
Abstract
Defects in product packaging are one of the key factors that affect product sales. Traditional defect detection depends primarily on artificial vision detection. With the rapid development of machine vision, image processing, pattern recognition, and other technologies, industrial automation detection has become an inevitable trend because machine vision technology can greatly improve accuracy and efficiency; therefore, it is of great practical value to study automatic detection technology of the surface defects encountered in packaging boxes. In this study, machine vision and machine learning were combined to examine a surface defect detection method based on support vector machine where defective products are eliminated by a sorting robot system. After testing, the support vector machine training model using radial basis function kernel detects three kinds of defects at the same time under the ideal condition of parameter selection, and the effective detection rate is 98.0296%.
Introduction
The printing quality of the packing box can improve customer recognition of a product. In the process of printing packing boxes, defects are often caused by the printing process and mechanical precision, which cause defective products. The common surface defects include pattern shift, cracks, blur, color spots, uneven edges, and so forth. In order to effectively improve the quality of the box, the manufacturer needs to test the packing box and try to remove every unqualified products during the production process. Traditional visual inspection and quality control are done by professional inspectors through manual inspection to eliminate unqualified products. However, in addition to the slow speed, low detection efficiency, a large number of man-hours, and material and site resources, manual inspection has the following shortcomings:
Long repeated labor causes the human eye to become fatigued, which leads to poor detection.
A unified quality standard cannot be guaranteed. Manual inspection, different people, and even the same person in different conditions make it difficult to achieve a unified judgment standard.
Environmental factors such as light and temperature can also affect the vision of the inspector.
Machine vision primarily relies on computers to simulate human visual function, extract information from objective objects, process and understand it, and ultimately use the information for actual detection, measurement, and control. Machine vision technology provides a good solution for the automatic detection of packaging defects. Compared to the printing quality detection and the traditional manual method, fast detection speed, and high accuracy, results are objective, can quickly and accurately detect the appearance of defects of the packing box, and provide a comprehensive analysis of the defect parameters, so as to judge whether or not the packing box is qualified or defective.
This paper introduces a product packaging box defect detection method combining image processing technology and support vector machine (SVM).1–4 Based on image processing technology and machine learning, it can detect defects and enhance the adaptability of product detection. In this study, a large number of samples used in this method, and the detection time and success rate, were counted. The results showed that the detection method using machine learning has a relative improvement in the rate of correctness and speed compared with the traditional pattern recognition technology.
The detection principle of the surface defect of the packing box based on SVM
Analysis of the common packing box surface defects
The surface defects of the packing box are caused primarily by the printing quality. According to the analysis of the factors that influence print quality, the defects are generally divided into two categories: shape defects and color defects.
Shape defect is mainly represented by distortion of shape feature. Color defects focus on color features such as color shadows. In most of the available image quality detection, some are suitable for evaluating the quality of the image. These tests include point quality, line quality, text quality, color quality, and super range spray.
The common printing defects can be divided into the following categories:
The area is relatively small, but the pixel value of RGB has great difference of point defects, such as printing, ink flying, stain, and particular character stencil.
The lateral and vertical migration of the image and the offset in all directions such as the inaccuracy of the printing and the walking plate, etc. will cause offset defects.
A wide range of image defects, such as paste version, dirty version, and ink that is too shallow or too heavy will cause defects in printing a large area.
The principle of defect recognition based on SVM
General process
From the original image to the accurate identification of defects, quality is divided into two parts: identification of the types of defects based on the basic image processing technology and the use of SVM training set to match the results to improve recognition speed and accuracy.
The overall process of defect identification is shown in Figure 1. In the first part, only the basic image processing technology is used without any machine learning algorithm (hereinafter referred to as “traditional image processing”), and the detection image of the input system is “grayscale processing,” which improves the efficiency of the system program and retains most of the original features of the image; the next step is to binarize the image and recognize it according to the set threshold. The remaining images of blurred and speckled defective samples are either “image displacement” or “qualified.” In this system, “Sobel edge detection” 5 and “image subtraction method” 6 are used to calculate the difference threshold between the detected image and template image. If the difference threshold is greater than the predetermined threshold, it is determined as “image displacement,” and if the difference threshold is smaller, it is determined as “qualified product.” At this time, the defect degree of the image can be determined, and the current recognition results can be classified into “SVM training samples.”

Blur.
In the SVM part, another program runs in the free time set by the system and trains all the collected samples with SVM. After the training is completed, it updates the XML training file, so that the system has a better “knowledge base” to judge defects.
In order to make the system adaptable to different scenes, including the change of illumination conditions or the change of the sample box, it is not necessary to rely on the specified threshold to determine the specific defect type. The system added the “SVM training machine” to help the basic image processing technology achieve a more accurate judgment. SVM training function is automatically classified through the nuclear mechanism. With the increase of the number of samples, the accuracy rate of automatic classification is improved, which is more convenient and easy to control than the above statistical threshold and difference points.
