
Abstract
Social media, in general, and Facebook in particular, have been clearly identified as important platforms for the dissemination of mis- and disinformation and related problematic content. However, the patterns and processes of such dissemination are still not sufficiently understood. We detail a novel computational methodology that focusses on the identification of high-profile vectors of “fake news” and other problematic information in public Facebook spaces. The method enables examination of networks of content sharing that emerge between public pages and groups, and external sources, and the study of longitudinal dynamics of these networks as interests and allegiances shift and new developments (such as the COVID-19 pandemic or the US presidential elections) drive the emergence or decline of dominant themes. Through a case study of content captured between 2016 and 2021, we demonstrate how this methodology allows the development of a new and more comprehensive picture of the overall impact of “fake news,” in all its forms, on contemporary societies.
Introduction
While not limited to social media, the spread of mis- and disinformation online has been identified as a critical global issue (United Nations News, 2022). Platforms like Facebook are particularly important for the dissemination of mis- and disinformation and related problematic content, given their global reach and significantly large and diverse user populations. While much research effort has been directed toward this emergent issue (see Pavliuc et al., 2023, for an excellent collection of such work), the patterns and processes of such dissemination are still not sufficiently understood. This is in part because existing studies often focus only on the dissemination of such content in the context of major events (national elections, the COVID-19 pandemic, etc.) or restrict their attention to content that has been explicitly identified as incorrect.
Vosoughi et al.’s influential study (2018) on “the spread of true and false news online,” for instance, defines “false news” narrowly as news that had been debunked by one of six independent fact-checking organizations. This produces valuable results, but its observations cannot easily be generalized, for example, to hyperpartisan news that is not explicitly false, but instead presents facts selectively and out of context, or to biased news commentary that makes its claims without providing a factual basis and is therefore more difficult to debunk effectively. Likewise, Dourado (2023) produced a compelling account of the nature of over 1,000 online accounts that shared any of 57 fact-checked “fake news” articles relating to the 2018 Brazilian presidential election, but this approach cannot capture the circulation of other problematic content that did not come to the attention of fact-checking organizations. We do not intend to diminish the importance and rigor of these studies, but point out their (acknowledged) limitations: they rely on a small database of fact-checked “fake” articles and limit their scope to a singular event.
There is a pressing need, therefore, to further extend analyses of the dynamics of news dissemination on social media platforms by considering a broader range of problematic news, and by developing more longitudinal perspectives that cover periods of heightened attention as well as everyday posting and sharing activities outside of such periods. This article presents a new computational methods stack for pursuing these and further aims, centered on a key piece of metadata, the Uniform Resource Locator (URL). The methods stack has been developed as part of a multi-year study into the aforementioned issues and seeks to enable the following:
The identification and thematic categorization, for Facebook, of the public pages, groups, and verified profiles that are most active in linking to identified sources of problematic information.
The identification and ranking of influence of sources of problematic information shared by these public spaces on Facebook, using Facebook’s own engagement metrics.
An examination of the themes and topics addressed, and the sources linked to, by the most active such public pages and groups, in their day-to-day activities beyond the sharing of problematic news content.
The examination and analysis of patterns of such activity over a 5-year timeframe, to identify the impact of major political and other events during that time on posting and sharing activity.
The article begins by outlining the role of link-sharing within mis- and disinformation ecosystems on social media platforms, and shows how tracking linked sources can enable a focussed study of their role as vectors of community activity and interaction. We enthusiastically take up the provocation by Giglietto et al. (2019) to “shift from exclusive attention to creators of misleading information to a broader approach that focuses on propagators and, as a result, on the dynamics of the propagation processes.” We then move to a full outline of the computational stack that we have assembled to enable the study of such problematic information. While the individual components of this stack are not new, their integration and use in service of our goals are the key innovation that this article contributes to the field. Finally, although the purpose of this article is chiefly methodological, we demonstrate the utility of our approach by examining Facebook link dissemination activities associated with a masterlist of known problematic websites, and conclude by outlining the various ways in which this stack can be tailored and adapted for subsequent studies.
Taken together, this methods stack allows for the development of a considerably more comprehensive account of problematic news dissemination activities on Facebook (or other such social platform) than exists to date, and of the actors involved in such activities. While, for the sake of brevity, in this article, we stop short of a comprehensive analysis of the content collected using the methods, we do outline several lines of inquiry that are enabled by these methods, and opportunities for further development and adaptation.
We focus our methods on Facebook for several critical reasons. First, in Q4/2022 Facebook reported 2 billion “active” daily users (MediaWeek, 2023), making it one of the biggest social media platforms in the world. Second, in spite of its size, relatively little of the vast academic literature on mis- and disinformation has paid attention to Facebook, because—unlike Twitter, Reddit, and other more “public” platforms—its data generally remain more elusive to researchers. The methods outlined in this article help to address this gap in scholarship. Finally, Facebook—and its public groups and pages in particular—are important vectors of disinformation spread within the broader online ecosystem. While this article does not track and analyze private spaces on Facebook (i.e., private accounts, or groups that have their visibility set to private), it nonetheless provides significant insight into how information flows on the platform as a whole, into the extent to which groups and pages share links to problematic content, as well as into the extent to which those groups and pages exhibit similar sharing patterns.
Approaches to Studying the Spread of Problematic “News” Content
The diverse and divergent phenomena now described as “fake news” have created a considerable moral panic across many established and emerging democracies. Understood as propagandistic misrepresentation or deliberate disinformation, “fake news” is being blamed for the apparently unexpected results of the 2016 UK Brexit referendum and US presidential election (Booth et al., 2017). Similarly, economic “fake news” campaigns have been employed to manipulate currencies and stock markets (Rapoza, 2017).
The rapid sharing of “fake news” through social media channels, by human and automated actors, is held responsible for smear campaigns against the political establishment, minority communities, and foreign groups in cases around the world (Applebaum, 2016). “Fake news” campaigns aimed at influencing or confusing public opinion, coordinated by state actors, have been revealed in parliamentary inquiries in the United States and elsewhere (Carr, 2017). Even the Pope has highlighted “nuntii fallaces” as a threat to peace (Holy See Press Office, 2018).
Conversely, earlier and more literal uses of the term “fake news” mainly referred to overtly satirical formats such as The Daily Show and The Onion (Harrington, 2012), while more recently the “fake news” label and discourse has also been used by populist politicians and media outlets on all sides of politics to dismiss critical mainstream news coverage (Carson et al., 2017)—echoing the Nazi-era slur Lügenpresse (“lying press”). Thus, independent of the veracity of specific news stories, the “fake news” discourse is also creating significant collateral damage to the public’s trust in the news they encounter in mainstream, alternative, and social media sources (Edelman, 2017).
