
Abstract
Objective
Since the public release of ChatGPT in late 2022, large language models (LLMs) have been rapidly adopted in medical education, and the emergence of the free and open-source Chinese model DeepSeek in 2025 has further accelerated local uptake. However, their academic impact and measurable outcomes remain unclear. This study aims to conduct a comprehensive bibliometric analysis of literature from 1999 to 2025, mapping the evolution, thematic landscape and emerging frontiers of LLM-assisted medical education, with particular attention to the post-ChatGPT phenomenon represented by DeepSeek, in order to clarify current research status and inform future directions for educators and policymakers.
Methods
English-language articles and reviews (1999–23/03/2025) were retrieved from the Web of Science Core Collection. Publication trends, co-authorships, co-citations, burst keywords and thematic clusters were analysed with CiteSpace 6.4.R1, R-bibliometrix and VOSviewer 1.6.20.
Results
The analysis revealed a sharp growth in publications after 2022, coinciding with the release of ChatGPT, with the United States, China and Canada emerging as leading contributors. Influential institutions included Mayo Clinic, University of Toronto and Karolinska Institutet. Research hotspots clustered around generative artificial intelligence (AI) applications, machine learning, simulation-based training and blended learning. Recent bursts of keywords such as ‘DeepSeek’ indicate expanding regional engagement and diversification of AI tools.
Conclusions
Large language model research in medical education is transitioning from exploratory commentaries to more applied and empirical investigations. While open-source models offer opportunities for broader access, critical challenges remain regarding measurable educational outcomes, ethical frameworks and global equity. Addressing these gaps through rigorous outcome-based studies and cross-institutional collaboration will be essential for the sustainable integration of LLMs into medical curricula.
Keywords
Introduction
On 27 January 2025, the newly released generative-artificial intelligence (AI) model DeepSeek-R1 was launched and was rapidly adopted, swiftly capturing market share to become one of the most popular AI applications. 1 DeepSeek's debut sparked widespread debate; experts have analysed at length how it differs from earlier systems, and its open-source, cost-free nature has made it particularly attractive in medical education. 2 Since the 1950s, when the concept of AI first emerged, AI has driven technological advances across diverse fields – including health care – and medical education, as a critical component of the health-care ecosystem, has been no exception.3,4 From rule-based expert systems in the 1960–1990s to today's generative AI (e.g., ChatGPT, DeepSeek) and multimodal AI that fuses text with medical imaging, AI tools are increasingly deployed to enhance training efficiency and effectiveness, offering precise, high-throughput support ranging from automated patient simulators to personalised learning algorithms. 5
The hidden Markov model, introduced in 1957, laid the foundation for sequence generation in domains such as speech and text, 6 laid the foundation for sequence generation in domains such as speech and text. 6 In the following decades, digital medical education also began to evolve, with innovations such as computer-assisted instruction, early e-learning platforms and virtual patient simulations providing the first technology-enabled learning experiences. By the 2000s, the rise of MOOCs and online learning environments further expanded access to medical education, while the 2010s saw the development of intelligent tutoring systems and rule-based chatbots, which demonstrated the potential of AI-driven personalisation in training.7,8 In parallel, advances in generative modelling transformed the technical landscape. In 2013, Diederik Kingma and Max Welling proposed the variational autoencoder, ushering in the era of practical probabilistic generative modelling. 9 This was followed by the introduction of GANs, WaveNet and BigGAN, which demonstrated the substantial quality improvements achievable through large-scale training.10–12
In 2020, OpenAI introduced GPT-3, with 175 billion parameters, marked a watershed for language generation and accelerated the adoption of generative AI across disciplines. 13 In 2021, OpenAI released DALL·E, achieving text-to-image generation and advancing multimodal modelling; CompVis subsequently open-sourced Stable Diffusion in 2022, lowering the barrier to high-quality image synthesis and democratising the technology.That same year, OpenAI launched ChatGPT (based on GPT-3.5), igniting global interest; dialogue-centred generative models such as ChatGPT rapidly permeated education and health-care practice. By November 2022, medical instructors and students were testing ChatGPT for clinical Q&A and simulated doctor–patient communication, and it quickly became a teaching aid.14,15
Early 2023 studies showed that ChatGPT achieved passing scores across all three steps of the United States Medical Licensing Examination (USMLE) – demonstrating its capacity for high-level medical knowledge processing. 16 Later that year, OpenAI released GPT-4 with support for multimodal input (text and images), which was subsequently introduced into medical imaging education, marking the first integration of AI into visual medical training. In early 2025, the China-developed generative-AI model DeepSeek-R1 went online; free and efficient, it offers a locally tailored digital solution for medical education.
