
Abstract
With technological advances, governments and companies gain opportunities to collect data to provide public benefits. However, such data collections and uses need to fulfill ethical standards and comply with citizens’ privacy preferences, which may vary across several dimensions. The Comparative Privacy Research Framework suggests specific comparative dimensions that may shape such privacy-related perceptions. I propose how to integrate into this framework a specific meso-level perspective for concisely operationalizing data uses context-specifically: the privacy theory of contextual integrity, developed by Helen Nissenbaum. This article presents an empirical application of this approach by investigating specific data use scenarios across countries, while simultaneously considering temporal, international, and individual-level variation. To this end, an online survey experiment was conducted in three countries (Germany, Spain, and the United Kingdom) in December 2022 and May 2023. In this experiment, respondents rated the appropriateness of fictitious data use scenarios. The scenarios varied by data type, data recipients, and conditions of data use. The results show that the effects of contextual parameters vary across countries to different degrees. Respondents react particularly sensitively to changes in data types, with health data being overall most accepted to be used. The relative acceptance of the data recipients clearly varies across countries. Country-level individualism is not consistently related to the desired level of control over data. These findings highlight the usefulness of contextual integrity to unmask meso-level, context-specific variations in privacy attitudes across countries. A meso-level perspective that operationalizes data uses according to contextual integrity can therefore inform comparative privacy research and privacy-related policymaking.
Introduction
Numerous data collection practices that aim to provide individual benefits produce data that may be also used for a public benefit. Digital patient records, smartphone movement collections, smart home and smart grid technologies, social media data—all these data can be used to provide immediate benefits to individuals, but also could be used for scholarly research or the improvement of public management. Novel data collection efforts and an internationalization of data markets, such as envisioned by Common European Data Spaces (European Commission, 2023), increase the opportunities for such public benefit data uses. However, these opportunities come with privacy concerns, for example, voiced by scholars who worry about undue surveillance (Newlands et al., 2020; Vitak & Zimmer, 2020). For ethical data collection and use, we need to design data use practices that are informed by citizens’ preferences, among others.
However, one-off privacy surveys on public preferences focusing on specific perceptions at a specific time and place are not readily generalizable across countries and contexts. Given the internationalization and cross-sectoral application of data regulations, more fine-grained comparisons become increasingly important. In the present article, I combine the comparative perspective of the Comparative Privacy Research Framework (Masur et al., 2024) with the context-based notion of privacy as “contextual integrity” (Nissenbaum, 2010) to show that investigating countries with respect to general privacy attitudes might miss important nuances in people’s perspectives on which kinds of data uses are acceptable. Contextual integrity can therefore meaningfully enhance the comparative power of the Comparative Privacy Research Framework by providing a template for context-specific comparisons across countries.
To this end, I empirically investigate how attitudes related to data use for public benefit vary across social contexts within and between countries. I conduct an international survey experiment that presents respondents with text descriptions of hypothetical data use scenarios. These scenarios vary by parameters as suggested by contextual integrity (data type, involved actors, conditions of data use), such that effects of changes in parameters on respondents’ acceptance can be estimated. The study was fielded in three countries with different levels of individualism, which was previously shown to be related to the acceptance of public benefit data use (Li et al., 2017; see section “Sample”): Germany, Spain, and the United Kingdom (UK). Moreover, I conduct the study at two time points as privacy attitudes may change over time with the salience of public issues related to a specific data use (Gerdon et al., 2021), and finally also consider individual-level predictors of acceptance.
In summary, the main research question is: Under which conditions do people deem data use for the public benefit appropriate, and do such attitudes vary across social contexts and countries over time? I answer this question with respect to the outlined four components of comparison: contextual, international, interindividual, and longitudinal. The resulting evidence on variations of privacy attitudes along these components allows (1) researchers to learn about the variability of privacy attitudes across countries as depending on social context and over time and thereby (2) policymakers to consider people’s preferences for an appropriate regulation of data use for public benefit.
Attitudes on Data Use for Public Benefit: Comparisons by Four Components
The collection of specific pieces of information about individuals may serve different kinds of purposes. For instance, physicians may collect health data of patients to provide diagnoses and treatments. The very same collected health data may also be used by researchers to study, for example, risk factors for specific diseases. The former purpose provides a direct personal benefit to the individual, while the latter purpose can lead to public benefits (such as better treatment options) that may translate into personal benefits. 1
More generally, following the definition by the National Data Guardian for Health and Social Care in England (2022), a “public benefit” arises from data use if the achieved benefits are not outweighed by risks, while benefits can also be of indirect nature. Furthermore, according to this definition, to be a “public benefit,” the broader public or a subsection of the public need to benefit, such that exclusively commercial benefit does not fall under this definition. In addition, the legitimacy of a public benefit data use hinges on whether it has a “social license” (Carter et al., 2015; Shaw et al., 2020) granted by the population. We therefore need to learn whether and under which conditions the (re-)use of individual data for public benefit purposes is deemed acceptable by the public. With the internationalization of regulations on data collection and use, it becomes increasingly important to also know how populations of different countries differ in their acceptance of specific data uses. Such knowledge could aid in formulating policies by showing how populations might react differently to specific data use endeavors (e.g., differences in likelihoods of opting in or out of sharing data from digital patient records with researchers).
In the present article, I argue that such international comparisons can be substantially enriched by comparing perceptions relating to specific data use contexts, additional to rather general privacy perceptions. To this end, I draw on the Comparative Privacy Research Framework (Masur et al., 2024) and extend it with the perspective of “contextual integrity” (Nissenbaum, 2010). The Comparative Privacy Research Framework cautions against the over-generalization of findings from privacy studies that focus on single units and offers a structured approach to, among others, international comparisons (Masur et al., 2024). More precisely, Masur et al. (2024) propose to study privacy-related phenomena, such as data use attitudes or behaviors, by comparing at least two “units of comparison” (on the macro-, meso-, or micro-level). They define five types of “categories” (cultural, social, political, economic, and technological) that may influence phenomena or moderate processes.
