
Abstract
Text data has been a longstanding pivotal source for social science research, providing an informative lens across disciplines including sociology, psychology, and political science. Its salient role in research, combined with the difficulty in numerically digesting unstructured data in natural languages, has been inspiring growing demands for natural language processing techniques to extract meaningful insights from vast text data. Breakthrough advances in natural language processing emerge with the recent expansion in data availability and computational resources, calling for an up-to-date comprehensive review for those methodologies and applications in social science research. This article reviews natural language processing techniques, detailing the procedure from representing unstructured text data to distilling semantic information, with expertise-based algorithms and unsupervised/supervised machine-learning methods. We then introduce their typical applications in producing research outcomes for sociology and political science. Keeping in mind challenges in data representativeness, interpretability, and biases, this review encourages utilizing natural language processing technique responsibly and effectively in social science research to improve quantitative understandings of emerging text data.
Keywords
Introduction
Natural language plays an essential role in the field of social science research. Both qualitative and quantitative text analysis techniques are extensively adopted in studies from different social science disciplines. For example, psychologists analyze natural language to grasp individuals’ emotions and inner thoughts (Tausczik and Pennebaker, 2010), political scientists extract people's political opinions from online or offline speeches and discussions (Grimmer and Stewart, 2013), and sociologists reveal social mechanisms by manually coding texts in books, diaries, and interviews (Krippendorff, 2019; Schwartz and Ungar, 2015).
We are now entrenched in the epoch of information, or the era of computation (Blei and Smyth, 2017). As of 2024, the monthly active users on X (formerly Twitter) have reached 335 million. These users send short texts to express their feelings or opinions, with X just one of many social media platforms (Statista, 2022). Simultaneously, Gutenberg has amassed over 70,000 electronic books (Gutenberg, 2024) and the volume of the Wikipedia database reaches 4.5 billion words (Wikipedia, 2024). These figures, though substantial, represent only a fraction of the vast amount of digital textual data. Other sources including newspaper archives, online forums, historical datasets, and administrative records further enrich the digital textual resources accessible to social science researchers. This large amount of textual data presents both opportunities and challenges for social science researchers. On the one hand, these data make it possible to study unprecedentedly large populations, but on the other hand, dealing with data on such a large scale is not an easy task.
The good news is that computational techniques offer scientists effective tools to handle large-scale data. The emergence of large-scale data has given rise to a new research field: computational social science. Computational social science has experienced rapid growth in the last two decades, with various techniques such as network analysis, large-scale simulation, and natural language processing (NLP) bringing many new discoveries to various disciplines (Edelmann et al., 2020). However, given the large number of comprehensive reviews on computational social science (Conte et al., 2012; Edelmann et al., 2020; Lazer et al., 2020; Mann, 2016; Theocharis and Jungherr, 2021), we do not intend to provide another comprehensive review of it here, but rather focus on the application of natural language processing in social science research. The current review will introduce NLP techniques that can support social science research and provide insights for more natural language-based studies.
NLP is a subfield of computer science, which involves a range of computational techniques for learning, understanding, and generating natural language (Chowdhury, 2003; Hirschberg and Manning, 2015). This review will discuss NLP techniques and their applications in social science, breaking them down into three layers: an underlying layer representing unstructured text data in a structured form, a middle layer extracting understandable information from that representation, and an upper layer utilizing that information for social science research outcomes. At the end of this review, we will briefly summarize the main challenges in this field.
Underlying layer: From unstructured text to structured data
Natural language data are inherently unstructured, without a well-defined format. This is very different from survey data—familiar to social scientists—that are usually structured for direct analysis. Therefore, the first challenge for NLP techniques is to transform unstructured text into structured formats that appropriately align with specific research outcomes. This typically involves two steps in practice: preprocessing and representation. Text preprocessing enhances data quality and feature extraction (Naseem et al., 2021), in which researchers reduce the noise in data by eliminating irrelevant information, emojis, spelling errors, etc. This seemingly easy step may have a substantial impact on the final outcomes (Bao et al., 2014).
There is a key difference between English and Chinese in this text preprocessing step: the space token acts as a perfect word divider in English, while no word divider is provided in Chinese. Therefore, word segmentation becomes an important first step when processing Chinese. Relevant techniques range from segmentation standards such as the Penn Chinese Treebank (CTB) (Xue et al., 2005) to deep learning models such as Yang et al. (2018). These techniques break down a Chinese sentence into word pieces.
After preprocessing, the text data are expected to have “informative” content only. Then we utilize representation techniques to convert the processed text into numerical data. Such a representation may directly count raw words as basic units, or infer the intrinsic semantic information embedded within the words. A recent review provides the principles and technical details of over 10 word representation models (Naseem et al., 2021).
Raw words: Vector space model, one-hot, bag of words, TF-IDF
A straightforward representation is representing every unique word as a separate basic unit. For example, in a corpus we define “I” as word #1, “you” as word #2, “utilize” as word #3, etc. That defines a four-dimensional space where each dimension corresponds to a unique word, as follows:

It is practically common for a unique word to appear multiple times in a document. One approach to represent this multiplicity, known as one-hot encoding, records only the presence or absence of each word while ignoring the frequency of their occurrence. As a result, a document vector under this approach contains only 1 and 0. This approach trades the information about word frequency for computational simplicity.
A more widely used alternative approach is Term Frequency-Inverse Document Frequency (TF-IDF), which considers word frequency to assess word weight. TF calculates the frequency of a word in a document, while DF represents the overall term frequency in the entire document corpus. The inverse is adopted to mitigate the influence of common words like “I”, “the”, “a”, etc. In TF-IDF representations, a word occurring frequently in a specific document but infrequently in the overall corpus is considered important and will get a high weight. TF-IDF for a particular word t in a document d of a corpus M is calculated as follows:
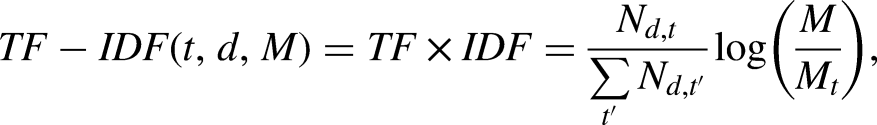
Word representation based on unique words is straightforward to implement. However, its assumption of word orthogonality prevents it from capturing dependence between words, and leads to unnecessary data sparsity and the curse of dimensionality when the number of unique words in a corpus is high. This calls for representation models that capture the intrinsic dependence between words in a lower-dimensional space, enabling a deeper understanding of text.
Latent dimensions behind words: Word embedding
Dropping the assumption of word orthogonality, a recent advancement known as word embedding attempts to construct a latent semantic space with unsupervised machine learning, where words are represented as points. The basic assumption behind word embedding is the distributional hypothesis, which posits that words occurring in similar contexts have similar meanings (Harris, 1954). Generating word embedding requires an unsupervised training process in a large corpus, during which the model counts the natural co-occurrence frequency of words and adjusts the word embedding to maximize the cosine similarity of the words that occur in similar contexts. Therefore, the word embedding can capture the semantic information of words. For example, “cat” in a word-embedding space is closer to “dog” than “car”. While training word vectors in large-scale corpora is computationally expensive, researchers can also use pre-trained models to generate word embedding directly.
