
Abstract
Studying images in social media poses specific methodological challenges, which in turn have directed scholarly attention toward the computational interpretation of visual data. When analyzing large numbers of images, both traditional content analysis as well as cultural analytics have proven valuable. However, these techniques do not take into account the contextualization of images within a socio-technical environment. As the meaning of social media images is co-created by online publics, bound through networked practices, these visuals should be analyzed on the level of their networked contextualization. Although machine vision is increasingly adept at recognizing faces and features, its performance in grasping the meaning of social media images remains limited. Combining automated analyses of images with platform data opens up the possibility to study images in the context of their resonance within and across online discursive spaces. This article explores the capacities of hashtags and retweet counts to complement the automated assessment of social media images, doing justice to both the visual elements of an image and the contextual elements encoded through the hashtag practices of networked publics.
Introduction
We see and interpret the world around us to an ever greater extent through the visual vernacular of social platforms. Yet, visual methods for digital research remain challenging. The study of social media images involves working with qualitative data on a quantitative scale (d’Orazio, 2013) introducing challenges related to the size of datasets and to the amount of work required for coding and tagging materials. As Hand (2017) accurately sets out, “In social media, the circulation of visual data destabilizes research objects in ways that challenge visual analyses of textual meaning” (p. 1). Hand is part of a larger scholarly call (among many others are Leszczynski, 2019; Rogers, 2013; Rose, 2016; Schreiber, 2017) that urges researchers to take into account the platform’s architecture when researching images circulating there. Several novel visual methodologies have been developed in order to address the challenges of studying images in the realm of social media. Although cultural analytics (e.g., Rose, 2016; Yamaoka et al., 2011) provides an automated, computer-based process through which visual patterns can be detected, this methodology is restricted to pattern analyses based on, for instance, color, saturation, hue, or the presence of faces. It does not attend to the expressive messages of images in the same manner as qualitative visual (content) analyses do (Rose, 2016). More recently, scholars of visual social media have been engaged in developing ways to make sense of digital images and image patterns as they circulate the web and social platforms. Amongst others are the innovative studies into platform vernaculars conducted by the Visual Methodologies Collective (Niederer, 2018), cross-platform analysis of image circulation by Pearce et al. (2018), and studies into tracing the spread of political movements through researching memes and their circulation within and across different platform “milieus” by the Open Intelligence Lab (Tuters & Hagen, 2019).
Scholarly attention toward addressing challenges in social media visual research is also increasingly directed toward the computational interpretation of visual data. Although highly problematic to use as a stand-alone method for analysis of social media images and their expressive meaning, we contend and demonstrate that combining machine vision with certain platform data—hashtag data and retweet counts in this case study—presents a way forward, holding interesting future possibilities, namely, in the selection of visuals one should study. This selection issue has been a daunting problem for social media researchers as, “for qualitative researchers, the identification, selection and organization of visual materials always involves negotiating complex issues of sample, representation, authenticity and exhaustiveness” (Hand, 2017, p. 8).
Our proposed method is particularly apt to address issues of selection when studying social media images, as hashtags hold the capacity to build a more relevant corpus, demarcate the data within that corpus, and allow for the comparison of visual languages via hashtags. Based on the performative character of sharing images through social media, Bechmann (2017) draws attention to the importance of user incentives for uploading images to a platform. She assesses machine vision and evaluation of meaning and social value. Our study proposes a method that enhances machine vision with platform data that is capable of signifying incentives to upload, thereby revealing—albeit partly—the expressive messages contained within visual materials. The affordances of social media initiate a networked construction of meaning by publics that are commenting, liking, sharing, and, as such, collectively shaping the meaning of images.
For this study, we aim to stipulate the need for taking platform data into account when assessing outputs from automated analyses of social media images. To get a sense of the contextual space of such images, hashtags are indispensable as they function as linguistic markers enacting the following social relation: “Search for me and affiliate with my value!” (Zappavigna, 2011, p. 789). Ambient affiliations may then garner engagement which take the shape of, for example, retweets, thereby amplifying the expressive meaning of the original message. Although a highly complex social practice, driven by cognition, discourses, ideology and social hierarchies, retweeting—and sharing in general—may be understood as ambient affiliations with expressed meanings and values for tweeted content, taking shape in a relational setting. These meanings and values reside within the amalgam that is a tweet. To draw attention to the visual aspect of aligning affectively on Twitter, we focus on tweets containing images and analyze such images on the level of their content (the modality of the image itself), as well as their expressive meaning that is co-created by publics who mark images with hashtags, thus shaping the discursive frameworks within which images circulate and resonate.
Whether images are taken up, or elevated into prominence through practices of sharing depends, obviously, on highly complex acts of meaning-making and representation. One prerequisite for any form of action is affect, and accordingly, we ground our research and approach to understanding sharing practices through affect theory. Following the affective turn (Clough & Halley, 2007), scholars across various fields have engaged in a long-standing discussion regarding where affect ends and emotion or action begins. In the “virtual take” on affect proffered by Massumi (2002), affect is seen as the “moving force” that precedes the emotional expression. In so doing, it separates affect from consciousness and representation, which runs against the connective structures of networked publics wherein representations are discursive (see Papacharissi, 2015; Wetherell, 2012). We, therefore, draw on Slaby and Wüschner’s (2014) reference to Heidegger, disbanding affectivity from inner states or individualist allegiances and placing affect in the thick of everyday social and interpersonal commerce (Slaby, 2017). As Slaby, explains, “In Heidegger’s account affectivity is always enmeshed with its constitutive modes of understanding and discourse; affectivity thus pervades a person’s entire situated existence as its passive-receptive dimension, not neatly separable from forms of active engagement” (p. 10). This connects to Wetherell (2015) who explains how “context, past and current practice are involved in the spreading of affect, no matter how random and viral it appears” (p. 154). More specifically: “We seem to be drawn to, empathize with, and are most likely to copy, imitate and share the affect of those we affiliate and identify with, and those whom we recognize as authoritative and legitimate sources” (Wetherell, 2015, p. 154). Expanding on this particular notion of social identification and situated affect (Reicher, 2001; Slaby, 2017), we chose to demonstrate our method through a case study involving images of victims of the ongoing Syrian war who are oftentimes distant others to publics on Twitter as users are mostly located in the Western hemisphere. 1
The analysis of empirical data aims to answer two questions: What representations of the Syrian war and its victims are amplified within different discursive frameworks, one topical, one sentimental? What do visual themes reveal about different intensities of affect that seem to surround particular content elements?
