
Abstract
Public health researchers have identified numerous health implications associated with land use. However, it is unclear which of multiple methods of data collection most accurately captures land use, and “gold standard” methods vary by discipline. Five desirable features of environmental data sources are presented and discussed (cost, coverage, availability, construct validity, and accuracy). Potential accuracy issues are discussed by using Kappa statistics to evaluate the level of agreement between data sets collected by two methods (systematic social observation [SSO] by trained raters and publicly available data from aerial photography coded using administrative records) from the same blocks in Chicago, Illinois. Significant Kappa statistics range from 0.19 to 0.60, indicating varying levels of intersource agreement. Most land uses are more likely to be reported by researcher-designed direct observation than in the publicly available data derived from aerial photography. However, when cost, coverage, and availability outweigh a marginal improvement in accuracy and flexibility in land-use categorization, coded aerial photography data may be a useful data source for health researchers. Greater interdisciplinary and interorganization collaboration in the production of ecological data is recommended to improve cost, coverage, availability, and accuracy, with implications for construct validity.
Keywords
The residential physical and built environment is considered an important domain of health risk factors and opportunities. Ample literature in public health and sociology demonstrates “neighborhood effects,” associations of neighborhood features such as socioeconomic disadvantage, affluence, and race/ethnic composition on health. Recent research emphasizes moving beyond correlations between neighborhood socioeconomic resources and health to relate specific features of the environment to precise outcomes through well-defined sociobiological processes.
Most importantly, health researchers, community sociologists, landscape ecologists, and urban planners have focused considerable attention on how features of “walkability” (defined various ways) influence physical activity. In particular, land use—the allocation of land to different uses such as residential, commercial, industrial, open space, and so on, and the mix and density of these uses—is hypothesized to affect health through a number of mechanisms. By shaping how people and goods move through an area, land-use mix and intensity can influence physical activity (Saelens & Handy, 2008), health (King, 2013b), access to health opportunities (Smiley et al., 2010), emotion (King, 2012), community social relations (Talen, 1999), and exposure to crime (Hipp, 2007) and pollution (Frank & Engelke, 2005). These and other sociobehavioral community characteristics in turn influence land-use change decisions by residents, local governments and institutions, and businesses.
Initial evidence for associations between land use and health has largely been based on proxy variables (e.g., population density, commute time, or the occupational mix of persons employed in the area.) Current work defining walkable urban form often includes three measures: residential density, street connectivity, and an entropy measure of land-use mix based on five categories (residential, commercial, institutional, recreational, and other; Frank et al., 2006; King, 2015).
Difficulty with environmental data collection has been a major focus of recent interdisciplinary attention, but no consensus has been reached. Broadly speaking, planning research often uses administrative records or remote sensing. Health researchers often use self-reports or community surveys, which cluster self-reports of respondents’ (or an ancillary samples’) surroundings (e.g., Bjornstrom, 2011; Echeverria, Diez-Roux, & Link, 2004; King, 2013a; King & Ogle, 2014). Urban sociologists tend to prefer systematic social observation (SSO) performed by trained raters who “hit the pavement” to record detailed information about neighborhoods of interest. Analysis of any of these data types typically involves use of a geographic information system (GIS) software package for visual and quantified display of information.
The present study assesses the level of agreement between two data sources, which measure land use using two different “gold standard” methods: (a) SSO by a trained rater and (b) remote sensing-based coded aerial photography data about whether each of eight types of land uses was present on 1,662 blocks in both 2002 SSO data from the Chicago Community Adult Health Survey (CCAHS) and aerial photography data coded by the Chicago Metropolitan Authority for Planning (CMAP; 2006). Many studies using land-use data adjust for or look for associations with neighborhood social composition, population density, or urban centrality (Duncan, Kawachi, White, & Williams, 2013; Neckerman et al., 2009; Ursell, Metcalf, Parfrey, & Knight, 2012). Neighborhoods with fewer children and older adults, as well as more disadvantaged and more affluent residents, are more likely to have smaller blocks and more intense land use (King & Clarke, 2015). Thus, it is important to consider whether contextual social conditions may influence how land use is measured. Bader, Ailshire, Morenoff, and House (2010) have suggested that contextual data issues might be a concern in disadvantaged neighborhoods with higher turnover and at higher population densities. We therefore examine whether race/ethnic composition, disadvantage, residential stability, population density, and distance from the central city “Loop” may predict disagreement between sources.
