
Abstract
Human–algorithm interaction has emerged as a pressing area in social media research because algorithms curate and govern most communication on social media. In the present study, we focus on the perceptions people have of algorithms as it relates to their identity and goals. Bridging interpersonal communication theory into human–algorithm interactions, we explicate the concepts of perceived algorithm responsiveness (PAR) and perceived algorithm insensitivity (PAI). In two preregistered studies, we examine PAR and PAI across the social media ecology, finding that TikTok has a higher PAR and lower PAI compared with Facebook and Instagram. Data suggest that algorithm awareness is only weakly correlated with PAR or PAI, and that PAR was a significant predictor of people’s social media enjoyment. These results contribute to research on human–algorithm interaction by conceptualizing and testing two new theoretical concepts to explain the algorithm responsiveness process.
Algorithms mediate communication on social media in ways that transform communication, relationships, and society. Social media algorithms are computational models for transforming data into personalized content that populates a person’s social feeds, such as the Facebook News Feed or TikTok’s “For You Page” (Bucher, 2017). Because what people see on social media is largely governed by algorithms, social media algorithms shape how people see themselves and others (Bhandari & Bimo, 2022) and behave on social media platforms (DeVito, 2021). Emergent questions about social media algorithms focus on the intersection of algorithms with identity, goals, and everyday life.
Research on how people perceive algorithmically curated content on social media has primarily focused on folk theories of how social feed algorithms operate (DeVito et al., 2018) and the interplay of algorithms with marginalized identities, such as LGBTQ (lesbian, gay, bisexual, and transgender) people on TikTok (DeVito, 2022; Simpson & Semaan, 2020). This research area suggests that identity development and maintenance happen via the personalized curation of algorithms (Lee et al., 2022). Therefore, how people interact with social media algorithms influences the many social categories, beliefs, and roles that make up a person’s identity and sense of self. Investigating the extent to which people perceive algorithms as validating and supporting their identity represents an opportunity to build theory regarding human–algorithm interaction.
Adopting the concept of responsiveness, defined as a process in which “individuals come to believe that relationship partners both attend to and react supportively to central, core defining features of the self” (Reis et al., 2004, p. 203), from interpersonal interaction, we conceptualize and empirically test perceptions of algorithm responsiveness to theorize the intersection of social media algorithms and identity. In Study 1, we explore the algorithm responsiveness process along two dimensions: perceived algorithm responsiveness (PAR) and perceived algorithm insensitivity (PAI). We introduce a measure of algorithm responsiveness, compare PAR and PAI across Facebook, TikTok, Instagram, and Twitter, and consider how algorithm responsiveness differs from awareness of algorithms. Study 2 replicates how PAR and PAI differ across social media and contends that perceptions of algorithm responsiveness predict the outcome of media enjoyment.
Understanding Human–Algorithm Interaction
Research on human–algorithm interaction involves investigations along multiple fronts: how social media algorithms function, how individuals perceive social media algorithms, and the effects of social media algorithms on behavior. We focus on how individuals perceive algorithms because users’ perceptions of algorithms influence how they share and connect with others online. On this front, researchers have primarily investigated folk theories of algorithms, or lay understandings of how algorithms work (DeVito et al., 2018). The most common folk theory across all social media platforms is that social media feeds are algorithmically curated via personal engagement metrics, meaning algorithmic curation is based on digital traces, including what content the user previously liked, commented on, and viewed (Eslami et al., 2016). Such mental models of algorithms are developed via a recursive process of information exchange between the person and the algorithm (DeVito, 2021). For instance, people change their behavior based on their folk theories, such as commenting on a friend’s profile more often or unfollowing certain accounts, which feeds new information to the algorithm.
Research on folk theories highlights an important principle of human–algorithm interaction—people seek to understand the algorithm in relation to their own identity, or an individuals’ understanding of themselves based on their past and present experiences (Erikson, 1959). For instance, TikTok users operate with a folk theory that algorithmic curation happens as an identity strainer: identifying, categorizing, and prioritizing certain identities over others based on the value the platform ascribes to that identity category, including body type, race, and sexuality (Karizat et al., 2021). This finding is consistent with interviews of LGBTQ TikTok users which found that the TikTok algorithm filters content in a way that simultaneously supports and harms their queer identity (DeVito, 2022; Simpson & Semaan, 2020). Karizat and colleagues (2021) see the relationship between algorithms and identity as a co-production, where people’s identity influences algorithmic curation but, in turn, algorithmic curation influences the identity development the user. This co-production prioritizes some facets of a person’s self-concept over others and exposes marginalized groups to algorithmic harms. However, people tend to hold more positive attitudes toward social media algorithms when the personalized content represents the multifaceted, dynamic aspects of the self (Lee et al., 2022). We build on this work at the intersection of algorithms and identity by repositioning this co-production as human–algorithm interaction. This theoretical invention allows for interpersonal communication theory to elaborate on the processes experienced during human–algorithm interaction.
