
Abstract
Background
The construction of a model to estimate patients’ status in early-stage diabetic kidney disease (ES-DKD) is needed. Thus, the risk factors playing a role in the disease diagnosis can be determined when routine examination outcomes are collected.
Objective
Routine examination outcomes can also be used to predict patients’ ES-DKD. A first-stage study is conducted on how successful conventional statistical models (CSMs) perform when sample sizes are small when compared to machine learning methods (MLMs).
Methods
A total of 268 observations were collected from two tertiary hospitals in Lanzhou with demographic information, basic medical history, and routine laboratory tests such as blood routine, common biochemical tests, and urine routine. Then, conventional statistical methods and MLMs are applied to establish models separately to determine optimal prediction models. In addition, machine learning has also been applied to establish fused models to explore new modeling methods.
Results
The validation set can better represent the actual performance of the models in clinical practice. Therefore, the comparisons are made based on the predictive performance of the two methods using the validation set. Ultimately, it was concluded that the ensemble model outperforms in terms of performance metrics. The CSMs perform poorly in terms of area under curve values. Compared to various MLMs, the performance of others is not inferior.
Conclusion
This article establishes multiple ES-DKD prediction models using CSMs and MLMs. New ideas and methods for the diagnosis, treatment, and prevention of ES-DKD in clinical practice are presented. This article also compares two modeling methods. A comprehensive model was established, which has excellent predictive and generalization ability and stability. Therefore, the integration of the advantages of MLMs based on CSMs is a very fruitful attempt. Fused models have a high chance of being the main research direction for future research to develop better models.
Introduction
The 10th edition report of the International Diabetes Federation (IDF) estimates that one out of 10 people is diagnosed with diabetes, and the number of patients increases constantly. 1 Diabetic kidney disease (DKD) is a common complication in diabetic patients. For example, the incidence of DKD in diabetic patients accounts for about 20%–40% of the population in China. 2 DKD has become the main cause of chronic kidney disease (CKD) and has resulted in renal disease even in the end stages.3,4 A renal biopsy, as a gold standard to diagnose the DKD, is invasive.5,6 However, its administration is poorly accepted by patients. Currently, urinary albumin-to-creatinine ratio (UACR), urinary albumin excess rate (UAER), and estimated glomerular filtration rate (eGFR) are widely administered in the clinical diagnosis of DKD. 7 Nevertheless, in the early stages of diseases, these indicators may not fluctuate significantly and provide detailed information, and some indicators are not reported in routine examinations, which can impair the patient's condition in the long run. If DKD is not treated timely, the symptoms get worse, and the stage of uremia and even fatal consequences are inevitable. Hence, finding easy and reliable ways to diagnose based on routine examination scores and not highly depending on using invasive methods is practically significant for patients who have potential DKD at early stages.
To find data-oriented methods, many researchers suggested mathematical models to predict DKD at an early stage as a diagnosis tool, so that the prediction and prognosis of diseases can be easily conducted. Hence, ambiguous diagnostic guidelines and invasive methods to diagnose DKD at an early stage could affect the patients less. To construct mathematical-based modeling in general, two sets of models, namely, conventional statistical models (CSMs) and machine learning methods (MLMs) can be used. Each group is equipped with its advantages and disadvantages. Although much research applies those two sets of modeling tools separately to determine better outcomes, a limited study has been conducted to compare them.
To compare those two sets of tools, the early predictive model for diabetic nephropathy was established, and the two methods were compared under the same conditions such as small sample size, the same data set, the same output variable, and the same grouping method to investigate how the CSMs and MLMs perform in the small sample sizes.
Methodology
The objective of the research
The research is a case-control study that had 179 cases in the 940th Hospital of the Joint Logistics Support Force of the Chinese People's Liberation Army (Hospital A) between 2018 and 2022 as the training set, and 89 cases in the First Hospital of Lanzhou University (Hospital B) from 2018 to 2022 as the test set. The two data sets are independent. Using EpiData software, under the same template and rules, patients’ data were collected randomly.
First of all, all patients have been clinically diagnosed with diabetes mellitus type 2 (T2DM). Secondly, patients in the early-stage diabetic kidney disease (ES-DKD) group were also clinically diagnosed as early diabetes nephropathy patients based on T2DM. In addition, DKD patients are clinically diagnosed according to diagnostic guidelines, patient history, B-ultrasound, whether there is diabetes retinopathy, puncture biopsy, and other methods.
According to the internationally recognized critical score of the DKD, the guideline for improving global outcomes (KDIGO) has been published for the reliability of the data. 8 The patients in the T2DM group (non-ES-DKD group) and the ES-DKD group were screened through the chronic kidney disease epidemiology collaboration equation (CKD-EPI).9,10 The diagnosis of DKD in the early stage, which is mild symptoms, and the changes in diagnostic indicators not being obvious, will be conducted based on data analysis. The “low risk” stage is defined as the ES-DKD score, which is the EGFR ≥ 60 mL/min/1.73 m2. Due to occasional normal and elevated eGFR levels of 120 in patients with ES-DKD, this study only limited the lower limit of eGFR in the ES-DKD group and did not limit the upper limit.