Our method uses automated annotation of images and analyzes these annotations in the context of their discursive frameworks (topical, sentimental). Amplification (retweets, RTs hereafter) of images is taken into account and assessed in the frameworks of affect theory and of research into the representation of war and suffering others (drawing from a.o. Boltanski, 1999; Chouliaraki, 2013; Chouliaraki & Stolic, 2017; Sontag, 2003; Zarzycka, 2012). The corpus consists of image tweets and meta data, which we demarcate through queries based on highly frequent and co-occurring hashtags, all pertaining to the Syrian war. Within these hashtags, we distinguish two categories: one topical and one sentimental (Meraz, 2017). Underlying these very different spaces are #war and related (co-occurring and frequently used) hashtags for the topical space, and #eyesonidlib for the sentimental, solidaric, space.
Similar image content elements are prone to take on different meanings in different hashtag spaces. The expressive meaning that certain objects and subjects represent in image content is specific to—or steered by—the contextual space in which the images circulate. Hashtags play a very directive role in constructing such discursive frames. Automated annotation allows “decontextualized” content to take center stage and make them visible—categorized by annotation in a networked structure (see Figures 2 and 3)—in such a way that it is possible to compare their resonance in different hashtag spaces.
Our mixed-methods approach tracks the discursive frames and their resonance within a giant social platform, Twitter, that is just like other platforms, essentially a walled garden and hard to access in a structured way. Categorizing social media images by their actual content within and across social platforms is extremely complex. Repurposing hashtags to demarcate issue spaces—although by no means without limitations, especially relating to issues of exhaustiveness and users complex workarounds (Gerrard, 2018; Rogers, 2013)—is one way to approach issues and classify them as topical or sentimental (Meraz, 2018). Within such diverging spaces, the automated labeling of images and sharing metrics of such images allows to read content elements within their hashtagged context. We employed the Google Cloud Vision API (application program interface), which produces textual output that in a networked file re-organizes images by their content elements, essentially creating a way to categorize images by their content quite similar to a “Google similar or reverse image search.” Our method enhances such networked visualizations of automatically “ordered” visual data, with the dimension of hashtag information (providing clues for user incentives and social values) and retweet metrics (amplification of affiliation with certain values carried by images).
Albeit a very specific annotation algorithm, currently outperforming IBM Watson and Microsoft Azure (Mintz and Silva, 2019), we acknowledge that the annotation of the Google Vision API is subjective, as the algorithm is fed certain data over others and is therefore more or less capable of assessing content elements accurately. We explore this subjectivity in our discussion of the analysis and proceed to argue for combining machine annotation with data generated by platform-afforded contextualization of the tweeted image. Hashtags allow for attaining a certain level of sensitivity in assessing the meaning of socially shared images, expanding automated labeling with the context of a discursive framework.
Literature Review: Images and Affective Affordances of Social Media
The case study demonstrating our new method is specifically designed to detect the affective potential of images representing a “distant war” through diverging discursive frameworks that are, as mentioned above, largely determined by hashtags, images annotated with topical, political, or sentimental (e.g., solidaric) hashtags. Drawing on Reicher (2001) and Wetherell (2015), we assume social identification as a crucial prerequisite for “copying affect of others,” having consequences for the amplification of certain visual representations of distant others. We situate our study in the rather complex field of affect theory and connect the framework of relational affect to visual representations of war and suffering circulating Twitter. Thereafter, we outline the interactions between “low-level” affordances and affective engagement as this plays out on social platforms.
Both the denotative and connotative content of images, the latter co-created by networked publics, exert potential impact on their audiences, that is, they potentially move bodies present in a socio-technical environment such as Twitter. This “being moved” with a certain intensity can lead to sharing behavior, such as retweeting image tweets. Obviously, such a simple sequential process cannot be assumed, as retweeting is a consequence of a complex social practice. We, therefore, situate the act of retweeting as a discursive affective practice, as laid out by Wetherell (2015), who insists on the value of a social practice approach to affect. She refers to Schachter and Singer’s (1962) experimental studies that evidence how, similar to emotions, affect is deeply social. Affective arousal requires an engagement with the social context to become defined or categorized as a particular kind of emotional state: “The individual’s interpretation and reading of their body is strongly influenced by what can be deduced from the scene at hand and from others’ responses” (Wetherell, 2015, p. 20). Thus, retweets that are the result of social hierarchy, certain discourses, or dominant ideologies are all accounted for when we approach this sharing practice as an affective discursive social phenomenon.
We focus on the affective agency of cultural objects (Traue et al., 2019) and regard digital images as such. That is, we understand digital images as having agency and affective potential, and accordingly, we view images as operative (Farocki, 2004; Hoelzl, 2014), not merely representational. More specifically, we understand images as affecting individual bodies present within the networked spaces of online platforms (Pybus, 2015). As such, images “do things” (Labanyi, 2011).