Compared with raw words-based methods, word embedding captures the semantic information of words, simultaneously avoiding the problem of sparsity and curse of dimensionality, and thus can effectively improve the performance of downstream tasks. Therefore, related algorithms have been widely adopted, with notable examples including Word2Vec (Mikolov et al., 2013), GloVe (Pennington et al., 2014), and FastText (Bojanowski et al., 2017). Apart from these word embeddings trained on English corpora, there are also those trained on Chinese texts, such as CA8 (Li et al., 2018) and CWE (Chen et al., 2015). These models are trained using Chinese corpora and are optimized for the structure of Chinese text, providing convenience for processing Chinese text. These algorithms are often used by social scientists to explore the meaning of text data. Inspired by commonly used psychological tests such as the implicit association test (IAT) for assessing biases, scholars have developed a word-embedding association test (WEAT) based on word embedding, and measured latent gender and racial biases in historical texts (Caliskan et al., 2017). WEAT has been adopted by many studies. Based on textual data from newspapers, books, websites, and other sources, researchers generate word embedding by GloVe, FastText, and Word2Vec, and then perform WEAT to analyze gender stereotypes in language (Charlesworth et al., 2021; DeFranza et al., 2020). Furthermore, researchers also use word embedding to explore topics such as changes in an artist's reputation following their death (Zhang et al., 2023) and the evolution of collective understandings of social class (Kozlowski et al., 2019).
When extracting semantic information from text, social scientists have a strong interest in the varying semantic meanings of a word across different contexts, such as different time periods, cultural contexts, or political affiliations. However, word-embedding techniques that only provide a global representation for one word struggle with such word ambiguity issues and fail to capture such heterogeneity. For example, the word “bank” can mean either a financial institution or the side of a river, yet it is represented by a single vector in these embedding models. One common approach is to distinguish different corpora and train separate word-embedding models, e.g. Garg et al. (2018). But this approach requires large corpora and substantial computation resources.
Recent models have brought better solutions. Sense2Vec tags words with their context, including the word class and named entity categories. For example, the word “bank” can be marked as “bank_NOUN” and “bank_VERB”, which reduces ambiguity to some extent (Trask et al., 2015). However, capturing nuanced contextual changes based solely on these features remains challenging. Other models incorporate contextual information from the text into the embedding process. MUSE, for example, uses embeddings from pre-trained models like Word2Vec and GloVe as base embeddings, and performs cluster analysis to identify different semantic contexts of the same word (Lee and Chen, 2018). However, this approach requires extensive contextual data and involves high computational complexity. A la carte embedding (ALC) also uses pre-trained models to provide global semantic information, and calculates the average vector of other words in the context to generate a new embedding (Khodak et al., 2018). This dynamic adjustment allows the embedding to better fit the current context without retraining the entire model. Researchers have further developed a conText embedding model based on ALC, applying it to study partisan differences in word usage, UK–US understandings of empire, and sentiment terms in Brexit parliamentary articles (Rodriguez et al., 2023). However, simple averaging may fail to capture deep semantic information and long-distance textual dependencies. Contextual embedding models based on deep learning, such as ELMo (Peters et al., 2018), BERT (Devlin et al., 2019), and GPT (Radford et al., 2018), address these issues effectively. They compute a context-based representation for each word, capturing deep meanings within text and considering context from left and right directions. These models achieve state-of-the-art performance across a wide range of natural language processing tasks. For a comprehensive survey on contextual embeddings, please refer to Liu et al. (2020).
Intermediate layer: From structured data to semantic information
Numeric representation of text data provides a foundation for semantically understanding text. Semantic extraction methods vary from dictionary-based methods that are straightforward to implement and compute, to clustering and topic modeling that captures the intrinsic relationship between words and documents, to more computationally intensive deep learning models achieving the most advanced understanding on text.
Flag of expertise: Dictionary
Initially, researchers mainly adopted dictionary-based approaches, i.e. a set of predefined “flag” keywords that characterize the text. Such a set is usually encoded in a dictionary—a data structure containing pairs of values and keys, typically mapping keywords to corresponding categories (Stoltz et al., 2024). For example, a simple sentiment lexicon can be defined as {“abandon”: “negative”, “benefit”: “positive”, “report”: “neutral”}, where each word is associated with the indicated sentiment. When using this lexicon to analyze the sentence “She was abandoned on a winter night”, researchers can count the frequency of each kind of sentiment and conclude that the sentiment of this sentence is negative.
Dictionaries have been extensively used in social science research over a long period. This can be traced back to the General Inquirer, in which researchers developed a lexicon to compare the tone of political speeches (Stone et al., 1966). Today, dictionaries remain popular and are widely used across various research topics. Researchers use dictionaries to extract features like linguistic abstractness (Snefjella and Kuperman, 2015) or cultural embeddedness (Goldberg et al., 2016) in a large corpus. The most prevalent application of dictionary-based methods is sentiment analysis. Researchers use sentiment lexicons to measure the sentiment of social media posts, enabling them to investigate how public sentiment changes in response to particular policies and events (Ahmed et al., 2017; Flores, 2017; Havey, 2020; Wei et al., 2023; Yu et al., 2022).
The wide usage of dictionary-based techniques is primarily due to their simplicity and low computational cost. Researchers easily get desired information by simply matching words and phrases in text, categorizing the text, or counting the word frequencies (Kroon et al., 2022). However, dictionary-based techniques have limitations. Firstly, constructing a dictionary requires extensive time and effort. Additionally, dictionaries also ignore contextual information and are thus susceptible to ambiguity. For instance, the word “bright” is often considered “positive” in sentiment lexicons, and researchers might incorrectly categorize the sentence “This room was bright” as “positive”. As a result, users of the General Inquirer often need to augment it to address ambiguity (Young and Soroka, 2012). Besides, many researchers also doubt the representativeness, effectiveness, and accuracy of dictionary-based methods (Guo et al., 2016; van Atteveldt et al., 2021).