Social media are, therefore, treated as a key site for intervention in the spread of “fake news,” reflected in various regulatory efforts and social campaigns directed at social media platforms by governments and civil society groups (Funke & Flamini, 2019). However, as outlined above, the term “fake news” unhelpfully limits our understanding of problematic news content. This is because verifiably “false” news, as tracked by Vosoughi et al. (2018) or Dourado (2023), is only a subset of such problematic content. Other forms include outright conspiracist news sites, hyperpartisan outlets that use selective sourcing and bad-faith news frames to push specific political agendas, state-backed disinformation campaigns, as well as more mundane forms of false information (i.e., misinformation) sharing on social media. There is thus a critical need to develop a more complete understanding of the highly networked link-sharing practices playing out across these platforms. For instance, what sources receive the most engagement from social media users? What social groups are aligned in sharing specific problematic content? And have link-sharing practices changed in response to key world events (e.g., the COVID-19 pandemic)?
As highlighted by D. M. J. Lazer et al. (2018), there is “little research focused on fake news and no comprehensive data collection system to provide a dynamic understanding of how pervasive systems of fake news provision are evolving.” While circumstances may have changed somewhat since 2018, particularly in light of the global pandemic, we still lack comprehensive, large-scale, and longitudinal approaches to understanding multi-scale patterns in problematic news content dissemination. Acker and Donovan (2019) further highlight that a problem in existing approaches (and datasets) developed for the study of the propagation of problematic information is that they fail to acknowledge the role that platform infrastructures and metadata play, in effect masking information of significance that can help us develop more comprehensive and rigorous accounts of the underlying dynamics.
Much attention has also been paid to the level of the account or user persona, seeking to determine the authenticity or inauthenticity of individual or groups of accounts. Bot detection frameworks (Martini et al., 2021; Yang et al., 2022) and analyses that seek to locate networks of accounts engaged in inauthentic activity (Giglietto et al., 2020; Graham & Digital Observatory, 2020) are popular methodological interventions. The popularity of these methods is due to several factors: it is straightforward to develop tests for reliability; there is overwhelming evidence for the involvement of state actors in bot campaigns, fuelling the sense of immediacy, and importance in countering such efforts; and such methods present immediate technological solutions for platforms that seek to limit the impact of such accounts. These methods tend to profile account metadata and post-level activity, combining natural language processing, machine vision, network science, and other advanced statistical techniques. Studies employing these methods often take on a qualitative forensic approach to discover and call out inauthentic activity that moves beyond expected norms of interaction, frequently in conjunction with events of significance (elections, crises, etc.).
However, while we do not wish to diminish the importance of research focussing on these phenomena, inauthentic and “bot” accounts are only one element in a much more complex mis- and disinformation landscape. Despite their popularity and methodological sophistication, the methods that identify them are less helpful for an investigation of content-sharing activities that are authentic, in terms of the social media actors driving them, yet nonetheless problematic, in terms of the content being shared. Genuine human actors are also substantially involved in sharing problematic content because they truly believe in its accuracy; in order to attack, confuse, or frustrate their opponents; to signal their alignment or support with influential political actors or groups; or for a variety of other reasons. Indeed, bots have been shown to be less influential than prominent social media accounts during contentious political events (González-Bailón & de Domenico, 2021) and in sharing vaccine-critical information (Dunn et al., 2020), for instance.
Therefore, further advancement in the study of the dissemination of problematic content on social media faces at least three major hurdles. First, because of the considerable contribution that “authentic,” uncoordinated activity by genuine human users makes to the spread of such content, we cannot rely on approaches that seek to detect bots or “coordinated inauthentic behaviour” alone. These approaches will be useful in determining how much broader dissemination patterns are affected or driven by bad-faith actors, but it is possible that such actors are entirely absent from a given dissemination event. Second, because much of the mis- and disinformation on any topic does not lend itself to (or is deliberately shaped to avoid) straightforward fact-checking, we cannot investigate the spread of problematic content, or the actors involved in spreading it, by tracing the dissemination of explicitly verified false information alone. Such content is only the tip of a much larger iceberg of hyperpartisan bias, selective misrepresentation, and deliberate obfuscation. Third, because of the substantial limitations that apply to platform data access it has proven difficult to investigate the patterns of problematic content dissemination at scale, over time, and beyond individual case studies (elections, vaccines), with historically more scholar-friendly Twitter being substantially overrepresented in the literature.
By outlining a new combination (or “stack”) of computational methods and applying them to a novel dataset drawn from Facebook through the CrowdTangle API, this article offers an approach that addresses these hurdles. By examining all link-sharing activity for the problematic content we have identified, we initially avoided a distinction between “authentic” and “inauthentic” accounts and sharing patterns (but left open the possibility of applying the relevant detection approaches and tools at a later stage of the analysis). Furthermore, by focussing on a very broad selection of suspected problematic news sources that is based on a number of prominent existing studies, we also explicitly and deliberately bypass the question of how and by what criteria specific sources of news or news-style content are identified as “fake news,” or more specifically as spreading mis-, dis-, or malinformation (Wardle & Derakhshan, 2017). Rather, then, our focus is on how, once a set of potentially problematic news sources have been identified according to a specific definition, we can track and analyze the patterns of news-sharing on Facebook for this set of news sources, at scale and longitudinally over a period of years.
Indeed, while our central interest is in applying this approach to the dissemination of problematic news sources, the methodological framework we describe here can be applied just as productively to the sharing of legitimate news content on Facebook, or indeed to the sharing of any other set of sources. However, in order to document and demonstrate our approach in practice in this article, we draw on the work of a number of earlier studies, predominantly focussing on the challenge of “fake news” in a US context, that have published substantial list of suspected sources of problematic information. We do so without passing judgment on the quality of these classifications, and encourage any researchers interested in implementing our approach in their own work to carefully review the lists of suspect sources upon which they build. How we compiled our list of potentially problematic sources, which we have dubbed FakeNIX, is explained below; first, however, we briefly outline the concept of the methods stack.
The Stack Approach
Computational communication science is an emergent discipline that centers of the use and development of computational approaches to facilitate communication research. From early studies of “big data” (D. Lazer et al., 2009), computational communication research has evolved to now encompass a sensibility toward not only the use of computational methods and data, but also an openness regarding precisely how these methods are developed, applied, and shared among the scholarly community (van Atteveldt et al., 2019). While much of this scholarship is focussed on reusability of data and code, ethics, and infrastructures (D. M. J. Lazer et al., 2020), another important consideration is how we convene discussions regarding the eventual selection and configuration of these research methods.
