
Abstract
Purpose
To evaluate the performance of three large language models (LLMs) in automated recognition of IOLMaster 700 reports and preoperative toric intraocular lens (IOL) planning.
Methods
The retrospective study analyzed preoperative examination reports of patients who underwent cataract surgery with toric IOL implantation. Three models (ChatGPT-5, ChatGPT-5 Thinking and DeepSeek Thinking) were instructed to extract key biometric parameters, evaluate a patient’s suitability for toric IOL implantation, and generate a plan. Model performance was evaluated based on structured-data recognition, refractive prediction outcomes and thinking times.
Results
Fifty-four eyes of 54 patients were analyzed. ChatGPT-5 Thinking model consistently achieved the highest agreement with clinical reference for all extracted parameters, and demonstrated more reliable extraction of axis information. ChatGPT-5 showed intermediate performance, while DeepSeek Thinking was the least consistent in axis-dependent fields but performed adequately for basic biometry. Refractive and axis prediction errors were smallest with ChatGPT-5 Thinking, yielding the largest proportion of cases within prespecified clinical thresholds and the highest concordance with the calculator-based reference plan. Analysis of thinking times showed that longer processing did not necessarily correlate with better accuracy.
Conclusions
Advanced LLMs show promise for automated interpretation of ophthalmic biometry reports and calculator-based toric IOL planning workflows. These findings support the feasibility of LLM-assisted workflow automation, with ChatGPT-5 Thinking providing the most favorable balance of accuracy and efficiency in this setting.
Keywords
Introduction
Cataract surgery with intraocular lens (IOL) implantation is the most commonly performed surgical procedure worldwide. 1 Nowadays, cataract surgery has evolved from a sight-restoring procedure to a refractive intervention, with growing patient expectations for high-quality uncorrected vision and spectacle independence. 2 It has been reported that approximately one-fourth of patients with cataracts have ≥ 1.0 diopter (D) of corneal astigmatism worldwide.3–5 With the development of toric IOLs, surgeons can provide satisfactory refractive results as patients demand spectacle independence, even in cases of corneal astigmatism.
The accuracy of postoperative refraction depends on three factors: precise preoperative ocular biometry and reliable IOL power/axis calculations, precise intraoperative alignment, and postoperative position of the toric IOL.6,7 According to Hirnschall et al., preoperative corneal measurement is the largest source of error in toric IOL power calculation, contributing 27% of refractive astigmatic error, followed by IOL misalignment (14.4%) and IOL tilt (11.3%). 6 In addition, study indicates that each degree of rotational misalignment decreases the effectiveness of a toric IOL by approximately 3%. 8 Therefore, the persistent challenges in minimizing these human-dependent errors necessitate the adoption of automated technologies to improve preoperative accuracy.
Large language models (LLMs) exhibit remarkable capabilities in processing and interpreting large volumes of complex datasets, which has already supported clinicians in diagnosis and treatment planning. In ophthalmology, LLMs have been applied to tasks such as diabetic retinopathy screening and glaucoma detection.9,10 As technology advances, LLMs now accept multimodal inputs, allowing them to analyze images and PDF documents in addition to text. Recent feasibility work has begun to explore the use of multimodal large language models in cataract surgery–related quantitative tasks, including IOL power calculation and comparison with standard formula outputs. These studies suggest that MLLMs may serve as workflow-support or backup tools, while also highlighting that current evidence remains focused on feasibility and formula replication rather than outcome-based clinical validation.11,12 A vision-enabled LLM can automate data extraction, streamline planning, reduce manual transcription errors, and provide surgeons with quicker, data-driven assistance for toric IOL planning However, research into LLM-assisted report recognition remains limited. Accordingly, this study compares three LLMs for their accuracy in identifying these biometric parameters and in supporting toric IOL planning for cataract surgery.
Methods
Study design and approval
This single-center, retrospective and methodological study was conducted at the Eye & ENT Hospital of Fudan University, Shanghai, China, utilizing patient data collected from November 2024 to May 2025. The study was approved by the hospital’s Institutional Review Board (Approval No. 2025275) and adhered to the principles of the Declaration of Helsinki. All participants provided written informed consent, and all patient-identifying information was anonymized prior to data analysis.
