
Abstract
In educational policy research, linking specific practices to specific outcomes is an important (though not the only) goal, which can bias researchers (and funders) toward employing purely quantitative methods. Given the context-specific nature of policy implementation in education, however, we argue that understanding how specific practices lead to specific outcomes in specific conditions or contexts is critical to improving education. Qualitative comparative analysis is a method of qualitative research that we argue can help to answer these kinds of questions in studies of educational policies and reforms. Qualitative comparative analysis is a case-oriented research method designed to identify causal relationships between variables and a particular outcome. Distinct from quantitative causal methods, qualitative comparative analysis requires qualitative data to identify conditions (and combinations of conditions) that lead to a particular result; it is context driven, just as many educational reforms must necessarily be. We contend that qualitative comparative analysis has the potential to be of use to educational researchers in investigating complex problems of cause and effect using qualitative data. As such, our aim here is to provide a general overview of the characteristics, processes, and outcomes of qualitative comparative analysis. In so doing, we hope to offer guidance to educational researchers around how and when to use qualitative comparative analysis, as well as recommendations for current educational issues that could be investigated with qualitative comparative analysis.
Qualitative research as a whole has many strengths: the emphasis on context, experience, and process makes qualitative methods well-suited to analyses interested in “how?” and “why?” questions. However, many qualitative researchers agree that causality and generalizability, in the more traditional sense, are not necessarily the goals of qualitative research, which is by nature more context-specific. Indeed, many scholars have emphasized the concept of “transferability” over generalizability as an outcome for qualitative studies (e.g. Lincoln & Guba, 1985; Tierney & Clemens, 2011). Others have argued that the criteria for rigor in naturalistic inquiry does need to be directly aligned to conventional notions of validity; for example, qualitative work could be evaluated for rigor based on its authenticity (See Lincoln and Guba, 1985 for more on this) or on its potential for “local causality” (Miles and Huberman, 1994). Yet, particularly in educational policy research, linking specific practices to specific outcomes is an important (though not the only) goal, which can bias researchers (and funders) toward employing purely quantitative methods (e.g. What Works Clearinghouse). Given the context-specific nature of policy implementation in education, however, we argue that understanding how specific practices lead to specific outcomes in specific conditions or contexts is critical to improving education. In other words, as Honig (2006) notes, the essential question is not “simply ‘what’s implementable and what works’ but what is implementable and what works for whom, where, when and why?” (p. 2). Qualitative comparative analysis (QCA) is a method of qualitative research that we argue can help to answer these kinds of questions in studies of educational policies and reforms.
QCA is a case-oriented research method designed to identify causal relationships between variables and a particular outcome (Fiss, 2010; Ragin, 2008). Distinct from quantitative causal methods, QCA requires qualitative data to identify conditions (and combinations of conditions) that lead to a particular result (Ragin, 1987); in other words, it is context-driven, just as many educational reforms must necessarily be. For example, if a policy researcher were interested in understanding how a set of particular implementation conditions impacted the success or failure of a reform, QCA is one method that would provide the analytical tools to make that connection. The chosen outcome and the conditions of a context that lead to that outcome are identified through spending time in the actual context (observations) and talking to the people involved in that context (through interviews, focus groups, etc.).
QCA offers advantages for social science researchers in particular, especially in studies with smaller sample sizes (Rihoux, 2006). For example, QCA allows researchers to meet some of the conflicting demands around research goals—namely, the desire to identify “what works”—and provide an in-depth analysis, along with some level of generalizability (Rihoux, 2006). In addition, QCA can mimic experimental or causal conditions (Ragin, 2014), which are notoriously difficult to establish in educational research. Still, this research method has not yet been significantly utilized by educational researchers, particularly in the United States. We contend that QCA has the potential to be of use to educational researchers in investigating complex problems of cause and effect using qualitative data. As such, our aim here is to provide a general overview of the characteristics, processes, and outcomes of QCA. We also offer a brief example of how QCA might be used to investigate a policy. In so doing, we hope to offer guidance to educational researchers around how and when to use QCA, as well as recommendations for current educational issues that could be investigated with QCA.
Causality in policy research
Causality is a complicated—and contested—notion in educational research (Maxwell, 2004). Cause-and-effect relationships are rarely simple, and it can be difficult to disentangle the impact of one specific variable on the outcome. In addition, the context-specific nature of educational settings and reforms make it difficult to make generalizations. As far as policy research goes, exploring the impact of policies or interventions can be hampered by contextual conditions that cannot always be captured by quantitative or qualitative research alone. With few exceptions, many outcomes in social science research are context-dependent and rely on the combination of several inputs. Still, many researchers and policymakers see causal analysis as the “gold standard” of research. For example, the Scientific Research in Education report, put out by the National Research Council (2002), emphasized experimental methods as the preferred method of investigation. In response, others have argued that traditional causal analysis neglects context and meaning (see Maxwell, 2004) and have promoted qualitative research as a method of identifying causality in particular cases, particularly in conjunction with quantitative analyses. Miles and Huberman (1994), for example, argue that qualitative research offers the opportunity to explore “local causality” and deals well with “the complex network of events and processes in a situation” (p. 147). Maxwell (2004) further parses out the spectrum of causality as a dichotomy of regularity, variance-oriented understandings of causation, and alternative, realist understandings. We acknowledge the complexity of the notion of causality. Here, we do not posit an alternative understanding of causality; instead, we argue that QCA has the potential to meet both criteria: it provides context and acknowledges the importance of meaning (“local causality”), while also examining how the regularity of conditions or variables may lead to specific outcomes.
QCA
QCA is a method through which researchers can use qualitative methods to examine cases in depth and link specific conditions, characteristics, or practices present within that case to particular outcomes (Ragin, 2008). Indeed, the goal of QCA is to identify and examine some of the configurations of conditions that are necessary for specific outcomes, whether desired or not (Ragin, 1987). In lieu of disaggregating cases into analytically separate aspects, QCA treats possible configurations as cases which has proven useful for educational researchers (see Coburn et al., 2012; Stevenson, 2013), as well as for sociologists, political scientists, and economists interested in studying large-scale complex phenomena (e.g. Fiss, 2010; Rubinson, 2017; Wagemann and Schneider, 2010).
The primary concerns of researchers employing QCA should be identifying relevant cases and factors in the organically occurring context of interest, as QCA produces case-based, as opposed to variable-based, results. Before data analysis, QCA, as an iterative data collection process (Wagemann and Schneider, 2010), can also be used to summarize data, check its coherence, test hypotheses and theories, review assumptions, and develop new arguments. Because it involves in-depth analysis of conditions and practices, QCA entails a high level of familiarity with the cases, as well as the theoretical knowledge and empirical insights that define the conditions and outcomes (Schneider and Wagemann, 2010). Thus, QCA is useful in answering research questions and analyzing mid-sized data sets for which neither standard statistical analyses (multivariate regression analysis) nor traditional qualitative analyses (case study, phenomenology, etc.) are appropriate approaches.
