
Abstract
Objective
To evaluate the performance of generative AI tools, specifically Ernie Bot and ChatGPT, in supporting online medical consultations in China, focusing on their accuracy, safety, and empathy, and to assess their potential role in addressing the supply-demand gap in the healthcare system.
Methods
We collected 233 trigeminal neuralgia consultations from a Chinese medical platform, including patient questions and doctor replies. Each question was input into ChatGPT-3.5 and Ernie Bot with role-specific prompts to generate large language models (LLMs) responses. Four blinded raters—two doctors and two patients—evaluated all responses using DISCERN and a modified PEMAT. Lexical, syntactic, and semantic analyses were conducted, with Spearman correlations assessing links between linguistic features and perceived quality.
Results
While doctors led in reliability, Ernie Bot scored highest overall, especially in empathy and clarity, likely due to stylistic choices rather than true understanding. Despite their fluency, LLMs remain prone to factual errors. Text analysis showed distinct linguistic patterns, with several features significantly correlated with perceived quality.
Conclusion
LLMs demonstrate strengths in perceived empathy and clarity but fall short in clinical accuracy and depth when addressing complex cases. Although they outperform doctors in communication-related aspects, their limitations in high-risk decision-making remain evident. As such, LLMs hold promise as adjunct tools for non-urgent consultations, but further refinement is needed to meet the standards of precise and personalized healthcare delivery.
Keywords
Introduction
Since the launch of China's healthcare reform in 2009, medical resources have expanded steadily.. 1 However, this growth remains inadequate given the rising demand driven by an aging population and improved living standards, with persistent disparities in resource distribution. 2 By 2023, China had 4.782 million licensed (assistant) doctors and 5.637 million nurses, translating to 3.4 doctors per 1000 people—lower than many developed nations. Meanwhile, medical demand surged, with outpatient visits reaching 9.55 billion, hospital admissions at 302 million, and 243 million cross-regional treatments, underscoring the urgent need for optimized resource allocation.3,4
Amidst these challenges, rapid internet development has driven the expansion of online healthcare services. By 2024, China had 1.099 billion internet users, with a penetration rate of 78.6%. 5 Online consultations have gained popularity, especially among younger populations, 6 and have helped alleviate the mismatch of medical resources by providing access to remote and underserved areas.7,8 However, these platforms have not fundamentally resolved supply shortages. Online consultations rely on part-time doctors with limited availability, resulting in low service capacity and inconsistent quality—data shows an average of just 0.38 patients consulted per doctor per day, with an online-to-offline workload ratio of 1:14. 9 Additionally, doctors often lack experience in virtual consultations, while communication barriers such as uncertain response times and limited real-time interaction further impact patient experience and service quality. 10
The emergence of ChatGPT in 2022 marked a milestone in AI, particularly in large language models, offering a potential solution to the shortage of online healthcare consultations. Unlike traditional doctor-led telemedicine, LLMs can rapidly process large volumes of patient inquiries, providing preliminary diagnoses and health management recommendations, thereby improving efficiency.11,12 LLMs have demonstrated early applications in medical imaging analysis and disease prediction, with some showing preliminary diagnostic capabilities.13,14 For example, ChatGPT has passed the United States Medical Licensing Examination and achieved high accuracy in identifying certain conditions. 15 ChatGPT has been shown to perform comparably to human doctors in cerebrovascular consultations, with higher perceived completeness and empathy but slightly lower clarity. 16 In another study, GPT-4o generated more accurate, concise, and comprehensive responses than doctors in thyroid eye disease consultations. 17 Google's medically trained model AMIE also outperformed clinicians in both accuracy and patient experience in simulated consultations. 18
The rapid integration of LLMs in healthcare has brought unprecedented opportunities, yet also raises critical ethical and regulatory challenges. Despite their extensive medical knowledge, LLMs’ real-world clinical reliability remains unverified, as their diagnostic quality is constrained by training data, reasoning abilities, and adaptability to new medical knowledge, potentially leading to inaccuracies, particularly in complex or rare diseases.19–21 Recent researches highlight critical and ethical risks including limited factual accuracy, unclear accountability, and inadequate protection of patient consent and data privacy.22–25 LLMs may produce confident but potentially misleading content, which could exacerbate health disparities and undermine clinical trust, especially in low-resource or linguistically diverse settings. Furthermore, compared to human doctors, LLMs face challenges in patient communication, emotional support, and personalized care, and patient acceptance of AI-generated medical advice varies across demographics.
This study aims to compare and evaluate the quality of medical responses provided by doctors and large language models, exploring the potential applications of LLMs in online healthcare consultations. The research objectives are as follows: 1. Assess the efficacy and feasibility of responses through expert and patient evaluations. 2. Analyze the textual features of responses using text mining techniques. 3. Examine the impact of textual features on the perceived efficacy and feasibility of the responses.