Comparing Data Sources
Little evidence is currently available to guide researchers in selecting among potential data sources on land use, which range from government documents to survey observations. Existing sources of land-use data vary in terms of (a) cost, (b) coverage, (c) availability, (d) construct validity, and (e) accuracy.
Cost
Little information is available about relative costs of various data collection methods.
Coverage
Data sources vary considerably in terms of coverage and ease of aggregation. Observations collected as part of a survey are usually conducted only at sampled locations within the study area, such as near respondents’ homes, but it is not known how sampled locations may differ from other nonsampled locations within the study area. Nor is it known how accurately characteristics are measured when aggregating from small areas to a larger area (such as when blocks are aggregated to characterize the census tract level). Choice of boundaries can induce a modifiable areal unit problem (Openshaw, 1983) such that associations between a contextual measure and an individual outcome differ depending on the boundary choice (Flowerdew, Manley, & Sabel, 2008). Many observational and administrative data sources specify a precise spatial unit, such as census tracts or housing units, which confine analysis to administrative boundaries and complicate investigation of spatial scale. Data collected by aerial photography or satellite imagery have a potential advantage in terms of coverage if it is available and consistently measured for the entire study site as a continuous surface rather than within particular geographic boundaries.
Availability
Availability of appropriate data is another issue. When the researcher seeks to add a land-use component to an existing data set, remote sensing–based and administrative measures are likely the only measures of ecological characteristics available, which include land use. Ideally, observation of time-variant ecological measures occurs at the same time as or before collection of individual-level data (as in the Project on Human Development in Chicago Neighborhoods [PHDCN], n.d.). Even when such administrative data exist, they may be difficult for the researcher to obtain, and their temporal relationship to survey data is largely a function of administrative rather than research concerns. For instance, before the introduction of the annual American Community Survey, community sociodemographic data in U.S.-based studies tended to come from the decadal censuses, which sometimes made it necessary to impute data for middle years (e.g., 1995). Some secondary data sets are compiled over a long period or do not include date of collection (e.g., Google Street View data). By contrast, satellite imagery and aerial photography do not require travel to the study site, which make them potentially appropriate when creating measures for surveys, which cover large spaces, especially those that do not involve on-site interviews. Remote methods are also unlikely to require institutional review board approval. Collecting observational data offers a researcher control when access to other sources of data is uncertain.
Construct Validity
Both secondary data sources (those not directly collected for the present project) and observational methods offer challenges in terms of construct validity. Ideally, the categories used to classify the built environment and land use should be based on hypotheses about the effects of precise features of the environment. This is a challenge when collection of data related to the built environment is time-intensive, given the rapid development of social ecological theory during the last decade. Hence, evolution of methods and theory also cause categorizations used in various SSOs to differ (see Liang, Li, & Ma, 2014; Mastrofski, Parks, & McCluskey, 2010; Sampson & Raudenbush, 1999). Even when the choice of category codes is consistent, the physical reality of the built environment may not be easy to classify in an SSO or administrative records. In some cases, the actual use of a property might not match the exterior appearance (e.g., a law office in a converted church) or the ownership (e.g., an industrial facility purchased by the adjacent university). When appearance, use, and ownership conflict, the appropriate coding may vary according to the nature of the research.
