
Abstract
Being tired of businesses exploiting user data for financial gain, individual data subjects are increasingly demanding a “fair share” of their data. Although recent policy efforts have addressed such public claims with ideas for a better deal (e.g., data dividends) or a better rule (e.g., data taxation), multiple proposals have catalyzed multiple intricacies than solutions. This article investigates the potential of an incentivized blockchain-powered social media platform as an alternative “third path” to better exercise our data rights. Drawing on Steemit, one of early blockchain social networks that pay its users for generating content, this study conducted topic modeling and content analyses to examine how ordinary users voluntarily and deliberately share aspects of themselves in their user-generated contents (UGCs) and how such “investment” was actually rewarded. Our finding suggests discreet behaviors of users in using personal details despite reward expectations. Users were more likely to share “qualified” aspects about self, such as life vision or philosophy, and personal traits than statistics-driven conventional demographic profiles. They also have implemented various privacy-aware identity strategies, characterized by the clear separation of personal and professional identities in online space. From the value standpoint, our findings reveal that the more one shares about oneself, the higher the reward and thus the realized value. The study discusses implications of this alternative technological solution for understanding data rights and privacy concerns in the context of the emerging economic layer on the platform.
Keywords
Introduction: An Uneven Playing Field for Data Subjects
In the era of ubiquitous connectivity, where a wide range of daily human activities in the digital domain is continuously datafied, data is becoming an asset that accelerates the exponential growth of the digital economy. People leave countless digital footprints with everything they do online, which then become converted into commodity values by businesses using their data (Samuelson, 2000; Zuboff, 2019). Data then becomes a base of wealth.
With this growing value of data in mind, one can ask: where is the “fair share” of the data users generate every day? A massive dataset reflecting one’s actions can have value as an expression of intangible individual investment, intellectuality (Reichman & Samuelson, 1997), identity, and creativity (Terranova, 2000; van Dijck, 2009) in the context of intellectual property and privacy rights. It can also have value as “behavioral surplus” extracted from user engagement (Zuboff, 2019), digital labor and audience commodification (Fuchs, 2015; O’Meara, 2019), or for Big Tech firms “appropriating” individual subjects (Couldry & Mejias, 2019) in the context of data capitalism and platforms. Whatever the basis for the value of data, it is not hard to trace the contribution of a data subject to each byte of data derived from numerous forms of online activities, including personally identifiable information (PII), web cookies, browsing and location histories, and a variety of user-generated content (UGC). Given this context, it is reasonable that humans, as producers, should be entitled to ownership rights over their data—rights that encompass not just the “ability to access, create, modify, package, or remove data” but also that strongly assure the right to “derive benefit from or sell data, or assign these access privileges to others” (Loshin, 2002, p. 31).
However, such rights to data ownership have not been sufficiently addressed by current legal and regulatory frameworks. For example, personal data is not yet a category of intangible intellectual property in US law (Glancy, 2010), and the term “ownership” has not been explicitly legislated (César et al., 2017). Data produced online are subject to an incomprehensible patchwork of sectoral laws and self-regulatory rules (Schwartz, 2012, p. 1623) and collected through strong-armed end-user license agreements that remove users’ control and rights. Similar problems exist in EU law, which never explicitly defines the concept of ownership of data (César et al., 2017; Janecek, 2018). This is true even of the General Data Protection Regulation (GDPR), one of the most powerful data protection regulations in the world. Throughout most of legal history, individual subjects’ data have been considered a matter of privacy and security rather than a matter of property and ownership (Wiebe, 2016; Wilks & Christie, 2013). Databases storing user data are copyrightable under intellectual property law using the principle of investment, originality, and creativity, but this is just a case sui generis (Boyle, 1996; Reichman & Samuelson, 1997).
Recently, there has been considerable focus on strengthening privacy and data rights legislation, evident in the EU GDPR, the California Consumer Privacy Act of 2018 (CCPA, 2018), and the California Privacy Rights Act of 2020 (CPRA), to facilitate users’ control over their data. These actions have stimulated other US states, such as New York, Virginia, Colorado, and Washington, and other countries, such as Brazil, to consider and enact more comprehensive and stronger data privacy laws from 2019 to 2021. However, it is still unclear how these actions will actually affect end users and what the intended and unintended or beneficial and damaging consequences of them will be.
Moreover, industry and government partnerships have strengthened to fully exploit the economic value chain of privatized and commoditized information (Schneier, 2015). The symbiotic cooperation between industrial and governmental sectors, driven by the long-ingrained spirit of market liberalism and national advantages, has always played a winning game with data. These actors have easily dismissed the question of fairness of the “deal” between data compilers and data subjects by claiming the trade-off between data privacy and the benefits of sharing data (Acquisti & Grossklags, 2005).