The features of SVM
Compared with traditional pattern recognition, the biggest difference in SVM is that it is an automatic learning feature from large data, rather than a pre-set feature. In the past decades, pre-set features were dominant in various applications of pattern recognition that relied mainly on the experiential knowledge of designers, which made it difficult to make use of the advantages of big data. Due to the manual adjustment of parameters, only a small number of fixed parameters are allowed in the setting of features. The advantage of SVM is obvious—the large data can contain tens of millions of parameters, which are widely used to train data in hundreds of thousands and millions of levels.
SVM is used for image processing with the following features:
Nonlinear mapping is the theoretical basis of the SVM method, and SVM uses the inner product kernel function to replace the nonlinear mapping to the high-dimensional space.
The optimal hyperplane for dividing the feature space is the target of SVM, and the maximum classification marginal thought is the core of the SVM method.
The support vector is the training result of SVM is the decisive factor in the SVM classification decision.
SVM is a novel method of small sample learning with a solid theoretical basis. It does not involve the probability measure and the law of large numbers, so it is different from the existing statistical methods. In essence, it avoids the traditional process from generalization to deduction, and achieves efficient transduction inference from training samples to prediction samples, which greatly simplifies the classification and regression problems.
The final decision function of SVM is only determined by a few support vectors. The complexity of computation depends on the number of support vectors rather than the dimension of the sample space.
A few support vectors determine the final result, which not only helps us grasp the key samples and eliminate a large number of redundant samples but also doomed the algorithm to be simple and robust. This “robustness” is mainly reflected in the following: The addition or deletion of support vector samples has no effect on the model. The support vector sample set has a certain robustness. In some successful applications, the SVM method is insensitive to the selection of the core.
Constructing a multi-classification SVM classifier
The steps of the multi-class SVM classification algorithm are as follows:
Feature extraction of the original image: the original image is de-noised and background color is processed, and then its feature points are extracted.
The training sample set is constructed, the appropriate SVM parameters are selected by the data of the training sample set, and the model of SVM is created.
The selection method of the kernel function of the SVM is studied, and the SVM with superior performance is finally obtained.
The test samples are tested and analyzed.
In order to detect surface defects, we first use the same type (size) of different defect image samples to train SVM models so as to construct a multi-class SVM classifier.
1. Structural training samples
First, we use the defect detection system to collect and store the three kinds of package defects, such as stain, blur, and shift, and collect 100 images as the training samples used in the experiment.
In order to construct the SVM training model, the specific data in Table 1, our team was trained in the acquisition of nearly 12,000 images in real production, including about 4800 defect image, image shift, spots, each blur defect type 1600, detection of qualified products 19,124 images. The training time is 204 h.
Training sample data.

2. Extraction of characteristic parameters
Considering the real-time requirement of the online surface defect detection system, the strategy of monolayer adaptive image decomposition is adopted. The sub-image decomposed by a single layer adaptive image is a component image of 1/4 sizes, with a total of four pieces. The four sub-images are low-frequency components, horizontal components, vertical components, and diagonal quantum images, respectively, while the information of defects is mainly retained in horizontal components and vertical components. We use the average value of each element, the standard deviation, and the maximum difference as the characteristic parameters to compare the energy so as to determine whether there is a defect in the image.
As for the detection and classification of packing box containing surface defects, we use Gray-Level Co-occurrence Matrix (GLCM) feature extraction of surface texture, selection of contrast, correlation, energy, and local homogeneity as the input of the classifier SVM.
Among them, GLCM is in a correlation through statistics of gray relation in the same position for such a texture feature extraction method of texture analysis. The method includes image comprehensive information on the direction, the local neighborhood, and the change range of gray distribution, and can also describe the two order statistics of the image gray.
In random texture surface defect detection, the performance of GLCM is better than that of gray-level histograms, autocorrelation method, and local binary pattern (LBP).
Contrast, correlation, energy, and local homogeneity are calculated as shown in the following formulas
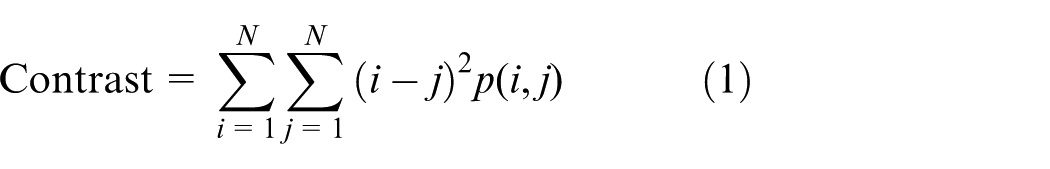
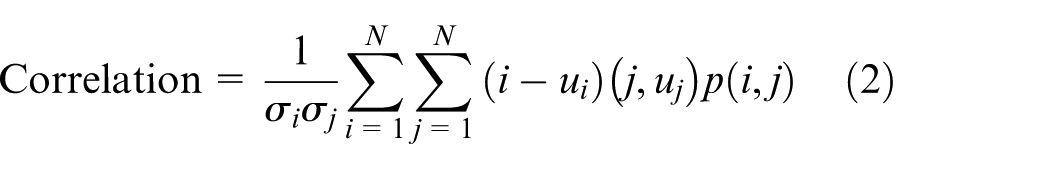

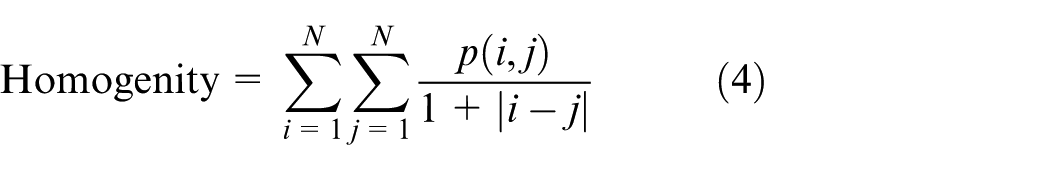
In equations (1) to (4), p(i, j) is a grayscale symbiotic matrix;
3. Definition of kernel function and related parameters
The primary advantage of SVM is to transform the linear inseparable problem in the low-dimensional input space into the linear separable problem in the high-dimensional attribute space by introducing kernel function, which greatly improves the nonlinear processing ability of the SVM.
