
Abstract
Objective
Accurate documentation of interpreter requirements and language preference within the electronic medical record (EMR) is essential for ensuring appropriate care and effective communication with patients who have non-English language preference (NELP). Our objective was to examine the accuracy of EMR documentation related to interpreter needs and language preferences for Hispanic patients at a large academic medical center.
Methods
This was a cross-sectional study conducted at the University of North Carolina Medical Center from May 2023 to July 2023. A total of 156 Hispanic patients were surveyed based on their clinical records and self-reported language needs. The main measure was the accuracy of EMR documentation compared to patients’ self-reported interpreter needs and preferred language.
Results
Among 156 Hispanic inpatients, 30.13% had mischaracterized interpreter needs in the EMR, with discrepancies including missing documentation (22%) and direct contradictions (9.92%). Mischaracterizations were significantly associated with male gender (OR = 0.310; 95% CI [0.140, 0.685]; p = 0.0038) and self-reported English proficiency (OR = 0.124; 95% CI [0.041, 0.374]; p < 0.001). Preferred language misclassification occurred in 9.68% of cases, and 7% had incorrect ethnicity documentation.
Conclusion
Significant inaccuracies in race, ethnicity, and language data documentation hinder equitable care. Addressing these gaps requires standardized documentation protocols, staff training, and objective language assessment tools to improve interpreter utilization and mitigate disparities for NELP patients.
Keywords
No study exists comparing patient-reported information, objective assessments of language proficiency, and electronic medical record (EMR)-captured language data to precisely quantify the extent of interpreter need inaccuracies.
Themes: health IT and informatics via EMR advancement and changing hospital policy and regulation to improve the underserved patients’ experience and access to care.
We provide theories on the systematic, logistical, and patient factors that intersect to drive EMR mischaracterizations for patients with a non-English language preference.
Our findings highlight an urgent need for reexamination of current hospital documentation and language assessment practices.
Interventions to enhance interpreter utilization and mitigate disparities include standardized protocols to ensure accurate race, ethnicity, and language data documentation, improved staff training, and integration of English proficiency and health literacy assessments into the hospital workflow.
Background
Language barriers are one of the greatest healthcare inequities faced by non-English language preference (NELP) patients in the United States. 1 The Department of Health and Human Services defines limited English proficiency as “the inability to speak, read, write, or understand the English language at a level that permits an individual to interact effectively with healthcare providers and social service agencies.” 2 Language barriers impede access to healthcare services, comprehension of health information, and informed decision-making.3–5
In 2022, the U.S. Census Bureau reported that 21.7% of respondents spoke a language other than English at home, 8.2% spoke English at a level less than “very well,” and 13.3% spoke Spanish at home. 6 Indeed, Spanish is the most common language other than English that is used at home in the United States. 7 Interpreters and language translation tools enable healthcare systems to enhance language equity for this expanding demographic. Culturally competent interpreters reduce healthcare inequities and improve NELP patients’ outcomes when language-concordant care—where providers and patients share a language—is unavailable.8,9 Unfortunately, interpreters are often underutilized due to reasons such as provider unfamiliarity, overestimation of either the patient's or provider's foreign language skills, and timing and logistical challenges.10–15
Hispanic/Latinx patients specifically face numerous barriers that impede them from receiving equitable healthcare in the United States. While LEP is the most common barrier, it is not the only one. Social factors such as immigration status, perceived racism or discrimination, unique cultural and culinary traditions, and family demands may also complicate Hispanic/Latinx patients’ relationships with the healthcare system and their healthcare providers, reducing trust in the healthcare system and ultimately resulting in worse care and outcomes for this patient population. 16
Legally, healthcare organizations must identify and document patients’ language needs in the electronic medical record (EMR) and provide appropriate language services, but interpreter underuse often propagates inaccurate EMR language needs documentation, and race, ethnicity, and language (REaL) data are often documented inconsistently.17–25 The absence of evidence-based procedures for assessing and documenting language proficiency, preferences, and interpreter needs exacerbates healthcare inequities.24–28 Understanding the factors contributing to EMR language mischaracterizations is essential for developing best practices in delivering language-equitable care. However, limited research has quantified the extent of this issue.