To ensure experimental consistency and control task variability, we focus on trigeminal neuralgia, a representative symptom-driven condition characterized by sudden, severe facial pain. The diagnosis of trigeminal neuralgia heavily relies on patient-reported symptoms rather than imaging or laboratory data, making it suitable for evaluating language-based consultation systems.26,27 Its structured diagnostic path and stable informational demands help reduce noise from task heterogeneity, 28 while its moderate sensitivity and clear boundaries enhance data collection and ethical feasibility in an online setting. 29 Prior studies also suggest that LLMs tend to perform more reliably in structured, language-dependent tasks than in complex, multimodal diagnostic scenarios.30,31 Moreover, the majority of existing LLM evaluations are centered on English-language models, overlooking the performance and risks of localized models in non-English healthcare contexts. To address this gap, we compare ChatGPT with Ernie Bot-a mainstream Chinese-language LLM developed by Baidu—focusing on how linguistic and cultural embedding may shape perceived empathy and clarity in medical dialogue. This comparison is particularly relevant given the rapid expansion of localized AI tools and their growing use in digital health services in China and other multilingual regions.
Material and methods
Data sources
We selected xunyiwenyao, a prominent Chinese online medical platform, as the data source due to its comprehensive collection of patient-doctor interactions. This study focuses on trigeminal neuralgia, a condition affecting 1.6 to 3 per 1000 individuals, 27 characterized by intense facial pain. Given that its diagnosis primarily relies on symptom descriptions rather than medical tests, it is ideal for text-based consultations. Using bazhuayu (https://www.bazhuayu.com/), we extract critical data from April to May 2024, including patient symptoms, treatment history, inquiries, doctor analyses, and recommendations (Figure 1). Additionally, to ensure accurate simulation of LLM responses, we collect doctors’ titles, specialties, and affiliated departments.

Example of online consultation for trigeminal neuralgia on a medical inquiry website.
Text generation with large language models
This study selected Ernie Bot and ChatGPT to generate large language model responses to patients’ questions. Ernie Bot is trained predominantly on Chinese-language web data, knowledge graphs, and search logs, with stylistic norms tailored to local user expectations. In contrast, ChatGPT is developed by OpenAI using primarily English corpora, often reflecting a more neutral, structured, and less affective tone. These distinctions allow us to explore whether model-specific language and interaction styles influence patient-perceived communication quality. For detailed technical background, please refer to the Supplemental Appendix A.
To improve the accuracy and applicability of LLMs in medical dialogues, we designed a role-playing prompt that includes attributes such as professional level and department affiliation. 32 All experimental procedures involving LLMs were conducted following standardized workflows in accordance with TRIPOD-AI guidelines for AI evaluation transparency. Specifically, we employed ChatGPT (gpt-3.5-turbo) and Ernie Bot (ERNIE-3.5–8 K), for which structured prompts and model parameters were predefined to ensure reproducibility. The structured prompt design comprised three components: Role Setting, defining the model as a senior neurologist with expertise in trigeminal neuralgia and related interventions; Task Description, instructing the model to perform comprehensive case analyses, consider differential diagnoses, reference authoritative clinical guidelines, and provide evidence-based therapeutic and lifestyle recommendations; and Writing Requirements, ensuring that responses employed accurate medical terminology, were patient-friendly, scientifically rigorous, well-structured, and empathetic. Relevant model parameters, including temperature, top_p, and maximum token limits, were consistently applied across all experiments. The exact prompts, selected patient questions, corresponding responses from doctors, ChatGPT, and Ernie Bot, along with relevant model configuration parameters, are provided in Supplemental Appendix B.