Understanding privacy as contextual integrity (as proposed by Nissenbaum, 2010) can enrich the Comparative Privacy Research Framework by drawing attention to the specific configuration of social contexts and their respective privacy norms. Nissenbaum understands social contexts as areas of social life such as healthcare and work that come with specific practices, roles, purposes, and norms (Nissenbaum, 2018). For instance, in the healthcare context, there may be specific rules, practices, and expectations of how data collected about a patient by a physician may be used and shared. Masur et al. (2024) explicitly refer to contextual integrity as providing a context-sensitive perspective on privacy. These meso-level social contexts are embedded in larger structural units such as political systems. What contextual integrity adds to the Comparative Privacy Research Framework is a concrete template to operationalize data uses within meso-level social contexts. Comparisons of attitudes toward data uses in these meso-level contexts can enhance macro-level country comparisons by unmasking context-specific differences in privacy attitudes beyond “general” privacy attitudes in the investigated countries (relatedly, see Martin & Nissenbaum, 2017). At the same time, country comparisons can reveal how the relevance of specific contextual factors varies across countries (e.g., Li et al., 2017). 2
Additional to these macro- and meso-level comparisons, on the micro-level, individuals may display different more general stances toward privacy (Gerber et al., 2018). For instance, age and gender, general privacy perceptions (Smith et al., 2011), and altruism (Y. Kim & Stanton, 2016; Silber et al., 2022) may shape how acceptable individuals deem data use for public benefit in a given situation. All these structural units may interact with each other to affect privacy attitudes (Masur et al., 2024), such that the effects of individual characteristics may vary by country and be more relevant in some social contexts than in others.
Finally, norms and attitudes within units of comparison may change over time due to changes in the societal environment, as previous research has demonstrated with respect to a (potentially temporary) increase of acceptance of use of health data for disease containment early in the COVID-19 pandemic (Gerdon et al., 2021). The Comparative Privacy Research Framework is explicitly open for longitudinal comparisons, due to the potential of major events to affect privacy perceptions (Masur et al., 2024).
Table 1 summarizes the comparative approach of the present article, which I will further explain in the following sections. In the following, I apply this theoretical background to the concrete case of privacy attitudes toward data use for public benefit.
Units of Comparison That I Simultaneously Compare in This Article, Based on the Comparative Privacy Research Framework (Masur et al., 2024).

Contextual Variation
As argued above, country-level macro comparisons of general privacy attitudes may miss important meso-level contextual differences (relatedly, see Martin & Nissenbaum, 2017). The notion of contextual integrity can enhance such comparisons by asserting that the appropriateness of data flows depends on compliance with privacy norms that are specific to the social contexts in which they are embedded (Nissenbaum, 2010). To assess the appropriateness of data flows, contextual integrity requires us to define which data are at stake under involvement of which actors and under which conditions. For instance, individuals may be willing to share detailed health information with doctors. At the same time, they might find it outraging if employers requested the voluntary sharing of such data. To concretely analyze and assess the appropriateness of a data flow, Nissenbaum provides a data flow template that consists of five parameters: data type, data subject, data sender, data recipient, and transmission principles (i.e., the prerequisites under which the data flow occurs).
Previous research has repeatedly shown that individual evaluations of data flows are sensitive toward changes in the specifications of data flow parameters (e.g., Martin & Nissenbaum, 2017; Terpstra et al., 2023; Utz et al., 2021). I now turn to discussing the contextual integrity parameters in more detail with respect to data use for public benefit and develop hypotheses and research questions.
With respect to data types, contextual integrity does not suggest that any data type is as such necessarily more sensitive than another, since sensitivity depends on context (Martin & Nissenbaum, 2017). Empirically, relatively much research has been dedicated to the specific case of health data use. For several kinds of health data, literature reviews have identified that public benefit uses are overall acceptable if the data are safe, the recipients are deemed trustworthy, and commercial interests are not the main focus, among others (Aitken et al., 2016; Hutchings et al., 2020; Kalkman et al., 2022). For social media data, research found that the acceptance of research uses depends on factors such as the research purpose, with a preference toward context-specific user experience research (Gilbert et al., 2021), but the acceptance of research may vary across social media platforms (Gilbert et al., 2023).
Acceptance of public benefit data use may further be affected by salient societal issues. One useful theoretical perspective is provided by Büchi et al. (2022) who draw on the theory of planned behavior and argue that privacy-related scandals may, in the long run, lead to more chilled digital communication behavior. I apply this argumentation to other societal events that make specific issues salient and could therefore (temporarily) affect individual’s attitudes on data use for issue-related contexts. Furthermore, I argue that salience may also lead to more appreciative attitudes toward data use, depending on the specific salient event. For instance, previous research has demonstrated that the COVID-19 pandemic increased the acceptance for the use of health data collected on smartphones for public benefit (Gerdon et al., 2021). However, such effects may be temporary (see below). For example, several attitudes relating to surveillance for public security were more favorable in the United States right after 9/11, but this attenuated in the following months and years (Best et al., 2006).
To test this relationship, I compare the acceptance of health data use with the acceptance toward other data types that vary in their relatedness to currently debated public issues, such as the COVID-19 pandemic. This includes energy use, data which became a potentially salient issue in 2022 in the face of increasing energy prizes, and the need to save energy. As less immediately salient data types, I investigate the yet important and frequently debated types of location data (e.g., see the critical discussion by Walsh, 2023) and social media data (Proferes & Walker, 2020):
H1: The use of health data for public benefit is more accepted than the use of other data types for public benefit that are less directly related to the pandemic.
With respect to data recipients, relatively much comparative research is available for health data. Studies show that researchers or associated institutions appear as more accepted health data recipients than government agencies, while companies are least accepted (K. K. Kim et al., 2015) and, for Germany, that pharmaceutical companies are less accepted than researchers associated with universities or research-related public agencies (Haug et al., 2023). While these results suggest relatively high acceptance of health data use by public entities, not all studies share this finding (Gerdon et al., 2021; or for public benefit purposes: Deruelle et al., 2023), and the findings may further vary by concrete data recipient and consent procedure. Some studies suggest that individuals could find the private sector using specific types of health data acceptable if public benefits stood above profit (see Aitken et al., 2016).
From a contextual integrity perspective, as I focus on public benefit purposes, a tendency toward higher acceptance for public recipients can be expected. Public recipients usually more frequently take part in contexts that have the explicit goal to foster public welfare than private recipients and therefore be deemed appropriate. Within public recipients, I expect that respondents consider researchers affiliated with public institutions to be the least likely expected to use data for out-of-context purposes and therefore may enjoy the highest acceptance ratings. These relationships may vary by concrete data type and the conditions of data use:
H2: Public actors, and particularly public researchers, are more accepted than private actors as recipients of data to use for public benefit. The effect of recipient interacts with data type and transmission principles.
With respect to transmission principles, several conditions to share data for public benefit exist. In opt-in scenarios, data are only used after the individual explicitly consents to data use. In the context of health data use for research, a review study found opt-in as the most favored approach, while results varied when deidentified data were to be shared (Stockdale et al., 2019). The review also concludes that individuals may change their opinions upon learning more about the benefits for research. However, review studies found that consent for use of medical records correlates with individual characteristics and that data sets that only include consented data may be biased (De Man et al., 2023; Kho et al., 2009). Opt-out approaches partially diminish this problem as data would be used as long as individuals do not explicitly indicate that they do not want their data to be used. A third option is to rely on data access regimes that include oversight bodies (Ausloos et al., 2020), such as Findata in Finland (Ausloos et al., 2020).
