
Abstract
As one of the major threats to women's health worldwide, breast cancer requires early diagnosis and accurate classification, since they are key to optimizing therapeutic interventions and ensuring precise prognosis. Recently, deep learning has demonstrated notable advantages in breast cancer image classification. However, their performance heavily relies on the proper configuration of hyperparameters. To overcome the inefficiencies and weaknesses of conventional hyperparameter optimization methods, like limited effectiveness and vulnerability to premature convergence, this research proposes a Multi-Strategy Parrot Optimizer (MSPO) and applies it to breast cancer image classification tasks. Based on the original Parrot Optimizer, MSPO integrates several strategies, including Sobol sequence initialization, nonlinear decreasing inertia weight, and a chaotic parameter to enhance global exploration ability and convergence steadiness. Tests using the CEC 2022 benchmark functions reveal that MSPO surpasses leading algorithms regarding optimization precision and convergence rate. An ablation study was conducted on three variants of MSPO through CEC 2022 to further validate the effectiveness of each key strategy. Furthermore, MSPO is combined with the ResNet18 model and applied to the BreaKHis breast cancer image dataset. Results indicate that the model optimized by MSPO notably surpasses both the non-optimized version and other alternative optimization algorithms using four assessment indicators: accuracy, precision, recall, and F1-score. This validates the promising application potential and practical significance of MSPO in medical image classification tasks.
Keywords
Introduction
Breast cancer, a preeminent malignant tumor threatening women's health globally, exhibits some of the highest incidence and mortality rates when contrasted with other cancers.1,2 Early diagnosis and accurate classification are pivotal for breast cancer treatment and prognosis. Therefore, creating efficient, intelligent, and precise systems to detect and classify breast cancer has emerged as a key research area in medical image processing.3–6
Recently, driven by the accelerated progress of computer vision alongside artificial intelligence, machine learning has shown great potential in analyzing medical imagery.7–9 Machine learning, through training classification models, helps doctors quickly diagnose breast mammograms, ultrasound images, or histopathological slides. This approach enhances diagnostic efficiency and cuts down on human errors.10–13 Among these methods, convolutional neural networks (CNNs) have emerged as a dominant approach for classifying breast cancer imagery. They excel at extracting image features. 14 Yet, although current models show good accuracy on different public datasets, their performance heavily relies on proper hyperparameter setup. The learning rate, batch size, and number of network layers—key hyperparameters governing model training dynamics and architectural complexity—are frequently optimized in deep learning. 15 Choosing or optimizing these hyperparameters is a major challenge, acting as a key bottleneck that restricts further enhancements in model performance.
Traditional methods for selecting hyperparameters mainly depend on exhaustive strategies like grid search and random search. Though these methods are simple to implement, they consume significant computational resources, operate inefficiently, and struggle with high-dimensional, nonlinear, and complexly interacting hyperparameter spaces.16,17 Recently, meta-heuristic optimization algorithms have become a research focus in hyperparameter optimization, thanks to their robust global search abilities and adaptability. 18 For example, Particle Swarm Optimization (PSO) and Genetic Algorithms (GA) have achieved successful implementation in model optimization tasks.19,20 However, these methods still encounter problems regarding the rate of convergence, stability, and a propensity to become stuck within local optima. Thus, both optimization efficiency and the ultimate model performance have room for enhancement.21,22
To overcome these shortcomings, this study presents a novel hyperparameter optimization approach—Multi-Strategy Parrot Optimizer (MSPO)—to improve breast cancer image classification performance. Building upon the original Parrot Optimizer (PO), MSPO incorporates several optimization strategies, such as Sobol sequence initialization, nonlinear decreasing inertia weight, and chaotic parameter. These additions boost the algorithm's stability during optimization and maintain its global-level exploration. MSPO is then integrated with ResNet18 and tested on public breast cancer image datasets. Results indicate that MSPO outperforms other optimization algorithms in four assessment indicators.
This research is structured as follows. The “Related works” section systematically analyzes the current research on breast cancer image classification. The “Multi-Strategy Parrot Optimizer” section introduces the mathematical model and algorithmic implementation of MSPO. The “Simulation experiment” section details the simulation experiments and results of MSPO. The “Application of MSPO in breast cancer image classification” section shows the application of MSPO in breast cancer image classification. The “Discussion on clinical integration and ethical considerations” section discusses clinical integration and ethical considerations. Finally, the “Conclusion” section summarizes the entire article.
Related works
Among the most prevalent malignant tumors globally, early diagnosis of breast cancer is essential to enhance cure rates and lower mortality. 23 Traditional diagnostic approaches for breast cancer mainly rely on physicians’ manual interpretation of imaging data, including mammography, ultrasound, MRI, and histopathological slides. However, such methods are time-consuming and limited by the physician's level of experience, which can lead to missed or incorrect diagnoses. 24 Recently, driven by the accelerated progress of computer vision alongside deep learning innovations, automated breast cancer diagnosis based on image analysis has received widespread attention.
CNNs, as a core technology in the field of deep learning, have exhibited notable superiority in breast cancer image classification. Numerous researchers have employed various network architectures—such as LeNet, AlexNet, VGG, and ResNet—for extracting features and categorizing breast cancer images.25,26
Chen et al. 27 developed a breast ultrasound image classification approach by integrating transfer learning techniques with an enhanced GoogleNet architecture, greatly improving the effectiveness of clinical diagnostic procedures. Tests indicated that this approach reached an accuracy of 96.37%, with the loss value dropping to 0.3492. Such a framework offers an effective automated means for clinical diagnostic assistance.
Srikantamurthy et al. 28 developed a breast cancer image classification approach based on a CNN-LSTM hybrid model. They combined InceptionResNetV2 and ResNet50 pretrained models to extract features and added LSTM layers to improve temporal feature learning. Through transfer learning, this framework notably decreased manual intervention and offered an effective means for automated, high-precision breast cancer subtype diagnosis.
Maleki et al. 29 developed a model for classifying breast cancer histopathological images. This approach uses a transfer-learning strategy, employing a pretrained DenseNet201 model to extract features and combining it with an XGBoost classifier for binary (benign/malignant) classification. Tests were carried out on the BreakHis dataset, containing images at four magnification factors: 40×, 100×, 200×, and 400×. Results indicated classification accuracy of 93.6%, 91.3%, 93.8%, and 89.1% respectively, with an average of 91.93%, surpassing existing approaches. This study shows that integrating DenseNet201 with XGBoost can effectively capture critical features of pathological images, greatly enhancing classification performance and offering an innovative approach for computer-aided diagnostic systems.
Liu et al. 30 developed a breast mammogram image classification approach by improving the VGG16 architecture. This approach optimizes the VGG16 network structure and uses data augmentation methods to broaden training samples and reduce sample imbalance. Tests indicated that the model reached an average recognition accuracy of 96.945% at four magnification factors (50×, 100×, 200×, and 400×), with rates over 95.5% for 50×, 100×, and 200× images. This study offers an effective and reliable technical approach in automatic breast cancer diagnostics via deep learning and provides useful perspectives for early-stage breast cancer identification.
These researchers have obtained high classification precision by employing enhanced CNN models and have also made progress in aspects like data preprocessing, image augmentation, and feature fusion. 31 However, although deep learning approaches perform well in classifying breast cancer images, their efficacy mainly relies on network architecture design and model parameter configuration, with hyperparameter selection especially affecting the model's final performance.32,33
Obayya et al. 34 developed a approach to categorize breast cancer histology images. The approach begins with image preprocessing, then extracts features using the SqueezeNet network and adjusts hyperparameters via an arithmetic optimization algorithm. Finally, a Deep Belief Network (DBN) carries out the classification. Test results revealed that this method achieved a maximum classification accuracy of 96.77% on datasets with different magnification levels, surpassing existing models such as VGG16 significantly. This approach offers an efficient and accurate technical solution for early breast cancer diagnosis.
Heikal et al. 35 introduced a breast tumor identification approach utilizing fine-tuning deep learning models. The process includes image preprocessing, then conducts feature extraction and classification with custom CNN and pretrained models. To boost the classification effect, the authors applied two meta-heuristic algorithms, Grey Wolf Optimization and Improved Gorilla Troops Organization, to adjust hyperparameters. The CNN model optimized by MGTO reached 93.13% accuracy in only 10 iterations, surpassing other models remarkably. This research offers a new way to adjust deep-learning models with meta-heuristic optimization methods, enhancing the performance of automated breast tumor diagnosis.