Patient selection
Eligible participants were cataract patients who had undergone phacoemulsification and implantation of an AcrySof IQ Toric monofocal IOL (Alcon Laboratories, TX, USA). For inclusion, eyes were required to have a postoperative corrected distance visual acuity (CDVA) of 0.10 logMAR or better and an absolute IOL rotation less than 10° at the 1-month follow-up examination. The exclusion criteria were as follows: (1) incomplete biometric data on the examination report; (2) a history of previous ocular surgery or ocular trauma; (3) the occurrence of intraoperative complications, such as an anterior capsular tear or posterior capsular rupture; and (4) the development of significant postoperative complications, including but not limited to severe intraocular infection or inadequate pupillary dilation. Given the high degree of similarity between bilateral eyes in the same individual, only one eye was included in the analysis for this study.
Biometric measurement
The IOLMaster 700 (Carl Zeiss Meditec AG) uses swept-source optical coherence tomography (SS-OCT) with a 1055-nm laser, enabling an acquisition speed of 2000 A-scans per second, a tissue penetration depth of 44 mm, and six line scans with an axial resolution of 22 µm. 13 Each patient’s axial length (AL), anterior chamber depth (ACD), lens thickness (LT), white-to-white (WTW) distance, keratometry (K) and total keratometry (TK) were measured. For toric IOL implantation, the spherical power (Sph), cylindrical power (Cyl), and intended axis were determined using the manufacturer’s online calculator (the manufacturer’s toric IOL calculator used represents the standard planning tool routinely used by cataract surgeons in clinical practice). Each IOLMaster 700 report was exported from the device software and converted into a full-page JPG image. During this process, all patient-identifying information was removed to ensure anonymization prior to analysis. Aside from anonymization, no additional manual annotation or modification of the biometric data was performed.
LLMs evaluation
The evaluation of LLM performance was conducted using three different models: ChatGPT-5 (Model A; OpenAI, USA), ChatGPT-5 Thinking (Model B; OpenAI, USA), and DeepSeek Thinking (Model C; DeepSeek AI, China). All models were accessed through their official web interfaces using default configurations, without parameter tuning, plugin integration, or external tools. For each evaluation, a new session was initiated to prevent carryover memory from previous interactions. The same prompt instructions and identical image inputs were used across all models to ensure consistent experimental conditions.
The LLMs were required to complete the following tasks: (1) Extract key biometric parameters from the IOLMaster 700 report, including AL, ACD, LT, WTW, K1/K2 and their axes, and TK1/TK2 and their axes; (2) Calculate the corneal astigmatism values, including ΔK and ΔTK; (3) Determine the suitability for implantation of a toric IOL; (4) Select the most appropriate spherical power for the IOL. If a toric IOL is recommended for implantation, calculate the cylinder power and the optimal implantation axis based on a fixed surgically induced astigmatism (SIA) of 0.2 D for the left eye and a standard incision location (140°). (Prompt in Supplementary material).
To account for potential output variability, each case was evaluated three times per model in independent sessions, with identical inputs and prompts and without access to previous outputs. These repeated runs were performed to assess response variability and repeatability and were not treated as independent clinical samples. In addition, system-reported completion times (ChatGPT-5 and DeepSeek) were recorded for exploratory analysis of processing duration.
Outcome measures
The primary outcomes of this study were structured recognition and refractive prediction performance. Structured recognition accuracy was quantified for each parameter and model using observed agreement and correctness (defined as the proportion of exactly matched parameters among all values). Model responses were provided in text format. The relevant biometric parameters and IOL recommendations were extracted from the model outputs by identifying the numerical values explicitly reported for each requested variable. These extracted values were then compared with the corresponding reference values from the original IOLMaster 700 reports. If a response contained multiple candidate values or ambiguous expressions, the value clearly labeled for the corresponding parameter was recorded. Responses that did not provide a valid numerical value for a required parameter were classified as invalid outputs and were excluded from agreement analyses. Refractive performance was evaluated for Sph, Cyl, and axis using mean error (ME), mean absolute error (MAE), and median absolute error (MedAE). Clinically relevant thresholds were pre-specified, including absolute spherical error ≤ 0.50 D, ≤ 1.00 D, and ≤ 1.50 D; absolute cylindrical error ≤ 0.50 D, ≤ 0.75 D, and ≤ 1.50 D; and absolute axis error ≤ 5°, ≤ 10°, and ≤ 15°.
