
Abstract
Many everyday tasks appear to be performed at an optimal rate that differs between individuals but is consistent within individuals. These optimal rates are estimated using a participant's Spontaneous Production Rate (SPR), the rate at which an individual produces sequences of sounds in the absence of external tempo cues. A previous study that measured SPRs in speech and piano production found no association between SPRs across tasks, a result suggesting that domain-specific constraints determine optimal rates. The present study addressed whether this dissociation would remain when music and speech are produced with the same effector system: vocal production. Participants spoke short, well-known phrases and sang familiar children's songs on “da” to avoid memorization of words. SPRs were measured by the mean inter-onset interval (IOI) between successively produced syllables or tones and showed large individual differences. Results showed consistent SPRs within individuals within each domain (speaking or singing) as well as consistent SPRs across the speaking and singing conditions. These results align with theories of optimal rates based on energy efficiency arising from biomechanical constraints rather than domain-specific communication goals.
Although actions such as walking, running, or speaking can be produced at a wide range of rates, individuals gravitate toward a natural or optimal rate. Optimal rates in the production of music and speech have been estimated through Spontaneous Production Rates (SPRs), which are rates at which one produces sequences of sounds in the absence of external cues such as a metronome or a partner's sound productions. SPRs vary across individuals within a single domain but tend to be consistent within individuals over time (Poeppel & Assaneo, 2020; Wright & Palmer, 2020; Zamm et al., 2016). SPRs may also vary across domains, such as speech and music. For instance, sequences of musical tones are generally produced at a slower rate than sequences of speech syllables (Ding et al., 2017; Patel, 2014).
A particularly compelling question concerns whether SPRs on one task predict SPRs on other tasks, for example, across speech and music. The presence of such correlations would support the hypothesis that individual differences in optimal rates reflect a non-domain-specific source of timekeeping. The current study addressed an apparent dissociation in the SPR values measured across domains of speech and music from a recent study (Pfordresher et al., 2021). Although individuals in that study produced SPRs at consistent rates across sequences within piano performances of different melodies (Pfordresher et al., 2021; Scheurich et al., 2018; Zamm et al., 2016), individuals’ spontaneous speech rates were independent of their spontaneous rates for musical melodies.
The comparison of speech and music performance in Pfordresher et al. (2021) differed with respect to effector system: Whereas the speech was produced verbally, the music was performed on a piano. On one hand, the dissociation may reflect differences in optimal rates based on differing biomechanics within each effector system (Nessler & Gilliland, 2009), leading to differences in the movement rates that minimize energy consumption (Hoyt & Taylor, 1981). Alternatively, the dissociation observed by Pfordresher et al. (2021) may reflect domain-based differences in rhythm production across music and speech, which have previously been reported for mean production rate (slower for music than speech, e.g., Ding et al., 2017; Ozaki et al., 2024), and rhythmic regularity (greater regularity for music than speech, e.g., Cummins, 2012; Lidji et al., 2011).
The current study compared speech and music production within the same individuals and effector system (vocal production) by asking participants to speak common phrases and sing familiar melodies (on “da” to reduce memory demands). We chose familiar speech sayings and familiar children's melodies because both types of sequences are highly memorable and are usually learned in an oral tradition, and thus have usually been heard at a variety of production rates. Production rates for similar speech and music examples to the ones used here have yielded significant individual differences in previous studies (Palmer et al., 2019; Pfordresher et al., 2021), but the two domains have not been directly compared within the same effectors. The absence of a significant correlation between speech and music SPRs (similar to Pfordresher et al., 2021) would support domain-based differences in timekeeping. The presence of a significant correlation between speaking and singing SPRs would suggest that the effector system being used and associated energy expenditure is driving the rate of production.