Aguerchi et al. 36 introduced a PSO-based automatic optimization approach for CNN hyperparameters in breast cancer classification. The research utilized the DDSM and MIAS datasets. In this process, PSO was used to dynamically modify hyperparameters like convolution kernel size, stride, and filter number, aiming to construct an efficient CNN architecture. Test results indicated that the optimized model attained 98.23% and 97.98% accuracy on the two datasets, showing around an 8% enhancement compared to conventional manual adjustment methods. This method automates hyperparameter setup via meta-heuristic algorithms, offering a novel solution for model deployment when resources are limited.
Emam et al. 37 presented a transfer learning framework integrating an improved Coati Optimization Algorithm. The research strengthened the traditional COA algorithm's global exploration ability and convergence rate, establishing the LFR-COA-DenseNet121-BC model to achieve adaptive hyperparameter optimization for the DenseNet121 network. Test results showed that, compared with classical architectures like VGG16 and ResNet50, the classification performance rose by 4.38%–7.19%, and CEC2022 standard tests validated the algorithm's global optimization edge. This study provides a scalable transfer learning optimization model for intelligent medical image diagnosis, notably improving the automation and clinical breast cancer screening consistency.
In conclusion, prior studies have displayed the remarkable capability of deep learning approaches, especially CNNs, along with their refined models, within automated diagnostic systems for breast cancer imaging. From traditional machine learning classification methods to advanced network architectures that incorporate multiple optimization strategies, these researchers have achieved notable progress in enhancing diagnostic accuracy, reducing manual intervention, and strengthening model robustness. However, the ultimate performance of these models is still notably influenced by hyperparameter selection, which sets higher requirements for future work.
Multi-strategy parrot optimizer
This section elaborates on the algorithmic architecture of the MSPO and its innovative improvement schemes. MSPO is an enhancement of the Parrot Optimizer (PO). In MSPO, algorithmic performance is systematically improved through three core strategies: Sobol sequence initialization, nonlinear decreasing inertia weight, and chaotic parameter.
In MSPO, parrots display four unique behavioral activity phases: foraging, staying, communicating, and fear of strangers. During each iteration, a parrot in MSPO randomly selects one of these four behaviors. These four behaviors of the parrot are illustrated in Figure 1. 38

The four behaviors of parrots where a is foraging, b is staying, c is communicating, and d is fear of strangers.
Mathematical model of MSPO
Population initialization
The arrangement of starting solutions within the search domain greatly influences both the speed of convergence and optimization performance of metaheuristic algorithms. An evenly spread initial population can remarkably boost the algorithm's search efficiency. The conventional PO algorithm generates its population through random sampling, resulting in poor traversal properties and uneven population distribution.
This research employs the Sobol sequence for population initialization. As a low-discrepancy sequence, the Sobol sequence replaces pseudorandom numbers with deterministic quasi-random numbers to achieve maximally uniform sampling point distribution. Consequently, when addressing probabilistic problems, the Sobol sequence provides superior computational efficiency and broader sampling coverage compared to conventional random initialization methods.
In MSPO, each parrot is treated as a potential solution. Let N denote the population size, dim represent the dimensionality, t indicate the current iteration number, T signify the maximum iteration count,
Consider a two-dimensional search space where each dimension has a range of [0, 1], with a population size of 100. Figure 2 presents scatter plots comparing population distributions generated by random initialization versus Sobol sequence initialization. The visualization demonstrates that the Sobol sequence produces significantly more uniform population distribution and broader coverage compared to random initialization.
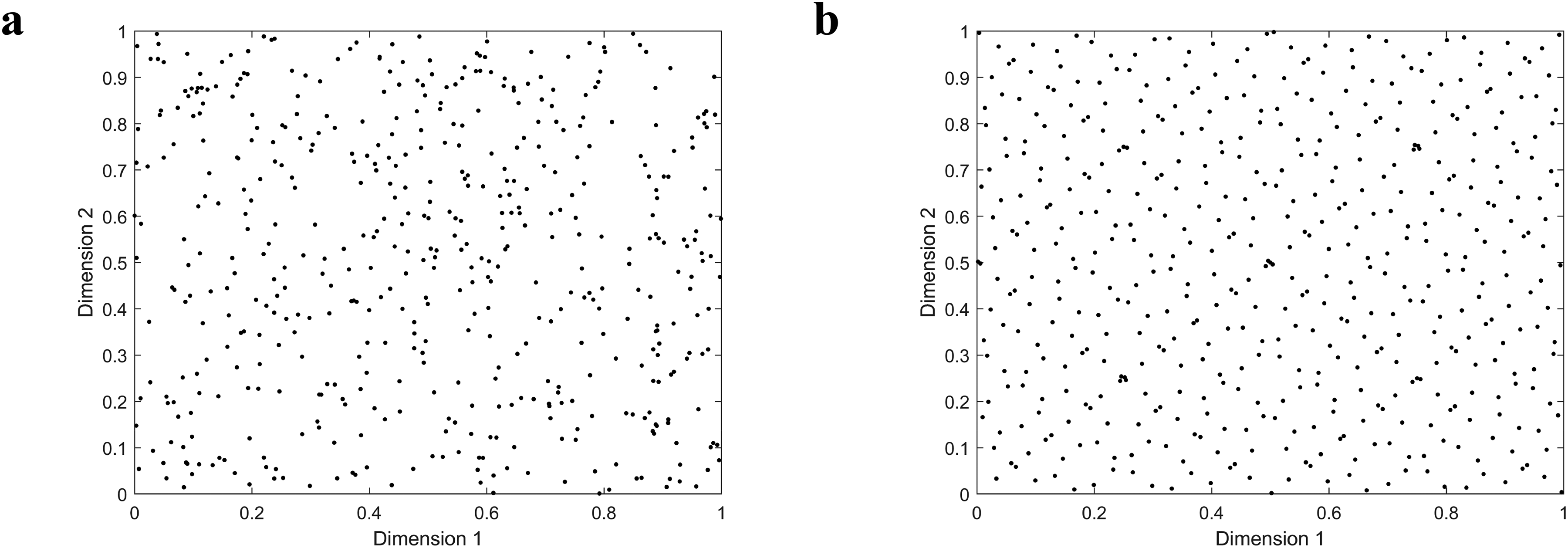
Distribution of the population under distinct initialization schemes where a is scatterplot of population distribution with random initialization, and b is scatterplot of population distribution with Sobol sequence initialization.
Foraging behavior
In MSPO's foraging behavior, parrots adjust their positions by observing food locations. The corresponding position update formula for parrots is given by equation (2):
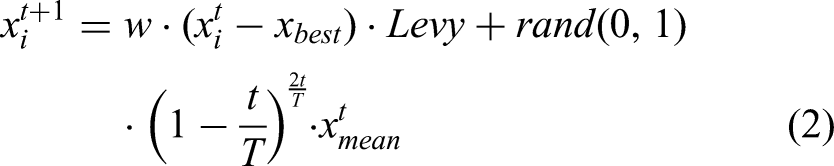
The mathematical formulation for calculating

The mathematical formulation for calculating

The nonlinear decreasing inertia weight w is mathematically defined by equation (5):


Variation curve of the inertia weight w over iterations.
Staying behavior
In MSPO's staying behavior, parrots fly toward their owner's vicinity and remain stationary for a certain duration. Accordingly, the position update formula for this behavioral phase is mathematically expressed by equation (6):
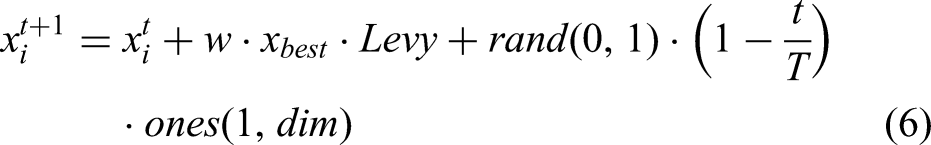
Communicating behavior
In MSPO's communicating behavior, parrots exhibit dual flight modes: collective flocking toward group communication or individual solitary flight. Assuming equiprobable selection between these behavioral modes. The position update mechanism is formally expressed by equation (7):

Fear of strangers’ behavior
In this phase, parrots flee from unfamiliar individuals and seek secure locations, with their positional update governed by equation (8):
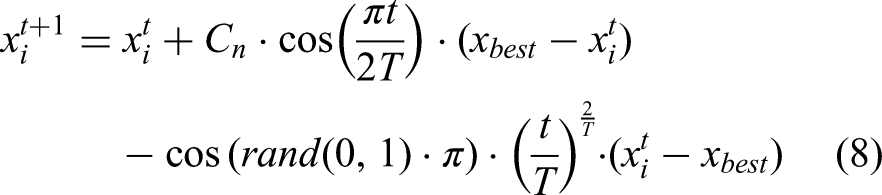
The parameter
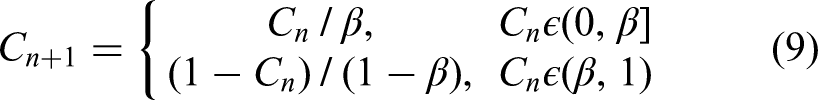

Time series plot of Tent map.