Recent years have exposed this contradiction in the data value chain: data has become one of the most valuable resources, which cannot be depleted while creating endless possibilities for companies, but a data subject can rarely evaluate or claim ownership over their everyday data contributions. Several policy proposals have been put forward to address this issue. Some argue for a better deal that allows people to get paid or opt-out of data collection (“Data Dividend Project,” Yang, 2021). Others call for a better rule by suggesting ideas related to data taxation (Thimmesch, 2016) or the Data Fiduciary model (Balkin & Zittrain, 2016; Whitt, 2019). However, these solutions have faced several difficulties, which have prevented them from actually being implemented.
Facing this conundrum, this study attempts to shed light on the “third path” that alternative technological solutions may bring by studying Steemit (https://steemit.com/), an incentivized and decentralized social network platform where users can be paid directly for the value they create, contribute, and share. Our focus is to investigate how users share aspects of themselves in their content and how this sharing is associated with the rewards connected to data. In the end, we elucidate the implications of this nascent social media platform for understanding data rights and privacy concerns in the context of the emerging economic layer on the platform.
Background
Steemit: BOSMs and a New Incentive Model
Steemit is a seminal form of BOSMs, Blockchain-powered Online Social Media platforms, that is characterized by four common features: (1) no central authority, (2) no censorship due to the key technological characteristics such as decentralization and anonymity, (3) rewarding mechanism for user contributions, and (4) content authenticity and quality motivated by economic incentives (Guidi et al., 2020a).
Inspired by Reddit’s provocative hypothesis, 1 Steemit was founded in March 2016 with a vision of mutually supportive communities where people can help each other with their “subjective contributions” (Steem Whitepaper, 2018, p. 3), meaning everyone’s different contribution will be recognized by the community for its added values. Unlike many other conventional social blogging platforms such as Reddit, Facebook, and Twitter, Steemit directly incentivizes users with STEEM cryptocurrency for their posting, commenting, sharing, and curating activities. Blockchain automates these value processes based on the community votes, requiring no intervention of central authority in general. Such an in-built incentive mechanism may have imposed a form of technology architecture that regulates or conditions one’s use or services in certain ways (Lessig, 2006); it may result in more user engagement and participation, including voluntary and deliberate disclosure, utilization, and sharing the information about themselves in the BOSM context.
Amid the hype over the Web 3 revolution and the availability of tools to crawl and analyze public blockchain data, recently there have been an increasing number of studies regarding the main properties of this burgeoning type of platform. Guidi et al. (2020a, 2020b) examined transaction activities and following–follower relationships on Steemit from a graph analysis perspective to understand how social and monetary aspects of BOSMs interrelated each other. Studies also paid attention to “special” actors such as witnesses (i.e., miner) and bots concerning their behaviors and influences on the platform (Guidi et al., 2021; Guidi & Michienzi, 2020). In a broader view, many scholars have examined social and economic dynamics on the Steemit network, such as the software architecture in linking and claiming rewards (Ba et al., 2022), communication patterns (Guidi et al., 2022), cryptocurrency market (Ba et al., 2020), and decentralization properties (Li & Palanisamy, 2019).
However, few studies have highlighted how the advent of an economic layer on the platform can influence user data activities in their production of content (Park, 2021). Furthermore, as studies have mainly been driven by computational approaches and large-scale data analysis, they have not sufficiently addressed the subtlety or specificity of individual productions. For example, Kapanova et al. (2020) extracted topics based on written posts on the platform, but such an approach leaves room for an in-depth qualitative understanding of the different conditions and factors that constitute the produced content.
To address these gaps, this study investigates how users share aspects of themselves in their content and how this sharing is associated with the rewards connected to data. Countering the precarious state of people’s rights to their data, which has only been loosely addressed and mainly exploited in the current legal and market frameworks, this study explores the potential of this new generation of social media for encouraging users to take greater control of the data that they generate every day.
STEEM Market: A Space of Aspiration or Cynicism
The Steemit ecosystem is based on STEEM, a unit of cryptocurrency built for the Steem blockchain applications. Every user activity on Steemit counts toward tangible STEEM rewards. This means that for most users, if not all, the STEEM value—the market price of one STEEM unit—may have been a crucial factor shaping their platform activities: the higher the STEEM price, the more motivated and active the user can be. Considering this market atmosphere as a modality of regulation, it is reasonable to assume the association between the STEEM market mood and users’ voluntary data activities in crafting UGCs. This means that our examination must be cognizant of the market conditions.
The price of cryptocurrency has been fluctuating in recent years. Several studies have reported the hype around cryptocurrency represented a Cryptocurrency Bubble, evident in the sharp rise and abrupt collapse of Bitcoin during the period from the end of 2017 to the beginning of 2018 when it lost more than half of its value (Kyriazis et al., 2020). Many other cryptocurrencies went through a similar path around that period. A Canadian economist Jean-Paul Rodrigue (2011) theorized the cycle of such an economic bubble by showing how the bubble unfolds in four stages comprised of “Stealth,” “Awareness,” “Mania,” and “Blow-off” phases (Figure 1). It describes how innovators and fast followers initially enter the market, then the price reaches a peak in value with the largest investment by the general public, and then eventually falls.