Method
Participants
Fifty-three students (mean age = 19.71, range = 18–27) were recruited through the University at Buffalo online participant recruiting software (SONA) and given partial course credit for Introduction to Psychology in exchange for their time. Participants gave informed consent to participate in the study and confirmed to have not been diagnosed with any hearing or speaking disabilities. Ten participants were excluded because of unfamiliarity with the song stimuli (n = 7) or producing the songs in a speech-like manner (n = 2). Forty-four participants were included in the final analysis. These participants had on average 1.64 years (range = 0–14 years) of formal training in singing (e.g., private lessons) and 3.31 years (range = 0–15) in organized singing (e.g., choir). Participants also averaged 3.93 years (range = 0–14 years) of formal training on a primary instrument. Six participants (11% of the sample) were non-L1 English speakers. Four participants listed Chinese (including Cantonese, Mandarin, and other Chinese languages), one participant listed Spanish, and one participant listed Somali as their native language. Of the individuals who were L1 English speakers, 22 (42% of the sample) were bilingual. All participants provided verbal informed consent as a precondition of undergoing any part of the procedure and having any data collected. Verbal consent was used given the low-risk nature of the study, and to guard the anonymity of participants. In the interest of anonymity, participant names were not recorded.
Apparatus
The experiment was conducted online during the COVID-19 pandemic lockdown through FindingFive (FindingFive Team, 2019), a behavioral research platform that allows for the collection of audio data from participants and is often used for speech and language studies. The researcher and participant used Zoom (Zoom Video Communications Inc, 2021) to communicate throughout the experiment (see Procedure), and Qualtrics (Qualtrics, Provo, UT) was used to administer the questionnaire at the end of the experiment.
Materials and Design
Figure 1 shows the design of this experiment. There were two spontaneous rate tasks representing the domains of speech and song. There were three stimulus items for each task and three trials per stimulus. Participants completed the speech task before continuing to the song task to prevent carry-over effects based on the rhythmic salience of the song trials.
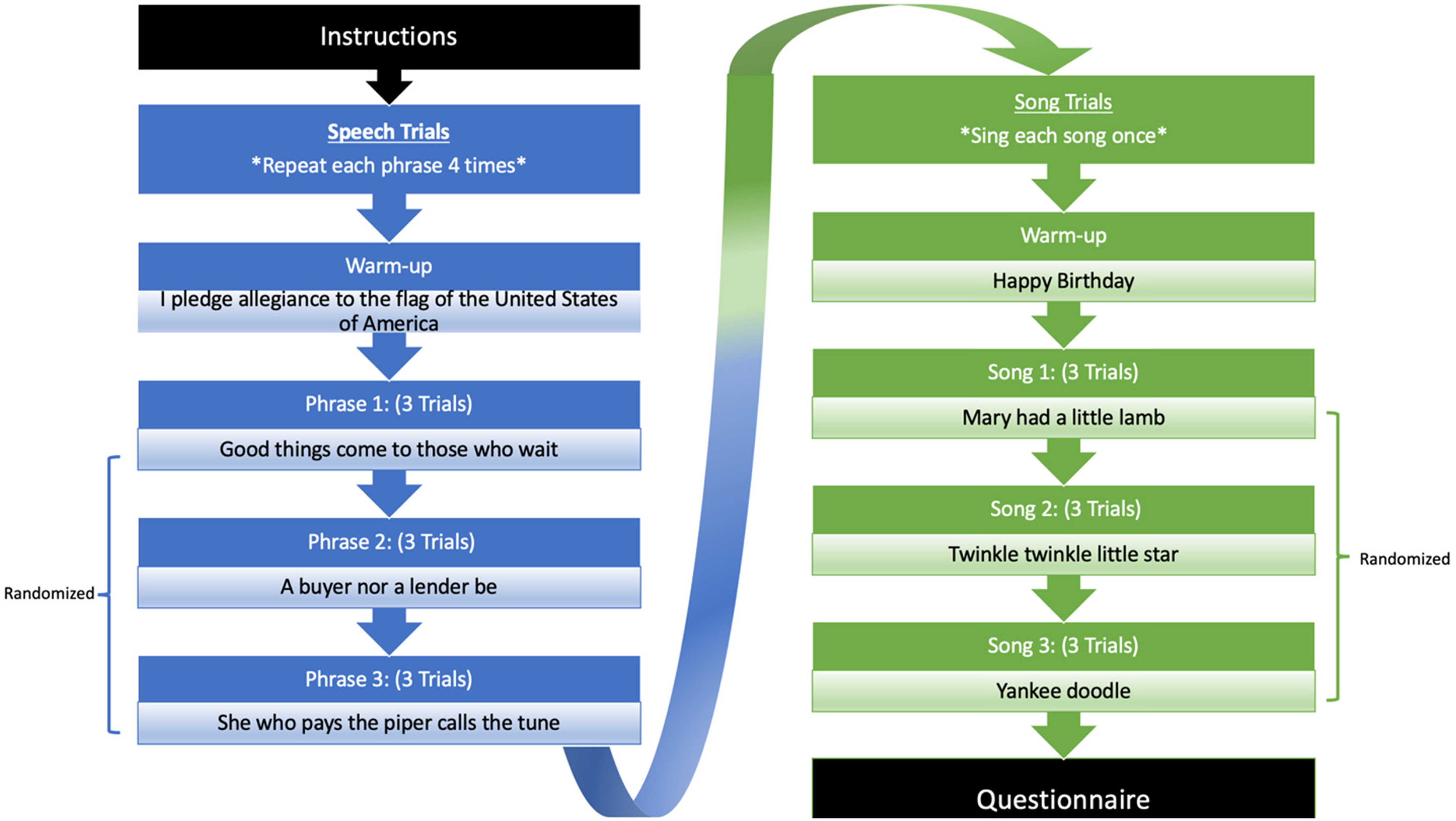
Experimental design of speech and song trials. Note. There are nine trials total for each condition. IOI is listed as the total number of IOIs within a single trial. For speech, number reflects IOIs before omission of IOIs between phrases. Each condition began with practice trials.
During the speech task, three short phrases served as stimulus items. Participants were asked to memorize all three phrases at the start of the task. The phrases were: A buyer nor a lender be, Good things come to those who wait, and She who pays the piper calls the tune. These phrases were chosen because they have a binary meter (consistent alternation of strong and weak syllable accents), they are of similar length (8–9 syllables), and the stressed syllables are easy to distinguish when marking onsets during analysis (see Data Analysis).
