
Abstract
Background and Aims
Empathy improves clinical outcomes, patient satisfaction, and adherence to treatment. Few studies have explored the real-world use of large language models in conveying empathy. We compared the empathy in emergency department (ED) discharge letters written by GPT-4 and physicians.
Methods
We conducted a retrospective, blinded, comparative study in a tertiary ED. All patients discharged for one 8-h shift were included. For each patient, we compared the original ED discharge letter to a GPT-4 generated letter. GPT-4 generated the letters using ED notes, excluding the original discharge letter. Seventeen evaluators (seven physicians, five nurses, five patients) compared the letters side by side. They were blinded to the source. Evaluators first chose between the AI and human letters. Then they rated each letter for empathy, overall quality, clarity of summary, and clarity of recommendations using a 5-point Likert scale.
Results
Evaluators preferred GPT-4 over physician letters in 83.7% of comparisons (1009 vs. 197; p < 0.001). GPT-4 letters received higher scores for empathy (median 4.0 vs. 3.0; p < 0.001), overall quality, and clarity of summary across all evaluator groups. Among patients, no significant difference was found in the clarity of recommendations (p = 0.771). Qualitative analysis showed that GPT-4's empathetic expressions, though sometimes generic, were perceived as effective.
Conclusion
GPT-4 shows strong potential in generating empathetic ED discharge letters. These letters are preferred by healthcare professionals and patients. GPT-4 offers a promising tool to reduce the workload of ED physicians. Further research is necessary to explore patient perceptions and best practices for integrating AI with physicians in clinical practice.
Introduction
Large language models (LLMs) like GPT-4 are changing healthcare. 1 GPT-4 performs comparably to physicians on exams like the United States Medical Licensing Examination (USMLE).2,3 Notably, the model also matches humans on USMLE empathy questions. 4 Furthermore, GPT-4 achieves similar medical scores to emergency department (ED) physicians.5,6 However, few studies have examined its real-world clinical use in soft skills like empathy.
Emergency departments worldwide face increasing patient volumes and a shortage of practitioners. 7 An aging population and the complexity of medical care add to these challenges. Administrative tasks such as writing detailed discharge letters increase workload, slowing patient throughput. Automating parts of this documentation process could reduce these burdens. This will allow ED physicians to spend more time on direct patient care.8–10
Empathy is crucial in the physician–patient relationship.11,12 It means understanding others, sharing their emotional experiences, and caring for them. Empathy significantly impacts healthcare outcomes. Physician empathy is linked to better results, higher satisfaction, and adherence to treatment.13,14 For example, empathy can enhance patient cooperation and compliance with treatment plans. 15 Hojat et al. showed that empathy correlates with better outcomes for diabetic patients. 16
Recent studies suggest that GPT-4 responses to patients are perceived as empathetic. This raises important questions about its ability to mimic human-like communication. However, previous studies evaluated mainly hypothetical scenarios, online experiments, or advice forums. Our study takes a different approach. We compare physician and GPT-4 responses in a real clinical setting—the ED. Moreover, previous studies used either physicians or the general public as evaluators. 17 We focus on three groups who need to understand discharge letters: physicians, nurses, and patients.11,16
We compare empathy in discharge letters written by GPT-4 and ED physicians. By focusing on empathy in a real-world clinical setting, we aim to determine whether AI can enhance both the clarity and emotional quality of medical documentation in emergency care.
Methods
Study design
We conducted a retrospective, blinded, comparative study. Our goal was to compare the empathy, clarity, and quality of GPT-4 and physicians’ letters. The study took place on April 3, 2024, in the ED of Sheba Medical Center. This is a large (1900 beds) tertiary center. A secondary evaluation was to assess the medical accuracy of GPT-4-generated letters.
Population and data collection
We included all ED discharged patients from one 8-h nurse shift (8 a.m. to 3 p.m.). For each patient, we created two discharge letters:
One written by the attending ED physician. One generated by GPT-4 based on the patient's ED physician notes. Physicians’ discharge letters were excluded from GPT-4 input notes.
