
Abstract
This article proposes a methodological framework that combines a Q-concourse questionnaire with Multiple Factor Analysis and Hierarchical Clustering on Principal Components (MFA/HCPC) to derive discourse typologies from large-N survey data. The framework offers four advantages. First, the Q-concourse translates naturally occurring statements into survey items, importing the contextual richness of qualitative discourse analysis into a quantitative design. Second, MFA reduces dimensionality while weighting thematically defined item blocks equally, preventing any correlated subset of variables from dominating the solution and preserving within-block covariance patterns. Third, HCPC scales efficiently to large samples, exploring up to 2ᵏ multidimensional configurations and thus overcoming the combinatorial limits of traditional Q-methodology. Fourth, by locating each respondent within the clustered factor space, HCPC links individual viewpoints to coherent narrative patterns, enabling precise reconstruction and extrapolation of discourse structures. The framework’s utility is illustrated with a national survey on human-genome editing in Australia.
Introduction
Discourses do more than convey opinions; they reveal how individuals express and process reasons, invoke values, and negotiate shared understandings. Discourses are particularly important in democratic contexts where justification and contestation shape public life (Dryzek and Niemeyer, 2008).
The challenge of capturing reason-giving at scale continues to present a major methodological shortcoming. Qualitative interviews and interpretive coding excel at uncovering the intricate layers of individual meaning-making, but they resist standardization and are logistically impractical for large datasets (Beach and Kaas, 2020). They offer deep insight—but at the cost of generalizability. Large-N surveys, on the other hand, are powerful tools for identifying macro-level patterns like consensus, polarization, or preference trends. However, this comes with a significant trade-off: they collapse rich and often contradictory personal narratives into simplified, isolated variables. Q-methodology sits in a conceptual middle ground. It seeks to capture subjective experience more holistically than traditional surveys by asking participants to rank a concourse of statements (Stephenson, 1953). This method can generate clear, person-centered discourse types that help surface the logic behind an individual’s worldview. Yet its strength in surfacing individuality also limits its scale. Because it assumes all statements carry equal weight and thrives only in small-N contexts, its findings often remain deeply tied to specific settings, making broader application difficult (Kampen and Tamás, 2014). Quantitative approaches like Latent Class Analysis (LCA), Latent Profile Analysis (LPA), and Principal Component Analysis (PCA) similarly aim to distil structure from response data. In doing so, they echo Q-methodology’s goal of identifying typologies or underlying dimensions. In contrast to Q-method’s interpretive framework, purely statistical techniques rest on stringent assumptions—such as conditional independence and uniform variable weighting. Although these assumptions facilitate scalability, they also risk oversimplifying the intricate relational and contextual nuances of argumentation that Q-methodology and qualitative approaches are designed to preserve.
Altogether, these approaches either compress complex rationales into aggregated summaries or limit them to a scale too small to generalize. This leaves a crucial void: a lack of scalable methods that can capture the narrative nature of reason-giving—how individuals stitch together beliefs, experiences, and justifications into cohesive, evolving stories. In this paper, a hybrid technique is proposed that combines elements from two established methodologies. First, a comprehensive concourse of discourse statements is assembled through survey design, drawing on principles of Q-methodology. Second, Multiple Factor Analysis followed by Hierarchical Clustering on Principal Components (MFA/HCPC) (Lê et al., 2008; Pages, 2004)—a pipeline originally developed for multi-omics research—is applied to large-N survey data derived from that concourse. Likert, continuous, or binary items are organized into thematic blocks (e.g. ethical and technical), each block is normalized to prevent dominance by any single set of items, and respondents are clustered within the resulting multidimensional factor space. This approach uncovers latent discourse typologies based on the structure of respondents’ reasons rather than individual item endorsements.
As developed throughout this paper, Q-concourse combined with MFA/HCPC offers four distinct advantages for tracing discourse structures within survey data.
(a) First, a Q-concourse lets us translate existing discourses into measurable survey items by inserting representative statements and considerations—preserving elements of in-depth qualitative analysis—directly into the questionnaire.
(b) Second, MFA balances the influence of thematically organized question blocks (e.g. ethical, economic, social, technical, or normative) by weighting each block equally during dimensionality reduction. This not only prevents any single set of correlated variables from dominating the analysis—addressing a common limitation of PCA, LCA/LPA, and Q-methodology—but also preserves within-block coherence: unlike PCA, LCA/LPA, and Q-methodology, MFA explicitly models relationships among variables within each thematic block, retaining the nuanced co-variation patterns that give shape to complex reasoning.
(c) Third, HCPC provides both scalability and a vast configuration space. Whereas Q-methodology is constrained by the number of statements (yielding at most one discourse type per unique ranking), HCPC can, in principle, explore up to 2ᵏ configurations based on k extracted factors. This flexibility makes it ideally suited for large-N datasets, allowing researchers to identify meaningful clusters among hundreds or thousands of respondents without sacrificing the subtleties of relational discourse structures.
(d) Fourth, HCPC lets us reconstruct and extrapolate narrative patterns by placing each respondent within a clustered discourse space—enabling the projection of individual perspectives onto broader, coherent discourse types.
The R package FactoMineR (Lê et al., 2008) and Factoextra (Kassambara and Mundt, 2016) provides all necessary routines for performing MFA, extracting factor scores, and carrying out HCPC, making the procedure transparent and reproducible (script for this study in the Online Supplemental Appendix).
To illustrate this approach, we apply it to a representative Australian survey conducted in June 2021 (Nicol et al., 2022), where Q-methodology was first used to develop the survey concourse for Citizens’ Jury participants on human genome editing and was subsequently administered to the broader population. For this example, we first subdivide Nicol et al. (2022) concourse of statements into ethical and technical dimensions related to genome editing, which then serve as the thematic blocks for the MFA analysis. We then perform MFA to generate factors that capture the essence of each dimension. Finally, we use HCPC to cluster respondents within this multidimensional factor space, revealing distinct discourse typologies and allowing us to position individuals relative to prototypical cluster centroids. In doing so, we demonstrate how MFA/HCPC maps the introspective dimension of discourse—showing not just which items citizens endorse but how they integrate reasons and values into coherent, collective patterns of argumentation. Validation and comparison with other techniques will offer a final assessment of the method’s strength, shedding light on its capacity to uncover discursive structures while examining the degree of overlap, divergence, and complementarity with alternative approaches such as LCA and PCA.
Conceptualizing and mapping discourses quantitatively
Discourses play a crucial role in shaping relationships and interactions between individuals. They represent verbal actions through which values and beliefs are communicated. Discourses can be understood as communicative operations executed through linguistic mechanisms, but these operations are also filled with content, meaning, and concepts (Armstrong, 2000).
However, discourses represent far more than isolated words or texts; they constitute structured aggregations of reasons and arguments that reflect deeper belief systems and worldviews, significantly guiding political behavior. From a very broad perspective, discourses can be seen as ensembles of ideas, concepts, and interpretative frameworks that assign meaning to social and political phenomena, emphasizing their inherently argumentative structure. Within this dimension, discourses serve as containers for values, beliefs, and ideas, reflecting personal and collective reasoning (Niemeyer and Dryzek, 2007). This aligns with the argumentative theory of reasoning, suggesting discourse serves primarily as a mechanism through which individuals justify and defend pre-existing beliefs, actively shaping collective understandings and public opinion (Mercier and Sperber, 2011). In public debates—such as those surrounding climate change—arguments often span multiple dimensions: economic (e.g. “renewable energy creates jobs”), social (e.g. “healthier communities”), ethical (e.g. “duty to future generations”), and technical (e.g. “energy efficiency”). Though diverse in form, these arguments frequently cohere around shared narratives—for instance, the urgency and desirability of sustainability. Rather than treating these arguments as isolated claims, researchers can conceptualize them as part of broader discourses: clusters of interrelated considerations that reflect deeper meta-concepts. By systematically coding arguments and tracing their co-occurrence within survey responses, scholars can move beyond qualitative typologies and use quantitative techniques to assess the coherence and prevalence of discursive patterns across a population. This approach allows for a more empirical understanding of how citizens reason about complex public issues, linking argumentative content to larger frames of interpretation.