Conceptualizing Algorithm Responsiveness
Bridging interpersonal communication theory into algorithm studies, we use the responsiveness process to conceptualize human–algorithm interaction because the responsiveness process is akin to the patterns of co-production described in algorithms and identity research (Karizat et al., 2021). We provide an abbreviated history of interpersonal responsiveness and then explicate algorithm responsiveness. The concept of responsiveness derives from interpersonal interaction research on intimacy development (Reis & Shaver, 1988). Along with self-disclosure, responsiveness is considered as a key factor in the intimacy development. When people disclose about themselves and perceive their partner to be responsive to their disclosure in a manner that shows understanding, validation, and care, intimacy grows (Choi & Toma, 2022). Whereas responsiveness originated to explain intimacy development, the concept has received wide adoption including research on self-esteem (Reis et al., 2018) and human–robot communication (Birnbaum et al., 2016), making it an organizing construct of interpersonal interaction (Reis et al., 2004). The responsiveness process is characterized by four steps: (1) self-disclosure (or other eliciting behavior) that expresses a need or want, (2) partner’s actual enacted response, (3) perceived partner responsiveness and insensitivity, and (4) interaction outcomes, such as intimacy, support, and so on (Reis & Clark, 2013). Responsiveness is a recursive process that influences both how the interaction unfolds and how interactants perceive the interaction.
Research suggests that perceived rather than enacted responsiveness is the key mechanism explaining why interpersonal interaction influences well-being and relationships (Choi & Toma, 2022; Reis & Shaver, 1988). Perceived partner responsiveness is defined as the extent to which people perceive their communication partner as understanding, validating, and caring for their core sense of self, goals, and needs; supportive and attentive interaction partners are perceived as highly responsive (Reis & Clark, 2013). Perceived partner insensitivity is the second dimension, or the extent to which a partner is perceived as lacking understanding, validation, and care for one’s core sense of self; detachment, discouraging, and dismissiveness interaction partners are perceived as highly insensitive (Crasta et al., 2021). When perceiving their partner to be responsive, people tend to disclose more about their emotions (Ruan et al., 2020), feel better about themselves, and are less defensive (Reis et al., 2018). Conversely, perceived insensitivity predicted less romantic relationship satisfaction (Crasta et al., 2021).
We posit that the responsiveness process extends into human–algorithm interactions because people extend their interpersonal perceptions to human–machine interaction, even when interacting with non-humanoid machines (Gambino et al., 2020). For example, when non-humanoid robots displayed verbal and nonverbal immediacy in response to a person’s disclosure, the robots were rated as more responsive and desirable than robots that remained neutral (Birnbaum et al., 2016). Another experiment on dehumanized chatbots found that supportive messages validating one’s affect and perspective reduced distress more so than messages that denied or criticized the person, mirroring how supportive messages function in interpersonal communication (Rains et al., 2020).
The responsiveness process is comparable to human–algorithm interaction where the human provides personal information to algorithms through digital traces, such as likes, views, or posting on the platform (i.e., Step 1: self-disclosure), algorithms respond to this personal information through curating personalized content in the feed (i.e., Step 2: enacted response), the user notices the personalization and perceives algorithms as understanding and supportive of their identity (i.e., Step 3: perceived partner responsiveness and insensitivity), and produces outcomes of the human–algorithm interaction (i.e., Step 4: interaction outcomes). Drawing from algorithms research, we hypothesize the algorithm responsiveness process as cyclical over time: people scroll through social feed and engage with content on the platform, receive new curated content, and adapt their perceptions of the algorithm in response (Karizat et al., 2021). When the social media algorithms are perceived as responsive, people may be able to better understand their own identities and engage more with algorithm-curated content on the platform (DeVito, 2021). On the contrary, if people perceive the algorithms as insensitive to their identity, they may either reduce their use of the platform or deliberately their change behavior on the platform to make the algorithm align more with their self-concept (e.g., searching for or liking content relevant to their identity, Lee et al., 2022).
Building from the perceptions of interpersonal responsiveness (Crasta et al., 2021), we propose algorithm responsiveness along two primary dimensions: (1) PAR and (2) PAI. PAR is defined as the degree to which people believe social media algorithms understand, validate, and support core defining features of the self. PAR should be higher when people perceive their social feeds are populated with content that matches their identity and motivations for using the platform. Conversely, PAI represents the extent to which people believe a social media algorithm misinterprets, suppresses, or undermines their identity and goals. PAI is indicated when algorithmically curated content fails to support one’s goal for using the platform, such as ignoring one’s interests or failing to appropriately adapt to feedback. PAI may also include instances of bias against a marginalized identity—a well-documented problem in algorithmic decision-making (Noble, 2018). The coexistence of PAR and PAI is consistent with previous work that has identified a crossfire of positive and negative mental models of algorithms, such as the TikTok algorithm helping find community while reinforcing harmful stereotypes (Simpson & Semaan, 2020).
PAR and PAI combine to theorize the perceived (mis)understanding, (dis)respect, and (un)supportiveness during human–algorithm interaction, describing the perception individuals hold about the alignment between the algorithmic self and the actual self (Lee et al., 2022). Similar to interpersonal responsiveness, we predict PAR and PAI will represent two unique perceptions of social media algorithms.
H1. Algorithm responsiveness has a two-factor structure: (1) PAR and (2) PAI.