Like other computational communication research, tracking the dissemination of problematic content in large multi-platform information ecologies necessitates complex interconnected and “stacked” computational processes. As defined by Leeftink and Angus (2023), stacks are a form of technical-knowledge architecture, and a pliant metaphor for helping discuss such computational-heavy method assemblages. Stacks refer to the chained processes that constitute most of our modern computational communication research methods, from data collection, cleaning, pre-processing, analysis, and communication.
Stack thinking involves more than just open technical descriptions of the various building blocks that comprise a specific research stack; it also involves open discussion of the rationale and reasoning behind specific components, whether these are driven by technical, social, or other considerations. An aim of stack thinking therefore is to usefully highlight not only the components within the stack but also points of potential failure. Stack thinking supports the open discussion of the full rationale of methods design, and for these reasons, we adopt it as a guiding approach throughout this article.
The stack that we developed relies on a combination of proprietary data services including Meta’s official Facebook data access service CrowdTangle and Google BigQuery (for data storage), and open-source software that includes Gephi, Python’s Gensim and LDAvis libraries, and additional custom Python code. The overall stack supports the identification of public pages and groups on the Facebook platform that share links to websites in our custom “FakeNIX” domain list over a multi-year period, ranks these pages and groups in terms of their centrality in the circulation of problematic information on the platform, then supports further data gathering of all public facing content from a subset of the most highly ranked pages and groups over the same period.
A significant consideration in the stack design is managing the large volume of content surfaced through this multi-tiered content discovery process. Analysis of various data gathered through this process is enabled through a combination of network, linguistic and topic modeling tools, in addition to descriptive statistics which we will outline and detail below. While the data discovery process is moderately customizable, the overall analytic workflows enabled through this stack design are limitless, hence, we outline a number of approaches we have used, but stop short of providing a declarative and constrained approach, instead encouraging future users to exchange, modify, and extend these analytical pipelines.
Methodology: The FakeNIX Stack
Our research stack is a highly chained (sequential) set of computational processes with significant networked dependencies (see Figure 1). Two main analytical pathways are enabled from two data collections, an initial set of Facebook posts from over 900,000 Facebook entities that include links to the FakeNIX domain list, and an extended set of all public posts gathered from a subset (n = 954) of top-ranked Facebook entities selected from this first set. In the following sections, we detail each element in this stack, starting at the FakeNIX Domain list, and proceeding through to the topic modeling and semantic network analysis components.

The overall computational methods stack.
FakeNIX Domain List: Constructing a Masterlist of URLs
Foundational to this stack is the establishment of a robust initial seed list of outlets suspected of publishing “fake news,” in its various definitions; we have labeled this list the Fake News Index, or FakeNIX. In compiling this list, we have followed the approach taken in Vargo et al. (2018), who created a meta-list of suspect sites that was itself compiled from the lists of “fake news” sites offered by various fact-checking services and research projects. We note again here, however, that the methodological framework described in this article does not rely inherently on the FakeNIX list of potentially problematic sources; it can be used with any initial masterlist of domains, constructed according to whatever criteria are most appropriate to the specific research project.
Using this approach, our project team compiled a new masterlist of over 2,300 sources of problematic news content that have been identified in the existing literature and related research projects. These include the major studies by Allcott et al. (2018), Grinberg et al. (2019), Guess et al. (2018, 2019), and Starbird et al. (2017), as well as public lists of problematic sources posted by the public dashboard project Hoaxy at Indiana University (Shao et al., 2016), by Merrimack College researcher Melissa Zimdars (Zimdars, n.d.; cf. Zimdars, 2016), and by BuzzFeed News editor Craig Silverman (2016). Indeed, several of these studies in turn build on each other, meaning that our list of problematic domains represents a new iteration of an ongoing, distributed, collaborative process between different research projects that aims to compile a list of problematic sources that, due to the rapid evolution of the disinformation landscape, can never be comprehensive, but contains at least the most significant and persistent sources of such content.
As there was considerable overlap and consistency between these iteratively produced lists, the final FakeNIX list used for this study contained a total of 2,312 domains. We note here that in our approach to compiling this list, we have refrained from including those additional domains which Grinberg et al. (2019, Suppl. 17), labeled as “yellow (low-quality journalism),” in order to maintain a focus on explicitly problematic news content rather than also track the circulation of merely sensationalist and tabloid reporting. We also note that, due to the selection of prior studies from which our list was compiled, and the overall focus on American and Anglophone “fake news” that persists in much of the literature, the domains on our list mainly address problematic news in English, meaning that our project is also limited largely to English-language (and here especially US-centric) news-sharing practices; however, our analysis of FakeNIX sharing patterns shows that such content is also shared widely in other national and language communities (including German, French, Spanish, Italian, Indian, and Brazilian). In future research, we intend to replicate the approach outlined here also for lists of problematic domains from other contexts—for instance, by building on the domains that the EU vs Disinfo project has documented to have posted pro-Russian mis- and disinformation aimed at European audiences (East StratCom Taskforce, 2022). In summary, the principal “output” of this stack element is a text list of URLs.
CrowdTangle Data Gathering
CrowdTangle is one of Meta’s official data collection portals, and offers a web-based dashboard and an Application Programming Interface (API). Both tools allow for the download of a subset of public Facebook and Instagram data, which includes most major public pages and groups indexed by the service. As a proprietary data access tool Meta controls access to CrowdTangle, and has come under increasing scrutiny regarding this gatekeeping approach, particularly recently when all new approvals for access were suspended (Reuters, 2022).
A further limitation of CrowdTangle is that the service does not provide independently verifiable statistics as to the extent of its coverage hence we cannot comprehensively know how the coverage matches the reality of the social media platforms themselves. Further still, data which is geo-blocked, age-restricted, or that which has been deleted (either by the platform or voluntarily) is not indexed. CrowdTangle must thus be seen as a data access portal, rather than as an archive. There have also been significant staff cuts and rumors regarding the ongoing sustainability of CrowdTangle which is of concern given its value in the conduct of this kind of research (Alba, 2022). Hence, a minor additional value of the exercise we undertake here is to create an archive of these problematic materials that can be maintained independently of the platform itself.
