
Abstract
Social work case files hold rich detail about the lives and needs of vulnerable groups. Traditional case-reading studies to gain generalisable knowledge are resource-intensive, however, and sample sizes thereby limited. The advent of ‘big data’ technology, and vast repositories of centrally stored electronic records offer social work researchers novel alternatives, including data linkage and predictive risk modelling using administrative data. Free-text documents, however – including assessments, reports, and case chronologies – remain a largely untapped resource. This paper describes how 5000 social work court statements held by the Child and Family Court Advisory Support Service in England (Cafcass) were analysed using natural language processing (NLP) based on simple rules and mathematical principles. Thirteen factors relating to harm and risk to children involved in care proceedings in England were identified by automated computer techniques, and almost 90% agreement with professional readers achieved when the factors were clear-cut. The study represents an innovative approach for social work research on complex social problems. In conclusion, the paper discusses learning points; practical implications; future research avenues; and the technical and ethical challenges of NLP.
Keywords
Introduction
The advent of ‘big data’ has demonstrated the potential and pitfalls of methods used to help understand and manage diverse areas of human endeavour, including customer preferences (Watada et al., 2020), traffic optimisation (Supangkat et al., 2019), political debate (Fournier-Tombs and MacKenzie, 2021) and healthcare (Dash et al., 2019). ‘Big data’ still evades clear definition but is often understood in terms of ‘three Vs’ (Information Commissioner’s Office, 2017):
In the social sciences, ‘big data’ may be viewed in terms of “the increased availability of new types of data which have not previously been available for social science research" (Connelly et al., 2016: 1). Crucially, ‘big data’ is ‘found’ (i.e. in existing database systems) as opposed to ‘made’ (via traditional research methods), bestowing on social work the major advantage of up-to-date, real-world, whole population data, without the heavy research costs entailed in collecting it for every study (Cariceo et al., 2018).
Within health and social care, understandings of risk have been shaped to a growing extent by probabilistic information (Søbjerg et al., 2020) and are increasingly derived from big data stores. These may be linked and anonymised by third-party agencies (Administrative Data Research Network, 2021; Nuffield Family Justice Observatory, 2021). For example, by joining care proceedings datasets with healthcare information and deprivation indicators, novel insights regarding parental health vulnerabilities emerge (Johnson et al., 2021). Predictive risk modelling applied to linked datasets (Cuccaro-Alamin et al., 2017) can also inform practice, for example child protection screening decisions (Chouldechova et al., 2018). Protecting children from maltreatment forms a key aspect of social care that raises ethical and human rights dilemmas (Duffy et al., 2006). Big data approaches may mitigate these by promoting consistency, equity and thereby transparency to service users (Coulthard et al., 2020).
‘Big data’ brings downsides. There are particular challenges to extracting meaningful knowledge from big data in some contexts, including health and social care (Wang et al., 2018). For social scientists, systems tend not to be optimised to facilitate extraction and analysis, rendering data ‘messy’ as opposed to ‘systematic’ in how it has been gathered for research purposes (Connelly et al., 2016). Within social work, much case detail is recorded as narrative text rather than numeric data, posing a significant challenge to existing technology. Although there are initiatives to quantify what has previously been purely qualitative text data (Taylor et al., 2020), it seems likely that analysing unstructured texts will be required for the fullest potential of big data to be realised in the near future, that is, by enriching insights gained from administrative and process data. One way to progress with this is through natural language processing (NLP).
NLP essentially refers to computer techniques that derive structured data from unstructured language, whether written or spoken. The more automated this can become, the more efficient and useful the process is likely to be. NLP, whilst burgeoning in business and medical applications, however, remains relatively undeveloped within social work and social care. Because it typically embraces cutting-edge computer science techniques, NLP may deter many researchers from such technical terrain (Crossley et al., 2014).
Effective NLP, however, requires not just a mastery of computer techniques, but a solid understanding of the textual material and its domain specific context (Gu et al., 2022). This paper describes an application of NLP within child protection social work that bridged social-computer science divides by applying professional knowledge alongside straightforward statistical methods of NLP that may be more accessible to non-computer scientists. The paper addresses the NLP component of a larger study which examined a range of factors influencing outcomes for children subject to applications by social workers for removal from parental care. Case-level factors, that is, of risk and harm to children, were derived using NLP, whereas process and demographic variables were extracted from administrative datasets and published governmental sources.
Because NLP represents innovation for social work research, we address two areas before covering the study’s methodology and results. Firstly, we examine the potential benefits NLP might offer to social work practice and research. Secondly, we outline NLP techniques and principles for an intended audience who are not computer specialists.
NLP: Potential benefits for social work
To date, NLP applied to social work has been limited, however many studies from related domains illustrate potential within this context. Here, we discuss these under the four broad headings: practice guidance; service description; predictive accuracy; transparency and equity.
Practice guidance
To make sense of extensive documentation, professionals must develop strategies, or personal ’rules of thumb’. Which are the key documents and their component sections that deserve the most attention? This inevitable ‘speed-reading’ approach can lead to relevant and important information being overlooked. The different decisions that professionals reach will also be guided by views already formed of a case, or verbal reports received, and can reflect confirmation bias (Spratt et al., 2015). Munro noted practitioners’ undue reliance in assessments on ‘evidence that was vivid, concrete, arousing emotion and either the first or last information received’ (Munro, 1999: 745). Written information was less likely to be noticed than verbal. In one case, all professionals attending a review overlooked a non-accidental injury recorded in a paediatrician’s report that all had read (Munro, 1999). Although these comments reflect practices observed more than two decades ago, they are likely to be relevant today as pressures on social workers reportedly mount, through increasing caseloads, and case complexity (Preston, 2022). Text summarisation technology using NLP (El-Kassas et al., 2021) aims to distill key points, indicate ‘red flags’, guide and prompt actions. These represent checks, balances and safeguards that might avert adverse outcomes.
Service description
Investigating the needs of service users, Bako et al. (2021) successfully applied NLP to electronic medical records. They gauged the numbers of patients attending a health care centre who were receiving social work support, as well as the nature and number of the interventions delivered. The authors concluded that NLP algorithms could be incorporated within existing systems, at low cost, to target resources more effectively using data otherwise hidden within free-text. Zhou et al. (2015) applied NLP to patient discharge summaries to identify the 20% of cases of depression that had escaped manual coding for the illness. Other studies have also used medical notes to quantify areas of social risk, for example, isolation and homelessness, that contribute to health outcomes within patient populations (Conway et al., 2019; Dorr et al., 2019). These studies show how NLP could potentially enhance understanding of the needs and difficulties of those who receive social work support.
Predictive accuracy
NLP has identified emotions associated with adverse outcomes, as well as real-world events. Cook et al. (2016) gauged suicidal ideation and psychiatric symptoms amongst discharged patients based on their text responses to general follow up questions relating to wellbeing.Van Le et al. (2018) analysed electronic medical records using dictionaries, comprising both medical and lay terms denoting emotions, to predict scores on four formal risk assessment instruments. Greenwald et al. (2017) applied NLP to patient discharge summaries to predict the likelihood of hospital readmission. These studies highlight how analysing unstructured text could foreseeably corroborate, refine or validate professional assessments, also flagging up possible anomalies.
