
Abstract
Algorithms and especially recommendation algorithms play an important role online, most notably on YouTube. Yet, little is known about the network communities that these algorithms form. We analyzed the channel recommendations on YouTube to map the communities that the social network is creating through its algorithms and to test the network for homophily, that is, the connectedness between communities. We find that YouTube’s channel recommendation algorithm fosters the creation of highly homophilous communities in the United States (n = 13,529 channels) and in Germany (n = 8,000 channels). Factors that seem to drive YouTube’s recommendations are topics, language, and location. We highlight the issue of homophilous communities in the context of politics where YouTube’s algorithms create far-right communities in both countries.
YouTube has been identified as the one social media platform that might be the most prone to negative effects due to algorithmic recommendations (O’Callaghan et al., 2014). This fear is closely related to what Pariser (2011) called the “filter bubble”: an algorithm-driven process that would encapsulate each internet user in their own personalized bubble. Academics and the general public picked up the concept quickly to describe or analyze public opinion formation and group formation in the political context. In recent years, however, the concept came under criticism as academic findings (e.g., Bruns, 2019; Hannak et al., 2013; Zuiderveen Borgesius et al., 2016) cast doubt on the public’s fear of filter bubbles. Yet, YouTube might be the exception to the rule (e.g., O’Callaghan et al., 2014). Not only did a recent Pew Research Center survey (2020) show that 67% of YouTube users occasionally follow the algorithmic recommendations, with an additional 11% saying that they regularly follow the platform’s recommendations. A study by O’Callaghan et al. (2014) found that YouTube’s algorithms formed a far-right ideological video bubble. And while it remains to be seen whether this holds true for YouTube in general or is more limited to (extreme) politics, these findings highlight the importance of investigating YouTube’s algorithms and the communities that they form; especially in the context of politics.
In this article, we are thus interested in the effects of YouTube’s recommendation algorithms and the communities that they create. Besides the mainstream communities on YouTube such as music and entertainment that make up the majority of content on the platform, we are especially interested in the communities that form around political channels as they have been identified in prior research as some of the most problematic on YouTube (Lewis, 2018; O’Callaghan et al., 2014). The political dimension of YouTube cannot be ignored as Lewis (2018), Munn (2019) and Baugut and Neumann (2020) highlighted that YouTube might play a role in political radicalization and is prone to recommend misinformation (Allgaier, 2019; Kaiser et al., in press). Indeed, if filter bubbles were to exist, the assumed effect would be the worst in the political context. Consequently, most scholars investigating the filter bubbles have analyzed news recommendations or media diets (e.g., Zuiderveen Borgesius et al., 2016).
In contrast, we are interested in the homophily of algorithmically created communities (i.e., communities that consist of similar channels; “birds of a feather stick together” or “like to like”; e.g., McPherson et al., 2001). As we analyze YouTube channels that are connected through algorithmic recommendations, our understanding of algorithmic homophily in this study is only loosely based on the sociological meaning of homophily. Instead, we refer to what Kossinets and Watts (2009) call induced homophily vis-à-vis choice homophily. Specifically, we call it algorithmically induced homophily, which is of course based on the choice of users in the first place. While we are not directly testing the filter bubble hypothesis, our analysis allows us to assess whether an important prerequisite is fulfilled on YouTube: the algorithmic creation of homogeneous channel clusters which can be best understood as the backbone of YouTube. We understand filter bubbles as algorithmically induced homophilous communities, while echo chambers can be understood as homophilous communities that are formed by deliberate user choices. We emphasize homophily with regard to channels as it increases the likelihood of being exposed to similar content.
Furthermore, we are interested in whether the algorithm leads to long-tail distributions that also strengthen smaller channels or reward already prominent channels through a Matthew effect (Merton, 1968). Möller et al. (2018) have described the Matthew effect with regard to algorithms that are based on popularity of items and that show all users the same recommendations.
We have structured this article as follows: We will first give an overview of the literature on algorithms to then focus on YouTube’s channel recommendation system for Germany and the United States to understand whether YouTube’s macro-level channel recommendation algorithm fosters the creation of homophilous communities, whether this holds true for both countries, and if so, which factors contribute to the formation of isolated communities. We focus on Germany and the United States as we wanted to compare two countries (1) that differ in language (and thus are less likely to overlap in channels), (2) where YouTube is one of the most used websites in general but also frequently used for news consumption (Newman et al., 2019), and (3) where YouTube is being used by political actors to spread their messages and find an audience (expressed through political party and candidate channels). For this analysis, we focus on YouTube’s now discontinued “related channels” function. While YouTube has discontinued this recommendation system in May 2019 (Kaiser & Rauchfleisch, 2019a), the analysis is still relevant as it allows us to illustrate the algorithmic Matthew effect. The analysis of the “related channels” function is especially instructive as it is not personalized—unlike YouTube’s video recommendations—and thus can be understood to be stable. We show in our study for the United States as well as Germany that the algorithm recommends far-right content, including conspiracy theories, White nationalist, or anti-feminist content, if people are interested in mainstream news and politics but rarely vice versa. Our study contributes to the literature on YouTube, but more importantly to the literature on algorithms in the political context.