Yet, to investigate argumentative levels, we need a relational analytical strategy—one well served by survey datasets. Surveys systematically track opinions on specific arguments, capturing their core meaning without overreliance on verbal elaboration. Unlike qualitative methods, surveys are easily replicated across large samples, making it practical to examine cognitive dimensions of discourse at scale.
Analytical and methodological constraints in discourse analysis
Existing techniques to isolate argumentative dimensions of discourses through survey or in-depth qualitative approaches generally suffer from analytical and methodological constraints. In this section we focus on such potential hurdles considering both survey and in-depth qualitative approaches.
- Survey-Analytical Constraints in Aggregating Data for Discourse Mapping: Surveys typically are analyzed from an item-centered understanding of issues, measuring individual preferences rather than identifying mutual, relational discourse narratives. Common quantitative methods like single-peaked preference analysis (Black, 1948), opinion polarization (Van Der Eijk, 2001), opinion consensus (Claveria, 2021), or opinion change (Evan, 1959) effectively measure outcomes such as consensus or polarization. However, these approaches are limited in capturing the argumentative dimension of discourse: they do not link participants to clusters of similar responses across the full set of statements that constitute a coherent discourse. In other words, they tend to overlook the relational and narrative dimensions of discourse, crucial for understanding how individuals’ perspectives interconnect.
- Qualitative Methodological constraints: Qualitative approaches, such as in-depth interviews, are valuable for capturing discursive narratives, as they are typically interpretive and subjective (Beach and Kaas, 2020). While subjectivity provides rich contextual meaning, it limits the replicability and systematic application to large datasets, as interpretations rely on transformative meaning-making rather than measurable tools. Though qualitative methods offer normative insight by inferring the meaning of discourses through theory (te Molder, 2015), they are often unsystematic and un-replicable. As a result, it is challenging to map discourse narratives across large samples or replicate findings consistently within any dataset, including smaller ones. This interpretive nature hinders their scalability for broader applications, making them impractical for large-scale discourse analysis.
In survey research, understanding discourses requires a shift from an item-centered to a participant-centered perspective. This shift enables us to view discourses as collective and dynamic entities, shared among individuals and evolving over time.
- Q-Methodology: Q-methodology uses inverted factor analysis to classify discourses based on participants’ perspectives (Stephenson, 1953). This method typically begins with in-depth interviews to identify key statements, which then serve as the basis for clustering participants according to their survey responses. While Q-methodology offers a unique, person-centered approach that aligns well with discourse analysis, it also presents several challenges, especially in large-N studies. Participants often need a strong understanding of survey and statistical methods to structure their responses correctly, which can be difficult without direct assistance in large-scale studies (Cross, 2004). Furthermore, the method assumes equal weighting of survey statements, potentially oversimplifying the complex nature of discourses. The context-specific nature of Q-methodology’s findings, while valuable, can limit their generalizability to other populations or settings (Hasandoost et al., 2017). These challenges are particularly evident when trying to map discourses across broad populations, where operational and empirical constraints can limit the method’s effectiveness (Kampen and Tamás, 2014). Nonetheless, Q-methodology’s qualitative, interpretive strengths make it a powerful tool for uncovering the underlying structure of public discourse, particularly in smaller, more focused studies.
- Latent Class/Profile Analysis (LCA-LPA): LCA and LPA are statistical techniques widely used to identify subgroups within a population based on categorical and continuous data, with model selection criteria such as AIC and BIC helping determine the optimal number of latent classes by balancing model fit and complexity. While effective for identifying latent structures, these methods can struggle with the complexities of discursive narrative analysis. Like Q-methodology, LCA-LPA assumes equal importance for all survey variables, which can flatten the data and obscure the nuanced roles different questions play in shaping discourses. The assumption of conditional independence within each class can be problematic when analyzing interrelated discursive narratives, potentially leading to misclassification. Second, LCA/LPA’s conditional-independence assumption —that within each latent class, observed variables are uncorrelated—often fails in discursive contexts where statements co-occur as part of coherent storylines (Nylund-Gibson and Choi, 2018). When items are meaningfully linked (for example, several statements that all invoke ethical concerns about future generations), the model can’t account for their residual correlations—leading to respondents being misclassified into the wrong class or to a single discourse being split into multiple artificial classes (Nylund-Gibson and Choi, 2018).
- Principal Component Analysis (PCA): PCA effectively reduces dimensionality without relying on a conditional-independence assumption—unlike LCA/LPA, it does not require that variables be uncorrelated within latent groups. However, PCA still treats all variables as equally important in constructing its components, which can obscure the relative weight that certain questions or statements carry in defining a discourse. Moreover, PCA remains fundamentally an item-centered technique: it focuses on patterns of covariation among variables rather than on grouping participants into coherent clusters. Although PCA does assign each individual a set of component scores, it does not inherently identify or delineate person-centered discourse types
Table 1 summarizes the principal shortcomings of current discourse-mapping methods—namely their item-centered focus, inability to aggregate underlying reasons, absence of weighting schemes, and limited scalability.
Summary methods’ analytical constraints.