DKD is a microvascular complication of diabetes, and diabetes retinopathy is also a microvascular complication. To exclude the interference of diabetes retinopathy, the non-ES-DKD group excluded diabetes retinopathy. Patients with kidney cancer and kidney tumors who suffer from severe kidney damage may have biased results, so both groups excluded such patients. Therefore, the following inclusion and exclusion criteria have been formulated.
Figure 1 defines both inclusion and exclusion criteria. The non-ES-DKD group includes patients who were clinically diagnosed with T2DM and never had diabetic microangiopathy such as ES-DKD, or diabetic retinopathy. Their eGFR values were 120–90 mL/min/1.73 m2. Patients without renal tumors or renal cancer were included. The ES-DKD group contains patients with clinically diagnosed type 2 diabetic nephropathy with eGFR ≥ 60 mL/min/1.73 m2. Patients without renal tumors or renal cancer were also included. Also, patients were excluded with missing data in the training and validation sets. The final training sets consisted of 75 non-ES-DKD group patients and 89 ES-DKD group patients, respectively, while the validation set consisted of 37 non-ES-DKD group patients and 49 ES-DKD group patients. The data were collected with all signed and informed consent by the patient upon admission. The ethics committees of both hospitals approved the content of the study.

Data entry and discharge process.
Methods
Both deduplication and denoising processes are conducted on datasets. The patients were excluded from the experiment. The qualitative attributes of the two datasets were coded. Finally, CSMs and MLMs were implemented to construct prediction models and were compared. The training sets were employed to construct the prediction models, and the validation sets were implemented to verify the results of the predictions.
Indicators
Table 1 presents quantitative data that includes age and laboratory indicators such as blood routine, biochemistry, renal function, HbA1c, and so on. Table 2 summarizes the qualitative attributes which are gender, hypertension history, other related history variables for kidney diseases, insulin utilization history, glycemic control, heredity, smoking, drinking, the history of T2DM (5 years as the boundary), urine pH, proteinuria, the history of T2DM (10 years as the boundary), and basic diseases. Other kidney diseases refer to kidney diseases other than diabetic kidney disease such as renal calculi, renal cysts, hydronephrosis, and so on. Urine pH is assigned to 6 as the cut-off point, and if < 6 the acidic stage is considered. Proteinuria is the presence of “+” as the cut-off point, namely, classified as positive or negative. Basic diseases refer to the presence of other diseases other than diabetes and its complications. Heredity refers to whether the family has a genetic history of type 2 diabetes. The onset time of T2DM is determined by the time from the patient's first diagnosis to the time of data collection. The history of T2DM, which is 5 years of illness, is accepted as the boundary since patients with a diabetes history of > 5 years may develop microvascular lesions. In the article, it is set since it will be used as an interference indicator of whether MLMs can eliminate similar interference. The history of T2DM, which is 10 years of illness, is accepted as the boundary since patients with a diabetes history of > 10 years may be the main cause of DKD. 11
The results of the single-factor analysis are based on quantitative data.

* p < 0.05 indicates a statistically significant difference between the non-ES-DKD and the ES-DKD groups. p ≥ 0.05 indicates that there is no statistically significant difference between the non-ES-DKD and the ES-DKD groups.
The results of the single-factor analysis are based on qualitative data.

T2DM: diabetes mellitus type 2; ES-DKD: early-stage diabetic kidney disease.
* p < 0.05 indicates a statistically significant difference between the non-ES-DKD and the ES-DKD groups. p ≥ 0.05 indicates no statistical significance between the non-ES-DKD and the ES-DKD groups.
Modeling based on conventional statistical methods
SPSS 21.0 (IBM, USA), R 4.3.2 (R Foundation for Statistical Computing, Austria), and GraphPad Prism 8.2.1 (GraphPad Software, USA), were utilized to construct CSMs. First, univariate analysis was performed. The dataset's normality assumption was conducted by running a nonparametric Kolmogorov-Smirnov test. Indicators conform to normality assumption and the homogeneity of variance test was conducted to run the one-way analysis of variance (ANOVA). If the normality assumption was not violated and the variances were equal, the independent sample t-test was used. If the Normalality assumption was verified and the variances were not equal, the Welch's t-test was conducted. If the normality assumption was not validated, a non-parametric test called the Mann-Whitney U-test was implemented. Also, the qualitative data were tested by the chi-square (χ2) test.
Secondly, the indicators found statistically significant, (p < 0.05), in univariate analysis were screened whether they could be used as independent variables by the LASSO regression model, stepwise regression model, the selection of the optimal subset, and other methods, respectively.
The logistic regression model is selected since it fits into the purpose of the experimentation. The statistically chosen independent attributes were employed in the logistic regression model that was also utilized as the prediction model. Then, the receiver operating characteristic (ROC) curve of the prediction model was drawn, and the area under curve (AUC) of the training set and the test set were computed and compared, respectively.