Phases of a bubble (from Jean-Paul Rodrigue, 2011).
Such a cycle to an extent resembles the changes in STEEM price over time. Figure 2 shows how the STEEM value peaked during the period between late 2017 and early 2018, supposably after going through both stealth and awareness phases, then eventually underwent a gradual decline like the blow-off phase above. As of 2022, this transitional pattern has not changed much since then. This contextual feature suggests that changes in the monetary value of rewards may have been associated with the extent of user engagement and participation.

Steem price chart (accessed at: https://coinmarketcap.com/currencies/steem/).
The study mainly concerns “bubble” (Mania phase) and “bust” (Blow-off phase), defining the bubble phase as the 2-month period between 1 December 2017 and 31 January 2018, and the bust phase between 11 September 2019 and 11 November 2019. The selection of these two periods is related to the change in mood of the general public according to the change in STEEM value in the mania to blow-off phase. As STEEM’s financial value moves from peak to trough, the picture of aspirations in users’ minds may have faded into cynicism over time, affecting not only the extent of their contributions but also their behaviors and strategies for how they express themselves.
Personal Data in UGC: Trade-offs Between a Sense of Value and Privacy Concerns
The value theory of privacy postulates that people value their data due to their sense of psychological ownership of it (Spiekermann & Korunovska, 2017). This sense of value can be significantly reinforced once they realize how their data, as an asset, is being traded in the market.
Similarly, creators of online content can value their personal data when they present some aspects of their selves in the content, such as selfies and vlogs, and when they realize how they can gain traction and/or make money through these aspects on UGC monetization platforms such as Steemit. The Web 2.0 environment and social media platforms have created such a breeding ground for a culture of self-expression in contemporary digital society, creating a vast amount of paid UGC based on, and tied to, one’s self.
Recently, due to the growing appeal to authenticity in online social networks (Salisbury & Pooley, 2017), people have become accustomed to managing their self-identity to look “real” through ongoing processes of performance and exhibition (Hogan, 2010). Although it cannot be sure that everyone performs or exhibits an authentic and genuine identity in their UGC, self-disclosure on social media, more often than not, is based on who the “performer” really is. On social media, people connect with someone new as well as people they already know, and identity theft or fraud is often condemned or even considered a crime. From another point of view, the construct of “authentic” identity is not fundamentally absolute, as in Goffman, so the lines between “real” and “fake” self-display are bound to become unclear in continuous performances in long-term relationship networks.
In such a context, authenticity performance can be interpreted as the result of online service users making careful decisions about whether or how much to disclose aspects of their selves, constantly encountering trade-offs between their sense of value and privacy concerns in their UGC productions. To an extent, this position is in line with the “privacy calculus theory” of economics and business disciplines. Studies have examined one’s decisions about whether to share private information for some returns, such as convenience, better services, and other benefits and, if so, how much to share (Acquisti et al., 2016; Barth & De Jong, 2017). Importantly, this theory views value and privacy perceptions on a continuum rather than existing as two extremes. Just as the sense of value is based on the person’s evaluation of a varied and complex set of values, people perceive privacy risks subjectively through various levels: negligible, limited, moderate, or substantial (Commission Nationale de l’informatique et des Libertés, 2012).
An emphasis on value generally helps mobilize individuals to create value through ongoing performance and exhibition (Hogan, 2010). Often expressed in ways such as personal branding and self-promotion in digital spaces, this practice, along with the inherent originality of one’s private personality, heightens expressive creativity to make the UGC “stand out.” The sensed value of one’s personal data in the form of UGCs can be acknowledged as an investment (Reichman & Samuelson, 1997) constituted by intellectuality, originality, creativity, and other substantial tangible/intangible resources. In this process, content generators may also desire to maintain some privacy while in “public” by (de)selecting aspects of their selves to express. Rooted in “performative privacy,” which is constituted by expressive strategies for privacy, such as wearing a hoodie in public (Skinner-Thompson, 2017), one can practice subtle obfuscation strategies online to cloak certain aspects of the self. For example, vloggers may only stage in a studio, thus trying to veil the specific region in which they reside. As such, the structure of values and privacy is so multilayered that balancing this trade-off can be a complicated and nuanced decision, and the resulting performativity can take on multilateral forms.
The reward system of emerging BOSMs raises some interesting points. Service users are usually not just aware of the market of their content’s data; they indeed experience the market. As people are rewarded and got traction through self-disclosure, they are more likely to feel a sense of value in their expressed selves strongly. Doing this can motivate users to be more active in their self-expression. However, it does not mean people will no longer conduct performative privacy acts. It is entirely up to individual users’ self-negotiation to decide whether or how much they will (not) perform for financial gain or privacy protection reasons.