Nowadays, the intensive effort required for preparing dictionaries has been partly mitigated by emerging advancements in crowdsourced and automatic dictionary construction. Crowdsourced dictionaries rely on web platforms like Amazon's Mechanical Turk, enabling researchers to recruit hundreds of annotators to expedite the labeling process, thereby reducing time cost and avoiding biases introduced by a small group of experts (Schwartz and Ungar, 2015). Deriving dictionaries from text starts with a substantial volume of text with specific labels. Initially, the text is segmented into words, and then the correlation between a word and the outcomes is identified through techniques such as pointwise mutual information. Finally, a dictionary is generated based on these findings (Schwartz and Ungar, 2015). For instance, scholars have generated a dictionary of new terms based on scientific publications and utilized it to investigate the idea diffusion process in science (Cheng et al., 2023). Furthermore, researchers may consider using open-source dictionaries. For example, the General Inquirer can be employed for political speech analysis, while the Linguistic Inquiry and Word Count (Pennebaker et al., 2015) can be used to quantify words reflecting emotions, thinking styles, and social concerns. There are many open-source dictionaries for measuring text sentiment, as well as online platforms that integrate various dictionaries (van Atteveldt et al., 2021; Zhao and Wong, 2023).
Co-occurrence: Clustering and topic modeling
The intensive human labor for creating dictionaries make dictionary-based methods less favored when large-scale corpora emerge with new terms. That motivates the adoption of machine-learning methods to automatically discover the hidden semantic information behind text. Such methods could be unsupervised, utilizing word co-occurrence relationships to generate categories and distill topics, or supervised, targeting at mapping from the word space to a predefined label space.
Unsupervised learning methods solely rely on the data to categorize text into categories without requirements of additional textual knowledge. Typical unsupervised learning methods include clustering techniques such as K-Means, and topic modeling methods like latent Dirichlet allocation (LDA) (Blei et al., 2003). These methods are helpful for social scientists, as they can efficiently uncover hidden patterns in large-scale textual data, and categorize these data into topics or clusters for further analysis.
Clustering algorithms group data into clusters based on feature similarity, maximizing intra-cluster similarity and inter-cluster distance (Ezugwu et al., 2022; Xu and Tian, 2015). Traditional clustering algorithms are categorized by different strategies, among which partition-based clustering, hierarchy-based clustering, and model-based clustering are commonly used by social scientists. Partition-based clustering algorithms, such as K-Means (Macqueen, 1967) and K-Medoids (Park and Jun, 2009), iteratively assign data points to clusters, updating centers until stabilization, but require a predefined number of clusters, which can be challenging in many contexts. Hierarchy-based clustering creates a tree-like structure by gradually splitting or merging data based on distance (Johnson, 1967), without the need of a predefined number of clusters. However, both partition-based and hierarchical clustering struggle with overlapping clusters and non-spherical shapes. Model-based clustering, such as Gaussian mixture models (GMM) (Rasmussen, 1999), can partially address these issues. These algorithms assume data as a mixture of probability distributions and can accommodate more complex data shapes and sizes, although the model distribution assumptions may also affect the clustering results. Clustering algorithms can effectively handle the classification of short texts, and many researchers apply clustering algorithms for event detection in large-scale social media texts (Mukherjee and Bala, 2017; Vijayakumar and Rajam, 2024). For a more systematic review of different types of clustering algorithms, please refer to the survey by Xu and Tian (2015).
While clustering groups data into similar clusters, topic modeling focuses on identifying the latent themes within a collection of documents and revealing their semantic structure. LDA is one of the most common topic modeling techniques used by social scientists. It is proved to be highly effective for analyzing large-scale text data. Utilizing word embedding containing semantic information, this method measures the relationships between texts through matrix operations to detect latent topics present in the text (Wilkerson and Casas, 2017). In LDA, each document is assumed to contain multiple topics, and each topic is generated by a group of words. LDA generates two distributions, namely a topic distribution for each document and a word distribution for each topic. The distributions are determined by the co-occurrence of words, and a document's topics are inferred based on the distributions. LDA is frequently employed to study discussion topics in online communities. For example, some researchers used LDA to investigate different themes of vaccine-related misinformation on X (Valdez et al., 2023) and others analyzed anti-vaccination sentiments on Facebook (Smith and Graham, 2019). Similarly, scholars used LDA to summarize online discussions and sentiments of Weibo users during the COVID-19 pandemic (Shi et al., 2022; Xie et al., 2021) and to analyze the development of public opinion (Han et al., 2020; Zhu et al., 2020). LDA has also been adopted in political science to study databases such as leader speeches to analyze important dynamics of political agendas (Catalinac, 2016; Quinn et al., 2010).
However, LDA also presents several limitations. First, LDA relies on word co-occurrence to extract topics, which leads to poor performance when handling short texts from social media (Hong and Davison, 2010). To address this issue, scholars have proposed the biterm topic model, which was specifically designed for short texts such as tweets (Cheng et al., 2014). Second, LDA determines topics based on the distribution of words, leading to the ignorance of contextual information. The structural topic model (STM) addresses this limitation by involving document-level metadata as covariates (Roberts et al., 2013, 2014). STM-based text analysis allows researchers to include features such as publication time, location, and demographic information of the authors. These features are crucial for social group analysis, making STM a popular choice among social scientists. STM is frequently adopted to analyze open-ended survey questions, as demonstrated in studies by Enria et al. (2021), Rothschild et al. (2019), Tvinnereim and Fløttum (2015), and Yan et al. (2024). Third, LDA utilizes the bag-of-words model to represent documents, which ignores the order of words and cannot capture deep semantic information. Recent topic models involve more comprehensive word-embedding techniques, such as Top2Vec (Angelov, 2020), which uses Word2Vec, and BERTopic (Grootendorst, 2022), which uses BERT. These models effectively address this issue by capturing more subtle semantic differences in the text. Egger and Yu (2022) conducted a survey over four topic modeling techniques, namely LDA, non-negative matrix factorization (NMF), Top2Vec, and BERTopic. Based on the results from 50,000 English X (Twitter) posts related to travel and COVID-19, it reported that while LDA revealed more topics related to geography and borders, it also generated more meaningless topics. Top2Vec was more policy-oriented, while BERTopic's topics were more related to aviation issues. However, unsupervised learning techniques do not have standardized evaluation criteria, and the interpretation of model results depends on the specific research context and domain knowledge (Hannigan et al., 2019).
Mapping: Naïve Bayes, SVM, tree
Supervised learning seeks for a mapping from input text to desired research outcomes. Researchers need to provide both input text and human-labeled results as ground truth to the model simultaneously. During the training process, the model utilizes this data for “learning”, namely continuously adjusting parameters to minimize the gap (often called “loss”) between the model outputs and the ground truth. After this training process converges, the fitted model is a function mapping input text to the desired output, thus accomplishing the task intended by the researchers (Grimmer and Stewart, 2013). Depending on the features of the desired output, supervised learning models can perform tasks including classification and regression. Specifically, all supervised learning involves three steps:
Data preparation: Researchers need to specify coding schemes and obtain a dataset with input text and desired output through human labeling. To ensure the reliability of annotations, it is generally necessary to have at least two annotators and report the kappa statistic (McHugh, 2012). Model training: Splitting the dataset into training and test sets in certain proportions (e.g. 0.8, 0.2), we use the training set to train the model. During training, the model continuously adjusts parameters to minimize the loss, thereby continuously optimizing the model. Model validation: The model is trained to label a larger-scale text data instead of human annotators. Therefore, measuring the performance of the model is crucial to ensure the reliability of the results generated by the model. Poor performance may lead to bias or even errors in the results. A common practice is to use the fitted model to make predictions on a test set with known human labels and compare the results and the labels. To avoid the influence of randomness, cross-validation can be used to validate the model and select the best model (Arlot and Celisse, 2010).
