
Abstract
Background
Therapeutic inertia (TI) remains a critical barrier to optimizing outcomes in multiple sclerosis (MS) and neuromyelitis optica spectrum disorders (NMOSDs).
Objective
We evaluated the proficiency of ChatGPT-4o in addressing complex neuro-immunological management challenges compared to practicing neurologists.
Methods
We conducted a comparative analysis using 21 clinical vignettes derived from a multicenter research framework. Responses from 290 neurologists were benchmarked against ChatGPT-4o, both with and without Retrieval-Augmented Generation (RAG). The primary endpoint was guideline-adherent decision-making at the item level, with the prevalence of TI as a secondary clinical outcome. Scenarios included MS therapy escalation, aquaporin-4-IgG positive NMOSD management, and serum neurofilament light chain integration.
Results
ChatGPT-4o with RAG achieved significantly higher guideline adherence in decision-making than neurologists (80.5% vs. 66.5%; p = 0.001). Multivariable generalized estimating equation models identified ChatGPT-4o as an independent predictor of evidence-based decision-making (Odds ratio 3.17; 95% confidence interval: 2.05-4.88; p < 0.0001). While the model demonstrated a lower propensity for TI overall, performance parity occurred in emerging biomarker scenarios where clinical consensus is still evolving.
Conclusions
ChatGPT-4o demonstrated superior guideline adherence and reduced TI compared to neurologists. Integrating Large Language Models as clinical decision-support tools may enhance the standardization of neuro-immunological care and serve as a valuable adjunct to mitigate human cognitive biases.
Keywords
Introduction
The management of multiple sclerosis (MS) and neuromyelitis optica spectrum disorders (NMOSDs) has seen significant therapeutic advances with the development of highly effective, mechanism-specific therapies.1,2 In MS, the prompt use of high-efficacy treatments is critical to reduce relapse rates, limit new lesion formation, and prevent disability progression.1,3 Similarly, in NMOSD, preventing relapses is essential to avoid permanent disability and long-term accumulation of damage.4,5 Furthermore, new tools like testing for serum neurofilament light chain (sNfL) have emerged to detect subclinical neuroaxonal damage, positioning them as powerful aids for prognosis and timely therapeutic adjustments.6,7
Despite these pharmacological and monitoring advances, therapeutic inertia (TI), the failure to initiate or escalate treatment despite uncontrolled disease activity, persists as a primary obstacle to optimal care in MS and NMOSD.8,9 Factors such as aversion to ambiguity, low tolerance for uncertainty, and limited use of structured decision-support strategies have been identified as relevant contributors to TI.8–11 In this context, artificial intelligence (AI), specifically large language models (LLMs) such as ChatGPT, represents a potential adjunct for clinical decision support. 12 LLMs can potentially integrate complex information and align recommendations with guidelines, serving as a supportive framework to mitigate human cognitive biases and help reduce unintended variability in physician decisions while respecting clinical autonomy.13–20 The objective of this study was to evaluate whether ChatGPT-based recommendations demonstrate greater adherence to evidence-based guidelines and a lower prevalence of TI compared to practicing neurologists managing MS and NMOSD.
Methods
Study design
This study employed a secondary pooled analysis of data derived from 290 neurologists who participated in three multicenter, observational, cross-sectional studies in Spain: DIScUTIR MS, NewFeeLs-MS, and PREFERENCES-NMOSD.9–11 We recruited clinician participants through a collaboration with the Spanish Society of Neurology (SEN). The SEN invited members actively managing demyelinating diseases to participate via targeted electronic correspondence.
Clinical vignettes and scenario selection
We selected 21 clinical vignettes designed to emulate high-stakes, representative management challenges in MS and NMOSD care. These scenarios focused on the most frequent drivers of TI across three distinct contexts:
DIScUTIR MS study (n = 9): These cases evaluated the influence of neurologists’ behavioral risk preferences on disease-modifying therapy escalation in patients with relapsing-remitting MS exhibiting clinical or radiological activity.