Algorithms on Social Media Platforms
Before giving a survey of the literature, a necessary prerequisite is the definition of the term algorithm. We follow Striphas (2015, p. 403) who defines algorithms as “a formal process or set of step-by-step procedures, often expressed mathematically.” Furthermore, we understand algorithms as statistical models that can introduce bias in several stages of the process (Suresh & Guttag, 2019). It is important to note that recommendation systems can be based on (1) algorithmic choices that are independent from a single user’s choices and (2) algorithmic choices that are dependent on a single user’s choices. This is somewhat similar to the differentiation of choice homophily (dependent) and induced homophily (independent) (Kossinets & Watts, 2009). In this study, we are interested in algorithmically induced homophily. We understand homophily as the similarity between the channels that are connected by the algorithm. It is thus a more technical than a social understanding of homophily. Video recommendations on YouTube are personalized and thus to some extent dependent on an individual user’s behavior. Channel recommendations, however, are not personalized and thus independent from an individual’s behavior. While studies on personalized algorithms might give us an insight into the role of personalization for video recommendations, the results are hardly generalizable on a platform level. We thus look at YouTube’s channel recommendation system which can be generalized for the platform to understand the role algorithms have on the formation of problematic algorithmically induced communities or what Gillespie (2014) might call “calculated publics.” Such non-personalized platform-level algorithms can lead to audience concentration that follows a power-law distribution (Hindman, 2018) which could be problematic depending on the content that is recommended (Kaiser & Rauchfleisch, 2019b).
Literature About Filter Bubbles
The literature on algorithms and how they impact what kind of information users are exposed to spans across different fields such as computer science, sociology, criminology, economics, or communication science. Academic articles in these fields can generally be distinguished between papers that build upon the assumption that algorithms have consequences that need to be dealt with (e.g., Helberger et al., 2018; Nagulendra & Vassileva, 2014; Takahashi & Zhang, 2017; Wood, 2016) and papers that aim to identify algorithmic effects, for example, in the form of filter bubbles (e.g., Bakshy et al., 2015; Fletcher & Nielsen, 2017; Haim et al., 2017; Nelson & Webster, 2017).
Although there are several studies on the concept of filter bubbles (and even more so that mention the concept en passant), the definitions differ notably: Bozdag et al. (2014), for example, sum up both filter bubbles and echo chambers under the label of “cyberbalkanization,” while Groshek and Koc-Michalska (2017, p. 1390) write about “cultivating ideological filter bubbles that lacked cross-cutting information,” which are the products of self-selection. For Fletcher and Nielsen (2017, p. 479), filter bubbles are the result of “self-selection [that] will be reinforced by algorithms that are designed to show people more of what they like.” And for Bruns (2019), a filter bubble does not even require an algorithm; it “emerges when a group of participants choose to preferentially communicate with each other, to the exclusion of outsiders.” In general, the definitions differ between the focus of academics’ research (e.g., search engines, social networks, or news) and if and how the roles personalization and algorithms play can be empirically addressed. In this article, we understand the formation of filter bubbles as a potential, and rather extreme and similarly rare, algorithmic effect. We assume that algorithms might contribute to the formation of homophilous communities which mostly consist of similar channels (in the context of YouTube) but which are nevertheless connected to other communities. But as Geschke et al. (2019, p. 133) highlight, “homophily can be a strong contributing factor to the emergence of filter bubbles and echo chambers and consequently group polarization effects.” At the same time, Helberger et al. (2018, p. 194) add that without a clear definition of exposure diversity, potential phenomena like filter bubbles are hard to track in the first place, as we lack the benchmark for what is an acceptable exposure and what is not.
As algorithmic effects are hard to identify empirically, academics have used different theoretical proxies to measure their effect. For example, some academics argue that a polarization or fragmentation within their audience samples would be an indicator (e.g., Groshek & Koc-Michalska, 2017), as this would show that users are artificially not exposed to the other side. This is closely connected to the school of thought that looks at selective exposure and selective avoidance as key aspects of algorithmic exposure (e.g., Fletcher & Nielsen, 2017; Nelson & Webster, 2017). This is in line with Pariser’s (2011) idea that the algorithm would only show us what we would like to see and not confront us with content that we do not like. So, a lack of exposure to opposing views could be interpreted as evidence for filter bubbles. 1
Yet, the question, then, would be: what kind of exposure? In general, scholars differentiate between exposure to different sources (e.g., outlets like Breitbart or Huffington Post; Bakshy et al., 2015; Fletcher & Nielsen, 2017), views (e.g., Facebook’s news feed algorithm filters posts that are not in line with a user’s position; Gottron & Schwagereit, 2016), and users (e.g., Facebook’s news feed algorithm not only filters out positions but also users, in general, that a user does not interact with; Gottron & Schwagereit, 2016). Furthermore, some scholars that look at personalization further emphasize the need to differentiate between personalization by the user and by the algorithm (e.g., Hosanagar et al., 2014; Möller et al., 2018). Whereas the former describes the communities that users enter deliberately, the latter describes what Pariser described with the automated filter bubble.