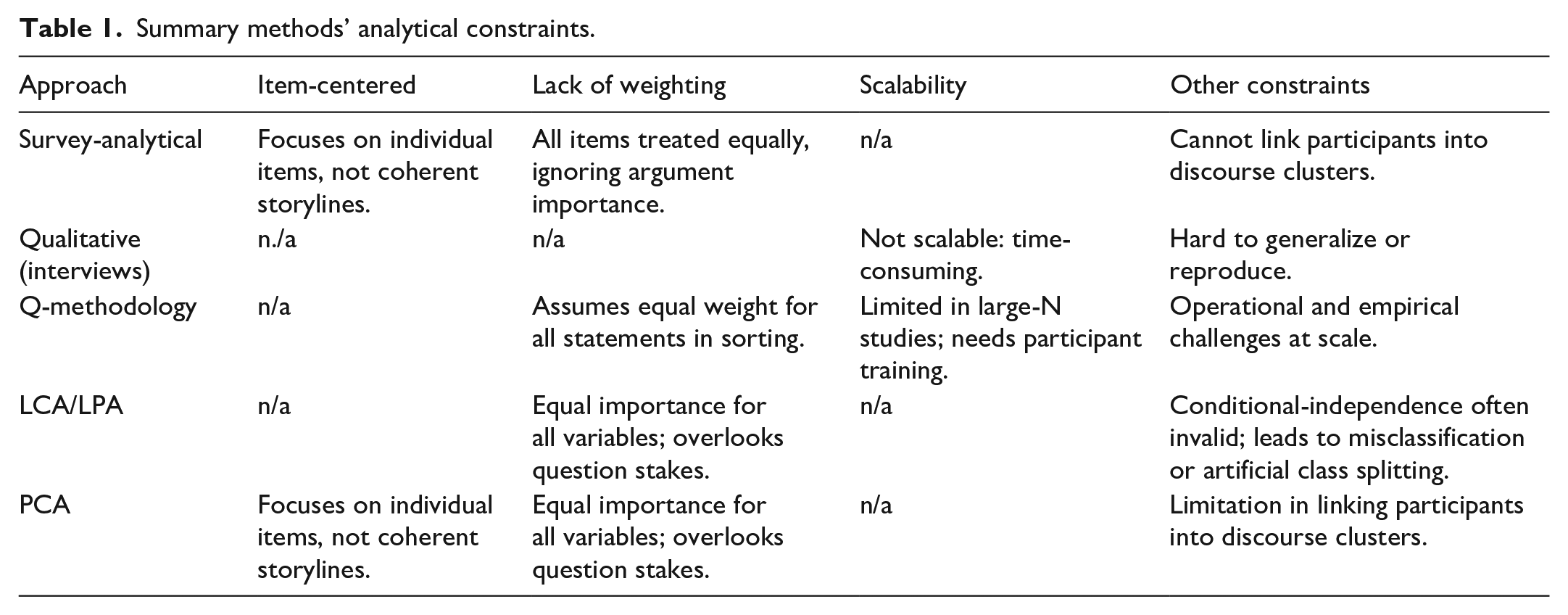
We can identify several key constraints that affect all existing methods for mapping discourses. First, most approaches remain item-centered, treating each question or statement in isolation rather than recognizing how arguments interlock to form a coherent narrative. Second, they fail to capture discourses as aggregations of reasons: instead of clustering participants around interrelated arguments, each method reduces complex storylines to independent items. Third, by assigning equal weight to every statement or variable, these techniques flatten nuance—treating all reasons as equally important and obscuring which arguments carry the most discursive force. Finally, scalability is a persistent challenge: qualitative interviews demand extensive coding and interpretation, Q-methodology requires intensive participant training, and even large-sample techniques like LCA/LPA can struggle with misclassification or model overfitting when discourse statements overlap. Together, these limitations hinder our ability to map richly structured, meaningful discourse clusters at scale.
Q-concourse, MFA, and HCPC
We address these constraints with a three-step method. First, we build a Q-method–inspired concourse by gathering all relevant statements on the topic, ensuring survey items reflect coherent arguments rather than isolated questions. Second, we use MFA to reduce dimensionality, grouping statements into thematic blocks and weighing each block so that no single set of items dominates—preserving nuanced discourse complexity. Third, we apply HCPC to cluster respondents within the MFA-derived space, yielding person-centered discourse types without forcing arbitrary classes. This pipeline—Q-concourse, MFA, HCPC—resolves item-selection issues, incorporates argument weighting, and scales to large samples while faithfully mapping multi-argument discourses.
Phase 1: Concourse of discourse central statements
The first priority in capturing discourses quantitatively is to choose items that, together, genuinely represent different discourse types. If the survey questions do not form a coherent set of arguments or positions, respondents’ answers cannot be meaningfully grouped into distinct narrative clusters. Q-methodology addresses this challenge by using the concept of a concourse—the complete “universe” of statements and ideas that people draw upon when discussing a particular topic. The concourse serves as the foundation for deciding which discourse elements should be translated into survey items. In practice, statements for the concourse can be gathered from public or political debates, journalistic sources, and social media platforms. Large-scale text-analysis tools—such as Natural Language Processing (NLP) and Natural Language Understanding (NLU), web scraping, Large Language Models (LLMs), and text-based factor analysis—can be used to extract, classify, and organize the sentences that embody distinct discourses. With the advent of LLMs in particular, this has become possible and is considered a reliable technique for automating the coding and triage of core discourse statements (e.g. Flechtner, 2025; Gilardi et al., 2023). Once this set of statements is established, the survey presents them to participants using Likert scales (or, where appropriate, continuous or binary responses). By grounding each question in real-world arguments, this approach enables the identification of authentic discourse clusters within the collected responses. In our study, we rely on Likert scales, which align with the ordinal structure commonly used when translating Q-method statements into survey formats. The aim is to preserve respondents’ subjective evaluations of discursive statements—something Likert items capture effectively by allowing for graded expressions of agreement. While continuous scales are theoretically possible, Likert formats arguably offer a more cognitively accessible and familiar response structure for measuring nuanced attitudinal positioning (Preston and Colman, 2000), especially in large-N contexts. This choice is consistent with best practices in survey research, which emphasize the importance of balancing measurement granularity with respondent comprehension to ensure data reliability.
Phase 2: Reason types weighing through multifactor analysis
The second priority is to identify patterns and narrative across surveys by weighing for different survey questions accordingly to the type of argumentation they are pointing to. MFA is a weighted factor analysis, and factor dimensions are generated by weighting and balancing sub-blocks of surveys’ questions. This allows the researcher to identify discourse dimensions that point to specific pre-existent analytical angles as differences on the theme of the questions. This is normatively important as it allows us to account for survey complexity and specific discourses fingerprint by giving specific weight to group of similar questions, by for example gathering questions according to an underline perspective as social, economic, political, geographical, and so forth. More technically, in MFA each group of variables are weighed by dividing all their elements by the square root of the first eigenvalues obtained by the PCA. Finally, the normalized tables are juxtaposed into a single matrix and subjected to a final PCA (Escofier and Pagès, 1994). This procedure allows each block variable to equally contribute to the percentage of inertia. 1 As weighted factor analysis, MFA allows discourses to improve dimensional characteristics as it accounts for survey specificities and meaningful frames.
Therefore, through MFA it is possible to account for within survey discourse complexity by operating a factor analysis that accounts and weight different block of questions that point to different angles of discourses concepts.
Phase 3: Person-centered clustering through Hierarchical Clustering on Principal Components
HCPC allows each survey’s participant to a specific configuration of discourses retrieved by MFA. HCPC provides a statistically precise understanding of discourses, as it analyses surveys dataset from denoised data, maximized within-cluster variation and external between-cluster variation. Through HCPC, it is possible to retrieve the core homogenous dimensional characteristics of discourse within each cluster by configuring MFA’s factors. Indeed, principal components are configured into a multidimensional Euclidean space and participants are assigned to a cluster according to their specific location within such dimensional space.
HCPC provides three specific sets of information that allow one for an in-depth characterization of each participant’s discourse.
- Participants are located on a multidimensional discourse map: Discourses retrieved by MFA and then configurated through HCPC into a 2k map. Specific participants’ discourses are typified into such multidimensional configuration of core dimensional discourses that MFA accounts for. This allows one to identify multiple discourses-shades into a thick multidimensional space. Practically, clusters are built by calculating each participant’s MFA’s component mean. Each participant is clustered considering their similarity in component-mean values with other participants and the statistical difference between their component-mean and the whole group component-mean. Each cluster is created by considering the principle of within-cluster homogeneity and between clusters heterogeneity that are isolated through significant test (i.e. v.test). The configurative factor map allows increasing the universe of possible discourses exponentially. By using a reduction ad absurdum example, if we submit 40 questions survey to 7 billion participants, the number of possible universe of discourses would not be only 40 (as in Q methodology) but a potential computational number of 240 discourses which represent the basis for cluster typification. This is a huge number 2 which is exponentially bigger than the sample considered.
- Survey questions homogeneity: Dimension configuration also allows one to identify a homogeneous set of survey questions within each cluster that are significantly different from the group answers. This allows isolating the core set of responses that characterize each participant within each cluster. Such core set of questions also represents the core discourse content for the cluster.
