
Abstract
Objective
To compare the reliability and readability of responses from Generative Pre-trained Transformer versions 3.5 (GPT-3.5) and 4.0 (GPT-4.0) on traumatic brain injury (TBI) topics against Model Systems Knowledge Translation Center (MSKTC) fact sheets.
Methods
This study analyzed responses from GPT-3.5 and GPT-4.0 for accuracy, comprehensiveness, and readability against MSKTC fact sheets, incorporating a correlation analysis between reliability and readability scores.
Results
Findings showed an improvement in reliability from GPT-3.5 (mean score = 3.21) to GPT-4.0 (mean score = 3.63), indicating better accuracy and completeness in the latter. Despite advancements, responses generally remained accurate but not fully comprehensive. Readability comparisons found the MSKTC fact sheets were significantly more reader-friendly compared to responses from both artificial intelligence (AI) versions, with no strong correlation between reliability and readability.
Conclusion
The study highlights progress in AI-generated information on TBI from GPT-3.5 to GPT-4.0 in terms of reliability. However, challenges persist in matching the readability of standard patient education materials, emphasizing the need for future AI developments to focus on enhancing understandability alongside accuracy.
Introduction
Traumatic brain injury (TBI) is a public health concern that affects millions of individuals, leading to significant morbidity and mortality. According to the Centers for Disease Control and Prevention (CDC), TBIs contributed to 214,110 hospitalizations in 2020 and 69,473 deaths in 2021. 1 Characterized by a disruption of normal brain function following head trauma, TBIs can range from mild concussions to severe, life-altering injuries.2,3 The long-term effects of TBI on both patients and families underscore the necessity of robust prevention, diagnosis, and management strategies, particularly in context of persistent cognitive-communication challenges that can impair daily life and psychosocial well-being.4–6
The dissemination of accurate medical information is essential in ensuring the well-being and informed decision-making of patients and their caregivers. 7 With the rise of social media in recent years, the rapid spread of medical information through various platforms and online resources has become more accessible than ever.8–10 However, this increased accessibility also presents the challenge of ensuring the reliability and comprehensiveness of medical content, particularly regarding complex topics such as TBI. 9 The accuracy and comprehensiveness of such information are crucial, as they directly impact the ability of patients and caregivers to grasp essential care and management principles. 7
The concept of readability is particularly pertinent to the field of TBI, where information complexity often exceeds the general public's health literacy.11,12 Ensuring TBI-related content is accessible and comprehensible can significantly improve how individuals understand and apply information in their care and recovery. 12 Efforts to improve the readability of TBI information not only support informed decision-making but also empower patients and caregivers in their journey toward rehabilitation and adaptation to life post-injury. 13
In recent years, artificial intelligence (AI) has been a growing area of interest in the general public. AI can be defined as the simulation of human intelligence processes by computer systems. 14 These may include learning (the acquisition of information and rules), reasoning (using rules to reach conclusions), and self-correction. 15 It has been utilized in various fields including finance, education and more recently, healthcare. 16 Within healthcare, many researchers have been studying the use and benefits of integrating AI into diagnostics, patient care plans and information management.17,18
Large language models (LLMs) are a specific application of AI capable of generating human-like text based on extensive datasets. 19 By processing text data, LLMs learn underlying patterns, overt connections, and linguistic structures, allowing them to produce responses that mimic human writing or conversational styles. 20 The use of LLMs has been explored in the healthcare setting including patient education, clinical decision support, and the analysis of electronic health records.17,18
Generative pre-trained transformer (GPT) models are advanced LLMs that can provide detailed responses to queries, allowing users to have chat-based interactions with an AI. 20 GPT-3.5 and GPT-4.0 are two versions of such models. GPT-3.5 is free to use and offers a wide range of capabilities for generating human-like text, from answering questions to translating languages. GPT-4.0, unlike its predecessor, is available via paid subscription and introduced improved capabilities with more up-to-date information and nuanced, contextually appropriate responses.
