
Abstract
Social media enables the performative actions needed for celebrities to build and maintain audiences. Platforms like Twitter mediate identity construction and interaction with fans while enabling environments that are co-constructed by celebrities, fans, and the platform itself. We use the theoretical lens of media richness to study the ways that different types of celebrities enact “micro-celebrity” by mapping three richness dimensions (contextual, interactional, and informational) into groupings of Twitter’s affordances. Utilizing crowdsourcing and regression analysis, we systematically weigh each affordance and generate richness scores for each dimension, for each tweet. Using these richness scores, we find that performance of different types of celebrity requires different affordance mixtures, and that these mixtures reflect differences in the environments within which celebrities operate. Our research contributes to work at the intersection of Twitter affordances and celebrity studies in new media, and provides a framework for generating richness scores.
Introduction
Social media have introduced a contemporary shift from broadcast to participatory media, through which content can now be produced, manipulated, and distributed by everyone with Internet access (Jenkins, 2006). The shift has brought about major changes to the traditional celebrity management model as celebrities can bypass attention brokers by engaging in “micro-celebrity” practices, defined as “a new style of online performance in which people employ webcams, video, audio, blogs and social networking sites to ‘amp up’ their popularity among readers, viewers, and those to whom they are linked online” (Senft, 2008, p. 25).
Instead of celebrity being “what a person is,” as powered by promotions and publicity of media industries (Turner, 2013), in social media it becomes “what a person does” as they engage in micro-celebrity practices (Marwick, 2015). Whether a product of social media or a transplant into the space, social media enables performative actions needed to practice celebrity such that we can forgo the binary perspective of celebrity (i.e., you are, or are not, a celebrity) in favor of a performative practice perspective (Marwick & boyd, 2011). Celebrities can perform activities, mediated by the affordances of platforms, that allow them to construct identity and build and maintain audiences at scales that satisfy niches of interest (Hambrick, Simmons, Greenhalgh, & Greenwell, 2010). In this perspective, the environment within which celebrities operate is co-constructed with their audience and peer group.
While literature has shown different ways celebrities use Twitter (Bennett, 2014; Pegoraro, 2010; Stever & Lawson, 2013), we are unaware of research that looks specifically at how different types of celebrities engage in different practices on Twitter or that shows how such comparative analysis could reflect the differences in media environments that different celebrity types face.
In this study, we examine how different types of celebrity (pop stars, athletes, and scientists) use different groupings of Twitter’s affordances through the theoretical lens of media richness (Daft & Lengel, 1986). We see different groupings as providing different dimensions of richness. For example, facial expression, tone of voice, and body language all combine to make a message rich and can be combined in different ways to communicate information (Mehrabian & Ferris, 1967). To measure richness across our groupings, we extend a Tweet Quality Assessment Framework (TQAF; Tanupabrungsun, Hemsley, Semaan, & Stromer-Galley, 2016) with the theoretical perspective of media richness and by using crowdsourcing and regression.
We find variation in how different types of celebrities emphasize different dimensions of richness. We also see differences in the range and variance of richness scores within dimensions. Using media richness theory, we discuss how these differences give us insight about the environments that celebrities and audiences co-construct.
Our research contributes to the literature at the intersection of celebrity (Marshall, 2006a, 2006b; Turner, 2013), Twitter affordances in system sciences (Seidel, Berente, Debortoli, & Srinivasan, 2016), HCI (Kaptelinin & Nardi, 2012), and celebrity studies in new media (Abidin, 2014, 2015; Marwick, 2013; Marwick & boyd, 2011; Senft, 2008). This work also makes a methodological contribution through our scoring framework that will be useful for research examining how different types of actors emphasize different dimensions of richness to gain insights into the environments within which those actors operate.
Background
Media Richness and Twitter
Media richness theory provides a conceptual framework for measuring a platform, and its affordances, in terms of the ability to deliver “rich information” that can change understanding, often by reducing ambiguity (Daft & Lengel, 1986). It suggests that some media channels are richer than other channels. In written memos, the information conveyed comes from the text itself, its formatting, and the context in which it occurs. By contrast, in a face-to-face setting, facial expression, tone of voice, and body language all provide additional cues to the words spoken, and work together as the information that changes understanding or communicates meaning.