In order to identify combinations of conditions (referred to as causal patterns) that lead to specific outcomes (referred to as case properties), the researcher has to identify specific outcomes of interest and collect deeply contextualized qualitative data. For example, an implementation researcher might identify “implementation fidelity” as an outcome and would then examine the conditions of each case (each school) by collecting a variety of qualitative data. Then, in conducting the analysis, the researcher would connect existing conditions in the cases to the outcome, looking for the conditions that supported fidelity and the conditions that hindered it. Of course, we are not claiming that all contributors to causal patterns and their relations can be identified. Rather, using the literature as a guide, researchers can identify possible contributors and examine whether or not those are indeed conditions that would be considered necessary or necessary but insufficient for a particular outcome. To continue to parse out which conditions are worth exploring, researchers using QCA also employ iterative data collection to explore the existing conditions in the case. The iterative nature of qualitative research—collecting and analyzing data simultaneously—allows for researchers to hone in on important contributors and to identify and flesh out the details of additional conditions as more data are collected and analyzed. This process is one place where QCA really stands out—though initial variables/conditions may be identified in the literature prior to data collection, the qualitative data collection process is much more interpretive and iterative, which can support a continuously evolving study that could trace the connections between conditions and outcomes in a more detailed manner. The “thick description” and rich detail, along with the extended time in the field required by a qualitative analysis, provides a level of detail and vicarious experience for the reader that can support researchers’ conclusions.
From this qualitative data collection and analysis process, a truth table—a data matrix which includes possible configurations of conditions and their associated empirical outcomes—is developed (Fiss, 2010). This table can account for many insufficient but necessary (INUS) conditions which, individually, may not be statistically significant in a regression model, but in certain combinations are causal recipes (Ragin, 2008). We discuss truth tables in further detail below.
QCA process
There are three types of QCA: crisp-set, fuzzy-set (fsQCA), and multi-value analyses (mvQCA). We will focus primarily on crisp-set QCA in this article because it is the foundation for the other types of QCA. In crisp-set QCA, an element is clearly a member of a dichotomous set or not and is assigned either a 1 for “fully in the set” or 0 for “fully out of the set” (Fiss, 2010; Wagemann and Schneider, 2010). In contrast, fsQCA requires researchers to determine the degree of membership in different sets as well as calculate the degree of membership in configurations. In this section, we discuss the process of conducting a crisp-set QCA in more detail.
To begin, QCA is conducted within the context of the literature and important theories related to the phenomenon of interest (Ragin, 2014). As with any study, the researcher should be well versed in current explanations and descriptions of the phenomenon. However, this becomes even more critical in the process of QCA because, as Ragin (2014) notes, literature and theory are the basis for the selection of causal variables and the interactions of these variables with each other (i.e. causal combinations). Thus, as the researcher reviews the literature, she would determine an outcome of interest, as well as any potential variables. She would then develop research questions based on these variables. Once the researcher is well versed in the literature and has developed appropriate research questions, data collection can begin. It should be noted, however, that the research questions and the conditions and outcomes of interest may evolve throughout the course of data collection—a phenomenon described in qualitative scholarship as “emergent design” (Creswell, 2007). This supports QCA in narrowing in on potential causal linkages between conditions and outcomes.
Data collection in QCA
In a QCA study, data collection is very similar to what it might be in any qualitative study—particularly, case study. The goal, just as it is in a case study, is to develop a comprehensive, in-depth understanding of the case or cases under investigation (Stake, 1995; Yin, 2014). A researcher may conduct interviews, focus groups, observations, and/or document analysis toward the goal of creating a rich description of the conditions of a case. If, for example, a researcher were interested in how teachers implemented iPads in their classrooms as part of a district-wide technology initiative, she would construct a case for each school in the district, and then interview administrators, teachers, and students in each school about the new initiative. She may also observe classrooms and professional development (PD) sessions to understand how the iPads are being implemented in classrooms and how the initiative is being taught and discussed in PD. This information would allow the researcher to develop a holistic understanding of each school as a case, including the conditions present or absent in each school that seem to facilitate implementation. The depth of data collection in the QCA analysis helps to flesh out the conditions, characteristics, and practices in the research site and ultimately provides support for the researchers’ conclusions. For a crisp-set analysis, however, the data will need to be binary (present or absent, true or false, etc.) and so any interval data collected will need to be recoded into a categorical bivariate variable: 0 or 1 (Ragin, 2014). Once the data are collected and coded, the researcher can move to the next step: constructing a truth table.
Truth tables
The truth table is one of the primary outcomes of a QCA study, through which the researcher can demonstrate and discuss conditions and causal linkages. A truth table distills the qualitative data into categorical bivariate variables, which at first glance may seem reductive. However, the researcher can also incorporate and present more traditional qualitative data to add credence to her claims and to better illustrate the findings presented in the truth table. Creating a truth table helps researchers to identify and demonstrate the conditions (or absence of conditions) that lead to specific outcomes. It’s key to QCA, but can also be the most confusing part of a QCA study. In this section, we will draw on an example from Ragin (2014) to illustrate the creation of a truth table. In this example, the outcome is increased test scores. The researcher is trying to figure out what conditions may have led to those increased test scores (or conversely, what conditions did not lead to increased test scores). The researcher is specifically interested in the presence or absence of a reading intervention leading to increased test scores, but has identified other variables of interest as well. The outcome, increased test score, is represented by a 1, while no increase in test score is represented by a 0. The three conditions that have been identified are whether the setting is rural (1) or not (0), whether a specific reading intervention was implemented (1) or not (0), and whether the class size was large (1) or not (0). As this is a hypothetical example, this is all the information needed to examine the creation of a truth table.
To begin, the observed case is inserted as rows for the combinations of variables that exist. Each row should then be used to code the outcome variable as present or absent (or true or false) (see Table 1).
Hypothetical truth table showing three causes of increased reading comprehension test scores (Ragin, 2014).
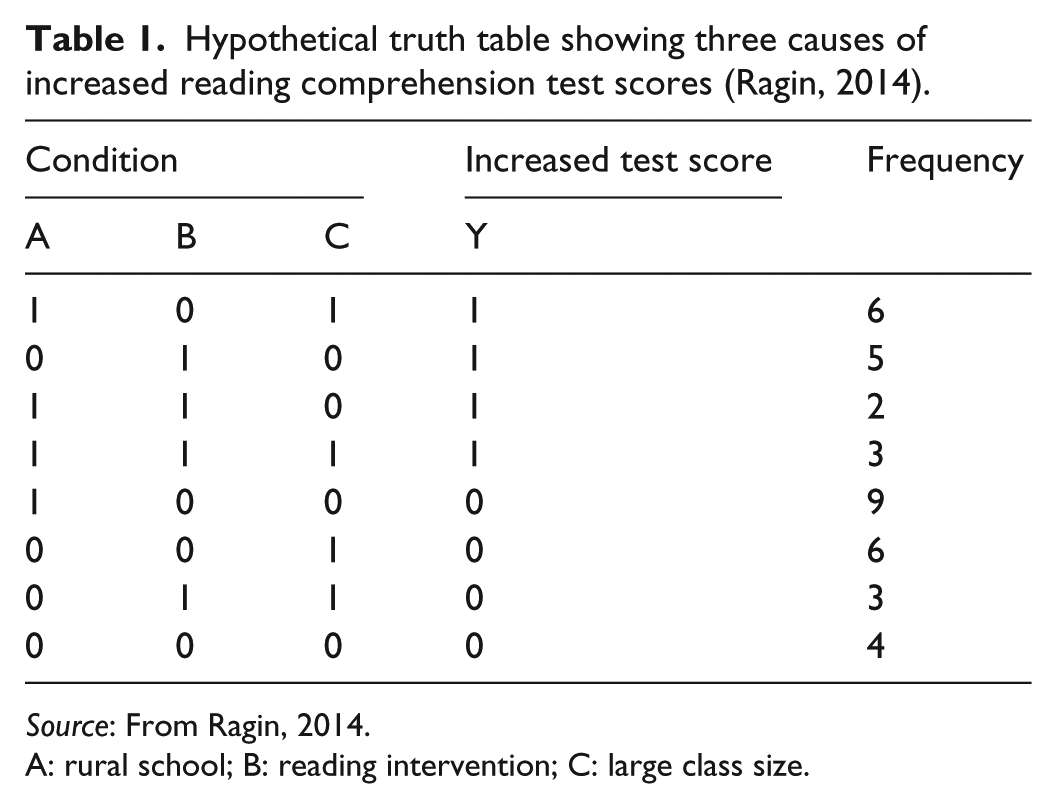
Source: From Ragin, 2014.