Ethics and consent
This study was approved by the Institutional Review Board (IRB) of Sheba Medical Center (approval no. SMC-0143-23). For the retrospective use of de-identified ED clinical notes to generate letters, the IRB granted a waiver of informed consent. All evaluator participants (physicians, nurses, and patients) viewed a written information sheet describing the study, its purpose, procedures, and confidentiality safeguards. Patients were informed that the survey would assess the clarity and empathy of discharge letters, was anonymous, and would be used solely for research. Proceeding to the questionnaire and submitting responses was considered to indicate written informed consent.
Artificial intelligence framework and prompting
We used a standardized prompt (see Supplement Prompt) to generate each GPT-4 letter. The prompt tasked GPT-4 to simulate the perspective of a senior ED physician. The prompt provided the LLM with de-identified follow-up notes from the ED visit. The notes were originally written in Hebrew. We excluded the discharge letter from all notes. The model was to produce a concise medical summary and discharge recommendations. We used the web-based version of GPT-4, generating a new instance for each prompt in May 2024.
Prompt for GPT-4 generation
A standardized prompt was used to guide GPT-4 in generating each letter. The model was instructed to act as a senior ED physician, produce a concise medical summary, and include clear discharge recommendations in professional yet empathetic language. A sample excerpt of the prompt is included here: “You are a senior physician in the emergency department. Please write a concise medical summary, including specific discharge recommendations if necessary. Be professional and empathetic, ensuring that empathy does not compromise professionalism.”
The full prompt text is provided in Supplementary Materials.
Evaluator recruitment and blinding
We recruited 17 evaluators for the study:
7 physicians (4 residents and 3 specialists) 5 nurses 5 patients
Evaluators came from staff within the institute and external individuals, including random ED patients. To minimize bias, evaluators were blinded to the source of the discharge letters and the purpose of the study. They were presented with side-by-side comparisons of the human-written letter (L1) and the GPT-4-generated letter (L2). The order of the letters was randomized, and there was no indication letters were GPT-4.
Evaluation process
The evaluation had two parts:
Evaluators compared the two letters for each patient using a structured questionnaire.
Three ED attendings independently assessed the medical accuracy of both types of letters. They were blinded to the source of the letters and unaware of which were GPT-4. Accuracy was rated on a 5-point scale, based on how closely the letter matched the ED notes of the patient.
