
Abstract
Objectives
Inadequate meal frequency (IMF) among children aged 6–23 months remains a pressing public health issue in Somalia, contributing to widespread malnutrition and hindering progress toward Sustainable Development Goals 2 (Zero Hunger) and 3 (Good Health and Well-being). This study investigates the most influential factors associated with IMF to inform targeted public health interventions.
Methods
Data from 4066 children were extracted from the 2020 Somalia Demographic and Health Survey, employing Five machine learning algorithms, Logistic Regression, Decision Tree, Random Forest, Support Vector Machine, and Gradient Boosting, and assessed for predictive performance using accuracy and area under the receiver operating characteristic curve (AUC-ROC) metrics. Feature importance was analyzed to identify key predictors of IMF.
Results
The prevalence of IMF was alarmingly high at 78.51%. The Gradient Boosting model outperformed other models with an accuracy of 89.55% and an AUC-ROC of 92.77%. Birth order emerged as the most dominant predictor across all models, accounting for 74.07% of the Gini importance in the Gradient Boosting model. Other significant predictors included child age, breastfeeding status, maternal education, household wealth, and region of residence.
Conclusion
The high prevalence of IMF highlights an urgent need for targeted interventions. Strategies focusing on families with higher birth order children, maternal education, and poverty reduction may be crucial for improving child nutrition in Somalia. These findings demonstrate the potential of machine learning approaches in informing public health strategies and predictive screening in resource-limited settings.
Introduction
Inadequate meal frequency (IMF) among children aged 6–23 months, characterized by consuming fewer meals than the World Health Organization (WHO) minimum recommendations, critically impedes optimal child health, growth, and development. 1 This developmental window is paramount for nutritional intervention, as deficiencies during this stage can lead to irreversible consequences, including stunting, impaired cognitive development, and increased susceptibility to infectious diseases.2–4 Addressing IMF is essential for achieving global health objectives, notably Sustainable Development Goal (SDG) 2 (End Hunger) and SDG 3 (Good Health and Well-being). 5 The WHO and UNICEF consistently emphasize appropriate complementary feeding, which includes adequate meal frequency, as a fundamental strategy to reduce child morbidity and mortality.6,7
Globally, a significant number of young children fail to meet the recommended minimum meal frequency.8,9 For instance, Sub-Saharan Africa (SSA) faces a particularly acute challenge, with consistently lower adherence to appropriate complementary feeding practices.10,11 A recent analysis of Demographic and Health Survey (DHS) data from 35 SSA countries indicated that only 38.47% of children met the Minimum Meal Frequency criteria. 11 Studies in neighboring countries like Ethiopia have reported IMF rates varying between 30.6% and 55.9%,12–15 while in Gambia, the figure was 57.95%, 16 and in Tanzania, context-specific factors also play a significant role. 17 These figures underscore the complex socio-cultural, economic, and environmental factors influencing feeding practices across diverse African contexts. 18
Somalia confronts one of the world's most severe and protracted humanitarian crises, characterized by decades of conflict, political instability, recurrent climatic shocks (e.g., droughts, floods), and widespread poverty, all of which critically undermine food security and nutritional outcomes for its children aged between 6–23 months. 19 The landmark Somalia Health and Demographic Survey (SHDS) 2020 revealed a dire nutritional landscape: a staggering 74.6% of children aged 6–23 months were not given any solid, semi-solid, or soft foods in the preceding 24 h. 20 This points to a pervasive pattern of IMF, a direct contributor to the high national rates of stunting (18%) and wasting (11%) among children under 5 years old.20–22
The etiology of IMF is multifactorial, with determinants operating at individual, household, and community levels, as consistently highlighted by WHO guidelines and numerous DHS-based studies across various settings, primarily in other Sub-Saharan African countries such as Ethiopia, Tanzania, and Ghana.11,17,23–27 Child characteristics (age, breastfeeding status, birth order), maternal attributes (education, age, parity), household factors (socioeconomic status, media exposure), and community context (type of residence, region of residence) are all recognized as influential.8,13,16,28–30 While traditional statistical methods, such as logistic regression, have been instrumental in identifying these general determinants, understanding their relative importance and potential complex correlation, especially in data-rich environments or contexts with intricate underlying patterns, remains a challenge. Notably, while determinants have been explored elsewhere, there is a significant gap in the literature regarding the specific drivers of IMF in the Somali context, a region with a unique and protracted humanitarian crisis.