To test the filter bubble concept, scholars have chosen different empirical methods which can be differentiated into two overarching lines of thought: one that aims at measuring audience behavior and the other on digital trace data which often assumes audiences: some have looked at search engine results (e.g., van Hoang et al., 2015; Yom-Tov et al., 2013) or browsing histories (e.g., Nelson & Webster, 2017), and others have conducted surveys to understand audience behavior (e.g., Dylko et al., 2017; Fletcher & Nielsen, 2017), looked at news sites (e.g., Möller et al., 2018) or platforms such as Google News (e.g., Haim et al., 2017), or social media platforms such as Facebook (e.g., Bakshy et al., 2015) and YouTube (e.g., O’Callaghan et al., 2014) to understand exposure of an assumed “shadow” audience.
In general, most studies were not able to identify filter bubbles, or if they could, the authors highlighted that they are very small or not in the political field (e.g., Haim et al., 2017; Hannak et al., 2013). In an analysis of web browsing histories of users who frequently visit news sites, Flaxman et al. (2016), for example, found evidence for a higher polarization of users’ attitudes. At the same time, they also show that social media users are more frequently exposed to opposite views than, for example, users who visit news sites directly.
The current state of research on filter bubbles is thus leaning toward filter bubbles not being a problem—neither on the audience nor on the assumed audience side—with most of the empirical studies suggesting that they either do not exist or are very weak, while there are only few studies that were able to detect filter bubbles.
As we analyze YouTube’s channel recommendation algorithm in this article, we will now focus on algorithms: As algorithms are not randomly created but rather deliberately designed, it can be assumed that certain features contribute more to their effects than others. Some of the studies presented above have highlighted categories that are especially relevant and that can be empirically measured. The first one in this context is themes. O’Callaghan et al. (2014), for example, identify extreme-right video bubbles on YouTube. These bubbles do not form around a specific topic such as the “refugee crisis in Europe” but around interests or a collective political identity, that is, themes. It is thus possible that filter bubbles can form on a more abstract level or where there is a higher sense of collective identity. Language and country-specific culture can also play an important role. Not only with personalized algorithms on the individual user level (e.g., Kliman-Silver et al., 2015), but also more generally on an aggregated level. Bozdag et al. (2014), for example, have shown that algorithms, quite intuitively, take national contexts into account. We understand national contexts in this study as signified by a channel’s language as well as location. The question thus is whether we can see this also on YouTube and to what extent the potential formation of homophilous communities can be explained with national context or themes. While it is not sufficient to just observe an algorithm to assess whether filter bubbles exist, the influence of the algorithm is a conditio sine qua non to filter bubbles.
Research Questions and Hypotheses
In our study, we focus on YouTube. The platform has over 2 billion active users in a month and is among the most popular sites in the world. It is also a platform where researchers were able to identify filter bubble tendencies for a certain theme (O’Callaghan et al., 2014). To account for the factor national context, we compare the cases of the United States and Germany. YouTube is prominent in both countries (over 50% of Americans and roughly 40% of Germans use the platform; Statista, 2018), there are distinct language barriers between the countries, and in both countries the far-right has become stronger in recent years.
We focus on the algorithmic channel networks on YouTube. We thus analyze the channel recommendations that are based on a non-personalized algorithm on YouTube. They are networks as every channel can be understood as a node in a network that is connected by recommendations (edges). Based on current research that highlight the impact of algorithms on our lives (e.g., Noble, 2018), we expect algorithms to have an impact on the formation of communities on YouTube that goes beyond what is randomly expected (see also Gillespie, 2014):
H1. The algorithmic channel networks will have clear differences to random networks with the same in- and out-degree distributions based on key network metrics (i.e., centrality metrics and modularity).
In comparing the algorithmic network with randomized networks that have the same in- and out-degree distribution, we can analyze the role of algorithms in the formation of communities on YouTube. This is important as it gives a baseline for evaluating YouTube’s algorithms and our findings. If we can show that the communities that we identify are not random, it shows the influence of YouTube’s recommendation algorithm.
Based on research by O’Callaghan et al. (2014), we assume to identify homophilous far-right communities in both national settings. We measure whether users will most likely be exposed to channel recommendations that stay within the community. To test this hypothesis, we refer to Bruns’ (2019; see also Krackhardt & Stern, 1988) analysis of filter bubbles on Twitter based on the E-I index which measures whether channel recommendations stay within a specific community or are pointing more often to channels belonging to other communities:
H2. The channel networks in Germany and the United States will show homophilous communities based on the E-I index.
As we highlighted above, algorithms will mostly take two criteria into account. First, we expect communities to form around certain themes. We thus ask the following:
RQ1. Do homophilous communities form around certain themes?