Each vector high-dimensional space in the inner product operation is handled by the kernel function in the input space; basically, there is no need to understand the specific nonlinear mapping; there are no more complicated calculation of the mapped samples in the high-dimensional attribute space, which is to say that after rising, dimension changes only the inner product operation that does not increase the complexity of the algorithm.
At present, the most commonly used kernel functions are linear kernel function, P-order polynomial kernel function, multilayer perceptron kernel function (sigmoid), and radial basis function (RBF) kernel. Each of these kernel functions has its own advantage, but RBF kernel function was more suitable for the classifier in this study. In this paper, RBF is used as the kernel function of SVM classifier. RBF is defined as follows
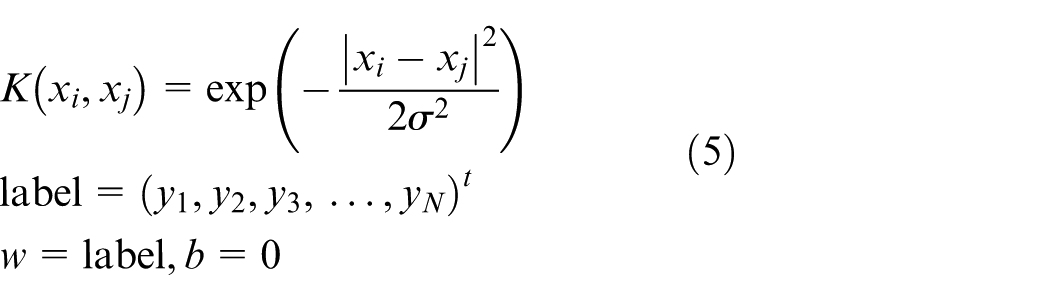
The RBF kernel function without number of polynomial kernel function, so it was a relatively simple model selection. Model selection and polynomial kernel function are relatively complex; the linear kernel function cannot deal with the nonlinear classification problem, and the RBF kernel function can be treated and can handle linear classification problems. The most special is that the linear kernel function is the special case of RBF, and with the same performance of Sigmoid kernel function and RBF kernel function in the selection of some specific parameters.
Vapnik and other scholars have shown that the selection of parameters (C, γ) directly affects the performance of the SVM classifier.8–11 Among them, C is the penalty factor of misclassified samples, and its main function is to control the punishment for wrong sample level and optimization in different sub-sample spaces if the value of C is different, and γ is the main complexity change sample subspace, so the linear classification can minimum error plays a key role.
4. Training SVM
The multi-classification SVM classifier is constructed as follows. It is known that there are R classifiers,
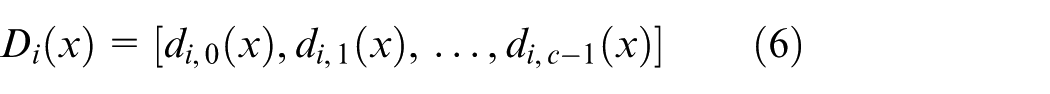
In equation (6), it is indicated that the classifier
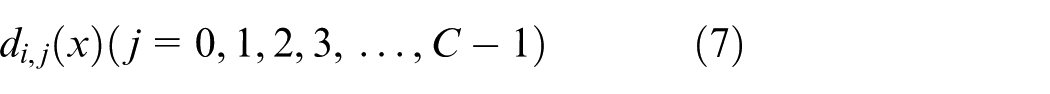
Then, for the sample x, the discriminant output of each known classifier is expressed in equation (8)
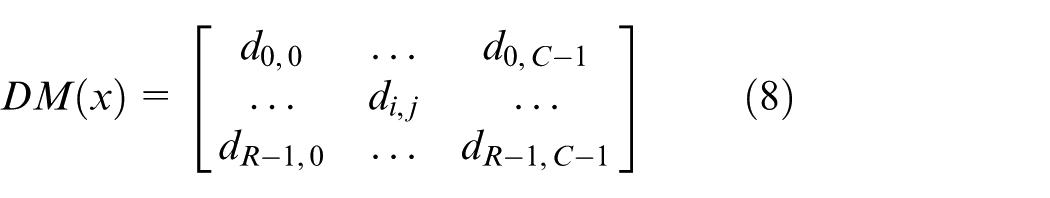
The DM(x) is the decision distribution matrix. The discriminant output of the i classifier is the line i of the DM(x). The discriminant output of each classifier is line i of DM(x), and each classifier’s support for class j is the column j of DM(x).