The novelty of this study lies in its pioneering application of a comprehensive suite of machine learning (ML) algorithms to identify and rank factors associated with IMF among children aged 6–23 months in Somalia, using the nationally representative SHDS 2020 data set. ML techniques, including Logistic Regression, Decision Tree, Random Forest, and Support Vector Machine (SVM), offer powerful tools for analyzing complex data sets, discerning non-linear relationships, and prioritizing predictors based on their contribution to model performance.31,32 Recent applications of ML in nutritional epidemiology and child health have demonstrated its utility in predicting outcomes like micronutrient deficiencies, stunting, and identifying key risk factors with potentially improved accuracy and nuanced insights compared to conventional methods alone.33–37 To our knowledge, this study represents the first application of such a diverse range of ML models to investigate the determinants of IMF specifically within Somalia, and potentially one of the first such comprehensive ML-driven analyses in the broader East African region, if not Africa, focusing on this critical Infant and Young Child Feeding (IYCF) indicator.
By leveraging the predictive power and feature importance capabilities of these five distinct ML models, this study aims to move beyond traditional associative analysis. The rationale for employing five different algorithms is threefold: first, to ensure the robustness of our findings by triangulating results from models with different underlying assumptions; second, to compare their predictive performance in a real-world public health context in Somalia, providing methodological insights; and third, to identify a potential best-performing model for future predictive screening applications in similar resource-limited settings. Our objective is to identify the most influential predictors of IMF in the Somali context, potentially uncovering patterns that might be less apparent with standard regression techniques and providing a data-driven prioritization of risk factors. The anticipated findings are expected to provide robust, evidence-based insights that will be invaluable for national and international stakeholders, including policymakers, public health practitioners, and humanitarian organizations, in designing and targeting contextually appropriate, high-impact interventions to improve IYCF practices, specifically meal frequency, reduce malnutrition, and ultimately enhance child survival and development in Somalia.
Materials and methods
Data source
This study utilized secondary data from the 2020 Somalia Demographic and Health Survey (SDHS), the first nationally representative health survey in the country. Conducted by the Somali National Bureau of Statistics (SNBS) in partnership with the Federal Ministry of Health, Federal Member State Ministries, the United Nations Population Fund (UNFPA) Somalia, and international partners, data were collected between February 2018 and January 2019 using Computer-Assisted Personal Interviewing (CAPI). A multistage stratified cluster sampling method was employed, with a three-stage design used in urban and rural areas and a two-stage design in nomadic areas. Each region was stratified into urban, rural, and nomadic categories except for Banadir, which is entirely urban, yielding 55 initial strata. Due to security concerns, eight strata were excluded (three from Lower Shabelle, three from Middle Juba, and two additional unspecified strata), resulting in a final total of 47 sampling strata. For this analysis, information was extracted from the Kids Record (KR), which includes comprehensive data on children aged 0–59 months. Permission to use the data set was obtained through a formal online request submitted via the SNBS Microdata Portal (https://microdata.nbs.gov.so) following user registration and approval. The SDHS is a vital source of demographic and health-related information in Somalia, playing a key role in guiding evidence-based policymaking, program development, and progress tracking toward national and international goals, including the SDGs, thereby supporting informed decision-making and enhancing the effectiveness of health and development interventions across the country.
Sample size
The study focused on children aged 6–23 months, the critical window for complementary feeding. From the initial SDHS 2020 data set, records for 4139 children aged 0–23 months were identified from the KR file. After data cleaning, which involved excluding cases with missing information on the outcome variable (meal frequency) or key covariates essential for the analysis, the final analytical sample comprised 4066 children aged 6–23 months. To ensure the findings are representative of the target population and account for the complex survey design (stratification and clustering), sample weights provided within the SDHS 2020 data set were applied throughout all descriptive analyses to adjust for the non-proportional allocation of the sample to different regions and to urban and rural areas during the survey's sampling stage.
Study variables
Outcome variable
The variable was constructed based on maternal recall of the types and number of meals the child consumed in the 24 h preceding the interview, as captured in the DHS questionnaire's IYCF module. The primary outcome variable was the meal frequency status of children aged 6–23 months within the 24 h preceding the survey interview. This was assessed according to the WHO 2008 guidelines for Minimum Meal Frequency, which vary based on a child's age and breastfeeding status (6). Specifically, the frequency of solid feeds was derived from the question: “How many times did the child eat solid, semi-solid, or soft foods yesterday?” For non-breastfed children, where milk feeds count toward the minimum frequency, the total frequency was calculated by summing responses to the following questions: “How many times did the child drink powdered, tinned, or fresh milk?”, “How many times did the child drink infant formula?”, and “How many times did the child eat yogurt?” Specifically:
Breastfed infants aged 6–8 months are expected to receive solid, semi-solid, or soft foods at least twice daily. Breastfed children aged 9–23 months are expected to receive such foods at least 3 times daily. Non-breastfed children aged 6–23 months should receive a minimum of four feedings per day. For non-breastfed children, these four feedings may include milk feeds (such as infant formula or animal milk), provided that at least one feeding consists of solid, semi-solid, or soft food.
