
Abstract
Introduction
Soft-robotic gloves have been developed to enhance grip to support stroke patients during daily life tasks. Studies showed that users perform tasks faster without the glove as compared to with the glove. It was investigated whether it is possible to detect grasp intention earlier than using force sensors to enhance the performance of the glove.
Methods
This was studied by distinguishing reach-to-grasp movements from reach movements without the intention to grasp, using minimal inertial sensing and machine learning. Both single-user and multi-user support vector machine classifiers were investigated. Data were gathered during an experiment with healthy subjects, in which they were asked to perform grasp and reach movements.
Results
Experimental results show a mean accuracy of 98.2% for single-user and of 91.4% for multi-user classification, both using only two sensors: one on the hand and one on the middle finger. Furthermore, it was found that using only 40% of the trial length, an accuracy of 85.3% was achieved, which would allow for an earlier prediction of grasp during the reach movement by 1200 ms.
Conclusions
Based on these promising results, further research will be done to investigate the possibility to use classification of the movements in stroke patients.
Keywords
Introduction
Motor impairment of the upper extremities due to stroke results in limited performance of daily life tasks. Worldwide, there are 62 million stroke survivors, 1 of which 77% suffer from upper limb motor deficits. 2 From this group, at least 60% failed to incorporate the affected hand in their daily life. 3 One of the major limiting factors is that they experience difficulties with grasping objects, due to muscle weaknesses, atypical muscle synergies, and spasticity. 4 Task-oriented therapy shows great benefits for regaining function in the affected hand, as compared to other physical therapies.5,6 To support the patients' grasp at home, several soft-robotic gloves have been developed to enhance grip, such as the SEM™ Glove (Soft Extra Muscle Glove) from Bioservo Technologies AB. Using force sensors, it detects when the user grasps an object, which subsequently activates the grasp support.7,8
A study on the feasibility of the ironHand (a soft-robotic glove based on the concept of the SEM™ Glove) has shown that a mean System Usability Score of 70.1% was achieved, 9 which indicates a good probability for acceptance by the users. However, the study also showed that the subjects performed tasks significantly faster without the glove as compared to with the glove, 10 since the glove detects the intention to grasp using interface force sensors, which allows grasp detection not earlier than the moment at which an object is actually touched. These findings are in line with the study of Polygerinos et al. 11 with an EMG controlled soft-robotic glove. To further enhance the performance of daily life tasks of the users while using a soft-robotic glove, it could be of interest to detect the intention to grasp an object as early as possible, e.g. using inertial sensing. In case the intention to grasp is detected earlier than using the force sensors, the support could be activated earlier, which might result in improved performance.
Several studies have been done to detect grasp intention in healthy subjects.12–16 These studies investigated whether it was possible to detect and predict the final hand posture as early as possible. Using position data from bend sensors and pressure sensors, De Souza et al. 12 achieved a recognition rate of 87% with multiple subjects. Heumer et al. 13 showed that a highly reliable recognition of grasp types can be achieved using bend sensors, if the user of the data glove trains the classifier (single-user classification); a reasonably good recognition was achieved for users who were not among those who trained the classifier (multi-user classification). Ekvall and Kragic 16 showed that the positions of the fingertips are very important to predict the final hand posture, as well as the roll angle and roll angle velocity of the hand. Furthermore, they showed that their method recognized the final hand postures with a 95% accuracy at 60% of grasp completion (the moment the subject touches the object), for a single-user model. For a multi-user model, the model performed optimally at 80% of grasp completion, with an accuracy of 65%. Naish et al. 15 used electromagnetic sensors in combination with electromyography to study the difference between grasp-to-eat and grasp-to-place movements. They showed that there were significant differences between the movements in timing of peak acceleration of thumb, index finger, and wrist.