Probability distribution histogram of Tent map.
Pseudocode of MSPO
Algorithm 1 outlines the pseudocode of MSPO. The procedure begins with initializing all algorithm parameters and the population. Subsequently, MSPO employs the four parrot behaviors to search for approximate solutions. Throughout the optimization procedure, every individual iteratively updates its position until reaching the maximum iteration count.

Flowchart of MSPO
The MSPO flowchart is based on iterative optimization as its core logic (see Figure 6). In the initial phase, algorithm parameters and population initialization are completed, followed by an iterative process. In each iteration, the system first checks whether the maximum number of iterations has been reached. If not, it randomly generates behavior identifiers (1–4), corresponding to triggering four behavior patterns: foraging, resting, communication, and stranger fear, and updates the individual's position according to their respective formulas. After updating the positions, the fitness values are calculated, and the global optimal solution is updated accordingly. This process repeats until the termination conditions are met, ultimately outputting the optimal solution. This process achieves efficient exploration and optimization of the solution space through the coordinated use of multiple behavioral strategies.
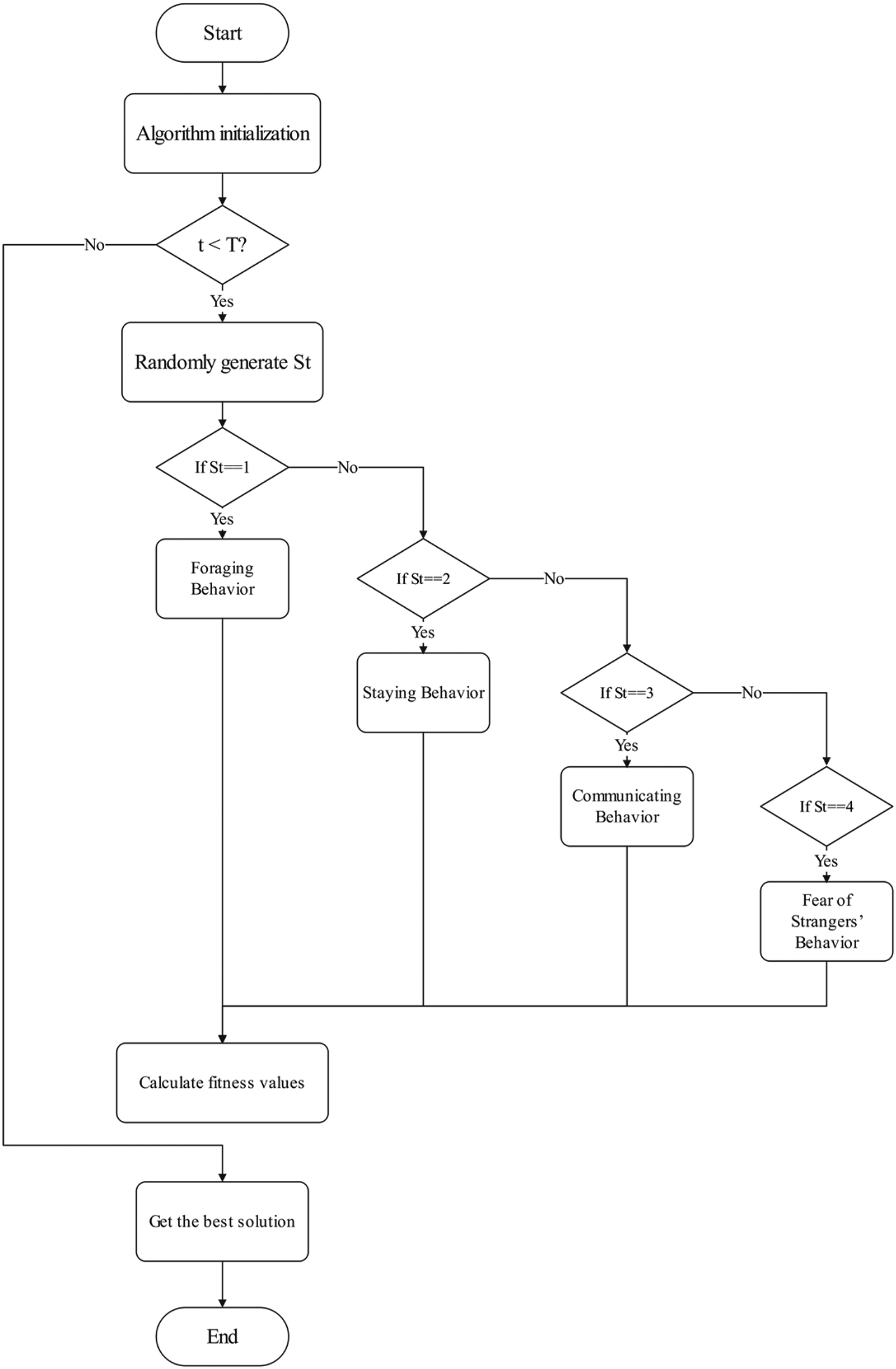
Flowchart of MSPO.
Simulation experiment
Experimental settings
To verify the performance of the MSPO, this study employs the 12 benchmark test functions from IEEE CEC 2022 for its evaluation. The CEC 2022 test function set, newly introduced in recent years, is widely utilized for algorithm evaluation. It comprises 12 benchmark functions for single-objective optimization, including one unimodal function (F1), four multimodal functions (F2–F5), three hybrid functions (F6–F8), and four composite functions (F9–F12). Additionally, all these test functions are minimization problems. Table 1 presents the details of these 12 benchmark test functions, including their theoretical optimal values. The 3D visualization surface map of the benchmark functions from the CEC 2022 suite, depicted in Figure 7, includes images of the 12 test functions within the range of [−100, 100].
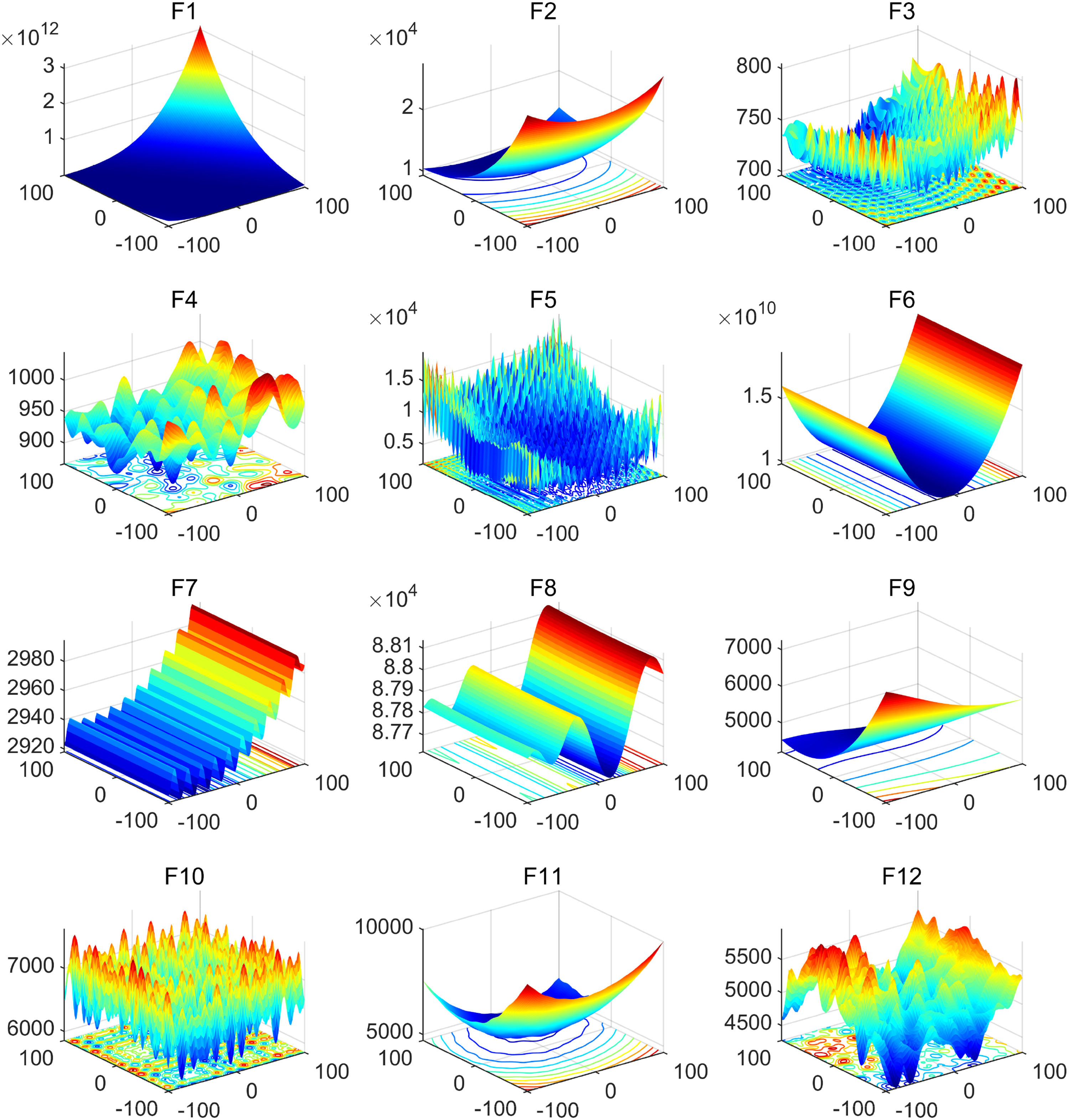
3D surface plots of the CEC 2022 benchmark functions.
