
Abstract
From the outset, computational sociologists have stressed leveraging multiple relations when blockmodeling social networks. Despite this emphasis, the majority of published research over the past 40 years has focused on solving blockmodels for a single relation. When multiple relations exist, a reductionist approach is often employed, where the relations are stacked or aggregated into a single matrix, allowing the researcher to apply single relation, often heuristic, blockmodeling techniques. Accordingly, in this article, we develop an exact procedure for the exploratory blockmodeling of multiple relation, mixed-mode networks. In particular, given (a)
Keywords
Introduction and background
Loosely defined as the partitioning of a social network’s

Sociomatrix
Consisting of 20 actors labeled A though T, imagine the presence of a 1 in row
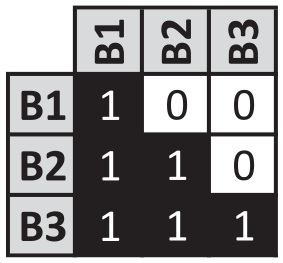
Image matrix for the permuted trust network seen on the right-side of Figure 1.
Collectively, the partitioning of the actors (right-side of Figure 1) and its associated image matrix (Figure 2) constitute a blockmodel for the trust network, and, in this case, the fit is perfect. That said, reality is rarely this kind, as inconsistencies between the ties of the positions and the partitioned network are the norm. Moreover, since its earliest formulation in the mid-1970s, blockmodeling has emphasized the necessity of incorporating multiple relations (Boorman and White, 1976; White et al., 1976). As White et al. (1976: 739) argue in their seminal paper, “many different types of tie are needed to portray the social structure of a population.” However, despite this foundational emphasis and several notable exceptions (e.g. Baker, 1986; Batagelj et al., 2007; Borgatti and Everett, 1992; Brusco et al., 2013b; Žiberna, 2014), the vast majority of published research over the past 40 years has focused on solving blockmodels for a single relation.
When multiple relations exist, a reductionist approach is often employed, where the relations are either stacked or aggregated into a single matrix, allowing the researcher to apply single relation blockmodeling techniques. Nonetheless, this simplification can mask structural nuances within the individual relations, and, as Doreian (2006: 128) rightly puts it, “we need an approach that permits different relations to have different structures.” In short, blockmodeling multiple relations remains an open, relevant problem.
Moreover, while improved methods for solving single relation blockmodels have been immensely valuable and are implemented in popular network analysis software, they are ultimately heuristics. Accordingly, while they provide good, locally optimal solutions, they cannot guarantee that better fitting solutions do not exist. Again, there are several notable exceptions where researchers have developed and implemented exact methods (e.g. Brandes and Lerner, 2010; Brusco et al., 2013a; Brusco and Steinley, 2009); however, these methods exist for a single relation.
Accordingly, in this paper we extend Brusco and Steinley’s (2009) exact procedure to the exploratory blockmodeling of multiple relation, mixed-mode networks. In particular, given (a)
To facilitate our explanation and provide researchers with a flexible set of tools, we derive our multiple relation, mixed-mode approach (section “Exact exploratory blockmodeling for multiple relation, mixed-mode networks using integer programming and structural equivalence”) from its initial application to single one-mode (Dabkowski et al., 2016; section “Exact exploratory blockmodeling for one-mode networks using integer programming and structural equivalence”) and two-mode networks (section “Exact exploratory blockmodeling for two-mode networks using integer programming and structural equivalence”). We illustrate these concepts using a simple, hypothetical example, and we apply our techniques to a real-world terrorist network.