10
NewFeeLs-MS study (n = 7): This module investigated the impact of sNfL biomarker integration on the propensity to initiate or intensify treatment.
11
PREFERENCES-NMOSD study (n = 5): Scenarios addressed the management of aquaporin-4-IgG positive NMOSD within an expended landscape of high-efficacy targeted therapies.
9
ChatGPT configuration and contextual retrieval
We utilized the OpenAI gpt-4o-2024-08-06 model for response generation and the text-embedding-3-large model for embedding generation. All prompts were processed via the official Application Programming Interface (API) with the temperature set to 0.7. This parameter was selected to balance determinism with creative synthesis, mirroring the default configuration of the standard ChatGPT web interface. To ensure data security, the API key was managed exclusively through encrypted environment variables and remained unexposed within the study code or documentation. Furthermore, employing a controlled API environment with a fixed model version served as a proactive strategy to mitigate data leakage. Given that the clinical vignettes originated from previous research, this methodology minimizes the risk of the model retrieving verbatim study content or pre-existing answer keys from its underlying training corpus.
Each vignette was evaluated under two conditions:
Without context: The model was provided only with the case scenario and questions. With contextual retrieval: The model was augmented using retrieval-augmented generation (RAG). Domain-specific clinical documents related to MS and NMOSD management and sNfL testing indications were converted to a vector database (ChromaDB).1,5,6,21 Relevant document excerpts, prioritized by semantic similarity and filtered by a score above 0.80, were retrieved and appended to the model's prompt for contextual guidance. Each case was processed multiple times (n = 10 repetitions) to assess variability in responses.
Outcome measures and definitions
The primary endpoint was guideline-adherent decision-making, defined at the item level as the provision of a correct response consistent with evidence-based guidelines. Specifically, a response was classified as correct if it mandated the escalation of disease-modifying therapy for patients exhibiting breakthrough disease activity, characterized by recurrent clinical relapses, new radiological activity on magnetic resonance imaging, or elevated sNfL levels. Secondary outcomes included the prevalence of TI and the identification of predictors for the association between participant's and case-based characteristics with correct responses. For the pooled analysis, we maintained the study-specific definitions of TI derived from the original frameworks:
NewFeeLs-MS and DIScUTIR MS studies: TI was considered present if there were at least three incorrect responses. PREFERENCES-NMOSD study: TI was considered present if there was at least one incorrect response. A more stringent definition was used in this study due to the high severity of NMOSD and the risk of irreversible disability accumulation following a single relapse.2,5
Statistical analyses
Demographic and professional characteristics were reported using mean (standard deviation [SD]), medians (interquartile range [IQR]), or number (percent), as applicable. A descriptive analysis summarized the percentage of correct answers provided by both ChatGPT and neurologists for each clinical scenario. Comparative analyses were then conducted to evaluate differences in performance between the model and clinicians. The proportion of correct responses was compared using either the Student's t-test or the Mann-Whitney U test, depending on the distribution of the data, with normality assessed prior to selection. Only cases evaluated by both participants (ChatGPT and neurologists) were included in this analysis. A generalized estimating equation (GEE) model with a logit link function was fitted to assess factors associated with the likelihood of providing a correct response (absence of TI).
Dependent variable: Correct answer (Yes/No). Independent variables: Type of responder (Participant: Neurologist or ChatGPT), and clinical case characteristics including patient demographics (age, time since diagnosis, Expanded Disability Status Scale [EDSS]), and disease-related characteristics (relapse, lesions, sNfL, and affectation), and participant characteristics (age, sex, years of professional expertise, and practice setting). Clustering: ChatGPT runs were treated as independent observations, but clinician responses were clustered by individual clinician to account for the correlation arising from each clinician evaluating multiple cases. This within-clinician correlation was explicitly accounted for in the GEE model. Model assessment: Model fit was evaluated using the quasi-likelihood under the independence model criterion (QIC), and the proportion of variance explained by the fixed effects was estimated using the marginal coefficient of determination (R2 marginal). Reporting: Odds ratios (ORs) with 95% confidence intervals (CIs) were estimated.