Within CrowdTangle, different dashboards can be set up through the web-based interface. Lists can then be created to monitor different public pages or groups indexed within CrowdTangle database. An API request takes the standard form of the following: https://api.crowdtangle.com/[endpoint]?token=[API_token]&[param1_name]=[param1_value]& [param2. . .]
Like any API, there are various parameters that can be set to limit the scope of each data query. One of the parameters is searchTerm, which allows text-based search, returning a set of posts that contain the search term, either in description text or text detected in the image through Optical Character Recognition (OCR) technology. For instance, “covid 19, vaccine refusals” will search for posts that contain “covid 19” or “vaccine refusals.” The timeframe can be adjusted through startDate and endDate. If they are set, only posts published after startDate and prior to endDate will be retrieved. inListIds is a comma-separated list of the IDs of lists to search within. 1
Various CrowdTangle API endpoints exist for different purposes. For instance, the posts endpoint searches the entire, cross-platform CrowdTangle database. Search terms are not required for the posts endpoint, meaning one can retrieve all posts without limiting to posts that only contain certain keywords. It will retrieve all posts from a list of accounts of interest or even the entire CrowdTangle database. The caveat is a token has a set rate limit associated with each endpoint. For each token, the posts endpoint allows six requests per minute at a maximum of 100 posts returned per request. The posts/search endpoint requires a search term, can be limited by lists and accounts, and has a same rate limit of six requests per minute. The links endpoint is used to retrieve posts that shared other Facebook post or a link from an external domain. These posts can be queried by the parameter link. This links endpoint has a rate limit of two requests per minute with maximum 1,000 posts returned per request. The links endpoint enabled us to curate an initial list of any Facebook pages/groups indexed by CrowdTangle that had shared links from the FakeNIX list.
Given the rate and return limits of the CrowdTangle API, we designed and deployed a custom python library “Crowd” to automate the process of curating data from the API through a few simplified steps. 2 To use Crowd, users need to first create a dashboard or multiple dashboards to acquire API token(s) from CrowdTangle. Once the code is downloaded and the environment is set up properly, users can select from one of the provided templates to set up the configuration and/or parameters to run a query. Different configuration templates (yaml files) are provided for different API endpoints and purposes. Parameters including the API token are set within the yaml file. The “crowd -c config.yml” command will then take all the parameters within that yaml file and run the tool accordingly. A request made using Crowd will return a list of Facebook posts in JSON format. An extra step is required to flatten each post, including separating an attribute that has multiple values and storing them in another table while using the platformId (unique identifier for the post) to link them back to the original post. For instance, a post can contain multiple images, and each image has a unique URL, those URLs will then be stored in a separated table alongside the platformId. The processed data would then be stored to a user-specified location in the yaml file, either locally on a desktop/laptop or using cloud storage. To date, we have designed support for Google Cloud through the specification for Google BigQuery dataset and table ids, future work could expand this to other cloud storage platforms.
Using the FakeNIX list as the primary input into this stack element (in addition to a time window over which to search), we retrieved all available Facebook posts, limited to public pages, public groups, and public verified profiles (henceforth, public spaces) that contained links to content on any one of these domains. While we are limited to assessing only the public dissemination of such content on Facebook, we suggest that further dissemination in private spaces is substantially driven by such public visibility. Using the CrowdTangle API, we gathered data for the period of 1 January 2016 to 31 March 2021, resulting in 42.6 million posts from 918,760 public spaces on Facebook. The overall distribution of collected posts reveals early spikes in FakeNIX-related posting activity in 2016 corresponding to the 2016 US election, and later spike in activity in 2020 corresponding to the COVID-19 pandemic, 2020 US election and 6 January 2021 USA Capitol Hill insurrection (see Figure 2).

The volume of posts (by week) containing problematic links collected from CrowdTangle using the FakeNIX list.
Network Analysis: Bipartite and On-Sharing Networks
With a database of 42.6 million Facebook posts, all of which contain at least one URL linking to an entry in our input FakeNIX list, we are in a position to construct the first analytical output of this stack, a network analysis. For this, we constructed two kinds of networks, bipartite Facebook/URL networks, and on-sharing networks.
The bipartite networks we construct connect Facebook pages/groups, from here on referred to as Facebook entities, to the domains that they embedded or shared (what some may be familiar with as outlinking). Bipartite networks are those whose nodes belong to two disjoint sets, in this case a set of Facebook entities, and a set of FakeNIX URLs. Edges connect nodes of the disjoint sets, but not within these sets, that is, Facebook entity → URL. This entity-domain network is constructed by stripping the extended URL details embedded in each Facebook post down to just the original FakeNIX domain, for example, site.com. The entity-domain network reveals sites that act as connectors for a diverse array of Facebook communities, or as central hubs for major clusters, and also the emergence of sub-networks that form around shared topical interests, such as specific conspiracy theories or ideologies.
A feature of CrowdTangle’s search function is that “embeds,” posts where one Facebook entity shares the content from another entity that contains an outlink to a FakeNIX source, are also captured through our data collection. We therefore also created a second on-sharing network that directly links these Facebook entities together. The on-sharing network is useful in tracking internal Facebook user migration and shared attention, specifically how some Facebook entities may co-opt followers through cross-linking activities. While the post that is embedded contains an outlink to a FakeNIX source, the on-sharing network is only concerned with the connection between the Facebook entity that originally posted this outlink, and the entity that embedded/shared this entity’s post. All networks are constructed using the Gephi open-source network modeling package (Bastian et al., 2009).
Rank Product Filtering: Sources for Extended Data Collection
The initial collection process based on FakeNIX, and subsequent network analysis provides many rich insights into the patterns and dynamics of link-sharing, but it is also important to consider other materials posted by the Facebook entities identified. Aside from posts that contain direct links to known problematic URLs, what other kinds of public content typify these various communities? Given the initial search netted some 918,760 Facebook entities, and that CrowdTangle’s rate limits are not designed for such transfer volumes, it is impractical to attempt to gather all content from these individually identified sources. Instead, we devise a ranking scheme to isolate a subset of 1,000 (500 pages and 500 groups) entities for deeper thematic analysis.
Explained in input/output terms within our stack, at this point of the stack, we are interested in filtering a longlist of identified Facebook entities (in the hundreds of thousands) down to a focussed shortlist (in the hundreds) of the most interesting entities (given a specific ranking criteria), and in gathering the entire public contents (posts) of the shortlist for further analysis. The input therefore is a list of Facebook entities, and the output a list of public Facebook posts.