Various supervised learning algorithms have been developed and widely used, each with its own strengths and weaknesses. No single machine-learning method is universally superior to any other, which is known as the “no free lunch” theory (Wolpert and Macready, 1997). Too simple models may fail to capture the features of the data, while overly complex models are more prone to overfitting and require more computational resources. The task is not to choose the best method but to select the most appropriate method based on the current research context. Here, we introduce several commonly used supervised learning algorithms and their applications.
Sequence: Deep learning models
Most of the aforementioned models use vectorized text, namely word embeddings, as input and treat these vectors as independent data points. Consequently, they rely solely on individual words or local contextual information, ignoring the crucial sequence information. This limitation results in poor performance in complex language processing tasks such as sentiment analysis, question answering, and language translation, which demand a deep understanding of complex language patterns like metaphors and rhetoric, as well as the ability to capture long-distance dependencies within the text.
Deep learning models have produced promising results in these tasks (LeCun et al., 2015). Like MLPs, the structure of a deep learning model is a stack of multiple layers of neural networks, but they typically have a larger number of layers (so-called “deep”). The nonlinear activation functions within each neural network enable the model to perform nonlinear transformations, and the multilayer structure allows it to represent deep features in a sequence of data. The most typical application of deep learning models is also in supervised learning, which involves data preparation, model training, and model prediction, as mentioned above. During training, the model updates the parameters of each layer based on the loss between the predicted and ground-truth labels. Although the large number of parameters makes the update steps seem computationally intensive, the back-propagation algorithm based on chain rules makes the training process quite manageable (Rumelhart et al., 1986). After training, trained models are expected to reach a good performance on the designed tasks. Many deep learning models have been used to tackle NLP tasks in various contexts. Here, we mainly introduce three classic models: RNN, LSTM, and GRU.
where
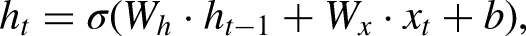
These deep learning models produce promising results in complex text processing tasks. Sentiment analysis is one of the most classic applications. During the COVID-19 pandemic, many researchers adopted these models to conduct sentiment classification of COVID-19-related text on social media platforms (Arbane et al., 2023; Nemes and Kiss, 2021; Xu et al., 2019). Besides, deep learning models are also commonly used for detecting online extremism (Gaikwad et al., 2021), cyberbullying (Fang et al., 2021; Murshed et al., 2022), and fake news (Ajao et al., 2018). Additionally, the excellent sequence data processing capabilities of deep learning models is also helpful in time series data. Some researchers use LSTM to train on the time series data of hot topics on Weibo, enabling them to predict changes in public opinion trends related to these topics (Mu et al., 2023). LSTM is also used to predict the COVID-19 pandemic trends in different countries (Wang et al., 2020). Some researchers also use RNNs to conduct counterfactual inference based on their performance in sequential prediction tasks (Poulos and Zeng, 2021).
Integration: Large language models
Recently, transformer-based large language models (LLM) like BERT (Devlin et al., 2019) and generative pre-trained transformer (GPT) (Radford et al., 2018) have attracted significant attention and become focal points of discussion. LLMs are pre-trained on large-scale datasets to acquire a foundational understanding of common language patterns. These models demonstrate impressive ability in various complex tasks, including natural language understanding, translation, text summarization, question answering, and even reasoning tasks, even reaching a higher score than humans in some benchmarks (Bang et al., 2023; Street et al., 2024; Qin et al., 2023). The impressive performance of LLMs can be attributed primarily to three features: the transformer-based architecture, pre-training, and the large scale of parameters.
BERT is one of the earliest and most extensively applied LLMs. BERT is a pre-trained deep bidirectional encoder representations model based on transformers. It conducts self-supervised pre-training by simultaneously considering the context of the text. BERT was pre-trained using BooksCorpus of 800 million words and English Wikipedia of 2.5 billion words. The pre-training phase involves two unsupervised tasks: masked language model and next sentence prediction. Pre-trained BERT models offer substantial language understanding, serving as valuable initialization for new tasks. The open sourcing of BERT models allows researchers to skip the expensive pre-training phase. Pre-trained BERT models are capable of achieving state-of-the-art performance across different tasks with just one output layer (Devlin et al., 2019). RoBERTa (Liu et al., 2019) and ALBERT (Lan et al., 2020) further enhance BERT by incorporating dynamic masking, parameter sharing, and modifying pre-training tasks. Pre-trained models’ ability relies on the pre-training corpus. The aforementioned BERT series models are mainly trained on English corpora, and thus unable to handle non-English texts. Researchers from China have released the Chinese-BERT-wwm model which is pre-trained on Chinese Wikipedia corpus and extended Chinese datasets (Cui et al., 2021). This model has proved to perform well in many Chinese-based language processing tasks.
BERT-based models have been applied in social sciences to various complex language understanding tasks, including sentiment classification (Field et al., 2022; Huang et al., 2021; Sivakumar and Rajalakshmi, 2022; Xie et al., 2024), measuring abstract concepts in political texts such as populism, nationalism, and authoritarianism (Bonikowski et al., 2022), and detecting polarization and ideology in texts and videos (Han, 2022; Lai et al., 2022).
Since the release of the GPT series by OpenAI (Brown et al., 2020; Radford et al., 2018, 2019), there has been an increasing emergence of models with billions of parameters. For example, GPT-3, with its massive scale of 175 billion parameters and 570 gigabytes of training data, has garnered significant attention and demonstrated effectiveness in various few-shot (even zero-shot) NLP tasks (Brown et al., 2020). The powerful text generation capabilities of GPT-3 enable its application in diverse domains, including question answering, summarization, conversation, basic arithmetic computation, and generating various types of text. However, the GPT series models after GPT-3 are no longer open-source, which means users must access these models through OpenAI's API. This also makes it more challenging to fine-tune the models for specific tasks. Consequently, other open-source large models like the Llama series (Dubey et al., 2024; Touvron et al., 2023a, 2023b) and Falcon (Almazrouei et al., 2023) have gained widespread use. Additionally, researchers from China have developed many large models optimized for Chinese, such as the GLM series (Zeng et al., 2024), Qwen (Bai et al., 2023), and Pangu-
Zero-shot or few-shot LLMs’ striking ability presents new possibilities for computational social science. Studies have shown that LLMs can be applied to analyzing psychological constructs across different languages (Rathje et al., 2024) and analyzing political stances and ideologies (Wu et al., 2023). Ziems et al. (2024) conducted a systematic analysis about the performances of different LLMs on various types of research tasks. The results indicate that zero-shot LLMs perform well in classification tasks on stance, emotion, figurative language, and utterance-level ideology. Although they do not perform better than carefully fine-tuned RoBERTa models, they offer an approach that can avoid the high expense of human labeling. However, researchers should also be aware that LLMS do not perform well in complex classification tasks like event argument extraction, semantic change, empathy or toxicity detection, and stereotype detection, which require expert opinions. Ziems et al. (2024) also pointed out that LLMs produce better results than human crowdsourcing in generation tasks including emotion-specific summarization, misinformation explanation, language reframing, etc. Beyond classification and generation tasks, researchers can also develop agents based on LLMs for social simulation experiments. For example, some researchers use LLMs to simulate human subjects (Argyle et al., 2023b) and social media dynamics (Gao et al., 2023a), or to conduct experiments related to personality (Jiang et al., 2024) or persuasion (Karinshak et al., 2023).