Our conceptualization of algorithm responsiveness rests upon algorithm awareness. Because algorithms have limited visibility, multiple studies have identified that algorithm awareness is required before perceptions of the algorithm can form (Eslami et al., 2015; Shin, 2020). Zarouali et al. (2021) identified two categories of algorithm awareness central to responsiveness: (1) content filtering and (2) human–algorithm interplay. Content filtering represents baseline awareness that media content is personalized via algorithms, whereas human–algorithm interplay represents a more sophisticated awareness about the use of “big data” to automatically personalize content curation. With the opaqueness of algorithms, many people were initially unaware that algorithms were operating underneath their social media feeds (Eslami et al., 2015). Media coverage and US congressional investigations into data privacy, disinformation campaigns, and other social media controversies have made these once invisible social forces more salient. Notably, algorithm awareness for social media is now higher than for other aspects of mediated life (Zarouali et al., 2021). People also report learning about algorithms after it is eerily predictive of their behavior, suggesting perceptions of algorithm responsiveness trigger once awareness is reached (Bucher, 2017).
Thus, we anticipate that the algorithm responsiveness process is predicated on the awareness that algorithms curate content (i.e., content filtering awareness) and that algorithms are using users’ information to adapt and alter that content (i.e., human–algorithm interplay awareness). However, we argue that algorithm awareness is a theoretically distinct concept from either PAR or PAI because awareness of algorithmically curated feeds is not equal to believing an algorithm understands, validates, and supports one’s sense of self (Karizat et al., 2021). We ask the following question to determine the distinction between these ideas:
RQ1. Does algorithm responsiveness differ from algorithm awareness: (a) content filtering and (b) human–algorithm interplay?
We further anticipate that PAR and PAI will differ across the social media ecology because each platform is accompanied by different sets of data and algorithms operating the curation of feeds. Research suggests that algorithm perceptions are driven by the experiences people have on various platforms and expectations for how that platform works (DeVito, 2021). Furthermore, people report having different types of interactions with algorithms on various social media platforms, with TikTok’s algorithm being more direct and interactive than others (Bhandari & Bimo, 2022). Similarly, TikTok differs from other social media by tailoring content from creators with overlapping interests, relying more on personalized content than personal relationships (Lee et al., 2022). One way to determine variability in the algorithm responsiveness process is a platform-to-platform comparison of PAR and PAI. We focus our investigation on four social media platforms, Instagram, TikTok, Facebook, and Twitter, which feature algorithmically curated feeds. We ask the following research question for our preliminary test of PAR and PAI:
RQ2. How do Instagram, TikTok, Facebook, and Twitter differ in (a) PAR and (b) PAI?
Method—Study 1
Sample
We recruited 935 participants via Amazon Mechanical Turk who spoke English and resided in the United States. A priori power analysis suggested a sample size of 463 to identify small effects, f2 = .05. Participants needed to have used at least one of the following social media in the past month to be eligible for this study: Instagram, TikTok, Facebook, and Twitter. A total of 805 participants passed data quality and attention checks and were included in data analyses. Demographics of the final sample included a mean age of 37.14 (SD = 11.28), with the majority (62.4%) identifying as female, 36.4% male, and 1.2% other; 79.5% identified as White, 9.8% Black, 8.3% Latinx/Hispanic, 8.3% Asian, with all other racial categories being <3.0%, and 9.4% identified as having more than one race or ethnicity. Please note this sample is largely homogeneous, missing marginalized identities that are excluded and harmed by algorithms, such as racial minorities, LGBTQ people, or individuals from the Global South. Data were collected in August–November 2021.
Procedures
Participants consented to participate in an Institutional Review Board (IRB)-approved study about social media use. All preregistered hypotheses, materials, data, and code are available online. 1 Participants were told that we were interested in understanding their opinions of social media algorithms. Participants were asked if they had used Instagram, TikTok, Facebook, or Twitter in the past month. Participants were allowed to select more than one option. Facebook was the most used social media platform in the past month (88.1%), followed by Instagram (72.9%), Twitter (56.5%), and TikTok (41.7%). Participants given a definition of a social media algorithm and were then randomly assigned to report on one of the social media platforms they had used in the past month. Because the random assignment was conditioned upon the use of social media in the past month, more participants were assigned to Facebook and Instagram. In the last round of data collection (n = 128), we reprogrammed the survey software to prioritize TikTok and Twitter in the random assignment to increase statistical power. In the end, 293 participants reported on Facebook, 208 on Instagram, 170 on Twitter, and 134 on TikTok. Finally, participants answered questions about their knowledge and perceptions of that medium and responded to personality and demographic questions. Comparisons of demographic information by social media platform are available in supplemental appendix Table A1.
Measures
Algorithm Awareness
We used two dimensions of the Algorithmic Media Content Awareness (AMCA) Scale (Zarouali et al., 2021): content filtering and human–algorithm interplay awareness. Participants responded to a series of statements about their awareness of social media algorithms on their assigned social media platform. Four items were included for content filtering awareness (e.g., “Algorithms are used to recommend posts to me on [Instagram]”), α = .81. Three items were included for human–algorithm interplay awareness (e.g., “The posts that algorithms recommend to me on [Twitter] depend on my online behavioral data.”), α = .85. Responses were collected on a 5-point Likert-type scale of (1) not at all aware to (5) completely aware.
PAR and PAI
We operationalized PAR and PAI using an adapted version of the Perceived Responsiveness and Insensitivity (PRI) scale (Crasta et al., 2021). Rather than asking participants to report on a person, we asked them to report on the responsiveness of the randomly assigned social media algorithm. Participants were instructed to think of the content within their feed(s) that is curated for them by algorithms on that platform. The scale has two dimensions, PAR and PAI. PAR included eight items such as “The [Facebook] algorithm understands me,” α = .94. PAI involved 7 items including “The [TikTok] algorithm dismisses my interests,” α = .93. The scale was administered on a 5-point Likert-type scale (1 = not at all, 5 = completely).