The wide range of technological affordances offered by new media introduces variety in media uses (Brinker, Gastil, & Richards, 2015; Dennis & Kinney, 1998), for example, one can make an email richer with images or emoticons. Just as organizations can select media channels that best solve their information problems (Daft & Lengel, 1986), new media users tend to appropriate technologies in ways that best serve their needs (Baym, Zhang, & Lin, 2004). Together this suggests that the richness of a medium is not necessarily a distinct objective value but varies by how it is appropriated to best serve the user’s needs. It also suggests that the richness of any individual tweet varies according to how it is constructed. Twitter offers certain technological affordances, or action possibilities (Kaptelinin & Nardi, 2012), that may work as cues to make any individual tweet richer than it would be without those cues. Thinking of the information problems as the tasks of broadcasting personal messages to generate shared meanings among senders and receivers (Baym, 2015; Berger, 2010), richer tweets are expected to be more efficient at delivering easily misunderstood messages.
Sophisticated users likely understand that different kinds of cues enhance a tweet’s richness in a way that supports understanding within the environments users operate in. Just as different organizations have different information needs (Daft & Lengel, 1986), the same is true for different media environments. Understanding how different groups of actors use these affordances may shed light on the differences in their public media environments.
Broadly speaking, this work explores how diverse types of sophisticated Twitter actors use affordances to change understanding within the environments they operate in. We operationalize sophisticated users as famous people practicing celebrity on Twitter.
Twitter Affordances
We think of characteristics in tweet text as affording different communicative action possibilities that reduce ambiguity in varying ways. Many of these affordances have emerged in a way that suggests these affordances have been culturally developed over time (Bruns & Burgess, 2011).
Hashtags have emerged as a key affordance to support searching and identifying trending topics in Twitter. They allow users to categorize their messages (Darling, Shiffman, Côté, & Drew, 2013) and signal the context within which the tweet occurs (Huang, Thornton, & Efthimiadis, 2010; Marwick & boyd, 2012). People use them to engage with specific topics (Bruns & Burgess, 2011; Huang et al., 2010) and for forming communities (Mendoza, Poblete, & Castillo, 2010). One reason hashtag use has become so widespread is because “Twitter flattens multiple audiences into one,” which is “a phenomenon known as ‘context collapse’” (Marwick & boyd, 2012, p. 22). Hashtags reduce ambiguity by allowing users to specify one or more audiences for the message. For example, an intimate remark intended for one’s significant other might be taken amiss if read by a coworker.
Twitter supports actions that enable different ways that users can interact. An @mention and @reply can be seen as a form of “addressivity” that references others, either as the intended recipient, as a third person being talked about, or a response to someone else’s tweet (Honey & Herring, 2009). While many may dismiss retweeting as simply amplifying a message, many scholars also consider retweeting as supporting human interaction. A retweet by a celebrity is an act of personal and public acknowledgment (Pennington, Hall, & Hutchinson, 2016) and creates a sense of intimacy for fans (Marwick & boyd, 2011). A retweet is also a conversational act. Users retweet to be part of the conversation, to express their agreement, and to signal that they are listening to or trying to curry favor with the person who tweeted (Boyd, Golder, & Lotan, 2010; Kwak, Lee, Park, & Moon, 2010; Metaxas et al., 2015; Seidel et al., 2016). Thus, retweeting can be a complex social calculation and a kind of signaling to either the original message sender, one’s audience, or both. If we accept retweeting as signaling, then we might think of it as similar to body language, like smiling at some and not at others.
Another set of affordances support embedding or referencing, thus making a tweet richer by including more information. In addition to the tweet text, users provide an information resource through URLs, photos, and videos.
Based on our reading of the literature, we think of these affordances as grouped into three logical categories: contextual (hashtags), interactional (@mentions, and retweets), and informational (text, URLs, videos, and photos). 1 Similar to the way that spoken words, tone of voice, and body language all work together to make the information rich in a face-to-face channel, we see our three affordance groupings working together as the information communicated. That is, the richness of a tweet is a product of the strategic combination of these groupings. While we note these dimensions are not perfect (e.g., a photo could help with context and a hashtag could be interactive), we believe that this breakdown reflects the literature above reasonably well. We expect that revealing the strategies employed by the celebrities will offer insights into the broad spectrum of media environments that they operate in and may shed light on how Twitter shapes celebrity practices in the age of social media.
Note that we will use the words “informational” and “information” differently: informational will refer to the grouping of affordances (text, URL, videos, and photos), while we will use “information” more broadly to include what is being communicated. Thus, we might refer to the information being communicated by the contextual affordance, or we might compare how different groups of actors use the informational affordance in combination with other affordances to inform (change understanding or reduce ambiguity) others.
Celebrities and Twitter
Celebrities have traditionally been the product of the promotions and publicity driven by media industries (Turner, 2013). Marshall (2006a) argues that the invasive lenses of mainstream media provide the public with the chance to see what celebrities are truly like outside of their constructed world through a system of representative individuals. One way to control their media persona in the face of media invasiveness is by employing layers of representation, for example, agents, managers, and publicists, who present a carefully “constructed personality” to the media, and thus the public (Turner, 2013).