A: rural school; B: reading intervention; C: large class size.
Ragin (2014) notes that contradictions may be present in the truth table. Each row of the table is assigned a consistency score based on the percentage of cases displaying that outcome; thus, a contradictory row is one which has a consistency score that is not equal to 1 or 0. A contradiction exists when no easily observable outcome can be decided on from the cases (e.g. for a row in the truth table where five cases have the outcome observed and five have the outcome not observed, it is difficult to code the row). Returning to the example, if during construction of the truth table there were 10 observations of aBc (urban schools with small class sizes using the reading intervention), and in five of the cases test scores increased and in five of the cases there was no increase, a contradiction would occur as the observations would be ambiguous.
The concept of ambiguous outcomes demonstrates a strength of QCA. Rather than determining that the reading intervention, for example, does not lead to increased test scores because the truth table demonstrates no clear linkage, QCA encourages researchers to further investigate what else might be going on. When faced with ambiguous outcomes, the researcher can treat contradictions as an opportunity to return to the data (Ragin, 2014). The ambiguous cases may indicate the presence of additional conditions that need to be examined (e.g. perhaps there is a community reading program students attend voluntarily). Further, a truth table can be generated to model contradictions (coded as 1 for presence of contradiction and all others as 0), which allows the researcher to derive the equation for causal combinations that are ambiguous. With this, researchers can reexamine causal variables and clarify the variable, or determine an additional variable. Finally, ambiguous cases can be coded as absence of outcome (conservative, all cases coded as no increase in test scores) or presence of outcome (retaining greater complexity, all cases coded as increased test score), though if possible, the researcher should return to the data. The process is similar to the constant comparative method outlined in grounded theory studies (Glaser and Strauss, 2017). In any case, the contradictions are more easily recognizable than they would be in a purely quantitative study and require the researcher to make a determination of what to do with them—usually collecting additional data and garnering additional context.
With ambiguous cases coded, a Boolean equation can be generated from the truth table. The initial equation will be an un-simplified equation with primitive expressions or all causal combinations that resulted in the outcome (Ragin, 2014). The equation contains the primitive expressions of causal combinations. Minimization will reduce the number of primitive expressions. Prime implicants, or more reduced expressions, can then be determined by examining the logical sets that are covered by the minimized expressions in the Boolean equation. In addition, a prime implicants chart is used to further simplify if the researcher is seeking maximum parsimony. Continuing again with the reading intervention example, constructing a truth table for the fictionally observed increases in test scores results in the primitive Boolean equation Y = ABC + AbC + ABc + aBc. Based on this equation, we can conclude that test scores increased when one of four following conditions existed: (1) rural schools with large classrooms implementing the reading intervention (ABC), (2) rural schools with large classrooms not implementing the intervention (AbC), (3) rural schools with small classrooms implementing the intervention (ABc), or (4) urban schools with small classrooms implementing the intervention (aBc). Minimizing the equation makes it a little more reader-friendly. This equation can be minimized as follows (Ragin, 2014). In rural schools with large classrooms, the increased test scores occurred in the presence and absence of the reading intervention (ABC and AbC). In this case, B is irrelevant, as the outcome occurs regardless of the presence of the intervention. This can be reduced to AC. In rural schools implementing the intervention, class size was irrelevant (ABC and ABc). This can be reduced to AB. Finally, in the presence of the intervention in small class sizes, school type was irrelevant (ABc and aBc) and can be reduced to Bc. The minimized equation is Y = AC + AB + Bc, or increased test scores are observed in rural schools with large class sizes, rural schools implementing the intervention, or either school type with small class sizes. Using a prime implicants chart (Ragin, 2014), this can be reduced further for maximum parsimony. The chart provides a visual for determining the logical coverage of the partially reduced combinatorial causes (Table 2).
Prime implicants chart (from Ragin, 2014).

With the simplified equation, inferences can be stated. In this case, AC and Bc cover all sets in the partially reduced equation, and the resulting reduced equation is Y = AC + Bc. Following the example, this equation indicates that increased test scores are observed in rural schools with large class sizes, or in small class sizes using the intervention. The researcher may wish to conduct further analysis by assessing the different combinations associated with the absence of the outcome. Say, for example, the Boolean equation derived from the truth table was Y = AC + Bc. This equation provides the sets of combinations of variables where the outcome is present. To determine the set of causal combinations associated with the absence of the outcome, De Morgan’s Law is used. From the example above, the absence of the outcome would be y = (a + c) (b + C). The equation for the absence of the outcome may provide further insight and help develop inferences.
Next, the researcher should use the equation to state the necessary and sufficient cases. In comparative analysis, it is important to consider both what is necessary for the outcome to occur and what is sufficient (Ragin, 2014). Necessary cases are those that are required for the outcome to be observed. Sufficient cases are those that can produce a certain outcome. These distinctions are only relevant in the context of the literature and relevant theories. From the equation, necessity and sufficiency can be inferred. Ragin (2014) provides the following breakdown

Ragin (2014) states that a discussion of necessity and sufficiency falls in line with comparative analysis, and Boolean algebra techniques provide the researcher with a useful tool for analyzing and discussing these conditions.
Finally, with the minimized Boolean equation and the analysis of necessity and sufficiency, the researcher should address the limits of the causal variables identified with different theories. No inferences beyond what is presented can be made. Taken all together, the basic process of QCA leads to the discussion of combinations of variables that lead to the outcome, and necessary and sufficient cases.
Deriving the Boolean equation
Boolean algebra, developed by George Boole, provides the tool for conducting QCA. In Boolean algebra, variables are coded as binary (1 and 0). This allows for several Boolean operations to be performed and for the logic of Boolean algebra to be interpreted. Boolean addition is best understood as a logical statement, not as arithmetic. For example, in the Boolean equation A + B = Z, “and A = 1 and B = 1, then Z = 1,” (Ragin, 2014: 89) then what we really mean is if A is true or B is true, then Z is true. Boolean addition is thus a logical or-statement. It is noted that, generally, in QCA, capital letters indicate the presence of the variable, while lowercase letters indicate the absence (e.g. A = the presence of some variable A (1) and a = the absence of variable A (0)). In other words, capital letters are the cases coded as 1, and lowercase letters are coded as 0.