Results and Discussion—Study 1
H1 predicted that algorithm responsiveness has a two-factor structure (i.e., PAR and PAI). We conducted a confirmatory factor analysis (CFA) using lavaan in R to determine if (1) the measure follows the anticipated two-factor structure, and (2) it functions similarly across the different social media algorithms. A multiple-group CFA was necessary to assess the appropriateness of measuring our constructs across the different contexts (Little, 1997). As expected, a one-factor model did not demonstrate adequate fit, χ2(77) = 1,792.05, root mean square error of approximation (RMSEA) = .169 (90% CI = [.162, .175]), comparative fit index (CFI) = .793, standardized root mean square residual (SRMR) = .105. The two-factor configural model demonstrated fit across groups (see Table 1). Next, we imposed two equality constraints to determine metric invariance across social media platforms: weak invariance (i.e., equal indicator loadings across groups) and strong invariance (i.e., equal loading intercepts across groups). We compare configural, weak, and strong metric invariance using the RMSEA difference test (Table 1). This test evaluates whether the RMSEA of the weak model does not exceed RMSEA 90% CI of the configural model, and the strong model does not exceed the RMSEA 90% CI of the weak model (Little, 1997). Metric invariance was established for both weak and strong models. The two-factor model, with constructs PAR and PAI, demonstrate adequate fit and metric invariance, meaning the constructs operated similarly across Instagram, TikTok, Facebook, and Twitter. We move forward with two perceptual dimensions of algorithm responsiveness: PAR and PAI.
Summary of Model Fit Indices for the Two-Factor Measurement for Study 1 and Study 2.
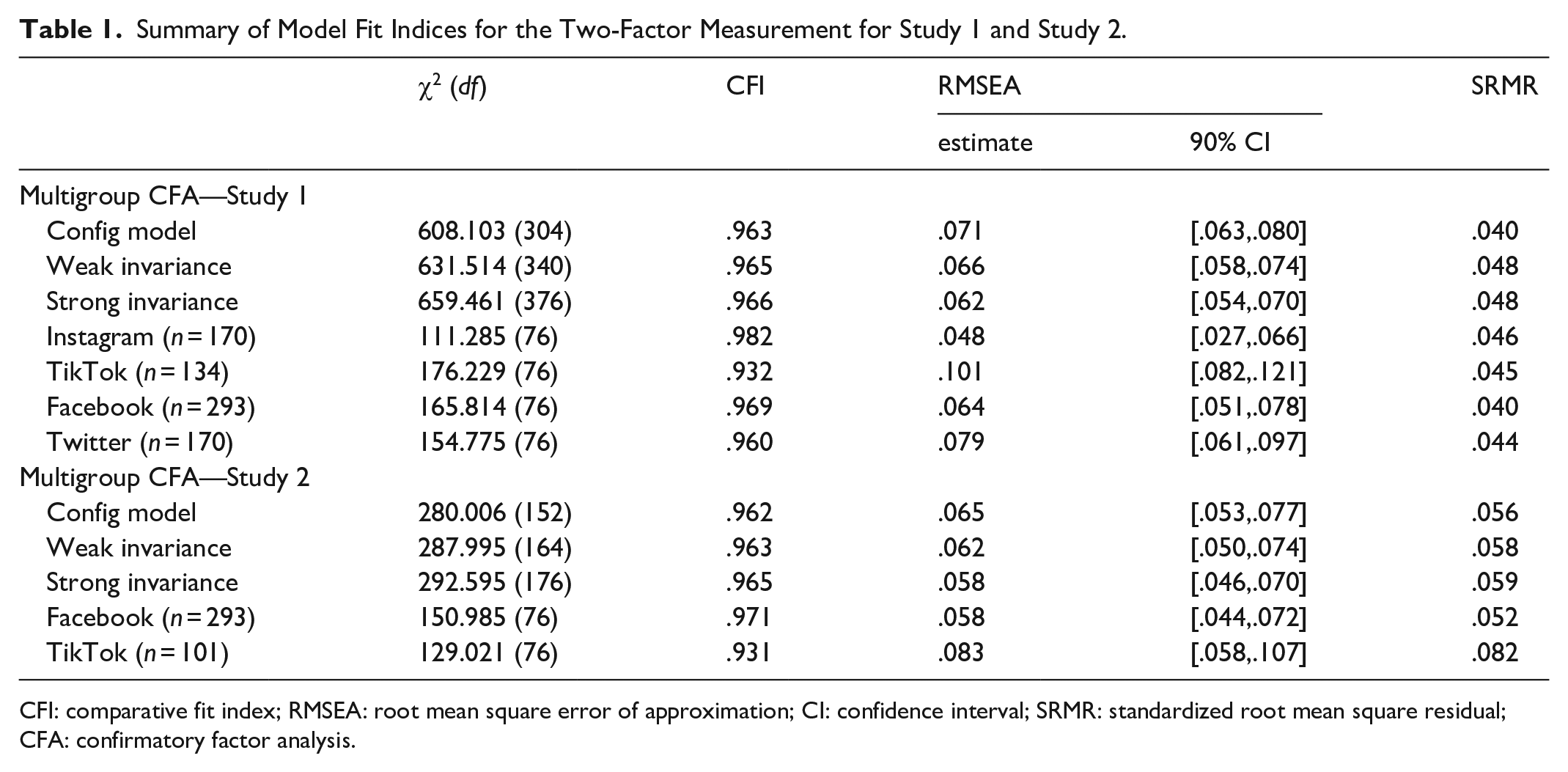
CFI: comparative fit index; RMSEA: root mean square error of approximation; CI: confidence interval; SRMR: standardized root mean square residual; CFA: confirmatory factor analysis.