During the data collection process, all questions were input individually into the gpt-3.5-turbo model and the ERNIE-3.5–8 K model to collect their responses. To eliminate potential learning biases or contextual influences, we adopted a new chat mode, ensuring that each question was answered independently. This process was conducted from April 2024 to May 2024, ensuring that no context from previous questions influenced subsequent responses, thereby minimizing systematic errors.
Evaluation of response effectiveness and feasibility
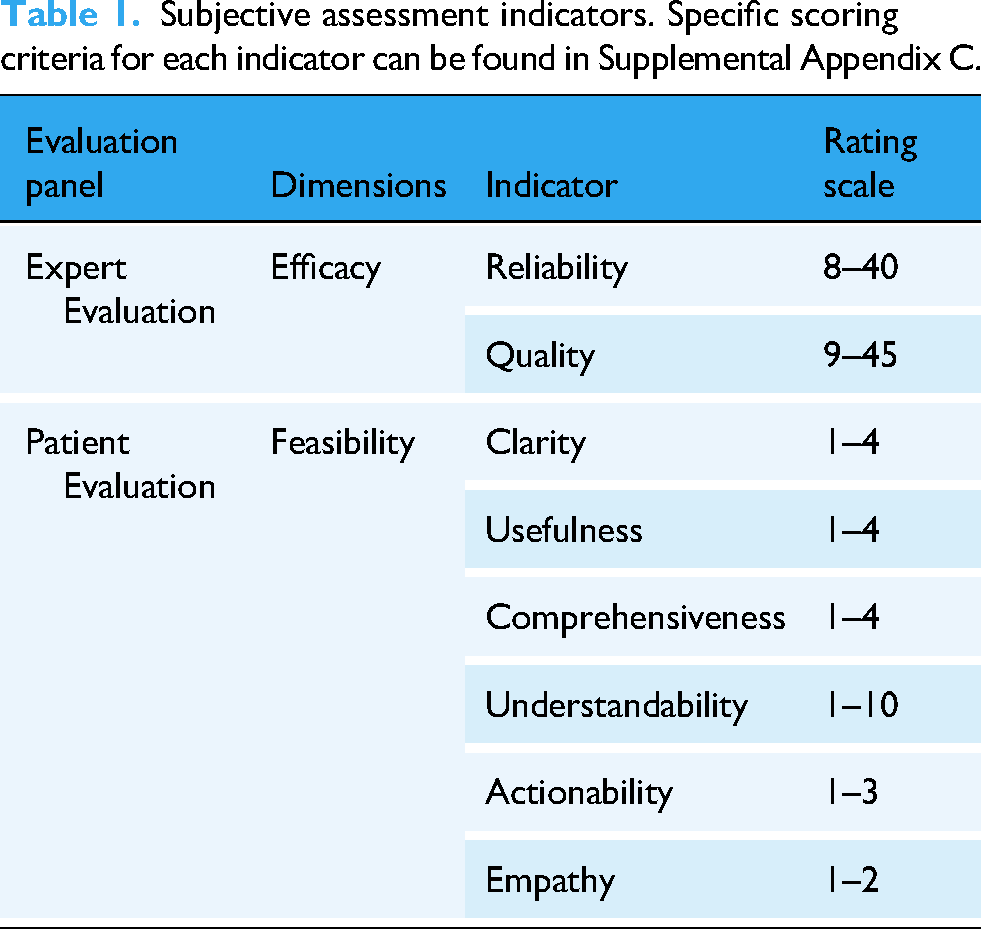
This cross-sectional observational study combining subjective assessments and objective text analysis was conducted in China from April to June 2024. Table 1 presents the subjective assessment of indicators. Two independent evaluation groups were designed to assess responses based on efficacy and feasibility. Efficacy was evaluated by two medical experts with over 10 years of clinical experience in tertiary medical centers, focusing on response reliability and quality. The DISCERN tool quantified efficacy, with questions 1–8 assessing answer reliability, 9–15 evaluating treatment quality, and question 16 providing an overall quality assessment. 33 Feasibility was assessed by two patients with clinical experience in treating trigeminal neuralgia, focusing on clarity, usefulness, empathy, and actionability. Evaluations were conducted using the Patient Education Materials Assessment Tool (PEMAT), which includes two subscales: PEMAT-U for understandability and PEMAT-A for the practicality of suggested actions.34,35
Subjective assessment indicators. Specific scoring criteria for each indicator can be found in Supplemental Appendix C.
To ensure the reliability and objectivity of subjective evaluations, we implemented a standardized multi-rater protocol incorporating structured training, pre-rating consistency testing, and rigorous bias control procedures. Briefly, all annotators were trained using validated instruments, followed by a consistency check to ensure inter-rater reliability. During the rating process, a triple-blind strategy was adopted to minimize potential source-related bias, including anonymization of response sources, randomized evaluation order, and independent rating assignment. For detailed training content, procedures, and quality assurance measures, please refer to Supplemental Appendix D and Supplemental Appendix E.
Analysis of response text features
We analyzed the textual features of the responses from three perspectives: words, sentences, and meaning. For word analysis, we utilized Python and the Jieba library to segment the text and gather frequency statistics, in order to ensure accurate recognition of specialized terminology, we extracted key terms related to “trigeminal neuralgia” from over 2000 academic papers in the CNKI database.
For sentence-level analysis, we examined the overall and average sentence lengths and conducted a differential analysis of high-frequency word pairs using a 2-gram model.
At the meaning level, we focused on evaluating the complexity, emotional tone, and semantic similarity of the responses. We measured text complexity using perplexity with a pre-trained BERT model. 36 Emotional polarity was assessed by analyzing the sentiment of individual words, while text and semantic similarities were quantified using the TF-IDF and Doc2Vec models.
Statistical analysis
Statistical analysis was performed using SPSS (IBM 26.0). The Intraclass Correlation Coefficient (ICC) was calculated to assess inter-rater reliability across all evaluated dimensions. We used a two-way random effects model with average measures and consistency type based on established psychometric standards. This model assumes raters and subjects are randomly sampled, focus on consistency in relative ranking regardless of absolute scores, and averages ratings from two raters per item. Calculations were performed in SPSS using a two-way ANOVA framework. For full methodological details and formulae, please refer to Supplemental Appendix F. Good consistency was indicated by an ICC value above 0.70. A one-way ANOVA tested whether differences between the three types of responses were significant. Spearman's correlation analysis. 37 explored the relationship between textual features and manual evaluation dimensions, quantifying the impact of text features on perceived characteristics with Spearman's Rho. The Spearman's Rho value, ranging from −1 to +1, indicates the degree of monotonic relationship between variables, with +1 as a perfect positive correlation, −1 as a perfect negative correlation, and values near 0 indicating no significant relationship.
