
Abstract
Background:
Depression is recognized as one of the most prevalent mental health disorders globally. Early detection and intervention can significantly reduce its negative impact on patients. Data from social media platforms provide new opportunities for early warning, intervention, and support for individuals with depression. However, traditional discriminative methods are limited in both the accuracy and interpretability of depression identification. Most studies focus on binary classification tasks, lacking more fine-grained identification.
Methods:
We model depression degree recognition as a multi-level text classification task and a multi-level text generation task, exploring more fine-grained identification in the Chinese context. We construct the depression degree ((Depression Weibo) dataset and the first multi-level interpretable depression degree instruction dataset. Based on these datasets and ChatGLM3, a Chinese open-source large language model, we train DepGLM. We also compare how fine-tuned large language models perform against multiple baseline models across different tasks.
Results:
The results show that the text classification model, DepGLM-tc, demonstrates superior accuracy compared to current state-of-the-art (SOTA) discriminative approaches, achieving a weighted F1 score of 84%. Meanwhile, the text generation model, DepGLM-tg, approaches the accuracy of SOTA discriminative methods and is capable of generating high-quality explanations comparable to ChatGPT.
Conclusion:
This study demonstrates that large language models fine-tuned for specific domains more accurately identify depression degree. Moreover, our model demonstrates enhanced performance in classification tasks.
Keywords
Introduction
Depression is one of the most commonly acknowledged mental health disorders in the world and has been identified as a leading cause of global disability, as well as one of the primary reasons for suicide. 1 Over the past decade, the prevalence of depression among young people has surged dramatically. 2 Depression is associated with a range of severely negative effects, and early identification and treatment have been shown to help reduce these impacts for patients. 3 However, many individuals suffering from depression remain undiagnosed and untreated due to illness stigmatization. 4 This stigma is a major barrier to accessing mental health services. With the advancement of the Internet, social media has become an essential component of everyday life for many people, and overcoming stigma is considered to be the main benefit provided by the Internet. 5 The large amount of user-generated content on social media reflect the real state and emotions of users in a timely manner. Analyzing social media posts is crucial for detecting mental disorders within the population. 6 Utilizing data from social media platforms to study the levels of depression expressed in user posts not only provides large-scale, real-time information but also offers new possibilities for early warning, intervention, and support for individuals with depression.
With the explosive growth of social media posts, researchers have increasingly investigated the application of deep learning and natural language processing (NLP) techniques to automatically identify depressive posts on these platforms. These studies demonstrate the potential to predict medical diagnoses of depression through the expressions in social media posts.7–9 Traditional depression recognition methods using deep learning models conceptualize the task as a text classification problem, with pre-trained language models (PLMs) achieving state-of-the-art (SOTA) performance. However, there is still significant potential for enhancement regarding both accuracy and interpretability. 4 Additionally, most studies focus on binary classification tasks, lacking more fine-grained recognition in depression. Recently, large language models (LLMs) have shown exceptional performance in NLP tasks and many other tasks. 10 LLMs can provide interpretable analyses, and their applications for depression degree recognition can be regarded as a text generation task aiming to provide detailed explanations and predictions. 11 Existing studies have assessed the effectiveness of LLMs in mental health classification tasks. These findings suggest that the accuracy of the zero-shot prompting method highlights the potential of LLMs for such classification tasks. 12 However, in zero-shot or few-shot prompting methods, closed-source LLMs continue to face challenges in achieving classification performance that matches that of SOAT supervised methods. 13 They are also highly sensitive to slight changes in prompts. 14 Fine-tuning for specific domains is an effective approach. However, it encounters two main challenges: (1) A shortage of high-quality training data, and (2) the lack of open-source foundational LLMs. 11
To address these limitations, we model depression degree recognition as a text classification task and a text generation task respectively, exploring the performance of the LLM after fine-tuning for different tasks. We construct the depression degree ((Depression Weibo (DW)) dataset and the first multi-level interpretable depression degree instruction (MIDDI) dataset. First, we crawl 12,074 posts from the Weibo depression community. After preprocessing the data, we invite professional annotators to annotate the posts to construct the DW dataset for subsequent text categorization tasks. Second, we prompt ChatGPT with expert-designed prompts to obtain detailed explanations for different annotation labels assigned to the posts. To ensure the reliability of the interpretations, we automatically assess the correctness, consistency, and quality of these explanations, and construct the MIDDI dataset for subsequent text generation tasks. Finally, based on the above datasets and the ChatGLM3, a Chinese open-source foundation LLM, we propose two models: The text classification model DepGLM-tc and the text generation classification model DepGLM-tg. We evaluate their accuracy in classifying depression degree. Experimental results indicate that the accuracy of DepGLM-tc exceeds the SOTA discriminative method, while the accuracy of DepGLM-tg is comparable to the SOTA discriminative method. Furthermore, we assess the quality of explanations generated by DepGLM-tg, the results show that DepGLM can produce explanations at the level of ChatGPT.
This study provides significant theoretical support for the application of LLMs in depression recognition. We categorize depression degree into four categories: No significant depressive symptoms, mild depression, moderate depression, and severe depression, allowing for more fine-grained identification within the Chinese context. We construct the MIDDI dataset, the first instruction-tuning dataset for multi-level interpretable depression degree recognition on social media. We introduce the text classification model DepGLM-tc and the text generation classification model DepGLM-tg, both of which achieve high accuracy in recognizing depression degree from social media data. As far as we know, DepGLM-tg is the first LLM with instruction-following capabilities for interpretable depression degree recognition and is capable of generating high-quality explanations for its predictions.
Related work
Early studies on depression detection in social media mainly rely on machine learning methods, where text features are extracted first and then traditional machine learning methods are applied for classification. Commonly employed feature extraction methods in depression recognition research include LIWC, TF-IDF, LDA, among others, 15 while classifiers such as SVM, Logistic Regression, Random Forest are widely used.16,17 With the advancement of deep learning, a growing number of scholars are applying deep learning algorithms to depression recognition in social media, such as CNN, RNN, Bidirectional Encoder Representation from Transformer (BERT) and RoBERTa.18–20 PLMs have emerged as the leading approach for diverse NLP tasks, including depression detection, significantly enhancing the accuracy of such detection methods.
Despite the impressive classification performance of these black-box models, some studies have explored interpretable approaches for depression analysis. Zogan et al. (2022) proposed an interpretable depression identification model HAN, which captures the interpretability of tweets from depressed users through hierarchical attention mechanisms at both the tweet and word levels to enhance depression detection. 16 Han et al. (2022) utilized contextual embeddings from BERT as input features, incorporating Metaphor Concept Mappings as additional features to improve model interpretability. 21 Additionally, researchers have integrated information from professional mental health measurement questionnaires, such as the Patient Health Questionnaire-9 22 and the Beck Depression Inventory (BDI), 23 to enhance model generalizability and out-of-domain performance.