- Participants defined into a prototypical space membership: The last analytical advantage of the HCPC technique is to locate prototypical participants in Euclidean space. Through HPCP, it is possible to locate each participant within the 2k MFA’s dimensions configuration and identify the cluster epicenter and the relative participant’s distance to such epicenter. The more a participant is closed to the cluster’s epicenter, the more they would be considered prototypical of such a cluster and fit the definitional aspect of the cluster-discourse.
As participant-centered clustering technique, MFA/HCPC allows to isolate dynamic representation of discourses into a multidimensional space and how participants are related to such dynamics.
Analysis of discourse: An empirical example
The empirical example proposed refers to a survey on consideration over human genome editing which was submitted to a quota-stratified sample of the Australian population (Nicol et al., 2022).
Survey overview
The population survey was administered online in March–April 2022 via a market-research firm’s panel to 1008 Australians (845 viable responses), using a quota-stratified approach to approximate national distributions of gender, age, education, religion, and state—rather than a purely probability-based sample. The average completion time was 23 minutes and 11 seconds. No post-survey weights are reported. The questionnaire was offered in English only, and although standard panel-provider incentives likely applied, no explicit incentive details are provided. As described in Nicol et al. (2022), the concourse of statements constituting the survey questions was selected following a two-step procedure. First 46 Q-sort statements were derived by thematically coding over 1200 source quotations (from expert interviews, public forums, media comments, and academic literature), which allowed two independent coders to identify emergent “insider” themes and then select or synthesize representative statements (with minor grammatical smoothing) to ensure that all salient dimensions—such as equity of access, safety concerns, and ethical limits—were captured; this pruning and validation yielded a final set of 46 items (Nicol et al., 2022). From those, 16 items were selected for the population survey using Niemeyer’s (2010) discursive-sampling approach: the team iteratively tested candidate subsets by computing each respondent’s indexed factor loadings from those items and comparing them to the full-set loadings, retaining the 16 statements whose indexed loadings correlated above r > 0.9 with the full-set loadings across all four discourses, thus ensuring that the smaller survey still faithfully reproduced the original factor structure (Nicol et al., 2022). The final population survey contains 16 questions which we manually divided into two subgroups (Table 2):
Ethical-normative considerations (Type E): These considerations explore the moral, philosophical, cultural, and societal implications of genome editing. They delve into subjective unmeasurable judgments, inherently subjective, qualitative, and deeply personal, making them difficult to qualify them into a concrete output, but refer to a system of values, rights, identity, and broader societal consequences (e.g. fairness, autonomy, and cultural beliefs).
Technic-practical considerations (Type T): These questions focus on the practical, scientific, and operational aspects of genome editing, such as its safety, efficacy, risks, or tangible outcomes. They address empirical or measurable implications, even if those indirectly raise ethical concerns.
Survey questions characterization.

The Ethical block contains questions addressing the moral dimensions of human genome editing, such as its perceived moral impact (Q3, Q4, and Q9), ethical constraints (Q5 and Q14), rights (Q1, Q8, and Q13), broader societal implications (Q6, Q15). The Technological block focuses on evaluating concrete benefits (Q11) and risks (Q7) based on measurable outcome (Q2), assessing practical implications (Q16) and safety (Q10), excluding moral judgments and focuses on personal acceptance of a practical application (Q12).
Given the subjective nature of Q-methodology, where personal perspectives shape responses, some questions (e.g. Q2 and Q12) blend ethical-normative and technico-practical dimensions. We classified these as Type T based on their primary focus—measurable outcomes (e.g. genetic diversity for Q2) or practical decisions (e.g. personal consent for Q12)—while recognizing secondary ethical implications, such as societal consequences or autonomy.
Discourse mapping
MFA was conducted to account for the survey’s analytical framework, with particular emphasis on balancing and integrating both ethical and technical concerns. This approach ensures that the analysis reflects the nuanced interplay between moral considerations and the practical implications of technology. In this respect the two blocks of survey questions, ethical and technological perspectives, received the same overall weight. As the technological block (Type T) contains 6 questions and the ethical block (Type E) 10 questions, the relative weight of each single Type E question will be slightly smaller than the relative weight of the Type T.
The MFA identified three distinct dimensions, capturing a cumulative explained variance of 57.5% for the survey data. This result surpasses the threshold of 55% cumulative variance commonly recommended in the literature (e.g. Field, 2013), suggesting that these dimensions provide a robust representation of the underlying constructs.
Considering the dimensional factor characteristic of the analysis we have a possible universe of discourses that is equal to 23 configurations of factors (eight discourses).
Each dimension is characterized by a set of specific survey questions that are represented in figure 2 through variables’ cosine-squared (cos2) values. 3 Cos2 provides information on factor dimension identity, as it details which variable contributes most to that dimension. A higher cos2 value means that a variable is more strongly associated with the dimension, playing a significant role in defining it (Abdi and Williams, 2010). Each dimension is represented on the axes (Dim1, Dim2, and Dim3), corresponding to MFA components that capture data variation. Dim1 explains 35.6% of the variance, while Dim2 and Dim3 account for 15.4% and 6.1%. These dimensions help identify latent structures in survey data, clustering similar questions. For instance, in Figure 1, quadrant 1 (Dim1 vs Dim2) highlights Q3_12 and Q3_11, while quadrant 2 (Dim1 vs Dim3) shows Q3_13 and Q3_5, contributing significantly to Dim 2.
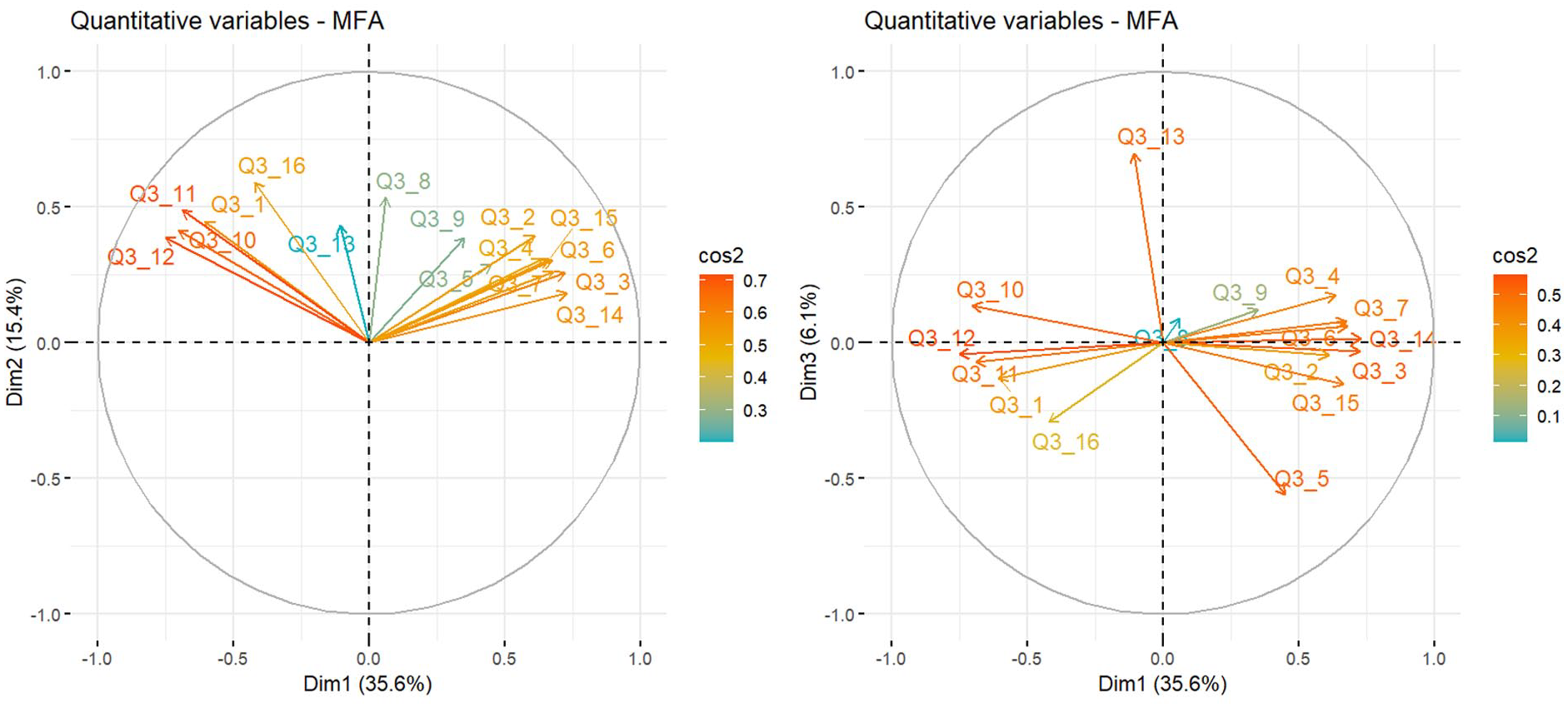
MFA dimensions and survey questions.
