
Abstract
Computational communication research (CCR) has emerged as an early and active subfield within computational social science, offering novel methodological approaches to address classical and emerging questions in communication research. This paper reviews the evolution and methodological developments in CCR in both the international research community and Chinese mainland, emphasizing the role of computational methods such as user analytics, content mining, and computational experiments. We map the alignment between traditional quantitative methods and computational ones, demonstrating how CCR methods have complemented and enhanced existing research paradigms. Through empirical applications, we illustrate the utility of CCR in understanding user behavior, content dynamics, and communication effects. We conclude with a discussion on the challenges of using computational methods in the Chinese context and the future directions for CCR.
Keywords
The rise and growth of CCR around the world
Computational communication research (CCR) is a substream of computational social science (CSS), formally launched by the publication of what has come to be referred to as the “CSS manifesto” in 2009 (Lazer et al., 2009). However, there had already been various efforts to use computational methods to collect and analyze digital data across almost all disciplines or fields of the social sciences, identified as “social computing”, “digital social research”, “internet social science”, and so forth. Most of these efforts were largely separate from one another.
Our team is a case in point. In 2005, we started a long-term collaboration between our Web Mining Lab (a communication research lab at City University of Hong Kong) and the Tianwang Lab (an internet search engine led by Xiaoming Li at Peking University) to study the structure, content, and use of Chinese websites (Zhu et al., 2008). Drawing on the fruitful results, the two teams coauthored a series of articles advocating the necessity and benefits of interdisciplinary collaboration between the social sciences and computer science. For example, one of our articles was titled “Let the Social Sciences Ride on the Information Technology (IT) Bullet Train” (Li and Zhu, 2006) and another “An Easy and Affordable Tool for e-Social Science Research” (Zhu and Li, 2007a). Note that we renamed our collaborative approach from the generic “IT” to more specific “e-social science” (eSS) within a year, borrowing from the international conference series on eSS. We actively participated in the eSS community (Zhu and Li, 2007b) and took the lead in contributing an entry on eSS for Wikipedia (https://en.wikipedia.org/wiki/E-social_science).
After the declaration of the CSS manifesto (Lazer et al., 2009), we quickly embraced CSS, as did many other similar teams around the world, as the unifying identity for social scientists using computational methods to study social questions. Subsequently, “computational X” has become a popular brand for the application of CSS to specific disciplines or fields, including CCR, the establishment of which was led by our team. In our first introduction to CCR (Zhu et al., 2014), we reviewed more than a dozen empirical studies that employed CSS to investigate the “5W” questions (i.e. who says what to whom through which channels and with what effects?), which is the classical definition of communication (Lasswell, 1948). By organizing CSS studies of communication along the 5W framework, we explicitly illustrated that CSS is a “new (methodological) bottle” for “old wine” (substantive research questions). We also edited two special issues on CCR (Peng et al., 2019; Van Atteveldt and Peng, 2018) to further promote the new approach to the mainstream of communication research. Other members of our team published three books on CCR in Chinese (Xu et al., 2015; Zhang et al., 2018; Zhou and Liang, 2022).
In addition to research and publications, we have helped build the institutional infrastructure of CCR for both the international community and its Chinese counterpart. In 2016, we led a group of 50 scholars around the world to establish a Computational Methods (CM) Interest Group within the International Communication Association (ICA), which is the flagship learned society of communication worldwide. The ICA CM Group, of which Tai-Quan Peng (one of the authors) served as the inaugural chair, was soon upgraded to the CM Division when its membership reached 200, the fastest growth in the ICA's history. Since 2019, ICA CM has published its official journal, Computational Communication Research. We duplicated the effort in China by establishing the Chinese Association of Computational Communication Research (CACCR) in 2018, with Jonathan Zhu (one of the authors) as the founding president. CACCR is also a division of the Chinese Association for the History of Journalism and Communication, which is also the flagship learned society of communication in the country. Both ICA CM and CACCR hold annual conferences and organize student technology competitions, often in collaboration with social media firms.
In retrospect, we believe that there are at least three factors facilitating communication researchers to be one of the early and active adopters of CSS. First, communication research has closely followed the arrival of “new” media at the time, for example, radio in the 1920s–40s, TV in the 1950s–70s, and online media (including web media, social media, and mobile media) in the 1990s–2010s. Each of the new media came with its unique data, for example, audience ratings for radio and TV and online user logs for online media, which helped communication researchers to be acutely aware of and familiar with big data. Second, communication has been an interdisciplinary field with substantial overlaps with information and networking technology, which required communication researchers to possess computing skills (e.g. programming) and resources (e.g. servers and data storage), though at a modest scale. Third, various intellectual connections exist (e.g. probability sampling, causal inference, and supervised classification) between the traditional quantitative methods widely used by communication researchers and the emerging computational methods (to be detailed in the next section). Our team happened to have access to all the necessary human/machine resources and practical experience when CSS emerged, which enabled us to play an instrumental role in the formation and growth of CCR around the world. Furthermore, by producing more than a dozen PhD graduates in CCR, with half working in Chinese mainland and the other half in other regions (including the United States, Hong Kong, and elsewhere), we have also served as a bridge for the synchronization of CCR between the international communication community and its Chinese counterpart.
Overview of CCR methodology
Communication is a mature discipline in the social sciences, with at least 100 years of formal history, as marked by the publication of Journalism Quarterly in 1924 (Dimitrova, 2023). While highly diverse and interdisciplinary, communication research with both a quantitative and qualitative tradition 1 has largely remained focused on the 5W questions discussed above (Lasswell, 1948). Prior to the era of online big data, communication researchers used three types of quantitative methods—survey, experiment, and content analysis—to study the 5W questions (see column 1 of Table 1). After the emergence of the CSS approach, communication researchers have selected from the CSS armory three sets of computational methods—user analytics, content mining, and computational experiments—–to complement the existing alignment between conceptual questions and quantitative methods (column 2 of Table 1; for a more detailed discussion, see Peng et al., 2019).
Mapping between research questions and methods in communication.

Note: * Found data refer to the datasets that had been collected by others for purposes other than the current study whereas made data refer to the datasets that are collected by the current researcher(s) for a specific research aim.
Table 1 provides a comparative introduction to computational communication methods. The horizontal comparison within each row shows the similarities and differences between each pair of quantitative and computational methods for the relevant research question(s). Both content analysis and content mining are used to study communication content (e.g. news reports, entertainment programs, advertisements, interpersonal messages) sent by given source(s) through the given channel(s). Furthermore, both content analysis and content mining use found data that pre-exist rather than made data created by the researcher. The two methods differ in the ways the found data are collected and processed. Content analysis involves human operation that is labor intensive with results largely trustful, whereas content mining involves, mostly, computer automation that is highly efficient with results that are less trustful. Similar comparisons largely hold for the pairs between survey and user analytics and between offline experiments and computational experiments. We will further elaborate on the strengths and weaknesses of the computational communication methods in relation to their quantitative counterparts in the respective sections below.
The vertical comparison across the rows of column 2 in Table 1 shows the similarities and differences among the three computational methods. Content mining and user analytics rely on found data, whereas computational experiments are made data, which makes computational experiments particularly suitable for examining communication effects. While both rely on found data, content mining measures self-reported data, which offer rich information to identify and describe users’ motivations, whereas user analytics rely on behavioral data, which provide more valid measures of what users actually do without information on why they do so. In short, each of the CCR methods bears unique utilities, strengths, and weaknesses. Whenever possible, CCR scholars integrate multiple methods (e.g. content mining and user analytics, as in Zhu et al., 2019; computational experiment and user analytics, as in Bond et al., 2012) to complement one another or cross-validate the results.
