
Abstract
In this article, we argue that, in an era of platformization of culture, social media users tend to relate with brands through modalities that are more informed by platforms’ affordances (i.e., by the technical architecture of and participatory cultures thriving on social media platforms), rather than shared systems of values and meanings promulgated within brand communities or influencers’ fandoms. Our argument grounds on an analysis of 757,776 Instagram posts related to six global brands, through which we show how users create branded content by following and reproducing a memetic logic. Drawing on our empirical results and Limor Shifman’s theory of Internet memes, we introduce the notion of memetic brands. Memetic brands are collections of branded social media posts, which derive from a standard branded template that repeats from user to user with small compositional changes at every iteration and on top of which users attach expressions of their vernacular creativity. In the process, memetic brands vehiculate a hypersignification, that is, an implicit discourse on fluid and situational consumption. Through the concepts of affordances-based brand relations and memetic brands, the article contributes (from a theoretical and methodological point of view) to the emerging literature on platformization of culture.
Introduction
The concept of brand can be defined in multiple ways. From a sociological perspective, a brand can be seen as a socio-symbolic space that favors interactions among actors. More specifically, Lury (2004) conceives the brand as an object that connects a heterogeneous set of actors (companies, marketers, consumers, legal experts, etc.). As such, the brand configures as a “platform,” intended as both “a technical or physical support and a set of conventions” that enables and/or constraints different forms of interactions among those actors (Lury, 2004, p. 5). This dynamic is particularly visible within digital environments, which permit to observe (more directly) how different actors connect around and relate to brands (Arvidsson, 2005). Brand relations have been a significant focus of social research ever since the pioneering work of Fournier (1998). Fournier argued that consumers see brands as phenomenologically significant to their sense of selfhood, suggesting that brand relations could be conceptualized under headings, such as “love and passion,” “self-connection,” “commitment,” and “intimacy” (Fournier, 1998, pp. 363–365). Social media has multiplied the opportunities for consumers to interacting with brands and extending theirselves through them (Belk, 2013). Since the advent of Web 2.0, consumer culture and media scholars have extensively studied the forms of brand relations users weave with brands and among each other around brands on social media (Brodie et al., 2013). Schematically, it is possible to identify two main kinds of relations: community-based and influencer-based. In the first one, consumers use social media as a common ground to meet and converse with other like-minded users about brands toward which they feel the same emotional connection; in the process, they come to build a shared brand culture and identity (Schau et al., 2009). Especially, research has emphasized that online brand communities are privileged environments for identity work (Thompson, 2014); members use brands to define who they are, articulate a sense of belonging, and develop a moral register (Luedicke et al., 2010) or even to find pseudo-religious affinity (Belk & Tumbat, 2005). All of this is “typically centered on shared consumption experiences with the brand” (Muñiz & O’Guinn, 2001, p. 421).
The second mode of relation is linked to the rise of micro-celebrity practices and influencer culture on social media (Senft, 2013). Social media scholars have highlighted how many social media users, rather than building meaningful relations around a brand or consumer practice, deploy trending hashtags, often containing famous brand names, to achieve visibility and popularity for their own profiles, to acquire “Instafame” (Marwick, 2015). Rather than the focus on identity work, brands instead operate as tools in such practices of self-branding where they are deployed in a calculative and reflexive way to achieve visibility and recognition (Marwick, 2013). In this modality, brands figure less like totemic symbols of identity and more as media that can reinforce the power or the visibility of a message. This attitude is particularly evident in social media influencers’ activities, who post frequently on brands (De Veirman et al., 2017). Influencers do that not necessarily to display a particular passion toward brands, but rather for instrumental purposes, that is, to display a particular cultural and social capital (Fiers, 2020) and gain visibility (Abidin, 2019). Influencers use brands to promote their personal brand and aggregate a community of followers around it. On their side, followers post and talk about brands more to stay engaged with the influencer community, rather than to express a particular affection toward brands (Abidin, 2016).
Alongside these two types of relations, we propose a third one that we call affordances-based. We contend that social media users can also engage with brands through modalities that are informed by platforms’ affordances, that is, by the technical architecture of social media and participatory cultures thriving on those platforms—rather than shared systems of values and meanings promulgated within brand communities or influencers’ fandoms. To explore affordances-based brand relations, we draw on the analysis of 757,776 Instagram posts related to six global brands, through which we show how users tend to create branded content by following and reproducing a memetic logic (Leavitt, 2014). Memes are standardized multimodal texts spreading rapidly across Internet networks, which users (re)appropriate, remix, and modify to contribute to larger pools of subcultural production and collective expressions of sentiment circulating in dispersed digital publics (Rogers, 2019). Meme culture is a sheer example of “natively digital culture” afforded by the socio-technical architecture of and participatory cultures inhabiting social media environments (Gal et al., 2016; Shifman, 2014b). Specifically, through our empirical analysis, we show that Instagram provides users with a grammar and vernacular they use to develop memetic relations toward brands. On the one hand, Instagram offers an infrastructure that favors imitative practices (rather than conversational ones) and the technical means (e.g., photos and captions) through which users compose meme-like posts. On the other hand, the platform hosts and circulates standardized branded imaginaries that users use to express private experiences and emotions. The recurrence of the same “memetic logic” across the six brands analyzed suggests us that it derives from a broader Instagram culture rather than local brand subcultures. Drawing on these results, we introduce the concept of memetic brand, intended as a collection of branded posts which derive from a standard branded template that repeats itself from user to user with small compositional changes at every iteration and on top of which users attach expressions of their vernacular creativity. Such collection of posts shares and vehiculates an implicit discourse on fluid and situational consumption.
The article contribution is twofold. First, by showing how brand relations are shaped by social media affordances, it contributes to the emerging field of study on “platformization of culture” (Duffy et al., 2019)—focusing more on culture in an anthropological sense, that is, as emerging from the everyday digital practices of platforms’ users, rather than on the relation between cultural industries and platforms. Second, from a methodological point of view, it shows that the Internet meme can be a suitable heuristic to interpret the processes of platformization of culture on social media (Nieborg et al., 2020). In fact, our intent is not to demonstrate that consumers use memes to relate to brands (and among each other) on social media, rather we use the concept of “meme” as a metaphor to capture the mutation of brands relations within social media platforms. In this, we took inspiration from the concept of “algorithmic brands” featured by Carah and Angus (2018). Carah and Angus do not mean that nowadays brands are using algorithms for developing their campaigns; rather the authors employ the concept of algorithm as a metaphor for describing how brands operate in the current social media and big data ecology. By exploiting ad hoc and ubiquitous digital devices, brands constantly tap into consumers’ everyday digital activities to feed and adjust their communication, marketing, and business strategies—this within an infinite loop of data capture, strategy implementation, and feedback recording, which mimics the functioning of an algorithm.