Indeed, “celebrity management” is a highly controlled and regulated institutional model (Marwick & boyd, 2011). Marwick and boyd see celebrity “as an organic and ever-changing performative practice” (Marwick & boyd, 2011, p. 140) who needs to grow and maintain an audience. Marwick and boyd avoid referring to celebrity as what a person is and instead focus on the concept of celebrity as what a person does (Marwick, 2015; Marwick & boyd, 2011).
Social media have transformed the celebrity model from the “representative system” to “presentative system” (Marshall, 2014). That is, social media are presentational media employed by individuals to make and publish content that supports their presentation of the self to others. Senft (2008) defines these practices as “micro-celebrity.”
Micro-celebrity is a set of self-presentation techniques in which people construct and maintain a carefully crafted persona by publishing content (Abidin, 2014; Hearn, 2008), using strategic intimacy (Abidin, 2015; Senft, 2008), and regarding their audience as fans (Marwick & boyd, 2011; Mavroudis & Milne, 2016). Although celebrities still benefit from mainstream media attention, they are increasingly using social media sites for promotional discourses, to bypass the mainstream media, and to interact and communicate with the public directly (Marwick, 2013; Stever & Lawson, 2013; Ward, 2016). As a result, they have more control over the presentation of their persona and the relationship they have with fans (Turner, 2013). When it comes to Twitter, fans are given access to a celebrity’s personal life, directly interact with celebrities, and believe themselves to be a part of the network. Being a real-time updater, Twitter creates the sense of “being there” with celebrities and becomes an intimate form of communication for celebrity–fan relationships (Stever & Lawson, 2013).
In this work, we examine Twitter uses by celebrities in different cultural domains. As the promotional discourse in one domain is quite different from another (Turner, 2013), we expect to see differences in celebrity practices in different domains, and that these differences may be observable by comparing the richness scores of their tweets. For example, Marshall (2006b) contends that pop stars must be virtual members of their audience and maintain close and intimate relationships with them, while for sports stars, it is their private lives that attract greater public interest and thus maintain their celebrity status despite a decline in sporting achievements (Turner, 2013).
We also add another type of celebrity, scientist stars, whom we expect to provide a good point of comparison. Arguably, scientists are the most awkward fit into the definitions of celebrity, and yet, as scientists ourselves, we are aware of how we represent, and are expected to bring prestige to, our institutions. The traditional model of publish or perish has been augmented with tools (social media) that allow us to promote our work to our peers and the public. Thus, we suggest that some scientists have turned to micro-celebrity practices on social media to perform celebrity. Some research even considers some scientists as participating in celebrity culture as public intellectuals (Dahlgren, 2012; Nisbet, 2014), while others note that public intellectuals need to maintain scientific neutrality, be credible, and make public impact (Baert & Booth, 2012), suggesting that the ways they engage in self-promotion on Twitter might be both similar to and different from other types of celebrities.
Specifically, we examine how pop music, athlete, and scientist stars engage in self-promotion through Twitter. We expect that different celebrity types may tolerate ambiguity in some ways, while attempting to reduce it in others.
Pop Stars, Athletes, and Scientists on Twitter
Pop stars use Twitter to inform followers about products and performances (Stever & Lawson, 2013) by including URLs (Seidel et al., 2016). Many of the most popular celebrities, as measured by followers, appear to give their audience a candid and uncensored look into their lives (Bennett, 2014; Marwick & boyd, 2011). This apparent access is facilitated through the informational content of tweets (text, links, and photos), and by interacting with their followers. A study of Lady Gaga fans suggests that she tweets both public and private elements of her life while interacting with fans, sometimes in direct messages (Bennett, 2014).
Athletes use Twitter to interact with fans by asking questions or talking about their personal lives (Frederick, Lim, Clavio, Pedersen, & Burch, 2014), often more openly than they can when mediated by the mainstream media (Pegoraro, 2010). They provide commentary and opinions about sporting events that cultivate an insider perspective for fans (Kassing & Sanderson, 2010) and respond to fans’ queries (Pegoraro, 2010).
Scientist stars use Twitter to disseminate their ideas and knowledge on matters of public concern like climate change (Nisbet, 2014), both within scientific communities and with the public (Ogden, 2013). Studies have noticed the use of Twitter for promoting their work (Nisbet, 2014; Van Eperen & Marincola, 2011) by sharing and retweeting links to newly published works (Thelwall, Tsou, Weingart, Holmberg, & Haustein, 2013). Another important use is conference live-tweeting, where participants post tweets about the content of sessions. These tweets are situated, or contextualized, as part of the overall conference discussion by the inclusion of a hashtag (Darling et al., 2013; Ross, Terras, Warwick, & Welsh, 2011).