Finally, R software was implemented to construct the Nomogram, calibration curve, and decision curve analysis (DCA).
The logistic regression model is given by the following equation:
The modified form of the logistic regression model is attained by the following equation:
Modeling based on machine learning methods
Python 3.10.13 (Python Software Foundation, USA) was implemented to crunch the data to construct the prediction model based on MLMs.
First, the data was standardized by subtracting the mean from each observation value and dividing by the standard deviation. Each feature has a mean of 0 and a standard deviation of 1. Equation (3) presents the process.
Standardization transforms the data into a standard normal distribution. Thus, the prediction model is not affected by the different measurement units of the attributes and can extract the relationship between different features.
Next, feature screening is performed. Feature selection is an important technique to reduce the dimensionality of a dataset and improve model performance. The random forest (RF) algorithm is implemented to screen significant attributes to reduce the effect of the high dimensionality problem in the data set. We chose RF for feature selection primarily due to its robustness and interpretability in estimating feature importance. Specifically, RF provides a natural ranking of features by evaluating the decrease in node impurity or the increase in model error when a feature is permuted. 12 These importance scores offer a practical and effective way to identify relevant features without requiring strong assumptions about data distribution or linearity. Moreover, it does not require additional hyperparameter tuning specifically for feature selection, making it more straightforward and stable in practice. RF-based feature selection has been widely adopted across various domains. Díaz-Uriarte and Alvarez de Andrés 13 demonstrated its effectiveness in gene selection for bioinformatics applications, highlighting its robustness in handling noisy and high-dimensional data. Genuer et al. 14 provided a comprehensive analysis of its theoretical underpinnings and practical utility in variable selection, especially in high-dimensional settings. Furthermore, Kursa and Rudnicki 15 introduced the Boruta algorithm, an extension of RF, to perform all-relevant feature selection with improved stability. These studies collectively support the suitability of RF as a reliable and interpretable tool for feature selection in complex learning tasks.
Also, several datasets in implementations have a problem of imbalanced classes, where some categories have far more observations than others. The performance of the constructed model can be negatively affected by imbalanced assessment when classification problems are under consideration. To resolve the issue, researchers suggested a variety of resampling methodologies to enhance the class distribution of data sets. For example, the SMOTEENN and SMOTETomek algorithms will be utilized to mitigate the imbalanced category problem in the article and effective syntheses from the data sets will be achieved.
The SMOTEENN methodology combines oversampling and undersampling methods. The class imbalance issue was eliminated by the Synthetic Minority Over-sampling Technique (SMOTE) to synthesize new samples and edited nearest neighbors (ENNs) to clean overlapping parts of samples. The SMOTE is based on analyzing the minor samples and synthesizing new minor samples. Then, the ENN is conducted to get rid of samples that may have been mislabeled.
SMOTETomek is another methodology that is used for offsetting imbalanced data categories, which combines SMOTE and Tomek links. Tomek links are a pair of nearest-neighbor samples, but they belong to distinct classes. The category boundaries can be made clearer by removing one or both samples from such a sample pair. When the SMOTE and Tomek links are combined, the classification performance is enhanced by first utilizing the SMOTE methodology to increase the minority class samples and then employing Tomek links to eliminate the overlapping areas between the two classes.
Finally, the model was constructed, and trained by 10-fold cross-validation, and a variety of common classification algorithms were comprehensively compared, including logistic regression (LR), support vector machine (SVM), K-nearest neighbor (K-NN), Naïve Bayes (NB), deep neural network (DNN), adaptive boosting (Ada-Boost), gradient boosting (GBDT), RF, light-GBM, cat-boost, and XG-boost. An ensemble model, which combined an NB algorithm and an RF algorithm, is also employed in the research. The optimization approach used for all mentioned models is based on tuning parameters manually.
The fused model is derived by utilizing an ensemble learning method that combines the prediction outcomes of several models to enhance the overall performance. Generally simple averaging, weighted averaging, voting, and stacking are just basic fusion methodologies. Equation (4) presents the fusion implementation.
More accurate predictions can be attained and a better and more effective auxiliary tool for clinical diagnosis can be generated when fused models are constructed.
Results
Results of the CSMs
Univariate statistics
The differences in quantitative and qualitative data between the non-ES-DKD group and the ES-DKD group in the training set were compared. Table 1 presents the quantitative data with the mean ± SD (standard deviation) when the normality assumption is verified and the median and IQR (inter-quantile range) when normality assumptions are not validated. Age, RDW-CV, MPV, ALT, ALB, A/G, Ca, CO2, AG, OSM, TBA, urea, CRE, eGFR, and HbA1c are statistically significant variables since all p-values are < 0.05. Namely, statistically significant differences are found for those variables between the DM and ES-DKD groups. Table 2 presents the qualitative data of the variables called hypertension, other kidney diseases, using insulin, glycemic control, heredity, time of T2DM (5 years as the boundary), proteinuria, and time of T2DM (10 years as the boundary) that are statistically significant since all p-values are < 0.05. Namely, statistically significant differences are found for those variables between the DM and ES-DKD groups. However, other quantitative and qualitative indicators are found not statistically significant since all p-values are > 0.05. Namely, no statistically significant differences are found for those variables between the DM and ES-DKD groups.