User analytics
What is user analytics?
User analytics is a set of computational methods for collecting and analyzing online user behavior based on logs data (Zhu et al., 2019). User logs data refers to the detailed records of user interactions and activities on social media platforms, often stored in the backend databases inaccessible to the public. The logs data typically include timestamps of user actions, such as posting frequency, content types (e.g. text, images, videos), and engagement metrics (e.g. likes, comments, shares).
Unknown to many current generations of online user researchers, user logs analytics existed in communication research long before the advent of the internet. Advertising-funded media (e.g. radio and TV) needed data on their audience size and exposure preferences. Between the 1920s and 1960s, the audience data were collected by self-reported surveys (including incidental calls and diaries). In the 1970s, the subjective survey method gave way to a more objective method—an electronic device (the “Peoplemeter”) attached to TV sets to automatically monitor viewership (“ratings data”, see Webster et al., 2006). The resulting ratings have virtually the same data structure as the online user logs data (with each row representing who was watching/browsing which channel/page at what point in time). Although the size of the ratings data is much smaller, it still can be up to half a million rows per user per month. Beyond the physical similarity, user analytics in the age of big data largely inherits conceptual and analytical metrics from TV ratings analysis. This inherent connection helped some ratings researchers (including us) to quickly become early adopters of CSS.
Why conduct user analytics?
An easier way to understand the benefits and costs of user analytics is to compare it with the survey method on the one hand and content mining on the other.
Survey vs. user analytics
Both aim to understand user behavior, such as who used which medium, offline or online, for how long, and with what companion event or activity. However, they differ significantly in the nature of the data collected. Surveys rely on self-reported statements, which can be subject to biases like social desirability, memory errors, and other intentional or unintentional problems. In contrast, user analytics utilizes actual behavioral records, providing more reliable insights through precise tracking of interactions over time. While surveys typically focus on specific research questions with limited scope, user analytics can capture broader patterns and trends across various platforms, allowing for longitudinal analysis and a more comprehensive understanding of user engagement and media effects.
User analytics vs. content mining
Both are based on found data from online sources that have been collected by others (usually online posting platforms). However, they also differ in the type of data measured. User analytics is concerned with behavioral characteristics (e.g. quantity, timing, responses) of how users spend their time online, mostly privately (i.e. invisible to other users, see Benevenuto et al., 2009, as detailed below). Content mining focuses on user-generated content (UGC) such as posts, comments, shared photos or videos, which are publicly visible. Due to the public nature of UGC, it generally involves social desirability, factual errors, and other human-made problems. Under specific conditions, some aspects of content (e.g. the date and time of posting) are objective and can thus be treated as user logs data, as shown in the second application case (blogs and microblogs on Sina.com) presented below.
How to collect and analyze user logs data?
There are generally four ways to collect user logs data: (1) purchasing from original data sources or their agents, (2) downloading from open-source archives, (3) retrieving from commercial or open-source application programming interfaces (APIs), and (4) direct scraping from public websites (Liang and Zhu, 2017; Zhu et al., 2019). Each approach has its own strengths and weaknesses in terms of technical difficulty, collection time, resulting data format, permission required, payment incurred, and fit to a given purpose (for elaborations, see Table 1 in Zhu et al., 2019). Regardless of the approach, user data collection inevitably encounters legal, ethical, commercial, and technical regulations and standards (Massimino, 2016).
To collect user analytics data, researchers should employ a systematic approach that spans the full lifecycle of social media platforms. This involves gathering data from diverse sources, including UGC, interaction logs, and engagement metrics across multiple platforms. Researchers should ensure random sampling of users to enhance representativeness and minimize bias. Data collection methods may include tracking user behavior through APIs, web scraping, and utilizing built-in analytics tools provided by social media platforms. Additionally, researchers should focus on collecting longitudinal data to analyze trends over time, allowing for a comprehensive understanding of user interactions and media effects.
Once collected, user logs data are generally analyzed using the same statistical techniques as in quantitative social sciences, such as multiple regression, structural equation modeling (SEM), or social network analysis. Furthermore, it is not only necessary but also informative to adopt the longitudinal version of regression, SEM, or network analysis to analyze user logs data because the data almost always carry a built-in timestamp.
In short, user analytics has made significant contributions to the understanding of social media dynamics. User analytics provides a robust framework for analyzing user behavior through actual interaction data, enabling researchers to uncover patterns in content consumption and production. The empirical studies selected below illustrate how user analytics can effectively measure the impact of UGC on engagement and offline participation. By integrating user analytics with traditional research methods, the studies demonstrate the potential for comprehensive insights into media effects, user behavior, and the evolving landscape of social media.
Empirical application 1: prevalence of invisible activities and silent interactions on social media
Scholars of social media widely believe that social media enable all ordinary users to 1) become active content creators, for example, “citizen journalists” in the West or “self-media” in China; and 2) connect with strangers of similar views or interests. These claims have been supported by survey studies with self-reported evidence but questioned by user analytics with behavioral logs. Benevenuto et al. (2009) is a classical study of the latter. Collaborating with a social network aggregator in Brazil, the authors collected click-stream logs on how 30,000 + users spent their time on Orkut, a popular social media platform of the pre-Facebook era, over the course of 12 days. They identified 42 types of user activity from the data, which were collapsed into two categories: activities visible to others (e.g. writing, posting, commenting, sharing photos/videos) and activities invisible to others (browsing or lurking other users’ profiles, homepages, photo albums, friend lists, etc.). It turned out that invisible browsing accounted for more than 90% of all the activities the users engaged in. The authors found a similar prevalence of invisible activities on three other social media platforms, including MySpace, Hi5, and LinkedIn. Evidently, it is only possible to detect such findings through behavioral logs recorded in the backend.
The authors reported other interesting patterns when they divided the social interactions between each pair of friends on Orkut into visible interactions (e.g. sending messages or leaving comments) and silent interactions (lurking the peer's content). While those popular users (who had a larger number of friends) engaged in visible interactions as infrequently as the unpopular users (the red area in Figure 1), the more popular users performed more silent interactions (the gray area). Therefore, the authors called attention to “the potential bias in studies of interactions using only visible data” (Benevenuto et al., 2009: 58).