Framework
Study setting
The University of North Carolina Medical Center (UNCMC) is a >950-bed quaternary care center in Chapel Hill, NC, serving 37,000 patients annually. Compared to other NC hospitals, UNCMC inpatients are 2.05 times more likely to be Hispanic: 11.7% of patients in fiscal year 2021 reported Hispanic ethnicity.29–31 The UNCMC offers language access services including certified in-person, video, and phone interpreters in >200 languages. Front desk intake staff are trained in REaL data collection through a “Training & Development” guide and a “REaL Data Collection” module, which introduces healthcare disparities, summarizes the EMR documentation workflow, and includes scripts to facilitate patient-friendly information gathering. Intake staff are required to document patients’ preferred language and interpreter needs at every visit.
Context
In a project funded by a health equity grant from the North Carolina Translational and Clinical Sciences Institute, we hypothesized that language barriers delay activation of the rapid response (RR) system—used to identify and intervene in clinically deteriorating inpatients 32 —and contribute to disparities in care during acute clinical events for NELP patients. The project team used an objective criterion to preemptively activate the RR team for adult hospitalized NELP patients. Interpreters were also integrated into the RR team. This led to better detection of clinical deterioration, more effective mobilization of resources, and improved outcomes for this vulnerable group.33,34 During the initiative, the team frequently encountered incomplete or incorrect EMR documentation of patients’ language preferences and interpreter needs, which hindered the accurate identification of patients for the targeted intervention.
Therefore, we created a survey to explore the degree of language data mischaracterizations in our hospital EMR and assess patients’ English proficiency. We hypothesized that EMR documentation of preferred language and interpreter needs would contain significant inaccuracies among Hispanic/Latinx adults with varying levels of English and Spanish proficiency, and that a substantial proportion of Spanish-speaking patients would overestimate their English proficiency.
Methods
REDCap survey design
The primary study instrument was a REDCap survey designed to compare both patient-reported and EMR data (Figure 1; Appendix A). The survey was designed to identify patients whose REaL data, particularly preferred language, were mischaracterized. It also included a validated health literacy assessment used to assess patients’ English proficiency and health literacy, thereby helping to identify patients likely to benefit from an interpreter. Additional details of how the survey collected REaL data are described in “Measures” below. The survey comprised three sections, which gathered: i) EMR-reported REaL data; ii) patient-reported REaL data; and iii) the Short Assessment of Health Literacy in English or Spanish (SAHL-E or SAHL-S). Initially, a two-item branched screening algorithm assessed patients’ self-reported English proficiency, preferred language, and interpreter needs (Figure 1). If patients indicated a preferred language of English (PLE), no interpreter need, or English proficiency, they completed the SAHL-E. The SAHL is a publicly available, validated, 18-item tool for assessing adults’ health literacy by presenting a medical term alongside two distractor words (Appendix B). Participants select the word most similar to the medical term, earning one point per correct response. Scoring between 0 and 14 indicates low health literacy.
35
In this study, participants who scored ≤14 on the SAHL-E also completed the SAHL-S to differentiate between limited English proficiency (SAHL-S > 14) and low health literacy (SAHL-S ≤ 14). Patients who reported English proficiency, listed PLE, and/or indicated no need for an interpreter completed the SAHL-E to evaluate their English proficiency. Participants who indicated preferred language Spanish (PLS) or scored ≤14 on the SAHL-E completed the SAHL-S. Upon completion, surveyors recorded the patient's EMR-documented interpreter needs. No health-related data were collected.