Performing the self can thus involve intricate and strategic decision-making to manage and share specific aspects, layers, or pieces of personal information (Jeong & Coyle, 2014; Jeong & Kim, 2017). For instance, it may relate to how people manage the boundaries of their identities online, as exemplified by the construct of online behavior management boundaries (OBMB) (Batenburg & Bartels, 2017). According to OBMB, people use a variety of personal information to separate or weave their “personal” or “professional” selves. This is often accompanied by subtle expressions aimed at enhancing (sharing only positive self-images) or verifying selves (showing negative and positive selves simultaneously). In doing so, people may use skills or techniques in a way that stylizes and develops their personal brand identity, including multiple media elements such as images, videos, text, or audio, among other things (Davis & Weinshenker, 2012; Panahi et al., 2012). The degree of originality can also vary, depending on whether the content is fully self-generated, remixed, or copied (Jin, 2013).
Additionally, there are specific types of personal details in UGC that might engage in people’s self-negotiation between their sense of value and privacy. First, there is implicit self-presentational information that helps infer one’s identity, primarily based on user’s immediate actions, such as location-based, behavior-based, and social activity-based information (e.g., a selfie taken at a coffee shop). On the other hand, explicit forms of information consist of personal information that offers more context to infer who the performer is through group membership, educational, socioeconomic, or cultural backgrounds, or family information (e.g., a selfie taken at a coffee shop, explaining she was doing her school assignment). See Appendix for further details.
In this context, our research question delves into how the entrance of a new system of data valuation intersects with one’s data activities—thus, the practice of investing private information in UGC production and how it is valued by the community. Specific questions, referring to this novel system, are the following:
RQ1. What types of personal information were voluntarily disclosed and utilized, that is, invested?
RQ2. How was each type of personal information valued according to the platform’s own currency, STEEM?
RQ3. How do the types of personal information invested and the reward value differ in different market conditions?
RQ4. How does one strategically manage/express her identity using various types of personal information?
RQ5. How do the characteristics of managed/expressed identities relate to the reward value?
Data and Methods
Data Collection
A mixed-methods design was applied combining topic modeling (RQ1 to RQ3) and content analysis (RQ4 and RQ5) methods. We collected user posts via Steem API. Regarding the topic modeling analysis, we scraped all user posts using #Introduceyourself (tag for self-introduction) created during the aforementioned two periods of interest: Mania phase (M-phase hereafter, from 1 December 2017 to 31 January 2018) and Blow-off phase (B-phase hereafter, from 11 September 2019 to 11 November 2019). In total, 54,253 and 16,710 user posts were collected, respectively, for each period. For the content analysis, we collected all user posts with the #blog tag generated during the M-phase only (150K), and randomly sampled 1K of them. 2 Only posts written in English language were included in the analysis. Topic modeling analysis applied only text elements, whereas content analysis considered audiovisual elements such as photos and videos in addition to text. We also analyzed a set of metadata information that records the STEEM rewards earned by authors for each post.
Topic Modeling Analysis (RQ1 to RQ3)
Computational topic modeling approaches using natural language processing (NLP) were applied to extract the primary dimensions of voluntary self-disclosure from the collected user posts. The study employed latent Dirichlet allocation (LDA) approach using Gensim package (https://radimrehurek.com/gensim/index.html) of Python framework for finding the latent structure of a vast collection of documents (Blei et al., 2003; Hoffman et al., 2010). It is an unsupervised learning algorithm that automatically and efficiently derives hidden thematic structure of large corpora based on patterns of word co-occurrence. To this end, the study explored the topics of personal information disclosed in UGCs (RQ1). The economic gain—STEEM coins—from each topic space was also statistically described (RQ2). As well, the two topic spaces of M- and B-phase corresponding to the changing cryptocurrency prices were compared to see if there were any differences (RQ3).
The basic workflow including data scraping, language detection and filtering, preprocessing, LDA modeling, and model assessments as well as visualization was illustrated in Figure 3. Note that corpora for M- and B-phases were processed separately, but an almost identical procedure was applied to implement the analysis for each corpus. The number of topics (K) is largely determined by adopting a two-step approach (Maier et al., 2018): (1) the intrinsic coherence of a specified model and (2) qualitative examination of candidate models guided by the study’s theoretical framework. Topic coherence evaluates the consistency of a single topic by assessing the degree of semantic similarity between highly relevant words in a given topic. Ranging from 0 to 1, there are no strict criteria for acceptable coherence scores, but the model with the highest score usually offers meaningful and interpretable results (Maier et al., 2018). Qualitative interpretation is based on the most relevant terms, most representative posts, and visualized models using pyLDAvis extension that shows topic proportions in the corpus, semantic distance between topics, and so on.

Basic workflow of LDA topic modeling.