The article is structured as follows. In the first part, we discuss the concepts of affordances, grammars, and vernaculars and the related theories of networked and affective publics. These concepts and theories are crucial to properly frame and understand mimetic behaviors unfolding on social media and show the reader that the empirical results presented in the article do not stem from the subjective interpretations of the authors but are instead consistent with the specific technical, social, and cultural properties of social media platforms. The subsequent paragraph on memes serves as trait d’union between the first part and methodology. On the one hand, we show that memes share some grammars and vernaculars which are informed by the affordances of social media publics. On the other hand, mainly drawing on Limor Shifman’s (2014a) theory of Internet memes, we discuss the structural and semantic characteristics of memes that we use as a heuristic to interpret our empirical results. We then proceed to describe the research design and, drawing on our findings, we discuss the concept of affordances-based brand relations.
Theoretical Background
Social Media Affordances, Grammars, and Platform Vernaculars
Affordances consist in a set of contextual constraints and props that shape the usage of technology, which emerge at the intersection between the devices’ properties and the users’ perception of their utility—perceptions that are in turn shaped by the cultural meanings and practices of use shared by those social groups users belong to (Bucher & Helmond, 2017). This complex array of constraints and props “determines the socially mediated possibilities that the devices offer for action” (Fernández-Ardèvol et al., 2020, p. 3). When it comes to digital platforms, such as social media, affordances can be seen at the intersection between the platform politics (Gillespie, 2010) and cultures of use (Rieder et al., 2018), that is, between the technical architecture of a platform that shapes patterns of communication (e.g., hashtags, algorithms, etc.) and the collective practices of those social groups that use the platform and its technicalities for specific communicative purposes (e.g., participatory cultures) (Rieder et al., 2020). To empirically observe and describe the impact of social media affordances on socio-cultural processes, scholars suggest taking into consideration two key dimensions of digital media: grammars (Gerlitz & Rieder, 2018) and vernaculars (Burgess, 2006). The concept of grammar describes the fact that every digital environment constraints activities into specific “units of actions” and provides the very means to perform such actions (Agre, 1994). For example, Twitter drives users toward reactive interactions rather than conversational ones, and at the same time provides them with retweets, that is, the very means that allow them to pursue reactive interactions. The term vernacular derives from Burgess’s (2006) concept of vernacular creativity, which is intended as a particular form of cultural production initiated by “ordinary” Internet users (Atton, 2001), who, with no professional means and business purposes, create aesthetic artifacts through which they capture, represent, and reflect on mundane aspects of their everyday life (Negus & Pickering, 2004). In relation to digital media, vernaculars refer to those linguistic conventions characterizing a specific digital environment (Manovich, 2017). Consider, for example, Instagram stories. Instagram stories are digital devices that permit users to simulate intimate interactions. To convey a sense of intimacy to their audiences, stories-makers tend to articulate visual narrations in which they open their backstage to the public. This linguistic convention comes from Instagram influencers, who carefully crafted and promoted it through their public performances (Audrezet et al., 2020). Reflecting specifically on the intersection between grammars and vernaculars on social media platforms, and the ways they affect communications on social media, Gibbs et al. (2015) propose the concept of platform vernacular. The term “refers to the different narrative patterns that shape content and the flow of information” (Niederer & Colombo, 2019, p. 55) across a given platform, which is not solely driven by the creativity of individual users but rather shaped by the “specificities of the platform, its material architecture, and the collective cultural practices that operate on and through it” (Gibbs et al., 2015, pp. 257–258). This concept amounts to be particularly useful for this article since, throughout the article, we will see that memetic brands are not random entities, but instead cultural artifacts directly informed by the “material architecture and collective cultural practices” of Instagram.
In the next two paragraphs, we review the literature on networked and affective publics to show how social media affordances—along with their grammars and vernaculars—shape users’ patterns of activity and content production, channeling them toward forms of reciprocal imitation and collective expressions of sentiment.
Networked Publics and Imitation Practices
A useful concept to better understand to what extent social media affordances affect social behavior is that of networked publics. According to danah boyd (2011), networked publics are publics that are “restructured by networked technologies” and are “simultaneously (1) the space constructed through networked technologies and (2) the imagined community that emerges as a result of the intersection of people, technology, and practice” (p. 39). This peculiar interplay between communication technologies, cultural artifacts, and social practices has a profound impact on how sociality unfolds online. In networked publics, the usually ephemeral products of communication, such as opinions or self-presentation acts, become “material” objects that are persistent, searchable, replicable, and scalable. As a consequence, users’ social performances are constantly exposed to invisible audiences, meaning that they can never be fully sure of who is watching their content production and its cultural appropriateness (Pitcan et al., 2018). Another important characteristic of networked publics is their ephemerality. Usually they “pop up” around digital devices, such as hashtags, that serve to collate posts related to a specific topic (e.g., #wikileaks) and coordinate distributed discussions among large groups of dispersed users, who disband when the topic ceases to be trending (Bruns & Burgess, 2011).
Therefore, affordances of social media compel users to confront with social spaces that are fluid (e.g., emerging around ephemeral trending hashtags) and contexts of interaction that are fuzzy (populated by invisible audiences). Given these precarious structural conditions, people do not necessarily enter the social media environments with a rational and a pre-planned content or self-presentation strategy in mind (Rettberg, 2017). More simply, users tend to instantaneously “react” to contingent content popping up on their screens (Nieborg & Poell, 2018). According to Geboers (2019)—who studied social interactions around the iconic photo of Alan Kurdi on Instagram—when exposed to social media content, users develop, basically, only two strategies of (re)action: aligning to or diverting from opinions and/or emotions vehiculated by a given post (e.g., to like or not to like posts, posting a comment of agreement or disagreement, etc.). Such “reactive attitude” is a form of collective participation that is observable in the context of online consumer culture as well. Duplication and imitation are staple mechanisms at the base of viral campaigns, which exhort online consumers to repost original branded content (Mills, 2012). In the same way, influencers often create branded posts or selfies which template they invite their followers to imitate—(see, for example, Outfit of The Day contests) (Abidin, 2016). Similar dynamics can be observed in more spontaneous consumer formations too. For example, the principal activity of the One Direction fandom on Twitter consists in pushing One Direction-related hashtags through the trending topics of the platform by copy-and-pasting multiple times the same message (e.g., #onebigannouncement) (Arvidsson et al., 2016). Nicoll and Nansen (2018) are more explicit in defining the imitative practices played out by users around branded content on YouTube, speaking of “mimetic video production.” By analyzing 100 toy unboxing videos on YouTube (created by both amateur kids and professional youtubers), Nicoll and Nansen (2018) come to the conclusion that “children’s modes of production as amateur content producers both shape and are shaped by the shared and standardized conventions of this video genre” (p. 1).