Furthermore, we include Germany and the United States as countries to find out whether national context (i.e., location and language) has an influence on the networks and potential formation of an algorithmic formed community. We rely here on prior research (De Koster & Houtman, 2008; O’Callaghan et al., 2014; Rauchfleisch & Kaiser, 2020) that puts emphasis on country-specific as well as far-right communities. We expect to find country-specific bubbles, even in the far-right that can mainly be explained with a shared language. We thus ask the following:
RQ2. Do homophilous communities form around countries (location)?
RQ3. Do homophilous communities form around languages?
Method and Data
To answer these questions empirically, we first had to define a set of channels for each country to start our sampling. To account for political as well as “mainstream” YouTube communities, we decided to use four lists for each country. For politics we used a list of far-right, far-left, as well as mainstream political channels. In addition, we used the most popular 250 mainstream channels for each country. We created a list of prominent far-right and far-left organizations and individuals based on lists from the Southern Poverty Law Center as well as academic literature (e.g., Caiani et al., 2012; Rauchfleisch & Kaiser, 2020; Zhou et al., 2005). We further searched online for recommendations of far-right or far-left YouTubers. We found several recommendations on Reddit as well as Quora and added these channels to the already existing list of far-right and far-left organizations and actors. As these lists served as seed lists for our snowball method, the goal was not to already have all channels but rather to have a diverse set of signals that would allow us to, then, identify new channels in the next step. Furthermore, we used YouTube searches for political parties, political actors, as well as keywords like “Antifa,” “communism,” “socialism,” or “anarchism” on YouTube. For the political mainstream, we used political parties and politicians including Democrats, Republicans, Green Party, Libertarians, and Democratic Socialists of America. For Germany, we used all parties represented in at least one state parliament. The list of mainstream channels consists for each country of the 250 most popular (by subscribers) national channels (Social Blade, 2018).
For the data collection (crawler and scraper) and the analysis, we relied on R-scripts. Only for the Louvain algorithm that we applied to identify the different communities we used a Python library (Traag, 2015). We collected all of our data in March 2018. Since these lists are incomplete and potentially biased, we first collected all channels that these channels/owners (USA = 1,354; GER = 622) recommended themselves (not algorithmically recommended) with a scraper. In this way, we wanted to make sure that we had included the channels that our starting set deemed important. Next, we followed YouTube’s channel recommendations for our starting set in three steps focusing only on the YouTube algorithm’s recommended related channels. Before YouTube removed the “related channels” feature, there were two forms of channel recommendations: (1) “related channels” that are algorithmically curated by YouTube and (2) channels that are recommended by the channel owners themselves. Neither do all channel owners recommend channels nor do all channel owners activate YouTube’s automated recommendation system. However, if a channel owner does not have the recommendation system activated, they also will not be recommended by YouTube’s channel algorithm. Furthermore, to prevent sampling-artifacts and to evaluate whether after three steps the network is saturated enough, we tested up to eight steps and found that after three steps we were mostly capturing foreign channels (e.g., from Asia) but no additional key domestic channels. It is important to note that channel recommendations are not personalized on a user level. This means that every time a channel page is opened even by different individual users, the same set of channels is recommended. 2
We ended up with 13,529 unique channels for the United States and 8,000 unique channels for Germany (see Figure 1). To identify different communities within the network and to calculate the modularity, we used the Louvain algorithm (Blondel et al., 2008) for directed graphs in Python (Traag, 2015) and visualized the networks with Gephi (nodes = channels, edges = recommendations). We intentionally use the Louvain algorithm as the algorithm identifies communities that lead to the highest possible modularity. This is in line with the goal of this study to evaluate the formation of homophilous communities.

Networks (USA: nodes = 13,529 and edges = 41,001; GER: nodes = 8,000 and edges = 23,988) visualized in Gephi. Node labels only for the three channels with the highest in-degree per community (color).
To check whether out-networks are the product of YouTube’s algorithms or based on random chance, we compare our observed algorithmic networks with a statistical test. Instead of creating just random networks based only on the number of vertices and the density, we additionally consider the in-degree as well as the out-degree distribution of our networks. We used the same out-degree and in-degree distributions for vertices as in our observed network and did not allow loops as well as multiple edges (fixed degree sequence mode; Zweig, 2016). The random networks with fixed in- and out-degree distributions were created with functions in the package igraph in R (Csardi & Nepusz, 2006).
Next, we compare our measured YouTube networks with 100 randomly created networks with fixed in- and out-degree distributions for each country which serve as a baseline. As network metrics we choose the average path lengths as well as the closeness centrality of the network to compare the general structure of the networks. We also identified the community structures in each network with the Louvain algorithm. In a last step, we calculated the modularity as well as the E-I index for the network based on the community classification (see also Bruns, 2017).