In addition, some studies leverage multimodal information to significantly enhance the accuracy of depression detection methods, such as audio, video, vision, and textual data. Reece and Danforth (2017) screened for depression through photos posted by users to Instagram. 24 Toto et al. (2021) developed a multimodal approach called AudiBERT for depression Recognition, which integrates pre-trained audio embeddings and text embeddings from a BERT encoder. 25 Niu et al. (2023) extracted audio and video features to identify indicators of depression in vocal tone and facial cues, leveraging complementary information across modalities to improve model detection accuracy. 26
LLMs can effectively process large amounts of natural language text and simulate human interaction behavior, showing promising applications in the field of mental health care. 14 Some researchers have utilized LLMs to assist doctors in diagnosing and identifying diseases. By integrating medical big data with artificial intelligence and LLMs, more precise, efficient, and intelligent medical diagnosis and treatment can be achieved. Tu et al. (2023) constructed Med-PaLMMultimodal, a multimodal biomedical generalized large model that can flexibly encode and interpret biomedical data including clinical language, images, and genomes. 27 Additionally, some researchers have employed LLMs as classification models for mental health identification. Lamichhane (2023) evaluated the performance of the gpt-3.5-turbo model in three mental health classification tasks: Stress recognition (binary classification), depression recognition (binary classification), and suicide recognition (five-class classification) using the OpenAI API interface. 12 The classification accuracy of zero-shot prompting method indicates the potential of language models in mental health classification tasks. Most studies address multiple mental health issues,11,12,28 while a few focus on single mental health conditions. 4 The most commonly studied mental health statuses include stress, suicide, depression, and anxiety. However, due to the limitations in the availability of open-source datasets, most research has primarily focused on simple binary mental health detection tasks, such as the binary depression detection datasets Depression_Reddit 29 and CLPsych15 (CLP), 30 with few studies concentrating on more fine-grained mental health identification. Skianis et al. (2025) evaluated the effectiveness of LLMs in predicting mental health conditions severity in different languages (Greek, Turkish, French, Portuguese, German, and Finnish), including four-class depression prediction and five-class suicide prediction. 31
Unlike PLMs, LLMs can not only serve as classification models for mental health detection but also as text generation models, providing interpretable text for mental health detection results. Lan et al. (2024) proposed the DORIS depression detection system by combining LLMs and GBT classifiers, improving the model’s interpretability. 4 Xu et al. (2024) conducted an in-depth evaluation of several LLMs, such as Alpaca, Alpaca-LoRA, FLAN-T5, GPT-3.5, and GPT-4, for mental illness prediction tasks using online text data. They also carried out an exploratory case study to assess the mental health reasoning abilities of these models. 32 Galatzer-Levy et al. (2023) evaluated the ability of the LLM Med-PaLM2 in the medical field to predict mental function from patient interviews and clinical descriptions. The study analyzed 145 cases of depression, 115 cases of PTSD, and 46 clinical cases of various diseases. The results showed that Med-PaLM2 can effectively assess mental function. The model performed strongest in predicting depression scores and its predictions were statistically indistinguishable from human clinical raters. 33 These studies, based on zero-shot and few-shot prompting approaches, have rarely focused on building interpretable datasets for instrution fine-tuning. Yang et al. (2024) constructed the first multi-task, multi-source interpretable mental health instruction dataset and trained the MentaLLaMA model. Compared to general-purpose LLMs, MentaLLaMA improved accuracy and explanation quality, demonstrating strong generalization capabilities and the ability to adapt to unseen tasks. 11
Therefore, we categorize depression degree into four categories: No significant depressive symptoms, mild depression, moderate depression, and severe depression, allowing for more fine-grained identification within the Chinese context. We created the first multi-label interpretable depression degree instruction dataset MIDDI, and performed instruction fine-tuning on general-purpose LLMs. To the best of our knowledge, our system is the first model designed for interpretable depression degree identification that allows for more fine-grained depression identification at the post level. The model achieves high accuracy and interpretability, effectively bridging the gap in previous studies.
Methods
This is a computational modeling study aimed at developing a new interpretable model for recognizing depression degree from social media text. We model depression recognition as two tasks: Text classification and text generation, and evaluate how LLMs fine-tuned for these tasks perform compared with baseline models. The study was conducted in Shanghai, China, from June 2024 to December 2024.
This section describes the methodology used to construct the DW dataset and the MIDDI dataset. The process consists of three main steps: Raw data collection, generation of interpretations through ChatGPT, and multi-faceted automated evaluation of the generated interpretations. After constructing these datasets, we further compared them with baseline models to assess their effectiveness. To provide a clearer overview, Figure 1 presents a flowchart of the overall methodology, outlining the sequential steps from dataset construction to model comparison and evaluation.
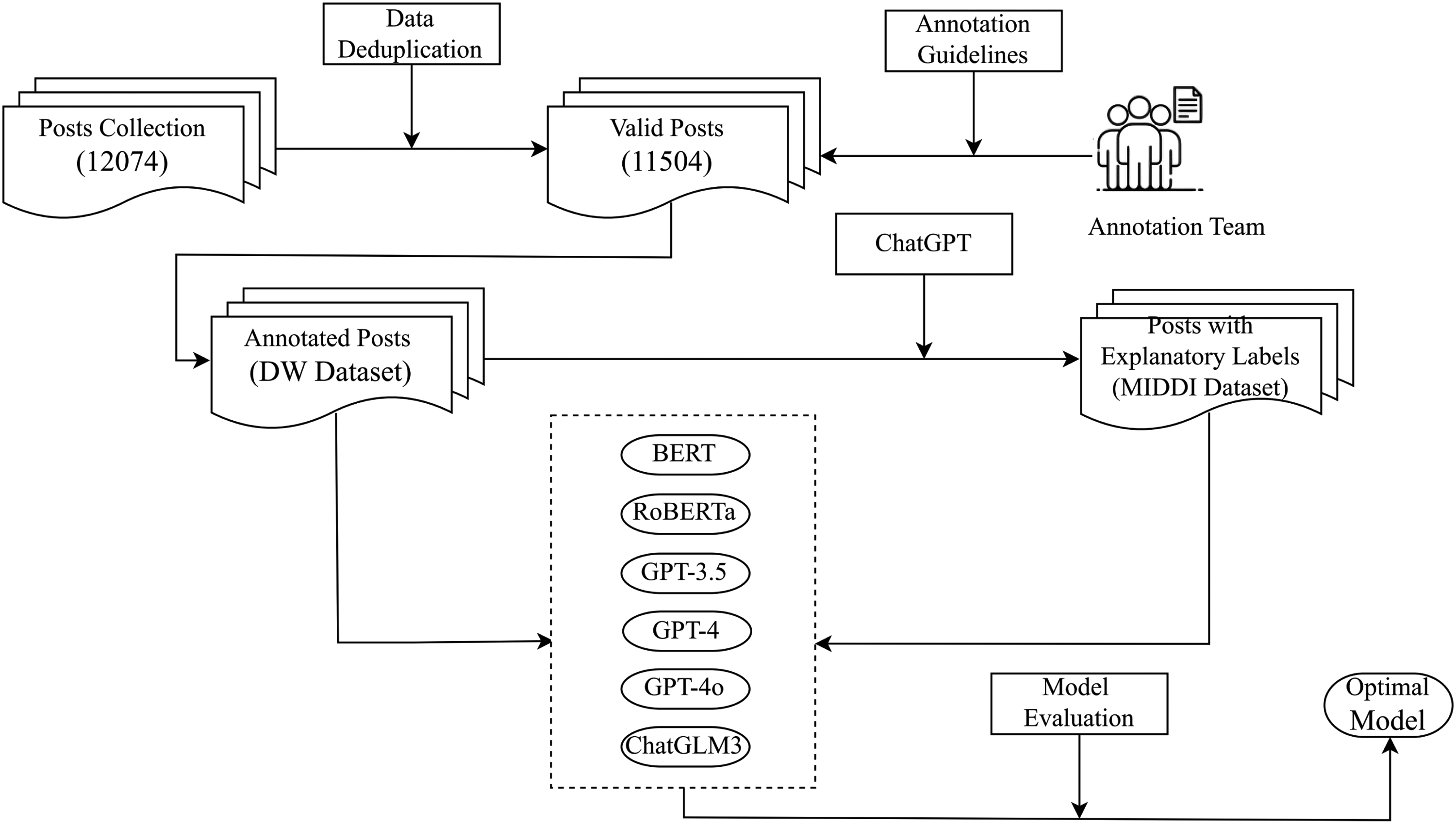
Flowchart of the overall methodology.