The literature suggests that celebrities use Twitter to inform and interact with their audiences, sometimes using hashtags to contextualize their messages. Also, there are differences in the ways celebrities emphasize some types of communication over others. That is, celebrities may use combinations of the three groupings of Twitter affordances mentioned above—informational, interactional, and contextual—in different ways.
The literature discussed above has not compared how different celebrity types have mixed affordances. Nor has it explored what such an analysis can tell us about the different information environments within which they operate. Our study addresses these aspects. Thus, our questions are as follows: RQ1—In what ways do celebrities utilize Twitter differently to perform celebrity? and RQ2—What can such an analysis tell us about the environments within which celebrities perform?
Method
To answer our questions, we extended a framework for assessing tweet quality, and employed inferential statistics to verify observed differences in celebrity types.
Twitter Data
We constructed three datasets by employing a toolkit (Hemsley, Ceskavich, & Tanupabrungsun, 2014) that collects tweets using a streaming API. The datasets comprise tweets from the top pop stars, athletes, and scientists who have achieved offline status and successfully made use of Twitter. The lists were curated by The Guardian (https://goo.gl/0cvSPS), Forbes (http://goo.gl/gXEtLV), and Science (http://goo.gl/hWlMq5). These lists used similar methodology: they constructed a list of celebrities within an associated context and sorted them by number of Twitter followers.
We chose the top 30 users from each list who were individuals, not bands, teams, or organizations that tweeted in English. We collected tweets from these accounts for 30 days (2 August 2016 to 3 October 2016; Table 1; Figure 1).
Descriptive Statistics of Tweet Frequency Per User.

SD: standard deviation.
Distribution of Tweet Counts by Users.
To give readers a sense of the collections, we note the first, 15th, and 30th person, and their follower count at the time of collection, for each dataset.
Pop stars: Justin Bieber (85M), Demetria Lovato (37M), and Pitbull (22M).
Athletes: Christiano Ronaldo (44M), Kevin Harvick (699k), and Mark Teixeira (327k).
Scientists: Neil deGrasse Tyson (2.4M), Oliver Sacks (76k), and Jerry Coyne (19k).
Analytical Methods
To examine differences in the tweeting behavior of politicians while running for office versus after holding office, Tanupabrungsun et al. (2016) developed a TQAF to measure four dimensions of tweet quality: contextual, interaction, informational, and an unweighted combination of the three dimensions for an overall quality score. The basic idea of this framework is the foundation for this study’s framework since their quality dimensions are similar to our affordance groupings.
The Tanupabrungsun et al. framework has a few important limitations. It does not include embedded content like videos and photos, and it treats each dimension and each affordance within dimensions as equivalent. For example, when calculating the interaction quality score, retweets, @mentions, and @replies are all weighted equally. Likewise, when calculating the overall tweet quality score, the contextual, interactional, and informational quality scores are all weighted the same. Early work in psychology, however, suggests that body language, tone of voice, and spoken words all have significantly different weightings in communicating meaning (Mehrabian & Ferris, 1967), which suggests that different affordances and dimensions should be weighted differently.
We therefore improved the Tanupabrungsun et al. framework in a few important ways. First, we weighted each of the individual affordances in each dimension differently. Likewise, when calculating an overall richness score, the affordance groupings are weighted differently. Second, we included embedded content (i.e., videos and photos). And, finally, we rooted the framework conceptually in Daft and Lengel’s (1986) media richness theory.
Our affordance and dimension weighting method uses a simple linear combination (equation (1)). Each of the affordances within a group is represented by vi and their corresponding weights with bi. For the overall score, the formula is the same, except vi represents the scores calculated for each of the three groups. As discussed below, the weights are found using crowdsourcing

It is important to note that each affordance is included in only one richness dimension, and that we assigned each affordance based on the literature discussed above. The 140-character limit restricts tweets from scoring high in all dimensions. We refer to this as a
We measure informational richness with tweet length, URLs, and embedded content (i.e., photos, videos, and GIFs). Tweet length reflects the idea that more text will generally be less ambiguous and more apt to promote understanding than less text. As such, longer tweet text is scored higher. Note that we remove URLs, #hashtags, @usernames, and retweet artifacts (RT @username:) before calculating tweet length to ensure we do not double-count the affordances.