Transparency and equity
When NLP is used to predict human decisions, a further potential benefit emerges. Using written judgements published on the internet, Aletras et al. (2016) predicted, with near 80% accuracy, the word clusters associated with judges’ rulings on applications received by the European Court of Human Rights. By a similar concept, Tupper et al. (2016) identified the words most associated with social worker decisions to accept incoming referrals for further action. These studies did not examine risk of real-world events, but in fact shed light on the factors leading professionals to their conclusions. This analysis is important if we are to measure and promote consistency, transparency, and equity in decision-making processes. Kahneman et al. (2016) argue that inconsistency in decisions is always higher than professionals estimate it to be, but can be reduced through simple rules, to which adherence may be monitored, and agreed exceptions allowed. Accordingly, NLP could provide another tool to render services more equitable across decision-makers and geography, promoting transparency to those who use them, and the public purse which funds them.
NLP: methods and techniques
Broadly, NLP approaches fall into two categories (a) ‘rules-based’ and (b) ‘machine-learning’, however most projects, including those cited above, will use a combination. Essentially, the former leaves the human in full control, with experts setting the rules for algorithms to follow, and human readers testing the results. Rules may be based on professional knowledge, literature searches and focus groups, etc. For example, a rules-based method to determine the prevalence of substance misuse within a population of service users might seek the terminology professional assessors use to describe the problem. Relevant terms might then be counted within assessment reports, and reading exercises used to determine how accurately high word counts reflect this area of difficulty. On the other hand, a machine learning approach tasks the computer with delivering the answers. By providing a large volume of ‘labelled’ reports, a computer can detect for itself the key words, clusters and associations associated with the ‘correct’ answer, that is, ‘does, or does not, involve substance misuse’.
To understand the strengths and limitations of each approach, it is necessary to consider context and goals. Rules-based methods can introduce human bias, whereas machines dispassionately detect word associations and fine-tune the weight to attach to each. Over thousands of iterations, computers ‘learn’ and produce increasingly accurate results. Building this type of artificial intelligence requires, however, vast quantities of labelled data which in some contexts may not exist. For example, machine learning may be the optimal approach to determine themes associated with five-star customer reviews, when thousands are available, and the views of customers are unknown. Machine-learning might also be appropriate in a social work context to assess the factors associated with a known outcome, for instance a referral being accepted or rejected. If, however, the purpose was to estimate the prevalence of a specific factor from unseen document texts, many human raters might need to read and rate the documents first and might still disagree.
Nor can human judgement and potential bias be entirely avoided through more technical solutions. Whereas machines may return word clusters associated with given outcomes, humans must interpret and define the themes that the computer-generated clusters represent.
Unsupervised approaches can be most valuable where the themes are novel, for instance where customer responses to a new product are unknown. In a domain such as social work, however, the types of difficulties and range of needs that service users typically experience are well known to practitioners and policy makers, and are sometimes also prescribed within assessment frameworks. In this instance, using an unsupervised approach may yield few surprises, whereas a rules-based approach may be pragmatic and cost-effective. The researcher first defines the factors indicated by the literature and professional input, then uses simple rules that can be applied consistently across every document processed, to identify the specific factors present within document texts. Rules set by humans, as opposed to machine learning technology, are also transparent, in that it is possible to explain how they were created and implemented. This forms a crucial consideration, when assessments and predictions inform important decisions about people’s lives (Rudin, 2019).
Improving precision within NLP
Perhaps the most straightforward NLP approach views each text as a ‘bag of words’, upon which a range of techniques may be applied, ignoring word ordering, sentence construction or grammar (Juluru et al., 2021). Many words, however, convey different meanings according to their surrounding terms, rendering simple word counts error-prone in some situations. Furthermore, although some terms, for example ‘dementia’, are semantically unambiguous, their usage dictates their relevance to the purposes of each study. ‘Dementia’, for instance, may be either a current problem, one that has been ruled out by diagnostic tests, merely suspected, or attributable to another family member cared for by the patient. Word sense disambiguation (Navigli, 2009) is a complex aspect of NLP embracing approaches that clarify word meaning, whilst other techniques, including negation, sentiment, and temporal analysis can clarify whether a term is present/ruled out, used positively/negatively, or is current/historic (see Harkema et al., 2009, for an applied example). Crucially, such techniques require word ordering to be preserved, and usually complex pre-processing of sentence construction. Importantly, whether such sophistication is needed, or whether a ‘bag of words’ approach is appropriate, requires understanding the context and purpose of document texts. This will be explained further in the next section, under ‘assumptions and principles’.
The study
Aim
This study set out to estimate, using NLP, the prevalence of case level factors known to be linked to risk and harm for children subject to care proceedings.
Governance and ethics
Research approval was obtained from Ulster University’s Research Ethics Committee, and Cafcass Governance. The project involved highly sensitive data relating to thousands of vulnerable service users, therefore data privacy raised the most pressing concerns. Life-changing decisions usually involve sensitive data however, making it unethical not to subject such data to rigorous scrutiny (Hayes and Devaney, 2004).
For big data projects, it is recognised that obtaining informed consent from data subjects will not be feasible (Information Commissioner’s Office, 2017) Anonymised data, however, does not fall within data privacy law, therefore anonymisation represents the preferred safeguard. Full anonymisation, however, involves removing all potentially identifying details, even indirect identifiers, that is, that which might be combined with data or knowledge available elsewhere to a data recipient. Because the motives and means of those who might seek to misuse data in this way cannot be known, full anonymisation is technically impossible, however data are deemed sufficiently anonymised where the re-identification risk is ‘remote’ (Information Commissioner’s Office, 2012). This standard is more straightforward to assure when anonymised data is released to a restricted and vetted audience, and securely stored (Elliot et al., 2016). A risk-based approach to assessing privacy concerns is thus required (Stalla-Bourdillon and Knight, 2017).
For maximum protection of data security, all data were collected using a Cafcass-supplied dedicated laptop. The lead researcher authorised to handle the data was police checked and underwent information assurance training. All sensitive details were processed and anonymised within the Cafcass secure IT environment prior to transfer for secure storage and further processing at Ulster University. This approach, termed the ‘safe site’ model (Elliot et al., 2016), facilitates external research by complying with data protection law and minimising risk of inadvertent disclosure, whilst reducing demands on the data controlling organisation’s staff and resources.
Assumptions and principles
As stated above, NLP precision may require analysing word context to ensure the meaning of terms can be captured accurately. By taking account of the context and purpose of documentation, more straightforward approaches may be possible. This project’s methodology exploited three observations. First, that court documents are evidential texts, written to support intrusive state intervention. As such,
Documentation
Since 2014, all local authorities in England must file a social work evidence statement (SWET) with the court for each care application issued. Averaging seven-thousand words (excluding standard text and identifiers), the SWET comprehensively summarises all prior agency involvement, the harms each child has experienced, the difficulties facing the family, and the options available to the court. Of the many documents the court must consider, the SWET is arguably the most influential as it sets out the local authority’s case at the outset of proceedings. The Word document format renders it amenable to automated processing. Copies of these statements for each local authority are held centrally by Cafcass within their electronic case management system (ECMS).
Software and processing
Processing and analyses were conducted in Microsoft Excel using formulae alongside bespoke programmes (termed ‘macros’) created within Visual Basic for Applications (VBA), the integral programming language supplied with all Microsoft Applications. Extensive use of pattern-match search and replace operations was enabled by the Regular Expressions (Regex) VBA add-in. Historically, VBA has been used by the wider community of advanced Excel users rather than computer scientists, who might consider it less powerful or appropriate for complex tasks. As stated above, however, more sophisticated technology tends to be less accessible to social scientists and a social work research skillset, with the consequence that NLP might not be attempted at all. This project represented a valid starting point, using traditional, tried and tested technology that was also fully transparent.
A simplified summary of the complex processing techniques can be provided here, outlining the essentials required to give an overview of the key parts of the method. More detailed information can be found in the supplementary data file, or by email to the corresponding author.