Despite the growing interest in AI and its applications within healthcare, there remains a notable gap in the literature regarding the use of LLMs for the dissemination of information on complex health topics, particularly TBI. This study aims to evaluate the reliability and readability of GPT-3.5 and GPT-4.0 responses compared to current evidence-based resources available to the public. While this study focuses on comparing GPT-3.5 and GPT-4.0 due to their current prevalence in the field, the authors acknowledge that other models (e.g. Copilot, Gemini, Bard) may offer different performance profiles.21,22 Future research initiatives should explore these alternatives to further enhance the robustness and generalizability of findings.23,24
Methods
Nature of study and selection criteria
This study was designed as a cross-sectional analysis, conducted at the Hackensack Meridian JFK-Johnson Rehabilitation Institute. The top five most-viewed TBI fact sheets from the Model Systems Knowledge Translation Center (MSKTC) between December 1, 2022, and January 1, 2024, were identified. Most recent view data was collected in February 2024. This criterion ensured that the included fact sheets aligned with real-world relevance and patient-centered outcomes by focusing on the resources most frequently accessed by individuals seeking information on TBI.
MSKTC fact sheets
The MSKTC, an initiative of the American Institutes for Research, plays a pivotal role in converting health information into accessible and accurate language and formats for individuals with TBI, including their families and caregivers. This national center receives funding from the National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR), part of the Administration for Community Living, U.S. Department of Health and Human Services, under the grant number 90DPKT0009. The development of these fact sheets at MSKTC is a collaborative effort with the Traumatic Brain Injury Model Systems, ensuring the health information provided is grounded in research evidence and professional consensus. A dedicated team of authors, including community representatives, crafts each fact sheet, which then undergoes approval by a specialized editorial team. 25 Permission was obtained from the MSKTC to use fact sheet data for this study.
Data collection and AI interaction
To facilitate a direct comparison between AI-generated responses and the MSKTC fact sheets, the research team converted the subheadings of included fact sheets into questions. This process was intended to simulate real-world scenarios where patients or their caregivers pose specific queries regarding TBI. This decision allowed a direct comparative analysis between AI responses and fact sheets.
Evaluation of reliability and readability
The reliability of GPT-3.5 and GPT-4.0 responses was evaluated using a 1–5 Likert scale that assesses the accuracy and comprehensiveness of responsiveness, using the MSKTC fact sheets as a gold standard. To ensure both a structured and objective evaluation of the LLM responses generated, the following criteria were used:
5 - Comprehensive and accurate with additional factual and useful information: All information from the fact sheet is addressed with more useful and factual information present. 4 - Comprehensive with no additional factual information: All information is covered and is accurate but does not discuss additional information. 3 - Accurate but incomprehensive: Information is accurate but missing key information mentioned or discussed in fact sheet. Additional information may be present. 2 - Partially accurate with incorrect information: Contains information that contradicts what is present within the fact sheet. Additional information present, despite whether it is factual or useful, does not contribute in this context. 1 - Completely inaccurate: Prompt provided by LLM contradicts what is provided within the fact sheet.
Scores were determined independently by 3 graders at different levels of medical training (a double-board certified brain injury physician, a physical medicine & rehabilitation resident and a medical student). Each grader completed evaluations separately, without discussing them, and did not have access to the other graders’ scoring. A separate team member, who was not involved in the evaluation, then compiled all scores. The mode score for each respective LLM response was the consensus value (Figure 1).