For the song task, participants were asked to produce three familiar songs: Mary Had a Little Lamb, Twinkle Twinkle Little Star, and Yankee Doodle. Participants only had to be familiar with the tune and not the words to the songs; all participants sang the melodies on the syllable “da”. The songs were chosen because they are highly familiar to most participants and have a binary meter. If participants were unfamiliar with one or more of these songs and thus unable to perform them from memory, they were instructed to perform one or both of the following back-up songs: Bingo or London Bridge is Falling Down. The back-up songs were chosen for their structural similarity to the original songs. The order of back-up songs was randomized if participants had to perform both Bingo and London. Ultimately, only Twinkle Twinkle Little Star and Mary Had a Little Lamb were used in the final analysis because these songs were remembered and reproduced by all participants, whereas familiarity with other songs was inconsistent.
A background questionnaire measured participants’ ages at which they started learning any non-native languages as well as their musical background, using self-reported years of training in organized singing (including choir, musical ensembles, musical theatre, etc.), formal training in singing, and formal training on any primary instrument. We screened for the possibility of congenital amusia, a disorder affecting the perception of pitch and overall recognition of music (Ayotte et al., 2002; Peretz, 2016), by asking the level of difficulty a participant had in recognizing music when lyrics are absent, and we screened for possible beat-deafness (Phillips-Silver et al., 2011) by asking participants how hard was is for them to find the beat of the music.
Procedure
An email was sent before the scheduled experiment that instructed the participants to use a laptop and wear headphones with a built-in microphone to minimize background noise. The experimenter instructed some participants to use their computer microphone if the microphone quality through their headphones was poor. The experiment began with the participant opening a Zoom window where they would meet the researcher. The researcher then gave instructions on how to access the FindingFive website and asked the participant to screen-share the FindingFive window. This allowed the researcher to monitor the progress of the experiment and provide instruction when necessary. After the participant read the consent form on Finding Five and provided informed consent, the researcher described the study and directed the participant to keep their microphone on at all times. Additionally, FindingFive allows participants to rerecord a trial and to listen to their audio recording. Participants were instructed not to use these features. The researcher then turned off the zoom camera and monitored the remainder of the session using audio only, to avoid potential discomfort caused by the participant being watched throughout the session.