We calculate the overall E-I index (Krackhardt & Stern, 1988) for the networks based on the identified communities. We follow Bruns’ (2017) suggestion to use the E-I index for each community to evaluate whether a group of channels potentially leads to a homophilous community. The E-I index ranges from 1 to −1 and describes a community’s outward orientation in terms of connections in relation to its inward connections; that is, if a community has more connections with other communities than within itself, its E-I index will be closer to 1, and if most of its connections are within the community, that is, homophilous, it is closer to −1. In general, the E-I index “draws on the total count of internal and external connections from cluster members” (Bruns, 2017, p. 10). In line with the E-I index that ranges from 1 (heterogenic) to −1 (homogeneous), we understand homophilous communities to be between 0 and −1. As we understand isolated communities as very homophilous, we define them to start at −0.75 (the most homophilous 12.5% of the network).
For our final research question which depends on language, we used the second version of Google’s Compact Language Detector (Ooms, 2018). We downloaded all the channel descriptions over the YouTube API (Application Programming Interface). 3
Results
Random Networks
For each country network, we created 100 random networks with the same density (number of edges) and sequence of in-degrees and out-degrees as they are “fixed” elements on YouTube with the channel recommendations. Most channels have six recommendations, which is the maximum of recommendations the algorithm shows a user.
Our analysis shows for both country networks similar results (see Table 1). Overall, for both countries all metrics are statistically different from the random networks. Both random networks have a higher average path length than our measured YouTube networks. To traverse the whole random networks with the same in- and out-degree distribution, it takes on average over 15 steps, whereas both our observed networks have an average path length of around 7. Furthermore, the closeness centrality is higher in the random networks than in our observed networks. While the difference in the US case is small and overall the closeness centrality score for the networks is rather low, it indicates that the random networks have a stronger center that connects the network. Yet, out of all our calculated scores, the closeness centrality shows the smallest difference between the random networks and our observed YouTube networks.
Comparison of US and German YouTube Channel Network With Randomly Generated Ones.
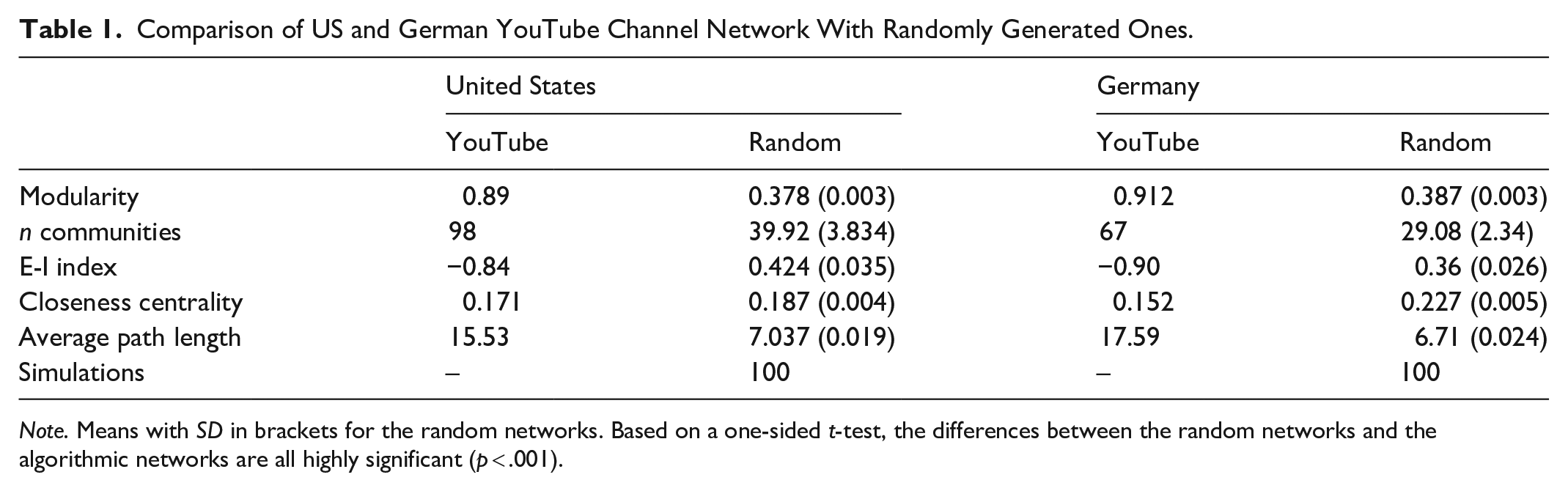
Note. Means with SD in brackets for the random networks. Based on a one-sided t-test, the differences between the random networks and the algorithmic networks are all highly significant (p < .001).
The modularity score shows that of all the measured scores, there was the largest difference between the random and observed networks for both countries. The YouTube networks have a modularity of around ~0.9, whereas the modularity score of the random networks is just below 0.4. This suggests that the US and German channel networks are both internally highly distinct and modular.
Our analysis shows that the key network metrics of our algorithmic channel networks are clearly different from the metrics of the respective random networks with the same degree of distribution. We thus reject the null hypothesis as the algorithmic networks on YouTube are indeed very different from randomly generated ones.