As maternal interview questions in DHS typically capture only solid, semi-solid, or soft food intake, milk feedings (for non-breastfed children) were computed separately (if applicable and data permitted) and combined with reported food feedings to obtain the total daily feeding count. Children who met or exceeded the minimum number of required feedings for their age and breastfeeding status were categorized as having “Adequate” meal frequency (coded as 0). Those who did not meet the requirement were categorized as having “Inadequate” meal frequency (IMF, coded as 1).
Independent variables
All independent variables selected for this study were categorical in nature. The selection of independent variables was guided by the UNICEF conceptual framework for malnutrition, 7 prior literature on determinants of IMF,11,13,14,17,25,28–30,38–40 and the availability of relevant indicators within the SDHS 2020 data set. These variables were categorized into three analytical levels: individual, household, and community.
Data preprocessing
Data preprocessing was conducted using Python (Version 3.9) with Pandas and Scikit-learn libraries. Missing values for predictor variables were minimal after initial cleaning but were handled by mode imputation for categorical features. Categorical variables were numerically encoded using label encoding for ordinal features (e.g., education level, wealth index) and one-hot encoding for nominal features (e.g., region) to prepare them for ML algorithms. The outcome variable (IMF) was already binary (0/1).
Statistical analysis
Descriptive statistics (weighted frequencies, percentages) were calculated for all variables. Bivariable associations between independent variables and IMF were assessed using the Chi-Square test, applying survey weights, to ensure that the results of the bivariable analysis were representative of the entire population of Somali children aged 6–23 months. A p < .05 was considered statistically significant. Feature importance was derived from the trained models (coefficients for Logistic Regression; Gini importance for Random Forest, Decision Tree, Gradient Boosting; permutation importance for SVM) to identify key predictors. All statistical analyses were performed using STATA (Version 16) and Python (Version 3.9) with libraries including Pandas, NumPy, Matplotlib, Seaborn, and Scikit-learn (Version 1.2.0 or as per notebook).
Machine learning models
Given the nature of the data set (complex interrelations) and the research objective (binary classification of IMF and identification of important factors), we selected five ML algorithms known for their robustness and interpretability: Logistic Regression, Decision Tree, Random Forest, and Gradient Boosting. Additionally, SVM was included for its powerful classification capabilities. Each algorithm was chosen for its suitability for binary classification tasks and its unique approach to modeling relationships between features and the outcome variable.
Logistic Regression: A linear model that estimates the probability of a binary outcome based on a linear combination of input features, using the logistic function to map the output to a probability between 0 and 1.
41
It provides interpretable coefficients for feature importance. Decision Tree: A non-parametric model that partitions the data into subsets based on the values of input features, creating a tree-like structure of decisions to predict the outcome. It is highly interpretable and can capture non-linear relationships.
42
Random Forest: An ensemble learning method that constructs multiple decision trees, each trained on a random subset of the training data and a random subset of the input features. The final prediction is made by averaging (for regression) or voting (for classification) the predictions of all individual trees, improving accuracy and reducing overfitting.
43
It also provides feature importance scores. Gradient Boosting: An ensemble learning technique that builds models sequentially, where each new model corrects errors made by previous models. It typically uses decision trees as base learners and is known for its high predictive accuracy by combining many weak learners into a strong learner.42,44 SVM: A powerful algorithm that finds an optimal hyperplane to separate data points belonging to different classes in a high-dimensional space. A linear kernel was primarily used for efficiency and interpretability, although other kernels (e.g., radial basis function) were explored during hyperparameter tuning45,46
Model development and training
For model development and training, the data set was partitioned into an 80% training set and a 20% testing set. Stratified sampling, based on the outcome variable (IMF status), was employed to ensure proportional representation of the outcome variable in both the training and testing sets, thereby ensuring that models were trained and subsequently evaluated on samples representative of the study population. 44 The designated training set was utilized for the development of ML algorithms. The testing set was reserved for an independent and unbiased evaluation of the final models’ predictive performance. To ensure the generalizability of the model outputs to the national population and to appropriately account for the complex survey design inherent in the SDHS, sample weights were integrated during the training of ML algorithms amenable to such weighting, including Logistic Regression and tree-based ensembles like Random Forest and Gradient Boosting.