However, along with the impressive performance of LLMs come various threats, and social bias in LLMs is a typical example. LLMs are mainly trained on raw internet-based content, which contains various biases, stereotypes, misrepresentations, and other patterns that may affect marginalized groups. Numerous studies have demonstrated that the content generated by LLMs inherits and even exacerbates these social biases (Abid et al., 2021; Bender et al., 2021; Gallegos et al., 2024; Kotek et al., 2023; OpenAI et al., 2024). Investigating these biases and intervening through various alignment techniques has become a new topic in the field of computational social science (Wang et al., 2023).
Upper layer: From semantic information to social science research outcome
After text representation and understanding, semantic information is now readily accessible for social science research. This distilled semantic information provides a new lens to advance research on traditional social science topics, such as bias, elections, cultures, and the science of science. Moreover, social media emerge with millions of users engaged in communication, interaction, and expression of emotions and ideas through short textual messages. This online world presents dynamics distinct from the physical society. The recent availability of large-scale textual data on social media, along with advanced natural language processing techniques offering refined granularity of text understanding, have together inspired an emerging community studying online engagement and communications on social media with an unprecedented level of detail. In this section, we demonstrate the application of semantic information to social science research, using representative examples from sociology and political science. These two fields have been at the forefront of adopting natural language processing techniques, primarily due to their rich availability of textual data sources and the complexity of the relationships and interactions they address. It is also worth noting that disciplines such as cognitive science and psychology are increasingly utilizing NLP techniques. Although they are not covered extensively in this review, their growing adoption is significant and should not be overlooked.
Sociology: Social bias, culture, science of science
Social bias
One of the most prevalent areas of study involves the measurement of gender bias implicit within language. Cognitive psychologists have utilized word-embedding techniques across diverse text datasets, ranging from books, dictionaries, and web pages, to lyrics and textbooks, to measure the presence of gender biases in language. This body of work has consistently identified pervasive implicit biases against women (Bailey et al., 2022; Betti et al., 2023; Charlesworth et al., 2021; DeFranza et al., 2020; Jiao and Luo, 2021; Lucy et al., 2020; Napp, 2023). However, some research indicates a gradual reduction in gender stereotypes over time (Jones et al., 2020). Beyond the analyses based on word embedding, scholars have employed various NLP techniques to explore potential gender disparities. For instance, Markowitz (2022) analyzed patient–physician records using the Linguistic Inquiry and Word Count tool to uncover gender differences in patient–physician relationships. Research findings indicate that physicians tend to pay more attention to the emotions of female patients compared to male patients. Similarly, Czymara et al. (2021) employed topic modeling to examine the experiences during the COVID-19 lockdown in Germany, revealing a greater negative impact for women on both physical and cognitive levels of work, which may exacerbate gender inequalities. Additionally, Parthasarathy et al. (2019) examined the relationship between gender and political influence using transcripts from constitutionally mandated village assemblies, revealing women's relative disadvantage and silence compared to men.
Scholars have conducted research on ethnicity bias based on text data. Similar to gender bias, some scholars employ word embedding to measure the association between ethnicity-related vocabulary and other terms. For instance, a study based on Texas history textbooks revealed that the most commonly mentioned individuals are predominantly White, while Black individuals are often depicted as having limited agency and power (Lucy et al., 2020). Another study utilizing the Contemporary American English Corpus found that the United States’ racial framework is deeply ingrained in American English, with racial/ethnic groups being differently associated with notions of superiority and Americanness (Lee et al., 2024). Moreover, van Loon et al. (2022) discovered that merely assessing the frequency of Black names could predict anti-Black bias across various regions. Markowitz (2022) conducted research based on patient–physician records, revealing that physicians also attended to fewer emotions expressed by Black/African and Asian patients compared to White patients. Additionally, Kennedy et al. (2021) utilized topic modeling to analyze the text of rental advertisements in Seattle, investigating how neighborhoods’ racial composition was described. The findings indicated that while White neighborhoods emphasized trust and connections to neighborhood history and culture, listings from non-White neighborhoods tended to offer more incentives and focused on transportation and development features, thus demonstrating the existence of racialized neighborhood discourse.
Researchers have also conducted text analyses on discrimination and biases concerning older adults. Analyzing Twitter (now X) data related to older adults during the COVID-19 pandemic, studies have identified instances of discrimination and negative emotions directed towards the elderly or other vulnerable groups. Interestingly, despite this negativity, it has been observed that such negative sentiments are gradually decreasing over time (Ng et al., 2022; Xiang et al., 2021).
Cultural sociology
Cultural sociology examines culture from a sociological perspective, exploring its formation, transformation, and influence. Text serves as one of the vital carriers of culture and is central to the study of cultural sociology (Bail, 2014), hence NLP has introduced new possibilities for cultural sociology. Michel et al. (2011) utilized a database containing 5,195,769 digitized books and employed frequency-based calculations to measure vocabulary, syntactic changes, fluctuations in the fame of prominent figures, and shifts in collective memory. Kozlowski et al. (2019) also utilized a dataset comprising millions of books to train word-embedding models, measuring the cultural significance of social classes in text and finding that the markers of class changed continuously during the 20th-century economic transformation while their cultural dimensions remained stable. Zhang et al. (2023) constructed a vast historical corpus from digitized texts of 20 newspapers spanning 1795 to 2020 and researched collective memory about artists. They built word-embedding models for different periods and measured the association between artist names and vocabulary related to reputation, thus gauging artists’ reputations. The results indicated that most artists attained peak reputations before death, followed by a decline, losing nearly one standard deviation per century. These studies exemplify excellent use of large-scale data for researching cultural transformations.
In addition to the aforementioned studies based on large-scale historical data, NLP also supports more micro-level research. For instance, Light and Odden (2017) employed text data from music review websites to conduct topic modeling on factors related to consumer reviews of music, thereby understanding how contemporary consumers assess the value of cultural products. McCumber and Davis (2024) investigated changes in the standards of “elite environmental aesthetics” based on articles from the New York Times travel section from 2000 to 2019 and explored the impact of climate change on these standards.