• All statistical analyses were performed using IBM SPSS Statistics and data visualizations were generated using RStudio. A two-sided p-value < 0.05 was considered statistically significant for all analyses.
Results
Study population
This analysis included the responses of 290 neurologists pooled from DIScUTIR MS (N = 96), NewFeeLs-MS (N = 116), and PREFERENCES-NMOSD (N = 78) studies. Overall, the cohort comprised clinicians with a mean (SD) age of 40.2 (9.9) years, of whom 51.7% were male. These neurologists had a mean of 13.9 (8.8) years of professional experience, 74.1% worked in academic hospitals, and saw a median (IQR) of 15.0 (8.0–25.0) patients per week. Additionally, 70.7% attended congresses of the European Committee for Treatment and Research in Multiple Sclerosis, and 62.8% were authors of peer-reviewed publications. When analyzed by study, TI was observed in 66.0% of neurologists in the DIScUTIR MS, 91.8% in the NewFeeLs-MS, and 38.5% in the PREFERENCES-NMOSD. Further details are summarized in Table 1
Characteristics of the study population.

ECTRIMS: European committee for treatment and research in multiple sclerosis; IQR: interquartile range; SD: standard deviation; NMOSD: neuromyelitis optica spectrum disorder; MS: multiple sclerosis.
ChatGPT responses
In general, ChatGPT's responses were highly consistent across the 10 repetitions per case, with the model producing identical answers in most scenarios or showing minimal variability, typically limited to two different response patterns. The percentage of correct responses generated by ChatGPT without context is presented in Table 2, showing that the model provided 100% correct answers in all included cases for the PREFERENCES-NMOSD study, 100% correct responses for cases 1 and 5 and 0% for the remaining cases in the NewFeeLs-MS study, and 100% correct responses in 6 out of 9 case scenarios and between 60% and 90% in the remaining ones for the DIScUTIR MS study.