Heuristics for the exploratory blockmodeling of multiple relation, mixed-mode networks
As mentioned earlier, a common approach when blockmodeling multiple relations is stacking or aggregating the multiple adjacency or affiliation matrices into a single matrix. For instance, consider the extremely simple, hypothetical example given in Figure 3. Consisting of
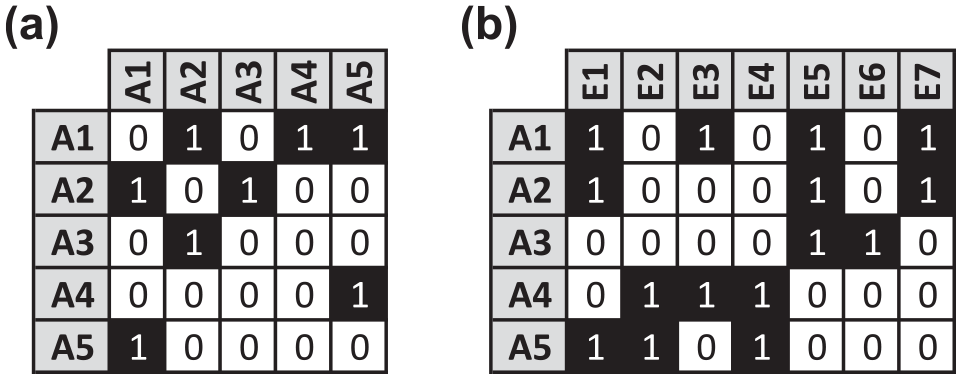
Hypothetical multiple relation, mixed-mode network consisting of
With this in mind, a popular heuristic for partitioning
Applying this to our hypothetical example, our first task is to project the
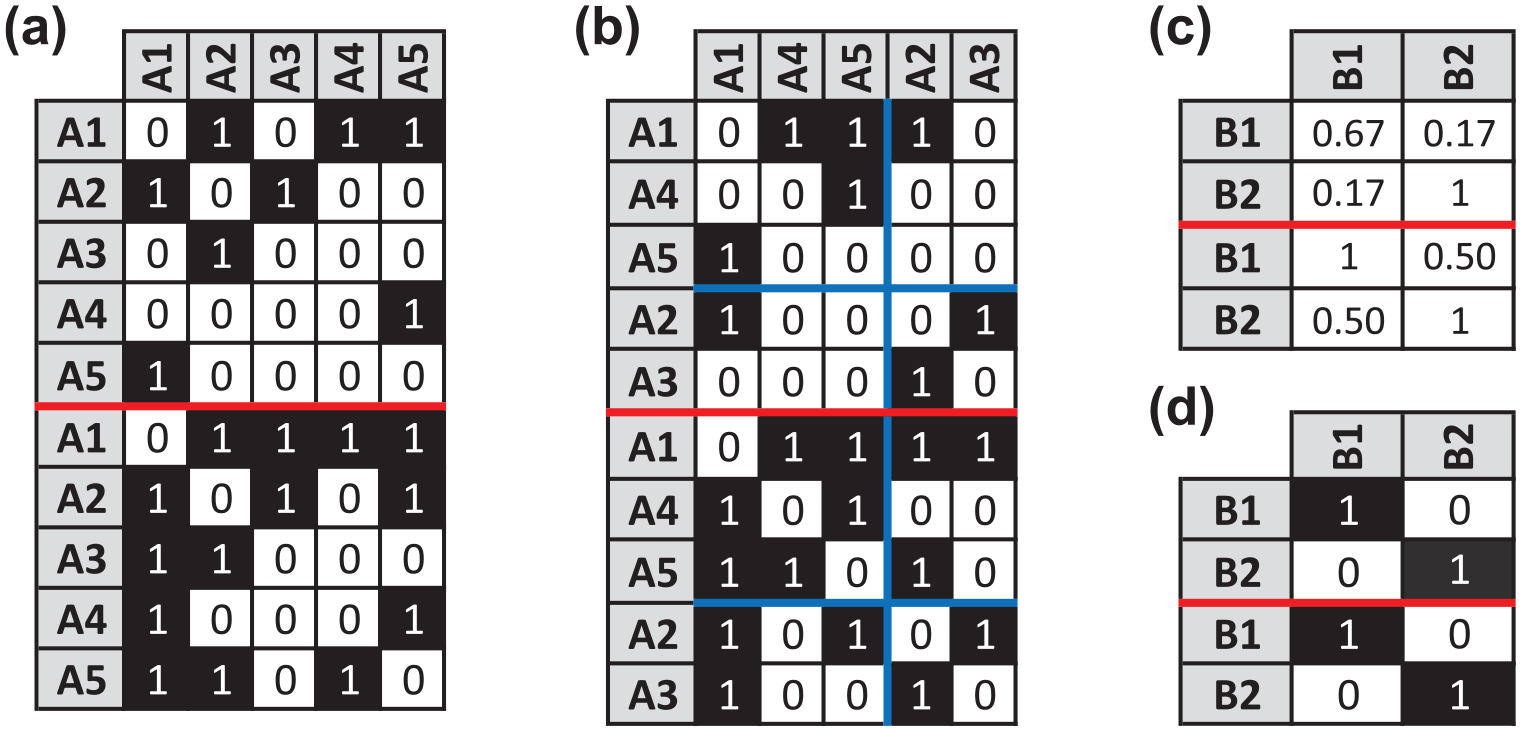
Solution from indirectly partitioning the actors of the hypothetical network using CONCOR. Panel (a) depicts the stacked adjacency matrices where the top-half is
As Panel (d) of Figure 4 shows, the image matrices derived from CONCOR reflect an insular, compartmentalized social structure where actors in position
To address both of these shortcomings, Doreian et al. (2005) developed an alternative, direct approach, which is based on minimizing the number of inconsistencies between a permuted, partitioned adjacency (or affiliation) matrix and its corresponding image matrix. Specifically, if actors
Using this construct, Doreian et al. (2005: 150) employ a simple actor (or event) relocation routine to minimize the number of inconsistencies, and this is implemented for a single relation in Pajek (Mrvar and Batagelj, 2013). Dabkowski et al. (2015) further extend Pajek’s implementation of Doreian et al.’s (2005) direct approach to multiple one-mode networks using an augmented adjacency matrix and appropriate penalties and constraints, and they note that their extension can be modified to accommodate two-mode networks.
As such, it seems reasonable to assume that we can adapt Dabkowski et al.’s (2015) approach for our hypothetical multiple relation, mixed-mode example, and, in fact, it is quite simple and similar to Žiberna’s (2014) true multilevel approach. To illustrate this, we first note that Pajek treats one-mode and two-mode networks differently with respect to inconsistencies. Specifically, in one-mode networks Pajek assumes that self-ties are irrelevant, and the main diagonal of the adjacency matrix is ignored. For our actor-by-actor network in Panel (a) of Figure 3, this is the desired behavior. That said, for our actor-by-event network in Panel (b) of Figure 3, it is a different story, as there are no self-ties in an
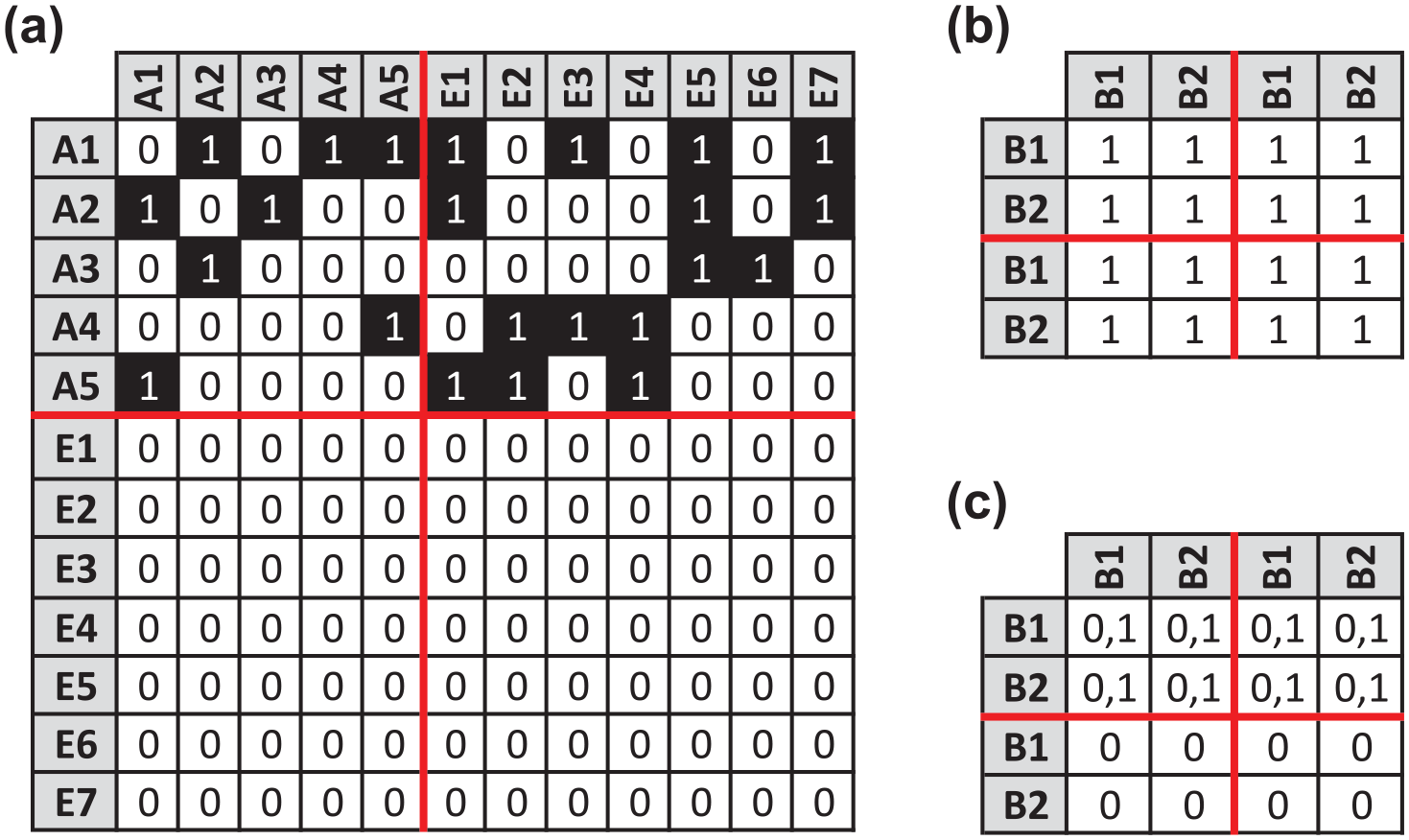
Model input for directly partitioning the actors and events of the hypothetical network using Pajek. Panel (a) reflects the augmented adjacency matrix where the top-left and top-right quadrants contain
Our next task is to feed Pajek constraints that force it to maintain the assignment of individual actors and events within their respective actor and event positions. Assuming we want to split both the actors and events into two positions, this implies there are four total positions, and we designate the first two positions as actor positions and the last two positions as event positions. As such, we need constraints that prohibit actors (A1 through A5 in Panel (a) of Figure 5) from being assigned to the last two positions, as well as constraints that prohibit events (E1 through E7 in Panel (a) of Figure 5) from being assigned to the first two positions.