Statistical analyses
All statistical analyses were performed using SPSS Statistics for Windows (v. 22.0, IBM Corp) and R statistical software (v. 4.3.3). Normality was assessed with the Shapiro–Wilk test. Continuous variables are summarized as mean ± standard deviation (SD) or median (interquartile range, IQR) and compared across models by t-test, one-way ANOVA, or Kruskal–Wallis tests, as appropriate. Categorical variables are presented as n (%) and compared by χ2 or Fisher’s exact tests with 95% confidence intervals (CIs). Agreement for structured recognition was quantified per parameter and model by Cohen’s kappa (κ) with 95% CIs. Furthermore, the association between model thinking time and per-case recognition accuracy was modeled as a continuous exposure using nonlinear smoothing (LOESS). All tests were two-sided, and p < 0.05 was considered statistically significant.
Results
This study comprised 54 eyes of 54 patients. Each case was evaluated three times per model in independent sessions to assess response variability and repeatability. Patient demographics and baseline characteristics are summarized in Table S1.
Parameter recognition accuracy
The accuracy rates of parameter identification for the three models.

AL = axial length, ACD = anterior chamber depth, LT = lens thickness, WTW = white-white diameter, K1 = flat keratometry, K2 = steep keratometry, TK = Total keratometry, IOL = Intraocular lenses.
Cohen’s κ for agreement between the clinical reference and three models.
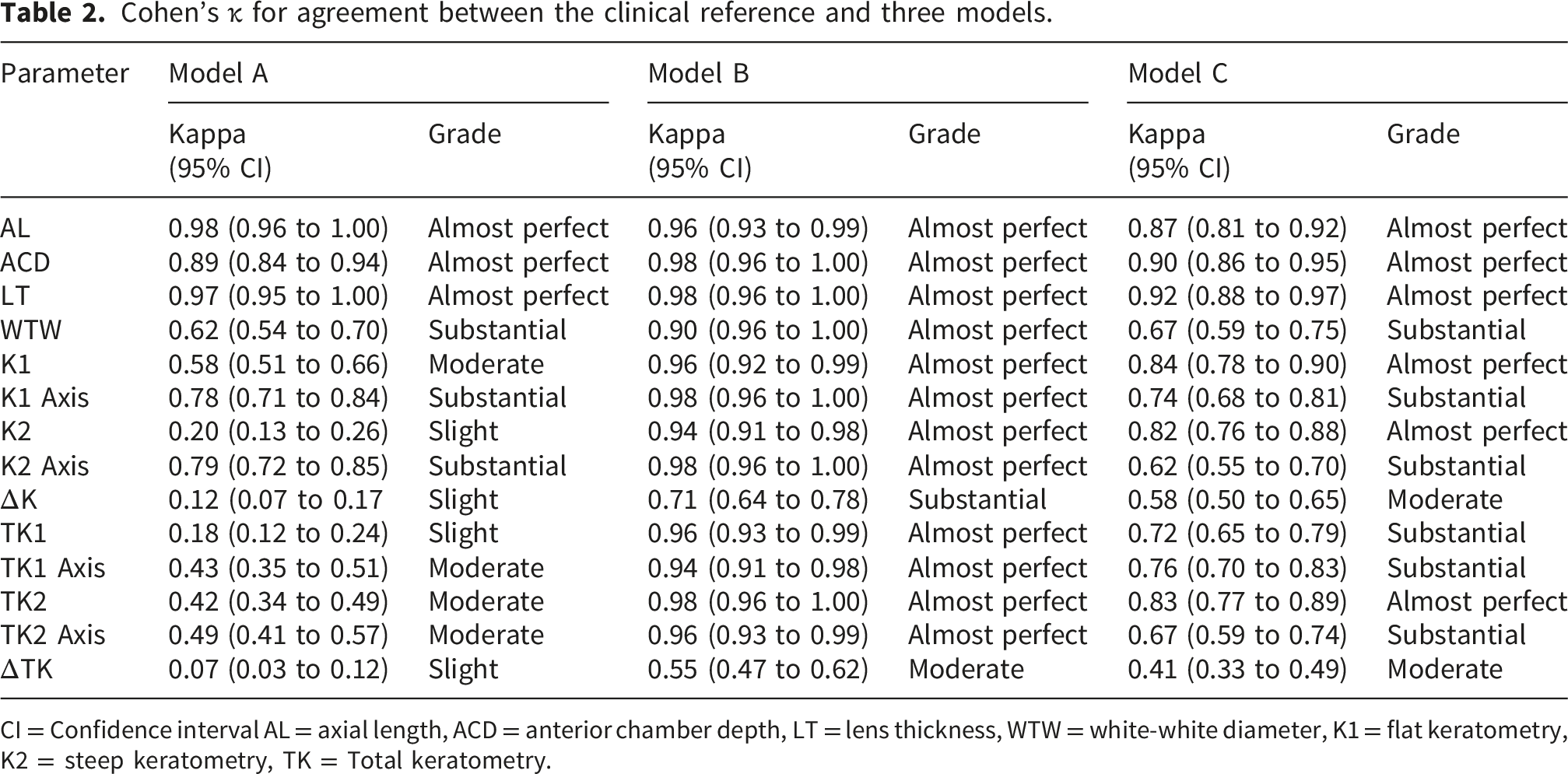
CI = Confidence interval AL = axial length, ACD = anterior chamber depth, LT = lens thickness, WTW = white-white diameter, K1 = flat keratometry, K2 = steep keratometry, TK = Total keratometry.
Refractive prediction and toric IOL planning assistance
Comparison of ME, MAE, and MedAE for predicted sph, cyl, and axis among three models.

ME = Mean error, MAE = Mean absolute error, MedAE = Median absolute error, SD = Standard deviation, IQR = Interquartile range, Sph = Spherical, Cyl = Cylindrical.
Thinking times analysis