Notwithstanding these advances, AI has raised significant concerns. The opacity of training data and internal mechanisms in AI-driven educational models can yield outputs that are inaccurate or outdated. 17 Model accuracy varies, and responses to identical prompts may be inconsistent – or even mutually contradictory.15,18 Medical students must therefore approach AI-generated explanations with critical scrutiny and recognise the potential for error. Seamless integration of AI into education also risks attenuating learners’ capacity for independent thought and innovation 19 ; over-reliance on AI-generated resources can devolve into academic misconduct.20,21 Because medical education encompasses not only factual knowledge but also context-dependent clinical reasoning, educational institutions must rigorously evaluate AI use to balance convenience against risk, enabling efficient acquisition of knowledge while fostering personalised development of clinical thinking.
Interest in AI-enhanced medical education is accelerating, and bibliometric studies have summarised the field's progress.22–24 Barrington et al. analysed 267 publications up to 2023, focusing on ChatGPT's roles across specialties, research, education and clinical practice; they highlighted the rapid, geographically uneven growth of large language model (LLM) applications in health care and emphasised the need for improved standardisation and accuracy. 22 Wu et al. reviewed 247 English-language journal articles published between 30 November 2022 and 16 August 2023, offering a more detailed analysis of research objectives and sub-disciplinary domains in medicine. 23 However, due to the relatively short time frame, both reviews remained largely at the exploratory stage of ChatGPT applications, with limited literature and insufficient supporting evidence. By contrast, another review incorporated 371 articles published up to July 2024, with a broader retrieval window starting from 2017, and provided a more comprehensive analysis of generative AI in medical education, particularly regarding geographic distribution, collaboration patterns and applications across specialties. 24 Nevertheless, this review primarily addressed generative AI as a whole and did not delineate the developmental trajectory of LLMs.
Therefore, this study adopts 1999 as the starting point to provide a comprehensive overview of LLMs in medical education, capturing both their early explorations and subsequent rapid expansion. To date, no systematic evaluation has assessed their applications or measurable impact on learning outcomes. To address this gap, we conducted a bibliometric analysis to examine the scale and trajectory of research in this field and to explore how AI can be effectively integrated into medical education. In doing so, we also draw on established educational theories to interpret the opportunities and challenges of generative AI, aiming to offer a comprehensive perspective that both clarifies the current landscape and informs future directions.
Methods
Database construction
A dedicated database was constructed in the Science Citation Index Expanded via the Web of Science Core Collection (WoSCC). The search strategy combined AI-related terms with medical-education descriptors:
TS = (‘DeepSeek’ OR ‘ChatGPT’ OR ‘GPT-3’ OR ‘GPT-4’ OR ‘Large Language Models’ OR ‘Transformers’ OR ‘Natural Language Processing’ OR ‘Machine Learning’ OR ‘Artificial Intelligence in Education’ OR ‘Conversational Agents’ OR ‘Generative Language Models’ OR ‘Text Generation Models’ OR ‘BERT’ OR ‘BART’ OR ‘Text-to-Text Transfer Transformer’ OR ‘LaMDA’) AND (‘Medical Education’ OR ‘Medical Training’ OR ‘Clinical Education’ OR ‘Health Professions Education’ OR ‘Medical Curriculum’ OR ‘Medical Pedagogy’ OR ‘Continuing Medical Education’ OR ‘Graduate Medical Education’ OR ‘Undergraduate Medical Education’ OR ‘Medical E-Learning’ OR ‘Medical Distance Learning’)
Records were restricted to articles and reviews published in English between 1999 and 2025/03/23.
Data extraction and cleaning
The WoSCC output (n = 837) was exported as plain-text and tab-delimited files. Duplicate records were removed, yielding 656 unique entries for CiteSpace processing. Publication year, citation counts, author affiliations and keyword fields were retained for analysis. The corpus comprised 482 research articles (73.5%), 67 review articles (10.2%), 35 early-access items (5.3%) and 27 editorial materials (4.1%). Excluding early-access items and editorial materials.
Bibliometric indicators and visualisation
Annual publication and citation curves were plotted in Excel and fitted with second-order polynomials. Co-authorship, co-citation and keyword co-occurrence networks were generated in VOSviewer 1.6.20. Time-zone views, burst detection and cluster labels were computed with CiteSpace 6.4.R1. The Bibliometrix R package supplemented descriptive metrics such as h-index, average citations per item and country productivity.
Bibliometric indicators included: (i) annual publication trends; (ii) geographic and institutional productivity; (iii) thematic hotspots based on keyword co-occurrence; (iv) journal distribution; and (v) high-impact papers by citation performance (Figure 1).