With respect to penalties, unlike Dabkowski et al.’s (2015) onerous requirement to maintain the assignment of actors to identical positions across multiple one-mode networks, we have a single one-mode network of actors augmented by a second two-mode network of events. This greatly simplifies our model, as it eliminates the need for Dabkowski et al.’s (2015) variable penalties, and we can view each inconsistency equivalently across the blockmodel, allowing us to use the simple penalty matrix of 1’s seen in Panel (b) of Figure 5. Finally, we need to specify the permissible block types in the image matrix. Captured in Panel (c) of Figure 5, we allow Pajek to consider both 0 and 1 blocks in the substantive cells (the top-half of Panel (c)), while we set the lower blocks to 0 to match the zero-row padding of the augmented adjacency matrix.
Armed with these constraints, penalties, and permissible block types, we loaded the model into Pajek (see Appendix I in the online supplemental material for the.net and.mdl files), and Figure 6 displays the optimal solution returned after 200 repetitions. As indicated by the red cells and font in Panel (a) of Figure 6, there are 13 inconsistencies between the permuted, partitioned augmented adjacency matrix and its corresponding image matrix in Panel (b). Moreover, the actor partitioning and its associated image matrix match the results returned by CONCOR in the top-halves of Panels (b) and (d) of Figure 4, lending some support to CONCOR’s indirect approach. Nonetheless, while Pajek’s output looks convincing, its relocation routine generates locally optimal results, and we have no assurance that better solutions do not exist. Of course, our angst will only grow with larger, messier real-world examples.
Solution returned by Pajek. Panel (a) gives the permuted, partitioned augmented adjacency matrix, where red cells and font denote inconsistencies. Panel (b) provides the corresponding image matrices.
Exact exploratory blockmodeling for one-mode networks using integer programming and structural equivalence
In order to alleviate concerns related to the potential suboptimality of blockmodeling heuristics, one can employ exact procedures that guarantee globally optimal solutions. An excellent example of this approach is Brusco and Steinley’s (2009) use of integer programming to find optimal partitions for one- and two-mode blockmodels when the image matrix is prespecified. Known as confirmatory blockmodeling, they apply their method to several well-known, previously studied social networks, confirming the global optimality of heuristically obtained results. When the image matrix is not known in advance (i.e. exploratory blockmodeling), Brusco and Steinley (2009) note that their approach can be applied to all possible image matrices of a given size, provided the number of positions is small.
In a recent paper, Dabkowski et al. (2016) extend the applicability of Brusco and Steinley’s (2009) work to the exploratory blockmodeling of one-mode networks by demonstrating how a much smaller collection of image matrices can cover all possible image matrices of a given size. Specifically, Dabkowski et al. (2016) develop an algorithm to generate a set of non-isomorphic, binary image matrices, and they further reduce the size of this set by identifying and removing image matrices with structurally equivalent positions. In short, the computational savings are impressive. For example, while there are
Although the details of their work are beyond the scope of this paper, Brusco and Steinley’s (2009) integer program, as modified by Dabkowski et al. (2016), plays a central role in the development of our exact exploratory blockmodeling for multiple relation, mixed-mode networks. As such, we provide Dabkowski et al.’s (2016) formulation below, along with additional discussion and expanded notation to denote one-mode networks.
One-mode optimization model (Dabkowski et al., 2016)
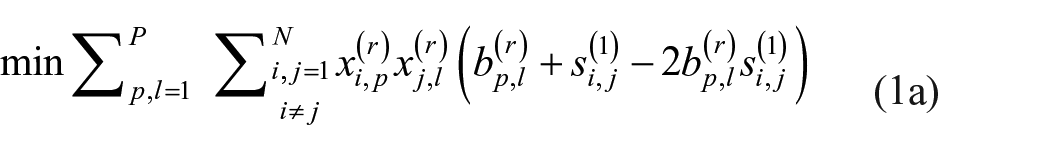
s.t.
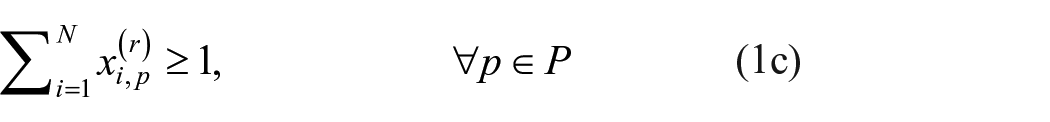
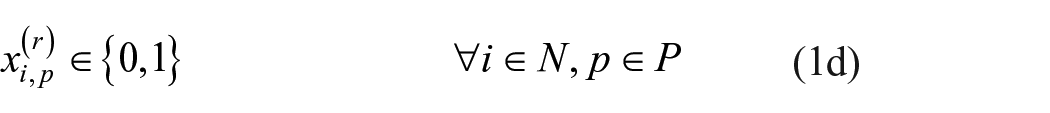
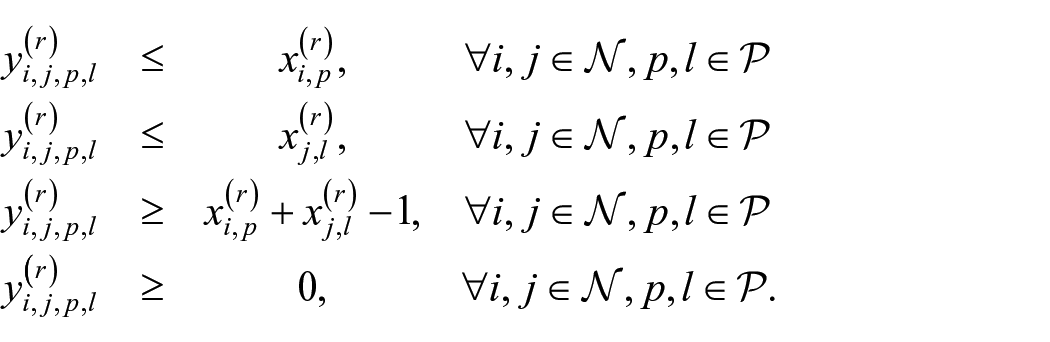
Specifically, if both
Application to hypothetical example
Returning to our hypothetical example, we can apply Dabkowski et al.’s (2016) exploratory procedure to its one-mode network (Panel (a) of Figure 3). In this case, we have

Distillation of the minimal, non-isomorphic set of
Starting with the top panel, there are 16 possible 2-position, one-mode binary image matrices, and 6 pairs of these matrices are isomorphic, implying each member of a given pair can be obtained by permuting the other member’s first row and column with its second row and column. Highlighted by red boxes, there is no need to find the optimal partition for both matrices in a given pair, as the actors assigned to the first and second positions in the first matrix can simply be swapped in the second matrix. Therefore, without loss of generality, we can remove the second matrix from each pair, yielding the 10 non-isomorphic image matrices seen in the middle panel of Figure 7.