Secondary sources may require considerable validation and probing because they were not designed for health and social research. For instance, when social scientists conduct household listings as a preliminary to survey sampling, they try to consider all the possible places people might live, such as an apartment over a store. Land-use data designed for commercial or planning purposes, however, may not focus on capturing secondary residential uses of commercial properties, even when changing the primary land use by rezoning, widening a road, or selling the property would change the secondary use. Likewise, “off the books” uses of residential or other land for commercial purposes (Schaefer-McDaniel, Caughy, O’Campo, & Gearey, 2010), which may be observed at the street level, might not appear in records or be visible from the air. However, planners and developers might be interested in more detailed categories of industrial properties than would social survey designers, and that information might turn out to be useful to health researchers. Each group might learn from the other.
Accuracy
More research is needed to evaluate the accuracy of various ecological measurement systems such as SSO (Brownson, Hoehner, Day, Forsyth, & Sallis, 2009). “Head-to-head” comparisons across methods may be especially valuable. Clarke, Ailshire, Melendez, and Bader (2010) compared a Google Street View–based neighborhood audit with an SSO, finding high rates of observed agreement and Kappa values ranging from 0.31 for presence of institutional land to 0.71 for presence of high-rise housing. Bader and colleagues (2010) compared the level of agreement between SSO measures of the presence of neighborhood businesses and listings of businesses from commercial databases. Kappa values for different business types ranged from 0.32 to 0.70. Most business types were more likely to be reported by the SSO, but the authors concluded that the use of either data source could be reasonable, considering cost and the purpose of the research.
Method
The goal of the article is to evaluate the level of agreement between data collected by two methods from the same blocks in Chicago, Illinois, and whether this agreement varies by neighborhood social composition, population density, and urban centrality. One data set comes from a SSO by trained raters as a component of a large study of the social determinants of health. The second is a publicly downloadable data set, which is partially based on (a) remote-sensing technology applied to aerial photography and (b) coding using administrative records for use by local urban planners.
SSO Data