All categories of samples have a decision template for the most typical decision distribution, such as equation (9)

It compares the decision distribution matrix DM(x) of an unclassified sample with the decision template of each category, and the most similar category is the category of the sample
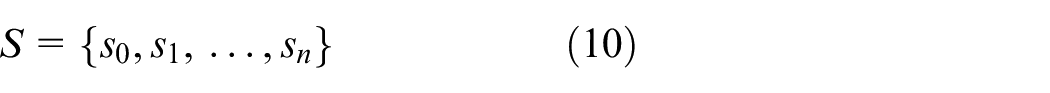
Assuming that equation (10) is a set of trained data sets, the definition of a decision template

Equation (11), DM

For the test sample x, we calculate the decision distribution matrix DM(x) and then calculate the similarity degree of DM(x) and equation (12) as the support for the category. Here, we use the normalized Euclidean distance between DM and DT as the similarity measurement function for equation (13)
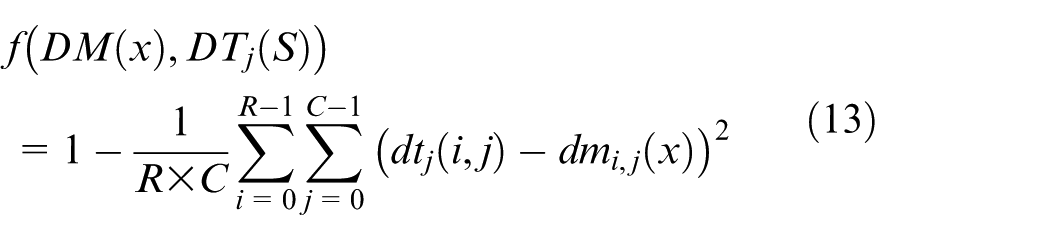
Development and implementation of detection and sorting system
The whole system consists of high-speed industrial cameras, computers, sorting robots, and transmission devices, as shown in Figure 2. The industrial camera sends the image of the packing box to the computer, and the computer carries out the image processing and outputs the judgment result. The process of computer image processing technology is divided into two parts: basic image processing, which can identify defects, and advanced image processing, which can automatically distinguish defects according to the result set of SVM training machine.

Spot.
The hardware system consists of an industrial CCD camera, light source, computer, and a sorting robot. CCD is a semiconductor device, the full name is “charge coupled device”, is an image sensor which can convert optical images into digital signals. The CPU of the PC machine uses Intel I5.7500, and the graphics card is GTX1050TI. The CCD camera is a signal collecting unit; the resolution is 1600 × 1200, and the image frames per second is 52 fps. The shortest exposure time is 20 µs. The light source illuminates the printed matter so that the CCD camera can get the best image signal.
The detection sample moves on the conveyor belt. When the sample motion reaches under the camera, the system analyzes whether the object in the video stream reaches the designated area according to the real-time value of the pattern matching algorithm. After the sample movement specifies the area, the CCD camera can capture all the images of the sample completely; the defect detection system calculates the “defect weight,” calculates the degree of defect, and determines the type of the defect. The original images without processing are saved to the training database as SVM training samples and transmitted to the SVM trainer at the same time to match the possible types of defects. The samples in the training database are compared with the results obtained from the image processing, and the output is “qualified” or “unqualified.” The sorting robot performs the sorting operation according to the comparison results.
The manipulator grasping algorithm of the sorting robot is an adaptive neural network control method with the full state constraint proposed by He et al.12 The learning machine is used to compensate the unknown nonlinearity in the dynamics of the manipulator. The augmented controller ensures that the closed-loop control manipulator follows a specified reference model so that it can match the reference model accurately after the initial iteration. The manipulator of this system is a three-degree-of-freedom manipulator. The hardware design takes two cases into consideration: full state and output feedback control. For the output feedback of the unknown state of the system, a high gain observer is used to estimate the state.7
The defect detection system runs in the Windows 10 environment, the development tool is Visual Studio 2015, the platform for image detection is OpenCV3.2.0, the interface is written and the program is implemented, and Visual C++ with good compatibility is selected. The functions of the detection software are opening CCD detection, setting the weight of defects, adjusting contrast, adjusting focal length, changing exposure time, training SVM samples, and so on. The program interface is shown in Figure 3.

Shift.
Experiments and discussion
Defect recognition without SVM
Taking a soap box as an experimental sample, this paper mainly studies three common printing defects—blur, spot, and pattern shift—which are shown in Figures 4–6, respectively. These three kinds of defects will appear according to different proportions, depending on the quality of printing equipment and materials.