These studies show promising results regarding grasp recognition using classification methods. However, to detect grasp intention before it can be detected by interface force sensors, the algorithm should be able to distinguish a reach-to-grasp movement from a reach movement. None of the above studies investigated whether they could distinguish a reach-to-grasp movement from a reach movement without grasp (e.g. pointing at something or waving). All studies only included reach-to-grasp movements with different kinds of grasps in their experiments. Therefore, an experiment should be done containing both movements. In addition, all studies used multiple sensors to detect the grasp intention. However, it is of interest to investigate the minimal number of sensors needed to accurately distinguish between the two movements: the fewer sensors are needed, the more robust the system will be for application and the easier and cheaper it is to implement the sensors in soft-robotic gloves. It was hypothesized that a minimal number of sensors could be achieved by detecting reach-to-grasp movements using hand opening and closing or flexion and extension of the wrist. This was measured using the relative angular velocity of the fingers and forearm with respect to the hand respectively.
Hence, the goal of this study was to investigate the best sensor combination for the classification of reach-to-grasp and reach movements without the intention to grasp, based on tracking of hand and finger movement using inertial sensing. Subsequently, it was investigated whether it was possible to predict the intention to grasp during reach movements. Both single-user and multi-user classification were studied using support vector machine (SVM) classifiers.
Methods
Subjects
Sixteen healthy subjects were recruited for the experiment (6 male, 10 female; age: 24.78 ± 7.3 years; all dominant right-handed). Subjects met the following inclusion criteria: (1) the subject should be at least 18 years old; (2) be healthy with full arm function intact; and (3) be dominant right-handed. Exclusion criteria were: (1) motor impairment; and (2) wounds or other limiting factors on the hand for applying the sensors or the glove or while performing the tasks. All subjects provided informed consent prior to the start of the experiment. Ethical clearance was obtained from a local ethics committee.
Instrumentation
The angular velocities of the hand segments were measured using an inertial measurement system,
17
with inertial measurement units (IMUs) placed on phalanges of the fingers, thumb, dorsal side of the hand and distal end of the arm (see Figure 1). The sensors' placings chosen to be analysed to detect flexion and extension of the fingers were the distal phalanges of the thumb, index finger, and middle finger, and the dorsal side of the hand. To detect flexion and extension of the wrist, an additional sensor was placed on the distal end of the forearm on the dorsal side, next to the ulnar styloid process.
Instrumentation of the experiment. The SEM™ Glove is the soft-robotic glove worn by the subject. The white sensors are the IMUs.
Next to the IMUs, the SEM™ Glove from Bioservo Technologies AB7,8 (see Figure 1) was used. The SEM™ Glove records the time at which the force sensors detect that the user grasps objects.
Set-up
The table was prepared by taping the directions of five horizontal locations (0°, 45°, 90°, 135°, and 180°). The distances of the locations were determined using the reaching range of motion of the subject. The initial hand position was located in the middle of the semicircle, at the edge of the table, with the elbow flexed to 90° and held close to the body. See Figure 2 for a schematic of the set-up.
Task locations for the experiment. The subject is seated with his right hand in the middle of the circle.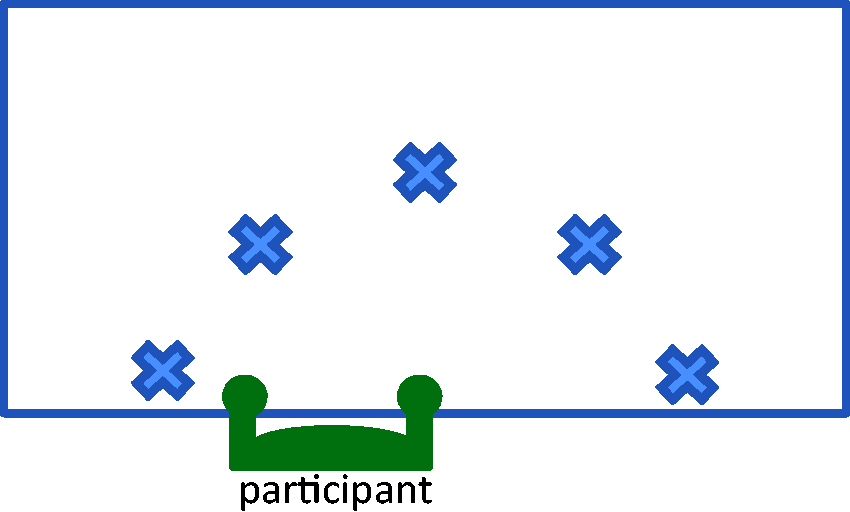
Protocol
The experiment was started with performing exercises for the sensor-to-segment calibration (as described in the next section). Then, the subjects were verbally instructed to perform four different tasks towards one of the five locations: (1) grasp a bottle of water (2) grasp a tennis ball; (3) reach to hold the hand above location with the palmar side of the hand facing downward towards the table; and (4) reach while supinating the arm to hold the hand above location with the dorsal side of the hand facing downward towards the table. The grasp-related tasks represent the two most common grasps in stroke patients: cylindrical and spherical grasps 18 ; the reach-related tasks closely resemble the grasp-related tasks, with respect to the direction of movement and the rotation of the lower arm. The tasks were performed six times for each location. Besides, all tasks were performed for two different initial hand postures, i.e. (1) opened hand, resting on the table with the palmar side of the hand facing down; and (2) a fist, resting on the table with the medial side of the hand facing down. In total, the subject performed 120 grasp and 120 reach movements. The order of the tasks was randomised, as well as the order of the initial hand posture and the locations.