Interactional richness is measured with @mentions, @replies, and retweets or quotes. While we can see the case for treating retweets as a form of information diffusion, we find the arguments of Seidel et al. (2016) and boyd et al. (2010)—characterizing retweeting as conversational acts that support human interaction—more compelling. This view is supported by our regression models, discussed in the next section. While a variable for retweet was not significant in the informational richness model, it was in the interactional model, suggesting the crowd felt that retweets fit better under interaction. Note that we did not count any @mentions after a retweet artifact. For a manual retweet like “@abc RT @def”: only @abc would be counted. Although manual retweets have been rare in recent years, we did find a few in our dataset (less than 5%).
Our measure of contextual richness is the number of hashtags. This is our sparsest measure, with only one variable. However, by its very nature, Twitter collapses context such that without hashtags all tweets appear to belong in the same space. Twitter, then, is not a context-rich environment by its very nature. In addition, users embrace hashtags to specify one or more contexts for their message.
Weighting Development
To weight each affordance’s contribution to its richness measure, we used a combination of annotation by crowdsourcing and regression, where the coefficients of the regression become our weights. We used the same process to find the contribution of each richness dimension to an overall richness measurement.
Annotation by Amazon Mechanical Turk (AMT)
From the total of 10,379 tweets, we created a 10% stratified tweets sample that was proportionally and randomly chosen from each type of celebrity. Each tweet was annotated by three AMT workers to achieve high reliability (Nowak & Rüger, 2010). Each task asked a worker to look at the tweet, imagine it was from a celebrity, and assess its richness four times: once for each richness dimension and once as an overall assessment.
They rated each measure as “high” if the tweet matched the definition:
High informational. “informative; easy to read and understand and could be a complete statement or be useful, or actionable”;
High interactional. “clear attempt to interact with others; may create a sense of approachability or acknowledge others”;
High contextual. “attempts to engage with an ongoing topic or discussion; could be related to current events, viral topics or memes.”
We specified that workers be located in the United States, with approval ratings higher than 90%. We performed a repeatability test (Blanco et al., 2011) to check if the labels from different pools of workers were consistent over time. We ran a second batch of annotation tasks using the same tweets, settings, and eligibility criteria, but used all new workers.
We used a “majority voting” technique to obtain the final labels and calculated inter-coder agreement for each dimension using Cohen’s Kappa, comparing the results from two batches. Although Cohen’s Kappa is typically used for assessing the agreement of two coders, we applied this to the final labels of our two batches to assess the consistency of the labeling over time (Nowak & Rüger, 2010). The coefficients of 0.77, 0.74, 0.72, and 0.81 for informational, interactional, contextual, and overall measure, show that the annotations from different pools of workers were consistent over time.
Regression Models
Given that our AMT results are dichotomous (high/low), we built three logistic regression models to find the weights for informational, interactional, and overall dimensions. A model is not needed for contextual richness since it includes only one variable (hashtag count).
Logistic regression models the relationships between a binary outcome and independent variables using maximum likelihood estimation to estimate the regression coefficients (Faraway, 2004). The model assumes a binary outcome (one for desired outcome), a sufficiently large sample (30 observations per predictor), and no multicollinearity (Pampel, 2000).
Our dependent variables are the final AMT labels (1 = high). The independent variables depend on the richness dimension being modeled. To obtain weighting factors for the richness functions, we exponentiated the coefficients to odds ratios, and scaled them 0–1. To test that our models do not suffer from multicollinearity, we verified that the variance inflation factor for each variable is below four (Faraway, 2004). We also tested the models for their goodness-of-fit using a chi-square likelihood ratio test. The low p-value indicates that our predictors explain the variations in the response significantly better than the null model.
Table 2 presents our informational model using the AMT answers to the informational richness question as the outcome, and tweet length, URL, and multimedia as predictors, all of which are statistically significant.
Informational Richness Model.