As one of the most popular social media platforms in China, Sina Weibo attracts an increasing number of users to share their thoughts. 34 Users can join the communities they are interested in and share their lives. Among these communities, the Super Community of Depression serves as a dedicated forum for mental health discussions, where users express their thoughts and experiences related to depression. As of June 4, 2024, the Super Community of Depression contained approximately 1.067 million posts. Instead of using specific keywords, we collected data directly from the Super Community of Depression, scraping posts based on their popularity (e.g., ranked by likes, comments, or shares). This approach allowed us to capture widely engaged content relevant to our study. We randomly scraped 12,074 posts, covering the period from December 31, 2022, to January 8, 2024. After removing duplicate posts, 11,504 unique posts remained for analysis. To ensure privacy and ethical compliance, our data collection was restricted to publicly available posts, no private or restricted content was accessed. Before processing, all personally identifiable information (e.g., user IDs, usernames, timestamps and location) was removed to prevent any re-identification. The dataset therefore consisted solely of de-identified text used for model training. All data was stored on secure, exclusive servers and the access was strictly limited to our research team. The data was used solely for academic purposes. The data collection process adheres to ethical research guidelines and Weibo’s terms of service and applicable guidelines. This study was reviewed by the Ethics Committee of Shanghai University (ECSHU), which confirmed that it did not require formal ethical approval . A waiver document is available and serves as official confirmation of ethical compliance.
Based on the most commonly used scales in clinical assessments of depression, including the Hamilton Depression Scale, 35 Self-Rating Depression Scale, 36 and BDI, 37 this study classifies depression degree into four levels: No significant depressive symptoms, mild depression, moderate depression, and severe depression. This is also a commonly used standard in previous research for depression classification.19,31,38.
During the manual annotation process, we reference the annotation guidelines designed by Wang et al (2019). 19 A depression degree of 0 indicates that the poster shows no depressive tendencies and is merely describing some of the common life stresses, such as work, study, or family pressures. A depression degree of 1 indicates that the poster is experiencing mild depression. In these posts, user expresses feelings of despair about life or describes the condition status and treatment associated with depression. A depression degree of 2 indicates that the poster is experiencing moderate depression. In these posts, user mentions suicidal or self-harming thoughts, but without specific details regarding time or location. A depression degree of 3 indicates that the poster is experiencing severe depression. These posts describe that the user describes a specific implementation plan for suicide or self-harm, or has committed a suicidal or self-harming act. In addition, when patients self-report being diagnosed with mild, moderate, or severe depression, we label the posts accordingly based on their self-report. Table 1 presents definitions and examples for the different levels of depression.
Definitions and examples for the different levels of depression.

Definitions and examples for the different levels of depression.
To ensure the reliability of the annotations, three doctoral students with psychology-related academic backgrounds participated in the labeling process. All three annotators hold doctoral degrees, with their thesis work specifically focusing on the identification and assessment of mental health conditions (particularly depression) and the exploration of associated psychosocial factors. This background provides them with solid theoretical foundations and practical expertise in mental health evaluation.
The annotation process was conducted in three rounds following a protocol adapted from Wang et al. (2019). Before the formal annotation, two annotators independently labeled a random subset of 300 posts and discussed their disagreements to improve the annotation guidelines. In the first formal round, the same two annotators labeled the full dataset, achieving a Cohen’s kappa coefficient of 0.48. In the second round, after further refining the guidelines based on observed inconsistencies, the same two annotators re-annotated only the posts with disagreement. Their agreement improved substantially and reached a kappa of 0.93, indicating a high level of agreement and consistency across annotations. In the third round, a third annotator reviewed the remaining inconsistent cases and made the final labeling decisions after discussion with the original annotators. We attribute the substantial improvement in agreement to the refinement of annotation guidelines after the first round and the annotators’ greater experience in resolving ambiguous cases during the second round. This multi-stage process ensured that all labels were assigned with consensus and produced a dataset with high reliability and consistency, which we refer to as the depression degree (DW) dataset.
Despite the availability of manually annotated classification labels, there is a notable absence of data offering detailed and dependable explanations for these annotations. To address this, we employ ChatGPT to develop explanations for the samples in the DW dataset, a method that has demonstrated reliability in previous interpretable mental health studies.11,28 Firstly, we ask psychological experts to write one query instruction for the dataset and manually create 35 interpretation examples for each level. The explanations written by the experts form a golden explanation set G, containing 140 samples. For the convenience of model training and evaluation, all expert-generated explanations followed this template:
Label:[label].Reasoning:[explanation]
In this format, [label] represents the classification label, and [explanation] refers to the associated explanation content. Furthermore, we randomly select one explanation example for each level from the golden explanation set G and incorporate them as few-shot examples in the system prompt. To increase the quality of the generated explanation texts, we extract the classification labels from the original dataset. Finally, we construct the prompt using the query instruction, the few-shot expert-generated examples, and the label corresponding to the target posts. Figure 2 shows a specific example of the prompt. Considering that the model was trained in Chinese, English translations are also provided on the right for clarity.

Prompt example.
To maintain the standard of the explanations provided, we carry out a detailed evaluation of the outputs generated by ChatGPT. Given the high volume of generated explanations, we carry out an automated evaluation of all collected data based on three criteria: Correctness, consistency, and quality. Correctness refers to the model’s capability to make accurate label predictions, consistency pertains that the explanation offer clues and analysis that align with its predicted labels, and quality indicates that the generated explanation should present high-quality corroborative evidence in terms of reliability, professionalism, and so on.