Case sampling
Thirty-one thousand care order applications (i.e. for child removal from current home circumstances) in England, initiated and concluded between 1 January 2015 and 31 December 2017, were identified from the Cafcass database by routine database query. A VBA-automated analysis of the documentation held for these cases identified 5320 SWETs, in accessible format on the prescribed template, and dated within 30 days of the application date. This represented a substantial sample of the 31,000 cases. All SWETs identified were saved to a dedicated electronic folder.
Pre-processing
Pre-processing operations typically undertaken in NLP projects were kept to a minimum, to preserve legibility of the contents for later scrutiny and the rating exercise undertaken by professional readers (described below). Punctuation was retained but separated from adjacent words, and stop-words (e.g. ‘the’, ‘and’ ‘to’) were left in place. Capitalisation was retained to create rules to classify terms. Pattern-match search and replace rules were used to identify and process names, addresses, and other potentially identifying information.
All word documents were batch-processed, using loop procedures applied sequentially each document in the folder. The five-thousand Word document texts were standardised for automated transfer to Excel, one paragraph of text per Excel cell. This format enabled faster processing, and the use of cell references to more readily identify and process certain contents.
Word classification
Using a pattern-match search and extract routine, all 460,000 unique terms, that is, proper nouns, names, numbers, and neutral words, etc. were listed from the 38-million-word document set. Using specialist dictionaries and look-up formulae, each term was classified as either a neutral term, a name, a place, etc. Mis-spelt terms were excluded. Ambiguous terms (belonging to more than one category) were further classified using rules, based for instance on capitalisation or adjacent terms.
Anonymisation
Once classified, all direct and indirect personal identifiers, including agency and professional details, place names and nationalities, were redacted. To preserve document sense, however, case names were pseudonymised on a case-by-case basis by searching and replacing case names provided in tabular form at the start of the document. Original names were not retained, therefore this instance of pseudonymisation complied with data protection legislation. Out of caution, a few ambiguous terms that defied accurate classification were simply redacted, to avoid the possibility of personal information remaining, with minimal loss of meaning later reported.
Document-term matrix
Employing a ‘bag of words’ approach, 32,000 neutral words and phrases were identified across the document set. A document-term matrix was created by listing these terms, with the document reference numbers across column headings. Frequency counts for every word and phrase were obtained for each document.
TF-IDF transformation
The most useful terms are those that occur often but only in some documents, that is, most powerfully discriminate between documents. For example, ‘mother’ occurs very often but tells us little. The term-frequency-inverse document frequency (TF-IDF) score is derived from a mathematical formula that assigns the highest weights to the most commonly occurring, in the fewest documents (Manning and Schütze, 2000, Chapter 15). The effect of the transformation is shown below at Table 1, which lists the relative position of terms before and after transformation.
The 10 highest scoring terms by TF-IDF, and their ranked frequency before TF-IDF transformation.
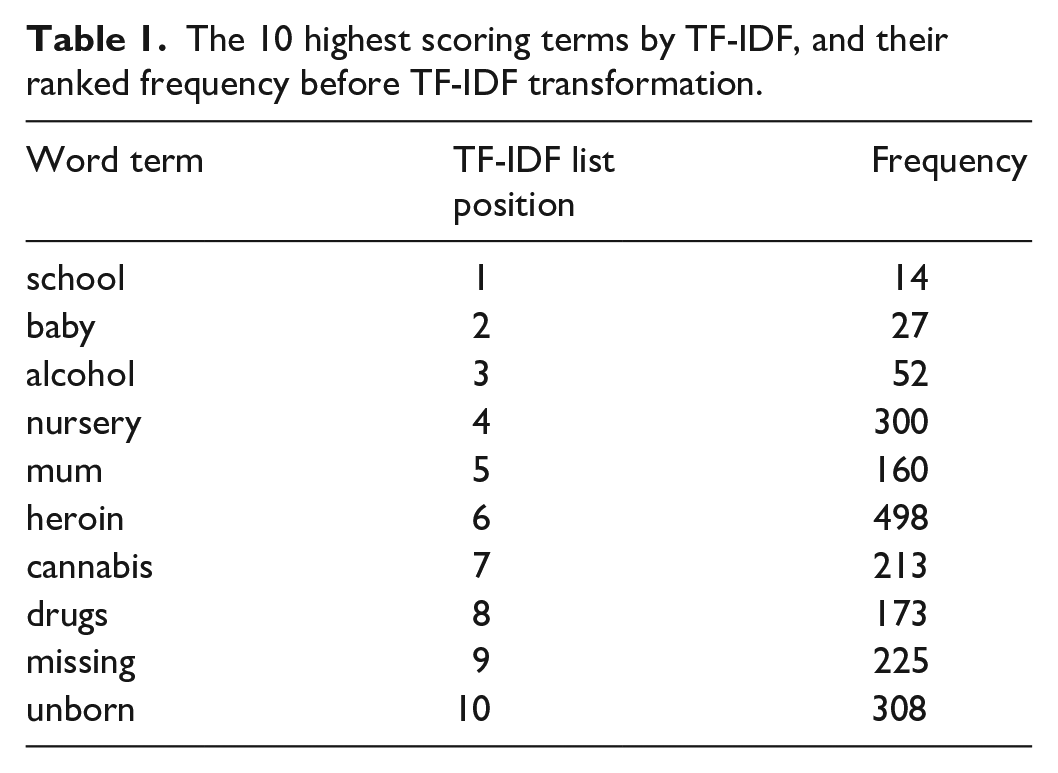
The two-thousand highest scoring TF-IDF terms were those mathematically indicated to be the most powerful. The application of the TF-IDF formula thereby avoided a measure of subjectivity in the selection of these terms.
Selection of case factors
The case factors examined in this study were those indicated by existing research and policy to be prevalent within child protection procedures and care proceedings (Masson et al., 2008; Great Britain Department for Education, 2020). In relation to parental difficulties, these were: domestic violence; mental health; alcohol misuse; illegal drug use; criminality, learning disability, unstable lifestyle (as gauged by housing and financial hardship), inadequate home conditions, deficiencies in basic care (clothing, diet, hygiene), and poor engagement with services. The four areas of child harm used to classify UK child protection planning are neglect, physical harm, emotional harm, and sexual harm. Where possible, sub-categories were included, for instance terms relating to drug misuse were assigned to ‘Class A’ (e.g. ‘heroin’, ‘opiates’) and ‘Class B’ (e.g. cannabis, amphetamines) – see Figure 1 below.