Participants began the speech trials with a warm-up trial that involved repeating I pledge allegiance to the flag of the United States of America four times, as shown in Figure 1. The warm-up helped to ensure that participants understood the instructions and performed the tasks correctly. During the warm-up trial and following speech trials, participants were instructed to read and memorize the phrase on the screen for 5 s. In all speech trials, participants were instructed to repeat the phrase at a consistent and comfortable rate. Minimal instruction on how to perform the task allowed participants to interpret the phrases on their own and produce them in a natural manner. Once the phrase disappeared from the screen, participants recorded themselves repeating the phrase from memory four times with pauses between repeats for each individual trial. If the participant needed more time to see or practice the stimulus, the phrase appeared again on the screen until the participant was ready to record. Participants spoke the phrase from memory to avoid the effects of reading on spontaneous speaking rate and to encourage a more natural speaking rate. There were three consecutive trials for each phrase. Phrases were presented in a randomized order.
Participants next completed the song trials, as shown in Figure 1. They began the song trials by singing the warm-up song, Happy Birthday, using the syllable “da” for each sung note. During the warm-up trial and following song trials, the lyrics of the songs were displayed on the screen for 10 s to aid participants’ memory for the tune. In all song trials, participants were instructed to repeat the melody at a comfortable and consistent rate. Participants were instructed to recall the melody and to practice singing the melody using “da” instead of the words. Singing on “da” was used to provide a clear consonant sound to mark syllable onsets, to prevent the length of the phonemes from influencing their spontaneous singing rate, and to reduce memory demands that might influence the singing (e.g., Racette & Peretz, 2007). Once the words to the song automatically disappeared from the screen, participants recorded themselves singing the melody from memory on “da” once for each individual trial. Songs were only repeated once for each individual music trial because each melody contained four musical bars that approximated the total duration of each speech trial (which contained four repeated phrases). There were three consecutive trials for each song. Songs were presented in a randomized order. The entire experiment lasted 60 min.
The researcher sent the questionnaire link to the participant through the Zoom chat once the FindingFive session was complete. When the survey was submitted, the researcher granted course credit to the participant and ended the Zoom session.
Data Analysis
Participants’ SPRs were assessed by marking sung tone onsets and syllable onsets and by calculating the mean of all inter-onset intervals (IOIs) for each trial (one melody repetition for music; four repetitions of one spoken phrase for speech). For speech production, the onset of each syllable was identified using Gentle (Version 0.10.01), a forced aligner program that uses media files and audio transcripts to mark the onset of each phoneme automatically and precisely. We confirmed the accuracy of Gentle as a marking tool through a comparison between hand-marked IOIs and Gentle markings for speech trials of one participant. There were no significant differences between hand marked IOIs (M = 0.1898, SD = 0.08) and the automatically segmented Gentle IOIs (M = 0.1871, SD = 0.08), t(251) = 0.42, p = .67 across trials. Additionally, correlations between hand marked IOIs and Gentle IOIs for Buyer, r(82) = .56, p < .001; Good, r(70) = .87, p < .001; and Piper, r(94) = .85, p < .001 were all highly significant. Analyses omitted the IOI defined by the onset of the final syllable of a phrase and the onset of the first syllable of the next phrase in the trial because participants tended to pause in-between repetitions (cf. Pfordresher et al., 2021). The inclusion of these pauses would inaccurately inflate the estimate of an individual's SPR.
For song production, the onset of each “da” tone was marked manually using Praat (Boersma & Weenink, 2022). The researcher used visual cues from the spectral content and amplitude envelope of the sound in addition to auditory cues to hand-mark the onset of each “da”. IOIs that included half notes were also omitted because participants tend to shorten long durations, making the ratio of half notes to quarter notes closer to 1:1.7 rather than the correct notated ratio of 1:2 (Bengtsson & Gabrielsson, 1980; Repp et al., 2012). All IOIs in the remaining trials were used in the song analysis as participants did not pause in between notes or lines. The songs Bingo, Yankee Doodle, and London Bridge were not included in the song analysis because the majority of participants were unfamiliar with them and did not sing them.