Content Analysis (RQ4 and RQ5)
Among the 155,988 user posts with #blog tag created between 1 December 2017 and 31 January 2018 (M-phase), 1K randomly selected posts were analyzed using Dedoose, a cross-platform application for analyzing various types of qualitative and mixed-methods research data. We established a coding framework that characterizes the types and features of self-disclosure in UGCs, based on the five criteria mentioned in the previous section: (1) mode of communication (i.e., formats, multiple media elements), (2) authorship (original, remix, or copied), (3) OBMB (personal vs professional; enhance vs verify), (4) implicit personal details, and (5) explicit personal details (see Appendix for details). This framework aimed to measure how identities were strategically managed/expressed in UGCs (RQ4) and how they were valued (RQ5).
Two coders worked on the 1K posts. To ensure the reliability of the coding, the coders performed sample coding on 25 randomly selected posts and measured Cohen’s kappa (κ) inter-coder reliability, for it addresses the limits of simple percent agreements that do not account for agreements that coincidentally occur (McHugh, 2012). Most criteria for the established coding frame indicate acceptable levels of consistency between the coders with scores ranging from moderate to substantial (from 0.46 to 0.84, see Table 3 for details).
Results
Topic Modeling Results (RQ1 to RQ3)
As a result of testing candidate LDA models with varying number of topics (K) from 1 to 20, the optimal topic numbers for M-phase and B-phase were 10 (c = .440) and 8 (c = .513), respectively, as suggested by the coherence score. Figure 4 visualizes the topic models for both M-phase and B-phases fitted to avoid overlaps while making each topic space unique as possible; besides, the interpretation of the top 30 most relevant terms and 10–20 most representative posts for each topic substantiated the final model selection. Each topic is circled and is sorted in ascending order according to the prevalence of given topics in the corpus. 3 The position of circles in the two-dimensional chart represents semantic distance between topics.

Inter-topic distance map for M-phase (left) and B-phase (right). PC: principal component.
Information Investment and Return During and After the Bubble
Table 1 describes the M-phase and B-phase topics related to information about themselves that individual users contributed to Steemit. The M-phase model was constituted by major topics such as self-expression (32.1%), self-disclosure (23.8%), personal narratives (13.7%), and personal relationships (11.0%), followed by Edu/work history, creative work, and lifestyle and leisure. The rest 10.4% was about the usage of the platform and coin market. Noteworthy that users adopted different self-display strategies in areas of self-expression and self-disclosure. The former focused on qualified aspects of self, such as life vision, mission, faith, or personal qualities with lengthier explanations, for example: “. . . I am quick to say how I feel and people find it offending well . . . I never worry about things especially things I can’t change.” By comparison, the latter centers on descriptive and fragmented facts such as name, birth date, gender, occupation, and ethnicity/nationality: “. . . So my name is XX, I was born in Peureulak on 11 March 1999 and I live in Aceh Indonesia in YY district. And my profession is . . . my hobby is . . .” It resembles the typical user profiling of data companies. The topic of personal narratives consists of personal stories or anecdotes based on one’s own experiences, memorable events, or something heard from others.
Extracted Topics, Keywords, and Descriptions for M-Phase and B-Phase Topics.

M-phase (N = 26,413) and B-phase (N = 7,039). The number label of topics (1, 2, 3 . . .) corresponds to the topic numbers in Figure 4.
The specified topic models of the M-phase and B-phase in Table 1 suggest that how the mood of general public was heightened during the peak stage and then subsequently dampened as the bubble bursts. A comparison of the characteristics of the two topic spaces reveals a clear difference between the two stages: there was less self-disclosure during B-phase, with no “self-expression” and “Edu/work history” topics. People were reluctant to express themselves in detail, mainly providing basic descriptions of demographic information. For a similar lifestyle topic, M-phase was more about actual experiences in everyday life, but people posted more general information in B-phase. Similarly, during the burst, the proportion of each topic space changed, as incoming users were more likely to focus on instrumental purposes around the Steemit platform and coin markets for money management (Figure 5).

Change in the information space from the M-phase to the B-phase.
Table 2 shows how the rewards for UGCs in the topic spaces are distributed across the two time periods, respectively. For M-phase, the topics that received the highest summed incentives were “self-expression,” “self-disclosure,” “Steemit platform,” and “personal narratives” (in order). However, concerning the median, rewards for the “self-disclosure” were highest, followed by “self-expression” and “personal relationships” (rewards of “creative work” was not reported as there were only 25 sample posts). The B-phase continued the high-value realization associated with “self-disclosure” as reported during the peak. As well, there was a change in ranks of value realization between topic spaces during and after the time of the bubble. By the median, “Steemit platform” was more highly valued than “personal narratives” and “personal relationships” during the B-phase, as opposed to the M-phase.
Rewards Realized During M- and B-Phases.

SBD: STEEM Dollars; SD: standard deviation.