Flow chart of the literature searching and screening in the study.
Results
Annual distribution of publications and citations
The search strategy yielded 837 records. As a corpus, these papers have been cited 16,262 times (excluding 927 self-citations) by 13,767 citing documents (excluding 355 self-citing articles), with a mean of 19.4 citations per item. The overall h-index is 56, indicating that 56 papers have garnered at least 56 citations each.
Figure 2A depicts temporal trends in publication output and citation counts from 1999 to 2025. Both metrics remained low and relatively stable until 2018, followed by a marked uptick in 2019 and an exponential surge during 2023–2024 – coinciding with the widespread adoption of ChatGPT and other generative-AI milestones in medical education.

(A) The polynomial curve fitting of publication and citation growth in generative AI application in medicine education. (B) Analysis of top 10 most-cited journals.
Figure 2B shows that JMIR Medical Education is the most prolific outlet in this domain, leading all journals in publication volume during the study period.
Contributing countries/territories and institutions
National output was mapped with VOSviewer 1.6.20 (Figure 3A). The United States leads the field with 289 publications (15.67% of all records), followed by Canada with 96 publications (5.20%) and the United Kingdom with 94 publications (5.10%). In total, nine countries/regions each generated ≥ 60 papers in this domain (Figure 3B).

(A) The publication distribution across countries. (B) A network map displaying countries that have published more than 10 papers in the field of generative AI application in medicine education. (C) A network map showcasing institutions engaged in research on generative AI application in medicine education.
Institutional analysis performed in CiteSpace 6.4.R1 identified 367 active organisations. Mayo Clinic is the most productive, contributing 70 papers (Figure 3C). Among the ten highest-output institutions, eight are based in the United States; the University of Toronto (Canada), the University of California system (USA) and Karolinska Institutet (Sweden) are notable pioneers driving this transformative research landscape (Table 1).
The top 10 institutions involved in research on generative AI application in medicine education.

Authors
VOSviewer identified more than 2490 individual researchers who have contributed to studies on generative AI in medical education. Among them, 267 authors have published at least two papers on this topic (Figure 4A); the remainder is represented by single-article contributors. By citation count, Hauer ranks first with 234 citations, followed by Eric with 176 citations (Table 2).

A network map showing authors (A) highly published authors and (B) highly cited authors.
These are the top 15 published authors and co-cited authors who have been most influential in research on generative AI application in medicine education.

Author co-citation analysis (VOSviewer, Figure 4B) included all authors cited ≥ 10 times, generating a network of 124 nodes. Each node denotes an author; circle size is proportional to publication count, while opacity diminishes as output decreases. The number and thickness of connecting edges reflect the frequency of co-citation. Nodes sharing the same colour form clusters, indicating authors who are frequently cited together. Results from productivity and co-citation analyses were congruent: prolific authors tend to co-occur more often. Within the top 15 most-cited authors, Kung, T. H. occupies the leading position (98 citations), with OpenAI in second place (97 citations) (Table 2).
Citations and journals
Table 3 lists the ten most-cited articles. The study titled ‘Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models’ is the citation frontrunner with 91 citations, underscoring the field's swift progress and dense output.
These are the top 10 academic literatures that have been most active in publishing research on generative AI application in medicine education.

A CiteSpace co-citation analysis traced the intellectual evolution of generative-AI research in medical education. Figure 5 reveals that the majority of highly co-cited journals emerged within the past two years, highlighting the rapid and prolific expansion of this research domain.