Building on Boolean addition, Boolean multiplication represents the logical and-statement. For example, in the Boolean equation Y = aBc, the outcome is observed in the absence of variables a and c and in the presence of B. The causal combination must include all cases, keeping with the logic of the and-statement. For example, if an outcome of increased test scores on a reading comprehension test was observed, and the input variables were rural school (A), reading intervention (B), large class size (C), then based on the equation Y = aBc, one could only conclude that the intervention improved test scores in urban schools with small class sizes.
The generalizability of the intervention could not be inferred without further observations of cases. This is similar to the idea that a larger sample size leads to increased power in a traditional quantitative analysis, but in QCA it is less about sample size and more about depth and detail of the observations. This requires combinatorial logic—looking at the combination of causal variables that lead to an outcome (Ragin, 2014). For example, in the equation Y = Abc, the equation looks at the combination of causal variables. In this case, the presence of A, along with the absence of b and c, leads to the outcome. Using the example above, in this case (Y = Abc, instead of Y = aBc), test scores increased at rural schools (A) with small class sizes (c), without the reading intervention (b). No inference of A as an independent causal variable can be made without further cases. For such a conclusion, the Boolean equation would need to be simplified to Y = A (A includes all subsets of A (ABC, ABc, AbC, Abc, etc.)). Researchers must be careful, however, not to focus too much on only the presence or absence of a condition. The context of the cases always remains important and any inferences made must take that into account. Indeed, the emphasis on context and focus on the particulars of the cases is what strengthens QCA as a method.
Once a Boolean equation is derived for the presence of the outcome variable, De Morgan’s law can be used to find the equation for the absence of the outcome variable, without having to construct a new truth table (Ragin, 2014). Simply, De Morgan’s law states that from the equation for positive outcomes, the variables can be recoded present to absent and absent to present (e.g. Y = AC + Bc: A becomes a, C becomes c, B becomes b, c becomes C). Then, the researcher recodes logical and- to logical or-statements and vice versa (ac becomes (a + c)). This gives y = (a + c)(b + C) = ab + aC + bc. Using the example of the fictional reading intervention on comprehension test scores (Y = AC + Bc), De Morgan’s law would provide the following equation for no observed increase in test scores: y = (a + c)(b + C) = ab + aC + bc. That is, no increase in test scores would be expected in urban schools without the intervention, urban schools with large class sizes, or small class sizes without the intervention. Reconfiguring the equation in this way allows the researcher to make clearer statements.
QCA in existing research
Since the publication of The Comparative Method in 1987, QCA, as both a research approach and an analytical technique, has been applied in various ways by researchers in the social sciences, and its uses have evolved with time. Marx et al., (2014) described what they consider the first epoch of QCA’s application in the social sciences, 1984–1997, as one in which QCA was primarily confined to the realm of political sociology, most notably research concerned with industrial democracy, welfare states, thresholds for revolutionary activity, impetus for social movements, and trade unions. Focusing on that first period of early adoption of QCA, Marx, Rihoux, and Ragin (2014), using the COMPASSS (COMParative methods for Systematic cross-caSe analySis network) database, identified 77 applications of QCA, including book chapters, books, and journal articles, 39 of which were double-blind peer-reviewed journal articles, and several of which appeared in top-tier sociological journals. In terms of rate of application, there was an obvious uptick in the 1990s: 13 studies were conducted in 1991, and 12 were conducted in 1996 and 1997.
Since that first era, QCA’s possibilities have become of interest to researchers in a number of fields, but its applicability to political science has only become more apparent. According to Marx, Rihoux, and Ragin (2014), in their review of the COMPASSS database, QCA applications in political science have been climbing steadily since 1992, with a strong increase from 2003 (2009, 2010, and 2011 were all years in which there were more than a hundred applications). Marx, Rihoux, and Ragin (2014) attribute this growth to two dynamics, a growing interest in case-based and comparative case research and a cohort of researchers who have applied QCA developing courses for the European Consortium for Political Research (ECPR), exposing interested colleagues to QCA and, ultimately, leading to more journal publications. The topics being explored with QCA have expanded since that first epoch as well and now include party politics, public administration, policy analysis, approaches to governance, and methods of regulation, to name a few.
In sociology, QCA has been employed for cognitive mapping and criminology research (among other things). In its first era, QCA was used to identify the most prevalent combination of individual and situational contexts for instrumental and expressive homicides, respectively, as well as the combinations they share. For example, Miethe and Drass (1999), in their analysis of the Uniform Crime Reporting database’s (UCR) Supplementary Homicide Reports of single-victim and single-offender homicides, found that the vast majority of homicides entail a combination of individual and situational factors. While this conclusion was hardly novel, even in 1999, the researchers’ use of QCA to compare instrumental homicides (crimes committed during other crimes like rape or robbery) to expressive homicides (crimes that result from lovers’ triangles, arguments, and the like) made effective use of QCA’s ability to simultaneously consider the presence of individual (e.g. offender and victim demographic information) and situational factors. The researchers derived these factors from established law enforcement agency identifiers (e.g. gang affiliation in the case of offenders and age in the case of victims) and the case classification (instrumental or expressive) from the realms of law enforcement, law, and social science. Their review of the literature also framed the debate regarding the instrumental-expressive dichotomy, in contrast to the theory that they are simply the bookends of a continuum. Using QCA to identify causal condition patterns to explore the robustness of an existing paradigm, like the instrumental-expressive dichotomy, was not only a defensible approach for Miethe and Drass (1999), but one which would advance the field of criminology theoretically and practically. Determining if prevalent combinations of individual and situational contexts held constant across subsets of instrumental and expressive crime supported this approach. Using regression or analysis of variance (ANOVA) would not have allowed for a holistic consideration of the cases, wherein factors were treated as if they could have had more influence in one causal combination than another. Combinations were coded as instrumental in the truth table if they occurred at least five times in the case of instrumental homicides and at least twenty for expressive homicides, as the latter were four times as likely at the time of the research.
Using the literature to identify outcomes and factors, subsets to test robustness, and instrumental coding of combinations is good practice for QCA, regardless of the field in which it is being employed. In business, researchers have used QCA and the aforementioned refinements to analyze economic markets, economic shocks, and trends in housing and entrepreneurship. fsQCA has even been used to analyze Global Entrepreneurship Monitor (GEM) data, providing more insight into traditional linear regression analyses that have established the relationship among the GEM’s Total Entrepreneurial Activity rate and entrepreneurial attitudes and social values geared toward entrepreneurship (Coduras et al., 2016). This study was similar to that of Miethe and Drass (1999), in that the researchers were not pursuing causality, but, rather, the confirmation of a relationship that had been identified using traditional statistical approaches. While QCA should not be seen only as a means of confirming relationships or theoretical underpinnings, its use as a nuanced method of holistic consideration in contexts where such multi-faceted consideration of factors had previously been restricted is encouraging. The fact that QCA was used in its methodological youth as well as in modern times to corroborate findings arrived at using other approaches demonstrates its staying power and diversity across a variety of fields and applications.