Correctness: We include the annotated labels from the manually labeled dataset in the prompts to assist ChatGPT in producing precise explanations. An explanation is considered correct when its reasoning leads to the same conclusion as the expert-assigned label in the manually annotated dataset and the model does not raise any contradictions or doubts. This ensures that the evaluation of explanation correctness is based on independently established expert annotations. We note that ChatGPT occasionally expresses disagreement with the specified labels in its responses and sometimes does not follow the required language and format. For examples that do not meet language and formatting standards, we prompt ChatGPT for another round of output until the responses conform to the requirements. After the above adjustments, ChatGPT only expresses disagreement with the specified labels for six posts in the dataset. For these cases, we invite psychological experts to conduct a manual review of the prompts and responses in order to adjust or rewrite the classifications and explanations.
Consistency: Since all ChatGPT responses adhere to the template, consistency is evaluated by assessing whether the information in the [explanation] supported the [label] in each response. We extract the content by “Label” and “Reasoning” tags separately, and employ the set of [explanation] from ChatGPT responses to perform a training split on each raw data. We divide all data into training and testing sets in the ratio of 7:3 to train a BERT-based classifier. The specific formula is presented below:
Here,
Quality: Yang et al. (2024) 11 conducted a careful manual assessment of mental health explanatory texts generated by ChatGPT using supervised few-shot prompts. Generated texts were assessed on four aspects: Consistency, reliability, professionalism, and overall assessment. The study demonstrated that ChatGPT with supervised few-shot prompts could generate explanations with strong overall performance, achieving high consistency scores while delivering reliable information and multiple pieces of evidence supported from a psychological perspective. For evaluation, we apply BART-Score to automatically assess the quality of the generated explanations. BART-Score is one of the most advanced metrics for text evaluation, comprehensively measuring various perspectives including informativeness, fluency, and authenticity. 39 It has been widely validated in machine learning and AI research. In our study, the generated explanations were compared with the golden set G, where higher scores indicate that generated explanations are closer to the dataset annotated by experts in both semantics and content. While BART-Score provides a meaningful assessment of text quality, future research may benefit from exploring complementary metrics for a more comprehensive evaluation.
While the MIDDI dataset in its entirety was not independently validated by domain experts, we randomly selected 30 posts along with their generated explanations for two clinical psychiatrists to review. Both psychiatrists evaluated the generations independently and confirmed that the BART-Score effectively reflected the quality of explanations. This validation enhances the clinical reliability of our evaluation methods to some extent.
All posts in the DW dataset, along with their corresponding explanations generated by ChatGPT, constitute the MIDDI dataset. The test results show that the BART-score on the golden explanation set G is above
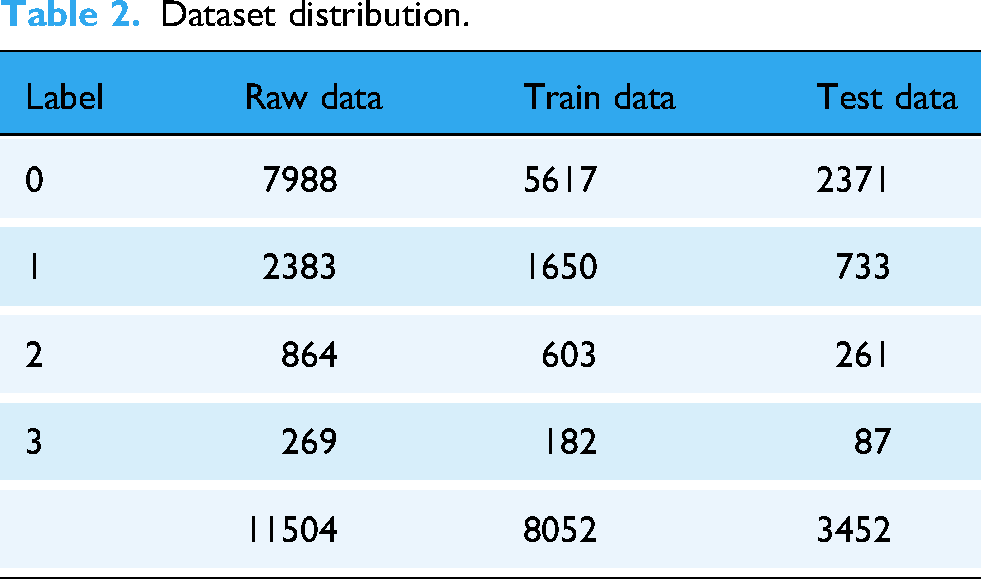
Dataset distribution.
To compare with our model, we choose the following PLMs and LLMs with good performance and representativeness as benchmark models.
We select classification models as baseline models as previous mental health analyses have been framed as text classification tasks. Moreover, large-scale PLMs have achieved SOTA performance in numerous NLP tasks. 40 However, since none of these classification models can generate explanatory text, we only use these models in accuracy comparisons. In this paper, we select the following models for experimental analysis:
Bert(110M) 41 : The Bert model developed by Google is capable of understanding the context of words and is used for natural language understanding tasks. Given that this study focuses on Chinese data, we select the Bert-base-chinese model for training.
Roberta(110M) 42 : Roberta is a NLP model proposed by Facebook. By investigating the impact of key hyperparameters and the scale of the training data on the model’s effectiveness, Roberta makes a series of improvements and optimizations to the Bert model, improving the model’s performance across different natural language understanding tasks.
In recent research, the application of LLMs such as GPT-3 43 and ChatGPT has gained attention in the realm of mental health analysis. These models have proven to be effective at recognizing stress, depression, and suicide risk in social media posts. While LLMs exhibit exceptional language understanding capabilities, they still face challenges related to bias, data imbalance, and language specificity. 44 In this paper, the following most representative models from the OpenAI series are selected for experimental analysis:
GPT-3.5(175B): GPT-3.5 is an enhanced version of GPT-3, which covers a broader range of domains in its training data, allowing the model to perform even better in comprehending and generating text. GPT-3.5 shows significant improvements in NLP capabilities. We select the better performing and most cost-effective model gpt-3.5-turbo.
GPT-4(1.8T) 45 : GPT-4 is optimized in terms of model architecture and training algorithms, resulting in significant improvements in context understanding, reasoning abilities, and accuracy of generated text. Similarly, we select the gpt-4-turbo model for its superior performance.
GPT-4o: GPT-4o maintains the same high level of intelligence as GPT-4 but offers faster response times, lower usage costs, and higher rate limits. GPT-4o is a lightweight model designed to provide efficient AI solutions for resource-constrained devices.
Due to the aforementioned LLMs are closed-source, we utilize OpenAI’s API to access these models. In light of the restricted availability of the API and the significant costs associated with fine-tuning GPT-3.5 or GPT-4, we leverage zero-shot prompting and few-shot prompting methods for instruction tuning. Informed by prior research, we construct a straightforward classification instruction for instruction tuning. Meanwhile, since this study is a four-class classification task, it is essential to include the criteria for categorization in the instructions. We construct the templates using a rule-based approach, and directly use the evaluated explanations generated by ChatGPT as responses to these prompts. The specific instruction tuning templates are presented in Table 3.