Mean IOI was first calculated for each trial, following removal of any outliers. The mean and SE were then computed across the trial means and constituted the primary dependent variable. Outliers were defined separately for each participant and task (speech or song) as being more than three standard deviations away from the mean across all trials in that subset. This process led to negligible loss of data (N = 42 IOIs removed, 34 from speech trials and 8 from song trials, 0.002% of all IOIs). Any dysfluencies in speech or song productions were removed in the process of removing outliers.
Results
Figure 2 shows mean IOIs for each participant ordered from fastest to slowest SPR, showing the individual differences in song and speech. Each bar represents the mean IOI of the trials for a single participant and task. Participants are ordered from fastest to slowest in both graphs based on the IOI distribution in the song production task. As can be seen, SPRs varied considerably between individuals in each production task. We next address how closely associated these individual differences are across tasks and how consistent individuals are within each task.

Mean IOI by participant for each task. Note. Mean (SE) SPR across item using mean IOI for each individual: (A) mean IOI for song productions; (B) mean IOI for speech productions. Participants are ordered on the x-axis in both graphs based on the song task. Y-axis scale varies across graphs to highlight the range of individual differences within each task. Each gray bar represents an English L1 participant, and each red bar represents an English L2 participant.
SPR Correlations
Speech and Song
Figure 3A plots the associations across speech and song tasks for the mean IOIs shown in Figure 2. Each point reflects the mean IOI across sung trials for a participant and the corresponding mean IOI across speech trials for the same participant. This correlation was significant, r(42) = .54, p < .001. The four participants who spoke English as a second language (color coded using red dots) produced sequences more slowly than most other participants but followed the same pattern of association. The correlation between speech and song also remained significant when English L2 participants were removed, r(36) = .43, p = .004.
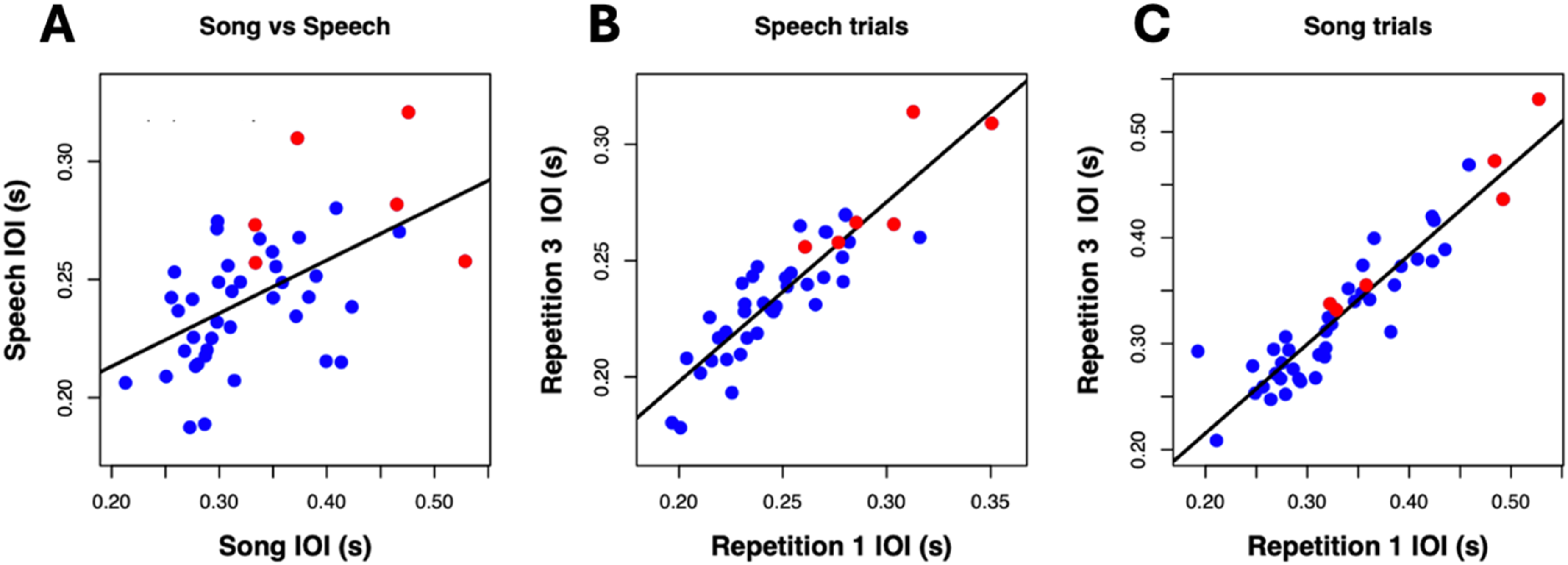
Associations within and between speech and song performance. Note. Mean IOI is shown (A) between speaking and singing, (B) within the first and third repetition for all speech trials, and (C) within the first and third repetition for all song trials. Each blue dot represents an English L1 participant, and each red dot represents an English L2 participant.