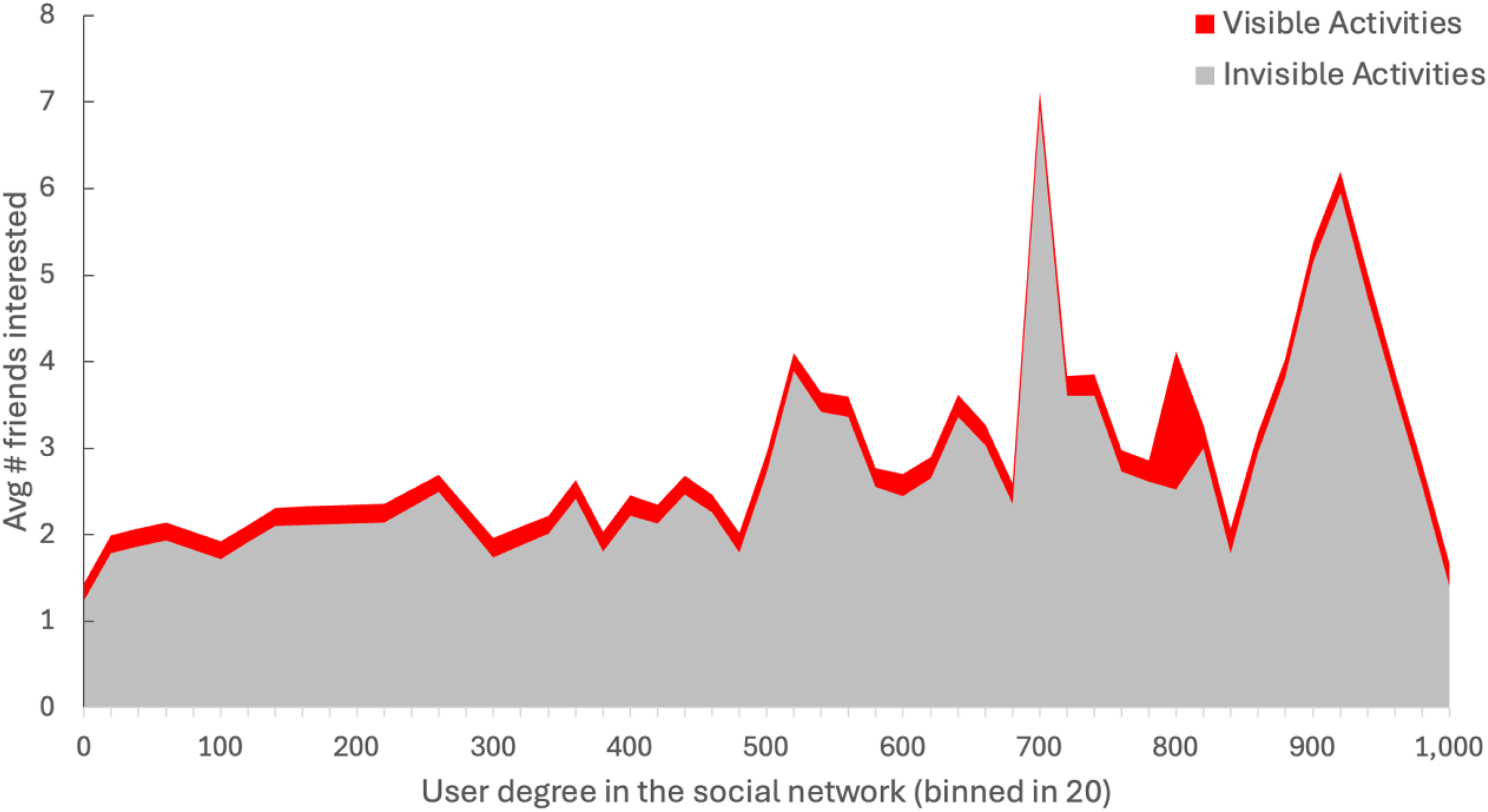
Activities by user popularity on Orkut.
Empirical application 2: dynamic relationships between UGC platforms
Blog websites are arguably the first genuine UGC platform, where ordinary, professional, and institutionalized individuals share what they see and think on an unprecedentedly massive scale. While blogging remains the primary channel of UGC for many parts of the world, it has largely died off in China after experiencing explosive growth around 2005–2010. Scholars and industry analysts have invariably attributed the demise of blogging to the rise of microblogging, which uses similar technology to provide more diverse and flexible services. Sina.com is a commonly cited case: its blog site (blog.sina.com.cn, denoted as “the blog” hereafter) declined as its microblog site (weibo.com.cn, “Weibo”) emerged.
To test the displacement hypothesis, we made use of two unique features of Sina.com. First, it automatically creates a publicly visible homepage for all new users when registering an account on the blog and Weibo, respectively. That means the full usage history of all users of either platform, no matter how active or inactive, is publicly available from the front-end web posts. Second, while all users can display a nickname for their UGC posts, Sina.com assigns a unified ID for every user on both sites, which is also publicly visible on the user's profile page. This makes it possible to map the blog and Weibo for each user, without dipping into the backend databases.
The two features enable us to detect a dynamic relationship between the two UGC sites (Figure 2). There was limited competition between the blog and Weibo because only 30% of the initial blog users switched to microblogging when Weibo was launched in August 2009 (13% were “permanent users”, who would remain blog users over the long term, and 17% were “post-switch dropouts”, who would eventually go on to quit blogging for microblogging), whereas the other 70% dropped out before or right after 2009 (46% were “quick quitters”, who made the switch immediately, and 24% were “gradual dropouts”, who did not switch immediately but did so soon after the launch of Weibo). Not shown in Figure 2 are multiplatform users, including blog users who continued blogging while adopting microblogging and Weibo users who started with microblogging and then expanded to blogging (Hou et al., 2022). Although a small proportion of the total, these multiplatform users evince a cooperative, instead of competitive, relationship between the two UGC platforms. The research design based on the user behavioral measurement we adopted in the study enables us to identify complex and dynamic relationships and determine the relevant causal directions.
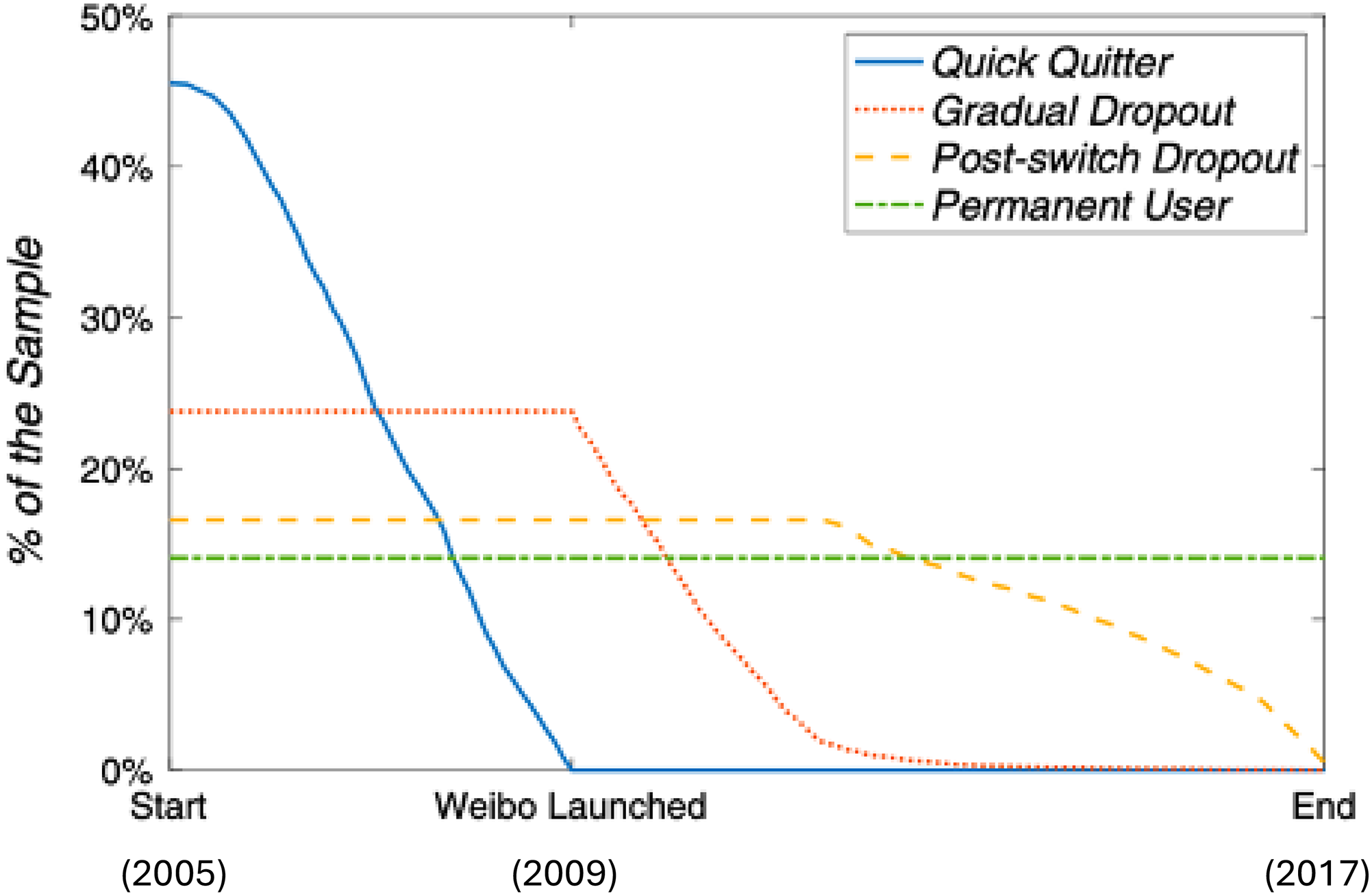
Survival curves of Sina bloggers, 2005–2017.