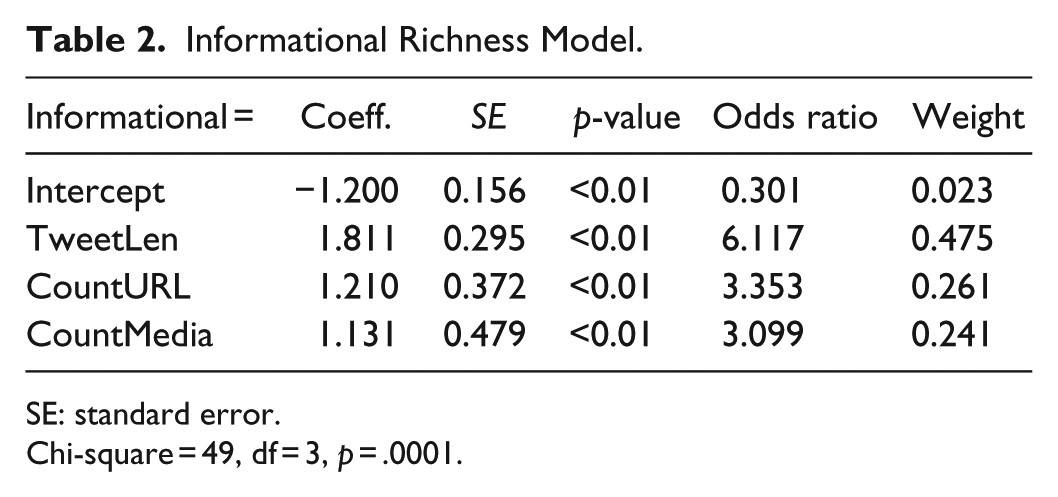
SE: standard error.
Chi-square = 49, df = 3, p = .0001.
The interactional model (Table 3) uses the AMT answers to the interactional question as the outcome, and @mention, @replies and retweets or quotes as the predictors. All but the intercept term are statistically significant. It is usually recommended to include the intercept term even though it is not significant unless the outcome is known to be entirely dependent of the predictors. Thus, its significance (or nonsignificance) is not substantial especially when we are interested in the relationships between dependent and independent variables not the intercept term (Faraway, 2004).
Interactional Richness Model (* Indicates a Nonsignificant Term).

SE: standard error.
Chi-square = 10.3, df = 2, p = .0058.
Table 4 presents the overall richness model uses AMT labels from the overall quality question as the outcome. The predictors are the AMT answers to the three richness dimensions. In this way, we find a weighted ranking of the richness dimensions that contribute to an overall richness assessment of a tweet, as per the AMT workers.
Overall Richness Model.

SE: standard error.
Chi-square = 309.8, df = 3, p = .0001.
Richness Score Functions
With the obtained weighting factors (Tables 2 to 4), our richness functions are as follows




We use the functions for calculating the richness scores in each dimension for each tweet. Finding richness scores for each tweet allows us to aggregate scores in different ways. We could have found the median richness scores of all tweets in each of the celebrity types. The unit of analysis would be at the celebrity group level. This flexibility is certainly a strength of the framework but suggests that researchers should think carefully about how different aggregations may lend themselves to a different unit of analysis.
In this work, the unit of analysis is at the celebrity level. That is, we group tweets by users, and find their central tendency scores. This allows us to compare not only the central tendencies of each celebrity group but also the variance within groups.
Findings
Since our richness scores are not normally distributed, we use the median score of each user, for each dimension (Table 5). Medians are typically used for robust inferential tests (Conover, 1971).
Central Measures of Richness Scores.

To test for differences across celebrity types, for each dimension, we perform a Kruskal–Wallis rank sum test (Conover, 1971), a nonparametric test of two or more samples. The test does not make assumptions about the distribution of data and can be regarded as a nonparametric version of analysis of variance (ANOVA) tests. When the shape and scale of the samples are similar, the null hypothesis is that the medians of all groups are identical; otherwise, the null hypothesis is that the samples are drawn from the same population.
The Kruskal–Wallis’s chi-square test statistic for informational scores is 9.61 (df = 2, p-value = .008), indicating a significant difference in informational scores across celebrity types. We performed two-sample Kolmogorov–Smirnov post hoc tests to identify where the difference lies. The null hypothesis for this test is that the two samples are drawn from the same continuous distribution (Conover, 1971). The tests show that the differences are from two pairs: scientists versus pop stars (p = .01) and scientists versus athletes (p = .03). These results suggest that scientists tended to create tweets with the highest informational scores, but there is no difference between pop stars and athletes.
For contextual richness scores, the Kruskal–Wallis test indicates a significant difference among celebrity types (chi-sq = 8.25, df = 2, p = .01). Our post hoc tests show no significant difference between pop stars and athletes, but scientists scored lower than pop stars (p = .00) and athletes (p = .03). The tests on interactional and overall richness scores indicate no significant difference among the celebrity types.