There are many qualities that can be considered useful in whitling down such a longlist to a core set of the most “influential” entities. To assist in our process, we adopt a technique from population genetics called the rank product (Breitling et al., 2004), which usefully combines multiple distinct (possibly non-parametric) quantities into a single rank. Rank product can be understood as a simple geometric mean of the combined ranks of multiple quantities of interest. Based on metrics available to us from CrowdTangle, we settled on the following four measures: subscriber count, domain count, link count, and post engagement which we expand upon below. Each quantity was ranked individually, and the rank product calculated as follows:


Subscribers is the number of page subscribers, noting this metric is not available for public groups as CrowdTangle does not expose a metric for the number of group members. The rationale for including subscribers is to identify those pages that have larger audiences and therefore more potential influence across the platform. Domains and links relate directly to the FakeNIX list, domains being the count of distinct FakeNIX domains linked to from this Facebook entity, while links is the total count of posts that include FakeNIX domains, regardless of which specific FakeNIX domain they link to. Domains therefore is a proxy measure for the diversity of distinct FakeNIX sources, to locate those entities that link to a greater variety of FakeNIX sources, while links are a measure of sustained attention toward the sharing of FakeNIX sources. Finally, engagement is a measure of reception by the Facebook community following this Facebook entity, it is a sum of all standard Facebook engagement measures (likes, reactions, comments, and shares). Engagement attempts to capture the extent to which FakeNIX-related content is received and encouraged by community.
Using the page and group rank products, we identified 500 pages and 500 groups that shared links to these sources most actively, generated the most engagement, and or had the most followers, and for this combined list of 1,000 spaces gathered all of their available posts (independent of whether these posts linked to the sources in our masterlist or not). This more comprehensive data collection process utilized the Crowd tool, but due to the considerable length of time involved (several months) in acquiring these data, a small number of pages and groups disappeared from CrowdTangle. These few pages (19) and groups (27) were likely removed by Facebook, or deleted by the page/group admins. At the end of several months of data collection, we amassed ~70 million posts from 481 pages, and 473 groups, spanning 1 January 2016 to 31 December 2021. This extended collection enables us to examine whether these spaces linked exclusively to problematic news sources or mixed such sources with more mainstream outlets; and what topics these spaces addressed in their day-to-day activities.
Topic and Semantic Network Analysis
We use these extended page and group datasets to inform longitudinal and in-depth analysis regarding what additional materials are shared and discussed within Facebook entities that play a significant role in the sharing of FakeNIX content. These last analytical components of our stack are designed to enable quantitative and qualitative interpretation, through a combination of network and content analysis. Here we include computational content analysis to determine the thematic focus of the Facebook spaces included in the extended dataset (Angus, 2022), and network analysis to identify overlaps in content focus using a semantic similarity network approach (Angus & Wiles, 2018). We use temporal information throughout to examine how such patterns evolve over time, against the context of world events.
Facebook posts contain an array of text material, including descriptions, captions, and link summary text. We combined these various text fields into a singular text field per-post. With the intention of performing topic modeling using Latent Dirichlet Allocation (LDA), we aggregated posts into individual quarters (2016 Q1, 2016, Q2, . . . , 2021 Q4), per Facebook entity, producing a total of 22,896 input texts. These text files were then fed through Python’s Gensim LDA model implementation beginning at 10 topics and increasing the number of topics two at a time to the point where increasing the number of topics tends to have no marked improvement in coherence scores. For this, we found that 40 topics produced a stable number of distinct and interpretable topics for the corpus. Outputs from the topic model included aggregate topic weightings for each Facebook entity, and topic weightings per quarter. Outputs also included word sets and weightings associated with each topic for interpretation of the topic and its latent meaning.
We also produced word count and bigram statistics for the entire corpus (broken down per Facebook entity), as an additional mechanism to thematically characterize and interpret each individual entity in the extended data collection. Word statistics like this, when combined with topic models, can be a simple but effective way to qualitatively profile input texts (Angus, 2022). Bigrams, in particular, can be a useful mechanism to surface repeated slogans or sign-offs (god bless), issue references (climate change), and other common multi-name entities (e.g., Donald Trump, White House).
Analysis
Bipartite and On-Sharing Networks
The bipartite entity-domain network links 918,760 Facebook entities with the 2,312 unique sources of problematic information (from the FakeNIX list) on which they draw using weighted edges reflecting multiple shares of the same domain by that entity. We used the ForceAtlas 2 network layout algorithm (Jacomy et al., 2014), 3 finding that it gave the best trade-off between performance and interpretability given the size and scale-free nature of the network. The on-sharing network was constructed through the same process as the entity-domain network.
These networks reveal a structure of URL posting (outlinking) and on-sharing that is dominated by large clusters of Facebook entities that are broadly aligned with the conservative and progressive sides of domestic US politics (see Figures 3 and 5). This US-centrism is partly a result of the largely US-centric lists of problematic information sources that we build on, but possibly also due to the hegemonic nature of US politics on the global stage. Focussing on the entity-domain network, on the conservative side, hyperpartisan right-wing domains such as The Daily Wire and Breitbart are central information hubs, connecting several smaller communities that center on Second Amendment rights, Christian evangelism, and Tea Party politics. For progressives, domains such as Occupy Democrats and Common Dreams are among the most prominent, and links from these domains are shared by communities that are supportive of the left-wing US senator Bernie Sanders, or critical of the democratic establishment more broadly.

Entity-domain network overlaid with dominant thematic clusters that emerge from the dissemination practices within public Facebook spaces, 1 January 2016 to 31 March 2021.

Detailed zoom of the entity-domain network visualization in Figure 3, focussing on conspiracist and alternative worldview clusters.

The Facebook on-sharing network (Facebook entities linking to other Facebook entities), for the entire 1 January 2016 to 31 March 2021 period. Clear community structures determined using Gephi’s modularity algorithm (colored and labeled) are visible within the on-sharing network, organized around national politics, and other thematic groupings (climate change, alt-health).
The entity-domain network also contains several clusters representing international interests, especially from France, Germany, Italy, Brazil, India, and the United Kingdom. These broadly geographically defined groupings, in turn, are loosely connected by a range of interests that are shared across the network (see Figure 4): from anti-vaccination, and alternative health and medicine clusters (which have been especially active since the emergence of the COVID-19 pandemic) through to alternative finance spaces promoting cryptocurrencies and related services (here, the libertarian finance blog Zero Hedge dominates). Both conservative and progressive Facebook spaces occasionally also share such problematic content (such as alternative treatments for autism, unproven medicines to combat COVID-19, advice on emerging cryptocurrencies, or conspiracy theories). This demonstrates that the dissemination of problematic information is not limited to overtly political topics, nor always neatly aligned with simplistic political scales from right to left.