However, we know little about which of these transmission principles are more accepted across public benefit contexts (for context-specific research see, for example, on using phone data during the COVID-19 pandemic: Office of the Australian Information Commission & Lonergan Research, 2020). Given the scarcity of cross-context research, I formulate an open research question on this parameter:
RQ1: Which modes of consent do individuals accept more than other modes for data use for public benefit?
International Variation
As argued above, evaluations of social contexts, and thereby the effectiveness and acceptance of international policies surrounding these contexts, may vary by country. Previous privacy research has paid particular attention to cultural differences between countries by drawing on Hofstede’s cultural dimensions (see Hofstede et al., 2010), which may also shape acceptance of data use for public benefit. However, one should be cautious to assume that there was a “national culture” permeating all domains of social life consistently (Masur et al., 2024). Different social contexts may have their very own privacy-related norms (Nissenbaum, 2010) that are not fully determined by general cultural orientations.
Among the cultural dimensions that pertain to the Hofstede approach, some scholars assess the individualism dimension to be the most central dimension for privacy by which to compare cultures (as discussed in Liu, 2022). Empirical research frequently identified effects of individualism on privacy-related phenomena. For instance, an international survey experiment found that public benefit uses of data are relatively more accepted than other uses by individuals with a more collectivist cultural background as compared with individuals with a more individualist cultural background (Li et al., 2017). The study also found that individualism is related to stronger effects of the option of “notice and control” methods on acceptance, and to lower acceptance of government as data collector. In a similar vein, another study on contact tracing apps found higher use willingness in China (which is considered rather collectivist) than in Germany and the United States (which are comparatively more individualist; Utz et al., 2021). However, other studies provided an opposite relationship or null findings for individualism (see Engström et al., 2023; Trepte & Masur, 2016). Beyond individualism, less consistent or null effects have been found for the dimension of uncertainty avoidance (Engström et al., 2023; Schumacher et al., 2023; Trepte et al., 2017).
Given these findings, higher levels of individualism in a country may be associated with a higher desire of transmission principles that allow the affected individual more control over data flows. However, international differences may be hard to pinpoint to individualism with few countries of comparison, as countries may differ in further respects. Under this circumstance and partly contradictory findings, I approach international differences with an exploratory research question:
RQ2: Do countries with higher levels of individualism desire higher levels of control over data flows?
Interindividual Variation
Additional to the macro- and meso-levels, there may also be variation on the micro-level in assessing data use for public benefit, that is, individual differences within and between countries. Attitudes on data use for public benefit can relate to either of its constitutive elements of data use (i.e., privacy attitudes) and public benefit. Concretely, I distinguish between four types of relevant individual-level variables: (1) general attitudes and perceptions related to privacy, (2) perceptions with respect to specific elements of data flows, (3) general attitudes and perceptions related to the provision of public benefits, and (4) affinity toward technology and socio-demographic variables. First, individuals may differ with respect to privacy concerns, for instance, due to personality characteristics and own privacy-related experiences (Smith et al., 2011), and with respect to how they value privacy. The acceptance of data use scenarios may vary with individual general privacy concerns—possibly mediated by scenario-specific perceptions—(Kehr et al., 2015) and, second, with general perceptions relating to the parameters of the specific scenario: trust in data recipients (Kao & Sapp, 2022; Trein & Varone, 2023) and perceived sensitivity of data types (Mothersbaugh et al., 2012). Third, data use specifically for public benefit may be more accepted among individuals who value such public benefits higher more generally (relatedly for issue importance: Trein & Varone, 2023) and who have a more positive relationship to, or picture of, society, for example, who are more altruistic (Y. Kim & Stanton, 2016; Silber et al., 2022) and have higher interpersonal trust. Fourth, given the focus on digital data collection in the present article, familiarity with digital technologies may also affect privacy perceptions (e.g., Park, 2013). Finally, age and gender may affect privacy perceptions (Schomakers et al., 2019):
RQ3: Does the overall level of acceptance of data use scenarios vary with age, gender, general privacy concerns, perceptions relating to specific flow parameters, perceptions on public benefit uses of data, altruism, interpersonal trust, and with affinity toward technology?
Longitudinal Variation
Finally, comparisons on all three levels (macro, meso, and micro) are contingent on the specific time point of the comparison. Perceptions on the importance and salience of privacy may change with major societal events (Büchi et al., 2022). Given that privacy has been intensely discussed during the COVID-19 pandemic, for example, due to contact tracing, privacy perceptions related to public health may have changed. A previous study found that acceptance of use of health data from smartphones for disease containment has increased from 2019 to spring 2020, but not for other non-pandemic-related data use scenarios, which supports the notion of context-dependent effects of societal developments (Gerdon et al., 2021). This notion has also found support with a longitudinal study on privacy attitudes in the United States, which has shown that acceptance to use fitness tracker data for medical research increased from 2019 to 2020 and then stayed higher, while this was not the case with government collecting data to counter terrorism, toward which acceptance decreased (Goetzen et al., 2022). However, salience or its effect may wane over time: Wnuk et al. (2021) conducted a longitudinal study in Poland and found that acceptance for (partly rather intrusive) surveillance technologies decreased between May and December 2020, that is, during the COVID-19 pandemic. This tendency did not change even when the pandemic threat was particularly high in the second wave of the pandemic.
Research therefore suggests that privacy attitudes related to health data may vary with the severity of the pandemic situation. However, it is unclear how severe the shifts in societal circumstances need to be to affect privacy attitudes. I compare developments in attitudes toward health data use with attitudes toward the use of other data types that are either also affected by current public issues (energy use data) or that are less immediately affected by current public issues (location and social media data):
RQ4: Does the acceptance of health data use, relative to the acceptance of using other data types, change with the pandemic situation?
Method
Experimental Design and Questionnaire
To compare a variety of data use scenarios within multiple social contexts, an online survey experiment (“vignette experiment,” see Auspurg & Hinz, 2015) was conducted. In this experiment, people’s attitudes toward several hypothetical scenarios in which data are used for the purposes of research and public management were measured. This experiment entails 33 text descriptions (so-called “vignettes”) of hypothetical data use scenarios and allows researchers to estimate how changes in scenario characteristics affect acceptance. The vignettes vary by factors that can take on different levels (Auspurg & Hinz, 2015), with the factors representing contextual integrity parameters. 3 Table 2 shows the factors and levels. The full list of vignettes is available in the Supplementary Materials/ (Section V).
Experimental Design: Vignette Factors and Levels.

The data subject is described depending on the data type (e.g., “resident” for energy use data).