Benchmark functions of the CEC 2022.

In addition, to validate the validity of MSPO, it was evaluated against six other well-known algorithms. These algorithms include Parrot Optimizer (PO), 38 Whale Optimization Algorithm (WOA), 39 Sine Cosine Algorithm (SCA), 40 Harris Hawks Optimization (HHO), 41 Genetic Algorithm (GA), 42 and Bat Algorithm (BA). 43 Table 2 provides specific information about these algorithms, including the values of the algorithm parameters.
Parameter configurations for comparison algorithms.

This experiment was implemented using MATLAB R2024b. To evaluate MSPO more comprehensively, every optimization algorithm is executed 30 times, and three evaluation metrics are taken, including best, mean, and standard deviation (STD). These evaluation metrics are the most common statistical metrics, and they can measure the optimization ability and stability of the algorithms from different perspectives. Furthermore, to make a fair comparison, every optimization algorithm was initialized using a swarm of 30 individuals, set to run for 1000 iterations, and a dimension of 10.
Experimental results and analysis
Under identical experimental conditions, MSPO and the comparison algorithms were executed on the CEC 2022 for comprehensive performance evaluation. Table 3 provides the experimental results of MSPO and the six established algorithms across all 12 test functions, including three evaluation metrics. The data demonstrates that MSPO outperforms competing algorithms on most benchmark functions. Notably, for functions F2, F10, and F12, MSPO achieved superior performance across three evaluation metrics.
Experimental results on the test function of CEC 2022.
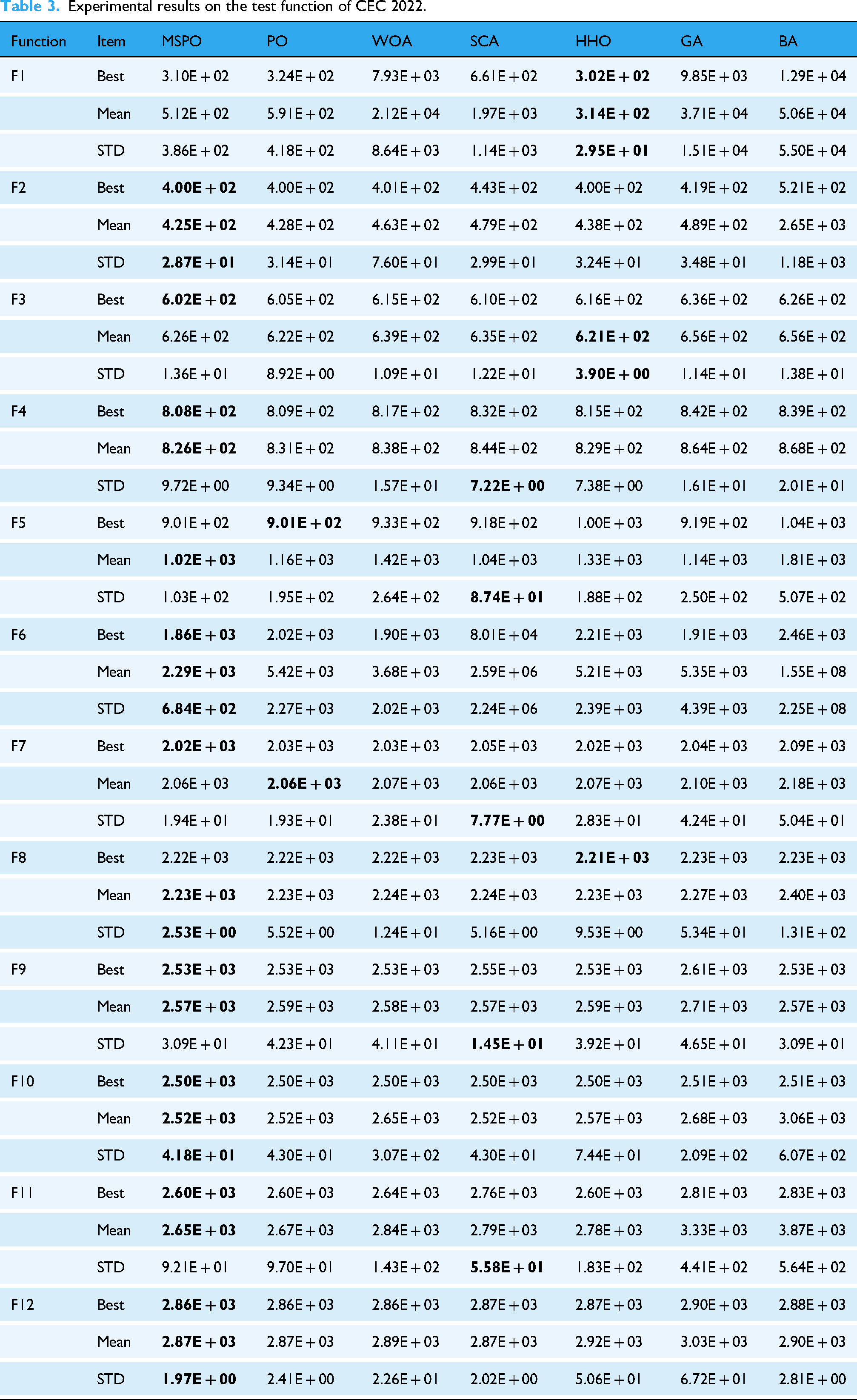
To additionally confirm the comprehensive advantages of the developed MSPO, this paper provides a ranking comparison of its performance with six mainstream optimization algorithms (including PO, WOA, SCA, HHO, GA, and BA) in terms of the average performance metrics (Mean) based on the CEC 2022 benchmarking test functions. The specific evaluation covers 12 test functions (F1 to F12), each of which assigns a ranking score from 1 (best) to 7 (worst) to each algorithm, respectively. The relevant outcomes are summarized in Table 4.
Ranking of algorithms.