The SSO was conducted for the CCAHS, which is a multistage area probability sample of 3,105 adults in the city of Chicago during 2001-2003. A trained observer rated each of the 1,662 blocks on which at least one sampled respondent lived, with two raters providing evidence of agreement for a subset of blocks. The rater walked around a block twice, first observing the (usually four) sides of the block, and then observing the adjacent areas facing the block. Block ratings included assessments of the physical condition of the buildings, street, amenities, and perceived physical and social conditions, as well as housing, commercial, and overall land-use typologies. The present study focuses on ratings of land-use and housing types.
Aerial Photography Data
The 2001 Land-Use Inventory (CMAP, 2006) was compiled by the Chicago Area Authority for Planning. The data collection was designed to contribute to long-range population, household, employment, land use, and transportation planning conducted by CMAP. CMAP scanned and digitized aerial photographs and manually traced outlines of land uses in ArcGIS, using supplemental remote sensing and address list data to verify land use and location of boundaries, with extensive cross-checks reported in the data documentation. Discrepancies were further investigated.
Data Comparability
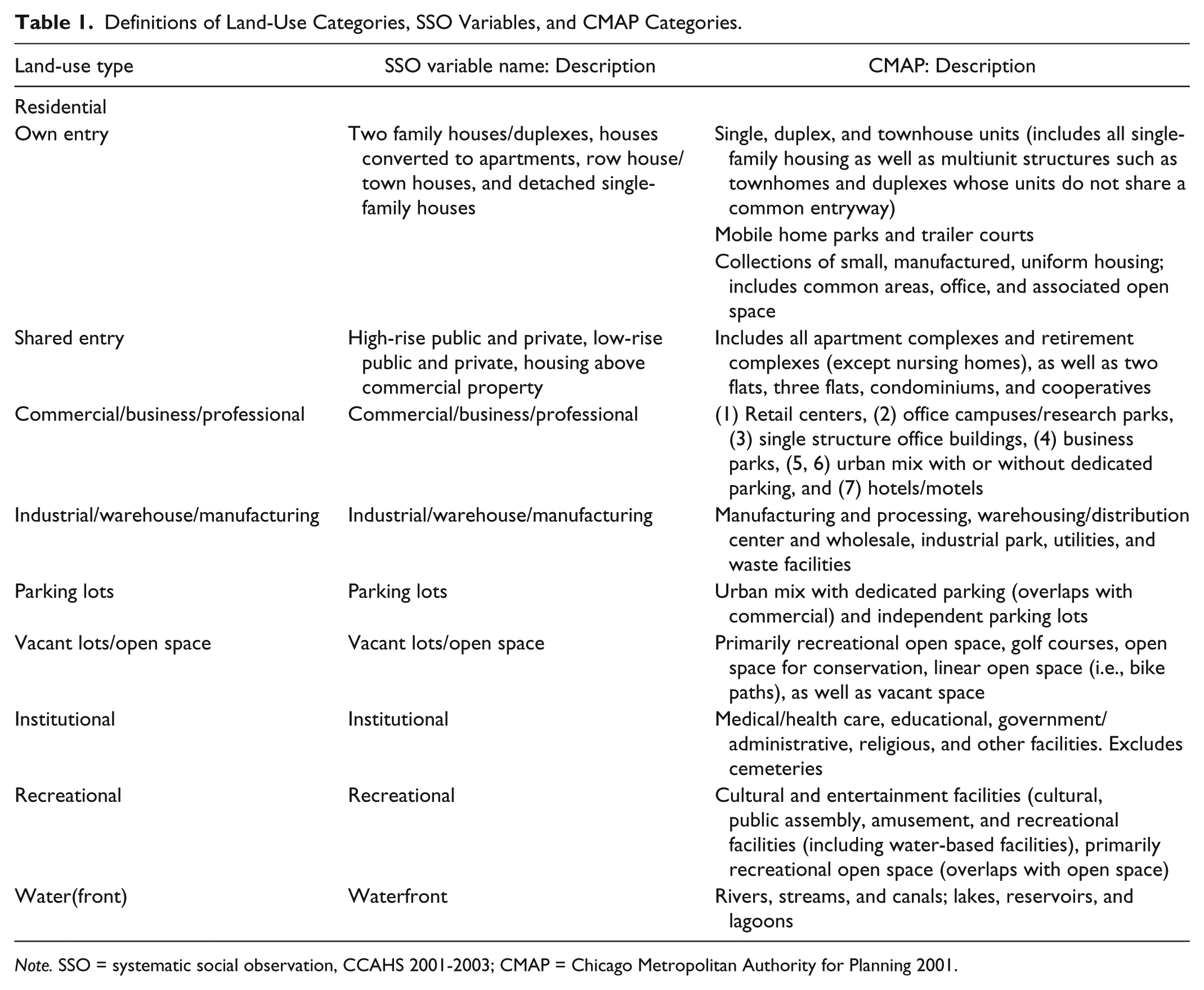
To create comparable measures between the two sources, we created Census block-level dichotomous measures of the presence of each type of land use, which was found in both data sources, including secondary land uses from CMAP. To maximize comparability, we recoded the CMAP land uses to approximate the SSO land-use categories (residential, commercial/business/professional, industrial/warehouse/manufacturing, parking lots, open space and vacant space, institutional, recreational, and waterfront.) Because SSO raters consider adjacent block faces when coding blocks, we considered land uses in the CMAP, which fell within a 40-foot buffer around the Census block boundaries as being present on that block.
Table 1 shows descriptions of land-use categories. The SSO categorized dwellings into nine categories: (a) high-rise public apartments, (b) high-rise private apartments, (c) low-rise public apartments, (d) low-rise private apartments, (e) two-family houses/duplexes, (f) row houses/townhouses, (g) housing above commercial properties, (h) houses converted to apartments, and (i) single-family homes. The CMAP reported only four: (a) single, duplex, and townhouse units; (b) multifamily units; (c) farmhouses; and (d) trailer park/mobile home units, with farmhouses not present in the sampled blocks and only one block containing mobile home units. Two categories of residences were thus created based on comparison of SSO and CMAP housing categories: single household/single-entry homes and multiple household/shared-entry homes.
Definitions of Land-Use Categories, SSO Variables, and CMAP Categories.