Survey and health literacy assessment workflow.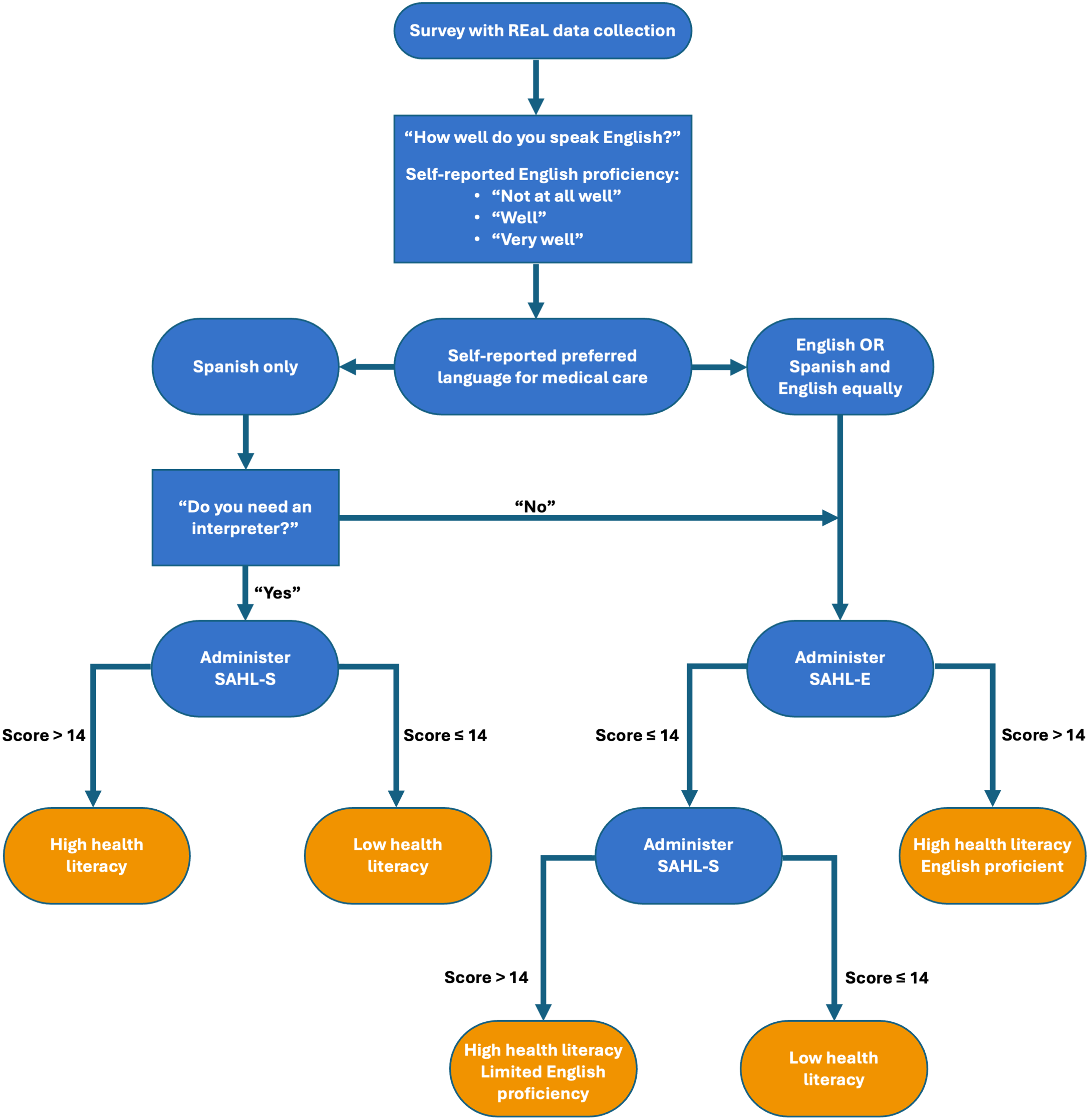
Survey administration
Surveys were conducted by bilingual UNC students who completed all institutionally required training. Survey administration was standardized through virtual trainings and an instructional video led by the primary author. Surveyors were blinded to the EMR-recorded preferred language to avoid purposefully selecting one group of patients (i.e., PLE) and distorting mischaracterization results. To maintain surveyor blinding while allowing for comparison between EMR and self-reported data, a secondary report was created, containing the medical record number and documented interpreter needs at hospital admission. Surveyors selected Hispanic/Latinx PLS and PLE patients from the automated report. They then traveled to patients’ rooms and, using a laptop, explained the study and obtained consent using a script, initially in English but switching to Spanish if needed. On the spot, eligible participants then completed the survey while questions were read to them from the laptop.