Figure 1 shows a graphical abstract, including the overall study design, the parallel processes of generating discharge letters, the composition of the evaluator panel, and key findings. Each of the 17 evaluators independently assessed all 72 paired discharge letters (human vs. GPT-4), yielding 1206 total comparisons.
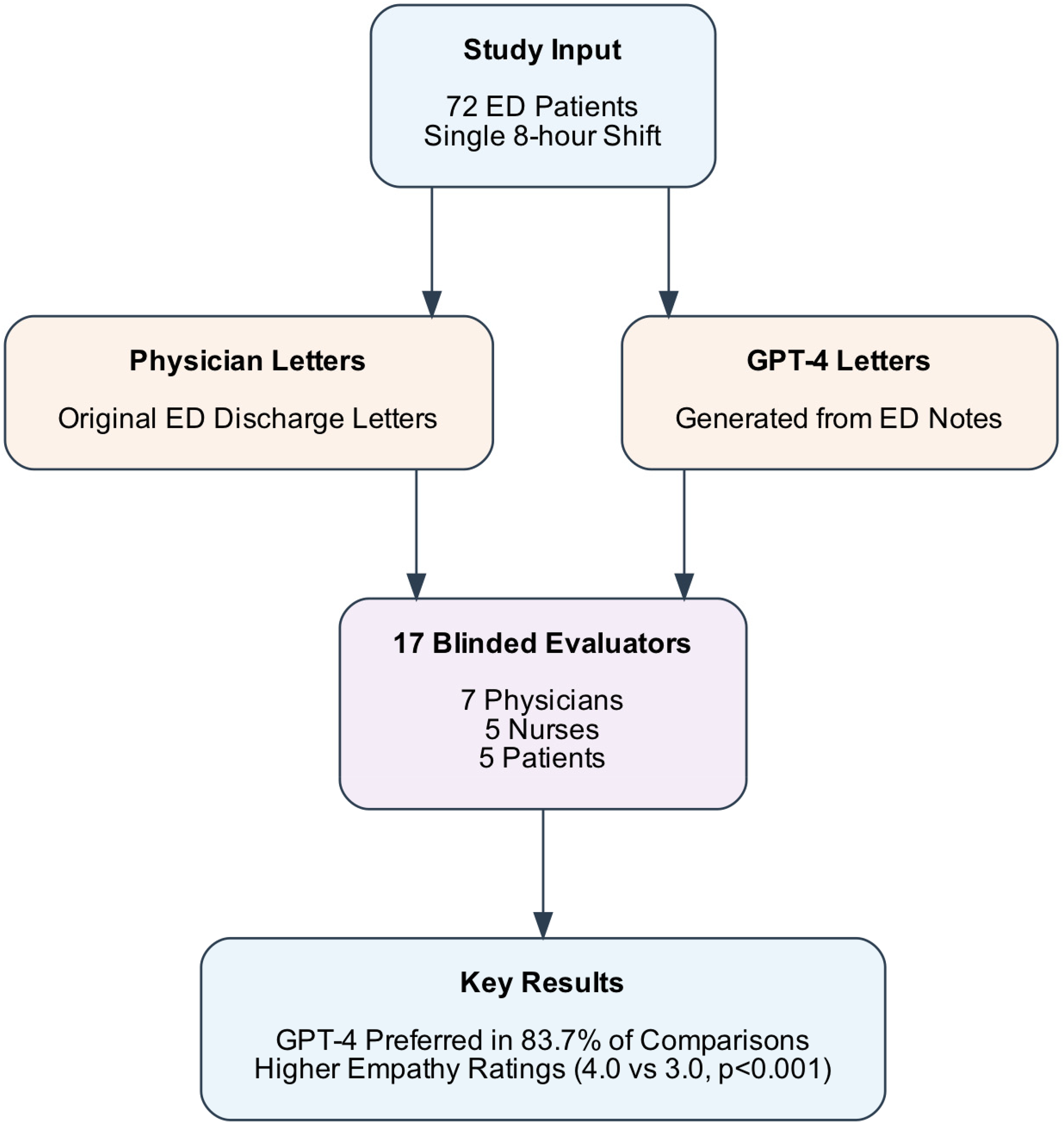
Study design and key results flow diagram. The diagram illustrates the process of comparing GPT-4-generated and physician-written emergency department (ED) discharge letters. Starting with 72 ED patient cases from a single 8-h shift, the study generated two sets of discharge letters that were evaluated by a blinded panel of 17 evaluators (seven physicians, five nurses, five patients). GPT-4 letters were consistently preferred and demonstrated significantly higher empathy ratings compared to physician-written letters.
Outcome measures
Primary Outcomes: The main outcome was the empathy of the GPT-4 letters compared to those written by ED physicians.
Secondary Outcomes: We evaluated clarity and overall quality of GPT-4-generated letters by the evaluating groups (physicians, nurses, patients). We also assessed the medical accuracy of the letters, as rated by independent evaluators.
Statistical analysis
Ordinal variables were summarized using medians and interquartile ranges. Categorical variables were reported as proportions. We used the Mann–Whitney U test for comparisons of ordinal data. We used chi-square tests for binary data. Additionally, we performed a qualitative analysis of empathy in the human and AI letters. All analyses were performed using Python Ver 3.9. Statistical significance was defined as p < 0.05.
Qualitative analysis
We used a simple two-part rubric. “Generic” empathy means supportive phrasing that isn’t tied to the person's case (e.g., a stock reassurance). “Tailored” empathy means wording that speaks directly to the patient's symptoms, diagnosis, or situation. Supplementary Table S2 shows paired examples for each category to guide future coding.
We coded 15 paired examples as ‘generic’ vs. ‘tailored’ empathy (see Supplementary Table S2). While GPT-4 often used generic phrasing, evaluators nonetheless rated these as effective. A future quantitative content analysis could score the proportion of tailored vs. generic statements.
Results
Study characteristics
During a single ED shift, 72 patients were discharged. Each received a discharge letter that we used in our study. These letters, written by human physicians, were compared to ones crafted by GPT-4. We had 17 evaluators: physicians, nurses, and patients (see Supplementary Table S1). They ranged in age from 25 to 74 years, with most (53%) in the 35–44 age group. This diverse group provided a broad perspective on empathy, clarity, and quality.