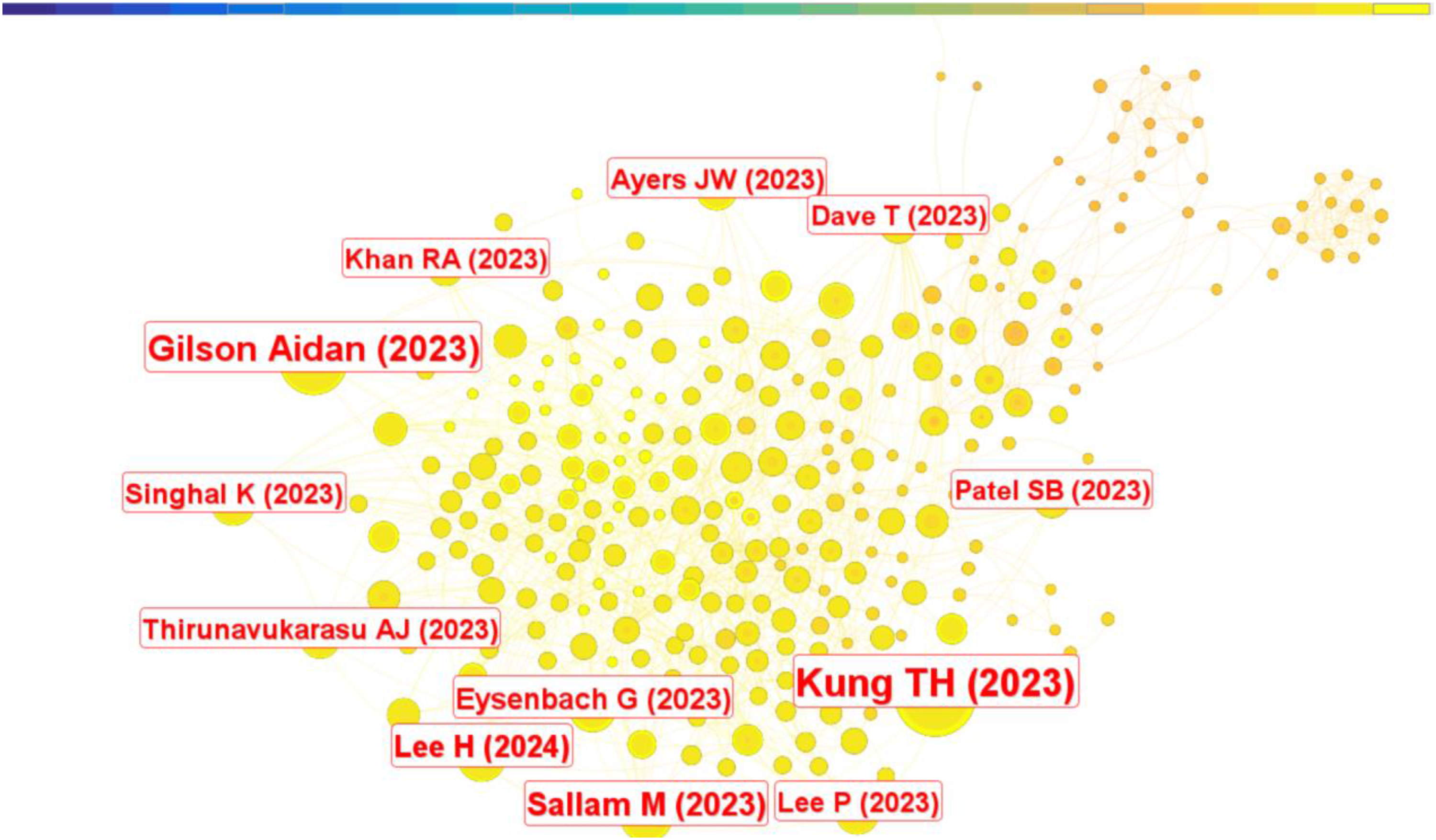
Application of CiteSpace: Co-citation analysis of the literature.
Keywords
Keyword co-occurrence
Because keywords distil a paper's central concepts, mapping their co-appearance illuminates the intellectual framework and hotspots of a research field. A co-occurrence network generated with CiteSpace is shown in Figure 6. The most frequent terms are listed in Table 4; collectively they outline the core logical structure of generative-AI applications in medical education.

A keyword co-occurrence map using citespace reveal the relationship between keywords involved in generative AI in medicine education.
The top ten keywords appeared the most.

Keyword timeline view
Cluster analysis further clarifies thematic foci. CiteSpace grouped the retrieved keywords into clusters ranked by size, with cluster #0 the largest. Twelve clusters were selected for timeline inspection:
#0 large language model, #1 breast cancer risk, #2 applying basic genetic principle, #3 machine learning, #4 blended learning, #5 clinical advisory panel, #6 predictive analytics, #7 trauma surgery, #8 middle-income, #9 taxonomy using psychosomatic medicine exam question and #12 prevention.
The temporal evolution of each cluster is depicted in Figure 7.

The study utilised cluster analysis to identify patterns and relationships among keywords involved in research on generative AI in medicine education.
Keyword burst analysis
Citation-burst detection in CiteSpace highlights rapidly emerging terms – widely regarded as markers of research frontiers. Among 2508 keywords, the 25 strongest bursts were identified and ranked by onset year, duration and burst strength. The earliest burst term was ‘breast cancer association consortium’ (2015). ‘Machine learning’ exhibited both the greatest burst strength (18.61) and the longest active period, beginning in 2016 (Figure 8A–C).