Company recipients were always defined as “researchers at an Internet company,” as these can be associated with handling different types of data for various purposes. As there is no public agency recipient that could be directly associated with such a multitude of data uses, the vignettes refer to different specific public agencies depending on data type. The two public and the one private recipient come with different data use purposes to create realistic scenarios. The purpose for university and company researchers always is research, and for agencies it is planning or control. For instance, researchers (both public and private) may use health data to study diseases. Public agencies are presented to use data for planning or control purposes, e.g., location data for infrastructure planning.
To describe the “ethics board,” I refer to “committee of independent ethics experts” and “data centres” as simplifications that work across data types. The exact means to either accept or reject the data use is adjusted to data type to increase plausibility. The basis for all descriptions of the transmission principles is that individuals are informed about the data use.
Each respondent was presented with four vignettes, receiving exactly one random vignette for each of the four data types. The order of shown data types was random, with one exception: As the social media vignettes did not contain all possible combinations of vignette factors (see Note 3), these vignettes were always placed in the last position and I treat them as a separate experiment in order to maintain a fully factorial experimental design (see Auspurg & Hinz, 2015) for the other vignettes. Respondents were asked to evaluate each presented scenario by rating the appropriateness of the data use on a seven-point scale. 4 Afterwards, respondents were shown items that measure relevant concepts for the research questions on interindividual variation. 5 The questionnaires are available in Section Q and information on cognitive pre-tests and a pilot study is available in Section M of the Supplementary Materials.
Sample
The vignette experiment was conducted as part of an online survey. The survey was fielded in three countries that varied in their levels of individualism according to the Hofstede cultural values index (Hofstede Insights, 2023): Germany, Spain, and the UK. According to Hofstede’s dimensions, the UK is a state with a high level of individualism, while Germany displays medium values (Hofstede Insights, 2023). Spain is one of the countries with the lowest individualism scores in Europe (Hofstede Insights, 2023).
Respondents were invited to participate via a commercial non-probability online panel provider (Bilendi). Respondents can self-select into the respondent pool and are then invited and incentivized by the provider to participate in specific surveys. For this survey, crossed age and gender quotas were applied that correspond to the respective population distributions based on Eurostat data from 2020. While inference with non-probability samples is oftentimes problematic (Elliott & Valliant, 2017), the goal is to estimate effects of experimental stimuli, which non-probability samples can be useful for (Jamieson et al., 2023; Kohler & Post, 2023), and to explore associations with individual-level variables.
The survey was fielded at two time points: 14 to 21 December, 2022 (Wave 1) and 11 to 22 May 2023 (Wave 2). 6 Based on these two cross-sectional samples, I also constructed a longitudinal data set of respondents who participated in both waves. In the second wave, each recurring respondent received the same vignettes in the same order as in the first wave.
The sample sizes for analysis are as follows: Wave 1: 1,682 respondents (Germany: 562; Spain: 564; UK: 556); Wave 2: 1,795 respondents (Germany: 594; Spain: 603; UK: 598). Wave 2 comprises 1,110 respondents who already participated in wave 1; the remaining number of participants was newly recruited. 7 Details on the sample and exclusion criteria are available in the Supplementary Materials (Section M).
Results
To address the hypotheses and research questions on contextual and international variation, I use the data from Wave 1 and regress perceived appropriateness on the vignette variables and on country dummy variables, while controlling for age and gender. To this end, I run linear mixed-effects models with random intercepts for the respondent-level. I investigate further context-dependencies of effects of data recipients by adding respective interaction terms. To answer the research question related to interindividual variation, I add individual-level variables to the regression models. For the longitudinal comparisons, I inspect changes in acceptance (note that I will use the terms “acceptance” and “perceived appropriateness” interchangeably for easier text flow) of specific scenarios from Wave 1 to Wave 2. Finally, I use the Wave 2 data for a replication of the Wave 1 results by running the same regression analyses as in Wave 1 and inspecting whether substantive changes occur. Table 3 summarizes the models that will be shown in the “Results” section. 8
Overview of Used Regression Models.

I analyze responses to the “social media” vignettes as a separate experiment (see “Method” section) using OLS regression. I ran two additional types of models to check whether the findings are robust to model and data choices: (1) models that include respondents that I defined as speeders and (2) logistic cumulative link mixed models (Christensen, 2019) that treat the outcome variables as ordinal. I focus on the interpretation of the linear mixed-effects models and highlight important substantive differences compared with the two other types of models. Note that I cannot directly compare effect sizes of the ordinal models with other models (Mood, 2010).
Note that although I draw on a non-probability sample, I calculate standard errors as an orientation using the, respectively, implemented procedures of the software. However, the focus is on the interpretation of effect strength.
Age and gender distributions (Supplementary Table T1) and summary statistics for all other individual-level variables are available in the Supplementary Materials (Table T2a for Wave 1 and Table T2b for Wave 2).
Contextual and International Variation in December 2022
Before turning to the regression analyses, I descriptively inspect the mean values of the vignette scenarios across countries in Wave 1. The mean perceived appropriateness varies across countries and vignette factors (Figure 1). While the ratings do not vary strongly for some vignettes and between single vignette levels, some patterns are discernable. The highest perceived appropriateness is found for health and energy data, followed by location data and then by social media data. However, the lower acceptance of social media vignettes could be partly driven by always being the last vignette to be shown to respondents (see below). Finally, while not true for each single scenario, respondents from the UK appeared as the overall most accepting country, followed by Spain and then Germany. The Supplementary Materials contain the exact mean and median values (Table T3a) and the full distribution of answers for each vignette (Figure F1a).