Further in-depth analysis of these network structures, drawing on a mixed-methods approach that incorporates both computational cluster detection using the Louvain modularity algorithm (Blondel et al., 2008) and manual close reading and interpretation of the Facebook metadata for the most prominent spaces in each cluster, shows that these broader groupings often subdivide into smaller subordinate clusters. Figure 5 demonstrates this for the archipelago of clusters in the on-sharing network, ranging from outright conspiracy theories through alternative health and medicine to esoteric beliefs in astrology (also seen in the entity-domain network in Figure 4). It is notable that such conspiracist and alternative knowledge sources often serve as a bridge between otherwise opposing ideologies; again this suggests that individuals and communities at the fringes of mainstream political movements are especially open to engagement with other, not inherently political fringe worldviews as well.
It is within the on-sharing network that we also see the influence of Russian state-backed media outlet Russia Today (see Figure 6). RT is a well-known source of Russian state-backed propaganda and conspiracy thinking, and positions itself as an “outsider” to the normative political discourses of the countries it is located within (Glazunova, 2022). The central location of RT-aligned Facebook entities here reveals the extent to which RT uses on-sharing practices as a mechanism of influence within the Facebook ecosystem, and their trans-national multilingual engagement activities (Glazunova et al., 2022).

The on-sharing network visualization from Figure 5, but this time focussing on a specific cluster of RT-related Facebook entities that are centrally located within the network.
While RT seems to act as the central “broker” in the middle of the on-sharing network, returning to the entity-domain network, it is notable that in spite of the considerable ideological differences especially between the more overtly political progressive and conservative clusters, there nonetheless appears to be a considerable amount of cross-linking between them—indicating that conservatives post links to problematic sources that are predominantly associated with progressive US politics, and vice versa. We speculate that this points in the first place to a practice that may be described as oppositional or “hate-linking” (cf. Roberts & Wahl-Jorgensen, 2020), where partisans from one side of politics draw attention and link to the content in outlets from the other side in order to criticize and condemn those counter-ideological views. If so, this would represent a continuation, on Facebook, of the earlier practices of explicitly oppositional reading by hyperpartisan activists that Gentzkow and Shapiro (2011) identified as early as 2011: in their example, “visitors to stormfront.org, a ‘discussion board for pro-White activists and anyone else interested in White survival’, are twice as likely as visitors to Yahoo! News to visit nytimes.com in the same month” (p. 1823).
Entity Ranking and Thematic Analysis
The rank-product process surfaced 954 Facebook pages and groups from which we obtained all public posts over a 6-year period. The entire contents were profiled using an LDA topic model which produced 40 individual topics that largely broke down into the following thematic groupings, noting that some of the thematic descriptors combine several topics. The topics included vary in prominence as well, and future analysis will more fully unpack these results and provide richer descriptions and examples of these topics and their proponents:
Conspiracy and alternative viewpoints: Earth, wellness, and new-age spirituality, with alignment to African and Indigenous themes Natural food and recipes Anti-vaccination
Politics: US Conservatives, Pro-Trump, MAGA US Progressives, Bernie Sanders fandom Italian right-wing populism Vietnamese Brazilian politics (leans pro-Bolsonaro) Filipino politics (leans pro-Duterte) Turkish, Norwegian, and Swedish politics (leans pro-Russia) Hindi news (leans pro-Modi) Israel and Palestine
Miscellaneous: Religious issues from a Catholic and Evangelical perspective Entertainment, media and sport with a focus on Black and lesbian, gay, bisexual, transgender, queer, intersex (LGBTQI+) perspectives Crime, law enforcement
These thematic groups largely align with themes observed from the initial collection and entity-domain and on-sharing networks. We do note, however, extended reference to wellness, spirituality, and a problematic co-option of Indigenous tropes in one highly prominent thematic cluster. We also observe a stronger focus on crime and law enforcement narratives, centered on critical US mass shooting incidents, and racialized policing (from a conservative standpoint). Much of this discussion relating to police is from the entities affiliated with American multinational conservative cable news television channel Fox News, as well as other local US cable news entities.
Examining the bigrams from the extended collection (see Figure 7) reveals a strong focus on American Political figures: Donald Trump, Hilary Clinton, Bernie Sanders, Joe Biden, and Barack Obama. Largely polarizing US political issues are also present in this list, with the law enforcement theme reflected in “police officer,” ongoing issues with respect to the highly partisan US “supreme court,” in addition to long-running issues of “health care” and “climate change.” We also note that the bigram data support that it is largely Facebook groups (not pages) that tend to orient strongly toward the religious issues identified in the thematic clustering above.