Measures
Self-reported English proficiency
Each patient's perception of their English proficiency was self-reported using the U.S. Census Bureau's categories for English proficiency, which include: “not at all,” “not well,” “well,” and “very well.” 6 For analysis, English proficiency was categorized as “No” (including “not at all” and “not well”) or “Yes” (including “well” and “very well”).
Ethnicity
The Pew Research Center's standard two-question format, aligned with U.S. Census Bureau guidelines, first asks whether participants identify as Hispanic, Latinx, or of Spanish origin. The alternative census question combined race and ethnicity into a single item, listing “Hispanic” as a response option. 36 In an attempt at comprehensiveness, we merged the first question from the standard two-question format with the alternative census question so that participants could be asked if they identified as Hispanic, Latinx, or of Spanish origin, then followed by listing their country of origin. 36
Other demographic factors
Surveyors also collected demographic data from UNCMC's EMR (age, ethnicity, race, primary language, legal sex). In the survey they administered verbally to patients, surveyors also collected patients’ self-reported information, including ethnicity, race, highest level of education, level of Spanish fluency, level of English fluency, preferred language for medical care, and the patient's own assessment of whether they required an interpreter in medical settings.
Sample size justification
A priori power analysis was performed to determine the sample sizes of PLS and PLE patients required to detect interpreter need mischaracterizations. In a pilot study, we gathered language/interpreter need data from 57 patients, finding that 30% with PLS and 7% of the overall surveyed group had their interpreter needs mischaracterized (Appendix C). Therefore, we established a 42-day data collection period to achieve a minimum sample of 88 PLS and 61 PLE patients, ensuring a 5% margin of error. Due to the limited sample size and 42-day period, survey administration was not randomized. Instead, daily quotas were established for each sample group to regulate the number of surveys conducted.
Inclusion and exclusion criteria
The study included adults (≥18 years) hospitalized at UNCMC, excluding the Intensive Care Unit, between 16 May 2023 and 31 July 2023. Eligibility was restricted to patients documented in our EMR as “Hispanic/Latinx” with a PLE or PLS. Patients were excluded if they did not meet the inclusion criteria. For simplicity, individuals unable to participate due to delirium, dementia, encephalopathy, psychosis, personality disorders, or intellectual disabilities were excluded, as were those who spoke neither Spanish nor English, declined participation, or could not complete the survey due to comprehension difficulties. However, it is likely that language mischaracterizations are commonplace among the populations excluded here and speakers of other languages. During the data collection period, a report was generated every four hours identifying all eligible patients (Appendix D). 156 unique patient records were included in our study. Of the 203 patients initially surveyed, 47 were excluded due to incomplete survey data or inability to participate (Appendix E).
Analysis
Self-reported demographic information (e.g., gender, sex, ethnicity, level of education, English proficiency), preferred language, and interpreter needs were compared with EMR-recorded information. Descriptive statistics included study population demographics expressed as percentages (sex, age, education, etc.) and proportions of patients whose interpreter needs, ethnicity, and preferred language were mischaracterized (i.e., self-report did not match EMR). Chi-square tests (Mantel–Haenszel Chi-Square) were used to evaluate whether there was a significant relationship between mischaracterizations, specifically interpreter need, and various categorical variables as described in Table 1 (statistical significance denoted as p < 0.05). Kappa values were used to assess the degree of erroneous data. Odds ratios were used to predict the likelihood of patients having their interpreter needs mischaracterized based on variables such as age and gender, the only two variables found to have statistically significant differences. These were all conducted in SAS 9.4 by an automated report created by a single biostatistician.
Analysis of interpreter need mischaracterizations.