Science of science
Science of science is an emerging interdisciplinary research field that investigates the mechanisms behind scientific research (Fortunato et al., 2018). Leveraging extensive bibliographic data, researchers can construct intricate citation networks, collaboration networks, and study topics such as idea diffusion and teamwork in science (Edelmann et al., 2020). However, besides these network-based computational techniques, text-based analysis also provides many new insights. For instance, McMahan and Evans (2018) developed an information-theoretic statistical model to compute the ambiguity of given words in scientific texts. Their model revealed that humanities, law, and environmental and earth sciences exhibit the highest ambiguity. Vilhena (Vilhena et al., 2014) measured the communicative efficiency of specialized knowledge and language across different fields based on citation structures and phrase frequencies in articles, finding that communicative efficiency decays with citation distance in a field-specific manner.
Some scholars utilize NLP to study the dynamics of scientific development in specific disciplinary domains. For example, a study explored the divide in sociological methodology. Analyzing word frequencies in 8737 articles from 1995 to 2017, they demonstrated the existence of methodological divergence but found a slight increase in quantitative research published in comprehensive journals over time (Schwemmer and Wieczorek, 2020). Another study addressed the decline discourse in organizational sociology by automatically classifying articles published in comprehensive sociological journals since the 1950s using SVM. They applied topic modeling to organize the themes in the relevant articles, finding that while the overall publication level of organizational sociology has not significantly decreased compared to 20 years ago, there has been a decline in theoretical and methodological diversity (Grothe-Hammer and Kohl, 2020).
NLP has also been applied to study gender inequality in science. Key and Sumner (2019) examined systematic difference in topic selection between male and female researchers. They used topic modeling to analyze abstracts of 2055 political science papers, inferred the gender of researchers from their names, and summarized gender differences in research topics. The results revealed that women are more interested in topics such as race, healthcare, narrative and discourse, and branches of government, while big topics in political science, such as voting, campaigns, and congress, are predominantly dominated by men. This finding partly explains the lower publication rates and citation counts among women. Larregue and Nielsen (2024) explored gender differences in research funding. Combining interview data with content analysis of funding proposals, they found that gender differences in funding might be related to gender differences in disciplinary focus, thematic specializations, and methodologies.
Political science: Election, engagement, polarization
Campaigns
Natural language processing techniques have offered new tools to analyze campaigns like election for political science research. In early years, topic modeling was commonly used for text analysis. For instance, Catalinac (2016) analyzed 7497 election manifestos from the 1994 Japanese elections using topic models to understand different strategies of candidates under various electoral systems. Similarly, DiMaggio et al. (2013) adopted LDA to analyze how governments assist artists and arts organizations. Recently scholars started to utilize pre-trained models for more complex text classifications. Bonikowski et al. (2022) analyzed speech records of Democratic and Republican presidential candidates from 1952 to 2020 to investigate whether frames of radical-right campaigns have gradually spread to centrist parties. They employed a pre-trained RoBERTa model, fine-tuning it based on human-labeled data to accurately identify political frames in 71,808 segments of election speeches, achieving good accuracy. The study revealed trends in the presence of different political frames and the strategies employed by candidates in their speeches.
Scholars have also focused on election campaigns based on social media. Barack Obama's successful strategy on social media helped him set records of donations and grassroots mobilization (Tumasjan et al., 2011), making social media platforms pervasive tools in election campaigns. Numerous studies have discussed the use of Twitter/X in elections, exploring the tendency of individuals with different demographic features to use Twitter/X and its connection with electoral opportunities, with more emphasis on how political parties and candidates use Twitter/X (Jungherr, 2016). In these studies, NLP techniques are applied to text analysis of party and candidate social media posts to understand the sentiments and political inclinations of their content. Tumasjan et al. (2011) conducted sentiment analysis on 100,000 tweets containing party or candidate mentions during the 2009 German federal election, finding that the mere number of party mentions can reflect the election result, and tweet sentiment is highly correlated with voters’ political preferences. Other scholars studied the relevance of topics discussed by electoral members online to the public. They used naïve Bayes to identify political topics in the text and observed the relationship between candidates and the public on different platforms. The research indicated that politicians and their audiences discuss different topics on social media, and politicians use Facebook and Twitter/X for different purposes, related to the distinct target groups candidates encounter (Stier et al., 2018). Livne et al. (2011) studied the use of Twitter by House, Senate, and gubernatorial candidates during the 2010 US elections, finding significant differences in social media usage patterns among people of different political affiliations, suggesting that conservative candidates more effectively use social media platforms.
Polarization
Another line of research focuses on the polarization of viewpoints in traditional media such as newspapers and explores its impact on individuals. Using a dictionary-based approach, Hart et al. (2020) examined the politicization and polarization of COVID-19-related content in US newspapers and online news, finding higher levels of politicization in newspapers compared to online news and suggesting that such politicization and polarization may contribute to the polarization of attitudes towards COVID-19 in the United States. Similarly, Chinn et al. (2020) measured climate change-related news content and found increasing politicization, a rise in political actors, a decline in scientific actors, and increasing polarization. Huang et al. (2021) investigated how opinions in news reports about China influence public opinion. They used BERT to label opinions in China-related reports from the New York Times and combined this with survey data to demonstrate how events in international relations shape social media opinions and, consequently, public opinion.
Within discussions of social media dynamics, polarization has recently attracted significant attention. Polarization refers to the tendency of more extreme opinions and sentiments on controversial topics. Data suggests that political polarization has intensified over the course of modern US history, and this trend may also exist in other countries (Geiger, 2014). Consequently, an increasing number of studies are focusing on the causes and potential consequences of polarization (Ferguson, 2021).
Some studies have explored the contribution of social media use to polarization. Researchers have extracted and analyzed the sentiment, polarity, and topics of the textual social media data, and provided a detailed investigations of polarization in social media. For instance, Zollo et al. (2015) utilized SVM to analyze over one million Facebook comments, examining the sentiment dynamics within and between communities discussing science and conspiracy news. They found that regardless of content, the longer the discussion continues, the more negative the emotions become. Similarly, Quattrociocchi et al. (2016) studied Italian and US Facebook users, conducting sentiment analysis on comments in online debates. Combining this with social network analysis, they discovered that the more active a polarized user is, the more they tend towards negative sentiments on both science and conspiracy posts.