E-I Index
As the modularity score is extremely high for our algorithmic networks, it comes as no surprise that the E-I index for both algorithmic networks shows a high negative value (Table 1). To test H2, we compared the E-I index for each algorithmic network with the mean E-I index of the random networks. The random networks have in both cases a positive value. A single sample t-test shows highly significant results for both networks (see Table 1; United States = −0.084, t(99) = 366.1, p < .001, M = 0.424, SD = 0.035; Germany = −0.084, t(99) = 486.1, p < .001, M = 0.36, SD = 0.026. We can thus reject the null hypothesis. This means that most channel recommendations in our observed YouTube networks stay inside each community, and relatively speaking, only few connections exist between communities. The YouTube networks are clearly homophilous.
To further investigate the homophily of the communities, we additionally calculated the E-I index for each community within our algorithmic networks. Whereas Bruns (2017, p. 8) defined an E-I index of −0.58 as showing “substantial filter bubble tendencies,” we understand every community with a lower E-I index than −0.75 as exhibiting “filter bubble tendencies.” The closer the communities’ E-I index is to −1, the more likely it is that they are isolated communities with −1, meaning that there are no connections to other communities at all. All our identified communities in both networks have a lower E-I index than −0.6. Except for 7 out of 98 communities in the US case and 2 out of 67 in the German one, all communities have a lower E-I index than −0.75, thus showing clear filter bubble tendencies. In the next step, we only included communities with more than 100 channels for the analysis of the themes and the national context. Similar to Bruns (2017), we thus focus only on the core communities within the networks (USA: 38 of 98 communities; GER: 28 of 67 communities).
Themes and National Context
In RQ1–3, we are interested in the role the different criteria we established above play in the formation of homophilous communities. First, we named the communities based on their most linked to channels with regard to their themes and discussed the classification among the authors for RQ1. To evaluate the channels, we read the titles as well as the channel description. If the description was not clear, we checked the most recent videos of a channel. Then, we analyzed the percentage of channels per country in each community (channel information including location available via YouTube’s API) for RQ2. We then used a language classifier to code each channel’s description with respect to the used language for RQ3. Given this article’s space limitations, we will predominantly focus on political communities, as these are generally seen as the potentially most problematic for society.
Themes
We find that homophilous communities form around themes. We do not, for example, see the formation of issue-specific (perhaps with the exception of the League of Legends—a popular online strategy game—community in the US network) but rather of activity (e.g., choreography or fitness), ideology (e.g., far-right or far-left), or genre-based (e.g., gaming or music genres) communities (see Figure 2). The guns community, for example, consists of different channels that focus on shooting and hunting as activity, whereas the National Rifle Association’s (NRA) channel is located in the far-right and politics community. Furthermore, most communities deal with popular culture like gaming, sports, or music, and only few communities focus on politics (Burgess & Green, 2009). However, these political communities are, with the exception of the “liberal/mainstream news” community, in the United States rather problematic as they mostly consist of far-right or far-left channels. While there are some non-far-right channels in the far-right communities such as Fox News or GOP (Republican) channels in the United States or mainstream political party channels in Germany, these represent a minority in a network theory sense. The most recommended channel in the far-right and politics community, for example, are the Alex Jones Channel (InfoWars host; channel has been deleted since), Styxhexenhammer666 (a far-right, libertarian YouTuber), and Fox News. But the community furthermore consists of far-right personalities such as Richard Spencer (US White supremacist), Brittany Pettibone (US far-right YouTube), or David Duke (former Ku Klux Klan leader). In Germany, the far-right community consists of not only the far-right political parties AfD (Alternative for Germany; far-right) and NPD (National Democratic Party of Germany; extreme right) but also the right-wing extremist Identitarian Movement (youth organization presenting itself as a far-right social movement). So, while the far-right and politics communities in Germany and the United States technically include channels of different viewpoints, a visual inspection shows that the moderate ones are located on the fringe of the bubble, while the far-right channels are in the center (see Figure 1). Our findings thus indicate that when YouTube gets political, it mostly pushes users to the far-right and into a filter bubble.

E-I index for communities in the United States and German network. Ordered by number of channels in community.
National Context: Location
Based on the information that the channel owners provided in their description, we find that there are country-specific channel communities. Among the largest communities, there are 21 communities in the US case and 6 in the German case that consist of predominantly (>50%) US or German channels (see Figure 3). However, this leaves 17 communities in the US network and 22 in the German one that are strongly connected through the recommendation algorithm and thus homophilous but that cannot be explained with the channel owner’s country setting.

Percentage of US and German channels in the US and German network.
While the domestic communities include particular music or gaming ones, thus showing that there are dedicated domestic communities that deal with hip hop, for example, they notably also include communities like “guns,” “far-right and politics,” “religious right I and II,” and the “manosphere” in the US case and the “far-right and politics” in the German one. It is also interesting to note that while “liberal/mainstream news” barely has over 50% US channels, the “far-left” is very international. In contrast, both far-right and politics communities are domestic or, at least, clearly distinguishable by language (e.g., the German-language community also includes Austrian far-right channels). We can further see that US channels are more prevalent in the German communities than vice versa. Indeed, it seems as if YouTube pushes users to US channels, most likely because most channels on YouTube are from the United States and/or the most successful ones are from the United States. It is also worth emphasizing that the country setting is chosen by the channel owner. As we know from Twitter, this information has its weaknesses (e.g., Ajao et al., 2015). In a next step, we will thus look at the role language plays in the formation of isolated communities.