Model evaluation
To assess the predictive performance of the developed ML models on the held-out testing data set, several key evaluation metrics were employed. These metrics included:
Accuracy represents the proportion of correctly classified instances among the total number of cases examined. It is calculated as follows:
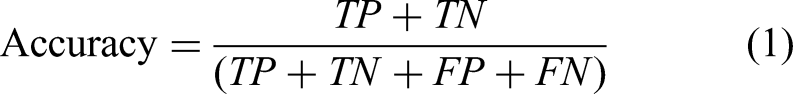
Precision measures the proportion of correctly predicted positive cases out of all instances classified as positive. It is defined as:

Recall (Sensitivity) quantifies the model's ability to correctly identify true positive cases and is expressed as:

Specificity measures the ability of the model to correctly identify true negative cases and is given by:
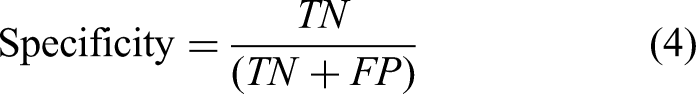
F1-Score is the harmonic mean of precision and recall, providing a balanced measure that accounts for both false positives and false negatives. It is computed as follows:

Area Under the Receiver Operating Characteristic Curve (AUC-ROC): A comprehensive measure of a classifier's ability to distinguish between classes across various probability thresholds. A higher AUC-ROC value indicates superior discriminatory power. 47
Classification reports, including precision, recall, and F1-score for each class (Adequate Meal Frequency and IMF), and confusion matrices were also generated to provide a detailed understanding of model performance. Feature importance was extracted from models (Logistic Regression coefficients, Decision Tree/Random Forest feature importance's, and permutation importance for SVM) to identify key determinants.
Ethical considerations
The SDHS 2020 data collection protocol was approved by the Institutional Review Board (IRB) of the SNBS. Informed consent was obtained from parents or legal guardians for children's participation in the original survey. This study involves secondary analysis of publicly available, anonymized data, thus not requiring separate ethical approval. Data confidentiality and anonymity were maintained throughout the analysis.
Results
Prevalence of IMF
The overall weighted prevalence of IMF among children aged 6–23 months in Somalia was alarmingly high at 78.51% (95% CI [77.1%–79.9%]) (Figure 1). This indicates that over three-quarters of the children did not meet the WHO minimum requirements for meal frequency.

Prevalence of inadequate meal frequency.
Sociodemographic characteristics of the study participants
The analysis included a weighted sample of 4066 children aged 6–23 months. The socio-demographic characteristics of these children, their mothers, and their households are presented in Table 1.
Characteristics of study participants (weighted n = 4066).

Slightly over half (52.44%) of the children were male. The largest proportion of children belonged to the 12–17 months age group (45.21%), followed by the 18–23 months group (22.43%), 6–8 months (18.74%), and 9–11 months (13.62%). Nearly half (48.44%) were reported as currently breastfeeding, while 51.56% were not. The majority of children (69.99%) were reported as being of normal size at birth, with 30.01% reported as underweight. First-born children constituted 21.69% of the sample, while 67.10% were of birth order 2–3, and 11.21% were of birth order four or higher.
Maternal characteristics highlighted significant challenges. A vast majority of mothers (82.03%) had received no formal education, with only 13.44% having primary education and a mere 4.53% having secondary or higher education. Most mothers (93.25%) were married. The predominant maternal age group was 20–29 years, accounting for 54.81% (25.38% for 20–24 years and 29.43% for 25–29 years). Mothers aged 15–19 years comprised 7.91% of the sample. Parity data showed that 44.61% of mothers had 0–3 children ever born, 42.63% had 4–7, and 12.76% had 8 or more. Home births were common (75.94%), compared to 24.06% delivering in a health facility. A large proportion of mothers (67.46%) reported having no exposure to mass media (radio, television, or newspapers/magazines).
The community and household context revealed that the majority of children resided in urban areas (61.38%), with substantial proportions in rural (27.01%) and nomadic settings (11.61%). Households were predominantly headed by males (69.86%). Regarding household head's age, 76.64% were under 30 years. Most households (61.01%) had more than four members. Household wealth distribution showed significant disparities, with 43.98% of children living in households classified within the poorest or poorer wealth quintiles (22.78% poorest, 21.20% poorer), while 16.23% were in the richest quintile.
To assess potential multicollinearity among predictor variables, a correlation heatmap was generated (Figure 2). The heatmap indicated that most inter-variable correlations were weak to moderate (absolute values generally <0.4, with a few exceptions like Age group and Children ever Born showing a correlation of −0.64), suggesting that multicollinearity was not a major concern for the subsequent modeling.

Correlation heatmap of predictor variables.
Bivariable analysis of factors associated with IMF
Table 2 presents the results of the bivariable analysis examining the association between various characteristics and IMF status, using the Chi-Square test.
Bivariable associations between characteristics and meal frequency status.

Several child characteristics were significantly associated with IMF (p < .001). As noted, IMF was highest among children aged 12–17 months (82.1%) and those still breastfeeding (83.6%). Birth order demonstrated an exceptionally strong association (p < .001); IMF was dramatically lower for first-born children (27.6%) compared to the extremely high rates observed for children of birth order 2–3 (91.8%) and ≥4 (97.4%). Child's sex and size at birth were not significantly associated with IMF in the bivariable analysis (p = .918 and .195, respectively).