Various hypotheses exist to explain social media polarization, and among them the most famous one is the “echo chamber effect“ (Cinelli et al., 2021). This effect describes how social interactions on social media are driven by homophily, and thus users with similar ideologies tend to congregate, leading individuals to be surrounded by homophilic information. Colleoni et al. (2014) employed NLP techniques to analyze political orientation in Twitter texts, thereby measuring political homophily. Their findings showed that Democrats demonstrated higher political homophily, whereas Republicans following official Republican accounts exhibited even greater levels of homophily. Similarly, Jiang et al. (2021) used BERT to analyze COVID-19-related discourse on Twitter, confirming the existence of echo chambers. Gao et al. (2023b) focused on short video platforms, utilizing BERT to study comments on Chinese short video platforms. They found that echo chamber members tend to showcase themselves to attract peer attention, and cultural differences can impede the development of echo chambers. In addition, a separate study discovered that emotionally charged Twitter messages tend to be retweeted more frequently and rapidly compared to neutral ones (Stieglitz and Dang-Xuan, 2013).
While the aforementioned studies primarily adopted sentiment analysis to analyze text, some scholars have explored polarization through topic modeling methods. For example, Farrell (2016) utilized structural topic modeling to study texts related to climate change counter-movements, identifying key themes and measuring their prevalence. They found that organizations sponsored by businesses were more likely to write and disseminate texts aimed at polarizing climate change issues.
Engagement
Social media plays an increasingly crucial role in the political arena. Social media platforms provide individuals with a platform for large-scale, open, real-time political discussion, enabling people to share information without geographic limits (Spaiser et al., 2017). They also facilitate the dissemination of political movement-related information, as seen in events like the “Twitter revolution” during the Arab Spring (Cottle, 2011). Individual expressions of political attitudes on social media, coupled with authorities’ dissemination of information, have introduced new data and research topics into political science.
One of the widely discussed topics is how social media affects people's political engagement. Social media provides individuals with a space for political expression across distances, and numerous studies have explored individual online political engagement. In these studies, sentiment analysis based on text plays a crucial role. For instance, Shugars and Beauchamp (2019) investigated the reason and motivation for engagement in online political debates. Based on the results of sentiment analysis and topic modeling, they constructed a model to predict one's engagement in online debates, with an accuracy exceeding 98%. Field et al. (2022) utilized RoBERTa to study the emotions expressed in tweets related to participating in “Black Lives Matter” protests, finding that posts expressed a high degree of anger and disgust, but positive emotions such as friendship and pride resulting from the protests may outweigh other expressed emotions. Scholars have also inferred demographic information such as gender and ethnicity from Twitter/X data and analyzed the online political behavior and participation of different groups (Brandt et al., 2020).
However, social media is not merely a platform for individual expression. Similar to traditional media, various forces in social media potentially control the discourse. A study analyzing Twitter messages related to the 2011–2012 Russian protests found that pro-government users employed a variety of communication strategies to shift political discourse and marginalize opposite voices on the platform (Spaiser et al., 2017).
Social media is also seen as revolutionary and capable of sparking offline social movements (Harlow, 2012). Online connections reduce organizational costs, making activities more likely to erupt unexpectedly (Enikolopov et al., 2020). Related studies have investigated the dynamics from online discussions to offline movements. By conducting sentiment analysis on 65,613 tweets related to the Indian Nirbhaya protests, researchers found a significant similarity between the emotional patterns of online discussions and offline protests, suggesting resonance between online discussions and offline activities (Ahmed et al., 2017). Reda et al. (2024) conducted sentiment analysis and topic modeling on millions of tweets, constructed a score to quantitatively assess social movement tendencies, and found that this score can accurately predict resource mobilization within the same time frame. Gallacher et al. (2021) analyzed online conversations between members of protest groups from opposite sides of the political spectrum and violence occurrence during these protests and rallies. By examining 25 events, including protests, marches, or gatherings, they found that increased engagement between groups online is associated with increased violence when these groups meet in the real world.
Bots
The prevalence of automated accounts, such as social bots, is one of the distinguishing features of the online world. Social bots are programmed to fulfill specific tasks, including disseminating messages or engaging in particular social behaviors, thereby influencing the online society (Ferrara et al., 2016). Detecting and analyzing content generated by these bots has become a new object of research attention.
Scholars have developed algorithms to detect the presence of social bots and measure their political inclinations (Stukal et al., 2019; Sanovich et al., 2018). Others have focused on the impact of social bots’ activities on human behavior. For example, studies have revealed that social bots tend to propagate negative and inflammatory content, contributing to the polarization of online discussions (Stella et al., 2018). In another study, researchers analyzed the diffusion structure and content of political events based on sentiment analysis and network analysis, revealing that verified accounts were more visible than unverified bots in event coverage, but social bots attracted more attention than human accounts (González-Bailón and De Domenico, 2021). Researchers have also explored Coronavirus Conspiracy Talk, finding that both social bots and humans contribute to related discourse. In these scenarios, social bots are designed to create moral panic, while humans exploit conspiracy talk to gain attention (Greve et al., 2022).
Bots can also serve very positive purposes. Argyle et al. (2023a) developed a social bot to act as an at-scale, real-time moderator in divisive political conversations. This social bot can provide suggestions on language use during live discussions. Evidence suggests that these intervention measures enhance conversation quality and democratic reciprocity.
Challenges and directions for future research
Challenges
Representativeness
Although natural language processing provides researchers with a range of tools for processing and studying text data, it also raises some concerns. One of the common criticisms researchers face is the question of whether the samples of digitized text represent the overall population of interest. Although decreasing in recent years, a longstanding digital divide exists (DiMaggio and Bonikowski, 2008). On platforms like X, the users are compositionally different from and do not perfectly represent the entire population of the United States (Adams-Cohen, 2020; Diaz et al., 2016). Survey evidence indicates that around 42% of young people aged 18–29 use X, while this figure is only 6% among those aged 65 and above. Additionally, 25% of urban residents use X compared to only 13% of rural residents (Pew Research Center, 2024). These biases in user distribution pose potential threats to research results, and researchers must be aware of these threats.
Inherent bias
Another potential threat of NLP technology is the bias inherent in the models. Biases inherent in language can be absorbed during the machine-learning process and may alter NLP models’ predictions (Bail, 2024). Researchers summarized four types of biases that NLP models may exhibit: label bias, where the output labels in the training data diverge substantially from the real world; selection bias, which refers to non-representative observations; over-amplification, where the model tends to amplify small differences in predicted outcomes; and semantic bias, where embedding contains societal stereotypes (Shah et al., 2020). Almost all language models, from word embedding to large language models like BERT and GPT, cannot perfectly avoid semantic bias. Rozado (2023) conducted a multilingual political bias test on ChatGPT and found that it tends to hold left-leaning views, which may be related to the fact that the training materials for large language models are mainly sourced from the Internet, which is dominated by influential institutions in Western society. In addition to political bias, it is evident that NLP models may also exhibit ethnicity bias, gender stereotypes, and other biases (Gross, 2023; Rozado, 2020).
Interpretability
NLP techniques also face challenges in interpretability. Although some statistically based supervised machine-learning methods have good interpretability, deep learning models that handle more complex tasks are often considered black boxes. Apart from results and performance, it is difficult for us to understand what happens within the model. This to some extent limits the application scenarios of NLP models in social science research.