Supplemental appendix Table A2 displays all descriptive statistics and bivariate correlations. RQ1 asked about the correlation between algorithm responsiveness (i.e., PAR and PAI) and algorithm awareness, (i.e., content filtering and human–algorithm interplay). PAR had a small positive correlation with content filtering, r(786) = . 19, p < .001, and human–algorithm interplay, r(791) = .20, p < .001. Being aware that an algorithm is curating content and influenced by one’s digital traces was associated with viewing the social media algorithm as somewhat more responsive. PAI shared a small negative correlation with awareness of content filtering, r(787) = −.10, p = .004, and awareness of human–algorithm interplay, r(792) = -.19, p < .001. All correlations were r = .20 or less, suggesting algorithm awareness and responsiveness are weakly related to one another.
RQ2 asked if PAR and PAI differed by social media platform. We used a linear regression to compare PAR and PAI by social media platform, controlling for content filtering awareness, human–algorithm interplay awareness, frequency of social media use, gender, and age (see Table 2). The results suggest that PAR differs by social media platform, F(3, 773) = 6.14, p < .001. Mean comparisons show that TikTok (M = 2.86, SE = .12) as having higher PAR than Facebook (M = 2.52, SE = .10, p = .001) and Instagram (M = 2.59, SE = .11, p = .02) but not Twitter (M = 2.66, SE = .11, p = .21). All other social media platforms were not significantly different from one another in terms of PAR. PAI also differed by social media platform, F(3, 774) = 7.43, p < .001. Post hoc comparisons revealed that Facebook’s algorithm (M = 2.79, SE = .11) was rated as more insensitive than TikTok’s algorithm (M = 2.37, SE = .13, p < .001), although there was no statistical difference between Facebook and Instagram (M = 2.59, SE = .12, p = .09) or Twitter (M = 2.59, SE = .11, p = .14). No other significant differences emerged for social media platform and PAI (see Figure 1).
Multiple Regression Predicting PAR and PAI—Study 1.

PAR = perceived algorithm responsiveness; PAI = perceived algorithm insensitivity.
Note. Facebook is the comparison category for social media platforms. Female is the comparison category for gender
p < .05. **p < .01. ***p < .001.

Estimated marginal means for PAR and PAI across social media platforms.
Study 1 was a preliminary study to determine the viability of algorithm responsiveness, specifically the extent to which algorithms were perceived as responsive to their self-concept. Mirroring interpersonal interactions, our results suggest two dimensions of algorithm responsiveness—PAR and PAI—that can be modeled across the social media ecology. Our data also suggested that algorithm awareness was a distinct, yet related, concept to algorithm responsiveness, which represents an important conceptual advance in understanding algorithm perceptions. Comparisons of social media platforms found that TikTok was higher in PAR than both Instagram and Facebook, whereas Facebook was greater in PAI than TikTok. Thus, the content that the TikTok algorithm curates was viewed as affirming and validating our participant’s sense of self and goals more often than Facebook and Instagram, with Facebook’s algorithm providing insensitive decisions more often than TikTok. These results are consistent with previous research focusing on the TikTok algorithms that found that algorithms support identity development (Karizat et al., 2021; Lee et al., 2022).
Study 2
Although offering preliminary support for two perceptual dimensions of algorithm responsiveness, Study 1 does not elaborate consequences of human–algorithm interaction. The four-step algorithm responsiveness process theorized here posits that PAR and PAI will explain outcomes of human–algorithm interaction. There are numerous outcomes of human–algorithm interaction, such as social connection (Lee et al., 2022), platform spirit (DeVito, 2021), or algorithmic exclusion (Simpson & Semaan, 2020), and, in Study 2, we focus on media enjoyment as a platform-level outcome of the algorithm responsiveness process.
Media enjoyment is a central construct of social media effects research (Reinecke et al., 2014), that is defined as positive affective (i.e., fun) and cognitive (i.e., convenience) attitudes toward a medium (Nabi & Krcmar, 2004). Media enjoyment theory (MET) hypothesizes primary two factors contributing to media enjoyment: (1) competence using the communication technology, and (2) social influence from one’s social network about the communication technology (Taylor et al., 2020). In terms of competence, Zarouali et al. (2021) refer to content filtering awareness as the basic competence of algorithms, suggesting competence on the site requires algorithm awareness and is a baseline for the algorithm responsiveness process to engage. Although becoming aware of algorithms initially undermines satisfaction with the platform, in the long term, it increases satisfaction because people feel more competent using the platform (Eslami et al., 2015). In terms of social influence, research shows that attitudes of friends and family about a social media platform (Taylor et al., 2020) and peer pressure to use Facebook predict one’s enjoyment with the platform (Reinecke et al., 2014).