Instruction prompt template.

Instruction prompt template.
In this section, we describe a detailed overview of the training process for DepGLM. Training a specialized LLM from the ground up demands a large amount of computational resources and a vast corpus of data. 46 A more practical strategy is to construct DepGLM by leveraging existing general pre-trained LLMs. In this study, we select the ChatGLM3 model, 47 a Chinese open-source LLM with approximately 6 billion parameters, as our base model. We choose ChatGLM3 as the base model mainly because of its excellent performance in various NLP tasks. In addition, ChatGLM3 is more adaptable to Chinese corpus.
Based on the DW dataset and the MIDDI dataset, we fine-tune the ChatGLM3 to construct our DepGLM model. We start by splitting the DW dataset and the MIDDI dataset into a 7:3 ratio for the training and test sets. Regarding the text classification task, we fine-tune the ChatGLM3 model using the DW dataset and identify the optimal model according to the test set results. Instead of setting the hyperparameters once and for all, the final configuration in this study is the result of multiple rounds of iterative tuning based on empirical experiments and grid search. In the initial modeling stage, we systematically explored several key hyperparameters. The AdamW optimizer
48
is employed for training the model. For the maximum learning rate, we tested values of 1e-5, 2e-5, 3e-5, 4e-5 and 5e-5, ultimately selecting 1e-5 based on performance. The batch size was set to 1 due to hardware constraints (Intel Core i9-14900KF CPU and NVIDIA RTX 4090 GPU). The number of training epochs was chosen from a range of 2 to 10, with 3 epochs yielding the best results. Gradient accumulation steps were also tuned within the range of 1–4, and 1 was selected as the optimal value. Considering the small number of training epochs and our dataset size, early stopping was not applied in this study. For the text generation task, we train the model on the MIDDI dataset to construct the DepGLM-tg (DepGLM-text generation) model. Using a similar grid search process, we set the number of epochs to 10 and the maximum learning rate to 2
Results
Correctness assessment
Table 4 displays the outcomes of the accuracy evaluation. The Bert model still achieves SOTA performance with a weighted-F1 measurement of 0.81, while the Roberta model performs poorly with a weighted-F1 score of 0.71. This discrepancy may be attributed to the language of the corpus used during the model’s pre-training, as Bert-base-chinese is pre-trained entirely on the Chinese corpus. Considering the relatively smaller parameter sizes of these models, we infer that fine-tuning PLMs is still the most effective approach for detecting varying levels of depression. Additionally, the quantity of language-specific samples in the pre-training corpus significantly impacts model performance. However, a major limitation of these methods is their lack of interpretability in decision-making.
Accuracy evaluation results on the test set.
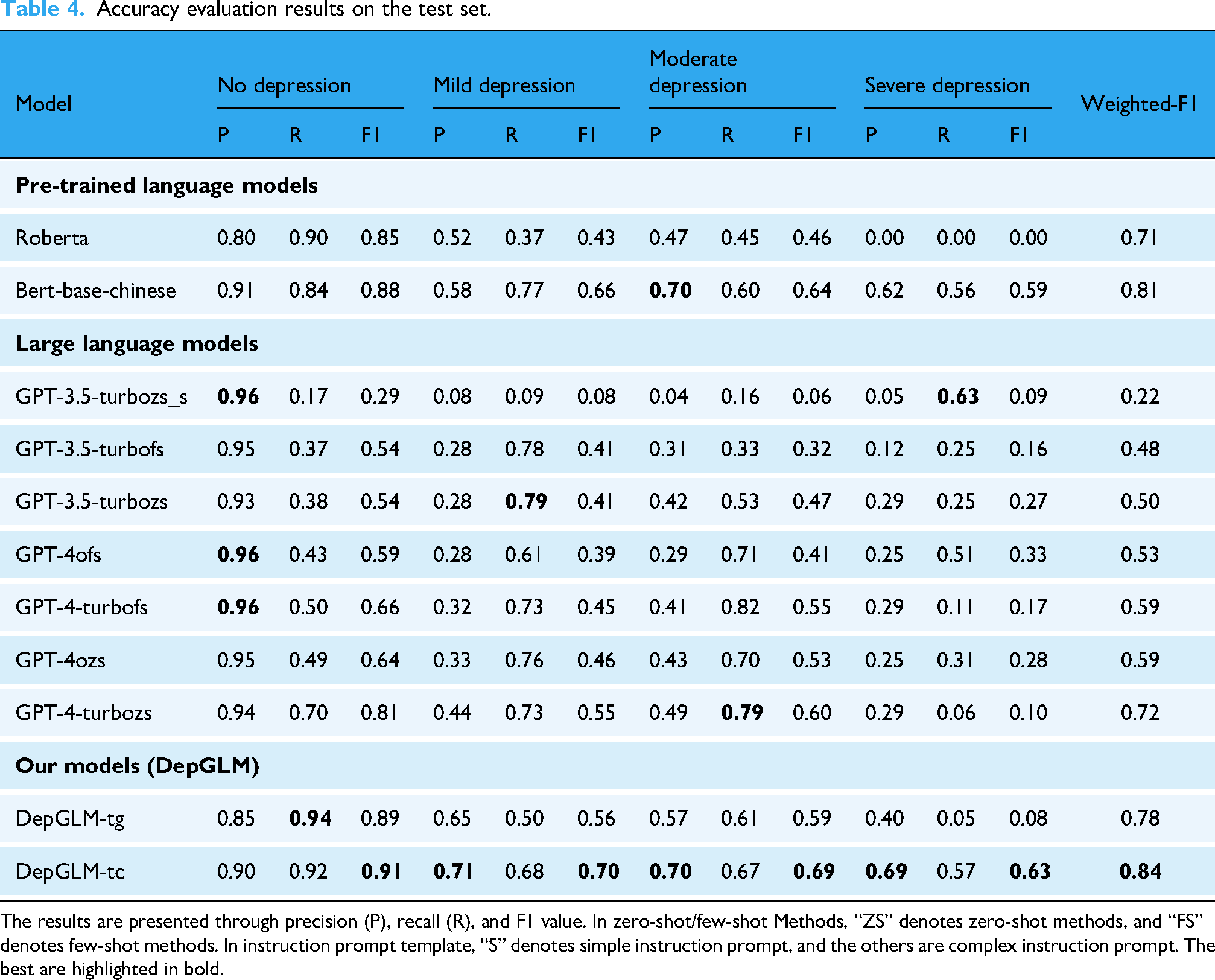
Accuracy evaluation results on the test set.
The results are presented through precision (P), recall (R), and F1 value. In zero-shot/few-shot Methods, “ZS” denotes zero-shot methods, and “FS” denotes few-shot methods. In instruction prompt template, “S” denotes simple instruction prompt, and the others are complex instruction prompt. The best are highlighted in bold.