The associations between speech and song IOIs were generally reliable at the level of individual item pairs, as shown in Table 1. As can be seen, every paired speech and song item yielded significantly correlated IOIs. The association between speech and song IOIs was also present for individual trials (speech/song correlation averaged across items for trial 1, r = .60, p < .001; for trial 2, r = .58, p < .001; for trial 3, r = .48, p < .001).
Associations across speech and song stimuli by item.

Note. Mean SPR correlated across speech-song items. *p < .05, **p < .01, ***p < .001. All correlations, except for Good vs. Mary, p = .07, and Buyer vs. Twinkle, p = .06, remained significant when English L2 participants were removed. Degrees of freedom for each comparison are paired with the superscript next to each correlation: 137; 238; 339; 440.
Speech SPRs
Figure 3B shows the correlations of mean IOI across trials within the speech production task. Each point reflects the association between a participant's mean IOI for trial one averaged across all three spoken phrases and the corresponding mean IOI for trial three averaged across all three phrases for the same participant. We focused on comparisons across the first and third trials, excluding trial two, to avoid associations based on repetition across contiguous trials. Speech IOIs between the first and third repetition of all phrases were significantly correlated, r(41) = .90, p < .001. The four participants who spoke English as a second language (color coded using red dots) produced sequences more slowly than most other participants but followed the same pattern of association. The correlation between the first and third repetition for speech also remained significant when English L2 participants were removed, r(35) = .85, p < .001.
Speech IOIs were likewise reliably associated at the level of item. Table 2 displays correlations of IOIs between the first and third trials of each item (main diagonal) as well as correlations of mean IOIs, aggregated across trials, between different items (upper triangle). All correlations were statistically significant, indicating high reliability, although correlations with Buyer were significantly lower than the correlation between Good and Piper (t-test for dependent correlations, Cohen & Cohen, 1983, p < .01 for both r values). Together, these results provide evidence that participants exhibited consistent SPRs for speaking.
Associations within and across speech stimuli by item.

Note. Diagonal reflects comparison within each phrase using first and third trial of the phrase. Correlations in the upper triangle are correlations between phrases where mean IOI for each phrase is averaged across repetitions. **p < .01, ***p < .001. All correlations remained significant when English L2 participants were removed. Degrees of freedom for each comparison are paired by the superscript next to each correlation: 137; 241; 339; 432.
Song SPRs
Figure 3C shows the correlations of mean IOI across trials for the song task. The analysis of this correlation matched the analysis used for the speech task. Overall, singing IOIs between the first and third repetitions of Mary and Twinkle melodies were significantly correlated, r(42) = .93, p < .001. The four participants who spoke English as a second language (color coded using red dots) produced sequences more slowly than most other participants but followed the same pattern of association. The correlation between the first and third repetitions of a song also remained significant when English L2 participants were removed, r(35) = .89, p < .001.
This association was reliable for individual items. Table 3 displays the correlations of IOIs between the first and third trial of each individual item (main diagonal) as well as correlations of mean IOIs, aggregated across trials, between different items (upper triangle). All correlations comparing Mary and Twinkle were statistically significant, indicating high reliability for these two stimuli.
Associations within and across song stimuli by item.

Note. Diagonal reflects comparison within each song using first and third trial of that song. Off-diagonal is the correlation between songs averaged across trials. ***p < .001. Degrees of freedom for each comparison are paired by the superscript next to each correlation: 139; 237.