Empirical application 3: have mobile phones fragmented our daily lives?
Many, if not all, people believe that the ubiquitous use of mobile phones has led our daily lives to become increasingly fragmented, raising concerns about how mobile phone usage may disrupt our work/study routines, interpersonal interactions, and even personal health. It is easy to support this time fragmentation hypothesis through self-reported surveys. However, a more rigorous test requires behavioral measurements, such as mobile phone usage logs. For this purpose, it is necessary to have an operational procedure to quantify the frequency of mobile phone use. We first developed a measurement for mobile phone use sessions, defining a session as a continuous sequence of user-initiated tasks on a mobile device (Zhu et al., 2018). Specifically, we employed a screen-based approach, where a session begins when the user unlocks the screen and ends when it is locked again. This method effectively distinguishes between intentional user actions and machine-activated tasks, providing a clearer picture of user behavior.
We then applied the session measurement to an open-source dataset obtained from the Device Analyzer Project at Cambridge University (Wagner et al., 2013), which included mobile phone logs from over 30,000 users. We focused on a subset of 3100 active users who had consistent records over three months. By analyzing the number of sessions per day, we were able to identify changes (or lack thereof) in mobile phone usage over time.
As shown in Figure 3, only 19% of the users exhibited a significant increase in the number of sessions over the study period, while 38% showed a decrease, and 47% had no significant change. As such, there is very weak evidence to support the time fragmentation hypothesis, suggesting that mobile phone use may not be leading to the expected fragmentation of daily life among the users under study. Of course, a longer observation period is necessary to draw more definitive conclusions about the impact of mobile phone usage on daily routines.
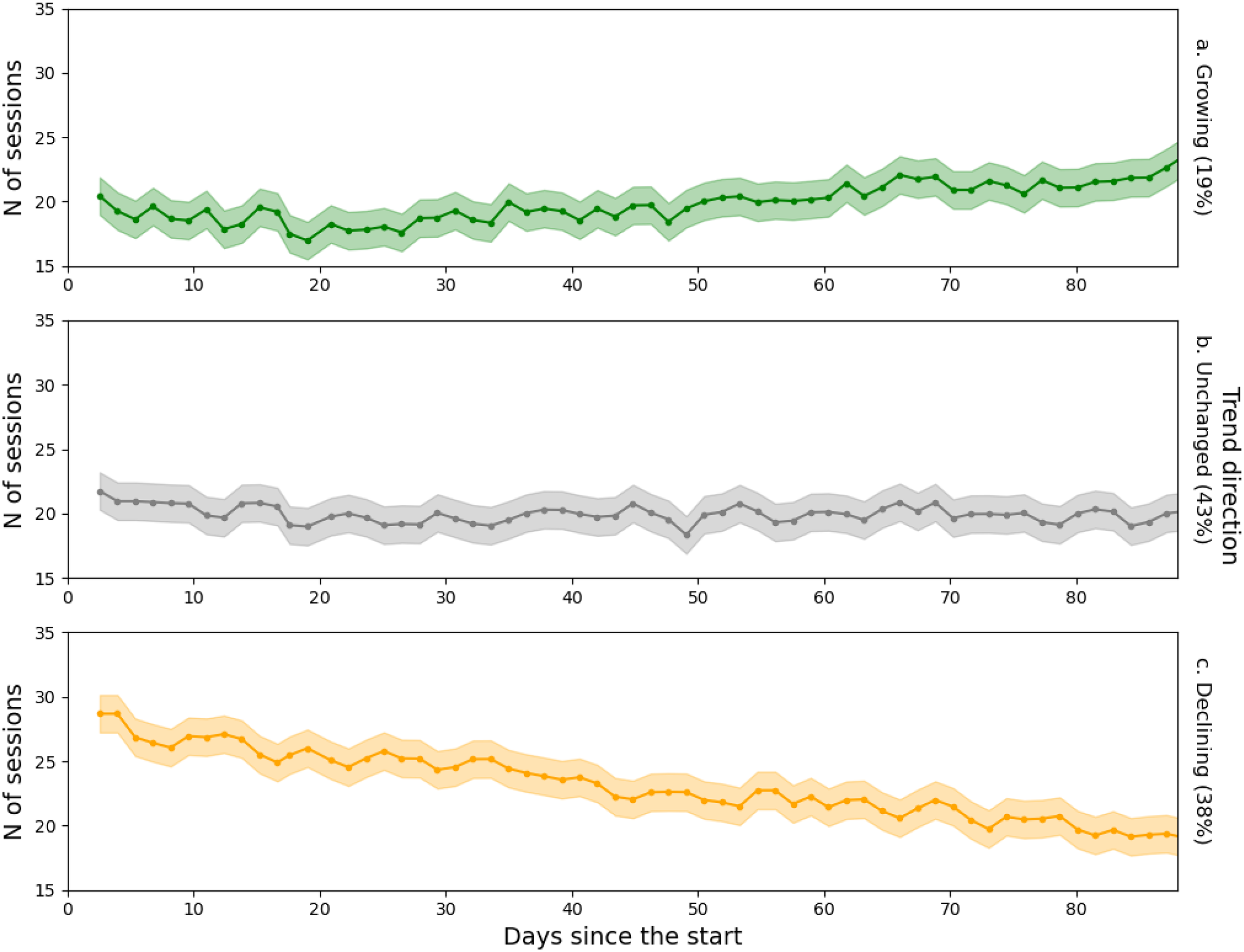
Changes in the significance and direction of the fragmentation trend.