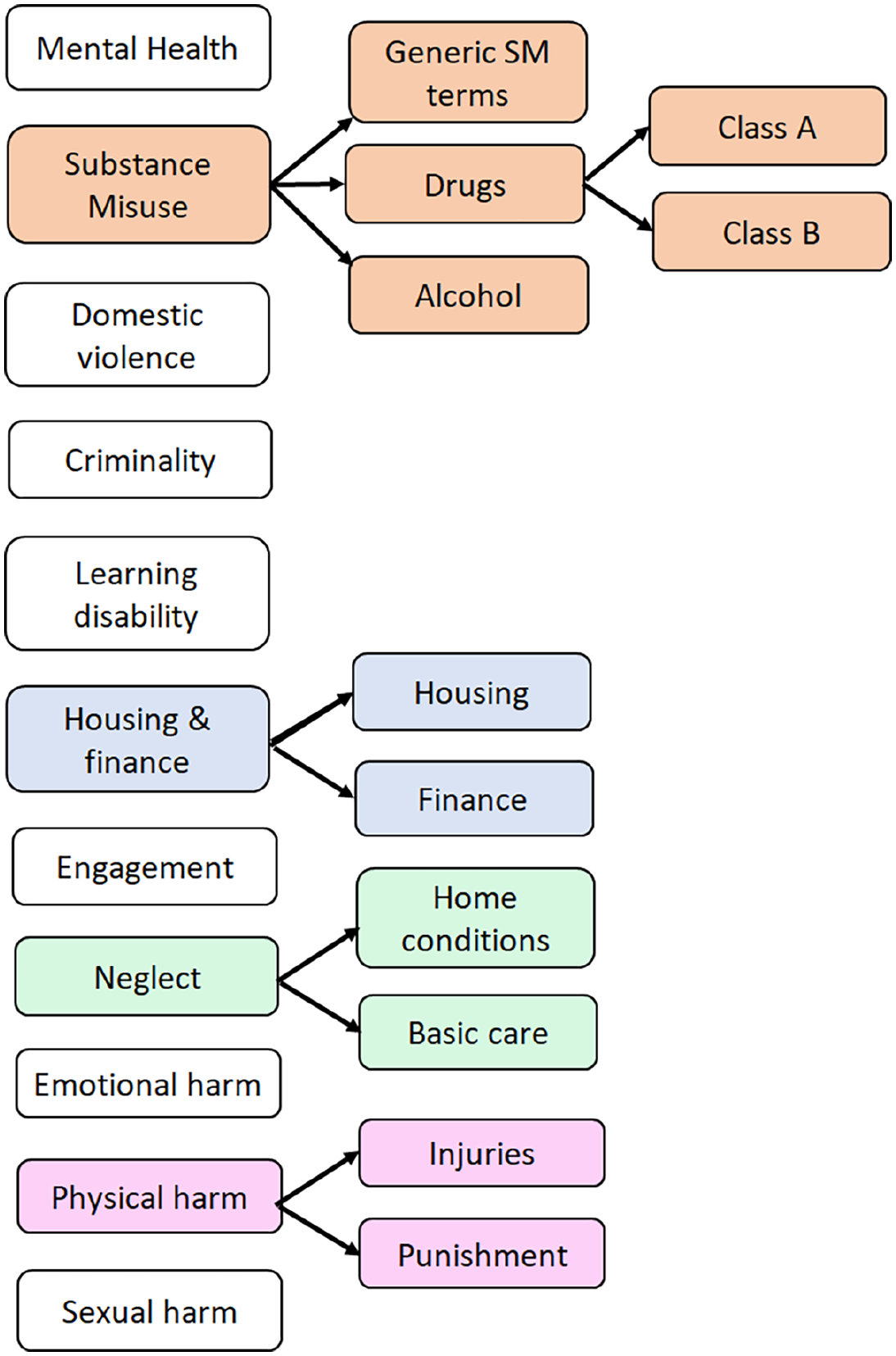
Framework for constructing case factors from linked sub-factors.
Assigning terms to case factors
As stated earlier, words may convey different meanings. In this project, enabled by the document context and purpose (see above, ‘assumptions and principles’), a simpler approach to clarifying meaning was adopted. Using professional judgement, terms were either (a) discounted, (b) where unambiguous, assigned to case factors, or (c) where their meaning was ambiguous, tested by selecting up to 100 random instances of the term and its surrounding context, throughout the document set. A VBA routine was created to automate the process of locating term examples and assisting the scoring of their relevance. The process is illustrated in Figure 2, below.
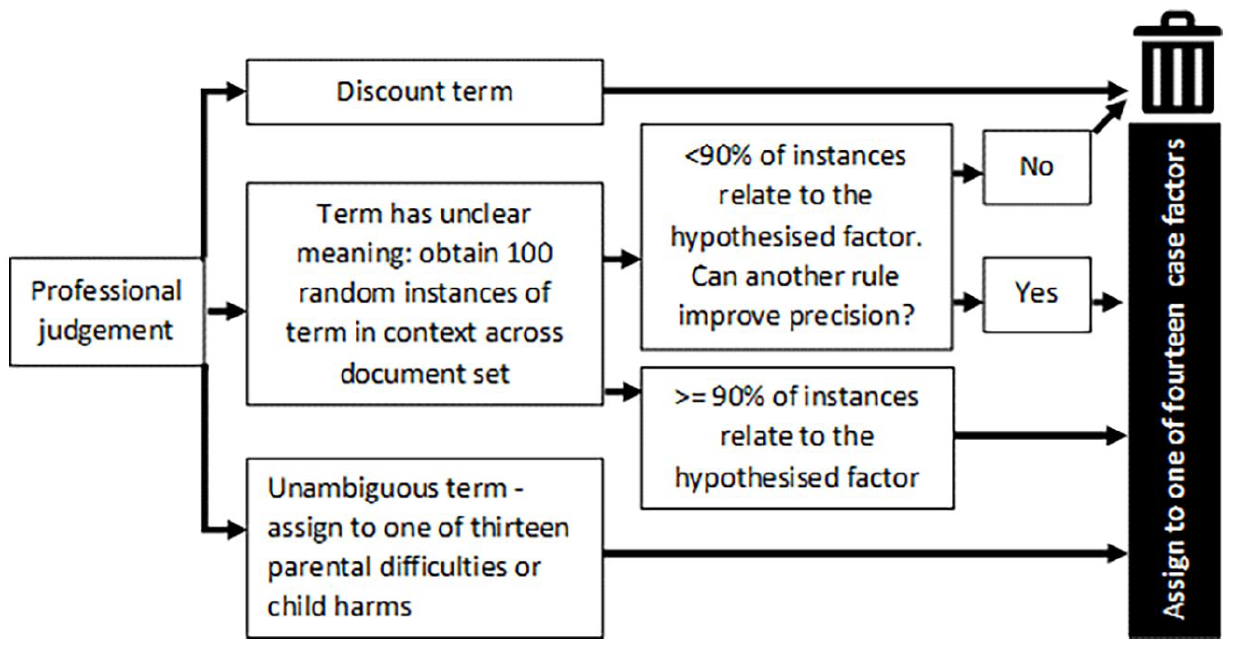
Process for assigning terms to case factors.
For example, of the top 10 terms listed in Table 1, four must be set aside. ‘School’, ‘baby’, ‘nursery’ and ‘unborn’ appear very often in some documents, and not at all in others, probably because they reflect the ages of the subject children (more accurately obtained from other sources), rather than parental difficulties or harms. A fifth term, ‘mum’ must also be discounted because it more likely represents a stylistic idiosyncrasy of the statement author, or a direct quote from a child. The terms ‘alcohol’, ‘heroin’ and ‘cannabis’, however, have unambiguous meanings and may be assigned to the categories ‘Alcohol misuse’, ‘Class A drugs’ and ‘Class B drugs’. The word ‘drugs’ itself was evaluated in a sample of 100 random sentences containing the term. It was found that in this document context at least, social workers in England use ‘drugs’ to denote the illicit type (in 100% of instances examined), whereas ‘medication’ is the preferred term for drugs which are prescribed. Exceptions are likely to be sufficiently rare to assign the terms ‘drug’ and ‘drugs’ to the broader category of ‘drugs misuse’ (see Supplemental data file).
Having sorted and assigned the terms by the process described above, counts for each term were calculated for each document, and combined to arrive at total counts for each of the case factors contained in Figure 1. (The full list of terms assigned and counted can be found in the Supplemental data file). Two sets of word counts were calculated, absolute and adjusted, the latter derived by dividing total word counts by the overall document word length. Adjusted counts performed less well in all future analyses, probably because social workers do not simply repeat the same information, and the results which follow are based on absolute term counts.