Adding to the psychological approach of MET, we predict that PAR and PAI will independently contribute to media enjoyment of social media platforms because these concepts capture the human–algorithm interaction. For instance, college-aged TikTok users report that it was the quality of the content curated by the algorithm that drew people to use TikTok more than other platforms (Bhandari & Bimo, 2022). Feeling that social media algorithms thoughtfully respond and validate one’s identity, motivations, and goals should predict more enjoyment of that platform, whereas beliefs that an algorithm is dismissing and discouraging one’s interests or identity will likely make using that social media platform less enjoyable. Ultimately, we predict that one reason that people have different levels of media enjoyment from Facebook and TikTok is PAR and PAI:
H2. PAR is positively associated with medium enjoyment.
H3. PAI is negatively associated with medium enjoyment.
RQ3. Does (a) PAR and (b) PAI mediate the relationship between TikTok versus Facebook and medium enjoyment?
Method—Study 2
A total of 665 participants who have used either Facebook or TikTok in the past month were recruited from Amazon Mechanical Turk, excluding participants from Study 1. Participants identified as English speaking and residing in the United States. In all, 406 participants passed data quality and attention checks, which our a priori power analysis indicated was enough to detect a small effect, f2 = .05, with at least 80% power. The average age of participants was 37.48 (SD = 9.90) and 52.5% were male, 47.0% female, and 0.5% non-binary or other gender. Racial identity was as follows: 78.3% White, 10% Black or African American, 9.6% Asian, 7.8% Latinx/Hispanic, with all other racial categories <3.0%. All hypotheses, procedures, and materials were preregistered prior to data collection in January 2022.
Procedures
The procedures for Study 2 mirrored Study 1, with one notable difference. Participants were randomly assigned to either Facebook (n = 302) or TikTok (n = 104) only, rather than all four media. These two social media platforms were selected because these media were the only social media with significant differences in both PAR and PAI in Study 1. The unbalanced assignment is due to fewer participants using TikTok (n = 180, 44.3% of the sample) in the past month than Facebook (n = 388, 95.6% of the sample).
Measures
Algorithm Responsiveness
The same scale for Study 1 was used to measure algorithm responsiveness (Crasta et al., 2021). A multigroup CFA confirmed the two-factor structure across Facebook and TikTok (see Table 1). Reliabilities for both dimensions were high: PAR (α = .92) and PAI (α = .92).
Algorithm Awareness
Operationalization of algorithm awareness followed Study 1. Acceptable reliability was established for algorithm curation (α = .72) and human-data interplay (α = .72).
Medium Enjoyment
We adopted two items from Ledbetter’s (2009) medium enjoyment scale. Items represent the affective (e.g., “[Facebook] is fun), and cognitive (e.g., “[TikTok] is convenient”) dimensions of the concept, r = .44 (Nabi & Krcmar, 2004; Taylor et al., 2020). Responses were solicited on a 7-point Likert-type scale (1 = strongly disagree, 7 = strongly agree).
Social Influence
We measured social influence from friends using an established 6-item measurement (1 = strongly disagree, 7 = strongly agree) from Taylor et al. (2020). Example items include “My friends enjoy communicating through [Facebook].” After 2 dropping reverse coded items, the scale demonstrated adequate reliability, α = .84.
Results and Discussion—Study 2
To test H2–3 and RQ3, we implemented structural equation model (SEM) with nonparametric bootstrapping (10,000 samples with replacement) using the lavaan package in R. A multigroup CFA analysis first determined the manifest indicators loaded onto the latent constructs as anticipated, χ2(208) = 328.97, RMSEA = .055 (90% CI = [043 to .066]), CFI = .950, SRMR = .061. The structural model contained four variables of interest (1) medium, (2) PAR, (3) PAI, and (4) medium enjoyment. Medium was dummy coded (Facebook = 0, TikTok = 1). Age, frequency of social media use, content filtering algorithm awareness, and social influence were controlled in the analysis. Appendix Table A2 includes the descriptive information and bivariate correlations. See Figure 2 for the constructed model, which demonstrated model fit,

Indirect effect of PAR and PAI on medium enjoyment.
First, we tested if there was a positive association between PAR and medium enjoyment (H2) and a negative association between PAI and medium enjoyment (H3). Results show that PAR predicted medium enjoyment, B = .31, SE = .06, β = .25, p < .001. The more responsiveness participants reported, the more they enjoyed the medium. Critically, the significant relationship between PAR held after controlling for other antecedents of medium enjoyment from MET: social influence from friends, B = .39, SE = .06, β = .25, p < .001, and algorithm content filtering awareness, B = .15, SE = .09, β = .09, p = .08. However, PAI shared no statistically significant relationship with medium enjoyment, B = −.05, SE = .04, β = −.05, p = .17.
RQ3 asked if PAR mediated the relationship between the social media platform and medium enjoyment. To determine the mediation, we established the relationship between the independent variable (i.e., social media platform) and mediators (i.e., algorithm responsiveness and insensitivity). Replicating our results in Study 1, the model found that TikTok’s algorithm was rated as more responsiveness than Facebook’s algorithm, B = .38, SE = .08, β = .19, p < .001. In addition, Facebook’s algorithm was rated as more insensitive than TikTok’s algorithm, B = −.35, SE = .12, β = −.14, p = .005. The relationship between the mediators and the dependent variable (i.e., medium enjoyment) was established by testing H2–3. Finally, the bias-corrected bootstrapping indicated an indirect effect from social media platform on medium enjoyment via PAR (RQ3a), B = .12, 95% CI [.061, .200], SE = .03, β = .05. There was no evidence of an indirect effect via PAI, B = .02, 95% CI [-.003, .057], SE = .02, β = .01. Although there was evidence of an indirect effect via PAR, the significant relationship between social media platform remained, B = .49, 95% CI [.31, .69], SE = .09, β = .20.