Moving into educational research, some recent applications include analyzing educators’ collegial networks as tools for adjusting instruction while maintaining pedagogical fidelity (Coburn et al., 2012), and the effects of teachers’ and learners’ digital repertoires on pedagogy (Coburn et al., 2012; Stevenson, 2013) combined qualitative social network analysis and QCA to explore the relationship between social networks and the sustainability of initiative implementation. The researchers found that a combination of strong ties, high-depth interaction, and high expertise supported the sustainability of reform-driven instructional approaches, which most effectively occurs when instruction is adjusted while maintaining the core pedagogical approach. The design and methodological considerations are sound, but this study highlights one of the challenges of using QCA alone or with other methods: Defining the parameters of the outcomes by which cases will be classified (positive or negative or according to some other determination) must be very deliberate or else risk becoming problematic. A positive outcome in the (Coburn et al., 2012) study was instructional approach sustainability, but what constitutes sustainability is up for debate. The researchers defined it as the degree to which educators use the practices of interest in high-quality ways after scaffolding for the instructor is removed. Similarly, they determined how expertise would be quantified (degree to which instructors in the social network had participated in professional learning opportunities in mathematics).
Defining and quantifying outcomes and factors in research using QCA takes on an extra layer of importance in that truth tables cannot be methodologically sound without clear, distinct parameters. Stevenson (2013) had a similar challenge (Coburn et al., 2012) in attempting to determine if technology has an impact on learning by using fsQCA to determine the role of digital repertoires in shaping pedagogical outcomes. To clearly quantify the outcome of interest and the main factor, students’ and teachers’ digital repertoires were quantified by the Becta Measures of Attainment Survey, while the pedagogical outcomes were measured using a metadata framework for digitally based pedagogical activities created and validated by the CANDLE project.
QCA in education
Though we argue that QCA is underutilized specifically in educational policy research, it has been used to a certain extent within the broad field of educational research. Onwuegbuzie and Weinbaum (2017) conducted a study based on previous research that demonstrated how five qualitative data analysis approaches can be used to analyze and to synthesize information from a literature review. The authors provide a framework for using a qualitative data analysis technique to analyze and to interpret literature review sources, a process called QCA-Based Research Synthesis (QCARS). The authors explain how to conduct a QCARS using a QCA software program. They noted that Ragin’s QCA can be applied in the literature review process by scrutinizing the findings and interpretations offered in each selected article and then documenting the different configurations of conditions connected with each case of an observed outcome.
QCA, in its various forms, can support researchers during the literature review process, as well as paradigm testing, relationship confirmation, and the exploration of causal combinations, an especially useful application in the realm of educational research. Glaesser et al. (2009), for example, examined the roles of substantive understanding and procedural understanding required to complete an open-ended science investigation. Using fsQCA, the authors compared the performance of undergraduate students on two investigation tasks. These tasks diverged with regard to the amount of substantive content required. fsQCA, which permitted calibrated representation of the General Certificate of Secondary Education (GCSE) science scores of participants, was chosen for its ability to explore causal combinations and alternative pathways for outcomes, rather than the additive effect on the outcome provided by regression models. Using fsQCA, the researchers determined that both substantive understanding and an understanding of ideas about evidence were involved in completing tasks proficiently, but as evidenced in their first table, the two student groups were different when it came to age, sex, social background, GCSE science score, and access to university. fsQCA was only used for the GCSE score, but other causal conditions, such as access, might also have benefited from such a treatment.
fsQCA certainly provides more nuance when it comes to certain causal conditions, like participants’ scores on standardized tests, but not applying the methodology strategically or consistently can be problematic. Though QCA has conceptual as well as methodological applications in educational research, where mid-sized data sets abound, researchers seeking to use it must not only consider which variables to include and how to calibrate them, but also the generalizability and applications of their research. For example, Balthasar (2006) formulated a study that shed light on QCA’s applications, but, by his own admission, no generalizability of the findings concerning the impact of institution distance. Balthasar employed QCA in a study focusing on the influence of institutional distance between evaluators and those being evaluated on the use of evaluations. The results presented are from 10 case studies in Switzerland. QCA was used in a combination of case- and variable-centered comparisons. Concerning methodology, the authors point out that QCA plays an important role in increasing the attention to patterns of combinations for the type of use and influencing factors related to the environment and the evaluation process, but because only 10 Swiss cases underwent the systemic evaluation, the determination that, under certain conditions, institutional distance between evaluators and evaluatees has no influence on the use of evaluations is not generalizable. Nevertheless, the results of the QCA offered a detailed analysis of the explored conditions, which is, in and of itself, useful for future research.
As the previous example illustrates, it is commendable when researchers are honest about the generalizability and practical applicability of findings, especially when the goal was exploration of a theory or method. However, educational researchers are particularly concerned with practical application, so those considering employing QCA should determine that using it will provide more insight than would case study or traditional statistical approaches. If the focus is on describing or examining a new phenomenon, for example, case study might be more appropriate (though it could eventually build to a QCA). In addition, if the researcher is interested primarily in participants’ experiences as they describe them and understand them, then phenomenology or narrative might be better suited. At the very least, QCA is most appropriate in cases with mid-sized data sets where causal relationships between variables and a particular outcome are the focus. That said, though, QCA is not limited to the consideration of simple policy problems. On the contrary, QCA is ideal for complex policy problems at the local (Glaesser et al., 2009), state (Trujillo and Woulfin, 2014), national (Miethe and Drass, 1999), regional (Castellano, 2010), and global (Toots and Lauri, 2015) level, and its basic condition-identifying logic can be extrapolated out into “why” and “how” paradigms, as well.
At the state level, Trujillo and Woulfin (2014) posed the following research questions in their use of QCA to investigate an intermediary (Roots for Reform) marketing equity-oriented instruction in California, where 73% of students are of color: “Why does an intermediary employ the reforms that it does?” and “What are the consequences of an intermediary’s reforms for teachers’ instruction?” The researchers used QCA to show how policy impacts reforms and instructional content, but not pedagogical approaches with English Language Learners (ELLs) or students of color. They conducted a case study of the intermediary by gathering data from six elementary schools in three districts over the course of 6 months in order to generate a crisp-set QCA truth table establishing which standards-based conditions were present at schools working with an intermediary that claimed to be offering specialized instructional tools for ELLs and students of color. Using QCA to consider how Roots for Reform’s mission differed from its reform mechanisms due to a post-No Child Left Behind policy environment shows how complex research problems can be addressed with QCA.
In a study at the regional level, Castellano (2010) sought to analyze the determinants of broadband diffusion in 27 countries in the European Union, considering supply-side factors, as well as demand-side conditions, such as secondary educational attainment. Castellano’s (2010) findings suggest that high secondary school attainment is a necessary condition for countries to be broadband innovators.