Note. SSO = systematic social observation, CCAHS 2001-2003; CMAP = Chicago Metropolitan Authority for Planning 2001.
As with comparison of any two data sets created by different organizations, there are limitations in comparability. Rather than being a weakness of the present study, the difficulty in comparison underscores the need for research on data collection. Although the CMAP reports a limited set of secondary land uses, in practice the data do not include any location where housing and other land uses are combined, which corresponds to the SSO’s category of housing above commercial property. This likely results from two factors. First, because the data are designed for planning rather than social survey purposes, the project was likely less concerned with secondary land uses. Second, the data result from aerial photography, which might fail to capture side entrances, vertical stacking, and other features, which might be visible from the ground. Results from sensitivity analyses (not shown) support this categorization.
The SSO parking lot category does not have a direct counterpart in CMAP. Here, we assume that parking lots are present in areas categorized by CMAP as urban mix with dedicated parking and combine this with independent parking lots to produce a measure indicating parking presence. Because SSO raters stand at the block face to code parking lots, they may not note presence of parking lots behind buildings. CMAP, by contrast, would not be expected to report parking lots on block faces such as for apartment or office buildings, and institutions, not coded as “urban mix”; these parking areas would be coded according to the purpose of the buildings they belong to. Neither data set would report on-street or vacant lot parking.
Characterization of vacant and open space provides additional challenges. The SSO’s vacant and open space category does not specify whether construction is included. Although construction might be a frequent mode of land-use change, and thus for discrepancies in land-use categorization across the short term, land under construction is not conceptually the same as vacant land. We therefore omit the construction categories from the CMAP and include only the category “primarily recreational open space, golf courses, open space for conservation, linear open space (i.e., bike paths), and other open space, as well as vacant space.”
Comparison of water land use across datasets can be complicated because water, open space, and transportation land uses often co-occur. The SSO allows reports of multiple uses; the rater may report water and open space if both are present, although no category exists for transportation. By contrast, the CMAP reports only one category and may select transportation or open space rather than water.
Analyses
We measure the degree of agreement between the two data sources and the extent to which disagreement is related to sociodemographic characteristics of the neighborhood. The degree of agreement between the two data sources on the presence of each land-use type is measured using Kappa statistics, which report the intersource reliability considering that some agreement could be expected by chance. Specifically, the Kappa statistic is the ratio of the observed agreement to the expected agreement, based on the marginal frequencies in both data sources. We use conventional benchmark categories for agreement (Landis & Koch, 1977): almost perfect (0.81-1.00), substantial (0.61-0.80), moderate (0.41-0.60), fair (0.21-0.40), and slight (0.00-0.20).
Next, we consider whether disagreement between data sources might be higher when land uses are less formal, such as informal commercial land uses in disadvantaged or Hispanic neighborhoods (Venkatesh, 2009). We expect the SSO would be more likely to report informal land uses, because they would be visible at the street level but not in administrative records. However, it might also be possible for administrative records to list a land use that did not have external markings, resulting in a report in the CMAP but not in the SSO. Land-use turnover might also be higher in neighborhoods where residential stability is lower, making properties difficult to code or resulting in category changes between the two data collection times. If characteristics of neighborhoods are unrelated to disagreement between sources, researchers can feel more confident in choosing either source.
To evaluate whether disagreement between the two sources is systematically related to the sociodemographic characteristics of the neighborhood, we create a dichotomous indicator variable for agreement for each block and fit logistic regression models, which report the log-odds of agreement about the presence of a particular land use on a block. We use four variables in our analysis to describe tract-level socioeconomic composition, following Bader and colleagues (2010). We prefer the tract-level data over block group data because tracts are likely large enough such that tracts may influence the presence of land uses rather than land uses influencing nearby socioeconomic conditions. That is, a block group containing a large factory might have low population density and socioeconomic status precisely because of proximity to the factory, whereas this phenomenon should be somewhat smoothed out at the tract level.