An important component and driver of imitative practices on social media is affect (Stage, 2013), which impacts on online social interactions, and forms of cultural production are well explained by the theory of affective publics (Papacharissi, 2016).
Affective Publics and Collective Expressions of Sentiment
In the last decade, media theory underlined that social media do not only foster opinion exchanges on a large scale but also the sharing and circulation of affectivity on a global scale—through the wide diffusion of ad hoc features, such as emoji, memes, GIFs, and photos (Döveling & Sommer, 2017). To this purpose, Papacharissi (2016) coined the term affective publics, which she defines as “networked public formations that are mobilized and connected or disconnected through expressions of sentiment” (p. 311). The affective publics’ notion expands boyd’s conceptualization of networked publics, as it stresses that users who participate in online publics might be materially networked by digital infrastructures (e.g., hashtags) but are socially and culturally connected through mutual exchanges of affective intensities. Thus, affective publics are not structured around a specific content per se, but rather on the circulation of affective intensities that are vehiculated by the pieces of content that users post. Arguably, affectivity is the property that structures affective publics and keeps them together, even though it amounts to be a very ephemeral entity. In fact, affect is not an emotion: it is a generic flow that coalesces into a specific emotion according to the specific goals of a public (Geboers & Van de Wiele, 2020). This double movement between affect and emotions is particularly visible in visual vernaculars developing within affective publics on social media (Niederer, 2016).
Pedwell (2017) conceives affective publics as made by global audiences who use emotions as universal language to communicate—insofar, a real conversation among users is hampered by linguistic barriers and the huge scale of digital media environments. Anyhow, emotions are not universal but context-dependent, that is, they make sense in the specific cultural context in which they are situated (McCarthy, 1994). Here, the mediation of visual vernaculars comes to play a crucial role: they provide a common cultural code through which emotions can be materially expressed and, eventually, shared (Ash, 2015). For example, Döveling et al. (2018) show that affective publics emerging around hashtags, such as #PrayForParis or #JesuisCharlie, hinge on the circulation of repetitive visual repertoires which, even though imbued with subjective meanings, serve to signal a common sentiment of grief in front of an invisible global audience (Van den Bulck & Larsson, 2019). A similar point is made by Gibbs et al. (2015) in their study of the affective public emerging around the hashtag #funeral on Instagram, to which members participate by producing a repetitive visual repertoire made of selfies. The authors come to the conclusion that selfies are not so much acts of self-presentation, but rather devices to capture a given moment and communicate its affective intensity to a distant audience. As Gibbs et al. (2015) specify, Instagram users use selfies “to mark the funeral event, location, and experience, and as such its use acts as a form of presencing, communicating a person’s emotional circumstances and affective context” (p. 265).
Anyway, it remains unclear the cultural value of such ephemeral social formations aggregating around momentary expressions of sentiment. In fact, affective publics look like heterogeneous assemblages of private emotions, which seem incapable to coalesce into any kind of coherent and collective cultural meaning, such as common discourses, ideologies, or identities (Geboers, 2019). This point is made explicit in brand publics’ theory (Arvidsson & Caliandro, 2016). Brand publics are forms of affective publics made by a multitude of disconnected consumers who converge in mass on branded hashtags (e.g., #louisvuitton) and use them as platforms to stage private identities and emotions (Bardhi & Eckhardt, 2017). Inevitably, such motley set of individualized actors associates to brand a heterogeneous array of incoherent and idiosyncratic meanings (Parmentier & Fischer, 2014), which, by, default, does not undertake any process of cultural recomposition and, thus, can do nothing but diluting in the vastity and messiness of cyberspace (Andrejevic, 2013).
Nevertheless, in this scenario, the concept of meme might turn out to be a useful heuristic to help researchers in retrieving a common ground of action and meanings within flows of sentiment permeating digital publics revolving around brands or consumer products.
Memes
Social media, with their array of affordances, networked and affective publics, represents a fertile ground for the production and circulation of memes and meme cultures. Memes are collections of standardized multimodal texts spreading rapidly across digital networks, which consist in user-created derivatives that stem from an original piece of content (Milner, 2016). In this way, memes permit collective participation even in dispersed digital environments (such as, social media platforms), which do not favor direct interactions among users. In fact, conceived as devices of communication, memes represent an effort to initiate and keep going (simulated) conversations among disconnected audiences populating networked publics. As Rogers (2019) explains, “by making and circulating a [meme]—such the infamous one of Trump’s wrestling a CNN reporter—one contributes to the larger pool of subcultural production, adding materiality to a sentiment” (p. 192). Often characterized by irony, memes trigger conversations on disparate topics, spanning form politics, show business and social issues. As cultural content, memes can be conceived as an expression of vernacular creativity (Burgess, 2006). Anyway, although an expression of vernacular creativity—that is spontaneous and not governed by formal endowments of cultural capital and/or social hierarchies—memes do not manifest through infinite and idiosyncratic repertoires of symbols, instead they tend to coalesce into an extremely small number of formulations (Wiggins & Bowers, 2015).
A comprehensive and systematic definition of memes is provided by Limor Shifman (2014a), who defines Internet memes as “a group of digital items that (a) share common characteristics of content, form, and/or stance; (b) are created with awareness of each other; and (c) are circulated, imitated, and transformed through the internet by multiple users” (Shifman 2014a, p. 341). Differently from Dawkins (1976), here a meme is not a single cultural entity (e.g., a joke, a jingle, etc.) that succeeded in reproducing itself (by leaping from brain to brain), but rather a collection of content that had a massive circulation and exposure among dispersed audiences located on different digital platforms. In fact, in Shifman’s views, what is important when studying memes, it is not so much the tracking of the “original piece of content” from which all the other derivatives spring, but rather the exploration of discourses that memes vehiculate and social connections they enable.
Focusing on visual media, Shifman identifies three different genres of memes: (a) reaction photoshops; (b) stock character macros; and (c) photo fads: Reaction Photoshops are collections of edited images created in response to a small set of prominent photographs, which may be labelled memetic photos. [. . .]. Stock character macros are image macros (images superimposed with text) that refer to a set of stock characters representing stereotypical behaviors. [. . .]. Photo fads are staged photos of people who imitate specific positions in various settings. (Shifman, 2014a, p. 343)
Shifman (2014a) maintains that, notwithstanding their intrinsic specificities and differences, all memes share three main characteristics: two structural and one sematic, that is, prospective photography, operative signs, and hypersignification. Prospective photography refers to the fact that every meme hinges on a standard template that each user is expected to stick to and reproduce. Then, on top of such template, a user can add a personal inscription (e.g., a new text), thus expressing his or her own creativity. In this sense, memes carry operative signs, that is, “textual categories that are designed as invitations for (creative) action” (Shifman, 2014a, p. 354). Despite memes invite users to creative action, such creativity does not take random forms. In fact, as Wiggins and Bowers (2015) argue, the generative capacity of a meme is constrained “by the syntax rules assigned by the initial meme” (p. 8). In fact, a certain degree of literacy—in the field of digital subcultures (Jenkins et al., 2013)—is required to use a meme correctly (Katz & Shifman, 2017). Although the conversations enabled by memes are simulated, phatic and highly subversive participants are anyway expected to stay on topic, that is, preserving and not diverging from the specific discourse embedded in the meme (Nissenbaum & Shifman, 2017)—it is not a case that users failing in using a meme correctly are often object of public shaming and trolling (Phillips, 2019).