We also present the confusion matrices for each model, as shown in Figure 3, which facilitate a deeper understanding of the models’ classification performance. For instance, the confusion matrix for the Bert-base-chinese model demonstrates high accuracy in detecting depression degree, particularly excelling in distinguishing between mild and severe depression. In contrast, Roberta performs relatively well in classifying mild and moderate depression, but struggles to effectively differentiate severe depression from other levels of depression. Even the strongest baseline models show limited capability in detecting severe depression, while DepGLM-tc succeeds in achieving relatively more reliable recognition.

Confusion matrices of models sorted by weighted F1 score. Vertical axis: True labels; horizontal axis: Predicted labels. Diagonal cells show the number of correctly predicted instances for each class; off-diagonal cells indicate misclassifications. (a) Models with F1 from 0.22 to 0.53; (b) Models with F1 from 0.59 to 0.72; (c) Models with F1 from 0.78 to 0.84.
We evaluate classification performance using three standard metrics: Precision, recall, and F1 score.
Precision measures the proportion of correct predictions among all posts the model assigned to a specific category—“When the model predicts a certain depression degree, how often is it correct?”
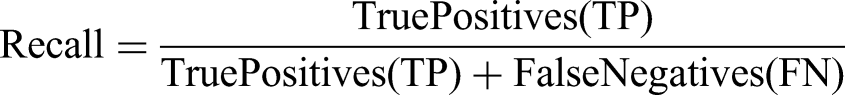

Moreover, different instruction tuning templates significantly impact model performance. By analyzing the confusion matrices, we observe that theGPT-3.5-turboZS_s model shows a significant improvement in classification performance compared to the GPT-3.5-turboZS model. This improvement is especially notable in accurately identifying mild and moderate depression. The misclassification rates have also been significantly reduced. The results show that instructions with specific criteria for depression degree classification can effectively enhance the model’s performance in multi-level mental health analysis. This results in nearly a 30% performance boost compared to simpler instructions. This can be attributed to the contextual learning capabilities of LLMs, 43 where the core of contextual learning is rooted in leveraging the model’s contextual comprehension skills to accomplish the task. The model infers by relying on the contextual information given in the input (including examples and task descriptions), rather than relying solely on explicit training processes.
In the comparison of few-shot prompting methods, we are surprised to find that the capability of the model GPT-3.5-turboFS is inferior to that of GPT-3.5-turboZS, with a decrease in the weighted-F1 score by 2%. Similarly, the few-shot prompting methods for GPT-4-turbo and GPT-4o also exhibit reduced accuracy to varying extents when compared to zero-shot prompting methods. We reviewed several misclassified posts and found that zero-shot models successfully recognized the implied depressive tone in posts containing Internet buzzword like “YuYu,” which sounds similar to “depression” in Chinese. In contrast, few-shot models tended to misclassify them due to the lack of such expressions in the provided examples. It is possible that in our experimental analysis, the few-shot examples embedded in the prompts are not comprehensive enough and confused the model’s identification of the depression degree classification criteria. As a result, the models may have learned incorrect patterns, leading to a decline in performance.
In our model with instruction fine-tuning, DepGLM-tc achieved a weighted-F1 value of 0.84, surpassing the best baseline model, Bert-base-chinese, by a margin of 3%. The confusion matrix reveals that DepGLM-tc demonstrates a balanced performance across all categories. It excels in accurately classifying moderate and severe depression, particularly in identifying severe cases, where even the strongest baseline model has a higher misclassification rate. This indicates that, after instruction fine-tuning for the text classification task, the model has the ability to exceed SOTA in terms of accuracy for mental health analysis. However, DepGLM-tg has a weighted-F1 value of only 0.78, indicating that after instruction fine-tuning for the text generation task, the model has the ability to approach SOTA in terms of accuracy for depression degree recognition. In the evaluation of the model’s accuracy, we find that the text classification task is more accurate than the text generation task. This suggests that, while instruction tuning improves both tasks, the model performs better in classification. This may be due to the more structured and straightforward nature of classification tasks, in contrast to the complexity of generating coherent and contextually appropriate explanatory text.
We use the evaluation scores from the BART-Score to measure the quality of the model’s generated explanatory text on the golden set G. We find that after fine-tuning only for the text classification task, the DepGLM-tc model is unable to generate reasoning-based explanatory texts, even under chain-of-thought prompting. 50 This limitation aligns with previous findings, 32 suggesting that fine-tuning models for classification tasks may not be sufficient for producing high-quality explanations. This highlights the constraints of current fine-tuning approaches, especially when it comes to generating complex, reasoning-driven outputs in psychological health analysis.
We compare the quality of explanations generated by DepGLM-tg on the golden set G with the results obtained from GPT-3.5 and GPT-4 under supervised few-shot prompting with labeled supervision. Additionally, we compare the few-shot prompting results of GPT-3.5 with its zero-shot prompting results. Specifically, we use the prompts as the labeled supervision prompts. To simulate few-shot prompting, we remove the allocated labels but retain the expert-generated few-shot examples. For the zero-shot prompting, we remove both the allocated labels and the expert few-shot examples. This setup allows us to compare the models’ ability to generate quality explanations under different prompt configurations and supervision levels.
The findings can be seen in Figure 4. The BART-Score of the model ranges between -3.4 and -3.9. The few-shot prompting results of GPT-3.5 significantly outperform the zero-shot prompting results, which differs from previous accuracy assessment. Our evaluation of the data reveals that most of the data in GPT-3.5’s zero-shot prompting method do not follow the template. In contrast, the few-shot prompting approach generally produces responses that adhere to the template. This can be attributed to the model’s contextual learning capabilities. At the same time, we observe that the model in the few-shot prompting method of GPT-3.5 suffers from the hallucination problem, 51 where the model generates non-existent depression degree categories, such as a classification level of “4.”

Evaluation scores for the BART-Score on the golden set.
In our experiments, we observe that the few-shot prompting results with labeled supervision from GPT-4 were slightly lower than those from GPT-3.5. This indicates that GPT-4 does not exhibit significant improvements over GPT-3.5 in the quality of explanation text generation. GPT-3.5 achieves performance that is equivalent to GPT-4 in terms of explanation generation quality, while incurring lower inference costs. Therefore, GPT-3.5 is more suitable for constructing the MIDDI dataset to obtain large-scale responses. The DepGLM-tg model outperforms both GPT-3.5 and GPT-4, despite being significantly smaller in params size. This highlights the effectiveness of instruction tuning on the MIDDI dataset and the exceptional quality of explanations generated by the DepGLM-tg model.