Neighborhood sociodemographic data come from Summary File 3 of the 2000 U.S. Census. The first scale is referred to as “neighborhood disadvantage” because it combines measures of the proportion of households with incomes of less than US$15,000 and incomes of at least US$50,000 (reverse coded), as well as rates of family poverty, public assistance, unemployment, and vacant housing. The percentage non-Hispanic White and the Hispanic/foreign-born scale (which combines measures of the percentage of Hispanics and the percentage foreign born) capture ethnic composition. The Residential Stability Scale is composed of the percent residing in their homes for 5 years or more and percent home ownership.
We also include a measure of distance in kilometers from Chicago’s central business district (“The Loop”—specifically, the site where the Sears Tower was located) to the centroid of the block polygon because certain land uses (e.g., shared-entry residential, commercial/business/professional) are more common closer to downtown, and this may influence the likelihood of intersource agreement. Failing to report a land use during coding (in either data source) when that land use is actually present might also be more likely when more land uses are present (Bader et al., 2010).
Finally, we include a variable indicating the time difference in months between the data collections. About 10% of the SSOs occurred within 8 months of the aerial photography, whereas about 90% occurred between 18 and 22 months later. Even on a 2-year time scale, we suspect that it will be relatively rare for land uses to completely change categories, but available data do not allow us to quantify the impact of land-use change on the discrepancies. However, according to the CMAP, less than 1% of the sampled blocks contained construction, and half of that construction was residential. Analyses of source agreement exclude three blocks for which the SSO observation date was missing.
Results
Table 2 reports the results of the level of agreement analysis. The SSO and coded aerial photography data display considerable agreement, which ranges from 90% (K = 0.60) for shared-entry residential land use to 59% (K = 0.19) for vacant lots/open space. Agreement about industrial/warehouse/manufacturing land use (88%, K = 0.44) and shared-entry housing (90%, K = 0.60) was moderate. There was less agreement within the own-entry residential category (76%, K = 0.22), although single-entry homes might be expected to be relatively simple to identify. This is almost certainly due to disagreement about housing type category, particularly to the ambiguity about houses converted to apartments. There is disagreement about the presence of any residential land for only nine blocks, and agreement that there is no residence on one block. Institutional and recreational land uses (76%, K = 0.52; and 82%, K = 0.50, respectively) also show moderate agreement. The level of agreement on the presence of parking lots (69%, K = 0.37) is better than might be expected when considering that the CMAP data only report certain categories of parking lots (independent lots and lots associated with mixed urban commercial use); we expect the SSO to report more parking lots associated with apartments, institutions, offices, and so on. All Kappa values are significant, indicating more agreement than would be expected by chance.
Kappa Statistics and Tabulations of Agreement on Census Block Land-Use Category Presence Between Data Sources, Chicago, Illinois, 2001-2003 (n = 1,659).

Note. SSO = systematic social observation; CMAP = Chicago Metropolitan Authority for Planning.
We then cross-tabulated reports of presence of each land-use category by source. The last four columns of Table 2 report the frequency of blocks on which (a) the land use is reported present by both data sets, (b) the land use is not reported in either data set, (c) only the SSO reports the land use is present, and (d) only the CMAP reports the land use is present. Where disagreement occurred, it was more commonly the case that only the SSO had reported the land use rather than that only the CMAP had reported the land use. This is especially true for both types of residential land uses and vacant lots/open space, although the data sets are about equally likely to report industrial/warehouse/manufacturing and parking lot land uses, and water(front) (which is present at low frequency).