The goal of Study 2 was to examine the association between perceptions of algorithm responsiveness and medium enjoyment to examine the fourth step of the algorithm responsiveness process. PAR was positively associated with medium enjoyment; whereas PAI was not significantly associated with medium enjoyment. These data suggest that when our participants perceived the platform algorithms to be understanding, validating, and caring for their own identity, they are more likely to enjoy using that medium. PAR was a significant predictor of media enjoyment above and beyond those antecedents of enjoyment predicted by MET, highlighting the role of human–algorithm interaction on social media use and effects. Furthermore, there was an indirect effect between the social media platform (Facebook vs. TikTok) and medium enjoyment. More enjoyment of TikTok (vs. Facebook) was significantly mediated through higher PAR. Although there was evidence of an indirect effect via algorithm responsiveness, the direct effect of social media platform remained. TikTok was reported as more enjoyable social media platform than Facebook independent of the PAR level. Therefore, part of the difference, but not all, in medium enjoyment between Facebook and TikTok was attributable to PAR.
General Discussion
Against the backdrop of growing algorithmic influence on identity, we aimed to further understand human–algorithm interaction by examining the perceptions people have about how responsive or insensitive algorithmically curated feeds are to their identity, motivations, and goals. Through theoretical innovation at the intersection of interpersonal theory and algorithms, we advanced and empirically tested PAR and PAI as an approach to understanding people’s perceptions of social media algorithms. This work contributes to communication theory by explicating responsiveness as an aspect of human–algorithm interaction, which highlights how social media algorithms can support and undermine identity and goals.
Across two studies, our results suggest that PAR and PAI are concepts for human–algorithm interaction that operates similarly across a variety of social media platforms. Our data showed consistent differences in perceptions of PAR and PAI between social media platforms, with TikTok having higher PAR and lower PAI than Facebook. These two studies also suggest that both dimensions of algorithm responsiveness differ from algorithm awareness, and Study 2 found that PAR partially explains why our participants had differing levels of media enjoyment between Facebook and TikTok. We review our contributions to communication and social media research.
PAR and PAI
Reconsidering the co-production of algorithms and identity (Karizat et al., 2021) as a process of human–algorithm interaction, we proposed a four-step algorithm responsiveness process, which centers around perceptions of algorithms being responsive and sensitive to one’s sense of self. The first contribution of this manuscript is conceptualizing and empirically testing two dimensions of human–algorithm interactions—PAR and PAI—across multiple social media platforms. Participants in our sample consider the curated content on social media platforms in relation to how well the algorithm is supporting their identity and motivations for using the platform as well as if the algorithm appears to be responding appropriately to new information provided about interests, hobbies, and motivations. Elaborating this perception of algorithms into two dimensions of responsiveness provides insight into the social media cognitions people have about how algorithms simultaneously support and ignore the multifaceted, dimensions of their identity (Lee et al., 2022). Social media algorithms can provide validating content that fits within a person’s identity or motivations, while also suppressing, disparaging, or harming other facets of identity (DeVito, 2022; Simpson & Semaan, 2020). As part of our initial establishment of PAR and PAI, we investigated the extent to which being aware of the algorithm (i.e., content filtering and human–algorithm interplay; Zarouali et al., 2021) differed from algorithm responsiveness. We found that awareness is associated with responsiveness but being aware of algorithms does not necessarily mean also people perceive those algorithms as responsive. This finding establishes the difference between knowing that a social media algorithm is generating personalized content from data and evaluating that personalization within the self.
To investigate how users evaluate different social media algorithm decisions in relation to the self, we compared PAR and PAI across social media platforms. We found that TikTok’s algorithm was rated as higher in PAR than Facebook and Instagram and lower in PAI than Facebook. There were little differences between Twitter, Instagram, and Facebook in terms of PAR and PAI. TikTok’s algorithm may result in a different type of interaction than other platforms because individuals are more directly interacting with TikTok’s algorithm (Bhandari & Bimo, 2022). The salience of social media algorithms primarily happens when the algorithm has failed or mispredicted a person’s goals or social identities (Bucher, 2017), and our participants experienced this most often while browsing on Facebook. Previous research describes the interplay of algorithms and identity as a dynamic process (Karizat et al., 2021; Lee et al., 2022); thus, PAR and PAI are likely fluid concepts that will exhibit within-platform variability over time as people interact more with the algorithm. Research should consider the longitudinal development of algorithm responsiveness including how various types of curated content (i.e., enacted response) promote different perceptions. Another contribution regarding PAR and PAI is providing a close-ended survey measure that is flexible to numerous social media platforms, adapting a vetted survey measure (Crasta et al., 2021). There are few measures for understanding algorithms at the present time (Zarouali et al., 2021), and the development of reliable and adaptable measures should aid research in trying to build theory. However, the validity of the measure across different samples (e.g., teens or people outside the United States) is still questionable and warrants future research.