Speaking of “specific discourses vehiculated by memes,” the concept of hypersignification comes into play. Hypersignification means that the code of the message is the message itself. According to Shifman (2014a), memes “are more about the process of meaning-making than about meaning itself” (p. 344). For example, the infamous meme “The Situation Room” is not about the capture of Osama bin Laden, but rather about the “staged authenticity” featured by political communication on social media. Therefore, users participating in the above “memetic conversation” are expected to keep propagating the latter meaning, not the former.
Therefore, prospective photography, operative signs, and hypersignification are the three key semantic elements that make memes communication devices that enable forms of shared language and collective conversations within social media platforms, that is, within digital environments which affordances do not favor direct social interactions and forms of group discussions (Van Dijck, 2013). In this context, memes are able to reconstruct a sense of community among dispersed groups of social media users inhabiting fluid digital spaces and a cultural fragmented world (Eckhardt & Bardhi, 2020).
Therefore, to conclude, it is possible to observe that the memetic culture is an expression of the influence of social media affordances on users’ collective activities. In fact, they provide a specific grammar (prospective photography, operative signs) and vernacular (hypersignification and/or common discourses) that are able to keep together the individualized and disconnected members of digital publics populating social media platforms.
Methods
Methodological Framework and Research Question
The general scope of the digital investigation presented in this article is to explore new forms of brand relations emerging on social media. Specifically, our empirical work draws on a dataset of 757,776 Instagram posts that we explored and analyzed by following a digital methods approach (Rogers, 2013). Digital methods employ “online tools and data for the purposes of social and medium research” (Rogers, 2017, p. 75). This approach (by default) combines quantitative and qualitative techniques (Marres, 2017). On one hand, digital methods make extensive use of quantitative IT techniques to collect, sample, organize, and analyze digital data (e.g., scraping; Marres & Weltevrede, 2013); on the other hand, they take advantage of qualitative technique (such as manual content analysis) to make sense of (samples of) digital data and put them into context (Caliandro & Gandini, 2017; Niederer, 2016).
To analyze our data, we employed an exploratory approach to big data—which is an approach introduced by digital methods scholars (Rieder et al., 2020). In essence, we explored our (big) database by following an iterative process between quantitative and qualitative analysis (on bigger and smaller samples), which informed each other. In turn, the process of interpretation of results followed a similar grounded logic since we combined data-driven and theory-driven approaches (Langlois & Elmer, 2013). To put it simply, our theoretical constructs of “memetic brands” and “affordances-based brand relations” emerged gradually after several iterations of data analysis and literature review (Glaser & Strauss, 2009). (Anyway, for the sake of clarity, we will present below our analytical procedures and results in a linear manner). Thus, to develop this exploratory approach properly and effectively, we decided to start from a “broad” research question, rather than a prefabricated hypothesis (Tukey, 1977). Specifically, we formulated the following research question: What is the role of affordances in shaping brand relations?
Data Collection
Our digital investigation is based on a dataset of 757,776 Instagram posts collected in 2015 and related to six prominent global brands: #starbucks, #mcdonalds, #smirnoff, #greygoose, #zara, #louisvuitton. We chose these six brands with the aim of gathering a dataset that was homogeneous and variable at once (Kunda, 1992). These brands are homogeneous in the sense that they are all well-known and popular global brands, with a strong presence on Instagram. 1 This allowed us to analyze brands that can be deemed to be relevant for consumers, independently from their nationality—in fact, at the time of the data collection, it was not possible to interrogate the Instagram’s application programming interface (API) by selecting a specific language. These six brands are heterogeneous too since we selected both top and bottom shelf brands within different product sectors. This variability has been strategic for our research purposes since it made easier to observe the influence of platform logics on brand culture.
We collected Instagram posts using a custom-written Python script programmed for interrogating the Instagram API (Russell, 2013). The script was set to pull all the posts containing the following hashtags: #starbucks, #mcdonalds, #smirnoff, #greygoose, #zara, and #louisvuitton. We extracted all the posts uploaded on Instagram over a 1-month period (30 November 2015 to 31 December 2015), so obtaining a large dataset of 757,776 posts. Besides the posts, the script also retrieved the related metadata, such as likes, hashtags, and captions.
Operationalizing Memetic Brands on Instagram
Although not all memes are visual, their most common online manifestations certainly are. For this reason, we deemed Instagram an appropriate fieldsite to pursue our goals—with its 1 billion active users, Instagram is currently the most prominent photo-sharing platform worldwide (We Are Social, 2021). Moreover, several scholars already acknowledged the importance of Instagram as a site to explore meme culture (Abidin, 2020; Ging & Garvey, 2018; Skjulstad, 2020). Consider also that the Instagram’s grammar is particularly suitable to study memetic-like artifacts: Instagram allows users to compose kinds of multimodal texts that make posts resemble a lot a stock character macro. In fact, one can consider photos as devices through which users can post, produce, and reproduce standard and stereotypical images, while the photo caption as a device through which they can attach their own “creative texts” on top of standard images. In this way, Instagram photos and captions configure as the “semantic space” where one can observe, trace, and measure prospective photography (or standard visual templates) and operative signs (or manifestation of vernacular creativity).
Specifically, to our aims, we considered as a branded template a picture depicting a brand or branded object, which, in terms of composition, repeats itself with few, slight, or no changes over a certain number of posts. While we considered as a consumer operative sign the manifestation of users’ vernacular creativity expressed through photo captions, in which users describe and/or try to communicate to a distant audience: (a) their personal relation/experience with the brand; and/or (b) the situation in which the brand/branded object was consumed; and/or (c) the situation in which the picture was taken.
As far as hypersignification is concerned, of course, this has not been an object of an a priori operationalization, but rather of a posteriori interpretation. We tried to grasp the meta-code vehiculated by Instagram posts through a close reading of them (Rasmussen Pennington, 2017), considering the visual and written features of posts as whole, that is, as a network of different semantic layers that are all crucial to understand the meaning and context of a post (Niederer & Colombo, 2019).