Descriptive analysis of correct answers: ChatGPT-4o (without context) versus neurologists.
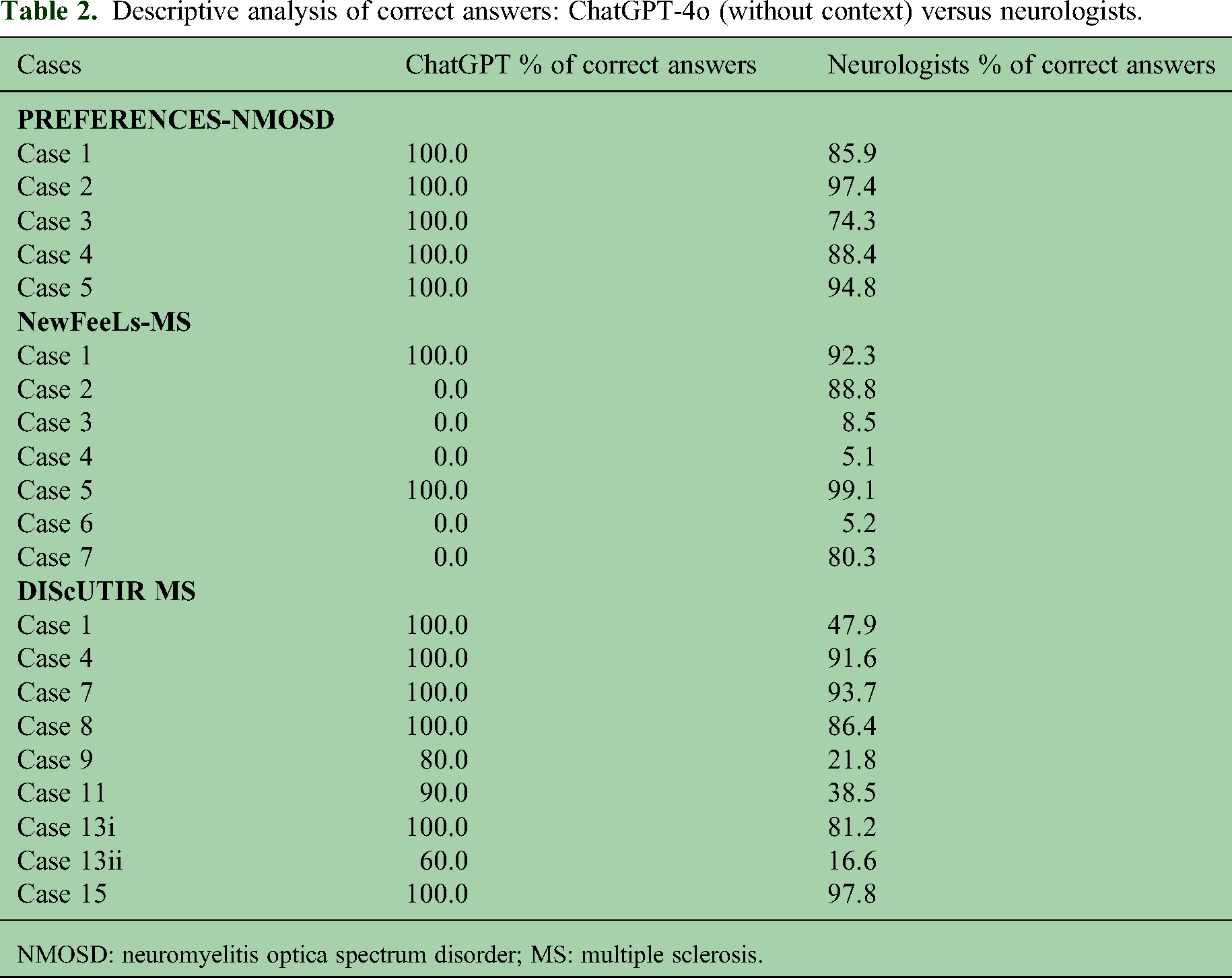
NMOSD: neuromyelitis optica spectrum disorder; MS: multiple sclerosis.
When ChatGPT was provided with context, a slight improvement in performance was observed, resulting in a 100% correct response rate across all evaluated cases for the PREFERENCES-NMOSD and DIScUTIR MS studies, while in NewFeeLs-MS, correct responses were observed in 100% of the iterations for cases 1 and 5, in 90% for case 2, and 0% in the remaining cases (Table 3).
Descriptive analysis of correct answers: ChatGPT-4o (with context) vs neurologists.

NMOSD: neuromyelitis optica spectrum disorder; MS: multiple sclerosis.
Performance comparison between ChatGPT-4o and neurologists
When analyzing results across all studies combined, ChatGPT-4o demonstrated a significantly higher percentage of correct responses than neurologists in both conditions: Without context (mean: 72.9% vs. 66.5%; p = 0.038) and with context (mean: 80.5% vs. 66.5%; p = 0.001) (Figure 1A).

Comparative analysis of guideline-adherent responses between ChatGPT and neurologists. Results are presented for (A) the combined study dataset, (B) the PREFERENCES-NMOSD study, (C) the DIScUTIR MS study, and (D) the NewFeeLs-MS study. Individual dots represent the percentage of correct responses for each clinical vignette, while bars and vertical lines indicate the mean and standard deviation, respectively. Inter-group means were compared using the Mann–Whitney U test for the combined dataset, the NewFeeLs-MS study, and the DIScUTIR MS study (with clinical context); a Student's t-test was utilized for all other analyses. NMOSD: neuromyelitis optica spectrum disorder; MS: multiple sclerosis. Statistical significance is denoted as: *p < 0.05; **p < 0.01.