The study identified burst keywords associated with research on generative AI in medicine education, which represent the most active and influential research topics in the field. (A) Ranking by beginning. (B) Ranking by strengths. (C) Ranking by duration. (D) Keywords are clustered on the time scale and output as map.
Burst terms linked explicitly to medical education cluster after 2019. Combined with the VOSviewer timeline, these results indicate increasing specialisation in applying generative AI to education (Figure 8D). The most recent bursts – ‘medical education’, ‘ChatGPT’, ‘OpenAI’, ‘LLMs’ and ‘multiple-choice question’ – directly reference generative-AI tools; additional terms such as ‘patient care’ reflect downstream educational applications. In Figure 8, green bars correspond to 2021–2025, while red segments denote the active duration of each burst keyword.
Discussion
Trajectory and educational impact of generative AI
Our longitudinal analysis demonstrates a pronounced upward trajectory in the deployment of generative AI within medical education between 1999 and 2025. Growth is heavily skewed toward the past five years, coinciding with the release of LLM systems such as ChatGPT and DeepSeek. Prior to 2019, scholarly activity in this niche was largely dormant; however, following the public launch of ChatGPT in 2022, annual publication volume rose exponentially and peaked in 2023 (Figure 2A). This surge temporally aligns with reports that ChatGPT achieved passing scores on all three steps of the USMLE, an outcome that signalled to educators and researchers the practical readiness of LLMs for high-stakes, clinically oriented tasks. The data therefore suggest that landmark demonstrations of LLM competence catalyse rapid adoption and scholarly interest, creating a feedback loop in which clinical validation accelerates pedagogical experimentation.
Journal distribution and open-access landscape
The corpus is highly concentrated in a small set of high-impact journals specialising in digital health, AI methodology and educational innovation. JMIR Medical Education leads output with 63 articles (1999–2025), 98.9% of which are Gold open access, underscoring the journal's commitment to rapid, barrier-free dissemination. As a Q1 venue, JMIR functions not only as a publication outlet but also as an incubator for technology-enhanced teaching strategies – virtual patient simulators, case-based learning modules and personalised learning paths driven by generative AI figure prominently in its pages.
Academic Medicine (impact factor 5.3) and Medical Education also feature prominently. While traditionally focused on pedagogical theory and clinical assessment, these journals have increasingly incorporated LLM-enabled innovations, spurred in part by ChatGPT's notable USMLE performance and the ensuing debate over AI as an assessment adjunct. 16 Geographically, the bulk of high-impact articles originate from North America and Europe; contributions from Asia, Africa and Latin America remain sparse. This asymmetry mirrors long-standing disparities in medical-education research and could impede the global diffusion of AI-enhanced pedagogy.
Finally, although JMIR Medical Education approaches universal open access, other flagship journals such as Academic Medicine maintain comparatively low OA proportions. Limited access in lower-resource settings may exacerbate existing inequities, restricting the ability of educators worldwide to engage with and implement generative-AI advances.
Geographical and institutional distribution of generative-AI research in medical education
The adoption of generative AI in medical training is closely tied to national attitudes toward innovation and corresponding regulatory frameworks. Our geo-mapping confirms marked concentration in a handful of high-income countries. The United States accounts for almost 34.5% of all publications – well ahead of China (12.8%) and Canada (5.2%) – and, together with Canada and the United Kingdom, contributes 54.5% of the global output (Figure 3A). This pattern mirrors the aggregated distribution of medical-education resources and technological capacity.
At the institutional level, Mayo Clinic leads with 70 papers, followed by the University of Toronto and the University of California system (each 61 papers) and Karolinska Institutet (59 papers) (Figure 3C). These centres have been early movers in melding LLM technology with bedside teaching and affiliated with the United States. Mayo Clinic's portfolio spans clinical simulation, virtual learning platforms and AI-assisted skills assessment, underscoring the translational intent of its research. Such productivity rests on robust funding streams, permissive AI governance and close collaboration between top-tier universities and health-care providers. Notably, the landmark release of ChatGPT by OpenAI (San Francisco, California) in November 2022 further entrenched the United States as a focal point for standards and best-practice development.
The data also exposes stark regional asymmetries: contributions from Africa, South America and South-East Asia collectively account for <5% of the literature, indicating that LLM deployment remains largely confined to wealthier settings. This concentration reflects disparities in resources and is shaped by multiple barriers. Limited access to high-performance GPUs and stable computing infrastructure, compounded by challenges such as electricity supply, network bandwidth and hardware costs, restricts the capacity for research. At the same time, the external costs of scholarly production remain high, including expensive article processing charges, limited opportunities for fee waivers and weaker integration into international academic networks. Data governance and compliance requirements further constrain progress, as restrictions on cross-border data sharing and the lack of standardised privacy-protection frameworks complicate research efforts. In addition, insufficient faculty training and limited systematic AI education hinder the development of local expertise. Together, these factors raise the barriers to entry and reduce both visibility and sustained engagement for underrepresented regions.