National Context: Language
We find that language plays a part in the formation of homophilous communities: While we can see that only eight communities in the US network are non-majority English-language channels, only six communities in the German-language network have German as the main language (see Figure 4). For example, all political communities in both networks consist of mostly English- or German-language channels. This is especially true for the far-right communities in Germany and the United States When it comes to music, we can see that two domestic communities (schlager and hip hop) are predominantly German language, while the more general communities (e.g., Electronic music, international pop, or heavy metal) are much more international. Yet, we also see that there are only few communities that represent a mix of different languages (e.g., Gaming III: LoL or Gaming: CS:GO). Indeed, we have several communities that form around languages like Russian or Brazilian YouTube communities. As neither English nor German language is restricted to the United States or Germany, these results can only be seen in combination with their location as indicative of a national context. English-language channels, for example, can be from the United Kingdom or New Zealand and also from channel creators who prefer to create their content in English to potentially attract a larger audience (e.g., Pewdiepie—a Swedish YouTuber whose channel is in English and who attracted over 100 million subscribers). Our analysis shows that the German-language network has a few core communities and many communities which connect to the international YouTube sphere. In the United States, we see that we only reach few communities that are not English-speaking, thus signaling the importance of English on YouTube and also the importance of the US YouTube for the platform.

Distribution of languages in each channel community within the US and German network.
When comparing the results of language and location, we can see that these are highly correlated in both countries (GER: r = .98 and p < .001; USA: r = .87 and p < .001). In a country like Germany, which shares the same language only with few other (and less inhabited) countries, this may not be as surprising, but it is interesting to note that this is true for the United States as well. In all, 21 of the 38 US communities were predominantly (>.5) in English and also from the United States. Among these were “religious right,” “guns,” and “far-right and politics” and also “hip hop” or “makeup.” In Germany, only 6 of 28 were predominantly in German and from Germany. These were, for example, “celebrities and beauty shows,” “gaming,” and also “far-right and politics.”
Discussion
From YouTube’s perspective, the formation of homophilous channel communities is not a bug but a clear sign that their algorithms work as intended. The results not only show the relevance of the national context for the formation of homophilous communities but also highlight that this is especially true for political communities. Indeed, if one is interested in rock music, one would expect a recommendation algorithm to suggest more of the same and not, for example, Ikebana techniques. However, our results show that for YouTube, the political channels tend to be more extreme and are, often, connected to a right-wing ideology and conspiracy theories. In Germany, for example, news channels and moderate political parties are at the border of the right-wing community. While YouTube’s algorithms point from these channels toward channels like the far-right political parties AfD (Alternative for Germany) or NPD (National Democratic Party of Germany) or far-right media, the algorithm rarely points back. So if you are interested in German politics, the algorithm will recommend far-right content to you, but if you are interested in far-right content, the algorithm will rarely recommend mainstream news or political parties. We observed similar trends in the United States, where the liberal/mainstream community is the pathway to the far-right community (YouTube recommended Alex Jones on Fox News’ channel), which consists of conspiracy theory, White nationalist, or anti-feminist. One explanation for this is certainly that there are just more far-right channels than there are centrist or leftist ones.
But the general trend on YouTube seems to be what we call the algorithmic Matthew effect (Merton, 1968): already prominent channels will be at the center of each homophilous community and will get recommended from the smaller channels at the edges of the communities. This leads more users to these channels, which then again strengthens the prominence of these channels in the recommendations. The algorithms consequently re-enforce a channel’s prominence within the community, thus, potentially, forming a filter bubble. So, while mainstream political parties are in the far-right community in the German network, they are not the center but a pathway to the prominent channels within the community.
With regard to isolated algorithmic communities that could be the precondition for filter bubbles, the algorithmic Matthew effect is a double-edged sword. On the one hand, the effect might lead to strong mainstream bubbles that attract the highest number of subscriptions on the platform. This could be a problem if one is concerned with diversity of themes and opinions. On the other hand, the Matthew effect may lead to a stronger isolation of specific bubbles and their constant reproduction. In the case of the far-right bubbles, strong channels such as the—now banned—Alex Jones Channel pull more moderate channels into the right-wing bubble. Anderson’s (2006) long tail as well as Hindman’s (2009) discussion of power laws helps to understand why many filter bubble studies observe the dominance of several major news sources. Both our recommendation networks show a power-law distribution with roughly the same parameters for the in-degree (see Figure 5). While long tails (Anderson, 2006) usually mean more diversity, there is still a dominating mainstream, as Hindman (2018, 2009) argues. In our case the mainstream on YouTube consists mainly of entertainment channels. However, more extreme channels like The Alex Jones Channel (with 164 recommendations the third highest in-degree in the US graph) dominate locally in their own community. The interesting question, then, is what happens in the long tail. Some more extreme right-wing channels on YouTube are part of this long tail in which issues are framed and strong opinions are expressed, or as we have shown elsewhere, misinformation is being recommended (Kaiser et al., in press). This means, for example, mainstream media are reporting in a neutral way about the refugee crisis. All users consume this news. But some users then additionally watch mostly channels in the right-wing bubble that lead to more extreme opinions.