Sensor-to-segment calibration
Each experiment started with a sensor-to-segment calibration as described by Luinge et al., 19 in order to estimate the anatomical rotation axes. For the calibration, the subject was asked to perform the following tasks: (1) to stand upright with the elbow of the right arm flexed in 90° and the dorsal side of the hand facing upwards, (2) to flex and extend the fingers, (3) abduct and adduct the fingers and thumb, (4) flex and extend the thumb, (5) flex and extend the wrist, (6) adduct and abduct the wrist, and (7) to flex and extend the elbow. The coordinate systems of all segments are defined according to the coordinate system of the whole body when in anatomical position, i.e. the x-axis is defined to be the anterior-posterior axis pointing forward, the y-axis is the medial-lateral axis pointing to the right, and the z-axis is the vertical axis pointing down. The x-axis represents the movements abduction and adduction; the y-axis flexion and extension; and the z-axis supination and pronation. The direction of the y-axis was determined using the direction of the angular velocity during flexion (second task for the fingers, fourth task for the thumb, fifth task for the dorsal side of the hand, and seventh task for the lower arm); the direction of the x-axis was determined by measuring the direction of gravity while standing upright with the elbow flexed to 90° (first task); the direction of the z-axis was determined using the cross-product of the direction of the x- and y-axis. To make the system orthogonal, the direction of the x-axis was recomputed using the cross-product of the y-axis and the z-axis. Using the rotation matrices containing the three unit vectors of the segments, the data from the gyroscopes measured in the IMU coordinate systems were rotated to the coordinate systems of the body segments. 19
Data analysis
Pre-processing
The data from the gyroscopes and the SEM™ Glove were pre-processed by removing the bias. The bias of the sensors was removed by manually selecting a baseline at the beginning of the recording, in which there is no movement of the hand and no force on the SEM™ Glove force sensors. The data from the IMUs were then filtered with a 4th order, zero-lag, low pass Butterworth filter with a cut-off frequency of 6 Hz.20,21
Classification
Two discrete classes were defined for the classification: Grasp and Reach. Since an SVM classifier is able to find patterns in high dimensional, nonlinearly separable data and since it is very accurate for classification of exactly two classes, the SVM classifier was used for classification of the data.22,23 Classification was done for both single-user and multi-user scenarios. In case of a single-user classifier, the classifier was trained and tested by the same subject. In case of a multi-user classifier, the classifier was trained by all subjects except one and tested by the subject excluded from the training set. The SVM classifiers were trained using 10-fold cross-validation. Six kernels were investigated: the Linear kernel, Quadratic kernel, Cubic kernel, Fine Gaussian kernel, Medium Gaussian kernel and the Coarse Gaussian kernel. The accuracy of all kernels was investigated for five subjects for both single-user and multi-user classification, after which the best kernel was selected for further analysis with all subjects.