Overall preference for letters (GPT-4 vs. human)
Across 72 comparisons, evaluators strongly preferred GPT-4 (L2) over human letters (L1). Out of 1206 total comparisons, L2 was preferred in 1009 (83.7%) instances, while L1 was preferred in 197 (16.3%) instances (p < 0.001). GPT-4 was also preferred across all separate evaluated groups (all p < 0.001). The separate group’s analysis is shown in Figure 2.
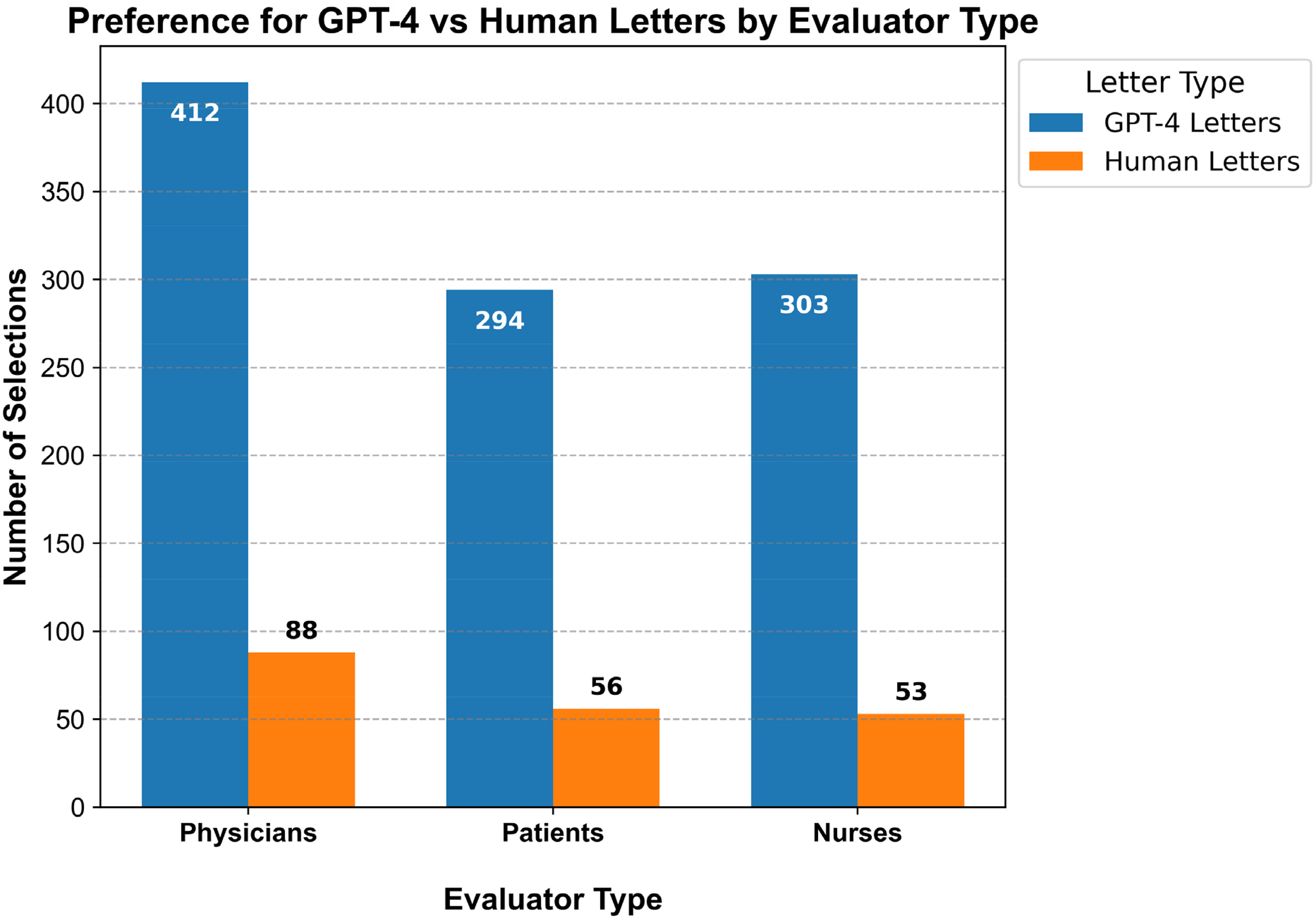
Comparisons of overall preference of letters of GPT-4 and physicians discharge letters by evaluator groups (physicians, nurses, patients).