STEEM Dollars (SBD) is a type of stable coin that has a circulating supply of 11,274,491 SBD (as of 16 May 2022, USD2.71 for 1 SBD). At the time of the study, the price of 1 SBD ranged between USD2.4 and USD13.15 during M-phase and USD0.5 and USD0.8 during B-phase.
Content Analysis Result (RQ4 and RQ5)
Of 1K sampled posts, 175 posts were filtered due to their language (non-English). Of the 825 posts, 335 posts (43%) consist personal details in whole or in part of the post, but the remaining 470 posts (57%) did not contain any identifying information. The latter did not risk their privacy in pursuing incentives, usually talking about general topics such as local and international affairs, crypto-based projects or coin market analysis, or other miscellaneous subjects. For these sample posts lacking personal information, the study only coded for the mode of communication and its authorship. The analysis of the 43% of posts with self-representations primarily addresses RQ4 and RQ5.
Strategies of Identity-Expression and Realized Values
For a considerable proportion of the sample (335 posts, 41.6%), any form of self-expression through UGC was a common practice. The comprehensive characteristics of such posts, outlined in Table 3, can be encapsulated in three prominent identity management strategies: (1) identity separation (separator, 74.6%), (2) identity integration (integrator, 19.1%), and (3) information balancing (self-expression) that tends to be more separated than integrated, observed in selfies (69.1% vs 27.3%) and vlogs (60% vs 35%); no text for self-expression when posting selfies and vlogs (texts in mode of communication, 0%).
Strategic Identity Management Practices in UGCs.

UGC: user-generated content; OBMB: online behavior management boundaries.
Bold values highlight user practices that are prominent in identity management activities.
Kappa was not computed for audio, text, and video components due to its very low usage. Each post can apply to more than one category.
Separate audio other than video sound.
First, the most frequently observed management strategy is identity separation. In this strategy, users deliberately select and display only one aspect of their self: either their personal or professional identity. This strategy is usually centered on expressing personal identities based on day-to-day life and entertaining activities (Explicit—daily life/ent. 72.8%), often also including sensitive work-related backstories (e.g., sex workers’ complaints about “clients”). These so-called “separators” were found to present a limited self-image in a reserved way rather than actively managing and refining their self-identity through enhancement (3.2%) or verification (6%).
In contrast, “integrators” tend to express personal and professional identities together, thus disclosing more of themselves than the separators, such as their social identities (82.8%), personal talents (39.1%), and relationships (29.1%). Relatedly, integrators are more likely to pursue identity verification (17.2%) than separators to gain favor or endorsement from others, despite personal shortcomings such as drinking, drug problems, or embarrassing family secrets. Besides, integrators are more likely to post original content created by them (92.2%) than separators, who present separated identities (84%).
Finally, the “information balancing” strategy was primarily used in posts with visual information about oneself, such as selfies or vlogs: when visualized self-presentation is the key component of a post, other non-visual media (e.g., texts, hyperlinked webpages) were less likely to be used. They also tended to separate their personal and professional identities rather than integrate them. Since self-portraits such as selfies and vlogs are inherently revealing, it is speculated that users are trying to avoid excessive self-exposure. This article’s analysis also showed that some vloggers only use their voices or wear costumes to avoid exposing their visual identities.
Table 4 shows how values were realized according to the identity management practices above. The posts with personal information earned significantly higher rewards than those without, mean difference = 4.70, t(803) = 3.37, p < .01. According to a one-way analysis of variance, there was a significant difference in realized values depending on whether it is created by the author or not, F(2, 767) = 5.10, p < .01: posts with original touches were likely to receive a higher reward than copied work. However, no significant difference was found between original and remix content. Although marginally significant, the reward values were greater when personal-professional identities were expressed together than when they are separated, mean difference = 5.95, t(293) = 1.74, p < .1. Moreover, although statistical testing was limited, posts with visualized personal content tended to receive higher rewards on average (M = 10.96 SBD).
Identity Management Practices and Realized Value in STEEM Currency (Unit: SBD).

SD: standard deviation; OBMB: online behavior management boundaries.
p < .01, †p < .1.
Discussion and Conclusion
Although legal debates over personal data have not been framed to grant property rights to individuals, data’s economic potential has become increasingly undeniable. Each interested party now seeks to benefit from almost every unit of data that makes up one’s life: not just a set of PII but data by-products based on countless individual online activities. Shoshana Zuboff (2019) coined such “behavioral surplus” of users as “the new means of production” that not only improve corporate services but also feed corporations’ machine intelligence to build momentum in future behavioral markets.
