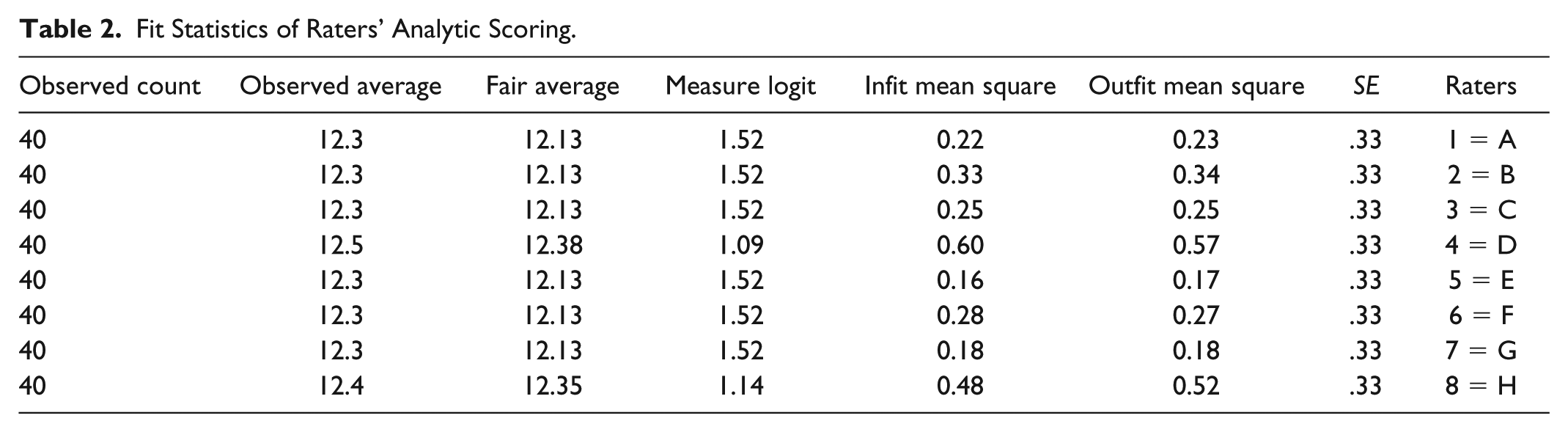
Fit Statistics of Raters’ Holistic Scoring.

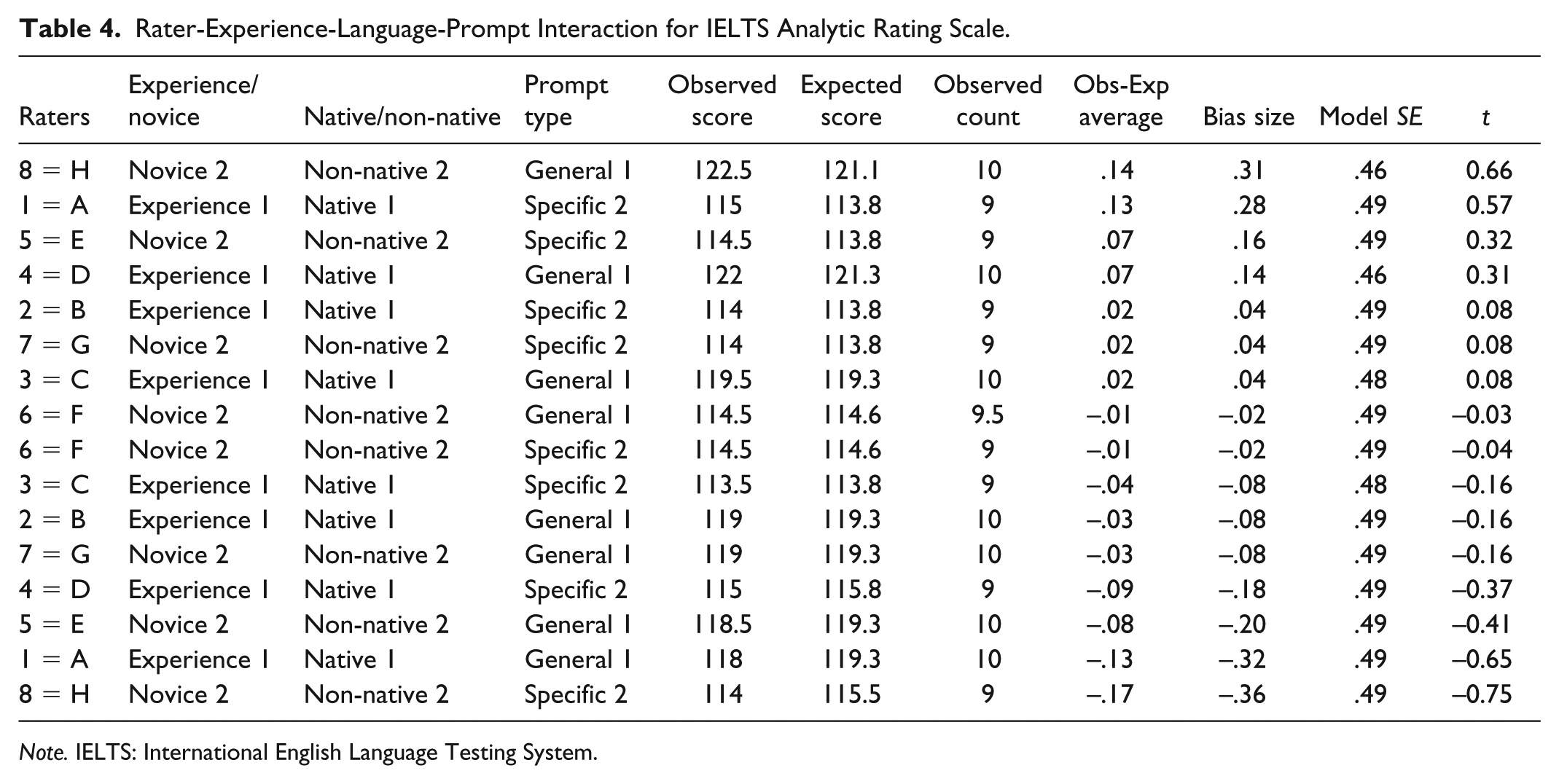
Tables 4 and 5 illustrate a bias analysis of rater by experience, language background, and prompt difficulty for the analytic and holistic rating scale, respectively. Of 16 bias terms in all, there were no significant bias interactions between given categories. As can be observed, there are not t values greater than +2 or smaller than –2, hence no significant bias/interaction.
Rater-Experience-Language-Prompt Interaction for IELTS Analytic Rating Scale.
Note. IELTS: International English Language Testing System.
Rater-Experience-Language-Prompt Interaction for TOEFL Holistic Rating Scale.

Note. TOEFL: Test of English as a Foreign Language.
Discussion and Conclusion
As was previously cited, this study dealt with modeling facet interactions and because we had five facets to run MFRM, then we had “higher-way interactions” (Eckes, 2011, p. 95). The findings portrayed that the interactions were statistically nonsignificant signifying that both novice and experienced raters rated essays leniently whether they used TOEFL holistic scale or IELTS analytic scale. It is interesting that raters’ language background has not got any effect upon scoring essays. Therefore, we can say that the questions raised by the study did not get positive answers, which is, perhaps to our interest. Raters when using IELTS analytic scale showed overfitting pattern and the summary of fit statistics of polytomous Rasch model suggests that lower than 0.5 are “less productive for measurement, but not distorting of measures” (Engelhard & Wind, 2018, p. 265); these overfitting may be indicating that “the rater is overusing certain categories of the rating scale” (Knoch, 2007, p. 7). If true, further analyses of raters’ trait scales are needed especially when analytic rating scales are used.
The next finding is concerned with prompt difficulty. Two tasks, as was previously cited, were given to the examinees: to write about a general topic and another pertinent to their major they were studying. The researcher was interested to know if raters score essays in an unbiased manner if the tasks are different. The results were quite notable. When essays were scored on the basis of IELTS analytic scores, several patterns appeared. Non-native Rater F acted quite unlike the other raters in that in both general and major-specific topics she was quite lenient. Besides, Rater H, a non-native novice rater with a high educational background, was quite similar to native experienced Raters C and D in that all three were lenient in scoring essays on major-specific task but severe in general topic. Perhaps, this similarity can be associated with rater’s educational background, which liken her to native experienced raters.