Representations of Distant Suffering and Social Media
To advance an understanding of how the affective potentialities of images operate through the platform affordances of Twitter, we assess and compare images and their amplification within different hashtag spaces—topical and sentimental—all pertaining to a distant conflict with which it is difficult to identify for the larger part of the Twitter audience, which also tilts quite heavily toward the Western hemisphere. For this largely Western public, the ongoing Syrian conflict spurred relatively short bursts of public attention in the past decade, often initiated by affective images. The mobilization of publics through media frames was based on “opposing sentiments,” or as Sajir and Aouragh (2019) put it, “. . . the mobilization of a culture of fear, some cases verging on the absurd, but jarred with momentary outbursts of support cultivating solidarity and unity” (p. 567). While some images punctured the “callousness” of spectators of suffering, loads of images seem to have no significant resonance and some images fuel fear, normalizing a non-critical take on the discourse of “crisis” that Europe is engulfed by waves of potentially dangerous migrants (Sajir and Aouragh, 2019).
Based on research into the visual representations of refugees in European news, Chouliaraki and Stolic (2017) constructed a typology of visibilities consisting of five visual “tropes” that characterized imagery: (a) visibility as biological life, associated with monitorial action; (b) visibility as empathy associated with charitable action; (c) visibility as threat, associated with state security; (d) visibility as hospitality, associated with political activism; and (e) visibility as self-reflexivity, associated with post-humanitarian engagement with people like “us.” These typologies are relevant to this study as they sit close to the idea of social identification as a prerequisite for affective alignment with certain values. In other words, culturally or geographically distant others are represented in such a way so as to increase an image’s chance to “affect.” Chouliaraki’s (2013) concept of post-humanitarian solidarity outlines how distant sufferers are rendered invisible due to the self-reflexive nature of contemporary solidarity, which inhibits solidarity for suffering “others” that are unlike us. Chouliaraki demonstrates how in post-humanitarian appeals for solidarity, the suffering of victims begets the emotions of the spectator. This self-reflexivity obfuscates the underlying causes of the depicted suffering, obscuring reasons to act as we are consumed by our own emotions. Chouliaraki’s proposed alternative of agonistic solidarity may be seen as an attempt to reach a cosmopolis: a space wherein we may imagine ourselves caring for others, not because they are reflections of ourselves but because they are different from us.
Nikunen (2019) discusses how a new media environment amplifies such mechanisms of ‘strategic silence’—or rendering the causes of distant suffering invisible—and at the same time, she found social media open up new spaces of appearance for marginalized voices. She discusses the potential of voice and agency through outlining the political impact of a Finnish-based blog—Migrant Tales—in which marginalized voices address injustice, leading mainstream media to follow-up. Moreover, in a comparative analysis between mainstream media and Twitter, Nerghes and Lee (2019) found that news circulating the two spaces both converges and diverges. Unlike mainstream media, Twitter offered a more positive public discussion on the refugee crisis that offered an “alternative and multifaceted narrative, not bound by geo-politics, raising awareness and calling for solidarity and empathy towards those affected” (Nerghes & Lee, 2019, p. 275).
Twitter’s Affective Affordances and Machine Vision
The agency of publics that is attained discursively through social media occurs via within the affordances of social platforms, including “low-level” affordances such as buttons. Contemporary practices of affective expression on social platforms encompass the use of social buttons (Bucher, 2012) that, in turn, inform the algorithmic feed. Such buttons serve the commercial interests of platforms, but also pre-structure feelings and enable possibilities of expressing affective engagement with web content, while measuring and aggregating those responses (Gerlitz & Helmond, 2013). The most immediate way for Twitter users to engage is through buttons, such as liking or retweeting. “Liking” does not propagate images across the platform, though it affects the algorithmic visibility of images. Thus, because the algorithmic properties of the Twitter feed are unknown to us, we focused on retweet counts.
It is essential here to stress the performative character of users that express themselves through diffuse images: online publics are monitoring others (Mortensen & Trenz, 2016) and aware of being monitored themselves, meaning that practices of engagement hold intentionality (Papacharissi, 2015). Through the naming, articulation, and circulation of particular images, specific contexts emerge that can only be read when we are aware of the social space in which such images live. Bechmann and Bowker (2019), therefore, rightly refer to the importance of user incentives that drive the diffusion of, and engagement with, images. The performative intention of the uploader of the image, as Bechmann points out (it can also be the person commenting or reacting to an image), is not taken into consideration by image recognition algorithms that are trained to identify faces and features in pictures. As Bechmann (2017) argues,
If we want to understand social media images, it is not beneficial solely to train the algorithm on images from websites or Imagenet because this would result in an excessively generalized semantic meaning by collapsing entities into categories that are not suited for social media. (p. 1794)
Bechmann suggests that the algorithms of machine vision applied in social media contexts need to gain sensitivity for, first, the composition of the image (i.e., what is foregrounded in the image, what is in the center, what is acted upon), and, second, algorithms should be more tuned to the incentives for the uploader of an image that operates in a certain context. We argue that the second point may be accounted for without waiting for companies to tweak their vision algorithms. Key to understanding the social values underlying visual practices are the hashtags with which images are, we argue, contextualized.
Bechmann (2017) proposes a model that would expand the recognition of faces and features with such incentives or “social values.” The social value of the picture is important when it is used for user profiling and predictions, and it would enhance computer vision performance when applied to social media. While the construction of a vision algorithm modeled for the accurate assessment of social media visuals is not within the scope of this article, we demonstrate how combining automated assessment with hashtag driven analyses of images is a useful mixed-methods approach.