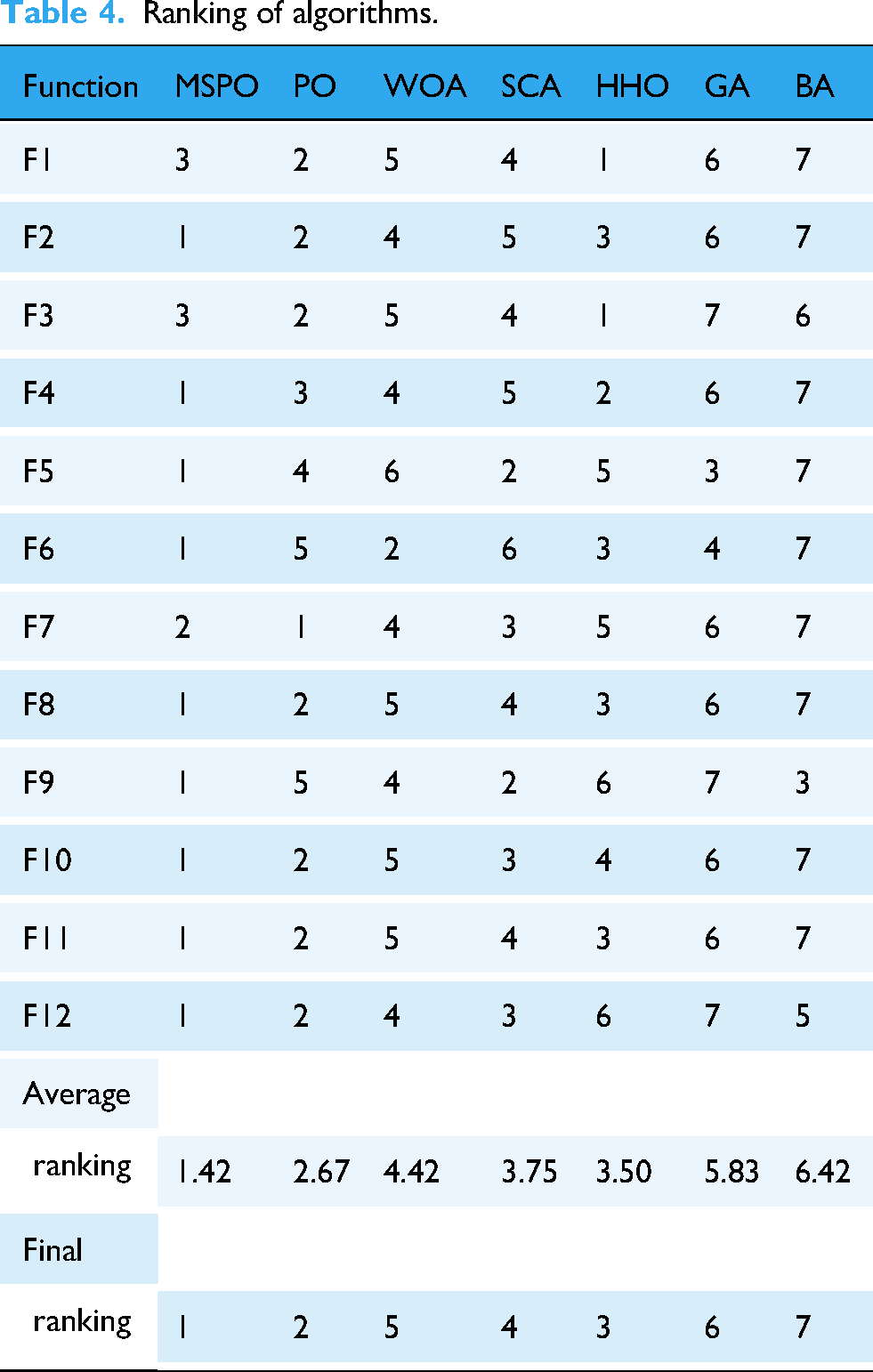
In the ranking statistics, the MSPO algorithm performs particularly well, obtaining high ranking scores in most functions. For example, MSPO achieves the first place in nine functions, highlighting its superior global exploration capability in addressing complex optimization scenarios including multi-peak, hybrid, and combinatorial functions. In addition, MSPO also maintains top performance in the remaining functions (e.g., F3 and F7) and finally obtains an excellent average ranking of 1.42, which significantly outperforms other algorithms. PO ranks second with an average ranking of 2.67, while WOA and SCA rank fifth and fourth with 4.42 and 3.75, respectively. The overall rankings of GA and BA lag relatively behind, ranking sixth and seventh, respectively. This result fully demonstrates that MSPO shows stronger adaptability, stability, and performance consistency in a variety of complex function scenarios, and can find more optimal solutions in most cases, with a wide range of application potentials.
To visually illustrate the search effectiveness and convergence rate of the MSPO algorithm in the optimization process, its convergence curves with the other six comparative algorithms (PO, WOA, SCA, HHO, GA, and BA) on some of the CEC 2022 benchmark functions are plotted in this paper as shown in Figure 8. Each subplot uses the iteration number as the x-axis and the optimal solution value of the relevant function as the y-axis, illustrating how each algorithm's performance evolves during the iteration.
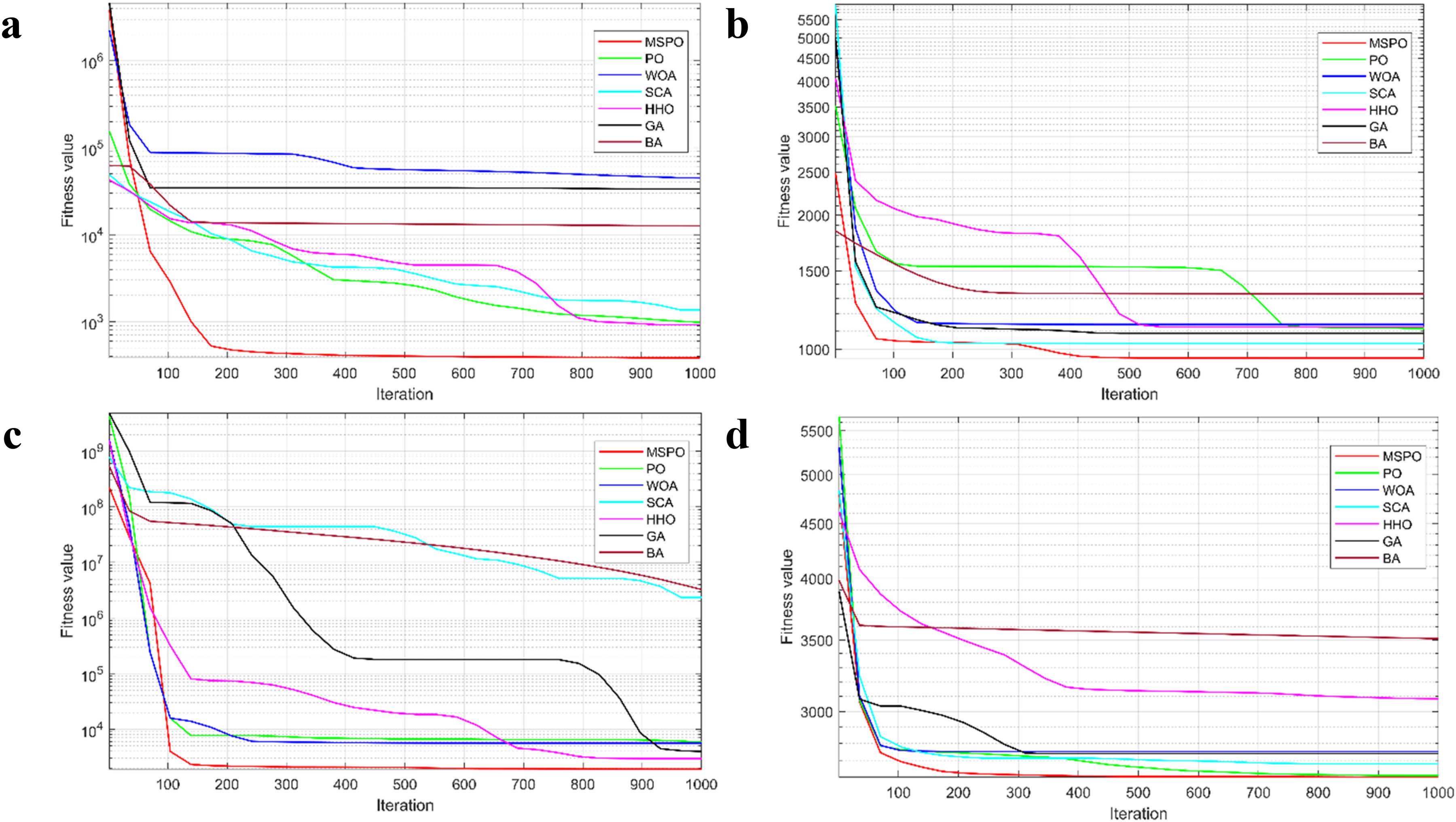
Convergence curve of algorithms where a is F1, b is F5, c is F6, and d is F11.
On the F1 function, MSPO exhibits a rapid decline in the initial phase, completing the main performance improvement within only the first 200 iterations, and then continuing to approach the global optimum at a steady rate. In contrast, the remaining algorithms exhibit some degree of fluctuation in early searches. For the multimodal function F5, MSPO still maintains an efficient descent trend and shows more stability in the middle and late iterations. PO and SCA have significantly higher final convergence values than MSPO despite their initial descent ability. F6 is a hybrid function, which usually puts a higher demand on the optimization algorithm's global search and its dynamic local optima avoidance. From the figure, it can be observed that MSPO not only starts descending faster compared to other algorithms but also continues to search deeper into the search space and finally obtain the lowest function value. In contrast, SCA and BA stagnate after converging to the local optimum and are difficult to optimize further. When facing the more challenging combinatorial function F11, the advantage of MSPO is again demonstrated. Its convergence path is smooth and continues to approach the optimal region, which is much better than the performance of most of the compared algorithms.