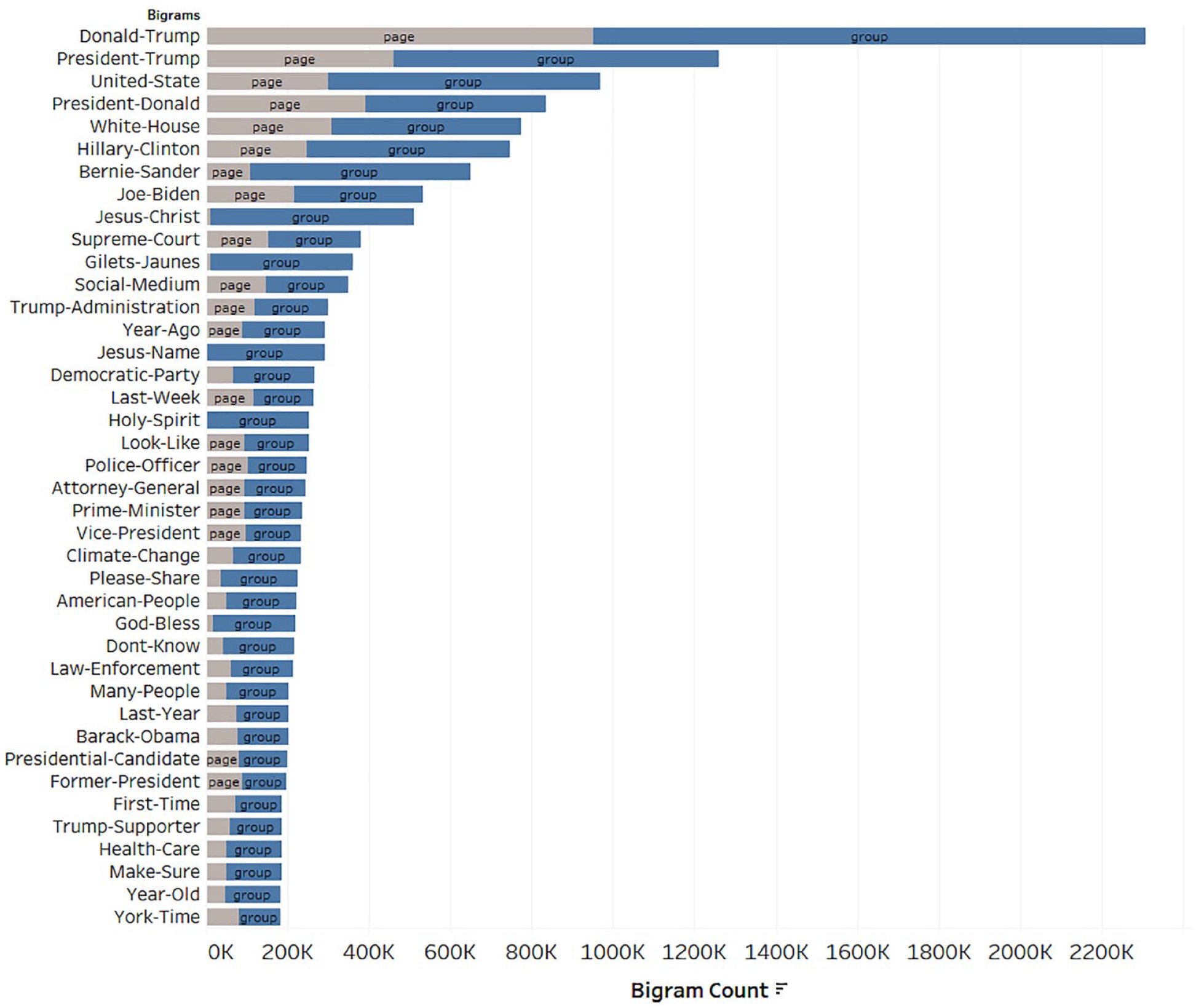
Top 40 bigrams generated from text fields in posts from the 954 Facebook entities in the extended collection.
We also use the LDA topic weightings per entity to project these 954 Facebook entities into a semantic similarity network (see Figure 8). This semantic map groups entities according to the degree of semantic overlap. Within this map, we note a significant concentration of pro-Trump accounts at the top of the network, and conspiracy outlets toward the bottom of the network. We also note far-right US political agitators such as Tucker Carlson and Ben Shapiro concentrated throughout the center which may reflect their role as key agenda setters in this ecosystem. Not shown in this network are several peripheral sub-clusters that link to entities in non-English language groups, which is unsurprising given the bias toward English in the underlying corpus will naturally lead to these entities preferentially clustering with other entities in their own language group and be pushed away from the central core.
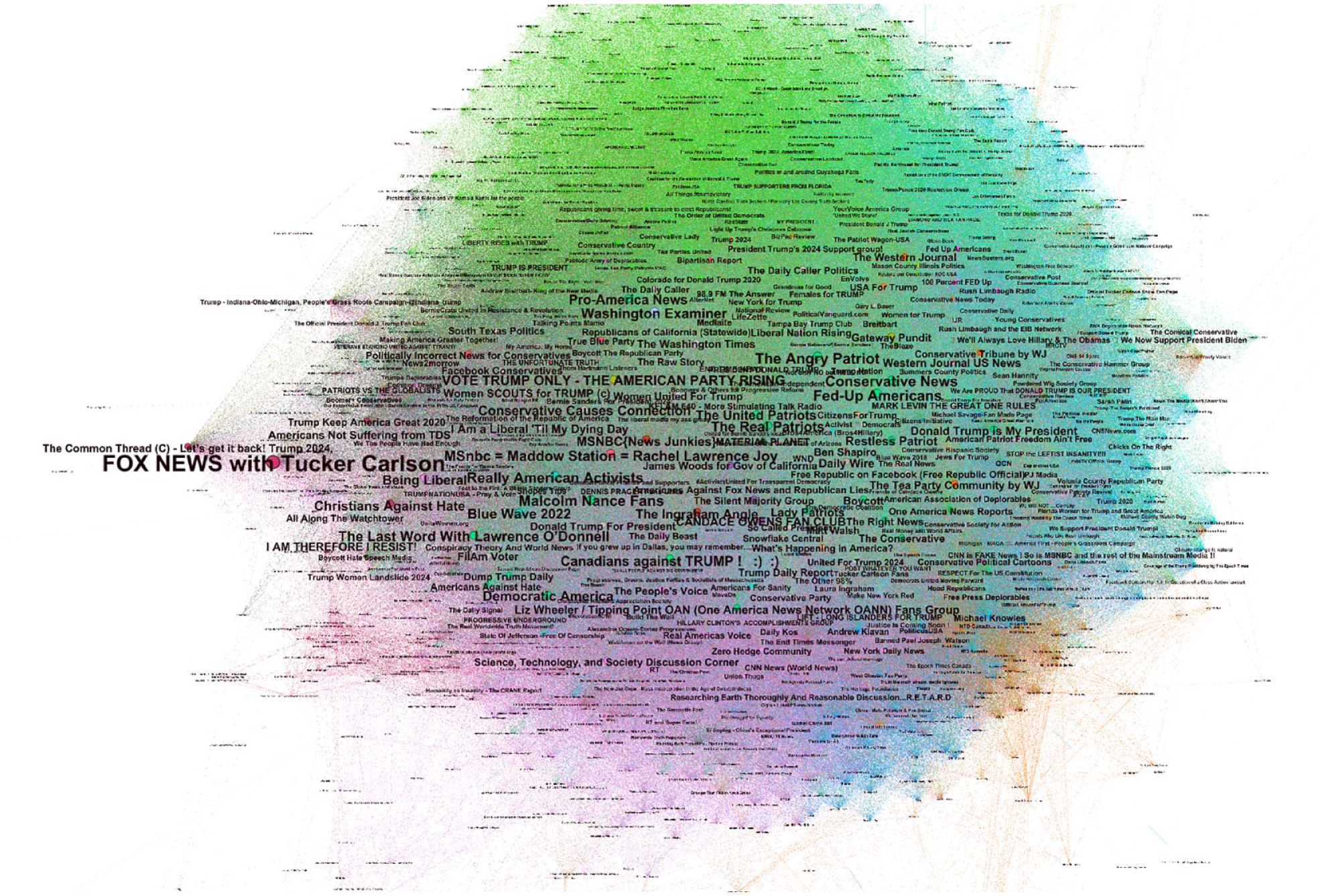
Semantic similarity network for the 954 Facebook entities from which we obtained 6 years’ worth of posting activity.