At the global level, Toots and Lauri (2015) analyzed quality assurance (QA) policies of 30 countries in civic and citizenship education (CCE) by using fsQCA. The main goal was to discover “combinations of institutional and contextual factors that are systematically associated with a high achievement in citizenship education” (Toots and Lauri, 2015: 247). The authors assumed that there are several pathways to a successful education. Two pathway models were created (accountability and participatory) with notable conditions and characteristics. Data analysis showed six configurations of contextual and institutional aspects. The authors state that fsQCA allowed improved contextualization of large-scale survey results by using qualitative data. This allowed the investigation of associations between macro social and policy design features, and student achievements.
Overall, QCA is getting more attention as a method for educational research. In educational research, QCA provides a methodologically sound means to analyze mid-sized data sets for which traditional statistical analyses are not appropriate because the number of data clusters does not provide sufficient statistical power for multivariate regression or hierarchical linear modeling (HLM). It also bridges the worlds of the qualitative and quantitative in that it can be used as an analytical method within case studies. It is often appropriate when embedded as a methodology in case studies that spend 6 months or more gathering qualitative data from sites that are similar in size, location, and demographic composition. Rigorous qualitative data-gathering and appropriate coding approaches can then be used to develop truth tables wherein researchers determine whether a condition is present and, if using fsQCA, to what degree. From there, educational researchers can analyze the combination of conditions that leads to a particular outcome and, if desired, suggest avenues for future research based on those conditions. In some instances, the goal of studies employing QCA is to provide methodologically sound reasoning for conducting variable-specific studies in the future. We argue that QCA could be especially useful in research examining policy and policy implementation. In the next section, we provide a brief example of a QCA analysis to show how QCA could be used to examine a particular policy—an early alert policy for math students.
Applying QCA: university math early alerts
Our university employs an early alert intervention where students enrolled in courses, particularly freshmen level courses, can be alerted by their instructors or university staff if there is reason for concern. Instructors may alert students for various reasons, including attendance concerns, missing assignments, low quiz or test scores, in danger of failing, or cannot pass. Students enrolled in mathematics courses are included in this intervention. The math department alerts students at varying rates of consistency, with many, but not all, instructors using the early alert system. The intervention for math students varies from other departments to include the traditional outreach from the Academic Advising department as well as outreach from the Math Center. Students who are alerted receive several emails initiating contact. These emails are from the instructor (system-generated, and instructors may opt to alert with a no-email option as well as email the students themselves), their Academic Advisor, and from the Program Coordinator of the Math Center. The focus of this brief example analysis was on those students who responded to the Math Center.
We used QCA to explore the relationship between several input variables and one of two outcome variables: passed fall semester math course (passed) and enrolled in courses for the spring 2018 semester (enr S18). The dichotomous input variables included in the analysis were 1st time freshman (coded 1 if 1st time freshmen, 0 if not), fulltime student (enrolled in 12 or more credits in the fall, coded 1 if fulltime, 0 if not), used the Math Center (either visiting the center and/or using peer study sessions; inclusion was three or more times for either, coded 1 if three or more visits, and 0 if two or fewer visits), early alert meeting with the Program Coordinator (coded 1 for those who scheduled and attended a meeting, 0 if no meeting), and enrolled in Math 1120 Business Calculus or above (below Math 1120 are pre-calculus, college algebra, and the developmental math courses, coded 1 if enrolled in Math 1120 or above, 0 if pre-calculus or below). The interaction of these variables with regard to each outcome was of interest.
For this preliminary (and ongoing) analysis, we chose variables as they related to the program and goals of the early alert intervention. The early alert program is targeted and focuses on lower divisional courses. As a university wide intervention, the target population is freshmen. Status as a first time freshmen is a salient characteristic for the impact of the program. In addition, full time status and math course level have been linked with student success and retention and were included for this reason. The remaining variables are all associated with the intervention. When alerted, students are encouraged to meet with the Program Coordinator to discuss resources and math study skills. This meeting is a major component of the intervention. Finally, students may incorporate more tutoring resources simply because they received the alert. This is a more intuitive approach to variable selection, as the variables included were directly related to the program, and this list is not exhaustive (future analysis might include variables such as advisor meeting, faculty meeting, employment status, etc.). As we continue the study, additional variables will be added to incorporate the necessary pieces from the literature, as well as any gathered from interviews.
Observations were collected from the fall 2017 semester sample of students who were alerted in their respective math courses. The following truth tables provide the cases associated with each outcome and the number of occurrences observed in the sample. Note that a lowercase letter signifies that the variable was not observed in the case (Tables 3 and 4).
Truth table: passed math course with a C– or better.
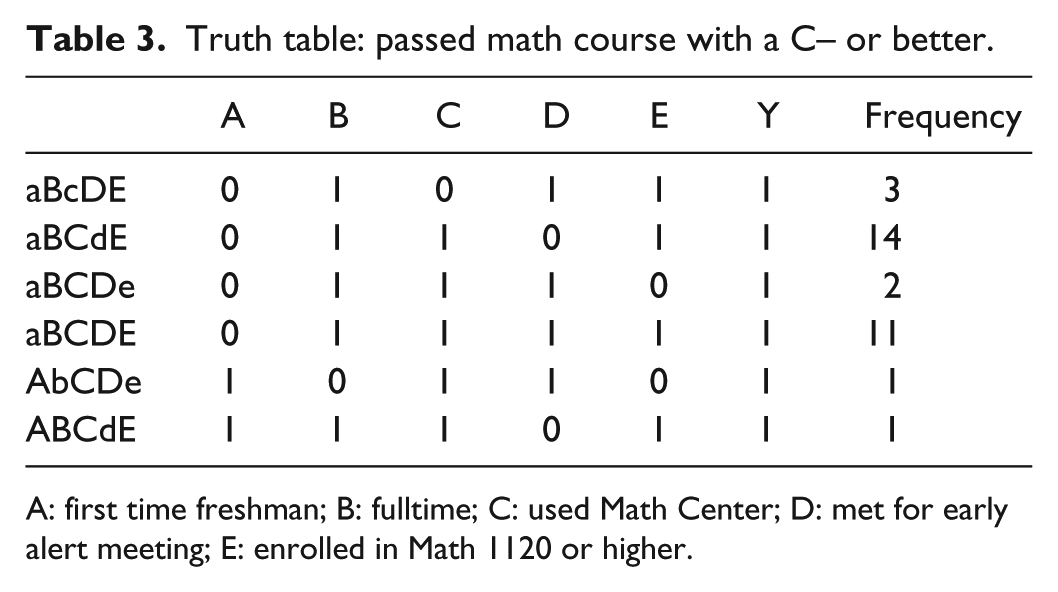
A: first time freshman; B: fulltime; C: used Math Center; D: met for early alert meeting; E: enrolled in Math 1120 or higher.
Truth table: enrolled in spring 2018 semester.