*Odds ratios were not calculated for these statistically nonsignificant variables.
Results
Demographics
The study captured a higher proportion of male patients (n = 95; 60.90%) and individuals with at least a high-school education (n = 86; 56.21%). Additionally, 72/156 (46.15%) patients reported lacking English proficiency, regardless of their SAHL-E performance (Table 2).
Self-reported patient demographics.

SAHL: Short Assessment of Health Literacy.
N = 156. Age was classified into two categories in all analyses: “younger” (<45 years) and “older” (≥45 years). Health literacy was evaluated based on the highest score achieved on the SAHL in either language and categorized as “Low” (≤14 or failing) and “High” (>14 or passing). Spanish proficiency was determined based on patients’ self-report.
Interpreter needs mischaracterization
Including patients who self-reported as “unsure” or had “blank/unknown” recorded for interpreter needs in the EMR, there were 47/156 interpreter needs mischaracterizations (30.13%) (Table 3). The Chi-square value was 24.0317, and the weighted Kappa statistic was 0.6539, indicating moderate agreement by McHugh's interpretation. 37 The mischaracterization frequency did not differ significantly between EMR-documented PLE and PLS groups.
Electronic medical record (EMR)-documented versus self-reported interpreter need.

*Blue = discordance between EMR documentation and self-report.
Of the 47 mischaracterizations, 7 (14.89%) involved discrepancies between self-reported interpreter needs and those in the EMR (e.g., “Yes” vs. “No”). In 35/47 cases (74.47%), interpreter needs were not recorded in the EMR. Of these 35, 14 patients self-reported needing an interpreter, while 20 reported not needing one. Of the 47 total mischaracterizations, 5 (10.64%) involved patients who self-reported “unsure” for interpreter needs. Among these, EMR documentation indicated that four required an interpreter, while one did not.
After excluding the “unsure” and “blank/unknown” groups, we identified seven mischaracterizations, yielding a Chi-square value of 1.2857 and a Kappa statistic of 0.8767, indicating strong agreement between self-reports and EMR documentation. This suggests that the remaining data accurately reflected interpreter needs, with a 12% error rate.
A model fit analysis, controlling for preferred language, education, age, gender, health literacy, and English proficiency, found that males were significantly more likely to have their interpreter needs mischaracterized (OR = 0.310, 95% CI [0.140, 0.685], p = 0.0038; Table 1). Males were 69% more likely to experience mischaracterization than females, with rates of 42.6% for males compared to 22.1% for females (χ2(1, N = 156) = 7.38, p = 0.0066). Additionally, patients who self-reported English proficiency were 87.6% more likely to have their interpreter needs misclassified compared to those who reported no English proficiency (OR = 0.124, 95% CI [0.041, 0.374], p < 0.001). The mischaracterization rate was 39.30% among those who reported English proficiency, compared to 19.40% for those who did not (χ2(1, N = 156) = 7.20, p = 0.0073).
Preferred/primary language mischaracterizations and language proficiency
Of the 155 patients who self-reported their preferred language, 15 (9.68%) had incongruent EMR preferred language documentation. Among the 62 patients listed as PLE in the EMR, seven self-reported their preferred language as Spanish (11.29%). Conversely, 8/93 patients listed as PLS in the EMR self-reported their preferred language as English (8.60%). The weighted kappa was 0.7989, indicating that 20% of the data collected was erroneous, either in self-reports or EMR records, although the chi-square was not significant (χ2(1, N = 155) = 0.0667, p = 0.7960). Among the 22 patients who first completed the SAHL-E, 10 later passed the SAHL-S, suggesting that health literacy was not the issue and that these patients could benefit from interpreter assistance.
Ethnicity
Ethnicity was mischaracterized in 11/156 cases (7%). There was a nonsignificant trend toward association in interpreter need mischaracterizations and patients who were listed as Hispanic/Latinx in the EMR (χ2(1, N = 156) = 1.9915, p = 0.1582). Among the 10 patients who self-identified as Hispanic/Latinx but were recorded as “No/Unknown” for ethnicity in the EMR, interpreter needs were accurately documented in 50% of cases, while the other 50% were mischaracterized.