At this point, we note that the zero matrix’s first row is equal to its second row, and its first column is equal to its second column; the first and second positions have an identical pattern of ties. Accordingly, by definition, these positions are structurally equivalent, and they can be merged, allowing us to fit a more parsimonious
With our indices, data, and decision variables established, we coded the formulation in C ++ and solved the series of integer programs using CPLEX 12.3.0 via IBM’s Concert Technology library. This returned the unique globally optimal image matrix seen in Panel (a) of Figure 8 with the corresponding partition given in the permuted adjacency matrix in Panel (b). With four inconsistencies (denoted by red cells and font), this solution matches the one-mode portion of Pajek’s optimal solution in Panel (a) of Figure 6.
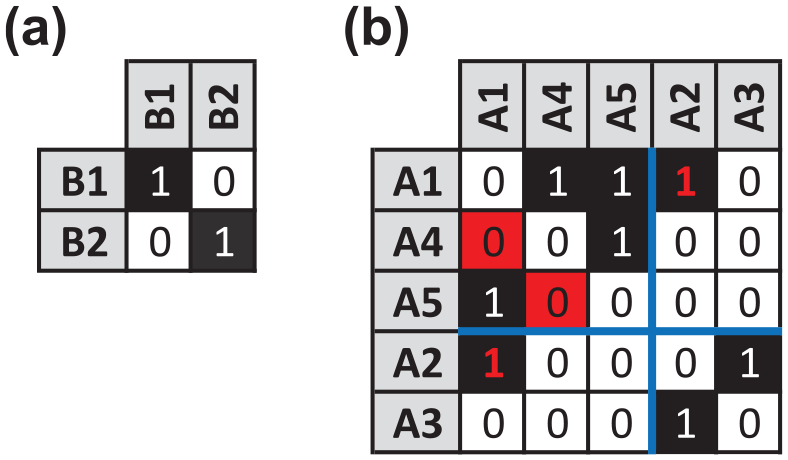
Solution returned by Dabkowski et al.’s (2016) exact exploratory approach for blockmodeling one-mode networks. Panel (a) gives the unique globally optimal image matrix. Panel (b) provides the permuted, partitioned adjacency matrix, where red cells and font denote inconsistencies.
Exact exploratory blockmodeling for two-mode networks using integer programming and structural equivalence
As noted earlier, Brusco and Steinley (2009) also formulated integer programs to find globally optimal partitions for two-mode blockmodels when the image matrix is prespecified. Given our desire to perform exact exploratory blockmodeling of multiple relation, mixed-mode networks, extending their work in a manner similar to Dabkowski et al. (2016) seems natural, and the modified optimization model is given below.
Two-mode optimization model
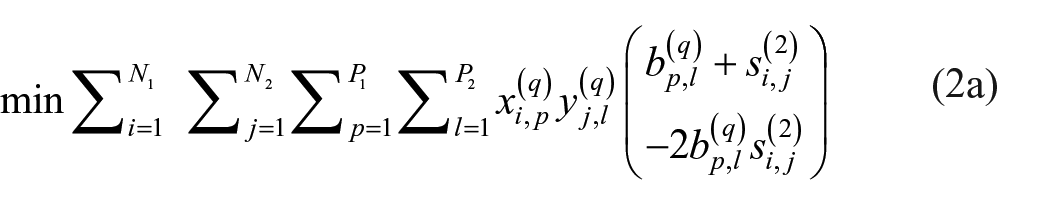
s.t.




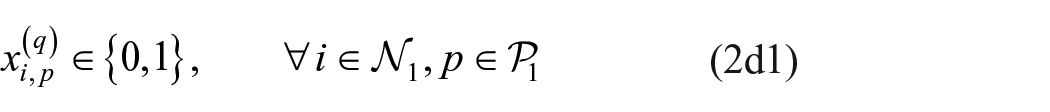
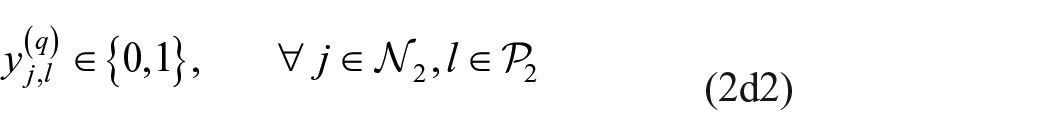
Minimal set of non-isomorphic two-mode image matrices
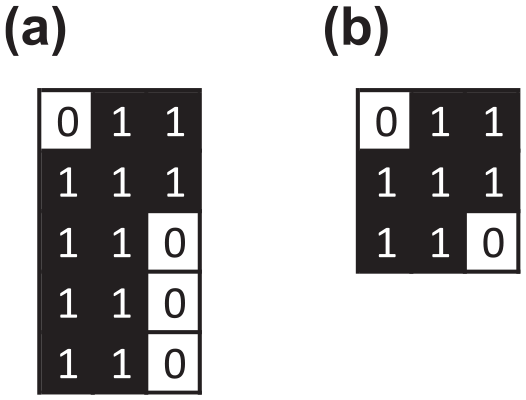
Consistent with the one-mode optimization model, we solve the minimization problem for each member of the minimal, non-isomorphic set of image matrices. In this case, however, the image matrices are two-mode, and finding isomorphisms and assessing structural equivalence are slightly different. Specifically, unlike the one-mode image matrices in Figure 7 (which have a single set of positions and, therefore, rows and columns must be permuted together), two-mode image matrices have two sets of positions, and rows and columns can be permuted independently. In addition, unlike the positions of the one-mode image matrices in Figure 7 (which are structurally equivalent if both their rows and their columns are identical), positions in two-mode image matrices are structurally equivalent if either their rows or their columns are identical. Moreover, once an identical pair of rows (or columns) is identified, only the identical rows (or columns) are merged. To visualize these differences, consider Figure 9, which shows the distillation of all possible 2-position, two-mode binary image matrices into a minimal, non-isomorphic set.