Screening of independent variables
Figure 2 depicts the outcomes of the LASSO regression model. According to the first line on the left of Figure 2(a), λ_min is 0.01876504, and 18 variables are screened, which are as follows: RDW-CV, MPV, ALT, ALB, A/G, Ca, AG, OSM, TBA, urea, CRE, HbA1c, hypertension, other kidney diseases, using insulin, glycemic control, heredity, and the history of T2DM (10). On the first line on the right of Figure 2(a), λ_1se is 0.03598965, and 15 variables are screened, which are as follows: the RDW-CV, MPV, ALB, A/G, Ca, AG, TBA, urea, CRE, hypertension, other kidney diseases, using insulin, glycemic control, heredity, and the history of T2DM (10).

Least Absolute Shrinkage and Selection Operator (LASSO) regression.
Based on the independent variables selected by LASSO regression, the stepwise regression method was implemented to run the second screening, and nine independent variables were finally included in the logistic regression model. Those attributes are MPV, ALB, AG, CRE, hypertension, other kidney diseases, glycemic control, a history of T2DM (10), and heredity.
The construction of the logistic regression model and nomogram
The chosen independent attributes were employed in the multivariate binary logistic regression model. Equation (5) presents the predicted model.
The Hosmer and Lemeshow goodness of fit test results of the model were presented as follows: the chi-square (5.503), the activity, 8 and the p-value (0.7027 > 0.05). Table 3 presents the predictions.
The predictions are generated by the logistic regression model.

ES-DKD: early-stage diabetic kidney disease.
The odd ratios (OR) of the respective variables in the model were calculated, and the results are given in Figure 3. Except for the OR < 1 of ALB, the OR values of other independent variables were all > 1. Therefore, ALB was a protective factor, and MPV, ALB, AG, CRE, hypertension, other kidney diseases, glycemic control, the history of T2DM (10), and heredity were risk factors. The p-values of MPV, ALB, AG, hypertension, other kidney diseases, the history of T2DM (10), and heredity were all < 0.05. So MPV, AG, hypertension, other kidney diseases, the history of T2DM (10), and heredity are independent risk factors for T2DM to ES-DKD, respectively.

The forest plots of the logistic regression OR values.
Figure 4 depicts the nomogram of the logistic regression model, where the vertical line shows the demo case, which is represented by the parameters of MPV = 11.6, ALB = 43.9, AG = 7.6, CRE = 72, glycemic control = unsatisfactory, hypertension = no, other kidney diseases = no, time of the T2DM(10) = “<10 years,” heredity = no. This patient has T2DM with a 0.0178 risk for ES-DKD, which is very low. However, controlling blood sugar levels with other influencing factors should still be a focus. If a more comprehensive cure is needed, multifactorial treatment can be administered.

Nomogram.
ROC curve, calibration curve, and DCA
Figure 5 depicts the prediction performance of the constructed model assessed by the ROC curve. Figure 5(a) presents the ROC curve of the training set, with an AUC of 0.939, a decision threshold of 0.729, a specificity of 0.960, and a sensitivity of 0.775, respectively. Figure 5(b) depicts the ROC curve of the validation set, with an AUC of 0.765, a decision threshold of 0.964, a specificity of 0.948, and a sensitivity of 0.469, respectively. AUC scores in the validation and training sets differ, where the AUC score in the validation set is greater than 0.7 which implies that the model still has good predictive performance and generalization capability. Nevertheless, its predictive performance is slightly worse than that of the model in the training set.

Receiver operating characteristic (ROC) curves.
Figure 6 depicts the calibration curves of the constructed model. The calibration curve of the constructed model was close to the reference line. Therefore, the predicted probability is in good agreement with the actual probability, which suggests a good-performing model.

Calibration curve.
Figure 7 depicts the DCA of the constructed model. The green, blue, and red curves show full intervention, no intervention, and the model curve, respectively. The model curve is above the blue and green curves in most cases, so the model has good net returns in most cases.

Decision curve analysis (DCA).
The results of machine learning models
Feature selection
Table 4 presents the importance of each evaluated and ranked feature in the training set. Figure 8 depicts the results of the top 20 important features to train the subsequent model. The dimensionality of the dataset was effectively reduced, while retaining the features that are most helpful for prediction, thereby improving the performance and generalization capability of the constructed model.