Significant associations were also found between IMF and several maternal factors (p < .001). Children of the youngest mothers (15–19 years) had the lowest IMF prevalence (51.8%), which increased significantly for mothers in older age groups. Maternal education showed a strong inverse relationship (p < .001), with IMF prevalence falling sharply from 79.5% for children of mothers with no education to 44.9% for those whose mothers had higher education. Place of delivery was also significant (p < .001), with children born at home experiencing higher IMF (80.9%) compared to those born in a health facility (70.8%). High parity (total children ever born) showed a strong positive association with IMF (p < .001). Marital status was not significantly associated (p = .327).
Among household factors, the age of the household head was significant (p < .001), with a notably high IMF prevalence (92.3%) for households headed by individuals aged 41–54 years. Family size was also significant (p = .040), with slightly higher IMF in smaller families (≤4 members: 81.0%) compared to larger families (>4 members: 76.9%). Sex of the household head (p = .069) and media exposure (p = .303) were not significantly associated with IMF.
All examined community-level factors demonstrated highly significant associations with IMF (p < .001). Strong regional disparities were evident, and residence type was critical, with nomadic children having the lowest IMF (61.8%) compared to rural (78.8%) and urban (81.6%) children. Household wealth quintile showed a clear gradient (p < .001), with IMF prevalence decreasing significantly from the poorest (83.3%) to the richest (67.9%) quintile.
Machine learning algorithms performance
Five ML models were trained and evaluated for their ability to classify IMF. The performance metrics on the test set are summarized in Table 3.
Predictive performance of machine learning algorithms for IMF.

The Gradient Boosting algorithm demonstrated superior discriminatory power, achieving the highest AUC-ROC of 92.77%, closely followed by Random Forest (91.70%) and Logistic Regression (91.16%). The SVM also exhibited strong performance (AUC-ROC: 90.47%), whereas the Decision Tree model yielded a substantially lower AUC-ROC (77.24%). These comparative performances are visually depicted by the Receiver Operating Characteristic (ROC) curves in Figure 3. In terms of overall accuracy, Gradient Boosting (89.55%) and SVM (89.43%) were the top-performing models. The F1-score for the primary class of interest, “Inadequate Meal Frequency” (Class 1), was highest for Gradient Boosting (93.12%) and SVM (93.02%), indicating a robust balance between precision and recall for identifying instances of IMF.

Receiver operating characteristic (ROC) curves of the five models.
Figure 4 shows that all models demonstrated strong capability in identifying inadequate meal feeding (Class 1), evidenced by consistently high true positive (TP) counts (ranging from 522 to 557), reflecting robust sensitivity to the majority class. However, performance in correctly classifying adequate meals (Class 0) varied more substantially, with true negatives (TN) spanning 126–149. The Decision Tree exhibited the highest error rates for both false positives (FP = 63; adequate meals misclassified as inadequate) and false negatives (FN = 74; inadequate meals missed as adequate), indicating poorer calibration for minority-class recognition. In contrast, SVMs achieved the highest TN (149) and lowest FP (40), optimizing specificity for adequate meals, while Random Forest maximized TP (557), prioritizing sensitivity to inadequacy. Gradient Boosting and Logistic Regression balanced these metrics effectively, with the latter achieving the lowest FN (42), minimizing critical failures to detect inadequate feeding. The pervasive class imbalance (596 inadequate vs. 189 adequate samples) underscores the challenge of minority-class precision and suggests context-dependent model selection, prioritizing FP reduction (e.g., SVM for resource conservation) or FN minimization (e.g., Random Forest for safety-critical applications).

Confusion matrices for (a) Decision Tree, (b) Logistic Regression, (c) Random Forest, (d) SVM, and (e) Gradient Boosting models.
Feature Importance
To identify the principal determinants of IMF, feature importance was assessed for each of the ML models. The methods for deriving importance varied by model: absolute magnitude of coefficients for Logistic Regression, Gini importance for tree-based models (Random Forest, Decision Tree, Gradient Boosting), and permutation importance for the SVM.
For the Gradient Boosting model, which demonstrated superior predictive performance in the evaluation, Birth Order emerged as the overwhelmingly most influential feature, with an important score of 0.741, as depicted in Figure 5. Subsequent features, while considerably less impactful, included Breastfeeding status (0.053), Region (0.033), Child age (0.031), and Maternal age group (0.027).