On TOEFL based scoring, raters differed in severity and/or leniency in two tasks as well. Interestingly, Rater C, just like analytic scoring, was severe in scoring essays on general topic but lenient in scoring major-specific essays. In fact, she was not the only one in this regard. Raters E and G, also, showed the same pattern. The reason for this similarity can be sought in their same educational background or age or gender or in the case of Raters C and G a long teaching practice. Any of these are just hunches calling for further quantitative and qualitative methods to enable researchers to get to the bottom line of truths rather than surmises.
In addition to the main findings of the study which showed statistically nonsignificant biases among the raters, several patterns emerged, which can pave the way for further future research. (a) First, L1-Persian Rater H differed from other raters. From one perspective, she was the lenient one when scoring analytically on the basis of IELTS; however, she appeared the most severe one while scoring essays holistically; (b) Second, when essays were scored based on IELTS analytic rating scale, both experienced and novice raters performed quite alike. It was not true with essays which were holistically scored though, with experienced raters more lenient and novice ones more severe. As to these findings, in all, the raters were more consistent in analytic scoring (separation index = 0.33) whereas this was not the case with raters scoring holistically (separation index = 1.57). Chi (2001) in a comparison between holistic and analytic scoring running MFRM states as follows: “for rater severity, analytic scoring provided more consistency than holistic scoring” (p. 379). Likewise, Kuo (2007) asserts that for “scoring candidates’ written responses of New Senior Secondary (NSS) Liberal Studies public examination, analytic rubric appeared to be more appropriate for the assessment” (p. 179). In contrast, the results of this study do not concur with those of Barkaoui’s (2010) in that he found that “ the experienced raters tended to be more severe” whereas “the novice raters tended to be more lenient” (p. 31); (c) Third, in this study, raters’ language background did not introduce bias into scoring; in fact, some research focused on the effect of raters’ language background on scoring of speech samples (e.g., Winke, Gass, & Myford, 2013). Their study revealed that “matches between the raters’ L2 and the test takers’ L1 resulted in some of the raters assigning ratings that were significantly higher than expected” (p. i).
In closing, several issues need further inspection. First of all, this study had a limited scope for generalizing the results, inter alia, the number of raters and examinees. Second, perhaps, it could be better to have raters with a diverse language background. Although the idea of bias has been extended to raters and tests (DRF and DTF), it would be a rational extension if we could have Differential Task Functioning, Language, or Experience Functioning within the concept of raters functioning. As Eckes (2011) contends, “there has been a notable lack of research into the personal and situational determinants of rater severity” (p. 55). Finally, a mixed method approach may be of enormous help when raters are surveyed about their intuitions and biases toward assessment. Both introspective and retrospective interview, questionnaires, Talk/Think aloud, or any sort of protocol analysis would contribute much to our understanding of the reasons why raters behave differently/similarly and unanimously/at odds with other raters on different scoring procedures.
Footnotes
Appendix A
Appendix B
IELTS Writing Band Descriptors.