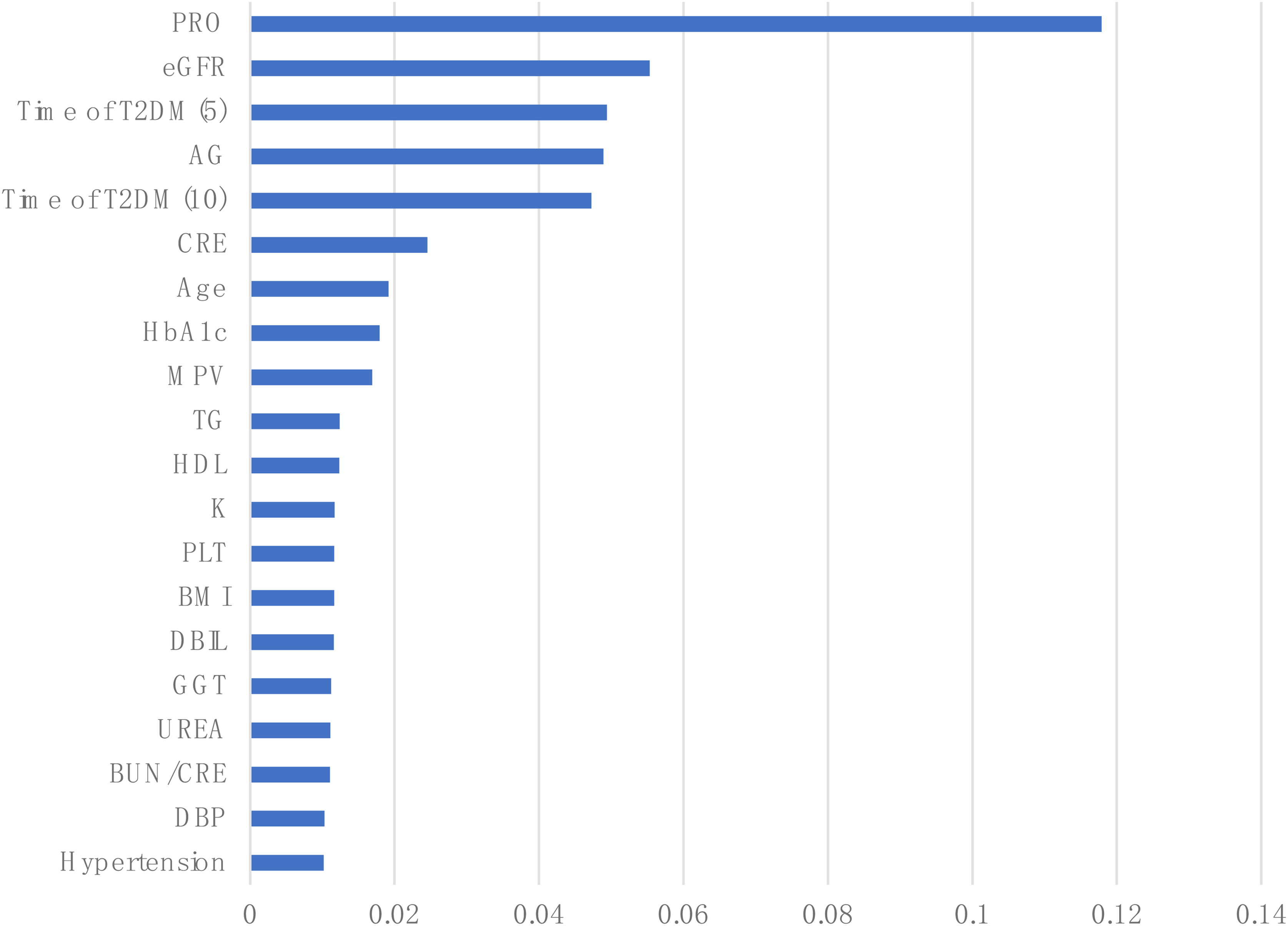
The importance of the top 20 features.
The results of feature importance.

eGFR: estimated glomerular filtration rate; T2DM: diabetes mellitus type 2; CRE: creatinine; HbA1c: hemoglobin A1c; MPV: mean platelet volume; TG : triglyceride; HDL: high density lipoprotein cholesterol; PLT: platelet; BMI: body mass index; DBIL: direct bilirubin; GGT: γ-glutamyltransferase; BUN/CREA: blood urea/creatinine; ChE: cholinesterase; HYC: homocysteine; PDW: platelet distribution width; SBP: systolic blood pressure; DBP: diastolic blood pressure; WBC: white blood cell count; RBC: red blood cell count; HGB: hemoglobin; ALT: aminotransferase; AST: aminotransferase; CK: creatine kinase; AFU: α-L-fucosidase; OSM: osmolality.
Handling class imbalance
Any two features in the training set were selected, and the visualization of the distributed predictions before and after the equalization of the dataset is run is shown in Figure 9. A few classes (class 0) have almost the same amount of data as class 1 after balancing is run.

The distribution of the data before and after SMOTEomek resampling.
ROC curve
The ROC curves of the MLMs are shown in Figures 10 and 11. The AUC values of the training and validation curves for each model are close, indicating that each model has good generalization ability. Both specificity and AUC values were obtained.