Content mining
What is content mining? A natural departure and scale-up from content analysis
The study of message content has long been a cornerstone of communication research. Messages, whether conveyed through speech, text, or visual media, serve as the primary vehicle for the transmission of ideas, emotions, and information between individuals and groups. Understanding the nature, structure, and impacts of these messages is crucial for unpacking the complexities of communication processes, from interpersonal exchanges to mass media dissemination. Content analysis is one of the most well-developed and widely used methods (Berelson, 1952; Krippendorff, 2024) in communication research to systematically examine messages. As a research tool, content analysis allows scholars to quantify and analyze the presence, meanings, and relationships of certain words, themes, or concepts within texts or sets of texts. This method has been employed to explore a wide range of issues, from media framing and representation to public opinion and discourse patterns. In recent years, the emergence of online content and the advent of computational methods have revolutionized the field of content analysis.
Although both traditional content analysis and emerging content mining rely on found data, they differ significantly in several key dimensions. First, the source of data has become increasingly heterogeneous in content mining. While traditional content analysis typically relied on well-established sources such as news media, broadcasting companies, and publishers, content mining now deals with content generated across all sectors of society, including the general public, social media influencers, celebrities, and public officials. This shift has broadened the scope of analysis but also introduced greater variability in data sources. Second, the data in content mining is often more unstructured and lacks context. Unlike traditional media content, which tends to be more formal and well-contextualized, UGC on social media is frequently brief and fragmented, posing challenges for processing and interpretation. Finally, the volume of data in content mining is exponentially greater than that in traditional content analysis. This vast quantity of data presents significant challenges in filtering out random noise and identifying meaningful signals during the preprocessing and analysis stages.
Although more computationally automated, content mining cannot fully replace traditional content analysis. Content analysis provides crucial metrics and methodological rigor that are essential for handling the heterogeneity and volume of online content. For example, traditional content analysis includes well-established procedures for assessing the validity and reliability of findings (e.g. Krippendorff's alpha), which are critical for ensuring that results are both accurate and replicable. Additionally, techniques such as representative sampling are central to content analysis, allowing researchers to draw meaningful conclusions from large and diverse datasets. These methodological strengths of content analysis continue to be vital in ensuring that the insights gained from content mining are methodologically robust and scientifically sound.
How to mine online content with computational methods
The methods of content mining have evolved significantly, with computational methods becoming increasingly sophisticated over time. Early approaches often relied on dictionary-based natural language processing (NLP), where predefined word lists and lexicons were used to identify and categorize content based on sentiment, topics, or themes. While these methods provided valuable insights, they were limited by their reliance on static word lists, which could struggle to capture the nuances and evolving nature of language on social media.
As the field advanced, unsupervised and supervised machine learning techniques became more prevalent. Unsupervised methods, such as topic modeling and clustering, allow researchers to discover hidden patterns and groupings within large datasets without prior labeling, making them particularly useful for exploratory analysis. On the other hand, supervised learning methods, including support vector machines, decision trees, and neural networks, leverage labeled data to train models that can accurately classify and predict outcomes based on new data. These methods have been instrumental in automating the analysis of vast amounts of social media content, improving the efficiency and accuracy of sentiment analysis, topic detection, and other tasks.
In recent years, the development of transformer models, particularly large language models (LLMs) like GPTs (generative pre-trained transformers), has marked a significant leap forward in the ability to analyze and generate human-like text. These models, built on deep learning architectures, excel at understanding context, detecting subtle language patterns, and even generating coherent and contextually relevant text. LLMs offer powerful tools for analyzing complex social media content, providing insights that were previously unattainable with traditional methods. Their capacity to process and interpret vast amounts of data with high accuracy has opened new frontiers in communication research, enabling more nuanced and sophisticated analyses of online content.
Table 2 summarizes and compares content mining techniques used in communication research. Despite the shared and distinct characteristics, these techniques have been effectively applied to address both long-standing and emerging questions in communication research. One of the enduring questions in communication research is to understand what is communicated, perceived, and felt by individuals, groups, organizations, and societies. Content mining techniques offer new tools for observing public opinion and sentiment. With the advent of online content and its unique features, these content mining techniques have also been integrated with other methods to tackle new questions that were previously challenging to answer. A notable example of this is the analysis of information production, consumption, and diffusion.
Comparison of popular content mining techniques in CCR.

Empirical application 1: content mining as a thermometer of public opinion and sentiment
As mentioned earlier, traditional content analysis and cutting-edge content mining techniques are applied to different types of data, each offering unique insights into public discourse. Traditional content analysis primarily focuses on established sources, such as news organizations, commercial companies, and public figures, which tend to reflect the perspectives of social elites. In contrast, content mining techniques leverage the vast availability of UGC and advancements in computational efficiency to analyze material produced by individuals from various social sectors. These techniques can capture what the public thinks and feels on an unprecedented scale, providing a complementary thermometer to gauge public opinion and sentiment (Golder and Macy, 2014).
Platforms such as Twitter/X, Facebook, and Reddit have become critical spaces for public expression, where individuals can freely share their thoughts, feelings, and reactions to current events. The user-centered and anonymous nature of these platforms enables a more candid and diverse range of opinions, which can be captured in real time. Researchers have increasingly turned to computational methods such as sentiment analysis, topic modeling, and social network analysis to process and analyze the vast amounts of UGC produced on these platforms. These methods allow for the identification of key issues in public discourse (Walter and Ophir, 2019), the detection of public agenda dynamics (Sun et al., 2014), the mapping of public sentiment over time (Golder and Macy, 2011), and the understanding of social interaction patterns (Avalle et al., 2024).
Despite stringent government regulations on social media in China, platforms like Weibo, WeChat, and Douyin (TikTok) have become valuable alternatives for gauging public opinion and sentiment. This is particularly important in China, where both domestic and foreign researchers face challenges in conducting traditional surveys and public opinion polling. These challenges include limitations in data collection, social desirability bias, and a general reluctance among the Chinese public to express opinions that could be considered sensitive or controversial. These factors hinder the ability to obtain an accurate and comprehensive understanding of public sentiment through conventional methods in China.
The relative anonymity of social media allows for more open expression, providing a dynamic and effective alternative to conventional methods and offering a more nuanced understanding of public opinion and sentiment. Researchers have harnessed the power of these platforms to analyze public opinion and sentiment on a wide range of topics in the Chinese context. For example, studies have examined responses to government policies (Deng et al., 2021), public health crises (Lu et al., 2021; Shi et al., 2022), international issues (Tao and Peng, 2023), science discovery (Chen and Zhang, 2022), and social movements (Li et al., 2021). The time-stamped nature of social media content also enables the tracking of sentiment shifts in response to specific events, offering insights that were previously difficult to obtain.
Empirical application 2: content mining as a lens to observe information production, consumption, and diffusion
The time-stamped, interactive, and networked nature of social media data has revolutionized the study of information dynamics, providing researchers with unprecedented opportunities to observe the production, consumption, and diffusion of information in real time. Unlike traditional media, where information flows are often linear and controlled by gatekeepers, social media platforms enable a more decentralized and interactive exchange of content. This shift allows researchers to explore how information is created, shared, and consumed across diverse audiences, offering insights into the complex processes that drive public discourse in the digital age.
Information production: censorship and misinformation
Social media content offers a valuable lens for understanding the production of information, particularly in the context of censorship and misinformation. In many regions, including China, the production of information is heavily influenced by government policies and regulations. Censorship plays a significant role in shaping the content that circulates on social media, as certain topics are subject to restrictions or adjustments to align with broader policy objectives. By analyzing patterns of content deletion, keyword filtering, and other forms of censorship (King et al., 2013, 2017; Timoneda, 2018), researchers develop insights into the mechanisms of information control and the impact of these practices on public discourse.