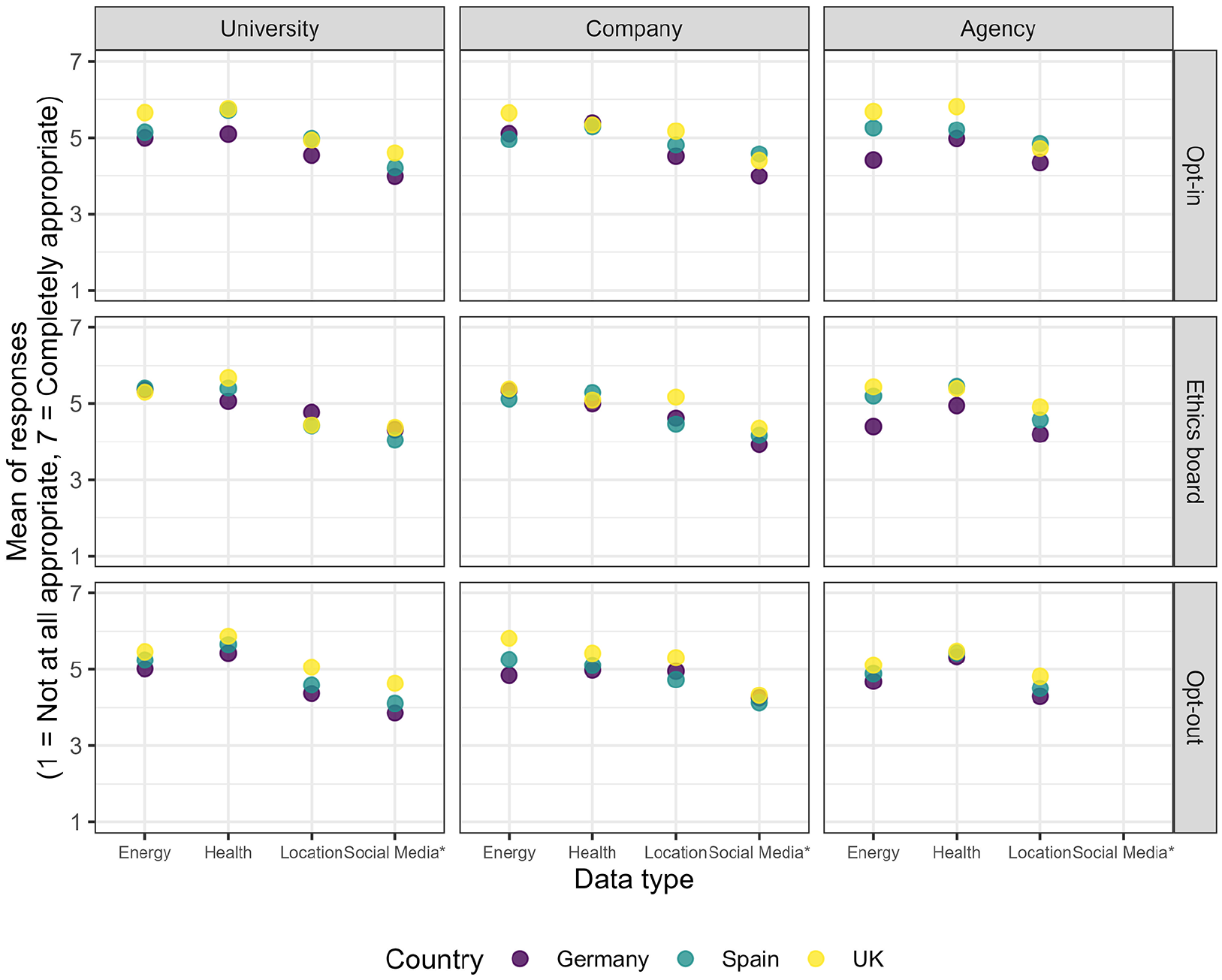
Arithmetic mean values of perceived appropriateness of all vignette scenarios in Wave 1 (December 2022).
To answer H1, H2, and RQ1 (the effects of vignette factors on acceptance), I compare the effects of vignette factors on perceived appropriateness ratings across countries. To this end, I run regression analysis with pooled data from all countries as well as separately for each country.
I first run linear mixed-effects models that only contain the vignette levels, vignette positions, country dummies, age, gender, and a random intercept for the respondents (Figure 2; M1 columns in Table T4a in the Supplementary Materials; ordinal and speeder models in Tables T4b and T4c). The results show that among vignette factors, the data types have the strongest effects. Scenarios with health data overall appear as more accepted than energy use data, while location data use is rated lower. However, in the UK, there are no meaningful differences between health and energy use data (albeit the effect is slightly stronger in the ordinal model). These findings support H1 (“health data use is more accepted than the use of other data types”) in Germany and Spain, while for UK, the use of health and energy data is similarly accepted.

Linear mixed-effects model regression coefficients and 95% confidence intervals for effects of vignette levels on perceived appropriateness in Wave 1, based on four separate models.
While respondents overall do not strongly differentiate between company and university researchers, there is a slight preference for the latter in Germany and Spain. Moreover, except for in Spain, respondents rate vignettes with public agencies similar or lower than vignettes with researchers. This rejects H2 (“public actors, and particularly public researchers, are more accepted than private actors”) overall, there being only a slight such tendency in Spain. To learn whether the recipient effect varies by data type and transmission principles, I add the respective interactions in two separate models. That is, there is one model with interaction between recipient and data type (Model 2) as well as one model with interactions between recipient and transmission principle (Model 3). All results are available in Table S1 in the Supplementary Materials (columns M2 and M3).
The results for Model 2 show that many interactions between recipients and data types are likely random—given the oftentimes small effect sizes and large standard errors—but there are some stronger effects. There is a positive interaction effect between agencies and health data in Germany. Agency recipients are in tendency more accepted for location data than for energy use data. Companies are in tendency less accepted for health data and more accepted for location data, compared with energy use data; however, for companies, there are barely such differences in Germany.
The results for Model 3 show mostly small and likely random interaction effects between recipients and transmission principles. Two of the more consistent findings are that the combination of an agency recipient and opt-out compared with the reference categories is somewhat less accepted in the UK, and that the combination of company and ethics board is somewhat more accepted in Spain, again compared with the reference categories.
In summary, the results confirm the expectation that recipient and data type interact. There is less consistent evidence for strong interactions between recipient and transmission principle, although somewhat stronger effects show for specific combinations.
Finally, I analyze the additional experiment on social media data (Table T5a in the Supplementary Materials; ordinal and speeder models in Supplementary Tables T5b and T5c). The social media vignette was always placed in the last position and never contained a public agency as a recipient. The results show that most effects could be random, but there are some tendencies. Again, overall acceptance is higher in UK and Spain than Germany, but the latter difference is smaller than in the previous models. Depending on the country, respondents assess company researchers differently, as compared with university researchers. In Germany, there are no strong differences (except for a somewhat stronger negative effect in the model with speeders), while there is a higher relative acceptance in Spain and a lower relative acceptance in the UK. The effects of transmission principles in tendency vary by data recipient and across countries (see Supplementary Table T5a for details).
Based on these results, I can answer RQ1 (“Which modes of consent are more accepted?”). The above models show no overall strong differences between opt-in and opt-out procedures (except for a somewhat stronger negative effect for opt-out in the case of social media data in Spain). Ethics boards are in tendency less accepted than opt-in procedures. Particularly the latter effect varies by country.
This leads to RQ2 (“Do countries with higher levels of individualism desire higher levels of control over data flows?”). While acceptance in all three countries barely changes between opt-in and opt-out procedures, UK respondents are somewhat relatively more skeptical about ethics boards. Spanish respondents accept ethics boards slightly less than opt-in. If individualism was responsible for international differences, there should be clearer differences in the acceptance of transmission principles (especially for opt-out vs opt-in) particularly between UK and Spain. Moreover, contrary to expectation, the overall acceptance is highest in the UK. The answer to RQ2 thus is that there is no clear and consistent association of a higher desire for control with higher country-level individualism.