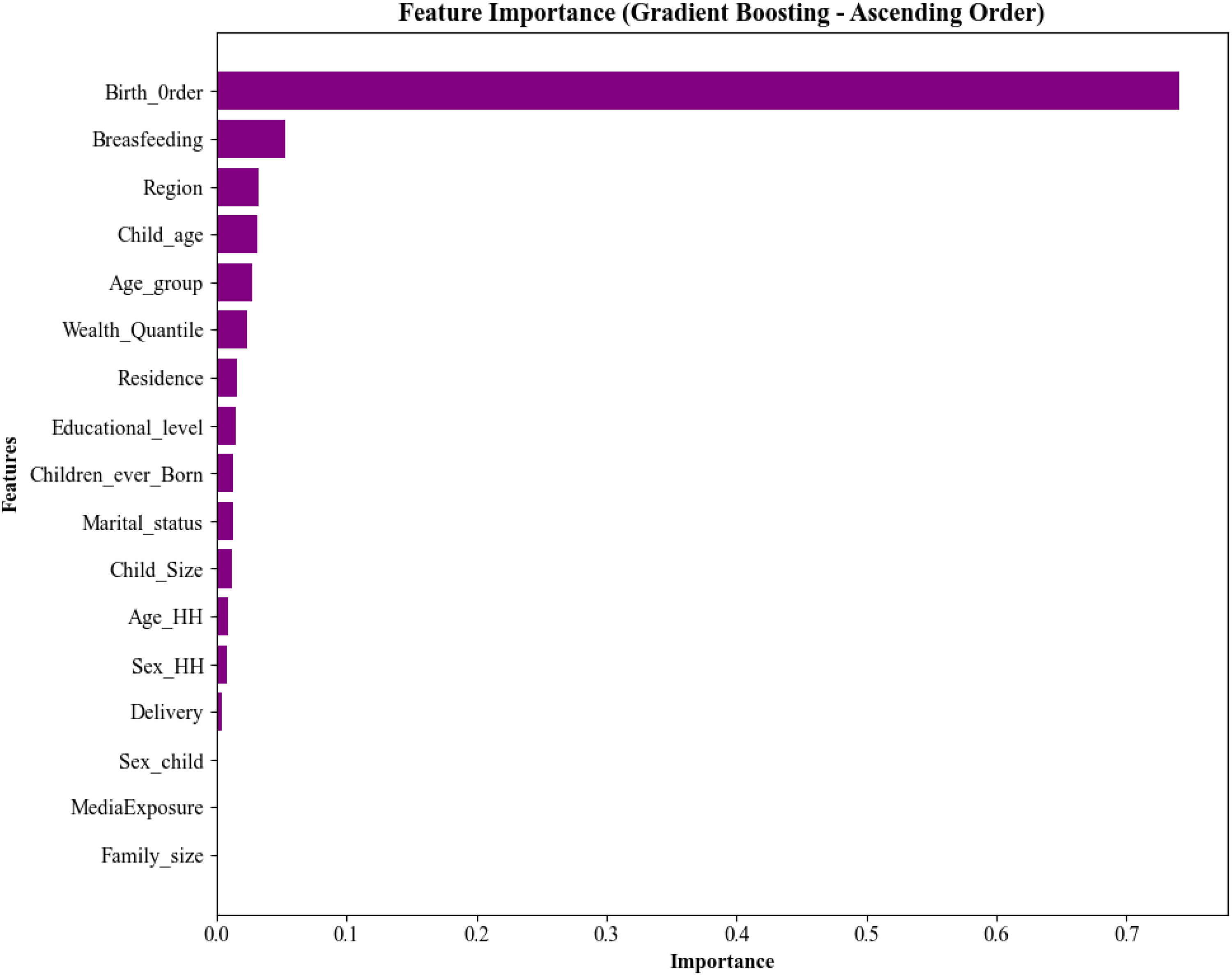
Most important factors using Gradient Boosting (in descending importance).
Figure 6(a–d) presents the five most important factors associated with IMF using Logistic Regression model. Analysis of coefficient magnitudes also identified Birth Order as the most significant predictor (coefficient magnitude: 3.214). Other features with notable importance were Breastfeeding status (0.753), Marital status (0.458), Child Size at birth (0.345), and Delivery (place of delivery). The Random Forest model, as depicted, similarly highlighted Birth Order as the primary predictor (importance: 0.347). This was followed by region (0.120), Maternal age (0.073), Wealth Quantile (0.068), and Child age (0.057). For the Decision Tree model, Birth Order again held the highest importance (0.419). Other key predictors identified by this model included Region (0.114), Maternal age group (0.081), Wealth Quantile (0.074), and Child age (0.033). Using permutation importance, the SVM also identified Birth Order as the most critical feature (importance: 0.263). Notably, many other features exhibited zero permutation importance in this model, suggesting a strong reliance on Birth Order for its predictions.

Top five feature importances across models. Subplots (a), (b), (c), and (d) display the top five feature importances for Logistic Regression, Random Forest, Decision Tree, and SVM (permutation importance), respectively. In all subplots, features are ranked in ascend.