Analyses of thinking times showed that Model C required a longer thinking time distribution compared to Model B (p < 0.001) (Figure 1). To further explore the relationship between reasoning duration and model performance, we analyzed the association between thinking time and parameter recognition accuracy, defined as the proportion of correctly extracted biometric parameters relative to the reference report (Figure 2). The LOESS smoothing curve demonstrates an initial increase in recognition accuracy with increasing thinking time, followed by a gradual stabilization of the curve. This pattern suggests diminishing improvements in accuracy beyond a certain reasoning duration, which we describe as a plateau in the accuracy-time relationship. Representative example cases spanning oblique, with-the-rule (WTR), and against-the-rule (ATR) astigmatism phenotypes are provided in Supplementary Table S4 to improve clinical interpretability of the model outputs. Comparison of thinking time between Model B and Model C. Relationship between thinking time and accuracy for Model B and Model C.

Discussion
In recent years, numerous studies have indicated that LLMs hold immense potential in text-based tasks within clinical ophthalmology.14,15 More recently, feasibility studies have begun to explore the use of multimodal large language models for cataract surgery–related quantitative tasks, including IOL power calculation and comparison with standard formula outputs. These studies suggest that MLLMs may support certain computational or workflow-assistance tasks in cataract surgery planning. 12 To our knowledge, this study provides a systematic comparison of three advanced LLMs in ophthalmic biometry parameter recognition, refractive prediction accuracy, and preoperative workflow assistance for toric IOL planning. The study demonstrates significant differences in performance across the three models. Specifically, ChatGPT-5 Thinking consistently achieved the highest accuracy and the lowest predictive errors across all evaluated dimensions, relative to ChatGPT-5 and DeepSeek Thinking, particularly in refractive prediction and toric IOL planning assistance.