| Task response | Coherence and cohesion | Lexical resource | Grammatical range and accuracy | |
|---|---|---|---|---|
| 9 | ● fully addresses all parts of the task ● presents a fully developed position in answer to the question with relevant, fully extended and well supported ideas |
● uses cohesion in such a way that it attracts no attention ● skillfully manages paragraphing |
● uses a wide range of vocabulary with very natural and sophisticated control of lexical features; rare minor errors occur only as “slips” | ● uses a wide range of structures with full flexibility and accuracy, rare minor errors occur only as “slips” |
| 8 | ● sufficiently addresses all parts of the task ● presents a well-developed response to the question with relevant, extended and supported ideas |
● sequences information and ideas logically ● manages all aspects of cohesion well ● uses paragraphing sufficiently and appropriately |
● uses a wide range of vocabulary fluently and flexibly to convey precise meanings ● skillfully uses uncommon lexical items but there may be occasional inaccuracies in word choice and collocation ● produces rare errors in spelling and/or word formation |
● uses a wide range of structures ● the majority of sentences are error-free makes only very occasional errors or inappropriacies |
| 7 | ● addresses all parts of the task ● presents a clear position throughout the response ● presents, extends and supports main ideas, but there may be a tendency to overgeneralize and/or supporting ideas may lack focus |
● logically organizes information and ideas; there is clear progression throughout ● uses a rage of cohesive devices appropriately although there may be some under-/over-use ● presents a clear central topic within each paragraph |
● uses a sufficient range of vocabulary to allow some flexibility and precision ● uses less common lexical items with some awareness of style and collocation ● may produce occasional errors in word choice, spelling and/or word formation |
● uses a variety of complex structures ● produces frequent error-free sentences ● has good control of grammar and punctuation but may make a few errors |
| 6 | ● addresses all parts of the task although some parts may be more fully covered than others ● presents a relevant position although the conclusions may become unclear or repetitive ● presents relevant main ideas but some may be inadequately developed/unclear |
● arranges information and ideas coherently and there is a clear overall progression ● uses cohesive devices effectively, but cohesion within and/or between sentences may be faulty or mechanical ● may not always use referencing clearly or appropriately ● uses paragraphing, but not always logically |
● uses an adequate range of vocabulary for the task ● attempts to use less common vocabulary but with some inaccuracy ● makes some errors in spelling and/or word formation, but they do not impede communication |
● uses a mix of simple and complex sentence forms ● makes some errors in grammar and punctuation but they rarely reduce communication |
| 5 | ● addresses the task only partially; the format may be inappropriate in places ● expresses a position but the development is not always clear and there may by no conclusion drawn ● presents some main ideas but these are limited and not sufficiently developed; there may be irrelevant detail |
● presents information with some organization but there may be a lack of overall progression ● makes inadequate, inaccurate or overuse of cohesive devices ● may be repetitive because of lack of referencing and substitution ● may not write in paragraphs, or paragraphing may be inadequate |
● uses a limited range of vocabulary, but this is minimally adequate for the task ● may make noticeable errors in spelling and/or word formation that may cause some difficulty for the reader |
● uses only a limited range of structures ● attempts complex sentences but these tend to be less accurate than simple sentences ● may make frequent grammatical errors and punctuation may be faulty; errors can cause some difficulty for the reader |
| 4 | ● responds to the task only in a minimal way or the answer is tangential; the format may be inappropriate ● presents a position but this is unclear ● presents some main ideas but these are difficult to identify and may be repetitive, irrelevant or not well supported |
● presents information and ideas but these are not arranged coherently and there is no clear progression in the response ● uses some basic cohesive devices but these may be inaccurate or repetitive ● may not write in paragraphs or their use may be confusing |
● uses only basic vocabulary which may be used repetitively or which may be inappropriate for the task ● has limited control of word formation and/or spelling; errors may cause strain for the reader |
● uses only a very limited range of structures with only rare use of subordinate clauses ● some structures are accurate but errors predominate, and punctuation is often faulty |
| 3 | ● does not adequately address any part of the task ● does not express a clear position ● presents few ideas, which are largely undeveloped or irrelevant |
● does not organize ideas logically ● may use a very limited range of cohesive devices, and those used may not indicate a logical relationship between ideas |
● uses only a very limited range of words and expressions with very limited control of word formation and/or spelling ● errors may severely distort the message |
● attempts sentence forms but errors in grammar and punctuation predominate and distort the meaning |
| 2 | ● barely responds to the task ● does not express a position ● may attempt to present one or two ideas but there is no development |
● has very little control of organizational features | ● uses an extremely limited range of vocabulary; essentially no control of word formation and/or spelling | ● cannot use sentence forms except in memorized phrases |
| 1 | ● answer is completely unrelated to the task | ● fails to communicate any message | ● can only use a few isolated words | ● cannot use sentence forms at all |
| 0 | ● does not attend ● does not attempt the task in any way ● writes a totally memorized response |
|||
Note. IELTS = International English Language Testing System.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.