Because algorithms are biased (DeVito, 2022; Noble, 2018), a pressing future direction is to build bridges between work on algorithmic harm and algorithm responsiveness among members of marginalized groups, such as Black users or LGBTQ people. Such an extension has implications for the theory of algorithm responsiveness. PAI, for example, may be thought of as a psychological consequence of algorithmic symbolic annihilation (i.e., when algorithms promote normative or stereotypical aspects of identities, further marginalizing diverse populations; Karizat et al., 2021). If algorithmic curation dismisses marginalized voices, then PAI may be increased for members of those groups, highlighting an opportunity to study algorithmic harm via responsiveness. The recursive algorithm responsiveness framework provided here helps establish the process by which individuals of marginalized identities may resist such algorithmic harms as well.
In Study 2, we tested our hypothesis that PAR and PAI represent mechanisms for predicting outcomes of human–algorithm interaction by connecting to media enjoyment (Eslami et al., 2015). Among our sample, PAR contributed to the enjoyment of social media above and beyond users’ competence with the platform’s algorithms or social influence from friends. Furthermore, we found an indirect effect of social media platforms on enjoyment via PAR, suggesting that PAR explains, partially, why our sample found TikTok more enjoyable than Facebook. These data corroborate reports that young adults have recently flocked to TikTok because the algorithm is perceived as better at understanding the user’s interests, hobbies, and future selves (Bhandari & Bimo, 2022; Lee et al., 2022). These results also speak of theories of media enjoyment (e.g., Reinecke et al., 2014; Taylor et al., 2020), pointing out that the quality of human–algorithm interactions contributes to the experience of media enjoyment. Our results are consistent with previous studies finding that changes in algorithms that conflict with goals spark emotional outrage, dissatisfaction, or platform exodus (DeVito, 2021).
An opportunity exists to find synergy between PAR and PAI with ongoing research on algorithms and identity. For instance, algorithm responsiveness may play a role in platform spirit (DeVito, 2021), or how users perceive a platform by contrasting the platform’s promises, history, ideals, actions, and functionality against the user’s goals. Perceptions of algorithm responsiveness may be particularly helpful in unpacking ideas of platform spirit related to the user’s sense that social media algorithms can help them accomplish their goals. Similar to how certain algorithmic folk theories buoy or damage platform spirit (DeVito, 2022), PAR may construct a positive platform spirit, whereas PAI may erode positive platform spirit. In addition, given that responsiveness fosters feelings of closeness (Choi & Toma, 2022), investigations should consider if PAR or PAI of TikTok explains the sense of belonging people experience on the platform via algorithms promoting content from similar others (Lee et al., 2022).
Thinking more broadly about human–algorithm interactions, our study offers one answer for research in this arena. Building our conceptualization of PAR and PAI off interpersonal communication theory helped to establish a theoretical foundation for conceptualizing the processes of human–algorithm interaction. Despite algorithms being elusive, ever-changing, and lacking transparency or typical social cues, our data suggest that people’s evaluations of responsiveness mirror that of interpersonal interactions. Although we do not anticipate that all principles of interpersonal communication to extend into algorithms, this finding is consistent with other work on human-machine communication (Gambino et al., 2020). Application of ideas from interpersonal theory may serve as a springboard for how to study how people understand these evasive and hidden systems.
Limitations
Our findings should be considered with several limitations. TikTok, Facebook, Twitter, and Instagram contain different types of media content and social relationships. Although we prompted participants to think of the social feed curated by algorithms, it is unclear if the findings are attributable to the different types of content or connections inherent to each platform, rather than the algorithm itself (Lee et al., 2022). Our sample, as with most Mechanical Turk samples, lacked diversity and had primarily WEIRD characteristics (Western, Educated, Industrialized, Rich, and Democratic demographics). This limitation matters when studying algorithms because algorithms have known biases for racial, sexual, and other minority populations (Noble, 2018). Yet, it is noteworthy that algorithm responsiveness mattered even with these fairly homogeneous majority group samples, which one may argue to be least likely to respond differently to algorithms. Building from these findings, future research should consider a wider variety of people with differing identities. Furthermore, Mechanical Turk participants tend to represent elite internet users (Ross et al., 2010), and this means differences between algorithm responsiveness and awareness may be attributable to the digital literacy of our sample. Another potential limitation to our findings is the direct asking of questions about algorithms may have created a demand effect because it is possible that, due to the limited visibility of social media algorithms, people are not cognizant of responsiveness or insensitivity at all.
Conclusion
Due to the opaqueness of social media algorithms, people experience them through their perceptions. This research aimed to understand those perceptions of social media algorithms as they intersect with people’s identity and goals. The results suggest that people who use social media make judgments about how responsive and insensitive the algorithmically curated content is to their core sense of self and how well the algorithm “listens” to information. PAR and PAI help to unpack the consequences of the ever-growing presence of human–algorithm interactions in everyday life.
Supplemental Material
sj-docx-1-sms-10.1177_20563051221144322 – Supplemental material for An Initial Conceptualization of Algorithm Responsiveness: Comparing Perceptions of Algorithms Across Social Media Platforms
Supplemental material, sj-docx-1-sms-10.1177_20563051221144322 for An Initial Conceptualization of Algorithm Responsiveness: Comparing Perceptions of Algorithms Across Social Media Platforms by Samuel Hardman Taylor and Mina Choi in Social Media + Society
Footnotes
Acknowledgements
The authors give special thanks to Dr. Andrew Ledbetter for assisting with the CFA and SEM, and the two anonymous reviewers who helped to improve the contribution of this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.