Comparison of ratings for GPT-4 and human-written discharge letters
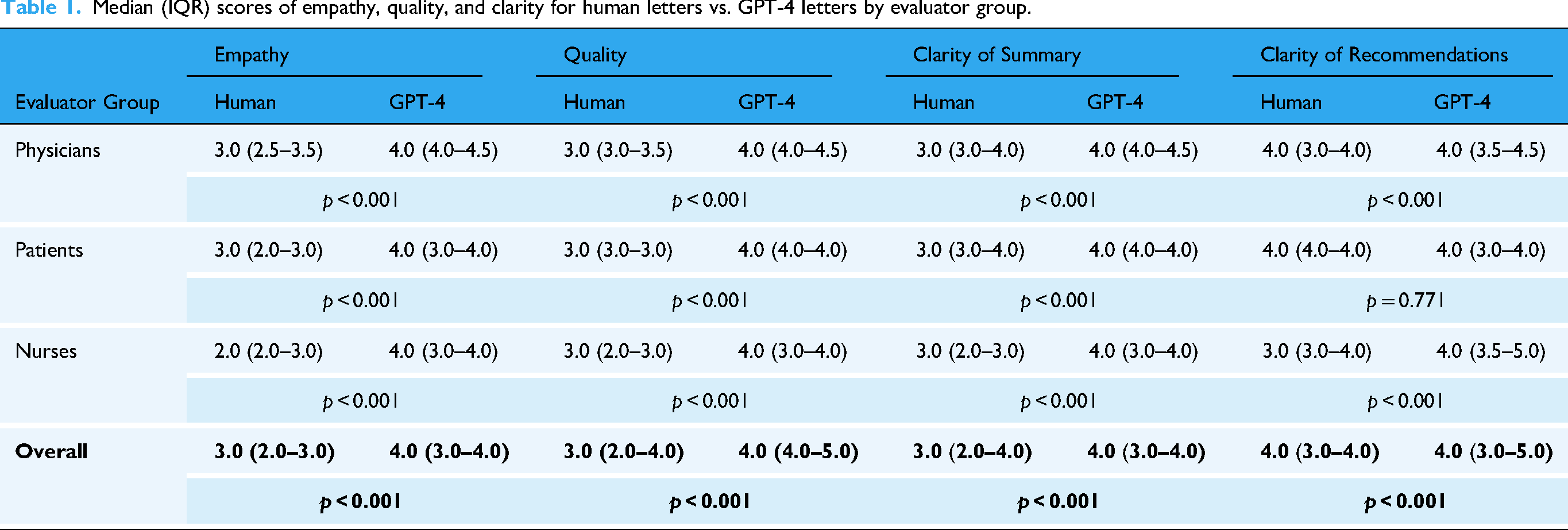
GPT-4 letters were rated higher than human letters in most categories across all evaluator groups (Table 1). Significance was shown for empathy, overall quality, and clarity of the summary (all p < 0.001). The only exception was the clarity of recommendations in the patients’ group (p = 0.771). In the overall analysis, GPT-4 letters consistently outperformed human letters (p < 0.001).
Median (IQR) scores of empathy, quality, and clarity for human letters vs. GPT-4 letters by evaluator group.
Subgroup analysis based on gender and age
Overall, GPT-4 letters received higher ratings across most subgroups and metrics. A few exceptions were seen in clarity of recommendations for certain groups (Table 2).
Median (IQR) scores of empathy, quality, and clarity for human letters vs. GPT-4 letters by evaluator categories.