Database
The data from the gyroscopes were cut into small pieces, which are called ‘trials’. One trial contains the data from the moment the subject starts performing one of the tasks, until the moment that the subject either grasps the object, or reaches the location for the reach-related tasks. The beginning and end of the trials were found using a threshold detector algorithm for the angular velocity, with a threshold of ± 0.1 rad/s. In case of the grasp-related tasks, the end of the trial was considered the moment the SEM™ Glove detected the grasp. The data were cut into 240 trials per subject.
After selecting the trials for data analysis, the resulting database was subdivided into a training set and a test set. The minimum number of trials needed to train the classifier accurately was 70, as examined using a learning curve 24 from data obtained during a trial prior to this experiment. Two different types of databases were created: for single-user and for multi-user classification.
Single-user database
From both the grasp and reach trials, 25% was randomly selected for the test set. Hence, the test set consisted of 60 trials (30 grasp, 30 reach) and the training set consisted of 180 trials (90 grasp, 90 reach).
Multi-user database
The database for multi-user classification consisted of the trials of one subject in the test set, and the trials of the remaining subjects
Feature extraction
To easily detect flexion and extension of the fingers and wrist, all segment movements were expressed with respect to the dorsal side of the hand. This was done using the norm of the angular velocity vectors and using the relative angular velocity of the segments. The norm of the angular velocity vector defines the movement of segment a with respect to the dorsal side of the hand (
For all trials, the mean and standard deviation (SD) were determined for the norm of the angular velocity vectors and for the relative angular velocities. These features were used as input for the SVM classifier. In total, 8 features were extracted from the trials based on the norm of the angular velocity vectors of the segments (4 segments × 2 (mean and SD)); and 24 features were extracted based on the relative angular velocity of the segments (4 segments × 3 directions (x, y, and z) × 2 (mean and SD)).
Feature selection
Combinations of features used to train SVM classifiers.
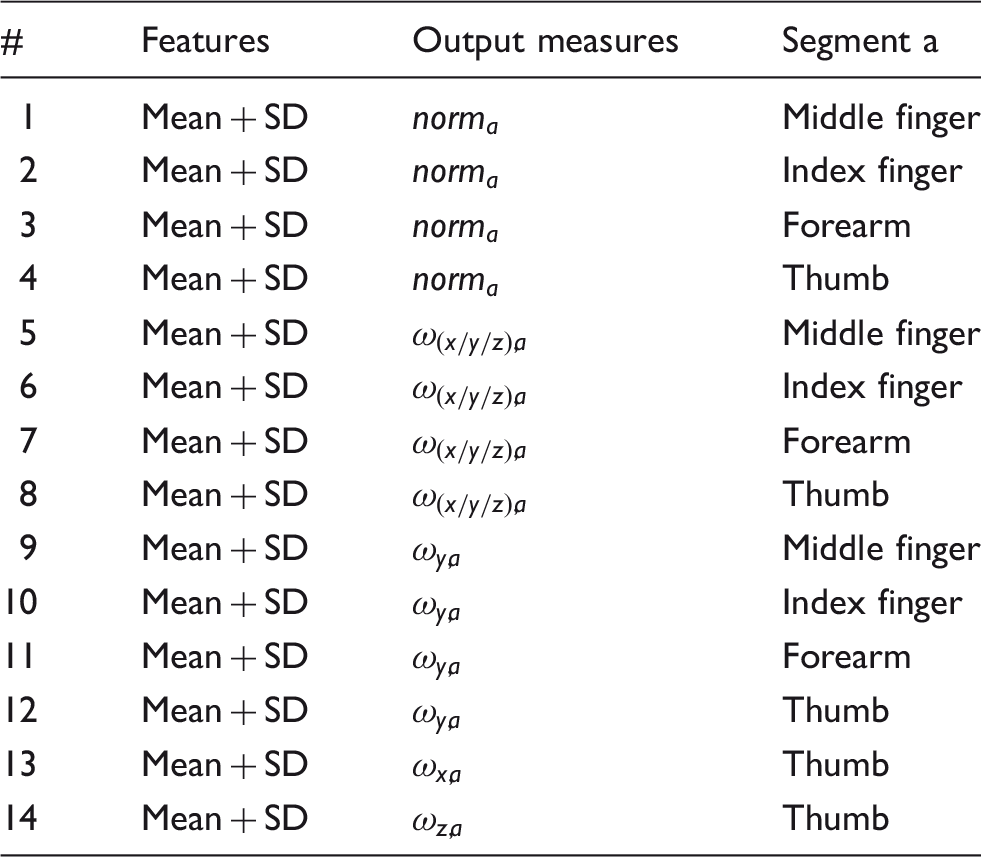
Note: In total, the SVM classifiers were trained for 14 different combinations of features.