The ROC curve of the training set. (a) ROC curve of ensemble model. (b) ROC curve of Naive Bayes. (c) ROC curve of RF. (d) ROC curve of Cat-Boost. (e) ROC curve of XG-Boost. (f) ROC curve of Ada-Boost. (g) ROC curve of GBDT. (h) ROC curve of KNN. (i) ROC curve of DNN. (j) ROC curve of Light-GBM. (k) ROC curve of SVM. (l) ROC curve of LR.

The ROC curve of the validation set. (a) ROC curve of ensemble model. (b) ROC curve of Naive Bayes. (c) ROC curve of RF. (d) ROC curve of Cat-Boost. (e) ROC curve of XG-Boost. (f) ROC curve of Ada-Boost. (g) ROC curve of GBDT. (h) ROC curve of KNN. (i) ROC curve of DNN. (j) ROC curve of Light-GBM. (k) ROC curve of SVM. (l) ROC curve of LR.
Ensemble model
We selected RF and NB for the components of the ensemble model based on their complementary performance characteristics observed in our experiments. As shown in Table 5, the NB classifier achieved the highest precision (100.00%) among all individual models, but its recall was comparatively lower (87.76%). In contrast, RF achieved the highest recall (97.96%) but had a relatively lower precision (76.19%). This suggests that NB is more conservative and accurate when it predicts a positive class, whereas RF is more comprehensive in capturing positive samples but may introduce more false positives.
Performance comparison of the classification models.
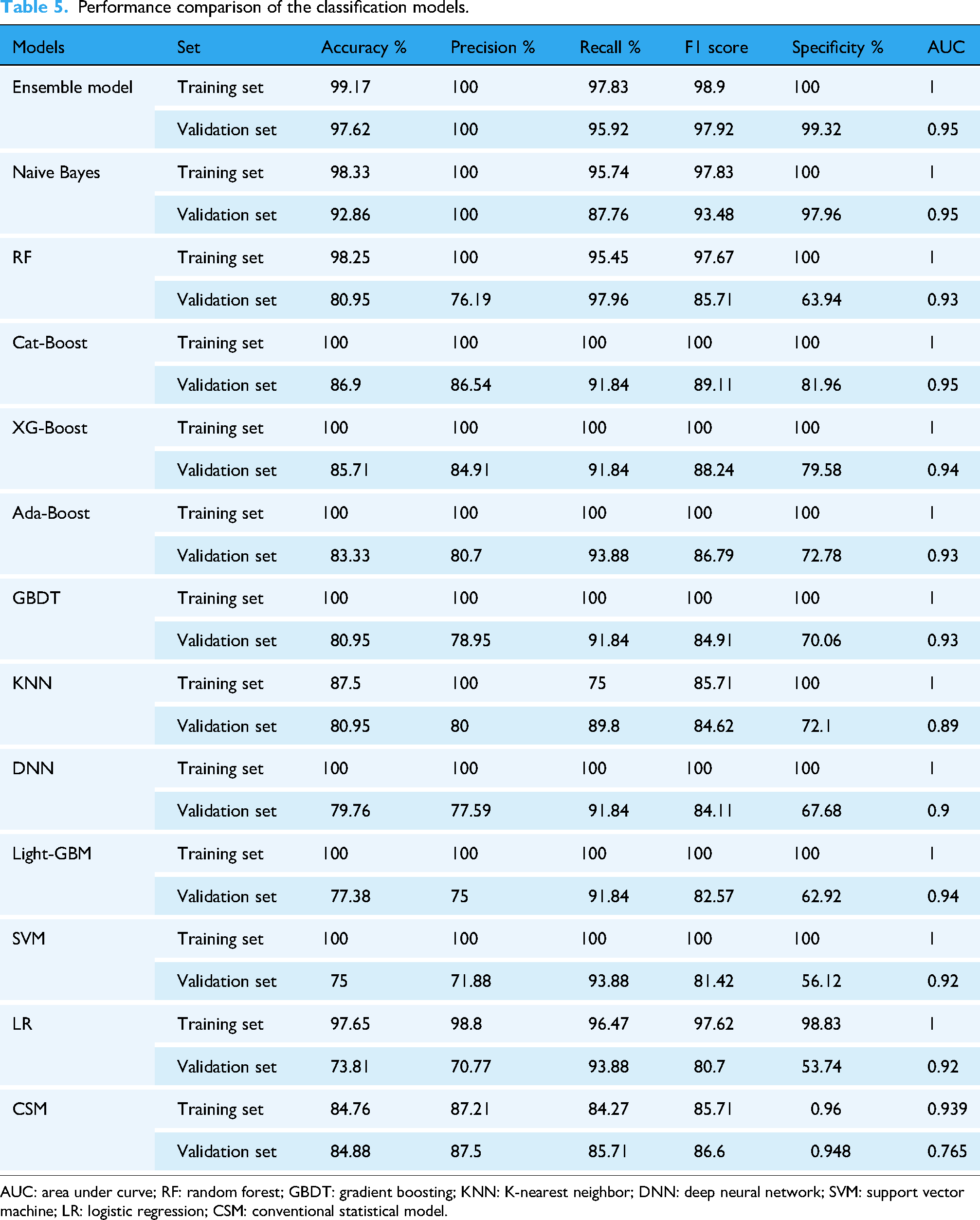
AUC: area under curve; RF: random forest; GBDT: gradient boosting; KNN: K-nearest neighbor; DNN: deep neural network; SVM: support vector machine; LR: logistic regression; CSM: conventional statistical model.