Table 5 summarizes the comprehensive performance comparison of the MSPO algorithm proposed in this paper with mainstream optimization algorithms such as PO, WOA, SCA, and HHO on the CEC 2022 benchmark functions. In terms of metrics such as average ranking and optimal number of iterations, MSPO achieved the optimal average ranking of 1.42 in 12 test functions and ranked first in 9 functions, comprehensively outperforming other comparison algorithms, thereby validating its strong global search capability and stability.
Summary of MSPO and other optimization algorithms on CEC 2022.
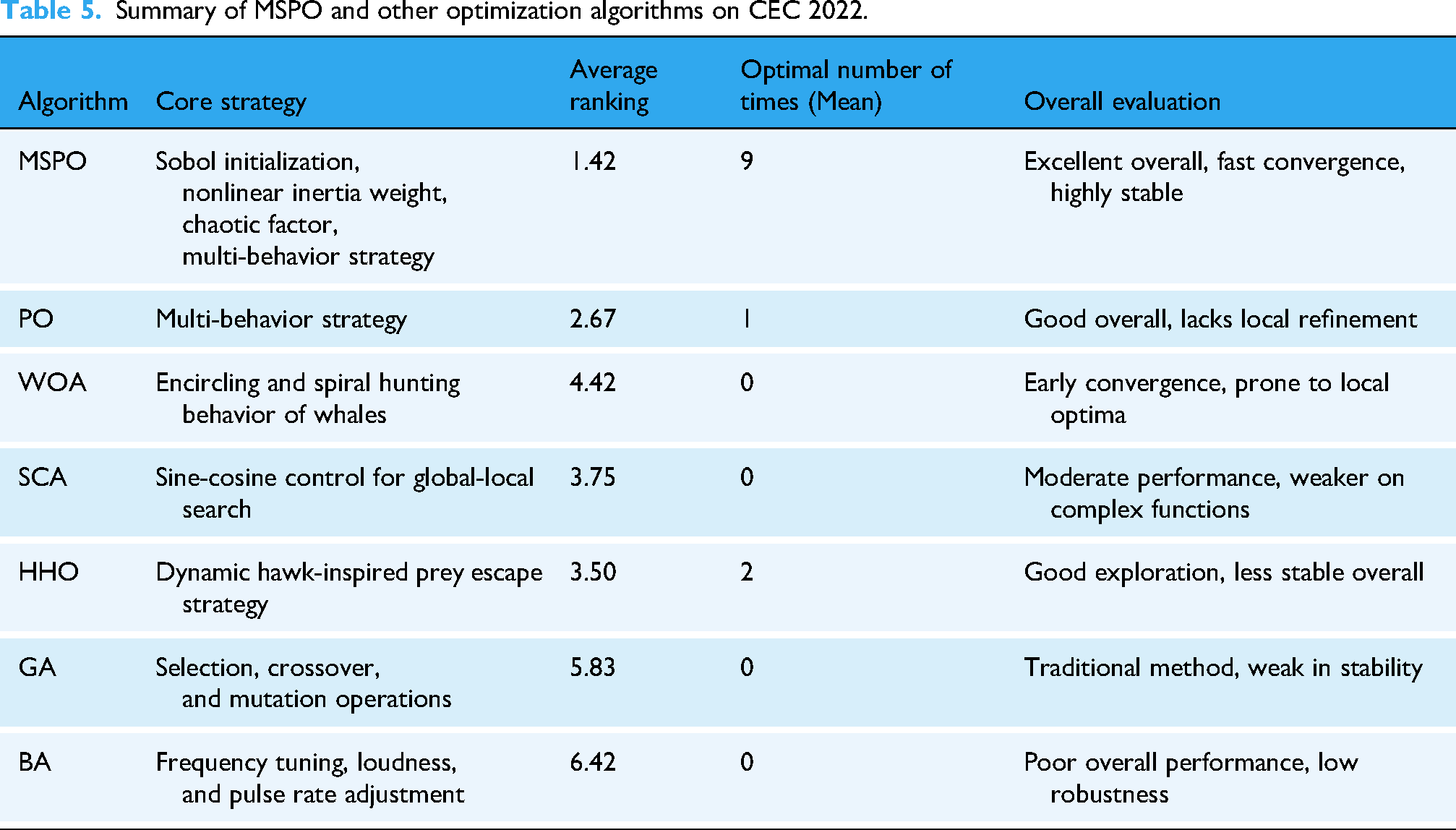
In summary, MSPO verifies its superiority in tackling complex optimization problems through experiments on the CEC 2022. Moreover, compared with other excellent algorithms, MSPO excels in convergence speed, search accuracy and stability of results, further proving its competitiveness and practical value in solving global optimization problems.
Ablation study
To further validate the effectiveness of each key strategy in the MSPO algorithm, this section analyzes the independent contributions of its three core improvement modules, Sobol sequence initialization, nonlinear decreasing inertial weight, and chaos parameter, through ablation experiments. Specifically, we constructed three variants while keeping the remaining parts consistent, sequentially removing each strategy, and compared them with the complete MSPO model to assess the impact of each strategy on the overall performance of the algorithm.
The settings for the three variants of MSPO are as follows: MSPO-NoSobol (replacing Sobol sequence initialization with standard uniform random initialization), MSPO-NoInertia (removing nonlinear decreasing inertia weights), and MSPO-NoChaos (replacing chaotic parameter perturbations with random perturbations).
The experiments were still based on the 12 benchmark functions from CEC 2022, run under the same settings, with each algorithm executed in 30 independent trials. The Best, Mean, and STD of the fitness values for each function were used as evaluation metrics. All population sizes were set to 30, the maximum number of iterations was 1000, and the problem dimension was 10.
Table 6 presents the performance statistics of MSPO and its three variants on CEC 2022.
Experimental results of the ablation experiment.
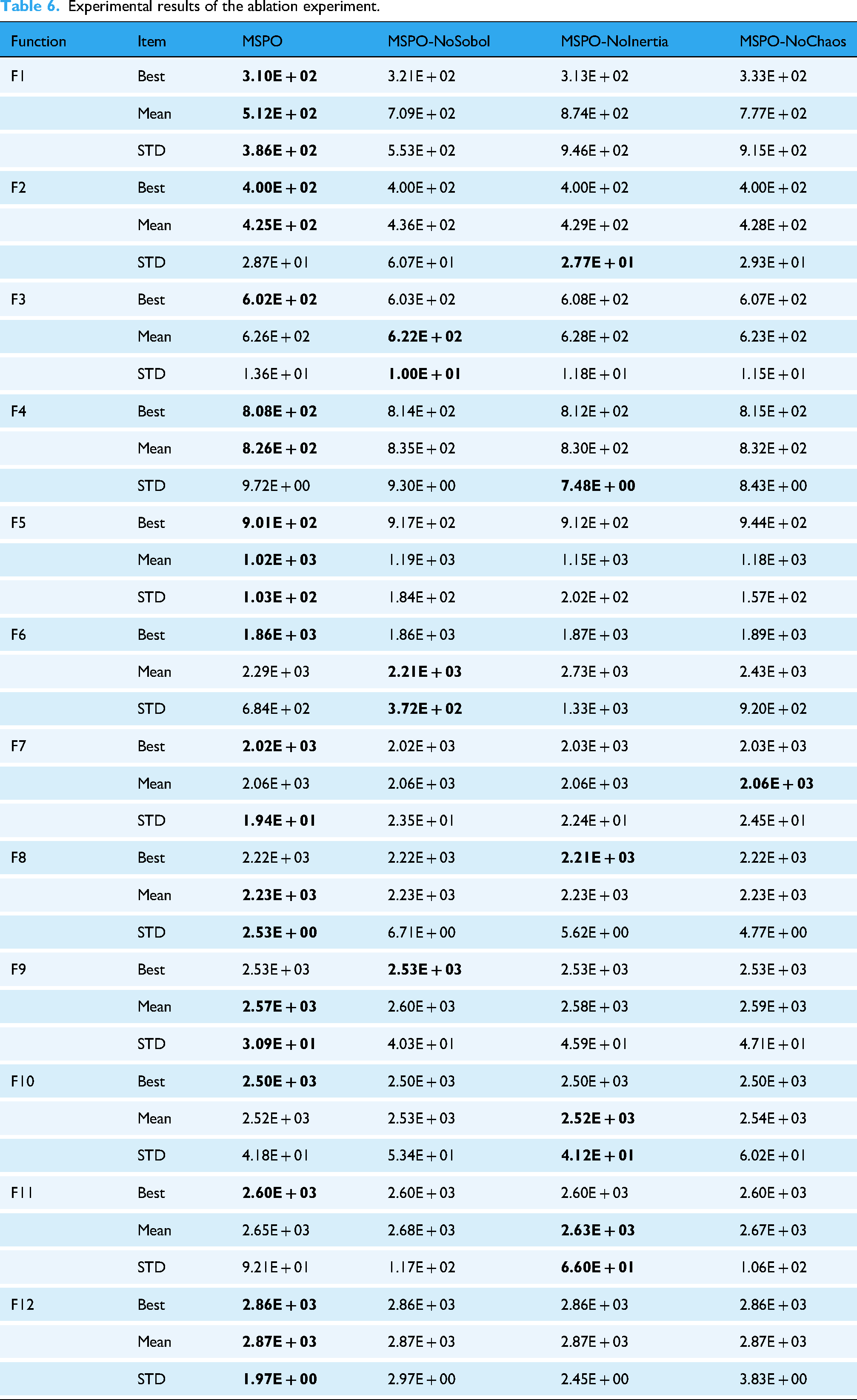
As shown in Table 6, the complete MSPO algorithm achieved better average fitness values and smaller standard deviations for most functions, demonstrating strong optimization capabilities and stable results. Specifically, on the F1 function, the average value of MSPO is 5.12E + 02, significantly outperforming the results of the other three variants. In particular, the average value of MSPO-NoInertia reaches 8.74E + 02, and the standard deviation also increases significantly, indicating that the non-linear decreasing inertia weighting strategy plays a crucial role in optimizing stability and convergence accuracy. Additionally, the removal of the Sobol sequence initialization strategy (MSPO-NoSobol) also led to performance degradation in multiple functions, such as the average fitness of F1 and F5 increasing to 7.09E + 02 and 1.19E + 03, respectively, with the standard deviation also significantly expanding, indicating that this strategy helps improve the uniformity of the initial population distribution and global search capability. The removal of the chaos factor (MSPO-NoChaos) did not show as obvious improvements as the previous two strategies in some functions, but its average performance in complex functions was still inferior to the complete model, indicating that chaos perturbation plays a certain role in enhancing local search in the later stages.