The advent of DeepSeek (China, 2025) – open-source and cost-free – has the potential to lower barriers in low-resource environments, offers a potential pathway to mitigate some of these barriers.
Open-source LLMs can be deployed locally, ensuring compliance with data residency requirements while reducing reliance on costly commercial APIs and cross-border connectivity. Advances in model compression, quantization and lightweight fine-tuning allow these models to run on modest hardware, thereby widening accessibility. Moreover, their adaptability enables researchers to tailor applications to local languages, curricula and educational needs, improving their contextual relevance in medical education. Nevertheless, open-source availability alone is insufficient. Broader support remains essential, including access to high-quality multilingual training corpora, structured faculty development programmes, standardised ethical review tools and stronger international collaborations. With such complementary infrastructures in place, open-source models like DeepSeek may serve as powerful equalisers, helping to foster equitable and sustainable integration of generative AI into medical education across diverse global contexts.
Leading authors and institutional influence
More than 2490 researchers have published on generative-AI applications in medical education, underscoring the field's breadth. Examination of citation impact and collaboration networks yields insights into current priorities and likely future directions.
Karen E. Hauer tops the citation list with 234 citations; her work centres on AI-assisted assessment and optimisation of student learning trajectories, highlighting novel opportunities for selection, instruction and evaluation while repeatedly calling for alignment with educational goals and ethical safeguards.25,26 Eric Westman (176 citations) focuses on AI-driven neuro-imaging analytics.27,28 Daniel Rueckert (170 citations) has pioneered multimodal AI for teaching anatomy and radiology, integrating 3-D anatomical simulation, virtual reality (VR) and interactive case learning to enhance students’ grasp of complex structures and pathologies.29–33 Rueckert also cautions that even state-of-the-art LLMs cannot yet deliver fault-free diagnostic reasoning, and that erroneous outputs may mislead trainees – reinforcing the need for critical appraisal of AI recommendations. 34 Collectively, these leaders frame AI as a double-edged sword: efficiency gains must be balanced against potential disruption of traditional pedagogical models.
Co-occurrence mapping (VOSviewer; Figure 4B) shows that these authors sit at the hubs of dense, interdisciplinary networks – Hauer collaborating mainly with assessment specialists, Rueckert with imaging scientists – illustrating the heterogeneous skill sets required for effective LLM deployment.
Notably, OpenAI emerges as a highly co-cited ‘author’ (Table 2). Its prominence underscores the symbiosis between foundational AI research and educational implementation. As ChatGPT and successor models evolve, continued cross-disciplinary collaboration – linking domain experts, computer scientists and pedagogy scholars – will be essential to keep instructional tools state-of-the-art and context-relevant.
Most-cited articles
Highly cited papers often serve as lodestars that shape subsequent inquiry. In the present corpus, a small cluster of publications exerts disproportionate influence on the agenda for AI-enabled medical education (Table 3).
The citation leader is the study by Kung et al., published on 9 February 2023, entitled ‘Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models’. Accruing 91 citations, this work delivered the first systematic appraisal of ChatGPT's performance on the USMLE. ChatGPT achieved accuracy rates close to – or exceeding – the passing threshold (∼60%) across all three examination steps, with overall answer–explanation concordance of 94.6%. Moreover, 88.9% of responses included at least one ‘novel clinical insight’ (difference-of-insight score 0.458 vs. 0.199; p < 0.0001). 16 These metrics demonstrate that LLM-driven reasoning approaches the competence expected of senior medical students, positioning generative AI as a plausible adjunct for mastering complex clinical reasoning.
This landmark contribution provided the field's first empirical proof that a generative model can not only craft high-quality medical answers but also navigate the rigours of high-stakes assessment. By proposing LLMs as virtual tutors and personalised learning companions, the paper catalysed broader acceptance of AI's pedagogical utility.
Subsequent high-impact reports – such as ‘ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns’ – introduced the concept of ‘AI-driven self-directed learning’, emphasising bidirectional interaction and real-time feedback between students and conversational agents. 35 Collectively, these foundational studies inaugurated a new era in which generative AI underpins standardised testing, personalised instruction and intelligent tutoring systems. They also surfaced parallel debates on academic integrity – including plagiarism, fabrication and other forms of misconduct – underscoring the dual obligation to harness AI's efficiencies while safeguarding ethical standards.