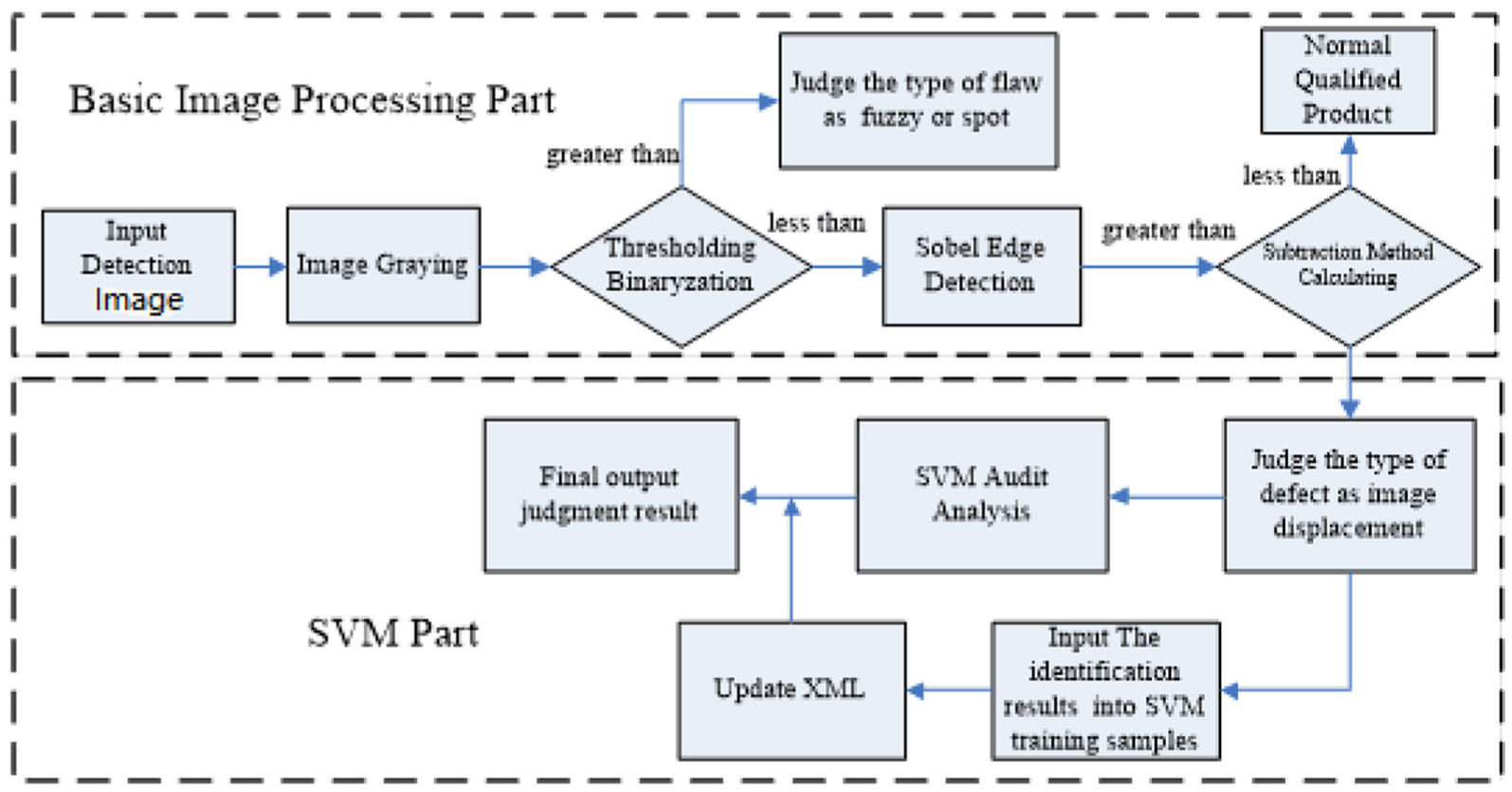
General process of defect recognition.

Defect detection system and sorting robot.
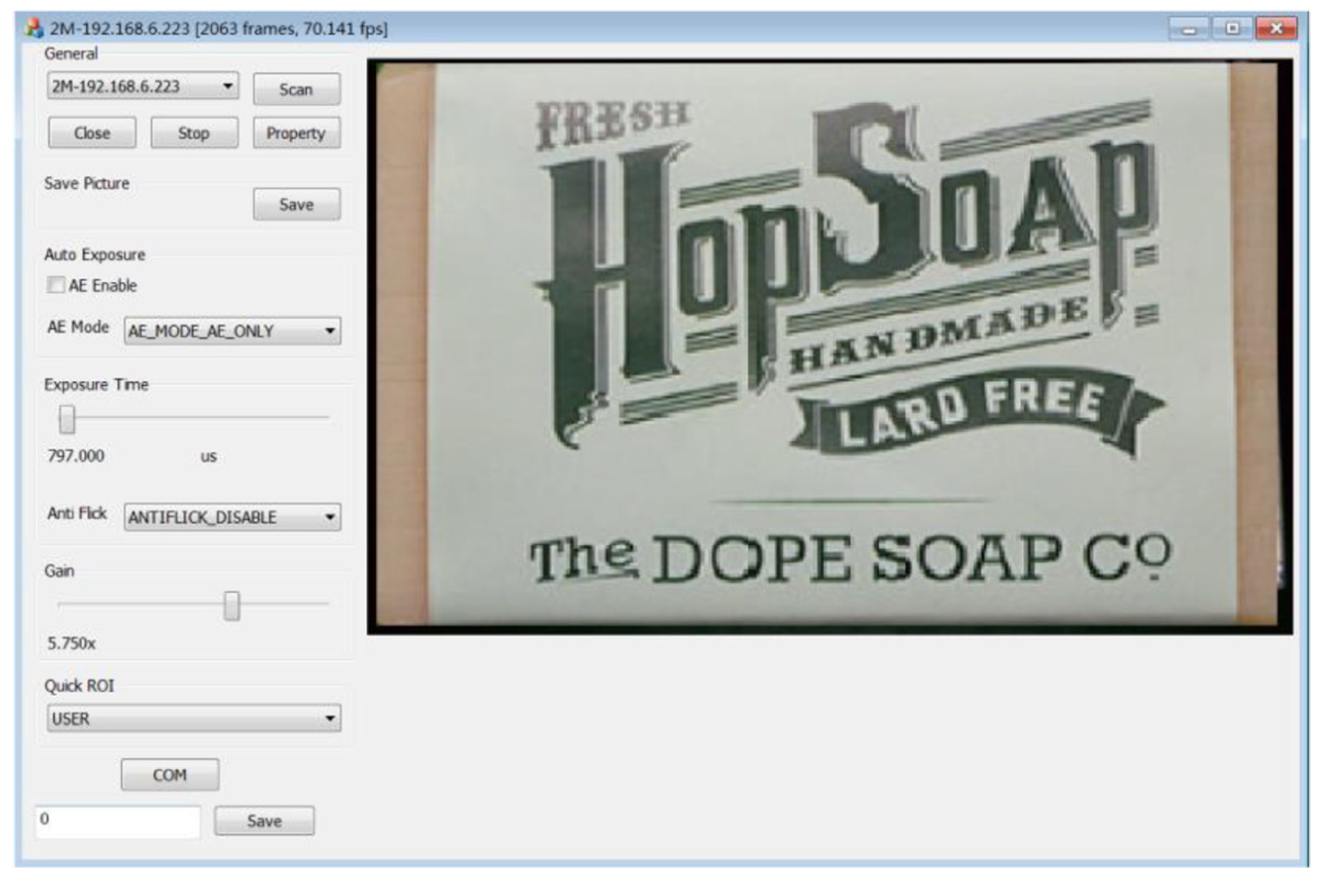
Detection system software interface.
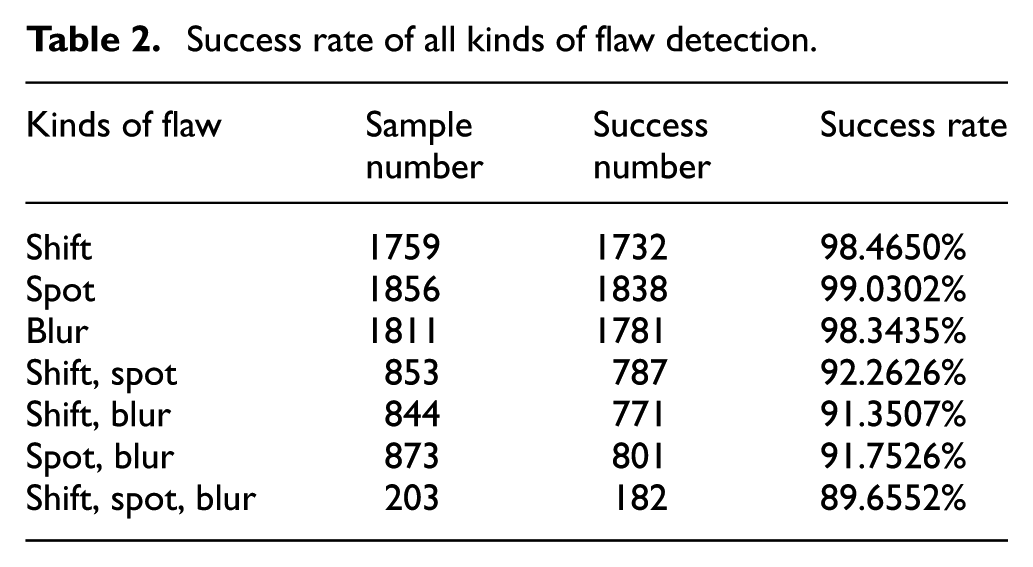
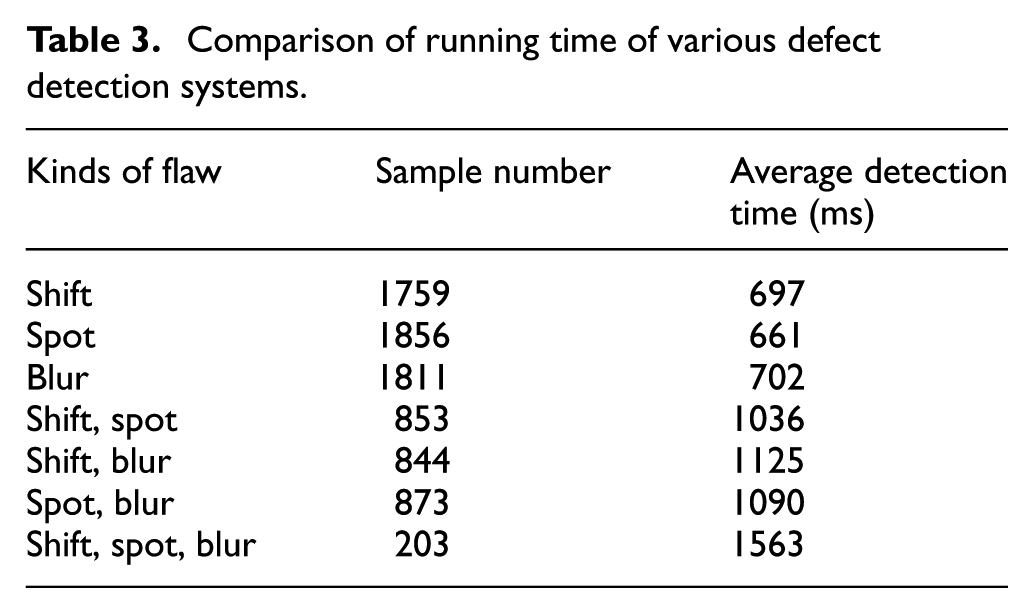
Many experiments without SVM were done. In this experiment, the samples exceeded 8100 product images, including six possible combinations of defects. As shown in Table 2, as the type of defect increased, success drops from 98% to 92%, and finally down to 89%. In addition, the time of detection and recognition increased with the improvement of the complexity of the defect, as shown in Table 3.