Directions for future research
In the previous section, we primarily focused on how NLP technologies can assist researchers in extracting semantic information. However, with the rapid developments in LLMs, these models have demonstrated impressive capabilities in text understanding and generation. These advancements open up new possibilities for computational social science research, allowing us to explore how models can be adopted in various stages of research and in tasks beyond text analysis. Here, we will discuss three possible directions.
Assist in research design and data labeling
LLMs have the potential to serve as research assistants. For instance, researchers can use LLMs to help generate necessary research materials, such as images or texts needed in psychological experiments to evoke different emotions in subjects, or political texts conveying different ideologies (Bail, 2024). Besides, LLMs can also be applied in data annotation and thus replace the expensive and time-consuming human labeling. Many studies have shown that zero-shot GPT models can reach similar or even better performances than crowdsourcing platforms like Amazon Mechanical Turk in annotation tasks (Mellon et al., 2024; Ziems et al., 2024). Ziems conducted a systematic review about using LLMs for annotation tasks. They examined the performance of 13 different language models across 20 classification tasks at the word, sentence, and document levels, as well as five generation tasks. The results indicated that while zero-shot LLMs may not perform as well as fine-tuned RoBERTa in classification tasks, they can achieve or even exceed human annotators. Moreover, in generation tasks, LLMs generally outperform trained human annotators. Therefore, they suggest researchers to use zero-shot LLMs to assist data annotation tasks, but to be careful when conducting research in sensitive topics. Additionally, researchers can guide LLMs to complete more challenging generation tasks required in research.
In this part, three future topics are worth attention: (1) the potential biases that models may introduce into the labeled data, and how upcoming models will address this issue; (2) the possibility of multimodal data labeling (such as audio, images, etc.) brought by multimodal LLMs; (3) the performance of LLMs in labeling tasks across different languages and cultures, e.g. annotation tasks based on Chinese text.
Simulate social behavior
LLMs have been proved to have the ability to simulate individual personalities or possible behaviors (Argyle et al., 2023b; Bail, 2024), which makes it possible for LLM agents to simulate real social processes. This social simulation has two possible directions. The first is using LLM agents to replace certain participants in research. Argyle et al. (2023b) indicated that algorithmic biases in LLMs are related to demographics, and LLM-based samples are able to simulate real-world samples in various aspects. Similarly, Jiang et al. (2024) used prompts to assign different personas to LLMs and then conducted Big Five personality tests and story-writing tasks on these agents. The results showed that the agents behaved consistently with their assigned personas, both in the Big Five test and in the story-writing task. Larger models and more prompting data are expected to further enhance the performances of simulation. Systematic research is still necessary on how different models and different input would produce different simulation results.
The second direction is at the system level, where researchers can use LLM agents playing different roles to observe social processes within specific social contexts. Park et al. (2023) presented one of the most classic LLM-based social simulation researches, in which they constructed a small town with 25 agents, each with different personalities. Similar to human society, these agents exhibited emergent social behaviors in the town. This makes it possible to simulate social processes using LLM agents, and such simulation allows social science scholars to observe the interaction between individual micro-behaviors and macro-phenomena within specific social structures. Some researchers have constructed social media simulation systems, in which LLM agents trained with social media data interacted with each other (Gao et al., 2023a). The agents successfully predicted the diffusion of information and emotions. However, more discussion is needed on whether the simulation results of LLM agents are reliable.
Facilitate causal inference
Recently, the interdisciplinary field of LLMs and causal science has gained significant attention. In fact, there exists a mutually supportive relationship between LLMs and causality: LLMs can enhance causal estimation, while causality can also increase the robustness of LLMs and reduce issues such as bias and hallucination (Feder et al., 2022; Liu et al., 2024). Here, we will briefly discuss three examples of how LLMs enhance causality. Firstly, the collaboration between LLMs and causality makes more complex causal estimation possible, such as where textual data serve as confounders, treatments, or outcomes. For a comprehensive review, please read Feder et al. (2022). Multimodal models further enable causal estimation involving modalities such as images and sounds. Secondly, the language understanding capabilities of LLMs allow them to better extract commonsense causality from text. Compared to past methods based on keywords or linguistic patterns, LLMs can handle complex causal relationships in text more effectively, enabling researchers to extract causal relationships from knowledge bases or scientific literature (Cui et al., 2024). Thirdly, researchers can utilize the generation ability of LLMs for data augmentation, generating counterfactual data that cannot be obtained in reality to achieve better causal estimation (Li et al., 2024).
With the release of more causal benchmarks and the enhancement of models’ causal abilities, LLMs may be able to handle higher-dimensional data, discover more complex causal structures, and perform more robust causal estimation. However, the integration of LLM-based causal inference into social science research is still insufficient.
NLP is advancing rapidly, with new breakthroughs emerging every few months, or even monthly. We believe that social scientists need to proactively engage in this interdisciplinary dialogue, exploring more data, applying innovative techniques, and drawing more conclusions. This is not only because NLP makes research more convenient but also because in the era of data explosion, embracing new technologies to conduct research based on large-scale data is the only way to keep up with understanding and interpreting the world.
Conclusion
Natural language processing techniques have long been accelerating social science research. Early attempts like dictionary-based methods are accurate and compact but require expert knowledge, and therefore pose scalability challenges particularly in large-scale complicated scenarios. An alternative solution extracts semantic information by representing documents in a word space, which may or may not be further projected onto an Euclidean space for geometric interpretation. Machine-learning techniques have empowered us to explore high-dimensional text data. Unsupervised learning methods like topic modeling are straightforward to implement but may produce results that are difficult to interpret if not appropriately configured. Conversely, supervised learning methods such as support vector machine and decision trees rely on human inputs to target well-defined research outcomes, at a significantly higher expense in hiring human helpers. To address the challenges of sparseness and high cost of human inputs, and the increasing need of processing complex text, pre-trained large language models are proposed to offer a promising head start on traditional natural language processing tasks. Instead of training from scratch, such tasks are training upon a pre-trained neural network which has encoded rich linguistic and semantic information extracted from vast corpora. Such methods significantly enhance text understanding capabilities and expand the boundary of text analysis with explosively new scenarios that were not possible before. However, along with their powerful ability of text understanding come high extensive computational expenses. The above natural language processing techniques have transformatively impacted social science research such as analyzing online engagement and exploring the science of science. Combined with unprecedented availability of digital text data, those techniques offer a powerful toolkit for revealing insights from vast and diverse data sources.
Natural language processing techniques do not come without challenges. Concerns in data representativeness, amplified social biases, and limited interpretability together call for cautious engagement of social scientists. It is imperative for social science researchers to not only address methodological issues but also proactively engage with the natural language processing community to (re)design models in a manner more aligned with ethical regulations.
Footnotes
Author contributions
Yuxin Hou and Junming Huang wrote and revised the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by High-performance Computing Platform of Peking University.