Research significance
In this research, we explore the potential of LLMs for different depression degree identification, framing it as a multi-level task to enable more fine-grained depression detection. We model depression degree identification as both a text classification and a text generation task, leading to the development of the DepGLM-tc and DepGLM-tg models. Evaluation results demonstrate that DepGLM-tc yields the highest weighted F1 score of 0.83 on accuracy assessment, which outperform the SOTA discriminative method. However, it lacks the ability to generate interpretable textual explanations. Although DepGLM-tg is capable of generating high-quality explanations, its accuracy is relatively low. This may be because DepGLM-tg is a text generation model. It focuses on producing coherent and fluent text. In contrast, DepGLM-tc is a text classification model. It is trained to predict specific labels. Generation tasks typically require the model to understand more complex contextual relationships, and the quality of the generated text is significantly influenced by the breadth and diversity of the model’s reasoning. 43 This may lead to lower accuracy in specific tasks compared to classification tasks. Although DepGLM-tg has some advantages in interpretability, its fine-tuning process can be affected by the inherent openness and diversity of generation tasks. Generative models tend to produce multiple possible outputs rather than optimizing accuracy. 52 This diversity can result in lower accuracy in certain contexts because it does not strictly optimize for a single objective like classification tasks do. On the other hand, DepGLM-tc benefit from a clearly defined classification objective, allowing it to improve accuracy through supervised learning. 53
Furthermore, we examine the impact of few-shot and zero-shot prompting methods on the performance of LLMs. Our findings indicate that under fine-tuning instructions with detailed depression degree classification criteria, few-shot prompting does not improve model performance. Instead, it leads the model to learn incorrect patterns and thus decreases performance. We believe specific example selections play a crucial role, designing a more diverse and representative set of examples could improve performance. Moreover, prompt engineering approaches such as chain-of-thought may further help mitigate this issue.
The key contributions of this paper are outlined as follows: (1) As far as we know, this research represents the first application of LLMs for detecting depression in the context of Chinese social media and culture. (2) This paper conducts a more fine-grained depression detection by framing depression degree as a four-class classification task. (3) This study models depression degree detection as both a text classification task and a text generation task, and examines the performance of LLMs when performing different task fine-tuning.
Case study
The confusion matrix results indicate that DepGLM-tc demonstrates relatively balanced performance. It achieves improvement in identifying all four depression categories, with relatively lower accuracy in detecting severe depression. DepGLM-tg shows a similar pattern, however, compared to DepGLM-tc, it has larger errors in classifying mild and moderate depression. Through output analysis, we found that the model performs well in most cases. For example, the post “I’m living like a walking corpse. I’ve never succeeded at anything, and I don’t feel any desire inside me. It feels like I don’t want anything at all” was correctly classified as mild depression, reflecting symptoms of low motivation desperation. Similarly, “I’m sorry for not getting better—it’s my fault. I’ve been a burden to everyone. I’m such a mess” was also accurately identified as mild depression, capturing self-blame and feelings of worthlessness. Another post, “This is how my whole life will be. I completely ruined a good hand of cards
However, error analysis reveals several issues in depression degree detection. Table 5 provides a systematic categorization of error types along with their average post lengths. We find that shorter posts are more likely to result in severe misclassifications, such as predicting “no depression” for cases that are actually “severe depression”. In contrast, longer posts provide richer contextual cues that helps the model infer users’ depression degree more accurately. Moreover, the model tends to underestimate depression degree (n=302) rather than overestimate it (
Systematic categorization of error types.

Systematic categorization of error types.
There are two possible solutions for these types of errors: First, introducing more similar samples to aid the model in learning the meanings of these words; second, incorporating additional context from the same user to assist the model in making accurate predictions.
In practical applications, DepGLM-tc can be embedded into mental health assessment systems to detect varying levels of depression across different types of textual data, such as social media posts, online forums and patient records. The model’s ability to process large-scale text data makes it suitable for real-time applications and its balanced performance across categories supports more detailed and targeted mental health monitoring.38,54 DepGLM-tg complements the process by generating natural language explanations to assist professionals in understanding and interpreting model outputs. This greatly enhances transparency and trust in AI decision-making. Used together, the two models offer a foundation for interpretable and scalable mental health screening. To achieve practical deployment, we propose a staged application approach. In early stages, the models can be used behind the scenes in mental health platforms with their outputs reviewed by trained professionals. In the medium term, APIs may be developed to support integration into existing digital mental health services or well-being apps. With sufficient expert validation and feedback, these models could be adapted to support automatic classification or identification of high-risk cases in environments where timely intervention is critical.
Although our model demonstrates strong predictive performance and introduces a novel framework for multi-level and explainable depression detection on social media, it is important to emphasize that this work is exploratory in nature. The primary contribution lies in the theoretical advancement of using instruction-tuned LLMs for this task, including the construction of a new dataset and the optimal predicting model. Compared with clinically validated tools, our evaluation of consistency and explanation quality is not yet sufficient for diagnostic application and requires clinical validation before deployment. Future research will need to incorporate expert validation and integration with standardized assessment tools before clinical relevance can be established. Recognizing this limitation is critical, as overestimating the model’s clinical reliability could lead to inappropriate or even harmful use in real word. The model may assist in preliminary mental health assessments, but it should never be viewed as a replacement for professional diagnosis. Automated depression detection systems have specific potential risks. For example, users may treat model results as final diagnostic conclusions. This may affect their psychological responses by influencing their mood and shaping how they perceive their own mental health. Misclassification remains a risk, potentially causing undue distress, confusion or even delays in seeking professional help. Case studies of such errors show that the model could lead to dangerous biases and negative consequences for users. 32
Additionally, privacy and data security are critical issues that must be addressed to protect the rights of research participants and users. To safeguard users’ personal privacy, all data used for model training and analysis must be anonymized and de-identified. Appropriate data security measures must be implemented during model usage to protect users’ personal health data, such as cloud-based secure storage, access controls, and prevention of data leaks, including regular security audits, data encryption, and secure data transmission. 54 Furthermore, informed consent must be obtained from users. Finally, clear legal and ethical guidelines are required to define responsibilities and ensure that these systems are deployed safely and responsibly in order to prevent misuse or unintended consequences.
Showing manually classified clinical data to LLMs may also introduce further potential risks. There remains a possibility that information could be stored on external servers and thus increase the risk of unintended disclosure. Additionally, bias is a concern. Any bias introduced during manual classification by researchers could be amplified through model learning, which may compromise the reliability of the results. In fact, LLMs inherently carry certain biases. When performing reasoning tasks, they tend to exhibit cognitive biases similar to human. For instance, they overemphasize negative information while suppressing positive or neutral content during iteration process. 60 Moreover, they may unintentionally reinforce stereotypes related to race, gender, or occupation.56,57 What’s more, the application of Western-centric mental health conceptualizations to Chinese social media data may introduce cultural value biases. 58 Even LLMs that have passed explicit bias evaluations may still contain latent biases, 59 highlighting the necessity of our continued attention and regulation.