In addition to censorship, the production of misinformation is another critical area of study within the broader context of information production on social media (Lazer et al., 2018). Misinformation, often spread intentionally to deceive or manipulate public opinion, poses significant challenges to the integrity of online discourse. The open and participatory nature of social media platforms makes them particularly susceptible to the rapid spread of false information, which can have far-reaching consequences for public trust and decision-making. Researchers have utilized computational methods to detect and analyze misinformation (Grinberg et al., 2019), examining how it is produced (Shu et al., 2017), who disseminates it, and what factors contribute to its spread (Guess et al., 2019).
Information consumption: user engagement with online content
User interactions on social media platforms—such as likes, shares, retweets, and comments—serve as key indicators of how messages resonate with audiences and how public sentiment evolves in response to new developments. These interactions provide a rich dataset for understanding the dynamics of information consumption, offering insights into not only what content is being consumed but also how it is being received and interpreted by different segments of the audience.
The ability to analyze user engagement through computational methods has significantly advanced our understanding of the interactive and participatory nature of public opinion. Unlike traditional methods, which often rely on retrospective self-reporting or limited sample sizes, computational approaches enable researchers to capture real-time data on how users engage with content (Lee and Peng, 2023). This offers a more nuanced and immediate picture of how individuals and communities react to specific pieces of information. User engagement with news articles can reveal how certain topics gain traction and influence public discourse (Yang and Peng, 2022). Similarly, the way audiences interact with advertising messages offers insights into consumer behavior and the effectiveness of marketing strategies (Zhang and Peng, 2015). In the realm of public health, analyzing engagement with health information allows researchers to assess the spread of crucial messages and identify potential barriers to effective communication (Wang et al., 2019).
Information diffusion across individuals, borders, and platforms
The networked nature of social media offers a unique opportunity to study how information diffuses across various dimensions—individuals, geographical borders, and platforms. Unlike traditional media, where information typically flows in a one-way, top-down manner, social media platforms enable users to actively engage with and disseminate content, creating complex networks of information exchange. By analyzing these interactions, researchers can trace the pathways through which (mis)information and emotion spread (Kramer et al., 2014; Vosoughi et al., 2018), identify the overall structure of information dissemination (Goel et al., 2016), and detect influential users and key nodes in the diffusion process. The ability to map the flow of information within social networks provides valuable insights into how ideas, narratives, and trends gain traction and spread within specific communities (Wang et al., 2016) or across broader publics. This level of analysis offers a deeper understanding of the mechanisms of virality and the formation of public opinion, revealing how content circulates and influences discourse.
Geo-tagged data on social media further enriches this analysis by enabling the study of information diffusion across geographical borders (Sun et al., 2016). Tracking where content is posted and how it is shared across different locations allows researchers to observe the movement of information between regions and countries. This is particularly valuable in the context of global events or issues, where understanding the transnational flow of information can illuminate how global narratives are received and adapted within various cultural and political contexts.
Cross-platform studies (Lu et al., 2022; Wang et al., 2023; Yin et al., 2024) also play a crucial role in understanding information diffusion by examining how content migrates between different social media ecosystems. For instance, analyzing the spread of a narrative that originates on Twitter/X and then appears on Chinese platforms like Weibo or Douyin can provide insights into the cross-cultural and cross-linguistic dynamics of information flow. Cross-platform analysis reveals how content is adapted, translated, and reinterpreted as it moves from one platform to another. This approach advances our understanding about how global conversations are localized for different audiences and how information from Chinese social media platforms may circulate back to the global stage.
Challenges in mining online content in the Chinese context
Studying online content on Chinese social media presents common and unique challenges. Content regulation practices frequently lead to the deletion or alteration of posts, making it difficult to obtain complete and accurate datasets. Additionally, self-censorship among users further complicates the task of capturing genuine public sentiment.
Linguistic and cultural complexities add another layer of difficulty. Chinese social media is rich in diverse languages, dialects, and internet slang, which are often used creatively. These linguistic nuances can be challenging for standard NLP tools to interpret accurately. Moreover, understanding cultural references and symbols requires contextual knowledge that may be inaccessible to researchers unfamiliar with Chinese culture.
The issue of validity is critical. The dynamic nature of social media content, influenced by censorship, algorithms, and user behavior, raises questions about the reliability of the data. In the traditional content analysis, communication researchers commonly calculate the mutual agreement between coding decisions made by two or more independent coders to ensure inter-coder reliability. The practice has been followed by some computational communication researchers by validating machine coding results with human coding results (i.e. supervised learning). However, many other computational content mining studies solely rely on machine coding results (unsupervised learning). To address these concerns, researchers should employ robust methodologies, such as triangulating data from multiple sources and using advanced analytical techniques to decode and interpret content accurately. Transparency in the research process, including clear documentation of methods and limitations, is essential for ensuring the validity of findings.
Computational experiments
What are computational experiments?
Experimental design has been a key research method from the very beginning of communication science. It includes three essential components: treatments, random assignment of treatments, and post-treatment measures. Experiments take various forms: lab, field, and survey experiments (Druckman et al., 2011). All these experiments could be conducted online, transforming them into computational experiments. Online platforms afford complex research designs and data recording methods, significantly scaling up the data being collected, leading to the possibility of computational experiments either leveraging digital platforms as the fields or employing computational methods for data collection or outcome measures. For that reason, computational experiments are also called web-based experiments, or digital experiments by some CCR scholars.
To highlight the uniqueness and novelty of the experiments in CSS, Salganik (2018) proposed classifying experiments according to two dimensions: lab–field and analog–digital. Lab experiments are conducted in labs, while field experiments are conducted in natural settings. Analog experiments are conducted without using digital infrastructure for manipulation or measurement, while digital experiments use digital platforms for participant recruitment, randomization, treatment delivery, and outcome measurements. Within this 2 × 2 design space, digital field experiments are most likely to be computational.
Recently, intelligent agents (IAs) based on LLMs, such as ChatGPT, have presented the potential to facilitate experiments in communication research. In addition to human participants in previous experiments, current experiments could involve human-like agents. In computational experiments, it is technically easy to create IA accounts on social media platforms. Even in lab experiments, it is also possible to employ intelligent robots to examine human–robot interaction. Therefore, we add one more dimension to the design space: human–IA.
Given this evolving situation, we present the three-dimensional model in Table 3 to classify the current experiments in social sciences. In addition to digital field experiments with human participants, some experiments involving IAs could be computational. Like digital field experiments with human subjects, digital field experiments with IAs typically need computational tools for manipulation, data collection, and analysis. However, intensive computing is not necessary for human–robot studies, given that it is unlikely to involve many robots in existing studies (e.g. Edwards et al., 2023). Nevertheless, it is possible for digital lab experiments involving IAs to be computational if they involve large-scale digital trace data with IAs or with computational measures (e.g. Chuang et al., 2024).
The three-dimensional design space of experimental design.