Results
Differences in perceptual dimensions of responses from human doctors and large language models
Figure 2 presents the evaluation results of specialists and patients. In terms of ‘efficacy,’ doctors’ answers (mean 25.04, SD 3.05) were more reliable than those of ChatGPT (mean 23.40, SD 2.24) and Ernie Bot (mean 24.65, SD 2.74) (Figure 2(A)). However, Ernie Bot (mean 26.04, SD 3.05) had the best ‘Quality’ of answers (Doctor: mean 24.90, SD 2.23; ChatGPT: mean 24.45, SD 2.48) (Figure 2(B)). Although Ernie Bot outperformed ChatGPT, some repeated sentences in both responses may have come from the same information source. For feasibility, LLMs scored higher on ‘Clarity’ (Doctor: mean 3.37, SD 0.47; ChatGPT: mean 3.39, SD 0.58; Ernie Bot: mean 3.68, SD 0.44) (Figure 2(C)), ‘Usefulness’ (Doctor: mean 2.77, SD 0.61; ChatGPT: mean 3.43, SD 0.49; Ernie Bot: mean 3.82, SD 0.34) (Figure 2(D)), ‘Comprehensiveness’ (Doctor: mean 2.76, SD 0.63; ChatGPT: mean 3.36, SD 0.43; Ernie Bot: mean 3.80, SD 0.32) (Figure 2(E)), ‘Understandability’ (Doctor: mean 5.52, SD 0.63; ChatGPT: mean 6.83, SD 0.78; Ernie Bot: mean 7.42, SD 0.86) (Figure 2(F)), ‘Actionability’ (Doctor: mean 1.70, SD 0.59; ChatGPT: mean 2.76, SD 0.36; Ernie Bot: mean 2.85, SD 0.28) (Figure 2(G)), and ‘Empathy’ (Doctor: mean 0.11, SD 0.28; ChatGPT: mean 0.48, SD 0.50; Ernie Bot: mean 0.32, SD 0.47) (Figure 2(H)). Tukey Post Hoc Test showed significant pairwise differences (P < .001) across evaluation dimensions.
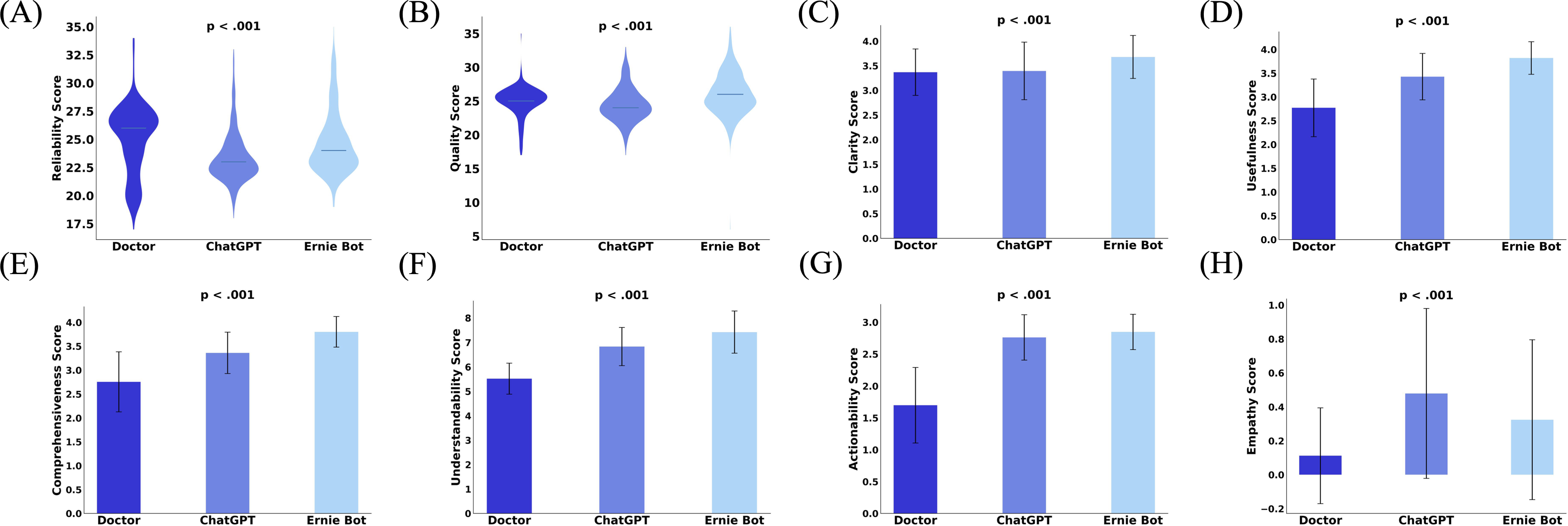
(A) Reliability scores (scores range from 8 = worst to 40 = best) for the three groups answering the efficacy dimension. (B) Quality scores (scores range from 9 = worst to 45 = best) for the three groups answering the efficacy dimension. (C) Clarity scores for the three groups answering the feasibility dimension (scores range from 1 = worst to 4 = best). (D) Usefulness scores (scores range from 1 = worst to 4 = best) for the three groups answering the feasibility dimension. (E) Comprehensiveness scores (scores range from 1 = worst to 4 = best) for the three groups answering the feasibility dimension. (F) Understandability scores for the three groups answering the feasibility dimension (scores range from 1 = worst to 10 = best). (G) Actionability scores for the three groups answering the feasibility dimension (scores range from 1 = worst to 3 = best). (H) Empathy scores of the three groups answering the feasibility dimension (scores range from 1 = worst to 2 = best).
To better quantify the magnitude of observed differences between human and LLM-generated responses across evaluation dimensions, we calculated Cohen's d as a standardized measure of effect size (Table 2). Relative to doctor responses, Ernie Bot achieved large effect sizes in actionability (d = 2.48), comprehensiveness (d = 2.09), and usefulness (d = 2.13), as well as moderate to large effects in clarity and empathy (d = 1.24–0.55).