The fitted power-law lines for both recommendation networks correspond to a power-law distribution (KS test not significant; Germany, α = 2.99, xmin = 10; United States, α = 2.66, xmin = 6). Cumulative distribution function (CDF) on the y-axis with a log-scale and in-degree on the x-axis with a log-scale.
This study also has its limitations. We were not able to take a closer look at homophilous communities that form around individual personalization. As there are worries that YouTube might radicalize people with its algorithm (e.g., Lewis, 2018), we lack the empirical research to back these worries up. Although our study contributes to the role of YouTube’s algorithms, we only account for one form of personalization—personalization on an aggregate level. 4 While the channel recommendation could be directly measured as a stable network, the algorithmic personalization on a user level (e.g., video recommendations) can only be measured using data from multiple accounts (cf. Covington et al., 2016). We opted for an analysis of the channel recommendation as it can be measured as a stable system in contrast to the video recommendation and channel subscriptions, which are very popular on YouTube. Thus, the potential impact of the channel recommendation, especially on more personalized algorithms on the micro level, should not be underestimated. Furthermore, it would be interesting to compare more than just two countries with each other to tease out the role country-specific culture and language play in the formation of homophilous communities. We identified more than just an English-language and a German-language community (e.g., French or Spanish-language communities). While we only used data from March 2018, future research could also look at the stability of filter bubbles over time. 5 This temporal element would further show whether a filter bubble is stable or not. In addition, our study shows that homophilous communities do not have to be political. The question, then, that needs further research is whether the private and cultural spheres are affected by these communities or not. In addition, academics could look at the homophilous communities we identified from a qualitative perspective to understand the similarities and differences within those bubbles. Finally, YouTube has discontinued its “related channels” function in May 2019 (Kaiser & Rauchfleisch, 2019a). This is a general challenge in internet research as Karpf (2012) describes in his essay about internet time and it limits our research as the study cannot be replicated. As stated above, we believe that this analysis has still merit as it contributes to our knowledge of the formation of algorithmically formed homophilous communities, and as such can be used by other scholars as a point of reference when thinking and analyzing algorithms on YouTube but also on other platforms that use similar recommendation algorithms. Furthermore, our finding that YouTube’s channel recommendation algorithms have promoted far-right channels in Germany and the United States is relevant for scholars of the extreme-right in both countries. The results we identified with the channel recommendation algorithm are, as we know from single topic studies (O’Callaghan et al., 2014), even more pronounced with video recommendation algorithms, as individual variables on user level influence the personalized video recommendations. Indeed, while the feature might have been discontinued, its potential effects in bringing like-minded users together, as well as pushing users to more extreme channels still linger. Although no new user will get far-right channel recommendations, the feature that got introduced in mid-2013 created and reproduced communities like those highlighted in this article and might have had a role in the creation of what Becca Lewis (2018) calls networks of “alternative influence.” And while these “calculated publics” (Gillespie, 2014) are at first just that—communities that were formed through an algorithm—users nevertheless were exposed to the recommendations, saw what other channels were there and similarly which channels did not get recommended, contributed to the recommendations based on their behavior, and reinforced the algorithms by using their recommendations. This effect is what we call the “algorithmic Thomas theorem” (Kaiser & Rauchfleisch, 2018): while the communities that algorithms form through their recommendations are an approximation of similar content, in the minds of users they might form a public.
Our analysis shows that the recommendation algorithm creates the homophilous communities that are a precondition for the creation of filter bubbles. This does not mean users will just follow these recommendations without any agency, but it shows that there is the potential that users might get nudged into problematic isolated bubbles, at least on the channel level. Furthermore, algorithmic decision-making will become more important in the years to come given the discussions surrounding machine learning or artificial intelligence (AI) and the many different fields of our lives where these algorithms are being applied to. In recent years, several scholars have published books on the roles algorithms play in our daily lives (e.g., Bucher, 2018; Noble, 2018; O’Neil, 2016; Pasquale, 2015). Against this background, it is important to empirically test where and how algorithms and personalization are being used and to what effect. Maybe it makes sense to discard the filter bubble concept in its most extreme form and instead focus on the influence of specific algorithms and where these algorithms lead to problematic outcomes.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: Jonas Kaiser’s work was funded by the German Research Foundation (DFG; Grant No: KA 4618/1-2). Adrian Rauchfleisch’s work was funded by the Ministry of Science and Technology, Taiwan (Grant No 108-2410-H-002-007-MY2).