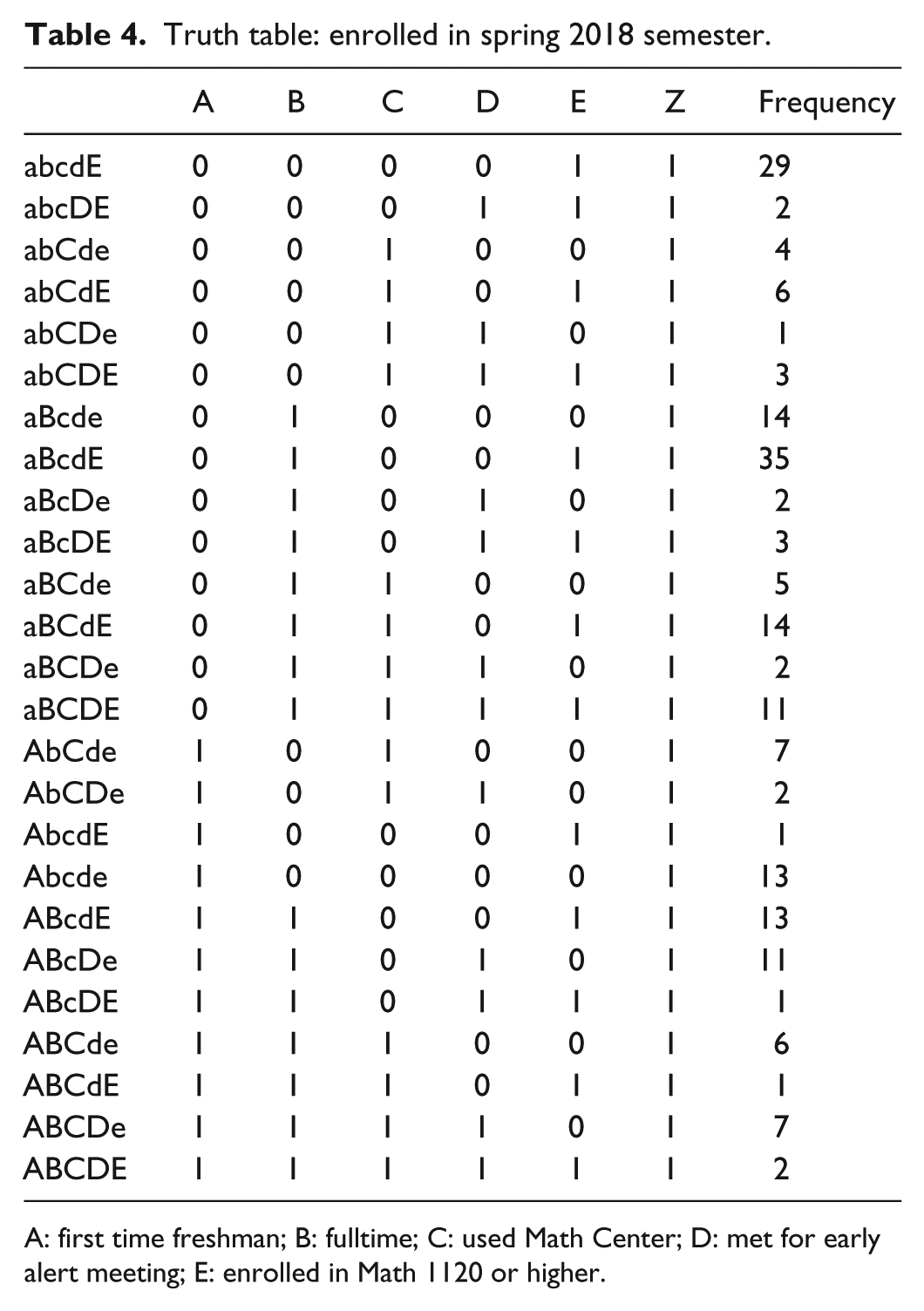
A: first time freshman; B: fulltime; C: used Math Center; D: met for early alert meeting; E: enrolled in Math 1120 or higher.
We pulled the following simplified Boolean equations from the truth tables
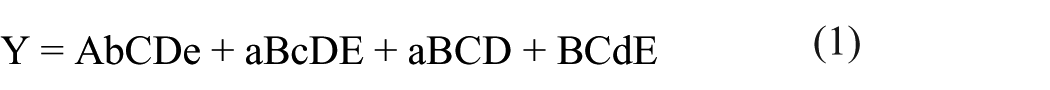
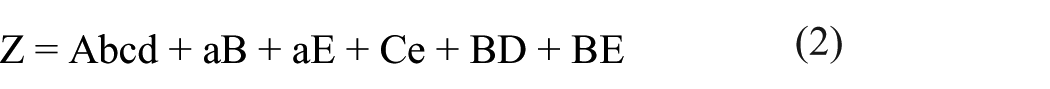
The equations were generated directly from the observed cases, using the truth table. Cases were compared and reduced using Boolean algebra. Any cases that differed in only one variable were combined. For example, in Table 3, cases 3 and 4 differ only in variable E (aBCDe and aBCDE, respectively). These were combined to give the simplified causal combination aBCD. The equations can then be modified by factoring to highlight the relationships and variables. This factoring is called theoretical factoring (Ragin, 2014)
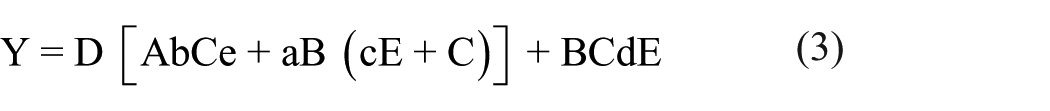
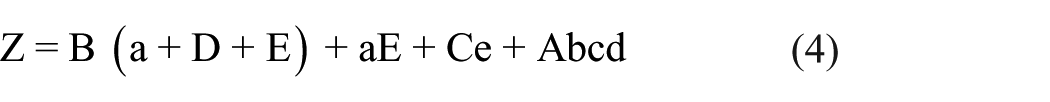
The equations provide the observed causal combinations that resulted in the outcome. The causal combinations can be summarized as follows. From equation (3), students who were alerted in their math class in the fall 2017 semester passed their course when the following causal combinations were observed:
Students who met for an early alert meeting who (a) were first time freshmen, enrolled part time, used the Math Center, and were enrolled in pre-calculus or below; or (b) were not first time freshmen, enrolled fulltime, who (i) did not use the Math Center, and were enrolled in calculus or above, or (ii) used the Math Center.
Students who did not meet for an early alert meeting who (a) were full time students, used the Math Center, and were enrolled in calculus or higher.
From equation (4), students who were alerted in their math class in the fall 2017 semester enrolled in spring semester courses when the following causal combinations were observed:
Students who were enrolled full time who (a) were not first time freshmen, (b) met for an early alert meeting, (c) were enrolled in calculus or higher.
Students who were not first time freshmen and were enrolled in calculus or higher;
Students who used the Math Center and were enrolled in pre-calculus or lower;
Students who were first time freshmen, enrolled part time, who did not use the Math Center, and did not meet for an early alert meeting.
Breaking these findings down, there were a couple of conditions that were particularly important: having an early alert meeting or being enrolled in higher-level math classes. It also looks like using the Math Center was helpful. This is work that is ongoing, so we would not generalize from this preliminary data, but it serves to illustrate how QCA could be used and what findings it can generate. Using QCA as our research method in this case allows to identify particular combinations of characteristics and behaviors that were associated with student success and retention, as well as what factors to take into account in considering the university policy on early alerts. The findings are holistic and provide a context for the interaction of the characteristics and behaviors of observed variables. For example, looking at students who met for an early alert meeting, QCA has provided three causal combinations that were observed with the result (passed). Having the meeting was sufficient for certain students, but not necessary in leading to the outcome on its own. The role of the early alert meeting is contextualized, and the dependence of the variables on each other is more easily seen. Still additional qualitative data will be needed to better parse out relationships and to provide context and support for our findings as they are generated.