Distillation of the minimal, non-isomorphic set of
Once again, we start with 16 possible image matrices, and 5 groups of these matrices (enclosed within red boxes) are isomorphic. For example, permuting the rows of
Moving on to structural equivalence, the four non-isomorphic image matrices inside red boxes have structurally equivalent positions which can be merged. For instance, the columns of
An apt real-world example of this is given in Table 3 of Brusco and Steinley’s (2009) paper, where they report the globally optimal number of inconsistencies for a
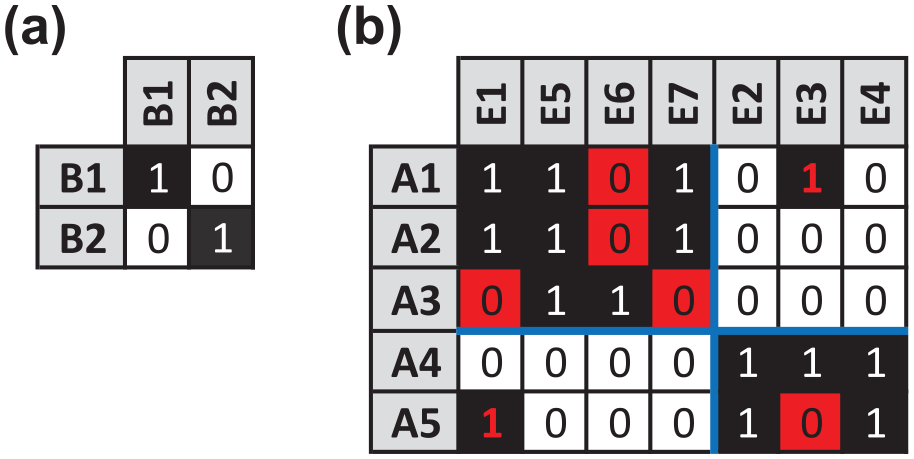
Two-mode image matrices for Supreme Court voting data (Brusco and Steinley, 2009: 582).
To verify this computationally, we used Brusco and Steinley’s (2009) integer program to find the globally optimal solution for the
Of course, as the number of row and/or column positions increases, deriving the minimal, non-isomorphic set can no longer be done by hand. Accordingly, we developed a simple algorithm in the open source, statistical software R, and we verified it with known results (see Appendix II in the online supplemental material). As Table 1 clearly highlights, the computational advantage of fitting these minimal, non-isomorphic sets is tremendous, and it increases as the number of actor and event positions grow. For example, if we were interested in finding the globally optimal
Total number of image matrices to fit for two-mode blockmodels with four or fewer actor and event positions.

Application to hypothetical example
Applying this approach to the two-mode portion of our hypothetical example, we have
Solution returned by the exact exploratory approach for blockmodeling two-mode networks. Panel (a) gives the unique globally optimal image matrix. Panel (b) provides the permuted, partitioned adjacency matrix, where red cells and font denote inconsistencies.
Exact exploratory blockmodeling for multiple relation, mixed-mode networks using integer programming and structural equivalence