The fusion of RF and NB was therefore considered to balance these strengths, leveraging the high precision of NB and the high recall of RF, to achieve a more robust and stable classification outcome. This approach aligns with common ensemble learning principles, where combining diverse models with complementary strengths can yield improved overall performance.16,17
Comparison of prediction models
The summary performance of all models is shown in Table 5. The predictive performance between the training set and the validation set is not significantly different for the first three models regarding machine learning models, but significantly different for the latter few models. However, the AUC curves of all models are not significantly different from each other and the values are quite impressive. The prediction performance between the training set and the validation set does not differ significantly in the traditional model. However, the difference in AUC between the two is much larger than that of machine learning. This indicates that the constructed model based on the traditional methods has a slightly weaker generalization ability and poor stability after LASSO regression regularization and secondary screening of influencing factors. Hosmer and Lemeshow's goodness of fit test gives rise to a good fit. Therefore, the significant difference in AUC between the two may be due to the retention of too many influencing factors. However, this article aims to identify as many indicators as possible to predict early DKD and provide new indicators and models. For clinical selection, two groups of methods were compared at the same level. Therefore, to maintain consistency in experimental objectives, methodology should be kept dominant as much as possible, while also ensuring that the results have clinical significance.
Because the validation set can better represent the actual performance of the model in clinical practice. So this experiment compares the predictive performance of two methods based on the validation set. The ensemble model outperforms all models in terms of performance. However, the CSM performs poorly in terms of AUC values. Compared to various MLMs, the performance of others is not inferior.
Discussion
Two different types of modeling tools, which are conventional and machine learning, are implemented and compared in the article.
When the screening of independent variables is under consideration, CSMs are very different from MLMs. MLMs sorted out all factors based on importance criteria and then included the top 20 factors as the independent attributes based on their importance scores. The CSMs first execute univariate analysis and remove the factors not statistically significant between the two groups. In many cases, due to small sample sizes, group differences not found to be statistically significant are removed. However, MLMs are not greatly affected by the issue. For example, the outcomes generated by Hu et al., 18 Yang and Jiang, 19 and Hukportie et al. 20 suggested that DBP and BMI are related to diabetic nephropathy. However, this article suggested that DBP and BMI are directly excluded from the CSM since they are not statistically significant, while BMI and DBP were retained in the MLM and employed as independent variables to construct the model. CSMs in the second screening stage of variables and model fitting suggest that the PRO and eGFR are two indicators used in the model. Hosmer and Lemeshow's goodness of fit test shows a statistically significant relation since the p-value is < 0.05. However, the model fit is not good, so they are excluded. However, studies6,21–24 suggested that eGFR and urinary protein have a strong correlation with diabetes. This article suggests that the two indicators, PRO and eGFR, have a strong correlation with the disease, which is much more related than other indicators, however, when these two indicators are included in the CSM, the model fitting will be poor. On the other hand, MLMs do not have this issue. Overall, MLMs as modeling tools are superior to CSMs when filtered-out variables are a concern. However, MLMs have this shortcoming. In the article, a set of similar variables, the history of T2DM (5) and the history of T2DM (10), are designed. The CSM well eliminated one group, while the MLM included both groups in the variable selection process.
Since the number of independent variables is limited in the model fitting stage, Riley et al. 25 suggested that the CSM has limitations due to the sample size. Hence insufficient sample size can also lead to poor fit of the model or affect the predictive performance of the model. Only nine variables are included in the CSM due to these limitations. However, MLMs included 20 variables.
Most studies implementing the CSMs26–32 suggested that the sample sizes of the two groups are roughly equal or can be slightly different, but the difference should not be large, which will have a great impact on the prediction performance of the model when data balance between the two groups are a concern. However, the prediction performance is better after running handling class imbalance when MLMs are implemented.33–35 Therefore, the significance of the process of handling class imbalance is underlined.
The CSM tool is easy to operate, learn, understand, and interpret. However, there are few modeling methods available for CSMs. On the other hand, the toolset of MLMs has several options to model. Only one modeling method in CSMs is implemented in the research. When compared with CSMs, MLMs are cumbersome operationally. Thus, they do not have the mentioned favorable features of what the CSM tool has.
Based on predictive performance, CSMs have good predictive performance compared to various MLMs, except for slightly lower AUC.