Success rate of all kinds of flaw detection.
Comparison of running time of various defect detection systems.
Defect identification with SVM
The SVM kernel function used in this article is RBF and has been tested. The optimal values of the penalty factor C and the kernel parameter γ are 4.942 and 0.429, respectively. When the σ value of the radius of influence of the RBF support vector is 0.001, the classification of “displacement” is the best and the recognition success rate in the test is 99.8294% (as shown in Table 4). For the “spot” detection, the optimal values for C and γ are 2.812 and 0.356, respectively, and the σ value remains unchanged. The deviation of the detection failure is mainly due to the use of the RBF training model when judging “spot” and “blur.” In order to improve the data classification effect of the SVM kernel function, the σ value is reduced to 0.00001.13–16 In the “spot” detection, the C and γ values remain unchanged, and the final detection “blur” success rate reaches 99.7239% (as shown in Table 4), 0.0472% higher than the “spot” detection success rate.
Detection success rate of all kinds of defects before and after using SVM.
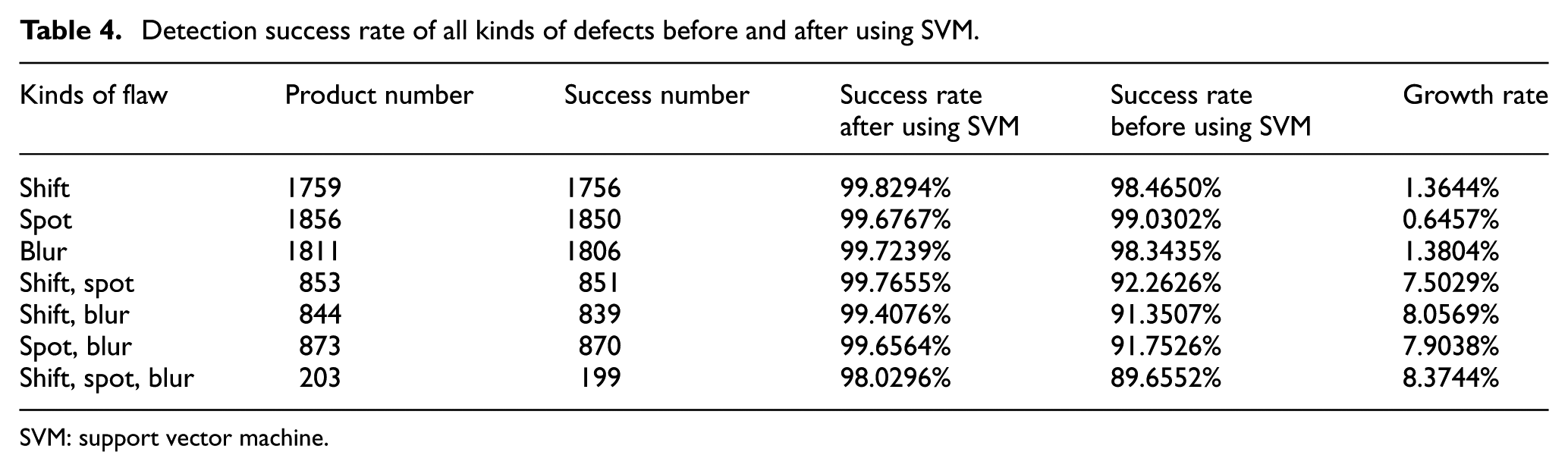
SVM: support vector machine.
After the completion of the SVM training process, the XML feature files generated by the training were introduced into the system for testing. The experiment used all the samples of the previous experiment to reconduct the test of the success rate of the defect discrimination, and the data obtained are shown in Table 4. We can see that in a single defect detection, the effect of SVM was not as good as that of traditional image processing, but SVM was obviously better at detecting more than one defect. In addition, from the execution time comparison of Table 5, with the increase of defect complexity, the time consumed by SVM was better than the traditional detection method.