Speech and Song Mean IOI Comparisons
We next report group differences in overall mean SPRs across speech and song tasks using the average of the trial IOI means in a task for each participant. Means by participant for both groups are shown in Figure 2. On average, participants produced sung melodies (M = 0.33, SD = 0.07) at a significantly slower rate than they produced spoken phrases (M = 0.24, SD = 0.03), t(43) = 10.26, p < .001. Further analyses within item revealed that each possible comparison between the mean IOI across trials for a spoken phrase and the mean IOI for a sung melody yielded significant differences, with larger IOIs (slower tempo) for songs (p < .001 for each comparison). The present results thus converge with other studies suggesting slower event rates for music than for speech production (e.g., Ding et al., 2017; Pfordresher et al., 2021).
Effects of Musical Training and Repetition
We next assessed whether formal musical background influenced participant SPRs and the association between SPRs for speech and music. No measures of musical background (years of group or private lessons in singing or on their primary instrument) correlated significantly with mean IOIs for speech or song (all p's > .10). This result replicates Scheurich et al. (2018) who also found no association between musical training and SPR. We next divided participants into groups based on a median split for years of private lessons (2 years). Both musicians, r(27) = .53, p = .001, and non-musicians, r(14) = .51, p = .02, yielded significant correlations of mean IOI across speech and song. Both groups also yielded significant correlations within the speech task (musicians, r(26) = .92, p < .001; non-musicians, r(14) = .86, p < .001) and within the song task (musicians, r(26) = .94, p < .001; non-musicians, r(15) = .91, p < .001). These findings mirror the results shown in Figure 3. Musical training thus does not appear to influence the degree of association between speech and song SPRs.
Speech and song trials included repetition within and across trials under conditions designed to maximize rhythmic stability. To address whether timing consistency resulted from repetition, we analyzed SPRs based on the mean IOI from the first and last repeated phrases across the three successive trials for an item. In spoken trials, the 1st and 12th utterances of the same phrase were compared. In song trials, the 1st phrase of trial 1 within a song (e.g., the sung tones corresponding to the first phrase “Mary had a little lamb” or the first phrase “Twinkle twinkle little star”) was compared with the last phrase from the 3rd trial (e.g., “His fleece was white as snow” or “How I wonder what you are”). SPRs were highly correlated between the first and last repetitions both for speech, r(40) = .72, p < .001, and for song, r(41) = .76, p < .001. Most important, IOIs were significantly correlated between speech and song for the very first repeated phrase in each trial, r(40) = .58, p < .001, suggesting that the correlation reported earlier across tasks was not a byproduct of repeating a given rhythmic structure across the three successive trials. Mean IOIs were significantly lower (faster) for the last spoken phrases across the three trials than for the first spoken phrase, t(41) = 6.38 p < .001, but the same tendency to speed up was not found for song production (p = .14).
Discussion
This study investigated the relationship between Spontaneous Production Rates (SPRs) in speech and music when both tasks share the same effector system, vocal production. Mean produced inter-onset intervals (IOIs), an estimate of SPR, were significantly correlated across singing and speaking, suggesting a common source of optimal timing across these tasks. This contrasts with previous results from Pfordresher et al. (2021), who found no association between the same individuals’ speech and music SPRs when music was produced on a keyboard – a different effector system from speech. These results thus support theories of optimal timing based on biomechanical constraints associated with effector systems (Derrick & Gick, 2021; Hoyt & Taylor, 1981; Nessler & Gilliland, 2009), also applied to individual differences in SPRs (Engler et al., 2024). As in the previous study, participants exhibited highly reliable SPRs within each task, and associations among SPR values across tasks at the item level were also reliable.
The present study also replicated previous findings suggesting that SPRs are slower overall for music than for speech production (Ding et al., 2017; Pfordresher et al., 2021). However, it is worth noting that the rate differences across tasks found here are significantly smaller than the differences reported in Pfordresher et al., who used novel melodies that participants had to memorize, thus creating a greater memory load. Mean differences across speech and song IOIs for each participant were significantly larger in the previous study (M = 0.25, SD = 0.12) than in the current study (M = 0.02, SD = 0.05), t(33) = −9.56, p < .01. The songs included in the current experiment are often learned from hearing others sing them in a casual setting, rather than being exposed to a single recording or performance. Therefore, these songs do not usually have a specific associated tempo that could affect production rates. Furthermore, we chose to use these familiar songs for musical stimuli to aid fluency in production. The use of these stimuli leaves open the possibility that the present findings may be influenced by associations between text and tune (despite the fact that text was not used in production) and/or associations between imagined words and their typical tempo.