Pairwise Cohen's |d| effect sizes across perceptual dimensions.

Based on the above data, we can preliminarily infer that LLMs—particularly Ernie Bot—demonstrated strong performance in terms of response quality and patient-perceived experience. Patients may have perceived Ernie Bot's responses as more helpful and emotionally supportive across specific dimensions. Notably, the differences between doctor- and LLM-generated responses yielded large effect sizes, suggesting statistically meaningful and perceptually salient differences. In contrast, the perceptual differences between ChatGPT and Ernie Bot were marginal. While effect size estimates help contextualize statistical significance, their practical and clinical implications should be interpreted with caution, particularly given the limited sample size and the inherently subjective nature of the evaluations.
Furthermore, systematic evaluation of the medical accuracy of consultation texts indicated that, although LLMs perform well in dimensions such as empathy, they remain susceptible to generating hallucinations. These hallucinations appear plausible but are factually incorrect, thereby posing potential clinical risks. Error analysis indicated that human doctors produced 2 incorrect answers (0.86%), Ernie Bot 6 incorrect answers (2.58%), and ChatGPT 17 incorrect answers (7.30%). In certain cases, LLMs misprioritized therapeutic options; for instance, electrical stimulator implantation, which is primarily a palliative intervention, was occasionally suggested as a first-line treatment. Table 3 presents the primary error types along with representative examples. The data indicate that human doctors rarely committed Explanation or Treatment Plan Errors, whereas LLMs (Ernie Bot and ChatGPT) frequently exhibited errors across all four categories (Table 3). Representative examples and a detailed classification of hallucination types are provided in Supplemental Appendix G, along with the potential clinical consequences if such responses were adopted by patients. The observed error types include diagnostic misjudgments, inaccurate etiological explanations, and inappropriate treatment recommendations, particularly in high-risk interventions. 38
Summary of primary error types in human and LLM responses.

Textual feature differences between responses from human doctors and large language models
Figure 3 shows the results of the text analysis. Doctors’ responses had significantly higher frequencies of nouns (Doctor: mean 25.62, SD 0.35; ChatGPT: mean 23.59, SD 0.23; Ernie Bot: mean 23.86, SD 0.19), time words (Doctor: mean 0.71, SD 0.07; ChatGPT: mean 0.43, SD 0.04; Ernie Bot: mean 0.62, SD 0.04), verbs (Doctor: mean 20.96, SD 0.35; ChatGPT: mean 18.43, SD 0.17; Ernie Bot: mean 17.92, SD 0.15), and adjectives (Doctor: mean 3.57, SD 0.17; ChatGPT: mean 2.48, SD 1.09; Ernie Bot: mean 2.73, SD 0.07) compared to AI-generated responses (P < .001 for all). In contrast, doctors’ responses contained fewer conjunctions (Doctor: mean 4.39, SD 0.19; ChatGPT: mean 6.86, SD 0.11; Ernie Bot: mean 6.61, SD 0.10) and prepositions (Doctor: mean 2.06, SD 0.12; ChatGPT: mean 3.88, SD 0.07; Ernie Bot: mean 3.74, SD 0.06) (P < .001 for both). The higher noun frequency in doctors’ replies suggests they provide more specific, practical information, while the greater use of time words and verbs shows their focus on giving clear guidance, such as “follow up in three months” or “reduce sugar and salt.” LLM responses, with a higher proportion of function words, reflect their reliance on these words to maintain sentence structure and coherence.

(A) Distribution of lexical shares for the three groups of responses. (B) Distribution of perplexity for the three sets of responses. (C) Sentiment polarity distribution of the three sets of responses. (D E) Semantic similarity and textual similarity. comp1: Mean similarity of pairwise comparisons of ChatGPT and doctor responses, comp2: Mean similarity of pairwise comparisons of Ernie Bot and doctor responses, comp3: Mean within-group similarity of doctor responses, comp4: Mean within-group similarity of ChatGPT responses, comp5: Mean within-group similarity of Ernie Bot responses, comp6: Mean of similarity between patient questions and doctor replies, comp7: Mean of similarity between patient questions and ChatGPT replies, comp8 :Mean of similarity between patient questions and Ernie Bot replies. Detailed explanations of all abbreviations and variables presented are available in Supplemental Appendix F.
In terms of meaning, ChatGPT and Ernie Bot's responses had lower PPL values and were concentrated in the low PPL range compared to doctors (Doctor: mean 3.17, SD 4.58; ChatGPT: mean 1.48, SD 0.18; Ernie Bot: mean 1.46, SD 0.27) (Figure 3(B)). Doctors’ responses, more flexible and varied, often include metaphors, similes, and idioms, resulting in higher PPL values and a long-tail distribution. Regarding sentiment, doctors’ responses had more dispersed emotional polarity, with patients perceiving a stronger emotional tendency (Doctor: mean 0.45, SD 0.36; ChatGPT: mean 0.35, SD 0.18; Ernie Bot: mean 0.37, SD 0.15) (Figure 3(C)). Statistically significant differences were found between doctors and the AI (P < .001), but no significant difference was found between ChatGPT and Ernie Bot (P = 0.335).