At this point, we have optimization models for the exact exploratory blockmodeling of one- and two-mode networks. Combining them to accommodate multiple relation, mixed-mode networks is natural, and the optimization model is given below.
Mixed-mode optimization model
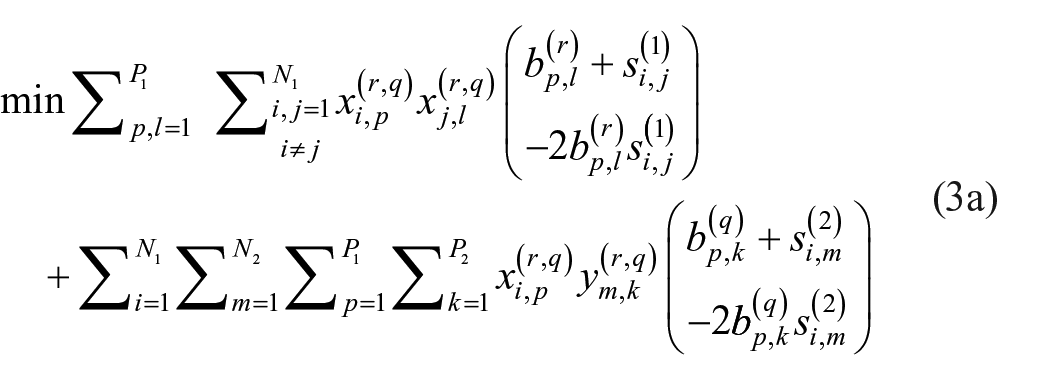
s.t.
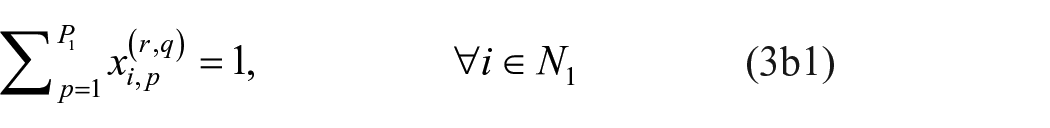
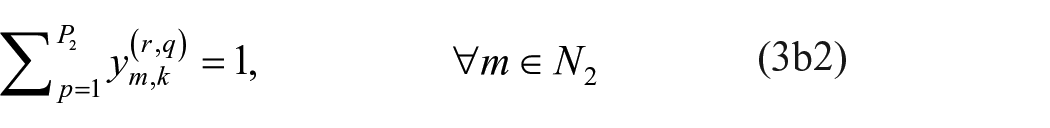
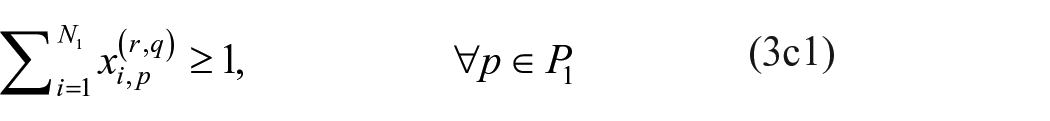
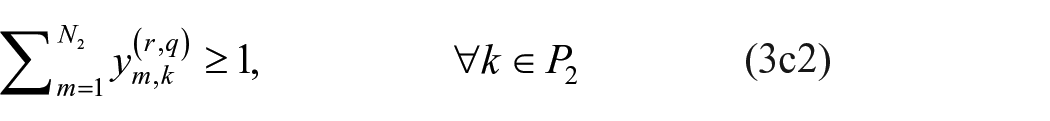
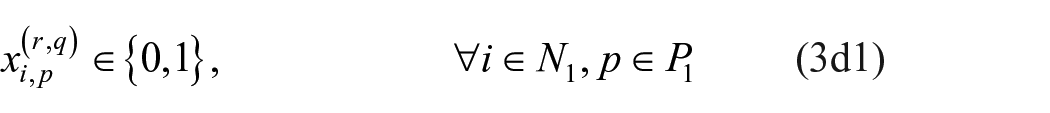
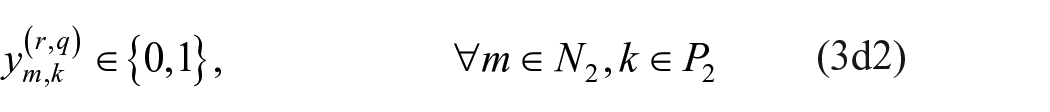
Minimal set of non-isomorphic multiple relation, mixed-mode image matrices
As with the two-mode network, to derive our minimal, non-isomorphic set of mixed-mode binary image matrices we must modify our notions of finding isomorphisms and assessing structural equivalence. Specifically, in a multiple relation, mixed-mode network, the rows of the
Assuming there are two actor and two event positions, we can illustrate this using Figure 12. Starting with the top panel, there are

Distillation of the minimal, non-isomorphic set of
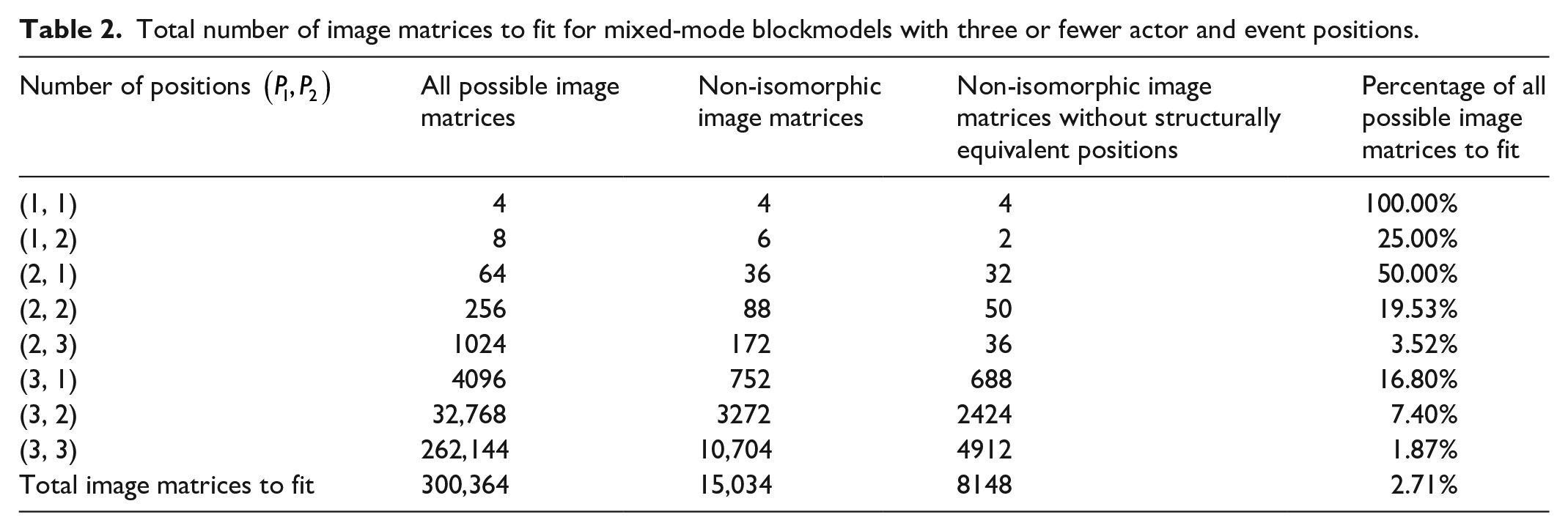
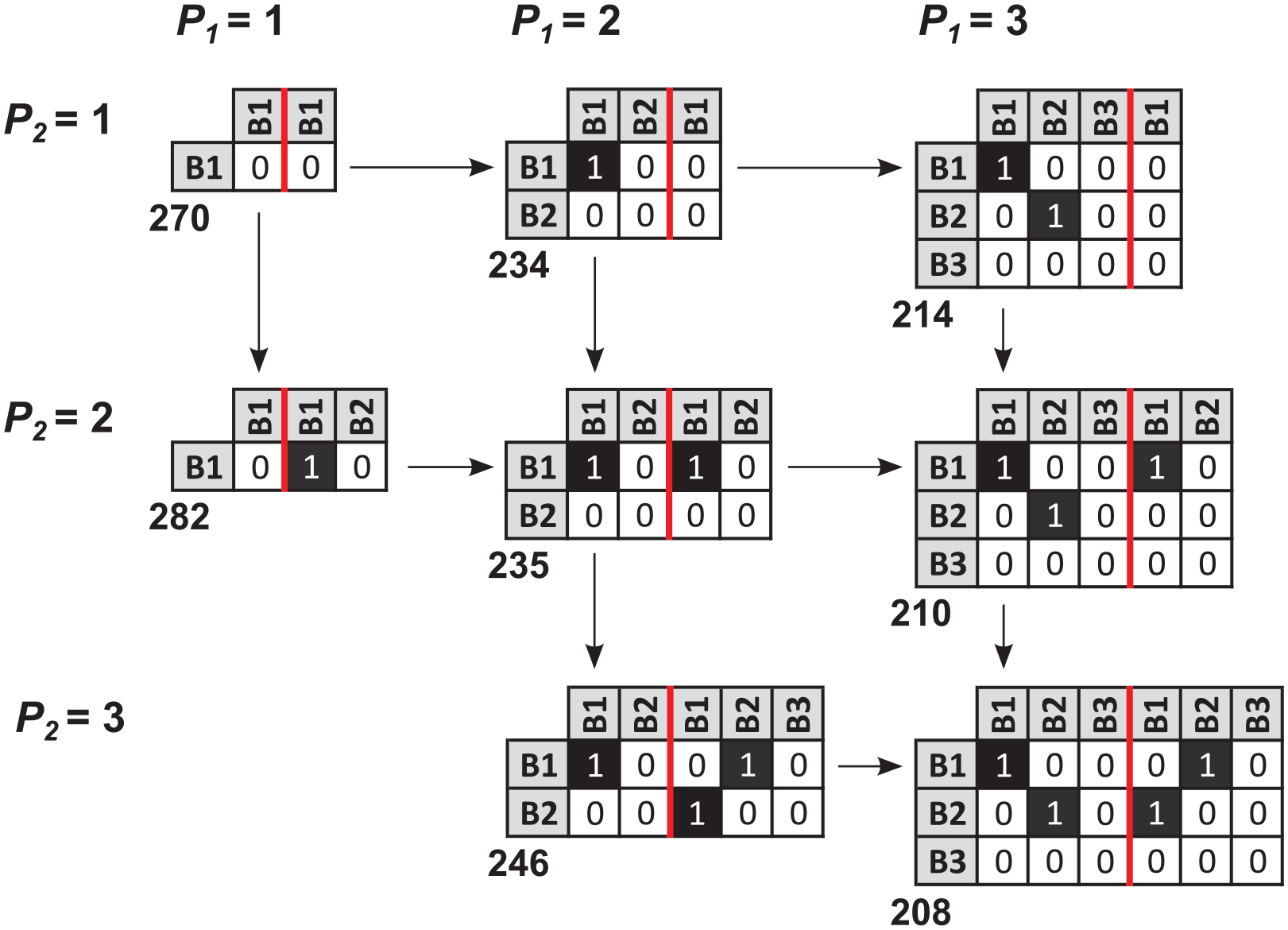
Even for a small number of positions, manually deriving the minimal, non-isomorphic set of multiple relation, mixed-mode image matrices is tedious and error-prone. As such, we made minor modifications to our two-mode algorithm and implemented it in R (see Appendix III in the online supplemental material). The results of running it for three or fewer actor and event positions are given in Table 2, and, once again, there are significant computational savings. Specifically, if we want to find the globally optimal multiple relation, mixed-mode blockmodels with three or fewer actor and event positions, we only need to fit 2.71% or 8148 of the 300,364 possible image matrices. Admittedly, this is still a significant computational chore, but it is two orders of magnitude more manageable.