Speech and song elicited large individual differences, with the fastest participant's speech at approximately twice the speed of the slowest participant, and the fastest participant's song at approximately three times the speed of the slowest participant. These differences are much larger than the smaller differences within participant, which ranged from approximately one-fold to two-fold differences across speech and song rates. The fact that the same participants exhibited correlated SPRs across tasks but a difference in their mean rates across tasks may seem initially puzzling. If SPRs are entirely determined by the biomechanisms of effector systems, then one might expect similarity in the mean values across domains. The results thus imply that optimal rates reflect biomechanical constraints in part, as well as domain-specific differences. For instance, an individual may choose to speak at a faster rate to signal urgency, or to sing a lullaby at a slower rate to calm an infant, thus demonstrating the role of communicative goals. Communicative goals may also explain the mean difference we found between the song stimuli. We found faster (shorter) mean IOIs for the production of Mary Had a Little Lamb (M = 0.32, SD = 0.09) than Twinkle Twinkle Little Star (M = 0.36, SD = 0.08, p < .001). Twinkle Twinkle Little Star may be slower to help soothe and calm a child, whereas Mary Had a Little Lamb may be faster to maintain a child's attention and keep them engaged. Indeed, flexibility in rate of production can be critical to sequence performance (Schultz et al., 2016). This flexibility appears to be limited, however, as individuals have been shown to gravitate toward their SPR when their production rates exceed what appears to be an optimal range (Scheurich et al., 2018). In other words, parents may choose to speak faster or sing slower than their SPR, but their productions still fall in their optimal range. Future studies may include a second effector system (e.g., hand/finger movements versus vocal movements) to distinguish between the influence of effector systems and communicative goals on SPRs.
The present study is the first we know of that compares SPRs across language and music production while controlling for the effector system. We focused on vocal production as the most natural and widespread modality for communication in both domains. Future research should address whether cross-domain associations in SPRs hold for other effector systems (e.g., comparing rhythmic arm movements in signed speech with rates of cello bowing). Comparisons of spontaneous rates in the production of nonsense syllables and unfamiliar musical styles may provide a measure of articulatory constraints unaffected by meaning-based factors. Research conducted on spontaneous rates could also help inform the practice of music therapy. For Parkinson's patients, cuing with a musical beat while walking has shown to increase walking pace, stride length, and symmetry (Arias & Cudeiro, 2008; Benoit et al., 2014). Internal cues (patient singing) appear to reduce gait variability and thus may be more beneficial than external cues (radio, Harrison et al., 2017). Thus, the use of rhythmic music to guide gait recovery, as well as to guide optimal exercise rates in normal control participants, may benefit from titrating the acoustic rate to the individual, in contrast to having the patient synchronize with a non-optimal rate selected by the therapist via external cues. Future research could explore whether synchronization to a musical tempo based on the SPR of a Parkinson's patient during walking may reduce that individual's fear of falling and improve walking cadence and general quality of life. In addition, research that addresses how effector systems and communicative goals modulate SPR and how to best measure SPR may prove beneficial in therapy techniques that rely on rhythmic productions, such as speech and music therapy. Overall, taking SPR and measurement techniques into consideration during therapy may provide a new way to individualize treatments that could improve patient outcomes and provide a more comfortable environment for patients.
Footnotes
Action Editor
Jessica Grahn, Department of Psychology, Western University Brain and Mind Institute.
Peer Review
Leendert Plug, Linguistics and Phonetics, University of Leeds; Matthias Heyne, Communication Disorders, State University of New York at New Paltz.
Contributorship
All authors researched the literature and conceived the study. All authors were involved in the study design. NC and PQP were involved in gaining ethical approval, participant recruitment and data analysis. NC wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
This study was approved by the ethical committee of the University at Buffalo (approval/study ID number: STUDY00005000).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.