This superior performance was consistent across the PREFERENCES-NMOSD study and the DIScUTIR MS study. In both of these studies, the model showed a significantly higher percentage of correct responses compared to clinicians under both conditions:
Conversely, for the NewFeeLs-MS study, no significant differences were observed in the percentage of correct responses between ChatGPT-4o and neurologists, either without context (mean: 28.6% vs. 54.2%; p = 0.191) or with context (mean: 41.4% vs. 54.2%; p = 0.518) (Figure 1D). Based on these findings, ChatGPT-4o demonstrated a lower tendency to exhibit TI in treatment decision-making compared to neurologists.
Factors associated with correct responses
We performed multivariable GEE analyses to determine whether the type of responder and patient-specific demographic or clinical characteristics were independently associated with guideline-adherent decision-making. To ensure model stability and convergence, the sex variable was excluded from all models due to a highly unbalanced distribution (male sex represented in only 2 of 21 clinical vignettes). Two separate models were analyzed: One considering responses from ChatGPT-4o without context and the other considering responses from ChatGPT-4o with context.
The multivariable GEE model showed that ChatGPT-4o without context was an independent predictor and more likely to provide correct responses compared with clinicians, indicating a positive association between ChatGPT-4o participation and correct responses (p = 0.042) (Table 4). The presence of both lesions and relapses were positively associated with correct responses, suggesting that TI was less likely to be observed in scenarios reflecting active disease (p < 0.0001 and p = 0.011, respectively). The EDSS score was negatively associated with correct responses in the model (p < 0.0001). Similarly, the second model confirmed that ChatGPT-4o with context was an independent predictor and more likely to provide correct responses compared with clinicians (p < 0.0001) (Table 5). The presence of lesions and relapses were associated with correct responses (P < 0.0001 and P = 0.006, respectively). Conversely, the EDSS score was negatively associated with correct responses (p < 0.0001).
Factors associated with correct responses in the multivariable GEE model (ChatGPT-4o without context).

A multivariable GEE model with a logit link function was fitted, considering correct response (yes/no) as the dependent variable, and participant (ChatGPT without clinical context/neurologist), along with patients’ demographic and clinical characteristics from each case, as independent variables. Population-averaged ORs with 95% CIs and P-values are presented. QIC: 1879.43. R2-marginal: 0.461. CI: confidence interval; EDSS: Expanded Disability Status Scale; GEE: generalized estimating equation; OR: odds ratio; sNfL: serum neurofilament light chain; QIC: quasi-likelihood under the independence model criterion.
Factors associated with correct responses in the multivariable GEE model (ChatGPT-4o with context).

A multivariable GEE model with a logit link function was fitted, considering correct response (yes/no) as the dependent variable, and participant (ChatGPT with clinical context/clinician), along with patients’ demographic and clinical characteristics from each case, as independent variables. Population-averaged ORs with 95% CIs and P-values are presented. QIC: 1834.13. R2-marginal: 0.477. CI: confidence interval; EDSS: Expanded Disability Status Scale; GEE: generalized estimating equation; OR: odds ratio; sNfL: serum neurofilament light chain; QIC: quasi-likelihood under the independence model criterion.
Discussion
Generative AI, particularly LLMs such as ChatGPT, represents a transformative advancement in clinical decision-support.12,22–24 These systems are redefining the acquisition of evidence-based information and the interpretation of complex therapeutic data. While the utility of LLMs is enhancing triage, diagnostic accuracy, and patient communication across multiple specialties, their application is especially salient in neurology, where therapeutic landscapes for complex pathologies are evolving rapidly.