Data Analysis
To analyze the content of a such big collection of pictures, we took advantage of a software for automated visual analysis: Google Vision API (GVA), a machine learning-based image recognition toolkit provided as a service by Google (Geboers & Van de Wiele, 2020; Mulfari et al., 2016). Although very useful, GVA releases an output that is not intuitive to interpret and, especially, not immediately usable to meet academic research objectives (Mintz & Silva, 2019). For each photo parsed, the software returns a long string of labels, like this one: [{‘label_desc’: ‘bottle’, ‘label_score’: 0.87};{‘label_desc’: ‘table’, ‘label_score’: 0.95}; etc.]. Each label corresponds to a specific entity recognized in the photo (a bottle, a plastic container, a table, etc.). For each label, the software provides a score of accuracy, namely the percentage to which the software is “certain” of having correctly recognized the image feature (i.e., how likely the label “cat” corresponds to an image featuring a feline). Thus, we had to repurpose (Rogers, 2013) GVA to get more refined results and, especially, a set of coding categories useful to distinguish the different content of the pictures and, ultimately, identify possible patterns of repetition. To this purpose, we manually explored a random sample of 6,000 posts (1,000 for each brand) to (a) check for possible semantic overlap among labels (e.g., bag, purse = bag) and (b) have an initial sense of the content of each image. This manual exploration was also aided by ImageSorter, a free software, that sorts the collection of images by color and so helps researchers to identify possible visual patterns with a dataset (see Figure 1). Such a procedure allowed us to come up with a set of few and specific coding categories that permitted us to develop an automated content analysis on our big dataset (see Table 1 for the coding book). We checked the reliability of our coding categories by asking two external analysts to code a random sample of 3,000 images (500 for each brand). We assessed the intercoder reliability through the Krippendorff’s (2012) alpha. Considering all the brands, we obtained an average score of 0.85, 2 which is considered appropriate in the literature (Lacy et al., 2015). Finally, we manually explored a random sample of 2,400 posts’ captions (400 for each brand)—a number we reached by saturation (Weber, 2005)—to study the consumer operative signs and hypersignification. After a grounded and iterative process (Altheide, 1987), we distinguished four categories: (1) narrative captions, messages in which users describe the situation in which the picture was taken and/or a personal experience in which a brand is involved (e.g., “new light for me!! love my coworkers! #greygoose #vodka”); (2) passionate captions, messages that express an explicit appreciation (or deprecation) toward a brand (e.g., “I like #starbucks, students always in here working”; (3) promotional captions, messages in which users exploit the popularity of the brand to promote their personal brands or products (e.g., “#featurepoints download free apps and earn amazing rewards! click the link in my bio #starbucks #pokemon #fifa”); (4) non codable (n.c.) (e.g., “#louisvuitton _ _”). We also used wordclouds of hashtags to give a general idea of the most recurred keywords appearing in the captions.

ImageSorter output.
Coding Book.

Note. Here is an example from the Starbucks dataset; the coding of the other five brands followed the same logic.
Ethical Considerations
We collected our data through the Instagram API, in a period (2015) when they were still publicly open—therefore, no scraping techniques have been used to circumvent Instagram’s Terms of Service (Bainotti et al., 2020). Moreover, the posts analyzed in this study are “available to anyone with access to the internet, including those without an Instagram account” (Fiers, 2020, p. 6). Also, results are presented in an aggregate form. Images and captions displayed in the article have been processed in an ethical manner since (a) when present, faces in the pictures are obscured; (b) photos do not include usernames; (c) captions are not associated to any specific username or photo. Finally, we displayed very “neutral” pictures and captions since they portrait very common objects and generic narrations—(that is, for example, they do not disclose any sensitive information, such as sexual or political orientations of a user).
Findings
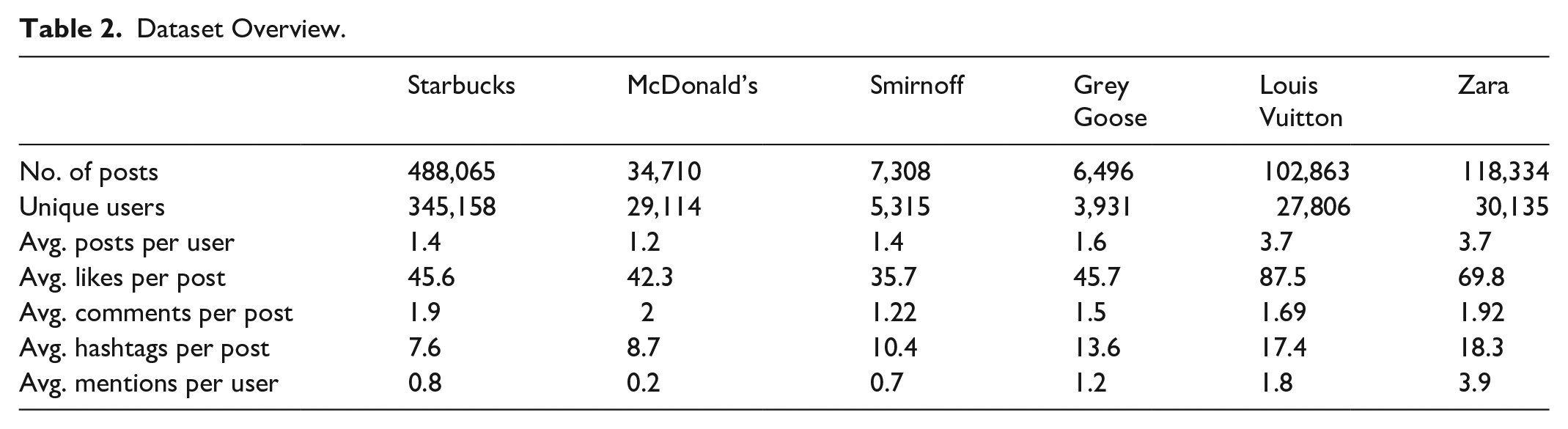
Overall Stats
General stats provide insightful information on patterns of activities and forms of interaction users develop around the six brands. First, if we look at the average number of posting, commenting, and mentioning (Table 2), we see that users are not only scarcely active but also very little interactive. 3 They do not seem interested in engaging with other like-minded consumers in a classical communitarian way and discuss about the brands they are passionate for. This suggests that our users coalesce into a kind of social formation that is assimilable to a brand public (rather than a brand community) (Moufahim et al., 2018). Focusing again on the stats, it is worth noting that (for all brands) the average like count always exceeds the average number of comments and reciprocal mentions. Therefore, branded posts seem to trigger, mostly, mere “reactions,” rather than rational debates. To conclude, this brief quantitative analysis let us understand that users converge into brand public formations, in which social interaction grounds on connectivity and reactivity. Such results seem indicating that, by following our six branded hashtags, we run into an appropriate fieldsite for the exploration of imitative and mimetic online behaviors.