Feature importance analysis (Figure 6a–d) consistently identified Birth Order as the paramount predictor of IMF across all models, though its quantification varied by method: highest magnitude in Logistic Regression coefficients (3.214), greatest importance weight in Random Forest (0.347) and Decision Tree (0.419), and dominant permutation importance in SVM (0.263). Secondary predictors diverged across models: Breastfeeding status, Marital status, and Child Size were prominent in Logistic Regression, whereas Region, Maternal Age, and Wealth Quantile recurred in tree-based models. Notably, SVM exhibited exclusive reliance on Birth Order, with zero importance assigned to other features. Despite methodological differences, key determinants like Region, Maternal Age, Child Age, and Wealth Quantile persistently surfaced across multiple models, reinforcing their robust epidemiological association with feeding outcomes and value for targeted interventions.
Discussion
This study, leveraging ML approaches on data from the inaugural SDHS 2020, provides novel insights into the determinants of IMF among children aged 6–23 months in Somalia. The overall weighted prevalence of IMF was found to be an alarming 78.51%, starkly positioning Somalia among countries with the poorest IYCF practices globally. This rate significantly exceeds those reported in neighboring Ethiopia (ranging from 30.6% to 47.0%)13,14 and pooled estimates for SSA, where approximately 38.5% meet Minimum Meal Frequency. 11 To our knowledge, this research represents the first application of diverse ML models, Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, and SVM to analyze IMF-related outcomes in Somalia, and potentially the first such comprehensive ML-driven analysis in the broader East African region for this specific IYCF indicator.
The application of five distinct machine-learning algorithms enabled a robust identification and ranking of factors associated with IMF. The comparative performance of these models is presented in Table 3 and further illustrated using ROC curves (Figure 3) and confusion matrices (Figure 4a–e). Ensemble-based approaches, such as Gradient Boosting and Random Forest, which aggregate multiple decision trees, demonstrated superior predictive performance compared with the single Decision Tree model. This finding suggests that complex and potentially non-linear relationships between the covariates and IMF outcomes may be more effectively captured by these algorithms, although their performance may also reflect advantages such as variance reduction and improved generalization. In contrast, the relative performance of Logistic Regression indicates that additive and approximately linear associations between specific predictors and the probability of IMF remain informative, implying that simpler parametric relationships continue to contribute meaningfully to prediction alongside more flexible machine-learning models.
The feature importance analysis across all ML models consistently identified Birth order as the most significant predictor of IMF. As illustrated by the Gradient Boosting model, our best performer (Figure 6), birth order accounted for an overwhelming 74.07% of its Gini importance. This dramatic finding, where higher birth order substantially increases the risk of IMF, suggests severe intra-household resource dilution and caregiver burden, potentially exacerbated in the Somali context by large family sizes and socio-economic fragility (Ministry of Planning, 2020). While higher birth order is often linked to poorer IYCF outcomes,13,48 the extreme magnitude identified by our ML models underscores a critical vulnerability for later-born Somali children, demanding highly targeted interventions.
This primacy of Birth order was further corroborated by the feature importance analyses of the other four models, Logistic Regression, Random Forest, Decision Tree, and SVM, as summarized in the combined visualization presented in Figure 6(a–d). Across these diverse algorithms, Birth order consistently ranked as the top predictor. For instance, in the Logistic Regression model, Birth order exhibited the largest coefficient magnitude. Similarly, the Random Forest and Decision Tree models highlighted Birth order with the highest Gini importance scores among their respective top five features. The SVM, using permutation importance, also identified Birth order as the most critical feature, with many other features showing negligible importance, suggesting a strong reliance of the SVM on this single predictor.
Beyond Birth order, other factors consistently appearing with notable importance across several models (as seen in Figure 6) included Breastfeeding status (prominent in Gradient Boosting and Logistic Regression), Region (important in Random Forest, Decision Tree, and Gradient Boosting), and Maternal Age group (featuring in Random Forest and Decision Tree). The common paradoxical finding in IMF analyses, where currently breastfed children show higher IMF,14,25,49,50 was evident in our bivariable results, and its continued predictive importance in ML models emphasizes the need for nuanced messaging around complementary feeding alongside breastfeeding.
Socio-economic determinants, namely maternal education and household wealth, were also identified by our ML models as important factors. For example, Wealth quantile was among the top predictors for both the Random Forest and Decision Tree models, while educational level or related proxies like Maternal Age group also showed relevance. This aligns with a vast body of literature from SSA and beyond,8,11,13,15,16,51 including ML-driven studies on micronutrient deficiencies in Ethiopia. 34 Given that 82.03% of mothers in our sample had no formal education and 43.98% of children lived in the poorest/poorer households, these findings underscore the profound impact of socio-economic disparities on child nutrition in Somalia.