SVM: support vector machine; SD: standard deviation.
The training of all 14 combinations was done for five (test) subjects for both single-user and multi-user classification, after which the two best combinations were selected for further analysis with all subjects. The selection of the best features and SVM classifier was based on the accuracy of the classifier, visual inspection of the scatter plots of the features, the ROC-curve of the classifier (showing sensitivity relative to specificity), and the training and prediction speed of the classifier.
Grasp intention detection
In order to investigate whether it was possible to predict the intention to grasp during reach movements (second goal of this study), the influence of selecting only a certain part (%) of the signal for both training and testing of the classifier on the accuracy of the classifier was analysed. This was investigated using the data sets for single-user classification. The part of the signal selected for training and testing (e.g. a classifier trained using 30% of the trial length was tested on a test set with also 30% of the trial length) is from the beginning of the trial until a certain percentage of the original trial length.
Results
Subjects
Due to hardware mall function, five subjects were excluded from data analysis. Therefore, the data of 11 subjects were analysed (4 male, 7 female; age: 25.7 ± 8.6 years; all dominant right-handed).
Kernel and feature selection
Based on visual inspection of the scatter plots of the features (for an example, see Figure 3) and on the accuracies of the SVM classifiers after cross-validation (see Figures 4 and 5), the two best feature combinations were selected: the mean and SD of the relative angular velocity about the anatomical x-, y-, and z-axis middle finger and index finger (combination 5 and 6, respectively, as listed in Table 1). The x-axis represents ab- and adduction, the y-axis flexion and extension, and the z-axis pronation and supination.
Scatter plot of the features mean and SD of the relative angular velocity about the anatomical y-axis of the middle finger. The y-axis represents flexion and extension. Boxplot showing the accuracies of single-user SVM classifiers for all feature combinations. The SVM classifiers were trained using six different kernels for each feature combination. The numbers representing feature combinations correspond with the numbers in Table 1. SVM: support vector machine. Boxplot showing the accuracies of multi-user SVM classifiers for all feature combinations. The SVM classifiers were trained using six different kernels for each feature combination. The numbers representing feature combinations correspond with the numbers in Table 1. SVM: support vector machine.


Mean kernel performance for single-user classification of the top two feature combinations.

Mean kernel performance for multi-user classification of the top two feature combinations.

Classification single-user
Accuracy of classifier predictions for single-user and multi-user classifiers.

Note: The single-user classifiers were trained using a training set of 180 trials and a test set of 60 trials. The multi-user classifiers were trained using a training set of 2400 trials from 10 subjects and a test set of 240 trials.
Classification multi-user
Table 4 also shows the accuracy of classifier predictions for the two best multi-user classifiers. The highest mean accuracy of 91.4% was achieved using a Fine Gaussian SVM classifier, with the features mean and SD of the relative angular velocity of the middle finger about the anatomic al x-, y-, and z-axis. The mean training speed is 2.2 s and the mean prediction speed is 34,000 observations/s. The next best feature for multi-user classifier is the relative angular velocity of the index finger about the anatomical x-, y-, and z-axis, with an accuracy of 91.2%.
Grasp intention detection
Accuracy of classifier predictions for only a part of the signal for single-user classifiers.

Note: The SVM classifier was trained using a training set of 180 trials, a Cubic kernel, and 10-fold cross-validation. The features used for training were the mean and SD of the relative angular velocity of all anatomical axes of the middle finger. The trials used for training contained only a part (%) of the original trial. The trained classifiers were tested on a test set containing the corresponding part of the trials.