For similarity, doctors’ responses showed lower intra-group average semantic similarity (comp1: 0.61, comp2: 0.60, comp3: 0.58, comp4: 0.62, comp5: 0.61) (Figure 3(D)) and text similarity (comp1: 0.07, comp2: 0.09, comp3: 0.05, comp4: 0.07, comp5: 0.07) (Figure 3(E)). In contrast, ChatGPT and Ernie Bot's responses had higher average text similarity to doctors’ replies, reflecting that doctors use more varied language in their responses. While both LLMs showed language proficiency, they exhibited higher semantic similarity, indicating more content homogeneity. Regarding question-answer similarity, doctors’ responses differed more from the questions’ wording, while LLMs closely followed the question's wording (comp6: 0.06, comp7: 0.18, comp8: 0.21) (Figure 3(E)). However, doctors’ responses were more contextually relevant and focused on the core of the question, while LLM responses often diverged from the main topic (comp6: 0.80, comp7: 0.47, comp8: 0.54) (Figure 3(D)).
Impact of textual features on perception
Table 4 presents the results of the correlation analysis between text features and perceived response attributes in healthcare consultations. The appropriate use of prepositions, nouns, conjunctions, and verbs in text can enhance the quality and reliability of responses from doctors, as well as improve patients’ perceptions of empathy, clarity, usefulness, comprehensiveness, understandability, and actionability. In particular, the correlations between understandability and the use of nouns (Spearman ‘s Rho = 0.80, P < .001), verbs (Spearman ‘s Rho = 0.74, P < .001), and prepositions, (Spearman ‘s Rho = 0.78, P < .001) as well as comprehensiveness and the use of verbs (Spearman ‘s Rho = 0.73, P < .001) and nouns (Spearman ‘s Rho = 0.76, P < .001), are nearing high correlations. The use of nouns (Spearman ‘s Rho =0.51, P < .001) and verbs (Spearman ‘s Rho = 0.50, P < .001) also shows a moderate correlation with clarity (Spearman ‘s Rho > 0.50). At the sentence level, shorter average sentence lengths can improve the actionability of the text (Spearman ‘s Rho = 0.15, P < .001). At the semantic level, lower text perplexity can improve performance across all human evaluation metrics, especially in terms of the understandability (Spearman’s Rho = 0.60, P < .001) and actionability (Spearman’s Rho = 0.52, P < .001) of the response text, where the relationship is moderately correlated. Additionally, emotional support in the text can enhance the empathy felt by patients (Spearman’s Rho = 0.25, P < .001) and the relevance between the response text and the question can improve the usefulness (Spearman’s Rho = 0.40, P < .001) comprehensiveness (Spearman’s Rho = 0.35, P < .001), understandability (Spearman’s Rho = 0.40, P < .001), and actionability (Spearman’s Rho = 0.43, P < .001) of the response, and these metrics show moderate correlations.
Spearman correlations between text features and perceived response quality dimensions. Conj, Noun, Prep, and Verb indicate the proportion of conjunctions, nouns, prepositions, and verbs in the text, respectively.

Length refers to the average number of words in the text. PPL measures the text perplexity, indicating how uncertain or unpredictable the text is. Emotion represents the level of emotional support conveyed in the response. Relevance assesses the semantic similarity between the response and the question.
We emphasize that the findings should be interpreted as statistical associations rather than causal relationships. Spearman's rank correlation is a non-parametric method that captures monotonic associations but does not imply directionality or causality between variables. 39 The observed negative correlation between noun usage and perceived understandability does not necessarily indicate that reducing noun density would directly enhance comprehension. LLMs capable of producing clearer responses may adopt an overall simplified linguistic style, of which lower noun frequency is merely one co-occurring feature. 40 Moreover, multiple linguistic features—such as reduced use of medical jargon, enhanced emotional tone, or simplified sentence structure—often change simultaneously, making it difficult to isolate the independent contribution of any single variable. These feature clusters may reflect broader latent constructs, such as a “patient-friendly communication style”.41,42 Therefore, we caution against overinterpreting individual correlations as definitive drivers of patient's perceived communication quality.
Discussion
LLMs enhance clarity and emotional support but fall short in medical depth
LLMs demonstrate notable advantages in clarity, language fluency, and emotional support when compared to human doctors, particularly in symptom-driven consultations such as those involving trigeminal neuralgia. Our findings revealed higher ratings for LLMs in empathy and clarity dimensions, consistent with prior studies showing that LLM-generated responses tend to be more readable and emotionally engaging for patients. 43
Effect size analyses further support these distinctions. Ernie Bot achieved large effect sizes relative to doctors in several user-centered dimensions. These results suggest that patients perceived its responses as more actionable and emotionally supportive, particularly in low-risk informational scenarios such as lifestyle guidance or postoperative care. Although these differences were statistically significant, their practical or clinical relevance warrants cautious interpretation. Perceived advantages in style and tone do not necessarily equate to diagnostic accuracy or medical appropriateness. Given the limited sample size and the subjective nature of evaluation metrics, further research is needed to determine whether LLMs can safely and effectively complement human expertise in more complex clinical contexts.