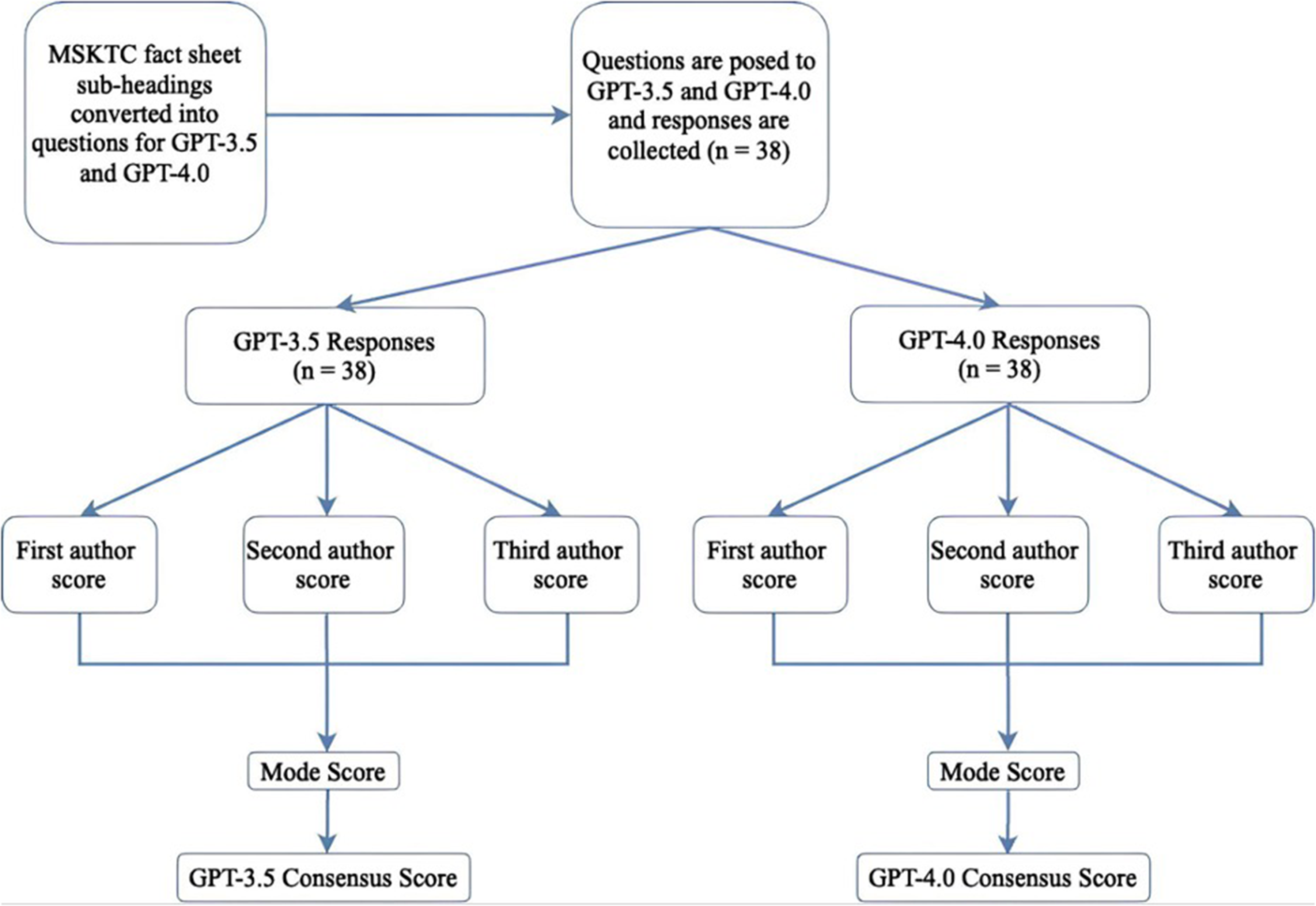
Flow chart of evaluation process for GPT-3.5 and GPT-4.0 responses.
Readability scores were calculated for GPT-3.5, GPT-4.0, and MSKTC Fact sheet responses using the Flesch Kincaid Reading Ease (FKRE), Flesch Kincaid Grade Level (FKGL), Gunning Fog Score (GFS), Simple Measure of Gobbledygook (SMOG) Index, Coleman Liau Index (CLI), and Automated Readability Index (ARI). These indices were selected due to their widespread acceptance and utility in assessing health materials. The FKRE scores text on a 100-point scale, where higher scores indicate simpler content. FKGL evaluates readability by assigning a U.S. school grade level to the text, demonstrating the educational level required for comprehension. The GFS estimates the number of years of formal education needed to understand a text, thereby measuring its complexity. SMOG Index calculates the educational level necessary to fully comprehend a text, particularly for health and safety information. The CLI predicts grade level needed to understand text based on sentence length and letter count. The scale also favors character over syllable counts for reliability across texts. Lastly, the ARI also provides a grade level estimation, but based on characters per word and words per sentence. These readability scales were calculated for MSKTC fact sheet text and LLM responses. 26
Data analysis
Inter-rater agreement was determined through calculation of the Weighted Cohen's Kappa Coefficient. The normality of the data distribution was assessed using the Shapiro–Wilk test to ensure the appropriate selection of statistical tests based on data characteristics. If data was normally distributed, statistical significance between groups was determined using parametric testing (independent t-test). If data was not normally distributed, non-parametric testing was utilized (Mann–Whitney U test). Correlations between reliability and readability metrics were calculated using Pearson correlation test for parametric variables and Spearman correlation test for non-parametric variables. In addition to hypothesis testing, Cohen's d effect sizes and 95% confidence intervals (CIs) were calculated to quantify the magnitude and precision of the differences between groups. Statistical analysis of data was conducted using SPSS version 26 (IBM SPSS Statistics for Windows, Armonk, NY: IBM Corp.).