Child age was another consistently important predictor, as demonstrated by the Gradient Boosting, Random Forest, and Decision Tree models. The bivariable analysis showed higher IMF in the 12–17 months age group, a pattern also observed in Ethiopia and SSA,11,13 indicating this transitional period for breastfeeding and caregivers being less vigilant on active feeding unlike the period of initiation of complementary feeding, is a high-risk window in Somalia, a finding confirmed by its predictive significance in our ML models. The importance of Region in the Gradient Boosting, Random Forest, and Decision Tree models points to localized contexts of conflict, food security, service access, and cultural norms heavily influencing feeding practices in Somalia, consistent with spatial heterogeneity findings in Ethiopia.13,14,34
The application of ML in this study offers distinct advantages. Methodologically, the use of five distinct algorithms served as a form of sensitivity analysis; the consistent identification of Birth Order as the primary predictor across models with fundamentally different approaches (e.g., the linear Logistic Regression, the tree-based Random Forest, and the hyperplane-based SVM) significantly strengthens the validity of this finding. Beyond confirming known risk factors, the consistent ranking of predictors like Birth Order with such high importance across diverse algorithms provides robust evidence for prioritization. Furthermore, ML models can implicitly capture non-linear relationships and complex association between variables that traditional regression models might not fully elucidate, 36 crucial in a multifaceted issue like IMF in a complex humanitarian setting. The high predictive accuracy of models like Gradient Boosting (accuracy: 89.55%) suggests their potential utility in identifying high-risk children or communities for targeted interventions, a key aim of ML in public health.35,37 This could be particularly valuable in a data-scarce context like Somalia, where such models could be developed into screening tools for community health workers, allowing them to prioritize households for nutritional support even when direct measurement of dietary intake is not feasible. However, some factors significant in bivariable analyses or traditional regressions in other studies media exposure, place of delivery, as seen in Harindintwari et al. (2024) or Kang et al. (2019), showed lower or inconsistent importance in our ML models for Somalia, possibly due to the overwhelming influence of dominant factors like birth order in this specific context or algorithmic differences in predictor weighting.51,52
Strengths and limitations
Key strengths of this study include its use of the first nationally representative SDHS data for Somalia, the application of a suite of robust ML algorithms for predictor identification, and a substantial sample size. This ML-centric approach provides a novel and timely lens on IMF determinants in a data-scarce, fragile context, representing a pioneering effort in this specific research area for Somalia. However, the study is subject to limitations inherent in cross-sectional DHS data, such as the potential for recall bias in dietary intake reporting and the inability to definitively establish causality. The exclusion of eight insecure strata from the original SDHS sampling frame may also affect the generalizability of findings to the most vulnerable and hard-to-reach populations. While ML models are powerful in identifying complex associations and achieving high predictive accuracy, the “black box” nature of some algorithms can make the direct interpretation of specific relationship effects challenging, although feature importance metrics provide valuable insights into predictor contributions. Furthermore, the meal frequency indicator itself is quantitative and does not capture the qualitative aspects of dietary intake, such as nutrient density or diversity.
Future research
Building on these findings, future research should aim to incorporate longitudinal data to explore causal pathways and the temporal dynamics of IMF. Qualitative studies are warranted to delve deeper into the socio-cultural drivers of the observed feeding patterns, particularly the extreme risk associated with high birth order and the potential protective factors in nomadic communities. Expanding the ML approach to include a wider array of potential predictors, such as detailed household food security indicators, paternal characteristics, and access to specific health and nutrition services, could further refine predictive models. Investigating the application of more advanced ML techniques, including deep learning or hybrid models, might also yield additional insights, particularly if richer data sets become available. Finally, exploring the operationalization of these ML models into practical screening tools for community health workers or program planners could translate these research findings into tangible public health impact.
Conclusion
This study used ML-driven analysis of the SDHS 2020 data that reveals an extremely high prevalence of IMF among young Somali children. Birth order emerged as an exceptionally dominant predictor, alongside child age, breastfeeding status, maternal education, household wealth, and regional context. These findings, underscored by the robust performance of ML models like Gradient Boosting, call for urgent, multi-sectoral interventions. Priorities should include targeted support for families with high birth order children, initiatives to empower women through education and economic opportunities, poverty reduction strategies, and geographically tailored programs. The insights gained from this ML approach can help refine targeting strategies and improve the effectiveness of nutritional interventions in this critical humanitarian context.
Footnotes
Ethical approval
This study is based on secondary analysis of the SDHS 2020 data set. The original data collection protocol was approved by the IRB of the SNBS. Informed consent was obtained from parents or legal guardians for all child participants in accordance with established ethical standards. As this research utilizes publicly available, anonymized data, no additional ethical approval was required for this study. Confidentiality and anonymity were strictly maintained throughout the analytical process.
Consent for publication
This study uses anonymized secondary data where individual consent for publication is not required.
Authors' contributions
Mohamed Abdirahim Omar was responsible for authoring the paper, conducting the analysis, composing the results section, and preparing the manuscript. Omran Salih contributed to editing, analyzing, reviewing, and correcting the manuscript for scientific integrity. Omran Salih also served as Mohamed Abdirahim Omar's supervisor throughout the study. Both authors contributed to conceiving the research topic, exploring the idea, performing the analysis, and drafting the manuscript. The authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.