Interindividual and International Variation in December 2022
To answer RQ3 on the associations of individual-level variables with perceived appropriateness, I add variables to Model 1 that are related to trust, altruism, perceived sensitivity of data types, other privacy-related perceptions, device use, and affinity toward technology.
I focus on the effects of individual-level variables across models (Figure 3; Table T6a in the Supplementary Materials; ordinal and speeder models in Supplementary Tables T6b and T6c). On average, female respondents report somewhat lower acceptance than male respondents. Four associations are relatively consistent across countries: higher trust in data recipients comes with higher acceptance, while higher perceived sensitivity of data types comes with lower acceptance (note that sensitivity and trust always refer to the specific data type or data recipient shown in the vignette). General privacy concerns are associated with lower acceptance, while agreement with the statement that “The privacy of individuals may be invaded if this results in a greater benefit to society” (own translation from Trepte, 2020) comes with higher acceptance. Additional to these consistent associations, more thinking about privacy in times of the pandemic is associated with higher acceptance in the UK. Altruism has a positive association with acceptance, particularly in Germany. The same is true for the number of used devices in Spain. Otherwise, there are mostly small and likely random associations (although single effects appear more meaningful in the alternative model types). With respect to the effects of vignette factors, it is noteworthy that controlling for the individual-level variables, public agencies appear as the most accepted recipient in Spain, while company recipients are most accepted in Germany and the UK.

Linear mixed-effects model regression coefficients and 95% confidence intervals for effects of vignette levels and individual-level characteristics on perceived appropriateness in Wave 1, based on four separate models.
Longitudinal Variation
To answer RQ4 (“Does the acceptance of health data use, relative to the acceptance of using other data types, change with the pandemic situation?”), I first inspect changes in perceived appropriateness from Wave 1 (December 2022) to Wave 2 (May 2023) across data types and countries. To this end, I use a data set that only contains respondents who participated in both waves (see details on the construction of this sample in Supplementary Materials Section M). The Supplementary Materials contain mean values—plotted (Figure F2) and as a table (Table T3b)—and the full distribution (Figure F1b) of vignette responses in Wave 2.
When analyzing longitudinal changes in acceptance separately for each data flow parameter or by country, only small differences over time are observed (Figure 4; with speeders: Figure F3 in Supplementary Materials). A comparison of changes between more specific vignette scenarios reveals a more nuanced picture (Figure 5; exact values in Table T7a in Supplementary Materials). Acceptance changed only slightly for several combinations of data types and recipients. However, in the UK, health data use became less accepted for companies and more accepted for universities. Changes for energy and social media data are almost consistently negative and, in some cases, relatively small. Moreover, there are some stronger increases in acceptance for location data use. With respect to RQ4, these results still show that the acceptance of health data did not overall decrease (or increase) much more relative to other data types. While there are stronger changes for health data with specific recipients in the UK (and partly Spain), there are similarly strong changes for other settings (when including speeders, however, the decrease for company recipients in the UK is particularly strong, but the increase for public agency is less pronounced; see Figure F4 and Table T7b in the Supplementary Materials). However, some changes vary considerably when further taking into account transmission principles (but note that the number of responses per combination is lower in this more fine-grained analysis). In some cases, the ratings of the same data type and recipient changes into different directions depending on transmission principles (Supplementary Table T8a and Supplementary Figure F5a without speeders, Supplementary Table T8b and Supplementary Figure F5b with speeders). Still, ratings of health data vignettes do not stand out to have overall changed particularly more than other ratings.

Changes in arithmetic means of responses from Wave 1 (December 2022) to Wave 2 (May 2023) among those respondents who participated in both waves.
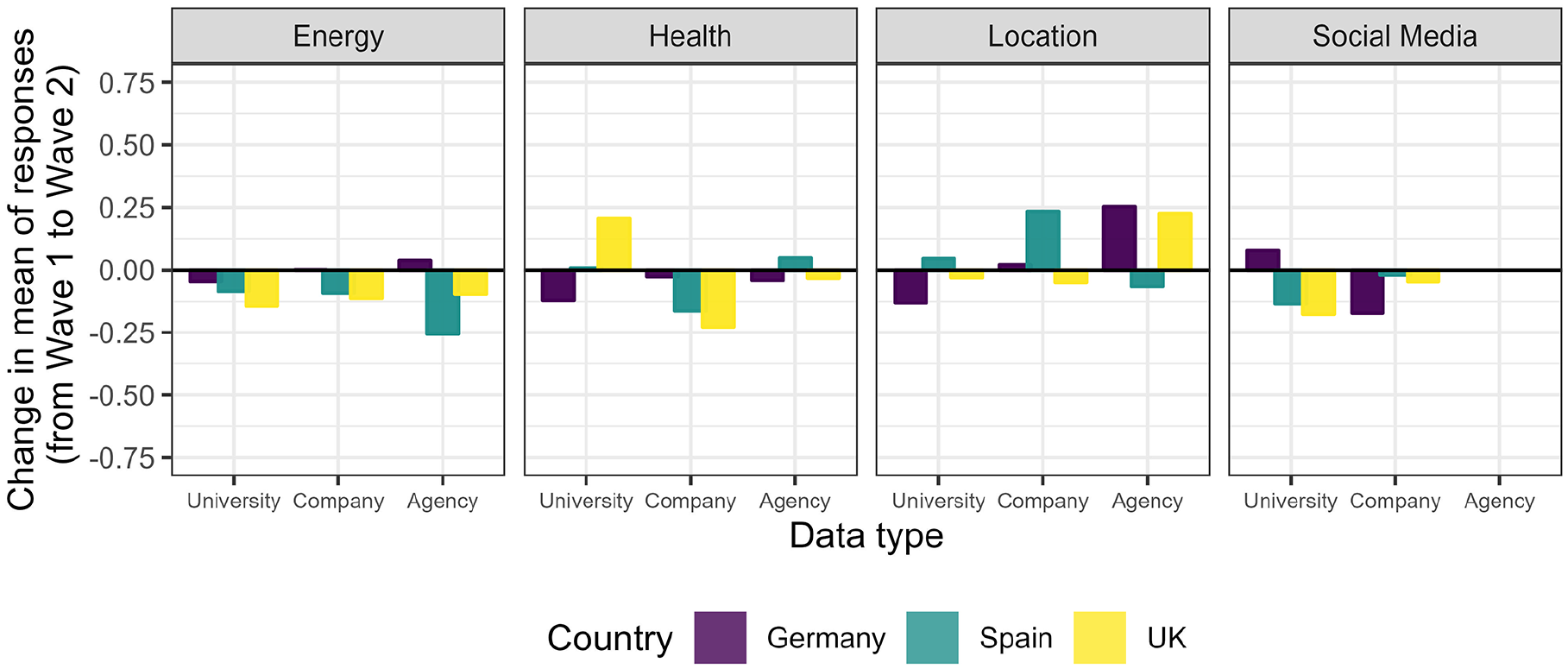
Changes in arithmetic means of responses from Wave 1 (December 2022) to Wave 2 (May 2023) among those respondents who participated in both waves.