Results
The top five most-viewed MSKTC fact sheets in the specified time included: (a) Facts About the Vegetative and Minimally Conscious States After Severe Brain Injury; (b) Memory and TBI; (c) Headaches After TBI; (d) Changes in Emotion After TBI; (e) Irritability, Anger, Aggression After TBI. A total of 114 grades were collected and 38 questions were used in this study representing the subheadings of each fact sheet.
Reliability
Analysis of GPT-3.5 reliability scores demonstrated moderate agreement among graders with Weighted Kappa coefficients ranging from κ = 0.384 to κ = 0.646. In contrast, evaluation of GPT-4.0 scores showed an improvement in inter-rater agreement, with Weighted Kappa values ranging from κ = 0.650 to κ = 0.709.
The mean reliability score for GPT-3.5 responses was 3.21 ± 0.84, indicating a moderate level of accuracy and comprehensiveness across the 38 evaluated questions. The distribution of scores is shown in Table 1 and demonstrated that a predominant number of GPT-3.5 responses were categorized as accurate but incomprehensive (73.7%), with a smaller proportion being comprehensive and accurate with additional useful information (15.8%). A minimal proportion contained partially accurate information with inaccuracies (10.5%). In contrast, GPT-4.0 exhibited a mean reliability score of 3.63 ± 0.94, reflecting a moderate level of reliability overall. 31.6% of responses were rated as comprehensive and accurate, including additional factual and useful information. The majority of GPT-4.0 responses remained accurate but incomprehensive (68.4%), showing an improvement in the model's ability to generate reliable information.
Distribution of reliability scores: GPT-3.5 and GPT-4 performance.
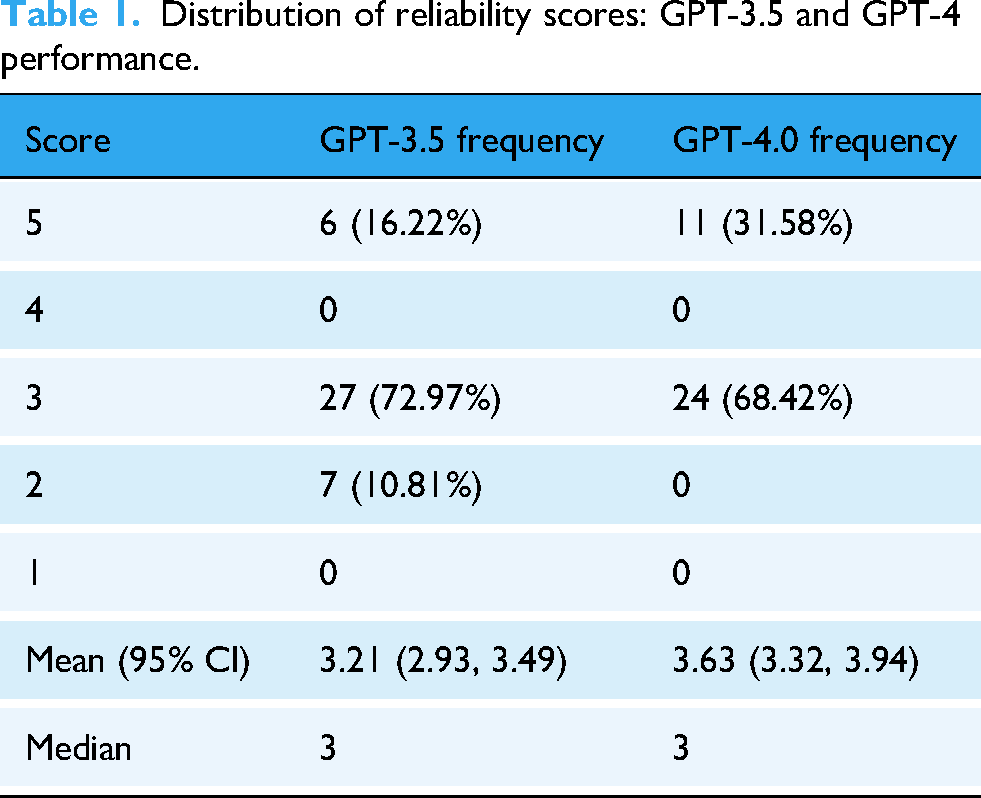
Upon statistical analysis using the Mann–Whitney U test, it was observed that GPT-4.0 responses were significantly more reliable than those from GPT-3.5 (p = 0.03; d = 0.47, 95% CI [0.15, 0.79]), indicating a small-to-moderate effect size. However, analysis of reliability scores among individual fact sheets showed no significant difference when comparing the distribution of scores across individual TBI-related topics (p > 0.05).