In Table 3, we report odds ratios estimated from the regression of block disagreement. There were no clear and consistent patterns of association of sociodemographic variables with coding disagreement. Only 25 of the 60 coefficients of sociospatial associations (with the 10 land uses) estimated were significant at p < .05. There were no significant predictors of disagreement on residential land use overall, but percent White predicted much more disagreement on own-entry and shared-entry housing. Disadvantage predicted coding discrepancies about own entry, while shared-entry discrepancies were more common in residentially stable areas and less common in Hispanic/foreign-born areas. Neighborhood-level percent non-Hispanic White predicted less disagreement on institutional, commercial, and vacant/open land uses, perhaps indicating more stable or larger institutions in White locales. Also, Hispanic/foreign-born composition and disadvantage also predict disagreement on commercial and industrial land uses, and disadvantage predicts less agreement on parking lots. Residential stability predicts disagreement on shared-entry housing and predicts agreement on parking lots, water(front), and recreational land use. Population density is associated with shared-entry, industrial, recreational, and water(front) land uses. Months elapsed between SSO and CMAP data collections did not predict disagreement, a finding consistent with a limited role of change over time as a source of disagreement. Distance from the downtown Loop area predicts less disagreement on several land uses (shared-entry housing, commercial, industrial, vacant/open, and recreational), the same variables predicted by population density. The pseudo-R2 values (ranging from .01 to .07) suggest that the socioeconomic characteristics, density, and proximity of the neighborhood to the central business district predict very little of the disagreement between sources.
Odds Ratios (Standard Errors) of Block Disagreement Within Neighborhood Clusters on Demographic Characteristics by Land-Use Type, Chicago, Illinois, 2001-2002.
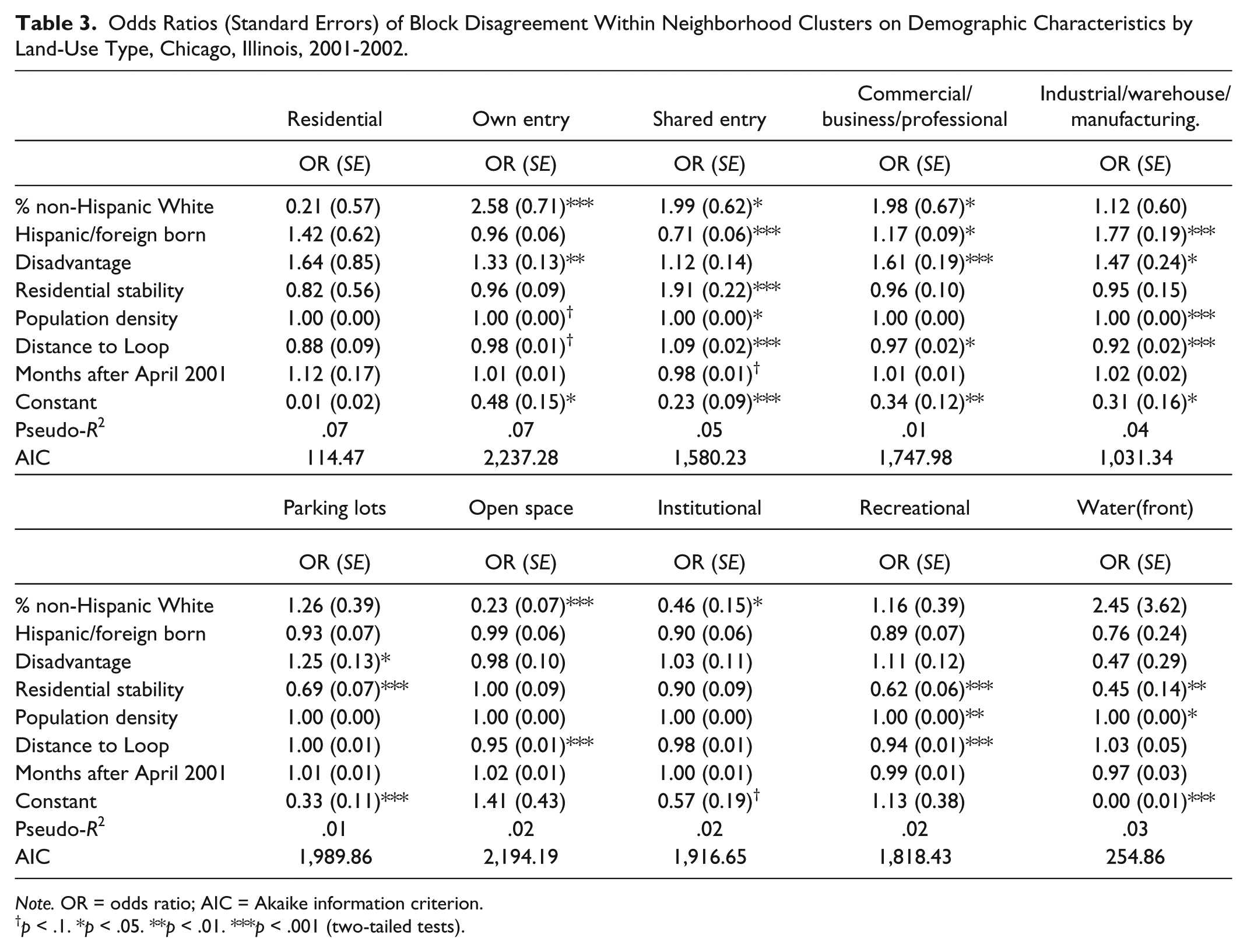
Note. OR = odds ratio; AIC = Akaike information criterion.