Dataset Overview.
Branded Templates
In this paragraph, we display the results of the visual content analysis supported by GVA. Through this analysis, we show users create common imaginaries around brands, made by very standard and extremely repetitive visual repertoires (see Figures 3 and 4). Drawing on Shifman’s vocabulary, we assimilate such standard visual repertoires to forms of prospective photography that we call branded templates.
The “raw” label count released by GVA (Figure 2) already provides some clues about the standardization of visual imaginaries around brands: #Starbucks: cup = 135,226; #McDonalds: product = 6,890; #Smirnoff: drink = 3,473; #GreyGoose: distilled beverage = 1,420; #LouisVuitton: product = 52,311; #Zara: product = 42,561. Anyway, a more refined content analysis, based on ad hoc coding categories, is needed to make clear our point—(after all, what does product mean?).

Label distribution for all brands.
As far as #Starbuck is concerned, of the 488,065 pictures, 62.72% of them depict the iconic branded cup in the foreground, with slight tweaks for each photo (e.g., a red cup, a transparent cup, a cup on a table, a cup held by a hand, more than one cup, etc.). This percentage can be reasonably raised up to 72.9%, if we sum the category Cup to Food (Figure 3); in fact, the category Food entails pictures which composition does not diverge so much from those falling into the category Cup: pictures with the Starbucks cup in the foreground accompanied by a piece of food. Regarding #McDonalds, of the 34,710 pictures, 41.45% have been codified as Food: a category that collates photos of McDonald’s products (hamburgers, chips, drinks, etc.) displayed on a tray, with slight differences from post to post. #Smirnoff presents a distribution that is very similar to Starbucks, with 68.18% of pictures (n = 7,308) displaying a Smirnoff bottle—with small tweaks from photo to photo (e.g., a bottle on a table, a bottle held by a hand, etc.). #GreyGoose (n = 6,496) shows an interesting distribution, that is, a distribution dominated by two main categories: Bottle (37.28%) and Portrait (33.78%). Anyhow, both categories gather collections of repetitive images. As far as Bottle is concerned, there is nothing new compared to what we saw for #Smirnoff or #Starbucks. While, regarding the category Portrait, it is possible to observe a gallery of very standardized selfies and portraits: one or more male subjects cheering while holding a big bottle of Grey Goose. #Zara (n = 118, 334) presents a very standardized photos’ distribution: 69.9% of the pictures have been coded as Pose. This category features a gallery of selfies depicting (mostly) young women taking a picture in the mirror while holding their smartphones and wearing (probably) Zara garments (Figure 4). Finally, #LouisVuitton (n = 102,863) presents a peculiar distribution, even though not completely odd. The most recurrent category is Portrait (28.9%), which does not entail a particularly standard imaginary (except for the selfie genre per se). Also, the category distribution seems quite heterogeneous and even. Nevertheless, if we delve into some of the coding categories (Bag, Gift, Shoes, and Wallet), we can find again stocks of repetitive images (Figure 5).
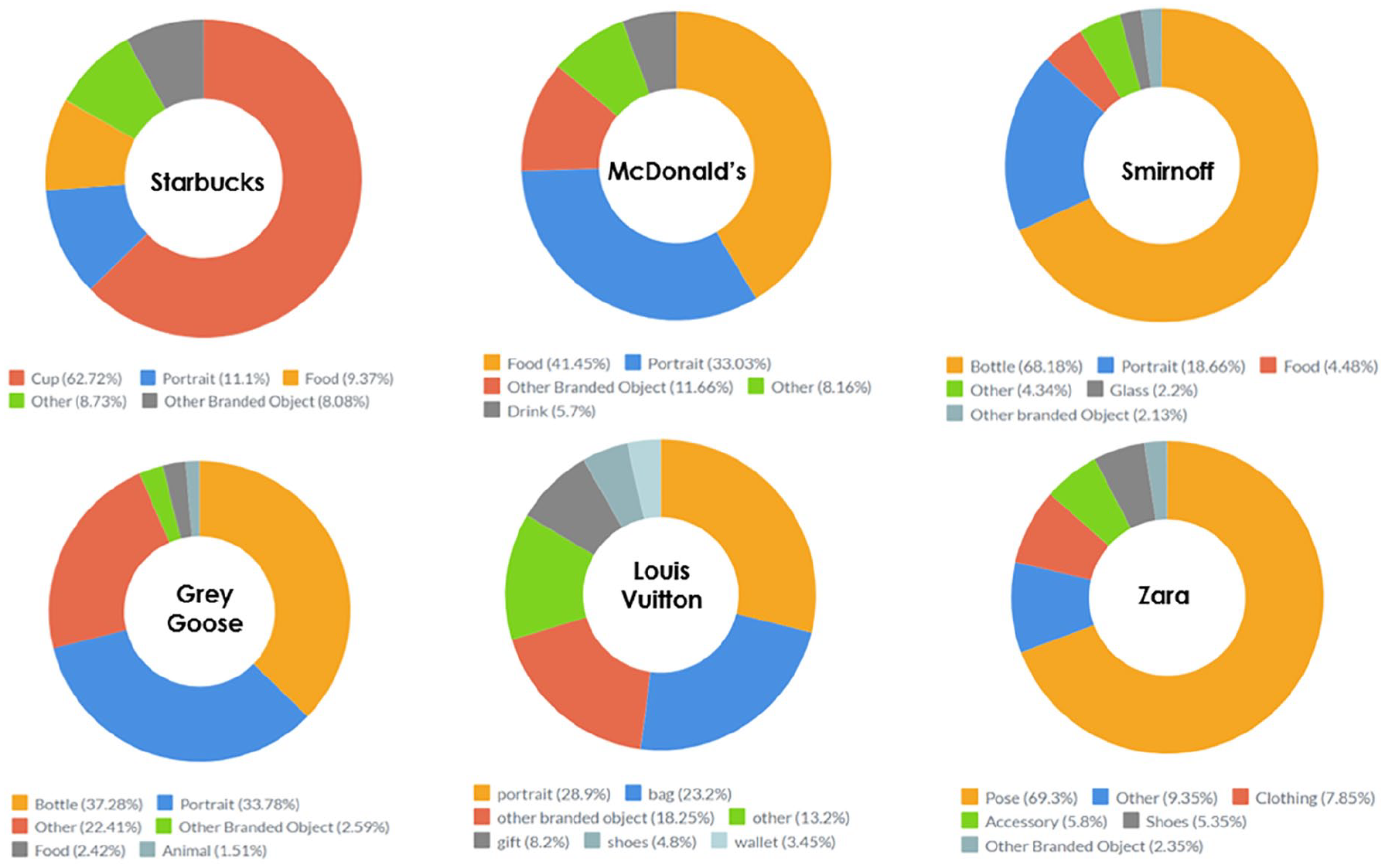
Results of the automated visual content analysis for each brand.