Establishing cut-off thresholds
Earlier, we discussed how an understanding of document context may avoid complex NLP techniques that determine whether search terms are currently relevant (as opposed to historic, hypothetical or ruled out). In this study, the social work court statements were evidential, permitting the probabilistic rule that terms repeated frequently denoted problems. This approach creates the challenge of determining the scoring level at which a case factor could reliably be denoted present, because accepting very low scores might lead to spurious case factor identification. To address the problem, three cut-off scoring thresholds were tested. First, all cases scoring zero were denoted as factor absent. Next, of those cases scoring above zero, the lowest scoring 10%, 17.5% and 25% of cases were respectively calculated and also rated factor-absent. The first (10%) threshold cut-off thus produced the most generous estimate of factor prevalence, and the third (25%) the most conservative. Note, because absolute scores were used, and expressed as integers, the 10%, 17.5%, and 25% levels could not be matched exactly to the scores obtained and represent the minimum percent of cases excluded for each threshold cut-off. The process is explained further in the Supplemental data file.
Grading factor severity
All cases scoring above each of the threshold cut-offs were divided into four quartiles ranked by algorithmic score, each representing a step-up in factor severity. In all, this approach created five categories; factor-absent, quartile 1 (low-level concern), quartile 2, (moderate concern), quartile 3 (raised concern) and quartile 4 (serious concern), as illustrated in Figure 3 below.
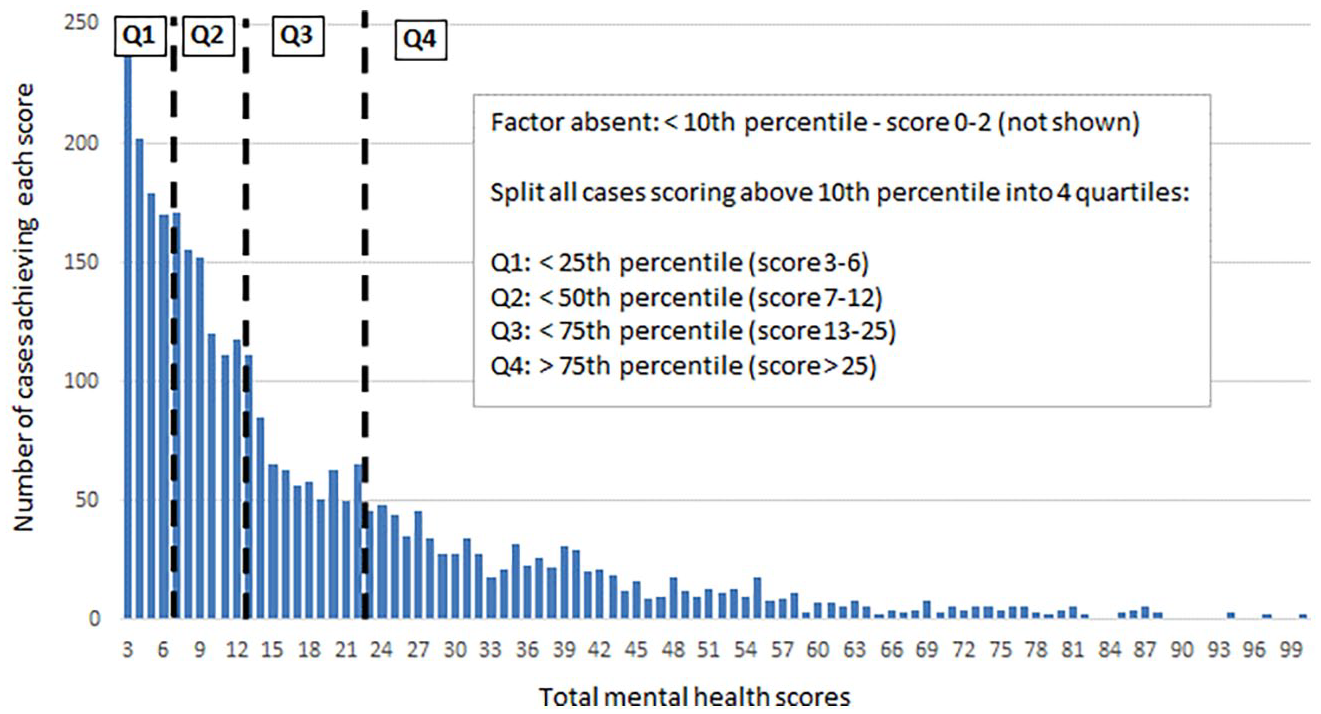
Establishing thresholds for factor presence/absence, and grading factor severity. This table uses the lowest, most inclusive threshold (10%).
Validation: Case rating exercise
To compare automated case-factor ratings with human judgement, 10 SWETs were randomly selected from those comprising within 500 words of the 7000 mean word length. These documents were re-assembled into legible yet fully anonymised SWETs and rated by volunteer family court lawyers (solicitors and barristers) for the presence or absence of 13 case factors, using the form approved by the governance committee and contained in the Supplemental data file. These factors included the four categories of harm: (neglect, physical/emotional/sexual harm), whether injuries had been sustained, and parental difficulties in the areas of alcohol misuse, use of illegal drugs, mental health, domestic violence, learning disability, offending, lack of cooperation with agencies and inadequate home conditions.
The lawyers were approached at a County Court during a typical working week during ‘down time’ whilst lawyers were waiting for cases to be called. The project was discussed with the volunteers who were asked to devote the same attention to the document that their usual practice would allow. All participants necessarily adopted a speed-reading strategy, completing the exercise on average in around 20 minutes. All lawyers reported taking sufficient time to consider the case from the information provided, and that there was no information removed during anonymisation that hampered the task.
The lead researcher also read the same 10 SWETs, slowly and thoroughly. Six of the ten SWETs were also read by two lawyers. This yielded six SWETs rated by the researcher and two lawyers, and four by researcher and one lawyer (only 16 lawyers could be recruited). Algorithmic case factor scores were later obtained for all 5320 SWETs, including the 10 in the test set. Algorithmic classification was conducted several months after the rating exercise, therefore the automated scores for the sample SWETS were not known by the researcher when rating the SWETs.
Statistical analysis
Overall, 324 case factor ratings were obtained, yielding 259 pairwise human-human comparisons of the same document case factor, and 324 human-computer comparisons. Interrater agreement was compared for the following group comparisons: lawyer versus lawyer, lawyer versus researcher, lawyer versus algorithm, researcher versus algorithm, and all humans versus algorithm. A chi squared test was used to assess differences in level of agreement between these paired comparisons. Note – measures of interrater reliability, typically used in areas such as exam gradings, were not suited to this methodology as they indicate an objective benchmark of reliability usually achieved by prior training according to consistent criteria. The focus of this exercise was on the comparative performance of the groups. Earlier studies have noted that computer-human rating agreement may be low but may still outperform human-human agreement (Williamson et al., 2012).
Results
Identification of case factors
Case factor prevalence estimates are summarised in Table 2 below.
Estimates of case factor prevalence across 5320 SWET documents.