Replication of December 2022 Results With Data From May 2023
Finally, I make use of the full data set for Wave 2 that comprises respondents who already participated in Wave 1 as well as newly recruited respondents. I treat this second wave as a replication of the first wave and check whether the substantive findings with respect to the hypotheses and research questions hold. However, this approach cannot reveal whether any differences are attributable to changes over time or to differences in sample composition.
I run all models from Wave 1 again with data from the second wave and show all regression tables in the Supplementary Materials (Tables with ending letters d to f). The finding holds that health data are more accepted than the other data types (H1). In fact, in Wave 2, there are somewhat stronger positive effects for health data for the UK, compared with Wave 1. Also, public recipients (H2) are again not overall clearly more accepted than company recipients, although the relative acceptance of the latter in tendency is lower. As for transmission principles and their importance across countries (RQ1 and RQ2), opt-out is the overall most accepted transmission principle in Spain in Wave 2 (except when using social media data), while opt-in and opt-out are again most accepted in the other countries. The individual-level variables (RQ3) overall display the same tendencies as in Wave 1, but women display rather equal acceptance compared with men in the UK. However, the associations with interpersonal trust and of thinking about privacy in times of the pandemic tend more toward zero. Moreover, the differences between recipients tend to be somewhat smaller, a slight exception being a relatively higher acceptance of agency recipients in the UK than in Wave 1. The resulting cross-country patterns may be somewhat more in line with the differences in levels of individualism in the respective countries but are still not clearly consistent and pronounced. Across models, there are changes in effects for further specific constellations—especially for the interaction effects and for the case of social media data—that can be ascertained from the respective tables.
Discussion
The results demonstrate considerable variation of perceived appropriateness of data use for public benefit across contexts. The contextual effects, moreover, vary by country and, to some extent, over time. These findings support the notion that contextual integrity is a useful approach for comparative research across countries: Additional to country comparisons with respect to general privacy notions, contextual integrity can reveal context-specific differences between countries that may otherwise remain unnoticed (while this gap between general and specific perceptions has already been argued for within single countries, Martin & Nissenbaum, 2017). This study integrates contextual integrity into comparative privacy research (see Masur et al., 2024) and demonstrates that future research can operationalize data uses in meso-level social contexts by drawing on contextual integrity’s data flow parameters. The results also show that some individual-level variables are mostly consistently associated with higher or lower acceptance. In the following, I discuss more specific implications and research avenues with respect to contextual, international, interindividual, and longitudinal comparisons, before turning to limitations of the study.
Among contextual factors, changes in data types had the strongest effects on acceptance. The relatively high acceptance of health data use is somewhat striking as one might consider this data type to be particularly sensitive. Indeed, a higher sensitivity of data types is associated with lower acceptance, but the positive estimates for health data remain. This finding supports the notion that sensitivity is a context-dependent concept (Martin & Nissenbaum, 2017). The relatively higher acceptance of health and energy use data, compared with location data, could be explained by their particular societal relevance, while the lower acceptance for social media vignettes may be due to an order effect. Further longitudinal research would need to investigate whether this represents a temporary or stable difference in preferences.
Importantly, the findings highlight the relevance of contextual integrity parameters for international comparisons. For instance, public agencies are relatively less accepted data recipients in Germany compared with the other countries. These findings have two implications for future comparative privacy research. First, country comparisons of meso-level social contexts can identify cross-country differences that are not captured by general differences in privacy perceptions, for example, in health versus energy use contexts. Second, data use contexts that appear similar across countries may be differently evaluated by the respective populations, calling for further cross-country research using the notion of contextual integrity. For instance, while acceptance toward data use by public agencies may appear overall relatively lower in Germany, the acceptance of this data recipient still varies by used data type within Germany: As data types were particularly influential, separate ordinary least squares (OLS) models for each country and data type in the Supplementary Materials further illustrate data type- and country-specific differences (Tables T9a to T9f) for interested readers.
The found differences across countries are not clearly and consistently explainable by country-level individualism, although the results from Wave 2 resemble the expected patterns somewhat more than those from Wave 1. Future research may further context-specifically investigate cultural dimensions that better explain the found differences. For instance, Germany scores high and the UK scores low on Hofstede’s dimension of “uncertainty avoidance,” with Spain being ranked between these two countries (Hofstede Insights, 2023). However, it may be that country-level cultural variables cannot capture the complexities that are inherent to international comparisons. Scholars criticized Hofstede’s cultural dimensions approach for various reasons, among them methods-related concerns and considering it a too positivist approach (discussed in Jackson, 2020). As the Comparative Privacy Research Framework suggests, countries may differ with respect to a variety of categories, not only the cultural aspect of individualism (Masur et al., 2024). To learn more about the concrete categories that matter, future research would need to include a large variety of countries that differ with respect to multiple categories at different levels, such as the economic category (see Masur et al., 2024). For example, degrees of free market economy (Masur et al., 2024) could be related to the establishment of relatively free use of data in the respective countries. However, while country-level characteristics may explain some of the differences between countries, the present study suggests that a context-specific view is necessary to avoid undue generalizations to all kinds of data uses.
The analysis further explored associations between individual-level variables and acceptance. The results show that even after taking into account contextual factors, several general privacy-related perceptions are still associated with acceptance. Adding to Martin and Nissenbaum’s (2017) suggestion that context-specific preference measurements may partly close the gap between stated privacy concerns and situation-specific data sharing behavior (the so-called “privacy paradox”), these findings imply that the measurement of general perceptions may still be worthwhile in context-based research. Future research needs to investigate how context-specific alongside general privacy perceptions translate into data sharing behavior.
Some changes in perceived appropriateness over time were found in the longitudinal comparisons of specific contextual constellations, but not pronouncedly and universally for the acceptance of health data use. It might be that respondents were on average not overly concerned about the COVID-19 pandemic anymore already at the time of data collection in December 2022. As for energy supply problems as another salient public issue, there is a tendency toward decreased acceptance from December to May, but these changes are overall not very strong. However, given some stronger changes for specific constellations, these results highlight again that privacy research and policymaking need to reflect how the timing of data collection—for example, during a specific crisis—might affect context-specific results. Momentary assessments of public opinion do not necessarily constitute a “social license” (Shaw et al., 2020) to carry out questionable data uses. Instead, they constitute one element of an assessment of the appropriateness of a data use, along with further legal considerations and, as suggested by contextual integrity, the discussion of context-specific and more general values and goals at stake (Nissenbaum, 2010).