While difficult to capture in a static article such as this, we also utilized Gephi’s temporal network capabilities to map the semantic similarity network over the 6 years captured, quarter-by-quarter. The dynamic semantic similarity network reveals a significant realignment of nodes at the advent of the COVID-19 pandemic in Q1-2020, which leads to clusters relating to conspiracy thinking and alternative health becoming much more centrally located in the overall network, where they had previously been largely isolated in a sub-cluster at the periphery of the network.
Discussion and Future Directions
This analysis has provided a glimpse into the many analytical avenues afforded through this new computational stack. The initial composition of the FakeNIX list and extraction of content linking to these materials through CrowdTangle allowed for the identification and thematic categorization, for Facebook, of the public pages and groups that are most active in linking to identified sources of problematic information. We extended beyond this initial identification process using a ranking approach that identified and ranked the influence of sources of problematic information shared by these public spaces on Facebook. Our network-based analysis approaches using domain-entity and on-sharing networks then allowed an examination of the themes and topics addressed, and the sources linked to, by the most active such public pages and groups. For the extended collection, this was expanded to include additional activities beyond the sharing of problematic news content, analyzed using topic modeling and semantic network analysis.
It must be acknowledged that this stack relies heavily upon access to Meta’s CrowdTangle platform which is a proprietary data access and analysis platform that is not available to all researchers. The analyses afforded by this stack showcase the value for platforms, both in terms of general societal good, but also for their own benefit in improving the quality of their platform experience for users, in providing access to data. We strongly advocate for the expansion and further democratization of such data access (Bruns, 2019a), highlighting the many and varied avenues of valuable research that could be enabled through such (Pasquetto et al., 2020).
In further work, the stack, or indeed any single stack component, could be expanded or refactored through additional qualitative and quantitative analysis techniques. Our analysis of the dynamics of content sharing over time, as one example, only begins to explore the many possibilities, that could include much more detailed examination of specific themes and ideas and their evolution, especially in response to major events such as the 2016 US presidential election campaign; the early controversies surrounding the Trump Administration; the emergence of the COVID-19 pandemic; the 2020 US presidential election campaign; and the events surrounding the 6 January 2021 attack on the US Capitol. Such analysis could examine the shift in sources circulating through the various clusters in these networks, the rise and decline of specific Facebook spaces as especially active or influential hubs in the network, and the evidence for coordinated posting and sharing activity among these spaces.
Another avenue of investigation afforded through this stack, which we briefly examined, was the presence of counter-ideological reading and linking. This concept is particularly important as it provides necessary counter-evidence to controversial theoretical concepts such as “echo chambers” or “filter bubbles” (Bruns, 2019b). It would be inherently counterproductive for political hyperpartisans and conspiracy theorists who see it as their mission to relentlessly criticize their political opponents and/or convince new audiences of the righteousness of their cause to sequester themselves in hermetically sealed information cocoons; rather, it must necessarily be their mission to break through into new information spaces, and to engage, constrictively or disruptively, with the participants there. Our initial domain-entity, and on-sharing network analysis provides starting evidence to support such a claim.
Another direction is to extend the sources included within the FakeNIX list of problematic information sources, perhaps in an iterative fashion. Using our ranking approach, we have identified the most prominent, active, and influential Facebook spaces based on metrics that incorporate their count of followers, the volume of user engagement they received (including likes, reactions, comments, and on-sharing), the number of links they posted, and the number of distinct domains they linked to. In combination, these metrics result in an aggregate ranking that balances spaces that have many followers but are relatively inactive; spaces that have fewer followers but generate high levels of engagement; spaces that are highly active but focus mainly on a single source of problematic information; and spaces that draw on a wide range of sources: in short, it produces a diverse cross-section of Facebook spaces in our dataset that are performing strongly against one or more of the major activity and engagement metrics that are commonly used to describe the Facebook performance of such spaces. It is possible then to examine the most prominent websites shared in addition to our initial list, and assess any missing sources for potential inclusion.
Future possibilities aside, the most significant limitation we identify with the stack as presented is one that is outside of our direct control, that it is highly fragile due to the ongoing uncertainty relating to CrowdTangle as a stable and well-maintained data access tool (Alba, 2022). This underscores the importance of continuing efforts from academics, civil society, and governments in doing everything possible to force platforms to provide, and indeed expand data access for public interest research (Bruns, 2019a). This fragility however is only in reference to CrowdTangle, and despite this, the overall stack is highly reconfigurable, a simple refactoring of the Crowd component that gathers data from a platform of interest using the FakeNIX list would see the stack able to be utilized on a wide variety of social platforms where such domain-based search/retrieval functions exist.
Finally, then, such work is also grounded in and builds upon conceptions of disinformation as collaborative work (Starbird et al., 2019). It is now well understood that successful and persistent mis- and disinformation dissemination is not simply the work of small teams of human operators or automated bots, but relies crucially on involving a larger network of genuinely supportive “true believers”: it employs the principles of crowdsourcing to facilitate the spread of problematic information. Through continuing mixed-methods, qualitative and quantitative analysis of the discursive strategies of the 954 most prominent Facebook pages and groups whose longitudinal activities are captured in our dataset, we can begin to pay particular attention to how these actors attempt to engage ordinary human participants in their efforts to further their hyperpartisan worldviews.
We leave off then where we began, that we pursue this work in the first place to arrive at a more distinct understanding of the various forms of mis- and disinformation that are commonly encapsulated under the problematic term “fake news,” and to develop a more diversified set of definitions for such problematic forms of information; this continues and extends the important efforts of scholars such as Wardle and Derakhshan (2017) and Jack (2017). This improved understanding—which should not remain limited to Facebook as a platform for such information disorder, of course—is intended to assist in further efforts to combat problematic information online, informing platform providers’, policy-makers’, media literacy educators’, and other stakeholders’ efforts to prevent, reduce, and counteract the spread of mis- and disinformation. In addition, the development of more specific definitions for the different forms of mis- and disinformation that are circulating online also contributes to our and other researchers’ efforts to study the public discourses around the problematic term “fake news”: we hope that greater conceptual specificity will also reduce the use of “fake news” as a defense mechanism in political debate.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Department of Education and Training > Australian Research Council DP200101317