Hashtags as Signifiers for Social Value
For news photographs, captions have often been recognized as the space where meaning would reside. As Sontag (2003) outlined, “Whether the photograph is understood as a naive object or the work of an experienced artificer, its meaning—and the viewer’s response—depends on how the picture is identified or misidentified; that is, on words” (p. 25). In the context of social media, this is no different; almost “more than words,” hashtags are linguistic markers that function as online metadata (Zappavigna, 2011). Because hashtags are made searchable by the interface, they connect tweets from users who have no preexisting follower/followee relationship. Processes of suggestion, imitation, and learning—memetic dynamics—as well as Twitter’s trending topics functionality promote a shared use of certain hashtags for events, cultural expression, or engagement in ongoing conversations (Leavitt, 2014). This memetic potential as laid out by Leavitt is especially interesting to our study of socially constructed meaning of images. Hashtags and hashtag publics are extensively studied through the use, diffusion or repurposing of the tags themselves. However, such hashtags interact with images and this visual layer is to date understudied (Nerghes & Lee, 2019; Schreiber, 2017). As the meaning of social media images greatly depends and potentially shifts as a result of memetic hashtag practices, we can no longer ignore this visual layer and we can only study it meaningfully, by taking their hashtags into account.
Data and Methods
Data were collected through the Twitter Capture and Analysis Tool developed by the Digital Methods Initiative (DMI-TCAT; Borra & Rieder, 2014), using a targeted query of relevant terms and hashtags (see Note 1). To answer the above research questions, our approach to analysis depended on aligning Twitter content to on-the-ground events that produced spikes in activity, and presumably patterns of visual affect. For this, we focused on the period of activity from 18 November to 18 December 2018, consisting of 1.04 million tweets from 386,131 distinct users. Since Twitter’s platform architecture evolved from a friend-following network to an event-following network (Rogers, 2013), we demarcated the time span of our dataset using an on-the-ground event (Figure 1): 2 a chemical attack in Aleppo that prompted military strikes by Russia (“Syria War: Aleppo ‘Gas Attack’ Sparks Russia Strikes,” 2018).
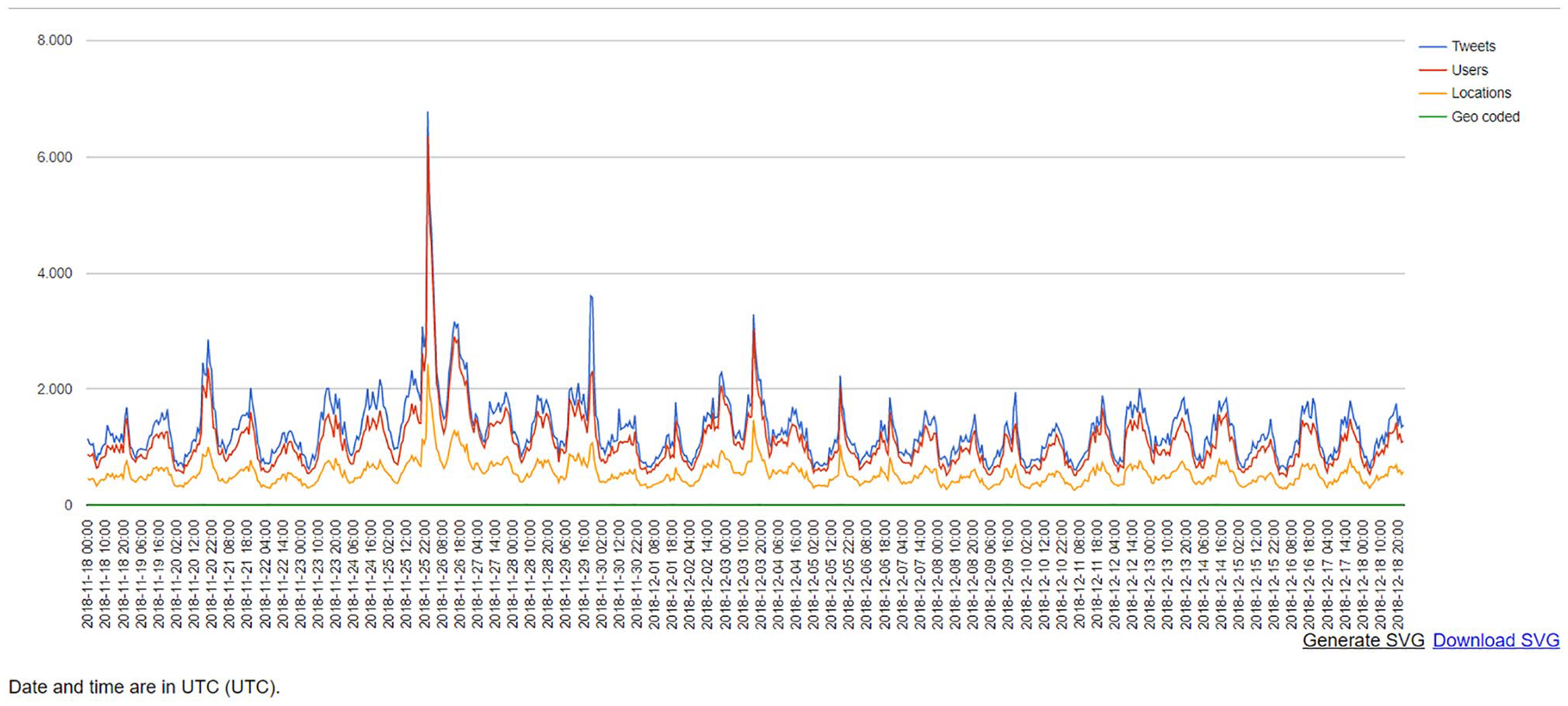
This graph represents tweet activity during the demarcated time span of November 18 to December 18, 2018. The spike reflects increased activity surrounding chemical attacks of the Assad government on Aleppo.
To further focus our analyses and tease apart distinct visual patterns, we examined hashtag frequencies from within this time period and drew three random samples of tweets (N = 1,000) based on targeted queries. These targeted queries 3 were created based on Meraz’s selection and categorization of political hashtags, whereby explicit popularity (i.e., frequency within the dataset) was used as justification for inclusion within the sample. From two categories—topical/issue tags and sentiment tags (Meraz, 2017)—the most frequent tags were identified.