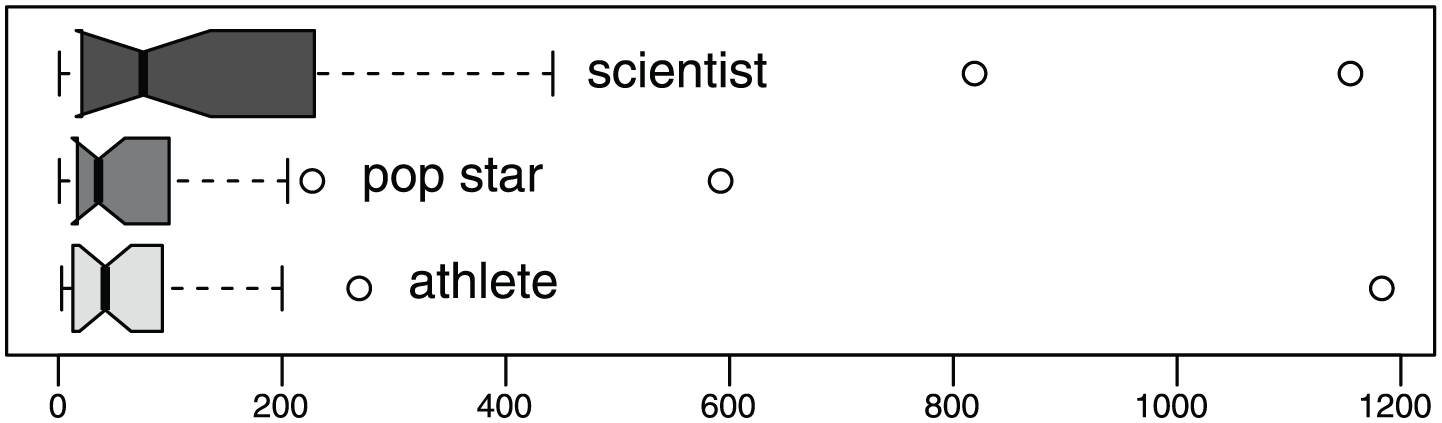
Figure 2 (and Table 5) shows that pop stars tend to have noticeably larger variances than others. Tighter variance in one group compared to other groups may suggest that celebrities within some groups have narrower ranges of tweeting behaviors. We use Fligner-Killeen, a robust nonparametric test for homogeneity of variance across two or more groups, based on the deviation from the median (Conover, 1971). The null hypothesis is that the variances are the same. While we did not find a variance difference for the informational dimension, we found that the variance of richness scores between celebrity types are different for interactional (p = .02), contextual (p = .001), and overall (p = .001) dimensions.

Distributions of richness scores by celebrity types. Each box is marked with the median (dark bar inside).
Discussion
Use of Twitter to Mediate Micro-Celebrity Practices
We organize Twitter’s affordances into three richness dimensions. Each dimension can potentially reduce ambiguity, or change understanding, in different ways. The 140-character limit means celebrities cannot create messages that are perfectly rich in all three dimensions simultaneously. When we considered this, along with Turner’s observation that different celebrity types employ different promotional discourses (Turner, 2013), we raised and answered RQ1, that different types of celebrities emphasized different richness dimensions. Such differences reflect the environments within which celebrities operate, and helped us answer RQ2 as discussed below.
While our scientists scored significantly higher than others in informational richness, they scored lower in contextual richness. This suggests that scientists place a higher priority in creating more complete, less ambiguous text, as indicated by tweet length, and distributing and promoting their (or other’s) work through the inclusion of URLs, than in setting multiple contexts for their messages (Ogden, 2013; Thelwall et al., 2013). This is interesting given the attention in the literature to academics’ live-tweeting during conferences (Darling et al., 2013; Ross et al., 2011), but it is easily explained when we note that most conferences use a single hashtag and that we are trained to know and focus on our specific audience. The priority may also reflect the fact that scientists gain prestige, in part, by being credible; our audiences may judge us more harshly for incomplete sentences, grammatical errors, and ambiguity than they would for other types of celebrities. Together this suggests that scientists operate in an environment that values message clarity and that some contextual ambiguity may be tolerated to achieve those goals.
Athletes and pop stars tend to have similar richness scores across richness dimensions. This reflects their similar, entertainment-centric environment. Both scored lower than scientists in informational richness, suggesting that they have more grammatical leeway within their co-constructed environments. That is, their audiences may forgive, or even expect, casual, short, or incomplete sentences rather than more formal and well-constructed ones. In addition, ambiguity within the informational dimension may actually benefit pop stars who may prefer and may even be skilled at allowing for multiple interpretations that fuel gossip (Marwick & boyd, 2011). Part of the explanation for the lower informational score is likely a result of these groups scoring higher in the contextual dimension. Turner argues that for pop stars to sustain their authenticity and fans’ commitment, they must be virtual members of their audiences (Turner, 2013). Thus, we expect that pop stars and athletes would be very clear about which audience their message is intended for. Being seen participating in many discussions supports the view that they are virtual members of an audience as well. Emphasizing multiple contexts also extends their reach to multiple audiences, which seems key in their performative practice of celebrity.