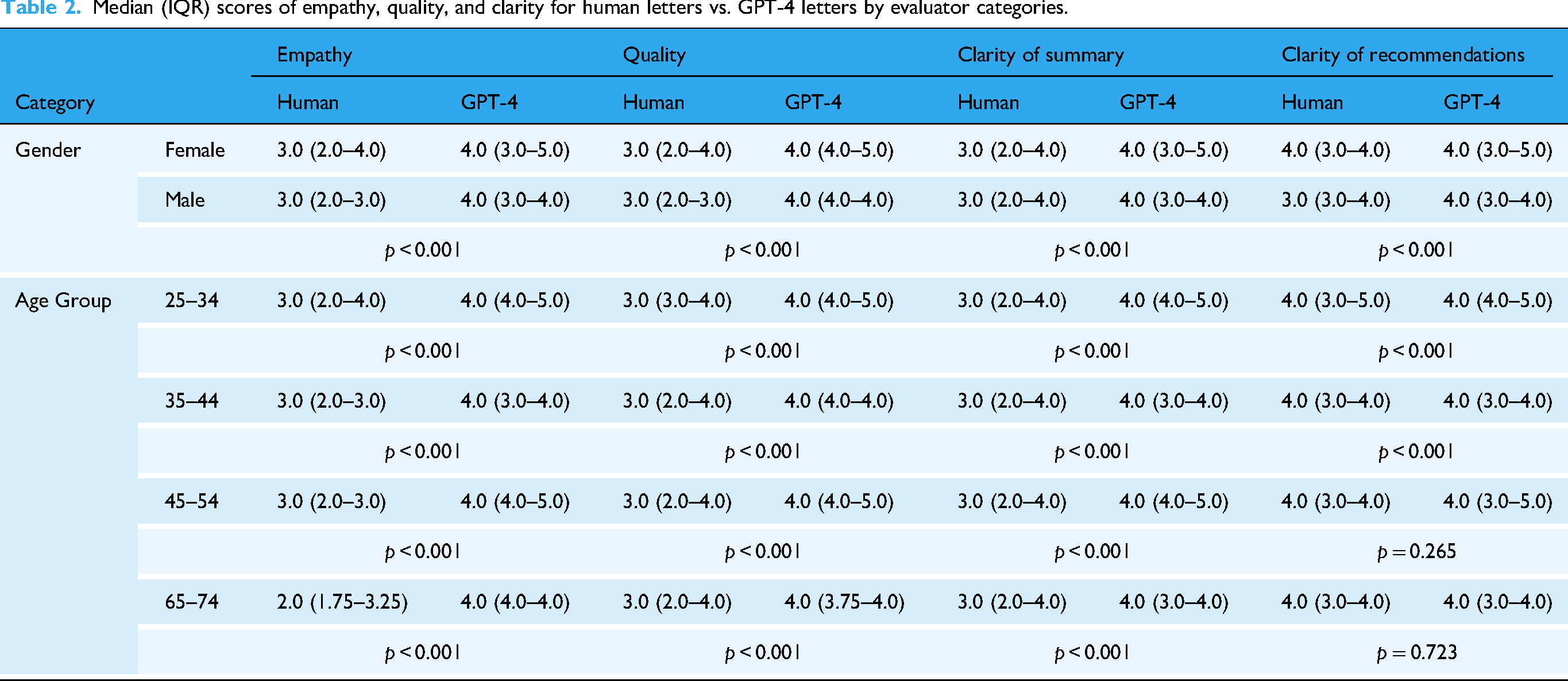
Gender: Both females and males rated GPT-4 higher than human letters across all metrics. Females showed a strong preference for GPT-4 in empathy, quality, and clarity of the summary (p < 0.001). A smaller but significant difference was seen in clarity of recommendations (p < 0.001). Males also rated GPT-4 higher across empathy, quality, and clarity (p < 0.001). Research suggests that women are more attuned to empathy. This may explain their heightened sensitivity to empathetic elements in the discharge letters. 18
Age: GPT-4 was consistently rated higher for empathy, quality, and clarity in the 25–34, 35–44, and 45–54 age groups (p < 0.001). However, in the 45–54 and 65–74 age groups, no significant difference was found for clarity of recommendations (p = 0.265, p = 0.723, respectively).