Given this, the study sought to explore the potential of an innovative social media platform in which personal data could create value activities based on data subjects’ voluntary and deliberate investment of self. The study’s topic modeling analysis continues to resonate with the “qualified self” discussed in Humphreys (2018). It reveals that users are more willing to share their qualified, contextual selves by disclosing personal traits, life goals, and visions that go beyond conventional demographic profiles that easily fit into “quantified” statistics-driven consumer profiling. Furthermore, by comparing the peak and troughs of the markets, the study suggests that this market atmosphere could be a relevant factor for self-expression in online spaces. For example, as the price of cryptocurrency has declined, users’ self-displays have become relatively monotonous, and the realized value of all topic areas has decreased. Thus, the study provides another empirical criterion to recognize the value of personal information. Just as data markets have treated quantifiable information as useful, people tend to value engaging personal stories or in-depth self-representation from users.
At a more granular level, the content analysis findings offer an opportunity to see how ordinary users strategically manage their self-image in ongoing identity performances, balancing the anticipated values and privacy concerns. Even within the unique incentive structure of blockchain-powered social media, people take various stances on performing the self and negotiating their privacy boundaries. The study identified three key identity strategies: identity separation, identity integration, and information balancing practices. The more one shares about oneself, the higher the reward and thus the realized value: posts that present personal-professional identities together are more likely to be valued by the community than those that separate the two; posts with visual self-representations tend to obtain higher rewards than those that do not. In addition, the value of original works is significantly much higher than copied works. This result is noteworthy in that it shows how the collective and autonomous decision-making of the community advocated and enacted the value of the identity performed.
Altogether, the above results demonstrate that such practices in UGC demand the user become a multivariate agent with diverse dimensions as a user, data generator, or content creator, which is always a complex and laborious task (Davis, 2014; van Dijck, 2009). Ongoing identity performances of self in UGC entail intellectuality, creativity, and labor to perform, exhibit, and carefully manage one’s self-image (Terranova, 2000; van Dijck, 2009). This commitment to performativity combined with originality (as each and every person is unique) clearly showcases the creator’s investment, arguably to the extent that it grants full and transferable ownership to individual data subjects, as was acknowledged in the case of databases.
Importantly, this study has shown the case wherein a user can actually experience a real market of their volunteered personal data, specifically self-representation and expressions, in a decentralized rewards platform, thereby demonstrating how users value their personal data. This finding further elaborates the value theory for personal data by providing a context in which users can recognize that their personal information can indeed become a tradable asset. Furthermore, this study hints at how Steemit has emerged as a space of value for the “qualified self” and a space of negotiation for the actor of performative privacy conducting privacy-aware information activities. However, these results should be interpreted with caution as the user-centric value realized through self-disclosure in this study does not necessarily coincide with data value in the context of data capitalism. Steemit was a revolutionary vision at the time of its launch, but its present outlook is not optimistic—its users have complained about scammers, automated voting by bots, and other malicious activities. Furthermore, Steemit is not the only use case of blockchain-based social media platforms, so studies should further examine the implications of technology, platform governance, and its design aspects. Finally, as this study centered on personal information at the blurred boundaries of data and content, it did not include automatically collected digital footprints in its scope.