The literature suggests that one of the ways pop stars and athletes perform celebrity is through interaction on Twitter (Hambrick et al., 2010; Marwick & boyd, 2011). Thus, we would expect them to rank much higher in this dimension. The fact that pop stars and athletes did not score higher than scientists in this dimension does not suggest that interaction was not important to them. Rather, it could be the crowding-out effect due to the high contextual scores for these celebrity types. Specifically, the 140-character constraint means that when a user includes many hashtags, it will crowd out other types of richness. We also note that pop stars and athletes have significantly more followers than scientists. Prioritizing hashtags as a way of blending themselves into a community is probably a better way than interacting with fans individually.
Taken together, this suggests that pop stars and athletes may be skilled at performing a kind of personal interaction broadcast using casual sentence structure and hashtags to indicate inclusiveness. The differences in the audience scale may also suggest that different mixtures of richness are more effective at different environment scales.
When we turn to the overall richness scores, we did not find a significant difference in central tendencies. Since we saw differences in other dimensions, we see the similarity in overall scores as suggesting that celebrities are using an appropriate mixture of affordances best suited for their own media environments. This might suggest that although celebrities have different information needs depending on their environment, they adjust how they communicate to meet the constraints of the platform (Walther, 1992).
Delving deeper into the celebrity practices and environments, we looked at the variances of scores. We found a significant difference in interactional, contextual, and overall dimensions where the variances were higher for pop stars, indicating a broader range of tweet behavior. One explanation for this is that some celebrities see Twitter as an opportunity to bypass not only mainstream media but also their own image-management team (Turner, 2013).
This seems to apply less for athletes whose variances are lower than others in interactional and overall dimensions. We note that sports teams impose strict social media rules on players and have even started training seminars for rookies (Kanno-Youngs, 2015). Also, audiences may consider athletes to be role models and have certain behavioral expectations for them (Turner, 2013). Together, the expectations and social media training may manifest in athletes being risk averse, resulting in our observation of a semi-uniform usage of Twitter. Thus, the audiences’ levels of expectations and acceptance of celebrity behavior may be comparable, reflected by examining the variance in richness dimensions of our celebrity tweets.
Learning from Crowds
In the overall richness score, the informational richness dimension, which focuses on the quantity of information (text, URLs, and multimedia), is weighted the most at 0.44. The crowd indicated that length of text in tweet is the most important feature in this dimension, which makes sense given that more information should do a better job at reducing ambiguity.
The crowd weighted contextual richness, the frequency of hashtags, next at 0.30. Thus, the crowd sees context—for example, knowing the intended audience or relevant topic of a message—as the second most important dimension of richness. This is likely because users need context to correctly interpret a message, thereby reducing ambiguity.
The last grouping is interactional with a weight of 0.26. Half of the score is accounted by @mentions (and @replies). Retweets are slightly less valued, yet useful in promoting interactivity between celebrities and their fans.
This work has a few limitations. First, we cannot generalize beyond Twitter. Work similar to ours, but comparing activities on Facebook and Twitter, could provide insights about the differences in audiences, platforms, and celebrity performance. Our data collection covered one month and so may not capture yearly cyclic events or changes over a longer scale, though with our framework, such work would be possible. Our study is about comparing different groups of celebrities on Twitter and not about trying to understand the changing nature of celebrity as a cultural construct (a good source for this is Turner, 2013). Also, we do not control for the number of followers a celebrity has. This reflects a conscious choice: by adopting the perspective of celebrity as practice (Marwick & boyd, 2011), we eschew a process of selecting actors with more than some arbitrary number of followers. Rather, different celebrity types will operate in larger and smaller environments, which may be reflected in how they emphasize one dimension over another.
Conclusion
We extended Tanupabrungsun et al.’s (2016) framework with the theoretical perspective of media richness, crowd work, and regression models. Using the framework, we suggest that the activities needed to achieve the goals of gaining and maintaining an audience (Turner, 2013) differ by celebrity groups, who operate in environments that are co-constructed by the celebrities, fans, and tools, like Twitter, that mediate their practices.
We expect this framework will provide a way for researchers to compare actors in different contexts, for example, politicians, CEOs, and activists. Researchers studying social movements may find that the successful activist groups use messages richer in some dimensions than others. Another fruitful area may be looking at how the emphasis on various richness dimensions by actors may change over time and whether or not such changes are predictive of changing markets or social conditions.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.