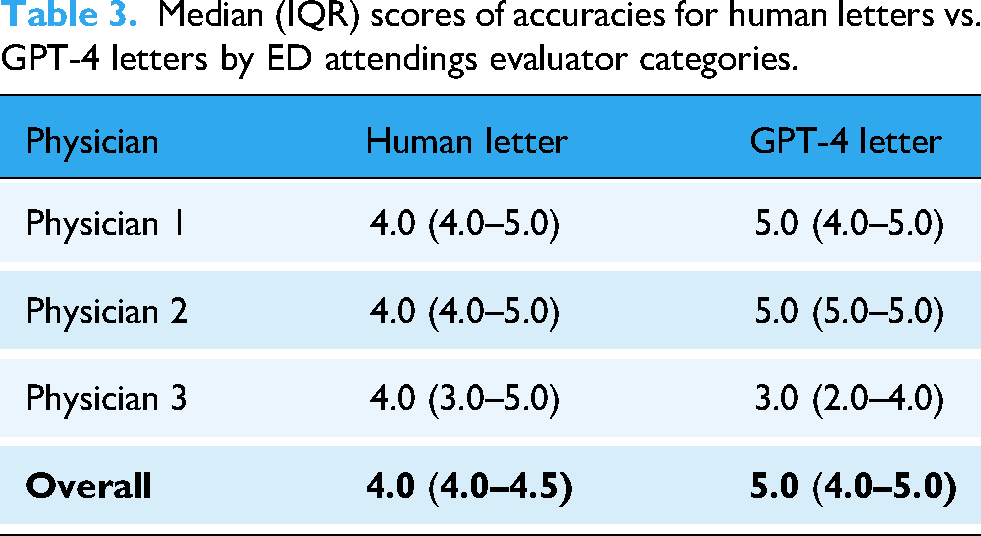
Accuracy evaluation
Three senior ED attendings rated both human-written (L1) and GPT-4-generated (L2) letters on a scale of 1 to 5. As shown in Table 3, the overall median accuracy score for L2 was higher than L1 (L1 4.0 vs. L2 5.0, p = 0.025).
Median (IQR) scores of accuracies for human letters vs. GPT-4 letters by ED attendings evaluator categories.
Qualitative analysis
We compared GPT-4-generated and physician-written discharge letters to see how empathy was conveyed.
In one physician’s letter for a patient with a chronic condition, the doctor offered personalized support: “I understand that managing your symptoms has been challenging. We are here to support you every step of the way. Please contact us if you experience any new symptoms.” In contrast, the GPT-4-generated letter stated: “Your condition has been stable. We recommend follow-up care with your primary physician if there are any changes.” While accurate, GPT-4's letter lacked the personal reassurance seen in the physician's note.
However, in other cases, GPT-4 showed a sufficient level of empathy. For example, a GPT-4 letter for a patient with a recent cancer diagnosis included: “We know this diagnosis may be overwhelming, and we are committed to helping you through this difficult time. Please reach out with any concerns.” This language was more general compared to the physician's note for the same case, which was more clinical and concise. Yet, evaluators rated the GPT-4 letter higher for clarity and perceived empathy.
Supplementary Table S2 provides 15 examples of how empathy was conveyed in both AI and physician letters. Although GPT-4's responses may sometimes rely on standard expressions of empathy, evaluators consistently favored these letters over those written by physicians. In these cases, GPT-4's approach, though perhaps “generic,” was not seen as a limitation by most evaluators and was overwhelmingly preferred overall (L1 vs. L2).
Discussion
This study shows the potential of GPT-4 in creating empathetic discharge letters in the ED. Evaluators consistently preferred GPT-4 letters over those written by physicians. They rated GPT-4's letters higher in empathy, clarity, and overall quality. Both physicians and nonphysician evaluators gave GPT-4 higher scores across most metrics. Empathy and clarity stood out as key strengths.
While discharge letters have historically served primarily as provider-to-provider communication, in many modern healthcare systems, they are increasingly shared directly with patients. This evolution underscores the emerging importance of empathy in discharge documentation, as patients rely on these letters to understand their condition and follow-up instructions.
Previous studies have shown that LLMs can surpass medical experts in summarizing clinical texts and generating discharge summaries.9,19,20 These models produce content comparable to human-written summaries. Patients often perceive AI summaries as equally clear. However, they are sometimes perceived as lacking the personal touch of human documents. 21 In our study, GPT-4 letters were rated more accurate than those written by physicians. This suggests that AI like GPT-4 may enhance the accuracy of medical documentation. Accurate records are crucial for patient safety and outcomes.
Our study is unique. It focuses on generating full discharge letters in a real, high-stakes clinical setting. We emphasize mainly empathy—key aspect of effective patient communication. By assessing these qualities in a real-world ED setting, we provide insight into AI's ability to balance technical accuracy and emotional connection in clinical documentation.