Secondary findings
Ethnicity mischaracterizations were not significantly associated with preferred language mischaracterizations. Among those who self-reported English fluency, 64% were 18–45 years old (χ2(1, N = 156) = 13.4691, p < 0.001), indicating that younger individuals tend to report greater English proficiency. Reporting English proficiency was strongly associated with higher education levels (<HS graduate vs. ≥HS graduate; Χ²(1, N = 153) = 41.7030, p < 0.001) and greater health literacy (high vs. low; Χ²(1, N = 156) = 30.2101, p < 0.001). This suggests that younger patients, those with higher education, and those with greater health literacy are more likely to report English proficiency.
Discussion
Effective communication between healthcare providers and patients is fundamental to high-quality care. Despite legal and ethical mandates, significant gaps persist, disproportionately affecting NELP patients. 17 These patients experience worse health outcomes and greater difficulties accessing healthcare services.33,38–40 Contributing factors include interpreter underuse and EMR inaccuracies, both of which hinder effective communication and perpetuate disparities.3,8,27
Accurate EMR language needs documentation is necessary for reliable interpreter deployment. Thirty percent (47/156) of patients in our study had discrepancies between self-reported and EMR-documented interpreter needs, with a Chi-square of 24.0317 and a weighted Kappa statistic of 0.6539, indicating moderate McHugh's interpretation. This would suggest that 35% of the data on interpreter need is erroneous because only one source, either the EMR or self-report, can be correct. 37 While the two data sources show moderate agreement, a significant level of mischaracterization suggests widespread errors in recording interpreter needs. Twenty-two percent (35/156) of patients had crucial documentation missing in the EMR. Among those with complete documentation (n = 121), 12 (9.92%) had interpreter need inaccurately documented. Mischaracterizations were more prevalent among male patients and those reporting higher English proficiency. These findings align with vast literature highlighting the challenges of accurately documenting REaL data, which, when inaccurate, exacerbate healthcare inequities.18,23–25 One novel result is that our study captured a larger proportion of male Spanish-speaking patients, when in fact women have previously been noted to be more receptive to being surveyed.
We observed a nonsignificant association between patients classified as “Hispanic/Latinx” in the EMR and interpreter need mischaracterization. The complexities of racial and ethnic self-identification likely contribute to this issue. Many Hispanic/Latinx individuals do not distinguish between race and ethnicity as surveys often require, leading to inconsistent or unclear classifications. A 2015 survey found that 67% of people consider “Hispanic” to be part of their racial and ethnic background, leaving many unsure how to respond to race-related questions when “Hispanic” is not included as an option. 41 The 2010 Census and the 2014 National Survey of Latinos found that for the question of race, 12–37% of participants reported “some other race,” wrote in responses (e.g., “Mexican”), were unsure how to answer, or refused to respond. 42 In our study, some patients expressed confusion about the terms “Latinx” and “Hispanic,” while others self-reported differently than their EMR classification. Such inconsistencies can distort the identification of patients who require language services, particularly if classification is based on an oversimplified or incorrect understanding of cultural and linguistic backgrounds.
From our study findings and a review of relevant literature, we postulate that REaL data mischaracterizations stem from three interrelated categories: 1) documentation failures; 2) structural barriers; and 3) patient-driven complexities.
Documentation failures
Mischaracterizations in EMR documentation often result from administrative oversight, inadequate staff training, and inconsistent data entry practices. Without proper training, staff may assume patients’ language needs, leading to EMR documentation errors. Autopopulation features, such as those at our institution that allow for previous responses to demographic information to be pulled forward, can propagate outdated or incorrect information, making inaccuracies more persistent. Additionally, simple data entry mistakes—such as misclassifying language preferences or entering incorrect patient identifiers—further disrupt service provision. Overreliance on standardized EMR templates also reduces the precision of recorded language needs by failing to capture nuanced patient preferences. Moreover, insufficient EMR training leaves staff unaware of best practices for documenting REaL data, increasing the risk of mischaracterizations. Finally, failure to routinely update patient records results in outdated language preferences that may no longer reflect a patient's actual communication needs. Addressing these failures requires comprehensive EMR training, routine data verification, and standardized documentation protocols to ensure accurate and equitable language services.