Total number of image matrices to fit for mixed-mode blockmodels with three or fewer actor and event positions.
Application to hypothetical example
Armed with the model in section “Optimization model,” we can now find the globally optimal blockmodel (or blockmodels) for our hypothetical multiple relation, mixed-mode network (seen in Panel (a) of Figure 13). As with the 2-mode network, our integer program has 24 binary decision variables that need to be assigned for each of the 50 image matrices in the minimal, non-isomorphic set, and solving them yields the 2 global optima seen in Figure 13.
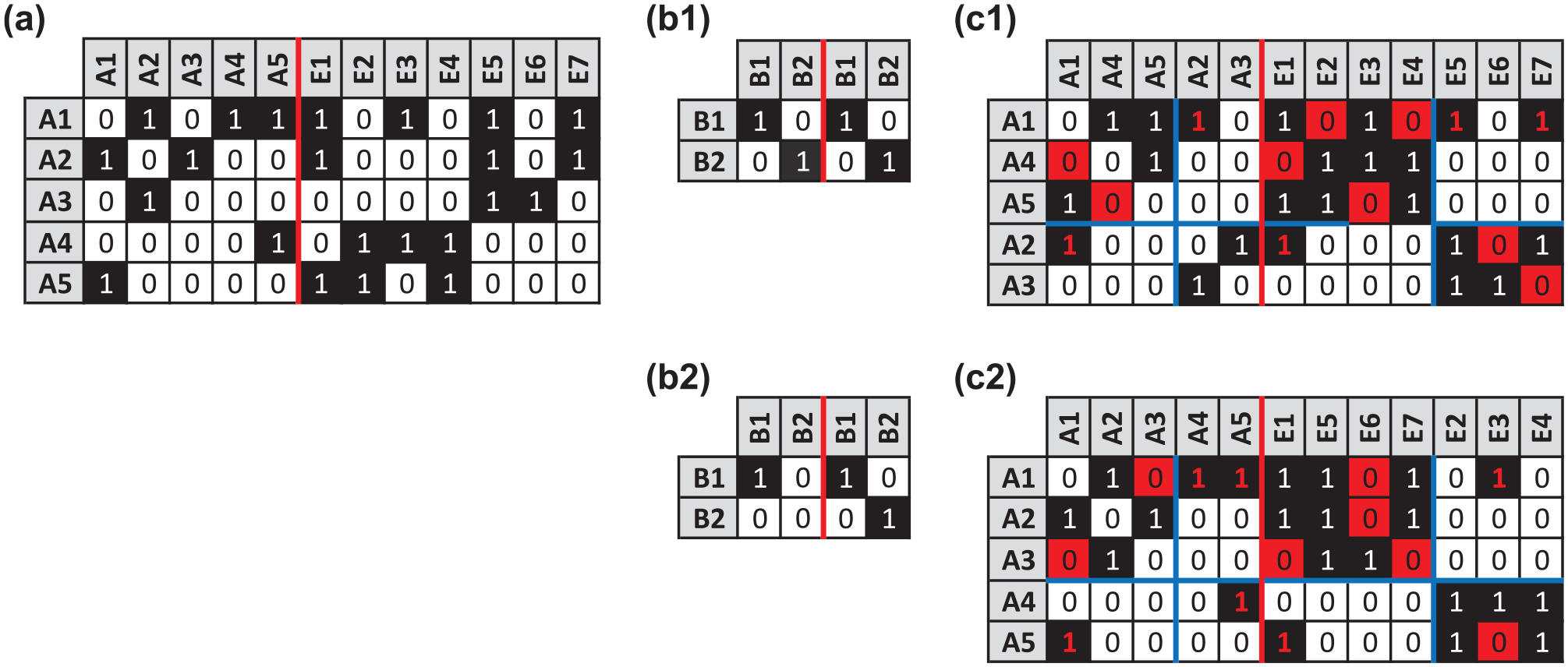
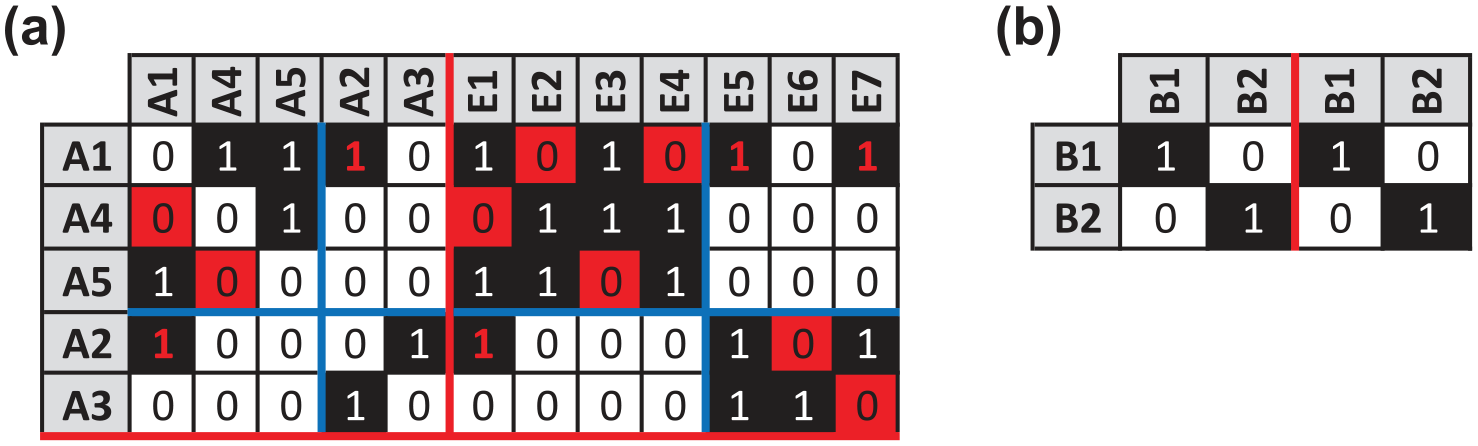
Solution returned by the exact exploratory approach for blockmodeling multiple relation, mixed-mode networks. Panel (a) shows the hypothetical network. Panels (b1) and (b2) give the globally optimal image matrices. Panels (c1) and (c2) provide the corresponding permuted, partitioned networks, where red cells and font denote inconsistencies.
The first solution, given in Panels (b1) and (c1), is identical to the solution in Figure 6. With 13 inconsistencies (denoted by red cells and font), it confirms the global optimality of Pajek’s heuristically generated solution. On the other hand, the second solution, seen in Panels (b2) and (c2), reflects a different social structure. Specifically, actor A1 is clustered with A2 and A3 versus A4 and A5, and A4 and A5 no longer occupy an actor position with a self-tie. Moreover, event E1 is clustered with E5, E6, and E7 versus E2, E3, and E4. In fact, subsequent rerunning of the Pajek model seen in Appendix I in the online supplemental material returned the second solution in Figure 13, as well as an alternative assignment of actors and events for the images matrices in Panels (b1) and (b2). Of course, on a basis of inconsistencies, none of these solutions is best; they are equally compelling. Confronted with this situation, the researcher would need additional, substantive evidence to select a best fit. Alternatively, she could embrace the dissonance and view the solutions as reasonable abstractions of the same network.