Overall, the experimental results in Table 6 fully validate the synergistic effect of MSPO's various improvement strategies in enhancing the algorithm's overall performance. Together, they form an optimization framework with strong global search capability, high convergence accuracy, and good robustness, significantly outperforming simplified versions lacking any of the strategies, highlighting the importance and effectiveness of multi-strategy integration mechanisms in solving complex optimization problems.
Application of MSPO in breast cancer image classification
In current medical settings, machine learning techniques have been extensively utilized in categorization of medical images, particularly playing a significant role in breast cancer image classification. However, the effectiveness of models is influenced by the selection of hyperparameters. To address this, we employ the proposed MSPO to optimize hyperparameters for machine learning in breast cancer image classification tasks.
Experimental settings
ResNet18, a classical lightweight variant of Residual Networks, effectively addresses the vanishing and exploding gradient problems inherent in deep neural networks through innovative residual blocks and skip connections that enable cross-layer signal propagation. In breast cancer image classification tasks, this architecture strikes an optimal balance between providing sufficient feature representation depth and maintaining computational efficiency.
It is worth noting that ResNet18 was selected as the classification model in this paper primarily due to its practicality and experimental convenience. As a lightweight residual network, ResNet18 has a relatively simple structure, high training efficiency, and is convenient for conducting multiple rounds of hyperparameter optimization experiments under limited computing resources. More importantly, the focus of this study is to verify the effectiveness and stability of the proposed MSPO algorithm in deep neural network hyperparameter optimization tasks, rather than to conduct a systematic comparison of various network architectures. Therefore, selecting ResNet18 allows us to focus more closely on evaluating the performance improvement effects of the optimization algorithm itself. It is essential to note that MSPO, as a general meta-heuristic optimization method, is independent of specific network structures, and its optimization strategies are equally applicable to more complex deep learning models, such as DenseNet and EfficientNet.
To validate the applicability of MSPO in breast cancer image classification, we selected the publicly available BreaKHis 400X dataset. 44 This histopathological image dataset comprises 547 microscopic biopsy images of benign breast tumors and 1146 malignant counterparts obtained from histopathology slides. Representative samples from this dataset are presented in Figure 9.
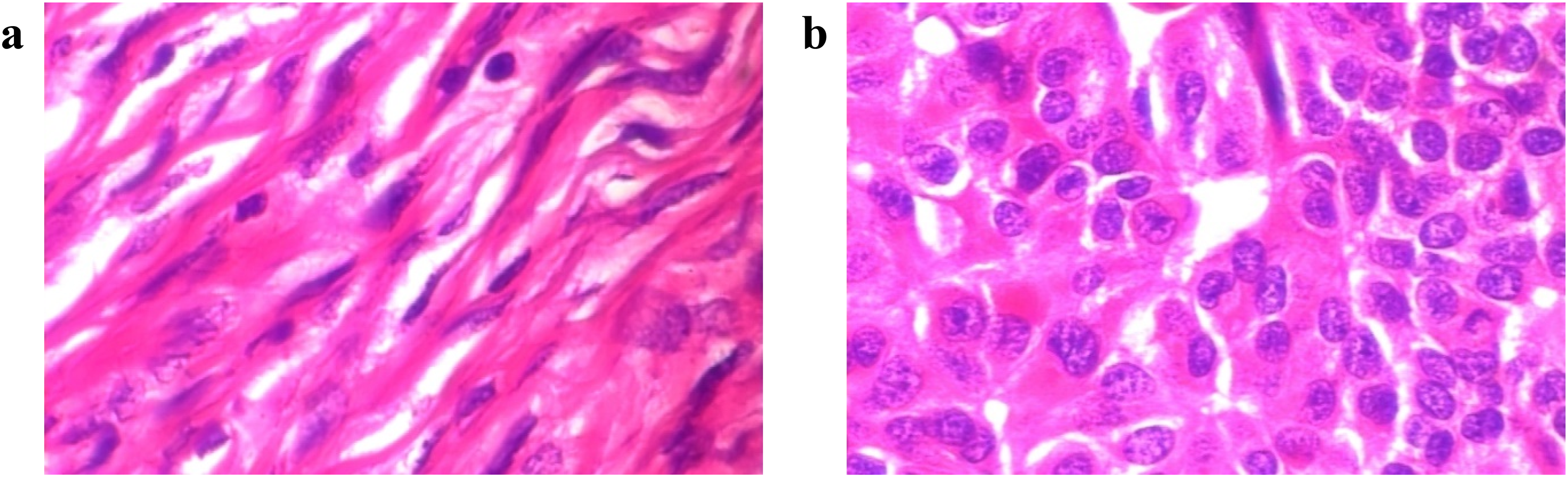
Sample images of the BreaKHis 400X dataset where a is Benign, and b is malignant.
To assess the optimization capability of MSPO, this research selected the PO algorithm that secured the second position in preliminary comparative experiments, along with HHO, SCA, and WOA algorithms ranked third, fourth, and fifth in comprehensive performance evaluation, as benchmark algorithms. Table 7 illustrates the configuration parameters across all algorithms. In addition, we will also compare the results with the ResNet18 model without hyperparameter optimization.
Parameter configurations for comparison algorithms (application).
In addition, each optimization method was initialized with a swarm size of 30 and capped at 50 iterations. The hyperparameters MaxEpochs and MiniBatchSize of ResNet18 were designated as optimization targets, resulting in a search space dimensionality of 2 for all algorithms. Data was stochastically partitioned into training and test sets at a 7:3 ratio. During training, data augmentation techniques were systematically implemented: horizontal flipping with 50% probability and random translations along X/Y axes within a [−30, +30] pixel range. These stochastic transformations were dynamically applied during each training iteration to enhance data diversity and improve model generalization capabilities.