We then conducted a co-occurrence analysis through constructing a network of the hashtags in the dataset November to December 2018. After locating the most frequently appearing hashtags in the co-occurrence network, a manual coding scheme (adapted from X. Wang et al., 2011) was used to group hashtags. Using an inductive approach to grouping similar topics and issues embedded within networked content (Meraz, 2017) analysis revealed distinct clusters associated with more or less resonating images in both networks. To strengthen our justification for targeted queries based on hashtag frequency, we also examined hashtag co-occurrences during this period, and thus expanded the parameters for our subsamples. The first group of selected hashtags constitute a topical cluster (#war, #humanrights, #politics, #protests, #stopwar), and the second relates to a single hashtag #eyesonidlib, which did not cluster significantly with other hashtags in the entirety of the co-occurrence hashtag network. It is targeted at the Idlib province of Syria, one of few remaining anti-Assad strongholds in the region (“Syria War: Why Does the Battle for Idlib Matter?,” 2018). After identifying query parameters, random samples of 1,000 tweets were drawn from the larger November to December sample and used for analysis. Thus, co-occurrence analysis of frequently used hashtags gave birth to two distinct discursive tag spaces: a topical and a “sentimental” (solidaric) hashtag space.
Automated Object Annotation of Images
To arrive at specific visual themes that resonated, this study includes object labels that are generated by Google’s Cloud Vision API, introducing automated content analysis. Computer vision may be defined as the collection, analysis, and synthesis of visual data via computing, with several objectives including recognition of faces and semantic content like objects, entities, and contexts within images (J. Wang et al., 2015). Despite advancements, computer vision deals with limits defined both by technical challenges (Smeulders et al., 2000) and cultural and discriminatory biases (Mintz and Silva, 2019). Such biases can be traced by research, such as that of Mintz and Silva (2019), who compare three APIs: Google Cloud Vision, IBM Watson, and Microsoft Azure. In their comparison, the Google API outperforms the other two for object recognition specificity, and all three APIs seem to favor the performance of cultural neutrality with generic categories scoring higher than specific terms.
As Google Cloud Vision is currently outperforming alternatives for object label specificity—object labels being the output most relevant for the purpose of this study—we chose this specific API. It should be noted that studying platforms through their APIs (e.g., Twitter Graph API, Google Cloud Vision API) hold both analytical opportunities as well as important limitations and considerations to take into account (Rieder, 2013; Rieder et al., 2015). These are not only of technical character but also suggest different directions and methods of analysis (Marres & Weltevrede, 2013). APIs and platforms themselves—each with specific features, interfaces, and database architectures—carry implications for both how and what to study when it comes to social media (content). Marres and Weltevrede (2013) suggest to “understand these devices and platforms as part of our ‘methodology’ and simultaneously as part of the ‘object’ of analysis” (p. 322).
We employed the Memespector tool (Rieder et al., 2018) to access the Google API. Memespector allows for several outputs, of which object annotation is the output we used as it comes closest to “content analysis” of the images. Memespector also generates an image network wherein images are connected via annotated object labels (referred to as label-image networks from here on). This output can be enhanced by adding dimensions of platform data. As the theoretical framework directs us to assess relational affective potentiality of image tweets, we chose to use retweet metrics as our added dimension. To be sure, retweets do not guarantee enhanced visibility; however, they suggest greater reach and thus increased potential to relationally affect present individuals. We chose to depict retweet counts through the size of the images. Using cluster analysis, both the associated images and their annotated labels revealed visual themes that appear to resonate within certain hashtag spaces.
Visual Network Analysis and Machine-Constructed Themes
Network analyses can be conducted in myriad ways, using the unique characteristics of networks in both qualitative as well as quantitative ways (Castells, 2010; Latour, 2005; Scott, 2017). From a quantitative point of view, social network analysis (SNA) is perhaps the most renowned, which utilizes the mathematical qualifications of networks to account for structural aspects of social processes (Borgatti et al., 2009). For present purposes, we do not address mathematical properties of the machine-generated networks, and instead discuss the relational composition of similar image elements within two discursive hashtag spaces. The particular practice of retweeting then makes visible how some image tweets are more prominent than others and how this relates to the larger sample of images. This fits with a qualitative approach of network interpretation, as deployed within a variety of fields (Knox et al., 2006). We follow Decuypere (2019) who states, “. . . qualitative approaches largely adopt the notion ‘network’ as a method that allows to trace the complex entanglements by means of which specific practices are constituted” (p. 2). These approaches claim to adopt more open, flexible, and descriptive methodologies as compared with more formalistic methods of SNA (Gamper et al., 2012). Thus, the visual network analyses we conducted are concerned with visual rather than structural (social) properties of networks (Decuypere, 2019; Latour et al., 2012; Venturini et al., 2016).
The spatialization algorithm we used—Force Atlas 2 in Gephi—is force-directed, pushing out nodes with low degrees and pulling together nodes that are highly connected through the annotated object labels generated by the Vision API. This allowed us to qualitatively identify similarly annotated clusters of content before we analyze them in relation to their hashtag classifications.
Visual Themes and Resonance across Contextualized Spaces
While an exhaustive review of all images in the networks is beyond the scope of this article, we instead let retweet resonance and network characteristics (e.g., clusters of similar images) guide the selection of prominent images that are similar in object content within all three hashtag spaces, but contextualized differently, in order to capture the contextual specificity of certain hashtag spaces. As this article is proposing a methodological approach to examine visuals on social media, its scope does not entail an exhaustive visual analysis of individual images.
The objective image content—surfacing through automated annotation—clusters images in such a way that it de-contextualizes images and reveals how content elements are distributed via frequent and co-occurring hashtags. We then use retweet metrics to determine which images resonated within each content cluster. The contextualization of resonant images was then compared across the two hashtag spaces in order to distinguish the interplay between hashtags (contextualization) and visual content.