From the Correlation circle we can observe the most important characterizing variables for each dimension extracted. In this respect by considering high cos2 and correlational values we can define each dimension characteristic and provide a label to each dimension positive value:
- Dimension 1 (Dim1)—Socio-techno distrust: this dimension is characterized by negative values of Q3_10, Q3_11, and Q3_12, and positive values in Q3_2, Q3_3, Q3_4, Q3_14, and Q3_7. This dimension refers to a general mistrust and fear toward technology (Q3_7 and Q3_14) strong ethical concerns over human genome editing with strong emphasis on social repercussion (Q3_3 and Q3_4). This vision is reflected in strong concern on genome editing application on human and future humans (Q3_10, Q3_11, and Q3_12). By and large this dimension is similarly related to the profound social risk dimension identified in the mapping study of the Citizens’ Jury report by using Q methodology (Nicol et al., 2022).
- Dimension 2 (Dim2)—Inevitability and identity in genetic tech: this dimension is characterized by positive values on Q3_16 and Q3_8. This dimension is characterized by a fatalistic attitude toward this technology which is seen as unavoidable (Q3_16), but also believe that genes play a strong role in human intrinsic identity beyond biological dimension (Q3_8).
- Dimension 3 (Dim3)—Lack of cultural limits and tech choices: This dimension is characterized by a positive value on Q3_13 and negative on Q3_5, showing no cultural constrained (Q3_5) over such technology. As culture is constraining human relationships, individuals should not be in the position to decide for themselves in relation to the issue at stake (Q3_13). This dimension is strongly similar to the idea of profound principal concerns pointed out by Nicol et al. (2022) mapping study.
Dimensional negative values represent the symmetric opposite of the positive values. In Dim1, the negative pole reflects socio-technological trust and optimism, with minimal concern for the social risks of human genome editing. Dim2’s negative pole is characterized by technological free-choice and identity flexibility, where human identity transcends genetic makeup, and genome editing is seen as unnecessary for human survival. Lastly, Dim3’s negative values are linked to individual autonomy and technological liberalism, with strong support for personal choice in technology-related decisions.
HCPC analysis
HCPC locates participants on the dimensional map (Figure 2) and estimates their cluster by calculating Euclidean distance to the cluster epicenter. Each cluster is isolated using a significant test (v-test) on MFA factors and specific survey questions, clustering participants by within-cluster similarity and between-cluster diversity. Figure 2 shows the final cluster mapping based on MFA dimensions.
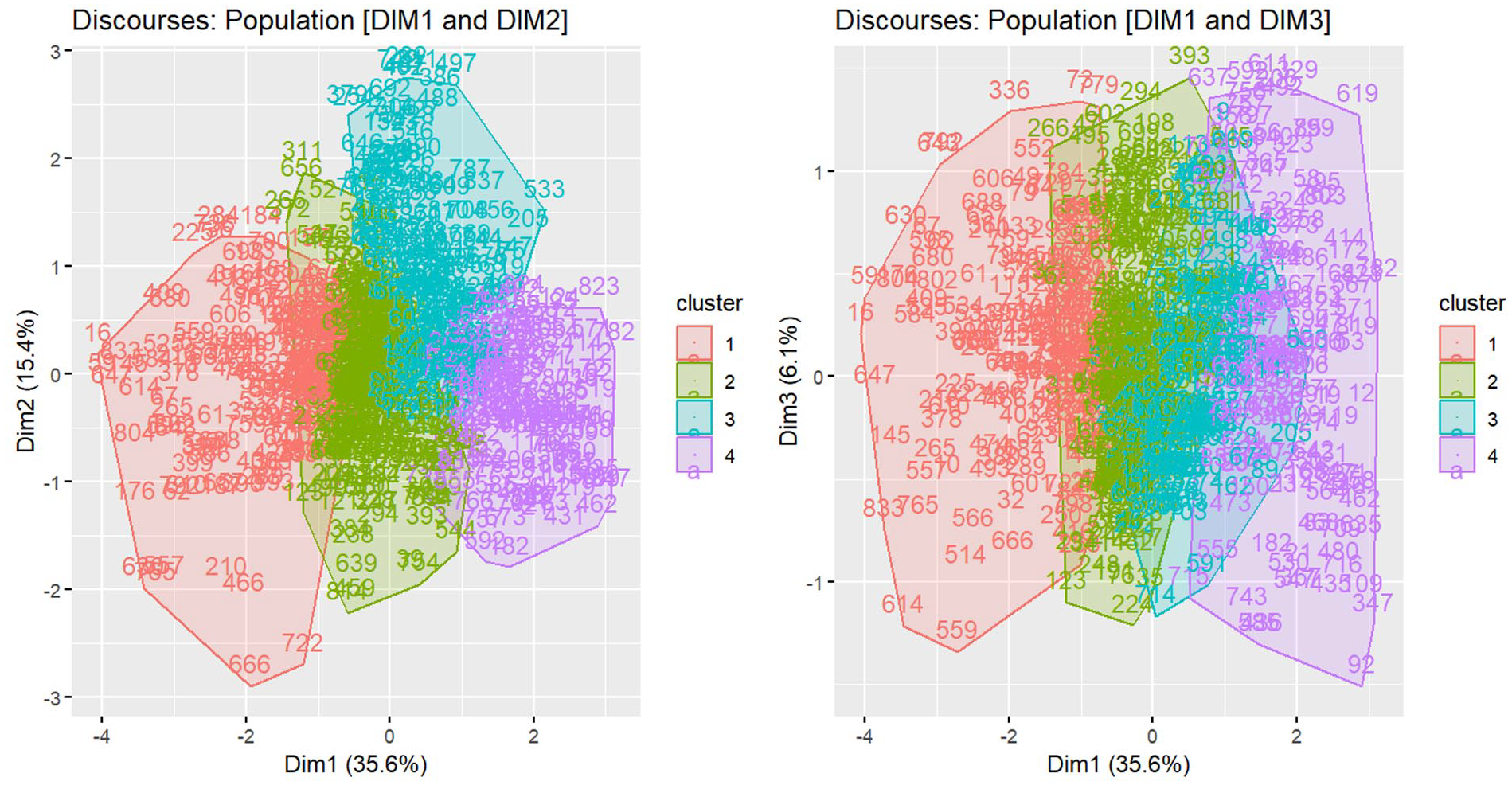
Discursive clusters.