A detailed examination of the textual data indicated that these high empathy scores often stemmed from templated expressions—e.g., recurring phrases such as “I understand your discomfort”—which lacked adaptation to the patient's specific context or atypical concerns. This suggests that emotional resonance may arise more from stylistic fluency than from genuine contextual understanding.23,44 Furthermore, these stylistic features may obscure substantive flaws. Despite their empathetic tone, LLMs occasionally produced responses containing factual inaccuracies or oversimplified clinical reasoning, such as inappropriate treatment suggestions or omission of relevant comorbidities. This observation is consistent with concerns about factual hallucinations in LLM-generated medical content, 45 where emotional fluency may conceal medically unreliable or even unsafe advice. These findings underscore the need to integrate fact-verification mechanisms into empathetic generation pipelines, ensuring that communication quality does not come at the cost of clinical reliability. 24
LLMs simplify medical text but lack professionalism
Our findings reveal that LLMs outperform human doctors in terms of linguistic clarity, structural coherence, and conciseness, consistent with prior research indicating that AI-generated responses are more readable and systematically organized.46,47 This linguistic advantage is also supported by studies showing that LLMs tend to use shorter sentences, more functional words, and lower topic density, which facilitate patient comprehension and engagement.48,49 Such simplification improves the emotional tone and overall user experience. 50 However, this stylistic strength may come at the cost of reduced professional specificity. Our analysis shows that LLMs frequently rely on generalized terms such as “certain medications” or “individual differences,” and exhibit highly patterned use of hedging and neutral phrasing. These generic expressions—while promoting consistency and reducing cognitive load—can weaken the delivery of risk disclosures and personalized medical reasoning.
While our findings suggest that language features such as reduced noun density or higher emotional expressiveness are positively associated with perceived clarity and empathy, this does not imply improved factual accuracy. In fact, recent work has shown that LLM-generated medical texts—although stylistically clearer—may contain more factual inaccuracies compared to those written by clinicians. 51 Other studies have found that mainstream LLMs like ChatGPT and DeepSeek still struggle with diagnostic reasoning tasks, with accuracy rates under 60% on standardized clinical scenarios. 52 However, targeted improvements, such as the use of retrieval-augmented generation, have shown promise in enhancing output correctness in breast cancer Q&A tasks. 53 These findings reinforce the need to interpret associations between linguistic features and perceived quality cautiously, as stylistic fluency may sometimes mask factual errors or limit clinical reliability.
Beyond linguistic features and user perceptions, the deployment of LLMs in medical contexts necessitates careful ethical and legal considerations. Prior work has documented the “hallucination” phenomenon in AI-generated medical advice, posing direct risks to patient safety if misinformation is accepted uncritically. 22 Legal responsibility remains unclear as existing frameworks lack explicit regulations for AI-related clinical errors, complicating accountability. 25 Transparency and patient autonomy are further challenged by opaque AI decision-making processes and insufficient disclosure of AI involvement in care. 54 Additionally, AI systems must be monitored to prevent perpetuating health disparities caused by biased training data, a concern highlighted in recent mental health AI ethics analyses.23,24 Incorporating these dimensions underscores the imperative for multidisciplinary governance frameworks that balance innovation with safety, fairness, and patient rights.
Reasons for higher ratings of Ernie Bot
Several factors may explain the higher subjective scores received by Ernie Bot, especially in dimensions such as empathy, clarity, and actionability. First, its fine-tuning on native Chinese clinical language likely improved lexical familiarity, syntactic fluency, and cultural congruence, thereby enhancing perceived trustworthiness.55,56 Second, Ernie Bot frequently employed emotionally supportive phrasing (e.g., “I understand your concern,” “It's best to consult a doctor promptly”), which has been associated with increased perceived empathy and user satisfaction in prior studies.57,58
In contrast, ChatGPT's outputs often included cautious disclaimers (e.g., “I cannot provide medical advice”), reflecting its global deployment and risk-averse design. While important for safety, this approach may reduce perceived usefulness in low-risk scenarios. Prior literature also highlights this tradeoff between communicative warmth and legal safeguards in medical AI applications.24,59 These findings underscore the importance of balancing linguistic relatability and clinical appropriateness in deploying LLMs for patient-facing tasks.
Limitations and future directions
While our study offers novel insights into the performance of LLMs in structured, symptom-driven diagnostic tasks, several limitations should be acknowledged. First, we focused exclusively on trigeminal neuralgia, a disease with well-defined diagnostic pathways and high linguistic homogeneity, which facilitated internal validity and fair comparison between human and AI-generated responses. However, this narrow disease context may limit the generalizability of our findings to other clinical scenarios with more complex, heterogeneous presentations.30,60 In particular, the unique communication patterns and emotional demands associated with psychological, oncological, or pediatric conditions remain unexplored. Additionally, although we employed a rigorous rating framework involving both medical professionals and patient representatives, the limited number of raters may constrain the generalizability of subjective assessments, even though interrater reliability was shown to be high.
Furthermore, this study was limited to single-turn, text-based interactions, which fall short of capturing the complexity of real-world, multi-turn clinical dialogues. Unlike the structured patient queries used in our dataset, actual online consultations typically involve iterative clarification, contextual reasoning, and dynamically evolving emotional needs. As such, the ability of LLMs to maintain coherence, resolve ambiguity, and deliver context-sensitive responses requires further empirical investigation. In addition, our correlation-based textual analysis does not account for potential confounding variables and cannot establish causal relationships between specific linguistic features and perceived quality.