The qualitative interpretation of networks follows the typology of visibilities of refugees as advanced by Chouliaraki and Stolic (2017) on the basis of news images and theories of witnessing distant suffering more generally. We expand on research based on news images as empirical material, which, for the case of Twitter, makes sense: as Nerghes and Lee (2019) argue, a complete separation of mainstream news media and Twitter is no longer viable, as “the sharing and discussing of news between news outlets and Twitter users is a genuine bi-directional exchange” (p. 277). News outlets and social media actors co-create narratives, whereby, as Nerghes and Lee found in their comparative analysis of mainstream media and Twitter, social media create new spaces that transform narratives by creating awareness and calling for solidarity toward those affected (De Andrés et al., 2016).
Findings: Hashtag Visualities and Resonance
As set out above, the decontextualized object elements were categorized and visualized in a networked structure by the Google Cloud Vision API, with image size corresponding to retweet volume. We first describe most prominent content as annotated by the Google Cloud Vision API and differences in visual objects across both hashtag spaces, then proceed by analyzing images containing these prominent elements, and “read” them within their hashtagged contextualization, thus expanding on earlier research into visual representations of war, suffering, and their affectivity.
Across both image-label networks generated via Google Cloud Vision API, we see a clear divide between the topical visuality and the visuality present within the sentiment space (Figures 2 and 3). Particularly, the latter is more uniform in its visual language, predominantly showing children and resonant artwork that commemorates a recently deceased activist, whereas the topical space is more diverse in both content and location of retweet intensity—distinctions we return in more detail later on.

The image-label network for the topical hashtag space (based on tag-based queries for #war, #humanrights, #politics, #protests, #stopwar).

The image-label network for the solidaric hashtag space (based on tag-based query for #eyesonidlib).
The Topical Framework: Acts and Consequences of War
The topical space (comprised of #war, #humanrights, #protests, #politics, #stopwar) is diverse in image content; however, in terms of visibility, inanimate imagery characterizes the most RT’d (retweeted) images; this aligns with what Mirzoeff (2006) argues of what we see and relate to in the media: “the semiotic domain wherein a specific ‘politics of representation’, the ‘struggle over who is to be represented’ and how, is played out” (p. 76). The top three images are organized around the labels: Military, Vehicle, and an Earthquake label that the API regularly annotates when confronted with the consequences of bombardments. Other content elements that resonate are images of fire and children; one of the three visible images is a particularly tragic image of a man with a deceased child in his arms (see Figure 4).

Heartbreaking image that aligns with a regime of visibility as empathy. Such images are less present and less resonant in the topical hashtag space.
What connects all elements of image content within this hashtag space is the focus on depicting both the acts and consequences of war, where the military acts and their inanimate consequences (fire, rubble) are more resonant via retweet than the human consequences of war that are depicted through affected children. Although less RT’d, such human elements are also present. A crying man holding a deceased child (Figure 4) fits the regime of visibility as empathy, which “privileges intimate snapshots of individuals or couples, such as a crying child, a mother with her baby or a rescue worker in action” (Chouliaraki & Stolic, 2017).
This visibility as empathy almost juxtaposes compositions in the regime of visibility “as biological life,” where massification in depicting people takes the perspective of distance and ignores the uniqueness of people as persons. Individuation adopts a close-up perspective and has the potential to offer a more humanized representation of refugees. Here, it is the imagery of the child that figures as emblematic of the individualized visualities of empathy (Burman, 1994). The child is ubiquitous in another hashtag space that of sentiment represented in our study by a single hashtag: #eyesonidlib.
The Sentiment Space: Individuation and Commemoration
The sentiment space is based on a hashtag that expresses a message that could be interpreted as both a call to witness the fate of people in heavily bombed Idlib and a general message of solidarity. Highly resonant images in this space (#eyesonidlib) are clustered by the labels Art and Illustration. Where illustrations or other artworks in the topical and political spaces largely function as political or activist pamphlets, here, the highly RT’d illustrations focus on the commemoration of the deceased, including activist Raed Fares (who was killed on 23 November). In short, the topical hashtag space seems to use illustrations for advocacy-related purposes, whereas illustrations in the sentiment space conveyed emotions of loss and commemorated victims.
Apart from illustrations remembering victims or calling for solidarity through artwork, the larger part of the visual language in this space consists of images of children. Such images fit a regime of visibility as empathy, which Chouliaraki and Stolic (2017) critique: while recognizing the humanizing potential of the individualization of suffering often present in images of children, this imagery can be held accountable for infantilizing refugees, for depicting them predominantly as distressed, clueless, and powerless. As Burman (1994) argues, children “plead, they suffer, and their apparent need calls forth help,” echoing “the colonial paternalism where the adult-Northerner offers help and knowledge to the infantilised-South” (p. 241). Infantilization may thus aim at mobilizing empathy in the name of “our” humanity, yet, in portraying refugee children in need, ultimately deprives them of agency and voice.
Another visual trope within the sentiment space is organized by the Vision API based on background elements of the images, including mud, adaptation, and soil (see Figure 5). As the large part of the dataset depicts people (often children), the API starts labeling and organizing images based on background elements of pictures, in this case organizing images that not only share background elements but also fit the same regime of visibility, that of visibility as biological life in which “a ‘mass of unfortunates’ on fragile dinghies or in refugee camps situate refugees within a visual regime of biological life” (Chouliaraki & Stolic, 2017, p. 1167). These images construct a humanity reliant on Western emergency aid or rescue operations to survive, and so inevitably dispossessed of will and voice. In this space, such images pertain to the depiction of hardship with refugee camps.

When people are present in all images, the Google Cloud Vision API clusters the images based on the labels of background elements of the images.