Optimization comparison of running time before and after SVM for all kinds of flaw detection.
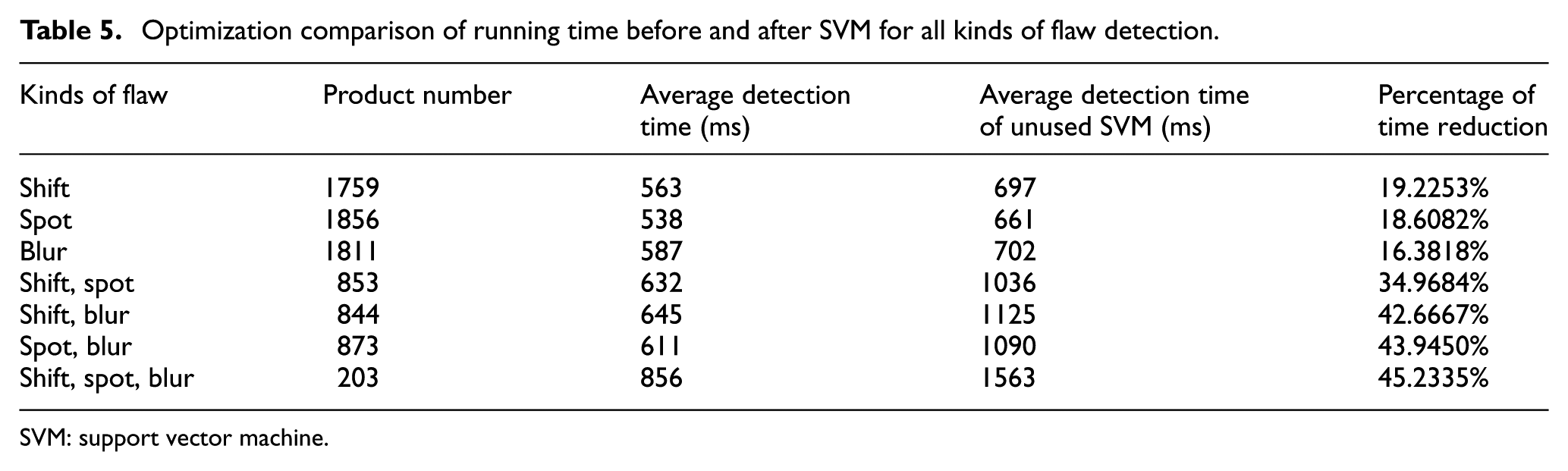
SVM: support vector machine.
In order to verify the feature adaptation of SVM, our team conducted a different set of experiments. We selected six common boxes in the market to identify defects. They are Products A, B, C, and D, as shown in Figure 7.

Six kinds of packing boxes.
The defect feature model obtained from the previous experiments is used to identify the packaging boxes of other products. Experiments show that the feature model has been able to identify three kinds of surface defects: shift, spot, and blur. The experimental data are shown in Table 6, and the running time is shown in Table 7. Experiments show that machine learning is feasible for detecting defects in packaging boxes. As long as the number of training samples is guaranteed, computer learning can adapt to similar defects of different products.
Success rate of other brands.
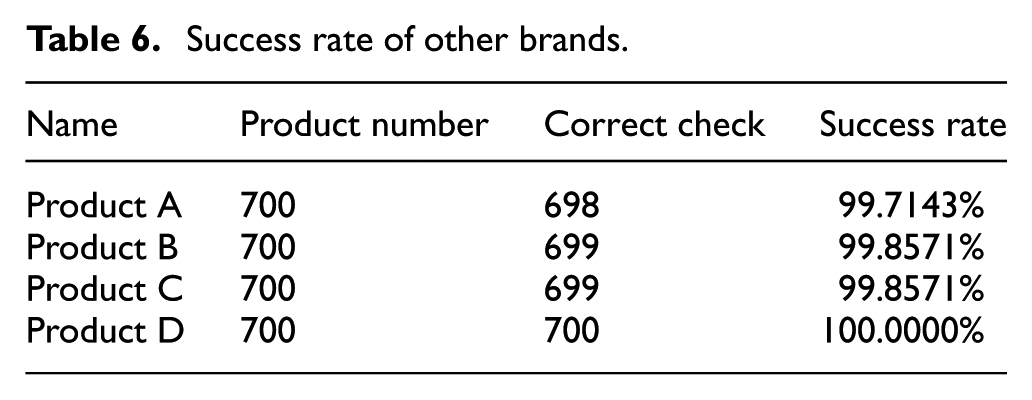
Comparison of running time of other brands.

Conclusion
In this paper, an SVM training model of multilayer perceptron kernel function is proposed. The classifier is used to judge whether there are defects on the surface of the printed packaging box. Experiments show that the correct rate of this method is 8.3744% higher than that of traditional pattern recognition technology, and the effective detection rate is 98.0296%. This research has been applied to the printing and packaging carton pipeline sorting manipulator to use machine vision to quickly identify printing defects, reduce the cost of manual sorting, and improve the production efficiency of packaging industry.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Scientific Research Projects of Universities in Guangzhou of Guangzhou Education Bureau, under Grant 1201620306.