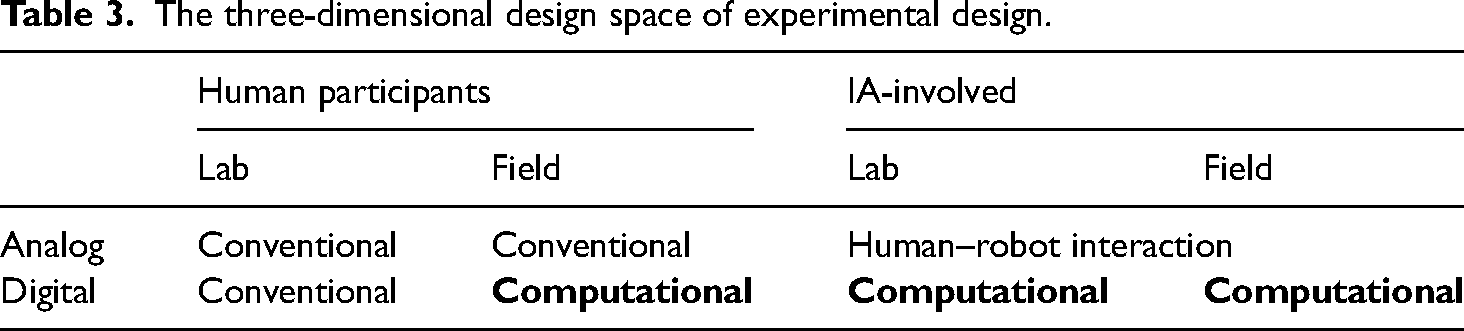
A question remains in Table 3 as survey experiments are missing. Should online survey experiments be classified as computational? This largely depends on the extent to which online platforms are involved in the experiments and whether variables are measured computationally. If the “online” aspect is limited to participant recruitment and sampling, then the experiments would be categorized as traditional (Muise and Pan, 2019). However, if the survey experiments heavily depend on the interfaces or features provided by online platforms, then they should be considered computational. Modern online survey platforms such as Qualtrics offer advanced features for engaging with participants. It is even feasible to integrate ChatGPT into surveys via programming. For example, Liang and Ng (2023) have conducted a computational experiment leveraging the programming functions of a survey platform. In addition to recruiting representative online participants, some participants were randomly asked to post a comment to a news article by picking two words from a randomly generated list of vulgar words in Cantonese. In this way, we could test the expression effects of public swearing (those who picked vulgar words in their comment).
Why conduct computational experiments?
Computational experiments vs. other computational methods
It has been a great challenge in CSS using unobtrusive data for causal inferences. Given that computational experiments could benefit from the features afforded by real-world digital platforms, it is straightforward to collect large-scale user behavioral logs and content data automatically. Theoretically, the techniques and methods in user analytics and content mining can also be applied to computational experiments. The obvious advantage of computational experiments over user analytics and content mining is that researchers have more control over the treatment materials and the assignment of treatment, with similar post-treatment measures as user analytics and content mining. Nevertheless, computational experiments are usually expensive for researchers, made data are less natural than unobtrusive data and thus have lower external validity, and only a few researchers would have the opportunity to work with the top platforms with more representative users.
Computational experiments vs. traditional experiments
Lab experiments have long been challenged for their low external validity because of non-representative participants (usually college students), unnatural settings, unusual stimuli, and obtrusive measures of outcome variables (Peng et al., 2019). The other two forms of traditional experiments solve some of the problems: population-based survey experiments can be conducted with representative participants, and field experiments are conducted in natural settings. Regarding these problems with validity, computational experiments, especially digital field experiments, offer many advantages. Online field experiments significantly reduce costs compared to offline field experiments. It is also much easier to recruit representative participants because subjects can work remotely online. Since everything is virtual on digital platforms, the intervention stimuli could be much more natural (e.g. by altering the algorithms; see Kramer et al., 2014; Nyhan et al., 2023). Finally, unlike offline experiments, computational experiments could trace the user log data and measure the process and outcomes unobtrusively and computationally.
How to conduct computational experiments
As we discussed above, the methods involved in user analytics and content mining could also be applied to computational experiments. Therefore, in terms of data collection, statistical modeling, and analytical strategies, they are quite similar to the other two methods. The unique aspects rely on the research design. Salganik (2018) has summarized four strategies for conducting digital field experiments. The most influential one is to collaborate with the top platforms, like Facebook and Twitter/X (e.g. Kramer et al., 2014; Nyhan et al., 2023). The cost is low but not available for most researchers. The second is to design experiments based on existing systems but not through formal collaboration. For example, Matz et al. (2017) conducted an advertising experiment using Facebook's advertising system. The third is to build computational experiments, either lab-like or field-like. The survey experiments, as we mentioned above, should be such examples. Last, researchers could create their own platform products, though this is less realistic in academia.
Furthermore, Muise and Pan (2019) have pointed out additional considerations in conducting online field experiments in Asia, especially in China. First, the ethical and legal considerations: researchers must ensure compliance with local laws and ethical principles, considering the unique legal and ethical landscape in Asia. Second, construct validity: it is crucial to design proxies for variables and outcomes that accurately capture the phenomena being studied, given that many outcome measures in digital field experiments use computational metrics, for example, traffic and number of likes. Third, randomization and spillover: researchers need to address potential issues with randomization and spillover, especially in online settings where units are not independent of each other. Finally, statistical significance: with large sample sizes, researchers should focus on effect sizes, transparency, and pre-registration.
Empirical application 1: digital experiments estimating communication effects
Many communication researchers are interested in using digital experiments to examine different communication effects on social media platforms. For instance, Bond et al. (2012) found that by manipulating the Facebook interface, social messages containing cues from users’ friends were more effective than informational messages alone. This resulted in increased political self-expression, information-seeking, and real-world voting behavior. Matz et al. (2017) conducted three field experiments on Facebook leveraging Facebook's advertising platform. The results showed that matching persuasive appeals to traits like extraversion and openness-to-experience increased clicks and purchases by up to 50%. Kramer et al. (2014) manipulated the emotional content in users’ News Feeds by reducing positive or negative posts on Facebook. Findings revealed that emotional states can be transferred without direct interaction or nonverbal cues.
Most recently, a group of communication researchers published a series of empirical studies to test the impacts of algorithms on Facebook and Instagram using large-scale field experiments. Nyhan et al. (2023) examined the effect of reducing exposure to like-minded content on Facebook during the 2020 US presidential election. They conducted a large-scale field experiment with 23,377 consenting US adult Facebook users, reducing their exposure to like-minded sources by about one-third. The study found that while this intervention increased exposure to cross-cutting and neutral content, it did not significantly affect users’ political attitudes or beliefs. Guess et al. (2023) investigated the effects of feed algorithms during the 2020 US election. Users were assigned to either the default algorithmic feeds or reverse-chronological feeds. The study found that moving users to chronological feeds significantly reduced their time on the platforms and their engagement. However, the chronological feed did not significantly alter levels of political polarization, knowledge, or participation. Allcott et al. (2024) conducted a large-scale randomized experiment involving over 35,000 users who were paid to deactivate their accounts for six weeks before the 2020 US election. The study found that deactivating Facebook and Instagram reduced political participation, mainly online, and had no significant effect on political knowledge overall. The effects on polarization, perceived election legitimacy, candidate favorability, and voter turnout were minimal.
Conducting digital experiments is expensive for academic research, and only a few studies have been conducted on Chinese websites. Nevertheless, it is valuable to do so because Chinese society has unique political features and is culturally conservative. King et al. (2014) created accounts on numerous Chinese social media sites, submitted posts with varying content, and observed which were censored. They found that posts about collective-action events were more likely to be censored than those criticizing the government or its leaders. Another one, using a similar approach, is from Chen et al. (2016). The authors conducted an online field experiment across 2103 Chinese counties to examine factors influencing local officials’ responsiveness to citizen demands. The findings revealed that the risks of collective action and the practice of reporting to higher levels of the government significantly increased responsiveness, while claims of loyalty did not.