The images described above concerning the conditions of camp life tap into a different regime than another cluster in the sentiment space—that of images clustered around the labels People and Child, which connect to portraits of children (Figure 6). The affective power of portraits lies in how they depict the face of the other; the photographic portrait encourages one to attach meaning according to one’s own worldview, silencing outside voices and cultures (Zarzycka, 2012), and thus engaging in a distancing work through quasi-ethnographic means of seeing photographs. As portraits leave out particularities of otherness, they invite a more self-reflexive engagement with images of others.
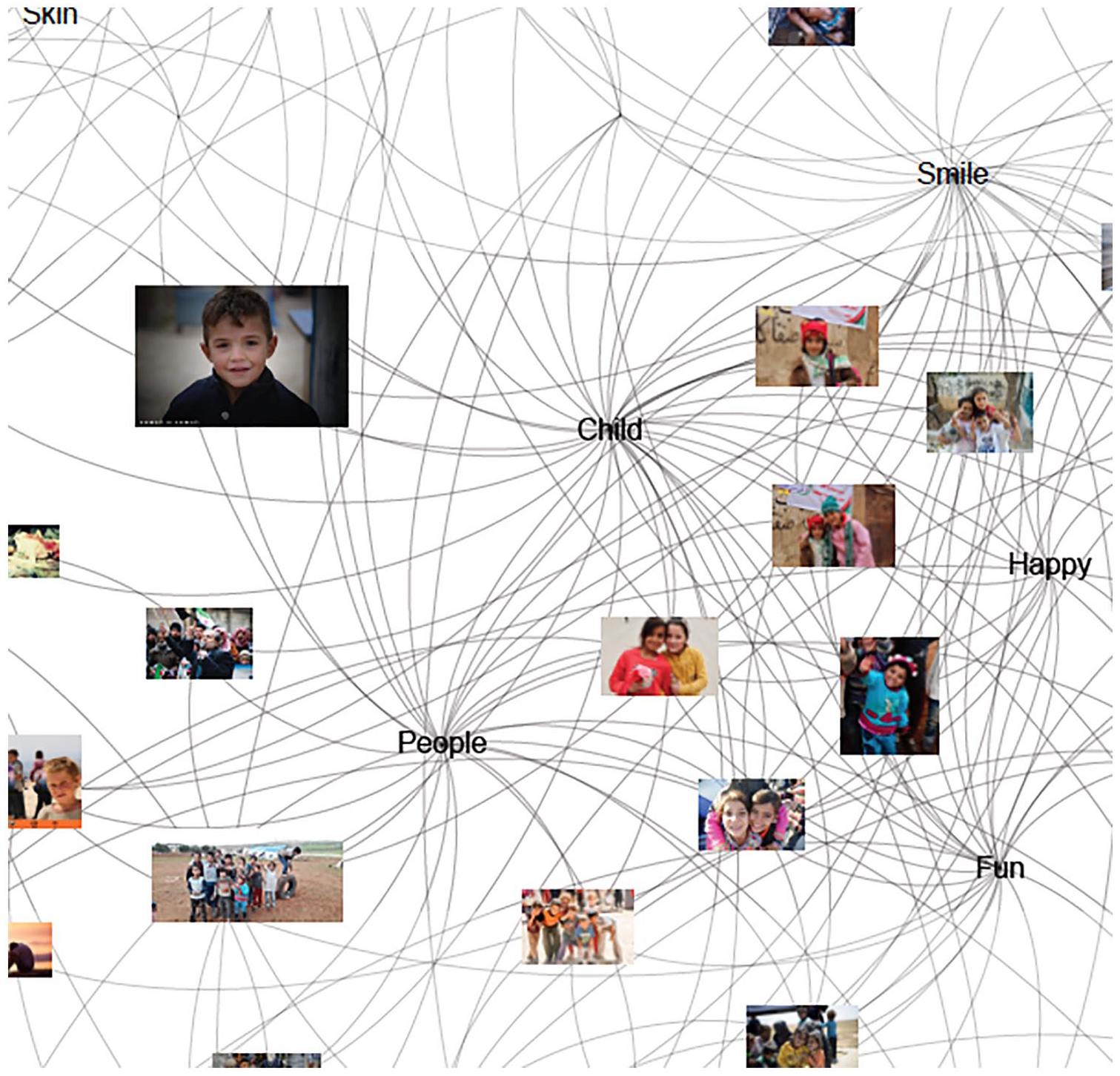
Portraits get labeled and clustered around People and Child, which are close to labels that characterize these portraits in the solidaric space: Fun and Happy.
Discussion: Hashtag Visualities and Filling the “Gaps” in Machine Annotation
The analysis of both the topical and the sentimental hashtag spaces show distinct visual languages in which similar image objects and subjects are present; however, both their composition and tweeted context (hashtag co-created meanings) pertain to different messages. These hashtag-driven messages also influence the visuality of image protagonists. Their meanings can be related due to the prior demarcation by hashtag categories (topical versus sentimental; Meraz, 2018). As mentioned earlier, the typologies of visibility applied in reading the hashtag networks—visibility as biological life, empathy, and self-reflexivity—emerge based on empirical investigations of news media by Chouliaraki and Stolic (2017), which are media ecologies distinct from Twitter to an extent. Yet, as previously mentioned, the comparative study by Nerghes and Lee (2019) suggests both similarities and differences in imagery between traditional news media and Twitter. Note that both studies examine refugees specifically and not the Syrian war, while we include tweets that were tagged topically or politically so as to explore hashtags and their (distinct) visual content. We demarcated distinct discursive spaces that pertain to a call for solidarity and topical hashtags. This hashtag driven data separation singles out a dimension of news narratives that is particularly present on Twitter, that of creating awareness and calling for solidarity as set out by Nerghes and Lee, which complement the mainstream news space. Where Nerghes and Lee contributed to our understanding of differences and convergences between mainstream and new media (Twitter), we have added an understanding of the visual layer of tweets.