Readability
Analysis of readability demonstrated that MSKTC fact sheets significantly outperformed both GPT-3.5 and GPT-4 responses across all scales (p < 0.001). Effect size analyses further revealed very large differences between the fact sheets and the AI-generated content, with Cohen's d values ranging from 1.50 to 2.60 for GPT-3.5 and from 1.07 to 2.49 for GPT-4.0. When comparing the readability metrics of the two LLMs, GPT-4.0 responses had significantly better scores compared to those produced by GPT-3.5 (p < 0.05), with effect sizes ranging from 0.57 to 0.76, indicating a moderate improvement. Mean and median scores for each readability metric for MSKTC fact sheets, GPT-3.5 and GPT-4.0 responses are shown in Table 2.
Readability metrics GPT-3.5, GPT-4.0 and MSKTC fact sheets.

Correlation analysis
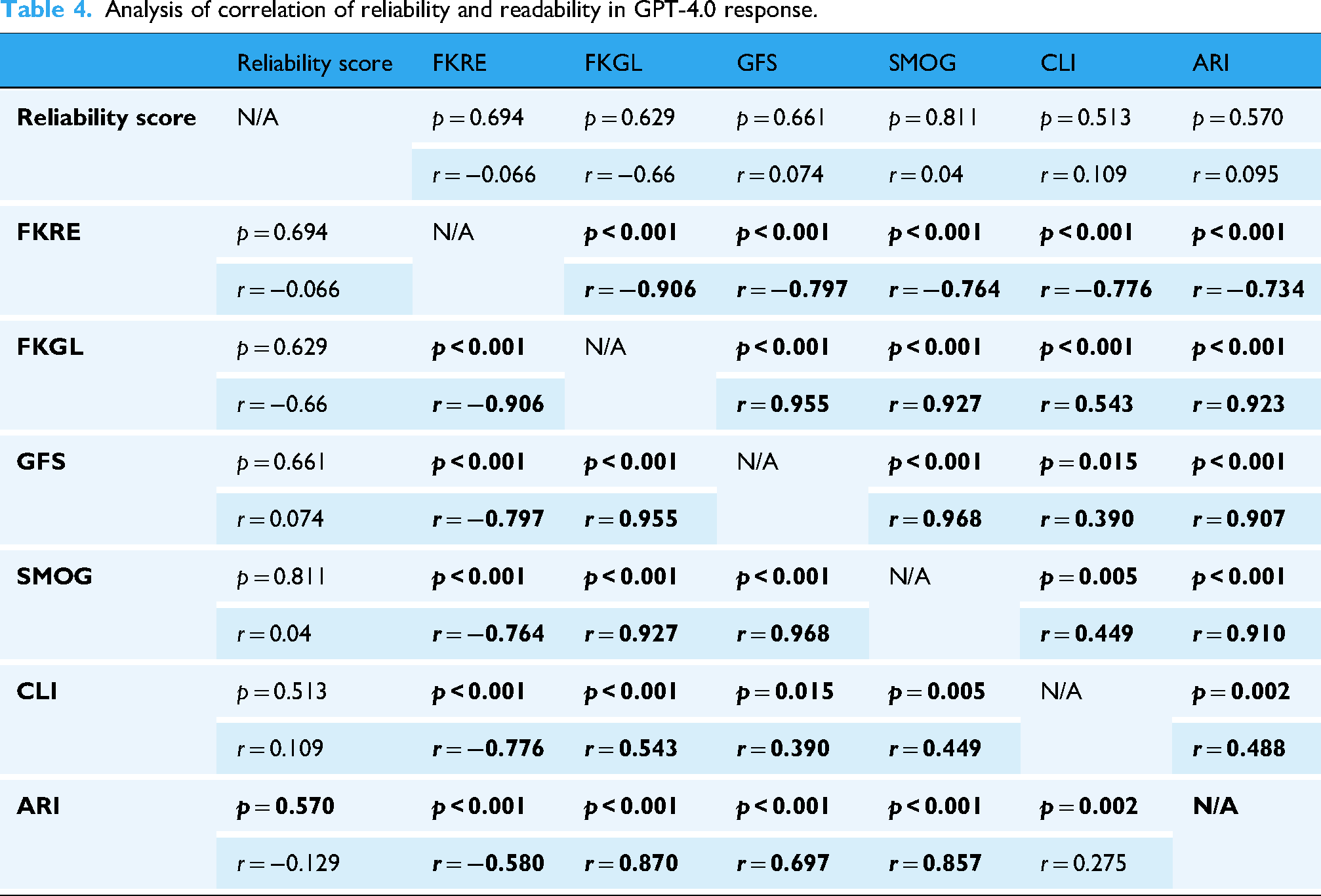
Correlation analysis using Pearson and Spearman coefficient calculations showed that there was no significant correlation between the reliability scores of both GPT-3.5 and GPT-4.0 and the readability metrics. Within the readability scores themselves, a strong negative correlation was evident among most scales for both versions of GPT, indicating that measures of text simplicity and complexity are inversely related as expected. Specifically, the FKRE demonstrated significant negative correlations with other readability formulas across both LLMs. This correlation data is detailed in Tables 3 and 4 for GPT-3.5 and GPT-4.0, respectively.
Analysis of correlation of reliability and readability in GPT-3.5 responses.

Analysis of correlation of reliability and readability in GPT-4.0 response.
Discussion