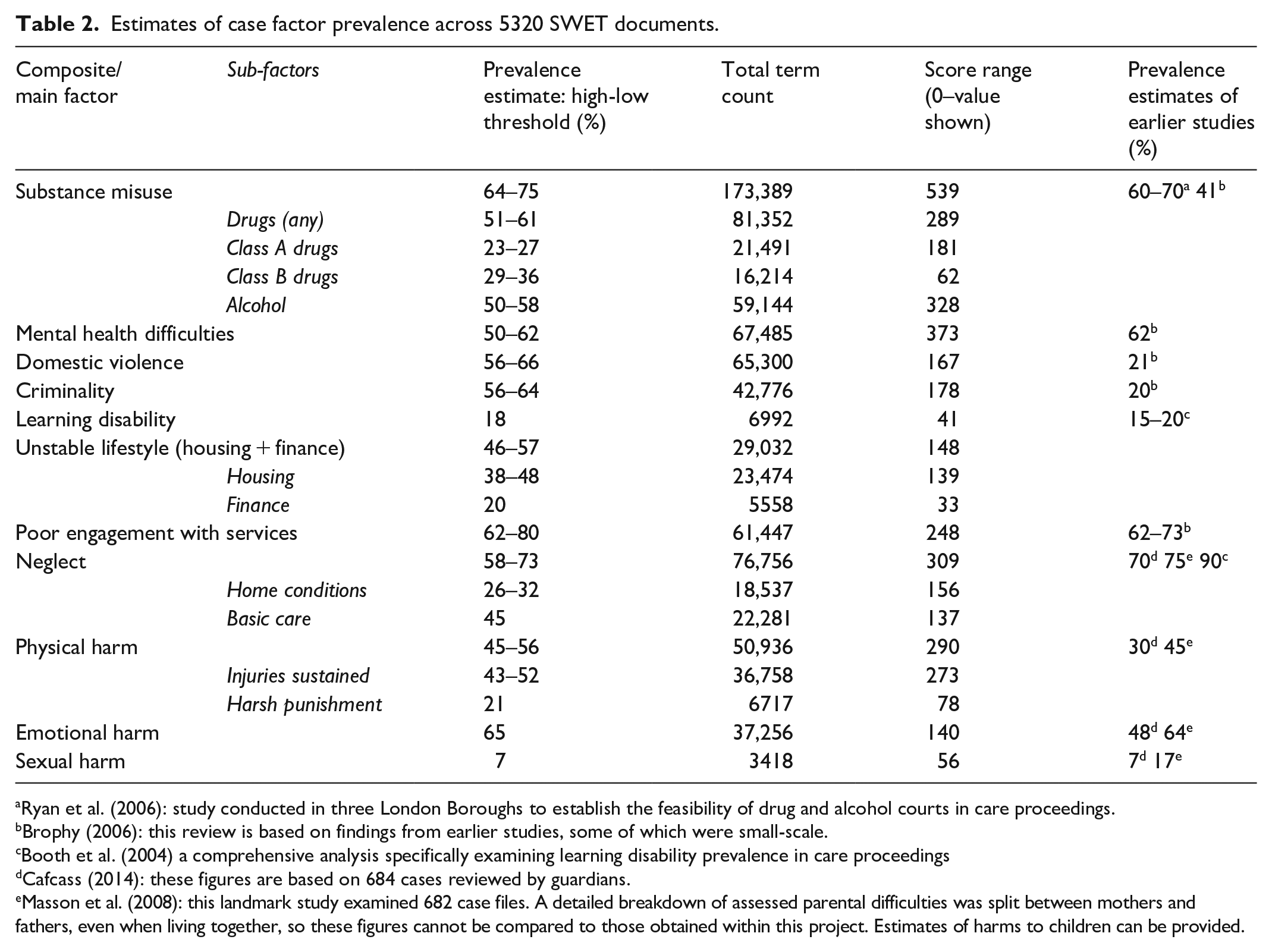
Ryan et al. (2006): study conducted in three London Boroughs to establish the feasibility of drug and alcohol courts in care proceedings.
Brophy (2006): this review is based on findings from earlier studies, some of which were small-scale.
Booth et al. (2004) a comprehensive analysis specifically examining learning disability prevalence in care proceedings
Cafcass (2014): these figures are based on 684 cases reviewed by guardians.
Masson et al. (2008): this landmark study examined 682 case files. A detailed breakdown of assessed parental difficulties was split between mothers and fathers, even when living together, so these figures cannot be compared to those obtained within this project. Estimates of harms to children can be provided.
In Table 2, Column 2 shows lower and upper estimates according to the methodology set out above. Column 3 shows the total number of terms that it was possible to identify in respect of each factor, and the scoring range for each factor is shown in Column 4. Column 5 shows prevalence estimates arrived at by earlier case-reading studies which examined care applications. The breakdown of terms, counts, and statistical analysis for all case factors can be viewed in the Supplemental data file.
Interpretation and discussion
Table 2 shows how the prevalence estimates appear broadly similar to those obtained in comparable research. The earlier studies cited, however, embraced different methodologies and sample sizes, themselves reaching divergent estimates. This study’s findings fall within the range that might be anticipated and accordingly justify further investigation of this innovative methodology, but are insufficient as they stand to be proven statistically reliable. Moreover, the total term counts/score ranges for the main factors identified varied widely (3418–173,389; 41–539) and some potentially valuable factors could not be reliably captured at all using these methods.
For some factors, powerful terms were readily identifiable and abundant, most notably in relation to substance misuse, which embraces ‘heroin’, ‘cannabis’, ‘alcohol’, etc. Such words are both unambiguous and hard to avoid when case histories feature this problem. Other concepts, such as emotional harm, may be denoted by a wider range of more ambiguous terms, including ‘lack of emotional warmth’ or ‘failure to meet emotional needs’. In other instances, phrases were found to apply equally to parental difficulty and children’s need, for instance ‘learning disability’, whereas terms describing specialist learning disability assessments related to parents, but were used less frequently. In further cases, style convention enabled distinctions to be made; ‘mental health’ was found to be the preferred social work term for adult difficulty, and ‘emotional health’ used for children. These examples illustrate the challenges and complexities of capturing meaning without sophisticated technology. The opportunities afforded by context might not permit these techniques to be generalised across country or time. Notably, however, even the most powerful software would struggle with nuance that is rooted in a specific professional context. Furthermore, what is hard for an algorithm to detect may equally pose challenges to humans; one reader’s concept of ‘lack of emotional warmth’ may not be interpreted as ‘emotional harm’ by the next. Unlike humans, however, it is possible (at least within the present methodology) to find out exactly how the algorithm arrived at its prediction.
Estimating the prevalence of an issue within a population is qualitatively different from predicting its presence in an individual case. False positive and false negative errors that occur over thousands of cases may tend to balance out, however in individual cases, the potential for error incurs greater consequence. This next section of the results focuses on the accuracy of predictions within individual cases.
Case-rating exercise
Here, human and computer-assigned case factor ratings are compared. Each case included in this exercise required judgements in relation to 13 individual factors, yielding 130 predictions each by the algorithm and researcher. Ten cases were also rated by at least one lawyer, with six cases rated by two lawyers independently. Some factor ratings were left blank by lawyers, resulting in 65 instances where two lawyers independently rated the same case factor.
Where a factor was judged present, professional ratings were coded on a 4-point scale, as were algorithmic scores. Although a relatively small-scale study, 583 pairwise ratings were obtained. This was insufficient to enable meaningful comparisons of graded scores, however statistically significant results emerged when ratings were expressed as a binary decision (i.e. case factor present included all scores of 1 and above, for automated and human predictions). Ratings provided by the lawyers (speed-readers) and the lead researcher (detailed reader) differed significantly, therefore are differentiated in the following analyses.
Algorithmic predictive accuracy; sensitivity and specificity
First, Table 3 summarises the algorithm’s capacity to detect case factors correctly when present, and to rule them out when absent. This analysis requires the ‘correct’ answer to be known, although this is not possible where there is significant disagreement between human raters, as occurred in this study. Instead, the best measure available was used, by including only those 84 classifications (65% of the total) upon which all human raters (whether two or three) agreed upon the presence or absence of a factor. This table shows predictive accuracy at the three threshold levels tested.