Structural barriers
Structural barriers to accurate EMR documentation stem from systemic issues such as a lack of standardized documentation practices and biases that hinder the identification of minoritized patients.11,24,43,44 Technological limitations further exacerbate these challenges by preventing real-time updates. Additionally, high workloads and time constraints often force healthcare providers to rely on assumptions about a patient's language proficiency or take shortcuts in documentation.
Miscommunication remains a persistent issue, and it is possible that numerous factors, such as language barriers, lack of language aids, interpreter scarcity, and prior negative healthcare experiences, may discourage patients from requesting assistance. Implicit biases and assumptions during provider–patient interactions also influence how REaL data are documented. Combined with organizational cultures that prioritize efficiency over accuracy, these structural challenges perpetuate care inequities. To address them, healthcare systems must standardize documentation protocols, invest in adaptable and interoperable EMRs, and commit to fostering an environment that mitigates bias while ensuring accurate, patient-centered data collection. Guidelines exist for improving data collection and should be widely adopted.45–50 Improved EMR documentation increases interpreter use and leads to more consistent care for NELP patients.18,51
Likewise, structural racism, discrimination, and immigration-related fears can limit healthcare utilization and discourage patients from requesting language assistance. Additionally, the pressures of an English-dominant environment may lead some patients to underreport their language needs. 52 Healthcare providers also often overestimate their ability to communicate effectively with NELP patients and may rush through these interactions, exacerbating care disparities. 13
It is equally important to consider cultural factors that shape patient responses to language-related inquiries—patient-driven complexities—the third key category impacting data accuracy.
Patient-driven complexities
At UNCMC, language needs are identified through patient self-report at intake with minimal follow-up, a method that overlooks variations and nuances in language proficiency. Some patients with limited English may decline interpreter services due to pride, previous negative experiences, or a desire to avoid being perceived as a burden. Others may overestimate their English proficiency, as evidenced by the 10 patients in our study who failed an objective English literacy assessment despite reporting proficiency. Additionally, variations in inquiry methods and inconsistent terminology—such as “primary language,” “preferred language,” and “language spoken at home”—further complicate documentation accuracy.
Our results suggest that current practices for identifying interpreter needs may be outdated, a concern shared by other health systems. 43 The traditional NELP construct may not fully capture the nuances of individual patients’ language needs, particularly for those with some conversational proficiency who still require support in medical contexts.3,11,52,53 Buser et al. stressed that depending solely on patients’ self-assessment of language proficiency and perceived interpreter need is inadequate for ensuring safe and effective care.21,54 The distinction between language need vs. preference is exemplified by the 10 patients who failed in SAHL-E but passed the SAHL-S.
Scenarios in which a patient insists on speaking English and declines an interpreter, despite objective indicators of limited proficiency, present risks to both care quality and medical-legal accountability. Addressing these complexities requires a more objective approach to assessing language needs, reducing reliance on subjective self-reporting.
Limitations
This study is limited by its focus on adult Hispanic/Latinx patients at a single institution over a period of less than two months, which, along with our sampling strategy, influences the generalizability and external validity of the findings presented here. The rate of language needs mischaracterizations may vary in different patient populations (e.g., had we included patients in ICU settings or children), in other geographical settings where the distribution of common language needs within the patient population is different, and in patients who speak languages other than Spanish. Focusing on Spanish-speaking patients with unique cultural barriers than other ethnic groups may lead to higher or lower levels of cultural competence from hospital staff and institutions for addressing those barriers. That said, some issues, such as the desire not to share sensitive information with an interpreter or pride, may persist across cultures. The absence of a control group of non-Hispanic/Latinx patients with similar language needs restricts our ability to isolate systemic factors contributing to misclassification. Additionally, the terms “Hispanic” and “Latinx” and common approaches to collecting race/ethnicity data can cause confusion. While we attempted to avoid these issues, as described in our Methods section, we could potentially have achieved even higher specificity and granularity in collecting this information with a free-text box for patients to describe their ethnicity in our survey instrument in case our predetermined categories did not appropriately capture their identity.