While the Google Cloud Vision API has shown greater granularity for image annotation (Mintz and Silva, 2019) and overall performance in specificities, our analysis reveals how this particular vision API fails to recognize elements pertaining to war settings. Children are connected to the label Play, which might be due to the fence in front of the child, potentially mistaken for being a playground. Another example of insensitive annotation is the excruciatingly sad image of a crying man, holding a deceased child in his arms. This image present in the topical network and resonating significantly (RT count = 26) is annotated with the label Humans and Arm, and unfortunately incorrect with the labels Sleep and Nap. Another instance of things “going wrong” with annotations is found in a cluster with labels referring to body parts, such as Flesh, Knee, Joint, Mouth, and Facial Hair. Unsurprisingly, the body parts annotations are correctly connected to images of deceased or severely wounded people; however, the machine also annotated one image of a deceased man as Zombie. Another instance of bias occurs whenever there is a man in a suit: this is typically recognized by the system as Business-Related, which aligns with findings of Rieder and Sire (2014) that Google is business-oriented. Such “errors” are only partly due to a lack of contextual knowledge that cannot be derived from the modality of the image itself, which alone what the Vision API takes as input. Some biases may be tackled by training the algorithm with images of war and the consequences thereof. This also makes clear why researchers of visual social media need to study the images circulating platforms by using natively digital data, generated by the affordances of the platforms (Rogers, 2013). We endorse the need for a “digital methods approach,” which enhances the selection of images to study so we may read image content in the networked contextualization within which they circulate.
Visual objects circulating through platforms, databases, and devices add myriad complexities for the analysis of images. Indeed, their processes are not merely user-driven but also algorithmically defined. Many argue that visual objects in digital formats are ephemeral: fluid, often re-workable, and less durable than print equivalents. Much of this fluidity is the result of continual algorithmic classification and reordering (Hand, 2017). Our proposed methodology is by no means exhaustive in addressing these complexities, but for the presently conducted and similar research, we do see promising future possibilities in approaching the analysis of social media visuals, as we may account for the networkedness of the environment through which images circulate while also attending to image content.
While image software is becoming increasingly adept at recognizing what images depict, capturing the expressive content of an image remains, heretofore, problematic. Rose (2016) rhetorically suggests that digital methods do not (yet) provide means for examining the compositional modality of the image itself. She summarizes this critique within academia: “Those automated and/or large-scale methods simply cannot focus on what matters in contemporary visual culture: people doing all sorts of complex, thoughtful, creative, ‘idiotic’ things, with all sorts of anticipated and unanticipated effects” (p. 305). We respond by arguing that merely applying automated computational analyses to images without making use of the socio-technical context of the platform within which images circulate and layers of meaning are added is, indeed, limiting. However, when we demarcate image data via hashtags, we may at least partially enhance “social media contextualization” of images that steer discursive frameworks. Through retweet data, then, we add an understanding of how regimes of visibility—or their visualities as Mirzoeff (2006) puts it—are shaped by the communicative architecture of the platform. Through retweet metrics, we can see patterns of affective resonance of visual elements within hashtag spaces—thereby suggesting an element of affective intensity surrounding those particular elements. However, Twitter’s power asymmetry, amplified by the platform’s communicative architecture (Halavais, 2014), makes it extremely difficult to infer whether resonance is related to a tweet’s actual visual content or to the status of the tweeter, that is, his or her followership. However, if varying followership numbers are controlled for, through for example a follower/retweet ratio, the visual elements that diffuse despite the status of the initial tweeter become more apparent. We did not control for variance in followership, as we sought to demonstrate how the label-image networks alongside retweet metrics also reflect the reach of prominent actors within the studied hashtags spaces.
Future Directions
To understand the subjective contextualization of images by networked publics (i.e., against our present use of the Google Cloud Vision API), we also tested the feasibility of text-image networks using WordIJ (Danowski, 2013), which analyzes text-based documents for term frequency and co-occurrences. Following the removal of peripheral content and stopwords, we embedded image files within their associated tweets, using the same samples from our earlier analyses (see for example Figure 7). Albeit preliminary and beyond the scope of this study, this demonstrates the capacity to holistically examine the network of images alongside their discursive framing, which future research should build upon and enhance.

Example of the topical hashtag space (#war, #humanrights, #politics, #protests, #stopwar) reworked into a semantic network, using WordIJ.
Conclusion
Apart from the errors due to one-sided training of the machine (inferred dominance of marketing-related labels and positivity bias), the object recognition was fairly accurate. Even the labeling of illustrations and text-based images—the latter being ubiquitous on Twitter specifically—was correct. Of course, they currently remain insensitive toward contexts of war: images of destroyed buildings and rubble are annotated consistently as Earthquakes and images showing people gathering, combined with enough blue sky, will generate labels such as Recreation and Tourism. Still, the accuracy in recognition of untangled image elements, we acknowledge, does not mean we can conduct visual analysis of the expressive content of images. Despite its limitations, the Google Cloud Vision API proves to be a valuable way of clustering images for network visualizations based on their (often correct) object labels pertaining to specific image content elements. When combined with relevant platform data and with more qualitative sensitivity toward incentives for tweeting certain content, this seems to be a direction that holds promising possibilities for future research.
A byproduct of using the API is that it provides a method to perform a “similar” image search, much like the similar images search one can execute using Google Similar Images for the web. This was something that could not be done in the walled gardens that are social platforms. Although not similar in formal modalities, images with shared objects are clustered together by networking images and Vision API labels. Also the tool clusters duplicate images automatically, which resembles functions of tools such as ImageSorter, however with the bonus of added layers of networked information providing a qualitative layer to the networked data.
Networking hashtag-contextualized images by their objective content (annotated labels of objects and subjects present in images) and adding a platform rank dimension to the network provides an opportunity to analyze images in such a way that we can untangle content elements in the same vein as content analysis while—through entering the image data by their hashtags—retaining a certain degree of sensitivity for the social media context in which these images are given meaning to.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.