Keyword-centric insights
Keyword co-occurrence analysis (Figure 6; Table 4) confirms that ‘artificial intelligence’ (198 occurrences), ‘medical education’ (153) and ‘machine learning’ (95) dominate the discourse. Their prominence encapsulates three intertwined research directions:
Technological disruption – how AI reshapes instructional design and assessment;
Learning outcomes – empirical evaluation of AI's impact on cognition, skills acquisition and clinical decision-making.
Immersive modalities – the fusion of VR with generative AI to create interactive learning experiences.
‘Artificial intelligence’ anchors the entire technological paradigm, driving the digital and intelligent transformation of medical curricula. ‘Medical education’ signals the primary application domain, where pedagogy is shifting from instructor-centric teaching to AI-assisted learning. This transformation now spans flipped-classroom case previews, online surgical simulations, virtual dissections and adaptive course recommendations. For example, Lee et al. showed that LLM-generated interactive cases enhanced pre-class preparation in a flipped-classroom format. 36
The field's two flagship journals, JMIR Medical Education and Academic Medicine, together with landmark demonstrations of ChatGPT's USMLE performance, 16 have created a research-practice feedback loop: rapid dissemination, classroom experimentation and iterative refinement of generative-AI tools.
A timeline analysis (Figure 7) charts the thematic evolution. Pre-2019, keywords gravitated toward ‘artificial intelligence’, ‘virtual learning’ and ‘medical simulation’, reflecting proof-of-concept work. 2019–2022 saw a pivot to ‘machine learning’, ‘personalised learning’ and ‘clinical simulation’, signifying translation from algorithmic research to instructional deployment. From 2023 onward, the vocabulary shifts again to ‘ChatGPT’, ‘DeepSeek’, ‘large language models’, and – for the first time – ‘medical licensing examination’ and ‘virtual patients’, marking real-world uptake in high-stakes assessment and immersive teaching. The timeline analysis indicates a step-wise evolution of generative AI: early research focused largely on core algorithms and proof-of-concept studies, whereas the advent of large-language models has precipitated a rapid broadening of real-world applications in medical education – particularly in clinical simulation, intelligent assessment and virtual teaching environments.
The burst-detection results corroborate this trajectory. Cluster #3 ‘machine learning’ exhibits the highest burst strength (18.61) and longest duration (n = 4) (Figure 8B-C), underscoring sustained scholarly attention. Rueckert's work exemplifies this focus, demonstrating multimodal AI (text + imaging) for anatomy instruction and authoring pivotal radiology papers that leverage advanced machine-learning techniques.29–33
Kung's USMLE study likewise validates LLM feasibility in examination contexts: peak accuracies reached 75.0% (Step 1), 61.5% (Step 2 CK) and 68.8% (Step 3) in the open-ended format, with overall answer–explanation concordance of 94.6%. 16 These findings lend empirical support to cluster #9 ‘taxonomy using psychosomatic medicine exam question’.
The co-occurring term ‘predictive analytics’ (#6) signifies a shift from technological validation toward optimisation, such as using AI to forecast students’ learning bottlenecks and tailor remediation.
Finally, ‘blended learning’ (#4) highlights the integration of face-to-face and online modalities enriched by AI-generated micro-lectures and mechanism-of-disease animations – an approach already piloted in pathology, anatomy and emergency medicine. Because blended learning is inherently interdisciplinary, its rise echoes AI's own cross-disciplinary nature; future progress will hinge on collaborative teams that unite computer science, educational science and clinical expertise to ensure context-appropriate deployment across the health-professions spectrum.
Implications for learner development
The exceptional performance of ChatGPT on USMLE Step 1, Step 2 CK and Step 3 examinations showcases its instructional promise. 16 Two additional studies broaden this evidence base. Takagi et al. demonstrated that ChatGPT-4V attained an 84.5% accuracy rate on the 117th Japanese Medical Licensing Examination, virtually identical to the 84.9% achieved by human candidates. 37 Gilson et al. reported that ChatGPT surpassed the 60% pass threshold on multiple NBME Free Step 1 and Step 2 datasets, approximating the competence of third-year medical students. 15 Collectively, these findings indicate that generative AI can resolve learner queries, deliver cogent explanations and support personalised, high-efficiency, interactive study pathways.
Generative AI tools can also support self-directed learning, enabling students to explore content beyond the classroom at their own pace. At the same time, poorly designed prompts may add unnecessary cognitive load, a risk highlighted by instructional design frameworks. From a constructivist perspective, generative AI may further act as a mediating tool that facilitates active knowledge construction through interactive dialogue and contextualised feedback. These theoretical lenses provide a foundation for interpreting our bibliometric findings and help clarify both the opportunities and challenges of integrating AI into medical education.