Our study demonstrates that ChatGPT-4o provided a higher proportion of guideline-adherent recommendations and exhibited lower TI than practicing neurologists. These findings align with recent performance benchmarks. Notably, Schubert et al. 13 reported that ChatGPT outperformed human users on neurology board-style examinations, achieving an 85.0% accuracy rate against a mean human score of 73.8%. While that study established the model's proficiency in addressing theoretical, standardized questions, our analysis validates the model's capacity to navigate nuanced, simulated clinical vignettes, including those involving emerging biomarkers such as sNfL. By moving beyond rote recall to evaluate therapeutic decisions in MS and NMOSD, this study provides evidence that ChatGPT-4o can function as a reliable clinical decision-support tool to mitigate TI and enhance care consistency. Beyond diagnostic and therapeutic accuracy, preliminary evidence supports the broader clinical utility of LLMs. In NMOSD, ChatGPT-3.5 has demonstrated proficiency in early disease recognition. 25 Similarly, in MS care, several AI platforms have performed comparably to specialist neurologists in knowledge assessments. 19 Furthermore, ChatGPT has generated management explanations that patients with MS perceived as more empathetic than those provided by clinicians, suggesting a potential role in enhancing patient-provider communication. 20 Collectively, these findings indicate that when provided with structured clinical information, LLMs possess the capacity to supplement human reasoning and address unmet needs in well-defined neuro-immunological settings.
The optimization of performance through RAG underscores the critical importance of structured, context-specific input in mitigating baseline LLM limitations, such as factual inaccuracies or reliance on outdated data.16,26 However, the observed parity between the model and neurologists in the NewFeeLs-MS scenarios warrants consideration. 11 This component of the study evaluated sNfL testing, a context where clinical consensus and universally accepted protocols are still emerging.27–29 The resultant ambiguity appears to challenge both human clinicians and LLMs alike, illustrating that while LLMs are highly reliable within established parameters, they remain sensitive to dynamic and heterogeneous clinical evidence.13,30
Multivariable GEE analysis further suggests that AI integration can enhance decision-making uniformity. Consistent with clinical expectations, guideline-adherent responses were more frequent in scenarios featuring overt disease activity, such as clinical relapses or new radiological lesions.31–33 Beyond these traditional indicators, LLMs may eventually support personalized treatment strategies by integrating multimodal datasets. From a practical standpoint, the lower TI observed in ChatGPT-4o suggests its potential to support timely treatment optimization, thereby preventing the accumulation of irreversible disability. 12
The demographic profile of the participating neurologists represents a high-performance benchmark. With 74.1% of participants practicing in academic centers and 62.8% involved in peer-reviewed research, this cohort likely exhibits high baseline knowledge and adherence to specialized management guidelines. It is essential to clarify that the lower adherence observed among these neurologists does not suggest a deficit in medical knowledge or a failure to comprehend evidence-based recommendations. On the contrary, the observed TI likely reflects the inherent difficulty of applying standardized protocols to complex, real-world cases where clinicians must navigate ambiguity and balance individual patient risks. 29 Understanding these behavioral and systemic drivers is critical; it suggests that AI tools should not serve to “educate” expert physicians, but rather to provide a consistent, objective framework to mitigate cognitive biases, such as ambiguity aversion and low tolerance for uncertainty, that contribute to treatment delays and medical errors.8,10,34,35
We acknowledge that clinical guidelines are not infallible and may be perceived as too rigid to capture the granular complexities of individual care. Furthermore, formal guidelines often exhibit a significant temporal lag between the emergence of scientific evidence and its official publication. Consequently, expert neurologists frequently make therapeutic decisions aligned with the latest evidence before it is codified into standard protocols. While clinical intuition and nuanced, shared decision-making remain fundamental to high-quality medicine, guidelines provide a necessary framework to harmonize care. Within this context, AI tools function as a standardized measure to reduce therapeutic variability without replacing the essential judgment of the treating neurologist.
The integration of LLMs into clinical workflows should aim to provide concise, context-specific recommendations that complement expert judgment. Crucially, the ultimate clinical responsibility for patient care remains with the neurologist; thus, human supervision of all AI-generated recommendations is mandatory. 36 To ensure these systems are utilized as rigorous adjuncts to clinical reasoning, AI literacy must be prioritized within medical education.