We also recognize that our novel dataset construction approach involves using one AI system to assist in training another for mental health assessment. This may introduce a certain degree of circularity. Such circularity could potentially reinforce the inherent biases of LLMs and raise concerns about accountability and transparency. To mitigate these concerns, human oversight must remain central throughout all stages of data construction, model evaluation, and interpretation. Researchers should follow clear ethical guidelines and keep detailed records of each step to strengthen transparency. They should also monitor model behavior and clearly specify the components for which each author is responsible to ensure proper accountability. In this research, we randomly reviewed 20 posts every time the model generated 200 explanations. Based on the issues identified in these samples, we either modified or rejected problematic explanations and refined the prompt templates. Explanations that misinterpreted metaphors were the main targets of intervention. For instance, we modified “Every day feels like fighting monsters and leveling up, but it seems the battle never ends” from “show severe self-defeating cognition and moderate depressive tendencies” to “metaphorically express fatigue and frustration rather than clinical depression”. We call for the establishment of a widely accepted framework for transparency and accountability across the AI research community to prevent misuse and ensure the responsible deployment of such models. These practices will help enhance the reproducibility and credit of AI systems used in sensitive domains like mental health.
In addition to the potential ethical and practical risks, it is crucial to consider data governance and intellectual property issues associated with the use of ChatGPT. Prior to employing the ChatGPT API, the research team carefully reviewed OpenAI’s Terms of Service and ensured full compliance. We emphasize that this study was conducted exclusively for academic research and involves no commercial use. More importantly, DepGLM is a specialized academic model developed for depression monitoring rather than a general-purpose commercial language model. With respect to intellectual property, the study did not involve any copyrighted materials, such as source code, model components, or proprietary algorithms. According to OpenAI’s policy, users retain ownership of generated content provided that they comply with applicable laws and policies. This policy offers a reasonable basis for addressing ownership concerns in AI research and also reflects our commitment to respecting intellectual property rights. Nonetheless, we recognize that certain uncertainties regarding intellectual property persist in the broader field of AI research and call for clearer regulatory guidelines.
Limitations and outlook
Currently, this study focuses only on the post level. In the future, we will incorporate more relevant posts from the same users to perform depression detection at the user level. We will also explore fine-tuning DepGLM on data from other modalities, such as mental health questionnaire forms, to further enhance its capabilities. We currently focus only on the identification of depression degree, and in subsequent studies we will extend our approach to encompass a wider array of psychological health analyses and mental disorder detection tasks, including anxiety and bipolar disorder, such as anxiety disorders and bipolar disorder. Due to the sensitivity of the research topic and the high cost of expert-written explanations, this study uses synthetic data to construct the MIDDI dataset. We use ChatGPT to generate high-quality explanations for the text generation task. However, synthetic data does not fully replicate real-world data, potentially introducing biases and affecting the model’s generalizability. Future research will focus on validating the model with real-world medical data to enhance its applicability in practical settings. Although this study designs annotation guidelines, the actual labeling process relies on individual expert assessments. The lack of a standardized framework may introduce some degree of subjectivity in the labeling process. This subjectivity could affect the consistency of the annotations. Future research could explore the use of standardized protocols or involve additional experts to improve the reliability and validity of the labeling process. Furthermore, we also intend to incorporate other automated text evaluation metrics beyond BART-Score to provide a more comprehensive assessment of the generated explanations.
The fine-tuned model shows promising cross-platform potential. 32 However, since it is trained on data from the Weibo platform, it may reflect inherent biases. These include demographic imbalances, platform-specific language styles, and self-selection biases among social media users. 55 The model may perform better for certain groups, such as younger users or those more active on social media, while it could underperform for other groups, such as older individuals or marginalized groups less active on social media. Besides, the data were collected within a fixed time frame, certain exogenous factors may influence user behavior. For instance, the COVID-19 pandemic context might have affected how users expressed depressive emotions on social media, as this period corresponded to the post-pandemic recovery phase. This may limit the model’s temporal robustness and its ability to capture longer-term variations in user behavior and language. To address these limitations, future work is recommended to incorporate data from multiple platforms and extended time periods to improve the model’s temporal generalizability across broader populations and contexts. We plan to incorporate extensive statistical analyses like McNemar’s test or bootstrap confidence intervals to determine whether performance differences are statistically significant and further examine model robustness. Also, we intend to explore additional influencing factors, such as classification accuracy.
Notably, although DepGLM demonstrates excellent performance on social media data, its clinical validity remains untested. The model has not been evaluated on real patient populations, and social media expressions may not fully reflect clinical symptoms. As such, we emphasize that DepGLM should be regarded as an auxiliary tool for early detection, instead of a substitute for professional clinical assessment. Future work should focus on validating the model in clinical settings to establish its reliability and applicability in healthcare use.
Conclusion
In this study, we introduce the depression degree dataset and the first interpretable multi-level depression degree instruction dataset on social media. We utilize ChatGPT to produce high-quality explanations for the DW dataset in order to construct the MIDDI dataset. To ensure the reliability of the generated data, we perform rigorous automated evaluations. Based on the DW dataset and the MIDDI dataset, we train the first depression degree recognition system DepGLM. Model DepGLM-tc is designed for text classification tasks and is capable of identifying depression degree on social media with an accuracy that surpasses existing SOTA discriminative methods. DepGLM-tg is tailored for text generation tasks. It is capable of recognizing depression degree and providing detailed explanations of the causes. It achieves accuracy close to that of SOTA discriminative methods. At the same time, it generates high-quality explanations comparable to ChatGPT.
It is worth noting that our experimental results are far from being deployed in real-life situations. Text classification associated with depression should not be viewed as a substitute for diagnoses made by healthcare professionals. Instead, it acts as an important computer-assisted tool that plays a crucial role in early symptom detection and gaining insights into the underlying causes. This system is essential for facilitating early intervention and enhancing comprehension of the conditions.
Footnotes
Acknowledgments
The authors would like to express sincere gratitude to The National Social Science Fund of China for funding this research through Grant Number 23BGL271. We thank all the participants who contributed their time and effort to this research. Finally, we acknowledge the valuable feedback and suggestions from our colleagues and anonymous reviewers, which have helped to improve the quality of this manuscript.
Ethical approval
This study was reviewed by the Ethics Committee of Shanghai University (ECSHU), which confirmed that it did not require formal ethical approval. According to the Ethics Committee’s standing policy, such waivers do not come with a waiver number. A waiver document is available and serves as official confirmation of ethical compliance. In addition, a follow-up study using the same data processing procedures and the model proposed in this work has received formal ethical approval (ECSHU 2025-050, March 26, 2025).
Contributorship
Conceptualisation: Jingfang Liu, Jie Chen and Peng Ding; methodology: Jingfang Liu and Jie Chen; supervision of data collection: Jie Chen; validation: Jingfang Liu, Jie Chen and Peng Ding; formal analysis: Jie Chen; writing-original draft preparation: Jie Chen; writing-review and editing: Jingfang Liu, Peng Ding and Jie Chen. The final version of our manuscript has been reviewed and approved by all authors
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by The National Social Science Fund of China (Grant Number:23BGL271).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Use of AI tools
No AI tools were employed during the development of the manuscript. After the manuscript was completed, ChatGPT was employed solely to improve language quality. All authors carefully reviewed and revised the content and take full responsibility for the final version of the manuscript.
Guarantor
Jie Chen accepts full responsibility for the overall content and integrity of this article.