Future research should therefore extend the evaluation of LLMs along multiple dimensions: (1) covering a broader spectrum of diseases with varying linguistic and clinical complexity; (2) simulating real-time, multi-turn interactions that better approximate actual doctor—patient communication; and (3) incorporating multimodal inputs such as clinical images and structured health records to assess model performance in more realistic and information-rich contexts. Methodologically, future work could leverage causal inference frameworks, 61 mediation models, or experimental manipulations such as language-style interventions 62 to explore whether specific linguistic cues causally influence user ratings.
Finally, we emphasize the need for interdisciplinary efforts to address ethical and regulatory challenges associated with medical LLM deployment—particularly those concerning hallucination risks,22,54 transparency and user awareness, 45 and responsibility attribution in the event of medical harm. 63 These considerations are essential for ensuring that future LLM applications in healthcare are not only effective but also safe, accountable, and aligned with broader principles of medical ethics.
Conclusion
This study reinforces that while LLMs demonstrate notable advantages in clarity, emotional support, and accessibility, especially in delivering responses that patients perceive as helpful and understandable, they remain limited in handling complex clinical cases. Our findings align with prior research indicating that LLMs may generate text that is emotionally supportive yet potentially flawed in factual accuracy, particularly in domains requiring in-depth medical reasoning and personalized decision-making. The structured, empathetic language used by LLMs can enhance user trust but may also mask critical deficiencies in medical knowledge, echoing concerns about hallucination risks in AI-generated medical content. Thus, we advocate a cautious and principled approach to the deployment of LLMs in clinical contexts. LLMs may be safely applied to low-risk, non-urgent, and well-defined tasks, such as providing general health information, patient education, follow-up reminders, or summarizing non-critical patient-reported symptoms, where potential inaccuracies pose minimal risk. For moderate-risk tasks, including preliminary interpretation of patient symptoms, drafting differential diagnoses, summarizing consultation notes, or offering explanations of routine test results, LLM outputs should always be reviewed and validated by qualified healthcare professionals. High-stakes applications, including initial patient triage, medication prescribing, surgical planning, or critical diagnostic decisions, should not rely on LLMs without expert supervision because even minor errors could directly compromise patient safety. By adhering to this tiered framework, LLMs can be effectively leveraged to enhance patient communication and support clinical workflows while minimizing the risks associated with hallucinations or misinformation.
To advance the safe and effective integration of LLMs in healthcare, we recommend three key research and implementation directions. First, future studies should assess LLMs’ performance in multi-turn, context-rich dialogues that simulate realistic clinical encounters, as current evaluations often rely on isolated, single-turn response. Second, subjective quality scores should be complemented by real-world outcome measures to better capture clinical utility. Third, broader cross-lingual and multi-disease validation is essential, given potential cultural-linguistic biases and the varying demands of different clinical tasks. On the practical front, implementation should incorporate expert-in-the-loop validation systems to mitigate hallucination risks and ensure accountability. Additionally, robust legal and ethical frameworks must be established to clarify the responsibilities, transparency obligations, and informed consent requirements associated with LLM usage in clinical contexts. Only through such multi-layered safeguards can we ensure that LLMs contribute meaningfully and safely to the future of digital health.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251388140 - Supplemental material for Comparing large language models and human doctors in symptom-driven online medical consultations: A case study on trigeminal neuralgia
Supplemental material, sj-docx-1-dhj-10.1177_20552076251388140 for Comparing large language models and human doctors in symptom-driven online medical consultations: A case study on trigeminal neuralgia by Liantan Duan, Zhong Yao, Xiaoyu Li, Yifei Wu and Dongfang Sheng in DIGITAL HEALTH
Supplemental Material
sj-xlsx-2-dhj-10.1177_20552076251388140 - Supplemental material for Comparing large language models and human doctors in symptom-driven online medical consultations: A case study on trigeminal neuralgia
Supplemental material, sj-xlsx-2-dhj-10.1177_20552076251388140 for Comparing large language models and human doctors in symptom-driven online medical consultations: A case study on trigeminal neuralgia by Liantan Duan, Zhong Yao, Xiaoyu Li, Yifei Wu and Dongfang Sheng in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors gratefully acknowledge the invaluable contributions of all volunteers who participated in this study. This research was supported by the National Social Science Fund of China (Grant No. 23BTQ086), whose financial assistance is sincerely appreciated.
Ethics approval and consent
As this study did not involve real patient clinical interventions or the collection of private data, and all content was based on publicly available platform information or subjective evaluation tasks conducted by volunteers, formal approval from an institutional ethics board was not required. However, we adhered to fundamental principles of medical ethics in organizing the study, and all raters provided informed consent.
Consent for publication
All authors have read and approved the final manuscript. Dongfang Sheng acts as the guarantor of the study and accepts full responsibility for the integrity of the work.
Author contribution(s)
Liantan Duan contributed to conceptualization, visualization, writing the original draft, and editing and revising the final manuscript. Zhong Yao was responsible for conceptualization, investigation, data curation, and writing the original draft. Xiaoyu Li and Yifei Wu were responsible for data curation and formal analysis. Dongfang Sheng contributed to reviewing and editing the final manuscript, funding acquisition, and conceptualization. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Social Science Fund of China under Grant No. 23BTQ086.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The original data and materials used in this study are available from the corresponding author upon reasonable request.
AI usage declaration
AI tools were used only for English language polishing; all research design, analysis, and scientific content were solely handled by the authors.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.