Table 3 reports each cluster factor dimension characteristics, which ultimately defined the discourse mapping.
Clusters dimensional axes.
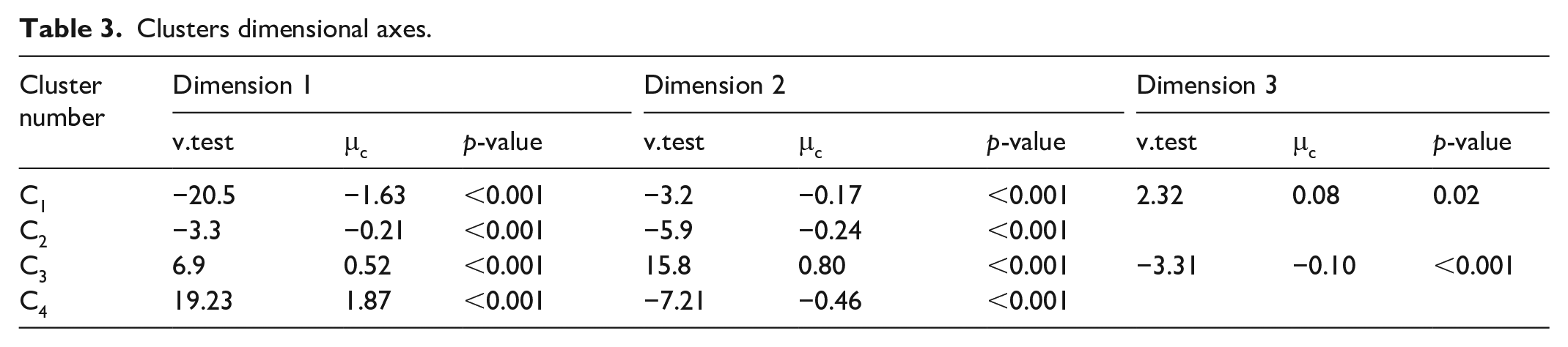
Cluster discourse labelling is operated by considering each cluster’s position toward specific MFA dimension.
- Progressive Genome Editing Proponents Cluster (Cluster 1—C1): C1 shows a strong negative location on Dim1 (μc = −1.63), linked to socio-techno trust and optimism, and moderate negative on Dim2 (μc = −0.16), related to free-choice and identity flexibility. C1 is moderately positive on Dim3 (μc = 0.08), showing no cultural concerns. People in this cluster strongly support genome editing, willing to modify their own or their children’s genes (Q3_10, Q3_11, and Q3_12), have a rational and optimistic view of science (−Q3_15), with little concern about social risks or environmental impact (−Q3_2, Q3_3, and Q3_4).
- Cautiously Optimistic Gene Editing Advocates Cluster (Cluster 2—C2): C2 shares some characteristics with C1 but is less extreme. Dim1 is moderately negative (μc = −0.21), and Dim2 is also negative but moderate (μc = −0.25). C2 participants support gene editing with sufficient scientific evidence (Q3_8), acknowledging socio-ethical concerns (Q3_3, Q3_4, and Q3_6) but not cultural or moral implications (−Q5). They view gene editing as somewhat scary (Q7) but remain cautiously optimistic.
- Ethically Constrained Risk Awareness Cluster: C3 is strongly positive on Dim2 (Identity and Inevitability in Genetics) and Dim1 (Socio-techno distrust), and negative on Dim3 (no cultural constraints). This cluster places strong emphasis on ethics (Q6 and Q5) and expresses significant concern about social risks (Q3, Q4, and Q7). Participants in C3 reject genome editing, even if proven safe (Q12).
- Critical Vigilance Cluster: C4 strongly aligns with socio-techno distrust (Dim1, μc = 1.87) and moderately with free-choice and identity flexibility (Dim2, μc = −0.46). C4 members are deeply concerned about human identity risks (Q3_6) and view gene editing as a quick fix (Q3_3). They oppose its use for personal or generational purposes (Q3_10, Q3_11, and Q3_12) and question its necessity for human survival (Q3_16).
General clusters’ overview
By and large the four clusters can be divided according to two big families. This is directly observable by visualizing the cluster dendrogram in Figure 3.
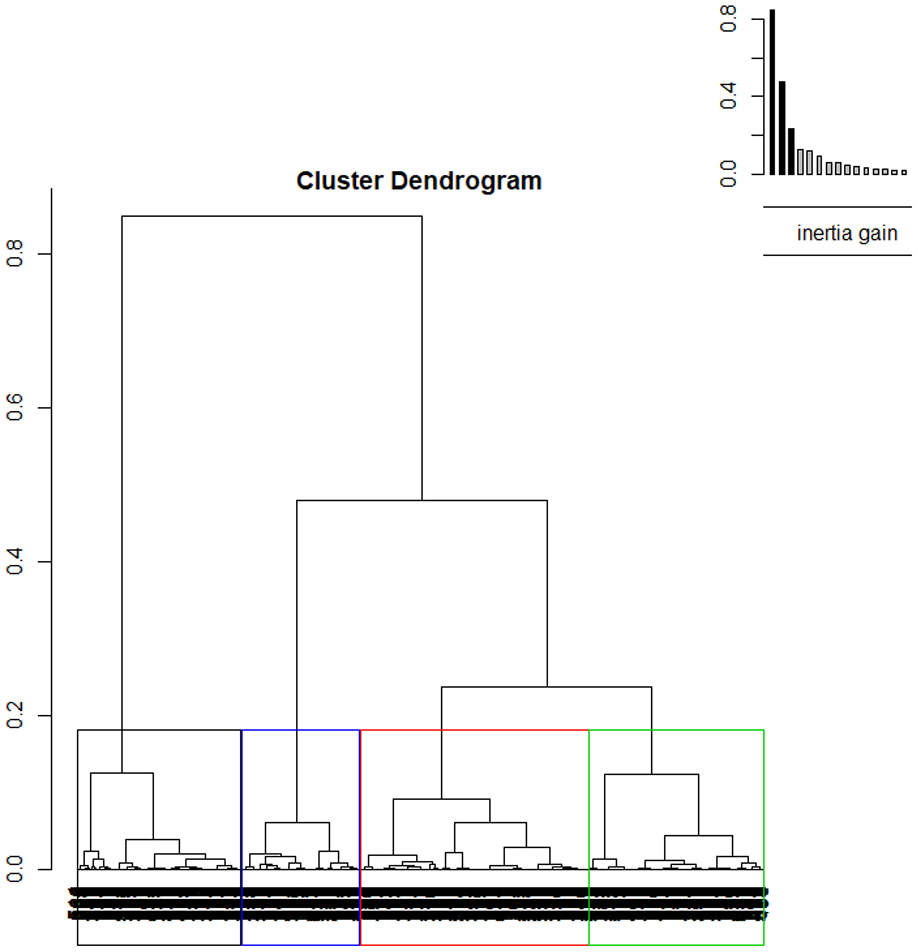
Clusters dendrogram.