Branded templates.

Branded templates for Louis Vuitton.
To conclude, we can observe that each brand seems to attract and generate its own “visual brand vernacular.” To this purpose, one can speculate on how it is possible that a bunch of disconnected users are not only able to co-create a common imaginary but also a very repetitive one. To answer this question is not simple: one should ask each user why he or she made the photo he or she made and from where got the inspiration for its composition—a task that would exceed the scopes of this article and the authors’ capacities to fulfill it. Nevertheless, some reasonable hypothesis can be put forth. First, as we saw earlier, literature demonstrates that when composing posts—and especially visual ones—users prefer to tap into the “content archives” already available on social media, rather than creating original content on their own (Beer, 2019). Second, if one looks at the brands’ social media profiles (especially on Instagram and Facebook), it is possible to notice that, in the case of Starbucks, Smirnoff, Grey Goose, and McDonald’s, such pages are saturated with pictures of coffee cups, bottles of alcohol and fast-food items displayed on trays—even though, understandably, the aesthetic quality of those pictures is manifestly more refined than that of the pictures in our database. For Zara and Louis Vuitton, it is not possible to observe coherent and standards visual repertoires on their social media profiles—(the photos they post are more professional, variegated, glamorous, and posh to those posted by our users). Anyhow, it is not uncommon to see close-up photos of fashion products or outfits and selfies on Influencers’ profiles (Abidin, 2019). Therefore, it is not unreasonable to think that our users did not have the need to discuss among each other to decide what kind of photo to post or have a clear idea of it in advance; they simply copied from a huge repository of (standard) images already at disposal on Instagram (and on social media in general)—by, of course, adding to them some (minimal) compositional changes according to their own creativity and/or communicative purposes.
Consumer Vernacular Creativity
In this paragraph, through the analysis of posts’ captions, we show how users manipulate branded templates by following a memetic logic. Specifically, they take advantage of branded standard images to circulate and express their personal narrations and emotions. Drawing on Shifman’s vocabulary, we assimilate such process to a form of operative sing, which we call consumer vernacular creativity.
Looking at the photos’ captions, we can see developing a semantic process similar to that Shifman observes while describing the meme genre called stock character macro. Captions seem to function like texts that users attach to a standard image to superimpose their personal (vernacular) creativity on a collective imaginary. Specifically, in our case, through their captions, users appear to superimpose descriptions of personal experiences and emotions over repetitive branded templates. Given their nature, these collections of texts convey a set of meanings that amount to be extremely heterogeneous and, in turn, difficult to codify into few, clear-cut and coherent categories. Therefore, instead of focusing on captions’ meaning, we focused on their format. In this way, we managed to identify three main categories of captions: passionate, promotional, narrative. On 2,400 captions analyzed, the vast majority have a narrative format (74%—against, 21% promotional, 14% passionate, and 1% n.c.)—indicating that users do not use brands so much to express their love/hate for them or gain visibility. As far as passionate and promotional captions are concerned, they display a very similar rationale, independently from the brand considered; that is, they consist in messages in which the brand is praised/deprecated or exploited as a (SEO) device to get visibility. See these two examples related to #Louisvuitton: (1) “I love #louisvuitton ♥♥♥”; (2) “507 Editon #louisvuitton #mclaren #postoftheday #mercedesbenz #bmw #porsche #tagsforlikes #followme.”
Narrative captions instead tend to change according to different brands. Regarding #Starbucks, we saw emerging a main “narrative plots” in which users attempt to communicate the feeling of finding themselves in relaxing moments where they enjoy a cup of coffee with family/friends or after some sort of activity, such as work, shopping, or sport (e.g., “Breakfast date with my little love at #starbucks this morning #momlife #toddlerlife”; “#starbucks break, #cycling is hard work”); also, the hashtags clouds in Figure 6 display several keywords that summarize well the contexts, situations, and emotions described in narrations discussed above. Narrations developing around #McDonalds present similar characteristics to those seen for #Starbucks. Users tend to pair the standard food tray picture with captions in which they describe relaxing moments in which they savor a McDonald’s meal (e.g., “Pancake breakfast to start the day, with a side of wordsearch to warm up the mind #mcdonalds”; “after The Subhuman [a metal band] I need a fucking tasty burger #mcdonalds #subhuman”). Attached to the iconic #Smirnoff bottle, we can observe a quite recurrent kind of narration, that is, a narration in which users celebrate a fun night with friends, which they spent either at home or in clubs and where they (usually) ended up drunk (e.g., “Christmas night #smirnoff #vodka #shot #drinks #drunk #booze #liquor #fun #party #cheer #friends #friday #cheers”). Although #GreyGoose presents two different brand templates, the narrations that both attract are very similar to those developing around #Smirnoff: “who is ready for new years eve?! #alcohol #party #newyears #drunk #drunkmode #greygoose #mixeddrinks #friends #girls #happy #great #wasted #hammered”; “crazy night in Seattle #greygoose #vodka #nihadalibegovic #partynight #party #alcohol.” As we saw in the previous paragraph, most of the picture marked with the hashtag #Zara fell into the categories “Pose.” Associated to this category, we observed a recurrent narration, which consists in a sort of real-time description of posters’ shopping activities or hauls (e.g., Just bought! Shopping Selfie #saturday #shopping #holiday #zara). Finally, #LouisVuitton attracts multiple branded templates that, in turn, aggregate different kinds of narrations. Anyhow, it is possible to identify a recurrent pattern in such variegated set of narrations. In their captions, users, very often, express gratitude toward friends, family members, or partners from which they received a Louis Vuitton product as a gift for Christmas (e.g., “I really do have the best husband ever!! Merry Christmas!!! #christmasgift #handbag #luxury” [Category: Bag]; “Exciting times—Matt is honestly the most kind-hearted person I know, love him #louisvuitton” [Category: Gift]).

Hashtags cloud for all the brands.
In conclusion, we can argue that different branded templates gather different kinds of narrations that articulate according to different plots—which description we gave earlier does not aim to be exhaustive or generalizable. Anyhow, we can equally argue that, besides their heterogeneity and specificities, all the narrations display a lowest common denominator (Hogan, 2010), that is a common discourse. In fact, it seems that, through their captions, users articulate micro-narrations in which they try to capture and communicate something of very ephemeral, that is, the emotional circumstances and affective context (Gibbs et al., 2015) in which their experiences of consumption are situated.