Empirical application 2: digital experiments involving IAs
Using social robots in digital experiments is not brand new. Human-like social media accounts have been created to examine peer influences on social media platforms. For example, Munger (2017) used Twitter/X bots to sanction harassers, varying the bots’ race (white or Black) and follower count (high or low). The findings revealed that sanctions from high-follower white bots significantly reduced the use of racist slurs, especially among anonymous users. Bail et al. (2018) randomly assigned a large sample of Twitter/X users to follow a Twitter/X bot for one month that exposed them to messages produced by elected officials, organizations, and other opinion leaders with opposing political ideologies. They found that exposure to opposing views actually decreased polarization.
LLM-based agents could scale up experimental studies with more personalized bots, providing new opportunities for communication studies. Based on Bail et al. (2018), Argyle et al. (2023) leveraged AI chat assistants powered by ChatGPT-3 to improve the quality of online political conversations. Participants were paired with someone holding opposing views and randomly assigned to either a control group or a treatment group where one participant received AI-generated rephrasing suggestions. The findings showed that the AI assistant improved the perceived quality of conversations and increased democratic reciprocity. However, these improvements did not change participants’ policy positions.
In addition to pairing IAs with human subjects, digital experiments could be conducted with IAs exclusively. For example, Chuang et al. (2024) proposed a method to simulate opinion dynamics using networks of LLM-based agents. The experimental setup involves LLM agents role-playing diverse personas and engaging in multi-turn conversations to study opinion evolution. The findings reveal that LLM agents tend to converge toward scientifically accurate information, limiting their ability to simulate resistance to consensus views. However, introducing confirmation bias through prompt engineering leads to opinion fragmentation, aligning with traditional agent-based models.
Conclusion
When we started this review, we did not intend to make it a theory-driven piece to test any hypothesis. After going over the process of how CCR has been adopted by communication scholars, we cannot help thinking that the process represents another neat confirmation of the diffusion of innovations (DOI) theory (Rogers, 2003). In particular, as predicted by DOI theory, the key ingredients of a successful diffusion, such as relative advantages (of computational methods), compatibility (between computational and quantitative methods), simplicity (of user-friendly tools) have facilitated the rapid and wide use of computational methods in communication research. Beyond diffusion, use of CCR methods have made substantive and measurable contributions to some of the long-standing debates on core communication theories, for example, limited effects (Bond et al., 2012), passive audiences (Benevenuto et al., 2009), and cooperative dynamics of public agendas (Sun et al., 2014), as reviewed above. It is fair to say that CCR is a “new bottle” of both “old wine” (established knowledge) and “new wine” (emerging phenomena).
Future prospects of CCR
It is challenging to predict the future of CCR, given that it is a rapidly evolving field. Nonetheless, certain trends can be anticipated.
First, computational methods are expected to become increasingly prevalent and integrated into the core research methodologies of communication science. Over the past decade, nearly all major communication departments in the United States, Europe, and Asia have hired faculty members specializing in CCR. Consequently, a growing number of PhD students are concentrating on CCR and have recently been trained and graduated. In many empirically oriented PhD programs, CCR courses are mandatory for all students, irrespective of their specific research topics or methodological preferences. Gradually, computational methods—similar to traditional surveys, content analysis, and experiments—have become a standard component of core methodologies in general communication education. In the long term, it is conceivable that the term “CCR” may become obsolete, as it will be subsumed under the broader category of communication research that inherently includes computational elements.
Second, while the development of CCR has been heavily predicated on advancements in technology and knowledge in computer science, this dependency may gradually diminish in the future. This trend is not indicative of a diminished importance of technology; rather, as has been discussed across this article, new technologies have modernized traditional approaches in communication research. Computational methods, akin to the role of statistics in quantitative research, have already facilitated a paradigm shift in communication methodology. Similar to how statistics are utilized in quantitative social sciences, the next generation of communication scholars may create their own computational models and tools tailored to their specific needs, rather than exclusively relying on developments from other disciplines. Examples of this shift are already evident, such as the structural topic modeling developed by Roberts et al. (2013). Furthermore, there is a growing body of literature on computational communication methods, as evidenced by an increasing number of articles published in journals such as Communication Methods and Measures and Computational Communication Research.
Challenges in applying CCR methods in the Chinese context
Applying computational methods such as user analytics, content mining, and computational experiments to Chinese social media presents both shared and unique challenges that researchers must carefully navigate. One significantly shared challenge across computational studies, whether in China or elsewhere, is the contamination of data by algorithms and bots. In online settings, the behaviors, content, and effects that computational communication researchers study may be influenced by a combination of real human actions, behaviors altered by platform algorithms, and bot-generated activity that mimics human behavior. This creates a complex environment where it is crucial to disentangle these confounding influences to accurately understand and interpret the data. In the Chinese context, this challenge is compounded by the pervasive influence of content regulation practices, which can further distort the fidelity of digital traces. Researchers need to be especially careful to make sure that their analyses separate real human responses and sentiment from content influenced by external factors, such as algorithms, bots, or content regulation.
Another pervasive challenge is the balkanization of individual social media platforms. Each platform operates within its own ecosystem, often with distinct user behaviors, content norms, and technical architectures. This balkanization necessitates tailored approaches for data collection and analysis. Access to data is often restricted by platform-specific APIs, and in some cases, researchers must rely on alternative methods like web scraping, which pose technical and legal challenges. This fragmentation also makes it difficult to draw generalizable conclusions, as studies conducted on one platform may not fully represent the broader social media landscape. Researchers must be cautious of the risk of “judging Hercules from his foot”, where findings from one platform are mistakenly extrapolated to represent wider phenomena.
As can be expected, the unprecedently fast growth of CCR approaches among Chinese communication scholars and students is frequently accompanied with a variety of underuse, misuse, and abuse of the methodology. For example, numerous text mining studies rely on the “bag of words” method to extract hot words and then present the results in a word cloud, leaving all contextual and other richer information underutilized. Many machine learning studies are not validated with independent data or fail to report sample accuracy rate or model goodness of fit. Some of the problems are caused by the lack of systematic training whereas some others may stem from intentional malpractices.
Ethical considerations are particularly salient when applying computational methods in the Chinese context. Issues of privacy and informed consent are heightened in an environment where users may be unaware that their data are being collected and analyzed, or where they may assume a greater degree of anonymity than is actually provided. The potential risks to users, including surveillance or punitive actions based on their online activities, raise serious ethical dilemmas for researchers. Navigating these challenges requires a careful balance between advancing scholarly inquiry and protecting the rights and safety of the individuals whose data are being studied. Researchers must adhere to the highest standards of ethical practice, ensuring that privacy is safeguarded, informed consent is respected, and the potential harms of data misuse are minimized. In the Chinese context, where unique political features can further complicate ethical considerations, it is crucial that researchers remain vigilant and proactive in addressing these issues.
Footnotes
Contributorship
The authors contributed equally to the conceptualization and writing of the article, with Zhu responsible for drawing Figures 1–![]() .
.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Centre for Communication Research, City University of Hong Kong (grant number 9360120).