This study has several limitations. First, fundamental differences exist between human clinical reasoning and the algorithmic generation of AI responses. While the simulated vignettes were designed to be clinically relevant, they may not fully encapsulate the multi-faceted complexities of real-world practice. Second, LLM performance is strictly contingent upon the quality and currency of its source material; any temporal lag in the integration of emerging guidelines could result in suboptimal recommendations. 36 Third, although we utilized current API versions and RAG to anchor responses to verified evidence, the risk of data leakage cannot be definitively excluded, as the specific training corpora for proprietary LLMs remain undisclosed. Finally, the inclusion of a predominantly academic cohort of Spanish neurologists may restrict the external validity of these findings regarding other healthcare systems or non-academic clinical environments. Future research should focus on validating LLM performance within more heterogeneous, global cohorts to ensure generalizability across diverse socioeconomic and institutional frameworks.
Conclusion
This study demonstrates that ChatGPT-4o can effectively assist therapeutic decision-making in neuro-immunological diseases, achieving accuracy levels comparable to or exceeding those of practicing neurologists. Specifically, the model exhibited lower rates of TI and significantly greater adherence to evidence-based recommendations, particularly when clinical context was provided through RAG. These findings contribute to the expanding body of evidence suggesting that LLMs can enhance clinical consistency, mitigate cognitive bias in complex neurological reasoning, and potentially reduce medical errors.
However, the ethical and responsible integration of this technology necessitates mandatory human supervision of all AI-generated recommendations and the formal incorporation of AI literacy into medical education. While these systems represent powerful tools for decision-making, they must be viewed as a supportive resource designed to complement, rather than replace, the nuanced and essential expert clinical judgment of the treating neurologist.
Footnotes
Data availability statement
The datasets generated during the analysis of the study are available from the corresponding author upon reasonable request.
Declaration of conflicting interest
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Gustavo Saposnik received consulting fees from Roche Farma Spain and is supported by the University of Toronto Scientific Merit award. Enric Monreal received research grants, travel support, or honoraria for speaking engagements from Almirall, Merck, Roche, Sanofi, BMS, Biogen, Janssen, and Novartis. Eduardo Agüera received speaking honoraria from Roche, Novartis, Merck, Sanofi, and Biogen. María Sepúlveda received speaking honoraria from Roche, Biogen, and UCB Pharma, and travel reimbursement from Biogen, Sanofi, Merck and Roche for national and international meetings. Gary Álvarez-Bravo received compensation for consulting services and speaking fees from Biogen, Novartis, Merck, Sanofi, Amgen, Roche, and BMS. Miguel A Hernández has served as a speaker/moderator in meetings and/or symposia organized by Biogen, Merck, Sanofi, Roche, Novartis, and BMS. He has received funding for research projects from Biogen, Novartis, Merck, Teva, Sanofi, Roche, and BMS. Javier Riancho received speaking, consulting fees and travel funding from Merck, Sanofi, Roche, Biogen, Novartis, BMS, Jannsen, Neuraxpharm, and Teva. Juan P Cuello received consulting fees, support for travel, fees honoraria for participation on data monitoring boards, speaking honoraria, and expert testimony from Novartis, Biogen, Merck, Sanofi, and Roche. Ángel Pérez-Sempere has received consulting and speaking fees from Merck, Novartis, Teva, and Roche. Rocío Gómez-Ballesteros and Jorge Maurino are employees of Roche Farma Spain. Aleix Solanes declare that he has no competing interests.
Ethical approval and informed consent statement
All component studies adhered to the principles of the Declaration of Helsinki and received formal approval from the Institutional Review Board of the Hospital Universitario Clínico San Carlos in Madrid, Spain.
Informed consent
All participants provided written informed consent.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Roche España (grant number NA).