I now turn to limitations of the article that were not already discussed above. First, as is commonly the case with vignette studies, we need to keep in mind potential limitations with respect to external validity (Eifler & Petzold, 2019). Moreover, this study can only speak about the concrete investigated scenarios. For instance, the company recipients were always defined as “researchers at an Internet company” and it is possible that recipients rate vignettes differently if more context-specific companies are involved. The relatively strong effects found for data types may also be due to the circumstance that the vignettes were structured around data types to make them appear plausible and to not present, for example, construction planning agencies using patient records. Moreover, some of the investigated scenarios may have been very hypothetical or unknown to respondents. With increasing concreteness or public awareness, attitudes toward these data uses may change.
Second, in principle, internationally different response behavior patterns (Kemmelmeier, 2016)—however, less so due to the experimental design—and potential variations in the interpretations of vignettes may account for some of the differences found between countries. Researchers also need to validate the cross-cultural invariance of privacy-related measurements (Ghaiumy Anaraky et al., 2021). Moreover, a larger number of countries might allow researchers to better disentangle effects of, for example, cultural and economic differences (see Masur et al., 2024) on privacy attitudes. While this study has detected differences even between three European countries, differences could be further pronounced particularly when extending comparisons to non-WEIRD—that is, western, educated, industrialized, rich, and democratic (Henrich et al., 2010)—countries.
Third, as explained above, the study is based on an online non-probability sample for which inference is only feasible under specific conditions and for specific fields of application (Kohler & Post, 2023). This means that while more confident claims with respect to experimental effects can be possible, for example, mere mean values are not to be inferred to the general populations of the respective countries. Moreover, as the questionnaire was fielded online, one could speculate that particularly older respondents in this sample might be more open to digital technologies than older individuals in the general population, which could explain the small or non-associations of age with acceptance. Thus, future research would need to confirm these findings with mixed-mode or offline probability samples.
Conclusion
The Comparative Privacy Research Framework (Masur et al., 2024) proposes to compare privacy-related phenomena across different levels and types of units. The present study draws on the concept of “contextual integrity” (Nissenbaum, 2010) to enhance comparative privacy research by focusing on social contexts as a meso-level unit of comparison. To this end, the contextual integrity data flow parameters offer a useful approach to operationalize data uses in meso-level social contexts. The present study applies this approach by employing a survey experiment in three countries (Germany, Spain, and the UK) and at two time points (December 2022 and May 2023) to compare privacy perceptions related to data use for public benefit along four components: contextual, international, interindividual, and longitudinal variation. The results show that the effects of data flow parameters vary across countries, but to different degrees. The strongest effects are found for the data type, with health data overall being the relatively most accepted data type overall. The effect for data recipients varies such as to lead to different substantive conclusions for the different countries. Country-level individualism was not found to be clearly and consistently associated with the desire for control over the data. Interindividually, several general privacy perceptions still matter after considering contextual factors. Finally, longitudinal comparisons show overall minor but context-dependent variation over time.
In conclusion, using the contextual integrity approach can unmask meso-level context-specific differences in the acceptance of data uses within and between countries. These differences could be relevant for ascertaining “social licenses” (see Shaw et al., 2020) regarding data use practices, for international privacy-related regulation, and for suggestions on sector-specific policies. This study can therefore serve as a call for more deliberately incorporating meso-level contexts in comparative privacy research that can inform privacy-related public decision-making.
Supplemental Material
sj-docx-1-sms-10.1177_20563051241301202 – Supplemental material for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment
Supplemental material, sj-docx-1-sms-10.1177_20563051241301202 for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment by Frederic Gerdon in Social Media + Society
Supplemental Material
sj-docx-2-sms-10.1177_20563051241301202 – Supplemental material for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment
Supplemental material, sj-docx-2-sms-10.1177_20563051241301202 for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment by Frederic Gerdon in Social Media + Society
Supplemental Material
sj-docx-3-sms-10.1177_20563051241301202 – Supplemental material for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment
Supplemental material, sj-docx-3-sms-10.1177_20563051241301202 for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment by Frederic Gerdon in Social Media + Society
Supplemental Material
sj-docx-4-sms-10.1177_20563051241301202 – Supplemental material for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment
Supplemental material, sj-docx-4-sms-10.1177_20563051241301202 for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment by Frederic Gerdon in Social Media + Society
Supplemental Material
sj-docx-5-sms-10.1177_20563051241301202 – Supplemental material for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment
Supplemental material, sj-docx-5-sms-10.1177_20563051241301202 for Attitudes on Data Use for Public Benefit: Investigating Context-Specific Differences Across Germany, Spain, and the United Kingdom With a Longitudinal Survey Experiment by Frederic Gerdon in Social Media + Society
Footnotes
Acknowledgements
The author thanks Ellen Laurischk, Kerstin Fischer, and Tonja Dingerdissen for their support in this research project, and Elsa Peris, Wiebke Weber, and Joshua Fullard for their work or support regarding questionnaire translation. He also thanks Frauke Kreuter, Helen Nissenbaum, and Thomas Fetzer for their comments and ideas, and the Kreuter-Keusch research group and the reviewers for helpful comments on this manuscript. A previous version of this article is part of the publication-based dissertation of the author (URN: urn: nbn:de:bsz:180-madoc-674360).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Volkswagen Foundation (Grant “The Covid-19 Pandemic and Data Sharing for the Public Good: Attitudinal, Ethical, and Legal Approaches to Privacy During the Pandemic and Beyond”). Further funding for data collection came from the Ludwig-Maximilians-Universität München. This work was supported by the University of Mannheim’s Graduate School of Economic and Social Sciences.
Data Availability
It is planned to publish the data in a safe data repository for scientific use. Until then, the data are available from the author upon request.
Ethical Approval and Consent
In Germany, research that does not involve patients usually does not require approval by an ethics committee. Yet, approval for this research endeavor was voluntarily applied for and obtained from the Ethics Committee of the Faculty of Mathematics, Computer Science, and Statistics at Ludwig-Maximilians-Universität München (approval: EK-MIS-2021-075, date: 4 February 2022; note that the surveys were initially intended to be conducted in Denmark and the United States instead of Spain and the UK). Respondents consented to participation on the first page of the questionnaire that contained information on the study and the use of data.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.