As it is possible to observe C2, C3, and C4 belong to the same family, while C1 belong to a separate family. The cluster dendrogram also allows us to visualize possible subdivision of discourses into smaller sub-clusters. These subclusters defined different discourses’ shades. For example, in our example, it would be possible to identify a more or less libertarian perspective as subcluster of C1 (i.e. black cluster) or a more or less prudent vision as subcluster of C3 (i.e. green cluster).
Each cluster has a similar magnitude comprised of between 17.22% of C4 and 33.33% of C2.
Prototypical case
The cluster approach also allows us to identify which cases are the most prototypical for each cluster by calculating each case’s distances to their respective cluster epicenter. This approach allows us to explore in more in-depth what set of responses characterize each cluster.
As within each cluster cases responses are highly correlated, the correlational values of between each clusters’ typical cases would provide information on the relationship between each cluster epicenter
Validation of the clustering approach
Ensuring the validity and robustness of the clustering results is critical for any analytical methodology. To this end, we implemented a three-pronged validation strategy, incorporating both internal and external approaches, to rigorously assess the reliability of our clustering outcomes.
First, we utilized a train-test split to internally validate the identified clusters, ensuring that the clustering model performs consistently across different subsets of the data (Egami et al., 2022). This step checks for internal validity by confirming that the clusters generalize well from the training data to the test data, indicating a reliable model. Second, to externally validate the method and assess the risk of overfitting, we applied the clustering approach to a random dataset. This random dataset, which was designed to mirror the original sample in terms of the number of participants (n = 850) and variables (n = 16), served as a control to test the robustness of the clustering method against noise. Finally, we employed a synthetic dataset specifically crafted to contain clear, predefined clusters. This dataset, also matching the original sample size and variables, allowed us to benchmark the clustering method’s effectiveness in identifying well-defined groups.
By using these complementary validation strategies, our approach not only tests the internal reliability of the clustering model but also ensures that the results are robust and generalizable beyond the specific dataset, thereby minimizing the risk of overfitting and enhancing the overall validity of the analytical process.
Internal validation
A key limitation of the methodology proposed in this study relates to the potential overfitting and identification challenges that may arise when using the discursive clusters generated by MFA/HCPC in subsequent analyses. This issue becomes particularly significant when these clusters—latent representations of the survey data—are utilized as outcomes or treatments in further statistical models. As highlighted by Egami et al. (2022), latent representations like these can complicate causal inference due to overfitting and identification issues. These problems arise when clusters capture noise or dataset-specific idiosyncrasies instead of the underlying structure of the discourse, leading to unreliable and non-generalizable results when applied to new datasets.
To mitigate these concerns, this study underscores the importance of internally validating clustering results through multiple approaches. Following the recommendations of Egami et al. (2022), a split-sample method was employed. This involved dividing the dataset into two distinct parts: the first for identifying discursive clusters (training data which represent 80% of our dataset) and the second for testing these clusters in subsequent analyses (test data which represent the remaining 20% of the dataset). This method helps prevent overfitting to the initial dataset, thereby improving the generalizability and robustness of the findings.
The effectiveness of this approach is visually supported by the representation of clusters in the PCA space (Figure 4).
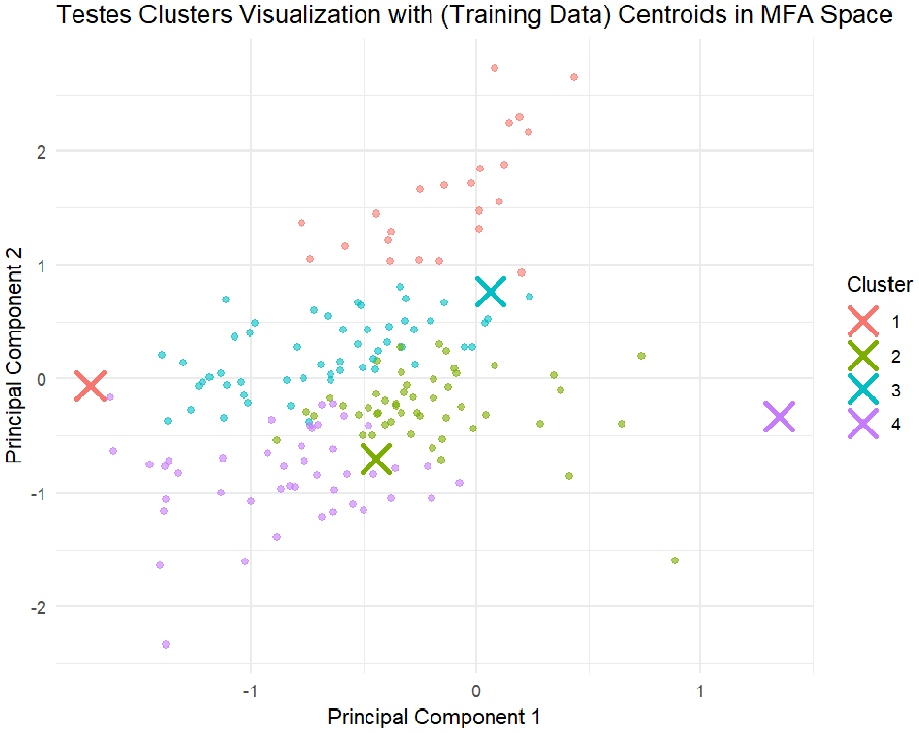
Tested versus trained clusters.
The clusters defined according to Egami et al. (2022) exhibit distinct patterns, which are visually discernible, though there are some areas where cluster boundaries remain somewhat ambiguous. The training data centroids indicate where the original clusters were expected to be centered, while the test data centroids show where the clusters center after applying the model to new data. The proximity of these centroids within each cluster suggests that the model generalizes well from the training data to the test data, indicating reasonable consistency in the clustering across both datasets. However, minor differences between the centroids may suggest some variability, warranting further exploration.
This visual evidence is supported by the silhouette test results (test data = 0.24 and train data = 0.22), which indicate that the clustering is reasonably effective, with a similar level of separation between clusters in both the training and test data. By incorporating these validation strategies, the study effectively addresses the overfitting and identification concerns highlighted by Egami et al. (2022). As a result, the clusters identified through MFA/HCPC are not only reliable but also robust and applicable in broader contexts, thereby enhancing the validity and credibility of the discursive analysis.
External validation with random dataset
The first approach used a randomly generated dataset to assess the MFA/HCPC methodology’s resistance to overfitting. Overfitting occurs when a model captures noise or random fluctuations in the data rather than actual patterns, resulting in unreliable, non-generalizable clusters (Hastie et al., 2009). By applying the method to data devoid of inherent structure, we aimed to test whether it could falsely detect clusters. The randomly generated dataset had no discernible patterns, ensuring that any clusters found would be artifacts of the method. After applying MFA with forced dimensionality (e.g. the first three eigenvalues explained only 23% of the variance) and clustering with HCPC, the Silhouette test (0.019) revealed extremely weak, diffuse clusters lacking internal coherence. This demonstrated that MFA/HCPC effectively avoids overfitting, as it did not impose structure where none existed, supporting findings from previous research (Handl et al., 2005).
External validation with synthetic data
The second validation approach involved using synthetic data designed to contain four distinct clusters, a common practice to assess clustering algorithms’ performance under controlled conditions (Hubert and Arabie, 1985). The synthetic dataset was created with clear separations between clusters, each characterized by a unique set of variables across dimensions extracted through MFA. These clusters were modeled after theoretical configurations discussed earlier in this study, providing a robust test for the MFA/HCPC method.