Characteristics of LLMs in ophthalmic data extraction and agreement
Our results confirm that advanced LLMs are fully capable of accurately extracting complex parameters from ophthalmic reports. ChatGPT-5 Thinking achieved “near-perfect” (κ ≥ 0.81) agreement with the clinical reference for all measured biometric and keratometric parameters. This finding aligns closely with the emerging trend of utilizing LLMs in medical domains, specifically for processing ophthalmic reports. 16 Previous research has demonstrated that LLMs can extract critical parameters such as AL, ACD, and corneal astigmatism from raw biometry reports with high accuracy, ranging from 95% to 100%. 11 The performance of ChatGPT-5 Thinking, especially in handling complex K and TK data, demonstrates that sophisticated LLMs can transcend simple text extraction to understand and process the complex relationships and precise numerical values of the parameters in ophthalmic reports.
However, we observed that the performance of ChatGPT-5 and DeepSeek Thinking dropped significantly to only “Moderate” when recognizing astigmatism-related parameters. This highlights that not all LLMs possess equal complex reasoning capabilities. Accurate identification of astigmatism indices requires the model to perform precise multivariable reasoning and calculation. 7 This limitation underscores the critical need for rigorous validation of LLMs’ domain-specific task performance before their integration into clinical workflows.
LLMs in toric IOL planning
For astigmatic patients, accurate toric IOL planning is essential to achieving satisfactory uncorrected vision, as errors in candidacy assessment, cylindrical power choice, or alignment may lead to significant residual astigmatism. 17 Toric IOL implantation is generally indicated for patients with corneal astigmatism exceeding 0.75-1.0 D.18,19 Our study revealed clear differences in the models’ reliability for recommending toric IOL implantation. ChatGPT-5 Thinking achieved the highest accuracy rate at 100.0%, a result that was significantly better than both ChatGPT-5 and DeepSeek Thinking. This performance suggests that ChatGPT-5 Thinking may serve as a reliable workflow-assistance tool for the toric candidacy component of preoperative planning by translating biometry data into an appropriate binary recommendation. Interestingly, the high accuracy of the LLMs suggests that their decision-making process is not reliant on a simple numerical threshold. Previous research recommends distinct clinical thresholds for Toric IOL implantation: Toric IOLs are considered for with-the-rule (WTR) astigmatism when the value exceeds 1.5 D, but for against-the-rule (ATR) astigmatism, implantation is advised when the value exceeds only 0.4 D.20,21 Therefore, the high accuracy (>90%) demonstrated by the three LLMs confirms that they do not rely solely on a simple ΔK threshold. Instead, their ability to perfectly manage toric IOL recommendations suggests they successfully integrated complex decision rules that account for astigmatism type.
Clinical superiority in refractive prediction
The accurate calculation of toric IOL power is a key factor for minimizing postoperative refractive error and ensuring spectacle independence in astigmatic patients.6,22 Regarding refractive prediction, ChatGPT-5 Thinking exhibited an advantage compared with both ChatGPT-5 and DeepSeek Thinking. This result is consistent with the current trend in cataract refractive surgery to utilize AI to enhance IOL calculation accuracy.23,24 Moreover, ChatGPT-5 Thinking had the largest proportion of cases falling within the tightest clinically acceptable thresholds (e.g., Sph ≤ 0.50 D). The excellent refractive prediction performance of ChatGPT-5 Thinking suggests potential utility in calculator-based toric IOL planning workflows. However, a significant limitation stems from the non-transparent nature of LLM computation. While the model’s strong performance suggests it successfully learned and internalized the underlying optical principles and empirical relationships of IOL calculation from its massive medical training data, the exact basis of its numerical outputs is not publicly disclosed. Consequently, it is plausible that these calculations are heavily reliant on, or derived from, existing, validated IOL calculation formulas (such as Barrett Universal II).
Analysis of efficiency and time-accuracy balance
The efficiency and computational cost of LLMs are critical factors for practical deployment. This is especially true within a high-throughput clinical setting, such as an ophthalmology clinic. Our thinking time analysis revealed that DeepSeek Thinking required a longer thinking time than ChatGPT-5 Thinking. However, its accuracy did not improve correspondingly. This result underscores the trade-off between efficiency and accuracy. 25 Furthermore, the plateau observed in the accuracy-time curve suggests a limit to the model’s thinking efficiency. Beyond a certain optimal processing time, additional reasoning does not yield significant marginal gains in recognition accuracy. Future development of LLMs for ophthalmic applications should focus on efficiency optimization to ensure their practicality within the fast-paced environment of an ophthalmology clinic.