Hypersignification
In Shifman’s theory, hypersignification refers to discourses vehiculated by memes, which aim at unearthing the cultural codes of communication itself, rather than conveying a specific meaning. Following the same line of thought, we can argue that the posts we analyzed vehiculate a discourse on the cultural codes of consumption, rather than shared meanings or evaluations related to the brands and products. Therefore, drawing on this conception, we can attempt to formulate some theoretical speculations on the hypersignification embedded in memetic brands. First, it is worth stressing that all the six brands analyzed (and related branded posts), besides their intrinsic differences, have a lowest common denominator (Hogan, 2010). They seem to work as “narrative device” to capture, materialize, and communicate something of very ephemeral and fluid, that is, the emotional circumstances and affective context in which different experiences of consumption are situated—rather than a particular bond or identification with the brand. In this sense, we can speculate that the Instagram posts we analyzed vehiculate a pictorial discourse on fluid consumption (Bauman, 2000). Fluid consumption has become a cultural trend that is more and more visible and traceable within social media environments (Bardhi & Eckhardt, 2017). In a social media era where consumers activities are increasingly datafied (Thompson, 2019), shaped by algorithms (Carah & Angus, 2018), and accelerated (Rosa, 2013), brands become mere data points in such (fluid) big data landscape. Differently from the post-modern era, brands are no more (or less and less) symbolic resources that, in a cultural context of fragmentation and fluidity, help consumers/social actors to fix and pinpoint their identity (Borgerson, 2005), by recomposing the fragmentation and stopping the flux (Elliott & Wattanasuwan, 1998). Instead, brands seem to become communication devices that, within a fluid and fragmented digital ecosystem, contribute to trigger and represent such cultural fragmentation and fluidity, and keeping it alive. Consider also that the fluidity of content production is a key cultural feature of most social media platforms (Nieborg & Poell, 2018). In fact, in these ecosystems, what is valuable are not specific pieces of content, which are constantly modified, substituted, and updated by social media algorithms and interfaces, but the flow of content itself—it is this peculiar form of meta-content that captures the attention of users and makes them stick to platforms (Van Dijck et al., 2018). But what kind of fluid consumption do social media users represent? According to our results, it seems that users put in scene a sort of situational consumption (Airoldi et al., 2016). Through their memetic pictures of brands, users tend to display the context in which the brand has been consumed, rather than the brand itself. Also, it seems that users try (implicitly) to signal the “proper” social and emotional context in which a specific brand should be consumed and/or situated. In this sense, the value of a brand does not seem to reside in being a symbolic resource for identity work (Fournier, 1998), an immaterial object for the construction of communities (Cova, 1997), or a promotional tool for visibility labor (Abidin, 2019), but rather in being “flexible enough” to be adaptable to specific (and private) emotional circumstances in consumers’ everyday lives. At the same time, its value seems to lay also in its capacity to facilitate the materialization, communication, and circulation of ephemeral emotions to a remote audience.
Conclusion
We started the exploration of our dataset by asking ourselves the following research question: What is the role of affordances in shaping brand relations? Drawing on the analysis presented in this article, we can argue that Instagram users relate to brands (also) through modalities that are affordances-based—and not necessarily informed by brand communities’ subcultures or influencers’ practices. Moreover, we showed that one of the possible manifestations of affordances-based brand relations is the memetic one. We highlighted how Instagram provides users with a specific grammar and vernacular through which they engage with brands by following a memetic logic. To frame this kind of relation, we propose to employ the concept of memetic brand, which we define as a collection of branded posts circulating across social media networks, which derive from a standard branded template that repeats from user to user with small compositional changes at every iteration and on top of which users attach expressions of their vernacular creativity. Users do not use so much a memetic brand to express their love/hate toward a specific brand or seek visibility for their personal brand, but rather as a “narrative device” to communicate the emotional circumstances and affective context in which the consumption of a brand is situated. In the process, the memetic brand vehiculates a hypersignification, that is, an implicit discourse on fluid and situational consumption.
Theoretically, the memetic brand’s notion is helpful to show how processes of platformization of culture do not pertain exclusively to the relations between cultural industries and platforms but also to culture in an anthropological sense, that is, as emerging from the everyday digital practices of platforms’ users. Consequently, from a methodological point of view, the notion of memetic brand can be also a useful heuristic to explore more mundane and ordinary processes of platformization of culture unfolding on social media.
Anyhow, our study has some theoretical and methodological limitations that need to be acknowledged. First, we must address (and disentangle) some possible ambiguities. As said, we consider the notion of “memetic brand” as a useful heuristic to study the processes of platformization of culture within social media. Therefore, it is important not to conflate the phenomenon of memetic brands with meme culture, which is much more participative, communitarian and subversive respect to those collective dynamics we observed in our digital inquiry. For the same reason, it would be equally incorrect to assume that consumers embrace and appropriate meme culture to structure their interactions around brands on social media. Moreover, the meme format is not completely comparable to the format of an Instagram post—for example, the text superimposed over a visual meme is (semantically) much more crucial than the text of an Instagram caption, which is not necessarily read by the user consuming a given post or crucial to understand the meaning of the post itself. More simply, as we specified in the “Introduction,” we used the concept of “meme” as a metaphor to capture the mutation of brands relations within social media platforms.
Second, although we believe we used an appropriate methodology to study the effects of platform logics and functioning on cultural processes, it cannot be denied that part of the results presented in this article are influenced by our techniques of data collection and analysis. Specifically, the Instagram API and GVA (naturally) drove us to focus our attention on preformatted and repetitive posts (that is, those directly captured by hash-tagging practices or labeled by Google’s machine vision algorithm in certain ways). In this way, we do not know much about those branded content (and the related subversive practices) that unfold “below the radar” (Boccia Artieri et al., 2021) of social media infrastructures (Gerrard, 2018) or beyond the algorithmic capacities of automated tools of data analysis (Abidin, 2021). Not acknowledging this carries the risk to conceive consumers on social media as intrinsically passive. That is why, it is very important to clarify that we do not claim that affordances-based brand relations are supplanting community and influencer-based relations, or that they are no more relevant for online consumers. Differently, we claim that the affordances-based relation is a third (and emerging) modality of brand relation that works alongside the other two, and, we believe, allows researchers to get a more comprehensive and holistic view of consumer-brand relations in the era of digital platforms. Therefore, in our opinion, further research (conducted with traditional/offline quantitative and qualitative methods) is needed to understand deeply how consumers actively and subversively reappropriate brands, extend themselves through them, and build communities around them, and use brands to develop shared systems of values and meanings below, between, and beyond the constraints of social media platforms.
Footnotes
Acknowledgements
The authors thank Adam Arvidsson, who inspired the writing of this article and encouraged to publish it, and Alessandro Gandini for his friendly review of the draft version of the article. They also specially thank Lucia Bainotti, with whom they discussed a lot about the concept of affordances-based relations. Finally, they sincerely thank the anonymous reviewers, whose comments have been integrated in the conclusion.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by Middlesex University London (internal grant issued on 8 March 2017).