Algorithmic accuracy assessed at three threshold cut-off levels.
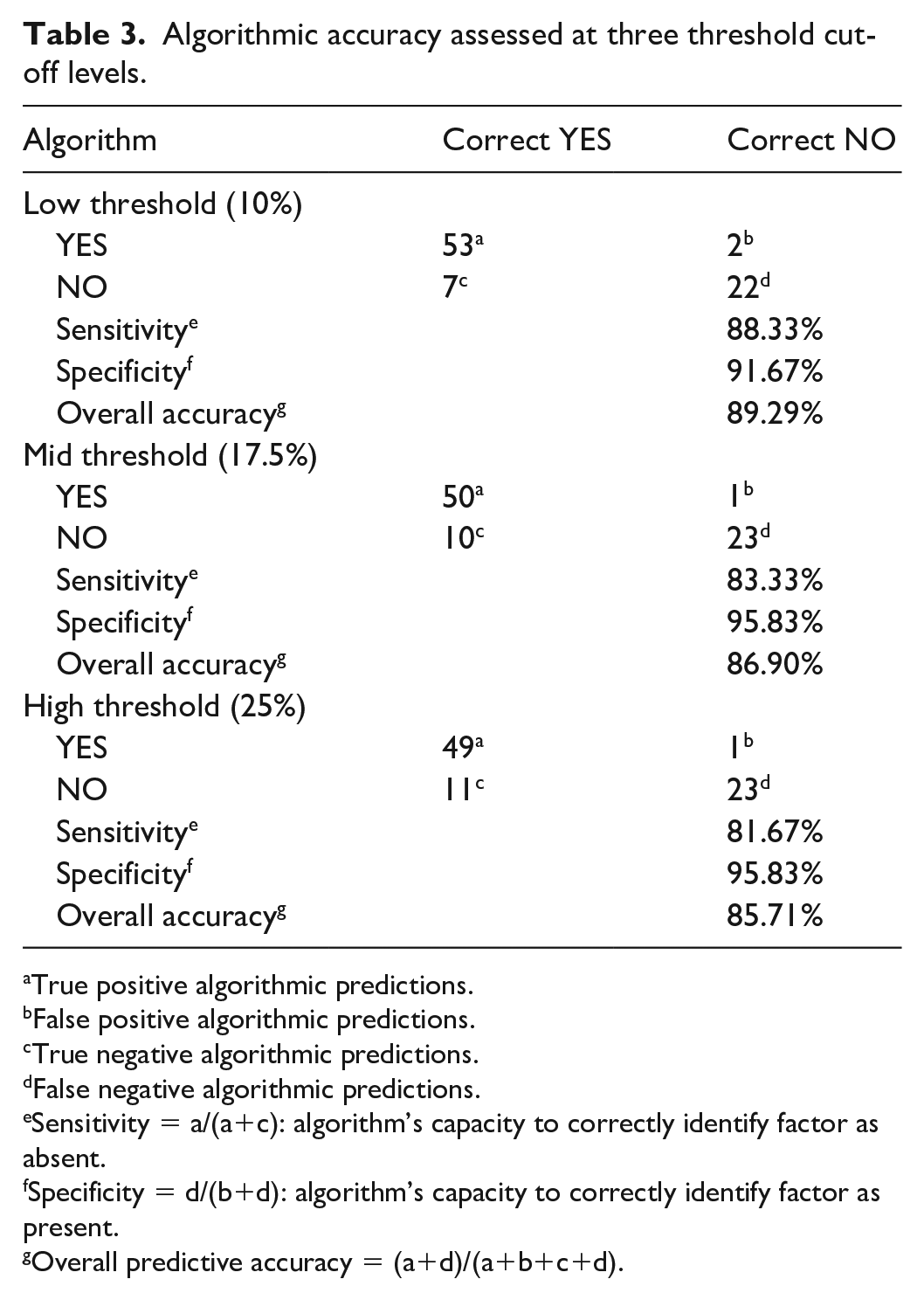
True positive algorithmic predictions.
False positive algorithmic predictions.
True negative algorithmic predictions.
False negative algorithmic predictions.
Sensitivity = a/(a+c): algorithm’s capacity to correctly identify factor as absent.
Specificity = d/(b+d): algorithm’s capacity to correctly identify factor as present.
Overall predictive accuracy = (a+d)/(a+b+c+d).
Interpretation
The algorithm demonstrated greatest overall accuracy when the most inclusive, lowest, 10% threshold applied, however the differences noted across thresholds are small and must be viewed in the context of relatively low numbers. The 89% accuracy obtained is therefore a promising early finding which confirms the value of further research, rather than conclusive results.
The higher specificity (92%–96%), or true negative rate, noted across all thresholds tested, indicates that the algorithm rarely detected factors that humans agreed to be absent (false positives). The slightly reduced sensitivity (82%–88%), or true positive rate, showed the algorithm less likely to pick up factors that humans judged present, that is, it made slightly more false negative predictions. If the 10% threshold should indeed be confirmed the most accurate, and false negative predictions more common, the prevalence estimates set out in Table 2 might represent conservative estimates.
It is important to note that sensitivity and specificity represent trade-offs and thresholds should be set with goals in mind. Raising the threshold, that is, tightening the inclusion criteria, led to an increase in false negative predictions, that is, tendency to miss factors that were present. If it were desirable, for instance, to ensure that no factor was missed, even if others were picked up in error, the threshold should be lowered, even if accuracy overall was sacrificed. For population prevalence estimates, and within this experimental design, the greatest overall accuracy was sought.
The higher number of case factors not detected may mean that there were insufficient terms identified with which the algorithm could capture certain concepts. Table 2 above illustrated how term counts across case factors varied widely. Further refinements could address this difficulty. The following tables, however, illustrate another contributory factor. Discordance between human judgements was highest when zero scores were assigned by the algorithm, indicating these cases may be the hardest to classify. A disproportionate number of low scoring cases were therefore excluded from the analysis summarised in Table 3 (60 human-agreed positive factors vs 24 negative). This is an acknowledged limitation.
Between group comparisons
The summary data for binary predictions by professional and algorithmic status are provided in Table 4 below. Henceforth only results for the lowest 10% threshold are shown. The Supplemental data file contains a breakdown for all thresholds.
Summary of binary factor ratings for all raters and computer.

Interpretation
Each case factor, on average, was rated present in just over half of cases by the algorithm and researcher, but in 72% of lawyer classifications. This difference was statistically significant (72.1% vs 54.6%, χ2 = 10.6, p < 0.01; 72.1% vs 53%, χ2 = 12.39, p < 0.001) and will be discussed later. Table 5 shows the levels of agreement between the different readers and algorithmic classifications. These are broken down by algorithmic score.
Levels of agreement for group comparisons, by algorithmic quartile score and sample size.