In this study, the reliability and readability of responses from LLMs, specifically GPT-3.5 and GPT-4.0, on TBI-related topics were compared against information within MSKTC fact sheets. Our analysis revealed a improvement in reliability scores from GPT-3.5 to GPT-4.0, with mean scores increasing from 3.21 to 3.63. This difference highlights the progression in AI's ability to produce not only accurate but also more comprehensive medical information. A mean score of 3.21 for GPT-3.5 suggests that responses often contained accurate information but were lacking in completeness, indicating a moderate level of reliability where key information from the fact sheets might have been omitted. The elevated mean score of 3.63 for GPT-4.0 demonstrates a shift towards responses that are not only accurate but also more complete. However, the responses provided still do not consistently meet the standard of adding substantial new, factual information compared to MSKTC fact sheet information. This detail shows the enhanced capability of GPT-4.0 in approaching but not fully achieving comprehensive and detailed medical advice, reflecting a significant advancement in AI's application to TBI information dissemination while also highlighting areas for further improvement.
The distribution of reliability scores demonstrates a significant change towards more comprehensive and accurate responses in GPT-4.0 compared to GPT-3.5. This improvement is important to consider, considering the critical nature of providing reliable health information to patients, caregivers, and healthcare professionals. Despite this improvement, the majority of responses from both versions were categorized as accurate but incomprehensive, pointing to an ongoing challenge in achieving completeness in AI-generated medical advice.
Significance testing of reliability scores reinforced the superiority of GPT-4.0 over GPT-3.5 in terms of reliability, with a significant difference observed between the two versions (p = 0.03). However, when examining the reliability scores across individual TBI-related topics, no significant difference was noted. While this suggests a consistent performance of the LLMs across a range of subjects, it may also reflect limitations in sample size and statistical power.