Overall, in a small sample size, CSMs and MLMs have their advantages and disadvantages. We cannot determine which one is better just because of the limited results of this experiment. Therefore, multiple comparisons should be made under different conditions. Both have their advantages and disadvantages and if their respective strengths can be retained and their shortcomings eliminated, it would be a good direction to be implemented. This article applies machine learning methods to integrate two MLMs into an ensemble model whose predictive performance is excellent.
At present, there are also applications of fused models in medical research, and their predictive performance is also very promising. Lu et al. 36 proposed a gate recurrent unit (GRU) and decision tree-based fusion model, and the accuracy of the fusion model was 98.31% and the precision was 96.73%. Khalid et al. 37 suggested that stacked classifiers were applied to construct a stacked model that combined gradient boosting, Gaussian NB, and RF, and the stacked model achieved 100% accuracy. Even though the proposed fusion model has higher accuracy and precision, its usability and practicality need to be tested in medicine. More research is needed to further verify the results of the proposed method.
This article applies multiple methods to establish a prediction model for ES-DKD. These models are all constructed based on commonly used testing indicators for clinical patients. During the modeling process, statistical methods were used to screen each indicator, leaving behind indicators with differences. Each model can be integrated with clinical practice. Extracting patient-related indicators through different models helps predict the risk of T2DM patients transitioning to ES-DKD. Due to different patient databases selected for model construction, the different indicators applied to the models established by different databases are found. Therefore, it cannot be said that the excluded indicators cannot be regarded to predict the disease, but can only indicate that there is no difference in the indicators between the two groups in the databases and, therefore they were not used to establish a model. Consequently, this model still has some limitations.
There are also some limitations to the research. The first point is that although this experiment aims to explore the comparison of two modeling methods under small sample sizes, the used sample size is too small. Secondly, in this experiment, due to the actual situation of the patients, the vast majority of them have some underlying diseases. This is in line with the current clinical situation, so it is impossible to avoid the impact of these potential diseases on the indicators. For example, diabetes or DKD may be improved while treating other basic diseases. When angiotensin-converting enzyme inhibitors (ACEIs) are used to treat hypertension, proteinuria is also treated, thereby reducing kidney function damage. This situation may affect the generalization ability of the model. Thirdly, all models established in this article have only been validated on the validation set and have not been clinically tested. Therefore, the practical application performance of the model in clinical practice still needs to be examined. The fourth point is that although the training set and validation set come from different hospitals, both hospitals are located in the same region. Therefore, the model established only has good predictive ability in that region but lacks generalization capability testing in different regions. The fifth point is that when establishing the model, there may be a risk of overfitting as a small number of indicators overlap with the patient's diagnostic indicators. In summary, this study should fully consider the aforementioned limitations and attempt to find solutions to these issues, so that the constructed model can be widely applied in clinical practice without affecting the aforementioned limitations.
Conclusion
This article establishes multiple ES-DKD prediction models using CSMs and MLMs to find some new routine clinical laboratory indicators that can be used for prediction. This provides new ideas and methods for the diagnosis, treatment, and prevention of ES-DKD in clinical practice, especially with the popularization and application of AI today. Mathematical models can be better applied in clinical practice and closely integrated with clinical practice. However, models built with different databases may have limitations due to geographical and special conditions, so newly established models need to be continuously improved in practical application and testing.
This article also compared two modeling methods. Compared to CSMs, MLMs have good stability and varying predictive abilities. Therefore, when applying MLMs for modeling, several different methods should be used to select the best one. The CSMs have relatively fixed modeling methods. However, compared to MLMs, the operation is simple and convenient. The predictive ability is also very good. This article also established an integrated model, which has excellent predictive capability, stability, and generalization capability. Therefore, fusion models will be the main research direction for future mathematical models. However, building a fused model is quite cumbersome. On the other hand, the integration of the advantages of MLMs based on CSMs would bring more promising outcomes.
Footnotes
Ethics considerations
The study protocol was approved by the 940th Hospital of the Joint Logistics Support Force of the Chinese People's Liberation Army's Ethics Committee (Ethical reference: 2022KYLL170). The study protocol was approved by the First Hospital of Lanzhou University Ethics Committee (Ethical reference: LDYYLL-2024-368).
Consent to participate
I promise to strictly follow the declaration of Helsinki, and each patient signed the informed consent.
Author contributions
YS and JC participated in the design of the experimental study, proposed the experimental protocol, and searched the literature. YS, JC, and CZ completed the preliminary writing of the manuscript. CZ, YS, JC, FM, QX, DW, and JZ collected, organized, and analyzed the data. HX, as the corresponding author, guided and improved the experimental design and protocol. All authors reviewed the article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is funded by the Fund of Gansu Provincial Health Commission of China [Approval No.: GSWSKY2022-03]. The funder does not play any role in research design, data collection and analysis, publishing decisions, or manuscript preparation.
Declaration of conflicting interests
YS and JC are co first authors with consistent contributions to this article. There are no potential conflicts of interest in other aspects.
Guarantor
Yingda Sheng.