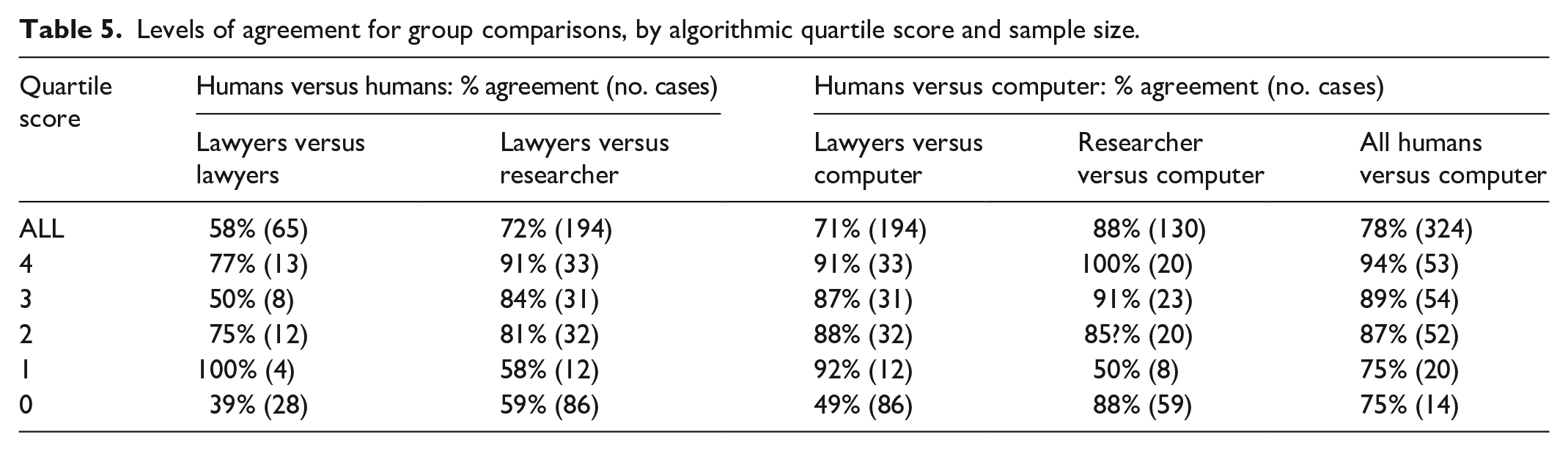
Interpretation
Overall, lawyers agreed with each other’s predictions in only 58% of instances, a level not significantly greater than chance, given the low number (65) of lawyer versus lawyer comparisons. Lawyer’s agreement with the researcher’s scores, however, was significantly improved (Søbjerg et al., 2020) (58% vs 72%: χ2 = 4.25, p < 0.05). Notably, the lawyers’ agreement with each other, the researcher, and the algorithm, improved for positive algorithmic scores. Indeed, where the algorithm assigned a high score of 4, their agreement with the researcher reached 91%, and 100% with the computer ratings. Earlier, Table 4 indicated the lawyers’ marked tendency to detect case factors as present when the computer and the researcher did not. It therefore appears that lawyers’ discordance is not constant but disproportionately attributable to those cases where the researcher and algorithm detected case factors absent. Moreover, Table 5 discounts the argument that lawyers may have been correct to detect case factors more often than the algorithm, because when lawyers disagreed with the algorithm’s negative prediction, they agreed with each other least of all, that is, 39% of the time.
The highest agreement was achieved between the researcher and the algorithm at 88%, significantly higher than the lawyers’ agreement with the algorithm at 71% (χ2 = 23.7, p < 0.001). Again, the difference was most marked in relation to algorithmic zero predictions.
Discussion
From more than 5000 substantial social work texts, this study used NLP to identify a range of factors commonly encountered within applications to remove children from parental care. It used straightforward statistical approaches, informed by professional judgement. Early indications suggest an accuracy comparable to that achieved by professional readers, as well as by studies that embraced a range of sophisticated machine learning NLP methods (Bako et al., 2021; Zhou et al., 2015). The factors identified included those most often associated with the greatest risk of maltreatment, notably domestic violence, substance misuse and mental health difficulties. At this early stage of development, these are encouraging results worthy of being built upon by further research.
The findings from the case rating exercise should be considered in relation to the reading styles employed. The researcher did not know the algorithmic scores as these had not been calculated when the exercise was conducted, so could not be influenced by them. The researcher rated all 10 texts, however, bringing consistency to the task, and considered each case slowly and thoroughly. Lawyers were busy, engaged in other duties, and read at speed. By implication, where cues are abundant, busy professionals and computers can reach consistent and accurate judgements. Where cues are sparse or absent, however, speed-reading strategies appeared less effective, even though the professionals expressed confidence in this approach. In marginal cases, lawyers apparently adopted less consistent, more risk-averse predictions. It is unsurprising that they would reach different views in less clear-cut cases, but more interestingly, this exercise suggests that either a detailed reading or algorithmic classification may provide a benchmark to promote accuracy and consistency even in these ‘grey areas’ of professional judgement. In the real world of resource constraints and extensive complex documentation, a thorough reading of each case document cannot be viable.
Whether professionals agree regarding marginal issues may be unimportant, but two areas of potential value for algorithmic prediction warrant further research. At the higher end of the scale, risk must be determined either high but manageable, or at a level requiring more radical intervention. Might algorithmic predictions promote consistency in relation to these ‘finely balanced’ higher-stakes decisions? Secondly, the case-reading task was atypical in one key aspect of practice. Lawyers came fresh to the task without pre-conceptions and with only the written text upon which to focus. More often, professionals rely on a range of discussions, documents, and prior knowledge of a case that is built and reshaped at each stage of a complex iterative process (Fengler and Taylor, 2019; McCafferty and Taylor, 2020). In this study, it was not possible to assess how prior knowledge, views formed of a case, and possible biases, might interact with speed-reading when making sense of an unseen document. Foreseeably in such instances, reflective of real-world practice, an algorithmic ‘backbone’ might add the greatest value.
Concluding remarks
This study represents one component of a broader ‘big data’ project which was able to use these factor ratings, alongside administrative and socio-economic data to determine the relative influence of process, societal, and individual case-level factors on decisions for children within the family courts. Those results will be published separately. Without NLP, a vital part of the decision jigsaw would have remained obscured.
The NLP methodology was innovative, and some components were conducted on a small scale. Further research would be required to determine the broader applicability of the findings, but this study at least confirms that further enquiries might prove fruitful. The main challenge lay in conducting NLP without the resources available to computer scientists, and to a large extent this was overcome, using techniques that were straightforward, intuitive, and transparent, founded on mathematical principles and professional knowledge.
In aiming to explain NLP and make it accessible to a social work audience, we highlighted examples of the potential contribution NLP technology might make to the field of social work: to practitioners through streamlining documentation and highlighting its critical aspects, to policy makers enquiring about the needs of service users, and to researchers seeking insights into the thought processes and factors driving key decisions. Our purpose was not to advocate for these developments which our findings do not address. Herein, we have focussed primarily on a novel methodological approach undertaken by researchers with a social work background. The rise of technological approaches to social work practice inevitably raises complex practical issues and ethical debates that fall beyond the scope of this paper (see Keddell, 2019, and references therein). At the same time, ongoing ethical and professional concerns regarding the use of digital ‘scientific’ methods within what is often seen primarily as ‘professional art’ Schrödter et al. (2020) need to take account of the specific details and potential of contemporary developments.
Considerable limitations are acknowledged, however, and summarised throughout this paper. There is no suggestion that computer science should not play a valuable role in further studies. Rather, it is argued that future collaborations between computer and social scientists should be founded on a greater understanding by researchers in social work of the benefits, methods, and pitfalls of the technology, and by computer technicians of the professional context and constraints. This paper seeks to further that understanding.
Supplemental Material
sj-xlsx-1-mio-10.1177_20597991221115967 – Supplemental material for Natural language processing to identify case factors in child protection court proceedings
Supplemental material, sj-xlsx-1-mio-10.1177_20597991221115967 for Natural language processing to identify case factors in child protection court proceedings by Beth Coulthard and Brian J Taylor in Methodological Innovations
Footnotes
Acknowledgements
We are grateful to Cafcass for supporting this study and making their data available and to Dr John Mallett, Ulster University, for support and advice during this project.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was funded by a PhD Scholarship from the Department of Education and Learning for Northern Ireland.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.