Challenges, however, remain substantial. Dergaa et al. note that opacity in model training data and architectures may yield inaccurate or outdated outputs – an acute concern in a rapidly evolving discipline such as medicine. 17 Although Walker et al. found no statistically significant difference between ChatGPT's responses and static Internet sources in terms of information quality, 38 critical appraisal skills are still essential; over-reliance risks academic misconduct including plagiarism and propagation of misinformation. 17 Moreover, Gilson et al. observed a pronounced decline in ChatGPT's accuracy as item difficulty increased, highlighting persistent limitations in deep clinical reasoning. 15
Ethical considerations further constrain deployment. Wang et al. warn that algorithmic bias, limited transparency and the potential erosion of empathy could compromise both decision-making fidelity and the patient–physician relationship 21 . Keyword co-occurrence analysis underscores this concern, with ‘risk’ emerging as a high-frequency term. Ultimately, while generative AI offers a powerful adjunct for medical training, its integration must be coupled with rigorous oversight, ethical safeguards and continued emphasis on humanistic competencies.
Conclusions
This bibliometric survey provides a systematic overview of generative-AI research in medical education. Between 2023 and 2025, scholarly attention widened from a single-model focus on ChatGPT to a multi-LLM landscape encompassing Gemini/GPT-4o, Med-PaLM 2, DeepSeek and others. Publication formats have simultaneously shifted: opinion pieces have fallen from 43% to a minority share, replaced by empirical and technical reports featuring experimental designs and benchmarking studies – signalling maturation of the field and foreshadowing the emergence of robust frameworks for evaluating educational outcomes.
Geographically, output remains US-centric but is becoming more diffuse, with increased contributions from China, Germany, Italy and Türkiye. Nevertheless, representation from low- and middle-income regions is still scant, underlining the need for comparative studies that examine AI-augmented teaching across diverse resource settings.
Several critical gaps persist. Ethical governance and output accuracy remain problematic, yet systematic mitigation strategies – covering prompt-engineering protocols, chain-of-thought transparency and domain-specific fine-tuning – are largely undeveloped. Although LLMs can now pass standardised examinations, their effect on bedside reasoning and other core clinical competencies is unverified; multicentre, blinded OSCE trials are required to compare AI-enhanced instruction with conventional curricula.
Policy lag is another concern. Ad hoc institutional guidelines lack harmonisation. A Delphi-based consensus on ‘AI literacy competencies’ for undergraduate medical education, coupled with a standardised, ethics-sensitive implementation guide, would offer actionable pathways for schools operating under varied resource constraints.
In sum, bibliometric evidence shows that curiosity-driven exploration of LLMs has rapidly progressed to domain-specific application. The 2025 landscape is pluralistic, globalising and ethically unsettled. The next value-added contributions will likely arise from multi-institutional outcome studies, rigorous head-to-head evaluations of competing LLMs and the development of frameworks that balance innovation with accountability. Future research should move beyond bibliometric mapping to empirically evaluate the educational impact of LLMs. This requires outcome-oriented research designs – including randomised controlled trials, pre–post assessments and multi-centre OSCEs – to assess not only knowledge acquisition but also clinical reasoning, communication skills and long-term professional competence. In addition, learning analytics and longitudinal follow-up studies could provide valuable insights into how AI-supported education influences learner performance over time. At the same time, greater emphasis is needed on cross-institutional and cross-national consensus-building to establish unified ethical and governance frameworks addressing data security, academic integrity, learning equity and faculty responsibility. Such efforts will provide both empirical evidence and practical pathways toward the standardised and sustainable integration of AI into medical education.
Footnotes
Ethics approval and informed consent
Not applicable. Although this study did not involve human or animal subjects, authors ensured that ethical standards were upheld throughout the research process. For instance, the literature review was conducted with integrity by accurately representing all data and ensuring proper citation of all sources to avoid plagiarism. Additionally, the selection of studies adhered strictly to the inclusion and exclusion criteria to maintain objectivity and transparency.
Consent for publication
The details of any images, videos, recordings, etc can be published, and that the person(s) providing consent have been shown the article contents to be published.
Contributorship
HW and WHS are equal contributors and co-first authors. All authors made a significant contribution to the work reported, whether that is in the conception, study design, execution, acquisition of data, analysis and interpretation or in all these areas; took part in drafting, revising or critically reviewing the article; gave final approval of the version to be published; have agreed on the journal to which the article has been submitted; and agree to be accountable for all aspects of the work.
Funding
Jilin University Undergraduate Education Reform Research Project, 202311.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.