When applied to the synthetic dataset, the MFA/HCPC approach successfully identified four of the four predefined clusters with high accuracy, correctly grouping participants according to their assigned cluster characteristics. This demonstrated the effectiveness in detecting distinct clusters in controlled conditions. The Silhouette test, scoring 0.83, further validated the accuracy, indicating well-defined clusters. This successful identification aligns with the literature supporting the use of synthetic data as a benchmark for validating clustering algorithms and ensuring the reliability of outcomes (Steinley, 2003).
Comparison with other techniques
Conceptual capabilities
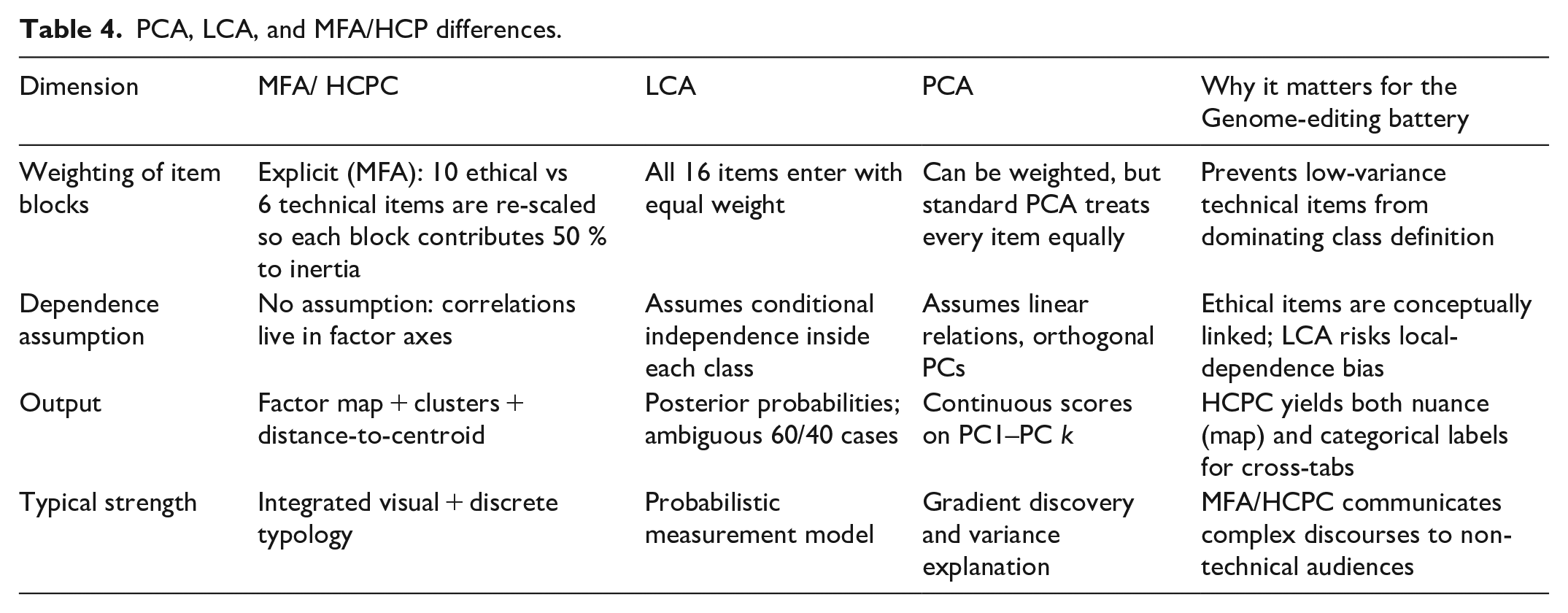
Table 4 displays the modelling assumptions that distinguish MFA/HCPC, LCA, and PCA. MFA inherits the geometric logic of PCA but rescales whole blocks of items—not individual variables—so that the 10 ethical and 6 technical questions each account for exactly half of the total inertia. The subsequent HCPC step then transforms the continuous factor space into discrete respondent types, side-stepping the conditional-independence requirement that can bias LCA when conceptually linked items reside in the same class. In other words, MFA/HCPC offers the variance-balancing advantages of PCA and the typological clarity of cluster analysis, without forcing an arguably unrealistic local-independence constraint. The right-hand column of Table 4 ties every design choice back to the ethical-versus-technical structure that shaped the Genome-editing questionnaire.
PCA, LCA, and MFA/HCP differences.
Empirical convergence on the Australian Genome-editing survey
To test whether MFA/HCPC merely renames patterns already captured by established techniques, we re-segmented the identical 843 respondents with LCA and with a two-dimensional PCA solution. We then cross-tabulated HCPC clusters (four groups) against (a) modal LCA classes and (b) PCA quadrants (High/Low PC-1 × High/Low PC-2). Pearson’s χ² measures association strength, Cramér’s V gauges effect size, and standardized residuals locate the cell pairs that drive each statistic (Table 5; see Online Supplemental Appendix for scripts).
χ² and Cramer V test.

In both head-to-head tests, Cramér’s V exceeds 0.55—a threshold usually taken as a large effect—showing that HCPC does not invent a new structure but rather sharpens one that LCA and PCA already detect. Yet residual matrices reveal that roughly 35%–40% of respondents occupy secondary cells, underscoring HCPC’s unique contribution: its distance-to-centroid metric flags marginal cases whose mixed profiles matter for nuanced policy work.
Implications for method choice
MFA/HCPC meets three criteria over LCA and PCA:
Theoretical fit: By block-weighting ethical and technical items, MFA explicitly embodies the questionnaire’s design logic, answering recent calls for theory-informed weighting in segmentation research.
Empirical robustness: High Cramér V values certify that HCPC clusters converge with, rather than contradict, the latent patterns recovered by LCA and PCA.
Communicability: Factor maps coupled with crisp cluster labels translate complex discursive landscapes into artefacts that policy stakeholders can grasp more readily than 16-line probability tables (LCA) or abstract eigenvectors (PCA).
Conclusion
Traditional survey analysis methods often simplify the rich cognitive dimensions of discourse, losing nuances critical for understanding complex political and social landscapes. The MFA and HCPC methodology, as highlighted in this study, adeptly avoids such reductive approaches. MFA acknowledges the intricate weight of varied question blocks, reflecting the cognitive complexity inherent in participant responses. Following this, HCPC clusters participants into refined groups, charting a multidimensional discourse map that mirrors the cognitive diversity within the surveyed population.
Maintaining complexity is crucial, particularly in areas such as political behavior and deliberative democracy, where the depth of public opinion and the intricacies of political discourse are paramount. By comprehensively capturing the cognitive dimensions of discourse, the MFA/HCPC framework promotes a more authentic and nuanced representation of democratic deliberation.
Supplemental Material
sj-docx-1-mio-10.1177_20597991251369126 – Supplemental material for Mapping discourses through Hierarchical Clustering on Principal Components
Supplemental material, sj-docx-1-mio-10.1177_20597991251369126 for Mapping discourses through Hierarchical Clustering on Principal Components by Francesco Veri in Methodological Innovations
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Genomics Health Futures Mission (GHFM) of the Medical Research Future Fund (MRFF).
Ethical considerations
This research was approved by the University of Tasmania Human Research Ethics Committee (project number H0021841) and the University of Canberra Human Research Ethics Committee (project number 9095).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.