In terms of readability, our analysis revealed that MSKTC fact sheets were significantly more readable compared to responses generated by LLMs. The difference emphasizes the need for further improvement in AI-generated content to enhance its accessibility to a wider audience. Although GPT-4.0 showed improved readability scores compared to GPT-3.5, the complexity of responses suggests that they may still require a higher level of education to be fully understood.
The role of readability in disseminating health information, especially concerning TBI, is vital. This has been demonstrated through several studies investigating the need for materials to be understandable for patients and caregivers. A study conducted by Abdul Rahman et al. demonstrated the importance of evaluating emergency department discharge instructions for mild TBI on parameters such as readability and understandability, highlighting the need for accessible information to support patient recovery and management. 27 Challenges in information accessibility, such as understaffing and short physician encounter times, further emphasize the importance of providing understandable and easily accessible materials. 28 Given the advancing AI technologies, LLMs serve as a potential solution to bridge the information accessibility gap for those impacted by TBI.
Statistical analysis of correlation between reliability and readability metrics revealed no significant correlation, indicating that the accuracy and comprehensiveness of information may not necessarily correlate with its ease of understanding. This finding suggests that efforts to improve the reliability of AI-generated content may not inherently enhance its readability.
The current study also evaluated the correlations among readability metrics, which demonstrated the inverse relationship between text simplicity and complexity. This aspect is significant for developers and users of AI in TBI information dissemination as it emphasizes the need for balance between providing detailed, accurate information and ensuring it is comprehensible to patients and caregivers.
Limitations
Despite providing meaningful insights, this study has several limitations. The sample size was limited to five TBI fact sheets from the MSKTC; although focusing on the most-viewed resources offered real-world relevance, it may not capture less frequently accessed but equally important information.5,6 Although GPT-4.0 outperformed GPT-3.5, most responses remained accurate but incomprehensive, highlighting persistent challenges in delivering complete medical guidance—a concern noted in previous studies.22,29 Additionally, our analysis was restricted to GPT-3.5 and GPT-4.0, even though other LLMs (e.g. Copilot, Gemini, Bard) may perform differently; this focused approach, however, enhances the clarity and practical relevance of our comparisons.21,30 Potential human bias in scoring and the inherent limitations of readability formulas—which cannot fully capture the complexities of patient comprehension influenced by factors such as health literacy and cultural background—also constrain our findings. Future studies should expand the scope to include a broader range of TBI resources, diverse LLMs, and direct patient and caregiver feedback to further validate and refine these findings.23,24
Conclusion
This study evaluated the reliability and readability of AI-generated information on TBI using LLMs, specifically GPT-3.5 and GPT-4.0, against established MSKTC fact sheets. Findings suggest that while GPT-4.0 shows promise in providing accurate and detailed information on TBI compared to its predecessor, both versions of GPT struggle to match the readability of traditional, research-based resources. Despite advancements, AI-generated responses often required a higher comprehension level, highlighting a gap in making complex medical knowledge accessible to the general public.
Future efforts should aim at refining AI technologies to produce health information that balances reliability with understandability. Incorporating feedback from healthcare professionals and patients could guide these advancements, ensuring AI tools evolve to meet real-world needs effectively. As AI's role in healthcare information continues to grow, prioritizing developments that bridge the accessibility gap will be crucial for enhancing patient education and support.
Footnotes
Acknowledgements
The authors thank the Model Systems Knowledge Translation Center (MSKTC) for providing us with viewing statistics for fact sheets for our analysis.
Ethical considerations
Not applicable. This research did not involve human participants, human data, or human tissue requiring approval from an Ethics Committee or Institutional Review Board.
Consent for publication
Not applicable. This manuscript does not include any data from individual persons, including individual details, images, or videos.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data generated or analyzed during this study are included in this article.
Guarantor
Matthew J Lee.
Yi Zhou was a resident physician at JFK Johnson Rehabilitation Institute but is now a Traumatic Brain Injury fellow at Mass General Brigham Spaulding Rehabilitation Center.