Limitations
Our study has several limitations. First, the cohort consisted of 54 eyes, and each case was evaluated three times per model in independent sessions to assess response variability and repeatability. These repeated runs represent response-level repeatability rather than independent clinical samples. Second, the reference standard used in this study was the manufacturer’s toric IOL calculator rather than surgeon-selected IOL plans or postoperative refractive outcomes. Therefore, the findings should be interpreted primarily as evidence of feasibility for automated report interpretation and workflow assistance, rather than direct validation of clinical refractive outcomes. Third, the sample size was relatively small and did not include important subpopulations such as highly myopic eyes or other complex ocular conditions. In clinical practice, surgeons often intentionally target slight residual myopia in these cases to reduce the risk of postoperative hyperopic shift and improve patient satisfaction, which deviates from the emmetropic target used in standard calculations. Fourth, the study was conducted at a single institution in one geographic region. Finally, the LLM outputs were evaluated using measurements from a single optical biometer, whereas real-world cataract planning typically integrates multimodal clinical data. Therefore, the current findings should be interpreted primarily as preliminary evidence supporting the feasibility of automated report interpretation using LLMs. Future studies should validate the performance of LLMs across more diverse patient populations, incorporate multimodal clinical measurements, and evaluate locally deployed open-source distilled models, which may offer advantages in deployment cost, data governance, and integration into hospital information systems for real-world clinical implementation.
Conclusion
In summary, this study systematically compared the performance of three advanced LLMs in preoperative toric IOL planning. The results demonstrate that ChatGPT-5 Thinking was significantly better than both ChatGPT-5 and DeepSeek Thinking, achieving high accuracy in both ophthalmic biometry parameter recognition and refractive prediction. These findings support the feasibility of applying general-purpose LLMs to automated interpretation of ophthalmic biometry reports and toric IOL planning workflows. LLMs possess substantial potential to evolve into reliable and efficient workflow-assistance tools in ophthalmology.
Supplemental material
Supplemental material - Comparison of three large language models in recognizing ophthalmological examination and supporting preoperative toric IOL planning
Supplemental material for Comparison of three large language models in recognizing ophthalmological examination and supporting preoperative toric IOL planning by Xuanqiao Lin, Yizhou Yang, Songlian Wang, Lei Cai, and Jin Yang in Digital Health.
Supplemental material
Supplemental material - Comparison of three large language models in recognizing ophthalmological examination and supporting preoperative toric IOL planning
Supplemental material for Comparison of three large language models in recognizing ophthalmological examination and supporting preoperative toric IOL planning by Xuanqiao Lin, Yizhou Yang, Songlian Wang, Lei Cai, and Jin Yang in Digital Health.
Footnotes
Ethical considerations
This single-center retrospective methodological study was approved by the Institutional Review Board of the Eye & ENT Hospital of Fudan University (Approval No. 2025275) and conducted in accordance with the Declaration of Helsinki.
Author contributions
X.L. and Y.Y. contributed equally to study design, development of the LLM evaluation protocol, data collection, statistical analysis, data interpretation, visualization, and drafting of the manuscript. S.W. was responsible for data management, coding support, and assisted with statistical analysis and result validation. L.C. and J.Y. conceived and designed the study, provided clinical supervision and resources, oversaw project administration, and critically revised the manuscript for important intellectual content. All authors read and approved the final version of the manuscript and agree to be accountable for all aspects of the work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the National Natural Science Foundation of China (Grant number 82171039).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The de-identified datasets analyzed during the current study are not publicly available because they will be used for subsequent related research, but are available from the corresponding author on reasonable request.
AI use disclosure
AI-assisted tools were used only for language editing and improvement of expression during manuscript preparation. All scientific content, data interpretation, and final revision of the manuscript were performed and approved by the authors.
Guarantor
Xuanqiao Lin is the guarantor of this work and accepts full responsibility for the integrity of the data and the accuracy of the data analysis.
Supplemental material
Supplemental material for this article is available online.