Analysis of the Noordin top terrorist network
Although illustrating our approach on the simple hypothetical example is useful for explanation and validation, testing it on larger, real-world networks is necessary for implementation. With this in mind, we selected a contemporary multiple relation, mixed-mode network with significant background and practical appeal, namely “Noordin’s Network”—a dark network centered on the Tanzim Qaedat al-Jihad (TQJ; or Organization for the Basis of Jihad) terror group (Everton, 2012).
Taking this tack, we can exploit Roberts and Everton’s (2011) relational data set, which leverages an International Crisis Group (2006) report to generate several TQJ networks, including an aggregated one-mode network reflecting trust and two-mode networks indicating participation in (or facilitation of) documented meetings or operations. In the case of the former, the trust network combines classmate, friendship, kinship, and soulmate ties between terrorists (Everton, 2012: 112). When binarized and restricted to the 40 members of Noordin’s network who were alive as of May 2006 (labeled A1 through A40), this yields the

Multiple relation, mixed-mode network for the 40 members of the Noordin Top Terrorist Network who were alive as of May 2006 (Roberts and Everton, 2011). The one-mode network (located to the left of the vertical red line) reflects the trust between terrorists, where a “1” in cell (i, j) indicates that terrorist i trusts terrorist j. The two-mode network (located to the right of the vertical red line) reflects the terrorists’ participation in (or facilitation of) 34 documented meetings or operations, where M1 through M20 represent meetings, O1 through O14 denote operations, and a “1” in cell (i, m) indicates terrorist i participated in event m (see supplementary document of Everton (2012) for additional details on these events). The yellow-shaded row and column (A27) denotes Noordin Mohammad Top, the self-proclaimed emir of the TQJ terrorist group, who was subsequently killed in September 2009 (Acharya, 2015).
Globally optimal image matrices for the multiple relation, mixed-mode network of the 40 alive members of the Noordin Top Terrorist Network, where the error score corresponding to each globally optimal
For example, we could augment the globally optimal

Multiple relation, mixed-mode network for the Noordin Top Terrorist Network, where the rows and columns have been permuted according to the globally optimal
Moreover, given our desire to identify potential replacements for Noordin (A27), the terrorists in the second actor position represent likely candidates. That said, at the time of Noordin’s death in September 2009, every member of this position was incarcerated and either sentenced to death or serving prison sentences through at least mid-2011 (International Crisis Group, 2006; Quiano, 2008). With this in mind, the first actor position provides the next logical place to look. After all, several members of the second position (including Noordin) trust members of the first position, and Noordin participated in multiple events with its members. Taking this approach, we find that four terrorists in the first position—{A2, A33, A36, and A39}—were free at the time of Noordin’s death (International Crisis Group, 2006). Of these, A39 (Urwah, who has been described as a “key lieutenant” [Stewart, 2009]) was killed alongside Noordin, and A36 (Ubeid) had left TQJ for another terrorist organization (International Crisis Group, 2009). With only two members of the first position left, A2 (Abu Fida)—the only free member of the first position trusted by Noordin—seems to be the likely successor.
Ultimately, however, a heretofore unknown named Syaifudin Jaelani, who operated “in a chameleon-like fashion . . . [and] patiently waited for three years to prepare suicide bombers” for the July 2009 attacks in Jakarta (Christanto, 2009), took the reins from Noordin. Syaifudin does not appear in Roberts and Everton’s (2011) relational data set, and no approach, no matter how exact, can make him materialize. This is not an indictment of our approach. It simply highlights a challenge of analyzing dark networks, namely, the actors typically prefer to remain anonymous. That said, Everton (see Everton and Cunningham, 2015) has expanded the size of the Noordin dataset to 237 individuals. Although this version is not yet publicly available, it is possible Syaifudin is among this expanded set.
Limitations
Among the limitations of our exact exploratory approach, the principal shortcoming is its scalability, especially as the number of actor and event positions grow. After all, in this paper, we restricted our real-world analysis to image matrices with three or fewer actor and event positions, and, while we feel this was illustratively and substantively sufficient, adding a fourth position makes the problem practically infeasible. Specifically, when we move from a
To combat such issues, Brusco and Steinley (2009: 584) recommend “a two-stage procedure [could be employed] . . . where a heuristic method is first used to identify an image matrix and the integer program is subsequently formulated and solved to identify the optimal solution for that image matrix.” Adopting this approach, our multiple relation, mixed-mode method in Pajek provides an attractive heuristic, as our experience suggests it yields exact solutions in a very reasonable amount of time. For example, when applied to the Noordin Top Terrorist Network in Figure 14, Pajek completed its 200 repetitions in less than 4 minutes, and the number of inconsistencies, image matrix, and partition of its best solution matched the globally optimal result in Figure 16 with one minor exception—Meeting #1 was no longer clustered with Operation #8; it was in the third event position. This not only reinforces previous findings on the excellent performance of the relocation routine used in Pajek but also reemphasizes the possibility of multiple global optima.
In fact, when one considers that CPLEX requires specialized training and Pajek is quite accessible, one might question the value of the integer programming approach at all. However, it is crucial to remember that objectively and definitively assessing the quality of Pajek’s solutions requires an exact method, and our integer programming approach fills this void. In sum, we see our exact and heuristic procedures as symbiotic, and both are currently necessary to analyze real-world multiple relation, mixed-mode problems of a non-trivial size.
Conclusion
From the outset, computational sociologists have stressed leveraging multiple relations when blockmodeling social networks. In the current era of big data and fast computation, our ability to harvest such networks and analyze them in an exact exploratory way has never been greater. Accordingly, in this paper we extended Brusco and Steinley’s (2009) exact procedure for the confirmatory blockmodeling of a single relation to the exploratory blockmodeling of multiple relation, mixed-mode networks. Given the computational complexity of this problem, we developed an algorithm to generate a minimal, non-isomorphic set of
Although we formulated our exact approach for multiple relation, mixed-mode networks with a single one- and two-mode network, extending it to multiple one- and two-mode networks is relatively straightforward. In fact, given the current emphasis on multilevel networks (e.g. Lazega and Snijders, 2015), this appears to be the next logical step. That said, unless we migrate to high performance / high throughput computing systems, increasing the number of relations without improving the efficiency of the current formulation seems somewhat fruitless. With this in mind, we hope this paper will inspire creative efforts to extend the applicability of exact methods to multiple relation, mixed-mode networks.
Supplemental Material
Suplementary_material – Supplemental material for Finding globally optimal macrostructure in multiple relation, mixed-mode social networks
Supplemental material, Suplementary_material for Finding globally optimal macrostructure in multiple relation, mixed-mode social networks by Matthew F Dabkowski, Neng Fan and Ronald Breiger in Methodological Innovations
Footnotes
Acknowledgements
The views expressed herein are those of the author(s) and do not reflect the official policy or position of the United States Military Academy, the Department of the Army, or the Department of Defense. In addition, author contributions are as follows: M.D., N.F., and R.B. designed research, performed research, and analyzed data; M.D. wrote the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.