Interestingly, there were no significant differences between groups for clarity of discharge recommendations. This was specifically demonstrated in the older age groups. This is a positive finding for physicians. It suggests that the important section of recommendations remains clear.
The high empathy ratings for GPT-4 align with prior research. Studies show that AI can generate responses perceived as compassionate, even in clinical settings.12,17 This is especially relevant in high-stress environments like the ED. Empathy plays a crucial role in guiding patients through the next phase of care. This includes self-care and follow-up with community physicians. Feeling seen and cared for may enhance patient adherence to treatment and follow-up care.22,23
Although GPT-4's approach may seem “generic” at times, this did not reduce its effectiveness. On the contrary, evaluators overwhelmingly favored the GPT-4 letters. This suggests that GPT-4's standardized yet empathetic responses were seen as helpful. In a direct, blinded comparison, GPT-4 consistently outperformed human-written letters across multiple metrics. In blinded head-to-head comparisons, GPT-4 letters were rated higher than physician-written letters across multiple domains. This demonstrates that even “standardized” empathy can be impactful in practice.
One caveat is that empathy ratings were assessed without disclosing who wrote the letters. Some studies have shown that when AI authorship is disclosed, the perceived empathy diminishes. 21 This could be attributed to bias against AI. 24 It might also stem from a fundamental human need for care from fellow humans—those capable of sharing in their pain or sorrow and genuinely caring for them. 25 This underscores the need for caution when implementing AI in direct patient care. Even if AI performs as well as or better than humans in some areas.21,24 However, AI should be seen as a tool to assist physicians with administrative tasks. The physician should have final control over the letter's content, editing, and signing.
By generating discharge letters, GPT-4 shows potential to reduce administrative burden. Automating this task could allow physicians to spend more time on patient care. This is critical in increasingly overcrowded and complex ED environments.26,27 Together, these results highlight the importance of balancing the strengths of AI with the qualities of human care. This might involve using AI as a copilot or ensuring a human-in-the-loop, though even this may come with a cost. 21
The ethical implications of AI-assisted discharge communication require careful consideration. Key issues include transparency to patients about AI involvement, maintaining physician accountability, and safeguarding privacy when using cloud-based models. Human oversight remains essential to ensure accuracy and patient trust.
Our study has limitations. The evaluators were from a single demographic, and the study was conducted at a single center. This limits the generalizability of the results. We evaluated GPT-4 exclusively. Open-weight and locally deployable models may be preferable in some clinical contexts for privacy, cost, or customization. Comparative studies are needed to assess whether results generalize across LLM platforms. Moreover, we did not use techniques such as retrieval-augmented generation or fine-tuning. Such a technique could have further improved GPT-4's performance. Despite this, GPT-4's zero-shot performance was rated highly by the evaluators. This indicates strong baseline capabilities. Additionally, while GPT-4 performed well in this study, further research is needed. We need to understand how patients perceive letters if they know that they were generated by AI. Lastly, future studies should explore whether cultural or institutional differences influence the reception of GPT-4 content.
Conclusion
In conclusion, in a blinded comparison, GPT-4 discharge letters were preferred over physician-written letters and rated higher in empathy and clarity. These findings suggest AI-assisted drafting may help reduce documentation burden while supporting patient-centered communication. Prospective, multicenter studies are needed to validate and refine these applications.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251389992 - Supplemental material for Evaluating empathy in GPT-4-generated vs. physician-written emergency department discharge letters
Supplemental material, sj-docx-1-dhj-10.1177_20552076251389992 for Evaluating empathy in GPT-4-generated vs. physician-written emergency department discharge letters by Gal Ben-Haim, Adva Livne, Uri Manor, David Hochstein, Mor Saban, Orly Blaier, Yael Abramov Iram, Moran Gigi Balzam, Ariel Lutenberg, Rowand Eyade, Roula Qassem, Dan Trabelsi, Yarden Dahari, Ben Zion Eisenmann, Yelena Shechtman, Girish N Nadkarni, Benjamin S Glicksberg, Eyal Zimlichman, Anat Perry and Eyal Klang in DIGITAL HEALTH
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.