Despite these limitations, a technology-based vision of redistributed data economy envisioned in this study addresses existing shortcomings of the current data economy. People have demanded fair deals or better rules to address the challenges of their rights to personal data and the distribution of data wealth. Still, little progress has been made on their actual implementation. In the case of Steemit, its blockchain-powered incentive mechanism, coupled with technological affordances, presented an alternative to exercising data rights to ensure direct user benefits. Along with the vision of Web 3.0, where individual users can directly control and monetize what they publish on the web, the potential of this alternative solution deserves to be taken more seriously to empower ordinary users in the contemporary data regime.
Footnotes
Appendix
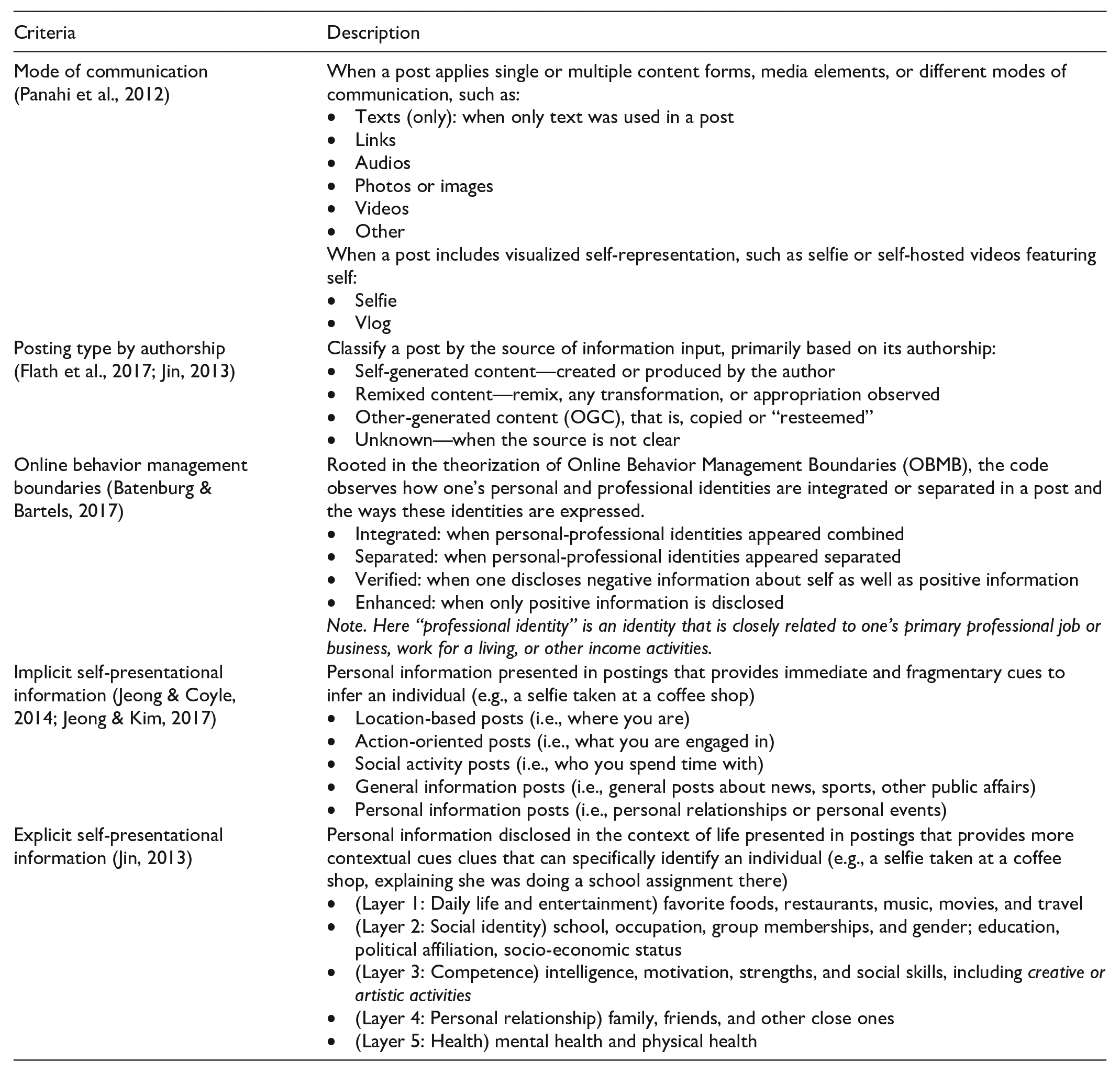
| Criteria | Description |
|---|---|
| Mode of communication (Panahi et al., 2012) | When a post applies single or multiple content forms, media elements, or different modes of communication, such as: • Texts (only): when only text was used in a post • Links • Audios • Photos or images • Videos • Other When a post includes visualized self-representation, such as selfie or self-hosted videos featuring self: • Selfie • Vlog |
| Posting type by authorship (Flath et al., 2017; Jin, 2013) | Classify a post by the source of information input, primarily based on its authorship: • Self-generated content—created or produced by the author • Remixed content—remix, any transformation, or appropriation observed • Other-generated content (OGC), that is, copied or “resteemed” • Unknown—when the source is not clear |
| Online behavior management boundaries (Batenburg & Bartels, 2017) | Rooted in the theorization of Online Behavior Management Boundaries (OBMB), the code observes how one’s personal and professional identities are integrated or separated in a post and the ways these identities are expressed. • Integrated: when personal-professional identities appeared combined • Separated: when personal-professional identities appeared separated • Verified: when one discloses negative information about self as well as positive information • Enhanced: when only positive information is disclosed Note. Here “professional identity” is an identity that is closely related to one’s primary professional job or business, work for a living, or other income activities. |
| Implicit self-presentational information (Jeong & Coyle, 2014; Jeong & Kim, 2017) | Personal information presented in postings that provides immediate and fragmentary cues to infer an individual (e.g., a selfie taken at a coffee shop) • Location-based posts (i.e., where you are) • Action-oriented posts (i.e., what you are engaged in) • Social activity posts (i.e., who you spend time with) • General information posts (i.e., general posts about news, sports, other public affairs) • Personal information posts (i.e., personal relationships or personal events) |
| Explicit self-presentational information (Jin, 2013) | Personal information disclosed in the context of life presented in postings that provides more contextual cues clues that can specifically identify an individual (e.g., a selfie taken at a coffee shop, explaining she was doing a school assignment there) • (Layer 1: Daily life and entertainment) favorite foods, restaurants, music, movies, and travel • (Layer 2: Social identity) school, occupation, group memberships, and gender; education, political affiliation, socio-economic status • (Layer 3: Competence) intelligence, motivation, strengths, and social skills, including creative or artistic activities • (Layer 4: Personal relationship) family, friends, and other close ones • (Layer 5: Health) mental health and physical health |
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2017S1A6A3A01078538).