Discussion
The results of the experiment clearly show that it is possible to distinguish reach-to-grasp from reach movements without the intention to grasp using machine learning. High accuracies were achieved for both single-user (98.2%) and multi-user classification (91.4%) using only two sensors: one on the dorsal side of the hand and one on the distal phalange of the middle finger. Compared to related work, the results are very promising: the single-user classifier achieved a similar accuracy than found by Heumer et al. 13 and the multi-user classifiers achieved a higher accuracy than found by De Souza et al. 12 and Heumer et al. 13 The performance of the multi-user classifier could be enhanced by scaling the features to for example the maximum velocity used by the user. Since every user uses a different velocity for opening the hand, it could be easier to distinguish the two classes Grasp and Reach using feature scaling in case of multi-user classification.
The results for grasp intention detection, as investigated using only a part of the trials, are very promising for the development of a real-time grasp intention algorithm. The detection is 600 to 1200 ms earlier with an accuracy of 90.6% and 85.3%, respectively. Hence, depending on the accuracy that is preferred to achieve, the IMU sensors can distinguish the movements much earlier than the force sensors detect the grasp. This is essential in order to improve grasp-supporting devices, such as the SEM™ Glove, since at this point in time, it takes longer to grasp with the supporting glove as compared to without the glove. A trade-off must be made between the preferred accuracy, and the preferred time between the prediction and the actual grasping of the object.
When developing the real-time grasp intention algorithm, the method used to filter the signal should be changed compared to the method used in this study. Since the data were filtered off-line, it was possible to filter the data zero-lag. However, this is not possible in real-time detection. Therefore, a latency will be introduced by the filter. How big the latency will be, depends on the filter and window used.
As an alternative for classification using machine learning, it could be of interest to look at a threshold detector in combination with a matched filter for real-time detection. Using a matched filter, it is possible to analyse the signal over time, which could hold very useful information. This information is not used in the machine learning methods that have been evaluated in the current study.
During training of the SVM classifiers, it was found that the accuracy differs extremely when different kernels are used. Since it is preferred to define one SVM classifier to be trained, an optimal combination of kernel and features was found which resulted on average in the highest accuracy. Hence, it could be that there are better performing SVM classifiers for single-users than the average best classifier. Therefore, when using single-user machine learning to detect grasp intention, it could be considered to find the best kernel for each user to enhance the performance of the system. The same yields for the features needed to predict grasp. For some users, the anatomical y-axis (representing flexion and extension) performs better than combining all three anatomical axes. In all cases, the features regarding the relative angular velocities of segments as determined using the sensor-to-segment calibration performed better than using the norm of the angular velocity vector.
Next to the kernel and features, the performance of the algorithm can be improved by personalising the trade-off between sensitivity and specificity. Someone that uses his hand most of the time to grasp something would benefit from a high sensitivity in order to detect every grasp. Whereas if someone still moves his hand a lot while for example talking, the person would benefit from a higher specificity, since it would be irritating to continuously make a fist of your hand while moving your hand around. The system would be even more improved if it possible to set the sensitivity and specificity according to the activity the user would like to perform.
For application of the grasp intention detection in wearable soft-robotic devices for support of hand function for people with hand limitations, it is needed to repeat this research with the target population. Since the degree of disability differs per patient, it could be that a multi-user classifier is not an option, despite the results of this research. In that case, it would be interesting to define the number of trials needed for training to see whether it is feasible to use single-user classifiers for this application.
Conclusion
In conclusion, both single-user and multi-user classifiers achieve high accuracies (98.2% and 91.4% respectively) in distinguishing reach-to-grasp from reach-without-grasp movements in healthy subjects. Promising results were found for the detection of grasp intention. At 70% sample length, an accuracy of 90.6% was achieved; at 40% sample length, an accuracy of 85.3% was achieved. These findings allow for a faster detection of grasp by 600 ms to 1200 ms (depending on the preferred accuracy). When similar results are achieved with this method in stroke patients, two IMU's could be used to control grasp-supporting devices to support hand function during daily life activities.
Footnotes
Acknowledgements
We would like to thank Bioservo and Marcel Weusthof for their assistance and guidance in this research.