Strengths and weaknesses of QCA as a research method
QCA’s strength lies in its ability to bridge qualitative and quantitative analysis, engage with causal complexity, and introduce set-theoretic methods to social science inquiry (Ragin, 2008). These methods allow the researcher to look beyond additive effects of variables and explore variable causal inferences. QCA’s capacity to explore causal combinations and alternative pathways for outcomes, rather than additive effects on the outcome provided by regression models (i.e. the underlying principle in regression models assumes linearity and independent variables that are independent of each other), lends to its strength as a model (Glaesser et al., 2009).
In social science research, it is challenging to disentangle the effects of different variables on the outcome. QCA allows for a holistic approach to causal inferences, uncovering patterns of conjunctural causation and equifinality (Amenta and Poulsen, 1994; Aus, 2009; Borgna, 2016; Grofman and Schneider, 2009; Rihoux et al., 2011; Thiem, 2014). This allows for exploration of contextualized cases and causation. Depending on the context, many pathways may lead to the outcome, and exploring this variability leads to a greater understanding of the phenomenon under study. In addition, QCA is an analytical approach, which allows replication. Replication allows falsifiability and enhances the rigor of educational findings (Rihoux et al., 2011). Falsifiability would lend more credibility to educational research and has a cumulative effect leading to better research outcomes and practices.
QCA can approximate causal conditions—this is particularly important point for educational policy research. It allows the researcher to gain in-depth insight into particular cases, but also produces some level of generalizability (Rihoux et al., 2011). This is done through the inclusion of multiple cases. A study of these multiple cases with QCA produces an equation that models the combinatorial factors that lead to the outcome. In developing this equation, researchers must explicitly address the assumption of limited diversity; an assumption is often hidden by implicit assumptions of statistical modeling (Borgna, 2016). Limited diversity of observations implies that the observed cases may not represent the whole of possibilities. QCA researchers must address this as they are constructing the truth table, explicitly stating assumptions upfront.
Still, QCA also has several weaknesses. First, in regard to collecting and analyzing data with the truth table, QCA researchers must confront the issue of ambiguous cases and decide how to proceed (Seawright, 2005). When cases share the same independent variables, but differ on the outcome, those disagreements must be addressed, either by returning to the data using some statistical process to determine the outcome of ambiguous cases, or removing them from the study. All of which may be impacted by researcher bias and may affect the validity of the study. Seawright (2005) argues further that this need for all cases to have a dichotomous outcome extends to cases not observed in the study.
In addition, Seawright (2005) points out that QCA is particularly vulnerable to distortion from missing data. Researchers using QCA would need to ensure that all cases contain data for the relevant independent and dependent variables. Any missing data would render the truth table unusable, and a simplified causal combinations equation could not be formed. This is because QCA assumes that all cases sharing the same observations on the independent variable are identical. If identical cases are omitted, through missing data, the assumption does not hold (Seawright, 2005). Seawright expands this notion to include all possible cases including any observable data that may be causally related to the outcome of interest (to include weather patterns or other uninteresting variables).
Finally, some scholars have argued that QCA’s causal inferences are suspect, and the inference of causality from observational data may be misleading. QCA relies on case observations to determine the independent variables that might be linked with a certain outcome. As Seawright (2005) notes, Boolean algebra uses logical operations to preserve the truth of the set, with outcomes having the same characteristics as the original data. As the data are drawn from observational studies, the outcomes only relate associations to the researcher. In other words, there can be no assumption that the observations are equal in expectation and that an accounting of the unobserved characteristics is impossible with QCA.
We would also note again that QCA is not always an appropriate approach, even with mid-sized data sets and questions focused on causal linkages. For example, in a study where the conditions are unclear or impermanent, there would be little point in conducting a QCA because it would be impossible to represent these conditions in a truth table. Rather, an exploratory case study might allow for better understanding of the phenomenon or case. In addition, as noted above, if a researcher’s focus is on participant experience, even if there is also emphasis on participants’ perceptions of cause-and-effect, then another kind of qualitative methodology may be more appropriate. As argued by Miles and Huberman (1994), the concept of “local causality” in cases can still be achieved by more traditional qualitative methodology, and participants’ perceptions of causality may be better analyzed by these other approaches.
QCA in future research: recommendations
For researchers interested in using QCA for future studies, there are many avenues worth exploring. QCA in educational research is a fairly new field. A non-exhaustive review of QCA literature (from www.compasss.org) showed most research occurred in the area of business and politics, and most of this occurred outside the United States. Educational researchers in the United States can take advantage of QCA’s strengths in combining qualities of qualitative, case-based research with the generalizability of quantitative methods. QCA can be used to explore vast topics within education at the international, national, and even local level (Basurto and Speer, 2012). Case comparisons at the international level can use Organisation for Economic Co-operation and Development (OECD) data to explore contextual factors that lead to student success in desired outcomes. In addition, student success at the national or local level can be examined to include such qualitative factors as the amount of parental involvement in school activities, or the quality of pre-school preparation and its impact on future success. Questions about whether parental involvement leads to greater student success could be investigated using QCA and a variety of collected data, including interviews, observations, outcome data, and document analysis.
The domain of student success is not the only avenue researchers must take. QCA can be used to explore a variety of education-specific research questions. For example, Kintz et al. (2015) explored teachers’ PD using QCA to identify the minimum combinations of conditions that contribute to high-depth discussion. They found that focusing on a single purpose was a necessary condition, but there were several additional, sufficient conditions, as well. QCA can also be used as a systematic process for literature reviews/syntheses (Onwuegbuzie and Weinbaum, 2017), either alone or as part of the literature review process in a study.
The complexity of educational systems and institutions would benefit from studies using QCA, as equifinality of cases would allow for a deeper exploration of the causal combinations that impact education. The impact of key social factors on education could continue to be explored, possibly shedding light on current issues related to education. Researchers could use QCA to explore issues that impact all stakeholders, from students to legislators. These studies could range from summary studies of what is being observed to studies testing existing theories or hypotheses (Rihoux et al., 2011). In addition, policy analysts could employ QCA to examine educational policy to compare policy programs or determine causal combinations that impact policy implementation or outcomes. The nature of QCA generates deterministic results which align with the nature of policy analysis.
In conclusion, we would like to point out that some of the support for QCA seems to come from the critique of qualitative research in general. We should be clear that having set processes and mathematical analyses does not, in and of itself, make QCA an inherently better research method than other qualitative traditions. Indeed, as discussed throughout this article, there are many cases where other methodologies are more appropriate. And having a smaller sample size does not inherently mean that the research is less rigorous or valuable. In the end, it is all about the context of the study and the research questions that the researcher is aiming to answer. If the research is meant to identify, describe, and explore conditions that lead to particular results, then QCA may indeed be the right research method.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.