p < .1. *p < .05. **p < .01. ***p < .001 (two-tailed tests).
As a follow-up to this analysis, visual comparison of sites where disagreement on presence of water(front) occurred with a map of hydrological features around Chicago revealed that all sites where intersource disagreements occurred were in fact in close proximity to water. The SSO reports of water on 24 blocks where the CMAP did not report water were likely due to the different data collection methods discussed above; it is unclear why the SSO did not report waterfront on 5 blocks that are adjacent to rivers.
Discussion
We have demonstrated that when direct observational data are not available or do not provide adequate coverage, publicly available aerial photography–based data may be a good option. For most land uses, there is a reasonably high agreement between the two sources, given the difficulties involved in creating comparability. The SSO protocol resulted in reports of more land uses than did the aerial photography method, and thus likely is more accurate, if false negatives are more common than false positives. Observed agreement was reasonable for most land uses (>75%, except parking and open space), especially given that the categories were not completely comparable across data sets. However, the Kappa coefficients were considerably lower (0.19-0.60), which is expected when particular land uses are relatively rare.
The correspondence between the two data sets was also lower than in other comparability research using the same Chicago SSO data (Bader et al., 2010; Clarke et al., 2010). However, Bader and colleagues (2010) examined only one type of land use (commercial businesses), and had more information available to achieve comparability between data sources. Geographic boundaries between parcels are much less clearly defined than administrative boundaries between businesses. Clarke and colleagues’ (2010) reports of agreements on land use between the SSO data and observational coding by a trained rater using Google Earth rely on the same categories, face rather than block-level data, and the same purposes in data collection.
Given the reasonable level of agreement between the two sources, decisions about what kind of source to use will likely depend on other factors. Using existing administrative data is inherently cheaper than collecting it. Validity of categories measured will depend on the predictors and outcomes of interest, but lack of information about assumptions made in categorization is a key challenge in comparing data sources. For this reason, we would urge the use of more detailed descriptions of land-use categories than are conventionally used, to make coding more straightforward and also facilitate comparison of categories across studies.
In terms of coverage, remote-sensing data are likely to excel: The SSO data are only available for 1,662 of Chicago’s approximately 24,000 blocks, whereas CMAP data were available for all of Chicago, as well as the surrounding counties. Data for outside city boundaries are often needed when constructing contextual measures for locations near boundaries.
This study contributes to research on ecological measurement. Analysis of the physical environment in general and land use in particular is a rapidly emerging literature, which holds promise for health and urban planning policy. But to advance this research agenda, both further research and additional insights are needed on data collection methodology.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the researchand/or authorship of this article: This work was supported by an appointment to the Research Participation Program of the Environmental Protection Agency (Office of Research and Development), administered by the Oak Ridge Institute for Science and Education through an interagency agreement between the US Department of Energy and the Environmental Protection Aency. This work does not represent the official policies of the Environmental Protection Agency.