To comprehensively assess the hyperparameter optimization capabilities of the algorithms, four evaluation metrics were adopted: Accuracy, Precision, Recall, and F1-Score. The corresponding computational formulas are formulated as follows: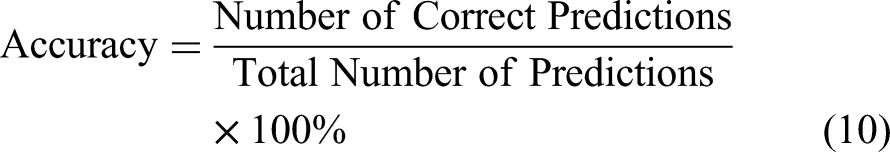
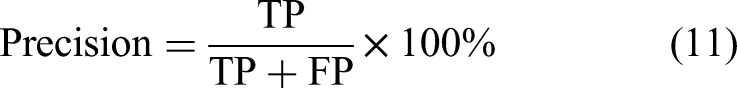
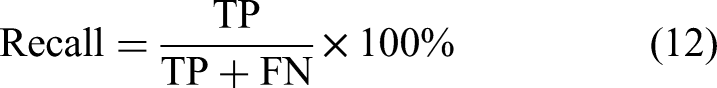
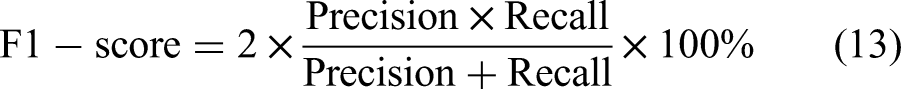
Experimental results and analysis
The optimized hyperparameters of ResNet18 (MaxEpochs and MiniBatchSize) obtained through MSPO, PO, HHO, SCA, and WOA algorithms are systematically documented in Table 8.
Optimization results of five algorithms.

As Table 8 shows, the adjustment of hyperparameters by different algorithms presents significant differences. For example, MSPO is optimized with MaxEpochs of 139 and MiniBatchSize of 55, while WOA is optimized with MaxEpochs of only 29 but MiniBatchSize of up to 255. This reflects the different strategies of the algorithms in balancing the number of training iterations and batch size.
According to the optimized results of the MSPO, PO, HHO, SCA, and WOA algorithms, their corresponding ResNet18 models are MSPO-ResNet18, PO-ResNet18, HHO-ResNet18, SCA-ResNet18, and WOA-ResNet18, respectively. The results of these models and the unoptimized ResNet18 results are shown in Table 9. Based on this table, a histogram of the experimental results can be drawn as visualized in Figure 10.

Histogram of the results of each model on four evaluation metrics.
Results of each model on four evaluation metrics.

The MSPO-ResNet18 model performed the best on all four metrics, achieving 97.64% for Accuracy, 97.30% for Precision, 97.30% for Recall, and 97.30% for F1-score. Compared to the unoptimized model, it has improved 4.33%, 3.99%, 6.07%, and 5.14% in each index, respectively. This significant increase not only verifies the ability of MSPO in searching for the optimal combination of hyperparameters but also reflects its overall enhancement of classification performance. PO-ResNet18 follows closely, with 96.46%, 95.70%, 96.27%, and 95.97% in the four indexes, which is slightly weaker than that of MSPO, showing a good global search ability, but with some limitations in the fine search stage. HHO-ResNet18 and SCA-ResNet18 have similar results in the four indexes, and their overall performance is stable, with F1-scores above 95%, but there is still a gap of about 1.5% compared to MSPO, suggesting its optimization ability in the local fine-tuning stage has some room for improvement. The four metrics of WOA-ResNet18 are comparatively low, and the F1-score is only 9.5%. F1-score is only 94.60%, and although it is still better than the base ResNet18 model, its overall performance improvement is limited compared with MSPO. The unoptimized ResNet18 model has the lowest performance in all four metrics, especially the weakest performance in Recall, which is only 91.23%, indicating that the model has a certain risk of leakage detection without optimized hyperparameters, and may be insufficient for the identification of malignant tumors.
Figure 10 presents the comparison results of each model on the four metrics through visualization. The four sets of bar charts clearly show the overall advantage of the MSPO optimized model, which is above the other models in all values and the relative difference is obvious, especially in the two items of Recall and F1-score, the lead of MSPO is more significant. This trend indicates that the MSPO-ResNet18 model not only improves the overall classification ability of breast cancer images but also strengthens the sensitivity to tumor samples, which can effectively reduce the rate of missed detection. In addition, although each comparative optimization algorithm improves the effectiveness of the original model to different degrees, there is a significant difference in the magnitude of improvement. The improvement of Recall by the optimization algorithms is generally larger, reflecting the key significance of rationally configuring hyperparameters to improve model sensitivity in the field of medical images. F1-score, as a comprehensive index, basically maintains the same improvement trend as that of Accuracy, which further corroborates the improvement of the optimization strategy on the overall balanced performance.
In summary, through the systematic comparative analysis of Table 9 and Figure 10, MSPO not only achieves optimal performance in numerical indexes but also shows overwhelming advantages in visual illustrations, which fully verifies the practical value and promotion prospect of the algorithm in medical image classification scenarios.
Discussion on clinical integration and ethical considerations
Although the MSPO optimization algorithm proposed in this study has shown excellent performance in breast cancer image classification, its integration into real-world clinical settings involves multiple challenges. From a systems perspective, MSPO-optimized models can be embedded into computer-aided diagnosis (CAD) platforms, functioning as decision support tools within radiology or digital pathology workflows. In low-resource environments, MSPO can facilitate lightweight model deployment by optimizing for computational efficiency, making real-time inference on edge devices feasible.
However, several challenges remain. First, interpretability remains a hurdle—clinicians require transparent reasoning for AI-driven decisions. Second, inter-institutional variability in imaging data (e.g., resolution, staining techniques) may affect generalizability. Additionally, integration with hospital systems (e.g., PACS, RIS) necessitates adherence to standards like DICOM and HL7.
Ethical issues must also be addressed: model training must preserve patient privacy through anonymization and secure handling; fairness must be ensured across demographic groups to prevent algorithmic bias; and liability in AI-assisted misdiagnosis must be clarified through institutional guidelines.
In summary, while MSPO holds potential for clinical deployment, careful consideration of system, technical, and ethical dimensions is vital for real-world impact.
Conclusion
In this article, we address the hyperparameter optimization issue in breast cancer image classification and propose an MSPO to boost the classification performance of deep learning models. Built upon the conventional PO, the proposed algorithm integrates the Sobol sequence initialization strategy, a nonlinearly decreasing inertia weight mechanism, and a chaotic parameter, which significantly boosts the algorithm's global exploration ability and stability. Simulation experiments on the benchmark functions from CEC 2022 demonstrate that MSPO outperforms six mainstream optimization algorithms regarding average performance, optimal solution quality, and result stability. Furthermore, ablation studies were performed on three variants of MSPO using CEC 2022.
We apply MSPO to the hyperparameter optimization of the ResNet18 model and conduct classification experiments on the BreaKHis breast cancer image dataset. Results illustrate that the MSPO-optimized ResNet18 model attains better accuracy, precision, recall, and F1-score than the unoptimized model and the models obtained through alternative optimization algorithms, exhibiting superior generalization capability and classification performance. In particular, the recall rises by 6.07% relative to the original model, confirming the proposed algorithm's validity and applicability in medical image classification tasks.
Future research will further explore the adaptability and robustness of the MSPO algorithm in a wider range of application scenarios. The current experiments are based solely on the BreaKHis dataset, which, while representative, cannot fully reflect the model's generalization capabilities under different imaging conditions, tissue types, or data sources. Therefore, subsequent research will consider incorporating additional breast cancer image datasets to enable cross-dataset, cross-resolution, and cross-modality experimental validation. Additionally, the transferability of MSPO to other medical image analysis tasks, such as lung CT screening and skin pathology image classification, will be explored to further assess its generalizability and practical deployment potential.
Footnotes
ORCID iDs
Ethical approval
Ethical approval was not required for this study as we analyzed publicly available data that was not collected from human subjects but from publicly available symptom checker apps.
Contributorship
Haonan Li: conceptualization, methodology, data curation, and writing—original draft. Vijay Govindarajan: validation and data curation. Tan Fong Ang: methodology, software, supervision, and formal analysis. Zaffar Ahmed Shaikh: validation. Amel Ksibi: formal analysis. Yen-Lin Chen: methodology, validation, and writing—review and editing. Chin Soon Ku: data curation, validation, and writing—review and editing. Ming Chern Leong: validation. Fatiha Hana Shabaruddin: validation. Wan Zamaniah Wan Ishak: validation. Lip Yee Por: conceptualization, methodology, supervision, formal analysis, project administration, validation, and writing—review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the AI for Medicine Research Grant Scheme (AIM-C09–2025), Universiti Malaya, Malaysia; the National Science and Technology Council in Taiwan under grant numbers NSTC-113–2224-E-027–001, NSTC-113–2622–8–027–009, and NSTC-112–2221-E-027–088-MY2; and the Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R759) at Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh 11671, Saudi Arabia. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.