Conclusion
Our study highlights significant mischaracterizations in EMR REaL data documentation, a problem that likely extends across U.S. healthcare systems. Interpreter need documentation inaccuracies were identified in 30.13% of Hispanic/Latinx patients evaluated. Addressing healthcare language barriers requires a multifaceted approach that ensures patient needs are accurately assessed, documented, and continuously updated to support equitable care.
Implementing standardized procedures for evaluating and recording REaL data is a critical step toward improving documentation accuracy and ensuring appropriate language support. Hospital administrations should prioritize this, alongside staff training on both data entry and the nuances of language needs. Establishing a protocol for reassessing interpreter needs at every visit, incorporating an “interpreter need” scaling system, and ensuring that EMRs are regularly updated can improve the objectivity and reliability of these assessments. Moreover, staff must be trained to recognize that language needs are dynamic: what may seem adequate for a routine visit may be insufficient in more complex medical discussions, such as informed consent or palliative care. Similarly, further studying a population like ours could prove useful to better understand what motivations cause male Spanish speakers to refuse interpreters and/or overestimate English proficiency.
However, improving institutional processes alone is insufficient if patient-driven complexities continue to influence documentation inaccuracies. Patient perceptions, prior experiences, and sociocultural pressures heavily impact self-reporting accuracy. If patients feel reluctant to request an interpreter, the cycle of mischaracterization will persist. Thus, objective, culturally sensitive methods of assessing language needs must be adopted.
Ultimately, system, staff, and patient factors interact in complex ways, and only through a comprehensive, interdisciplinary approach can healthcare institutions make meaningful progress in addressing language-based disparities. Accurate and reliable language need documentation is not merely an issue of administrative precision; it is a fundamental component of health equity. By refining assessment protocols, strengthening training, and developing culturally responsive evaluations, healthcare systems can take steps toward ensuring that language barriers do not remain a source of inequity in patient care.
Supplemental Material
sj-pdf-1-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-pdf-1-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-docx-2-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-docx-3-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Supplemental Material
sj-docx-4-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-docx-4-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Supplemental Material
sj-docx-5-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-docx-5-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Supplemental Material
sj-docx-6-dhj-10.1177_20552076251386884 - Supplemental material for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients
Supplemental material, sj-docx-6-dhj-10.1177_20552076251386884 for Evaluation of race, ethnicity, and language mischaracterizations in the electronic medical record for Hispanic/Latinx patients by Ricardo Crespo Regalado, Emily C. Bulik-Sullivan, Andrew G. Blank, Lauren D. Raff, Arielle Johnston, Morgan Beauchamp, Yang Lee, Christina Cobos, Mayerlin Alpizar, Veronica Cifuentes, Robert Agans, Carlton Moore and Evan J. Raff in DIGITAL HEALTH
Footnotes
Ethical considerations
The research and interventions posed minimal risk, and the project received an exemption from UNC's Institutional Review Board (22-2972) on 11 September 2022.
Consent to participate
Patients verbally consented to the survey after having the study explained to them, and we recorded consent in their survey record.
Contributorship
RCR, ECBS, and EJR contributed to every aspect of the study, including conceptualization, data curation, formal analysis, investigation, methodology, project administration, resources, software, supervision, validation, visualization, and writing. LDR contributed to conceptualization, investigation, methodology, and writing. AGB contributed to conceptualization, investigation, methodology, and writing. CM contributed to conceptualization, investigation, and writing—review & editing. RA contributed to data curation, formal analysis, and writing—review & editing. AJ, MB, YL, CC, MA, and VC contributed to investigation and writing—review & editing.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.